Pragmatic Enterprise Architecture (2014) Strategies to Transform Information Systems in the Era of Big Data
PART VI Operations Architecture
Abstract
This part is dedicated to the vast area of operations architecture, which involves all of the areas of specialization associated with one or more data centers of different sizes with potentially different purposes, such as being dedicated to disaster recovery, reporting and analytics, or some other purpose, which can also encompass an entire data center in the cloud. The specializations briefly addressed in this section are only the fundamental areas of specialization that a large organization is likely to require for the period of time necessary to establish the principles, standards, and frameworks that guide activities involving these particular areas of technology.
Keywords
operations architecture
countries with restrictions
directory services architecture
job scheduling architecture
infrastructure applications architecture
infrastructure architecture
telephone video architecture
desktop architecture
application server architecture
database server architecture
operational utilities architecture
virtualization architecture
release management architecture
system recovery architecture
failover architecture
disaster recovery architecture
system performance architecture
technical services architecture
problem management architecture
monitoring alerts architecture
configuration management architecture
change management architecture
help desk architecture
service-level agreement architecture
network architecture
firewall architecture
file transfer architecture
directory services
job scheduling
infrastructure applications
operations
telephony video architecture
teleconferencing
video conferencing
multimedia technologies
telephone system
adapters
drivers
DLLs
print utilities
VMware
Citrix
recovery
no failover
cold failover
warm failover
hot failover
high availability
HA clustering
HA hot-cold
HA hot-warm
HA hot-hot
fail back
DR
business continuity architecture
helpdesk architecture
Big Data
BI reporting architecture
SLA
metrics
MTBF
MTTR
OLA
operating level agreement
LAN
local area network
MAN
metropolitan area network
WAN
wide area network
subnets
sub-networks
DMZ
FTP
SFTP
AS2
PGP
SSL
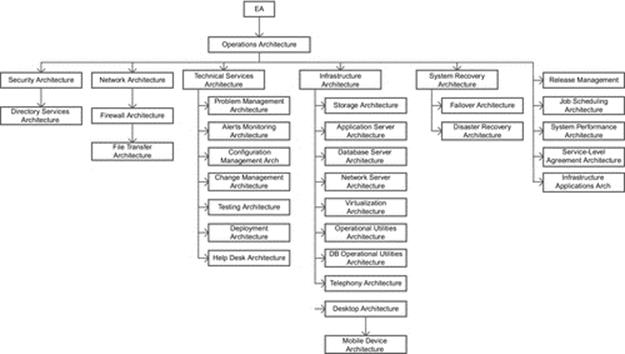
DIAGRAM Operations architecture overview.
6.1 Operations Architecture and Governance
A common global operating model for operations systems architecture and governance is one where there are three major regions each with a regional data center supporting an associated federation of local country data centers that must be maintained due to regulatory prohibitions on transmitting customer information outside the jurisdictional borders of those countries.
As of the publication of this book, the countries with restrictions already implemented include:
- Albania,
- Andorra,
- Argentina,
- Australia,
- Bosnia and Herzegovina,
- Canada,
- Chile,
- Croatia,
- all European Union (EU) member states,
- Hong Kong,
- Iceland,
- Israel,
- Japan,
- Liechtenstein,
- Macau,
- Macedonia,
- Mauritius,
- New Zealand,
- Norway,
- Paraguay,
- Peru,
- the Russian Federation,
- South Korea,
- Switzerland,
- Taiwan,
- Tunisia,
- United Arab Emirates (UAE),
- United States, and
- Uruguay.
The trend is abundantly clear as many other countries are also pursuing privacy legislation with many already in their legislative process, with none considering relaxation of their customer privacy restrictions.
As a result, going forward the frameworks for regional data centers will necessarily need to accommodate the need to support many in country data centers, with transfers of data that mask the categories of data that are restricted by each jurisdiction.
That said, regional data centers still play an important role that supports the enterprise. In fact, having regional data centers helps:
- provides support for shared services,
- addresses the different time zones,
- it mitigates a considerable part of the language differences and geographic differences, and
- lends itself to a general familiarity with cultural differences and sensitivities.
When regional and in country data centers are coordinated, they may make better use of global purchases, licensing, and services, although some services, such as power and communications, will always be dependent upon local providers and their associated in country infrastructures, and the many challenges associated with them.
