Threat Modeling: Designing for Security (2014)
Part III. Managing and Addressing Threats
Chapter 10. Validating That Threats Are Addressed
You've been hard at work to address your threats, first by simply fixing them, and then by assessing risks around them. But are your efforts working? It is important that you test the fixes, and have confidence that anything previously identified has been addressed.
Good testers have a lot in common with good threat modelers: Both focus on how stuff is going to break, and work on preventing it. Working closely with your testers can have surprisingly positive payoff for threat modeling proponents, a synergy explored in more detail in Chapter 17, “Bringing Threat Modeling to Your Organization.”
A brief note on terminology: In this chapter, the term testing is used to refer to a key functional task that “quality assurance” performs: the creation and management of tests. This chapter focuses only on the subset of testing that intersects with threat modeling. As shown in Figure 10.1, threat-model-driven testing can overlap heavily with security testing, but the degree of overlap will vary across organizations. Some organizations have reliability testing specialists. They need to understand the issues you find when looking for denial-of-service threats. Others might manage repudiation as part of customer readiness. Your security testers might also use fuzzing, look for SQL injection, or create and manage tests that are not driven by threat modeling.
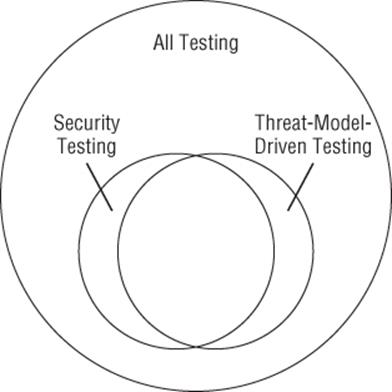
Figure 10.1 Different types of testing
This chapter will teach you about testing threat mitigations, how to examine software you acquire from elsewhere to check that threats are addressed to your satisfaction, explain how to perform quality assurance on your threat modeling activity, and discuss some of the mechanical and process elements of threat modeling validation. It closes with a set of tables designed to help you track your threat modeling testing activity.
Testing Threat Mitigations
You'll need both process and skills to test the mitigations you're developing. This section explains both, and also discusses penetration testing, which is often mistaken for a complete approach to testing security.
Test Process Integration
Anything you do to address a threat is subject to being tested. However you manage test cases, you should include testing the threats you've found and chosen to address. If you're an agile team that uses test-driven development, develop at least two tests per threat: one that exploits the easy (no mitigation) case, and at least one that attempts to bypass the mitigation. It can be easy, fun, and even helpful for your testers to go nuts with this. It may be worth the effort to ensure they start with the highest-risk threats, or the ones that developers don't want to fix. If you use bugs to track test development, you might want to file two test-creation bugs per threat. One will track the threat, and the other the test code for the threat. Then again, you might find this overkill. Giving threat model bugs unique tags can help you when you search for threat model test bugs. (For example, you can use “threatmodel” to find all bugs that come from threat enumeration, and “tmtest” for the test bugs.)
If you have some form of test planning, then you should ensure that the list of threats feeds into the test planning. A good list of threats delivered to a tester can produce an avalanche of new tests.
How to Test a Mitigation
If you think of threats as bugs, then testing threats is much like doing heavy testing on those bugs. You'll want to set up a way to reproduce the conditions that cause the bug to trigger, and create a test that demonstrates whether a fix is working. That test can be manual or automated. Sometimes the level of effort needed to code an automated test can be high, and you'll be tempted to test manually. At the same time, these are bugs you'd really prefer do not regress, which is an argument for automation.
Of course, unlike normal bugs, attackers will vary conditions to help them trigger your bugs, so good testing will include variations of the attack. The exact variation you'll want depends heavily on the threat. You should vary whatever the mitigation code depends on. For a simple example, consider an XSS bug in a website. Such bugs are often demonstrated by use of the JavaScript alert function. Therefore, perhaps someone has coded a test that looks for the string “alert.” Try replacing that with “%61%6C%65%72%74%0A.” Robert “RSnake” Hansen has a site dedicated to creating such variants—his “XSS (Cross Site Scripting) Cheat Sheet Calculator” (OWASP, 2013). You can use such a site to develop the skills to create your own variations.
As you develop tests for a threat, you can also consider how the mitigations you're developing can be attacked. This is very similar to attack variations, but goes back to the idea of second-and third-order threats discussed in Chapter 7, “Processing and Managing Threats.”
The skills required to perform testing of threat mitigations vary according to the type of threat and mitigation. There are test engineers at large companies who are experts at shell coding, that is, the specialized attack code used to take over control flow. There are others who are expert cryptographers, spending their days looking for mathematical attacks on the cryptography their employers develop.
