Cyber Security Basics: Protect your organization by applying the fundamentals (2016)
Section Three: Respond
“What happens is not as important as how you react to what happens.”
Ellen Glasgow
Introduction
It’s not a matter of “if” but “when” a security incident will hit. It is just a matter of time. Even if an entity has been lucky enough not to experience a significant security incident to-date, the appropriate stance to take is that it will happen at some point. This perspective can help ensure preparations take place.
Of an alert, an event or an incident, an incident is the most severe kind of information security issue. The order of severity is as follows:
· Alert
· Event
· Incident
Every day there are hundreds to thousands of alerts generated by various security sensors. The priority of the alert, and the analysis performed on it, determines which of these alerts should be considered security events. Resource limitations prevent treating every alert as an event. Alerts should therefore be tuned so that the number of events a team responds to on a typical day does not exceed their capacity to do so.
There will be some events that are severe enough that they are escalated to incident status. This is not done lightly, as a typical security incident requires the focus of the entire team to stop the damage and bring systems back to the pre-incident state (which can take several hours or even days.) Declaring an incident should involve getting prior approval from leadership, and having a response plan available to effectively and efficiently address the issue.
This section covers what goes into the response and remediation of security events and incidents. If a security team operates under the assumption that a serious security incident will eventually take place, that team will make sure that they are prepared. Operating under the belief that the organization is immune to attack (or worse, that everything is 100% secure) provides only a false sense of security, and is a setup for certain failure.
Maturity levels are not included in this section.
3.1 Event Handling
Only a small percentage of security events get escalated to security incidents. The majority of events can be handled by an individual security analyst, versus requiring an entire team to respond. There is a wide variety of security events that a typical organization faces on a regular basis, such as the following.
|
Source of Alert(s) |
Event |
|
Data Loss Prevention (DLP) |
An employee emailed a PowerPoint presentation to someone outside of the organization. |
|
Intrusion Prevention System (IPS) |
Network activity was observed that matches the signature of a known attack. |
|
Virtual Private Network (VPN) Concentrator |
An employee created a VPN tunnel from a location where the organization has no employees. |
|
Wireless Access Point (AP) |
An unregistered device was detected in the vicinity of a wireless access point (AP). |
|
Host Based Anti-Virus (AV) |
A file that was downloaded that was identified as malicious and quarantined. |
|
Malware Prevention System (MPS) |
An email sent to an officer of the company had an attachment that was analyzed. The attachment was determined to have a malicious payload. |
|
Firewall |
Scans were observed from an IP address registered to a country in Asia. |
|
Proxy |
An employee was blocked from accessing a web site that is categorized as gambling. |
|
Web Application Firewall (WAF) |
A request to the organization’s web site was observed that contained Unicode characters in the request string. |
Table 3.1: There are many possible security events that an organization can experience in a typical day.
Sometimes there will be a burst of several to thousands of events within a very short period of time. Internet-based scans are an example, which happen all the time. Much of it is just the background noise of the Internet, and can generate a lot of alerts quickly. A lot of these types of alerts are never elevated to an event that needs to be handled. Sensors can be tuned to filter out or suppress low-severity alerts so that they don’t turn into security events that distract from more important higher-severity issues. Events can also be triggered based on the volume of certain alerts, as it could indicate a coordinated attack.
A playbook should be used to provide instructions on how to handle a security event. There will be several different playbooks, as there will be several different kinds of events a team will encounter. Part of the response to an event is to determine whether or not it is indeed noise that should be suppressed to prevent similar events from being generated in the future. As attack methods constantly change and evolve, the security team should also constantly review its playbooks to ensure they continue to be relevant and effective.
3.1.1 Use Cases
A security team may be approached by other individuals and business units, asking for them to provide security monitoring, such as for a new application or system they are bring on-line. This request could be driven by regulatory requirements that need to be met. Simply requesting that Security “provide security monitoring” is an inadequate request, however. This is known as “throwing it over the fence.” The security team probably knows very little about the new system or software, and how to respond to many of the alerts it generates. In other words, it is not as simple as just saying “here, monitor this.”
Often, the security team is not the subject matter expert (SME) of systems and apps that live outside of security. To bridge this knowledge gap, included with the “hand off” should be use cases that are provided by the asset owner and/or SME. Each use case is a document for each alert the system may generate and the corresponding response that should be taken. For example: “If you see alert x, do the following…” Table 3.2 is an example use case document.
|
Request ID |
Acc001 |
|
Date of request |
11/03/2015 |
|
Requesting individual/unit |
Accounting |
|
Systems affected |
Ledger system |
|
Alert or event |
If a user creates invoice, then attempts to pay the same invoice, this is a conflict of interest. An alert should be generated and received by the security operations center. |
|
Request response to be taken |
Security should contact the manager of Accounting team. If the manager is not available, then the V.P. of Accounting should be notified. |
|
Requesting individual/unit signature |
Eric Delarosa, V.P. of Accounting |
|
Security team acceptance signature and date |
David Thompson, Manager of the Security Operations Center |
Table 3.2: Use Cases should be documented using a standard form to ensure all required information is collected. This helps ensure that adequate monitoring is provided for the customer.
