Computer Security Basics, 2nd Edition (2011)
Part II. Computer Security
Chapter 3: Computer System Security and Access Controls
Chapter 4: Viruses and Other Wildlife
Chapter 5: Establishing and Maintaining a Security Policy
Chapter 6: Web Attacks and Internet Vulnerabilities
Chapter 3. Computer System Security and Access Controls
Computer security covers a lot of territory: locking your server and telecommunications rooms, locking your machine, protecting your login accounts with strong passwords, using file protection and adhering to a regular backup schedule to keep your data from being destroyed, encrypting network communications lines, and using special shields to keep electromagnetic emanations from leaking out of your computer (TEMPEST). But when people talk about computer security, they usually mean what is called computer system security, which is a fancy way of saying data protection.
What Makes a System Secure?
In the most basic sense, computer system security ensures that your computer does what it’s supposed to do—even if its users don’t do what they’re supposed to do. It protects the information stored in it from being lost, changed either maliciously or accidentally, or read or modified by those not authorized to access it.
How does computer system security provide protection? There are four primary methods:
System access controls
These methods ensure that unauthorized users don’t get into the system and encourage (sometimes force) authorized users to be security-conscious—for example, by changing their passwords on a regular basis. The system also protects password data and keeps track of who’s doing what in the system, especially if what they’re doing is security-related (e.g., logging in, trying to open a file, using special privileges). System access controls are the soul of authentication.
The next section introduces the basics of system access controls. Appendix C describes the Orange Book accountability requirements, which specify the system access controls definedfor different levels of secure systems. The Orange Book is still an important reference for computer security, although technically it has been replaced by the Common Criteria.
Data access controls
These methods monitor who can access what data, and for what purpose. Another word for this is authorization, that is, what you can do once you are authenticated. Your system might support discretionary access controls; with these, you determine whether other people can read or change your data. Your system might support mandatory access controls; with these, the system determines access rules based on the security levels of the people, the files, and the other objects in your system. Role-based access controls are a hybrid system; these methods extend individual authorization to group memberships.
System and Security Administration
These methods perform the offline procedures that make or break a secure system—by clearly delineating system administrator responsibilities, by training users appropriately, and by monitoring users to make sure that security policies are observed. This category also involves more global security management; for example, figuring out what security threats face your system and what it will cost to protect against them.
Chapter 5 introduces the basics of system security planning and administration. Appendix C shows the Orange Book system administration requirements defined for different levels of secure systems.
System Design
These methods take advantage of basic hardware and software security characteristics; for example, using a system architecture that’s able to segment memory, thus isolating privileged processes from nonprivileged processes.
Although a detailed discussion of secure system design is outside the province of this book, the major Orange Book design requirements for different levels of secure systems are available in Appendix C.
System Access: Logging into Your System
The first way a system provides computer security is by controlling access to that system. Who’s allowed to log in? How does the system decide whether a user is legitimate? How does the system keep track of who’s doing what in the system?
Trying to log into a system is a kind of challenge/response scenario. You tell the system who you are, and the system requests that you prove it by providing information that matches what the computer has stored about you. In security terms, this two-step process is called identification andauthentication.
Identification and Authentication
Identification is the way you tell the system who you are. Authentication is the way you prove to the system that you are who you say you are. In just about any multi-user system that involves local area networks, and in most desktop and laptop PCs, you must identify yourself, and the system must authenticate your identity, before you can use the system. There are three classic ways to do so:
What you know
The most familiar example is a password. The theory is that if you know the secret password for an account, you must be the owner of that account. There is a problem with this theory: you might give your password away or have it stolen from you. If you write it down, someone might read it. If you tell someone, that person might tell someone else. If you have a simple, easy-to-guess password, someone might guess it or systematically crack it.
What you have
Examples are keys, tokens, badges, and smart cards you must use to unlock your terminal or your account. The theory is that if you have the key or equivalent, you must be the owner of it. The problem with this theory is that you might lose the key, it might be stolen from you, or someone might borrow it and duplicate it. Electronic keys, badges, and smart cards can be used as authentication devices and as access devices for buildings and computer rooms. Some of the most sophisticated new security tokens are physical devices that continually calculate new passwordsbased on time-of-day or according to secure algorithms. These passwords are similarly calculated back to the system for which entrance is sought, and the password from the petitioning party must match the password calculated locally.
What you are
Examples are physiological or behavioral traits, such as your fingerprint, handprint, retina pattern, iris pattern, voice, signature, or keystroke pattern. Biometric systems compare your particular trait against the one stored for you and determine whether you are who you claim to be. Problems sometimes occur with false positives and false negatives; occasionally, a valid user is rejected and an invalid user is accepted. In addition, a big problem with these authentication systems is that, on the whole, people aren’t comfortable using them.
Multifactor authentication
Multifactor authentication is a way to cascade the three methods listed previously such that if an attacker gets past one safeguard, they still have to pass another. Passwords are still, far and away, the authentication tool of choice. In a multifactor authentication system, username and password would be augmented with one of the other two systems. In fact, almost every time authentication devices such as tokens and biometric devices are used, they usually supplement, not replace, conventional login IDs and passwords. See Chapter 9 for additional discussion of authentication devices.
Login Processes
In most systems, you identify yourself to the system by entering some kind of unique login identifier or username, followed by a password. The identifier is typically a name, initials, department, or an account number assigned by the system administrator based on your own name and/or group. The password is typically a string of letters and/or numbers known only to you.
The exact method of the username/password authentication process varies depending on the network operating system. Generally, however, it involves one or more of the following:
Encryption
This method scrambles a password so that it cannot be deciphered by someone who monitors storage or transmissions. The opposite of encryption is clear text, in which password or other information is transmitted unmodified.
Challenge and response
With this method, the user is asked to authenticate at the beginning of the exchange, and frequently at random intervals thereafter.
The following subsections describe several models for these mechanisms.
Password Authentication Protocol
In Password Authentication Protocol (PAP), the user provides a username and password, and these are compared with values stored in a table to see if they match. PAP is essentially the same as the classic Unix login. With PAP, login information is transmitted in the clear, that is, unencrypted, or using clear text.
Challenge Handshake Authentication Protocol (CHAP)
The Challenge Handshake Authentication Protocol (CHAP) is a type of authentication in which the device doing the authenticating, usually a network server, sends the client program an ID value and a random number, and both the sender and peer share a predefined secret word, phrase or value. The client strings together the random value (or nonce), the ID, and the secret, and calculates a new value from them using what is called a hash function. This new value is sent to the authenticator, which has built the same string and calculated a similar hash. The authenticator compares the result with the value it received from the client. If the values match, the peer is authenticated. To increase security, the authenticator can be set to repeat the challenge-response process periodically throughout the communications session.
Mutual authentication
Mutual authentication can be thought of as two-way authentication. The client authenticates to the server, and then the server authenticates to the client or workstation. This allows the server to verify that the user is at an authorized workstation. If not, access is denied. Mutual authentication can prevent masquerade attacks, in which identity is pretended in order to gain access, or man-in-the-middle attacks, in which an attacker represents itself to the server as a valid client, and to the client as the valid server, taking advantage of the information flow to steal secrets or inject malicious data.
One-time password
The one-time password (OTP) is a variation of the username/password combination. With OTP, the user creates a password, and the system creates a variation of the password each time a password is required. In this way, the same password is never used twice. With OTP, even if an attacker learns a password by snooping, he won’t be able to use it again.
Per-session authentication
Setting up an authentication method that requires the client to reauthenticate for each exchange of information is burdensome, but it provides a great deal of security. One way to do per-session authentication is to increment a counter with every transmission. Because the password changes constantly, this form of authentication protects against attackers who snoop.