The opportunities for standards and frameworks for operations architecture are applicable to in country data centers. If anything, the emergence of additional in country data centers increases the need for operations architecture standards and frameworks to help avoid doing things differently in each country across the globe.
The products, licenses, and services that generally do not have a local dependency, and can be standardized globally, include:
- directory services architecture,
- job scheduling architecture,
- infrastructure applications architecture,
- infrastructure architecture,
- telephone video architecture,
- desktop architecture,
- application server architecture,
- database server architecture,
- operational utilities architecture,
- virtualization architecture,
- release management architecture,
- system recovery architecture,
- failover architecture,
- disaster recovery architecture,
- system performance architecture,
- technical services architecture,
- problem management architecture,
- monitoring alerts architecture,
- configuration management architecture,
- change management architecture,
- help desk architecture,
- service-level agreement (SLA) architecture,
- network architecture,
- firewall architecture, and
- file transfer architecture.
As such, the role of an operations architecture subject matter expert requires a broad combination of knowledge and cumulative experience in operations and governance disciplines involving various degrees of the above mentioned areas of architecture.
We will now briefly touch upon a collection of operations architecture disciplines mostly just to define the scope of their responsibility.
6.1.1 Directory Services Architecture
Directory services architecture is a discipline that develops the standards and frameworks for the capabilities used to organize and manage access rights of business users and IT resources to the applications, files printers, networks, and servers of the enterprise.
Unlike the traditional approach which is department centric, the objective of the modern framework is to optimize maintainability of LDAP with the level of granularity to manage the groups of individuals and resources at the business capability level, as well as within specific roles within those business capabilities.
A well-architected directory services business capability is able to effect additions, removals, and changes in access rights across the organization in minutes with a centralized workflow without error, as opposed to weeks with unforeseen complications and errors.
To achieve this, standards and frameworks must be made consistent across the enterprise, often requiring a transition plan that begins by gaining an understanding of the blend of architectures and cultures of administration that exist across the various directory services repositories.
Similar to disaster recovery architecture, the items that must be inventoried include:
- business capabilities,
- applications,
- technologies,
- equipment that support those business capabilities,
- use cases for directory services, and
- services offered by directory services with their related request types.
As such, the role of a directory services architect requires a broad combination of knowledge and cumulative experience in developing standards and frameworks of a directory services capability in a large conglomerate; the challenges of directory services; common traditional architectures and cultures of administration; and the business capabilities, applications, and technologies of the company.
6.1.2 Job Scheduling Architecture
Job scheduling architecture is an architectural discipline within operations architecture and governance that is responsible for the standards and frameworks to support a unified, centrally administered job scheduling capability across all computing platforms within a data center.
It is also a discipline that assesses, plans for, and monitors the implementation of a uniform job scheduling framework that illustrates the health of operational activities and provides simulation capabilities for changes being introduced into the job stream and run book.
When evaluating the current state of a large enterprise, one may find that there are several disparate methods being used to schedule the execution of a job.
As examples, job can be started:
- manually, or
- automatically by job scheduling capabilities provided in
- applications,
- database management systems (i.e., a number of which are mini operating systems),
- online transaction processing systems (e.g., OLTPs, a number of which are mini operating systems),
- operating systems, or
- standalone job schedulers.
The use of more than one job scheduling product or more than one method of scheduling jobs creates additional complexity, cost, and risk. Operations staff and their backup staff must possess knowledge and experience for each brand of job scheduler, causing more redundancy in staff than is typically required, with additional challenges in rotating personnel.
In contrast, a centralized job scheduler is the only approach that provides an ability to coordinate activities across all platforms using automation. The high-end job schedulers have a number of advanced features, such as facilitating simulations to test the impact of proposed job scheduling changes and impact analysis for what-if scenarios.
The common architectural features that should be evaluated across job schedulers include the ability to support:
- the full set of operating system environment required for your company,
- workload planning,
- modeling,
- forecasting,
- a high degree of fault tolerance,
- Web-based consoles,
- storing and transferring scripts to target platforms,
- event driven scheduling to eliminate wait times as opposed to clock based,
- install agents on every platform to communicate back to the scheduler,
- flexible user operating system accounts to avoid having excessive access rights and privileges than is necessary,
- file events to be able to initiate a job at the creation of a file as opposed to polling,
- file transfer capability to retain control when a file transfer fails,
- role based security administration, and
- full development life cycle support to:
- develop,
- test,
- approve, and
- deploy changes.
