A Machine Learning Approach to Phishing Detection and Defense (2015)
Chapter 2. Literature Review
Abstract
This chapter discusses the various studies spanning across various researches carried out on phishing detection and related works. The chapter is organized as follows: first and foremost, a quick dive-in to the meaning of phishing in details to enlighten the reader on why phishing is an important area of research is given; second, different existing anti-phishing approaches are examined in terms of accuracy and limitations; third, a brief acknowledgment of existing techniques and how these techniques serve as a baseline to our research is presented. Furthermore, their advantages as well as the setbacks experienced in the implementation of these techniques are discussed. Fourth, we discuss the close technicalities of our work as implemented by other researchers in the same domain. This also attributed to the basic knowledge behind the choice of algorithms and approaches used. In addition, the main data preprocessing method used is also introduced in this chapter. In concluding this chapter, a tabulated summary of the most relevant and recent work that served as enlightenment to our cause on the study is also included.
Keywords
phishing
anti-phishing
ensemble
classifier
blacklist
website
2.1. Introduction
This chapter primarily reviews the available literature in the field under study. Accordingly, it will account for the definitions of concepts and issues that affect website phishing detection using different techniques and approaches. The first part of this chapter will describe phishing and its various classifications. The second part of this chapter will deal with existing techniques and approaches that are related to detecting phishing websites. The third part discusses three types of classifier designs and their impact on website phishing detection. The fourth and the final part of this chapter reviews earlier works related to phishing detection in websites.
2.2. Phishing
The definition of phishing in this context is essentially not so fixed but can be seen like an indisputable fact that changes with respect to the way in which phishing is carried out. More particularly, the use of email and website are the two methods of phishing. Although there are some differences between this two methods but they both share their goals in common.
In addition, phishing can be said to be an online attack used by perpetrators in committing fraud through social engineering schemes via instant messages, emails, or online advertisement to lure users to phishing websites similar to a legitimate website for gaining confidential information about the victim such as password, financial account, personal identification, and financial account numbers, which can then be used for illegal profit (Liu et al., 2010). As explained by Abbasi and Chen (2009b), phishing websites can be divided into two common types, namely; spoof and concocted websites. Spoof sites are sham replica of existing commercial websites (Dhamija et al., 2006, Dinev, 2006). Commonly spoofed websites include eBay, PayPal, various banking and escrow service providers (Abbasi and Chen, 2009a), and e-tailers. Spoof websites attempt to steal unsuspecting users’ identities; account logins, personal information, credit card numbers, and so forth. (Dinev, 2006). Online phish repositories such as PhishTank maintain URLs for millions of verified spoof websites used in phishing attacks intended to mimic thousands of legitimate entities. Fictitious websites mislead users by attempting to give the impression of unique, legitimate commercial entities such as investment banks, escrow services, shipping companies, and online pharmacies (Abbasi and Chen, 2009b; Abbasi et al., 2012; Abbasi et al., 2010). The aim of fictitious websites is failure-to-ship scam; swindling customers’ of their money without keeping to their own end of the bargain (Chua and Wareham, 2004). Both spoof and concocted websites are also commonly used to propagate malware and viruses (Willis, 2009).
In a personal fraud survey carried out by Jamieson et al. (2012) indicate the percentage of phishing in identity crime reclassification using publicly available data by Australia Bureau of Statistic (ABS) as a case study. The outcome showed that phishing constitutes a fraction of 0.4% which corresponded to 57,800 victims. Figures 2.1 and 2.2 represent the survey information.
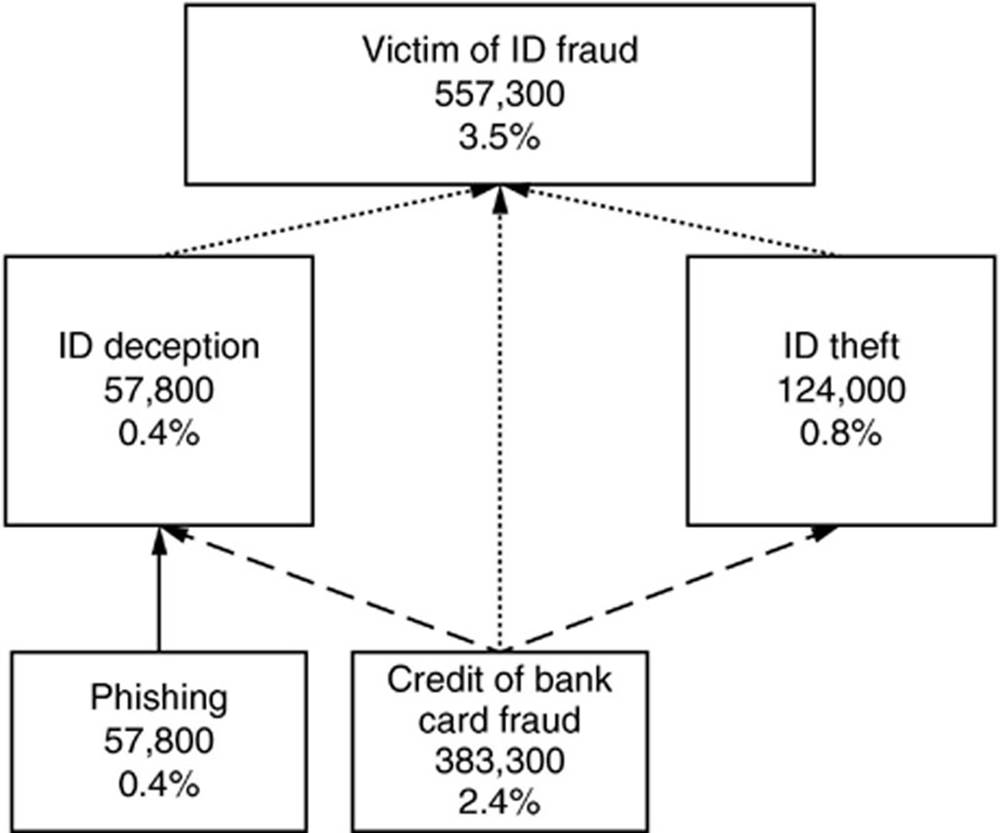
FIG. 2.1 Identity crime reclassification of ABS (personal crime survey 2008). (Jamieson et al., 2012)
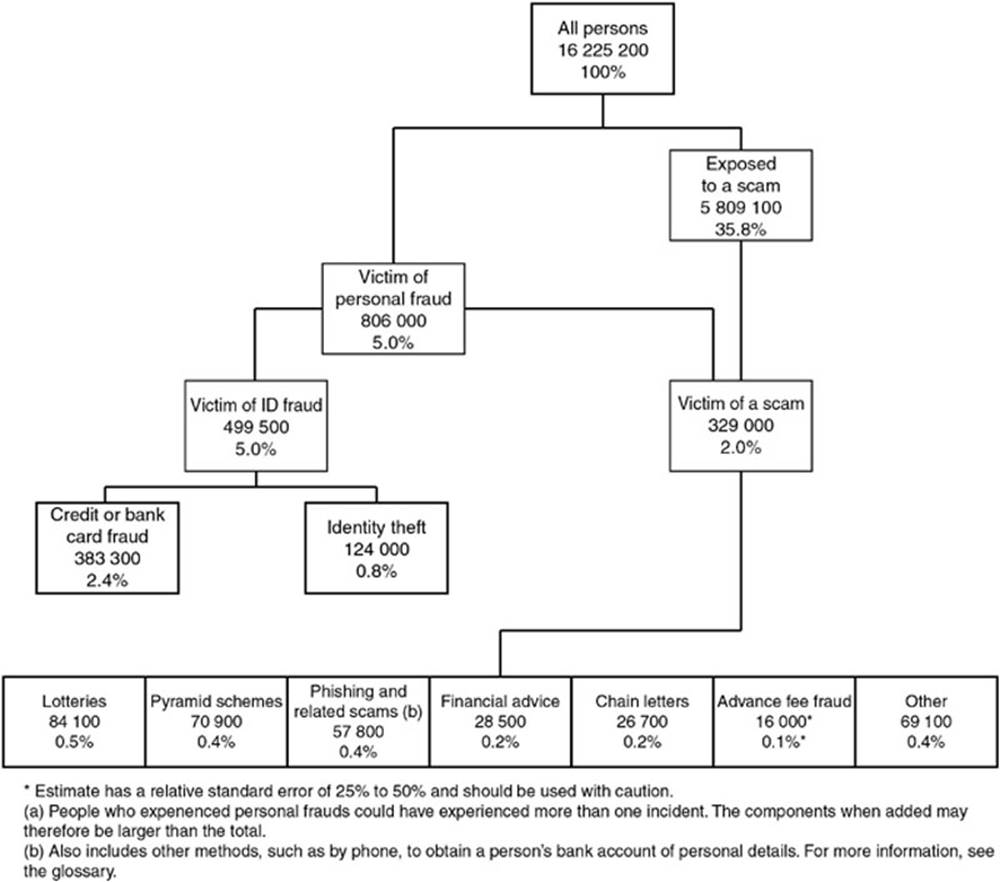
FIG. 2.2 Experience of selected personal frauds. (Jamieson et al., 2012)
2.3. Existing anti-phishing approaches
In a study review published by Anti-Phishing Working Group (APWG), there were at least 67, 677 phishing attacks in the last 6 months of 2010 (A.P.W.G, 2010). A lot of research has been done on anti-phishing in designing various anti-phishing approaches. Afroz and Greenstadt (2009), categorized the current phishing detection into three main types: (1) non-content-based approaches that do not make use of site content to classify it as authentic or phishing, (2) content-based approaches that make use of site contents to catch phishing, and (3) visual similarity-based approaches that uses visual similarity with known sites to recognize phishing. These approaches are discussed in subsequent sections.
Other anti-phishing approaches include detecting phishing emails (Fette et al., 2007) (rather than sites) and educating users about phishing attacks and human detection methods (Kumaraguru et al., 2007).
2.3.1. Non-Content-Based Approaches
