Multiplayer Game Programming: Architecting Networked Games (2016)
Chapter 4. Object Serialization
To transmit objects between networked instances of a multiplayer game, the game must format the data for those objects such that it can be sent by a transport layer protocol. This chapter discusses the need for and uses of a robust serialization system. It explores ways to handle the issues of self-referential data, compression, and easily maintainable code, while working within the runtime performance requirements of a real-time simulation.
The Need for Serialization
Serialization refers to the act of converting an object from its random access format in memory into a linear series of bits. These bits can be stored on disk or sent across a network and later restored to their original format. Assume that in the Robo Cat game, a player’s RoboCat is represented by the following code:
class RoboCat: public GameObject
{
public:
RoboCat(): mHealth(10), mMeowCount(3) {}
private:
int32_t mHealth;
int32_t mMeowCount;
};
As mentioned in Chapter 3, “Berkeley Sockets,” the Berkeley Socket API uses the send and sentdo functions to send data from one host to another. Each of these functions takes a parameter which points to the data to transmit. Therefore, without writing any special serialization code, the naïve way to send and receive a RoboCat from one host to another would look something like this:
void NaivelySendRoboCat(int inSocket, const RoboCat* inRoboCat)
{
send(nSocket,
reinterpret_cast<const char*>(inRoboCat),
sizeof(RoboCat), 0 );
}
void NaivelyReceiveRoboCat(int inSocket, RoboCat* outRoboCat)
{
recv(inSocket,
reinterpret_cast<char*>(outRoboCat),
sizeof(RoboCat), 0);
}
NaivelySendRoboCat casts the RoboCat to a char* so that it can pass it to send. For the length of the buffer, it sends the size of the RoboCat class, which in this case is eight. The receiving function again casts the RoboCat to a char*, this time so that it can receive directly into the data structure. Assuming a TCP connection using the sockets exists between two hosts, the following process will send the state of a RoboCat between those hosts:
1. Call NaivelySendRoboCat on the source host, passing in the RoboCat to be sent.
2. On the destination host, create or find an existing RoboCat object that should receive the state.
3. On the destination host, call NaivelyReceiveRoboCat, passing in a pointer to the RoboCat object chosen in Step 2.
Chapter 5, “Object Replication” deals in depth with Step 2, explaining how and when to find or create a destination RoboCat. For now, assume that a system is in place to locate or spawn the target RoboCat on the receiving host.
Once the transfer procedure completes, assuming the hosts are running on identical hardware platforms, the state from the source RoboCat successfully copies into the destination RoboCat. The memory layout for a sample RoboCat, as displayed in Table 4.1, demonstrates why the naïve send and receive functions are effective for a class that is this simple.

Table 4.1 Sample RoboCat in Memory
The RoboCat on the destination host has an mHealth of 10 and an mMeowCount of 3, as set by the RoboCat constructor. The RoboCat on the source host has lost half its health, leaving it at 5, and has used up one of its meows, due to whatever game logic has run on that host. BecausemHealth and mMeowCount are primitive data types, the naïve send and receive works correctly, and the RoboCat on the destination host ends up with the proper values.
However, objects representing key elements of a game are rarely as simple as the RoboCat in Table 4.1. Code for a more likely version of RoboCat presents challenges that cause the naïve process to break down, introducing the need for a more robust serialization system:
class RoboCat: public GameObject
{
public:
RoboCat(): mHealth(10), mMeowCount(3),
mHomeBase(0)
{
mName[0] = '\0';
}
virtual void Update();
void Write(OutputMemoryStream& inStream) const;
void Read(InputMemoryStream& inStream);
private:
int32_t mHealth;
int32_t mMeowCount;
GameObject* mHomeBase;
char mName[128];
std::vector<int32_t> mMiceIndices;
};
These additions to RoboCat create complications that must be considered when serializing. Table 4.2 shows the memory layout before and then after the transfer.
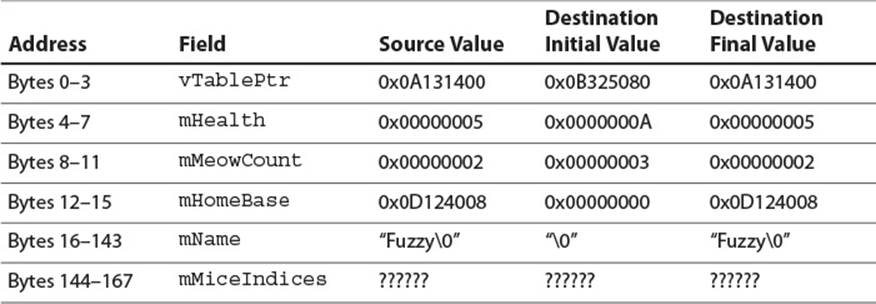
Table 4.2 A Complicated RoboCat in Memory
The first 4 bytes of RoboCat are now a virtual function table pointer. This assumes compilation for a 32-bit architecture—on a 64-bit system this would be the first 8 bytes. Now that RoboCat has the virtual method RoboCat::Update(), each RoboCat instance needs to store a pointer to the table that contains the locations of the virtual method implementations for RoboCat. This causes a problem for the naïve serialization implementation because the location of that table can be different for each instance of the process. In this case, receiving replicated state into the destination RoboCat replaces the correct virtual function table pointer with the value 0x0B325080. After that, invoking the Update method on the destination RoboCat would at best result in a memory access exception and at worst result in the invocation of random code.
The virtual function table pointer is not the only pointer overwritten in this instance. Copying the mHomeBase pointer from one process to another provides a similarly nonsensical result. Pointers, by their nature, refer to a location in a particular process’s memory space. It is not safe to blindly copy a pointer field from one process to another process and hope that the pointer references relevant data in the destination process. Robust replication code must either copy the referenced data and set the field to point to the copy or find an existing version of the data in the destination process and set the field to point there. The section “Referenced Data” later in this chapter discusses these techniques further.
Another issue evident in the naïve serialization of the RoboCat is the mandatory copying of all 128 bytes of the mName field. Although the array holds up to 128 characters, it may sometimes hold fewer, as it does in the sample RoboCat with mName equal to “Fuzzy.” To fulfill the multiplayer game programmer’s mandate of optimized bandwidth usage, a good serialization system should avoid serializing unnecessary data when possible. In this case, that requires the system to understand that the mName field is a null-terminated c string and to only serialize the characters up to and including the null termination. This is one of several techniques for compressing runtime data during serialization, more of which are discussed in detail later in this chapter in the section “Compression.”
The final serialization issue illustrated in the new version of RoboCat occurs when copying the std::vector<int32_t> mMiceIndices. The internals of the STL’s vector class are not specified by the C++ standard, and thus it is not clear whether it is safe to naïvely copy the field’s memory from one process to another. In all likelihood, it is not: There are probably one or more pointers inside the vector data structure referencing the vector’s elements, and there may be initialization code that must be run once these pointers are set up. It is almost certain that naïve serialization would fail to copy the vector properly. In fact, it should be assumed that naïve serialization would fail when copying any black box data structure: Because it is not specified what’s inside the structure, it is not safe to copy it bit for bit. Properly handling the serialization of complex data structures is addressed throughout this chapter.
The three problems enumerated earlier suggest that instead of sending a single blob of RoboCat data to the socket, each field should be serialized individually to ensure correctness and efficiency. It is possible to create one packet per field, calling a unique send function for each field’s data, but this would cause chaos for the network connection, wasting scads of bandwidth for all the unnecessary packet headers. Instead, it is better to gather up all the relevant data into a buffer and then send that buffer as a representation of the object. To facilitate this process, we introduce the concept of the stream.