6.1.3 Infrastructure Applications Architecture
Data center operations are so different than typical business applications and IT management applications that infrastructure applications architecture is best as a separate architectural discipline within operations architecture responsible for technology portfolio management, application portfolio management and application architecture for technologies, and applications that are specifically for the use within an operations environment. As a matter of fact, data center staff usually has a completely different culture. From what I’ve experienced, it is perhaps closer to the culture found working in a firehouse of a major city with a much higher degree of camaraderie and a detectably lower level of political correctness. These are real people that get right to the point without delay because they need to in order to keep their data center running. If you are thin skinned and intolerant of stress, OPS may not be the ideal career choice.
Unlike information systems applications, operations applications neither access business data nor support legal or regulatory reporting requirements, and as such, are best overseen by an individual with an extensive operations background.
As a result, applications that are operations based tend to be major technology purchases or applications that address gaps in operations automation to support any given operations capability.
While it is generally not acceptable for an operations area to have a software development capability, it should be noted that operations applications would not have access to business databases and business files, nor should they.
6.1.3.1 Infrastructure Architecture
Infrastructure architecture is responsible for the standards and frameworks for infrastructure specifications for automation systems and their components across all regional and in country data centers of the enterprise, including:
- production,
- failover,
- disaster recovery, and
- nonproduction environments to optimize the delivery of services for the best cost structure with flexibility and maintainability.
Many large companies outsource their data center’s hardware deployment and maintenance, while still retaining control over platform configurations to ensure the appropriate computing capacity to support the needs of the application systems in the various parts of their life cycle.
Note that you should always negotiate to retain control over the design of platform configurations. Of course the vendor will make sure that you will have to pay for whatever you select, but that is what will keep your folks from building computing platforms that will outperform HAL 9000.
Also, the fact that hardware deployment and maintenance may be outsourced does not in itself negate the need to manage infrastructure applications architecture. The vendor is your partner and improving the operational capabilities is just another role that must be negotiated in your outsourcing agreement.
The best outsourcing agreements are those that reward the vendor for implementing improvements in your operations. Just note that the only reasonable method to ensure verifiability of improvements is the appropriate identification and collection of metrics before and after.
6.1.3.2 Telephony Video Architecture
Telephony video architecture is responsible for the standards and frameworks involving the infrastructure and components across the globe involving:
- teleconferencing,
- video conferencing,
- internal and external company telephone systems, and
- multimedia technologies.
Deployment of telephony equipment for new hires is an ongoing process in every large organization. This architectural discipline has synergies with compliance architecture, particularly with regard to the records of telephony equipment and its potential for being involved in legal matters.
6.1.3.3 Desktop Architecture
Desktop architecture is responsible for the standards and frameworks involving the infrastructural components for desktop and portable computing across the globe involving:
- hardware,
- software, and
- accessories, including:
- virtualization components that may be required to support capabilities.
This includes the processes that establish, maintain, and decommission components efficiently across the enterprise, particularly while maintaining an accurate inventory of deployed components, their versions, and any applicable metadata.
Deployment of desktop equipment and the required refreshes for aging equipment is an ongoing process in every large company. This architectural discipline has synergies with data obfuscation architecture, particularly for the encryption of data held on the hard drives, and compliance architecture, particularly with regard to the decommissioning of equipment and its potential for being involved in records information management and legal holds.
6.1.3.4 Operational Utilities Architecture
Operational utilities architecture is an architectural discipline within infrastructure architecture that specializes in the standards and frameworks involving utility components, such as adapters, drivers, DLLs, and print utilities.
The role of an operational utilities subject matter expert requires a broad combination of knowledge and cumulative experience in developing the standards and frameworks to support operational utilities, including their selection, testing, upgrades, decommissioning, and their appropriate participation in configuration management for use in disaster recovery and system decommissioning.
