Multiplayer Game Programming: Architecting Networked Games (2016)
Chapter 7. Latency, Jitter, and Reliability
Networked games live in a harsh environment, competing for bandwidth on aging networks, sending packets to servers and clients scattered throughout the world. This results in data loss and delay not typically experienced during development on a local network. This chapter explores some of the networking problems multiplayer games face and suggests workarounds and solutions for those problems, including how to build a custom reliability layer on top of the UDP transport protocol.
Latency
Your game, once released into the wild, must contend with a few negative factors not present in the tightly controlled environment of your local network. The first of these factors is latency. The word latency has different meanings in different situations. In the context of computer games, it refers to the amount of time between an observable cause and its observable effect. Depending on the type of game, this can be anything from the period between a mouse click and a unit responding to its orders in a real-time strategy (RTS) game, to the period between a user moving her head and a virtual reality (VR) display updating in response.
Some amount of latency is unavoidable, and different genres of games have different latency acceptability thresholds. VR games are typically the most sensitive to latency, because we as humans expect our eyes to see different things as soon as our heads swivel. In these cases, a latency of less than 20 ms is typically required for the user to remain present in the simulated reality. Fighting games, first-person shooters, and other twitchy action games are the next most sensitive to latency. Latency in these games can range from 16 to 150 ms before the user starts to feel, regardless of frame rate, that the game is sluggish and unresponsive. RTS games have the highest tolerance for latency, and this tolerance is often exploited to good effect, as described in Chapter 6, “Network Topologies and Sample Games.” Latency in these games can grow as high as 500 ms without being detrimental to the user experience.
As a game engineer, decreasing latency is one manner in which you can improve your users’ play experience. To do so, it helps to understand the many factors that contribute to this latency in the first place.
Non-Network Latency
It is a commonly held misconception that networking delay is the primary source for latency in gameplay. While packet exchange over the network is a significant source for latency, it is definitely not the only one. There are at least five other sources of latency, some of which are not under your control:
![]() Input sampling latency. The time between when a user pushes a button and when the game detects that button press can be significant. Consider a game running at 60 frames per second that polls a gamepad for input at the beginning of each frame, then updates all objects accordingly before finally rendering the game world. As shown in Figure 7.1a, if a user presses the jump button 2 ms after the game checks for input, it will be almost an entire frame before the game updates anything based on that button press. For inputs that drive view rotation, it is possible to sample the input again at the end of a frame and mildly warp the rendered output based on altered rotation, but this is typically only done in the most latency-sensitive applications. That means that on average, there is half a frame of latency between a button press and the game’s response to that press.
Input sampling latency. The time between when a user pushes a button and when the game detects that button press can be significant. Consider a game running at 60 frames per second that polls a gamepad for input at the beginning of each frame, then updates all objects accordingly before finally rendering the game world. As shown in Figure 7.1a, if a user presses the jump button 2 ms after the game checks for input, it will be almost an entire frame before the game updates anything based on that button press. For inputs that drive view rotation, it is possible to sample the input again at the end of a frame and mildly warp the rendered output based on altered rotation, but this is typically only done in the most latency-sensitive applications. That means that on average, there is half a frame of latency between a button press and the game’s response to that press.
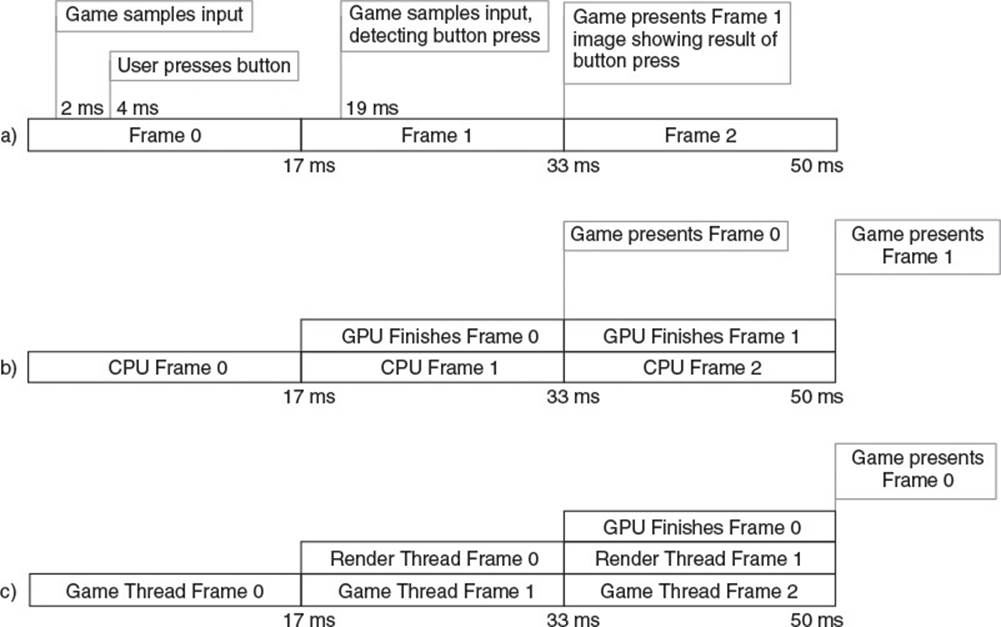
Figure 7.1 Latency timing diagrams
![]() Render pipeline latency. GPUs do not perform draw commands the moment the CPU batches those commands. Instead, the driver inserts the commands into a command buffer, and the GPU executes those commands at some point in the future. If there is a lot of rendering to do, the GPU may lag an entire frame behind the CPU before it displays the rendered image to the user. Figure 7.1b shows such a timeline common in single-threaded games. This introduces another frame of latency.
Render pipeline latency. GPUs do not perform draw commands the moment the CPU batches those commands. Instead, the driver inserts the commands into a command buffer, and the GPU executes those commands at some point in the future. If there is a lot of rendering to do, the GPU may lag an entire frame behind the CPU before it displays the rendered image to the user. Figure 7.1b shows such a timeline common in single-threaded games. This introduces another frame of latency.
![]() Multithreaded render pipeline latency. Multithreaded games introduce even more latency into the render pipeline. Typically, one or more threads run the game simulation, updating a world that they pass to one or more render threads. These render threads then batch GPU commands while the simulation threads are already simulating the next frame. Figure 7.1c demonstrates how multithreaded rendering can add yet another frame of latency to the user experience.
Multithreaded render pipeline latency. Multithreaded games introduce even more latency into the render pipeline. Typically, one or more threads run the game simulation, updating a world that they pass to one or more render threads. These render threads then batch GPU commands while the simulation threads are already simulating the next frame. Figure 7.1c demonstrates how multithreaded rendering can add yet another frame of latency to the user experience.
![]() VSync. To avoid screen tearing, it is common practice to change the image displayed by a video card only during a monitor’s vertical blanking interval. This way, the monitor will never show part of one frame and part of the next frame at the same time. This means that a present call on the GPU must wait until the vertical blanking interval for the user’s monitor, which is typically once every 1/60 of a second. If your game’s frames take only 16 ms, this is not a problem. However, if a frame takes even 1 ms longer to render, the rendering will not be complete by the time the video card is ready to update the display. In this case, the command to present the back buffer to the front will stall, waiting an extra 15 ms until the next vertical blanking interval. When this happens, your user experiences an extra frame of latency.
VSync. To avoid screen tearing, it is common practice to change the image displayed by a video card only during a monitor’s vertical blanking interval. This way, the monitor will never show part of one frame and part of the next frame at the same time. This means that a present call on the GPU must wait until the vertical blanking interval for the user’s monitor, which is typically once every 1/60 of a second. If your game’s frames take only 16 ms, this is not a problem. However, if a frame takes even 1 ms longer to render, the rendering will not be complete by the time the video card is ready to update the display. In this case, the command to present the back buffer to the front will stall, waiting an extra 15 ms until the next vertical blanking interval. When this happens, your user experiences an extra frame of latency.
Note
Screen tearing is what happens when a GPU presents a back buffer while the monitor is in the middle of refreshing the image on its screen. Monitors typically update the image on screen one horizontal row at a time, from top bottom. If the image being drawn to the screen changes in the middle of the update, the user observes the bottom half of the screen showing the new image while the top half still shows the previous image. If the camera is scrolling rapidly across the world, this can result in a shearing effect that makes it look as if the image were printed on a piece of paper, torn in half, and then one-half slightly shifted.
Most PC games give the user an option to disable vsync for enhanced performance, and some newer LCD monitors, known as G-SYNC, actually have variable refresh rates that can adjust to match frame rate and avoid the potential latency of vsyncing.
![]() Display lag. Most HDTVs and LCD monitors process their input to some extent before actually displaying an image. This processing can include de-interlacing, HDCP as well as other DRM, and image effects like video scaling, noise cancellation, adaptive luminance, image filtering, and more. This processing comes at a cost, and can easily add tens of milliseconds to the latency users perceive. Some televisions have a “game” mode that decreases video processing to minimize latency, but you cannot count on this to be enabled.