Tokens
A token can strengthen the authentication process by providing a “what you have” layer to the authentication process. A token or token card is usually a small device that supplies the response to a challenge that is received when trying to log on.
One type of a token is a credit card-size device with a built-in keypad. At login, the server issues a challenge with a number. The user keys this number into the token card, and the card displays a response. The user inputs this response and sends it to the server, which calculates the same result it expects to see from the token. If the numbers match, the user is authenticated.
Other tokens are based on time. They display a number that changes at regular intervals, usually several times each hour. The user logs in by entering her username and password, along with the time-based value from the token. If the value from the token matches a value the server has calculated, the account is authenticated, and access is granted.
The disadvantage of tokens is their small size and their price. If the token breaks or becomes lost, a replacement will be needed to gain access. Depending on the manufacturer and quantity purchased, tokens can run from $30 to $100 each. Software-based tokens are also available. At login, users enter a personal identification number (PIN), with which the soft token creates a one-time password. The PIN is never transmitted. The software token protects itself by refusing to work if an incorrect PIN is entered too many times.
Biometrics
Biometrics, using personal measurements such as fingerprints, hand outlines, iris and retina scanners, voice recognition, handwriting analysis, and keyboard analysis can be a one-stop shop for authentication, but it is seldom used that way. Biometric technologies are most effective if used as a “what you are” layer of authentication on top of a “what you know” or “what you have” layer. Biometric systems are prone to false positives (saying you are who you aren’t) and false negatives (saying you aren’t who you are), and most systems have an index of reliability that is calculated by combining the two ratios. Biometrics could be great for verifying a username or password, however, so look for more of it soon. Biometrics is covered in greater detail in Chapter 9.
Remote access (TACACS and RADIUS)
Even though broadband connections such as cable and DSL are becoming more widespread, dial-up type access is still widely used. To allow remote users to connect to the network, many businesses use modem banks that allow users to dial into the network. These connections must be secured and audited, and users must be able to be authenticated easily, in order to keep information available. But instead of a hundred or a thousand potential clients, anyone with a telephone and a computer becomes a potential login.
Specialized login and authentication systems have been developed to meet this need. Here are two of them:
§ Remote Authentication Dial-In User Service (RADIUS)
§ Terminal Access Controller Access Control System (TACACS)
Handling large amounts of login traffic can bog down a server. These protocols allow a network server to offload the user authentication and authorization to a central server. A typical enterprise network may have an access server attached to a modem pool, along with a RADIUS or TACACS server to provide authentication services. Remote users dial into the access server, and the access server sends authentication requests to the RADIUS or TACACS server. The RADIUS or TACACS server then authenticates users and authorizes access to internal network resources. Remote users are clients to the access server, and the access server is a client to the RADIUS server.
In addition to providing authentication, both services can track users, the duration of sessions, the protocols used during sessions, ports used, addresses contacted, and even the cause of session termination. Because these services can create logs, the audit trail can be examined to determine who is accountable for each individual session. Essential information about dial-up activity can be organized, charted, and examined. This means that authentication, authorization, and accounting functionality is often delegated to RADIUS or TACACS.
TACACS is documented in RFC 1492. RADIUS is defined in RFC 2139 (RADIUS Accounting, April 1997) and RFC 2865 (Remote Authentication Dial In User Service (RADIUS), June 2000).
DIAMETER
DIAMETER is a protocol that authenticates remote dial-up users, and also provides authorizations and accounting. DIAMETER grew out of the RADIUS protocol, which has limitations in how it can connect. RADIUS works only with modem-based protocols such as Serial Line Interface Protocol (SLIP) and Point to Point Protocol (PPP). In the past, RADIUS functionality was adequate; today’s environment, however, uses smart phones and hand-held devices that feature different protocols, so more flexible access methods are required.
DIAMETER adds new features to RADIUS, such as the ability to ask for additional logon information beyond basic authentication. DIAMETER uses the initial logon and authentication to identify a user, and then queries the user for additional information that might be used to strengthen the authentication, or gives her access to additional systems.
DIAMETER supports the following extensions to various network services:
Roaming Operations (ROAMOPS)
Procedures, mechanisms, and protocols to support user roaming among groups of Internet service providers (ISPs). Global operations with a single account should be used with applications requiring roaming.
Network Access Server Requirements (NASREQ)
Extends network access server design beyond simple dial-up and into virtual private network (VPN) support, improved authentication, and roaming.
IP Routing for Wireless/Mobile Hosts (MobileIP)
Development of the needed routing support to allow IP roaming using either IPv4 or IPv6 over multiple subnetworks and to different types of media.
DIAMETER is described in various Internet Engineering Task Force (IETF) draft standards, including:
RFC 3589: Diameter Command Codes for 3GPP Release 5, September 2003
RFC 3588: Diameter Based Protocol, September 2003
RFC 2486: The Network Access Identifier, January 1999
RFC 2607: Proxy Chaining and Policy in Roaming, June 1999
Kerberos
One of the most important and complicated authentication schemes is a network authentication protocol developed in the 1980s at the Massachusetts Institute of Technology (MIT), called Kerberos. Kerberos provides secure transport across insecure media, such as the Internet. Named after the three-headed watchdog guarding the underworld in Greek mythology, Kerberos follows a three-step login process:
1. The user provides a username and password. This login request is sent to an authentication server (AS), which performs the user authentication. When the AS receives the login request, it creates two copies of a new key called a session key. These session keys are used between the user and the resource she is trying to access.
2. One session key is encrypted with a key held by the user; the other is encrypted with a key held by the server. This server key is called a ticket. The AS sends both the user key and ticket back to the user. The user opens one copy using her key as the password, extracts the session ke, and checks to see that it is valid. The user can open only the copyencrypted with her key because the other was encrypted with the server’s key.
3. The user next creates another message, called the authenticator, adds to it the current time, and creates a checksum, which is a mathematical check performed on a series of characters in which the characters are added up (summed) and appended to the series. Subsequent users repeat the checksum process to determine if the checksum is identical. If not, the characters have changed in storage or transmission, and the data is usually discarded as a precaution. The user encrypts the checksum using the session key and then sends both the ticket and the authenticator to the server that is providing the desired resource.
4. The server receives both encrypted copies of the session key, uses its ticket (server key) to open the copy that was encrypted with that key, extracts the session key, and verifies it as coming from the user, which is determined by the fact the user’s key is present. The other message is opened with the session key. The server next compares the timestamp and checksum to the current time to identify the user and check the integrity of the message. If everything is valid, the server grants the user access.
5. Easy, right? In truth, Kerberos requires you to understand a few more details, but this explanation covers the basics. Kerberos can be considered a response to the advance of technology. Early networks were concerned with communication. Security was second to reliability. Most traffic was sent in the clear. The advent of tools such as packets allowed operators to see any unencrypted traffic as it traveled across the wire, which was not acceptable. Kerberos tries to solve this problem by providing strong encryption and sure authentication. Even though it introduces considerable complexity, Kerberos is a model on which many similar systems are built.
Two good resources for Kerberos information are the MIT Weblink for Kerberos (http://web.mit.edu/kerberos/www/) and the IETF RFCs (http://www.ietf.org/rfc/rfc1510.txt).
Passwords
In spite of all the options, far and away the most common method for authentication is the username/password combination, as is found on any Unix, Linux, or Windows system. For example, Unix systems display the prompt:
login:
and expect a first or last name or some prearranged combination of both, such as first initial followed by up to seven letters of the last name, or any other handle you’ve been given, in response.
After you enter your login ID, the system prompts for a password:
Password:
You type the password (which is ordinarily never echoed, or displayed, on the terminal screen, unless it is by a series of asterisks, which may or may not correspond to the number of keystrokes). The system then authenticates your identity by verifying that the entered password is valid for your account. You’ll be able to proceed only if the password you enter matches the password stored for you in the system.