6.1.3.5 Virtualization Architecture
Distinct from “data virtualization architecture” within information systems architecture, “virtualization architecture” is responsible for the standards and frameworks associated with operation-related technologies that can be virtualized, including software, such as VMware and Citrix, or hardware, such as storage virtualization (e.g., block virtualization, file virtualization, and disk virtualization), virtual desktop, and virtual memory.
With the advent of cloud computing, entire data center virtualization is a viable option for many organizations to consider.
6.1.4 Release Management Architecture
Once application systems are deployed into production, they can be functionally stable with few maintenance or enhancement requests, or they can be dynamic, rapidly evolving application systems potentially using agile development.
Release management architecture is responsible for the standards, frameworks, principles, and policies for planning the implementation of new versions, integration testing, user training, help desk training, user acceptance testing, defect management, and production deployment.
Release management architecture cooperates closely with the disciplines of life cycle architecture, configuration management architecture, change management architecture, and disaster recovery architecture.
6.1.5 System Recovery Architecture
System recovery architecture is responsible for the standards and frameworks for system recovery involving each type of technology across each type of operating system environment, typically including:
- z/OS,
- Windows,
- Novell, and
- UNIX.
As well as each type of platform, such as:
- tablet,
- smart phone,
- desktop/portable,
- Intel box, or
- mainframe.
This architectural discipline serves to assess, plan for, and monitor the design of standard recovery capabilities, failover and disaster recovery for the various types of environments deployed globally across an organization. Its specialization and scope is such that it is comprised of failover architecture and disaster recovery architecture.
6.1.5.1 Failover Architecture
Failover architecture is responsible for the standards and frameworks associated with failover of applications and infrastructure technologies involving the various types of components that comprise automated capabilities.
At a high level, there are a number of options for the recovery of an application system or technology.
First is the option of “no failover,” which is appropriate for business capabilities that can incur an indefinite delay for recovery without significant cost or risk to the company.
Second is the option “cold failover,” which is appropriate when the SLA involving the window of recovery fits the time required to restore database and application server from the backups, including the process of applying the transaction journals and rollbacking incomplete units of work.
Often such an environment is not dedicated, but compatible with the environment being recovered, including networking. This option provides failover ranging from days to weeks, depending upon the number of application systems being recovered.
The third option is a “warm failover,” where a dedicated environment is ready, backups have already been applied, and the tasks that remain are simply the process of applying transaction journals, rollbacking incomplete units of work, and potentially manually switching the network over to the new environment.
This option provides failover ranging from hours to days, depending upon the number of application systems being recovered.
The fourth option is a “hot failover,” also known as high availability (HA) failover, which generally has three levels associated with it. Potentially, a hot failover may use HA clustering and a low latency messaging technology to keep its alternate configuration current with active-active and active-backup, or both.
The three levels associated with “hot failover” are:
- HA hot-cold,
- HA hot-warm, and
- HA hot-hot.
6.1.5.1.1 HA hot-cold
The first “HA hot-cold” has a dedicated system already synchronized including its application and data, but requires relatively simple manual intervention, such as having a second gateway server running in standby mode that can be turned on when the master fails.
This option provides failover ranging from minutes to hours, depending upon the number of application systems being recovered.
6.1.5.1.2 HA hot-warm
The second “HA hot-warm” has a dedicated system already synchronized including its application and data, but requires the slightest manual intervention, such as having a second gateway server running in standby mode that can be enabled when the master fails.
This option provides failover ranging from seconds to minutes, depending upon the number of application systems being recovered.
6.1.5.1.3 HA hot-hot
The third is “HA hot-hot,” which has a dedicated system already synchronized including its application and data, but requiring no manual intervention. This is accomplished by having a second gateway server actively running simultaneously.
This option provides immediate failover regardless of the number of application systems being recovered.
6.1.5.1.4 Fail back
One additional failover strategy that exists is referred to as a “fail back,” which is the process of restoring a system to its configuration corresponding to its state prior to the failure.
6.1.5.2 Disaster Recovery Architecture
Disaster recovery (DR) architecture represents the technology side of business continuity architecture. While business continuity is responsible to identify business capabilities, and the applications and technologies upon which they are dependent from a business perspective, disaster recovery takes it to a greater level of detail from an IT perspective.
