Expert Oracle Database Architecture, Third Edition (2014)
Chapter 7. Concurrency and Multiversioning
As stated in the last chapter, one of the key challenges in developing multiuser, database-driven applications is to maximize concurrent access but, at the same time, ensure that each user is able to read and modify the data in a consistent fashion. In this chapter, we’re going to take a detailed look at how Oracle achieves multiversion read consistency and what that means to you, the developer. I will also introduce a new term, write consistency, and use it to describe how Oracle works not only in a read environment with read consistency, but also in a mixed read and write environment.
What Are Concurrency Controls?
Concurrency controls are the collection of functions that the database provides to allow many people to access and modify data simultaneously. As noted in the previous chapter, the lock is one of the core mechanisms by which Oracle regulates concurrent access to shared database resources and prevents interference between concurrent database transactions. To briefly summarize, Oracle uses a variety of locks, including the following:
· TX (Transaction) locks: These locks are acquired for the duration of a data-modifying transaction.
· TM (DML Enqueue) and DDL locks: These locks ensure that the structure of an object is not altered while you are modifying its contents (TM lock) or the object itself (DDL lock).
· Latches and Mutexes: These are internal locks that Oracle employs to mediate access to its shared data structures. We’ll refer to both as Latches in this chapter, although they might be implemented by a Mutex on your operating system, depending on the Oracle version.
In each case, there is minimal overhead associated with lock acquisition. TX transaction locks are extremely scalable both in terms of performance and cardinality. TM and DDL locks are applied in the least restrictive mode whenever possible. Latches and enqueues are both very lightweight and fast (enqueues are slightly the heavier of the two, though more feature-rich). Problems only arise from poorly designed applications that hold locks for longer than necessary and cause blocking in the database. If you design your code well, Oracle’s locking mechanisms will allow for scalable, highly concurrent applications.
![]() Note I used the phrase “longer than necessary.” That does not mean you should attempt to commit (end your transaction) as soon as possible. Transactions should be exactly as long as they need to be—and no longer than that. That is, your transaction is your unit of work; it is all or nothing. You should commit when your unit of work is complete and not before—and not any later either!
Note I used the phrase “longer than necessary.” That does not mean you should attempt to commit (end your transaction) as soon as possible. Transactions should be exactly as long as they need to be—and no longer than that. That is, your transaction is your unit of work; it is all or nothing. You should commit when your unit of work is complete and not before—and not any later either!
But Oracle’s support for concurrency goes beyond efficient locking. It implements a multiversioning architecture (introduced in Chapter 1) that provides controlled yet highly concurrent access to data. Multiversioning describes Oracle’s ability to simultaneously materialize multiple versions of the data and is the mechanism by which Oracle provides read-consistent views of data (i.e., consistent results with respect to a point in time). A rather pleasant side effect of multiversioning is that a reader of data will never be blocked by a writer of data. In other words, writes do not block reads. This is one of the fundamental differences between Oracle and other databases. A query that only reads information in Oracle will never be blocked; it will never deadlock with another session, and it will never get an answer that didn’t exist in the database.
![]() Note There is a short period of time during the processing of a distributed Two Phase Commit where Oracle will prevent read access to information. As this processing is somewhat rare and exceptional (the problem applies only to queries that start between the prepare and the commit phases and try to read the data before the commit arrives), I will not cover it in detail.
Note There is a short period of time during the processing of a distributed Two Phase Commit where Oracle will prevent read access to information. As this processing is somewhat rare and exceptional (the problem applies only to queries that start between the prepare and the commit phases and try to read the data before the commit arrives), I will not cover it in detail.
Oracle’s multiversioning model for read consistency is applied by default at the statement level (for each and every query) and can also be applied at the transaction level. This means that each and every SQL statement submitted to the database sees a read-consistent view of the database, at least—and if you would like this read-consistent view of the database to be at the level of a transaction (a set of SQL statements), you may do that as well, as we’ll see in the “Serializable” section in this chapter.
The basic purpose of a transaction in the database is to take the database from one consistent state to the next. The ISO SQL standard specifies various transaction isolation levels, which define how sensitive one transaction is to changes made by another. The greater the level of sensitivity, the greater the degree of isolation the database must provide between transactions executed by your application. In the following section, we’ll look at how, via its multiversioning architecture and with absolutely minimal locking, Oracle can support each of the defined isolation levels.
Transaction Isolation Levels
The ANSI/ISO SQL standard defines four levels of transaction isolation, with different possible outcomes for the same transaction scenario. That is, the same work performed in the same fashion with the same inputs may result in different answers, depending on your isolation level. These isolation levels are defined in terms of three “phenomena” that are either permitted or not at a given isolation level:
· Dirty read: The meaning of this term is as bad as it sounds. You are permitted to read uncommitted, or dirty, data. You would achieve this effect by just opening an OS file that someone else is writing and reading whatever data happens to be there. Data integrity is compromised, foreign keys are violated, and unique constraints are ignored.
· Nonrepeatable read: This simply means that if you read a row at time T1 and attempt to reread that row at time T2, the row may have changed, or it may have disappeared, or it may have been updated, and so on.
· Phantom read: This means that if you execute a query at time T1 and re-execute it at time T2, additional rows may have been added to the database, which will affect your results. This differs from the nonrepeatable read in that with a phantom read, data you already read has not been changed, but rather that more data satisfies your query criteria than before.
![]() Note The ANSI/ISO SQL standard defines transaction-level characteristics, not just individual statement-by-statement–level characteristics. In the following pages, we’ll examine transaction-level isolation, not just statement-level isolation.
Note The ANSI/ISO SQL standard defines transaction-level characteristics, not just individual statement-by-statement–level characteristics. In the following pages, we’ll examine transaction-level isolation, not just statement-level isolation.
The SQL isolation levels are defined based on whether or not they allow each of the preceding phenomena. I find it interesting to note that the SQL standard does not impose a specific locking scheme or mandate particular behaviors, but rather describes these isolation levels in terms of these phenomena, allowing for many different locking/concurrency mechanisms to exist (see Table 7-1).
Table 7-1. ANSI Isolation Levels
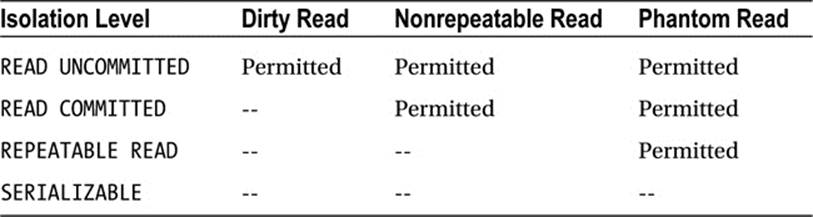
Oracle explicitly supports the READ COMMITTED and SERIALIZABLE isolation levels as they are defined in the standard. However, this doesn’t tell the whole story. The SQL standard was attempting to set up isolation levels that would permit various degrees of consistency for queries performed in each level. REPEATABLE READ is the isolation level that the SQL standard claims will guarantee a read-consistent result from a query. In their definition, READ COMMITTED does not give you consistent results, and READ UNCOMMITTED is the level to use to get nonblocking reads.
