Jump Start PHP Environment (2015)
Chapter 1 The Anatomy of Web Requests
Before we get into the nitty-gritty of setting up a good PHP environment, you need an understanding of how web requests actually work. This chapter will explain what happens when you punch a web address into your browser and receive a result. We’ll avoid being too technical―there’s no need to explain the nuts and bolts, as it would likely only confuse you. Instead, it will be a newbie-friendly explanation on how all the various aspects of web development and web consumption come together and create the Web you know and love. The main purpose of this chapter is to teach you where your programming language of choice (in this case, PHP) comes into play, and which parts of the mysterious web request it affects.
If you know the essentials of the Web and are familiar with the terms mentioned in the previous paragraph, feel free to jump to the next chapter.
The Client and the Server
You must have heard of the terms “client-side programming” and “server-side programming,” at least in job ads. In this part, we’ll briefly explain them before moving onto the details.
What is a client?
A client is your web browser.
In the context of the Web, while you are technically the client in the conventional sense of the word (you are doing the requesting and being served by software), the browser is considered to be the client software used to ask the server for something.
Once it receives this “something” (most often being a bunch of text), it decides how it should present it to you, the ultimate client.
What is a server?
Similar to the client, a server also has two meanings:
1. a program that answers questions posed by the client
2. a computer (a physical machine) onto which the server program is installed
In this book, and in the context of web development, we generally mean the former. In fact, throughout this book, we’ll learn how we can easily install a server program on our own computer, essentially “faking the Internet” and letting the computer think the website we’re developing is online and accessible by everyone.
Let’s look at the first point a bit more: how does a program answer questions?
In a nutshell, a server waits for a question such as “give me the text of the blog post from February 14th” and responds with either “OK, here: [some HTML, containing the text oft the post in question]” or “Sorry, I can’t find that, there’s nothing under February 14th.” Admittedly, I’m paraphrasing, but that’s more or less what happens. I’ve illustrated it in Figure 1.1.
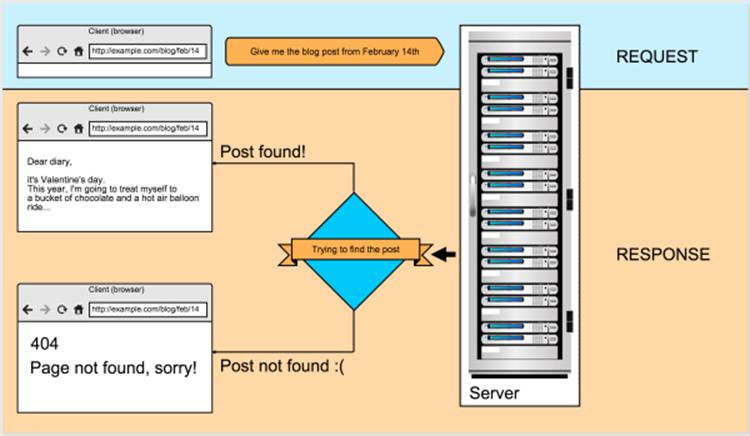
Figure 1.1. A simplified request to the server and its response
Web development is, in fact, a relatively simple matter of making the client ask the right questions, and teaching the server to give the right responses. Ready to go a little bit deeper into the rabbit hole? Here goes ...
Web Request Basics
While web request has a very specific meaning, it is often used as a blanket term for the communication between the client and the server. This entire communication process is neatly explained in Figure 1.2, a cute comic by VladStudio.
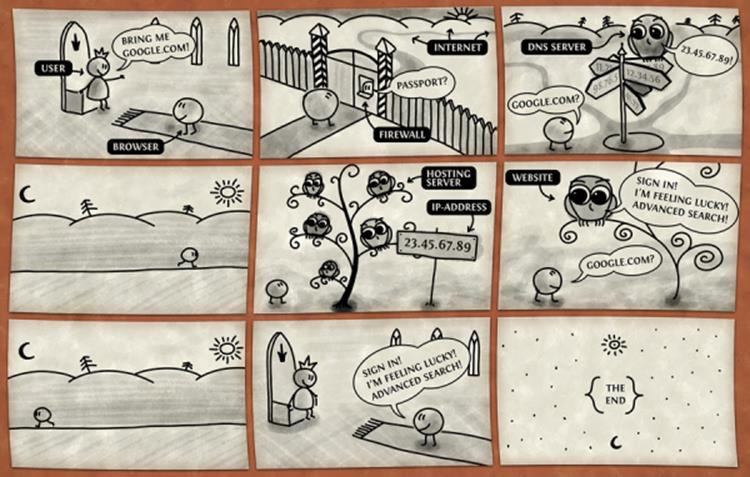
Figure 1.2. How Internet Works by VladStudio
How It All Works
Let’s break the comic in Figure 1.2 down.