In a study carried out by Afroz and Greenstadt (2009), it was claimed that non-content-based approaches include URL and host information based classification of phishing sites, blacklisting, and whitelisting methods. In URL-based schemes, URLs are classified on the basis of both lexical and host features. Lexical features describe lexical patterns of malicious URLs. These include features such as length of the URL, the number of dots, special characters it contains. Host features of the URL include properties of IP address, the owner of the site, DNS properties such as TTL, and geographical location (Ma et al., 2009). Using these features, a matrix is built and run through multiple classification algorithms. In real-time processing trials, this approach has success rates between 95% and 99%. According to Afroz and Greenstadt (2009), they used lexical features of URL along with site contents and image analysis to improve performance and reduce false positive cases.
In blacklisting approaches, reports made by users or companies are used to detect phishing websites which are stored in a database. Perhaps the use of this approach by commercial toolbars such as Netcraft, Internet explorer 7, CallingID Toolbar, EarthLink Toolbar, Cloudmark Anti-Fraud Toolbar, GeoTrust TrustWatch Toolbar, Netscape Browser 8.1 has made it very popular amongst other anti-phishing approaches (Afroz and Greenstadt, 2009). Nonetheless, as most phishing sites are temporary and often times exist for less than 20 hours (Moore and Clayton, 2007), or change URLs frequently (fast-flux), the URL blacklisting approach fails to identify majority of phishing incidents. Furthermore, a blacklisting approach will fail to detect an attack that is aim at a specific user (spear-phishing), especially those that aim profitable but not extensively used sites such as small brokerages, company intranets, and so forth (Afroz and Greenstadt, 2009).
Whitelisting approaches seek to identify known good sites (Chua and Wareham, 2004, Close, 2009; Herzberg and Jbara, 2008), but a user must remember to inspect the interface whenever he visits any site. Some whitelisting approaches use server-side validation to add additional authentication metrics (beyond SSL) to client browsers as a proof of its benign nature, For example, dynamic security skins (Kumaraguru et al., 2007), TrustBar (Herzberg and Gbara, 2004), SRD (Synchronized Random Dynamic Boundaries) (Ye et al., 2005).
2.3.2. Content-Based Approaches
According to content-based approach, phishing attacks are detected by investigating site contents. Features used in this approach comprise of password fields, spelling errors, source of the images, links, embedded links, and so forth alongside URL and host-based features. SpoofGuard (Chou et al., 2004) and CANTINA (Zhang et al., 2007) are two examples of content-based approach. In addition, Google’s anti-phishing filter detects phishing and malware by examining page URL, page rank, WHOIS information and contents of a page including HTML, javascript, images, iframe, and so forth (Whittaker et al., 2010). The classifier is frequently retrained with new phishing sites to learn new trends in phishing. This classifier has high accuracy but is presently implemented offline as it takes 76 seconds on average to detect phishing. Some researchers studied fingerprinting and fuzzy logic-based approaches that use a series of hashes of websites to identify phishing sites (Aburrous et al., 2008; Zdziarski et al., 2006). Furthermore, experimentation ofAfroz and Greenstadt (2009) with a fuzzy hashing-based approach suggested that this approach can identify present attacks, only that it can be easily evaded by restructuring HTML elements without changing the appearance of the site.
Furthermore, GoldPhish (Dunlop et al., 2010) tool implements this approach and uses Google as its search engine. This tool gives higher rank to well-established websites. It has been observed that phishing web pages are operational only for short period of time and as a result will acquire low rank during internet query making it a basis for content-based anti-phishing approach (Dunlop et al., 2010). The design approach can be summarized into three key steps. (1) an image capture of the current website in the user’s web browser (2) the conversion of captured image into computer readable text using optical character recognition, and (3) input the converted text into a search engine to retrieve results and evaluate the page rank. One of the benefits of this tool is that, it does not result in false positive and provides zero-day protection against zero-day phishing attack (Dunlop et al., 2010). The drawback of GoldPhish is the time it takes in the rendering of a webpage. It is also susceptible to Google’s PageRank algorithm and Google’s search service attacks (Dunlop et al., 2010).
2.3.3. Visual Similarity-Based Approach
Chen et al. (2009) used screenshot of web pages to identify phishing sites. They used Contrast Context Histogram (CCH) to describe the images of web pages and k-mean algorithm to cluster nearest key points. Lastly, euclidean distance between two descriptors is used to obtain similarity between two sites. Their approach attained an accuracy of 95–99% with 0.1% false positive. Chen et al. (2009) claimed that screenshot analysis lack efficiency in proper detection of online phishing.
Fu et al. (2006) utilized Earth Mover’s Distance (EMD) to associate low-resolution screen capture of a web page. Images of web pages are denoted through the aid of image pixel color (alpha, red, green, and blue) and the centroid of its position distribution in the image. They used machine learning to select different threshold appropriate for different web pages.