However, in Oracle, READ COMMITTED has all of the attributes required to achieve read-consistent queries. In many other databases, READ COMMITTED queries can and will return answers that never existed in the database at any point in time. Moreover, Oracle also supports the spiritof READ UNCOMMITTED. The goal of providing a dirty read is to supply a nonblocking read, whereby queries are not blocked by, and do not block, updates of the same data. However, Oracle does not need dirty reads to achieve this goal, nor does it support them. Dirty reads are an implementation other databases must use in order to provide nonblocking reads.
In addition to the four defined SQL isolation levels, Oracle provides another level, namely READ ONLY. A READ ONLY transaction is equivalent to a REPEATABLE READ or SERIALIZABLE transaction that can’t perform any modifications in SQL. A transaction using a READ ONLYisolation level only sees those changes that were committed at the time the transaction began, but inserts, updates, and deletes are not permitted in this mode (other sessions may update data, but not the READ ONLY transaction). Using this mode, you can achieve REPEATABLE READ andSERIALIZABLE levels of isolation.
Let’s now move on to discuss exactly how multiversioning and read consistency fit into the isolation scheme and how databases that do not support multiversioning achieve the same results. This information is instructive for anyone who has used another database and believes she understands how the isolation levels must work. It is also interesting to see how a standard that was supposed to remove the differences between the databases, ANSI/ISO SQL, actually allows for them. The standard, while very detailed, can be implemented in very different ways.
READ UNCOMMITTED
The READ UNCOMMITTED isolation level allows dirty reads. Oracle does not make use of dirty reads, nor does it even allow for them. The basic goal of a READ UNCOMMITTED isolation level is to provide a standards-based definition that caters for nonblocking reads. As we have seen, Oracle provides for nonblocking reads by default. You would be hard-pressed to make a SELECT query block in the database (as noted earlier, there is the special case of a distributed transaction). Every single query, be it a SELECT, INSERT, UPDATE, MERGE, or DELETE, executes in a read-consistent fashion. It might seem funny to refer to an UPDATE statement as a query, but it is. UPDATE statements have two components: a read component as defined by the WHERE clause and a write component as defined by the SET clause. UPDATE statements read and write to the database; all DML statements have this ability. The case of a single row INSERT using the VALUES clause is the only exception, as such statements have no read component, just the write component.
In Chapter 1, Oracle’s method of obtaining read consistency was demonstrated by way of a simple single table query that retrieved rows that were deleted after the cursor was opened. We’re now going to explore a real-world example to see what happens in Oracle using multiversioning, as well as what happens in any number of other databases.
Let’s start with the same basic table and query:
create table accounts
( account_number number primary key,
account_balance number not null
);
select sum(account_balance) from accounts;
Before the query begins, assume we have the data shown in Table 7-2.
Table 7-2. ACCOUNTS Table Before Modifications
|
Row |
Account Number |
Account Balance |
|
1 |
123 |
$500.00 |
|
2 |
456 |
$240.25 |
|
. . . |
. . . |
. . . |
|
342,023 |
987 |
$100.00 |
Now, our select statement starts executing and reads row 1, row 2, and so on.
![]() Note I do not mean to imply that rows have any sort of physical ordering on disk in this example. There really is not a first row, second row, or last row in a table. There is just a set of rows. We are assuming here that row 1 really means “the first row we happened to read” and row 2 is the second row we happened to read and so on.
Note I do not mean to imply that rows have any sort of physical ordering on disk in this example. There really is not a first row, second row, or last row in a table. There is just a set of rows. We are assuming here that row 1 really means “the first row we happened to read” and row 2 is the second row we happened to read and so on.
At some point while we are in the middle of the query, a transaction moves $400.00 from account 123 to account 987. This transaction does the two updates but does not commit. The table now looks as shown in Table 7-3.
Table 7-3. ACCOUNTS Table During Modifications

So, two of those rows are locked. If anyone tried to update them, that user would be blocked. So far, the behavior we are seeing is more or less consistent across all databases. The difference will be in what happens when the query gets to the locked data.
When the query we are executing gets to the block containing the locked row (row 342,023) at the bottom of the table, it will notice that the data in it has changed since the time at which it started execution. To provide a consistent (correct) answer, Oracle will at this point create a copy of the block containing this row as it existed when the query began. That is, it will read a value of $100.00, the value that existed at the time the query began. Effectively, Oracle takes a detour around the modified data; it reads around it, reconstructing it from the undo segment (also known as arollback segment; discussed in detail in Chapter 9). A consistent and correct answer comes back without waiting for the transaction to commit.
Now, a database that allowed a dirty read would simply return the value it saw in account 987 at the time it read it, in this case $500.00. The query would count the transferred $400 twice. Therefore, not only does it return the wrong answer, but also it returns a total that never existed in the table at any committed point in time. In a multiuser database, a dirty read can be a dangerous feature and, personally, I have never seen the usefulness of it. Say that, rather than transferring, the transaction was actually just depositing $400.00 in account 987. The dirty read would count the $400.00 and get the “right” answer, wouldn’t it? Well, suppose the uncommitted transaction was rolled back. We have just counted $400.00 that was never actually in the database.
The point here is that dirty read is not a feature; rather, it is a liability. In Oracle, it is just not needed. You get all of the advantages of a dirty read (no blocking) without any of the incorrect results.
READ COMMITTED
The READ COMMITTED isolation level states that a transaction may only read data that has been committed in the database. There are no dirty reads. There may be nonrepeatable reads (i.e., rereads of the same row may return a different answer in the same transaction) and phantom reads (i.e., newly inserted and committed rows become visible to a query that were not visible earlier in the transaction). READ COMMITTED is perhaps the most commonly used isolation level in database applications everywhere, and it is the default mode for Oracle databases, it is rare to see a different isolation level used.
However, achieving READ COMMITTED isolation is not as cut-and-dried as it sounds. If you look at Table 7-1, it looks straightforward. Obviously, given the earlier rules, a query executed in any database using the READ COMMITTED isolation will behave in the same way, will it not? It will not. If you query multiple rows in a single statement, in almost every other database, READ COMMITTED isolation can be as bad as a dirty read, depending on the implementation.
In Oracle, using multiversioning and read-consistent queries, the answer we get from the ACCOUNTS query is the same in READ COMMITTED as it was in the READ UNCOMMITTED example. Oracle will reconstruct the modified data as it appeared when the query began, returning the answer that was in the database when the query started.
Let’s now take a look at how our previous example might work in READ COMMITTED mode in other databases—you might find the answer surprising. We’ll pick up our example at the point described in the previous table:
· We are in the middle of the table. We have read and summed the first N rows.
· The other transaction has moved $400.00 from account 123 to account 987.
· The transaction has not yet committed, so rows containing the information for accounts 123 and 987 are locked.
