CoffeeScript in Action (2014)
Part 2. Composition
Chapter 6. Composing functions
This chapter covers
· Using functions for program clarity
· The problem with state
· Using functions to create abstractions
· Techniques for combining functions
In contrast to what you learned about objects, you needn’t learn any more features to compose programs with functions. Instead, you must learn how to create your own features by putting together functions using the basic function glue that you learned in chapter 3. This principle applies to trivial examples such as defining an average function in terms of sum and divide functions and to nontrivial examples that you’ll see in this chapter. To compose programs with functions, you must learn principles and techniques, not features.
Functions have inputs (arguments) and outputs (return values). In that sense, they’re like pipes. You need to know not only the different ways of connecting those pipes but also the principles and techniques you need to do so effectively.
In this chapter you’ll learn why it’s important to break programs into small, clear functions, and how variables and program state can get in the way of doing that effectively. You’ll then learn about using functions to create abstractions to make programs smaller and more manageable. Next, you’ll learn about some common patterns of abstraction in combinators and, finally, about how function-composition techniques are used to simplify typical CoffeeScript programs that are heavy on callbacks. Before beginning, be aware that this chapter deals with some abstract ideas and techniques that require close attention. With that in mind, first things first—clarity.
6.1. Clarity
A function describes a computational process. It’s important that the process that the function describes is represented clearly and accurately. You’ll begin with function composition and then look at a specific problem and how to describe it with functions. You’ll start with an optimization problem: how can Agtron maximize the profit from his online store when sales figures vary depending on sales prices?
By tracking purchases on his shop website, Agtron has found that when he sets the price for the PhotomakerExtreme (a camera) at $200, he sells (on average) 50 per day. For every $20 that he reduces the price, he sells an additional 10 units per day. Each PhotomakerExtreme costs Agtron $100 from the wholesaler, and it costs $140 per day to run the website.
To solve this problem by composing functions, you’ll define functions by describing what they do—using other functions.
6.1.1. Functions are descriptions
When you read the body of a function, the intention and meaning should be clear. Suppose your esteemed colleague Mr. Rob Tuse has previously written a function to evaluate the profit for a given price:
profit = (50+(20/10)*(200-price))*price-(140+(100*(50+((20/10)*(200-price)))))
Aside from clues that the words price and profit afford, can you tell what the function means? Can Rob? Not likely. How do you define profit to clearly indicate what it is? Starting by thinking about the relationship. The profit for a sale price is the revenue at that price minus thecost at that price:
profit = (salePrice) ->
(revenue salePrice) – (cost salePrice)
This profit function won’t work yet because revenue and cost aren’t defined. The next thing to do, then, is define them:
revenue = (salePrice) ->
(numberSold salePrice) * salePrice
cost = (salePrice) ->
overhead + (numberSold salePrice) * costPrice
These revenue and cost functions won’t work until overhead, numberSold, and costPrice are defined. Define them:
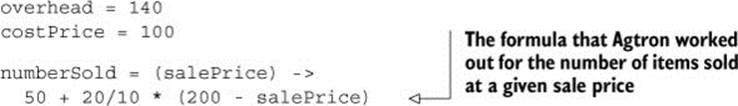
There’s nothing left to define. You have a solution:
overhead = 140
costPrice = 100
numberSold = (salePrice) ->
50 + 20/10 * (200 - salePrice)
revenue = (salePrice) ->
(numberSold salePrice) * salePrice
cost = (salePrice) ->
overhead + (numberSold salePrice) * costPrice
profit = (salePrice) ->
(revenue salePrice) – (cost salePrice)
Functions can be defined anywhere, so numberSold, revenue, and cost could be defined inside the profit function. When you do this, as shown in the following listing, they’re scoped inside the profit function, meaning that they’re encapsulated.
Listing 6.1. Profit from selling PhotomakerExtreme

It’s easier to comprehend a program with good encapsulation. A program with poor encapsulation is a bit like emptying all the boxes, jars, and packets from your pantry into one big bucket. Good for making soup, but not much good for anything else.
Before continuing, it’s time for an important lesson about parentheses.
6.1.2. Where arguments need parentheses
Remember that when you’re invoking a function with arguments, parentheses are optional:
![]()
But parentheses are sometimes necessary to indicate where the arguments end. Why? Well, how do you think this expression is evaluated?
revenue salePrice – cost salePrice
To your eyes this example probably looks like it subtracts the cost at the sale price from the revenue at the sale price. But that’s not how the CoffeeScript compiler sees it, and the JavaScript you get might not be what you expect:
revenue(salePrice(-(cost(salePrice))));
Unfortunately, the CoffeeScript compiler can’t read your mind, and the JavaScript it has produced has a syntax error. Parentheses are important to tell the compiler what to do. You should add parentheses for the function invocations:
![]()
Alternatively, you can put the parentheses on the outside:
![]()
Whether you prefer the parentheses inside or outside, you should give ambiguous expressions that contain function invocations parentheses to make them unambiguous.
As a program grows, you don’t just keep writing more and more functions. Instead, you often modify and adapt the functions you already have.
6.1.3. Higher-order functions revisited
In chapter 3 you learned the three basic ways that functions are glued together:
· Invocation through variable reference
· As an argument
· As a return value
In listing 6.1 only the first of these was demonstrated. Next, you’ll see the other two types of function glue used for generalizing and for partially applying a function.
Agtron isn’t selling just PhotomakerExtreme cameras but other types of cameras too. For those other cameras the overhead, costPrice, and numberSold are different from those for the PhotomakerExtreme. The profit function in listing 6.1 doesn’t work for other types of cameras. How can you generalize it to be used for other types?
Generalizing a function
One way to make the profit function more generally useful is by making overhead, costPrice, and numberSold arguments:
profit = (overhead, costPrice, numberSold, salePrice) ->
revenue = (salePrice) ->
(numberSold salePrice) * salePrice
cost = (salePrice) ->
overhead + (numberSold salePrice) * costPrice
(revenue salePrice) – (cost salePrice)
If the sale price is 100, the overhead is 10, the cost price is 40, and 10 products are sold, then the profit is 590:
tenSold = -> 10
profit 10, 40, tenSold, 100
# 590
The number sold for a product depends on other values such as the sale price. This is apparent when you use this new function for a photoPro camera and a pixelKing camera.

