Functional Thinking (2014)
Chapter 8. Polyglot and Polyparadigm
Functional programming is a programming paradigm, a framework for thinking a certain way about problems and the attendant tools to implement that vision. Many modern languages are polyparadigm (or multiparadigm): they support a number of different programming paradigms, such as object orientation, metaprogramming, functional, procedural, and many more.
Groovy is a multiparadigm language: it supports object orientation, metaprogramming, and functional programming styles, which are mostly orthogonal to one another. Metaprogramming allows you to add features to a language and its core libraries. By combining metaprogramming with functional programming, you can make your own code more functional or augment third-party functional libraries to make them work better in Groovy. In the next section, I show how to use metaprogramming via the ExpandoMetaClass to weave a third-party functional library (Functional Java) seemingly into the core of Groovy.
ORTHOGONALITY
The definition of orthogonal spans several disciplines, including mathematics and computer science. In math, two vectors that are at right angles to each other are orthogonal, meaning that they never intersect. In computer science, orthogonal components don’t have any effects (or side effects) on one another. For example, functional programming and metaprogramming are orthogonal in Groovy because they don’t interfere with each other: using metaprogramming doesn’t restrict you from using functional constructs, and vice versa. The fact that they are orthogonal doesn’t mean that they can’t work together, merely that they don’t interfere with each other.
Combining Functional with Metaprogramming
By now, you’re quite familiar with my number classification example. While useful, it still exists as a separate function. Perhaps number classification is key to my business, and I would like it woven into the programming language itself, for convenience. In Groovy, theExpandoMetaClass allows me to add methods to existing classes, including existing language classes. To make Integer classifier aware, I add the methods to Integer, as shown in Example 8-1, assuming the functional version of my number classifier from Chapter 2.
Example 8-1. Using metaprogramming to make Integer classifier aware
Integer.metaClass.isPerfect = {->
Classifier.isPerfect(delegate)
}
Integer.metaClass.isAbundant = {->
Classifier.isAbundant(delegate)
}
Integer.metaClass.isDeficient = {->
Classifier.isDeficient(delegate)
}
In Example 8-1, I add the three Classifier methods to Integer. Now, all integers in Groovy have these methods. Groovy has no notion of primitive data types; even constants in Groovy use Integer as the underlying data type. Within the code block defining each method, I have access to the predefined delegate parameter, which represents the value of the object that is invoking the method on the class.
INITIALIZING METAPROGRAMMING METHODS
You must add metaprogramming methods before the first attempt to invoke them. The safest place to initialize them is in the static initializer for the class that uses them (because it’s guaranteed to run before other initializers for the class), but this adds complexity when multiple classes need augmented methods. Generally, applications that use a lot of metaprogramming end up with a bootstrap class to ensure that initialization occurs at the appropriate time.
Once I’ve initialized my metaprogramming methods, I can “ask” numbers about categories:
assertTrue num.isDeficient()
assertTrue 6.isPerfect()
The newly added methods work on both variables and constants. It would now be trivial to add a method to Integer that returns the classification of a particular number, perhaps as an enumeration.
Adding new methods to existing classes isn’t in itself particularly “functional,” even if the code they call is strongly functional. However, the ability to add methods seamlessly makes it easy to incorporate third-party libraries—such as the Functional Java library—that add significant functional features.
Mapping Data Types with Metaprogramming
Groovy is essentially a dialect of Java, so pulling in third-party libraries such as Functional Java is trivial. However, I can further weave those libraries into Groovy by performing some metaprogramming mapping between data types to make the seams less visible. Groovy has a native closure type (using the Closure class). Functional Java doesn’t have the luxury of closures yet (it relies on Java 5 syntax), forcing the authors to use generics and a general F class that contains an f() method. Using the Groovy ExpandoMetaClass, I can resolve the method/closure type differences by creating mapping methods between the two.
I augment the Stream class from Functional Java, which provides an abstraction for infinite lists, to enable passing Groovy closures in place of Functional Java F instances. To implement this weaving, I add overloaded methods to the Stream class to map closures into F’s f() method, as shown in Example 8-2.
