The Go Programming Language (2016)
11. Testing
Maurice Wilkes, the developer of EDSAC, the first stored-program computer, had a startling insight while climbing the stairs of his laboratory in 1949. In Memoirs of a Computer Pioneer, he recalled, “The realization came over me with full force that a good part of the remainder of my life was going to be spent in finding errors in my own programs.” Surely every programmer of a stored-program computer since then can sympathize with Wilkes, though perhaps not without some bemusement at his naïveté about the difficulties of software construction.
Programs today are far larger and more complex than in Wilkes’s time, of course, and a great deal of effort has been spent on techniques to make this complexity manageable. Two techniques in particular stand out for their effectiveness. The first is routine peer review of programs before they are deployed. The second, the subject of this chapter, is testing.
Testing, by which we implicitly mean automated testing, is the practice of writing small programs that check that the code under test (the production code) behaves as expected for certain inputs, which are usually either carefully chosen to exercise certain features or randomized to ensure broad coverage.
The field of software testing is enormous. The task of testing occupies all programmers some of the time and some programmers all of the time. The literature on testing includes thousands of printed books and millions of words of blog posts. In every mainstream programming language, there are dozens of software packages intended for test construction, some with a great deal of theory, and the field seems to attract more than a few prophets with cult-like followings. It is almost enough to convince programmers that to write effective tests they must acquire a whole new set of skills.
Go’s approach to testing can seem rather low-tech in comparison. It relies on one command, go test, and a set of conventions for writing test functions that go test can run. The comparatively lightweight mechanism is effective for pure testing, and it extends naturally to benchmarks and systematic examples for documentation.
In practice, writing test code is not much different from writing the original program itself. We write short functions that focus on one part of the task. We have to be careful of boundary conditions, think about data structures, and reason about what results a computation should produce from suitable inputs. But this is the same process as writing ordinary Go code; it needn’t require new notations, conventions, and tools.
11.1 The go test Tool
The go test subcommand is a test driver for Go packages that are organized according to certain conventions. In a package directory, files whose names end with _test.go are not part of the package ordinarily built by go build but are a part of it when built by go test.
Within *_test.go files, three kinds of functions are treated specially: tests, benchmarks, and examples. A test function, which is a function whose name begins with Test, exercises some program logic for correct behavior; go test calls the test function and reports the result, which is either PASS or FAIL. A benchmark function has a name beginning with Benchmark and measures the performance of some operation; go test reports the mean execution time of the operation. And an example function, whose name starts with Example, provides machine-checked documentation. We will cover tests in detail in Section 11.2, benchmarks in Section 11.4, and examples in Section 11.6.
The go test tool scans the *_test.go files for these special functions, generates a temporary main package that calls them all in the proper way, builds and runs it, reports the results, and then cleans up.
11.2 Test Functions
Each test file must import the testing package. Test functions have the following signature:
func TestName(t *testing.T) {
// ...
}
Test function names must begin with Test; the optional suffix Name must begin with a capital letter:
func TestSin(t *testing.T) { /* ... */ }
func TestCos(t *testing.T) { /* ... */ }
func TestLog(t *testing.T) { /* ... */ }
The t parameter provides methods for reporting test failures and logging additional information. Let’s define an example package gopl.io/ch11/word1, containing a single function IsPalindrome that reports whether a string reads the same forward and backward. (This implementation tests every byte twice if the string is a palindrome; we’ll come back to that shortly.)
gopl.io/ch11/word1
// Package word provides utilities for word games.
package word
// IsPalindrome reports whether s reads the same forward and backward.
// (Our first attempt.)
func IsPalindrome(s string) bool {
for i := range s {
if s[i] != s[len(s)-1-i] {
return false
}
}
return true
}
In the same directory, the file word_test.go contains two test functions named TestPalindrome and TestNonPalindrome. Each checks that IsPalindrome gives the right answer for a single input and reports failures using t.Error:
package word
import "testing"
func TestPalindrome(t *testing.T) {
if !IsPalindrome("detartrated") {
t.Error(`IsPalindrome("detartrated") = false`)
}
if !IsPalindrome("kayak") {
t.Error(`IsPalindrome("kayak") = false`)
}
}
func TestNonPalindrome(t *testing.T) {
if IsPalindrome("palindrome") {
t.Error(`IsPalindrome("palindrome") = true`)
}
}
A go test (or go build) command with no package arguments operates on the package in the current directory. We can build and run the tests with the following command.
$ cd $GOPATH/src/gopl.io/ch11/word1
$ go test
ok gopl.io/ch11/word1 0.008s
Satisfied, we ship the program, but no sooner have the launch party guests departed than the bug reports start to arrive. A French user named Noelle Eve Elleon complains that IsPalindrome doesn’t recognize “été.” Another, from Central America, is disappointed that it rejects “A man, a plan, a canal: Panama.” These specific and small bug reports naturally lend themselves to new test cases.
func TestFrenchPalindrome(t *testing.T) {
if !IsPalindrome("été") {
t.Error(`IsPalindrome("été") = false`)
}
}
func TestCanalPalindrome(t *testing.T) {
input := "A man, a plan, a canal: Panama"
if !IsPalindrome(input) {
t.Errorf(`IsPalindrome(%q) = false`, input)
}
}
To avoid writing the long input string twice, we use Errorf, which provides formatting like Printf.
When the two new tests have been added, the go test command fails with informative error messages.
$ go test
--- FAIL: TestFrenchPalindrome (0.00s)
word_test.go:28: IsPalindrome("été") = false
--- FAIL: TestCanalPalindrome (0.00s)
word_test.go:35: IsPalindrome("A man, a plan, a canal: Panama") = false
FAIL
FAIL gopl.io/ch11/word1 0.014s
It’s good practice to write the test first and observe that it triggers the same failure described by the user’s bug report. Only then can we be confident that whatever fix we come up with addresses the right problem.
As a bonus, running go test is usually quicker than manually going through the steps described in the bug report, allowing us to iterate more rapidly. If the test suite contains many slow tests, we may make even faster progress if we’re selective about which ones we run.