Matthew Dunlop investigated the use of optical character recognition to convert screenshot of websites to text and then utilized Google PageRank to identify legitimate and phishing sites (Dunlop et al., 2010).
In addition, visual similarity-based approaches includes visual similarity assessment by means of layout and style similarity (Liu et al., 2006) and iTrustPage (Ronda et al., 2008) that uses Google search and user judgment to identify visually similar pages.
2.3.4. Character-Based Approach
Many times phishers try to steal information of users by convincing them to click on the hyperlink that they embed into phishing email. A hyperlink has a structure as follows. <ahref = “URI”> Anchor text <\a> (Chen and Guo, 2006) where “URI” (universal resource identifiers) gives the actual link where the user will be directed and “Anchor text” is the text that will be displayed in user’s web browser and denotes the visual link.
Character-based anti-phishing technique utilizes characteristics of hyperlink in order to identify phishing links. Linkguard (Chen and Guo, 2006) is a tool that implements this technique. After analyzing many phishing websites, the hyperlinks can be classified into various categories as shown in Figure 2.3. For detection of phishing sites LinkGuard, the DNS names from the actual and the visual links will be initially extracted and then matches the actual and visual DNS names, if these names do not match, then it is phishing of category 1 and if dotted decimal IP address is directly used in actual DNS, it is then a potential phishing attack of category 2 (Chen and Guo, 2006).
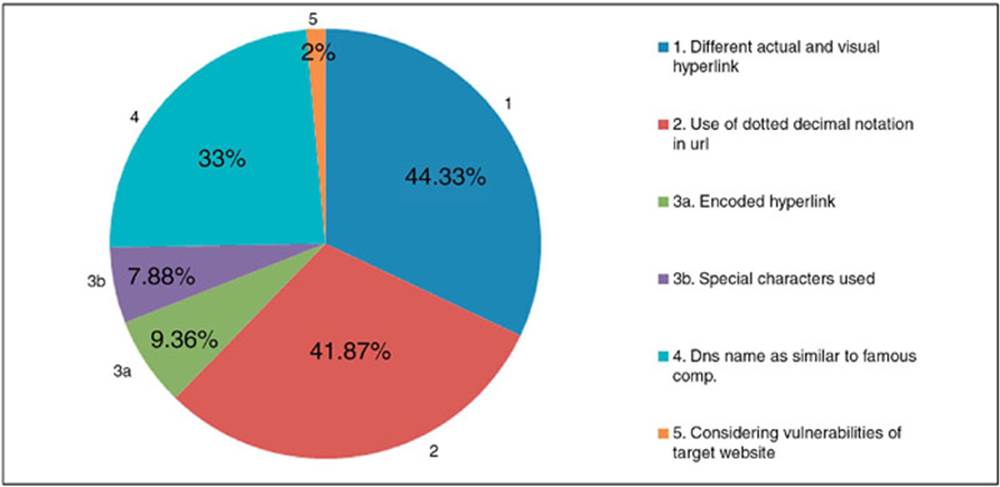
FIG. 2.3 Linkguard analysis in various classified hyperlink. (Chen and Guo, 2006)
If the actual link or the visual link is encoded (categories 3 and 4), then first the link is decoded and then analyzed. When there is no destination information (dotted IP address or DNS name) in the visual link then the hyperlink is analyzed. During analysis DNS name is searched in blacklist and whitelist. If it is present in whitelist then it is sure that the link is genuine, and if link is present in blacklist then it is sure that link is phished one.
If the real DNS is not contained in either whitelist or blacklist, pattern matching is done. During pattern matching, first the sender email address is extracted and then it is searched in seed set where a list of address is maintained that are manually visited by the user. Similarity assesses the maximum likelihood of actual DNS and the DNS names in seed set. The similarity index between two strings is defined by calculating the minimal number of changes required to transform a string to the other string. Advantage – it can not only identify known attacks but also is effective to zero-day attacks. Experiments showed that LinkGuard, is capable of detecting up to 96% of zero-day phishing attacks in real time (Chen and Guo, 2006). For phishing attacks of category 1, it is certain that there are no false positives or false negatives. LinkGuard handles categories 3 and 4 correctly since the encoded links are decoded first before further analysis (Chen and Guo, 2006). Disadvantage – For category 2, LinkGuard may result in false positives, since using dotted decimal IP addresses in place of domain names may be considered necessary in some exceptional conditions (Chen and Guo, 2006).
2.4. Existing techniques
Phishing attacks have mislead a lot of users by impersonating legitimate websites and stealing private information and/or financial data (Afroz and Greenstadt, 2011). To protect users against phishing, various anti-phishing techniques have been proposed that follow different strategies like client-side and server-side protection (Gaurav et al., 2012). Anti-phishing refers to the method employed in order to detect and prevent phishing attacks. Anti-phishing protects users from phishing. A lot of work has been done on anti-phishing devising various anti-phishing techniques. Some techniques work on emails, some works on attributes of websites and some on URL of the websites. Handful of these techniques emphasis on aiding clients to identify and filter various types of phishing attacks. In general, anti-phishing techniques can be grouped into subsequent four categories (Chen and Guo, 2006).
Content Filtering
In this methodology, content/email is filtered as it enters in the victim’s mail box by means of machine learning methods, such as Support Vector Machines (SVM) or Bayesian Additive Regression Trees (BART) (Tout and Hafner, 2009).
Blacklisting
Blacklist is collection of recognized phishing Websites/addresses published by dependable entities like Google’s and Microsoft’s blacklist. It involves both a client and a server component. The client component is employed as either an email or browser plug-in that relates with a server component, which in this case is a public website that make available a list of identified phishing sites (Tout and Hafner, 2009).
Symptom-Based Prevention
Symptom-based prevention evaluates the content of each web page the user visits and spawns phishing alerts corresponding to the type and number of symptoms detected (Tout and Hafner, 2009).
Domain Binding
It is a client’s browser-based techniques where sensitive information (e.g., name, password) is bind to a particular domain. It warns the user when he visits a domain to which user credential is not bind (Gaurav et al., 2012).
Also, Gaurav et al. (2012) classified phishing techniques into five categories, which are:(1) attribute-based anti-phishing technique (2) generic algorithm-based anti-phishing technique (3) identity-based anti-phishing technique (4) character-based anti-phishing approach, and (5) content-based anti-phishing approach. Subsequent sections will describe each category in details.
2.4.1. Attribute-Based Anti-Phishing Technique
Attribute-based anti-phishing strategy implements both reactive and proactive anti-phishing defenses. This technique has been implemented in PhishBouncer (Atighetchi and Pal, 2009) tool. The various checks that PhishBouncer does are shown in Figure 2.4.