HINTS FOR PROTECTING PASSWORDS
Both system administrators and users share responsibility for enforcing password security. Remember, password security is everyone’s responsibility. In addition to damaging your own files, someone who uses your password to break into a system can also compromise all the files in the system or network.
§ Don’t allow any logins without passwords. If you’re the system administrator, make sure every account has a password.
§ Don’t keep passwords that may have come with your system. Change all test, vendor, or guest passwords—for example, root, system, test, demo, and guest— before allowing users to log in.
§ Don’t ever let anyone use your password. If you must share it, say because you are at home, and someone at work needs it, change it as soon as possible, or consult a security administrator to create a new one until you can change yours.
§ Don’t write your password down—particularly on your terminal, computer, or anywhere around your desk. If you ever do write your password down, don’t identify it as a password. Better yet, add a few leading or trailing characters, and write two or three more potential passwords along with it. Consider writing it backwards.
§ Don’t type a password while anyone is watching.
§ Don’t record your password online or send it anywhere via electronic mail. In his book The Cuckoo’s Egg, Cliff Stoll reports how his intruder scanned electronic mail messages for references to the word “password.”
§ Don’t keep the same password indefinitely. Even if your password hasn’t been compromised, change it on a regular basis.
An old saying from the USENET: “A password should be like a toothbrush. Use it every day; change it regularly; and DON’T share it with friends.”
Passwords are your first defense against intruders. To protect your system and your data, you must select good passwords, and you must protect them carefully.
This all assumes that you are the only user of your computer. If you share a computer with multiple users, say workers on different shifts, or supervisors who keep accounts on your machine to aid maintenance, any one of the passwords could be the target of the attack.
HINTS FOR PICKING PASSWORDS
If you’re allowed to choose your own password, pick passwords that are hard to guess. Here are some suggestions:
§ Pick passwords that aren’t words (English or otherwise) or names (especially your own, that of a fictional character such as Hamlet or Gandolf, or that of a family member, a pet, or a car).
§ Pick a mix of alphabetic and numeric characters. Never use an all-numeric password(especially your phone number or social security number).
§ Pick long passwords. If your password is only a few letters long, an attacker can easily try all combinations. Most systems insist that your password be at least 6-8 characters. Some systems support passwords of up to 40 or more characters.
§ Pick different passwords for the different machines or network nodes you access.
§ Mixing special characters such as & or $ can help increase the pool of available characters a brute force attacker must cycle through. Be careful about using numbers that resemble letters, or 31337-speak, because the attackers know it well. Check with your system administrator to find which characters are allowed.
The best passwords contain mixed uppercase and lowercase letters, as well as at least one number and/or special character. The password you pick doesn’t need to be gibberish. In fact, if it is, you’ll be tempted to write it down, defeating the purpose of your careful selection. Some suggestions are:
§ Combine several short words with numbers or special characters; for example, I;did3it.
§ Use an acronym you’ve built from a phrase you’ll remember. For example, the acronym for “When in the course of human events” is Witcohe, but that one could be guessed. It’s better to pick a phrase that’s not recognizable. For example, the acronym for “Oh no, I forgot to do it” is Oniftdi.
§ Add a number or a special character for more security. For example :Onif;tdi or On5iftdi.
§ Pick a nonsense word that’s still pronounceable; for example 8Bektag or shmoaz12.
Protecting passwords
Access decisions are the heart of system security, and access decisions are based on passwords, so it’s vital that your system protect its passwords and other login information.
Most security administrators protect passwords in three important ways: they make passwords hard to guess, they make login controls hard to crack, and they protect the file in which passwords are stored.
Making passwords hard to guess is a matter of user training and occasionally testing to see if the system yields to a common dictionary attack. Such penetration testing can smoke out users who have weak, easily guessed passwords.
Making passwords hard to steal is a matter of hiding the file in which they are stored, and in some cases, performing a one-way encryption called a message digest, or hash which stores the passwords in an encrypted form.
Protecting your login and password on entry
Most vendors offer a whole smorgasbord of login controls and password management features that the system administrator can mix and match to provide optimal protection of a particular system. Because these security features are commercially attractive and relatively easy to implement, most systems tend to have a lot of them. Examples of such features are shown in Table 3-1.
Table 3-1. Sample login/password controls
|
Feature |
Meaning |
|
System messages |
Most systems display warning banners and announcement messages before and/or after you successfully log in. Formerly, the banners were friendly identifiers, but court cases showed that to be unwise. Some systems allow the system administrator to suppress these messages because they can provide a clue to an observer as to the type of system being accessed. If an intruder telnets in and finds out he’s talking to a Solaris system, for example, that’s a valuable clue. |
|
Limited attempts |
After a certain number of unsuccessful tries at logging into the system (the number can be specified by the system administrator), the system locks you out and won’t let you log in from that terminal. Some systems lock you out without informing you that this has happened. Modern attack scripts overcome this by trying to open several sessions at once. |
|
Limited time periods |
Certain users or terminals may be limited to logging in during business hours or other specified times. |
|
Incrementing login failure wait times |
Each time a login fails, a longer time must pass before allowing another attempt. That is, after the first attempt, it takes one second to reset; after the second attempt, two seconds; after the third, four seconds; and after the fourth, eight seconds. This thwarts brute force attacks. |
|
Last login message |
When you log in, the system may display the date and time of your last login. Many systems also display the number of unsuccessful login attempts since the time of your last successful login. This lets you know if your account was accessed by someone else—for example, you may notice a login in the middle of the night or a pattern of repeated attempts to log in. If you weren’t responsible for these attempts, notify your system administrator right away. |
|
User-changeable passwords |
In many systems, you’re allowed to change your own password any time after its initial assignment by the system administrator and may be required to change it after a certain interval. |
|
System-generated passwords |
Some systems require you to use passwords generated randomly by the system, rather than relying on your own selection of a difficult-to-guess password. Some systems let you view several random choices from which you can pick one you think you’ll be able to remember. A danger of system-generated passwords is that they’re often so hard to remember that users may tend to write them down. Another danger is that if the algorithm for generating these passwords becomes known, your entire system is in jeopardy. |
|
Password aging and expiration |
When a specified time is reached—for example, the end of the month—all passwords in the system may expire. The new passwords usually must not be identical to the old passwords. The system should give reasonable notice before requiring you to change your password; if you have to pick a password quickly, you’re likely to pick a poor one. In some systems, the system administrator can respond to a security breach by forcing a particular password, or all passwords, to expire immediately. The system may keep track of your passwords for an extended period to make sure you don’t reuse one that might have been guessed. |
|
Minimum length |
Because short passwords are easier to guess than long ones, some systems require that passwords be a certain length, usually six to eight characters, but longer is better. |
|
Password locks |
Locks allow the system administrator to restrict certain users from logging in or to lock login accounts that haven’t been used for an extended period of time. |
Protecting your password in storage
Every system needs to maintain its authentication data. Typically, valid passwords are stored in a password file. This file is accessed only under certain limited circumstances—when a new user is registered, when you change your password, or when you log in and need to be authenticated. As a security protection against imposters or compromised passwords, in most cases, administrators cannot access stored passwords. The best they can do is reset a password to a temporary value, such as “letmein” or “password,” and require a user to change the temporary password at the next login.
Protection of passwords is extremely critical to system security. Systems commonly use both encryption and access controls to protect password data.
Encryption
Most systems encrypt the data stored in the system’s password file. Encryption (described in Chapter 7) transforms original information into altered information that usually has the appearance of random text. Encryption ensures that even if file security is somehow breached, the intruder won’t be able to read the passwords in the file; they’ll look like gibberish.