We know what happens in Oracle when it gets to account 987—it will read around the modified data, find out it should be $100.00, and complete. Table 7-4 shows how another database, running in some default READ COMMITTED mode, might arrive at the answer.
Table 7-4. Timeline in a Non-Oracle Database Using READ COMMITTED Isolation
|
Time |
Query |
Account Transfer Transaction |
|
T1 |
Reads row 1, account 123, value=$500. Sum=$500.00 so far. |
-- |
|
T2 |
Reads row 2, account 456, value=$240.25. Sum=$740.25 so far. |
-- |
|
T3 |
-- |
Updates row 1 (account 123) and puts an exclusive lock on row 1, preventing other updates and reads. Row 1 had $500.00, now it has $100.00. |
|
T4 |
Reads row N. Sum = . . . |
-- |
|
T5 |
-- |
Updates row 342,023 (account 987) and puts an exclusive lock on this row. This row had $100, now it has $500.00. |
|
T6 |
Tries to read row 342,023, account 987. Discovers that it is locked. This session will block and wait for this row’s block to become available. All processing on this query stops. |
-- |
|
T7 |
-- |
Commits transaction. |
|
T8 |
Reads row 342,023, account 987, sees $500.00, and presents a final answer that includes the $400.00 double-counted. |
-- |
The first thing to notice is that this other database, upon getting to account 987, will block our query. This session must wait on that row until the transaction holding the exclusive lock commits. This is one reason why many people have a bad habit of committing every statement, instead of processing well-formed transactions consisting of all of the statements needed to take the database from one consistent state to the next. Updates interfere with reads in most other databases. The really bad news in this scenario is that we are making the end user wait for the wrong answer. We still receive an answer that never existed in the committed database state at any point in time, as with the dirty read, but this time we made the user wait for the wrong answer. In the next section, we’ll look at what these other databases need to do to achieve read-consistent, correct results.
The important lesson here is that various databases executing in the same, apparently safe isolation level can and will return very different answers under the exact same circumstances. It is important to understand that, in Oracle, nonblocking reads are not had at the expense of correct answers. You can have your cake and eat it too, sometimes.
REPEATABLE READ
The goal of REPEATABLE READ is to provide an isolation level that gives consistent, correct answers and prevents lost updates. We’ll take a look at examples of both, see what we have to do in Oracle to achieve these goals, and examine what happens in other systems.
Getting a Consistent Answer
If we have a REPEATABLE READ isolation, the results from a given query must be consistent with respect to some point in time. Most databases (not Oracle) achieve repeatable reads via the use of row-level shared read locks. A shared read lock prevents other sessions from modifying data that we have read. This, of course, decreases concurrency. Oracle opted for the more concurrent, multiversioning model to provide read-consistent answers.
In Oracle, using multiversioning, we get an answer that is consistent with respect to the point in time the query began execution. In other databases, using shared read locks, we get an answer that is consistent with respect to the point in time the query completes—that is, when we can get the answer at all (more on this in a moment).
In a system that employs a shared read lock to provide repeatable reads, we would observe rows in a table getting locked as the query processed them. So, using the earlier example, as our query reads the ACCOUNTS table, it would leave shared read locks on each row, as shown in Table 7-5.
Table 7-5. Timeline 1 in Non-Oracle Database Using READ REPEATABLE Isolation
|
Time |
Query |
Account Transfer Transaction |
|
T1 |
Reads row 1. Sum=$500.00 so far. Row 1 has a shared read lock on it. |
-- |
|
T2 |
Reads row 2. Sum=$740.25 so far. Row 2 has a shared read lock on it. |
-- |
|
T3 |
-- |
Attempts to update row 1 but is blocked. Transaction is suspended until it can obtain an exclusive lock. |
|
T4 |
Reads row N. Sum = . . . |
-- |
|
T5 |
Reads row 342,023, sees $100.00, and presents final answer. |
-- |
|
T6 |
Commits transaction. |
-- |
|
T7 |
-- |
Updates row 1 and puts an exclusive lock on this row. Row now has $100.00. |
|
T8 |
-- |
Updates row 342,023 and puts an exclusive lock on this row. Row now has $500.00. Commits transaction. |
Table 7-5 shows that we now get the correct answer, but at the cost of physically blocking one transaction and executing the two transactions sequentially. This is one of the side effects of shared read locks for consistent answers: readers of data will block writers of data. This is in addition to the fact that, in these systems, writers of data will block readers of data. Imagine if automatic teller machines (ATMs) worked this way in real life.
So, you can see how shared read locks would inhibit concurrency, but they can also cause spurious errors to occur. In Table 7-6, we start with our original table, but this time with the goal of transferring $50.00 from account 987 to account 123.
Table 7-6. Timeline 2 in Non-Oracle Database Using READ REPEATABLE Isolation
|
Time |
Query |
Account Transfer Transaction |
|
T1 |
Reads row 1. Sum=$500.00 so far. Row 1 has a shared read lock on it. |
-- |
|
T2 |
Reads row 2. Sum=$740.25 so far. Row 2 has a shared read lock on it. |
-- |
|
T3 |
-- |
Updates row 342,023 and puts an exclusive lock on row 342,023, preventing other updates and shared read locks. This row now has $50.00. |
|
T4 |
Reads row N. Sum = . . . |
-- |
|
T5 |
-- |
Attempts to update row 1 but is blocked. Transaction is suspended until it can obtain an exclusive lock. |
|
T6 |
Attempts to read row 342,023 but can’t as an exclusive lock is already in place. |
-- |
We have just reached the classic deadlock condition. Our query holds resources the update needs and vice versa. Our query has just deadlocked with our update transaction. One of them will be chosen as the victim and will be killed. We just spent a long time and a lot of resources only to fail and get rolled back at the end. This is the second side effect of shared read locks: readers and writers of data can and frequently will deadlock each other.
In Oracle, we have statement-level read consistency without reads blocking writes or deadlocks. Oracle never uses shared read locks—ever. Oracle has chosen the harder-to-implement but infinitely more concurrent multiversioning scheme.
Lost Updates: Another Portability Issue
A common use of REPEATABLE READ in databases that employ the shared read locks could be for lost update prevention.
![]() Note Lost update detection and solutions to the lost update problem are discussed in Chapter 6.
Note Lost update detection and solutions to the lost update problem are discussed in Chapter 6.
If we have REPEATABLE READ enabled in a database that employs shared read locks (and not multiversioning), lost update errors can’t happen. The reason lost updates will not happen in those databases is because the simple act of selecting the data leaves a lock on it, and once read by our transaction, that data cannot be modified by any other transaction. Now, if your application assumes that REPEATABLE READ implies “lost updates can’t happen,” you are in for a painful surprise when you move your application to a database that does not use shared read locks as an underlying concurrency control mechanism.
![]() Note In a stateless environment, such as a web-based application, lost updates would likely be a cause for concern—even in REPEATABLE READ isolation. This is because a single database session is used by many clients via a connection pool and locks are not held across calls.REPEATABLE READ isolation only prevents lost updates in a stateful environment, such as that observed with a client-server application.