Display lag. Most HDTVs and LCD monitors process their input to some extent before actually displaying an image. This processing can include de-interlacing, HDCP as well as other DRM, and image effects like video scaling, noise cancellation, adaptive luminance, image filtering, and more. This processing comes at a cost, and can easily add tens of milliseconds to the latency users perceive. Some televisions have a “game” mode that decreases video processing to minimize latency, but you cannot count on this to be enabled.
![]() Pixel response time. LCD displays have the additional problem that pixels just take time to change brightness. Typically this duration is in the single digits of milliseconds, but with older displays, this can easily add an extra half frame of latency. Luckily, the latency here presents more as image ghosting than absolute latency—the transition starts right away, but doesn’t complete for several milliseconds.
Pixel response time. LCD displays have the additional problem that pixels just take time to change brightness. Typically this duration is in the single digits of milliseconds, but with older displays, this can easily add an extra half frame of latency. Luckily, the latency here presents more as image ghosting than absolute latency—the transition starts right away, but doesn’t complete for several milliseconds.
Non-network latency is a serious issue and can negatively impact a user’s perception of a game. John Carmack famously once tweeted “I can send an IP packet to Europe faster than I can send a pixel to the screen. How f’d up is that?” Given the amount of latency already present in a single-player game, there is strong pressure to mitigate any network-influenced latency as much as possible when introducing multiplayer functionality. To do that, it helps to understand the root causes of network latency.
Network Latency
Although there are many sources of latency, the delay experienced by a packet as it travels from a source host to its destination is usually the most significant cause of latency in multiplayer gaming. There are four main delays a packet experiences during its lifetime:
1. Processing delay. Remember that a network router works by reading packets from a network interface, examining the destination IP address, figuring out the next machine that should receive the packet, and then forwarding it out of an appropriate interface. The time spent examining the source address and determining an appropriate route is known as the processing delay. Processing delay can also include any extra functionality the router provides, such as NAT or encryption.
2. Transmission delay. For a router to forward a packet, it must have a link layer interface that allows it to forward the packet along some physical medium. The link layer protocol controls the average rate at which bits can be written to the medium. For instance, a 1-MB Ethernet connection allows for roughly 1 million bits to be written to an Ethernet cable per second. Thus it takes about one millionth of a second (1 μs) to write a bit to a 1-MB Ethernet cable, and therefore 12.5 ms to write a whole 1500-byte packet. This time spent writing the bits to physical medium is known as the transmission delay.
3. Queuing delay. A router can only process a limited number of packets at a time. If packets arrive at a rate faster than the router can process them, they go into a receive queue, waiting to be processed. Similarly, a network interface can only output one packet at a time, so after a packet is processed, if the appropriate network interface is busy, it goes into a transmission queue. The time spent in these queues is known as the queuing delay.
4. Propagation delay. For the most part, regardless of the physical medium, information cannot travel faster than the speed of light. Thus, the latency when sending a packet is at least 0.3-ns times the number of meters the packet must travel. This means, even under ideal conditions, it takes at least 12 ms for a packet to travel across the United States. This time spent traveling is known as the propagation delay.
You can optimize some of these delays, and some you cannot. Processing delay is typically a minor factor, as most router processors these days are very fast.
Transmission delay is usually dependent on the type of link layer connection the end user employs. Because bandwidth capability typically increases as the packet moves closer to the backbone of the Internet, it is at the edges of the Internet where transmission delay is greatest. Making sure your servers use high-bandwidth connections is most important. After that, you can best reduce transmission delay by encouraging end users to upgrade to fast Internet connections. Sending packets that are as large as possible will also help, since you reduce the amount of bytes spent on headers. If those headers are a significant portion of your packet size, they translate to a significant portion of your transmission delay.
Queuing delay is a result of packets backing up waiting to be transmitted or processed. Minimizing processing and transmission delay will help minimize queuing delay. It’s worth noting that because typical routing requires examining only the header of a packet, you can decrease the queuing delay for all your packets by sending few large packets instead of many small packets. For instance, a packet with a 1400-byte payload typically experiences as much processing delay as a packet with a 200-byte payload. If you send seven 200-byte packets, the final packet will have to sit in the queue during the processing of the six prior packets and thus will experience more cumulative network delay than a single large packet.
Propagation delay is often a very good target for optimization. Because it is based on the length of wire between hosts exchanging data, the best way to optimize it is to move the hosts closer together. In peer-to-peer games, this means prioritizing geographical locality when match making. In client-server games, this means making sure game servers are available close to your players. Be aware that sometimes physical locality isn’t enough to ensure low-propagation delay: Direct connections between locations may not exist, requiring routers to route traffic in roundabout paths instead of via a straight line. It is important to take existing and future routes into account when planning the locations of your game servers.
Note
In some cases, it is not feasible to disperse game servers throughout a geographical area, because you want all players on an entire continent to be able to play with each other. Riot games famously encountered such a situation with their title, League of Legends. Because dispersing game servers throughout the country was not an option, they took the reverse approach and built their own network infrastructure, peering with ISPs across North America to ensure they could control traffic routes and reduce network latency as much as possible. This is a significant undertaking, but if you can afford it, it is a clear and reliable way to reduce all four network delays.
In the context of networking, engineers sometimes use the term latency to describe the combination of these four delays. Because latency is such an overloaded term though, game developers more commonly discuss round trip time, or RTT. RTT refers to the time it takes for a packet to travel from one host to another, and then for a response packet to travel all the way back. This ends up reflecting not only the two-way processing, queuing, transmission, and propagation delays, but also the frame rate of the remote host, as this contributes to how quickly it can send the response packet. Note that traffic does not necessarily travel the same speed in each direction. The RTT is rarely exactly double the time it takes for a packet to go from one host to another. Regardless, games do often approximate one-way travel time by cutting the RTT in half.
Jitter
Once you have a good estimation of the RTT, you can take steps, as explained in Chapter 8, “Improved Latency Handling,” to mitigate this delay and give clients the best experience possible for their given latency. However, when writing network code, you must be mindful that the RTT is not necessarily a constant value. For any two hosts, the RTT between them does typically hover around a certain value based on the average delays involved. However, any of these delays can change over time, leading to a deviation in RTT from the expected value. This deviation is known asjitter.
Any of the four network delays can contribute to jitter, although some are more likely to vary than others:
![]() Processing delay. As the least significant component of network latency, processing delay is also the least significant contributor to jitter. Processing delays may vary as routers dynamically adjust packet pathways, but this is a minor concern.
Processing delay. As the least significant component of network latency, processing delay is also the least significant contributor to jitter. Processing delays may vary as routers dynamically adjust packet pathways, but this is a minor concern.
![]() Transmission delay and propagation delay. These two delays are both a function of the route a packet takes: Link layer protocols determine transmission delay and route length determines propagation delay. Thus these delays change when routers dynamically load balance traffic and alter routes to avoid heavily congested areas. This can fluctuate rapidly during times of heavy traffic and route changes can significantly alter round trip times.
Transmission delay and propagation delay. These two delays are both a function of the route a packet takes: Link layer protocols determine transmission delay and route length determines propagation delay. Thus these delays change when routers dynamically load balance traffic and alter routes to avoid heavily congested areas. This can fluctuate rapidly during times of heavy traffic and route changes can significantly alter round trip times.
![]() Queuing delay. Queuing delay is a function of the number of packets a router must process. Thus as the number of packets arriving at a router varies, the queuing delay will vary as well. Heavy traffic bursts can cause significant queuing delays and alter round trip times.
Queuing delay. Queuing delay is a function of the number of packets a router must process. Thus as the number of packets arriving at a router varies, the queuing delay will vary as well. Heavy traffic bursts can cause significant queuing delays and alter round trip times.
Jitter can negatively affect RTT mitigation algorithms, but even worse, it can cause packets to arrive completely out of order. Figure 7.2 illustrates how this can happen. Host A dispatches Packet 1, Packet 2, and Packet 3, in order, 5 ms apart, bound for a remote Host B. Packet 1 takes 45 ms to reach Host B, but due to a sudden influx of traffic on the route, Packet 2 takes 60 ms to reach Host B. Shortly after the traffic influx, the routers dynamically adjust the route causing Packet 3 to take only 30 ms to arrive at Host B. This results in Host B receiving Packet 3 first, then Packet 1, and then Packet 2.