Most systems perform one-way encryption of passwords. One-way encryption means that the password is not intended to be decrypted—that is, deciphered into its original form. When the system administrator supplies you with your initial password, it’s encrypted before it’s stored in the password file. The original password is not preserved, not even in memory. Each time you log in and enter your password, the system encrypts the password you enter and compares the encrypted version with the encrypted password stored in the password file to be sure you’ve entered a valid password. Remember too that the password is never displayed on the terminal screen.
Access controls
Even encrypted passwords can be cracked by a determined foe. Many systems store encrypted password data in files known as shadow password files, which have the most restrictive protection available in the system. In most systems, access is limited to the system administrator, usually by specifying only the administrator’s ID in an ACL on the file. (See the discussion of ACLs in the section "Access Control in Practice.”)
Password attacks
There are two primary methods of password cracking. The first is to try to guess a password by trying every possible combination of characters, one attempt at a time (a so-called brute force attack). Like everything else, this process has been automated. Crackers now use computers to do the guessing. In theory, the longer the password, the longer it takes to try every combination. For example, with a password containing eight random characters, there are 2.8 trillion combinations. Even a fast computer could take weeks to saw through all possible combinations.
The second method is a dictionary attack. The dictionary attack works because most users don’t select random, or even decently secure passwords. Most users typically pick passwords that are laughably easy to guess—their initials, their childrens’ names, their license plates, etc. Studies indicate that a very large percentage of users’ passwords can easily be guessed. With the help of online dictionaries of common passwords (English words, names of people, animals, cars, fictional characters, places, and so on), crackers are quite likely to be able to guess a good many of the passwords most people are likely to choose. But if you select a good password (see the sidebar "Hints for Picking Passwords“), an intruder shouldn’t be able to guess it—with or without a dictionary.
Authorization
Once you’ve been authenticated, the system uses your ID (and the security information associated with it) to determine what you’re allowed to do in the computer or on the network. The process of determining your bounds is called authorization. For example, if you try to modify a sensitive file, the system checks your authenticated user ID against the list of IDs representing users who are authorized to read and write the data in that file. Only if your ID appears in that list will the system allow you to access the file.
Systems typically maintain a file containing information about your privileges and characteristics; in some systems, this is called a security profile, an authentication profile, or a user list. Your profile might tell the system what your clearance is (e.g., SECRET), whether you’re allowed to change your own password, whether you can log in on weekends, whether you can run backup programs and other privileged programs, and a myriad of other information. In some cases, your profile is in the same file as the password list; in other cases, the information might be kept in separate files. In any case, it’s vital that your system protect this information; any compromise can jeopardize the security of the entire system.
One of the important pieces of information that appears in your authentication profile or user list is an indication of what kind of user you are. Most systems support several categories of users, or roles; a typical set includes regular users, a system administrator, and an operator. Highly secure systems may define a security officer as a separate category. Each category of user has specific privileges and responsibilities—for example, specific programs the user can run. The system administrator, for example, may effectively be able to do anything in the system, including overriding or circumventing security requirements and creating new, spurious accounts for the use of attackers. (The power of the system administrator is a major issue in secure systems; see the discussion of administrative controls and least privilege in Chapter 5.)
Sensitivity labels
Every subject and object in a system supporting mandatory access controls has a sensitivity label associated with it. A sensitivity label consists of two parts: a classification and a set of categories (sometimes called compartments). For example, the label shown in Figure 3-1 has both parts.
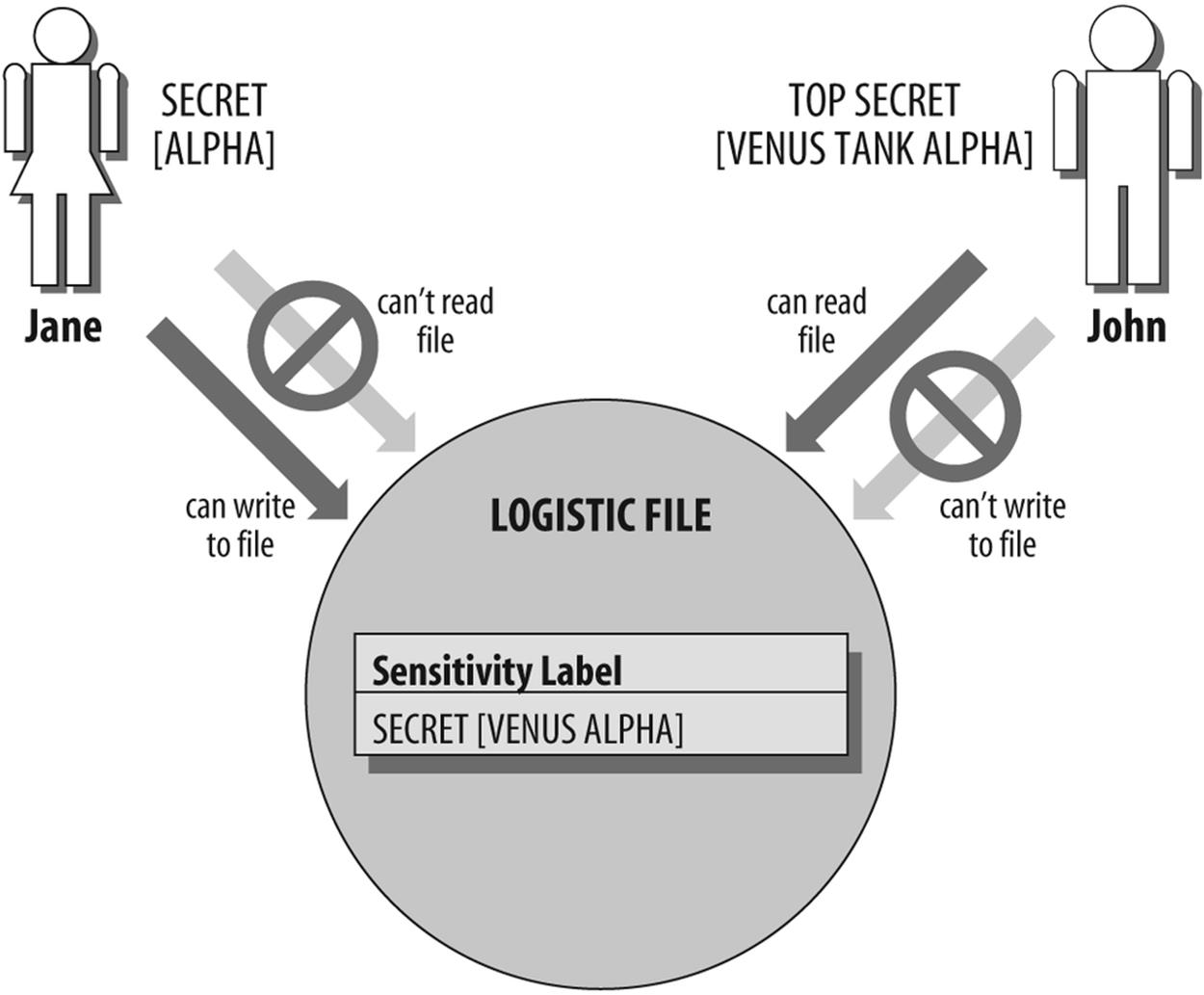
Figure 3-1. Sensitivity label that consists of two parts
The classification is a single, hierarchical level. In the so-called military security model (based on the Department of Defense multilevel security policy), there are four distinct levels:
TOP SECRET
SECRET
CONFIDENTIAL
UNCLASSIFIED
Each classification is more trusted than the classification beneath it.