You are the user―you are the king. You issue the commands and the browser obeys, happily. As the user, this is where your awareness of the process ends, and the next time you’re consciously addressed is in the second-to-last frame of the comic. The entire process in between is invisible to you, except when you’re a developer; then you’re a magic wizard king who can see everything that’s happening, but more on that in later chapters.
The browser goes through a firewall, which is usually taken for granted. You probably have some manner of firewall on your computer right now, or in your router/modem. The browser knows how to pass through it because you’ve told the guard the browser is okay and should be let through.
Then comes a part we’ve yet to mention: the DNS (domain name system) servers―a part so mystical and unapproachable to most, the vast majority of internet users (and developers, even!) take it for granted, accept that it exists, and try not to worry about it too much. The general consensus seems to be that, like questions about the meaning of life, queries about the origin of time and space, and the otherworldly deliciousness of peanut butter and banana combo, some things―such as the origin and purpose of DNS servers―are better left unquestioned. If you'd still like to know what they are, they'll be explained in the section called “For Those Who Want More” at the end of this chapter in greater detail.
In a nutshell, this is how they work. Every domain on the Internet (like “example.com”) is bound to a specific IP address (represented by the numbers on the signpost in the third frame of the comic). An IP address is a set of numbers identifying a given server; IP addresses tell the browser how to navigate the Internet to find the computer (server) it’s looking for.
Remember longitude and latitude from geography classes? They specifically define a geographical point on planet Earth, and are cross-country compatible, meaning anyone from anywhere will know how to a find a location if you give them the latitude and longitude values; however, we also have a human-friendly description for the most popular coordinates. For example, the name of the town I went to university in is Rijeka. Not many people will know where to find it on a map, but if I give them the coordinates (45.3167° N, 14.4167° E), they can easily locate it. A DNS server is a translator, a guide. This server knows which IP addresses match which domain name, and tells the browser where to go next.
Once redirected to a specific IP address, the browser knocks on the door of the hosting server. This particular server was mentioned in the previous section, and we refer to it only as “the server.” The browser brings with it the information that the user requested and asks the server for an answer to the question “google.com?”. The server answers: “Yes, under google.com, the file says ...” and gives the answer. The browser returns to the user (the king) and conveys the information. This part is what’s important for us developers―telling the server what answer to give for a specific question. Remember this part.
Front-end and Back-end
It’s time to define two more terms you must have heard at least once. Front-end development (also called client-side development) focuses on work with the client software, while back-end development (also called server-side development) deals with the server software.
When a server returns text to your browser (in Figure 1.2, this is the text that’s repeated to the king in the second-to-last frame) and your browser presents it to you, how that text looks and in what ways you can interact with it is front-end (or client-side) programming. When you open a website and a link is bold and a different color to the rest of the text, that change in appearance was achieved with client-side programming (HTML plus CSS). When you can drag an element around on the screen or initiate animations or sounds, it’s also achieved with client-side programming (specifically HTML and CSS accompanied by JavaScript).
Server-side programming, or back-end development, is the action of configuring the server computer and program (see the section called “What is a server?” for an explanation on this duality) to give back the appropriate data to the browser when asked. This typically means programming in a server-side language such as PHP. PHP will make some calculations or grab some data from a database, turn it into text that can be given to the browser, and the browser will take it and display it to the user.
Even though all content returned to the browser for delivery to the user is actually stored on the server, we call CSS and JavaScript “client-side” because their calculations happen in the browser. For example, if I told JavaScript to animate a square turning into a circle, the math behind the calculation will be happening in the browser. The server will only provide the formula and tell the browser: “When you take this back to your king, say it like this ...” On the other hand, server-side programming implies that all logic, calculations, formulas, and so on happen on the server, merely returning the end result. For example, if I have a website that counts the number of images uploaded by a user (such as Facebook counting the number of images in your album), this calculation will be done on the server, and only the final number will be given to the browser when it asks for this information.