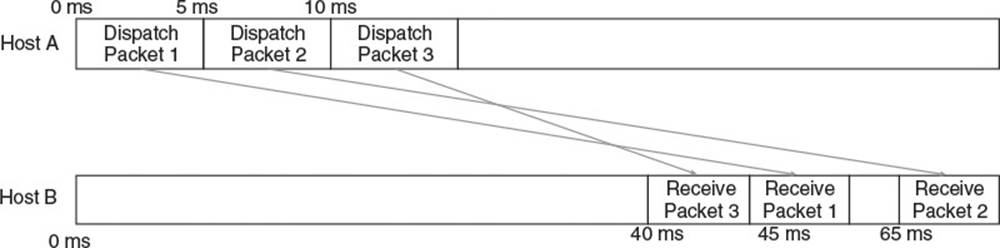
Figure 7.2 Jitter causing out of order packet delivery
To prevent errors due to packets arriving out of order, you must either use a reliable transport protocol, like TCP, that guarantees ordered packet delivery, or implement a custom system for ordering packets, as discussed in the latter half of this chapter.
Because of the problems jitter can cause, you should try to reduce it as much as possible to improve gameplay experience. Techniques that lower jitter are very similar to those that lower overall latency. Send as few packets as possible to keep traffic low. Locate servers near players to reduce the chance of encountering heavy traffic. Keep in mind that frame rate also affects RTT, so wild variations in frame rate will negatively impact clients. Make sure that complex operations are appropriately aggregated across multiple frames to prevent frame rate induced jitter.
Packet Loss
More significant than latency and jitter, the largest problem facing network game developers is packet loss. It’s one thing if a packet takes a long time to get where it’s going, but quite another if the packet never gets there at all.
Packets may drop for a variety of reasons:
![]() Unreliable physical medium. At its root, data transfer is the transfer of electromagnetic energy. Any external electromagnetic interference can cause corruption of this data. In the case of corrupted data, the link layer detects the corruption when validating checksums and discards the containing frames. Macroscale physical problems, such as a loose connection or even a nearby microwave oven, can also cause signal corruption and data loss.
Unreliable physical medium. At its root, data transfer is the transfer of electromagnetic energy. Any external electromagnetic interference can cause corruption of this data. In the case of corrupted data, the link layer detects the corruption when validating checksums and discards the containing frames. Macroscale physical problems, such as a loose connection or even a nearby microwave oven, can also cause signal corruption and data loss.
![]() Unreliable link layer. Link layers have rules about when they can and cannot send data. Sometimes a link layer channel is completely full and an outgoing frame must be dropped. Because the link layer makes no guarantee of reliability, this is a perfectly acceptable response.
Unreliable link layer. Link layers have rules about when they can and cannot send data. Sometimes a link layer channel is completely full and an outgoing frame must be dropped. Because the link layer makes no guarantee of reliability, this is a perfectly acceptable response.
![]() Unreliable network layer. Recall that when packets arrive at a router faster than they can be processed, they are placed in a receiving queue. This queue has a fixed number of packets it can hold. When the queue is full, the router starts dropping either queued or incoming packets.
Unreliable network layer. Recall that when packets arrive at a router faster than they can be processed, they are placed in a receiving queue. This queue has a fixed number of packets it can hold. When the queue is full, the router starts dropping either queued or incoming packets.
Dropped packets are a fact of life, and you must design your networking architecture to account for them. Regardless of packet loss mitigation, gameplay experience will be better with fewer dropped packets. When architecting at a high level, try to reduce the potential for packet loss. Use a data center with servers as close to your players as possible, because fewer routers and wires means a lower chance that one of them drops your data. Also, send as few packets as you can: Many routers base queue capacity on packet count, not total data. In these cases your game has a higher chance of flooding routers and overflowing queues if it sends many small packets than fewer large ones. Sending seven 200-byte packets through a clogged router requires there be seven free slots in the queue to avoid packet loss. However, sending the same 1400 bytes in a single packet only requires one free queue slot.
Warning
Not all routers base queue slots on packet count—some allot queue space to individual sources based on incoming bandwidth, in which case smaller packets can actually be beneficial. If only one packet of the seven gets dropped due to bandwidth allocation instead of slot allocation, at least the other six get queued. It’s worthwhile to know the routers in your data center and along heavily trafficked routes, especially because small packets waste bandwidth from headers, as mentioned in earlier chapters.
When its queues are full, a router does not necessarily drop each incoming packet. Instead, it may drop a previously queued packet. This happens when the router determines the incoming packet has higher priority or is more important than the queued one. Routers make priority decisions based on QoS data in the network layer header, and also sometimes on deeper information gleaned by inspecting the packet’s payload. Some routers are even configured to make greedy decisions intended to reduce the overall traffic they must handle: They sometimes drop UDP packets before TCP packets because they know dropped TCP packets will just automatically be resent. Understanding the router configurations around your data centers and around ISPs throughout your target market can help you tune your packet types and traffic patterns to reduce packet loss. Ultimately, the simplest way to reduce dropped packets is to make sure your servers are on fast, stable Internet connections and are as close to your clients as possible.
Reliability: TCP or UDP?
Given the need for some level of networking reliability in almost every multiplayer game, an important decision to make early during development is that between TCP and UDP. Should your game rely on the existing reliability system built into TCP, or should you attempt to develop your own, customized reliability system on top of UDP? To answer this question, you need to consider the benefits and costs of each transport protocol.
The primary advantage of TCP is that it provides a time-tested, robust, and stable implementation of reliability. With no extra engineering effort, it guarantees all data will not only be delivered, but delivered in order. Additionally, it provides complex congestion control features which limit packet loss by sending data at a rate that does not overwhelm intermediate routers.
The major drawback of TCP is that everything it sends must be sent reliably and processed in order. In a multiplayer game with rapidly changing state, there are three different scenarios in which this mandatory, universally reliable transmission can cause problems:
1. Loss of low-priority data interfering with the reception of high-priority data. Consider a brief exchange between two players in a client-server first-person shooter. Player A on Client A and Player B on Client B are facing off against each other. Suddenly a rocket from some other source explodes in the distance, and the server sends a packet to Client A to play the distant explosion sound. Very shortly thereafter, Player B jumps in front of Player A and fires, and the server sends a packet containing this information to Client A. Due to fluctuating network traffic, the first packet gets dropped, but the second packet, containing Player B’s movement, does not. The explosion sound is of low priority to Player A, whereas an enemy shooting him in the face is of high priority. Player A would probably not mind if the lost packet remained lost, and he never found out about the explosion. However, because TCP processes all packets in order, the TCP module will not pass the movement packet to the game when it is received. Instead, it will wait until the server retransmits the lower-priority dropped packet before allowing the application to process the high-priority movement packet. This may, understandably, make Player A upset.
2. Two separate streams of reliably ordered data interfering with each other. Even in a game with no low-priority data, in which all data must be transmitted reliably, TCP’s ordering system can still cause problems. Consider the prior scenario, but instead of an explosion, the first packet contains a chat message directed at Player A. Chat messages can be of critical importance so should be sent in some way that guarantees their receipt. In addition, chat messages need to be processed in order, because out of order chat messages can be quite confusing. However, chat messages only need to be processed in order relative to other chat messages. Player A would likely find it undesirable if the loss of a chat message packet prevented the processing of a headshot packet. In a game using TCP, this is exactly what happens.
3. Retransmission of stale game state. Imagine Player B runs all the way across the map to shoot Player A. She starts at position x = 0 and over the course of 5 seconds, runs to position x = 100. The server sends packets to Player A five times per second, each containing the latest x coordinate of Player B’s position. If the server discovers that any or all of those packets get dropped, it will resend them. This means that while Player B is approaching her final position of x = 100, the server may be retransmitting old state data that had Player B closer to x = 0. This leads to Player A viewing a very stale position of Player B, and getting shot before receiving any information that Player B is nearby. This is not an acceptable experience for Player A.
In addition to enforcing mandatory reliability, there are a few other drawbacks to using TCP. Although congestion control helps prevent lost packets, it is not uniformly configurable on all platforms, and at times may result in your game sending packets at a slower rate than you’d like. The Nagle algorithm is a particularly bad offender here, as it can delay packets up to half a second before sending them out. In fact, games that use TCP as a transport protocol usually disable the Nagle algorithm to avoid this exact problem, though at the same time, giving up the benefit of the reduced packet count it provides.
Finally, TCP allocates a lot of resources to manage connections and track all data that may have to be resent. These allocations are usually managed by the OS and can be difficult to track or route through a custom memory manager if desired.
UDP, on the other hand, offers none of the built-in reliability and flow control that TCP provides. It does, however, present a blank canvas onto which you can paint any sort of custom reliability system your game requires. You can allow for the sending of reliable and unreliable data, or the interweaving of separately ordered streams of reliable data. You can also build a system that sends only the newest information when replacing dropped packets, instead of retransmitting the exact data that was lost. You can manage your memory yourself and have fine-grained control over how data is grouped into network layer packets.
All this comes at a cost of engineering and testing time. A custom spun implementation will naturally not be as mature and bug free as that of TCP. You can decrease some of this risk and cost by using a third-party UDP networking library, such as RakNet or Photon, though you may sacrifice some flexibility going that route. Additionally, UDP comes with an increased risk of packet loss, because routers may be configured to deprioritize UDP packets as described earlier. Table 7.1 sums up the differences between the protocols.
