Real-time Analytics with Storm and Cassandra (2015)
Chapter 1. Let's Understand Storm
In this chapter, you will be acquainted with the problems requiring distributed computed solutions and get to know how complex it could get to create and manage such solutions. We will look at the options available to solve distributed computation.
The topics that will be covered in the chapter are as follows:
· Getting acquainted with a few problems that require distributed computing solutions
· The complexity of existing solutions
· Technologies offering real-time distributed computing
· A high-level view of the various components of Storm
· A quick peek into the internals of Storm
By the end of the chapter, you will be able to understand the real-time scenarios and applications of Apache Storm. You should be aware of solutions available in the market and reasons as to why Storm is still the best open source choice.
Distributed computing problems
Let's dive deep and identify some of the problems that require distributed solutions. In the world we live in today, we are so attuned to the power of now and that's the paradigm that generated the need for distributed real-time computing. Sectors such as banking, healthcare, automotive manufacturing, and so on are hubs where real-time computing can either optimize or enhance the solutions.
Real-time business solution for credit or debit card fraud detection
Let's get acquainted with the problem depicted in the following figure; when we make any transaction using plastic money and swipe our debit or credit card for payment, the duration within which the bank has to validate or reject the transaction is less than five seconds. In less than five seconds, data or transaction details have to be encrypted, travel over secure network from servicing back bank to the issuing bank, then at the issuing back bank the entire fuzzy logic for acceptance or decline of the transaction has to be computed, and the result has to travel back over the secure network:
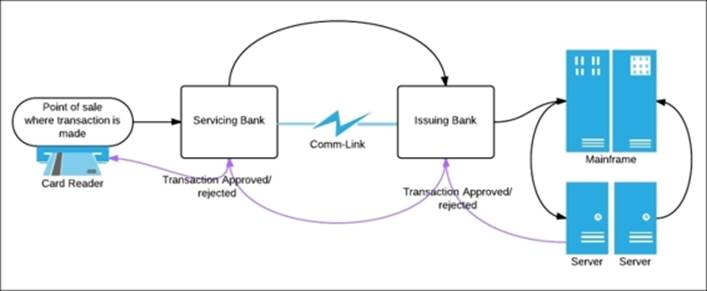
Real-time credit card fraud detection
The challenges such as network latency and delay can be optimized to some extent, but to achieve the preceding featuring transaction in less than 5 seconds, one has to design an application that is able to churn a considerable amount of data and generate results within 1 to 2 seconds.
Aircraft Communications Addressing and Reporting system
The Aircraft Communications Addressing and Reporting system (ACAR) demonstrates another typical use case that cannot be implemented without having a reliable real-time processing system in place. These Aircraft communication systems use satellite communication(SATCOM), and as per the following figure, they gather voice and packet data from all phases of flight in real time and are able to generate analytics and alerts on the data in real time.
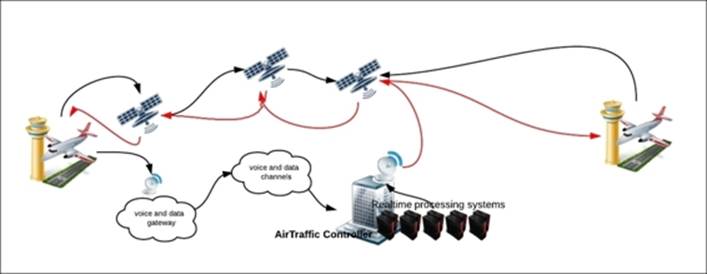
Let's take the example from the figure in the preceding case. A flight encounters some real hazardous weather, say, electric Storms on a route, then that information is sent through satellite links and voice or data gateways to the air controller, which in real time detects and raises the alerts to deviate routes for all other flights passing through that area.
Healthcare
Here, let's introduce you to another problem on healthcare.
This is another very important domain where real-time analytics over high volume and velocity data has equipped the healthcare professionals with accurate and exact information in real time to take informed life-saving actions.