The -v flag prints the name and execution time of each test in the package:
$ go test -v
=== RUN TestPalindrome
--- PASS: TestPalindrome (0.00s)
=== RUN TestNonPalindrome
--- PASS: TestNonPalindrome (0.00s)
=== RUN TestFrenchPalindrome
--- FAIL: TestFrenchPalindrome (0.00s)
word_test.go:28: IsPalindrome("été") = false
=== RUN TestCanalPalindrome
--- FAIL: TestCanalPalindrome (0.00s)
word_test.go:35: IsPalindrome("A man, a plan, a canal: Panama") = false
FAIL
exit status 1
FAIL gopl.io/ch11/word1 0.017s
and the -run flag, whose argument is a regular expression, causes go test to run only those tests whose function name matches the pattern:
$ go test -v -run="French|Canal"
=== RUN TestFrenchPalindrome
--- FAIL: TestFrenchPalindrome (0.00s)
word_test.go:28: IsPalindrome("été") = false
=== RUN TestCanalPalindrome
--- FAIL: TestCanalPalindrome (0.00s)
word_test.go:35: IsPalindrome("A man, a plan, a canal: Panama") = false
FAIL
exit status 1
FAIL gopl.io/ch11/word1 0.014s
Of course, once we’ve gotten the selected tests to pass, we should invoke go test with no flags to run the entire test suite one last time before we commit the change.
Now our task is to fix the bugs. A quick investigation reveals the cause of the first bug to be IsPalindrome’s use of byte sequences, not rune sequences, so that non-ASCII characters such as the é in "été" confuse it. The second bug arises from not ignoring spaces, punctuation, and letter case.
Chastened, we rewrite the function more carefully:
gopl.io/ch11/word2
// Package word provides utilities for word games.
package word
import "unicode"
// IsPalindrome reports whether s reads the same forward and backward.
// Letter case is ignored, as are non-letters.
func IsPalindrome(s string) bool {
var letters []rune
for _, r := range s {
if unicode.IsLetter(r) {
letters = append(letters, unicode.ToLower(r))
}
}
for i := range letters {
if letters[i] != letters[len(letters)-1-i] {
return false
}
}
return true
}
We also write a more comprehensive set of test cases that combines all the previous ones and a number of new ones into a table.
func TestIsPalindrome(t *testing.T) {
var tests = []struct {
input string
want bool
}{
{"", true},
{"a", true},
{"aa", true},
{"ab", false},
{"kayak", true},
{"detartrated", true},
{"A man, a plan, a canal: Panama", true},
{"Evil I did dwell; lewd did I live.", true},
{"Able was I ere I saw Elba", true},
{"été", true},
{"Et se resservir, ivresse reste.", true},
{"palindrome", false}, // non-palindrome
{"desserts", false}, // semi-palindrome
}
for _, test := range tests {
if got := IsPalindrome(test.input); got != test.want {
t.Errorf("IsPalindrome(%q) = %v", test.input, got)
}
}
}
Our new tests pass:
$ go test gopl.io/ch11/word2
ok gopl.io/ch11/word2 0.015s
This style of table-driven testing is very common in Go. It is straightforward to add new table entries as needed, and since the assertion logic is not duplicated, we can invest more effort in producing a good error message.
The output of a failing test does not include the entire stack trace at the moment of the call to t.Errorf. Nor does t.Errorf cause a panic or stop the execution of the test, unlike assertion failures in many test frameworks for other languages. Tests are independent of each other. If an early entry in the table causes the test to fail, later table entries will still be checked, and thus we may learn about multiple failures during a single run.
When we really must stop a test function, perhaps because some initialization code failed or to prevent a failure already reported from causing a confusing cascade of others, we use t.Fatal or t.Fatalf. These must be called from the same goroutine as the Test function, not from another one created during the test.
Test failure messages are usually of the form "f(x) = y, want z", where f(x) explains the attempted operation and its input, y is the actual result, and z the expected result. Where convenient, as in our palindrome example, actual Go syntax is used for the f(x) part. Displaying x is particularly important in a table-driven test, since a given assertion is executed many times with different values. Avoid boilerplate and redundant information. When testing a boolean function such as IsPalindrome, omit the want z part since it adds no information. If x, y, or z is lengthy, print a concise summary of the relevant parts instead. The author of a test should strive to help the programmer who must diagnose a test failure.
Exercise 11.1: Write tests for the charcount program in Section 4.3.
Exercise 11.2: Write a set of tests for IntSet (§6.5) that checks that its behavior after each operation is equivalent to a set based on built-in maps. Save your implementation for benchmarking in Exercise 11.7.
11.2.1 Randomized Testing
Table-driven tests are convenient for checking that a function works on inputs carefully selected to exercise interesting cases in the logic. Another approach, randomized testing, explores a broader range of inputs by constructing inputs at random.
How do we know what output to expect from our function, given a random input? There are two strategies. The first is to write an alternative implementation of the function that uses a less efficient but simpler and clearer algorithm, and check that both implementations give the same result. The second is to create input values according to a pattern so that we know what output to expect.
The example below uses the second approach: the randomPalindrome function generates words that are known to be palindromes by construction.
import "math/rand"
// randomPalindrome returns a palindrome whose length and contents
// are derived from the pseudo-random number generator rng.
func randomPalindrome(rng *rand.Rand) string {
n := rng.Intn(25) // random length up to 24
runes := make([]rune, n)
for i := 0; i < (n+1)/2; i++ {
r := rune(rng.Intn(0x1000)) // random rune up to '\u0999'
runes[i] = r
runes[n-1-i] = r
}
return string(runes)
}
func TestRandomPalindromes(t *testing.T) {
// Initialize a pseudo-random number generator.
seed := time.Now().UTC().UnixNano()
t.Logf("Random seed: %d", seed)
rng := rand.New(rand.NewSource(seed))
for i := 0; i < 1000; i++ {
p := randomPalindrome(rng)
if !IsPalindrome(p) {
t.Errorf("IsPalindrome(%q) = false", p)
}
}
}
Since randomized tests are nondeterministic, it is critical that the log of the failing test record sufficient information to reproduce the failure. In our example, the input p to IsPalindrome tells us all we need to know, but for functions that accept more complex inputs, it may be simpler to log the seed of the pseudo-random number generator (as we do above) than to dump the entire input data structure. Armed with that seed value, we can easily modify the test to replay the failure deterministically.
