Effective Ruby: 48 Specific Ways to Write Better Ruby (Effective Software Development Series) (2015)
2. Classes, Objects, and Modules
Object-oriented programming (OOP) is Ruby’s bread and butter. It’s often referred to as a purely object-oriented language because everything in Ruby is an object or can be turned into one, and I mean everything. From classes all the way down to numeric literals, Ruby exposes a consistent design that is found in few other languages.
Ruby’s object model was heavily influenced by Smalltalk and is probably a bit different than what you’re used to if you’re coming from languages like C++ or Java. The fact that classes are also objects is enough to send your mind into infinite recursion if you let it. Then there are some gotchas like subclasses not automatically initializing their superclasses and the ambiguity between defining variables and calling setter methods. This chapter tackles these issues and sorts them all out.
Additionally, I’ll explain the way Ruby actually builds inheritance hierarchies when you create classes, subclasses, and mix modules into them. Armed with this information you’ll be able to track down how methods are introduced into your class and where they came from. An important skill when dealing with large frameworks such as Ruby on Rails.
Understanding Ruby’s flavor of OOP will help you make better decisions and avoid long-term design mistakes. Especially when it comes to Ruby’s open and dynamic nature which can be used to create leaky abstractions and ignore encapsulation. Both of which will lead to maintenance nightmares and late night debugging sessions. Something which I’ll help you avoid.
Item 6: Know How Ruby Builds Inheritance Hierarchies
Question: When you send a message to an object, how does Ruby locate the appropriate method? Deceptively simple answer: Through the inheritance hierarchy. This answer is deceptive due to the way in which Ruby constructs inheritance hierarchies behind the scenes. This is one of those rare situations where Ruby goes out of its way to obscure what’s really going on under the covers, often leading to unnecessary confusion. The methods Ruby gives us for discovering which classes are part of a hierarchy don’t always tell the whole truth. Fortunately, the way the Ruby interpreter internally builds the inheritance hierarchy is both consistent and straight forward once you understand a few of its tricks.
Exploring how Ruby searches for methods will provide some good insight into the language’s implementation and give us the perfect environment for unraveling a class’s true inheritance hierarchy. Something you should definitely be aware of. The good news is that by the end of this item you’ll never again be surprised by Ruby’s object model. The bad news is that we’ll need to start by reviewing some classic OOP terminology and how a few general terms have specific definitions in Ruby. Bear with me for a few paragraphs.
• An object is a container of variables. These variables are referred to as instance variables and represent the state of an object. Each object has a special, internal variable that connects it to one and only one class. Because of this connection the object is said to be an instance of this class.
• A class is a container of methods and constants. The methods are referred to as instance methods and represent the behavior for all objects which are instances of the class.
Things get a little confusing and circular here because classes are themselves objects. Therefore each class is also a container of variables called class variables. Classes also have a connection with another class where their methods are kept. Technically, these methods are indistinguishable from instance methods but to avoid excessive confusion they are called class methods. In other words, classes are objects whose variables are called class variables and whose methods are called class methods. (Class objects can also have instance variables, but we’ll get to that in Item 15.)
• A superclass is a fancy name for the parent class in a class hierarchy. If class B inherits from class A, then A is the superclass of B. Classes have a special, internal variable to keep track of their superclass.
• A module is identical to a class in all respects but one. Like classes, modules are objects and therefore have a connection to a class which they are an instance of. While classes are connected to the Class class, modules are connected to the Module class. Internally, Ruby implements modules and classes using the same data structure but limits what you can do with them through their class methods (there’s no new method) and a more restrictive syntax.
• Modules have many uses in Ruby but for now we’re only concerned with how they contribute to the inheritance hierarchy. Although Ruby doesn’t directly support multiple inheritance, modules can be mixed into a class with the include method which has a similar effect.
• A singleton class is a much confused term for an anonymous and invisible class in the inheritance hierarchy.
• The confusion around these classes doesn’t necessarily come from their purpose as much as it does from their name. They are sometimes referred to as eigenclasses or metaclasses. Even the source code for the Ruby interpreter uses these terms interchangeable. In this book I’ll always refer to them as singleton classes since that’s the name you’ll see from within Ruby when working with the introspection methods such as singleton_class and singleton_methods.
Singleton classes play an important role in Ruby, such as providing a place to store class methods and methods included from modules. Unlike other classes, they’re created dynamically on an as needed basis by Ruby itself. They also come with restrictions. For example, you can’t create an instance of a singleton class. The only thing you really need to take away from this is that singleton classes are just regular classes which don’t have names and are subjected to a couple of limitations.
• A receiver is the object on which a method is invoked. For example, in “customer.name” the method invoked is name and the receiver is customer. While the name method is executing the self variable will be set to customer and any instance variables accessed will come from the customer object. Sometimes the receiver is omitted from method calls, in which case it’s implicitly set to whatever self is in the current context.
Phew! Now that we’re done with the vocabulary lesson we can explore Ruby’s object model and how it constructs inheritance hierarchies. Let’s start by putting together a small class hierarchy and use IRB to play with it:
class Person
def name
...
end
end
class Customer < Person
...
end
irb> customer = Customer.new
---> #<Customer>
irb> customer.class
---> Customer
irb> Customer.superclass
---> Person
irb> customer.respond_to?(:name)
---> true
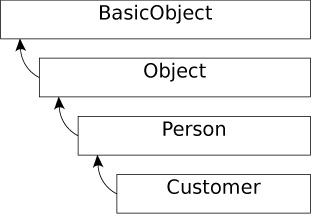
There’s nothing too surprising in this code. If you invoke the name method on the customer object the method lookup would happen exactly as you’d expect. First the Customer class would be checked for a matching instance method. It’s obviously not there so the search would continue up the inheritance hierarchy to the Person class where it would be found and executed. If the method hadn’t been found there Ruby would continue searching all the way up until it was either found or it hit the root class, BasicObject. You can see the complete hierarchy in Figure 2-1.
Figure 2-1. Customer Class Inheritance Hierarchy.
As you know, if the method lookup makes it all the way to the root of the class tree without finding a match it will restart the search where it began, this time looking for the method_missing method. Item 30 asks you to consider alternatives to defining your own method_missing method so we won’t consider it here. That is, other than to say there’s a default implementation of method_missing in the Kernel module which raises an exception to punish you for calling an undefined method.
Which reminds me, it’s time to take this simple example and throw a wrench into it:
module ThingsWithNames
def name
...
end
end
class Person
include(ThingsWithNames)
end
irb> Person.superclass
---> Object
irb> customer = Customer.new
---> #<Customer>
irb> customer.respond_to?(:name)
---> true
I’ve taken the name method out of the Person class and moved it into a module which is then included into the Person class. Instances of the Customer class still respond to the name method as you’d expect, but why? Clearly the ThingsWithNames module isn’t in the inheritance hierarchy because the superclass of Person is still Object, or is it? As it turns out this is where Ruby starts to lie to you and where we need to talk about singleton classes a bit more.
When you use the include method to mix in a module Ruby is doing something very sneaky behind the scenes. It creates a singleton class and inserts it into the class hierarchy. This anonymous and invisible class is linked to the module so they share instance methods and constants. In the case of the Person class, when it includes the ThingsWithNames module, Ruby creates a singleton class and silently inserts it as the superclass of Person. “But calling the superclass method on Person returns Object, not ThingsWithNames,” you say. Yep, and for good reason, the singleton class is anonymous and invisible so both the superclass and class methods skip over it. Therefore a more accurate class hierarchy needs to include modules too. And that’s exactly what Figure 2-2 contains.
Figure 2-2. Customer Class Inheritance Hierarchy With Modules.
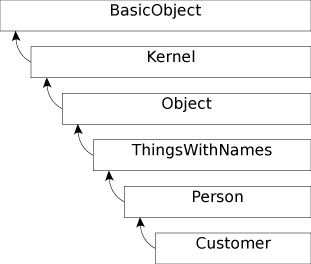
As each module is included into a class it is inserted into the hierarchy immediately above the including class in a last in, first out (LIFO) manner. Everything is connected through the superclass variable like a singly linked list. The net result is that when Ruby is searching for a method it will visit each module in reverse order, most recently included first. An important point to take away from this is that modules can never override methods from the class which includes them. Since modules are inserted above the including class Ruby always checks the class before moving upward. (Okay, this isn’t entirely true. Be sure to read Item 35 to see how the prepend method in Ruby 2.0 complicates this.)