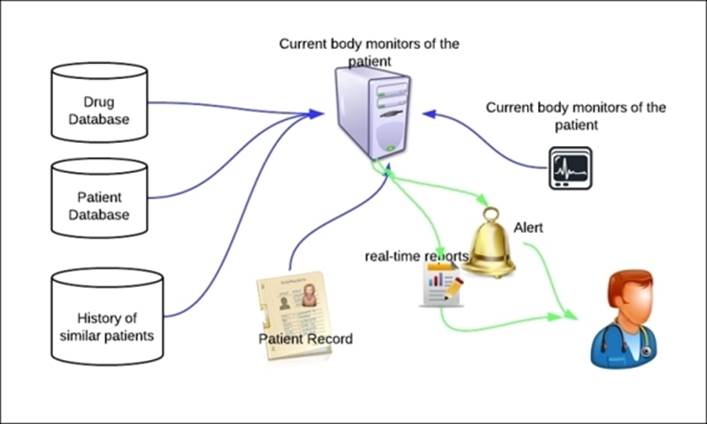
The preceding figure depicts the use case where doctors can take informed action to handle the medical situation of the patients. Data is collated from historic patient databases, drug databases, and patient records. Once the data is collected, it is processed, and live statistics and key parameters of the patient are plotted against the same collated data. This data can be used to further generate reports and alerts to aid the health care professionals.
Other applications
There are varieties of other applications where the power of real-time computing can either optimize or help people make informed decisions. It has become a great utility and aid in the following industries:
· Manufacturing: A real-time defect detection mechanism can help optimize production costs. Generally, in the manufacturing segment QC is performed postproduction and there, due to one similar defect in goods, entire lot is rejected.
· Transportation industry: Based on real-time traffic and weather data, transport companies can optimize their trade routes and save time and money.
· Network optimization: Based on real-time network usage alerts, companies can design auto scale up and auto scale down systems for peak and off-peak hours.
Solutions for complex distributed use cases
Now that we understand the power that real-time solutions can get into various industry verticals, let's explore and find out what options we have to process vast amount of data being generated at a very fast pace.
The Hadoop solution
The Hadoop solution is one of the solutions to solve the problems that require dealing with humongous volumes of data. It works by executing jobs in a clustered setup.
MapReduce is a programming paradigm where we process large data sets by using a mapper function that processes a key and value pair and thus generates intermediate output again in the form of a key-value pair. Then a reduce function operates on the mapper output and merges the values associated with the same intermediate key and generates a result.
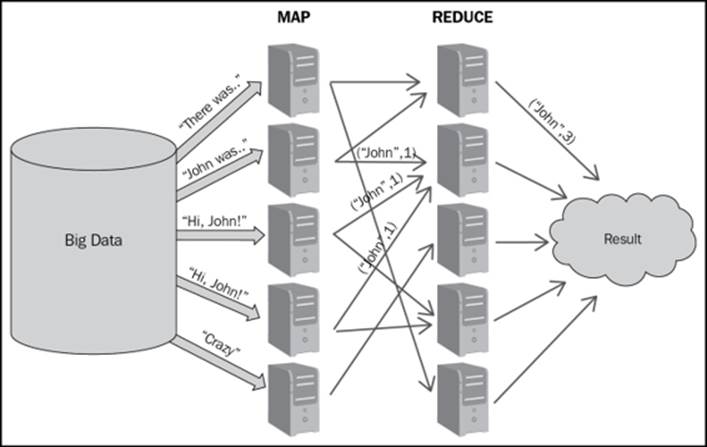
In the preceding figure, we demonstrate the simple word count MapReduce job where the simple word count job is being demonstrated using the MapReduce where:
· There is a huge Big Data store, which can go up to zettabytes or petabytes.
· Input datasets or files are split into blocks of configured size and each block is replicated onto multiple nodes in the Hadoop cluster depending upon the replication factor.
· Each mapper job counts the number of words on the data blocks allocated to it.
· Once the mapper is done, the words (which are actually the keys) and their counts are stored in a local file on the mapper node. The reducer then starts the reduce function and thus generates the result.
· Reducers combine the mapper output and the final results are generated.
Big data, as we know, did provide a solution to processing and generating results out of humongous volumes of data, but that's predominantly a batch processing system and has almost no utility on a real-time use case.
A custom solution
Here we talk about a solution that was used in the social media world before we had a scalable framework such as Storm. A simplistic version of the problem could be that you need a real-time count of the tweets by each user; Twitter solved the problem by following the mechanism shown in the figure:
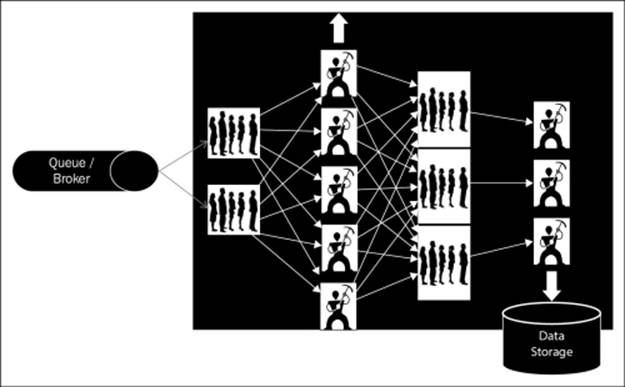
Here is the detailed information of how the preceding mechanism works:
· A custom solution created a fire hose or queue onto which all the tweets are pushed.