Note In a stateless environment, such as a web-based application, lost updates would likely be a cause for concern—even in REPEATABLE READ isolation. This is because a single database session is used by many clients via a connection pool and locks are not held across calls.REPEATABLE READ isolation only prevents lost updates in a stateful environment, such as that observed with a client-server application.
While this sounds good, you must remember that leaving the shared read locks behind on all data as it is read will, of course, severely limit concurrent reads and modifications. So, while this isolation level in those databases provides for lost update prevention, it does so by removing the ability to perform concurrent operations! You can’t always have your cake and eat it too.
SERIALIZABLE
This is generally considered the most restrictive level of transaction isolation, but it provides the highest degree of isolation. A SERIALIZABLE transaction operates in an environment that makes it appear as if there are no other users modifying data in the database. Any row we read is assured to be the same upon a reread, and any query we execute is guaranteed to return the same results for the life of a transaction. For example, if we execute the following, the answers returned from T would be the same, even though we just slept for 24 hours (or we might get an ORA-01555, snapshot too old error, which is discussed in Chapter 8):
Select * from T;
Begin dbms_lock.sleep( 60*60*24 ); end;
Select * from T;
The isolation level SERIALIZABLE assures us these two queries will always return the same results. Side effects (changes) made by other transactions are not visible to the query regardless of how long it has been running.
In Oracle, a SERIALIZABLE transaction is implemented so that the read consistency we normally get at the statement level is extended to the transaction.
![]() Note As noted earlier, there is also an isolation level in Oracle denoted READ ONLY. It has all of the qualities of the SERIALIZABLE isolation level, but it prohibits modifications. It should be noted that the SYS user (or users connected with the SYSDBA privilege) can’t have a READ ONLY or SERIALIZABLE transaction. SYS is special in this regard.
Note As noted earlier, there is also an isolation level in Oracle denoted READ ONLY. It has all of the qualities of the SERIALIZABLE isolation level, but it prohibits modifications. It should be noted that the SYS user (or users connected with the SYSDBA privilege) can’t have a READ ONLY or SERIALIZABLE transaction. SYS is special in this regard.
Instead of results being consistent with respect to the start of a statement, they are preordained at the time you begin the transaction. In other words, Oracle uses the undo segments to reconstruct the data as it existed when our transaction began, instead of just when our statement began.
That’s a pretty deep thought there: the database already knows the answer to any question you might ask it, before you ask it.
This degree of isolation comes with a price, and that price is the following possible error:
ERROR at line 1:
ORA-08177: can't serialize access for this transaction
You will get this message whenever you attempt to update a row that has changed since your transaction began.
![]() Note Oracle attempts to do this purely at the row level, but you may receive an ORA-08177 error even when the row you are interested in modifying has not been modified. The ORA-08177 error may happen due to some other row(s) being modified on the block that contains your row.
Note Oracle attempts to do this purely at the row level, but you may receive an ORA-08177 error even when the row you are interested in modifying has not been modified. The ORA-08177 error may happen due to some other row(s) being modified on the block that contains your row.
Oracle takes an optimistic approach to serialization—it gambles on the fact that the data your transaction wants to update won’t be updated by any other transaction. This is typically the way it happens, and usually the gamble pays off, especially in quick-transaction, OLTP-type systems. If no one else updates your data during your transaction, this isolation level, which will generally decrease concurrency in other systems, will provide the same degree of concurrency as it would without SERIALIZABLE transactions. The downside to this is that you may get the ORA-08177error if the gamble doesn’t pay off. If you think about it, however, it’s worth the risk. If you’re using SERIALIZABLE transactions, you shouldn’t expect to update the same information as other transactions. If you do, you should use the SELECT ... FOR UPDATE as described inChapter 1, and this will serialize the access. So, using an isolation level of SERIALIZABLE will be achievable and effective if you:
· Have a high probability of no one else modifying the same data.
· Need transaction-level read consistency.
· Will be doing short transactions (to help make the first bullet point a reality).
Oracle finds this method scalable enough to run all of their TPC-Cs (an industry standard OLTP benchmark; see http://www.tpc.org for details). In many other implementations, you will find this being achieved with shared read locks and their corresponding deadlocks, and blocking. In Oracle, we do not get any blocking, but we will get the ORA-08177 error if other sessions change the data we want to change as well. However, we will not get the error as frequently as we will get deadlocks and blocks in the other systems.
But—there is always a “but”—you must take care to understand these different isolation levels and their implications. Remember, with isolation set to SERIALIZABLE, you will not see any changes made in the database after the start of your transaction, until you commit. Applications that attempt to enforce their own data integrity constraints, such as the resource scheduler described in Chapter 1, must take extra care in this regard. If you recall, the problem in Chapter 1 was that we could not enforce our integrity constraint in a multiuser system since we could not see changes made by other uncommitted sessions. Using SERIALIZABLE, we would still not see the uncommitted changes, but we would also not see the committed changes made after our transaction began!
As a final point, be aware that SERIALIZABLE does not mean that all transactions executed by users will behave as if they were executed one right after another in a serial fashion. It does not imply that there is some serial ordering of the transactions that will result in the same outcome. The phenomena previously described by the SQL standard do not make this happen. This last point is a frequently misunderstood concept, and a small demonstration will clear it up. The following table represents two sessions performing work over time. The database tables A and B start out empty and are created as follows:
EODA@ORA12CR1> create table a ( x int );
Table created.
EODA@ORA12CR1> create table b ( x int );
Table created.
Now we have the series of events shown in Table 7-7.
Table 7-7. SERIALIZABLE Transaction Example
|
Time |
Session 1 Executes |
Session 2 Executes |
|
T1 |
Alter session set isolation_level=serializable; |
-- |
|
T2 |
-- |
Alter session set isolation_level=serializable; |
|
T3 |
Insert into a select count(*) from b; |
-- |
|
T4 |
-- |
Insert into b select count(*) from a; |
|
T5 |
Commit; |
-- |
|
T6 |
-- |
Commit; |
Now, when this is all said and done, tables A and B will each have a row with the value 0 in it. If there were some serial ordering of the transactions, we could not possibly have both tables containing the value 0 in them. If session 1 executed in its entirety before session 2, then table Bwould have a row with the value 1 in it. If session 2 executed in its entirety before session 1, then table A would have a row with the value 1 in it. As executed here, however, both tables will have rows with a value of 0. They just executed as if they were the only transaction in the database at that point in time. No matter how many times session 1 queries table B and no matter the committed state of session 2, the count will be the count that was committed in the database at time T1. Likewise, no matter how many times session 2 queries table A, the count will be the same as it was at time T2.
READ ONLY
READ ONLY transactions are very similar to SERIALIZABLE transactions, the only difference being that they do not allow modifications, so they are not susceptible to the ORA-08177 error. READ ONLY transactions are intended to support reporting needs where the contents of the report need to be consistent with respect to a single point in time. In other systems, you would use REPEATABLE READ and suffer the associated effects of the shared read lock. In Oracle, you will use the READ ONLY transaction. In this mode, the output you produce in a report that uses 50SELECT statements to gather the data will be consistent with respect to a single point in time—the time the transaction began. You will be able to do this without locking a single piece of data anywhere.