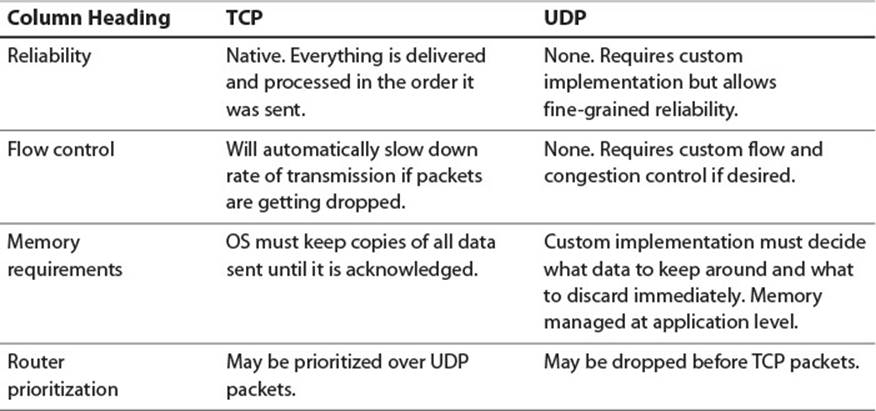
Table 7.1 Comparison of TCP to UDP
In most cases, the choice of which transport protocol to use comes down to this question: Does every piece of data the game sends need to be received, and does it need to be processed in a totally ordered fashion? If the answer is yes, you should consider using TCP. This is often true for turn-based games. Every piece of input must be received by every host and processed in the same order, so TCP is the perfect fit.
If TCP is not the absolute perfect fit for your game, and for most games it is not, you should use UDP with an application layer reliability system on top of it. This means either using a third-party middleware solution or building a custom system of your own. The rest of this chapter explores how you might go about building such a system.
Packet Delivery Notification
If UDP is the appropriate protocol for your game, you’ll need to implement a reliability system. The first requirement for reliability is the ability to know whether or not a packet arrives at its destination or not. To do this, you’ll need to build some kind of delivery notification module. The module’s job is to help higher-level dependent modules send packets to remote hosts, and then to notify those dependent modules about whether the packets were received or not. By not implementing retransmission itself, it allows each dependent module to retransmit only the data it decides should be retransmitted. This is the main source of the flexibility that UDP-based reliability provides that TCP does not. This section explores the DeliveryNotificationManager, which is one possible implementation of such a module, inspired by the Starsiege: Tribes connection manager.
The DeliveryNotificationManager needs to accomplish three things:
1. When transmitting, it must uniquely identify and tag each packet it sends out, so that it can associate delivery status with each packet and deliver this status to dependent modules in a meaningful way.
2. On the receiving end, it must examine incoming packets and send out an acknowledgment for each packet that it decides to process.
3. Back on the transmitting host, it must process incoming acknowledgments and notify dependent modules about which packets were received and which were dropped.
As an added bonus, this particular UDP reliability system will also ensure packets are never processed out of order. That is, if an old packet arrives at a destination after newer packets, the DeliveryNotificationManager will pretend the packet was dropped and ignore it. This is very useful, as it prevents stale data contained in old packets from accidentally overriding fresh data in newer packets. It is a slight overloading of the DeliveryNotificationManager’s purpose, but it is common and efficient to implement the functionality at this level.
Tagging Outgoing Packets
The DeliveryNotificationManager has to identify each packet it transmits, so that the receiving host has a way to specify which packet it acknowledges. Borrowing a technique from TCP, it does this by assigning each packet a sequence number. Unlike in TCP, however, the sequence number does not represent the number of bytes in a stream. It simply serves to provide a unique identifier for each transmitted packet.
To transmit a packet using the DeliveryNotificationManager the application creates an OutputMemoryBitStream to hold the packet, and then passes it to the DeliveryNotificationManager::WriteSequenceNumber() method, shown in Listing 7.1.
Listing 7.1 Tagging a Packet with a Sequence Number
InFlightPacket* DeliveryNotificationManager::WriteSequenceNumber(
OutputMemoryBitStream& inPacket)
{
PacketSequenceNumber sequenceNumber = mNextOutgoingSequenceNumber++;
inPacket.Write(sequenceNumber);
++mDispatchedPacketCount;
mInFlightPackets.emplace_back(sequenceNumber);
return &mInFlightPackets.back();
}
The WriteSequenceNumber method writes the DeliveryNotificationManager’s next outgoing sequence number into the packet, and then increments the number in preparation for the next packet. In this way, no two packets sent in close succession should have the same sequence number, and each has a unique identifier.
The method then constructs an InFlightPacket and adds it to the mInFlightPackets container, which keeps track of all packets that have not yet been acknowledged. These InFlightPacket objects will be needed later when processing acknowledgments and reporting delivery status. After giving the DeliveryNotificationManager a chance to tag the packet with a sequence number, it is up to the application to write the payload of the packet and send it off to the destination host.
Note
PacketSequenceNumber is a typedef so you can easily change the number of bits in a sequence number. In this case, it is a uint16_t, but depending on the number of packets you plan on sending, you might want to use more or fewer bits. The goal is to use as few bits as possible while minimizing the chance of wrapping the sequence number and then encountering a very old packet with a seemingly relevant sequence number from long before the wrap around. If you’re pushing the bit count as low as possible, it can be very useful to include an unwrapped 32-bit sequence count during development for debugging and verification purposes. You’d then remove the extra sequence count when making release builds.
Receiving Packets and Sending Acknowledgments
When the destination host receives a packet, it sends an InputMemoryBitStream containing the packet’s data to its own DeliveryNotificationManager’s ProcessSequenceNumber() method, shown in Listing 7.2.
Listing 7.2 Processing an Incoming Sequence Number
bool DeliveryNotificationManager::ProcessSequenceNumber(
InputMemoryBitStream& inPacket)
{
PacketSequenceNumber sequenceNumber;
inPacket.Read(sequenceNumber);
if(sequenceNumber == mNextExpectedSequenceNumber)
{
//is this expected? add ack to the pending list and process packet
mNextExpectedSequenceNumber = sequenceNumber + 1;
AddPendingAck(sequenceNumber);
return true;
}
//is sequence number < current expected? Then silently drop old packet.
else if(sequenceNumber < mNextExpectedSequenceNumber)
{
return false;
}
//otherwise, we missed some packets
else if(sequenceNumber > mNextExpectedSequenceNumber)
{
//consider all skipped packets as dropped, so
//our next expected packet comes after this one ...
mNextExpectedSequenceNumber = sequenceNumber + 1;
//add an ack for the packet and process it
//when the sender detects break it acks, it can resend
AddPendingAck(sequenceNumber);
return true;
}
}
ProcessSequenceNumber() returns a bool indicating whether the packet should be processed by the application, or just completely ignored. This is how the DeliveryNotificationManager prevents out of order processing. The mNextExpectedSequenceNumbermember variable keeps track of the next sequence number the destination host should receive in a packet. Because each transmitted packet has a consecutively increasing sequence number, the receiving host can easily predict which sequence number should be present in an incoming packet. Given that, there are three cases that might occur when the method reads a sequence number:
![]() The incoming sequence number matches the expected sequence number. In this case, the application should acknowledge the packet, and should process it. The DeliveryNotificationManager should increment its mNextExpectedSequenceNumber by 1.
The incoming sequence number matches the expected sequence number. In this case, the application should acknowledge the packet, and should process it. The DeliveryNotificationManager should increment its mNextExpectedSequenceNumber by 1.
![]() The incoming sequence number is less than the expected sequence number. This probably means the packet is older than packets that have already arrived. To avoid out of order processing, the host should not process the packet. It should also not acknowledge the packet, because the host should only acknowledge packets that it processes. There is an edge case that you must consider here. If the current mNextExpectedSequenceNumber is close to the maximum number representable by a PacketSequenceNumber and the incoming sequence number is close to the minimum, the sequence numbers may have wrapped around. Based on the rate at which your game sends packets, and the number of bits used in PacketSequenceNumber, this may or may not be possible. If it is possible, and themNextExpectedSequenceNumber and incoming sequence number suggest it is likely, then you should handle this the same way as you would the following case.
The incoming sequence number is less than the expected sequence number. This probably means the packet is older than packets that have already arrived. To avoid out of order processing, the host should not process the packet. It should also not acknowledge the packet, because the host should only acknowledge packets that it processes. There is an edge case that you must consider here. If the current mNextExpectedSequenceNumber is close to the maximum number representable by a PacketSequenceNumber and the incoming sequence number is close to the minimum, the sequence numbers may have wrapped around. Based on the rate at which your game sends packets, and the number of bits used in PacketSequenceNumber, this may or may not be possible. If it is possible, and themNextExpectedSequenceNumber and incoming sequence number suggest it is likely, then you should handle this the same way as you would the following case.