In order to effectively monitor a system, Security needs to know “what bad looks like,” and members of the security team are often not the best ones to determine this. There are general security best practice of course that apply to any IT system, but for any application-specific monitoring, the app owners and SME’s need to define alerts and their corresponding responses.
3.1.2 Support Tickets
For a team of security analysts that are handling several to hundreds of events on a daily basis, communication and documentation are essential. This prevents the duplication of work, reduces confusion, and helps ensure that events are responded to in a correct, timely and consistent manner. Use of a formal ticketing system can facilitate documentation that can be consulted by other team members. This is just a partial list of what ticket handling documentation can provide:
· Educational material for other analysts to learn how to handle future events
· Materials to support the further investigation of events (documentation needs to be retained for an amount of time that is defined by the team and/or organization)
· Support for the research and correlation of other security events and incidents
· Identify commonalities across multiple events
The ticketing system already used by the organization should be leveraged if possible. There is a caveat to this however. Given that the content of these security tickets should be considered confidential (as it could provide information valuable to an attacker) this data should physically reside in a location that is secured with controls that ensure least privilege, confidentiality, and data integrity. For example, the tickets could be stored in a repository database that resides on a network segment that is protected a separate firewall.
|
Ticket ID |
Sec103 |
|
Date of Event |
11/17/2015 |
|
Description |
Trudy Joplin made a VPN connection from Athens, Greece at 12/29/2015 05:11 AM. |
|
Resolution |
Contacted Trudy’s manager who confirmed Trudy is out of the country on vacation until 01/03/2016. |
|
Handled By |
Alice Leigh |
Table 3.3: Support tickets provide useful information that can reduce data and work duplication.
Per the example in Table 3.3, by having the out of country VPN connection handled once and documented, the next time Trudy “dials in”, the analyst handing the alert can quickly see that it has already been investigated and resolved.
3.2 Incident Response
Security incidents are thankfully rare, as compared to alerts and events. An organization will experience many different types of security events of varying severity on a daily basis. On the rare occasion an event will be determined to be severe enough to be classified as an incident. When that happens, an Incident Response Plan (IRP) should be used. Criteria should be defined in advance to determine whether the event should be treated as an incident.
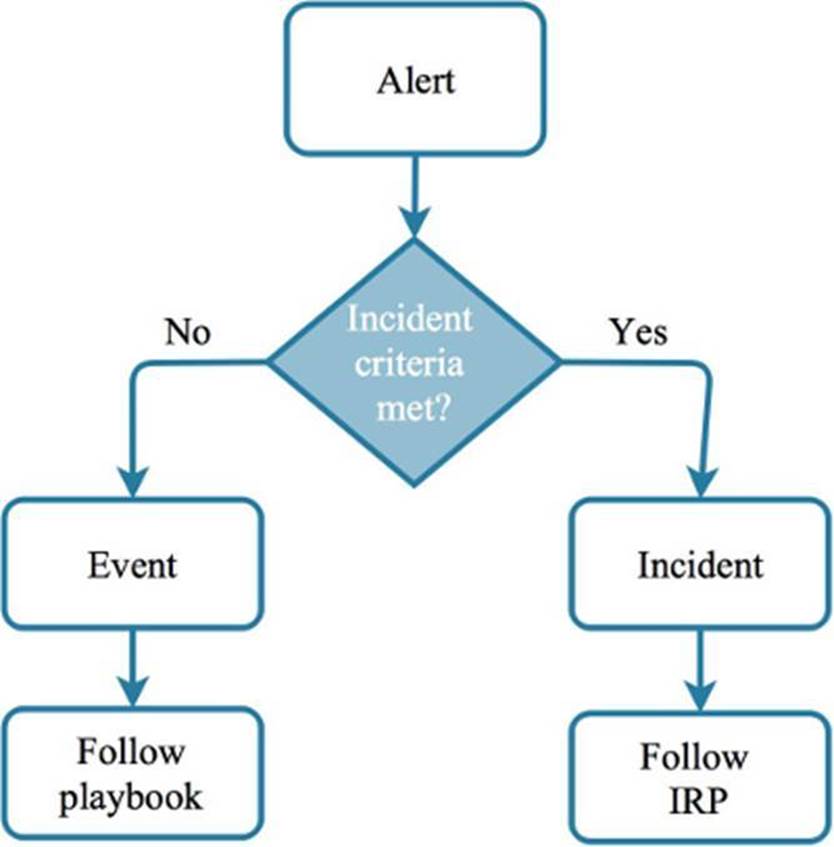
Figure 3.1: An alert has to meet certain criteria in order to be determined to be an incident. Otherwise it should be treated as an event.