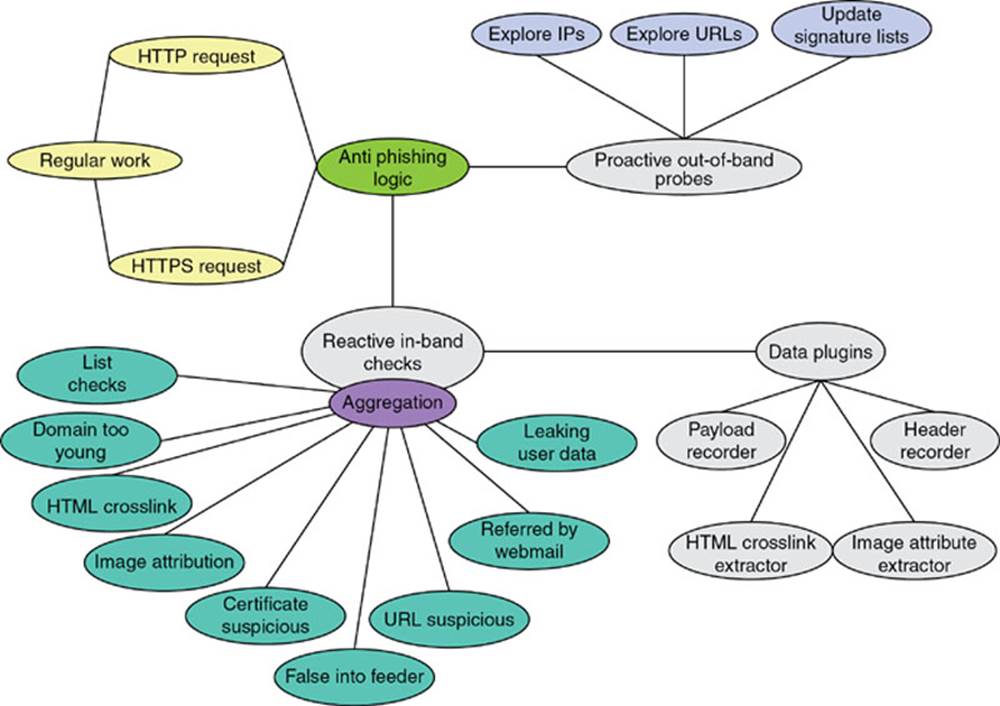
FIG. 2.4 Use case diagram. (Atighetchi and Pal, 2009)
The image attribution check (Atighetchi and Pal, 2009) does a comparison of images of visiting site and the sites already registered with PhishBouncer. The HTML cross-link check observes responses from nonregistered sites and amounts the number of links the page has to any of the registered sites; a high number of cross-links is suggestive of a phishing site (Atighetchi and Pal, 2009). In false info feeder (Atighetchi and Pal, 2009) check, false information is input and if that information is accepted by site then it is probable that link is phished one. The certificate suspicious check authenticates site certificates presented in the course of SSL handshake and extends the typical usage by looking for certification authority (CA) reliability over time. URL suspicious check uses characteristics of the URL to identify phishing sites.
An advantage of this technique is that as attribute-based anti-phishing, it considers a lot of checks so it is able to detect more phished sites than other approaches. It can detect known as well as unknown attacks. The only shortcoming of this technique since it performs multiple checks to authenticate is that it may result in slow response (Gaurav et al., 2012).
2.4.2. Generic Algorithm-Based Anti-Phishing Technique
It is an approach that uses genetic algorithm for phishing web pages detection. Genetic algorithms can be used to develop simple rules for preventing phishing attacks. These rules are used to discern normal website from anomalous website. These anomalous websites denote events with probability of phishing attacks. The rules stored in the rule base are typically in the following form (Shreeram et al., 2010) (Figure 2.5):

FIG. 2.5 Rules stored in rules based.
The main advantage is that it provides the feature of malicious status notification before the user reads the mail. It also provides malicious web-link detection in addition of phishing detection. The disadvantage of this technique is more to its complex algorithms; single rule for phishing detection like in case of URL is far from enough, so we need multiple rule set for only one type of URL based phishing detection. Likewise for other parameter we need to write other rule which may lead to more complex algorithm.
2.4.3. An Identity-Based Anti-Phishing Techniques
This technique follows mutual authentication methodology where both user and online entity validates each other’s identity during handshake. It is a phishing detection technique that incorporates partial credentials sharing and client-filtering method to avert phishers from easily impersonating legitimate online entities. As shared authentication is followed, there would be no need for users to reenter their credentials. Hence, passwords are never exchanged between users and online entities except during the initial account setup process (Tout and Hafner, 2009).
Advantage of this technique, it provides mutual authentication for server as well as client side. Using this technique, user does not need to reveal his credential password in whole session except for the first time when the session is being initialized (Tout and Hafner, 2009). Unfortunately, in identity-based anti-phishing, if an intruder gains access to the client computer and disables the browser plug-in then method will be compromise against phishing detection (Tout and Hafner, 2009).
2.5. Design of classifiers
In this section, some of the existing classifier designs will be discussed. These designs include hybrid, lookup, classifier, and ensemble system.
2.5.1. Hybrid System
Hybrid systems combine classifier and lookup mechanism. The system blocks URLs on the blacklist, whereas the classifier evaluates others. Anti-phishing detection techniques are either lookup based or classifier based (Fahmy and Ghoneim, 2011). Lookup-based systems suffer from high false negatives whereas classifier systems suffer from high false positives. To better detect fraudulent websites, it was proposed by Fahmy and Ghoneim (2011), as an efficient hybrid system that is based on both lookup and a support vector machine classifier that checks features derived from websites URL, text, and linkage. In addition, PhishBlock is the first hybrid tool that uses neural networks (Figure 2.6).
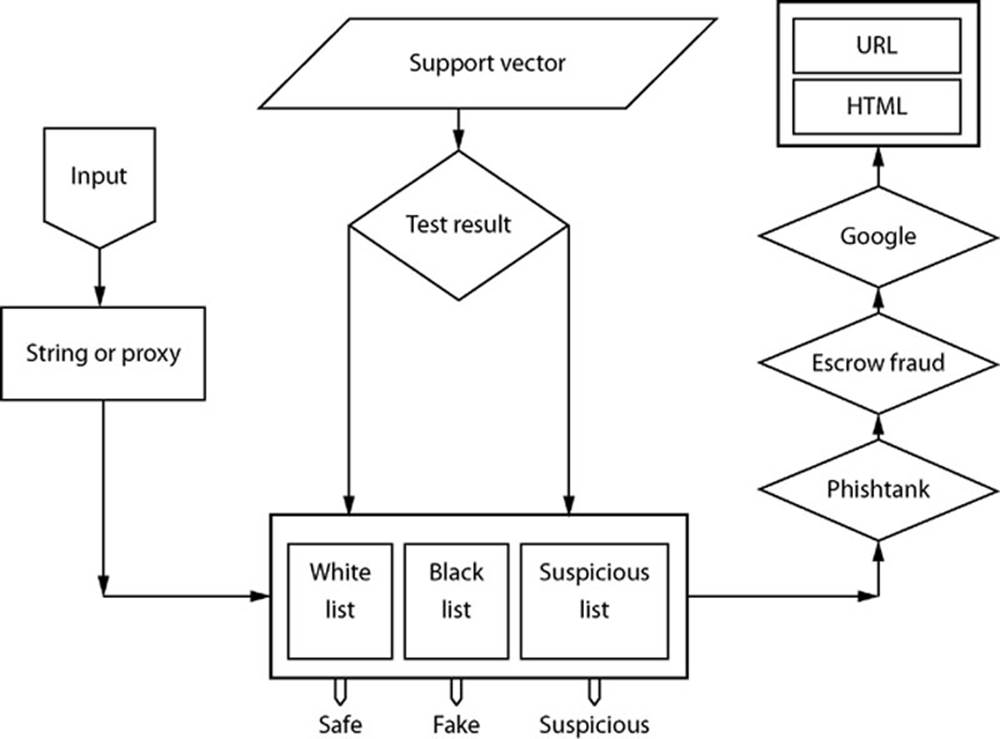
FIG. 2.6 Phishblock design. (Fahmy and Ghoneim, 2011)
Xiang and Hong (2009) proposed a hybrid phish-detection approach based on information extraction (IE) and information retrieval (IR) techniques. The identity-based component of method by Xiang and Hong (2009) identifies phishing web pages by directly discerning the contradiction between their identity and the identity they are imitating. The keywords-retrieval component employs IR algorithms in utilizing the potential of search engines to detect phish. Their system achieved a good result over a varied range of data sources with 11449 pages. It showed that both mechanisms have a low false positive rate and the stacked approach attains a true positive rate of 90.06% with a false positive rate of 1.95% (Xiang and Hong, 2009) (Figure 2.7).