![]() The incoming sequence number is greater than the expected sequence number. This is what happens when one or more packets get dropped or delayed. A different packet eventually gets through to the destination, but its sequence number is higher than expected. In this case, the application should still process the packet and should still acknowledge it. Unlike in TCP, the DeliveryNotificationManager does not promise to process every single packet sent in order. It only promises to process nothing out of order, and to report when packets are dropped. Thus it is perfectly safe to acknowledge and process packets that come in after previously transmitted packets were dropped. In addition, to prevent the processing of any old packets, should they arrive, the DeliveryNotificationManager should set itsmNextExpectedSequenceNumber to the most recently received packet’s sequence number plus one.
The incoming sequence number is greater than the expected sequence number. This is what happens when one or more packets get dropped or delayed. A different packet eventually gets through to the destination, but its sequence number is higher than expected. In this case, the application should still process the packet and should still acknowledge it. Unlike in TCP, the DeliveryNotificationManager does not promise to process every single packet sent in order. It only promises to process nothing out of order, and to report when packets are dropped. Thus it is perfectly safe to acknowledge and process packets that come in after previously transmitted packets were dropped. In addition, to prevent the processing of any old packets, should they arrive, the DeliveryNotificationManager should set itsmNextExpectedSequenceNumber to the most recently received packet’s sequence number plus one.
Note
The first and third cases actually perform the exact same operation. They are called out separately in the code because they indicate different situations, but they could be collapsed into a single case by checking if sequenceNumber ≥ mNextExpectedSequenceNumber.
The ProcessSequenceNumber() method does not send any acknowledgments directly. Instead, it calls AddPendingAck() to track that an acknowledgment should be sent. It does this for efficiency. If a host receives many packets from another host, it would be inefficient to send an acknowledgment for each incoming packet. Even TCP is allowed to acknowledge only every other packet. In the case of a multiplayer game, the server may need to send several MTU-sized packets to a client before the client has to send any data back to the server. In cases like this, it is best to just accumulate all necessary acknowledgments and piggy back them on to the next packet the client sends to the server.
The DeliveryNotificationManager may accumulate several nonconsecutive acknowledgments. To efficiently track and serialize them, it keeps a vector of AckRanges in its mPendingAcks variable. It adds to them using the AddPendingAck() code shown in Listing 7.3.
Listing 7.3 Adding a Pending Acknowledgment
void DeliveryNotificationManager::AddPendingAck(
PacketSequenceNumber inSequenceNumber)
{
if(mPendingAcks.size() == 0 ||
!mPendingAcks.back().ExtendIfShould(inSequenceNumber))
{
mPendingAcks.emplace_back(inSequenceNumber);
}
}
An AckRange itself represents a collection of consecutive sequence numbers to acknowledge. It stores the first sequence number to acknowledge in its mStart member, and the count of how many sequence numbers to acknowledge in its mCount member. Thus, multiple AckRanges are only necessary when there is a break in the sequence. The code for AckRange is shown in Listing 7.4
Listing 7.4 Implementing AckRange
inline bool AckRange::ExtendIfShould(PacketSequenceNumber inSequenceNumber)
{
if(inSequenceNumber == mStart + mCount)
{
++mCount;
return true;
}
else
{
return false;
}
}
void AckRange::Write(OutputMemoryBitStream& inPacket) const
{
inPacket.Write(mStart);
bool hasCount = mCount > 1;
inPacket.Write(hasCount);
if(hasCount)
{
//let's assume you want to ack max of 8 bits...
uint32_t countMinusOne = mCount - 1;
uint8_t countToAck = countMinusOne > 255 ?
255: static_cast<uint8_t>(countMinusOne);
inPacket.Write(countToAck);
}
}
void AckRange::Read(InputMemoryBitStream& inPacket)
{
inPacket.Read(mStart);
bool hasCount;
inPacket.Read(hasCount);
if(hasCount)
{
uint8_t countMinusOne;
inPacket.Read(countMinusOne);
mCount = countMinusOne + 1;
}
else
{
//default!
mCount = 1;
}
}
The ExtendIfShould() method checks if the sequence number is consecutive. If so, it increases the count and tells the caller the range was extended. If not, it returns false so the caller knows to construct a new AckRange for the nonconsecutive sequence number.
Write() and Read() work by first serializing the starting sequence number and then serializing the count. Instead of serializing the count directly, these methods take into account the fact that many games will typically only need to acknowledge a single packet at a time. Thus the methods use entropy encoding to efficiently serialize the count, with an expected value of 1. They also serialize the count as an 8-bit integer, assuming that more than 256 acknowledgments should never be needed. In truth, even 8 bits are high for the count, so this could easily be fewer.
When the receiving host is ready to send a reply packet, it writes any accumulated acknowledgments into the outgoing packet by calling WritePendingAcks() right after it writes its own sequence number. Listing 7.5 shows WritePendingAcks().
Listing 7.5 Writing Pending Acknowledgments
void DeliveryNotificationManager::WritePendingAcks(
OutputMemoryBitStream& inPacket)
{
bool hasAcks = (mPendingAcks.size() > 0);
inPacket.Write(hasAcks);
if(hasAcks)
{
mPendingAcks.front().Write(inPacket);
mPendingAcks.pop_front();
}
}
Because not every packet necessarily contains acknowledgments, the method first writes a single bit to signal their presence. It then writes a single AckRange into the packet. It does this because packet loss is the exception, not the rule, and there will usually be only one AckRangepending. You could write all of the pending ranges, but this would require an extra indicator of how many AckRanges are present and could potentially bloat a packet. In the end, you want some flexibility, but not so much that it places an undue burden on your reply packet capacity. Studying the traffic pattern of your game will help you craft a system that is flexible enough for your edge cases but sufficiently efficient on average: For instance, if you feel confident that your game will never need to acknowledge more than one packet at a time, you can remove the multi-acknowledgment system entirely and save a few bits per packet.
Receiving Acknowledgments and Delivering Status
Once a host sends out a data packet, it must listen for and process any acknowledgments accordingly. When the expected acknowledgments arrive, the DeliveryNotificationManager deduces that the corresponding packets arrived correctly and notifies the appropriate dependent modules of delivery success. When the expected acknowledgments do not arrive, the DeliveryNotificationManager deduces that packets were lost, and notifies the appropriate dependent modules of failure.
Warning
Beware that the lack of an acknowledgment does not truly indicate the loss of a data packet. The data could have arrived successfully, but the packet containing the acknowledgment itself might have been lost. There is no way for the originally transmitting host to distinguish between these cases. In TCP, this is not a problem, because a retransmitted packet uses the exact same sequence number it used when originally sent. If a TCP module receives a duplicate packet, it knows to just ignore it.
This is not the case for the DeliveryNotificationManager. Because lost data is not necessarily resent, every packet is unique and sequence numbers are never reused. This means a client module may decide to resend some reliable data based on the absence of an acknowledgment, and the receiving host may already have the data. In this case, it is up to the dependent module to uniquely identify the data itself to prevent duplication. For instance, if an ExplosionManager relies on the DeliveryNotificationManager to reliably send explosions across the Internet, it should uniquely number the explosions to ensure no explosion accidentally explodes twice on the receiving end.
To process acknowledgments and dispatch status notification, the host application uses the ProcessAcks() method, as shown in the Listing 7.6.
Listing 7.6 Processing the Acknowledgments
void DeliveryNotificationManager::ProcessAcks(
InputMemoryBitStream& inPacket)
{
bool hasAcks;
inPacket.Read(hasAcks);
if(hasAcks)
{
AckRange ackRange;
ackRange.Read(inPacket);
//for each InFlightPacket with seq# < start, handle failure...
PacketSequenceNumber nextAckdSequenceNumber =
ackRange.GetStart();
uint32_t onePastAckdSequenceNumber =
nextAckdSequenceNumber + ackRange.GetCount();
while(nextAckdSequenceNumber < onePastAckdSequenceNumber &&
!mInFlightPackets.empty())
{
const auto& nextInFlightPacket = mInFlightPackets.front();
//if the packet seq# < ack seq#, we didn't get an ack for it,
//so it probably wasn't delivered
PacketSequenceNumber nextInFlightPacketSequenceNumber =
nextInFlightPacket.GetSequenceNumber();
if(nextInFlightPacketSequenceNumber < nextAckdSequenceNumber)
{
//copy this so we can remove it before handling-
//dependent modules shouldn't find it if seeing what's live
auto copyOfInFlightPacket = nextInFlightPacket;
mInFlightPackets.pop_front();
HandlePacketDeliveryFailure(copyOfInFlightPacket);
}
else if(nextInFlightPacketSequenceNumber==
nextAckdSequenceNumber)
{
HandlePacketDeliverySuccess(nextInFlightPacket);
//received!
mInFlightPackets.pop_front();
++nextAckdSequenceNumber;
}
else if(nextInFlightPacketSequenceNumber>
nextAckdSequenceNumber)
{
//somehow part of this range was already removed
//(maybe from timeout) check rest of range
nextAckdSequenceNumber = nextInFlightPacketSequenceNumber;
}
}
}
}
To process an AckRange, the DeliveryNotificationManager must determine which of its InFlightPackets lie within the range. Because acknowledgments should be received in order, the method assumes that any packets with sequence numbers lower than the given range were dropped, and it reports their delivery as failed. It then reports any packets within the range as successfully delivered. There can be quite a few packets in flight at any one time, but luckily it is not necessary to examine every single InFlightPacket. Because newInFlightPackets are appended to the mInFlightPackets deque, all the InFlightPackets are already ordered by sequence number. This means that when an AckRange comes in, the method can go through the mInFlightPackets in order, comparing each sequence number to the AckRange. Until it finds its first packet in the range, it reports all packets as dropped. Then, once it finds the first packet in the range, it reports its delivery as successful. Finally it needs only report success for the rest of the packets in the AckRange and it can exit without examining any other InFlightPackets.