Streams
In computer science, a stream refers to a data structure that encapsulates an ordered set of data elements and allows the user to either read or write data into the set.
A stream can be an output stream, input stream, or both. An output stream acts as an output sink for user data, allowing the user of the stream to insert elements sequentially, but not to read them back. Contrariwise, an input stream acts as a source of data, allowing the user to extract elements sequentially, but does not expose functionality for inserting them. When a stream is both an input and output stream, it exposes methods for inserting and extracting data elements, potentially concurrently.
Often, a stream is an interface to some other data structure or computing resource. For instance, a file output stream could wrap a file that has been opened for writing, providing a simple method of sequentially storing different data types to disk. A network stream could wrap a socket, providing a wrapper for the send() and recv() functions, tailored for specific data types relevant to the user.
Memory Streams
A memory stream wraps a memory buffer. Typically, this is a buffer dynamically allocated on the heap. The output memory stream has methods for writing sequentially into the buffer, as well as an accessor that provides read access to the buffer itself. By calling the buffer accessor, a user can take all data written into the stream at once and pass it to another system, such as the send function of a socket. Listing 4.1 shows an implementation of an output memory stream.
Listing 4.1 Output Memory Stream
class OutputMemoryStream
{
public:
OutputMemoryStream():
mBuffer(nullptr), mHead(0), mCapacity(0)
{ReallocBuffer(32);}
~OutputMemoryStream() {std::free(mBuffer);}
//get a pointer to the data in the stream
const char* GetBufferPtr() const {return mBuffer;}
uint32_t GetLength() const {return mHead;}
void Write(const void* inData, size_t inByteCount);
void Write(uint32_t inData) {Write(&inData, sizeof( inData));}
void Write(int32_t inData) {Write(&inData, sizeof( inData));}
private:
void ReallocBuffer(uint32_t inNewLength);
char* mBuffer;
uint32_t mHead;
uint32_t mCapacity;
};
void OutputMemoryStream::ReallocBuffer(uint32_t inNewLength)
{
mBuffer = static_cast<char*>(std::realloc( mBuffer, inNewLength));
//handle realloc failure
//...
mCapacity = inNewLength;
}
void OutputMemoryStream::Write(const void* inData,
size_t inByteCount)
{
//make sure we have space...
uint32_t resultHead = mHead + static_cast<uint32_t>(inByteCount);
if(resultHead > mCapacity)
{
ReallocBuffer(std::max( mCapacity * 2, resultHead));
}
//copy into buffer at head
std::memcpy(mBuffer + mHead, inData, inByteCount);
//increment head for next write
mHead = resultHead;
}
The Write(const void* inData, size_t inByteCount) method is the primary way to send data to the stream. The overloads of the Write method take specific data types so that the byte count does not always need to be sent as a parameter. To be more complete, a templatedWrite method could allow all data types, but it would need to prevent nonprimitive types from being serialized: Remember that nonprimitive types require special serialization. A static assert with type traits provides one way to safely template the Write method:
template<typename T> void Write(T inData)
{
static_assert(std::is_arithmetic<T>::value ||
std::is_enum<T>::value,
"Generic Write only supports primitive data types");
Write(&inData, sizeof(inData));
}
Regardless of the method chosen, building a helper function to automatically select byte count helps to prevent errors by reducing the chance that a user will pass the incorrect byte count for a data type.
Whenever there is not enough capacity in the mBuffer to hold new data being written, the buffer automatically expands to the maximum of either double the current capacity or to the amount necessary to contain the write. This is a common memory expansion technique, and the multiple can be adjusted to suit a specific purpose.
Warning
Although the GetBufferPtr function provides a read-only pointer to the stream’s internal buffer, the stream retains ownership of the buffer. This means the pointer is invalid once the stream is deallocated. If a use case calls for the pointer returned by GetBufferPtr to persist once the stream is deallocated, the buffer could be implemented as std::shared_ptr<std::vector<uint8_t> >, but this is left as an exercise at the end of the chapter.
Using the output memory stream, it is possible to implement more robust RoboCat send functions:
void RoboCat::Write(OutputMemoryStream& inStream) const
{
inStream.Write(mHealth);
inStream.Write(mMeowCount);
//no solution for mHomeBase yet
inStream.Write(mName, 128);
//no solution for mMiceIndices yet
}
void SendRoboCat(int inSocket, const RoboCat* inRoboCat)
{
OutputMemoryStream stream;
inRoboCat->Write(stream);
send(inSocket, stream.GetBufferPtr(),
stream.GetLength(), 0);
}
Adding a Write method to the RoboCat itself allows access to private internal fields and abstracts the task of serialization away from the task of sending data over the network. It also allows a caller to write a RoboCat instance as one of many elements inserted into the stream. This proves useful when replicating multiple objects, as described in Chapter 5.
Receiving the RoboCat at the destination host requires a corresponding input memory stream and RoboCat::Read method, as shown in Listing 4.2.
Listing 4.2 Input Memory Stream
class InputMemoryStream
{
public:
InputMemoryStream(char* inBuffer, uint32_t inByteCount):
mCapacity(inByteCount), mHead(0),
{}
~InputMemoryStream() {std::free( mBuffer);}
uint32_t GetRemainingDataSize() const {return mCapacity - mHead;}
void Read(void* outData, uint32_t inByteCount);
void Read(uint32_t& outData) {Read(&outData, sizeof(outData));}
void Read(int32_t& outData) {Read(&outData, sizeof(outData));}
private:
char* mBuffer;
uint32_t mHead;
uint32_t mCapacity;
};
void RoboCat::Read(InputMemoryStream& inStream)
{
inStream.Read(mHealth);
inStream.Read(mMeowCount);
//no solution for mHomeBase yet
inStream.Read(mName, 128);
//no solution for mMiceIndices
}
const uint32_t kMaxPacketSize = 1470;
void ReceiveRoboCat(int inSocket, RoboCat* outRoboCat)
{
char* temporaryBuffer =
static_cast<char*>(std::malloc(kMaxPacketSize));
size_t receivedByteCount =
recv(inSocket, temporaryBuffer, kMaxPacketSize, 0);
if(receivedByteCount > 0)
{
InputMemoryStream stream(temporaryBuffer,
static_cast<uint32_t> (receivedByteCount));
outRoboCat->Read(stream);
}
else
{
std::free(temporaryBuffer);
}
}
After ReceiveRoboCat creates a temporary buffer and fills it by calling recv to read pending data from the socket, it passes ownership of the buffer to the input memory stream. From there, the stream’s user can extract data elements in the order in which they were written. TheRoboCat::Read method then does just this, setting the proper fields on the RoboCat.
Tip
When using this paradigm in a complete game, you would not want to allocate the memory for the stream each time a packet arrives, as memory allocation can be slow. Instead you would have a stream of maximum size preallocated. Each time a packet comes in, you would receive directly into that preallocated stream’s buffer, process the packet by reading out of the stream, and then reset the mHead to 0 so that the stream is ready to be received into when the next packet arrives.
In this case, it would also be useful to add functionality to the MemoryInputStream to allow it to manage its own memory. A constructor that takes only a max capacity could allocate the stream’s mBuffer, and then an accessor that returns the mBuffer would allow the buffer to be passed directly to recv.
This stream functionality solves the first of the serialization issues: It provides a simple way to create a buffer, fill the buffer with values from individual fields of a source object, send that buffer to a remote host, extract the values in order, and insert them into the appropriate fields of a destination object. Additionally, the process does not interfere with any areas of the destination object that should not be changed, such as the virtual function table pointer.