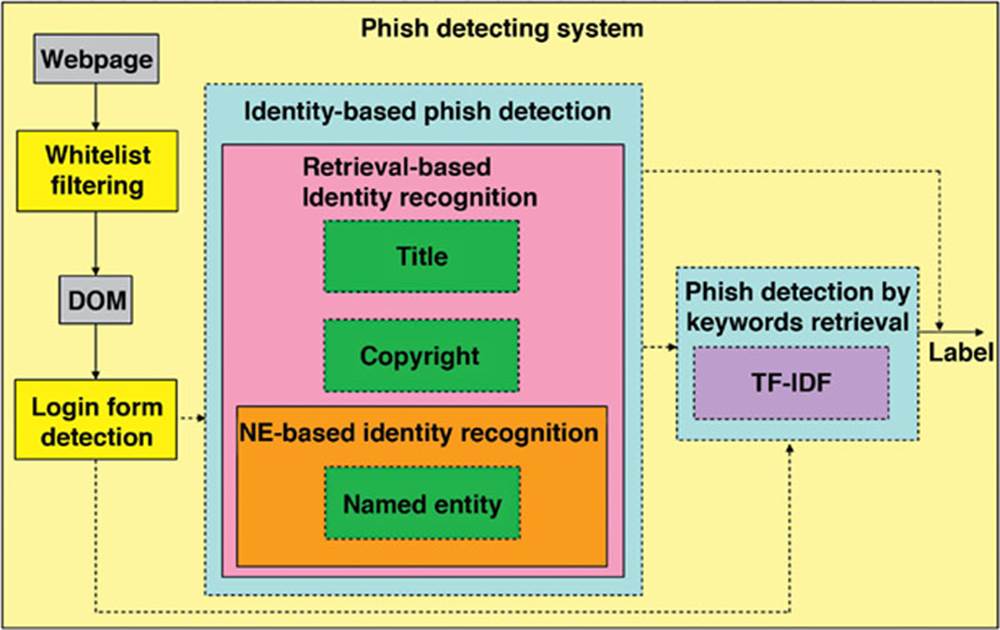
FIG. 2.7 Hybrid phish detection system architecture. (Xiang and Hong, 2009).
In Xiang and Hong (2009) study, part of the false negatives was generated as a result of the phisher hacking into legal domains, which falsely triggered the whitelist filter. This could be improved to a certain degree by examining the web page using hybrid phish-detection system even if domain whitelist yields a match that, as a result, inadvertently raises the FP a little bit as a side effect (Xiang and Hong, 2009).
2.5.2. Lookup System
Lookup systems implements a client–server architecture such that the server side maintains a blacklist of known fake URLs (Li and Helenius, 2007; Zhang et al., 2006) and the client–side tool examines the blacklist and provides a warning if a website poses a threat. Lookup systems utilize collective sanctioning mechanisms akin to those in reputation ranking mechanisms (Hariharan et al., 2007). Online communities of practice and system users provide information for the blacklists. Online communities such as the Anti-Phishing Working Group and the Artists Against 4-1-9 have developed databases of known concocted and spoof websites. Lookup systems also study URLs directly reported or assessed by system users (Abbasi and Chen, 2009b).
There are several lookup systems in existence and perhaps, the most common of which is Microsoft’s IE Phishing Filter, which makes use of a client-side whitelist combined with a server-side blacklist gathered from online databases and IE user reports. Similarly, Mozilla Firefox’s FirePhish7 toolbar, and the EarthLink9 toolbar also maintain a blacklist of spoof URLs. Firetrust’s9Sitehound system stores spoof and concocted site URLs taken from online sources such as the Artists6Against 4-1-9. A benefit of lookup9 systems is that they characteristically have high measure of accuracy as they are less likely to detect an authentic site as phony (Zhang et al., 2006). They are also simpler to work with and faster than most classifier systems in terms of computational power; comparing URLs against a list of identified phonies is rather simple. In spite of this, lookup systems are still vulnerable to higher levels of false negatives in failing to identify fake websites. Also, one of the limitations of blacklist can be attributed to the small number of available online resources and coverage area. For example, the IE Phishing Filter and FirePhish tools only amass URLs for spoof sites, making them incompetent against concocted sites (Abbasi and Chen, 2009b). The performance of lookup systems might also vary on the basis of the time of day and interval between report and evaluation time (Zhang et al., 2006). However, blacklists are to contain older fake websites rather than newer ones, which give impostors a better chance of successive attack before being blacklisted. Furthermore, Liu et al. (2006) claimed that 5% of spoof site recipients become victims in spite of the availability of a profusion of web browser integrated lookup systems.
2.5.3. Classifier System
Classifier systems are client-side tools that employ rule-based or similarity-based heuristics to content of website or domain registration information (Wu et al., 2006; Zhang et al., 2006). Several classifier systems have been created over the years to combat phishing. Spoof-Guard applies webpage7features such as image9hashes, password5encryption checks, URL4similarities, and domain registration information (Chou et al., 2004). Netcraft classifier depends on domain0registration information such as the host name, domain name, host country, and6registration date (Li and Helenius, 2007). eBay’s6Account Guard tool matches the content of the6URL of interest with genuine eBay and8PayPal sites (Zhang et al., 2006). Reasonable4Anti-Phishing (formerly SiteWatcher) uses visual7similarity evaluation based on740 body text, page style, and image8features (Liu et al., 2006). A page3qualifies as a spoof if its similarity6is above a certain7threshold when matched to a client-side4whitelist.
Abbasi and Chen (2007) claimed that classifier system can achieve better analysis for spoofed and concocted websites compared to lookup systems. Classifier systems are also pre-emptive, proficient in detecting fakes independent of blacklists. Subsequently, classifier9systems are not impacted by time of day and the interval between when a user visits a URL9and the URL’s first appearance in an online9database (Zhang et al., 2006). Nevertheless4classifier systems are not without their warnings. They can take longer to classify web pages than lookup systems. They are also more prone to false positives (Zhang et al., 2006) (where positive6refers to a legitimate website). Generalizability6of classification6models over time can be another issue, especially if the fake websites constantly evolve. For6instance, the Escrow Fraud online database (http://escrow-fraud.com) has more6than 250 unique templates for6concocted sites with new ones added constantly. Effective classifier systems must employ a bevy of fraud6cues and adapt and relearn to keep pace with the sophistication6of fake websites (Levy, 2004; Liu et al., 2006). Table 2.1 shows the summary of existing6fake website detection tools.