· A set of workers' nodes read data from the queue, parse the messages, and maintain counts of tweets by each user. The solution is scalable, as we can increase the number of workers to handle more load in the system. But the sharding algorithm for random distribution of the data among these workers nodes' should ensure equal distribution of data to all workers.
· These workers assimilate this first level count into the next set of queues.
· From these queues (the ones mentioned at level 1) second level of workers pick from these queues. Here, the data distribution among these workers is neither equal, nor random. The load balancing or the sharding logic has to ensure that tweets from the same user should always go to the same worker, to get the correct counts. For example, lets assume we have different users— "A, K, M, P, R, and L" and we have two workers "worker A" and "worker B". The tweets from user "A, K, and M" always goes to "worker A", and those of "P, R, and L users" goes to "worker B"; so the tweet counts for "A, K, and M" are always maintained by "worker A". Finally, these counts are dumped into the data store.
The queue-worker solution described in the preceding points works fine for our specific use case, but it has the following serious limitations:
· It's very complex and specific to the use case
· Redeployment and reconfiguration is a huge task
· Scaling is very tedious
· The system is not fault tolerant
Licensed proprietary solutions
After an open source Hadoop and custom Queue-worker solution, let's discuss the licensed options' proprietary solutions in the market to cater to the distributed real-time processing needs.
The Alabama Occupational Therapy Association (ALOTA) of big companies has invested in such products, because they clearly see where the future of computing is moving to. They can foresee demands of such solutions and support them in almost every vertical and domain. They have developed such solutions and products that let us do complex batch and real-time computing but that comes at a heavy license cost. A few solutions to name are from companies such as:
· IBM: IBM has developed InfoSphere Streams for real-time ingestion, analysis, and correlation of data.
· Oracle: Oracle has a product called Real Time Decisions (RTD) that provides analysis, machine learning, and predictions in real-time context
· GigaSpaces: GigaSpaces has come up with a product called XAP that provides in-memory computation to deliver real-time results
Other real-time processing tools
There are few other technologies that have some similar traits and features such as Apache Storm and S4 from Yahoo, but it lacks guaranteed processing. Spark is essentially a batch processing system with some features on micro-batching, which could be utilized as real time.
A high-level view of various components of Storm
In this section, we will get you acquainted with various components of Storm, their role, and their distribution in a Storm cluster.
A Storm cluster has three sets of nodes (which could be co-located, but are generally distributed in clusters), which are as follows:
· Nimbus
· Zookeeper
· Supervisor
The following figure shows the integration hierarchy of these nodes:
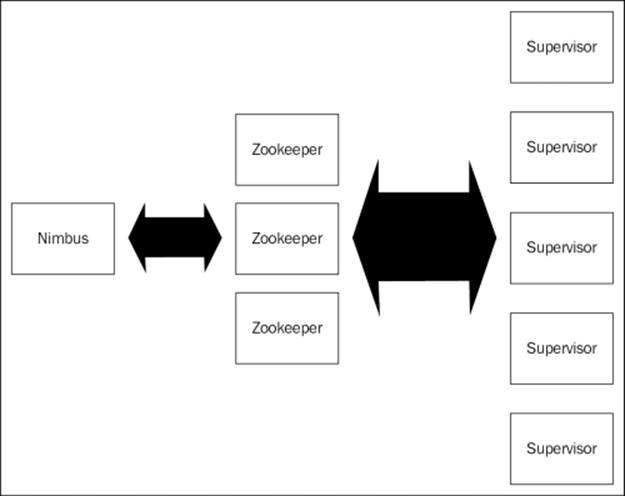
The detailed explanation of the integration hierarchy is as follows:
· Nimbus node (master node, similar to Hadoop-JobTracker): This is the heart of the Storm cluster. You can say that this is the master daemon process that is responsible for the following:
o Uploading and distributing various tasks across the cluster
o Uploading and distributing the topology jars jobs across various supervisors
o Launching workers as per ports allocated on the supervisor nodes
o Monitoring the topology execution and reallocating workers whenever necessary
o Storm UI is also executed on the same node
· Zookeeper nodes: Zookeepers can be designated as the bookkeepers in the Storm cluster. Once the topology job is submitted and distributed from the Nimbus nodes, then even if Nimbus dies the topology would continue to execute because as long as Zookeepers are alive, the workable state is maintained and logged by them. The main responsibility of this component is to maintain the operational state of the cluster and restore the operational state if recovery is required from some failure. It's the coordinator for the Storm cluster.