To recap: front end is when you write code that is executed in the browser (HTML, CSS, JavaScript), while back end is when you write code that is executed on the server before passing the final result onto the browser. PHP, server-side JavaScript, server-side Dart, Ruby, Python, and other programming languages fit the bill.
Time to go even deeper into the rabbit hole.
Server-side Languages
This book focuses on preparing a development environment for server-side programming. We won’t be dealing with HTML, CSS, or JavaScript; there are plenty of books on those out there, and setting up a client-side development flow is complex enough on its own. Instead, we’ll be dealing exclusively with server-side preparations, as it’s very easy to start off the wrong way. Just as a speck on a balloon will grow into a large stain as it fills with air, so too can a misstep in the beginning of a programming career grow into a long-term harmful habit.
As you may already know, examples of server-side languages include PHP, Ruby, and Python. They sit as programs on the server computer, as well as the server program. These languages take certain commands from the server program, and output the result of these commands back to it. It is this output that is given to the browser when a user asks for an answer to a certain question. In a nutshell, by telling the server “When a request comes in for the example.com website, run this file through PHP”:
<?php
echo "Hello World";
... we have given it a way to produce an answer for the client. The PHP file is then run, and the content “Hello World” is generated and sent back to the server program, which is then given to the browser. The browser takes it back to the user and simply repeats “Hello World.” The browser stops short of relaying the rest of the contents of the file; the php tag <?php and the keyword echo are skipped in the output. This is because the tag <?php tells the server to “Run this file through PHP” and then, when running the file through PHP, echo tells it “Output the following phrase onscreen.”
If you’re having trouble grasping this, see Figure 1.3, which expands on Figure 1.1.
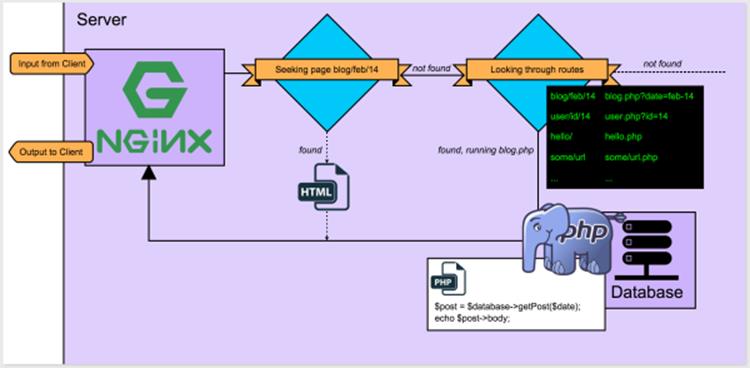
Figure 1.3. Server asks PHP for the answer if it’s unable to find one
In Figure 1.3:
· the digram represents the insides of the physical computer in Figure 1.1
· Nginx is a web server program installed on this machine
· Nginx receives input from the client in the form of a question (blog for February 14th)
· Nginx checks if there’s a page for blog/feb/14
· as there is none, Nginx checks the routes towards PHP files
· Nginx finds that it needs to run the blog.php script through PHP
· the blog.php script connects to the database and sends back the text for the given date
· the PHP engine sends this result to the server
· Nginx sends it back to the client
To recap: PHP is an answer generator for the server so it knows what answers to give to the browser’s questions. This way, the server doesn’t need to know the answers, it just knows that PHP does and asks it, then forwards the response to the browser. Imagine a “Hello YourName” page; it’s impossible to generate pages for every existing name, but we can have PHP ask for a name on one page, and then generate the answer to give to the server on another page.
What’s important to grasp here is the communication flow between client and server, and server and server-side language. This entire communication fits into the fifth and sixth frames in the comic in Figure 1.2. In fact, the part where the server program talks to the PHP program would happen entirely in the sixth frame.
Generating Answers with Server-side Languages
The last and deepest level of our rabbit hole is the actual conversation between the server program and a server-side language―in our case (and all future cases), PHP. We covered this to an extent in the previous section, but let’s look at another example now with a situation of when an answer cannot be found.
Let’s say that the server is asked the following by the client: “Can you get me whatever you have filed under example.com/user/id/54?” This is what happens next:
1. The server checks whether there’s something already prepared under the route: /user/id/54. If there are no files to be found there, it’s configured to ask PHP.
2. The server asks PHP: “Hey, can you find anything under /user/id/54?”
3. PHP activates and looks through its routes. Lo and behold, the route /user/id/54 says “activate file user.php with the parameter id of value 54.”