Flexibility has come at a price. The function now has four arguments, which is unwieldy and a little confusing. Don’t wake up one day to realize that all of your functions take nine arguments. Instead of a program made up of functions with more arguments than you can easily comprehend, use another little bit of function glue—the partial application—and return a function.
Partial application
The single-argument profit function was a good description of the profit for a given price of a single camera type. Adding more arguments made it more generally useful but obscured the meaning. How can you get a simple, single-argument profit function for different types of cameras?

To make this interface possible, change the profit function to return another function that accepts the single argument:

When invoked, this new profit function returns a function that will evaluate to the profit for a specific camera (this time it’s a camera called the x1) when it is invoked:

Why is this technique called partial application? Because only some of the arguments to the function have been provided, so the arguments have been partially applied. In this case the salePrice argument hasn’t yet been provided and hasn’t yet been applied.
So far you’ve been working on defining profit without looking at the larger program that it’s part of. What program is this profit function used for? Agtron is creating a web-based API for his online shop. The API provides information about users and products. Information about a product is accessible from a URL:
http://www.agtronsemporium.com/api/product/photomakerExtreme
A GET request to the URL for a product responds with information about that product in JSON format:

Consider in the next listing the program that Rob Tuse wrote to serve Agtron’s API (from listing 6.1). Rob started to implement the profit but never finished (perhaps because the program became too difficult to comprehend).
Listing 6.2. How not to write a program

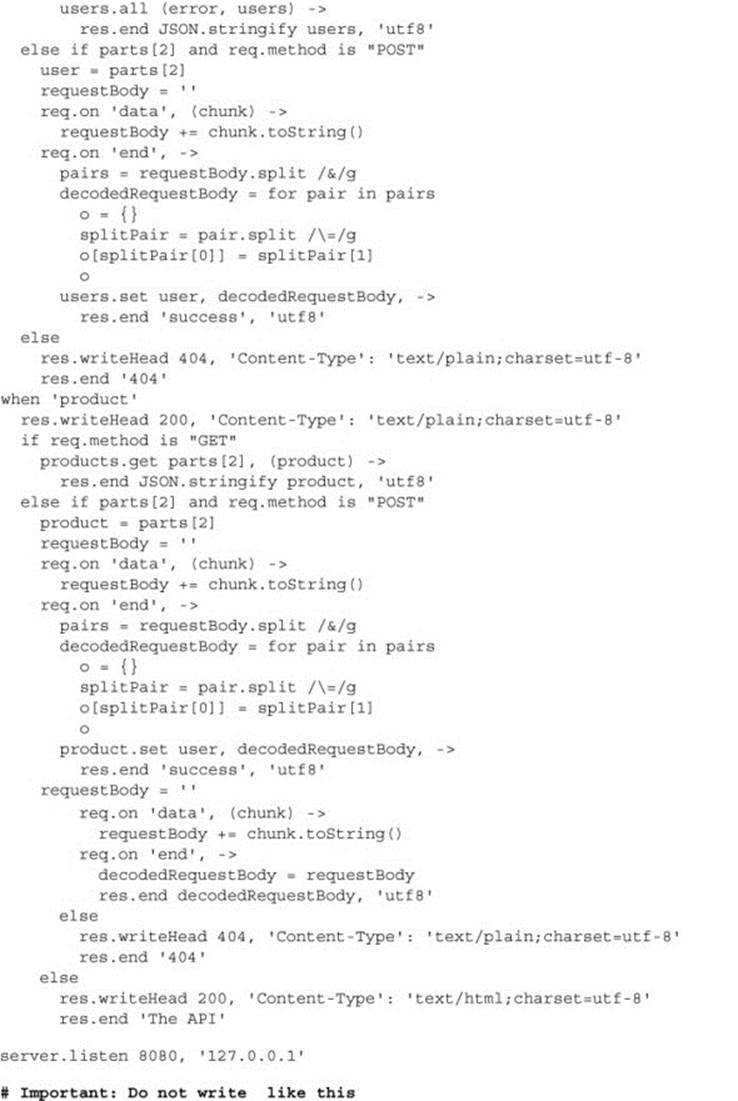
The server function in listing 6.2 is more than 60 lines long. Ouch! Way too complicated; if you write programs like that, you’ll get reactions like those of Scruffy and Agtron in figure 6.1.
Figure 6.1. How not to write programs

Why did Rob write the program like that? He didn’t know any better. You do, and you’ve already started to make the program easier to comprehend with the approach you took for defining profit. First, you broke it down by defining it in terms of other small functions. Then you made the solution more generic to work with different products. The original function was hard to follow:
profit = (50+(20/10)*(200-price))*price-(140+(100*(50+((20/10)*(200-price)))))
Your new version of the same function is more generally useful and explains what it means:
profit = (overhead, costPrice, numberSold, salePrice) ->
revenue = (salePrice) ->
(numberSold salePrice) * salePrice
cost = (salePrice) ->
overhead + (numberSold salePrice) * costPrice
(revenue salePrice) – (cost salePrice)
The overhead, costPrice, numberSold, and salePrice are all values that you either have or can work out using the information you have for a particular product. This will be useful later in this chapter as you continue to make improvements to the original program. First, though, you need to know about state.
Gluing existing functions together and building up new functions (and entire programs) are powerful techniques. When you see a programmer staring at the sky proclaiming an epiphany as the result of discovering functional programming, it’s usually because of this idea of composing functions (or indeed programs) entirely from other functions. Power requires discipline, particularly where it concerns state. It’s time to think about state and why you shouldn’t create it where it doesn’t already exist.
6.2. State and mutability
Just because CoffeeScript allows you to compose functions doesn’t mean that any program written in CoffeeScript is written in a functional style. A program can have lots of functions and not be written in a functional style. To quote from Chuck Palahniuk’s Fight Club, “Sticking feathers up your butt does not make you a chicken.”
Functional-style programming in CoffeeScript means composing functions. As you’ll see in this section, writing programs by composing functions becomes incredibly difficult if the program manages a lot of explicit state. How does state get into a program, and how can you deal with it? The most important thing to remember is that you should avoid having variables containing state wherever possible. What does this mean in practice, though? It’s time to find out by looking at variables and side effects, objects, and external state.
6.2.1. Variables, assignment, and side effects
Variable assignment is at odds with functional programming. Sure, assignment looks harmless enough,
state = on
state = off
until you discover what happens when you try to glue together functions that assign variables. Consider the numberSold function that evaluates to the number of units sold when invoked with a given sale price:
![]()
Compare it to a calculateNumberSold function that returns the value and sets a variable:
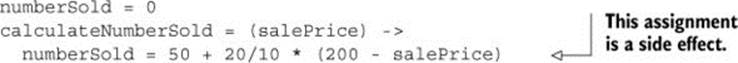
These functions evaluate to the same value, but the calculateNumberSold function assigns a value to an outer variable (a variable that’s not contained entirely within the function):
calculateNumberSold 220
# 10
Consider now the calculateRevenue function that uses the numberSold variable:
calculateRevenue = (salePrice) ->
numberSold * salePrice
Suppose you want to show Agtron a graph of the revenue for different cameras at different prices. To do this, you start by calculating the revenue for prices between 140 and 145 in a comprehension:
for price in [140..145]
calculateRevenue price
# [1400,1410,1420,1430,1440,1450]
Easy—except that the values are wrong and the graph will be wrong. The correct values are [23800,23688,23572,23452,23328,23200]. What went wrong? You forgot to invoke calculateNumberSold:
for price in [140..145]
calculateNumberSold price
calculateRevenue price
# [23800,23688,23572,23425,23328,23200]
It’s easy to forget in which order functions need to be evaluated. You also need to consider two other factors: other people (such as your good friend Mr. Tuse) and asynchronous programs.
6.2.2. Local state and shared state
Suppose calculateRevenue requests information from a database or makes a request from a web service. This means that calculateRevenue is asynchronous, which you know is very common in CoffeeScript programs. When things are asynchronous, your program looks different, as shown in the following listing.
Listing 6.3. Local state and shared state