Behind the scenes of automation, applications and technologies are dependent upon a myriad of application, database, and hardware and software infrastructural components, which only IT would be qualified to identify in its entirety.
The standards and frameworks of disaster recovery extend into standing up a disaster recovery capability, its regular testing, and cooperation with IT compliance to make disaster recovery standards and frameworks available to regulators.
Although it is obvious that the more holistically a company approaches disaster recovery architecture, the better it is actually by having an appropriate set of subject matter experts looking out for their specialized area of interests that makes it holistic.
For example, the disaster recovery architecture must cooperate closely with nearly all of the other enterprise architectural disciplines, including:
- technology portfolio architecture,
- infrastructure architecture,
- network architecture,
- firewall architecture,
- application and database server architectures,
- data in motion architecture,
- operational utilities architecture,
- application architecture,
- reporting architecture,
- workflow architecture,
- failover architecture,
- configuration management architecture,
- release management architecture,
- compliance architecture, and
- SLA architecture.
This will help ensure that the synergies among the architectural disciplines are being appropriately identified and integrated into their corresponding standards and frameworks.
Any operating environment that cannot be virtualized, such as certain technologies that cannot be stood up in a VMware environment, must have dedicated equipment where every last DLL and driver must be replicated in a disaster recovery site before the particular system can successfully be made operational.
The enterprises that look at disaster recovery most holistically realize the tremendous benefit that mainframe applications enjoy by greatly simplifying the majority of disaster recovery issues. In fact, it is easier to recover an entire mainframe in a disaster recovery scenario than it is to just identify the sequence in which hundreds of application systems across a distributed environment must be recovered to optimally support the business priorities for just a single line of business.
Modern enterprise architecture also recognizes that disaster recovery that depends upon the fewest number of individuals, and their knowledge, is far more advantageous in an emergency environment that cannot predict which staff resources will be available.
6.1.6 System Performance Architecture
System performance architecture is responsible for the standards and frameworks for performance monitoring plans, technologies, and procedures for each of the various types of components that comprise:
- an operating environment,
- application system,
- database management system,
- Big Data repository,
- BI reporting tools,
- deep analytics products,
- networks, and
- supporting infrastructure including the I/O substructure and resources of the computing platforms involved.
System performance architecture as a discipline involves a variety of information about hardware specifications, system capacity, system logs from a variety of component types, historical performance measurements, and capacity testing prior to deployment.
From our experience, very few large companies approach system performance correctly. Among the few are leading financial services companies who require that each new application be stress tested to its breaking point to determine in advance the maximum capacity that it can support.
The less effective alternative is to limiting capacity testing to levels that are believed to be the maximum number of users or transactions. When these guesses are wrong, the resulting surprises are rarely pleasant.
6.1.7 Technical Services Architecture
Technical services architecture is comprised of and oversees:
- problem management architecture,
- monitoring alerts architecture,
- configuration management architecture,
- change management architecture, and
- helpdesk architecture.
It develops the standards and frameworks for data center selection and management, data center supply and installation, and data center infrastructure including power, heating, and air conditioning, as well as fire prevention and suppression systems.
6.1.7.1 Problem Management Architecture
Problem management architecture collaborates closely with incident management, which is responsible for resolving incidents reported into a help desk.
In contrast, problem management architecture determines the standards and frameworks associated with retaining history and analyzing causes of incidents, including their trend analysis, to determine if there are patterns and correlated events that are at the root cause of incidents so that solutions may be developed to minimize or eliminate them, both in production and prior to production.
For example, with the proper frameworks in place, problem management in a large enterprise is likely to determine that a greater proportion of resources within their incident management departments are spent on addressing issues with Linux, as compared to UNIX, Windows, and z/OS.
This type of business intelligence should cause mission critical systems to choose UNIX rather than Linux, and it should cause them to factor in a higher level support costs for Linux within infrastructure architecture.
The role of a problem management subject matter expert for a large enterprise requires a broad combination of knowledge and cumulative experience in incident management and problem management, with familiarity across the broad spectrum of automation tools and disciplines to properly identify the architectural disciplines that should be engaged for each type of incident.
Collaboration with numerous other architectural subject matter experts will provide valuable cross training to a problem management architect. Given the quantities of data that can be involved, two areas of close collaboration should be with Big Data and BI reporting architecture.