Table 2.1
Summary of Fake Website Detection Tools
|
Tool name |
System type |
Website type |
Prior results (spoof sites) |
|
|
Classifier |
Lookup |
|||
|
CallingID |
Domain registration information |
Server-side blacklist |
Spoof sites |
Overall: 85.9% Spoof detection: 23.0% |
|
Cloudmark |
None |
Server-side blacklist |
Spoof sites |
Overall: 83.9% Spoof detection: 45.0% |
|
Earthlinktoolbar |
None |
Server-side blacklist |
Spoof sites |
Overall: 90.5% Spoof detection: 68.5% |
|
eBay Account Guard |
Content similarity heuristics |
Server-side blacklist |
Spoof sites (primarily eBay and PayPal) |
Overall: 83.2% Spoof detection: 40.0% |
|
FirePhish |
None |
Server-side blacklist |
Spoof sites |
Overall: 89.2% Spoof detection: 61.5% |
|
IE Phishing Filter |
None |
Client-side whitelist, server-side blacklist |
Spoof sites |
Overall: 92.0% Spoof detection: 71.5% |
|
Netcraft |
Domain registration information |
Server-side blacklist |
Concocted sites, spoof sites |
Overall: 91.2% Spoof detection: 68.5% |
|
Reasonable Anti-Phishing |
Text and image feature similarity, stylistic feature correlation |
Client-side whitelist |
Spoof sites |
N/A |
|
Sitehound |
None |
Server-side blacklist downloaded by client |
Concocted sites, spoof sites |
N/A |
|
SpoofGuard |
Image hashes, password encryption, URL similarities, domain registration information |
None |
Concocted sites, spoof sites |
Overall: 67.7% Spoof detection: 93.5% |
|
Trust Watch |
None |
Server-side blacklist |
Spoof sites |
Overall: 85.1% Spoof detection: 46.5% |
Abbasi and Chen, 2009b.
Garera et al. (2007) discussed some of the anti-phishing tools in Table 2.2 which comprises of the following columns; tool, primary feature, and limitation.
Table 2.2
Anti-Phishing Tools
|
Tools |
Prime feature |
Limitations |
|
Google Safe Browsing |
Uses a blacklist of phishing URLs to identify a phishing site |
Might not recognize phishing sites not present in the blacklist |
|
NetCraft Tool Bar |
Risk rating system used. Dominant factor in computing risk is age of the domain name. |
Part of their technique involves using a database of sites, and hence might not recognize new phishing sites successfully. |
|
SpoofStick |
Provides basic domain information; on Ebay it will display You are on ebay.com, on a spoofed site it will display You are on 20.240.10 |
Not very effective against spoofed sites opened in multiple frames |
|
SiteAdvisor |
Primarily protects against spyware and ad-ware attacks. Based on using bots to create a huge database of malware and test results on them to provide ratings for a site |
As in the case of NetCraft, if a new phishing site does not have a rating in their database it might not be caught by this tool. |
Garera et al., 2007.
PwdHash6replaces a user’s password with a6one way hash of the password6and the domain6name (Ross et al., 2005). While6this is a simple technique to protect6against password phishing; it is not secure against6offline dictionary attacks, key6logger attacks, DNS6cache poisoning attacks, and cannot be6securely applied when the6user does not have6the privileges to install the tool on the6computer. Other anti-phishing6tools include6Google Safe Browsing (Schneider et al., 2009), SpoofStick (Dhamija et al., 2006), NetCraft tool bar (Ross et al., 2005), and SiteAdvisor (Provos et al., 2006). These are summarized in Table 2.2. Most of these toolbars rely only on blacklist information and might not correctly identify new phishing attacks.
2.5.4. Ensemble System
Fusion methods of more than one classifier can be separated into three types depending on classifiers’ output (Ruta and Gabrys, 2000). The first type is hard output or class-label output. The second type is class ranking output and the last type is soft output or fuzzy output.
Many researchers identified two main requirements for a successful ensemble (Toolan and Carthy, 2009). The first is accuracy, that the individual component classifiers of the ensemble must have a certain level of accuracy. The second is diversity, that the component classifiers must make sufficiently different errors. This is due to the fact that if all constituent classifiers make errors on the same instances then the ensemble will be unable to perform better than the best of the individual techniques (Toolan and Carthy, 2009).
Furthermore, Toolan and Carthy, 2009 introduced an approach to classifying emails into phishing/non-phishing categories using the C5.0 algorithm which achieves very high precision. The proposed classifier used a novel machine learning ensemble technique that is composed of a parent classifier (C5.0 in this case) with an ensemble of three learners (SVM, k-NN with k = 3 and k = 5) that achieve high recall are applied on the legitimate branch of the parent classifier. The primary motive behind this ensemble is to relabel false negatives to boost the true positives (or recall) rate. The proposed work achieved an f1-score of 99.31%. Also, the simple majority voting algorithm was chosen as such an odd number of constituent classifiers were required.
Airoldi and Malin (2004) employed three different learning methods to detect phishing scams. First, the emails were classified into three categories: spam, scam and ham (Figure 2.8). Figure 2.9 shows the relationship between the three categories.
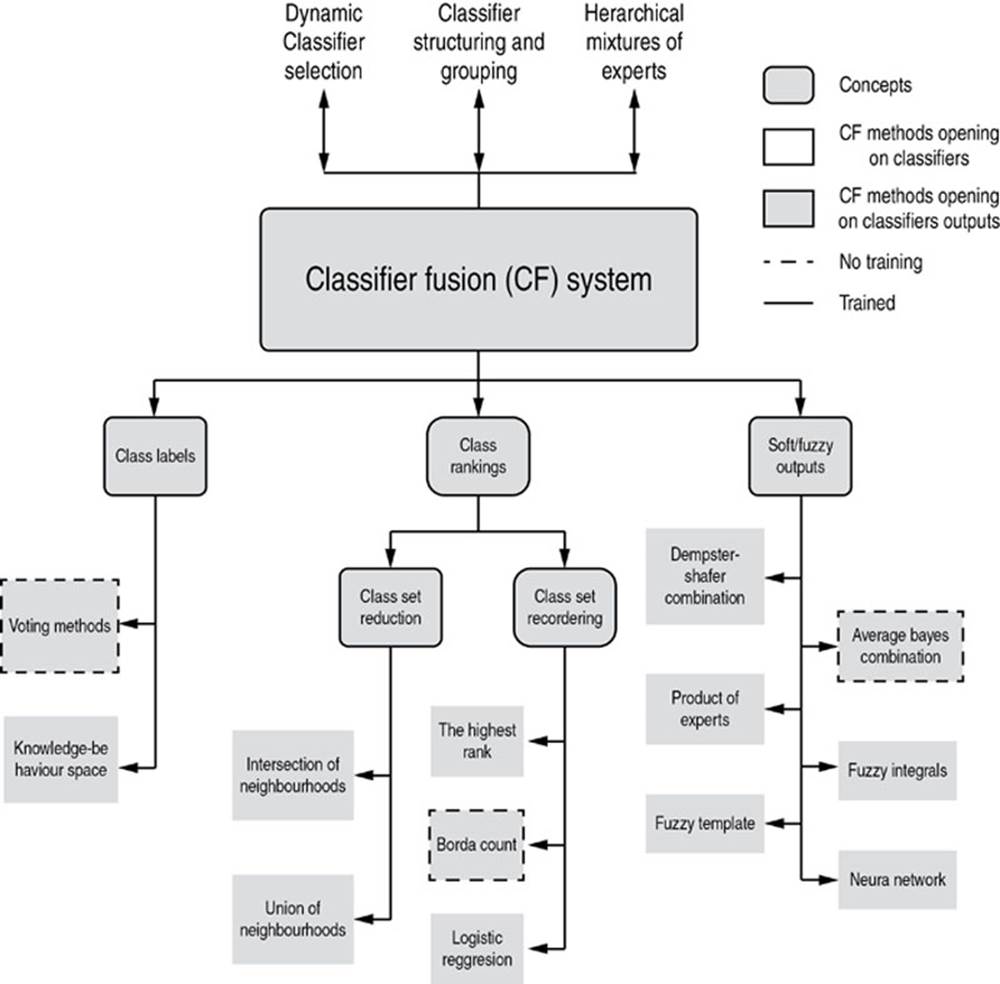
FIG. 2.8 Email categorization. (Airoldi and Malin, 2004)
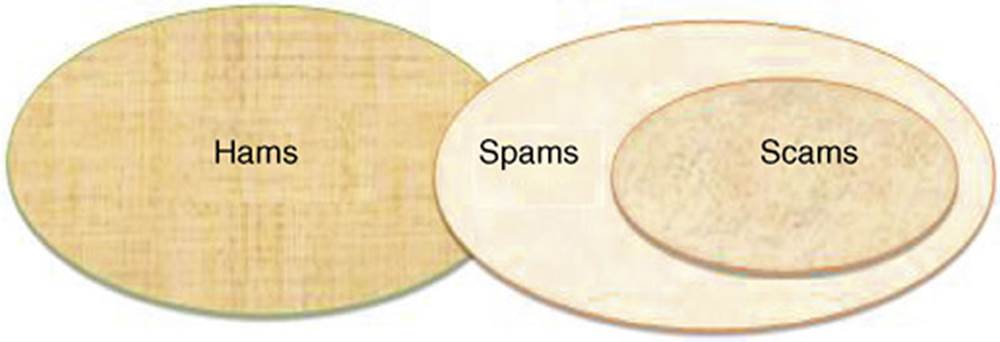
FIG. 2.9 Taxonomy of classifier fusion methods. (Zhang et al., 2006)