How an organization defines security incidents versus events should be determined well before an IRP is used. The definition of what constitutes an incident should be clear, and based on quantifiable and objective criteria. Once defined, the next step is to create the corresponding incident response plans. After the plans have been created, they need to be made readily available to those who will be executing them. The confidentiality of the plan should also be enforced (following the rule of least privilege) so that access to the IRPs are restricted to only those who have a “need to know.”
Once created, the IRPs should be reviewed on a regular basis. The best method of identifying flaws or improvement opportunities with an IRP is to review and exercise the plan. It is possible that a review will conclude that a plan is no longer relevant or necessary, at which point it can be retired and removed from the IRP repository.
The following section discusses what goes into the creation and maintenance of an effective incident response plan.
3.2.1 Incident Response Plan (IRP)
An IRP should be developed well in advance of an actual incident. The worst time to develop a plan is at the time it is needed. To help decide which incidents to prepare for, choose from attacks that your organization is most at risk for. News coverage of past incidents suffered by other organizations can also help identify scenarios to prepare for.
There are several elements that go into an effective IRP. These include the roles played by different members of the response team, the proper way to communicate updates about the incident as it is handled, and the resources that need to be immediately available to facilitate a quick response. The following discusses these elements in more detail.
3.2.1.1 Roles
Each individual on an Incident Response Team (IRT) should serve a specific function. Sometimes resource constraints cause an individual to serve more than one role. Either way, these are the functions that are provided by a well-defined IRT.
|
Role |
Description |
|
Coordinator |
The coordinator serves as the leader of the incident response team. As a conductor is to an orchestra, an IRT coordinator ensures that team members are fulfilling their roles, that the rhythm of the response is maintained, and that progress continues to move forward. The coordinator also ensures and that the team has the resources (technical and otherwise) needed for the duration of the response. The person serving this role needs to be able to pivot and perform quick thinking, as the incident response process may change directions several times until resolution. |
|
Scribe |
The scribe of the team is responsible for documenting everything that takes place throughout the incident response. The form of the documentation can be an electronic document used for later review, or a PowerPoint presentation slide displayed on a large screen for the entire team to view for updates. The documentation captured should be preserved for after-action analysis (to see what could be done better in the future) as well as potentially support investigations by law enforcement and/or the human resources (HR) department. |
|
Communicator |
This person is in charge of delivering throughout the incident response process. There are different kinds of people that require updates and information, such as the operations teams, leadership, executives, and customer support teams. The messages that are delivered need to be tailored to their respective audiences. Defining them, knowing what they need, and being aware of how to effectively communicate with them will serve the communicator well at the time of an actual incident. For smaller teams, the coordinator can also serve as the communicator. |
|
Analyst(s) |
There may be more than one analyst on a response team, each focused on a different aspect of handling the incident. Focus areas can include malware analysis, root cause analysis (RCA), intelligence gathering, and identifying how to return operations to the pre-incident state. Analysis may also apply curative actions, such as deploying new AV signatures or creating scripts to remove malware from endpoints. The actions taken should be under the direction of the coordinator so as not to conflict with policy, destroy evidence, or ironically cause more damage as a result. |
Table 3.4: There are several different roles that make up an effective incident response team.
3.2.1.2 Communication
A communication tree is a list of individuals who should be notified and kept in the loop whenever an incident takes place. This is more than just a simple list of individuals to send emails to, however.
The message needs to be tailored to the recipient. For example, leadership will probably not want to be aware of the technical minutia that goes into root cause analysis (RCA). Similarly, not all the security analysts need to be aware of the updates that leadership is providing to the board of directors.
In addition to contact information for individuals, a well-defined communication tree will include the different types of information that should be communicated, and who the appropriate audience is for each. Finally, the messages should be consistent, understandable and relevant to whomever is receiving the update and status messages.