The actual definition of classifications is up to a site’s system administrator or security officer. If your site is processing government classified information, your labeling setup has to support the military model. But in general, labels represent whatever set of classifications and categories make sense in your own environment. For example, at a commercial site, you might define this corporate hierarchy:
CORPORATE
BRANCH
DEPARTMENTS
Or you might define gradations in levels of trust:
EYES ONLY
OFFICERS ONLY
COMPANY PROPRIETARY
PUBLIC
Or:
RESTRICTED
CONFIDENTIAL
PUBLIC
The categories or compartments are nonhierarchical and represent distinct areas of information in your system. Together, the categories make up a category set or a compartment set. A set may contain an arbitrary number of items.
In a military environment, you might have categories such as:
ANTI-TERRORISM
TANK
SUB
VENUS
STEALTH
In a commercial environment, your categories might correspond to company departments, product names, ad campaigns, or any other setup you wish to implement:
ACCOUNTING
PR
MARKETING
SALES
R&D
The idea is that even someone who has the highest classification isn’t automatically cleared to see all information at that level. For example, to see information in the ANTI-TERRORISM category, you must “need to know” that information.
COMPARTMENTALIZED INFORMATION
Military information is often compartmentalized as well as rated for its sensitivity. Think of compartmentalization as a need to know. Even if an individual has a high security clearance, if there is no plausible need to know the facts of some matter or another, the data is off limits. This was once demonstrated rather abruptly by a Marine sergeant who was the crew chief of a helicopter equipped with a secret electronics package, presumably used for intelligence.
One day a curious captain walked into the ‘copter, and the sergeant summarily pushed him back out the door and down the stairs, spilling him onto the deck. This would not normally be considered a wise career move. However, the sergeant was likely demonstrating good security practice. Rank—Captain versus Sergeant—was in this case trumped by need to know. The sergeant knew good and well that the captain had no need to know about the special package on his ship, and took immediate precautions against compromising it.
In spite of the physical nature of the encounter, the fine traditions of the Corp were apparently upheld. As he sent the captain sprawling, the sergeant was heard to shout “Sorry, Sir!”
Access models
There are two general models of access you are likely to encounter. The Bell-LaPadula model is optimized for confidentiality and is used in defense circles; the Biba model is optimized for integrity and is used in financial transactions and business.
Bell-LaPadula model
In 1973, David Bell and Leonard LaPadula first described the DoD multilevel military security policy in abstract, formal mathematical terms, as mentioned in Chapter 2. In their Bell and LaPadula model, they used mathematical notation and set theory to define the concept of a secure state, the modes of access, and the rules for granting access. They called it the Basic Security Theorem. In that model, a subject’s (usually a user’s) access to an object (usually a file) is allowed or disallowed by comparing the object’s security classification with the subject’s security clearance. The three basic rules are as follows:
§ The *-property (star property)
§ The simple security condition
§ The tranquility property
The *-property, or star property, states that a subject is allowed write access to an object (usually a file) only if the security level of the object is greater than or equal to the clearance level of the subject. This makes it impossible for data from a highly cleared subject to become available to users with a lower security clearance in an object (file/directory) with a low security level. Without this rule, a user with a high security clearance could copy sensitive data into a low security clearance document—thus allowing “confidential” data to be written down, or to flow from a “top secret” to an “unclassified” level. Sometimes this is called the write up rule or no write down rule or the confinement rule.
The simple security condition is so named because it is not hard at all to grasp. The simple property states that a user (a subject) may only read a file (an object) if she has a security level equal to or greater than that of the file. It means that someone with a “secret” security level cannot read a file with a “top secret” security level; but can read a file with a “secret” or “confidential” security level. Sometimes this is called the read down rule or no read up rule.
The tranquility property states that the security level of an object cannot be changed while it is being processed by a computer system. This keeps a program or attack from modifying the sensitivity of a file while it is open and vulnerable.
Biba model
The military model is not the best for all cases. Another model you should know about is the Biba model, sometimes called the Bell-LaPadula upside down model. In business and banking, the integrity of data (that is not slipping a decimal point) may be of greater importance than secrecy. (For instance, if one purchases 10 million shares of a company’s stock, it will likely be in the financial pages soon as a major transaction, so secrecy is not terribly likely. But during the transaction, it would not be good to shift the decimal a spot and change each share’s price by 10 cents, which would alter the sale price by an amount even Bill Gates might notice.)
Whereas in Bell-LaPadula, a highly secured individual is not allowed to write documents with lower security to avoid letting information flow down, the Biba model denies a user of a lesser sensitivity from writing documents of a higher sensitivity. It is assumed that the accuracy and trustworthiness of data increases with the sensitivity of the document. To write up would be to risk contaminating higher integrity data with lower integrity data. Similarly, for a higher sensitivity user, to read lower integrity data could result in polluting a higher integrity document.
WHY ACCESS CONTROLS?
If you work alone on a PC, you don’t need to worry about access controls. You own all of your files, and you can read and write them as you wish. If you want to share a file with someone, you can copy it to a disk, open a network share to a folder in which you store the file, save the file on a common area of a server, or burn a CD-ROM or DVD and hand it over.
With shared computers, it isn’t as easy. As soon as you begin to work on a system that supports multiple users, you must start worrying about data protection and access controls. You may not want every user in the system to be able to read your files. You certainly won’t want them to change your files.
Even if you trust everyone on the system to keep away from your data, you need to protect against accidents. Suppose you and Joe Slow are working in separate areas of a shared directory. Both of you are working on the same projects, and you’ve both picked identical names for some of your files. With a few unfortunate keystrokes, Joe can change directories and delete one of your files, thinking it’s his own. If your files aren’t protected in any way, the system doesn’t put any obstacles in his path. Access controls on files (they usually apply to other system objects, such as directories and devices as well) provide protection against such disasters.
Access Control in Practice
Fortunately, you, the user, are isolated from the mathematical intricacies of access control models. These principles are codified in one of several access control mechanisms.
There are at least three basic types of access controls that provide different levels of protection to the files in your system:
§ Discretionary access control (DAC)
§ Mandatory access control (MAC)
§ Role-based access control (RBAC)
With discretionary access control (DAC) you decide how you want to protect your files and whether to share your data. With the more complex mandatory access control (MAC), the system protects your files. In a MAC system, everything has a label; using the security policy relationships established for your organization, the system decides whether a user can access a file by comparing the label of the user with the label of the file. Role-based access control (RBAC) grants you certain privileges based on your job function. If you are an accountant, you are allowed access and control similar to the other accountants. The following sections describe these access control types.
Discretionary access control
Discretionary access control is an access policy that restricts access to files (and other system objects such as directories and devices) based on the identity of users and/or the groups to which they belong.
What’s discretionary about discretionary access control? In contrast to mandatory access control, in which the system controls access, DAC is applied at your own discretion. With DAC, you, the file owner, can choose to give away your data; with MAC, you can’t.
Not only does DAC let you tell the system who can access your data, it lets you specify the type of access allowed. For example, you might want to let everyone in the system read a particular file, but you might want only yourself and your manager to be able to change it. Most systems support three basic types of access:
Read
If you have read access for a file, you can read the file.
Write
If you have write access for a file, you can write (change or replace) the file.
Execute
The execute permission is relevant only if the file is a program. If you have execute permission for a file, you can run the program.
Ownership
There are many types of discretionary access control. One simple method involves ownership of files, directories, and devices.
If you create a file, you’re the owner of the file. Your login ID, or some other identifier, is entered in the file header. A system might base all its access decisions on file ownership. If you’re the owner of the file, the system lets you read and change the file. If you’re not the owner, you have no rights to the file. This is a simple scheme, but not a very practical one. For one thing, it doesn’t let you share the file.
Virtually every system keeps track of file ownership and bases many access decisions on it (for example, regardless of other mechanisms, the system might let you delete a file only if you’re the file owner).
