Information Security A Practical Guide: Bridging the gap between IT and management (2015)
CHAPTER 5. QUICK AND DIRTY RISK ASSESSMENT
Chapter Overview
There are many risk assessment processes, but many are long and overly complicated. More and more organisations are moving to a more agile working environment, developing systems iteratively, changing functionality to meet the users’ requirements. This sort of working can make it very difficult to follow a complex risk management process. Traditionally these processes have been written favouring a waterfall development methodology.
In the modern digital age organisations need to be flexible to take advantage of opportunities as they present themselves. Depending on the organisation’s culture and risk appetite the decision on whether to proceed with a new service may depend on the outcome of a risk assessment. Following a traditional method may be too slow, meaning the organisation either misses the opportunity or proceeds without any knowledge of the risks.
Giving a small amount of risk advice rapidly is more enabling to the business than a lot of risk advice slowly. This is the reason why I have included this chapter, as it includes a lightweight, easily understandable risk process that can be applied quickly.
Objectives
In this chapter you will learn the following:
• How to identify risks
• How to categorise and prioritise risks.
Identifying Risks
Identifying risks can often be very difficult, as people’s minds move to the more traditional technical exploits and vulnerabilities. In the real world you have to think beyond the technology; there is the insider threat or even the process itself could be exploited. When identifying risks I use four categories: Internal, External, Process and Technical. These can be described as the following:
Internal: risks that are posed internally. This can be either from other internal systems or staff members. Examples of internal risks could be user error while administering the system, or if our system is reliant upon another system that is due to undergo maintenance. The defining factor of an internal risk is that its occurrence is within our control.
External: risks that are posed externally. This can include external systems that we are reliant upon or staff employed by service providers that we rely upon. Also included are acts of god or terrorism. Examples could be our internet service provider accidentally cuts us off or our data centre could be flooded.
Process: risks related to the process and operation of the system itself. This can include risks around the functionality provided by the system itself. Examples include weak passwords that can be guessed or the ability to fraudulently carry out a transaction.
Technology: risks that relate to the technology employed. These risks relate directly to the technology stack itself and how it is configured. Examples include the lack of a firewall on a network, missing antivirus or a weak cipher.
When identifying risks you should first document the system fully (Chapter 7), then work through each point of that system asking if there could be risks around Internal, External, Process or Technology factors. When deciding if there is a potential risk you should also refer to your threat sources and identify which of those would look to exploit that risk. This will help you identify which risks are most likely to happen because more threats exist in that area. More importantly it gives your risks context when discussing them with technical and management teams; you will be able to say who would exploit that risk. Risks that people can relate to in the real world are easier to communicate and will be taken more seriously.
Defining the Risk Level
Once our risks are identified we need some way of prioritising them. It is extremely unlikely that we will have an unlimited amount of money or time to fix all the risks found. In fact, if you are working on a highly sensitive project that does afford the time and resources to build a secure system then you should follow this process up with a more formal risk assessment.
There are two key parts to prioritising a risk: likelihood and severity. Likelihood is a measure of the chances of a risk occurring and how often it may happen. Severity deals with how severe the consequences would be if the attack were successful. By scoring the likelihood of a risk happening and its severity if successful we can rank the risk as low, medium or high. This is a very crude method of risk categorisation but it is rapid, and we are trying to be agile.
Severity
The severity has five ratings:
1. Extremely low
2. Low
3. Medium
4. High
5. Extremely high.
The next section describes these ratings, and includes example risks that could fall into each of these categories. Also, depending on your organisation you may want to realign the costs so that they better fit the size of the organisation.
Extremely Low: the impact of the breach is small as only informational data was stolen or corrupted. The remediation cost was small and mainly cost staff time to investigate.
Such attacks include:
• Port scan
• Identify active IPs and protocols.
Low: the impact of the breach is still small as only a small amount of non-sensitive data was stolen or corrupted. The remediation cost is still small and mainly only staff time was lost investigating the breach.
Such attacks include:
• Interception of non-sensitive data, for example a BBC news page
• Minor denial-of-service attack (noticed by network team but not users).
Medium: the attack was successful in stealing or compromising valuable data, although not sensitive. The system needs investment to conduct a full investigation and possibly new controls implemented, costing thousands of pounds.
Such attacks include:
• Theft of password hashes
• Theft of account names
• Denial-of-service noticed by users.
High: the system has been severely breached with large amounts of data stolen, including sensitive. The reputation of the organisation has been damaged and remediation work will cost millions of pounds.
Such attacks include:
• Theft of passwords
• User accounts compromised (although not root)
• Denial-of-service so that the service is unavailable.
Extremely high: the system has been completely compromised, and the service is no longer available or has had to be shut down. The reputation of the organisation is in tatters and work to remediate the breach will cost tens of millions of pounds.
Such attacks include:
• Root access achieved
• Breach of data protection laws.
Likelihood
Likelihood is applied in much the same way – how often would a threat source look to attack our system using the methods defined in one of our risks? The following list describes the frequency of attack:
• Less than once a year
• At least once a year
• At least once every six months
• At least once a month
• At least once a week.
Risk Table
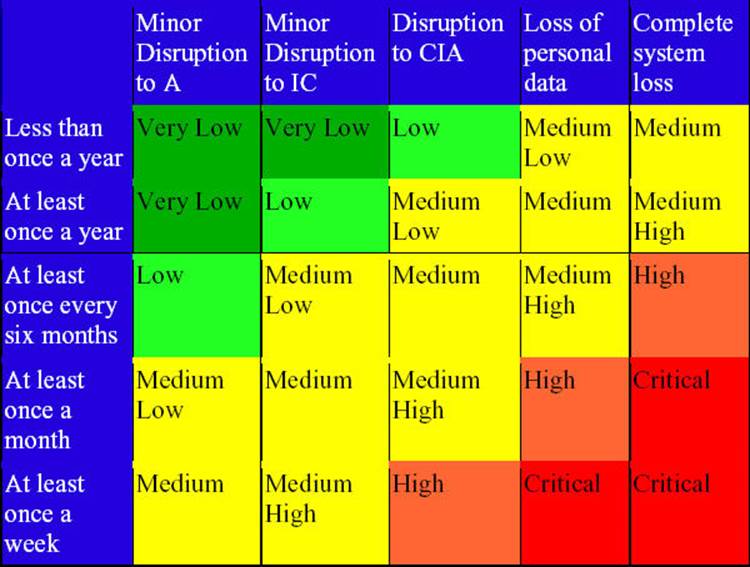
Realigning the Risk Level
You may be wondering at this point about the data that is to be hosted on the system and the impact if it is breached. It seems common sense that more sensitive data would have a higher risk category and non-sensitive data would have a lower risk category. However, unless you wish to compare risks from two separate systems then the realignment exercise is pointless as all risks would increase or decrease by the same amount. Instead, when discussing the risks I recommend setting the context of the risk be defining how critical the asset is. This can then drive the discussion on what risks we will fix, so, for high-risk systems we may want to fix all risks from low and above, and for low-risk systems we may only want to fix high risks and above.