The final else-if clause handles the edge case in which the first known InFlightPacket is somewhere inside the AckRange, but not at the front. This can happen if a packet recently acknowledged was previously reported as dropped. In this case, ProcessAcks() just jumps to the packet’s sequence number and reports all the remaining packets in range as successfully delivered.
You may wonder how a packet previously reported as dropped might later be acknowledged. This can happen if the acknowledgment took too long to arrive. Just as TCP resends packets when an acknowledgment is not prompt, the DeliveryNotificationManager should also be on the lookout for acknowledgments that have timed out. This is particularly useful when traffic is sparse, and there may not be a nonconsecutive acknowledgment to indicate a single dropped packet. To check for timed out packets, the host application should call theProcessTimedOutPackets() method each frame, given in Listing 7.7.
Listing 7.7 Timing Out Packets
void DeliveryNotificationManager::ProcessTimedOutPackets()
{
uint64_t timeoutTime = Timing::sInstance.GetTimeMS() - kAckTimeout;
while( !mInFlightPackets.empty())
{
//packets are sorted, so all timed out packets must be at front
const auto& nextInFlightPacket = mInFlightPackets.front();
if(nextInFlightPacket.GetTimeDispatched() < timeoutTime)
{
HandlePacketDeliveryFailure(nextInFlightPacket);
mInFlightPackets.pop_front();
}
else
{
//no packets beyond could be timed out
break;
}
}
}
The GetTimeDispatched() method returns a timestamp set at creation time in the InFlightPacket’s constructor. Because the InFlightPackets are sorted, the method only has to check the front of the list until it has found a packet that has not timed out. After that point, it is guaranteed all successive packets in flight have not timed out.
To track and report delivered and dropped packets, the aforementioned methods call HandlePacketDeliveryFailure() and HandlePacketDeliverySuccess() as shown in Listing 7.8.
Listing 7.8 Tracking Status
void DeliveryNotificationManager::HandlePacketDeliveryFailure(
const InFlightPacket& inFlightPacket)
{
++mDroppedPacketCount;
inFlightPacket.HandleDeliveryFailure(this);
}
void DeliveryNotificationManager::HandlePacketDeliverySuccess(
const InFlightPacket& inFlightPacket)
{
++mDeliveredPacketCount;
inFlightPacket.HandleDeliverySuccess(this);
}
These methods increment mDroppedPacketCount and mDeliveredPacketCount, accordingly. By doing so, the DeliveryNotificationManager can track packet delivery rates, and estimate packet loss rates for the future. If loss is too high, it can notify appropriate modules to decrease transmission rate, or the modules can notify the user directly that something might be wrong with the host’s network connection. The DeliveryNotificationManager can also sum these values with the mInFlightPackets vector’s size and assert they equal themDispatchedPacketCount, incremented in WriteSequenceNumber().
The aforementioned methods make use of InFlightPacket’s HandleDeliveryFailure() and HandleDeliverySuccess() methods to notify higher-level consumer modules about delivery status. To understand how they work, it’s worth looking at the InFlightPacketclass in Listing 7.9.
Listing 7.9 The InFlightPacket Class
class InFlightPacket
{
public:
....
void SetTransmissionData(int inKey,
TransmissionDataPtr inTransmissionData)
{
mTransmissionDataMap[ inKey ] = inTransmissionData;
}
const TransmissionDataPtr GetTransmissionData(int inKey) const
{
auto it = mTransmissionDataMap.find(inKey);
return (it != mTransmissionDataMap.end()) ? it->second: nullptr;
}
void HandleDeliveryFailure(
DeliveryNotificationManager* inDeliveryNotificationManager) const
{
for(const auto& pair: mTransmissionDataMap)
{
pair.second->HandleDeliveryFailure
(inDeliveryNotificationManager);
}
}
void HandleDeliverySuccess(
DeliveryNotificationManager* inDeliveryNotificationManager) const
{
for(const auto& pair: mTransmissionDataMap)
{
pair.second->HandleDeliverySuccess
(inDeliveryNotificationManager);
}
}
private:
PacketSequenceNumber mSequenceNumber;
float mTimeDispatched;
unordered_map<int, TransmissionDataPtr> mTransmissionDataMap;
};
Tip
Keeping the transmission data map in an unordered_map is clear and useful for demonstrative purposes. Iterating through an unordered_map is not very efficient and can lead to many cache misses. In production, if you have a small number of transmission data types, it can be better to just make a dedicated member variable for each type, or to store them in a fixed array with a dedicated index per type. If you need more than a few transmission data types, it might be worth it to keep them in a sorted vector.
Each InFlightPacket holds a container of TransmissionData pointers. TransmissionData is an abstract class with its own HandleDeliverySucess() and HandleDeliveryFailure() methods. Each dependent module that sends data via theDeliveryNotificationManager can create its own subclass of TransmissionData. Then, when a module writes reliable data into a packet’s memory stream, it creates an instance of its customized TransmissionData subclass and uses SetTransmissionData() to add it to the InFlightPacket. When the DeliveryNotificationManager notifies the dependent module about a packet’s success or failure, the module has a record of exactly what it stored in the given packet, allowing it to figure out how best to proceed. If the module needs to resend some of the data, it can. If it needs to send a newer version of the data, it can. If it needs to update custom variables elsewhere in the application, it can. In this way, the DeliveryNotificationManager provides a solid foundation on which to build a UDP-based reliability system.
Note
Each pair of communicating hosts requires its own pair of DeliveryNotificationManagers. So in a client-server topology, if the server is talking to 10 clients, it needs 10 DeliveryNotificationManagers, one for each client. Then each client host uses its ownDeliveryNotificationManager to communicate with the server.
Object Replication Reliability
You can use a DeliveryNotificationManager to send data reliably by resending any data that fails to reach its intended host. Simply extend TransmissionData with a ReliableTransmissionData class that contains all data sent in the packet. Then, inside theHandleDeliveryFailed() method, create a new packet and resend all the data. This is very close to how TCP implements reliability, however, and doesn’t take full advantage of the DeliveryNotificationManager’s potential. To improve upon the TCP version of reliability, you do not have to resend the exact data that dropped. Instead, you can send only the latest version of the data that was dropped. This section will explore how to extend the ReplicationManager from Chapter 5 to support reliably resending the most recent data, inspired by the Starsiege: Tribes ghost manager.
The ReplicationManager of Chapter 5 has a very simple interface. Dependent modules create an output stream, prepare a packet, and then call ReplicateCreate(), ReplicateUpdate(), or ReplicateDestroy() to create, update, or destroy a remote object, accordingly. The problem with this methodology is that the ReplicationManager neither controls what data goes in which packets, nor keeps a record of that data. This does not lend itself well to supporting reliability.
To send data reliably, the ReplicationManager needs to be able to resend data whenever it learns that a packet carrying reliable data has dropped. To support this, the host application needs to poll the ReplicationManager regularly, offering it a primed packet and asking if it has data it would like to write into the packet. This way, whenever the ReplicationManager knows about lost reliable data, it can write whatever it needs to into the provided packet. The host can pick the frequency at which it offers packets to the ReplicationManager based on estimated bandwidth, packet loss rate, or any other heuristic.
It’s worthwhile to extend this mechanism further and consider how things could work if the only time the ReplicationManager wrote data into packets were when the client periodically offered it an outgoing packet to fill. This would mean that instead of gameplay systems creating a packet whenever they have changed data to replicate, they can instead just notify the ReplicationManager about the data, and the ReplicationManager can take care of writing the data at the next opportunity. This nicely creates a further layer of abstraction between gameplay systems and network code. The gameplay code no longer needs to create packets or care about the network. Instead, it just notifies the ReplicationManager about important changes, and the ReplicationManager takes care of writing those changes into packets periodically.