Endian Compatibility
Not all CPUs store the bytes of a multibyte number in the same order. The order in which bytes are stored on a platform is referred to as the platform’s endianness, with platforms being either little-endian or big-endian. Little-endian platforms store multibyte numbers with their low-order bytes at the lowest memory address. For instance, an integer containing the value 0x12345678 with an address of 0x01000000 would be stored in memory as shown in Figure 4.1.

Figure 4.1 Little-endian 0x12345678
The least significant byte, the 0x78, is first in memory. This is the “littlest” part of the number, and why the arrangement strategy is called “little” endian. Platforms that use this strategy include Intel’s x86, x64, and Apple’s iOS hardware.
Big-endian, alternatively, stores the most significant byte in the lowest memory address. The same number would be stored at the same address as shown in Figure 4.2.

Figure 4.2 Big-endian 0x12345678
Platforms that use this strategy include the Xbox 360, the PlayStation 3, and IBM’s PowerPC architecture.
Tip
Endian order is usually irrelevant when programming a single-platform, single-player game, but when transferring data between platforms with different endianness, it becomes a factor which must be considered. A good strategy to use when transferring data using a stream is to decide on an endianness for the stream itself. Then, when writing a multibyte data type, if the platform endianness does not match the chosen stream endianness, the byte order of the data should be reversed when being written into the stream. Similarly, when data is read from the stream, if the platform endianness differs from the stream endianness, the byte order should be reversed.
Most platforms provide efficient byte swapping algorithms, and some even have intrinsics or assembly instructions. However if you need to roll your own, Listing 4.3 provides effective byte swapping functions.
Listing 4.3 Byte Swapping Functions
inline uint16_t ByteSwap2(uint16_t inData)
{
return (inData >> 8) | (inData << 8);
}
inline uint32_t ByteSwap4(uint32_t inData)
{
return ((inData >> 24) & 0x000000ff)|
((inData >> 8) & 0x0000ff00)|
((inData << 8) & 0x00ff0000)|
((inData << 24) & 0xff000000);
}
inline uint64_t ByteSwap8(uint64_t inData)
{
return ((inData >> 56) & 0x00000000000000ff)|
((inData >> 40) & 0x000000000000ff00)|
((inData >> 24) & 0x0000000000ff0000)|
((inData >> 8) & 0x00000000ff000000)|
((inData << 8) & 0x000000ff00000000)|
((inData << 24) & 0x0000ff0000000000)|
((inData << 40) & 0x00ff000000000000)|
((inData << 56) & 0xff00000000000000);
}
These functions handle basic unsigned integers of the given size, but not other data types that need to be byte swapped, such as floats, doubles, signed integers, large enums, and more. To do that, it takes some tricky type aliasing:
template <typename tFrom, typename tTo>
class TypeAliaser
{
public:
TypeAliaser(tFrom inFromValue):
mAsFromType(inFromValue) {}
tTo& Get() {return mAsToType;}
union
{
tFrom mAsFromType;
tTo mAsToType;
};
};
This class provides a method to take data of one type, such as a float, and treat it as a type for which there is already a byte swap function implemented. Templating some helper functions as in Listing 4.4 then enables swapping any type of primitive data using the appropriate function.
Listing 4.4 Templated Byte Swapping Functions
template <typename T, size_t tSize> class ByteSwapper;
//specialize for 2...
template <typename T>
class ByteSwapper<T, 2>
{
public:
T Swap(T inData) const
{
uint16_t result =
ByteSwap2(TypeAliaser<T, uint16_t>(inData).Get());
return TypeAliaser<uint16_t, T>(result).Get();
}
};
//specialize for 4...
template <typename T>
class ByteSwapper<T, 4>
{
public:
T Swap(T inData) const
{
uint32_t result =
ByteSwap4(TypeAliaser<T, uint32_t>(inData).Get());
return TypeAliaser<uint32_t, T>(result).Get();
}
};
//specialize for 8...
template <typename T>
class ByteSwapper<T, 8>
{
public:
T Swap(T inData) const
{
uint64_t result =
ByteSwap8(TypeAliaser<T, uint64_t>(inData).Get());
return TypeAliaser<uint64_t, T>(result).Get();
}
};
template <typename T>
T ByteSwap(T inData)
{
return ByteSwapper<T, sizeof(T) >().Swap(inData);
}
Calling the templated ByteSwap function creates an instance of ByteSwapper, templated based on the size of the argument. This instance then uses the TypeAliaser to call the appropriate ByteSwap function. Ideally, the compiler optimizes the intermediate invocations away, leaving a few operations that just swap the order of some bytes in a register.
Note
Not all data needs to be byte swapped just because the platform endianness doesn’t match the stream endianness. For instance, a string of single-byte characters doesn’t need to be byte swapped because even though the string is multiple bytes, the individual characters are only a single byte each. Only primitive data types should be byte swapped, and they should be swapped at a resolution that matches their size.
Using the ByteSwapper, the generic Write and Read functions can now properly support a stream with endianness that differs from that of the runtime platform:
template<typename T> void Write(T inData)
{
static_assert(
std::is_arithmetic<T>::value||
std::is_enum<T>::value,
"Generic Write only supports primitive data types");
if(STREAM_ENDIANNESS == PLATFORM_ENDIANNESS)
{
Write(&inData, sizeof(inData));
}
else
{
T swappedData = ByteSwap(inData);
Write(&swappedData, sizeof( swappedData));
}
}
Bit Streams
One limitation of the memory streams described in the previous section is that they can only read and write data that is an integral number of bytes. When writing networking code, it is often desirable to represent values with as few bits as possible, and this can require reading and writing with single-bit precision. To this end, it is helpful to implement a memory bit stream, able to serialize data that is any number of bits. Listing 4.5 contains a declaration of an output memory bit stream.
Listing 4.5 Declaration of an Output Memory Bit Stream
class OutputMemoryBitStream
{
public:
OutputMemoryBitStream() {ReallocBuffer(256);}
~OutputMemoryBitStream() {std::free(mBuffer);}
void WriteBits(uint8_t inData, size_t inBitCount);
void WriteBits(const void* inData, size_t inBitCount);
const char* GetBufferPtr() const {return mBuffer;}
uint32_t GetBitLength() const {return mBitHead;}
uint32_t GetByteLength() const {return (mBitHead + 7) >> 3;}
void WriteBytes(const void* inData, size_t inByteCount
{WriteBits(inData, inByteCount << 3);}
private:
void ReallocBuffer(uint32_t inNewBitCapacity);
char* mBuffer;
uint32_t mBitHead;
uint32_t mBitCapacity;
};
The interface of the bit stream is similar to that of the byte stream, except it includes the ability to pass a number of bits to write instead of the number of bytes. The construction, destruction, and reallocation for expansion are similar as well. The new functionality lies in the two newWriteBits methods shown in Listing 4.6.