Penetration Testing
Some organizations choose to use penetration testing to validate their threat models and/or add a level of confidence in their software. Penetration testing (aka pen testing) can supplement threat modeling. But there's a saying that “you can't test quality in.” That means all the testing you might possibly do will never make a product great. It will just help you fix the defects you happen to find. To make a quality product, you need to start with good design, good raw materials and good production processes, and then check that your output matches your expectation. In the same way, you can't test your product to secure. So, pen testing can't replace threat modeling.
Pen testing can be either black box or glass box. Black box pen testing provides only the software to the testers, who will then explicitly test assumptions you have about how much effort it takes to gain an understanding of the software. This is an expensive undertaking, especially compared to glass box pen testing, whereby testers are given access to code, designs, and threat models, and they are able to use those to better understand the goals of the software and the intentions of the developers.
If you choose to use pen testing as an adjunct to threat modeling, the most important thing is to ensure that you're aligned with the penetration testers regarding what's in scope. If they come back with a list of SQL injections and cross-site scripting attacks, will you be happy? (Either a yes or a no is fine as long as you're clear with the pen testers. An “I don't know” is likely to leave you unhappy.)
Checking Code You Acquire
Most of this book is focused on what you're building. But the reality is that much of the code in today's products comes from elsewhere, in either binary or source form. And not all of it comes with well-formed security operations guidance and non-requirements. Less of it comes with explicit threat models telling you what the creators worried about. This section shows you how to threat model code you've acquired, so you can validate if threats are addressed. The steps here are aligned with the four-stage framework expressed in the Introduction and in Chapter 1, “Dive In and Threat Model!”. You'll use a variety of tools to learn about the software you're looking at, create a model of the software from what you've learned, and then analyze that model. From there, standard operational approaches to addressing threats can come into play. You can apply these techniques to code you acquire from outside, or if you're an operations team, to code which is handed to you for deployment. This section is inspired by work by consultant Ollie Whitehouse (Whitehouse, 2013).
Note
The approaches here assume you do not have the time or the skills to de-compile or reverse engineer the binaries. Of course, if you do, you have more options and the capability to dig deeper. If you have source, you can of course compile it, and so the binary approaches will work, and may be easier (for example, find listening ports or account information by running the installer). Of course, that dynamic analysis has limitations; if on the third Wednesday of the month, the software opens a backdoor, bad luck if you start the next day and trust runtime analysis. This section also assumes you're looking at software which you have reason to believe you can trust. (For example, unexpected binaries on your USB drives may well be malware.)
Constructing a Software Model
Even if the product comes with an architecture diagram, it may not suffice for threat modeling. For example, it probably doesn't show trust boundaries. So you'll need to construct a model that's useful for threat analysis. To do that you need to dig into a set of questions, and then synthesize. In theory, you'll want to move from the outside in, enumerating architectural aspects of the software, including the following:
§ Accounts and processes:
§ New accounts created
§ Running processes
§ Start-up processes
§ Invoked or spawned processes
§ Listening ports:
§ Sockets
§ RPC
§ Web
§ Local inter-process communication
§ Administrative interfaces:
§ Documented
§ Account recovery
§ Service personnel accounts
§ Web and database implementation
§ Technical dependencies and platform information:
§ Changes to OS (for appliances/virtual machines)
§ Firewall rule changes
§ Permission changes
§ Auto-updater status
§ Unpatched vulnerabilities
If the software is delivered in binary form, you can use unix tools like ps, netstat, find (with the –newer option), or their equivalents on your platform to find listeners and processes. Similarly, the operating system can show you new accounts and start-up processes. Tools like Sysinternals' Autoruns on Windows can walk through the many possible ways to start a program on boot. Administrative interfaces are probably documented, although it's unfortunately common to have backdoors for service or recovery, so you can look into how you'd get in “if you forget your password.”
With this information, you can start to construct a software model. The components are the trust boundaries, and the processes are the processes within each. The listening ports get drawn as one end of data flows. If present, you'll need to dig deeper into web and databases, in technology-appropriate ways, to better understand what's happening in those complex subsystems. The administrative interfaces can add additional trust boundaries and possibly data flows. Technical dependencies (such as a web server or framework) may also introduce new processes or data flows, and the approach here can be applied recursively to those dependencies. There's one other aspect to check for dependencies: Are the dependencies up to date with security fixes? Searching a database like the US National Vulnerability Database for the dependency can give you an idea of what's been discovered in the version you have, or you can use free tools such as nmap or Metasploit to test it.