By using the current time as a source of randomness, the test will explore novel inputs each time it is run, over the entire course of its lifetime. This is especially valuable if your project uses an automated system to run all its tests periodically.
Exercise 11.3: TestRandomPalindromes only tests palindromes. Write a randomized test that generates and verifies non-palindromes.
Exercise 11.4: Modify randomPalindrome to exercise IsPalindrome’s handling of punctuation and spaces.
11.2.2 Testing a Command
The go test tool is useful for testing library packages, but with a little effort we can use it to test commands as well. A package named main ordinarily produces an executable program, but it can be imported as a library too.
Let’s write a test for the echo program of Section 2.3.2. We’ve split the program into two functions: echo does the real work, while main parses and reads the flag values and reports any errors returned by echo.
gopl.io/ch11/echo
// Echo prints its command-line arguments.
package main
import (
"flag"
"fmt"
"io"
"os"
"strings"
)
var (
n = flag.Bool("n", false, "omit trailing newline")
s = flag.String("s", " ", "separator")
)
var out io.Writer = os.Stdout // modified during testing
func main() {
flag.Parse()
if err := echo(!*n, *s, flag.Args()); err != nil {
fmt.Fprintf(os.Stderr, "echo: %v\n", err)
os.Exit(1)
}
}
func echo(newline bool, sep string, args []string) error {
fmt.Fprint(out, strings.Join(args, sep))
if newline {
fmt.Fprintln(out)
}
return nil
}
From the test, we will call echo with a variety of arguments and flag settings and check that it prints the correct output in each case, so we’ve added parameters to echo to reduce its dependence on global variables. That said, we’ve also introduced another global variable, out, theio.Writer to which the result will be written. By having echo write through this variable, not directly to os.Stdout, the tests can substitute a different Writer implementation that records what was written for later inspection. Here’s the test, in file echo_test.go:
package main
import (
"bytes"
"fmt"
"testing"
)
func TestEcho(t *testing.T) {
var tests = []struct {
newline bool
sep string
args []string
want string
}{
{true, "", []string{}, "\n"},
{false, "", []string{}, ""},
{true, "\t", []string{"one", "two", "three"}, "one\ttwo\tthree\n"},
{true, ",", []string{"a", "b", "c"}, "a,b,c\n"},
{false, ":", []string{"1", "2", "3"}, "1:2:3"},
}
for _, test := range tests {
descr := fmt.Sprintf("echo(%v, %q, %q)",
test.newline, test.sep, test.args)
out = new(bytes.Buffer) // captured output
if err := echo(test.newline, test.sep, test.args); err != nil {
t.Errorf("%s failed: %v", descr, err)
continue
}
got := out.(*bytes.Buffer).String()
if got != test.want {
t.Errorf("%s = %q, want %q", descr, got, test.want)
}
}
}
Notice that the test code is in the same package as the production code. Although the package name is main and it defines a main function, during testing this package acts as a library that exposes the function TestEcho to the test driver; its main function is ignored.
By organizing the test as a table, we can easily add new test cases. Let’s see what happens when the test fails, by adding this line to the table:
{true, ",", []string{"a", "b", "c"}, "a b c\n"}, // NOTE: wrong expectation!
go test prints
$ go test gopl.io/ch11/echo
--- FAIL: TestEcho (0.00s)
echo_test.go:31: echo(true, ",", ["a" "b" "c"]) = "a,b,c", want "a b c\n"
FAIL
FAIL gopl.io/ch11/echo 0.006s
The error message describes the attempted operation (using Go-like syntax), the actual behavior, and the expected behavior, in that order. With an informative error message such as this, you may have a pretty good idea about the root cause before you’ve even located the source code of the test.
It’s important that code being tested not call log.Fatal or os.Exit, since these will stop the process in its tracks; calling these functions should be regarded as the exclusive right of main. If something totally unexpected happens and a function panics, the test driver will recover, though the test will of course be considered a failure. Expected errors such as those resulting from bad user input, missing files, or improper configuration should be reported by returning a non-nil error value. Fortunately (though unfortunate as an illustration), our echo example is so simple that it will never return a non-nil error.
11.2.3 White-Box Testing
One way of categorizing tests is by the level of knowledge they require of the internal workings of the package under test. A black-box test assumes nothing about the package other than what is exposed by its API and specified by its documentation; the package’s internals are opaque. In contrast, a white-box test has privileged access to the internal functions and data structures of the package and can make observations and changes that an ordinary client cannot. For example, a white-box test can check that the invariants of the package’s data types are maintained after every operation. (The name white box is traditional, but clear box would be more accurate.)
The two approaches are complementary. Black-box tests are usually more robust, needing fewer updates as the software evolves. They also help the test author empathize with the client of the package and can reveal flaws in the API design. In contrast, white-box tests can provide more detailed coverage of the trickier parts of the implementation.
We’ve already seen examples of both kinds. TestIsPalindrome calls only the exported function IsPalindrome and is thus a black-box test. TestEcho calls the echo function and updates the global variable out, both of which are unexported, making it a white-box test.
While developing TestEcho, we modified the echo function to use the package-level variable out when writing its output, so that the test could replace the standard output with an alternative implementation that records the data for later inspection. Using the same technique, we can replace other parts of the production code with easy-to-test “fake” implementations. The advantage of fake implementations is that they can be simpler to configure, more predictable, more reliable, and easier to observe. They can also avoid undesirable side effects such as updating a production database or charging a credit card.
The code below shows the quota-checking logic in a web service that provides networked storage to users. When users exceed 90% of their quota, the system sends them a warning email.
gopl.io/ch11/storage1
package storage
import (
"fmt"
"log"
"net/smtp"
)
var usage = make(map[string]int64)
func bytesInUse(username string) int64 { return usage[username] }
// Email sender configuration.