Self/group/public controls
In many systems, you control access to your files by dividing the world of users into three categories and telling the system what the users in each category can do to your file. Some systems call these self/group/public controls. In Unix, they’re called user/group/other (UGO) controls:
Self
You—the creator or owner of the file.
Group
A set of users. For example, all the users in a particular department may be in the R&D group.
Public
Everyone else—users other than you and the other members of your group.
File permissions
Each file has a set of bits called file permissions associated with it. File permissions often have the meanings shown in Figure 3-2.

Figure 3-2. Self/group/public controls
If you list your files (with the correct option) in a Unix or Linux system, you’ll see such file permissions as the following:
-rw-rw-r-- 1 frank r&d 81904 Nov 7 13:25 UPDATES
If a dash (-) appears in place of a permission, the user does not have the corresponding permission to read, write, or execute the file. For instance, in the example, the file owner (frank) can read and write the UPDATES file (rw-), members of the file group (r&d) can read and write the file (rw-), and the rest of the world can only read the file (r--). (Ignore the first dash above; it has a special meaning to Unix.)
Consider a few more examples.
The CHESS file contains a game; its permissions look like this:
-rwxrwxrwx 1 libr games 61799 May 19 10:11 CHESS
Everyone can read, write, and execute this file.
The SRC95 file is a segment of code that several people in the r&d group are working on; its permissions look like this:
-rw-rw---- 1 sarah r&d 55660 Dec 19 11:42 SRC95
The owner and the other members of the group can read and change the file; no one else can access it.
The self/group/public controls are a good way to protect files. But what happens if you need to protect a file in different ways for different users, or if you want to keep one user from accessing a file?
If Sarah owns the FLAG file and wants Joe (a member of her group) to be able to read and change it, she’ll specify the following permissions:
-rw-rw---- 1 sarah r&d 22975 Jan 19 10:14 FLAG
If Sarah wants Joe to be able to read FLAG, and Mary to be able to read and change it, she could make Mary the owner of the file (with r and w permissions) and leave Joe as a member of the group that can read (r) only. But what if Joe’s group contains other users who aren’t trusted enough to read FLAG? How can Sarah exclude the sinister Sam, for example?
Discretionary access control may seem burdensome, but it is highly flexible. With some complicated maneuvering, it’s possible to accomplish these goals with self/group/public controls, but the more special cases you have, the more unwieldy this kind of file access becomes. The system we will explore next offers little such flexibility.
Mandatory access control
Mandatory access control is an access policy supported for systems that process especially sensitive data (e.g., government classified information or sensitive corporate data). Systems providing mandatory access controls must assign sensitivity labels to all subjects (e.g., users, programs) andall objects (e.g., files, directories, devices, windows, sockets) in the system. A user’s sensitivity label specifies the sensitivity level, or level of trust, associated with that user; it’s often called a clearance. A file’s sensitivity label specifies the level of trust that a user must have to be able to access that file. MACs use sensitivity labels to determine who can access what information in your system.
Together, labeling and MAC implement a multilevel security policy —a policy for handling multiple information classifications at a number of different security levels within a single computer system.
In the past, military systems were set up to handle one, and only one, level of security. The policy for such systems, known as a system high policy, required everyone who used the system to have the highest clearance required by any data in the system. A system that handled SECRET data, for example, could not be used by anyone who did not have a SECRET clearance (regardless of how well protected the SECRET data was).
Although many government sites still operate in system high mode, others support multiple security levels. This is done by dividing, or compartmentalizing, the data. Such systems support simultaneous use by users with the highest and the lowest clearances (or, potentially, with no clearances at all), and with access to many different types of sensitive compartmented intelligence (SCI).
Although this section tries to touch on the major issues involved with labeling, security levels, and MAC, these are complicated topics, with a lot of security history behind them. Appendix C discusses briefly how the Orange Book specified requirements in these areas.
Data import and export
In a mandatory access control system, it’s very important to control the import of information from other systems, and the export of information to other systems. MAC systems have a lot of rules about data import and export. They also control which system devices you can use to copy and print information; for example, you might not be allowed to print sensitive information on a printer located in a public area of your building. There are also rules for labeling devices and printed output (with banner pages and page headers and trailers). The discussion of specific labeling requirements is discussed in Appendix C.
Access decisions
In a MAC system, all access decisions are made by the system. Unlike DAC, which allows you to specify, at your own discretion, who can and cannot share your files, MAC puts all such access decisions under the control of the system. The decision to allow or deny access to an object (e.g., a file) involves an interaction between all three of the following:
§ The label of the subject—for example, your clearance:
TOP SECRET [VENUS TANK ALPHA]
§ The label of the object—for example, a file named LOGISTIC with a sensitivity label:
SECRET [VENUS ALPHA]
§ An access request—for example, your attempt to read the LOGISTIC file.
When you try to read the LOGISTIC file, the system compares your clearance to the file’s label to determine whether you’ll be allowed to read it.
Although multilevel security systems provide many benefits, they’re the source of many frustrations as well. For example, under some circumstances, you may write a file and then find you can’t read it!
Role-based access control
Role-based access control determines a user’s access based on that user’s role. For instance, financial managers may need to access all accounting data: taxes, payroll, receivables, collections, credit. A clerk in accounts receivable, however, will need only a subset of the accounting data, and an engineer over in R&D will need very little of it. The role a user is assigned to is based on the least privilege concept. The role is defined with the least amount of permissions or functionalities that is required to get the job done. If the privileges for a role change, permissions can be added or removed. This offers greater flexibility by changing the role instead of changing the user’s permissions.
Since a user can belong to more than one role at a time, there is the chance for conflict. One role may allow access to a resource where another role denies access to that resource. Conflicts like this need to be corrected on a user-by-user basis. As a general rule, the least permissive combinations are used.
Access control lists
It would be reasonable to ask how the models mentioned in the previous section are implemented. Access control lists (ACLs) are lists of users and groups, with their specific permissions. They offer a more flexible way of providing discretionary access control. ACLs are implemented differently on different systems. For example, in a Unix-based trusted system that uses a Unix security, you’d protect PAYROLL with ACLs in the form:
<john.acct, r>
<jane.pay, rw>
where:
§ john and jane are login IDs of users who are allowed access to the PAYROLL file.
§ acct and pay are group IDs of the users.
§ r and w indicate the type of access allowed; r means that the user can only read PAYROLL, w that he or she can also change it.
If john is in the acct group, he can only read the file. If he belongs to any other group, by default he has no access. Similarly, if jane is in the pay group, she can read and write the file.
ACLs usually support wildcard characters that let you specify more general access to files. For example, you might specify:
<*.*, r>
to indicate that any user (*) in any group (*) can read (r) the file. You might specify:
<@.*, rw>
to indicate that only the owner (@) of the file can read (r) and modify (w) it.
In some systems, you can indicate that a particular user is specifically not allowed to access a file—for example, by specifying a null character or the word none or null in place of an access character such as r or w.
<sam.*,none >
LEAST AND MOST PERMISSIVE ACCESS
There is a good example of an access conflict hiding in the example about john and the PAYROLL file. The ability of user john to access the file is affected by which groups he belongs to. As long as he is a member of only the acct group, he can read PAYROLL. Once he is part of an additional group, he loses access.
This conflict arises because of the least permissive principle. Cumulative permissions are handled differently by different network operating systems, such as NetWare, NetWare using Novell Directory Services, WindowsNT, and Windows 200x using Active Directory Services.
Fortunately, understanding the Unix UGO system will prepare you for any of the others. You will recognize the principles and will just need to learn their new names and how they are handled in that particular system. Also, this is an important but somewhat theoretical concept. In the real world, most administrators handle these issues by cloning a user who has the appropriate permissions and then changing the username. Don’t skip over this issue lightly: you will see access lists again, when you program perimeter defensive systems such as firewalls, firewall software packages for routers, and intrusion detection systems.