· Supervisor nodes: These are the main processing chambers in the Storm topology; all the action happens in here. These are daemon processes that listen and manage the work assigned. These communicates with Nimbus through Zookeeper and starts and stops workers according to signals from Nimbus.
Delving into the internals of Storm
Now that we know which physical components are present in a Storm cluster, let's understand what happens inside various Storm components when a topology is submitted. When we say topology submission, it means that we have submitted a distributed job to Storm Nimbus for execution over the cluster of supervisors. In this section, we will explain the various steps that are executed in various Storm components when a Storm topology is executed:
· Topology is submitted on the Nimbus node.
· Nimbus uploads the code jars on all the supervisors and instructs the supervisors to launch workers as per the NumWorker configuration or the TOPOLOGY_WORKERS configuration defined in Storm.
· During the same duration all the Storm nodes (Nimbus and Supervisors) constantly co-ordinate with the Zookeeper clusters to maintain a log of workers and their activities.
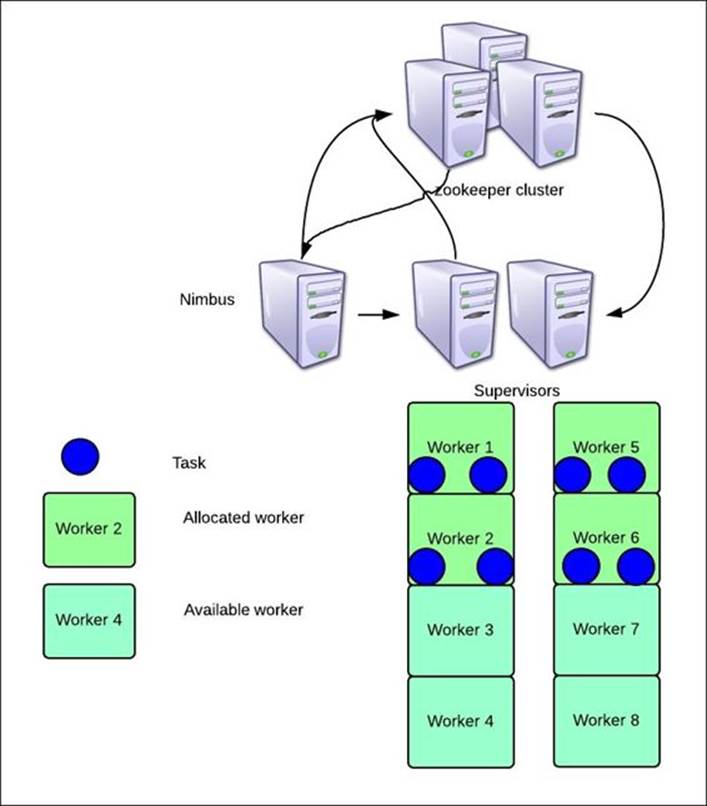
As per the following figure, we have depicted the topology and distribution of the topology components, which are the same across clusters:
In our case, let's assume that our cluster constitutes of one Nimbus node, three Zookeepers in a Zookeeper cluster, and one supervisor node.
By default, we have four slots allocated to each supervisor, so four workers would be launched per Storm supervisor node unless the configuration is tweaked.
Let's assume that the depicted topology is allocated four workers, and it has two bolts each with a parallelism of two and one spout with a parallelism of four. So in total, we have eight tasks to be distributed across four workers.
So this is how the topology would be executed: two workers on each supervisor and two executors within each worker, as shown in the following figure:
Quiz time
Q.1. Try to phrase a problem statement around real-time analytics in the following domains:
· Network optimization
· Traffic management
· Remote sensing
Summary
In this chapter, you have understood the need for distributed computing by exploring various use cases in different verticals and domains. We have also walked you through various solutions to handle these problems and why Storm is the best choice in the open source world. You have also been introduced to Storm components and the action behind the scenes when these components are at work.
In the next chapter, we will walk through the setup aspects and you will get familiarized with programming structures in Storm by simple topologies.