In listing 6.3 the totals variable is local to the revenueBetween function; other parts of the program can’t assign a value to it. On the other hand, numberSold is shared by all of the functions in the program because they’re all part of the same scope. This can have disastrous consequences.
Now imagine that calculateRevenue from listing 6.3 takes some time before it invokes the callback because it has to wait for a database. Approximate this with a setTimeout call:
oneSecond = 1000
calculateRevenue = (callback) ->
setTimeout ->
callback numberSold * salePrice
, oneSecond
You’re surprised when you find out what revenueBetween returns:
revenueBetween 140, 145
# []
You kept the totals in an array, assigned values to them, and returned the result. This imperative solution needed things done in a particular order but didn’t enforce that order—a move to asynchronous and the solution broke.
There’s one instinctive and imperative way to solve this: by adding even more state and going further down the rabbit hole!

Does it work now? Sadly, no. The order of the values will depend on the order in which the callbacks return. Sure, you’ll get the revenue values—just not in the order you want!
The problem becomes even worse if some other part of the program changes the value of numberSold while an asynchronous part of your program is waiting. Remember, numberSold is shared state for several functions.
Can revenueBetween get any more intertwined? Indeed it can. Suppose Mr. Tuse modifies the function to also log a message, and for some inexplicable reason changes the value of numberSold at the same time:

Now the program produces an array containing NaNs:
revenueBetween 140, 145
# [ 22400, NaN, NaN, NaN, NaN, NaN ]
Should you add more state to fix the problem? No. Please don’t. Instead, compose the asynchronous functions, as you’ll learn to do later in this chapter. Think about a program with hundreds of functions sharing hundreds of variables. How confident can you be that everything is done in exactly the correct order? How hard is it to test that they are? Avoid having variables containing state wherever possible.
How about object-oriented programming, then? After all, CoffeeScript has objects too. Object-oriented programming encapsulates state in objects. That’s a different approach to functional programming. What works in CoffeeScript? Think about those cameras; there used to be cameraobjects back in chapter 5, right? Where did they go?
6.2.3. Encapsulating state with objects
One object-based solution uses a Camera class with profit, and all of the functions that it uses are written as methods:

Notice that in this case the object phototaka500 isn’t modified after it has been created. No properties are set on the object; it’s all method calls, and none of the method calls change any properties on the object. Contrast this with a different approach to the same problem using objects, where methods are called for their side effects instead of for their return values:

These two solutions produce the same result. The difference lies in the implementation. The first solution doesn’t set any properties on the instance, whereas the second does. Consider for a minute which one is more like the following example that uses variables and shared state:

The object approach using instance variables is more like the version with shared state kept in variables. This style of programming is called imperative programming. All programs written in an imperative style have to answer the question of how to manage the explicit state. In an object-oriented programming style, state is managed by keeping it contained to individual objects. In a functional programming style, the state is essentially managed by not putting it explicitly in the program at all.
Functional programming and pure functions
A function that always returns the same value for the same arguments and that has no side effects is called a pure function. Because it’s very easy to create a non-pure function in CoffeeScript, it’s debatable to what extent it can be called a functional programming language. But first-class functions in CoffeeScript mean that, at the least, CoffeeScript supports functional-style programming.
State can’t always be avoided; there’s still state such as in a database or user interface. You can’t keep track of how many users have visited your website unless there’s state somewhere. Users can’t interact with a completely stateless interface. State exists and your program has to deal with it. The question is, exactly when is state necessary and where should it go?
6.2.4. World state
“Wait a minute,” says Scruffy. “It’s all well and good to take unnecessary state out of the program, but the real world has state! Without state there’s no way to sell cameras because there’s no stock count.” That’s right, Scruffy. There has to be state somewhere; the key is to isolate it and not to share it. In this case, suppose that the stock level is kept in a database. Databases are good at dealing with state. The values in the database are retrieved via callbacks:
db.stock 'ijuf', (error, response) ->
# handling code here
This database call could be on the client side or server side. It doesn’t matter.
In the next listing you see a comparison between keeping the state in your program and letting the database keep it. When you run this listing, you’ll be able to access one version on http://localhost:9091 and the other on http://localhost:9092. Note that this listing uses an external db that’s not shown here.
Listing 6.4. State in program or external?