Now that you’re comfortable with the interaction between modules and singleton classes it’s my duty to shake things up and introduce yet another weird (but lovely) wrench in the works:
customer = Customer.new
def customer.name
"Leonard"
end
If you haven’t seen this syntax before it can be a little confusing at first. But it’s pretty straight forward. The code above defines a method which exists only for this one object, customer. This specific method cannot be called on any other object. How do you suppose Ruby implements that? If you’re pointing a finger at singleton classes you’d be correct. In fact, this method is called a singleton method. When Ruby executes this code it will create a singleton class, install the name method as an instance method, and then insert this anonymous class as the class of the customer object. Even though the class of the customer object is now a singleton class, the introspective class method in Ruby will skip over it and still return Customer. This obscures things for us but makes life easier for Ruby. When it searches for the name method it only needs to traverse the class hierarchy. No special logic is needed.
This should also shed some light on why these kinds of classes are known as singleton classes. Most classes service many objects. The Array class, for example, contains the methods for every array object used in your program. Singleton classes, on the other hand, only serve a single object.
With no more tricks up my sleeve I’m left with only class methods to describe. You’ll be pleasantly surprised to know that you already completely understand them. They’re another form of the singleton method which we just explored.
Notice that when you define a singleton method you specify an object (almost like it’s the receiver) which will be the owner of the method. When you define a class method you do the exact same thing by specifying the class object, either through the class’s name or more commonly by using the self variable. An object is an object after all, even if that object is a class. Therefore class methods are stored as instance methods on a singleton class. See for yourself:
class Customer < Person
def self.where_am_i?
...
end
end
irb> Customer.singleton_class.instance_methods(false)
---> [:where_am_i?]
irb> Customer.singleton_class.superclass
---> #<Class:Person>
In the end, when Ruby wants to look up a method, it only has to consider the inheritance hierarchy. This works for both instance methods and class methods. Once you understand how Ruby manipulates the inheritance hierarchy the process for looking up a method is pretty easy:
1. Get the class of the receiver, which may actually be a hidden singleton class. (Remember that you can’t actually do this from Ruby code because the class method skips over singleton classes. You’d have to go straight to the singleton_class method.)
2. Search the list of instance methods which are stored in the class. If the method is found stop searching and execute the method. Otherwise continue to step 3.
3. Move up the hierarchy to the superclass and repeat step 2. (Again, the superclass may actually be another singleton class. From within Ruby—the superclass method specifically—it would be invisible.)
4. Steps 2 and 3 are repeated until Ruby finds the method or reaches the top of the hierarchy.
5. When it reaches the top, Ruby starts back at step 1 with the original receiver, but this time looking for the method_missing method.
As you can see, when methods are stored in invisible singleton classes it’s not as straight forward to see the entire hierarchy from within Ruby code. You can, however, piece together the real picture using a handful of methods which Ruby provides for introspection purposes.
• The singleton_class method returns the singleton class for the receiver, creating it if it doesn’t already exist.
• The ancestors method returns an array of all the classes and modules that make up the inheritance hierarchy. It can only be called on classes or modules and skips over singleton classes.
• The included_modules method returns the same array as ancestors with the exception that all the classes have been filtered out.
Thankfully, you’ll rarely need to use these methods. Knowing how the inheritance hierarchy is constructed and searched internally is enough to clarify most situations. That said, Item 35 includes a few examples just in case.
Things to Remember
• To find a method Ruby only has to search up the class hierarchy. If it doesn’t find the method it’s looking for it starts the search again, trying to find the method_missing method.
• Including modules silently creates singleton classes which are inserted into the hierarchy above the including class.
• Singleton methods (class methods and per-object methods) are stored in singleton classes which are also inserted into the hierarchy.
Item 7: Be Aware of the Different Behaviors of super
Suppose you’ve written a class which inherits from a base class. This base class defines a method which, in the context of your class, doesn’t quite do everything you need it to. You’ve therefore decided to improve the method. But you don’t want to completely replace the existing method since it already performs 90% of the necessary heavy lifting. You also don’t want to change the base class because that would break other code. Ignoring the fact that composition might be a better choice than inheritance, you plow ahead and override the method. You wind up with something like this:
class Base
def m1 (x, y)
...
end
end
class Derived < Base
def m1 (x)
# How do you call Base.m1?
end
end
You’ve gotten yourself into a pickle. The big question is, how do you call the version of m1 that exists in the superclass? If you try calling m1 from the Derived class you’ll just go into infinite recursion. That’s not going to help much. This is where super comes in:
def m1 (x)
super(x, x)
...
end
Now we’re getting somewhere. This version of m1 uses super to invoke its parent’s copy of m1, the one from the Base class. In this case super sort of stands in for Base#m1. You can use super in any way that you’d use Base#m1directly. This includes passing whichever arguments you want to the Base copy of m1 through super. (Just as long as the target method accepts those arguments.) This creates a subtle illusion which can bite you if you’re not careful.
Even though super is used and acts like a method, it’s actually a language keyword. This difference is important because super changes its behavior based on something that is supposed to be optional in Ruby, parentheses. Seriously, think about that for a second, choosing to omit parentheses when using super changes the way it works. It’s even slightly worse than it sounds. To see how parentheses change things we’ll need to review the three ways that supercan be written:
• The first way of using super is the least surprising, it’s the way we’ve been using it so far. If you give super at least one argument then it acts like a regular Ruby method and the parentheses are optional. In this form, super passes along the exact arguments it was given to the target method.
• If no arguments are given and no parentheses are used super will act in a way that you might not expect. Used this way super will invoke the target method with all of the arguments which were given to the enclosing method. It also forwards along the method’s block if one is associated with it.
There are a couple of side effects with this form of super that you should watch out for. First, using super this way only works if the target method accepts the same number of arguments as the enclosing method. As an example, this wouldn’t be the case for the Base#m1 and Derived#m1 methods we looked at earlier. Trying to use super with no arguments in Derived#m1 would result in an ArgumentError exception. You’ll be bitten by the same exception if the overridden method doesn’t expect any arguments but the enclosing method does.
The second thing to watch out for has to do with the value of the arguments given to the overridden method. If you mutate one of the enclosing method’s arguments before calling super with no arguments, super will pass their current value to the target method, not their original values. This seems pretty reasonable but something you need to be aware of.
• When you don’t actually want to pass any arguments to the overridden method you need to write super with an empty set of parentheses, i.e. super(). This looks especially weird in Ruby. Even those of us who prefer to use parentheses don’t do so when calling a method with no arguments. This use of super seems unnatural but it’s the only way to call an overridden method with no arguments (and no block).
Here are the same rules from above expressed in code:
class SuperSilliness < SillyBase
def m1 (x, y)
super(1, 2) # Call with 1, 2.
super(x, y) # Call with x, y.
super x, y # Same as above.
super # Same as above.
super() # Call without arguments.
end
end
The next thing we need to concern ourselves with is how super goes about finding the overridden method. It would appear that super simply calls the superclass’s copy of the current method, but that’s an oversimplification. In reality super considers the entire inheritance hierarchy and follows the rules laid out in Item 6, but with a minor change. When you use super it searches for a method with the same name as the current method, just higher up in the inheritance hierarchy. Therefore it needs to start at the next level up and continue from there.
If you remember our study of the inheritance hierarchy you’ll know that the next level up might be a singleton class. This is great because it means that super can be used to access overridden methods from included modules. For example:
module CoolFeatures
def feature_a
...
end
end
class Vanilla
include(CoolFeatures)
def feature_a
...
super # CoolFeatures.feature_a
end
end
This example also points out a limitation when using super. If you want to reach a method which is defined in a superclass and an included module also defines a method with the same name, super won’t work. Obviously, super is going to stop at the first matching method it finds, which would be in the module, not the superclass. If you happen to run into this situation you’ve probably made a serious design error though. Consider using composition instead of inheritance.