The three algorithms (Naïve Bayes, Poisson, and K Nearest Neighbor) are then used for text classification. First, emails are classified into two categories of frauds and non-frauds using these algorithms. Then based on consensus method (Miyamoto et al., 2007), combining the results of the proposed data-mining algorithms, we improve the classification results. The aim of Saberi et al. (2007) is to use ensemble methods on their results to improve our scam detection mechanism. Then by using majority voting ensemble classification algorithm, their results were merged in order to increase the accuracy. Experimental results show that the proposed method in Saberi et al. (2007) can detect 94.4% of scam emails correctly, whereas only 0.08% of legitimate emails are classified as scams.
Toolan and Carthy (2009) refer to a fusion method with no training that was employed to reduce processing time. One of the ensemble algorithms chosen was the simple majority voting algorithm; as such an odd number of constituent classifiers were required. All sets of classifiers of size three were chosen for ensembles. The same algorithm will be used for voting in this book. Simple majority voting is further discussed below.
2.5.4.1. Simple Majority Vote
Rahman et al., 2002 proposed that if there are n independent experts having the same probability of being correct, and each of these experts produces a unique decision regarding the identity of the unknown sample, then the sample is assigned to the class for which there is a consensus, that is, when at least k of the experts agree, where k can be defined as:
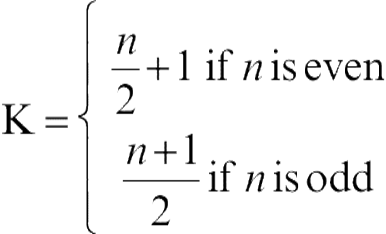 (2.1)
(2.1)
Assuming each expert makes a decision on an individual basis, without being influenced by any other expert in the decision-making process, the probabilities of various different final decisions, when x + y experts are trying to a reach a decision, are given by the different terms of the expansion of (Pc + Pe) x + y, where, Pc is the probability of each expert making a correct decision, Peis the probability of each expert making a wrong decision, with Pc + Pe = 1. Bernoulli (Todhunter, 1865) is credited with first realizing this group decision distribution. The probability that x experts would arrive at the correct decision is 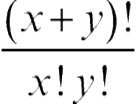 (Pc)x(Pe )y and the probability that they arrive at the wrong decision is (Pc)y(Pe)x. So in general, the precondition of correctness (Berend and Paroush, 1998) of the combined decision for x > y can be conveniently expressed as:
(Pc)x(Pe )y and the probability that they arrive at the wrong decision is (Pc)y(Pe)x. So in general, the precondition of correctness (Berend and Paroush, 1998) of the combined decision for x > y can be conveniently expressed as:
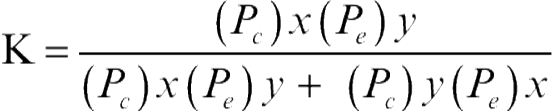 (2.2)
(2.2)
Reordering equation 2.2 and assuming the fraction of the experts arriving at the correct decision to be fixed, (e.g., x and y to be constant), it is possible to show that:
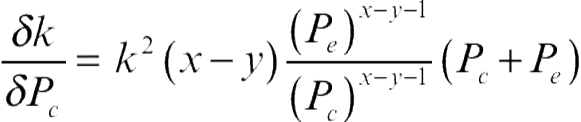 (2.3)
(2.3)
Since (x − y − 1 ≥ 0), 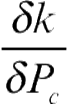 is always positive. Thus when x and y are given, as Pc increases κ increases continuously from zero to unity. This demonstrates that the success of the majority voting scheme (like most decision combination schemes) directly depends on the reliability of the decision confidences delivered by the participating experts. It is also clear that as the confidences of the delivered decisions increase, the quality of the combined decision increases.
is always positive. Thus when x and y are given, as Pc increases κ increases continuously from zero to unity. This demonstrates that the success of the majority voting scheme (like most decision combination schemes) directly depends on the reliability of the decision confidences delivered by the participating experts. It is also clear that as the confidences of the delivered decisions increase, the quality of the combined decision increases.
Recently, it has been demonstrated that although majority vote is by far the simplest of the variety of strategies used to combine multiple experts, if properly applied it can also be very effective. Suen et al. (1992) presented a method for decision combination incorporating different types of classifiers based on a straightforward voting scheme. A detailed study of the working of the majority voting scheme has been presented by Lam and Suen (1997) and Ng and Singh (1998) have discussed the applicability of majority voting techniques and have proposed a support function to be used in the combination of votes. Researchers have also used various types of classifiers in these majority voting schemes. Stajniak et al. (1997) presented a system having three voting nonlinear classifiers: two of them based on the multilayer perceptron (MLP), and one using the moments method. Parker (1995) has reported voting methods for multiple autonomous agents. Ji and Ma (1997) have reported a learning method to combine weak classifiers, where weak classifiers are linear classifiers (perceptron) which can do little better than making random guesses. The authors have demonstrated, both theoretically and experimentally, that if the weak classifiers are properly chosen, their combinations can achieve a good generalization performance with polynomial space-and time-complexity.
2.6. Normalization
As proposed by Al Shalabi and Shaaban (2006), data usually collected from multiple resources and stored in data warehouse may include multiple databases, data cubes, or flat files and as such could result to different issues arising during integration of data needed for mining and discovery. Such issues include scheme integration and redundancy. Therefore, data integration must be done carefully to avoid redundancy and inconsistency that in turn improves the accuracy and speed up the mining process (Jiawei and Kamber, 2001).