Directory Services
As I described previously, several systems are used to keep track of authorized users. Some of these systems, such as biometrics, are still waiting to catch on. Others, such as the username/password, are getting fairly aged. One of the improvements to occur in login technology is the integration of Authentication, Authorization, and Accounting (AAA) technologies. These improved directory systems keep track of the identity of each user, as well as attributes of that user, such as contact information, personal attributes, including what they can access, in some kind of directory services database. A directory service is essentially a large database that stores information about all the objects in a network and information about how these objects interact. Objects can be users, groups, hardware, or software.
One common directory service is Active Directory, used by Windows servers and domain controllers. The Active Directory implementation helps to organize all objects and resources in the network environment while acting as the central point for security as well. Active Directory provides a means to audit all the events that happen on login servers (domain controllers). Audit policies can be set to monitor specific activities, create reports, and notify specific personnel of these events. Group policies can be defined that govern groups of users and computers. These policies can be applied to sites, domains, or organizational units that are defined within the Active Directory structure.
Most current authentication services depend on a system of parameters defined in the ISO X.500 standard that defines a standardized way to keep a user and her attributes and permissions easily accessible. The X.500 standard is a comprehensive system, so much so that an X.500 directory is usually accessed using a lighter, simpler tool called Lightweight Directory Access Protocol (LDAP). This section describes X.500, and then discusses the use of LDAP, its applications, its problems, and its possibilities.
Email example
Perhaps the easiest way to gain appreciation for directory-based authentication is to consider the situation faced by email administrators in the days before LDAP and X.500. Imagine that a large company merges with another large company. Now imagine that the two companies use different email systems that are only nominally compatible. Every user must appear (have a mailbox) on each system, in order to log on. That means that two sets of administrators must frantically import the complete user list of the other company into each other’s systems. This also means, however, that each user ends up with two mail clients that must be checked frequently. Both halves of the new company will have a hard time efficiently communicating with each other, to say nothing of the confusion that will be faced by clients and customers.
Obviously, one way to simplify this situation is to import all users into one or the other mail system. This may not be the best approach, however, because email servers seem to operate in clusters that communicate amongst themselves according to users’ locations and system load. Migrating to one system or the other may force massive infrastructure changes and the possible interruption of services as the system is cut over. It may be easier just to scale up the systems on both sides and then sort it out later, using some kind of gateway servers to translate between the two systems.
Using an LDAP directory, however, all users appear in a common database that the system automatically replicates to login servers all over the network. Mail stores can be forwarded as users move from city to city. Changes to personal information, such as surnames, or changes in preferred salutation, or job title, can be updated in one place, and the change will propagate to wherever it is needed.
About X.500
ISO X.500 is an international standard. There are two outstanding features of X.500:
§ X.500 is object-based.
§ X.500 uses a hierarchical structure.
X.500 treats every listed computer and user as an object. Server “Framingham 12,” backup operator “tdiaz,” and System Admin “IMJasmine” are all objects. Every object has attributes. “Framingham 12” may have the IP address attribute of 200.16.212.12. User tdiaz has the attribute of belonging to the Backup Operator group. Admin Jasmin may have the firstname attribute of Ina and the lastname attribute of Jasmine. Ideally, the database schema for each class of object should be consistent. If there is a need to modify the schema to accommodate items of data from one company that are not present in the other, this should not be an unbearable task.
The second outstanding feature of X.500 is its hierarchical structure. Individuals and computers are given common names (CN). A common name is the name you or I might call something. Objects with common names are gathered into container objects called Organizational Units (OU). OUs are combined to form objects called organizations (O). The organizations in the hierarchy are grouped into objects called countries (C). Countries exist on the root, which is the top of the filesystem. This hierarchical structure is spelled out in Figure 3-3.
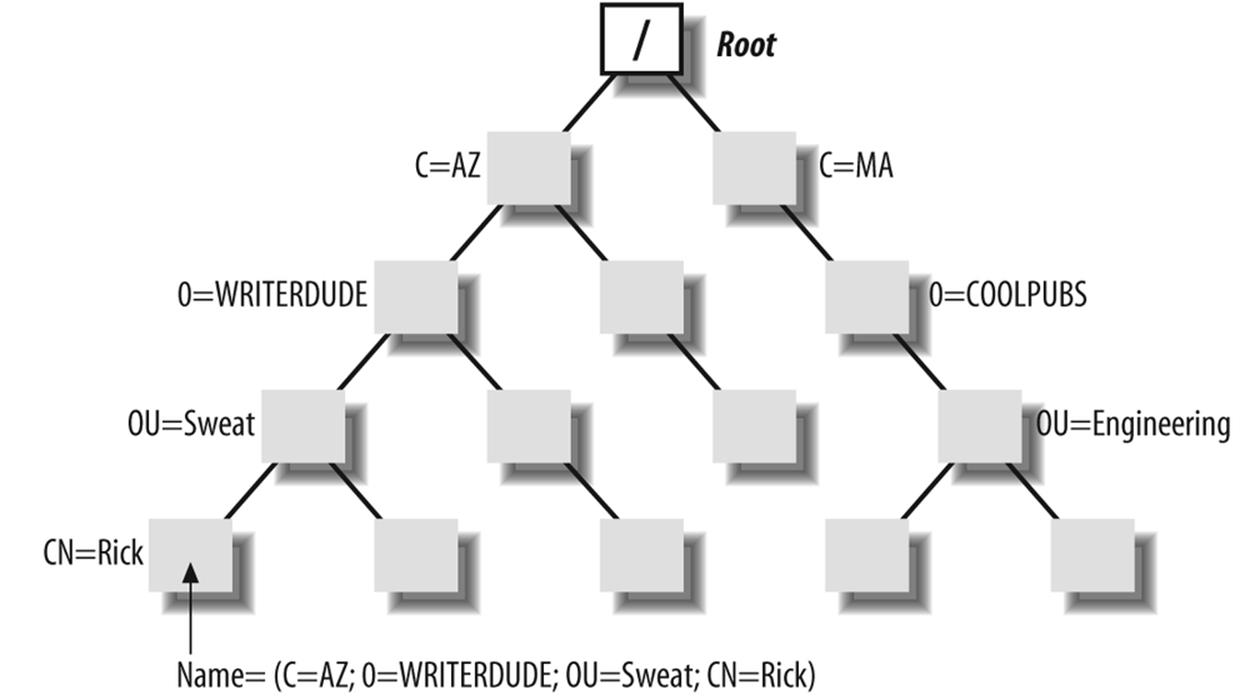
Figure 3-3. Discretionary access control with an access control list
The directory information tree (DIT) is not intended to be a general-purpose database. It is optimized for frequent reading but infrequent writing. It resembles a database, but the standard was developed to store information about objects relevant to telecommunications.
The advantage of the X.500 hierarchical system is that it standardizes the storage of files regarding user attributes and permissions. This makes it easier to share directory data or to copy it. Whether an object is a single user or an entire corporate division, copying addresses is as easy as directing that a copy of the required object be moved into the new directory tree, and all the subsidiary objects will follow. And once the copy gets moved, it is readily usable.
Each X.500 site has its own directory system. The administrators at each site need to keep only their own site’s data up to date. Users access the local X.500 system only. If the person being sought works at the local site, their entry will be found in the local X.500 system. If the person works at a remote site, the local X.500 system automatically contacts the remote X.500 system to retrieve the information. X.500 switching between local and remote access is transparent to the user. If the X.500 access to the remote sites proves to be too slow, the systems can be configured to automatically copy data to each other, and to regularly update the data. This process is called replication.
TIP
A key point of these directory-based systems is that they center on the individuals that wish to access the system, rather than on a static list of things such as passwords. Individual users are mapped in the directory according to where they fit into the larger scheme of organizations and enterprises.