This aim is achieved by using the same multiversioning as used for individual statements. The data is reconstructed as needed from the undo segments and presented to you as it existed when the report began. READ ONLY transactions are not trouble-free, however. Whereas you might see an ORA-08177 error in a SERIALIZABLE transaction, you expect to see an ORA-01555 snapshot too old error with READ ONLY transactions. This will happen on a system where other people are actively modifying the information you are reading. The changes (undo) made to this information are recorded in the undo segments. But undo segments are used in a circular fashion in much the same manner as redo logs. The longer the report takes to run, the better the chance that some undo you need to reconstruct your data won’t be there anymore. The undo segment will have wrapped around, and the portion of it you need would be reused by some other transaction. At this point, you will receive the ORA-01555 error and have to start over again.
The only solution to this sticky issue is to have the undo tablespace sized correctly for your system. Time and time again, I see people trying to save a few megabytes of disk space by having the smallest possible undo tablespace (“Why ‘waste’ space on something I don’t really need?” is the thought). The problem is that the undo tablespace is a key component of the way the database works, and unless it is sized correctly, you will hit this error. In many years of using Oracle 6, 7, 8, 9, 10, 11, and 12, I can say I have never hit an ORA-01555 error outside of a testing or development system. In such a case, you know you have not sized the undo tablespace correctly and you fix it. We will revisit this issue in Chapter 9.
Implications of Multiversion Read Consistency
So far, we’ve seen how multiversioning provides us with nonblocking reads, and I have stressed that this is a good thing: consistent (correct) answers with a high degree of concurrency. What could be wrong with that? Well, unless you understand that it exists and what it implies, then you are probably doing some of your transactions incorrectly. Recall from Chapter 1 the scheduling resources example whereby we had to employ some manual locking techniques (via SELECT FOR UPDATE to serialize modifications to the SCHEDULES table by resource). But can it affect us in other ways? The answer to that is definitely yes. We’ll go into the specifics in the sections that follow.
A Common Data Warehousing Technique That Fails
A common data warehousing technique I’ve seen people employ goes like this:
1. They use a trigger to maintain a LAST_UPDATED column in the source table, much like the method described in the last chapter in the “Optimistic Locking” section.
2. To initially populate a data warehouse table, they remember what time it is right now by selecting out SYSDATE on the source system. For example, suppose it is exactly 9:00 a.m. right now.
3. They then pull all of the rows from the transactional system—a full SELECT * FROM TABLE—to get the data warehouse initially populated.
4. To refresh the data warehouse, they remember what time it is right now again. For example, suppose an hour has gone by—it is now 10:00 a.m. on the source system. They will remember that fact. They then pull all changed records since 9:00 a.m. (the moment before they started the first pull) and merge them in.
![]() Note This technique may pull the same record twice in two consecutive refreshes. This is unavoidable due to the granularity of the clock. A MERGE operation will not be affected by this (i.e., update existing record in the data warehouse or insert a new record).
Note This technique may pull the same record twice in two consecutive refreshes. This is unavoidable due to the granularity of the clock. A MERGE operation will not be affected by this (i.e., update existing record in the data warehouse or insert a new record).
They believe that they now have all of the records in the data warehouse that were modified since they did the initial pull. They may actually have all of the records, but just as likely they may not. This technique does work on some other databases—ones that employ a locking system whereby reads are blocked by writes and vice versa. But in a system where you have nonblocking reads, the logic is flawed.
To see the flaw in this example, all we need to do is assume that at 9:00 a.m. there was at least one open, uncommitted transaction. At 8:59:30 a.m., it had updated a row in the table we were to copy. At 9:00 a.m., when we started pulling the data and thus reading the data in this table, we would not see the modifications to that row; we would see the last committed version of it. If it was locked when we got to it in our query, we would read around the lock. If it was committed by the time we got to it, we would still read around it since read consistency permits us to read only data that was committed in the database when our statement began. We would not read that new version of the row during the 9:00 a.m. initial pull, nor would we read the modified row during the 10:00 a.m. refresh. The reason? The 10:00 a.m. refresh would only pull records modified since 9:00 a.m. that morning, but this record was modified at 8:59:30 a.m. We would never pull this changed record.
In many other databases where reads are blocked by writes and a committed but inconsistent read is implemented, this refresh process would work perfectly. If at 9:00 a.m. when we did the initial pull of data, we hit that row and it was locked, we would have blocked and waited for it, and read the committed version. If it were not locked, we would just read whatever was there, committed.
So, does this mean the preceding logic just cannot be used? No, it means that we need to get the “right now” time a little differently. We need to query V$TRANSACTION and find out which is the earliest of the current time and the time recorded in START_TIME column of this view. We will need to pull all records changed since the start time of the oldest transaction (or the current SYSDATE value if there are no active transactions):
select nvl( min(to_date(start_time,'mm/dd/rr hh24:mi:ss')),sysdate)
from v$transaction;
![]() Note The preceding query works regardless of the presence of any data in V$TRANSACTION. That is, even if V$TRANSACTION is empty (because there are no transactions currently), this query returns a record. A query that has an aggregate with no WHERE clause always returns at leastone row and at most one row.
Note The preceding query works regardless of the presence of any data in V$TRANSACTION. That is, even if V$TRANSACTION is empty (because there are no transactions currently), this query returns a record. A query that has an aggregate with no WHERE clause always returns at leastone row and at most one row.
In this example, that would be 8:59:30 a.m. when the transaction that modified the row started. When we go to refresh the data at 10:00 a.m., we pull all of the changes that had occurred since that time; when we merge these into the data warehouse, we’ll have everything we need.
An Explanation for Higher Than Expected I/O on Hot Tables
Another situation where it is vital that you understand read consistency and multiversioning is when you are faced with a query that in production, under a heavy load, uses many more I/Os than you observe in your test or development systems, and you have no way to account for it. You review the I/O performed by the query and note that it is much higher than you have ever seen—much higher than seems possible. You restore the production instance on test and discover that the I/O is way down. But in production, it is still very high (but seems to vary: sometimes it is high, sometimes it is low, and sometimes it is in the middle). The reason, as we’ll see, is that in your test system, in isolation, you do not have to undo other transactions’ changes. In production, however, when you read a given block, you might have to undo (roll back) the changes of many transactions, and each rollback could involve I/O to retrieve the undo and apply it.
This is probably a query against a table that has many concurrent modifications taking place; you are seeing the reads to the undo segment taking place, the work that Oracle is performing to restore the block back the way it was when your query began. You can see the effects of this easily in a single session, just to understand what is happening. We’ll start with a very small table:
EODA@ORA12CR1> create table t ( x int );
Table created.
EODA@ORA12CR1> insert into t values ( 1 );
1 row created.
EODA@ORA12CR1> exec dbms_stats.gather_table_stats( user, 'T' );
PL/SQL procedure successfully completed.