Example 8-2. Mapping Functional Java classes into collections via metaprogramming
static {
Stream.metaClass.filter = { c -> delegate.filter(c as fj.F) }
// Stream.metaClass.filter = { Closure c -> delegate.filter(c as fj.F) }
Stream.metaClass.getAt = { n -> delegate.index(n) }
Stream.metaClass.getAt = { Range r -> r.collect { delegate.index(it) } }
}
@Test
void adding_methods_to_fj_classes() {
def evens = Stream.range(0).filter { it % 2 == 0 }
assertTrue(evens.take(5).asList() == [0, 2, 4, 6, 8])
assertTrue((8..12).collect { evens[it] } == [16, 18, 20, 22, 24])
assertTrue(evens[3..6] == [6, 8, 10, 12])
}
The first line in Example 8-2 creates a filter() method on Stream that accepts a closure (the c parameter of the code block). The second (commented) line is the same as the first, but with the added type declaration for the Closure; it doesn’t affect how Groovy executes the code but might be preferable as documentation. The body of the code block calls Stream’s preexisting filter() method, mapping the Groovy closure to the Functional Java fj.F class. I use Groovy’s semimagical as operator to perform the mapping.
Groovy’s as operator coerces closures into interface definitions, allowing the closure methods to map to methods required by the interface. Consider the code in Example 8-3.
Example 8-3. Groovy’s as operator coerces maps into interface implementations
h = [hasNext: { h.i > 0 }, next: {h.i--}]
h.i = 10 // ![]()
def pseudoIterator = h as Iterator // ![]()
while (pseudoIterator.hasNext())
print pseudoIterator.next() + (pseudoIterator.hasNext() ? ", " : "\n")
// 10, 9, 8, 7, 6, 5, 4, 3, 2, 1,
![]()
A map’s closures can refer to other members of the map.
![]()
as generates an implementation.
In Example 8-3, I create a hash with two name-value pairs. Each of the names is a string (Groovy doesn’t require hash keys to be delimited with double quotes, because they are strings by default), and the values are code blocks. The as operator maps this hash to the Iterator interface, which requires both hasNext() and next() methods. Once I’ve performed the mapping, I can treat the hash as an iterator; the last line of the listing prints true. In cases in which I have a single-method interface or when I want all the methods in the interface to map to a single closure, I can dispense with the hash and use as directly to map a closure onto a function. Referring back to the first line of Example 8-2, I map the passed closure to the single-method F class. In Example 8-2, I must map both getAt() methods (one that accepts a number and another that accepts aRange) because filter needs those methods to operate.
Using this newly augmented Stream, I can play around with an infinite sequence, as shown in the tests at the bottom of Example 8-2. I create an infinite list of even integers, starting with 0, by filtering them with a closure block. You can’t get all of an infinite sequence at once, so you musttake() as many elements as you want. The remainder of Example 8-2 shows testing assertions that demonstrate how the stream works.
Infinite Streams with Functional Java and Groovy
In Chapter 4, I showed how to implement a lazy infinite list in Groovy. Rather than create it by hand, why not rely on an infinite sequence from Functional Java?
To create an infinite Stream of perfect numbers, I need two additional Stream method mappings to understand Groovy closures, as shown in Example 8-4.
Example 8-4. Two additional method mappings for perfect-number stream
static {
Stream.metaClass.asList = { delegate.toCollection().asList() }
// Stream.metaClass.static.cons =
// { head, Closure c -> delegate.cons(head, ['_1':c] as fj.P1)}
Stream.metaClass.static.cons =
{ head, closure -> delegate.cons(head, closure as fj.P1) }
}
In Example 8-4, I create an asList() conversion method to make it easy to convert a Functional Java Stream to a list. The other method that I implement is an overloaded cons(), which is the method on Stream that constructs a new list. When an infinite list is created, the data structure typically contains a first element and a closure block as the tail of the list, which generates the next element when invoked. For my Groovy stream of perfect numbers, I need Functional Java to understand that cons() can accept a Groovy closure.