// NOTE: never put passwords in source code!
const sender = "notifications@example.com"
const password = "correcthorsebatterystaple"
const hostname = "smtp.example.com"
const template = `Warning: you are using %d bytes of storage,
%d%% of your quota.`
func CheckQuota(username string) {
used := bytesInUse(username)
const quota = 1000000000 // 1GB
percent := 100 * used / quota
if percent < 90 {
return // OK
}
msg := fmt.Sprintf(template, used, percent)
auth := smtp.PlainAuth("", sender, password, hostname)
err := smtp.SendMail(hostname+":587", auth, sender,
[]string{username}, []byte(msg))
if err != nil {
log.Printf("smtp.SendMail(%s) failed: %s", username, err)
}
}
We’d like to test it, but we don’t want the test to send out real email. So we move the email logic into its own function and store that function in an unexported package-level variable, notifyUser.
gopl.io/ch11/storage2
var notifyUser = func(username, msg string) {
auth := smtp.PlainAuth("", sender, password, hostname)
err := smtp.SendMail(hostname+":587", auth, sender,
[]string{username}, []byte(msg))
if err != nil {
log.Printf("smtp.SendEmail(%s) failed: %s", username, err)
}
}
func CheckQuota(username string) {
used := bytesInUse(username)
const quota = 1000000000 // 1GB
percent := 100 * used / quota
if percent < 90 {
return // OK
}
msg := fmt.Sprintf(template, used, percent)
notifyUser(username, msg)
}
We can now write a test that substitutes a simple fake notification mechanism instead of sending real email. This one records the notified user and the contents of the message.
package storage
import (
"strings"
"testing"
)
func TestCheckQuotaNotifiesUser(t *testing.T) {
var notifiedUser, notifiedMsg string
notifyUser = func(user, msg string) {
notifiedUser, notifiedMsg = user, msg
}
const user = "joe@example.org"
usage[user]= 980000000 // simulate a 980MB-used condition
CheckQuota(user)
if notifiedUser == "" && notifiedMsg == "" {
t.Fatalf("notifyUser not called")
}
if notifiedUser != user {
t.Errorf("wrong user (%s) notified, want %s",
notifiedUser, user)
}
const wantSubstring = "98% of your quota"
if !strings.Contains(notifiedMsg, wantSubstring) {
t.Errorf("unexpected notification message <<%s>>, "+
"want substring %q", notifiedMsg, wantSubstring)
}
}
There’s one problem: after this test function has returned, CheckQuota no longer works as it should because it’s still using the test’s fake implementation of notifyUsers. (There is always a risk of this kind when updating global variables.) We must modify the test to restore the previous value so that subsequent tests observe no effect, and we must do this on all execution paths, including test failures and panics. This naturally suggests defer.
func TestCheckQuotaNotifiesUser(t *testing.T) {
// Save and restore original notifyUser.
saved := notifyUser
defer func() { notifyUser = saved }()
// Install the test's fake notifyUser.
var notifiedUser, notifiedMsg string
notifyUser = func(user, msg string) {
notifiedUser, notifiedMsg = user, msg
}
// ...rest of test...
}
This pattern can be used to temporarily save and restore all kinds of global variables, including command-line flags, debugging options, and performance parameters; to install and remove hooks that cause the production code to call some test code when something interesting happens; and to coax the production code into rare but important states, such as timeouts, errors, and even specific interleavings of concurrent activities.
Using global variables in this way is safe only because go test does not normally run multiple tests concurrently.
11.2.4 External Test Packages
Consider the packages net/url, which provides a URL parser, and net/http, which provides a web server and HTTP client library. As we might expect, the higher-level net/http depends on the lower-level net/url. However, one of the tests in net/url is an example demonstrating the interaction between URLs and the HTTP client library. In other words, a test of the lower-level package imports the higher-level package.

Figure 11.1. A test of net/url depends on net/http.
Declaring this test function in the net/url package would create a cycle in the package import graph, as depicted by the upwards arrow in Figure 11.1, but as we explained in Section 10.1, the Go specification forbids import cycles.
We resolve the problem by declaring the test function in an external test package, that is, in a file in the net/url directory whose package declaration reads package url_test. The extra suffix _test is a signal to go test that it should build an additional package containing just these files and run its tests. It may be helpful to think of this external test package as if it had the import path net/url_test, but it cannot be imported under this or any other name.
Because external tests live in a separate package, they may import helper packages that also depend on the package being tested; an in-package test cannot do this. In terms of the design layers, the external test package is logically higher up than both of the packages it depends upon, as shown in Figure 11.2.
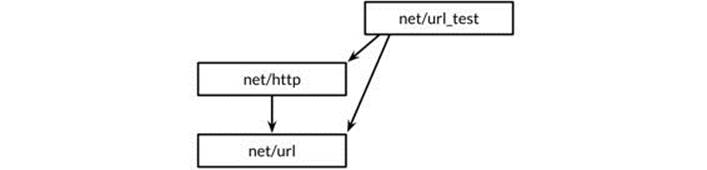
Figure 11.2. External test packages break dependency cycles.
By avoiding import cycles, external test packages allow tests, especially integration tests (which test the interaction of several components), to import other packages freely, exactly as an application would.
We can use the go list tool to summarize which Go source files in a package directory are production code, in-package tests, and external tests. We’ll use the fmt package as an example. GoFiles is the list of files that contain the production code; these are the files that go build will include in your application:
$ go list -f={{.GoFiles}} fmt
[doc.go format.go print.go scan.go]
TestGoFiles is the list of files that also belong to the fmt package, but these files, whose names all end in _test.go, are included only when building tests:
$ go list -f={{.TestGoFiles}} fmt
[export_test.go]
The package’s tests would usually reside in these files, though unusually fmt has none; we’ll explain the purpose of export_test.go in a moment.
XTestGoFiles is the list of files that constitute the external test package, fmt_test, so these files must import the fmt package in order to use it. Again, they are included only during testing:
$ go list -f={{.XTestGoFiles}} fmt
[fmt_test.go scan_test.go stringer_test.go]
Sometimes an external test package may need privileged access to the internals of the package under test, if for example a white-box test must live in a separate package to avoid an import cycle. In such cases, we use a trick: we add declarations to an in-package _test.go file to expose the necessary internals to the external test. This file thus offers the test a “back door” to the package. If the source file exists only for this purpose and contains no tests itself, it is often called export_test.go.
For example, the implementation of the fmt package needs the functionality of unicode.IsSpace as part of fmt.Scanf. To avoid creating an undesirable dependency, fmt does not import the unicode package and its large tables of data; instead, it contains a simpler implementation, which it calls isSpace.