EODA@ORA12CR1> select * from t;
X
----------
1
Now we’ll set our session to use the SERIALIZABLE isolation level, so that no matter how many times we run a query in our session, the results will be “as of” that transaction’s start time:
EODA@ORA12CR1> alter session set isolation_level=serializable;
Session altered.
Now, we’ll query that small table and observe the amount of I/O performed:
EODA@ORA12CR1> set autotrace on statistics
EODA@ORA12CR1> select * from t;
X
----------
1
Statistics
----------------------------------------------------------
0 recursive calls
0 db block gets
7 consistent gets
...
So, that query took seven I/Os (consistent gets) in order to complete. In another session, we’ll modify this table repeatedly:
EODA@ORA12CR1> begin
2 for i in 1 .. 10000
3 loop
4 update t set x = x+1;
5 commit;
6 end loop;
7 end;
8 /
PL/SQL procedure successfully completed.
And returning to our SERIALIZABLE session, we’ll rerun the same query:
EODA@ORA12CR1> select * from t;
X
----------
1
Statistics
----------------------------------------------------------
0 recursive calls
0 db block gets
10004 consistent gets
...
It did 10,004 I/Os that time—a marked difference. So, where did all of the I/O come from? That was Oracle rolling back the changes made to that database block. When we ran the second query, Oracle knew that all of the blocks retrieved and processed by that query had to be “as of” the start time of the transaction. When we got to the buffer cache, we discovered that the block in the cache was simply “too new”—the other session had modified it some 10,000 times. Our query could not see those changes, so it started walking the undo information and undid the last change. It discovered this rolled back block was still too new and did another rollback of the block. It did this repeatedly until finally it found the version of the block that was committed in the database when our transaction began. That was the block we may use—and did use.
![]() Note Interestingly, if you were to rerun the SELECT * FROM T, you would likely see the I/O go back down to 7 or so again; it would not be 10,004. The reason? Oracle has the ability to store multiple versions of the same block in the buffer cache. When you undid the changes to this block for the query that did 10,004 IOs, you left that version in the cache, and subsequent executions of your query are able to access it.
Note Interestingly, if you were to rerun the SELECT * FROM T, you would likely see the I/O go back down to 7 or so again; it would not be 10,004. The reason? Oracle has the ability to store multiple versions of the same block in the buffer cache. When you undid the changes to this block for the query that did 10,004 IOs, you left that version in the cache, and subsequent executions of your query are able to access it.
So, do we only encounter this problem when using the SERIALIZABLE isolation level? No, not at all. Consider a query that runs for five minutes. During the five minutes the query is running, it is retrieving blocks from the buffer cache. Every time it retrieves a block from the buffer cache, it will perform this check: “Is the block too new? If so, roll it back.” And remember, the longer the query runs, the higher the chance that a block it needs has been modified over time.
Now, the database is expecting this check to happen (i.e., to see if a block is “too new” and the subsequent rolling back of the changes), and for just such a reason, the buffer cache may actually contain multiple versions of the same block in memory. In that fashion, chances are that a version you require will be there, ready and waiting to go, instead of having to be materialized using the undo information. A query such as the following may be used to view these blocks:
select file#, block#, count(*)
from v$bh
group by file#, block#
having count(*) > 3
order by 3
/
In general, you will find no more than about six versions of a block in the cache at any point in time, but these versions can be used by any query that needs them.
It is generally these small hot tables that run into the issue of inflated I/Os due to read consistency. Other queries most often affected by this issue are long-running queries against volatile tables. The longer they run, the longer they run, because over time they may have to perform more work to retrieve a block from the buffer cache.
Write Consistency
So far, we’ve looked at read consistency: Oracle’s ability to use undo information to provide nonblocking query and consistent (correct) reads. We understand that as Oracle reads blocks for queries out of the buffer cache, it will ensure that the version of the block is “old” enough to be seen by that query.
But that begs the following questions: What about writes/modifications? What happens when you run an UPDATE statement, as follows, and while that statement is running, someone updates a row it has yet to read from Y=5 to Y=6 and commits?
Update t Set x = 2 Where y = 5;
That is, when your UPDATE began, some row had the value Y=5. As your UPDATE reads the table using consistent reads, it sees that the row was Y=5 when the UPDATE began. But, the current value for Y is now 6 (it’s not 5 anymore) and before updating the value of X, Oracle will check to see that Y is still 5. Now what happens? How are the updates affected by this?
Obviously, we can’t modify an old version of a block; when we go to modify a row, we must modify the current version of that block. Additionally, Oracle can’t just simply skip this row, as that would be an inconsistent read and unpredictable. What we’ll discover is that in such cases, Oracle will restart the write modification from scratch.
Consistent Reads and Current Reads
Oracle does do two types of block gets when processing a modification statement. It performs
· Consistent reads: When “finding” the rows to modify
· Current reads: When getting the block to actually update the row of interest
We can see this easily using TKPROF. Consider this small one row example, which reads and updates the single row in table T from earlier:
EODA@ORA12CR1> exec dbms_monitor.session_trace_enable
PL/SQL procedure successfully completed.
EODA@ORA12CR1> select * from t;
X
----------
10001
EODA@ORA12CR1> update t t1 set x = x+1;
1 row updated.
EODA@ORA12CR1> update t t2 set x = x+1;
1 row updated.
When we run TKPROF and view the results, we’ll see something like this (note that I removed the ELAPSED, CPU, and DISK columns from this report):
select * from t
call count query current rows
------- ------ ------ ---------- ----------
Parse 1 0 0 0
Execute 1 0 0 0
Fetch 2 7 0 1
------- ------ ------ ---------- ----------
total 4 7 0 1
update t t1 set x = x+1
call count query current rows
------- ------ ------ ---------- ----------
Parse 1 0 0 0
Execute 1 7 3 1
Fetch 0 0 0 0
------- ------ ------ ---------- ----------
total 2 7 3 1
update t t2 set x = x+1
call count query current rows
------- ------ ------ ---------- ----------
Parse 1 0 0 0
Execute 1 7 1 1
Fetch 0 0 0 0
------- ------ ------ ---------- ----------
total 2 7 1 1
So, during just a normal query, we incur seven query (consistent) mode gets. During the first UPDATE, we incur the same seven I/Os (the search component of the update involves finding all of the rows that are in the table when the update began, in this case) and three current mode getsas well. The current mode gets are performed in order to retrieve the table block as it exists right now, the one with the row on it, to get an undo segment block to begin our transaction, and an undo block. The second update has exactly one current mode get; since we did not have to do the undo work again, we had only the one current get on the block with the row we want to update. The very presence of the current mode gets tells us that a modification of some sort took place. Before Oracle will modify a block with new information, it must get the most current copy of it.