Listing 4.6 Implementation of an Output Memory Bit Stream
void OutputMemoryBitStream::WriteBits(uint8_t inData,
size_t inBitCount)
{
uint32_t nextBitHead = mBitHead + static_cast<uint32_t>(inBitCount);
if(nextBitHead > mBitCapacity)
{
ReallocBuffer(std::max(mBitCapacity * 2, nextBitHead));
}
//calculate the byteOffset into our buffer
//by dividing the head by 8
//and the bitOffset by taking the last 3 bits
uint32_t byteOffset = mBitHead >> 3;
uint32_t bitOffset = mBitHead & 0x7;
//calculate which bits of the current byte to preserve
uint8_t currentMask = ∼(0xff << bitOffset);
mBuffer[byteOffset] = (mBuffer[byteOffset] & currentMask)
|(inData << bitOffset);
//calculate how many bits were not yet used in
//our target byte in the buffer
uint32_t bitsFreeThisByte = 8 - bitOffset;
//if we needed more than that, carry to the next byte
if(bitsFreeThisByte < inBitCount)
{
//we need another byte
mBuffer[byteOffset + 1] = inData >> bitsFreeThisByte;
}
mBitHead = nextBitHead;
}
void OutputMemoryBitStream::WriteBits(const void* inData, size_t inBitCount)
{
const char* srcByte = static_cast<const char*>(inData);
//write all the bytes
while(inBitCount > 8)
{
WriteBits(*srcByte, 8);
++srcByte;
inBitCount -= 8;
}
//write anything left
if(inBitCount > 0)
{
WriteBits(*srcByte, inBitCount);
}
}
The innermost task of writing bits to the stream is handled by the WriteBits(uint8_t inData, size_t inBitCount) method, which takes a single byte and writes a given number of bits from that byte into the bit stream. To understand how this works, consider what happens when the following code is executed:
OutputMemoryBitStream mbs;
mbs.WriteBits(13, 5);
mbs.WriteBits(52, 6);
This should write the number 13 using 5 bits and then the number 52 using 6 bits. Figure 4.3 shows these numbers in binary.
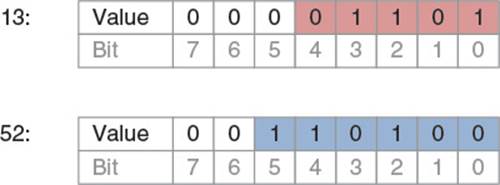
Figure 4.3 Binary representation of 13 and 52
Therefore, when the code is run, the memory pointed to by mbs.mBuffer should be left containing the two values, as in Figure 4.4.

Figure 4.4 Stream buffer containing 5 bits of 13 and 6 bits of 52
Notice the 5 bits of the number 13 take up the first 5 bits of byte 0, and then the 6 bits of the number 52 take up the last 3 bits of byte 0 and the first 3 bits of byte 1.
Stepping through the code shows how the method achieves this. Assume the stream has been freshly constructed, so mBitCapacity is 256, mBitHead is 0, and there is enough room in the stream to avoid reallocation. First, the mBitHead, which represents the index of the next bit in the stream to be written, is decomposed into a byte index and a bit index within that byte. Because a byte is 8 bits, the byte index can always be found by dividing by 8, which is the same as shifting right by 3. Similarly, the index of the bit within that byte can be found by examining those same 3 bits that were shifted away in the previous step. Because 0x7 is 111 in binary, bitwise ANDing the mBitHead with 0x7 yields just the 3 bits. In the first call to write the number 13, mBitHead is 0, so byteOffset and bitOffset are both 0 as well.
Once the method calculates the byteOffset and bitOffset, it uses the byteOffset as an index into the mBuffer array to find the target byte. Then it shifts the data left by the bit offset and bitwise ORs it into the target byte. This is all elementary when writing the number 13 because both offsets are 0. However, consider how the stream looks at the beginning of the WriteBits(52, 6) call, as shown in Figure 4.5.

Figure 4.5 Stream buffer immediately before the second WriteBits call
At this point, mBitHead is 5. That means byteOffset is 0 and bitOffset is 5.
Shifting 52 left by 5 bits yields the result shown in Figure 4.6.

Figure 4.6 Binary representation of 52 shifted left by 5 bits
Note the high-order bits are shifted out of range, and the low-order bits become the high bits. Figure 4.7 shows the result of bitwise ORing those bits into byte 0 of the buffer.

Figure 4.7 52, shifted left by 5 bits, bitwise ORed into the stream buffer
Byte 0 is complete, but only three of the necessary 6 bits have been written to the stream due to the overflow when shifting left. The next lines of WriteBits detect and handle this issue. The method calculates how many bits were initially free in the target byte by subtracting thebitOffset from 8. In this case, that yields 3, which is the number of bits that were able to fit. If the number of bits free is less than the number of bits to be written, the overflow branch executes.
In the overflow branch, the next byte is targeted. To calculate what to OR into the next byte, the method shifts inData right by the number of bits that were free. Figure 4.8 shows the result of shifting 52 to the right by 3 bits.

Figure 4.8 52, Shifted to the right by 3 bits
The high-order bits that overflowed when shifted left are now shifted to the right to become the low-order bits of the higher-order byte. When the method ORs the right-shifted bits into the byte at mBuffer[byteOffset + 1], it leaves the stream in the final state expected (see Figure 4.9).

Figure 4.9 Proper final state of the stream’s buffer
With the hard work done by WriteBits(uint8_t inData, uint32_t inBitCount), all that remains is for WriteBits(const void* inData, uint32_t inBitCount) to break the data up into bytes and call the previous WriteBits method 1 byte at a time.
This output memory bit stream is functionally complete, but not ideal. It requires specifying a number of bits for every piece of data written into the stream. However, in most cases, the upper bound for the number of bits depends on the type of data being written. Only sometimes it is useful to use fewer than the upper bound. For this reason, it increases code clarity and maintainability to add some methods for basic data types:
void WriteBytes(const void* inData, size_t inByteCount)
{WriteBits(inData, inByteCount << 3);}
void Write(uint32_t inData, size_t inBitCount = sizeof(uint32_t) * 8)
{WriteBits(&inData, inBitCount);}
void Write(int inData, size_t inBitCount = sizeof(int) * 8)
{WriteBits(&inData, inBitCount);}
void Write(float inData)
{WriteBits(&inData, sizeof(float) * 8);}
void Write(uint16_t inData, size_t inBitCount = sizeof(uint16_t) * 8)
{WriteBits(&inData, inBitCount);}
void Write(int16_t inData, size_t inBitCount = sizeof(int16_t) * 8)
{WriteBits(&inData, inBitCount);}
void Write(uint8_t inData, size_t inBitCount = sizeof(uint8_t) * 8)
{WriteBits(&inData, inBitCount);}
void Write(bool inData)
{WriteBits(&inData, 1);}
With these methods, most primitive types can be written by simply passing them to the Write method. The default parameter takes care of supplying the corresponding number of bits. For cases where the caller desires a fewer number of bits, the methods accept an override parameter. A templated function and type traits again provide even more generality than multiple overloads:
template<typename T>
void Write(T inData, size_t inBitCount = sizeof(T) * 8)
{
static_assert(std::is_arithmetic<T>::value||
std::is_enum<T>::value,
"Generic Write only supports primitive data types");
WriteBits(&inData, inBitCount);
}
Even with the templated Write method, it is still useful to implement a specific overload for bool because its default bit count should be 1, not sizeof(bool) * 8, which would be 8.
Warning
This implementation of the Write method works only on little-endian platforms due to the way it addresses individual bytes. If the method needs to operate on a big-endian platform, it should either byte swap the data in the templated Write function before the data goes intoWriteBits, or it should address the bytes using a big-endian compatible method.
The input memory bit stream, which reads bits back out of the stream, works in a similar manner to the output memory bit stream. Implementation is left as an exercise and can also be found at the companion website.