To ensure that the behaviors of fmt.isSpace and unicode.IsSpace do not drift apart, fmt prudently contains a test. It is an external test, and thus it cannot access isSpace directly, so fmt opens a back door to it by declaring an exported variable that holds the internal isSpacefunction. This is the entirety of the fmt package’s export_test.go file.
package fmt
var IsSpace = isSpace
This test file defines no tests; it just declares the exported symbol fmt.IsSpace for use by the external test. This trick can also be used whenever an external test needs to use some of the techniques of white-box testing.
11.2.5 Writing Effective Tests
Many newcomers to Go are surprised by the minimalism of Go’s testing framework. Other languages’ frameworks provide mechanisms for identifying test functions (often using reflection or metadata), hooks for performing “setup” and “teardown” operations before and after the tests run, and libraries of utility functions for asserting common predicates, comparing values, formatting error messages, and aborting a failed test (often using exceptions). Although these mechanisms can make tests very concise, the resulting tests often seem like they are written in a foreign language. Furthermore, although they may report PASS or FAIL correctly, their manner may be unfriendly to the unfortunate maintainer, with cryptic failure messages like "assert: 0 == 1" or page after page of stack traces.
Go’s attitude to testing stands in stark contrast. It expects test authors to do most of this work themselves, defining functions to avoid repetition, just as they would for ordinary programs. The process of testing is not one of rote form filling; a test has a user interface too, albeit one whose only users are also its maintainers. A good test does not explode on failure but prints a clear and succinct description of the symptom of the problem, and perhaps other relevant facts about the context. Ideally, the maintainer should not need to read the source code to decipher a test failure. A good test should not give up after one failure but should try to report several errors in a single run, since the pattern of failures may itself be revealing.
The assertion function below compares two values, constructs a generic error message, and stops the program. It’s easy to use and it’s correct, but when it fails, the error message is almost useless. It does not solve the hard problem of providing a good user interface.
import (
"fmt"
"strings"
"testing"
)
// A poor assertion function.
func assertEqual(x, y int) {
if x != y {
panic(fmt.Sprintf("%d != %d", x, y))
}
}
func TestSplit(t *testing.T) {
words := strings.Split("a:b:c", ":")
assertEqual(len(words), 3)
// ...
}
In this sense, assertion functions suffer from premature abstraction: by treating the failure of this particular test as a mere difference of two integers, we forfeit the opportunity to provide meaningful context. We can provide a better message by starting from the concrete details, as in the example below. Only once repetitive patterns emerge in a given test suite is it time to introduce abstractions.
func TestSplit(t *testing.T) {
s, sep := "a:b:c", ":"
words := strings.Split(s, sep)
if got, want := len(words), 3; got != want {
t.Errorf("Split(%q, %q) returned %d words, want %d",
s, sep, got, want)
}
// ...
}
Now the test reports the function that was called, its inputs, and the significance of the result; it explicitly identifies the actual value and the expectation; and it continues to execute even if this assertion should fail. Once we’ve written a test like this, the natural next step is often not to define a function to replace the entire if statement, but to execute the test in a loop in which s, sep, and want vary, like the table-driven test of IsPalindrome.
The previous example didn’t need any utility functions, but of course that shouldn’t stop us from introducing functions when they help make the code simpler. (We’ll look at one such utility function, reflect.DeepEqual, in Section 13.3.) The key to a good test is to start by implementing the concrete behavior that you want and only then use functions to simplify the code and eliminate repetition. Best results are rarely obtained by starting with a library of abstract, generic testing functions.
Exercise 11.5: Extend TestSplit to use a table of inputs and expected outputs.
11.2.6 Avoiding Brittle Tests
An application that often fails when it encounters new but valid inputs is called buggy; a test that spuriously fails when a sound change was made to the program is called brittle. Just as a buggy program frustrates its users, a brittle test exasperates its maintainers. The most brittle tests, which fail for almost any change to the production code, good or bad, are sometimes called change detector or status quo tests, and the time spent dealing with them can quickly deplete any benefit they once seemed to provide.
When a function under test produces a complex output such as a long string, an elaborate data structure, or a file, it’s tempting to check that the output is exactly equal to some “golden” value that was expected when the test was written. But as the program evolves, parts of the output will likely change, probably in good ways, but change nonetheless. And it’s not just the output; functions with complex inputs often break because the input used in a test is no longer valid.
The easiest way to avoid brittle tests is to check only the properties you care about. Test your program’s simpler and more stable interfaces in preference to its internal functions. Be selective in your assertions. Don’t check for exact string matches, for example, but look for relevant substrings that will remain unchanged as the program evolves. It’s often worth writing a substantial function to distill a complex output down to its essence so that assertions will be reliable. Even though that may seem like a lot of up-front effort, it can pay for itself quickly in time that would otherwise be spent fixing spuriously failing tests.
11.3 Coverage
By its nature, testing is never complete. As the influential computer scientist Edsger Dijkstra put it, “Testing shows the presence, not the absence of bugs.” No quantity of tests can ever prove a package free of bugs. At best, they increase our confidence that the package works well in a wide range of important scenarios.
The degree to which a test suite exercises the package under test is called the test’s coverage. Coverage can’t be quantified directly—the dynamics of all but the most trivial programs are beyond precise measurement—but there are heuristics that can help us direct our testing efforts to where they are more likely to be useful.
Statement coverage is the simplest and most widely used of these heuristics. The statement coverage of a test suite is the fraction of source statements that are executed at least once during the test. In this section, we’ll use Go’s cover tool, which is integrated into go test, to measure statement coverage and help identify obvious gaps in the tests.