So, how does read consistency affect a modification? Well, imagine you were executing the following UPDATE statement against some database table:
Update t Set x = x+1 Where y = 5;
We understand that the WHERE Y=5 component, the read-consistent phase of the query, will be processed using a consistent read (query mode gets in the TKPROF report). The set of WHERE Y=5 records that was committed in the table at the beginning of the statement’s execution are the records it will see (assuming READ COMMITTED isolation; if the isolation is SERIALIZABLE, it would be the set of WHERE Y=5 records that existed when the transaction began). This means if that UPDATE statement were to take five minutes to process from start to finish, and someone added and committed a new record to the table with a value of 5 in the Y column, then that UPDATE would not see it because the consistent read would not see it. This is expected and normal. But, the question is, what happens if two sessions execute the following statements in order:
Update t Set y = 10 Where y = 5;
Update t Set x = x+1 Where y = 5;
Table 7-8 demonstrates the timeline.
Table 7-8. Sequence of Updates

So the record that was Y=5 when you began the UPDATE is no longer Y=5. The consistent read component of the UPDATE says, “You want to update this record because Y was 5 when we began,” but the current version of the block makes you think, “Oh, no, I can’t update this row because Y isn’t 5 anymore. It would be wrong.”
If we just skipped this record at this point and ignored it, then we would have a nondeterministic update. It would be throwing data consistency and integrity out the window. The outcome of the update (how many and which rows were modified) would depend on the order in which rows got hit in the table and what other activity just happened to be going on. You could take the same exact set of rows and in two different databases, each one running the transactions in exactly the same mix, and you could observe different results, just because the rows were in different places on the disk.
In this case, Oracle will choose to restart the update. When the row that was Y=5 when you started is found to contain the value Y=10, Oracle will silently roll back your update (just the update, not any other part of the transaction) and restart it, assuming you are using READ COMMITTED isolation. If you are using SERIALIZABLE isolation, then at this point you would receive an ORA-08177: can't serialize access for this transaction error. In READ COMMITTED mode, after the transaction rolls back your update, the database will restart the update (i.e., change the point in time at which the update is “as of”), and instead of updating the data again, it will go into SELECT FOR UPDATE mode and attempt to lock all of the rows WHERE Y=5 for your session. Once it does this, it will run the UPDATE against that locked set of data, thus ensuring this time that it can complete without restarting.
But to continue on with the “but what happens if. . .” train of thought, what happens if, after restarting the update and going into SELECT FOR UPDATE mode (which has the same read-consistent and read-current block gets going on as an update does), a row that was Y=5 when you started the SELECT FOR UPDATE is found to be Y=11 when you go to get the current version of it? That SELECT FOR UDPDATE will restart and the cycle begins again.
This raises several interesting questions. Can we observe this? Can we see this actually happen? And if so, so what? What does this mean to us as developers? We’ll address these questions in turn now.
Seeing a Restart
It is easier to see a restart than you might, at first, think. We’ll be able to observe one, in fact, using a simple one-row table. This is the table we’ll use to test with:
EODA@ORA12CR1> create table t ( x int, y int );
Table created.
EODA@ORA12CR1> insert into t values ( 1, 1 );
1 row created.
EODA@ORA12CR1> commit;
Commit complete.
To observe the restart, all we need is a trigger to print out some information. We’ll use a BEFORE UPDATE FOR EACH ROW trigger to print out the before and after image of the row as the result of an update:
EODA@ORA12CR1> create or replace trigger t_bufer
2 before update on t for each row
3 begin
4 dbms_output.put_line
5 ( 'old.x = ' || :old.x ||
6 ', old.y = ' || :old.y );
7 dbms_output.put_line
8 ( 'new.x = ' || :new.x ||
9 ', new.y = ' || :new.y );
10 end;
11 /
Trigger created.
Now we’ll update that row:
EODA@ORA12CR1> set serveroutput on
EODA@ORA12CR1> update t set x = x+1;
old.x = 1, old.y = 1
new.x = 2, new.y = 1
1 row updated.
So far, everything is as we expect: the trigger fired once, and we see the old and new values. Note that we have not yet committed, however—the row is still locked. In another session, we’ll execute this update:
EODA@ORA12CR1> set serveroutput on
EODA@ORA12CR1> update t set x = x+1 where x > 0;
This will immediately block, of course, since the first session has that row locked. If we now go back to the first session and commit, we’ll see this output (the update is repeated for clarity) in the second session:
EODA@ORA12CR1> update t set x = x+1 where x > 0;
old.x = 1, old.y = 1
new.x = 2, new.y = 1
old.x = 2, old.y = 1
new.x = 3, new.y = 1
1 row updated.
As you can see, that row trigger saw two versions of that row here. The row trigger was fired two times: once with the original version of the row and what we tried to modify that original version to, and again with the final row that was actually updated. Since this was a BEFORE FOR EACH ROW trigger, Oracle saw the read-consistent version of the record and the modifications we would like to have made to it. However, Oracle retrieved the block in current mode to actually perform the update after the BEFORE FOR EACH ROW trigger fired. It waits until after this trigger fires to get the block in current mode, because the trigger can modify the :NEW values. So Oracle can’t modify the block until after this trigger executes, and the trigger could take a very long time to execute. Since only one session at a time can hold a block in current mode, Oracle needs to limit the time we have it in that mode.
After this trigger fired, Oracle retrieved the block in current mode and noticed that the column used to find this row, X, had been modified. Since X was used to locate this record and X was modified, the database decided to restart our query. Notice that the update of X from 1 to 2 did not put this row out of scope; we’ll still be updating it with this UPDATE statement. Rather, it is the fact that X was used to locate the row, and the consistent read value of X (1 in this case) differs from the current mode read of X (2). Now, upon restart, the trigger sees the value of X=2 (following modification by the other session) as the :OLD value and X=3 as the :NEW value.
So, this shows that these restarts happen. It takes a trigger to see them in action; otherwise, they are generally undetectable. That does not mean you can’t see other symptoms—such as a large UPDATE statement rolling back work after updating many rows and then discovering a row that causes it to restart—just that it is hard to definitively say, “This symptom is caused by a restart.”
An interesting observation is that triggers themselves may cause restarts to occur even when the statement itself doesn’t warrant them. Normally, the columns referenced in the WHERE clause of the UPDATE or DELETE statement are used to determine whether or not the modification needs to restart. Oracle will perform a consistent read using these columns and, upon retrieving the block in current mode, it will restart the statement if it detects that any of them have changed. Normally, the other columns in the row are not inspected. For example, let’s simply rerun the previous example and use WHERE Y>0 to find the rows in both sessions, the output we’ll see in the first session (the one that gets blocked) would be:
EODA@ORA12CR1> update t set x = x+1 where y > 0;
old.x = 1, old.y = 1
new.x = 2, new.y = 1
old.x = 2, old.y = 1
new.x = 3, new.y = 1
1 row updated.
So why did Oracle fire the trigger twice when it was looking at the Y value? Does it examine the whole row? As you can see from the output, the update was, in fact, restarted and the trigger again fired twice, even though we were searching on Y>0 and did not modify Y at all. But, if we re-create the trigger to simply print out the fact that it fired, rather than reference the :OLD and :NEW values, as follows, and go into that second session again and run the update, we observe it gets blocked (of course):
EODA@ORA12CR1> create or replace trigger t_bufer
2 before update on t for each row
3 begin
4 dbms_output.put_line( 'fired' );
5 end;
6 /
Trigger created.