Referenced Data
The serialization code can now handle all kinds of primitive and POD data, but it falls apart when it needs to handle indirect references to data, through pointers or other containers. Recall the RoboCat class (as shown next):
class RoboCat: public GameObject
{
public:
RoboCat() mHealth(10), mMeowCount(3),
mHomeBase(0)
{
mName[0] = '\0';
}
virtual void Update();
void Write(OutputMemoryStream& inStream) const;
void Read(InputMemoryStream& inStream);
private:
int32_t mHealth;
int32_t mMeowCount;
GameObject* mHomeBase;
char mName[128];
std::vector<int32_t> mMiceIndices;
Vector3 mPosition;
Quaternion mRotation;
};
There are two complex member variables which the current memory stream implementation cannot yet serialize—mHomeBase and mMiceIndices. Each calls for a different serialization strategy, as discussed in the following sections.
Inlining or Embedding
Sometimes network code must serialize member variables that reference data not shared with any other object. mMiceIndices in RoboCat is a good example. It is a vector of integers tracking the indices of various mice in which the RoboCat is interested. Because thestd::vector<int> is a black box, it is unsafe to use the standard OutputMemoryStream::Write function to copy from the address of the std::vector<int> into the stream. Doing so would serialize the values of any pointers that are in std::vector, which when deserialized on a remote host would point to garbage.
Instead of serializing the vector itself, a custom serialization function should write only the data contained within the vector. That data in RAM may actually be far away from the data of the RoboCat itself. However, when the custom function serializes it, it does so into the stream inline, embedded right in the middle of the RoboCat data. For this reason, this process is known as inlining or embedding. For instance, a function to serialize a std::vector<int32_t> would look like this:
void Write(const std::vector<int32_t>& inIntVector)
{
size_t elementCount = inIntVector.size();
Write(elementCount);
Write(inIntVector.data(), elementCount * sizeof(int32_t));
}
First, the code serializes the length of the vector, and then all the data from the vector. Note that the Write method must serialize the length of the vector first so that the corresponding Read method can use it to allocate a vector of the appropriate length before deserializing the contents. Because the vector is just primitive integers, the method serializes it all in one straight memcpy. To support more complex data types, a templated version of the std::vector Write method serializes each element individually:
template<typename T>
void Write(const std::vector<T>& inVector)
{
size_t elementCount = inVector.size();
Write(elementCount);
for(const T& element: inVector)
{
Write(element);
}
}
Here, after serializing the length, the method individually embeds each element from the vector. This allows it to support vectors of vectors, or vectors of classes that contain vectors, and so on. Deserializing requires a similarly implemented Read function:
template<typename T>
void Read(std::vector<T>& outVector)
{
size_t elementCount;
Read(elementCount);
outVector.resize(elementCount);
for(const T& element: outVector)
{
Read(element);
}
}
Additional specialized Read and Write functions can support other types of containers, or any data referenced by a pointer, as long as that data is wholly owned by the parent object being serialized. If the data needs to be shared with or pointed to by other objects, then a more complex solution, known as linking, is required.
Linking
Sometimes serialized data needs to be referenced by more than one pointer. For instance, consider the GameObject* mHomeBase in RoboCat. If two RoboCats share the same home base, there is no way to represent that fact using the current toolbox. Embedding would just embed a copy of the same home base in each RoboCat when serialized. During deserialization, this would result in the creation of two different home bases!
Other times, the data is structured in such a way that embedding is just impossible. Consider the HomeBase class:
class HomeBase: public GameObject
{
std::vector<RoboCat*> mRoboCats;
};
The HomeBase contains a list of all its active RoboCats. Consider a function to serialize a RoboCat using only embedding. While serializing a RoboCat, the function would embed its HomeBase, which would then embed all its active RoboCats, including the RoboCat it was currently serializing. This is a recipe for stack overflow due to infinite recursion. Clearly another tool is necessary.
The solution is to give each multiply referenced object a unique identifier and then to serialize references to those objects by serializing just the identifier. Once all the objects are deserialized on the other end of the network, a fix-up routine can use the identifiers to find the referenced objects and plug them into the appropriate member variables. It is for this reason the process is commonly referred to as linking.
Chapter 5 discusses how to assign unique IDs to each object sent over the network and how to maintain maps from IDs to objects and vice versa. For now, assume each stream has access to a LinkingContext (as shown in Listing 4.7) that contains an up-to-date map between network IDs and game objects.
Listing 4.7 Linking Context
class LinkingContext
{
public:
uint32_t GetNetworkId(GameObject* inGameObject)
{
auto it = mGameObjectToNetworkIdMap.find(inGameObject);
if(it != mGameObjectToNetworkIdMap.end())
{
return it->second;
}
else
{
return 0;
}
}
GameObject* GetGameObject(uint32_t inNetworkId)
{
auto it = mNetworkIdToGameObjectMap.find(inNetworkId);
if(it != mNetworkIdToGameObjectMap.end())
{
return it->second;
}
else
{
return nullptr;
}
}
private:
std::unordered_map<uint32_t, GameObject*>
mNetworkIdToGameObjectMap;
std::unordered_map<GameObject*, uint32_t>
mGameObjectToNetworkIdMap;
};
The LinkingContext enables a simple linking system in the memory stream:
void Write(const GameObject* inGameObject)
{
uint32_t networkId =
mLinkingContext->GetNetworkId(inGameObject);
Write(networkId);
}
void Read(GameObject*& outGameObject)
{
uint32_t networkId;
Read(networkId);
outGameObject = mLinkingContext->GetGameObject(networkId);
}
Note
When fully implemented, a linking system, and the gameplay code that uses it, must be tolerant of receiving a network ID for which there is no object mapped. Because packets can be dropped, a game might receive an object with a member variable that refers to an object not yet sent. There are many different ways to handle this—the game could either ignore the entire object, or it could deserialize the object and link up whatever references are available, leaving the missing ones as null. A more complex system might keep track of the member variable with the null link so that when an object for the given network ID is received, it can link it in. The choice depends on the specifics of the game’s design.
Compression
With the tools to serialize all types of data, it is possible to write code to send game objects back and forth across the network. However, it will not necessarily be efficient code that functions within the bandwidth limitations imposed by the network itself. In the early days of multiplayer gaming, games had to make do with 2400 bytes per second connections, or less. These days, game engineers are luckier to have high-speed connections many orders of magnitude faster, but they must still concern themselves with how to use that bandwidth as efficiently as possible.
A large game world can have hundreds of moving objects, and sending real-time exhaustive data about those objects to the potentially hundreds of connected players is enough to saturate even the highest bandwidth connection. This book examines many ways to make the most of the available bandwidth. Chapter 9, “Scalability,” looks at high-level algorithms which determine who should see what data and which object properties need to be updated for which clients. This section, however, starts at the lowest level by examining common techniques for compressing data at the bit and byte level. That is, once a game has determined that a particular piece of data needs to be sent, how can it send it using as few bits as possible?
Sparse Array Compression
The trick to compressing data is to remove any information that does not need to be sent over the network. A good place to look for this kind of information is in any sparse or incompletely filled data structures. Consider the mName field in RoboCat. For whatever reason, the originalRoboCat engineer decided that the best way to store the name of a RoboCat is with a 128-byte character array in the middle of the data type. The stream method WriteBytes(const void* inData, uint32_t inByteCount) can already embed the character array, but if used judiciously, it can most likely serialize the necessary data without writing a full 128 bytes.
Much of compression strategy comes down to analyzing the average case and implementing algorithms to take advantage of it, and that is the approach to take here. Given typical names in the English language, and the game design of Robo Cat, the odds are good that a user won’t need all 128 characters to name her RoboCat. The same could be said about the array no matter what length it is: Just because it allows space for a worst case, serialization code doesn’t have to assume that every user will exploit that worst case. As such, a custom serializer can save space by looking at the mName field and counting how many characters are actually used by the name. If mName is null terminated, the task is made trivial by the std::strlen function. For instance, a more efficient way to serialize the name is shown here:
void RoboCat::Write(OutputMemoryStream& inStream) const
{
...//serialize other fields up here
uint8_t nameLength =
static_cast<uint8_t>(strlen(mName));
inStream.Write(nameLength);
inStream.Write(mName, nameLength);
...