All of the preceding can be performed by any systems administrator who's willing to learn a bit about new tools. If you also have source code, it may be possible to, and even worth, digging in. You may learn about additional accounts where Windows impersonates, or unix sets uid. System calls such as fork and exec will show you where processes are spawned. Open, read, and especially socket and listen calls can reveal trust boundaries. (There are a near-infinite number of higher-level variants which implicitly create a socket andlisten.) Finding extra login interfaces is easier with the code, but will likely require more than just grepping.
Using the Software Model
When you have a model of the software you acquired, you can apply the techniques in Part II of this book to bear to find threats. You can look to see if they are appropriately mitigated. If you're looking for threats during a software evaluation or acquisition phase, you have a number of choices about the threats you find that are not mitigated to your satisfaction. Those choices include:
§ Bring them to the attention of the software producer.
§ Look for an alternate package.
§ Mitigate them yourself.
If you are bringing them to the software producer, be prepared for a discussion of the correct requirements, the tradeoffs involved in a fix, or other disagreements about the threats you've found. (For example, many proposed “improvements” to Windows permissions fail to consider what may break if those changes are made.)
Some backwards looking vendors may even threaten you, asserting that you've violated the license, although fortunately this is becoming less common.
If the producer is open source, don't be surprised if the answer is “we're accepting patches.”
If you're looking at threats after the software has been acquired, selected or deployed, your ability to select an alternative is dramatically lower. (Once again, threat modeling early gives you more flexibility.) Bringing them to the vendor or mitigating them yourself are your main choices.
Mitigating issues yourself means applying the “operational” mitigations found in Chapter 8, “Defensive Tactics and Technologies.” The most common forms of this are “slap a firewall in front of it,” and tunnel the network traffic over SSL or SSH.
You can make all this work a lot easier by looking for operational security guides and threat model documents as you select components. Components that come with such documentation are likely to require a lot less work on your part.
QA'ing Threat Modeling
While it is common for security enthusiasts to claim that you're never done threat modeling, at some point you need to ship, deploy, or otherwise deliver the software, and you may or may not be planning to do another version. As you get close to finishing (say, feature complete), you'll want to be able to close out the threat modeling work. If you use checklists or some other means of tracking what needs to be done to pass through the gate and call it feature complete, you should add threat model verification to the checklist. Verifying the threat model consists of ensuring the following:
§ The model actually matches reality closely enough.
§ Everything in the threat list is addressed and the threat model portion of the test plan is complete.
§ Threat model bugs are closed.
Model/Reality Conformance
As you finish addressing threats, you need to ensure that the threats you're addressing were found using a model that relates to what you built. In other words, if you did three major architecture revamps between the last time you did an architectural diagram of the system and now, the list of threats you found might not be relevant to what you've built. Therefore, you need to check whether your model is close enough to reality to be useful. Ideally, you do this along the way, by including threat modeling in your list of activities to do during an architectural redesign or major refactoring work. This also applies to deploying complex systems. The complexities of deployment often lead to on-the-fly changes. If those are substantial (say, turning off a firewall), then the threat model probably needs a revamp.
If your threat model leads to substantial redesign or architecture changes to address threats, “closing that loop” is tremendously important. If that's the goal, make sure you re-check the software model against the code around the time the code is getting checked in, or when the new systems are being deployed. Ideally, bring the people who made the changes into a room, and have them explain the changes that were made and the new security features.
Note
A meeting like this can sometimes devolve into security finding new threats against the new system. That may be acceptable, or it may seem like moving the goalposts. Upfront agreement on the meeting goals will reduce contention.
Task and Process Completion
Have you gone through each threat, and decided on a strategy and a tactic for addressing it? That might be to accept the risk and monitor, or it might be to use an operating system feature to manage it. You need to track these and ensure that you do an appropriate amount of work to avoid any falling through the cracks. (You might say that anything of severity less than some bar isn't worth the effort to track.) Good threat modeling tools make it easy to file a bug per threat. If you're using something without that feature, you need to file bugs manually.
There are two reasons why threats should lead to bugs that are like your other bugs, rather than a separate document. First, anyone shipping software has a way to manage bugs; and if you want your security issues managed, making them bugs puts them into the same machinery your organization is already using to assure quality. Second, bugs act as an exit point from threat modeling, allowing the normal machinery to take over, and enabling you to say, “We're done threat modeling that.”
Bug Checking
As you get closer to shipping, review the mitigation test bugs, ensuring that you've closed each one. This is where a tag such as tmtest is really helpful. Bugs that haven't been closed should be triaged like other bugs (with appropriate attention to the gravity of the bug), and fixed or, if appropriate, moved to the next revision.
Process Aspects of Addressing Threats
There are a few final aspects of how testing and threat modeling complement each other, and a few red flags that testers can use to quickly find issues, including a belief that data is “validated” where people are making assumptions.