EODA@ORA12CR1> update t set x = x+1;
fired
1 row updated.
After committing the blocking session, we’ll see the following:
EODA@ORA12CR1> update t set x = x+1 where y > 0;
fired
1 row updated.
The trigger fired just once this time, not twice. Thus, the :NEW and :OLD column values, when referenced in the trigger, are also used by Oracle to do the restart checking. When we referenced :NEW.X and :OLD.X in the trigger, X’s consistent read and current read values were compared and found to be different. A restart ensued. When we removed the reference to that column from the trigger, there was no restart.
So the rule is that the set of columns used in the WHERE clause to find the rows plus the columns referenced in the row triggers will be compared. The consistent read version of the row will be compared to the current read version of the row; if any of them are different, the modification will restart.
![]() Note You can use this bit of information to further understand why using an AFTER FOR EACH ROW trigger is more efficient than using a BEFORE FOR EACH ROW. The AFTER trigger won’t have the same effect—we’ve already retrieved the block in current mode by then.
Note You can use this bit of information to further understand why using an AFTER FOR EACH ROW trigger is more efficient than using a BEFORE FOR EACH ROW. The AFTER trigger won’t have the same effect—we’ve already retrieved the block in current mode by then.
Which leads us to the “Why do we care?” question.
Why Is a Restart Important to Us?
The first thing that pops out should be “Our trigger fired twice!” We had a one-row table with a BEFORE FOR EACH ROW trigger on it. We updated one row, yet the trigger fired two times.
Think of the potential implications of this. If you have a trigger that does anything nontransactional, this could be a fairly serious issue. For example, consider a trigger that sends an update where the body of the e-mail is “This is what the data used to look like. It has been modified to look like this now.” If you sent the e-mail directly from the trigger, using UTL_SMTP in Oracle9i or UTL_MAIL in Oracle 10g and above, then the user would receive two e-mails, with one of them reporting an update that never actually happened.
Anything you do in a trigger that is nontransactional will be impacted by a restart. Consider the following implications:
· Consider a trigger that maintains some PL/SQL global variables, such as for the number of rows processed. When a statement that restarts rolls back, the modifications to PL/SQL variables won’t roll back.
· Virtually any function that starts with UTL_ (UTL_FILE, UTL_HTTP, UTL_SMTP, and so on) should be considered susceptible to a statement restart. When the statement restarts, UTL_FILE won’t un-write to the file it was writing to.
· Any trigger that is part of an autonomous transaction must be suspect. When the statement restarts and rolls back, the autonomous transaction can’t be rolled back.
All of these consequences must be handled with care in the belief that they may be fired more than once per row or be fired for a row that won’t be updated by the statement after all.
The second reason you should care about potential restarts is performance related. We have been using a single-row example, but what happens if you start a large batch update and it is restarted after processing the first 100,000 records? It will roll back the 100,000 row changes, restart inSELECT FOR UPDATE mode, and do the 100,000 row changes again after that.
You might notice, after putting in that simple audit trail trigger (the one that reads the :NEW and :OLD values), that performance is much worse than you can explain, even though nothing else has changed except the new triggers. It could be that you are restarting queries you never used in the past. Or the addition of a tiny program that updates just a single row here and there makes a batch process that used to run in an hour suddenly run in many hours due to restarts that never used to take place.
This is not a new feature of Oracle—it has been in the database since version 4.0, when read consistency was introduced. I myself was not totally aware of how it worked until the summer of 2003 and, after I discovered what it implied, I was able to answer a lot of “How could that have happened?” questions from my own past. It has made me swear off using autonomous transactions in triggers almost entirely, and it has made me rethink the way some of my applications have been implemented. For example, I’ll never send e-mail from a trigger directly; rather, I’ll always use DBMS_JOB or something similar to send the e-mail after my transaction commits. This makes the sending of the e-mail transactional; that is, if the statement that caused the trigger to fire and send the e-mail is restarted, the rollback it performs will roll back the DBMS_JOB request. Most everything nontransactional that I did in triggers was modified to be done in a job after the fact, making it all transactionally consistent.
Summary
In this chapter, we covered a lot of material that, at times, might not have been obvious. However, it is vital that you understand these issues. For example, if you were not aware of the statement-level restart, you might not be able to figure out how a certain set of circumstances could have taken place. That is, you would not be able to explain some of the daily empirical observations you make. In fact, if you were not aware of the restarts, you might wrongly suspect the actual fault to be due to the circumstances or end user error. It would be one of those unreproducible issues, as it takes many things happening in a specific order to observe.
We took a look at the meaning of the isolation levels set out in the SQL standard and at how Oracle implements them; at times, we contrasted Oracle’s implementation with that of other databases. We saw that in other implementations (i.e., ones that employ read locks to provide consistent data), there is a huge trade-off between concurrency and consistency. To get highly concurrent access to data, you would have to decrease your need for consistent answers. To get consistent, correct answers, you would need to live with decreased concurrency. In Oracle that is not the case, due to its multiversioning feature.
Table 7-9 sums up what you might expect in a database that employs read locking versus Oracle’s multiversioning approach.
Table 7-9. A Comparison of Transaction Isolation Levels and Locking Behavior in Oracle vs. Databases That Employ Read Locking
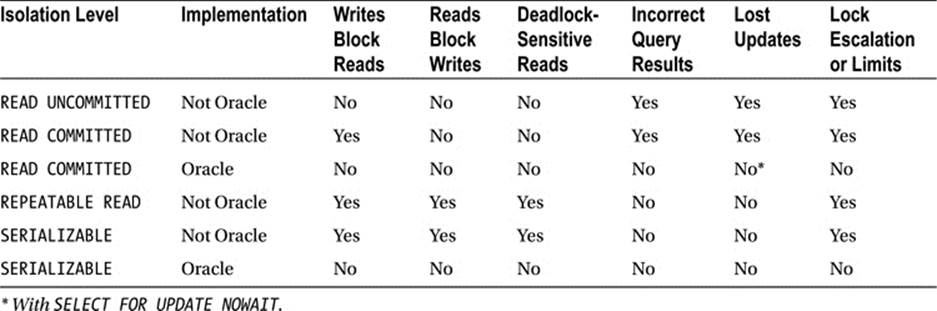
Concurrency controls and how the database implements them are definitely things you want to understand. I’ve been singing the praises of multiversioning and read consistency, but like everything else in the world, they are double-edged swords. If you don’t understand that multiversioning is there and how it works, you will make errors in application design. Consider the resource scheduler example from Chapter 1. In a database without multiversioning and its associated nonblocking reads, the original logic employed by the program may very well have worked. However, this logic would fall apart when implemented in Oracle. It would allow data integrity to be compromised. Unless you know how multiversioning works, you will write programs that corrupt data. It is that simple.