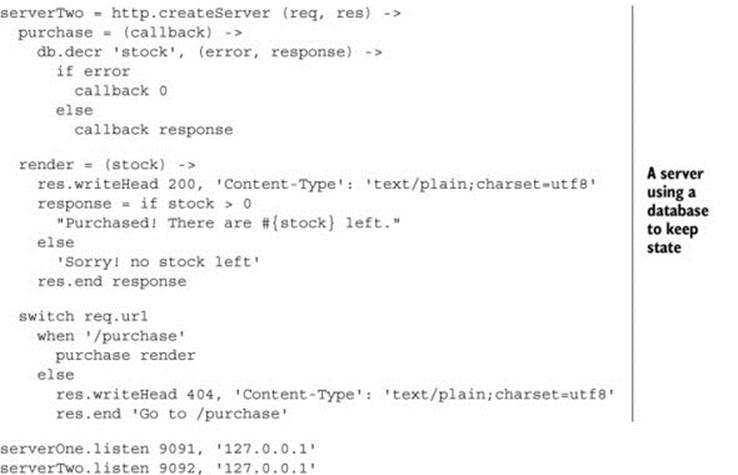
To put it loosely, state is somebody else’s problem. This also applies for state about the client; instead of keeping state about the client inside your application, it should be transferred to your application by the client.
Concurrency?
One problem with shared state is the trouble it creates for concurrent systems. If state depends heavily on things happening in a particular order, then a system where many things are happening at once is a challenge. CoffeeScript programs run on an event loop and only ever do one thing at a time, so the concurrency challenges aren’t the same as in a threaded environment. That said, state is still a problem.
Function composition and functional programming in general don’t work well when programs have explicit mutable state contained in variables or objects. You’ve learned that in order to be effective with function composition, you should avoid state in variables and objects wherever possible. When you do avoid state, you can glue functions together explicitly and also create abstractions. Functions can glue other functions together.
6.3. Abstraction
Abstractions can be created from an existing program by carving off small pieces and improving those—removing duplication as you go. In this section you’ll continue to improve listing 6.2 by creating abstractions and removing duplication.
6.3.1. Extracting common code
In listing 6.2 much of the duplicated code should have either never happened or been refactored once it became apparent. How does it become apparent? Well, consider what the program actually does.
The API you’re creating for Agtron’s shop is a thin wrapper for accessing some information in key-value store databases. The databases have two operations, set and get. The set operation takes a key, a value, and a callback function. The get operation takes a key and a callback. For example, the user data is loaded from the database in the same way that product data is loaded from the database:
users.get parts[2], (error, user) ->
res.end JSON.stringify user, 'utf8'
products.get parts[2], (product) ->
res.end JSON.stringify product, 'utf8'
There’s no meaningful name describing what these sections of the program do, so you start by naming them:
loadUserData = (user, callback) ->
users.get user, (data) ->
callback data
loadProductData = (product, callback) ->
products.get product, (data) ->
callback data
If you didn’t notice before that the code was repetitive, you definitely notice now. The saveUserData and saveProductData functions are almost exactly the same.
Instead of having variations of the same basic function appear repeatedly in your program, create an abstraction and eliminate the duplication:
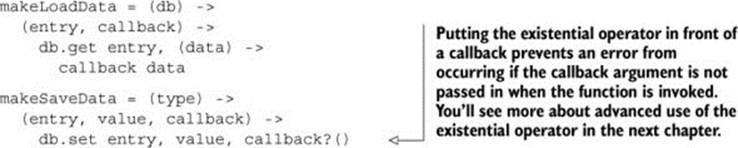
Both of these functions return functions. What are they used for? With these two functions you can create a loadUserData function and a saveUserData function:
loadUserData = makeLoadData 'user'
saveUserData = makeSaveData 'user'
You can use the makeLoadData function to create a function for loadAnythingData, literally:
loadAnythingData = makeLoadData 'anything'
The makeLoadData and makeSaveData functions are abstractions that allow you to create individual functions that are useful in specific circumstances. Now look at makeLoadData and makeSaveData; they’re basically the same. Extract the common parts to a single function:
makeDbOperator = (db) ->
(operation) ->
(entry, value=null, callback) ->
db[operation] entry, value, (error, data) ->
callback? error, data
This function returns a function that returns a function. When you see an abstraction by itself, it becomes apparent if it’s more complicated than it needs to be. You revise makeDbOperator to make it simpler:
makeDbOperator = (db) ->
(operation) ->
(entry, params...) ->
db[operation] entry, params...
When you added global variable assignments to your program, you got an immediate payoff, but it hurt you in the long run. Identifying and writing abstractions is the opposite. A little bit of effort now to create the right abstraction saves you pain in the long run. You can now generate loadand save functions for different data types from this single makeDbOperator function:
loadProductData = (makeDbOperator 'product') 'get'
saveProductData = (makeDbOperator 'product') 'set'
saveProductData 'photonify1100', 'data for the photonify1100'
loadProductData 'photonify1100'
# 'data for the photonify1100'
Writing a program always involves refining the abstractions as you go. When functions are the basic building block, this is done with the same basic function glue: invoking a function, passing a function as an argument, and returning a function.
By refining the abstractions in your program over time, you end up with a program that communicates what it does and that’s easier to modify. Even better, it’s the start of a library. To develop a really useful library, instead of starting with an idea for a library, extract it from a real project as an abstraction of ideas in that project. In listing 6.5 you can see the new version of the program.
When you run this new version of the program, you can view information about a specific product (such as the x1) by visiting the URL http://localhost:8080/product/x1. To see the profit for that same product at a given price point of 200, visit the URL http://localhost:8080/product/x1/profit?price=200.
The listing that follows is left deliberately without any annotations. The purpose of this is to show how far small named functions can go to make a program self-explanatory. Spend a bit more time to pore over this listing and learn how it works.
Listing 6.5. The improved program
http = require 'http'
url = require 'url'
{products, users} = require './db'
withCompleteBody = (req, callback) ->
body = ''
req.on 'data', (chunk) ->
body += chunk.toString()
request.on 'end', -> callback body
paramsAsObject = (params) ->
pairs = params.split /&/g
result = {}
for pair in pairs
splitPair = pair.split /\=/g
result[splitPair[0]] = splitPair[1]
result
header = (response, status, contentType='text/plain;charset=utf-8') ->
response.writeHead status, 'Content-Type': contentType
httpRequestMatch = (request, method) -> request.method is method
isGet = (request) -> httpRequestMatch request, "GET"
isPost = (request) -> httpRequestMatch request, "POST"
render = (response, content) ->
header response, 200
response.end content, 'utf8'
renderAsJson = (response, object) -> render response, JSON.stringify object
notFound = (response) ->
header response, 404
response.end 'not found', 'utf8'
handleProfitRequest = (request, response, price, costPrice, overhead) ->
valid = (price) -> price and /^[0-9]+$/gi.test price
if valid price
renderAsJson response, profit: profit price, costPrice, overhead
else
renderAsJson response, profit: 0
makeDbOperator = (db) ->
(operation) ->
(entry, params...) ->
db[operation] entry, params...
makeRequestHandler = (load, save) ->
rendersIfFound = (response) ->
(error, data) ->
if error
notFound response
else
renderAsJson response, data
(request, response, name) ->
if isGet request
load name, rendersIfFound response
else if isPost request
withCompleteBody request, ->
save name, rendersIfFound response
else
notFound response
numberSold = (salePrice) ->
50 + 20/10 * (200 - salePrice)
profit = (salePrice, costPrice, overhead) ->
revenue = (salePrice) ->
(numberSold salePrice) * salePrice
cost = (salePrice) ->
overhead + (numberSold salePrice) * costPrice
(revenue salePrice) - (cost salePrice)
loadProductData = (makeDbOperator products) 'get'
saveProductData = (makeDbOperator products) 'set'
loadUserData = (makeDbOperator users) 'get'
saveUserData = (makeDbOperator users) 'set'
handleUserRequest = makeRequestHandler loadUserData, saveUserData
handleProductRequest = makeRequestHandler loadProductData, saveProductData
onProductDataLoaded = (error, data) ->
price = (parseInt (query.split '=')[1], 10)
handleProfitRequest request,response,price,data.costPrice,data.overhead
apiServer = (request, response) ->
path = url.parse(request.url).path
query = url.parse(request.url).query
parts = path.split /\//
switch parts[1]
when 'user'
handleUserRequest request, response, parts[2]
when 'product'if parts.length == 4 and /^profit/.test parts[3]
loadProductData parts[2], onProductDataLoaded
else
handleProductRequest request, response, parts[2]
else
notFound response
server = http.createServer(apiServer).listen 8080, '127.0.0.1'
exports.server = server
In terms of the total number of lines, this program is no shorter; it would be possible to make it substantially shorter with different abstractions, but in this case communicating the intention of every part of the program is preferred to brevity. Choose techniques appropriate for your circumstances.
Abstraction isn’t always about extracting common code. Sometimes you need to change multiple things in a program at once. Instead of writing it in three places when you obviously don’t need to, you can start with the abstraction.
6.3.2. Adding common code
Imagine Scruffy calls you at 2:00 a.m. to inform you that the server for Agtron’s online store was running so hot that it burst into flames. Sure, nothing that dramatic really happens to you, but consider that your server is having problems because it’s using too much processing power, and you learn that the culprit is the database. Your program is making too many requests to the database, so you need to reduce the number of requests it receives. Here are the last 10 lines from the database log:
request GET 'All work and no play'
response 'makes Jack a dull boy' (5 ms)
request GET 'All work and no play'
response 'makes Jack a dull boy' (4 ms)
request GET 'All work and no play'
response 'makes Jack a dull boy' (2 ms)
request GET 'All work and no play'
response 'makes Jack a dull boy' (5 ms)
request GET 'All work and no play'
response 'makes Jack a dull boy' (5 ms)
That’s right; your program is constantly asking the database to fetch the same value. You might imagine that a clever database would cache the responses for you. You might imagine that, but all the while the server is on fire. What can you do?
Specific cache
You recognize that by caching the previous response you can avoid making another request to the database if you need the same value twice in a row. It’s tempting to just add caching to the makeDbOperator function, but where do you add it?
makeDbOperator = (db) ->
(operation) ->
(entry, params...) ->
db[operation] entry, params...
You only want to cache loading of data, not saving of data, and the makeDbOperator abstraction doesn’t know anything about loading and saving. This is a clear indication that makeDbOperator is the wrong place to implement this caching; if it has to know the difference between a load and a save, it has to know too much. The correct place to implement the caching is where you define loadProductData:

What if you need to cache something else in the future? You need a function that can cache any function.
General cache
As with previous examples, you can extract such a general function from the specific solution you already have. Note that for simplicity this solution is intended to work by using the first argument as the key and the last argument as the callback:
withCachedCallback = (fn) ->
cache = Object.create null
(params...) ->
key = params[0]
callback = params[params.length - 1]
if key of cache
callback cache[key]...
else
paramsCopy = params[..]
paramsCopy[params.length-1] = (params...) ->
cache[key] = params
callback params...
fn paramsCopy...
Now you can define a cached loadProductData by using withCachedCallback:
loadProductData = withCachedCallback ((makeDbOperator products) 'get')
This function will now cache each response forever. If you want it to cache items for a fixed time, you need to store each cache item with an expiry time:
withExpiringCachedCallback = (fn, ttl) ->
cache = Object.create null
(params...) ->
key = params[0]
callback = params[params.length - 1]
if cache[key]?.expires > Date.now()
callback cache[key].entry...
else
paramsCopy = params[..]
paramsCopy[params.length - 1] = (params...) ->
console.log params
cache[key] =
entry: params
expires: Date.now() + ttl
console.log cache[key]
callback params...
fn paramsCopy...
This caching technique can be applied in a general sense to any function, where it is known as memoization.
Memoization
Caching the evaluation of a function with specific arguments is called memoization. You’ve seen it used specifically to cache the loading of some data. To reinforce the concept, it’s worth also seeing a more abstract numerical example. Though not practical or exciting, memoizing a factorial function is a good way to understand this:

The value of factorial 5 is actually the value of factorial 4 multiplied by 5. This means that once factorial 4 has been evaluated, then 4 × 3 × 2 × 1 has already been done once, so factorial 5 could use the value already worked out instead of working the whole thing out again. Memoization is useful to avoid repeating the same evaluation. There’s something else interesting about the definition of factorial: it invokes itself. This is called recursion, and like memoization it’s useful not only for things like factorials but also for problems you actually have.
6.3.3. Recursion
Imagine now that the database is having more problems, and half of all requests to the users database result in a timeout. Data is retrieved from the database by invoking users.get with a callback function. When the request succeeds, you get data back as the second argument to the callback. You can see this happening by logging to the console:
logUserDataFor = (user) ->
users.get user, (error, data) ->
if error then console.log 'An error occurred'
else console.log 'Got the data'
logUserDataFor 'fred'
# 'Got the data'
When a timeout occurs, the callback is invoked with an error as the first argument:
logUserDataFor 'fred'
# 'An error occurred'
Ideally you’d have a database that doesn’t suffer frequent timeouts, but suppose the database can’t be replaced. The only way to fix the problem is to change the program so that if the database request fails, it will retry until it gets a response. How do you do this? The first retry is easy to write; just put it directly in the callback:
logUserDataFor = (user) ->
users.get user, (error, data) ->
if error then users.get user, (error, data) ->
if error then console.log 'An error occurred both times'
else 'Got the data (on the second attempt)'
else console.log 'Got the data'
How about the second retry or the third, fourth, or tenth retry? You certainly don’t want to nest 10 retries (that would be so horrendous that it’s not even shown here). Take a look at the alternative:

If the database finally responds the fourth time it’s called, you’ll see that logged:
logUserDataFor 'fred'
# 'An error occurred'
# 'An error occurred'
# 'An error occurred'
# 'Got the data'
It’s called recursion when a function invokes itself, either directly or indirectly. Although the recursive logUserDataFor function works, it’s a bit heavy-handed. Instead of trying the request again until the end of time (or the program is terminated), retry a failed database request once every second for the next 5 seconds before giving up:
logUserDataFor = (user) ->
dbRequest = (attempt) ->
users.get user, (error, data) ->
if error and attempt < 5
setTimeout ->
(dbRequest attempt + 1), 1000
else console.log 'Got the data'
dbRequest()
That’s not the end of your woes. It’s not just the users database that suffers timeouts. Suppose that all the databases suffer timeouts, and worse, other services that your program relies on have timeouts too. Instead of writing the same thing repeatedly, create an abstraction that can retry a failed request for any callback-based service:

The retryFor function returns a function that takes a single function argument and expects to be able to invoke that function attachment with a callback. To use the retryFor function to load user data, you first need to create a function that has all other arguments applied except the callback:
seconds = (n) ->
1000*n
getUserData = (user) ->
(callback) ->
users.get user, callback
getUserDataForFred = getUserData 'fred'
retryForFiveSeconds = (retryFor (seconds 5), (seconds 1))
retryForFiveSeconds getUserDataForFred, (error, data) ->
console.log data
If the database finally responds after three attempts, then the console output will reflect that:
Error: Retry in 1000
Error: Retry in 1000
Error: Retry in 1000
Success
With recursion you can solve complicated problems with a small amount of code. Unfortunately, there’s no such thing as a free lunch. A programming language that supports recursive functions must deal with the nature of recursion—it looks infinite.
Infinite recursion, tail calls, and the stack
Programs that make heavy use of recursion have a problem in JavaScript and CoffeeScript—they can run out of memory. Why? When you invoke a function stack, memory is allocated:

Only once the function returns is the memory allocated for it reclaimed. That’s a problem with a recursive function because, before returning, a recursive function invokes itself. You can see this in action on the CoffeeScript REPL, which uses the V8 runtime. This will warn you when you’ve exceeded the maximum call stack size:
memoryEater = -> memoryEater()
memoryEater()
# RangeError: Maximum call stack size exceeded
The memoryEater function is infinitely recursive because it always invokes itself. An infinitely recursive function will cause some runtimes to become unresponsive while they continue trying to allocate more and more memory.
A recursive function can run out of memory even without being infinitely recursive. This makes recursive functions a problem because they can run out of stack quite easily. Recursion doesn’t have to suffer this problem, though; consider the following recursive function:
tenThousandCalls = (depth) ->
if depth < 10000
(tenThousandCalls depth + 1)
Just by looking at it you can tell that it will invoke itself 10,000 times and then complete. If you were a computer, you could figure out before you invoke the function what it’s going to do and how much memory you need (or don’t need) to allocate. A JavaScript runtime can do the same thing. Where the recursive call is the last expression in the function body (the tail position), then the function is called tail recursive. If the runtime recognizes this, it’s possible to optimize the amount of memory it allocates. When a runtime can optimize for these types of recursive functions, then it’s said to have tail-call optimization or proper tail calls. Although CoffeeScript programs don’t currently have this optimization, it’s part of the next edition of the ECMAScript specification.
6.4. Combinators
So far you’ve written functions and created abstractions from those functions. Now that you have abstractions, you can create abstractions from those too. Combinators are abstractions of different ways of putting together functions. Until now, to compose programs using functions you’ve explicitly glued them together by invocation, through arguments, and as return values.
You don’t have to do things explicitly—combinators go a step beyond this. What happens when you compose functions without thinking about invocation, arguments, and return values at all?
6.4.1. Compose
Agtron has to pay tax (that’s one thing you don’t need to imagine). To calculate the tax, you first need to add up the profit for all of the products and then invoke a tax function with that value.[1] If you did this imperatively (with commands), you’d make all the individual calculations in sequence:
1 In practice, the arithmetic operators in JavaScript and CoffeeScript aren’t good when working with decimal values because JavaScript’s numbers use floating-point arithmetic, which isn’t accurate for decimal values. If you need to do arithmetic with decimal values, you should find an appropriate library for decimal arithmetic.

Imagine now that you also need to evaluate a loyalty discount for a user. To do this imperatively, you first work out the total amount they’ve spent and then use that value to determine the loyalty category:
userSpend = (user) ->
spend = 100
loyaltyDiscount = (spend) ->
if spend < 1000 then 0
else if spend < 5000 then 5
else if spend < 10000 then 10
else if spend < 50000 then 20
else if spend > 50000 then 40
fredSpend = userSpend fred
loyaltyDiscountForFred = loyaltyDiscount fredSpend
Function abstraction is about identifying patterns. What’s the pattern common to determining tax and determining a loyalty discount? They both invoke one function with an initial value and then invoke a second function with the result from the first function:
initialValue = 5
intermediateValue = firstFunction initialValue
finalValue = secondFunction intermediateValue
Why is the intermediate value there? It doesn’t make the program any clearer. Remove it:
initialValue = 5
secondFunction (firstFunction initialValue)
The same applies to calculating the tax. Instead of doing each calculation individually,
netProfitForProducts = netProfit products
taxForProducts = tax netProfitForProducts
you can put them together:
taxForProducts = tax (netProfit products)
So far, nothing earth-shattering. Think for a second, though; instead of assigning the result to a variable, what does a function that evaluates the final value look like?
taxForProducts = (products) -> tax (netProfit products)
You do this often, so you should get to know it properly by learning what it’s called. It’s called compose:
![]()
This little compose function lets you join together any two functions:
taxForProducts = compose tax, netProfit
loyaltyDiscountForUser = compose loyaltyDiscount, userSpend
Naturally, it also works for trivial little cases that you wouldn’t really want to do unless you were trying to learn how to compose:

Remember that functions are a bit like pipes. You can explicitly take output from one pipe and use it as the input to another pipe, or you can just connect the pipes together. Compose isn’t the only way you might want to connect functions together. In figure 6.2 you can see compose, as well as the other basic combinators before, after, and around that will be discussed in this section.
Figure 6.2. Visualizing compose, before, after, and around
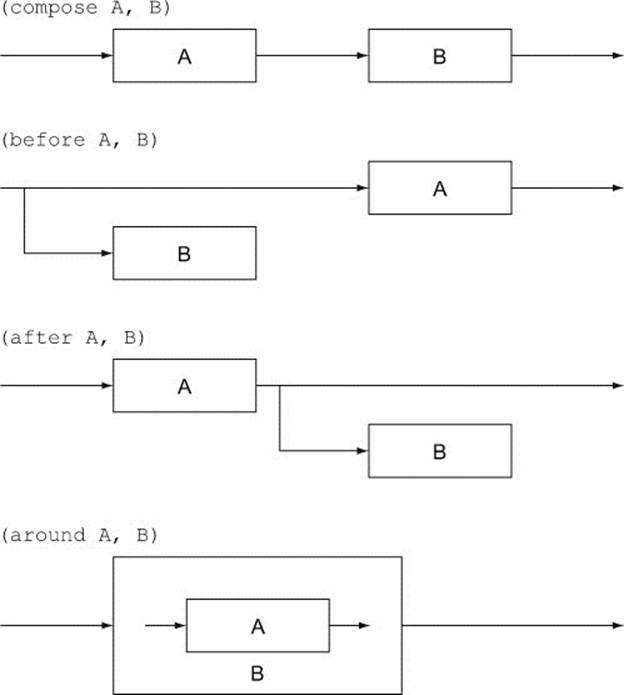
First on the menu are before and after. Dig in.
6.4.2. Before and after
Suppose Agtron needs to meet some incredibly bizarre bureaucracy requirements and tells you that you have to log every product that’s sold to an external service. You don’t have to worry about the service itself, because there’s an existing auditLog function that does it for you.
There’s an existing sale function, so you could just chuck an invocation of auditLog in there:
sale = (user, product) ->
auditLog "Sold #{product} to #{user}"
# Some other stuff happens here
Then Agtron tells you that you also need to log refunds, so you run along and add an auditLog there too:
refund = (user, product) ->
auditLog "Refund for #{product} to #{user}"
# Some other stuff happens here
Then Agtron tells you that you also need to log ... you know where this is headed and that it will quickly get tedious. What if instead you could add the logging code from the outside so that you could create a new auditedRefund function easily?
auditedRefund = withAuditLog refund
Or perhaps even assign a new function to the existing refund variable?
refund = withAuditLog refund
You can do this with the help of before. First, you need to implement it:

Now you can define the withAuditLog function:
withAuditLog = before (params...) ->
auditLog params...
You could also implement withAuditLog to use after instead of before. The difference is only in the order in which the functions are invoked. The definition for after is similar to that for before:
after = (decoration) ->
(base) ->
(params...) ->
result = base params...
decoration params...
result
The combinators after and before don’t change the behavior of the function that they wrap. When you need to change the return value, or the invocation of the wrapped function, then you need to use around.
6.4.3. Around
This one is fun. Suppose that the database is changed so that you need to open and close the connection to the database for each operation you do. For every place in the program where you do a set of database operations, you need to put an openConnection and a closeConnectionaround them:
openConnection()
doSomethingToTheDb()
doSomethingElseToTheDb()
closeConnection()
You quickly tire of adding the same two lines of code throughout your program. Worse, sometimes the database fails to open, and you have to graft on a fix for that too:
dbConnectionIsOpen = openConnection()
if dbConnectionIsOpen
doSomethingToTheDb()
doSomethingElseToTheDb()
closeConnection()
Instead of directly invoking the database open and close functions everywhere, you can use around:
around = (decoration) ->
(base) ->
(params...) ->
callback = -> base params...
decoration ([callback].concat params)...
A function that’s placed around another executes code both before and after it:
withOpenDb = around (dbActivity) ->
openDbConnection()
dbActivity()
closeDbConnection()
Now you can use withOpenDb everywhere:
getUserData = withOpenDb (users) ->
users.get 'user123'
Around doesn’t just get invoked and discarded: it can control whether or not the function it wraps is invoked at all. If openDbConnection evaluates to false when the database fails to open, then the database activity can be skipped:
withOpenDb = around (dbActivity) ->
if openDbConnection()
dbActivity()
closeDbConnection()
That makes around quite powerful and dangerous. It’s possible to implement combinators that have even more power (and that are even more dangerous), such as modifying the arguments to the wrapped function and controlling the return value of the created function.
Functions are often used as methods in CoffeeScript, so generic functions that create other functions need to work correctly when those functions are methods. What happens when these combinators are used with methods?
6.4.4. Working with objects
The tricky thing about method objects is referencing this (a.k.a. @). Suppose you have a program that controls the movement of a toy robot. The program must start the toy robot engine before making it move. The program also needs to stop the engine once it is done moving the toy robot. This is essentially the same problem as the previous database example, except that in this case, Robot is a class already implemented by Rob Tuse:
class Robot
constructor: (@at=0) ->
position: ->
@at
move: (displacement) ->
@at += displacement
startEngine: -> console.log 'start engine'
stopEngine: -> console.log 'stop engine'
forward: ->
@startEngine()
@move 1
@stopEngine()
reverse: ->
@startEngine()
@move -1
@stopEngine()
You can see that that’s repetitive. Instead of repeating the same code at the start and at the end of all the methods, you could use the existing around function to wrap all of the methods. Unfortunately, everything breaks when you change the Robot class to use the around defined so far:
class Robot
withRunningEngine = around (action) ->
@startEngine()
action()
@stopEngine()
constructor: (@at=0) ->
position: ->
@at
move: (displacement) ->
console.log 'move'
@at += displacement
startEngine: -> console.log 'start engine'
stopEngine: -> console.log 'stop engine'
forward: withRunningEngine ->
@move 1
reverse: withRunningEngine ->
@move -1
bender = new Robot
bender.forward()
bender.forward()
# TypeError: Object #<Object> has no method 'startEngine'
It doesn’t work because when the function is invoked indirectly, the @ reference is lost. Normally in CoffeeScript you use the fat arrow => to lexically bind the @ reference for a function. In this case, though, you don’t want to lexically bind the @, but dynamically bind it.
call and apply
Luckily, the Function prototype has two methods, call and apply, that can help you in the rare instances where neither the arrow (->) nor fat arrow (=>) provide what you need. Both call and apply allow you to invoke any function with a specific this bound.
With call you can invoke a function with a specific this and a set number of arguments. Here’s a modified example:
airplane =
startEngine: -> 'Engine started!'
withRunningEngine = (first, second) ->
@startEngine()
"#{first} then #{second}"
withRunningEngine 'Take-off', 'Fly'
# Object #<Object> has no method 'startEngine'
withRunningEngine.call airplane, 'Take-off', 'Fly'
'Take-off then Fly'
With apply you can invoke a function with a specific this and an array of arguments:
withRunningEngine.apply airplane, ['Take-off', 'Fly']
'Take-off then Fly'
Although the addition of the fat arrow to CoffeeScript removes many of the common uses of call and apply found in JavaScript, there are still occasions, such as now, when you’ll find them useful. Using apply you can create new versions of before, after, and around that can play nicely with methods. These new versions are shown in the next listing.
Listing 6.6. Before, after, and around with function binding
before = (decoration) ->
(base) ->
(params...) ->
decoration.apply @, params
base.apply @, params
after = (decoration) ->
(base) ->
(params...) ->
result = base.apply @, params
decoration.apply @, params
result
around = (decoration) ->
(base) ->
(params...) ->
result = undefined
func = =>
result = base.apply @, params
decoration.apply @, ([func].concat params)
result
With this new version of around, the robots can move again:
bender = new Robot 3
bender.forward()
# start engine
# move
# stop engine
# 4
bender.forward()
# start engine
# move
# stop engine
# 5
bender.reverse()
# start engine
# move
# stop engine
# 4
bender.position()
# 4
It takes some time to get used to these programming concepts. At first, it’s best to lightly use techniques that you’re less familiar with, until you can learn to use them effectively and without creating a mess.
These combinator functions are useful, but so far you’ve used them only with synchronous things. Much of your program is asynchronous and uses callbacks. Will these techniques work for asynchronous code?
6.4.5. Asynchronous combinators
Asynchronous functions that accept callbacks are more difficult to compose than functions that are used purely for their evaluation. So far you’ve looked at using combinators for a synchronous database and for synchronous robots. The real world isn’t so kind. Most of your CoffeeScript programming will be asynchronous.
Consider what happens when multiple asynchronous function calls must be called in order. Start with a fake asynchronous function that requires a callback:
forward = (callback) ->
setTimeout callback, 1000
You might have seen this written when the function needs to be called five times in sequence:

The nasty-looking cascade you see here is a common affliction in asynchronous programs. Surely there’s a way to defeat this problem by composing functions. To simplify things, consider two standalone asynchronous functions, start and forward:
start = (callback) ->
console.log 'started'
setTimeout callback, 200
forward = (callback) ->
console.log 'moved forward'
setTimeout callback, 200
How do you compose these asynchronous functions? The standard compose doesn’t work because it expects to use the evaluation of one function as the argument to another:
startThenForward = compose forward, start
startThenForward (res) ->
console.log res
# TypeError: undefined is not a function
You need a different composeAsync for asynchronous functions. Take a deep breath.
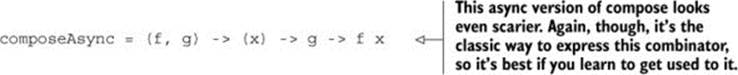
This version works, although it’s limited to functions that don’t take any arguments other than a single callback:
startThenForward = composeAsync forward, start
startThenForward ->
console.log 'done'
# started
# moved forward
# done
When the asynchronous functions have arguments other than a callback, things become more interesting. In the next listing you see asynchronous versions of before and after that Agtron has provided. Take an even deeper breath and then spend some time experimenting with them and dissecting them so that you begin to understand how they work.
Listing 6.7. Asynchronous before and after
beforeAsync = (decoration) ->
(base) ->
(params..., callback) ->
result = undefined
applyBase = =>
result = base.apply @, (params.concat callback)
decoration.apply @, (params.concat applyBase)
result
afterAsync = (decoration) ->
(base) ->
(params..., callback) ->
decorated = (params...) =>
decoration.apply @, (params.concat -> (callback.apply @, params))
base.apply @, (params.concat decorated)
There are other ways to deal with resources that are accessed asynchronously, such as treating them as streams of data, as you’ll learn about in chapter 9.
Continuations
This concept of passing in the rest of your program as a callback is similar to something called continuation-passing style. One of the criticisms of CoffeeScript in its current state is that callbacks all have to be nested. The asynchronous composition techniques presented here and the techniques shown in chapter 9 go a long way to helping solve that problem. Further, in chapter 13 you’ll see how JavaScript, and hence CoffeeScript, is evolving to have better language techniques for dealing with asynchronous code.
Later on, over coffee (robots drink coffee too), Agtron tells you what his philosophy professor once told him, “Our understanding of the world often gets tangled up until eventually it becomes one big knot. Philosophy is about teasing out those knots and untangling things so that you have simple explanations of things.” The same thing applies to the world of a program. Sometimes things get tangled up. If you pull harder on the knot, you make it worse. If you do surgery on the knot by cutting it, you can break the entire universe. The point is to instead tease out the tangles and make your program less intertwined. The techniques you’ve seen can help you to tease out some of the knots in your program.
6.5. Summary
Function composition is built on just a few basic techniques for gluing functions together. But the simplicity and flexibility of this approach allow you to construct your own programming abstractions. By naming a function, you’re growing the programming language yourself. By creating abstractions, you make it easier to construct similar parts of a language without having to write the same program over and over again. You’ve learned the techniques: keeping programs clear by naming functions, avoiding state, creating abstractions, creating abstractions of abstractions, and then also using these techniques to deal with callback functions in asynchronous programs.
In the next chapter you’ll look at programming style in CoffeeScript, advanced syntax, and some gotchas.
All materials on the site are licensed Creative Commons Attribution-Sharealike 3.0 Unported CC BY-SA 3.0 & GNU Free Documentation License (GFDL)
If you are the copyright holder of any material contained on our site and intend to remove it, please contact our site administrator for approval.
© 2016-2026 All site design rights belong to S.Y.A.