If I use as to map a single closure onto an interface that has multiple methods, that closure is executed for any method I call on the interface. That style of simple mapping works in most cases for Functional Java classes. However, a few methods require a fj.P1() method rather than a fj.Fmethod. In some of those cases, I can still get away with a simple mapping because the downstream methods don’t rely on any of the other methods of P1. In cases in which more precision is required, I may have to use the more complex mapping shown in the commented line in Example 8-4, which must create a hash with the _1() method mapped to the closure. Although that method looks odd, it’s a standard method on the fj.P1 class that returns the first element.
Once I have my metaprogrammatically mapped methods on Stream, I add to the Groovy implementation of Classifier to create an infinite stream of perfect numbers, as shown in Example 8-5.
Example 8-5. Infinite stream of perfect numbers using Functional Java and Groovy
def perfectNumbers(num) {
cons(nextPerfectNumberFrom(num), { perfectNumbers(nextPerfectNumberFrom(num))})
}
@Test
void infinite_stream_of_perfect_nums_using_funtional_java() {
assertEquals([6, 28, 496], perfectNumbers(1).take(3).asList())
}
I use static imports both for Functional Java’s cons() and for my own nextPerfectNumberFrom() method from Classifier to make the code less verbose. The perfectNumbers() method returns an infinite sequence of perfect numbers by consing (yes, cons is a verb) the first perfect number after the seed number as the first element and adding a closure block as the second element. The closure block returns the infinite sequence with the next number as the head and the closure to calculate yet another one as the tail. In the test, I generate a stream of perfect numbers starting from 1, taking the next three perfect numbers and asserting that they match the list.
When developers think of metaprogramming, they usually think only of their own code, not of augmenting someone else’s. Groovy allows me to add new methods not only to built-in classes such as Integer, but also to third-party libraries such as Functional Java. Combining metaprogramming and functional programming leads to great power with very little code, creating a seamless link.
Although I can call Functional Java classes directly from Groovy, many of the library’s building blocks are clumsy when compared to real closures. By using metaprogramming, I can map the Functional Java methods to allow them to understand convenient Groovy data structures, achieving the best of both worlds. As projects become more polyglot, developers frequently need to perform similar mappings between language types: a Groovy closure and a Scala closure aren’t the same thing at the bytecode level. Having a standard in Java 8 will push these conversations down to the runtime and eliminate the need for mappings like the ones I’ve shown here. Until that time, though, this facility makes for clean yet powerful code.
Consequences of Multiparadigm Languages
Multiparadigm languages offer immense power, allowing developers to mix and match suitable paradigms. Many developers chafe at the limitations in Java prior to version 8, and a language such as Groovy provides many more facilities, including metaprogramming and functional constructs.
While powerful, multiparadigm languages require more developer discipline on large projects. Because the language supports many different abstractions and philosophies, isolated groups of developers can create starkly different variants in libraries. As I illustrated in Chapter 6, fundamental considerations differ across paradigms. For example, code reuse tends toward structure in the object-oriented world, whereas it tends toward composition and higher-order functions in the functional world. When designing your company’s Customer API, which style will you use? Many developers who moved from Java to Ruby encountered this problem, because Ruby is a forgiving multiparadigm language.
One solution relies on engineering discipline to ensure that all developers are working toward the same goal. Unit testing enables pinpoint understanding of complex extentions via metaprogramming. Techniques such as consumer-driven contracts allow developers to create contracts (in the form of tests) that act as executable contracts between teams.
CONSUMER-DRIVEN CONTRACTS
A consumer-driven contract is a set of tests agreed upon by both an integration provider and supplier(s). The provider “agrees” that it will run the tests as part of its regular build and ensure that all the tests remain green. The tests ensure the assumptions between the various interested parties. If either party needs to make a breaking change, all the affected parties get together and agree on an upgraded set of tests. Thus, consumer-driven contracts provide an executable integration safety net that requires coordination only when things must evolve.