The code below is a table-driven test for the expression evaluator we built back in Chapter 7:
gopl.io/ch7/eval
func TestCoverage(t *testing.T) {
var tests = []struct {
input string
env Env
want string // expected error from Parse/Check or result from Eval
}{
{"x % 2", nil, "unexpected '%'"},
{"!true", nil, "unexpected '!'"},
{"log(10)", nil, `unknown function "log"`},
{"sqrt(1, 2)", nil, "call to sqrt has 2 args, want 1"},
{"sqrt(A / pi)", Env{"A": 87616, "pi": math.Pi}, "167"},
{"pow(x, 3) + pow(y, 3)", Env{"x": 9, "y": 10}, "1729"},
{"5 / 9 * (F - 32)", Env{"F": -40}, "-40"},
}
for _, test := range tests {
expr, err := Parse(test.input)
if err == nil {
err = expr.Check(map[Var]bool{})
}
if err != nil {
if err.Error() != test.want {
t.Errorf("%s: got %q, want %q", test.input, err, test.want)
}
continue
}
got := fmt.Sprintf("%.6g", expr.Eval(test.env))
if got != test.want {
t.Errorf("%s: %v => %s, want %s",
test.input, test.env, got, test.want)
}
}
}
First, let’s check that the test passes:
$ go test -v -run=Coverage gopl.io/ch7/eval
=== RUN TestCoverage
--- PASS: TestCoverage (0.00s)
PASS
ok gopl.io/ch7/eval 0.011s
This command displays the usage message of the coverage tool:
$ go tool cover
Usage of 'go tool cover':
Given a coverage profile produced by 'go test':
go test -coverprofile=c.out
Open a web browser displaying annotated source code:
go tool cover -html=c.out
...
The go tool command runs one of the executables from the Go toolchain. These programs live in the directory $GOROOT/pkg/tool/${GOOS}_${GOARCH}. Thanks to go build, we rarely need to invoke them directly.
Now we run the test with the -coverprofile flag:
$ go test -run=Coverage -coverprofile=c.out gopl.io/ch7/eval
ok gopl.io/ch7/eval 0.032s coverage: 68.5% of statements
This flag enables the collection of coverage data by instrumenting the production code. That is, it modifies a copy of the source code so that before each block of statements is executed, a boolean variable is set, with one variable per block. Just before the modified program exits, it writes the value of each variable to the specified log file c.out and prints a summary of the fraction of statements that were executed. (If all you need is the summary, use go test -cover.)
If go test is run with the -covermode=count flag, the instrumentation for each block increments a counter instead of setting a boolean. The resulting log of execution counts of each block enables quantitative comparisons between “hotter” blocks, which are more frequently executed, and “colder” ones.
Having gathered the data, we run the cover tool, which processes the log, generates an HTML report, and opens it in a new browser window (Figure 11.3).
$ go tool cover -html=c.out
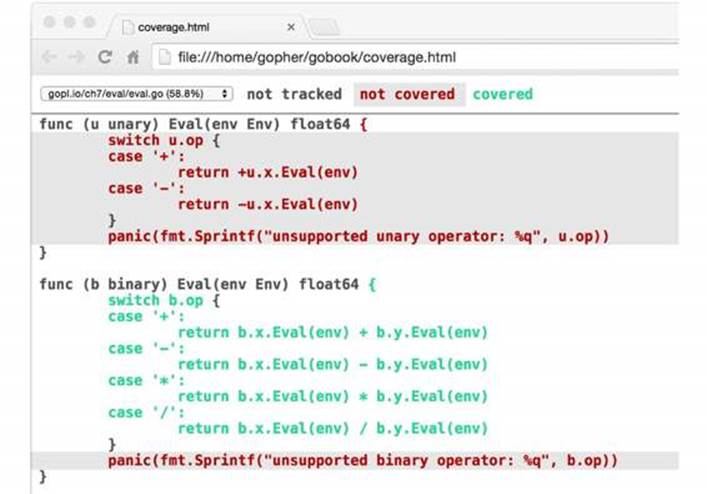
Figure 11.3. A coverage report.
Each statement is colored green if it was covered or red if it was not covered. For clarity, we’ve shaded the background of the red text. We can see immediately that none of our inputs exercised the unary operator Eval method. If we add this new test case to the table and re-run the previous two commands, the unary expression code becomes green:
{"-x * -x", eval.Env{"x": 2}, "4"}
The two panic statements remain red, however. This should not be surprising, because these statements are supposed to be unreachable.
Achieving 100% statement coverage sounds like a noble goal, but it is not usually feasible in practice, nor is it likely to be a good use of effort. Just because a statement is executed does not mean it is bug-free; statements containing complex expressions must be executed many times with different inputs to cover the interesting cases. Some statements, like the panic statements above, can never be reached. Others, such as those that handle esoteric errors, are hard to exercise but rarely reached in practice. Testing is fundamentally a pragmatic endeavor, a trade-off between the cost of writing tests and the cost of failures that could have been prevented by tests. Coverage tools can help identify the weakest spots, but devising good test cases demands the same rigorous thinking as programming in general.
11.4 Benchmark Functions
Benchmarking is the practice of measuring the performance of a program on a fixed workload. In Go, a benchmark function looks like a test function, but with the Benchmark prefix and a *testing.B parameter that provides most of the same methods as a *testing.T, plus a few extra related to performance measurement. It also exposes an integer field N, which specifies the number of times to perform the operation being measured.
Here’s a benchmark for IsPalindrome that calls it N times in a loop.
import "testing"
func BenchmarkIsPalindrome(b *testing.B) {
for i := 0; i < b.N; i++ {
IsPalindrome("A man, a plan, a canal: Panama")
}
}
We run it with the command below. Unlike tests, by default no benchmarks are run. The argument to the -bench flag selects which benchmarks to run. It is a regular expression matching the names of Benchmark functions, with a default value that matches none of them. The “.” pattern causes it to match all benchmarks in the word package, but since there’s only one, -bench=IsPalindrome would have been equivalent.
$ cd $GOPATH/src/gopl.io/ch11/word2
$ go test -bench=.
PASS
BenchmarkIsPalindrome-8 1000000 1035 ns/op
ok gopl.io/ch11/word2 2.179s
The benchmark name’s numeric suffix, 8 here, indicates the value of GOMAXPROCS, which is important for concurrent benchmarks.
The report tells us that each call to IsPalindrome took about 1.035 microseconds, averaged over 1,000,000 runs. Since the benchmark runner initially has no idea how long the operation takes, it makes some initial measurements using small values of N and then extrapolates to a value large enough for a stable timing measurement to be made.