3.2.1.3 Resources
A team will need certain non-personnel resources available in order to respond to an incident, and will need them at the start of the response. Key resources include the computers needs to perform the work. These may be the same equipment that is uses for day-to-day operations (e.g. desktop computers), or, if there is a war room (a location dedicated to responding to security incidents), the equipment there needs to be operational and ready to use. The following is a list of equipment that typically should be provided to all responders:
· Desktop or laptop PCs
· Operating systems and applications with current patches and updates
· Network connectivity
· Phone
· Chat/instant messaging
· Access to the latest information about the incident, such as viewing a centrally displayed dashboard that the entire team can view to get updates
Regarding network connectivity, it is preferable to have access to an Internet connection that is not connected to the organization’s network. This network connection should also ensure non-attribution, as it will be used to perform research and intelligence gathering. It should be assumed that when an incident takes place, the adversary is monitoring the response in some fashion, such as watching for connection requests from the target to IP addresses owned by attacker, for example. Using a non-attributable Internet connection avoids providing useful information to the adversary who may be watching. Therefore, incident response analysts should have access to a device that is on the internal network in order to use the internal email, chat and other resources. In addition, responders should also have access to a separate Internet connection that is not associated with the production network.
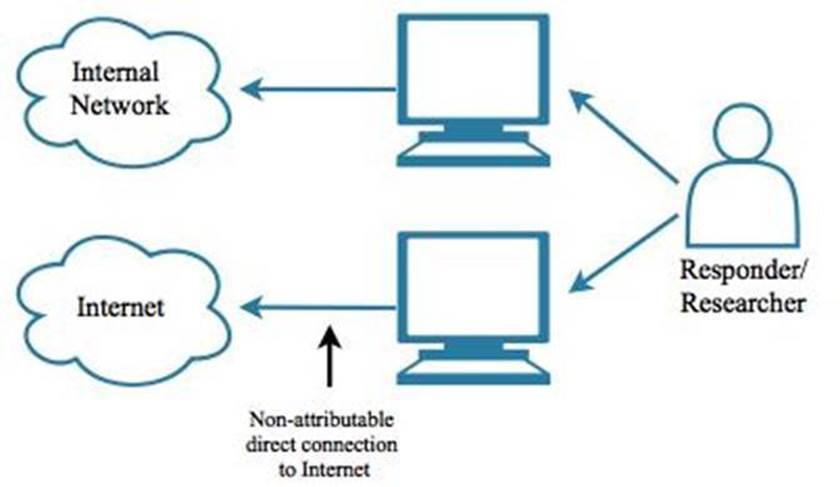
Figure 3.2: At least one response PC needs a non-attributable Internet connection for researching the attack and the attacker.
These resources should be tested periodically to ensure that they are ready at the time they are needed. A response should not be delayed because a computer is not working correctly, or because network changes are needed to provide the correct connectivity.
3.2.2 Data Preservation
It should be assumed that the data collected from an incident will be requested at a later date by law enforcement in order to support a legal investigation. The data collected from the incident may need to be used as evidence that something did or did not occur, or that someone (or some nation state) is or is not responsible for a criminal and/or damaging act.
In order for data to be admissible as evidence, it has to be credible. The integrity of the data needs to stand up to scrutiny. There should no doubt about whether the data has been tampered with since its creation. Even a reasonable doubt, such as the data owner cannot prove the integrity was maintained throughout the chain of custody, could make the data inadmissible.
Therefore, a data handling process should be defined and followed to support this requirement. Documentation surrounding any data movement, from the time the data was created, should be used. The handling of the documentation also needs to follow a strict process to ensure its unquestionable integrity.
|
ID |
E005 |
|
Data Description |
Log files from HR database |
|
Documented By |
Bruce Shaffer |
|
Filename(s) |
hr_11172015_1.log |
|
Created |
12/17/2015 0600 GMT to 12/17/2015 1300 GMT |
|
Details on Storage |
Copied from server hrmongo03 and burned to DVD on 12/17/2015 1530 by Bruce Shaffer. Used SFTP to transfer files from server to desktop (secwin42). |
Table 3.5: Data artifacts should be documented to ensure their integrity is without doubt. A data tracking form can be used for this purpose.
Forensic analysis may also need to be performed on the devices that were involved in the incident. In that case, these devices should also be treated as future evidence, and so a formal process should be defined and used to do the following:
· Safely remove device from the network
· Capture a snapshot of the memory and processes that are running
· Take an image of the hard drive before the malware can cover its tracks or otherwise destroy the ability to perform a forensic analysis of the device
Some variants of malware exists only in memory, so both a memory and hard drive capture is recommended. Forensic analysis is out of scope for this book, but be aware of the data preservation and retention policy for your organization to ensure that it is enforced by the incident response plan and process.