This also happens to create the perfect pathway for up-to-date reliability. Consider the three basic commands: create, update, and destroy. When the gameplay system sends a replication command for a target object to the ReplicationManager, the ReplicationManager can use that command and object to write the appropriate state into a future packet. It can then store the replication command, target object pointer, and written state bits as transmission data in the corresponding InFlightPacket record. If the ReplicationManager learns that a packet dropped, it can find the matching InFlightPacket, look up the command and object that it used when writing the packet originally, and then write fresh data to a new packet using the same command, object, and state bits. This is a vast improvement over TCP, because the ReplicationManagerdoes not use the original, potentially stale data to write the new packet. It instead uses only the current state of the target object, which could be a 1/2 second newer than the original packet by this point.
To support such a system, the ReplicationManager needs to offer an interface that allows gameplay systems to batch replication requests. For each game object, a gameplay system can batch creation, a set of property updates, or destruction. The ReplicationManager keeps track of the latest replication command for each object, so it can write the appropriate replication data into a packet whenever it is offered one. It stores these ReplicationCommands in mNetworkReplicationCommand, a member variable mapping from an object’s network identifier to the latest command for that object. Listing 7.10 shows the interface for batching commands, as well as the inner workings of the ReplicationCommand itself.
Listing 7.10 Batching Replication Commands
void ReplicationManager::BatchCreate(
int inNetworkId, uint32_t inInitialDirtyState)
{
mNetworkIdToReplicationCommand[inNetworkId] =
ReplicationCommand(inInitialDirtyState);
}
void ReplicationManager::BatchDestroy(int inNetworkId)
{
mNetworkIdToReplicationCommand[inNetworkId].SetDestroy();
}
void ReplicationManager::BatchStateDirty(
int inNetworkId, uint32_t inDirtyState)
{
mNetworkIdToReplicationCommand[inNetworkId].
AddDirtyState(inDirtyState);
}
ReplicationCommand::ReplicationCommand(uint32_t inInitialDirtyState):
mAction(RA_Create), mDirtyState(inInitialDirtyState) {}
void ReplicationCommand::AddDirtyState(uint32_t inState)
{
mDirtyState |= inState;
}
void ReplicationCommand::SetDestroy()
{
mAction = RA_Destroy;
}
Batching a create command maps an object’s network identifier to a ReplicationCommand containing a create action, and state bits specifying all the properties that should be replicated, as described in Chapter 5. Batching an update command binary ORs additional state bits as dirty so that the ReplicationManager knows to replicate the changed data. Game systems should batch update commands whenever they change data that needs to be replicated. Finally, batching a destroy command finds the ReplicationCommand for the object’s network identifier and changes its action to destroy. Note that if destruction is batched for an object, it supersedes any previously batched instructions, since in the latest state methodology, it makes no sense to send state updates for an object that has already been destroyed. Once commands have been batched, theReplicationManager fills the next packet it is offered using the WriteBatchedCommands() method shown in Listing 7.11.
Listing 7.11 Writing Batched Commands
void ReplicationManager::WriteBatchedCommands(
OutputMemoryBitStream& inStream, InFlightPacket* inFlightPacket)
{
ReplicationManagerTransmissionDataPtr repTransData = nullptr;
//run through each replication command and rep if necessary
for(auto& pair: mNetworkIdToReplicationCommand)
{
ReplicationCommand& replicationCommand = pair.second;
if(replicationCommand.HasDirtyState())
{
int networkId = pair.first;
GameObject* gameObj =
mLinkingContext->GetGameObject(networkId);
if(gameObj)
{
ReplicationAction action =
replicationCommand.GetAction();
ReplicationHeader rh(action, networkId,
gameObj->GetClassId());
rh.Write(inStream);
uint32_t dirtyState =
replicationCommand.GetDirtyState();
if(action == RA_Create || action == RA_Update)
{
gameObj->Write(inStream, dirtyState);
}
//create transmission data if we haven't yet
if(!repTransData)
{
repTransData =
std::make_shared<ReplicationManagerTransmissionData>(
this);
inFlightPacket->SetTransmissionData
('RPLM',repTransData);
}
//now store what we put in this packet and clear state
repTransData->AddReplication(networkId, action,
dirtyState);
replicationCommand.ClearDirtyState(dirtyState);
}
}
}
}
void ReplicationCommand::ClearDirtyState(uint32_t inStateToClear)
{
mDirtyState &= ~inStateToClear;
if(mAction == RA_Destroy)
{
mAction = RA_Update;
}
}
bool ReplicationCommand::HasDirtyState() const
{
return (mAction == RA_Destroy) || (mDirtyState != 0);
}
WriteBatchedCommand() starts by iterating over the replication command map. If it finds a network identifier with a batched command, defined as having either nonzero dirty state or a destroy action, it writes the ReplicationHeader and state, just as it did in Chapter 5. Then, if it has not yet created a ReplicationTransmissionData instance, it creates one and adds it to the InFlightPacket. Instead of doing this at the top of the method, it does this only once it has determined that it has state to replicate. It then appends the network identifier, replication action, and dirty state bits to the transmission data so that it has a complete record of what it wrote into the packet. Finally, it clears the dirty state in the replication command, so that it will not attempt to replicate the data again until it changes. By the end of the call, the packet contains all the replication data that higher-level game systems have batched, and the InFlightPacket contains a record of the information used during replication.
When the ReplicationManager learns of the packet’s fate from the DeliveryNotificationManager, it responds with one of the two methods in Listing 7.12.
Listing 7.12 Responding to Packet Delivery Status Notification
void ReplicationManagerTransmissionData::HandleDeliveryFailure(
DeliveryNotificationManager* inDeliveryNotificationManager) const
{
for(const ReplicationTransmission& rt: mReplications)
{
int networkId = rt.GetNetworkId();
GameObject* go;
switch(rt.GetAction())
{
case RA_Create:
{
//recreate if not destroyed
go = mReplicationManager->GetLinkingContext()
->GetGameObject(networkId);
if( go )
{
mReplicationManager->BatchCreate(networkId,
rt.GetState());
}
}
break;
case RA_Update:
go = mReplicationManager->GetLinkingContext()
->GetGameObject(networkId);
if(go)
{
mReplicationManager->BatchStateDirty(networkId,
rt.GetState());
}
break;
case RA_Destroy:
mReplicationManager->BatchDestroy(networkId);
break;
}
}
}
void ReplicationManagerTransmissionData::HandleDeliverySuccess
(DeliveryNotificationManager* inDeliveryNotificationManager) const
{
for(const ReplicationTransmission& rt: mReplications)
{
int networkId = rt.GetNetworkId();
switch(rt.GetAction())
{
case RA_Create:
//once ackd, can send as update instead of create
mReplicationManager->HandleCreateAckd(networkId);
break;
case RA_Destroy:
mReplicationManager->RemoveFromReplication(networkId);
break;
}
}
}
HandleDeliveryFailure() implements the real magic of up-to-date reliability. If a dropped packet contains a creation command, it rebatches the creation command. If it contains a state update command, it marks the corresponding state as dirty so that the new state values will be sent at the next opportunity. Finally, if it contains a destroy command, it rebatches the destroy command. In the event of successful delivery, HandleDeliverySuccess() takes care of some housekeeping tasks. If the packet contained a creation command, it changes the creation command to an update command so that the object will not be replicated as a creation the next time a game system marks its state as dirty. If the packet contained a destroy command, the method removes the corresponding network identifier from the mNetworkIdToReplicationCommandMapbecause there should be no more replication commands batched by the game.
Optimizing from In-Flight Packets
There is a significant optimization worth making to the ReplicationManager, again taking a lead from the Starsiege: Tribes ghost manager. Consider the case of a car driving through the game world for 1 second. If a server sends state reliably to a client 20 times a second, each packet will contain a different position of the car as it travels. If the packet sent at 0.9-second drops, it might be 200 ms later before the server’s ReplicationManager realizes and attempts to resend new data. By that point, the car would have stopped. Because the server was sending constant updates while the car was driving, there would already be new packets on their way to the client, containing updated positions of the car. It would be wasteful for the server to resend the car’s current position when a packet containing that very data was already in flight to the client. If there were some way for the ReplicationManager to know about the in-flight data, it could avoid sending redundant state. Luckily, there is! When the ReplicationManager first learns of the dropped data, it can search through the DeliveryNotificationManager’s list ofInFlightPackets and check the ReplicationTransmissionData stored in each one. If it sees state data in flight for the given object and property, then it knows it does not need to resend that data: It’s already on the way! Listing 7.13 contains an updated RA_Update case for theHandleDeliveryFailure() method that does just this.
Listing 7.13 Avoiding Redundant Retransmission
void ReplicationManagerTransmissionData::HandleDeliveryFailure(
DeliveryNotificationManager* inDeliveryNotificationManager) const
{
...
case RA_Update:
go = mReplicationManager->GetLinkingContext()
->GetGameObject(networkId);
if(go)
{
//look in all in flight packets,
//remove written state from dirty state
uint32_t state = rt.GetState();
for(const auto& inFlightPacket:
inDeliveryNotificationManager->GetInFlightPackets())
{
ReplicationManagerTransmissionDataPtr rmtdp =
std::static_pointer_cast
<ReplicationManagerTransmissionData>(
inFlightPacket.GetTransmissionData('RPLM'));
if(rmtdp)
{
for(const ReplicationTransmission& otherRT:
rmtdp->mReplications )
{
if(otherRT.GetNetworkId() == networkId)
{
state &= ~otherRT.GetState();
}
}
}
}
//if there's still any dirty state, rebatch it
if( state )
{
mReplicationManager->BatchStateDirty(networkId, state);
}
}
break;
...