Many C++ projects suffered from awkwardly spanning procedural and object-orientation programming styles Fortunately, modern engineering practices and exposure to the dangers in multiparadigm languages can help.
Some languages solve this problem by primarily embracing one paradigm while pragmatically supporting others. For example, Clojure is firmly a functional Lisp for the JVM. It allows you to interact with classes and methods from the underlying platform (and create your own if you like), but its primary support is for strongly functional paradigms such as immutability and laziness. Clojure doesn’t obviate the need for engineering disciplines like testing, but its idiomatic use doesn’t stray far from Clojure’s specific design goals.
Context Versus Composition
Functional thinking pervades more than just the languages you use on projects. It affects the design of tools as well. In Chapter 6, I defined composition as a design ethos in the functional programming world. Here I want to apply that same idea to tools and contrast two abstractions prevalent in the development world: composable and contextual. Plug-in-based architectures are excellent examples of the contextual abstraction. The plug-in API provides a plethora of data structures and other useful context that developers inherit from or summon via already existing methods. But to use the API, a developer must understand what that context provides, and that understanding is sometimes expensive. I ask developers how often they make nontrivial changes to the way their editor/IDE behaves beyond the preferences dialog. Heavy IDE users do this much less frequently, because extending a tool like Eclipse takes an immense amount of knowledge. The knowledge and effort required for a seemingly trivial change prevents the change from occurring, leaving the developer with a perpetually dull tool. Contextual tools aren’t bad things at all—Eclipse and IntelliJ wouldn’t exist without that approach. Contextual tools provide a huge amount of infrastructure that developers don’t have to build. Once mastered, the intricacies of Eclipse’s API provide access to enormous encapsulated power. And there’s the rub: how encapsulated?
In the late 1990s, 4GLs were all the rage, and they exemplified the contextual approach. They built the context into the language itself: dBASE, FoxPro, Clipper, Paradox, PowerBuilder, Microsoft Access, and their ilk all had database-inspired facilities directly in the language and tooling. Ultimately, 4GLs fell from grace because of Dietzler’s Law, which I define in my book The Productive Programmer (O’Reilly), based on experiences of my colleague Terry Dietzler, who ran the Access projects for my employer at the time.
DIETZLER’S LAW FOR ACCESS
Every Access project will eventually fail because, while 80% of what the user wants is fast and easy to create, and the next 10% is possible with difficulty, ultimately the last 10% is impossible because you can’t get far enough underneath the built-in abstractions, and users always want 100% of what they want.
Ultimately, Dietzler’s Law killed the market for 4GLs. Although they made it easy to build simple things fast, they didn’t scale to meet the demands of the real world. We all returned to general-purpose languages.
Composable systems tend to consist of fine-grained parts that are expected to be wired together in specific ways. Powerful exemplars of this abstraction show up in Unix shells with the ability to chain disparate behaviors together to create new things. In Chapter 1, I alluded to a famous story from 1992 that illustrates how powerful these abstractions are. Donald Knuth was asked to write a program to solve this text-handling problem: read a file of text, determine the n most frequently used words, and print out a sorted list of those words along with their frequencies. He wrote a program consisting of more than 10 pages of Pascal, designing (and documenting) a new algorithm along the way. Then, Doug McIlroy demonstrated a shell script that would easily fit within a Twitter post that solved the problem more simply, elegantly, and understandably (if you understand shell commands):
tr -cs A-Za-z '\n' |
tr A-Z a-z |
sort |
uniq -c |
sort -rn |
sed ${1}q
I suspect that even the designers of Unix shells are often surprised at the inventive uses developers have wrought with their simple but powerfully composable abstractions.
Contextual systems provide more scaffolding, better out-of-the-box behavior, and contextual intelligence via that scaffolding. Thus, contextual systems tend to ease the friction of initial use by doing more for you. Huge global data structures sometimes hide behind inheritance in these systems, creating a huge footprint that shows up in derived extensions via their parents. Composable systems have less implicit behavior and initial ease of use but tend to provide more granular building blocks that lead to more eventual power. Well-designed composable systems provide narrow local context within encapsulated modules.