The X.500 directory system can store lots of information, such as telephone and fax numbers, physical addresses, computer addresses, positions, responsibilities, and so on. The system can also be extended to store customized information. This large amount of data, and the inherent complexity of X.500, has led to the broad acceptance of a lightweight directory access protocol, called LDAP.
X.500 HISTORY
The X.500 directory is specified in the ISO/IEC 9594 multipart standard and in the ITU-T X.500 Series of Recommendations. There have been four versions of the X.500 standard.
1988 edition (First edition)
The first edition was issued as the multipart standard ISO/IEC 9594:1990 and as the CCITT X.500 (1988) Series of Recommendations.
1993 edition (Second edition)
The second edition was released as ISO/IEC 9594:1995 and as ITU-T X.500 (1993). This edition had some useful functions, such as shadowing of directory information, access control, and a significantly expanded information model and administrative capabilities.
1997 edition (Third edition)
The third edition was ISO/IEC 9594:1998 and ITU-T X.500 (1997). It provided several minor and some major extensions. It added a feature called contexts, which allowed information to be distinguished according to the context in which it was being accessed. Also added was OSI management of the directory. Important security features were also added and extended.
2001 edition (Fourth edition)
The fourth edition was issued as ISO/IEC 9594:2001 and as ITU-T X.500 (2001). This edition has several major extensions. It adds service management features, mapping-based matching, families of entries, and support for a pure TCP/IP stack.
Lightweight Directory Access Protocol
The Lightweight Directory Access Protocol (LDAP) standard defines a network protocol for accessing information from a directory. When it became apparent that directories would need to be standardized, IBM, Microsoft, Lotus, and Netscape agreed to support LDAP. LDAP was designed to adapt the complex X.500 directory system to the needs of modern networks, including the Internet. With LDAP, directory servers run on host computers on the Internet, which means that client programs that are LDAP-compliant understand the LDAP protocol, and can log on to the LDAP server and look up directory entries.
LDAP servers first index all the data in their entries. Then, when they process a query, they run the data through filters. These are short, user-configurable statements that describe what should be included or discarded. The filters weed out unneeded entries, leaving the user with just the selection she wants. It can be a person, a group, or an exotic set, such as “every user in the Pacific Northwest who says they have a portable 802.11 appliance.” Users can also select how much data they want returned in their queries so that their answer fits their needs, such as last name, first name, business title, email, and phone number.
The LDAP namespace
In the LDAP protocol, each listing in the directory is called an entry. Each entry can have one or more attributes. Each attribute has a type, and one or more values. Here’s an entry:
cn = mylittletestentry
objectclass = person
Where cn stands for commonName; mylittletestentry is the value of commonName for this entry; and the entry is given a type by use of an objectClass attribute.
The system and users tell one entry from another by giving it a name. Entries are named by one of their attributes. cn=mytestentry is this entry’s relative distinguished name (RDN).
Hierarchy
The LDAP namespace, like X.500, is hierarchical. This means that the full name of an object must include the path of the object. This full name is called the distinguished name (DN). (It may help to think of “distinguished” in this case as meaning “fully and uniquely identified” rather than “outstanding, noteworthy, or gray-haired.”)
LDAP storage capabilities
Almost anything can be stored in an X.500 directory. This can include text, ID photographs, biometric information used for identification and authentication, web addresses, FTP addresses, and other pointers. However, the more information is stored, the more memory is required.
Different types of data are held in attributes of different types. Each attribute type has a particular syntax. User-defined attributes, syntaxes, and object classes, make it possible for security administrators to make the directory fit their needs precisely.
LDAP is particularly useful in situations where the Internet is an integral part of the network or its authentication scheme. LDAP contains protocols that allow it to be self-replicating over multiple sites. These updates travel over the network as if they were regular network traffic.
Identity Management
One would think that with X.500 and LDAP, that directory-based login had reached perfection. Such is not the case. What happens to a given user who must interact with four or five networks in the course of a day? The administrative burden is heavy, even just keeping up with all the logins and the required changes and rotations. The burden is shared by network administrators, who have to maintain several databases for user logins and keep them all in sync. It would be much easier if a user could be authenticated and authorized by one process in a single database, and then have the network generate appropriate logon tokens or certificates that could serve many purposes. This would roughly be the equivalent of the Microsoft Passport system, in which a single logon authenticates the user in many services.
This emerging trend in single-point authentication and authorization is called identity management, or sometimes federated identity management. It is called federated because it provides unification—one standard login serving across several different applications, say a network logon, telephone long distance accounting, an email password, and a PIN, to gain access to secured areas.
At the root of identity management is a human need to reduce the burden of tracking multiple passwords; an economic need to avoid supporting and maintaining several different databases for the same pool of people; and a legal need to protect the privacy of users who may have private information, such as emergency medical information or information on disabilities or health conditions, stored in company directories. For instance, a switch could ensure that employees who are visually handicapped will receive corporate email announcements in a format suitable for text-to-speech software.
Software and standards for building interoperable identity-management systems are evolving rapidly; for example, the Security Assertion Markup Language (SAML) provides a common path to share end-user credentials. An example of an early deployment of a SAML integration application is a project between Boeing and Southwest Airlines that gives the airline’s mechanics single sign-on, web-based access to repair manuals stored on Boeing’s corporate networks. Service Provisioning Markup Language (SPML) is another new protocol nearing ratification. It is important because it promises to integrate systems that provision user accounts.
Financial and legal pressures
Organizations today face increased regulatory pressure to protect user privacy, ensure the accuracy of corporate financial data, and audit and log their efforts to ensure compliance with new laws. The laws of greatest concern at present are the Sarbanes-Oxley Act (adherence to standards in financial record keeping), the Gramm-Leach-Bliley Act (protection of personal financial data), the Health Insurance Portability and Accountability Act (secure transmission and storage of medical records), the Family Educational Rights and Privacy Act (privacy of student records), and the U.S. Patriot Act (antiterrorism and law enforcement). In the United Kingdom, there is the U.K. Data Protection Act and Regulation of Investigatory Powers Bill, as well. Businesses are struggling to adapt to these sometimes sweeping changes, especially regarding issues of privacy. It is far easier to control personal information in one well-secured database than it is when protected information is spread over a series of disparate databases. As owners and executives wake up to the possibility of fines and perhaps even imprisonment for failure to heed these new laws, the executive visibility of advanced management and control of records and data increases in importance and funding.
Summary
This chapter began with an introduction of simple username/password authentication systems, and continued into various authentication and authorization systems, including RADIUS, TACACS, DIAMETER, and Kerberos. The development of authentication, authorization, and accounting system continued on to the directory-based systems, X.500 and LDAP. Finally, we discussed the wave of the future, identity management.
Proper passwords are an effective first layer in the organization’s security policy. It is not difficult to develop strong passwords and change them frequently, but users tend to resist the practice, or else subvert it by writing the passwords down and leaving them where they can be seen. Multifactor authentication schemes, including biometrics, promise to greatly increase the security of networks and facilities.
If the need for increased security is needed, tokens can be added to the login process. This multifactor authentication method adds yet another layer to the defense in depth concept. Other factors discussed included using one-time passwords, Kerberos, and biometrics as a secure means to be authenticated.
Current directory-based login systems offer authentication, authorization, and accounting. As multiple authentication databases merge into federated identity management systems providing single-point login, increasing amounts of private information about users can be incorporated into the login process.
All materials on the site are licensed Creative Commons Attribution-Sharealike 3.0 Unported CC BY-SA 3.0 & GNU Free Documentation License (GFDL)
If you are the copyright holder of any material contained on our site and intend to remove it, please contact our site administrator for approval.
© 2016-2026 All site design rights belong to S.Y.A.