The reason the loop is implemented by the benchmark function, and not by the calling code in the test driver, is so that the benchmark function has the opportunity to execute any necessary one-time setup code outside the loop without this adding to the measured time of each iteration. If this setup code is still perturbing the results, the testing.B parameter provides methods to stop, resume, and reset the timer, but these are rarely needed.
Now that we have a benchmark and tests, it’s easy to try out ideas for making the program faster. Perhaps the most obvious optimization is to make IsPalindrome’s second loop stop checking at the midpoint, to avoid doing each comparison twice:
n := len(letters)/2
for i := 0; i < n; i++ {
if letters[i] != letters[len(letters)-1-i] {
return false
}
}
return true
But as is often the case, an obvious optimization doesn’t always yield the expected benefit. This one delivered a mere 4% improvement in one experiment.
$ go test -bench=.
PASS
BenchmarkIsPalindrome-8 1000000 992 ns/op
ok gopl.io/ch11/word2 2.093s
Another idea is to pre-allocate a sufficiently large array for use by letters, rather than expand it by successive calls to append. Declaring letters as an array of the right size, like this,
letters := make([]rune, 0, len(s))
for _, r := range s {
if unicode.IsLetter(r) {
letters = append(letters, unicode.ToLower(r))
}
}
yields an improvement of nearly 35%, and the benchmark runner now reports the average over 2,000,000 iterations.
$ go test -bench=.
PASS
BenchmarkIsPalindrome-8 2000000 697 ns/op
ok gopl.io/ch11/word2 1.468s
As this example shows, the fastest program is often the one that makes the fewest memory allocations. The -benchmem command-line flag will include memory allocation statistics in its report. Here we compare the number of allocations before the optimization:
$ go test -bench=. -benchmem
PASS
BenchmarkIsPalindrome 1000000 1026 ns/op 304 B/op 4 allocs/op
and after it:
$ go test -bench=. -benchmem
PASS
BenchmarkIsPalindrome 2000000 807 ns/op 128 B/op 1 allocs/op
Consolidating the allocations in a single call to make eliminated 75% of the allocations and halved the quantity of allocated memory.
Benchmarks like this tell us the absolute time required for a given operation, but in many settings the interesting performance questions are about the relative timings of two different operations. For example, if a function takes 1ms to process 1,000 elements, how long will it take to process 10,000 or a million? Such comparisons reveal the asymptotic growth of the running time of the function. Another example: what is the best size for an I/O buffer? Benchmarks of application throughput over a range of sizes can help us choose the smallest buffer that delivers satisfactory performance. A third example: which algorithm performs best for a given job? Benchmarks that evaluate two different algorithms on the same input data can often show the strengths and weaknesses of each one on important or representative workloads.
Comparative benchmarks are just regular code. They typically take the form of a single parameterized function, called from several Benchmark functions with different values, like this:
func benchmark(b *testing.B, size int) { /* ... */ }
func Benchmark10(b *testing.B) { benchmark(b, 10) }
func Benchmark100(b *testing.B) { benchmark(b, 100) }
func Benchmark1000(b *testing.B) { benchmark(b, 1000) }
The parameter size, which specifies the size of the input, varies across benchmarks but is constant within each benchmark. Resist the temptation to use the parameter b.N as the input size. Unless you interpret it as an iteration count for a fixed-size input, the results of your benchmark will be meaningless.
Patterns revealed by comparative benchmarks are particularly useful during program design, but we don’t throw the benchmarks away when the program is working. As the program evolves, or its input grows, or it is deployed on new operating systems or processors with different characteristics, we can reuse those benchmarks to revisit design decisions.
Exercise 11.6: Write benchmarks to compare the PopCount implementation in Section 2.6.2 with your solutions to Exercise 2.4 and Exercise 2.5. At what point does the table-based approach break even?
Exercise 11.7: Write benchmarks for Add, UnionWith, and other methods of *IntSet (§6.5) using large pseudo-random inputs. How fast can you make these methods run? How does the choice of word size affect performance? How fast is IntSet compared to a set implementation based on the built-in map type?
11.5 Profiling
Benchmarks are useful for measuring the performance of specific operations, but when we’re trying to make a slow program faster, we often have no idea where to begin. Every programmer knows Donald Knuth’s aphorism about premature optimization, which appeared in “Structured Programming with go to Statements” in 1974. Although often misinterpreted to mean performance doesn’t matter, in its original context we can discern a different meaning:
There is no doubt that the grail of efficiency leads to abuse. Programmers waste enormous amounts of time thinking about, or worrying about, the speed of noncritical parts of their programs, and these attempts at efficiency actually have a strong negative impact when debugging and maintenance are considered. We should forget about small efficiencies, say about 97% of the time: premature optimization is the root of all evil.
Yet we should not pass up our opportunities in that critical 3%. A good programmer will not be lulled into complacency by such reasoning, he will be wise to look carefully at the critical code; but only after that code has been identified. It is often a mistake to make a priori judgments about what parts of a program are really critical, since the universal experience of programmers who have been using measurement tools has been that their intuitive guesses fail.
When we wish to look carefully at the speed of our programs, the best technique for identifying the critical code is profiling. Profiling is an automated approach to performance measurement based on sampling a number of profile events during execution, then extrapolating from them during a post-processing step; the resulting statistical summary is called a profile.
Go supports many kinds of profiling, each concerned with a different aspect of performance, but all of them involve recording a sequence of events of interest, each of which has an accompanying stack trace—the stack of function calls active at the moment of the event. The go test tool has built-in support for several kinds of profiling.
A CPU profile identifies the functions whose execution requires the most CPU time. The currently running thread on each CPU is interrupted periodically by the operating system every few milliseconds, with each interruption recording one profile event before normal execution resumes.
A heap profile identifies the statements responsible for allocating the most memory. The profiling library samples calls to the internal memory allocation routines so that on average, one profile event is recorded per 512KB of allocated memory.
A blocking profile identifies the operations responsible for blocking goroutines the longest, such as system calls, channel sends and receives, and acquisitions of locks. The profiling library records an event every time a goroutine is blocked by one of these operations.
Gathering a profile for code under test is as easy as enabling one of the flags below. Be careful when using more than one flag at a time, however: the machinery for gathering one kind of profile may skew the results of others.