These abstractions apply to tools and frameworks as well—particularly tools that must scale in their power and sophistication along with projects, such as build tools. By hard-won lessons, composable build tools scale (in time, complexity, and usefulness) better than contextual ones. Contextual tools such as Ant and Maven allow extension via a plug-in API, making extensions that the original authors envisioned easy. However, trying to extend it in ways not designed into the API range in difficulty from hard to impossible: Dietzler’s Law redux. This is especially true with tools in which critical parts of how they function, such as the ordering of tasks, are inaccessible without hacking.
This is why every project eventually hates Maven. Maven is a classic contextual tool: it is opinionated, rigid, generic, and dogmatic, which is exactly what is needed at the beginning of a project. Before anything exists, it’s nice for something to impose a structure and to make it trivial to add behavior via plug-ins and other prebuilt niceties. But over time, the project becomes less generic and more like a real, messy project. Early on, when no one knows enough to have opinions about things such as life cycle, a rigid system is good. Over time, though, project complexity requires developers to spawn opinions, and tools like Maven don’t care.
Tools built atop languages tend to be more composable. My all-time favorite build language for personal and project work (almost without regard to the project technology stack) is Rake, the build tool in the Ruby world. It is a fantastic combination of simplicity and power. When I first migrated from Ant to Rake, I started poking around the Rake documentation to find out which tasks are available in Rake, hoping to find something simliar to the giant list of tasks (and extensions) familiar in the Ant world. I was disgusted by the lack of documentation until I realized that there wasn’t any for a reason: you can do anything you need within Rake tasks, because it’s just Ruby code. Rake has added some nice helpers for file list manipulation, but Rake mostly just handles tasks dependencies and housekeeping, getting out of the way of developers.
People will accuse me of bashing Maven, but I’m actually not—I’m trying to foster understanding for when it’s useful. No tool works perfectly in every context, and much grief visits projects that try to use tools outside their expiration date. Maven is perfect for starting new projects: it ensures consistency and provides a huge bang for the buck in terms of existing functionality. But the fact that something starts strong doesn’t mean that it scales well. (In fact, almost always the opposite is true.) The real trick is to use Maven until the day it starts fighting you, then find an alternative. Once you start fighting with Maven, it’ll never return to the rosy days when your relationship was young.
Fortunately, at least one Maven get-out-of-jail-free card exists in Gradle, which still understands the Maven stuff you already have, but is language-based rather than plug-in–based—implemented as a Groovy domain-specific language—making it more composable than Maven.
Many contextualized systems eventually become more composable by being redesigned as DSLs. Consider the 4GLs from the 1990s. Ruby on Rails and similar frameworks are just like those 4GLs, with a critical distinction: they are implemented as internal DSLs atop a general-purpose language. When developers in those environments hit the upper percentages of Dietzler’s Law, they can drop below the framework back to the underlying general-purpose language. Rake and Gradle are both DSLs, and I’ve come to believe that scripting builds is far too specific and unique to each project to use contextualized tools.
Functional Pyramid
Computer language types generally exist along two axes, pitting strong versus weak and dynamic versus static, as shown in Figure 8-1.