Finally, the last thing I want to warn you about is how super interacts with method_missing. If you think about it, as long as you only ever use super in a method which has the same name as another method in the inheritance hierarchy it won’t involve method_missing. On the other hand, if you’re an especially sleepy driver or doing some sort of voodoo metaprogramming you might wind up with a call to super which eventually invokes method_missing. In that case you’ll be glad you read this section.
As with normal method lookup, if super can’t find the method it’s looking for it will call method_missing to report the error. As you’d expect, Ruby starts its search for method_missing with the class of the original receiver. All this is fine and good, we even get a useful error message from the resulting exception:
class SuperHappy
def laugh
super
...
end
end
irb> SuperHappy.new.laugh
NoMethodError: super: no superclass method `laugh' for #<SuperHappy>
Internally, Ruby tracks whether or not method_missing is being invoked due to a bad super call and provides an extra bit of information along with the exception. But this only works if Ruby doesn’t find any definition of method_missing in the inheritance hierarchy and therefore uses the default implementation. Once any class in the hierarchy defines a method_missing method you’ll lose this useful detail. There’s no way to get it back, even if you make it a point to call super from within your implementation of method_missing.
Furthermore, method_missing will be invoked with details about a method that actually exists, just in the wrong place. If the SuperHappy class above defined a method_missing method it would get invoked when we call laugh because that method tries to use super to call another copy of itself which doesn’t exist. And what’s the first argument to method_missing? That’s right, it’s the name of the missing method which in this case would be :laugh. But SuperHappydoes have a laugh method, confusing huh?
If you’re counting reasons to avoid defining a method_missing method make sure to write this one down too (along with those mentioned in Item 30). In this case the NoMethodError exception from the default implementation of method_missing is demonstrably better than anything we could do in our own method_missing.
Things to Remember
• When you override a method from the inheritance hierarchy the super keyword can be used to call the overridden method.
• Using super with no arguments and no parentheses is equivalent to passing it all of the arguments which were given to the enclosing method.
• If you want to use super without passing the overridden method any arguments, you must use empty parentheses, i.e. super().
• Defining a method_missing method will discard helpful information when a super call fails. See Item 30 for alternatives to method_missing.
Item 8: Invoke super When Initializing Sub-classes
Classes in Ruby don’t have traditional OOP-style constructors. If we’re interested in controlling the initial state of our objects we need to write a method named initialize and do any necessary work there. This method is called at the right time by Class::new just after a new object has been freshly allocated. If you don’t write your own initialize method your class will inherit the default implementation from the BasicObject class. It’s not all that useful though. In fact, it’s a completely empty method which doesn’t do anything at all. It’s merely there so Class::new has something to call if you don’t define your own. Fortunately, there are plenty of times when BasicObject#initialize will suit your needs just fine. However, when you do need to define an initialize method there’s a slight catch to be aware of.
It’s easy to forget that initialize is just a regular old private instance method and therefore it follows all the normal method lookup rules. For example, if you wanted you could define a reset method which simply called initialize to reset all instance variables to their initial states. The choice to treat initialize as a regular method comes with a surprising consequence, however. When you write an initialize method you also override all other definitions of initialize which are higher up in the inheritance hierarchy. If you’re used to a language which has official constructors you might expect that all copies in the hierarchy are chained together instead of overriding one another. That’s not the case in Ruby. Consider this:
class Parent
attr_accessor(:name)
def initialize
@name = "Howard"
end
end
class Child < Parent
attr_accessor(:grade)
def initialize
@grade = 8
end
end
Looking at Parent#initialize, it’s clear that if you create a new Parent object the @name instance variable will be initialized with a default value. It’s also clear from Child#initialize that creating a new Child object will set up a @grade instance variable. The potentially unclear question is whether creating a Child object would also result in @name being set. Playing with the code in IRB clears things up.
irb> adult = Parent.new
---> #<Parent @name="Howard">
irb> youngster = Child.new
---> #<Child @grade=8>
irb> youngster.name
---> nil
Ouch. Ruby doesn’t automatically call overridden methods, not even initialize. In this case the initialize method in the Parent class isn’t called when using Child::new because the Child class has its own initialize method which overrides the one from Parent. Rewriting these initialize methods to take arguments will make this even clearer.
class Parent
def initialize (name)
@name = name
end
end
class Child < Parent
def initialize (grade)
@grade = grade
end
end
Now you can see the dilemma. Ruby doesn’t provide a way for us to specify the relationship between an initialize method in a subclass and the one from its superclass. It therefore has no way of knowing how to automatically call initialize in a superclass and pass the correct arguments. So it doesn’t and leaves the task for us to do manually. This can be quite surprising for new Ruby programmers and easy to forget even for those with experience.
Since Ruby doesn’t initialize parent classes for us, how do we do it ourselves? The solution comes from the fact that initialize is just like any other overridden method. That is, we can use the general purpose super keyword to call a method with the same name higher up in the hierarchy.
class Child < Parent
def initialize (name, grade)
super(name) # Initialize Parent.
@grade = grade
end
end
irb> youngster = Child.new("Abigail", 8)
---> #<Child @name="Abigail", @grade=8>
irb> youngster.name
---> "Abigail"
What we loose in automatic construction behavior we gain in flexibility. Using super in the initialize methods of subclasses gives us fine grained control over how and when we initialize superclasses. Should the superclass be initialized before the subclass? Do we need to set some instance variables before initializing superclasses? We’re free to mix and match behaviors as we see fit. Just make sure you remember to use super and take a moment to review some of its quirks which are discussed in Item 7.
Before we wrap up here I should remind you that initialize isn’t the only way to set up a new object. Ruby lets us create copies of objects using the dup and clone methods. When you use one of these methods the newly created copy is given a chance to perform any special copying logic by defining an initialize_copy method. If you override the initialize_copy method from a superclass you’ll definitely want to use super to let it set itself up correctly.
Things to Remember
• Ruby doesn’t automatically call the initialize method in a superclass when creating objects from a subclass. Instead, normal method lookup rules apply to initialize and only the first matching copy is invoked.
• When writing an initialize method for a class which explicitly uses inheritance, use super to initialize the parent class. The same rule applies when you define an initialize_copy method.
Item 9: Be Alert for Ruby’s Most Vexing Parse
When it comes to method naming rules, Ruby gives us a lot of freedom. While not as liberal as languages such as Lisp, Ruby does let us use one of three non-alphanumeric characters at the end of method names: “?”, “!”, and “=”. Two of those characters are purely aesthetic but one of them has special internal meaning to Ruby.
As you know, tacking a question mark on the end of a method name doesn’t change anything about the method nor does it make Ruby treat it any differently. It’s merely a naming convention adopted by Ruby programmers to indicate that a method returns a Boolean value. (Or what Ruby considers to be a Boolean value. See Item 1 for details.) This naming convention isn’t enforced and methods ending in “?” can still return whatever value they want. The exclamation point is similar, if not just a bit more vague. It usually means that the method will mutate the receiver but can also warn you about a potentially harmful action. Both are loose guidelines that Ruby programmers tend to follow. Ending a method name with an equal sign, on the other hand, is something entirely different.
Appending “=” to the end of a method’s name turns it into a setter method and allows you to invoke that method with some nifty syntax. Typically such methods take a single argument, update some internal state, and return their argument. This means that setter methods can also be used as lvalues (the left-hand side of an assignment).
class SetMe
def initialize
@value = 0
end
def value # "Getter"
@value
end
def value= (x) # "Setter"
@value = x
end
end
irb> x = SetMe.new
---> #<SetMe @value=0>
irb> x.value = 1 # Call setter.
---> 1
irb> x
---> #<SetMe @value=1>
Even though “=” is technically part of the method’s name, Ruby lets us place whitespace between it and the rest of the name. It looks like variable assignment but it’s actually just a plain old method call. You can see this more clearly when you add parentheses and remove the whitespace.
irb> x.value=(1)
---> 1
You may have never defined one of these setter methods by hand but most assuredly you’ve done it indirectly. That’s because Ruby has helper methods that write them for us. Both attr_writer and attr_accessor define setter methods which are exactly like the value= example above. They add a little bit of indirection which is why I bring them up. As long as you remember what these helper methods do, and the advice that follows, you’ll steer clear of any trouble.