6.1.7.2 Monitoring Alerts Architecture
Monitoring alerts architecture is responsible for standards and frameworks associated with monitoring business applications and infrastructural systems including policies regarding alert notifications to notify the appropriate operational areas as early as possible.
Monitoring alerts architecture collaborates closely with problem management architecture to centrally record all problems detected through automation and those detected manually that were routed through the help desk.
Early alerts may require support from CEP and artificial intelligence architecture. This discipline also provides direction on tools and technologies that can best support monitoring capabilities, the detection of issues, and the routing of alerts to appropriate stakeholders.
As such, the role of a monitoring alerts architect must understand logs and journals generated automatically by:
- operating systems,
- database management systems, and
- communications software.
Alerts architecture also collaborates closely with Big Data architecture involving technologies, such as Splunk, as one of the first Big Data business intelligence tools specializing in analyzing collections of automatically generated logs.
6.1.7.3 Configuration Management Architecture
Configuration management architecture is responsible for the standards and frameworks associated with uniquely identifying the complete set of components associated with a version of a system using an ontology pertinent to the components and their life cycle.
Configuration management is responsible for safekeeping the components that belong to a configuration in a repository, including status reporting of their life cycle, and their migration through environments that participate in that life cycle.
Essentially, configuration management acts as a procedural firewall between development resources and the movement of software assets through the development/deployment life cycle to production.
The one thing that we have observed that has never failed is that when organizations allow developers to migrate fixes into production themselves without following a prudent configuration management process, things happen and they are not always good.
In the modern view, configuration management architecture aims to provide complete transparency of configuration content and their movement through the development life cycle for each iteration, version or release.
Configuration management architecture collaborates closely with:
- change management, which determines what components and functionality will be developed and in what sequence;
- quality assurance and user acceptance testing, which determines the appropriate level of testing and whether the components meet the documentation and operational requirements to make it to the next step within their life cycle;
- migration control, which identifies and manages the migration of a complete configuration to the next environment within its life cycle; and
- production turnover, which turns over all system components and their associated documentation, deploys the configuration into production, and conducts a go/no go review by all stakeholders to determine whether the production deployment goes live or is backed out.
6.1.7.4 Change Management Architecture
For a useful definition of change management, “change management is the coordination of introducing new components, updating existing components, and removing decommissioned components associated with transitioning from one configuration of a system or application to the next iteration” and the impact of that transition.
Change management architecture (aka product management architecture) collaborates closely with configuration management architecture, to manage the components that belong to an iteration of a configuration.
In the modern view, change management architecture aims to provide complete transparency of component changes in each iteration, version or release. Change management is responsible for the standards and frameworks for determining the components of a system that require management, their functionality, and their sequence of development and deployment, which is communicated to configuration management.
Change management is responsible for planning and identifying the functionality and system components of a product, and project management may negotiate to ensure the functional requirements and system components are appropriate for the time and budget that is associated with the agreed to product changes.
6.1.7.5 Help Desk Architecture
Help desk architecture is responsible for the standards and frameworks for all first level support that is provided to assist the following with any type of question, request, or problem related to automation, procedural, or operational topic:
- customers,
- vendors, and
- employees.
In the modern view, help desk architecture aims to provide complete transparency of incidents with BI metrics for all issues being reported from across the globe to provide the various architectural disciplines of enterprise architecture with a view of incidents related to their areas of specialization, regardless of whether the incident was handled by level one support or transferred to level two or three support.
The role of a help desk subject matter expert requires a broad combination of knowledge and cumulative experience in the various stakeholders and use cases that a global help desk capability would provide.
Collaboration with other architectural disciplines will provide valuable cross training to a help desk architect. In modern enterprise architecture, problem management architecture collaborates closely with the Chief Customer Officer, and the various architectural disciplines that are associated with each category of help desk stakeholder and use case.
6.1.8 SLA Architecture
SLA architecture is responsible for establishing the standards and frameworks associated with service levels for each business capability, including the capabilities provided by the various areas associated with IT.
This requires that the services offered by each business capability are clearly understood, what their responsibilities and priorities are, as well as any commitments that have been made and must be made relative to them providing their services in compliance with standards within a specified range of time and cost.