3.2.3 Table Top Exercises
A plan has little value if it has not been rehearsed. Running through an IRP, ahead of responding to an actual incident, provides several benefits. First, it validates the plan itself, making sure it is current, relevant, and accurate. Next, it provides practice to the team who will be executing the plan when an incident takes place. Finally, it provides the opportunity to identify areas of improvement and to adapt to an ever-changing threat environment. Every time a plan is exercised will yield improvement opportunities, thereby improving the quality of the plan.
A tabletop exercise is a scheduled meeting with the security team where a scenario is presented. This scenario is prepared ahead of time, should be realistic, and challenge the team to determine the best way to respond. As the team works through the scenario, someone should be taking notes, as what is documented may end up in the final incident response plan.
3.2.4 Lessons Learned
One of the most important phases of incident response is the after action review. Once the dust has settled and operations have been restored to the pre-incident state, a meeting should be set up with the team to review the notes (taken by the scribe). This is a great opportunity to go over the incident and identify changes that can be made to improve the response plan if the incident were to re-occur. Once updates to the plan have been made, add them to a centralized document repository that the entire team has access to (and few others), and run through it again in a future tabletop exercise.
3.3 Change Management
Change is inevitable. This is especially true of software and IT systems. Changes are necessary for a variety of reasons, including:
· Adding features
· Removing functionality
· Fixing bugs
· Installing patches
· Applying updates
· Mitigating vulnerabilities
Something that cannot be changed should not be on the production network. This is because there is always a chance that a security vulnerability or other problem will be found. And when it is, it needs to be updated as quickly as possible (ideally before it is exploited.)
When a change is performed, it should be done in a controlled manner that minimizes the chance that something else will break as a result. There are plenty of examples of software patches, intending to fix something, actually ended up breaking something.
To minimize the risk of something going wrong, and being able to quickly recover if it does, a formal change management process should be followed. There are several frameworks available, such as:
· Capability Maturity Model Integration (CMMI)
· National Institute of Standards and Technology (NIST)
· Information Technology Infrastructure Library (ITIL)
Taking the time to integrate a formal change management process, or at least borrow some best practices from established frameworks, will pay dividends in terms of stability, security, and less rework (such as having to back out changes.)
3.4 Summary
Very few security alerts turn into incidents. The majority will be treated as events, and so need to be handled accordingly with the use of playbooks. For incidents, the ability to properly and efficiently respond requires an incident response plan that is rehearsed and reviewed on a periodic basis. There will be more than one plan to cover different scenarios. How a team responds to a data exfiltration incident is going to be different from how to handle an email worm eating its way through employee inboxes.
The roles the team members serve, the communications tree to be used, and a list of the resources required are all part of a good IRP. Team members should be prepared to serve their required roles, the communications plan should be reviewed and updated, and the required resources should be ready to use and have the connectivity required at the time of the incident. The worst time to discover that something is missing or misconfigured is at the time incident response starts.
Execution of the plan should be done with the assumption that legal proceedings will be part of the aftermath. All data—log files, documentation, memory captures and data on storage devices—should be treated as if they will be evidence in a future legal proceeding such as an investigation by law enforcement. Data handling requirements should be included in the plan, and all team members should be made aware and reminded at the time of the incident. The data retention policy of the organization should also inform the procedures to be used for the preservations of artifacts involved in an incident response.
An incident is a great learning opportunity. After-action results should be reviewed by the team to identify what went right, and what can be improved. Performing a “lessons learned” exercise is an important part of a successful IRP. This allows the team to improve the plan for next time (and it should always be assumed that there will be a next time.) Some IRPs may never be used, but when they are, the team and the organization will be thankful for the advanced work that was done to prepare for it.
3.5 Terms and Definitions
The following are the terms that were discussed in this section.
|
Term |
Description |
|
After Action Review |
Meeting with the team to discuss how an incident or event was handled. This provides an opportunity to identify what worked well, what could be improved, and to update documentation, playbooks and plans. |
|
IRP |
Incident Response Plan. This is the plan used by the incident response team to respond to an incident. This plan should be prepared ahead of time, and exercised periodically. |
|
IRT |
Incident Response Team. This is the group of individuals tasked with being on the front line for responding to security incidents in support of protecting the organization from attack. |
|
Playbook |
Documented procedure to be used for handling security events. |
|
Pre-Incident State |
The environment as it was before a security incident started. |
|
RCA |
Root Cause Analysis. This is an analysis process used to determine the origin of an event or incident. |
|
SFTP |
Secure File Transfer Protocol. A method of transferring files that is more secure than the legacy File Transfer Protocol. |
|
SME |
Subject Matter Expert. An individual who is most knowledgeable about a system, software or process. |
|
War Room |
A location dedicated to responding to security incidents. |