$ go test -cpuprofile=cpu.out
$ go test -blockprofile=block.out
$ go test -memprofile=mem.out
It’s easy to add profiling support to non-test programs too, though the details of how we do that vary between short-lived command-line tools and long-running server applications. Profiling is especially useful in long-running applications, so the Go runtime’s profiling features can be enabled under programmer control using the runtime API.
Once we’ve gathered a profile, we need to analyze it using the pprof tool. This is a standard part of the Go distribution, but since it’s not an everyday tool, it’s accessed indirectly using go tool pprof. It has dozens of features and options, but basic use requires only two arguments, the executable that produced the profile and the profile log.
To make profiling efficient and to save space, the log does not include function names; instead, functions are identified by their addresses. This means that pprof needs the executable in order to make sense of the log. Although go test usually discards the test executable once the test is complete, when profiling is enabled it saves the executable as foo.test, where foo is the name of the tested package.
The commands below show how to gather and display a simple CPU profile. We’ve selected one of the benchmarks from the net/http package. It is usually better to profile specific benchmarks that have been constructed to be representative of workloads one cares about. Benchmarking test cases is almost never representative, which is why we disabled them by using the filter -run=NONE.
$ go test -run=NONE -bench=ClientServerParallelTLS64 \
-cpuprofile=cpu.log net/http
PASS
BenchmarkClientServerParallelTLS64-8 1000
3141325 ns/op 143010 B/op 1747 allocs/op
ok net/http 3.395s
$ go tool pprof -text -nodecount=10 ./http.test cpu.log
2570ms of 3590ms total (71.59%)
Dropped 129 nodes (cum <= 17.95ms)
Showing top 10 nodes out of 166 (cum >= 60ms)
flat flat% sum% cum cum%
1730ms 48.19% 48.19% 1750ms 48.75% crypto/elliptic.p256ReduceDegree
230ms 6.41% 54.60% 250ms 6.96% crypto/elliptic.p256Diff
120ms 3.34% 57.94% 120ms 3.34% math/big.addMulVVW
110ms 3.06% 61.00% 110ms 3.06% syscall.Syscall
90ms 2.51% 63.51% 1130ms 31.48% crypto/elliptic.p256Square
70ms 1.95% 65.46% 120ms 3.34% runtime.scanobject
60ms 1.67% 67.13% 830ms 23.12% crypto/elliptic.p256Mul
60ms 1.67% 68.80% 190ms 5.29% math/big.nat.montgomery
50ms 1.39% 70.19% 50ms 1.39% crypto/elliptic.p256ReduceCarry
50ms 1.39% 71.59% 60ms 1.67% crypto/elliptic.p256Sum
The -text flag specifies the output format, in this case, a textual table with one row per function, sorted so the “hottest” functions—those that consume the most CPU cycles—appear first. The -nodecount=10 flag limits the result to 10 rows. For gross performance problems, this textual format may be enough to pinpoint the cause.
This profile tells us that elliptic-curve cryptography is important to the performance of this particular HTTPS benchmark. By contrast, if a profile is dominated by memory allocation functions from the runtime package, reducing memory consumption may be a worthwhile optimization.
For more subtle problems, you may be better off using one of pprof’s graphical displays. These require GraphViz, which can be downloaded from www.graphviz.org. The -web flag then renders a directed graph of the functions of the program, annotated by their CPU profile numbers and colored to indicate the hottest functions.
We’ve only scratched the surface of Go’s profiling tools here. To find out more, read the “Profiling Go Programs” article on the Go Blog.
11.6 Example Functions
The third kind of function treated specially by go test is an example function, one whose name starts with Example. It has neither parameters nor results. Here’s an example function for IsPalindrome:
func ExampleIsPalindrome() {
fmt.Println(IsPalindrome("A man, a plan, a canal: Panama"))
fmt.Println(IsPalindrome("palindrome"))
// Output:
// true
// false
}
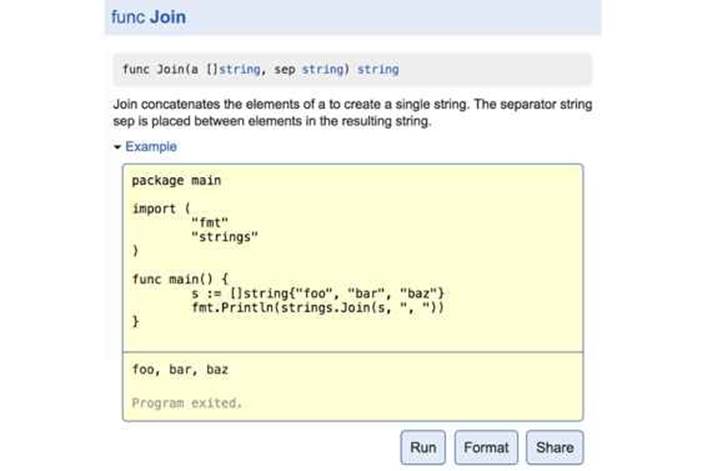
Figure 11.4. An interactive example of strings.Join in godoc.
Example functions serve three purposes. The primary one is documentation: a good example can be a more succinct or intuitive way to convey the behavior of a library function than its prose description, especially when used as a reminder or quick reference. An example can also demonstrate the interaction between several types and functions belonging to one API, whereas prose documentation must always be attached to one place, like a type or function declaration or the package as a whole. And unlike examples within comments, example functions are real Go code, subject to compile-time checking, so they don’t become stale as the code evolves.
Based on the suffix of the Example function, the web-based documentation server godoc associates example functions with the function or package they exemplify, so ExampleIsPalindrome would be shown with the documentation for the IsPalindrome function, and an example function called just Example would be associated with the word package as a whole.
The second purpose is that examples are executable tests run by go test. If the example function contains a final // Output: comment like the one above, the test driver will execute the function and check that what it printed to its standard output matches the text within the comment.
The third purpose of an example is hands-on experimentation. The godoc server at golang.org uses the Go Playground to let the user edit and run each example function from within a web browser, as shown in Figure 11.4. This is often the fastest way to get a feel for a particular function or language feature.
The final two chapters of the book examine the reflect and unsafe packages, which few Go programmers regularly use—and even fewer need to use. If you haven’t written any substantial Go programs yet, now would be a good time to do that.