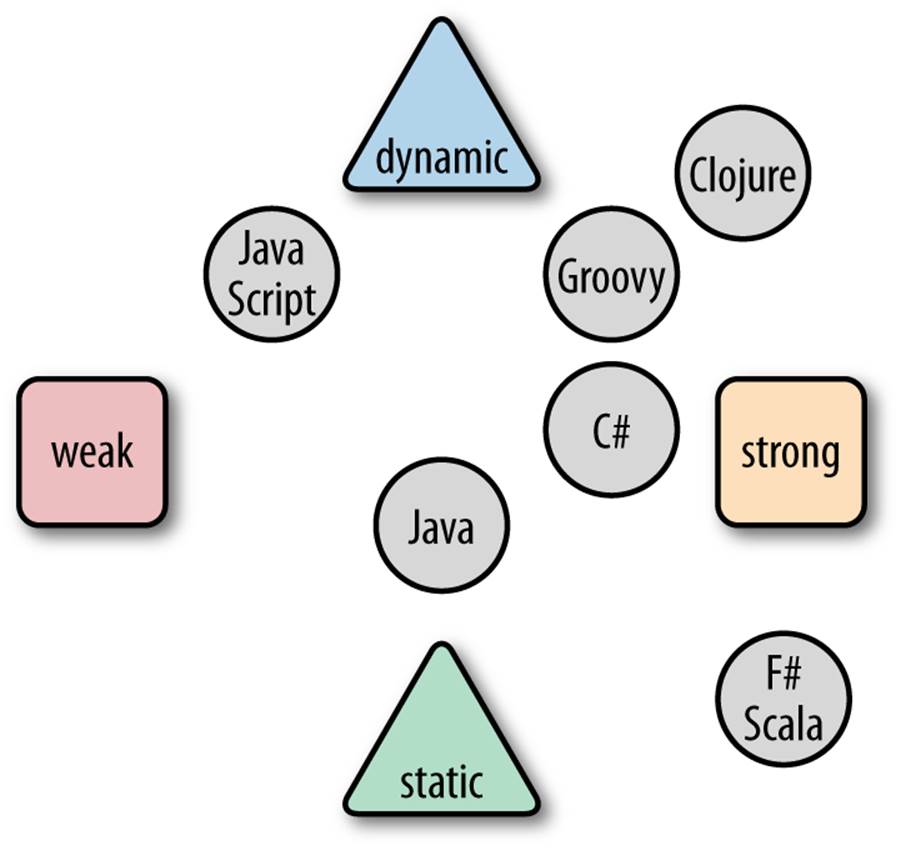
Figure 8-1. Language categories
Static typing indicates that you must specify types for variables and functions beforehand, whereas dynamic typing allows you to defer it. Strongly typed variables “know” their type, allowing reflection and instance checks, and they retain that knowledge. Weakly typed languages have less sense of what they point to. For example, C is a statically, weakly typed language: variables in C are really just a collection of bits that can be interpreted in a variety of ways, to the joy and horror (sometimes simultaneously) of C developers everywhere.
Java is strongly, statically typed: you must specify variable types, sometimes several times over, when declaring variables. Scala, C#, and F# are also strongly, statically typed but manage with much less verbosity by using type inference. Many times, the language can discern the appropriate type, allowing for less redundancy.
The diagram in Figure 8-1 is not new; this distinction has existed as long as languages have been studied. However, a new aspect has entered into the equation: functional programming.
As I’ve shown throughout this book, functional programming languages have a different design philosophy than imperative ones. Imperative languages try to make mutating state easier and have lots of features for that purpose. Functional languages try to minimize mutable state and build more general-purpose machinery.
But functional doesn’t dictate a typing system, as you can see in Figure 8-2.