4. PHP executes the file (the actual logic of the file is beside the point and outside the scope of this chapter) and receives a result. Maybe the result is the email address of the 54th user in the database. This email address is then given back to the server: “Sure, I found something under that route. The answer is: johndoe@example.com”.
5. The server responds with “Thanks!” and passes this message on to the client, who then presents it to the end user―you.
However, what if there’s nothing filed under that route? For example, there is a typo when the client requests example.com/urer/id/54 (rather than “user”). Here’s what happens:
1. The server checks whether there’s anything already prepared under the route: /urer/id/54. If no files are found, it’s configured to ask PHP.
2. The server asks PHP: “Can you find anything under /urer/id/54?”
3. PHP activates and looks through its routes, but fails to unearth anything. It returns a “404 Page not found” error to the server (as in Figure 1.1, bottom-left result). As you're most probably aware, 404 is a code that's common in web technologies and means that what you're looking for is unable to be found where you think it might be. Many such status codes exist, but there's no need to know them all in this phase of your career.
4. The server receives the 404 message and thinks “Hmm, PHP lucked out. Well, it has nothing, I have nothing, better return a page to the client that says we were unsuccessful.” The browser is then given a 404 page, which is usually just a textual warning such as “Whoops, you tried a wrong link!” but can also be as intricate as you want it to be.
I trust that this chapter was clear with the concepts it presented and helped you get your bearings in terms of where you are (or will be) in the grand scheme of PHP programming. In the section that follows, you’ll find some more technical information on web requests and DNS servers.
For Those Who Want More
DNS Servers
As mentioned before, every domain (such as example.com) on the Internet is bound to a specific IP address (such as 93.184.216.34). An IP address is a set of numbers identifying a given server. In other words, IP addresses tell the browser how to navigate the Internet to find the computer (server) it's looking for. A DNS server (also known as just name server) knows which IP addresses match which domain name, and tells the browser where to go next.
When trying to find out which IP address matches a domain name, the browser first checks its own cache―a saved list of previously visited domains. Every browser maintains this list and periodically refreshes it. If it finds the domain-IP combination in its own cache, the site loads faster because there’s no need to ask the DNS server for it. If the domain isn’t cached, the browser asks a program called the resolver (which is built into your operating system) to check the hosts file on the computer it’s installed on. The hosts file is where the user can actually define which website maps to which IP address. (We’ll be learning to use this file in later chapters.) If the necessary information isn’t there, the DNS cache on the router (routers usually have one, too) is checked, and if it’s not found there either, the ISP company’s DNS server is asked.
Up until that last step, everything was happening on your own computer, or, as we say, locally. Now that it’s time to visit the ISP, it’s no longer a local matter―it’s remote. If the ISP’s DNS server is without a record for the domain, it finds out and tells the browser, then caches the results for future queries. How does it find out? It dissects the domain name from right to left.
www.example.com is split up into fragments. The .com part, called the TLD or top-level domain, is first. There are many DNS servers around the world, often configured in such a way that multiple computers act as one. This is so that if one dies, others ensure the service is uninterrupted. The highest level of these servers are root servers, which know where to further look for details about a domain on any given TLD. The root server with the appropriate records for .com will know that it's a dot com, so will send you a query further in XYZ―XYZ being another name server that will know the example part. Further still, the www part (also known as the subdomain) will come into play, and be registered on a specific name server, too, in this confusing chain of names and servers. Once all the fragments (also known as labels: .com, example, and www) are resolved into an IP address, the result is sent back.
If you’d like to know more about root name servers and want to find out how the entire Internet’s smooth functioning depends on thirteen main computers (well, clusters of computers), take a look the root name server page on Wikipedia, or check out some amazingly comprehensive answers on Super User.
What Happens When You Type ...
A common programmer job interview question is “What happens when you type google.com into your browser’s address box and press enter?” While, in part, we explained this earlier (albeit in a simplified manner), check out Alex Gaynor’s excellent description if you’d like to know the exact details, from hardware to end software. It’s an extremely comprehensive but very well-written post. Note that, realistically, this level of detailed knowledge is unnecessary to be a good developer.
All materials on the site are licensed Creative Commons Attribution-Sharealike 3.0 Unported CC BY-SA 3.0 & GNU Free Documentation License (GFDL)
If you are the copyright holder of any material contained on our site and intend to remove it, please contact our site administrator for approval.
© 2016-2026 All site design rights belong to S.Y.A.