Speaking of trouble, we need to consider the ambiguity between assignment and setters. Because setter method invocation looks just like variable assignment it’s easy to confuse the two, even for experienced Ruby programmers. Consider this:
class Counter
attr_accessor(:counter)
def initialize
counter = 0
end
...
end
It’s not unreasonable to assume that the body of the initialize method is calling the counter= method, and it’s an assumption that a lot of people make. It’s not correct of course, it’s just a simple variable assignment. The initializemethod creates a new local variable called counter, sets it to 0, and then throws away a reference to it when the scope ends. Not at all what we wanted to do but obvious when you think about it.
There’s a parsing ambiguity between variable assignment and calling setter methods. Ruby resolves it by requiring that setter methods be called with an explicit receiver. In order to invoke a setter method instead of creating a variable you need to prepend a receiver to the method name. Therefore, to call the counter= method from within an instance method you need to use self as the receiver.
class Counter
attr_accessor(:counter)
def initialize
self.counter = 0
end
...
end
With self used as the receiver Ruby will parse our code correctly and invoke the counter= setter method instead of creating a new variable. You might think that you could avoid using self if you invoked the method with no whitespace and used parentheses (i.e. counter=(0)) but that doesn’t work either. We’re stuck with using self as an explicit receiver. Which leads to another problem.
Programmers bitten by this parsing rule tend to overcompensate by littering their code with unnecessary self receivers. While there’s nothing technically wrong with putting self in front of every method call, it sure is ugly. It’s a matter of taste for sure, but one which is fairly universal among Ruby programmers. See if you can spot the unnecessary uses of self in the following code:
class Name
attr_accessor(:first, :last)
def initialize (first, last)
self.first = first
self.last = last
end
def full
self.first + " " + self.last
end
end
Clearly the full method is using self redundantly. With no setter methods involved you can safely remove the use of self and rely on some simple parsing rules. When Ruby comes across an identifier like first or last it checks to see if there’s a variable in the current scope with a matching name. When it doesn’t find one it tries to look up the identifier as a method. In the case of the two attributes from the Name class, Ruby finds the getter methods defined by the earlier use of attr_accessor. Here’s another version of the full method which does the same thing as before but with less noise:
def full
first + " " + last
end
There should be no doubt in your mind at this point that setter methods are a special kind of animal. If you don’t want any surprises then you need to remember to call them with a receiver. But don’t let that fool you into thinking that all methods need receivers, especially when called from within instances methods. For every other type of method Ruby will automatically use self as the receiver if the method call is missing it.
Things to Remember
• Setter methods can only be called with an explicit receiver. Without a receiver they will be parsed as variable assignments.
• When invoking a setter method from within an instance method use self as the receiver.
• You don’t need to use an explicit receiver when calling non-setter methods. In other words, don’t litter self all over your code.
Item 10: Prefer Struct to Hash for Structured Data
Hash tables are very useful, general-purpose data structures which are employed heavily by Ruby programmers. The Hash class provides a simple interface for working with hash tables and is such a deep part of Ruby that, like arrays, it has its own dedicated syntax for creating new instances. When it comes to working with key-value pairs, Hash is definitely the go to class.
In fact, Ruby programmers use hashes all the time. Even method keyword arguments are implemented with the Hash class and a pinch of syntactic sugar. They’re so general that hashes can be used to emulate many other types such as arrays, sets, and even basic objects. When working with structured data in an OOP language we often have better choices than hashes, and Ruby is no exception. Let’s look at a typical use of the Hash class and then consider replacing it with something more appropriate.
Say you’re interested in exploring annual weather data from a local weather station. Armed with a CSV file from the National Oceanic and Atmospheric Administration (NOAA) you plan to load the data into an array and play around with it. Each row in the CSV file contains temperature statistics for a single month. You’ve decided to extract the interesting columns from each row and store them in a Hash. Consider this:
require('csv')
class AnnualWeather
def initialize (file_name)
@readings = []
CSV.foreach(file_name, headers: true) do |row|
@readings << {
:date => Date.parse(row[2]),
:high => row[10].to_f,
:low => row[11].to_f,
}
end
end
end
There’s nothing out of the ordinary here. Each row read from the CSV file is transformed into a hash which is then inserted into an array. After the initialize method is complete you’ll have an array of uniform hashes, that is, all of the hashes will have the same keys but different values. Essentially this array of hashes represents a collection of objects, except that you can’t access their attributes though getter methods. You have to use the hash index operator instead. This might be a minor issue but it’s one which will have an impact on the AnnualWeather class’ interface.
You shouldn’t allow this array of hashes to leak through the public interface. That’s because the keys for each hash are an internal implementation detail. Without class-level documentation, other programmers would have to read the entire definition of the initialize method in order to know which keys are populated with which CSV columns. It might not be much of a burden when initialize is the only method setting keys but as the class matures this might not be the case anymore. This is a weakness when using hashes to emulate objects and one which isn’t limited to the public interface.
Every time you want to work with these hashes internally you will need to go back to the initialize method to remind yourself which keys are available. Again, as long as the keys are set in a single method the burden is fairly low. Let’s consider a situation where you’re tempted to create a new key. Each month in the @readings array has high and low temperatures. You’d like to know the mean temperature of the year which means you’ll also need to know the mean temperature for each month.
def mean
return 0.0 if @readings.size.zero?
total = @readings.reduce(0.0) do |sum, reading|
sum + (reading[:high] + reading[:low]) / 2.0
end
total / @readings.size.to_f
end
Calculating the mean temperature for each month is pretty simple. Even so, it would be better if each object in the @readings array responded to a mean method so you could abstract away the logic. It’s possible to shoehorn such a method onto each of the hashes but at that point it should be clear that you’ve pushed the limits of this design. (We’re not working with JavaScript after all.)
Using hashes to stand in for really simple classes tends to happen a lot in Ruby. Sometimes it’s completely fine but more often than not we really should be creating dedicated types for these sort of objects. If you’re lazy like me, the thought of creating a new class for something so simple seems like an unnecessary chore. Fortunately, that’s exactly what the Struct class is for.
On the surface, using the Struct class is a lot like creating a new struct type in C++. However, if you dig deeper you’ll see that it’s actually more similar to a class generator than a data structure. Using Struct is simple and only requires a call to the Struct::new method with a list of attributes. The return value from this method is virtually identical to a new class which has getter and setter methods for each of the attributes. This new class also has an initialize method which accepts initial values for each of the attributes and sets them accordingly.
To replace the hashes we’ve been using so far we only need to make some minor changes to the initialize method.
class AnnualWeather
# Create a new struct to hold reading data.
Reading = Struct.new(:date, :high, :low)
def initialize (file_name)
@readings = []
CSV.foreach(file_name, headers: true) do |row|
@readings << Reading.new(Date.parse(row[2]),
row[10].to_f,
row[11].to_f)
end
end
end
As you can see, it’s common practice to assign the return value from the Struct::new method to a constant. This allows you to treat the constant like a class and create objects from it. This single line of code also makes it clear which methods you can expect objects of this new class to respond to. That’s already a big improvement over the individual hashes. Let’s see how this change affects the mean method:
def mean
return 0.0 if @readings.size.zero?
total = @readings.reduce(0.0) do |sum, reading|
sum + (reading.high + reading.low) / 2.0
end
total / @readings.size.to_f
end
The existing mean method required few changes but now has a much better OOP feel to it. Accessing the high and low attributes through getter methods has a subtle side effect too. Typos in attribute names will now raise a NoMethodError exception. The same isn’t the case when using hashes. Attempting to access an invalid key in a hash doesn’t raise an exception but instead returns nil. This usually means that you’ll wind up with a more obscure TypeError exception later in the code. Another improvement with Struct is that we can now do something which we wanted to do earlier, define a mean method for each month.
The Struct class is more powerful than it might first appear. In addition to a list of attributes, the Struct::new method can optionally take a block which is then evaluated in the context of the new class. That’s a mouthful but it means we can define instance and class methods inside the block. For example, here’s how you’d define the mean method:
Reading = Struct.new(:date, :high, :low) do
def mean
(high + low) / 2.0
end
end
For those times when it seems too heavy-handed to create a new class, Struct can be very useful. And unlike a bunch of unrelated yet uniform hashes, Struct lets you define instance and class methods. That’s perfect for when you need to add a few simple behaviors to these otherwise boring objects. They’re also properly typed with their own public interface making them more suitable for users of the AnnualWeather class. The reservations I had before about exposing an array of hashes through the AnnualWeather interface has been resolved, opening the way to an attr_reader for the @readings array. I’d say that’s an all around improvement.