}
Notice that, just as when serializing a vector, the method first writes the length of the serialized data before writing the data itself. This is so the receiving end knows how much data to read out of the stream. The method serializes the length of the string itself as a single byte. This is only safe because the entire array holds a maximum of 128 characters.
In truth, assuming the name is infrequently accessed compared to the rest of the RoboCat’s data, it is more efficient from a cache perspective to represent an object’s name with an std::string, allowing the entire RobotCat data type to fit in fewer cache lines. In this case, a string serializing method similar to the vector method implemented in the previous section would handle the name serialization. That makes this particular mName example a bit contrived for clarity’s sake, but the lesson holds true, and sparse containers are a good low-hanging target for compression.
Entropy Encoding
Entropy encoding is a subject of information theory which deals with compressing data based on how unexpected it is. According to information theory, there is less information or entropy in a packet that contains expected values than in a packet that contains unexpected values. Therefore, code should require fewer bits to send expected values than to send unexpected ones.
In most cases, it is more important to spend CPU cycles simulating the actual game than to calculate the exact amount of entropy in a packet to achieve optimal compression. However, there is a very simple form of entropy encoding that is quite efficient. It is useful when serializing a member variable that has a particular value more frequently than any other value.
As an example, consider the mPosition field of RoboCat. It’s a Vector3 with an X, Y, and Z component. X and Z represent the cat’s position on the ground, and Y represents the cat’s height above ground. A naïve serialization of the position would look like so:
void OutputMemoryBitStream::Write(const Vector3& inVector)
{
Write(inVector.mX);
Write(inVector.mY);
Write(inVector.mZ);
}
As written, it requires 3 × 4 = 12 bytes to serialize a RoboCat’s mPosition over the network. However, the naïve code does not take advantage of the fact that cats can often be found on the ground. This means that the Y coordinate for most mPosition vectors is going to be 0. The method can use a single bit to indicate whether the mPosition has the common value of 0, or some other, less common value:
void OutputMemoryBitStream::WritePos(const Vector3& inVector)
{
Write(inVector.mX);
Write(inVector.mZ);
if(inVector.mY == 0)
{
Write(true);
}
else
{
Write(false);
Write(inVector.mY);
}
}
After writing the X and Y components, the method checks if the height off the ground is 0 or not. If it is 0, it writes a single true bit, indicating, “yes, this object has the usual height of 0.” If the Y component is not 0, it writes a single false bit, indicating, “the height is not 0, so the next 32 bits will represent the actual height.” Note that in the worst case, it now takes 33 bits to represent the height—the single flag to indicate whether this is a common or uncommon value, and then the 32 to represent the uncommon value. At first, this may seem inefficient, as serialization now may use more bits than ever before. However, calculating the true number of bits used in the average case requires factoring in exactly how common it is that a cat is on the ground.
In-game telemetry can log exactly how often a user’s cat is on the floor—either from testers playing on site or from actual users playing an earlier version of the game and submitting analytics over the Internet. Assume such an experiment determines that players are on the ground 90% of the time. Basic probability then dictates the expected number of bits required to represent the height:
POnGround *BitsOnGround + PInAir *BitsInAir + 0.9*1 + 0.1*33 + 4.2
The expected number of bits to serialize the Y component has dropped from 32 to 4.2: That saves over 3 bytes per position. With 32 players changing positions 30 times a second, this can add up to a significant savings from just this one member variable.
The compression can be even more efficient. Assume that analytics show that whenever the cat is not on the floor, it is usually hanging from the ceiling, which has a height of 100. The serialization code can then support a second common value to compress positions on the ceiling:
void OutputMemoryBitStream::WritePos(const Vector3& inVector)
{
Write(inVector.mX);
Write(inVector.mZ);
if(inVector.mY == 0)
{
Write(true);
Write(true);
}
else if(inVector.mY == 100)
{
Write(true);
Write(false);
}
else
{
Write(false);
Write(inVector.mY);
}
}
The method still uses a single bit to indicate whether the height contains a common value or not, but then it adds a second bit to indicate which of the common values it’s using. Here the common values are hardcoded into the function, but with too many more values this technique can get quite messy. In that case, a simplified implementation of Huffman coding could use a lookup table of common values, with a few bits to a store an index into that lookup table.
The question remains, though, of whether this optimization is a good one—just because the ceiling is a second common location for a cat, it’s not necessarily an efficient optimization to make, so it is necessary to check the math. Assume that analytics show cats are on the ceiling 7% of the time. In that case, the new expected number of bits used to represent a height can be calculated using this equation:
POnGround *BitsOnGround + PInAir *BitsInAir + POnCeiling *BitsOnCeiling + 0.9 * 2 + 0.07 * 2 + 0.03 * 33 + 2.93
The expected number of bits is 2.93, which is 1.3 bits fewer than the first optimization. Therefore the optimization is worthwhile.
There are many forms of entropy encoding, ranging from the simple, hardcoded one described here, to the more complex and popular Huffman coding, arithmetic coding, gamma coding, run length encoding, and more. As for everything in game development, the amount of CPU power to allocate to entropy encoding versus the amount to allocate elsewhere is a design decision. Resources on other encoding methods can be found in the “Additional Readings” section.
Fixed Point
Lightning fast calculations on 32-bit floating point numbers are the boon and the benchmark of the modern computing era. However, just because the game simulation performs floating point computations doesn’t mean it needs all 32 bits to represent the numbers when sent across the network. A common and useful technique is to examine the known range and precision requirements of the numbers being sent and convert them to a fixed point format so that the data can be sent with the minimum number of bits necessary. To do this, you have to sit down with designers and gameplay engineers and figure out exactly what your game needs. Once you know, you can begin to build a system that provides that as efficiently as possible.
As an example, consider the mLocation field again. The serialization code already compresses the Y component quite a bit, but it does nothing for the X and Z components: They are still using a full 32 bits each. A talk with the designers reveals that the Robo Cat game world’s size is 4000 game units by 4000 game units, and the world is centered at the origin. This means that the minimum value for an X or Z component is −2000, and the maximum value is 2000. Further discussion and gameplay testing reveal that client-side positions only need to be accurate to within 0.1 game units. That’s not to say that the authoritative server’s position doesn’t have to be more accurate, but when sending a value to the client, it only needs to do so with 0.1 units of precision.
These limits provide all the information necessary to determine exactly how many bits should be necessary to serialize this value. The following formula provides the total number of possible values the X component might have:
(MaxValue + MinValue)/Precision + 1 + (2000 + +2000)/0.1 + 1 + 40001
This means there are 40001 potential values for the serialized component. If there is a mapping from an integer less than 40001 to a corresponding potential floating point value, the method can serialize the X and Z components simply by serializing the appropriate integers.
Luckily, this is a fairly simple task using something called fixed point numbers. A fixed point number is a number that looks like an integer, but actually represents a number equal to that integer divided by a previously decided upon constant. In this case, the constant is equal to the required level of precision needed. At that point, the method only needs to serialize the number of bits that is required to store an integer guaranteed to be less than 40001. Because log2 40001 is 15.3, the routine should require only 16 bits each to serialize the X and Z components. Putting that all together results in the following code:
inline uint32_t ConvertToFixed(
float inNumber, float inMin, float inPrecision)
{
return static_cast<uint32_t> (
(inNumber - inMin)/inPrecision);
}
inline float ConvertFromFixed(
uint32_t inNumber, float inMin, float inPrecision )
{
return static_cast<float>(inNumber) *
inPrecision + inMin;
}
void OutputMemoryBitStream::WritePosF(const Vector3& inVector)
{
Write(ConvertToFixed(inVector.mX, -2000.f, 0.1f), 16);
Write(ConvertToFixed(inVector.mZ, -2000.f, 0.1f), 16);
... //write Y component here ...