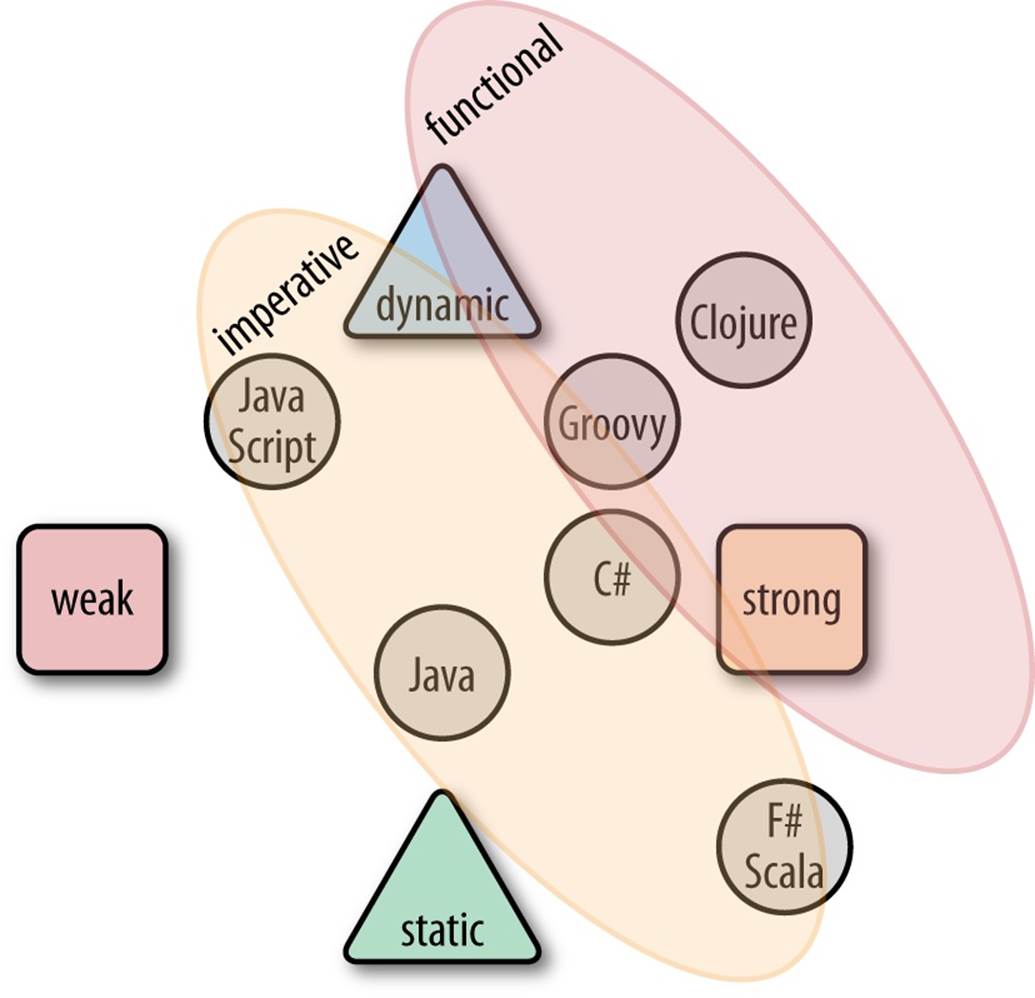
Figure 8-2. Languages with paradigm overlay
With the added reliance—even insistence—on immutability, the key differentiator among languages now isn’t dynamic versus static, but imperative versus functional, with interesting implications for the way we build software.
On my blog back in 2006, I accidentally repopularized the term polyglot programming and gave it a new meaning: taking advantage of modern runtimes to create applications that mix and match languages but not platforms. This was based on the realization that the Java and .NET platforms support more than 200 languages between them, with the added suspicion that there is no One True Language that can solve every problem. With modern managed runtimes, you can freely mix and match languages at the byte code level, utilizing the best one for a particular job.
After I published my article, my colleague Ola Bini published a follow-up paper discussing his Polyglot Pyramid, which suggests the way people might architect applications in the polyglot world, as shown in Figure 8-3.