}
The update case first captures the state that was dirty in the original replication. Then, it iterates through each of the InFlightPackets stored by the DeliveryNotificationManager. In each packet, it tries to find the ReplicationManager’s transmission data entry. If it finds one, it searches through the contained ReplicationTransmissions. For each replication, if the network identifier matches the identifier in the original dropped replication, it unsets any bits in the original state that are set in the found state. This way, the ReplicationManageravoids resending any state already in flight. If no bits are still set in the state by the time the method finishes checking all packets, it doesn’t need to rebatch any state at all.
The aforementioned “optimization” can require quite a bit of processing each time a full packet drops. However, given the typically low frequency of dropped packets, and the fact that bandwidth is often more dear than processing power, it can still be beneficial. As always, consider the tradeoffs in the specific context of your game.
Simulating Real-World Conditions
Given the hazards that await your game in the real world, it is important to create a test environment that can properly simulate latency, jitter, and packet loss. You can engineer a testing module to sit between a socket and the rest of your game and simulate real-world conditions. To simulate loss, decide the probability of a packet dropping that you’d like to simulate. Then, each time a packet comes in, use a random number to decide whether to drop the packet, or pass it on to the application. To simulate latency and jitter, decide the average latency and jitter distribution for the test. When a packet arrives, calculate the timestamp at which it would have arrived in the real world by adding its latency and jitter to the time at which it actually arrived. Then, instead of sending the packet to your game to be processed right away, stamp it with the simulated arrival time and insert it into a sorted list of packets. Finally, each frame of your game, examine the sorted list and only process those packets whose simulated arrival times are lower than the current time. Listing 7.14 gives an example of how to do so.
Listing 7.14 Simulating Loss, Latency, and Jitter
void RLSimulator::ReadIncomingPacketsIntoQueue()
{
char packetMem[1500];
int packetSize = sizeof(packetMem);
InputMemoryBitStream inputStream(packetMem, packetSize * 8);
SocketAddress fromAddress;
while(receivedPackedCount < kMaxPacketsPerFrameCount)
{
int cnt = mSocket->ReceiveFrom(packetMem, packetSize, fromAddress);
if(cnt == 0)
{
break;
}
else if(cnt < 0)
{
//handle error
}
else
{
//now, should we process the packet?
if(RoboMath::GetRandomFloat() >= mDropPacketChance)
{
//we made it, queue packet for later processing
float simulatedReceivedTime =
Timing::sInstance.GetTimef() +
mSimulatedLatency +
(RoboMath::GetRandomFloat() - 0.5f) *
mDoubleSimulatedMaxJitter;
//keep list sorted by simulated receive time
auto it = mPacketList.end();
while(it != mPacketList.begin())
{
--it;
if(it->GetReceivedTime() < simulatedReceivedTime)
{
//time comes after this element, so inc and break
++it;
break;
}
}
mPacketList.emplace(it, simulatedReceivedTime,
inputStream, fromAddress);
}
}
}
}
void RLSimulator::ProcessQueuedPackets()
{
float currentTime = Timing::sInstance.GetTimef();
//look at the front packet...
while(!mPacketList.empty())
{
ReceivedPacket& packet = mPacketList.front();
//is it time to process this packet?
if(currentTime > packet.GetReceivedTime())
{
ProcessPacket(packet.GetInputStream(),
packet.GetFromAddress());
mPacketList.pop_front();
}
else
{
break;
}
}
}
Tip
For an even more accurate simulation, consider incorporating the fact that packets are usually dropped or delayed in groups of sequential packets. When a random check indicates packets should be dropped, you can use another random number to determine how many packets in a row should be affected.
Summary
The real world is a scary place for multiplayer games. Players want immediate feedback from their inputs, and the forces of nature act to prevent that. Even without a network component, video games have to deal with many sources of latency, including input sampling latency, rendering latency, and display-based latency. With physical networking added to the mix, multiplayer games must also deal with latency from propagation delay, transmission delay, processing delay, and queuing delay. As a game developer, there are actions you can take to reduce these delays, but they may be very expensive and out of scope for your game.
Fluctuating network conditions lead to packets arriving late, out of order, or not at all. To build an enjoyable game experience, you need some level of reliable transmission to mitigate these issues. One way to guarantee reliable transmission is to use the TCP transport protocol. Although TCP is a well-tested, turn-key reliability solution, it has a few disadvantages. It works for games that need absolutely all their data transported reliably, but is not suitable for typical games that care more about up-to-date data than perfectly reliable data. For these games, UDP is the best choice because of the flexibility it offers.
When using UDP you have the ability and requirement to build your own custom reliability layer. The foundation of this is usually a notification system that alerts your game when packets arrive successfully and when they drop. By keeping a record of the data in each packet, the game can then decide how to act when notified about a packet’s fate.
You can build a variety of reliability modules on top of a delivery notification system. A very common module provides for redelivery of up-to-date object state in the event of packet loss, similar to the Starsiege: Tribes ghost manager. It does this by tracking the state sent in each packet, and then resending the latest version of any appropriate state not already in flight when notified of a lost packet.
It is important to test your reliability system in a controlled environment before exposing it to the harsh conditions of the real world. Using random-number generators and a buffer of incoming packets, you can build a system that simulates packet loss, latency, and jitter. You can then see how both your reliability system and your entire game perform under various simulated network conditions.
Once you have dealt with the low-level problems of the real world, you can begin to think about addressing latency on a higher level. Chapter 8, “Improved Latency Handling,” addresses the challenge of giving networked players as close to a lag-free experience as possible.
Review Questions
1. What are five processes which contribute to non-network latency?
2. What are the four delays which contribute to network latency?
3. Give one manner to reduce each network delay.
4. For what does RTT stand and what does it mean?
5. What is jitter? What are some causes of jitter?
6. Extend the DeliveryNotificationManager::ProcessSequenceNumber() to function properly in the case of sequence numbers wrapping back to 0.
7. Expand the DeliveryNotificationManager so that all packets received on the same frame are buffered and then sorted before the DeliveryNotificationManager decides which packets are stale and should be dropped.
8. Explain how a ReplicationManager can use the DeliveryNotificationManager to provide improved reliability over TCP, and send up-to-date data to recover from dropped packets.
9. Use the DeliveryNotificationManager and ReplicationManager to implement a two-player tag game. Simulate real-life conditions to see how tolerant your logic is of packet loss, latency, and jitter.
Additional Readings
Almes, G., S. Kalidindi, and M. Zekauskas. (1999, September). A One-Way Delay Metric for IPPM. Retrieved from https://tools.ietf.org/html/rfc2679. Accessed September 12, 2015.
Carmack, John (2012, April). Tweet. Retrieved from https://twitter.com/id_aa_carmack/status/193480622533120001. Accessed September 12, 2015.
Carmack, John (2012, May). Transatlantic ping faster than sending a pixel to the screen? Retrieved from http://superuser.com/questions/419070/transatlantic-ping-faster-than-sending-a-pixel-to-the-screen/419167#419167. Accessed September 12, 2015.
Frohnmayer, Mark and Tim Gift (1999). The TRIBES Engine Networking Model. Retrieved from http://gamedevs.org/uploads/tribes-networking-model.pdf. Accessed September 12, 2015.
Hauser, Charlie (2015, January). NA Server Roadmap Update: Optimizing the Internet for League and You. Retrieved from http://boards.na.leagueoflegends.com/en/c/help-support/AMupzBHw-na-server-roadmap-update-optimizing-the-internet-for-league-and-you. Accessed September 12, 2015.
Paxson, V., G. Almes, J. Mahdavi, and M. Mathis. (1998, May). Framework for IP Performance Metrics. Retrieved from https://tools.ietf.org/html/rfc2330. Accessed September 12, 2015.
Savage, Phil (2015, January). Riot Plans to Optimise the Internet for League of Legends Players. Retrieved from http://www.pcgamer.com/riot-plans-to-optimise-the-internet-for-league-of-legends-players/. Accessed September 12, 2015.
Steed, Anthony and Manuel Fradinho Oliveira. (2010). Networked Graphics. Morgan Kaufman.
All materials on the site are licensed Creative Commons Attribution-Sharealike 3.0 Unported CC BY-SA 3.0 & GNU Free Documentation License (GFDL)
If you are the copyright holder of any material contained on our site and intend to remove it, please contact our site administrator for approval.
© 2016-2026 All site design rights belong to S.Y.A.