}
The game stores the vector’s components as full floating point numbers, but when it needs to send them over the network, the serialization code converts them to fixed point numbers between 0 and 40000 and sends them using only 16 bits a piece. This saves another full 32 bits on the vector, cutting its expected size down to 35 bits from the original 96.
Note
On some CPUs, such as the PowerPC in the Xbox 360 and PS3, it can be computationally expensive to convert from a floating point to an integer and back. However, it is often worth the cost, given the amount of bandwidth it conserves. As with most optimizations, it is a tradeoff which must be decided upon based on the specifics of the individual game being developed.
Geometry Compression
Fixed point compression takes advantage of game-specific information to serialize data with as few bits as possible. Interestingly, this is just information theory at work again: Because there are constraints on the possible values for a variable, it requires a smaller number of bits to represent that information. This technique applies when serializing any data structure with known constraints on its contents.
Many geometric data types fall under just this case. This section discusses the quaternion and the transformation matrix. A quaternion is a data structure containing four floating point numbers, useful for representing a rotation in three dimensions. The exact uses of the quaternion are beyond the scope of this text, but more information can be found in the references in the “Additional Readings” section. What is important for this discussion is that when representing a rotation, a quaternion is normalized, such that each component is between −1 and 1, and the sum of the squares of each component is 1. Because the sum of the squares of the components is fixed, serializing a quaternion requires serializing only three of the four components, as well as a single bit to represent the sign of the fourth component. Then the deserializing code can reconstruct the final component by subtracting the squares of the other components from 1.
In addition, because all components are between −1 and 1, fixed point representation can further improve compression of the components, if there is an acceptable precision loss that does not affect gameplay. Often, 16 bits of precision are enough, giving 65535 possible values to represent the range from −1 to 1. This means that a four-component quaternion, which takes 128 bits in memory, can be serialized fairly accurately with as few as 49 bits:
void OutputMemoryBitStream::Write(const Quaternion& inQuat)
{
float precision = (2.f / 65535.f);
Write(ConvertToFixed(inQuat.mX, -1.f, precision), 16);
Write(ConvertToFixed(inQuat.mY, -1.f, precision), 16);
Write(ConvertToFixed(inQuat.mZ, -1.f, precision), 16);
Write(inQuat.mW < 0);
}
void InputMemoryBitStream::Read(Quaternion& outQuat)
{
float precision = (2.f / 65535.f);
uint32_t f = 0;
Read(f, 16);
outQuat.mX = ConvertFromFixed(f, -1.f, precision);
Read( f, 16 );
outQuat.mY = ConvertFromFixed(f, -1.f, precision);
Read(f, 16);
outQuat.mZ = ConvertFromFixed(f, -1.f, precision);
outQuat.mW = sqrtf(1.f -
outQuat.mX * outQuat.mX +
outQuat.mY * outQuat.mY +
outQuat.mZ * outQuat.mZ );
bool isNegative;
Read(isNegative);
if(isNegative)
{
outQuat.mW *= -1;
}
}
Geometric compression can also help when serializing an affine transformation matrix. A transformation matrix is 16 floats, but to be affine, it must decompose into a 3-float translation, a quaternion rotation, and a 3-float scale, for a total of 10 floats. Entropy encoding can then help save even more bandwidth if there are more constraints on the typical matrix to serialize. For instance, if the matrix is usually unscaled, the routine can indicate this with a single bit. If the scale is uniform, the routine can indicate this with a different bit pattern and then serialize only one component of the scale instead of all three.
Maintainability
Focusing solely on bandwidth efficiency can yield some slightly ugly code in some places. There are a few tradeoffs worth considering, sacrificing a little efficiency for ease of maintainability.
Abstracting Serialization Direction
Every new data structure or compression technique discussed in the previous sections has required both a read method and a write method. Not only does that mean implementing two methods for each new piece of functionality, but the methods must remain in sync with each other: If you change how a member variable is written, you must change how it’s read. Having two such tightly coupled methods for each data structure is a bit of a recipe for frustration. It would be much cleaner if it were possible somehow to have only one method per data structure that could handle both reading and writing.
Luckily, through the use of inheritance and virtual functions, it is indeed possible. One way to implement this is to make OutputMemoryStream and InputMemoryStream both derive from a base MemoryStream class with a Serialize method:
class MemoryStream
{
virtual void Serialize(void* ioData,
uint32_t inByteCount) = 0;
virtual bool IsInput() const = 0;
};
class InputMemoryStream: public MemoryStream
{
...//other methods above here
virtual void Serialize(void* ioData, uint32_t inByteCount)
{
Read(ioData, inByteCount);
}
virtual bool IsInput() const {return true;}
};
class OutputMemoryStream: public MemoryStream
{
...//other methods above here
virtual void Serialize(void* ioData, uint32_t inByteCount)
{
Write(ioData, inByteCount);
}
virtual bool IsInput() const {return false;}
}
By implementing Serialize, the two child classes can take a pointer to data and a size and then perform the appropriate action, either reading or writing. Using the IsInput method, a function can check whether it has been passed an input stream or output stream. Then, the baseMemoryStream class can implement a templated Serialize method assuming that the non-templated version is properly implemented by a subclass:
template<typename T> void Serialize(T& ioData)
{
static_assert(std::is_arithmetic<T>::value||
std::is_enum<T>::value,
"Generic Serialize only supports primitive data types");
if(STREAM_ENDIANNESS == PLATFORM_ENDIANNESS)
{
Serialize(&ioData, sizeof(ioData) );
}
else
{
if(IsInput())
{
T data;
Serialize(&data, sizeof(T));
ioData = ByteSwap(data);
}
else
{
T swappedData = ByteSwap(ioData);
Serialize(&swappedData, sizeof(swappedData));
}
}
}
The templated Serialize method takes generic data as a parameter and will either read it or write it, depending on the child class’s non-templated Serialize method. This facilitates the replacement of each pair of custom Read and Write methods with a corresponding Serializemethod. The custom Serialize method needs to take only a MemoryStream as a parameter and it can read or write appropriately using the stream’s virtual Serialize method. This way, a single method handles both reading and writing for a custom class, ensuring that input and output code never get out of sync.
Warning
This implementation is slightly more inefficient than the previous one because of all the virtual function calls required. This system can be implemented using templates instead of virtual functions to regain some of the performance hit, but that is left as an exercise for you to try.
Data-Driven Serialization
Most object serialization code follows the same pattern: For each member variable in an object’s class, serialize that member variable’s value. There may be some optimizations, but the general structure of the code is usually the same. In fact, it is so similar that if a game somehow had data at runtime about what member variables were in an object, it could use a single serialization method to handle most of serialization needs.
Some languages, like C# and Java, have built-in reflection systems that allow runtime access to class structure. In C++, however, reflecting class members at runtime requires a custom built system. Luckily, building a basic reflection system is not too complicated (see Listing 4.8).