Things to Remember
• When dealing with structured data which doesn’t quite justify a new class prefer using Struct to Hash.
• Assign the return value of Struct::new to a constant and treat that constant like a class.
Item 11: Create Namespaces by Nesting Code in Modules
Imagine you’re working on an application for ordering custom notebooks (the old fashion paper kind). Customers can choose among many binding styles such as metal spirals or the more traditional glue. You decide to create a class to represent binding styles and all the options that go along with them. Unfortunately, things don’t seem to be working as planned. What’s wrong with the following class definition?
class Binding
def initialize (style, options={})
@style = style
@options = options
end
end
At first glance everything seems to be correct. There are no syntax errors, yet if you were to play with this class in IRB you’d see that something is really wrong. While the code above appears to create a new class, that’s not actually what happens if you execute it. “If it doesn’t define a class what does this code do?” That’s a mighty fine question.
As you know, classes in Ruby are mutable, you can add and replace methods at any time. The syntax for defining a class is the same syntax which is used to modify one. In this case it just so happens that the class name you wanted to use has already been taken. Binding is a class which is part of the Ruby core library. Instead of defining a new class the code above reopens and modifies an existing class. Not exactly what you had in mind.
Any nontrivial application is going to run into this problem sooner or later. It’s an even bigger problem for library authors. What happens if more than one library defines the same class? How can you use both of the libraries at the same time? Thankfully, nearly every modern general purpose programming language has a solution to this problem, including Ruby. The way we isolate our names from one another is done with a process called namespacing.
Namespaces are a way to qualify a constant so it becomes unique. At the most basic level namespaces let you create new scopes where you can define constants that would otherwise conflict with one another. Since class and module names are both constants, namespaces can be used to isolate them as well.
All of the core Ruby classes are said to be in the “global” namespace. We’ll see what this actually means a bit later, but for now it’s enough to say that each of these class names can be used without any sort of qualification. In other words, if you fire up IRB and type Array, you mean “the Array class in the global namespace.” When you define a class without specifying a namespace you are placing that class into the global namespace. At the same time you’re running the risk of clashing with an existing name.
Creating a new class and placing it into a custom namespace is as easy as nesting the class definition inside a module:
module Notebooks
class Binding
...
end
end
Nesting the definition inside a module makes the Binding class distinct from, and avoids any confusion with, the core class of the same name. To reference this new class you need to include the module’s name along with the “class path separator” which is two colons:
style = Notebooks::Binding.new
Using modules to create namespaces isn’t limited to protecting classes, this technique can be used to place other constants and module functions inside a namespace as well. You can also nest modules within other modules to create arbitrarily deep namespaces. This is helpful in large applications and libraries as a way to keep code compartmentalized and modular.
When using namespaces it’s common practice is to mirror the namespace within the directory structure of the project on the file system. For example, under this scheme the class above would be found in the bindings.rb file located in a notebooks directory. In other words, the Notebooks::Bindings name maps to the notebooks/bindings.rb file.
Sometimes nesting classes in modules is cumbersome and causes unnecessary indentation. There’s an alternative syntax for creating classes inside a namespace. It only works if the namespace already exists, that is, the module which creates the namespace was previously defined. In this form you use the module name and class path separator directly in the class definition:
class Notebooks::Binding
...
end
Typically you’d use this style of class definition by first defining the namespacing module in a main source file and then load all remaining source files. But watch out, attempting to use this syntax without first defining the namespace will result in a NameError exception. This is the exception Ruby raises if it can’t find a referenced constant. Nesting constants inside one another adds some complexity to how you qualify the constants in your program but understanding how Ruby searches for them will clear things up.
Ruby uses two techniques for finding constants. First it examines the current lexical scope and all of the enclosing lexical scopes. (We’ll explore lexical scopes shortly.) If the constant can’t be found there Ruby searches the inheritance hierarchy. This is why you can use a constant defined in a superclass from within a subclass. As we’ll see later, this is also why we can use the so called “global” constants.
When dealing with namespaces we’re mostly concerned with lexical scopes, the actual nested locations where a constant is defined or referenced. They’re easier to see than read about so consider the following:
module SuperDumbCrypto
KEY = "password123"
class Encrypt
def initialize (key=KEY)
...
end
end
end
The module definition creates a lexical scope. Since the KEY constant and the Encrypt class are both defined in the same lexical scope the initialize method can use the KEY constant without qualifying it (i.e. giving the full class path to the constant). It’s important to understand that the lexical scope is different than the namespace created by the module. It has to do with the physical location where the constants are defined and used. If we change things up a bit you can see the difference:
module SuperDumbCrypto
KEY = "password123"
end
class SuperDumbCrypto::Encrypt
def initialize (key=KEY) # raises NameError
...
end
end
This time a namespace and a lexical scope are created with the module definition, but immediately after creating the KEY constant both are closed. The class is defined in the correct namespace but it doesn’t share the same lexical scope as the KEY constant and therefore can’t use it unqualified. This code raises a NameError exception because Ruby can’t find the KEY constant in the lexical scope or through the inheritance hierarchy. The fix is simple, just qualify the constant:
class SuperDumbCrypto::Encrypt
def initialize (key=SuperDumbCrypto::KEY)
...
end
end
It might seem a bit weird but that’s how it works my friend. Even stranger still, now that the constant is fully qualified it’s actually found through the inheritance hierarchy and not the lexical scope. The SuperDumbCrypto constant can be considered a global constant, but as it turns out, Ruby doesn’t actually have a global namespace. Instead all top-level constants are stored inside the Object class. Since almost everything in Ruby inherits from Object it can find top-level constants through the inherits hierarchy. And that explains why Ruby looks in two different places: the current lexical scope and the inheritance hierarch.
There’s one last way you can get stuck when using namespaces. Consider this:
module Cluster
class Array
def initialize (n)
@disks = Array.new(n) {|i| "disk#{i}"}
# Oops, wrong Array! SystemStackError!
end
end
end
The code above defines a Cluster::Array class which needs to use the top-level Array class. The lookup rules for constants say, that in this context, an unqualified Array constant means Cluster::Array, which isn’t what we want. The solution is to fully qualify the Array constant. Since it’s a top-level constant and we know those are kept in the Object class, the fully qualified constant name would be Object::Array. This looks a bit strange, so Ruby lets us abbreviate at it as ::Array. The following code works as expected:
module Cluster
class Array
def initialize (n)
@disks = ::Array.new(n) {|i| "disk#{i}"}
end
end
end
While namespacing adds a bit of complexity—particularly for unqualified constants—the feature is well worth the cost. Any nontrivial Ruby project is bound to be using them, especially libraries which are packaged as a Ruby Gem. Such libraries are expected to place all their constants under a namespace which matches the library name. Place nice with others, create and use namespaces.
Things to Remember
• Use modules to create namespaces by nesting definitions inside them.
• Mirror your namespace structure and your directory structure.
• Use “::” to fully qualify a top-level constant when its use would be ambiguous (e.g. ::Array).
Item 12: Understand the Different Flavors of Equality
Take a look at the following IRB session and ask yourself: Why does the equal? method return a different answer than the “==” operator?
irb> "foo" == "foo"
---> true
irb> "foo".equal?("foo")
---> false
As it turns out, there are actually four different ways in Ruby to check if objects are equal to one another. Sometimes the various methods overlap and compare the same way, but as you can see from above, that’s not always the case. Depending on the comparison method and the objects involved, you can get surprising results. They won’t be surprising much longer, however.
It might seem like having four different ways to compare objects for equality is a bit of an overkill. For most objects that’s certainly true and all four methods end up doing the same thing. But some give us several flavors of equality which often have subtle (and not so subtle) differences. For example, the various classes which represent numbers silently convert to one another when compared using the “==” operator:
irb> 1 == 1.0
---> true
Each time you define a class you inherit the four different equality testing methods. Understanding how they’re expected to work is important if you want to override any of them. This is especially useful if you plan on implementing the full range of comparison operators as discussed in Item 13. We’ll start with an easy one, the method that you’re supposed to leave alone.