The careful data integration is now acceptable but it needs to be transformed into forms suitable for mining. Data transformation involves smoothing, generalization of the data, attribute construction, and normalization. The main purpose of data mining is to discover unrecognized associations between data items in an existing database. It is the process of extracting valid, previously unseen or unknown, comprehensible information from large databases. The growth of the size of data and number of existing databases exceeds the ability of humans to analyze this data, which creates both a need and an opportunity to extract knowledge from databases (Cios et al., 1998). Data transformation such as normalization may improve the accuracy and efficiency of mining algorithms involving neural networks, nearest neighbor, and clustering classifiers. Such methods provide better results if the data to be analyzed have been normalized, that is, scaled to specific ranges such as [0.0, 1.0] (Jiawei and Kamber, 2001).
Since both the data collection and feature extraction is done manually for this project, there is a margin for bogus range of numbers which might lead to inaccuracy in the output result and as such normalization of data is needed. Furthermore, to normalize the data into small number margin between “0s” and “1s,” the use of rapidminer software (Akthar and Hahne, 2012) was adopted to create a model for normalization. First the dataset is converted into “.csv” and then imported into the software, where both the dataset and the normalization algorithm are linked and the output data collected and exported as “.csv.”
An attribute is normalized by scaling its values so that they fall within a small-specified range, such as 0.0 to 1.0. Normalization is particularly useful for classification algorithms involving neural networks, or distance measurements such as nearest neighbor classification and clustering. If using the neural network back propagation algorithm for classification mining, normalizing the input values for each attribute measured in the training samples will help speed up the learning phase. For distanced-based methods, normalization helps prevent attributes with initially large ranges from outweighing attributes with initially smaller ranges (Jiawei and Kamber, 2001).
2.7. Related work
Although there are numerous studies in classifier fusion method in phishing website detection, but research on choosing the most effective ensemble system components for anti-phishing continues to be fresh. Table 2.3 presents some studies on existing anti-phishing system either for phishing website detection or in similar domains. In the figure that follows this study has consulted some studies that are quite related to the main study. These studies were found useful and have provided a focus for this study. These are based on the following headings: (1)title of the study (2) names of author (3) brief descriptions of the studies (4) the experimental results, and (5) study limitations.
Table 2.3
Related Studies
|
Title of the study |
Author |
Briefly description of study |
Experimental results |
Study limitations |
|
Intelligent flushing website detection system using fuzzy techniques |
(Aburrouse et al., 2008) |
Tie proposed model is based on FL operators which is used to characterize me website flushing factors and indicators as fuzzy variables and produces six measures and criteria’s of website phishing attack dimensions with a layer structure. |
The experimental results showed me significance and importance of the phishing website criteria (URL Domain Identity) represented by layer one and the variety influence of the phishing characteristic layers on the final phishing website rate. |
The approach does not look for deviations from stored patterns of normal phishing behavior and for previously described patterns of behavior that is likely to indicate phishing. |
|
An anti-Phishing ppproach that uses training intervention for flushing websites detection is likely to indicate phishing. |
(Ainajim and Munro, 2009) |
This paper proposes and evaluates a novel anti-phishing approach that uses training intervention for Phishing websites detection (APTIPWD) in comparison to an existing approach (sending anti-phishing tips by emails) and control group. |
There is a significant positive effect of using the APTIFWD in comparison on with the existing approach and control group in helping users properly judging legitimate and phishing websites. |
Nil |
|
Identifying vulnerable websites by analysis of common strums in phishing URLs |
(Wardmaner et al., 2009) |
The propos ed method involves applying a –longest common substring algorithm to known phishing URLs, and investigating me results of that string to identify common vulnerabilities, exploits, and attack tools which may be prevalent among those who lack servers for phishing. |
The result demonstrated mat these application paths may be used as a basis for further investigation to expose and document the primary exploits and tools used by hackers to compromise web servers, which could lead to the revelation of the aliases or identities of me criminals. |
Nil |
|
Associative classification techniques for predicting e-banking phishing websites |
(Aburrous et al., 2010) |
The research proposed an intelligent, resilient aid effective model that is based on using association and classification data mining algorithms. They used a number of different listing data mining association and classification techniques |
The experimental results demonstrated me feasibility of using associative classification techniques in real applications and its better performance as compared to other traditional classifications algorithms. |
Nil |
Some studies have applied K-Nearest Neighbour (KNN) for phishing website classification. KNN classifier is a non-parametric classification algorithm. The major disadvantage of this classifier is that the accuracy falls with increase in the size of the training set. In addition, previous researches have shown that KNN can achieve very accurate results, that are sometimes more accurate than those of the symbolic classifiers. It was shown in a study carried out by Kim and Huh, 2011 that KNN classifier achieved the best result compared to other classifier such as linear discriminate analysis (LDA), na![]() ve Bayesian (NB), and support vector machine (SVM). In the study, they collected 10000 items of routing information in total: 5000 from 50 highly targeted websites (100 per website) representing the legitimate samples; and the other 5000 from 500 phishing websites (10 per website) representing the DNS-poisoning-based phishing samples. The initial dataset for phishing websites was obtained from a community website called PhishTank. An accuracy detection rate of about 99% was achieved. Also, since the performance of KNN is primarily determined by the choice of K, they tried to find the best K by varying it from 1 to 5; and found that KNN performs best when K = 1. This as well, helped in the high accuracy of KNN compared to other classifiers ensemble.
ve Bayesian (NB), and support vector machine (SVM). In the study, they collected 10000 items of routing information in total: 5000 from 50 highly targeted websites (100 per website) representing the legitimate samples; and the other 5000 from 500 phishing websites (10 per website) representing the DNS-poisoning-based phishing samples. The initial dataset for phishing websites was obtained from a community website called PhishTank. An accuracy detection rate of about 99% was achieved. Also, since the performance of KNN is primarily determined by the choice of K, they tried to find the best K by varying it from 1 to 5; and found that KNN performs best when K = 1. This as well, helped in the high accuracy of KNN compared to other classifiers ensemble.
Artificial neural network (ANN) consists of a collection of processing elements that are highly interconnected and transform a set of inputs to a set of desired outputs. The result of the transformation is determined by the characteristics of the elements and the weights associated with the interconnections among them. Since neural network gains experience over a period as it is being trained on the data related to the problem, the major disadvantage is in the time it takes for parameter selection and network learning. On the other hand, previous researches have shown that ANN can achieve very accurate results compared to other learning classification techniques. In a research carried out by Basnet et al. (2008), it was shown that artificial neural network achieved an accuracy of 97.99% using a dataset of 4000 phishing samples that was divided equally between training sample and testing sample; each having a sample of 2000.
2.8. Summary
This chapter covered important aspects of phishing. These are: the primary idea of phishing, existing anti-phishing techniques and approaches, and different designs of classifiers. This chapter has also covered website phishing detection plus some previous works at length. It further describes the particular issues faced by anti-phishing tools and pointed out some existing solutions for every one too. These problems pose challenges in the study regarding efficiency of anti-phishing tools. It had been proven that the majority of the literature was unsuccessful in eliminating the false positive rates, even when there is a relatively high detection rate. The issue of phishing detection using blacklist seemed to be outlined in certain studies due to increasing evolution of phishers. Other studies demonstrated the importance of combining the right set of classifiers in ensemble system is extremely important in achieving good detection results. Additionally, this research is concerned with detection rate of phishing website using different classifiers in ensemble and comparison with individual classifiers.