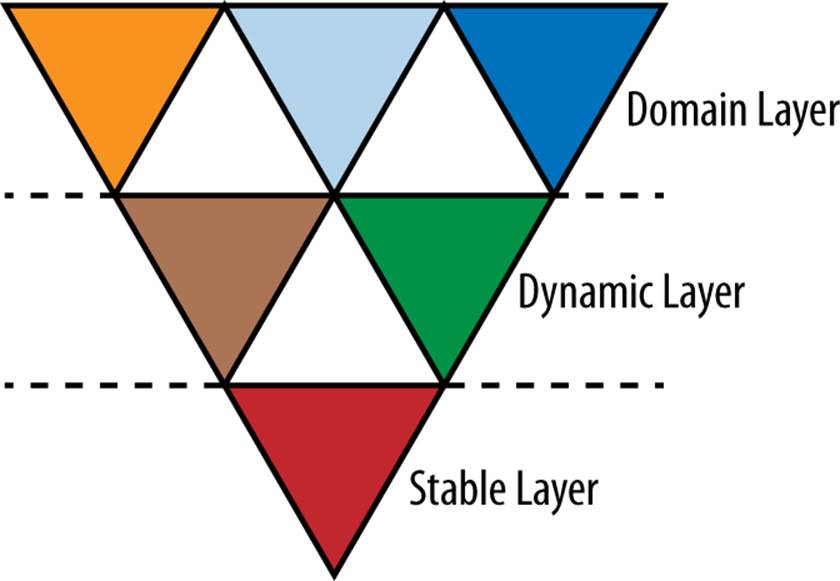
Figure 8-3. Ola Bini’s polyglot language pyramid
In Bini’s original pyramid, he suggests using more static languages at the bottommost layers, where reliability is the highest priority. Next, he suggests using more dynamic languages for the application layers, utilizing friendlier and simpler syntax for building things like user interfaces. Finally, atop the heap, are DSLs, built by developers to succinctly encapsulate important domain knowledge and workflow. Typically, DSLs are implemented in dynamic languages to leverage some of their capabilities in this regard.
This pyramid was a tremendous insight added to my original post, but upon reflection about current events, I’ve modified it. I now believe that typing is a red herring that distracts from the important characteristic, which is functional versus imperative. My new Polyglot Pyramid appears inFigure 8-4.
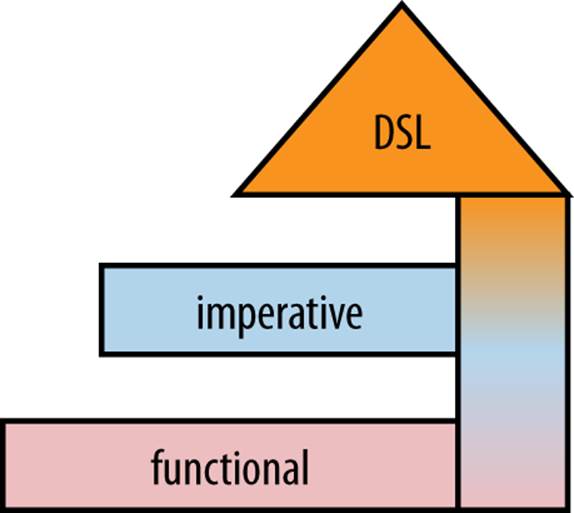
Figure 8-4. My functional pyramid
I believe that the resiliency we crave comes not from static typing but from embracing functional concepts at the bottom. If all of your core APIs for heavy lifting—data access, integration—could assume immutability, all that code would be much simpler. Of course, it would change the way we build databases and other infrastructure, but the end result will be guaranteed stability at the core.
Atop the functional core, use imperative languages to handle workflow, business rules, user interfaces, and other parts of the system for which developer productivity is a priority. As in the original pyramid, DSLs sit on top, serving the same purpose. However, I also believe that DSLs will penetrate through all the layers of our systems, all the way to the bottom. This is exemplified by the ease with which you can write DSLs in languages like Scala (functional, statically strongly types) and Clojure (functional, dynamically strongly typed) to capture important concepts in concise ways.
This is a huge change, but it has fascinating implications. Rather than stress about dynamic versus static, the much more interesting discussion now is functional versus imperative, and the implications of this change go deeper than the arguments about static versus dynamic. In the past, we designed imperatively using a variety of languages. Switching to the functional style is a bigger shift than just learning a new syntax, but the beneficial effects can be profound.
All materials on the site are licensed Creative Commons Attribution-Sharealike 3.0 Unported CC BY-SA 3.0 & GNU Free Documentation License (GFDL)
If you are the copyright holder of any material contained on our site and intend to remove it, please contact our site administrator for approval.
© 2016-2026 All site design rights belong to S.Y.A.