It may have surprised you in the example above when the equal? method didn’t return the same result as the “==” operator. Obviously they’re testing two different things. I would venture so far as to say that equal? is misnamed. Instead of comparing two objects based on their contents or values it’s actually checking to see if the two objects are the exact same object. That is, do they both have the same object_id. (Internally, the implementation of equal?checks to see if the two objects are both pointers to the same chuck of memory.)
Even though the two strings above have identical contents, they’re not the exact same object. They’re two different objects that just happen to have the same characters. Each time Ruby evaluates a string literal it allocates a brand new String object, even if the same exact string already exists somewhere else in memory. Of course, that’s what you want to happen. You wouldn’t want to mutate a string only to find out that you’ve accidentally mutated every other string in your program which has the same contents. (If you’re left wishing for copy-on-write strings you’re not alone. Ruby 2.1, however, has immutable string literals which share memory with other, identical strings. See Item 47 for details.)
An important point about the equal? method is that its behavior should be the same for all objects. That is, you shouldn’t override this method and give it a different implementation. Several existing classes have come to rely on how this method works and changing it is sure to break things in strange ways. If you want to compare objects then using equal? probably isn’t the method you want to use anyways. More often than not you’re interested in the “==” operator.
When comparing objects, “==” does what you think it’s going to do, and sometimes pleasantly surprises you. While each class is free to redefine “==”, the agreed upon behavior is that it will return true if two objects represent the same value. That explains the earlier string comparison and the test between 1 and 1.0. (Which, by the way, are represented by two different classes, Fixnum and Float.) This is probably more inline with what you would consider to be a comparison of equality.
If you don’t write your own implementation of “==” you’ll inherit the default implementation which does same thing as the equal? method. This probably isn’t very useful behavior. Obviously some objects should be considered equal even if they’re not stored in the same memory location. Instead, you want the “==” operator to consider the contents of the objects being compared. Maybe it’s as simple as comparing object attributes, record IDs, or delegating the comparison to another object. Either way, the “==” operator should be smarter than the equal? method. But resist the temptation to define “==” directly.
Item 13 explains how you can get “==” (and other operators) for free by defining the “<=>” operator and mixing in the Comparable module. If you’re interested in defining ordering operators like “>” you should definitely consider the advice in that item.
The next method on our equality tour is ambiguously named and a bit obscure. Nevertheless, it’s quite important. The eql? method is heavily used by the Hash class when comparing objects used as keys. You don’t want to insert the same key in a hash more than once and defining a reasonable eql? method gets you halfway there. We’ll look at the other half shortly.
By default eql? does the same comparison as equal?. That’s probably a bit stricter than what you want. If you define a class and use instances of that class as hash keys you’ll be in for a surprise if you don’t override the default implementation. Since the Hash class will be strictly comparing keys based on their object_id you’re likely to wind up with big hashes that don’t behave the way you’d expect them to. For example, consider the Color class below.
class Color
def initialize (name)
@name = name
end
end
Look what happens if we create two instances of that class with the exact same values, then attempt to use them as hash keys:
irb> a = Color.new("pink")
---> #<Color @name="pink">
irb> b = Color.new("pink")
---> #<Color @name="pink">
irb> {a => "like", b => "love"}
---> {#<Color @name="pink">=>"like", #<Color @name="pink">=>"love"}
Without knowing about the eql? method you’d probably expect the final hash to only have one key, not two. In order to get the hash to collapse both keys into one we need to define an eql? method along with another important method, hash. When objects are used as keys the Hash class needs to compute where in the data structure the object will reside. It does this by calling the hash method on the key object. Two objects which represent the same key should always return the same value from the hash method. But it’s also okay if dissimilar objects return the same hash value. That is, they don’t have to be unique. When this happens it’s called a collision and is resolved by further comparing the key objects with eql?. Objects which have the same hash value and result in true when compared with eql? are consider to be the same key.
Therefore, if we want two similar Color objects to represent the same hash key we need to implement the hash method and the eql? method. For such a simple class we’ll just manually delegate both to the @name attribute:
class Color
attr_reader(:name)
def initialize (name)
@name = name
end
def hash
name.hash
end
def eql? (other)
name.eql?(other.name)
end
end
irb> a = Color.new("pink")
---> #<Color @name="pink">
irb> b = Color.new("pink")
---> #<Color @name="pink">
irb> {a => "like", b => "love"}
---> {#<Color @name="pink">=>"love"}
In most situations you probably want to implement the “<=>” operator as described in Item 13, then simply make eql? an alias for “==”. “Why even bother having an eql? method if it’s just going to be an alias for the equality operator?” That’s a fair question and let me answer it by reminding you of the type conversion done by the “==” operator in the numeric classes. Look again at how “==” and eql? differ for them.
irb> 3 == 3.0
---> true
irb> 3.eql?(3.0)
---> false
irb> {3 => "I'm Three!"}[3.0]
---> nil
It might be fine to consider 1 equal to 1.0 when using the “==” operator but not when using the eql? method, and hence we have both. When defining your own classes you’ll have to decide how objects compare with one another when used as hash keys. If you choose to implement a sloppy version of the “==” operator you’ll need to define a stricter version of the eql? method. Otherwise alias eql? to “==”. I said it earlier but it’s worth repeating, be aware that if don’t define eql? you’ll pick up the default implementation which uses the same logic as the equal? method.
Finally, let’s take a look at an operator that you use all the time, maybe without even realizing it, the case equality operator. This operator is written with three equal signs (“===”) but it’s most often used indirectly, through the caseexpression. See for yourself:
case command
when "start" then start
when "stop", "quit" then stop
when /^cd\s+(.+)$/ then cd($1)
when Numeric then timer(command)
else raise(InvalidCommandError, command)
end
There are two different ways to use a case expression. The one we’re concerned with is chosen by Ruby when you supply an expression to the case keyword (the command variable above). This flavor of case uses the “===” operator to compare the given expression to each of the when clauses. It’s easier to see what’s going on if you remove the syntactic sugar and reveal the underlying if expression:
if "start" === command then start
elsif "stop" === command then stop
elsif "quit" === command then stop
elsif /^cd\s+(.+)$/ === command then cd($1)
elsif Numeric === command then timer(command)
else raise(InvalidCommandError, command)
end
Notice that the expression given to the case keyword always ends up as the right operand to “===”. That’s important. In Ruby the left operand becomes the receiver of the message and the right operand is the sole argument to the method call. It also means that operators in Ruby are not commutative because their behavior is decided by the left operand. Combining these two facts means you can rewrite the use of any operator as a normal method call:
irb> 1 + 2
---> 3
irb> 1.+(2)
---> 3
What does this have to do with the case equality operator? Well for one thing it’s important to know which object will wind up being the receiver. Knowing that the expression given to a when clause becomes the left operand to the “===” operator—and thus the receiver—tells you which implementation of the operator you’re dealing with. Not surprisingly, Ruby core classes have very useful variants of the case equality operator.
The default implementation of “===” is rather boring and passes its operands on to “==”. This is the version you’ll inherit in your classes. Things get interesting, however, when you look at classes like Regexp. The Regexp class defines a “===” operator which returns true if its argument is a string which matches the receiver (the regular expression). You have to use the regular expression as the left operand otherwise you won’t be using the “===” implementation from the Regexp class.
irb> /er/ === "Tyler" # Regexp#===
---> true
irb> "Tyler" === /er/ # String#===
---> false
Class and modules also get into the act with class method versions of the “===” operator. They all share a common implementation which returns true if the right operand is an instance of the left operand. It’s basically an operator version of the is_a? method with the receiver and argument reversed. This gives us the ability to use class and module names as arguments to the when clause. It’s good to know how this works if you strip away the case syntax. Consider the similarities between is_a? and “===”:
irb> [1,2,3].is_a?(Array)
---> true
irb> [1,2,3] === Array # Array#===
---> false
irb> Array === [1,2,3] # Array::===
---> true
It’s not very likely that you’ll need to define the “===” operator directly since the default implementation from Object is sufficient and can be found through inheritance. Still, if you want your objects or classes to have special behavior when used as an argument to the when clause in a case expression you’ll know which operator to override. Just remember which operand becomes the receiver and which the argument.