Listing 4.8 Basic Reflection System
enum EPrimitiveType
{
EPT_Int,
EPT_String,
EPT_Float
};
class MemberVariable
{
public:
MemberVariable(const char* inName,
EPrimitiveType inPrimitiveType, uint32_t inOffset):
mName(inName),
mPrimitiveType(inPrimitiveType),
mOffset(inOffset) {}
EPrimitiveType GetPrimitiveType() const {return mPrimitiveType;}
uint32_t GetOffset() const {return mOffset;}
private:
std::string mName;
EPrimitiveType mPrimitiveType;
uint32_t mOffset;
};
class DataType
{
public:
DataType(std::initializer_list<const MemberVariable& > inMVs):
mMemberVariables(inMVs)
{}
const std::vector<MemberVariable>& GetMemberVariables() const
{
return mMemberVariables;
}
private:
std::vector< MemberVariable > mMemberVariables;
};
EPrimitiveType represents the primitive type of a member variable. This system supports only int, float, and string, but it is easy to extend with any primitive type desired.
The MemberVariable class represents a single member variable in a compound data type. It holds the member variable’s name (for debugging purposes), its primitive type, and its memory offset in its parent data type. Storing the offset is a critical: Serialization code can add the offset to the base address of a given object to find the location in memory of the member variable’s value for that particular object. This is how it will read and write the member variable’s data.
Finally, the DataType class holds all the member variables for a particular class. For each class that supports data-driven serialization, there is one corresponding instance of DataType. With the reflection infrastructure in place, the following code loads up the reflection data for a sample class:
#define OffsetOf(c, mv) ((size_t) & (static_cast<c*>(nullptr)->mv)))
class MouseStatus
{
public:
std::string mName;
int mLegCount, mHeadCount;
float mHealth;
static DataType* sDataType;
static void InitDataType()
{
sDataType = new DataType(
{
MemberVariable("mName",
EPT_String, OffsetOf(MouseStatus,mName)),
MemberVariable("mLegCount",
EPT_Int, OffsetOf(MouseStatus, mLegCount)),
MemberVariable("mHeadCount",
EPT_Int, OffsetOf(MouseStatus, mHeadCount)),
MemberVariable("mHealth",
EPT_Float, OffsetOf(MouseStatus, mHealth))
});
}
};
Here, a sample class tracks a RoboMouse’s status. The static InitDataType function must be called at some point to initialize the sDataType member variable. That function creates the DataType that represents the MouseStatus and fills in the mMemberVariables entries. Notice the use of a custom OffsetOf macro to calculate the proper offset of each member variable. The built-in C++ offsetof macro has undefined behavior for non-POD classes. As such, some compilers actually return compile errors when offsetof is used on classes with virtual functions or other non-POD types. As long as the class doesn’t define a custom unary & operator, and the class hierarchy doesn’t use virtual inheritance or have any member variables that are references, the custom macro will work. Ideally, instead of having to fill in the reflection data with handwritten code, a tool would analyze the C++ header files and automatically generate the reflection data for the classes.
From here, implementing a simple serialize function is just a matter of looping through the member variables in a data type:
void Serialize(MemoryStream* inMemoryStream,
const DataType* inDataType, uint8_t* inData)
{
for(auto& mv: inDataType->GetMemberVariables())
{
void* mvData = inData + mv.GetOffset();
switch(mv.GetPrimitiveType())
{
EPT_Int:
inMemoryStream->Serialize(*(int*) mvData);
break;
EPT_String:
inMemoryStream->Serialize(*(std::string*) mvData);
break;
EPT_Float:
inMemoryStream->Serialize(*(float*) mvData);
break;
}
}
}
The GetOffset method of each member variable calculates a pointer to the instance’s data for that member. Then the switch on GetPrimitiveType casts the data to the appropriate type and lets the typed Serialize function take care of the actual serialization.
This technique can be made more powerful by expanding the metadata tracked in the MemberVariable class. For instance, it could store the number of bits to use for each variable for automatic compression. Additionally, it could store potential common values for the member variable to support a procedural implementation of some entropy encoding.
As a whole, this method trades performance for maintainability: There are more branches that might cause pipeline flushes, but there is less code to write overall and, therefore, fewer chances for errors. As an extra benefit, a reflection system is useful for many things besides network serialization. It can be helpful when implementing serialization to disk, garbage collection, a GUI object editor, and more.
Summary
Serialization is the process of taking a complex data structure and breaking it down into a linear array of bytes, which can be sent to another host across a network. The naïve approach of simply using memcpy to copy the structure into a byte buffer does not usually work. The stream, the basic workhorse for serialization makes it possible to serialize complex data structures, including those that reference other data structures and relink those references after deserialization.
There are several techniques for serializing data efficiently. Sparse data structures can be serialized into more compact forms. Expected values of member variables can be compressed losslessly using entropy encoding. Geometric or other similarly constrained data structures can also be compressed losslessly by making use of the constraints to send only the data that is necessary to reconstruct the data structure. When slightly lossy compression is acceptable, floating point numbers can be turned into fixed point numbers based on the known range and necessary precision of the value.
Efficiency often comes at the cost of maintainability, and sometimes it is worthwhile to reinject some maintainability into a serialization system. Read and Write methods for a data structure can be collapsed into a single Serialize method which reads or writes depending on the stream on which it is operating, and serialization can be data-driven, using auto- or hand-generated metadata to serialize objects without requiring custom, per-data structure read and write functions.
With these tools, you have everything you need to package up an object and send it to a remote host. The next chapter discusses both how to frame this data so that the remote host can create or find the appropriate object to receive the data, and how to efficiently handle partial serialization when a game requires that only a subset of an object’s data be serialized.
Review Questions
1. Why is it not necessarily safe to simply memcpy an object into a byte buffer and send that buffer to a remote host?
2. What is endianness? Why is it a concern when serializing data? Explain how to handle endian issues when serializing data.
3. Describe how to efficiently compress a sparse data structure.
4. Give two ways to serialize an object with pointers in it. Give an example of when each way is appropriate.
5. What is entropy encoding? Give a basic example of how to use it.
6. Explain how to use fixed point numbers to save bandwidth when serializing floating point numbers.
7. Explain thoroughly why the WriteBits function as implemented in this chapter only works properly on little-endian platforms. Implement a solution that will work on big-endian platforms as well.
8. Implement MemoryOutputStream::Write(const unordered_map<int, int >&) that allows the writing of a map from integer to integer into the stream.
9. Write the corresponding MemoryOutputStream::Read(unordered_map<int, int >&) method.
10. Template your implementation of MemoryOutputStream::Read from Question 9 so it works properly for template <tKey, tValue> unordered_map<tKey, tValue>.
11. Implement an efficient Read and Write for an affine transformation matrix, taking advantage of the fact that the scale is usually 1, and when not 1, is usually at least uniform.
12. Implement a serialization module with a generic serialize method that relies on templates instead of virtual functions.
Additional Readings
Bloom, Charles. (1996, August 1). Compression: Algorithms: Statistical Coders. Retrieved from http://www.cbloom.com/algs/statisti.html. Accessed September 12, 2015.
Blow, Jonathan. (2004, January 17). Hacking Quaternions. Retrieved from http://number-none.com/product/Hacking%20Quaternions/. Accessed September 12, 2015.
Ivancescu, Gabriel. (2007, December 21). Fixed Point Arithmetic Tricks. Retrieved from http://x86asm.net/articles/fixed-point-arithmetic-and-tricks/. Accessed September 12, 2015.
All materials on the site are licensed Creative Commons Attribution-Sharealike 3.0 Unported CC BY-SA 3.0 & GNU Free Documentation License (GFDL)
If you are the copyright holder of any material contained on our site and intend to remove it, please contact our site administrator for approval.
© 2016-2026 All site design rights belong to S.Y.A.