The metrics associated with service delivery will vary depending upon the type of service, such as:
- metrics associated with automation services or equipment,
- mean time between failure (MTBF),
- mean time to repair or recovery (MTTR), or
- metrics associated with operational workflows, such as
- time frame within which personnel will be assigned,
- time frame within which a status will be provided, and
- delivery of service completion.
In contrast, an operating level agreement (OLA) defines the relationship, coordination, and SLAs required among the various support groups that often must collaborate to address issues and outages of known and unknown origins.
The role of an SLA subject matter expert requires a broad combination of knowledge and cumulative experience in the business capabilities that are provided across the company globally, including IT, and vendors, especially outsourced IT operations vendors.
For example, it is experience with SLAs that creates awareness in subject matter experts that a percentage uptime SLA for a collection of systems as an aggregate is simply not as valuable as a percentage uptime SLA for each individual system.
This explains why outsourcing vendors only tend to offer SLAs for percentage uptime SLA for a collection of systems as an aggregate, as one problematic critical application can be statistically compensated for by 50 other stable applications.
6.1.9 Network Architecture
Network architecture is responsible for standards and frameworks for the various layers of communications networks, such as the seven open systems interconnection model, which includes:
- physical,
- data link,
- network,
- transport,
- session,
- presentation, and
- application layer.
These standards and frameworks address the types of networks, such as:
- local area networks (LAN) (i.e., under a kilometer),
- metropolitan area networks (MAN) (i.e., under a hundred kilometers), and
- wide area networks (WAN) (i.e., long distances over 100 km).
Network architecture includes their associated hardware, software, and connectivity within the facilities of the company and to external communications service providers, as well as plans for monitoring and assessing the various components and touch points to external service providers.
Not to be confused with use of the term “network architecture” when it pertains to the participating nodes of a distributed application and database architecture, this taxonomy of enterprise architecture refers to the application and database usage as “application and database network architecture.”
6.1.9.1 Firewall Architecture
Firewall architecture is responsible for the standards and frameworks associated with the architecture of sub-networks (aka subnets), which are a subdivision of an IP or TCP/IP network that exposes the company’s services to a larger untrusted network, such as the Internet.
Large companies use TCP/IP (i.e., transmission control protocol/Internet protocol) as the network protocol of choice, which is a protocol maintained by the Internet engineering task force (IETF) that organizes the functionality of the protocol into four layers specifying how data should be:
- formatted,
- addressed,
- transmitted,
- routed, and
- received at its destination.
For example, from highest to lowest, the layers of TCP/IP consist of the following:
- an application layer (e.g., HTTP),
- a transport layer (e.g., TCP),
- an internetworking layer (e.g., IP), and
- a link layer (e.g., Ethernet).
In firewall architecture, the architecture of subnets is used to create a DMZ, a term derived from “demilitarized zone,” to create a perimeter of around and between the networks of the enterprise that could be vulnerable to attack from users outside the networks of the company.
The global architecture of these subnets has long-term implications to a company’s ability to protect its networks while providing necessary access to support internal communications across data centers, company facilities, and vendors.
6.1.9.2 File Transfer Architecture
Unlike ETL which usually transports parts of databases within the same data center, file transfer architecture is responsible for the standards and frameworks for all methods of file transfer that are transported, such as FTP, SFTP, and AS2 to and from all data centers globally including all aspects of their approval process and security, as well as the use of digital signatures (e.g., PGP), SSL and various data encryption/decryption technologies, and high security certificates.
As a result, file transfer architecture collaborates with firewall architecture, infrastructure architecture, compliance architecture, data obfuscation architecture, and data governance.
6.1.10 Operations Architecture—Summary
Data centers care for and support the core machinery of the organization’s automation. Operations architecture ensures that the data centers, and their corresponding IT infrastructures, support systems, and applications are made available to the various users and stakeholders in as consistent a manner as possible.
Some organizations, which require machinery to manufacture their products, truly have a deep appreciation of the role that the data center plays in the day-to-day survival of the organization. Other organizations that rely solely on the movement of data and information to support their financial activity are actually more dependent upon their data center operations than those reliant upon manufacturing, but often demonstrate less appreciation of the health of their data centers, without which they would not be able to conduct a stitch of business.