Things to Remember
• Never override the equal? method. It’s expected to strictly compare objects and return true only if they’re both pointers to the same object in memory (i.e. they both have the same object_id).
• The Hash class uses the eql? method to compare objects used as keys. The default implementation probably doesn’t do what you want. Follow the advice in Item 13 and then alias eql? to “==” and then write a sensible hash method.
• Use the “==” operator to test if two objects represent the same value. Some classes like those representing numbers have a sloppy equality operator which performs type conversion.
• case expressions use the “===” operator to test each when clause. The left operand is the argument given to when and the right operand is the argument given to case.
Item 13: Implement Comparison via “<=>” and the Comparable Module
Item 12 discusses the four ways in which objects can be tested for equality. If you’re also interested in sorting and comparing objects then you’ll need to go one step further and define the remaining comparison operators. Unlike with the equality operators, classes don’t inherit default implementations of the other comparison operators. Fortunately, Ruby gives us a shortcut, one we’ll dig into shortly.
First, let’s make this interesting and implement a class which has unusual ordering. As programmers we’re so used to software version numbers that the strange notation doesn’t seem to bother us much. But to the uninitiated it’s unusual indeed. How does one compare “10.10.3” to “10.9.8”? The answer is obvious to us, yet if we compared them using lexicographical ordering these version numbers would come out wrong. To get it right you need to consider each component separately. That’s exactly what we’ll do in our Version class.
To keep things reasonable let’s work with version numbers that only have three parts (just like those above). The first part is the major version number, then the minor version number, and finally the patch level. We’ll also only deal with well-formed version numbers so we can focus on comparing them. That makes it easy to parse a version string into its individual components.
class Version
attr_reader(:major, :minor, :patch)
def initialize (version)
@major, @minor, @patch =
version.split('.').map(&:to_i)
end
end
An important point that I want to repeat is that classes don’t automatically inherit comparison operators, with one exception. We’ll see later that you only really need to define one comparison operator, namely “<=>”. This particular operator is in fact inherited from Object, but the implementation we get for free is incomplete. See what happens if we try to sort an array of Version objects:
irb> vs = %w(1.0.0 1.11.1 1.9.0).map {|v| Version.new(v)}
---> [ #<Version @major=1, @minor=0, @patch=0>,
#<Version @major=1, @minor=11, @patch=1>,
#<Version @major=1, @minor=9, @patch=0> ]
irb> vs.sort
ArgumentError: comparison of Version with Version failed
That’s not very helpful. The default implementation of the “<=>” comparison operator is to blame here. It only considers whether two objects are equal to one another (using equal? and “===”) and doesn’t do the full range of test which our implementation will be required to do. If the two objects being compared aren’t equal to one another it returns nil, which signals to the sort method that the comparison is invalid. That’s okay, you can’t expect much from a general purpose implementation. Let’s write our own.
Implementing the full range of comparison operators is done in two steps. The hardest part is writing a sensible “<=>” operator (informally referred to as the “spaceship” operator). Remember that in Ruby binary operators turn into methods calls where the left operand is the receiver and the right operand is the method’s first and only argument. When writing a comparison operator it’s common practice to name the argument “other” since it will be the other object you’re comparing the receiver with.
The “<=>” operator can stand in for the full range of comparison operators due to the flexibility of its return value. It can return one of four values:
• When it doesn’t make sense to compare the receiver with the argument then the comparison operator should return nil. It’s possible that the argument is an instance of another class or even nil. For some classes it might be useful to convert the argument to the correct type before doing the comparison, but more often it’s best to return nil if the receiver and argument are not instances of the same class. That’s what we’ll do with the Version class.
• If the receiver is less than the argument, return -1. In other words, if comparing the left and right operands with “<” should return true then you want “<=>” to return negative one.
• If the receiver is greater than the argument, return 1. This comparison is for the “>” operator. If comparing the left and right operands with “>” should return true then make sure “<=>” returns positive one.
• If the receiver is equal to the argument, return 0. The “==” operator will return true only when “<=>” returns zero.
We want the comparison operator for the Version class to work the way it does in the numeric classes. As a matter of fact, we’ll be able to implement our version in terms of the numeric one. As you can see, it follows the rules from above:
irb> 9 <=> "9"
---> nil
irb> 9 <=> 10
---> -1
irb> 10 <=> 9
---> 1
irb> 10 <=> 10
---> 0
When writing the “<=>” operator it’s often possible to delegate the comparison to an object’s instance variables. The three variables in the Version class are all instances of Fixnum which has a working implementation of the “<=>” operator. This greatly simplifies our work. To compare version numbers we need to consider the instance variables in the receiver (left operand) and those from the argument (right operand) in order from major number to patch level. We can stop comparing as soon as one of the variables from the receiver doesn’t equal the corresponding variable from the argument. In other words, if the two versions we’re comparing have different major numbers we don’t need to compare the minor numbers or patch levels to know which is greater than the other. If both major numbers are the same, however, we’ll need to repeat the comparison with the minor numbers, and so on to the patch levels. When all components are equal to one another our comparison operator should return 0 to indicate the equality of both version objects. Otherwise we just need to return the result of using “<=>” for the first pair of variables which don’t match. Consider the Version implementation of the comparison operator:
def <=> (other)
return nil unless other.is_a?(Version)
[ major <=> other.major,
minor <=> other.minor,
patch <=> other.patch,
].detect {|n| !n.zero?} || 0
end
Each component is compared separately and the results are stored in an array. All we need to do then is find the first non-zero element in the array (the first pair of components which aren’t equal). If all components are equal to one another then detect will return nil, in which case the method will return 0. Now we can sort an array of Version objects.
irb> vs = %w(1.0.0 1.11.1 1.9.0).map {|v| Version.new(v)}
---> [ #<Version @major=1, @minor=0, @patch=0>,
#<Version @major=1, @minor=11, @patch=1>,
#<Version @major=1, @minor=9, @patch=0> ]
irb> vs.sort
---> [ #<Version @major=1, @minor=0, @patch=0>,
#<Version @major=1, @minor=9, @patch=0>,
#<Version @major=1, @minor=11, @patch=1> ]
There’s one more piece we’ll need add in order for Version objects to be fully comparable. Beyond just sorting, we want to be able to use operators such as “>” and “>=” with these objects. As a matter of fact, there are actually five other operators which make up the full set of ordering operators, they are: “<”, “<=”, “==”, “>”, and “>=”. You’ll be happy to hear that we don’t have to implement them by hand. Instead, all we need to do is include the Comparablemodule.
class Version
include(Comparable)
...
end
That’s it. Now we can use all of the ordering operators and even one additional helper method:
irb> a = Version.new('2.1.1')
---> #<Version @major=2, @minor=1, @patch=1>
irb> b = Version.new('2.10.3')
---> #<Version @major=2, @minor=10, @patch=3>
irb> [a > b, a >= b, a < b, a <= b, a == b]
---> [false, false, true, true, false]
irb> Version.new('2.8.0').between?(a, b)
---> true
There are few final considerations when using the Comparable module. First, for some classes you might want to implement your own copy of the “==” operator so it’s more fuzzy than the one from Comparable. A good example was presented in Item 12 which showed that the numeric classes perform type conversions before making comparisons. If you want similar behavior you’ll have to write your own equality operator or change the conditions that cause “<=>” to return 0. Which option you choose depends on how you want the other comparison operators to be affected.
If you want “>=”, “<=”, and “==” to return consistent answers you should change the way “<=>” calculates equality. If they don’t need to be consistent with one another you can simply override “==” and make it less strict than the other comparison operators. For most classes, however, you’ll probably want to make all the operators consistent with one another.
Finally, if you want instances of your class to be usable as hash keys you’ll need to do two more things. The eql? method should become an alias for “==”. The default implementation of eql? does the same thing as equal? which doesn’t make sense if you have a “<=>” operator defined for your class. The alias will make the Hash class use the “==” operator defined by the Comparable module.
You’ll also need to define a hash method which returns a Fixnum. To get the best performance from the Hash class you should ensure that different objects return different hash values. Below is a simple example implementation for the Version class. Writing an optimized version of hash is outside the scope of this book.
class Version
...
alias_method(:eql?, :==)
def hash
[major, minor, patch].hash
end
end
Things to Remember
• Implement object ordering by defining a “<=>” operator and including the Comparable module.
• The “<=>” operator should return nil if the left operand can’t be compared with the right.
• If you implement “<=>” for a class you should consider aliasing eql? to “==”, especially if you want instances to be usable as hash keys. In which case you should also override the hash method.
Item 14: Share Private State Through Protected Methods
One of the major tenets of OOP is encapsulation, the idea that an object’s internal implementation will be just that, internal and hidden from the outside. This allows us to build a firewall. On one side we have the public interface which we advertise for others to use. Hidden on the other side is the private implementation which we’re free to change without fear of breaking anything external to the class. In Ruby this barrier is more theoretical than concrete, but it’s there nonetheless.
Take instance variables for example, they’re private by default. Without resorting to any backdoor metaprogramming they’re only accessible from within instance methods. If you want to expose them to the outside world you need to define so-called accessor methods. This is good news, you can safely store internal state in instance variables without worrying that it will accidentally become part of the public interface. Most of the time this is all fine and good but there’s one situation where this sort of encapsulation gets in the way. Sometimes one object needs to access the internal state of another. Consider this:
class Widget
def overlapping? (other)
x1, y1 = @screen_x, @screen_y
x2, y2 = other.instance_eval {[@screen_x, @screen_y]}
...
end
end
The Widget#overlapping? method checks to see if the receiver and another object overlap one another on the screen. The public interface for the Widget class doesn’t expose these screen coordinates, they’re an internal implementation detail. It would seem that our only alternative is to break the wall of encapsulation using some metaprogramming. This approach has drawbacks, however.
Usually, when designing classes with internal state, it’s a good idea to reduce the amount of code which accesses the state directly to the smallest number of methods possible. This makes it easier to test and reduces the amount of breakage when things change. Hiding state behind private methods also facilitates optimizations such as memoization (see Item 48). It’s better for maintainability if the Widget class keeps the screen coordinates private, even to the overlapping? method. This might tempt you into writing a private method to act as a gateway for the screen coordinates, but that won’t work in this situation.
Private methods behave differently in Ruby than they do in other OOP languages. Ruby only places one restriction on private methods, they can’t be called with an explicit receiver. It doesn’t matter where you are in the inheritance hierarchy, as long as you don’t use a receiver you can call private methods defined in superclasses. What you can’t do, however, is call private methods on another object, even when the caller and receiver have the same class. If you make the screen coordinates accessible through a private method you still won’t be able to use them in the overlapping? method. Thankfully Ruby has an answer to this, protected methods.
Where private methods can’t be used with a receiver, protected methods can. There’s just one catch though, and it’s a slightly complicated one at that. The method being invoked on the receiver must also be in the inheritance hierarchy of the caller. As long as both the caller and receiver both share the same instance method through inheritance then the caller can invoke that method on the receiver. The caller and receiver don’t necessarily have to be instances of the same class, but they both have to share the superclass where the method is defined.
For the Widget class, we can define a method which exposes the private screen coordinates without making them part of the public interface. By declaring this method as protected we maintain encapsulation while allowing the overlapping? method to access both its own coordinates and those of the other widget. No metaprogramming black magic required.
class Widget
def overlapping? (other)
x1, y1 = screen_coordinates
x2, y2 = other.screen_coordinates
...
end
protected
def screen_coordinates
[@screen_x, @screen_y]
end
end
This is exactly what protected methods were designed for, sharing private information between related classes.
Things to Remember
• Share private state through protected methods.
• Protected methods can only be called with an explicit receiver from objects of the same class or when they inherit the protected methods from a common superclass.
Item 15: Prefer Class Instance Variables to Class Variables
Ruby has two types of “at” variables, instance variables and class variables. Every object in a running Ruby application has its own private set of instance variables, you know, the ones whose names begin with “@”. Setting an instance variable in one object doesn’t affect variables in another. (Mutating a variable is a different story though, two objects sharing a reference to a third can certainly affect one another. See Item 16 for more detail.)
Class variables (those which begin with “@@”) are handled differently. Instead of being associated with a single object, they’re attached to a class and visible to all instances of that class. Setting a class variable in one object is immediately visible to another. Of course, this isn’t surprising, most object-oriented languages have these class-wide shared variables. What might be surprising, however, is how class variables and inheritance interact.
A common use for class variables—but certainly not the only use—is implementing the singleton pattern (not to be confused with Ruby singleton classes). Sometimes in larger applications you only want a single instance of a particular class and you want all of the code to access the same instance. Take a configuration class for example. You’d like to parse your configuration file once and then share it with the entire application, but without having to pass it around as an argument to every method that might need it. Basically, the singleton pattern is a glorified global variable.
Setting aside concurrency for a moment, let’s write a class which implements the singleton pattern and from which we can derive other classes:
class Singleton
private_class_method(:new, :dup, :clone)
def self.instance
@@single ||= new
end
end
By their very definition singleton classes shouldn’t have more than one instance, so it’s pretty typical to make the new method private. This prevents anyone from creating a new object from the outside. We do the same thing with dupand clone to ensure copies of the one true instance can’t be made. The only way to access this official object is through the instance class method. Its job is to make sure new is only called once and it does this by storing the singleton object in a class variable named @@single. If that variable is nil then the instance method will call new and assign the result to @@single. Otherwise it simply returns the value of @@single. Let’s create two classes which inherit from the Singleton class so that they can use the same logic:
class Configuration < Singleton
...
end
class Database < Singleton
...
end
So far so good. An application using these classes now has a way to access a single configuration object and a single database connection from anywhere in the code. Now, I wouldn’t be writing this if there wasn’t a problem, so let’s see what happens when we actually try to use these classes:
irb> Configuration.instance
---> #<Configuration>
irb> Database.instance
---> #<Configuration>
Oops. What happened? Obviously both classes are sharing the same class variable. When Configuration::instance is called the @@single variable is nil and therefore new is called and the resulting objected is cached. When Database::instance is called @@single already has a value (the configuration object) and that’s returned instead of calling new. The fix is easy but requires a little explanation.
Class variables in a superclass are shared between it and all of its subclasses. To make things a little messier, any instance of one of these classes can access the shared class variables and modify them. Instance methods and class methods all share the same class variables, making them practically as undesirable as global variables. Instances should therefore stick to working with instance variables. And therein lies the solution. Classes are objects, so they have instance variables too. Every class is a unique object and has its own private set of instance variables which can only be accessed from its class methods. Changing the @@single variable from a class variable to a class instance variable fixes the problem:
def self.instance
@single ||= new
end
irb> Configuration.instance
---> #<Configuration>
irb> Database.instance
---> #<Database>
If you haven’t seen instance variables inside a class method before it can be a bit strange. It’s also easy to confuse them with instance variables from one of their objects. But they do in fact belong to the class itself. This is made clearer if you remember that class methods are really an illusion. Because classes are objects, what we call “class methods” are actually instance methods for the class object. Class methods exist in name only.
Besides breaking the sharing relationship between a class and its subclasses, class instance variables also provide more encapsulation. While class variables (“@@”) can be accessed and modified directly from any instance or class method, class instance variables (“@”) are only accessible at the class definition level or from inside class methods. Therefore, instances of the class and other external code can only access these variables if you provide class methods for that purpose (e.g. Singleton::instance). You get to protect them just like any other instance variable, exposing access to them as necessary.
Oh, by the way, earlier I asked that we set aside any issues relating to concurrency. That’s because class variables and class instance variables have all of the same problems that global variables do. If your application has multiple threads of control then altering any of these variables without using a mutex isn’t safe. Thankfully, the Singleton module which is part of the Ruby standard library correctly implements the singleton pattern in a thread-safe way. Using it is simple:
require('singleton')
class Configuration
include(Singleton)
end
Things to Remember
• Prefer class instance variables to class variables.
• Classes are objects and therefore have their own private set of instance variables.
All materials on the site are licensed Creative Commons Attribution-Sharealike 3.0 Unported CC BY-SA 3.0 & GNU Free Documentation License (GFDL)
If you are the copyright holder of any material contained on our site and intend to remove it, please contact our site administrator for approval.
© 2016-2026 All site design rights belong to S.Y.A.