Threat Modeling Empowers Testing; Testing Empowers Threat Modeling
Writing code is hard; thinking through all the things needed to make the code work leaves little space in the brain for thinking about anything else, including what might go wrong. This level of focus and concentration on the problem at hand is part of why engineers can get so upset at interruptions: The problem at hand is complex enough to require full attention, and there's no room for minor issues like eating properly. There's “no room” in two senses: rational and emotional. In the rational sense, developers usually want to focus on developing great code. Thinking about all the ways to make the code better, faster, more capable, more elegant, and so on, requires less of a mental shift than thinking about what will go wrong. Many great developers have learned that they need to think about writing testable code and collaborating with testers, but that doesn't mean they're great at finding what will go wrong. The emotional sense of lacking room to think about what might go wrong means that after a lot of effort to make the code work, thinking about making it break is challenging.
Threat modeling has a natural ally in testers, especially when testing is seen as an “inferior” function to developing. If testing “owns” threat modeling, then test has a reason to be in architecture meetings. They need to be there to talk about how to threat model, and to start conducting tests early. If threat modeling is the reason testers are brought in early, then testers have a reason to drive effective threat modeling processes.
Validation/Transformation
It's common to see threat models that assert, incorrectly, that this input or that has been “validated.” This claim should be a red flag for testers, because it is never completely true. The data may well have been validated for some purpose or purposes. For example, is the following data valid? http://www.example.org/this/url/will/pwn/you.
It's a valid URL, in accordance with RFC 1738. It uses a domain that is nominally reserved for example use. Were it a real URL, a path this/url/will/pwn/you is probably unsafe to visit. It's easy to construct similar examples. For example, the e-mail addressadam+threat@example.org is valid (see RFC 822), but just try convincing many web forms of that. Many filter out the plus sign to make SQL injection attacks harder to carry out, along with the single quote character ('), which annoys a great many Irish people with names like O'Malley or O'Leary. Therefore, data can only be validated for a particular purpose or, better, to comply with certain rules.
The other approach to data is to filter and transform it. For example, if you have a system that is taking input that will be displayed on a website, you can do so more safely by ensuring it is ASCII, eliminating everything but a known good set and transforming bracketed strings into approved HTML strings. Your known good set could be A–Z, 0–9 and some set of punctuation. The advantage to a filter and transform approach is safety by design. By filtering out everything but known good, and then transforming them into something that includes “dangerous” input, attack code will need to pass through multiple bugs to succeed.
Document Assumptions as You Go
As you threat model, you'll find yourself saying, “I assume that …” You should write those things down, and testers should test the assumptions. How to do that will vary according to the assumption. Generally, you can test the assumptions by asking, “Could it ever not be true?” and “What can I break if this is false, incomplete, or an overgeneralization?”
This differs in a subtle but important way from the common prescription to “document all assumptions.” That advice leads people to try to document all assumptions as they start threat modeling, but what assumptions? When do you stop? Do you assume that no one will find a new solution to the factoring problem that underlies many public key cryptography schemes? It's usually a reasonable assumption, but documenting that in advance often feels like an exercise in pedantry. In contrast, documenting as you go is easier, constrained, and helps those who review the threat models.
Tables and Lists
Now that you know about the defensive tactics and technologies and the various strategies you can apply to manage risks, it's time to learn about the blocking and tackling elements. If you think back to Chapter 7, many of the tables there have a bug ID as their last column. The tables here, therefore, start with a bug ID. A simple table might look something like Table 10.1.
Table 10.1 Tracking Bugs for Fixing
|
Bug ID |
Threat |
Risk Management Technique |
Prioritization Approach |
Tactic |
Tester |
Done? |
|
4556 |
Orders not checked at server |
Design change |
Fix now to address, avoid dependencies. |
Code changes |
Alice |
|
|
4558 |
Ensure all changes to server code are pulled from source control so changes are accountable. |
Operational change |
Wait and see. |
Deployment tooling change |
Bob |
No |
|
4559 |
Investigate moving controls to business logic, which is less accessible to attackers. |
Design change |
Wait and see. |
Include in user stories for next refactoring. |
Bob |
no |
However, you'll notice that these threats are all being addressed, or have a strategy for addressing them. As you'll recall, this isn't always possible, so you might have additional tables for accepted risks (see Table 10.3) and transferred risks (see Table 10.4). That leaves out avoided risks, which are rarely worth tracking as bugs. If you maintain architecture documentation, you might include the insecure designs that were avoided. You can use a table like Table 10.2 to track how you're handling various risks, which can help you get an overview of where you stand overall. (With the right fields, you can also extract such a table from your bug tracking system.) In this list and the lists that follow, italics are used for fields that you might choose to include if you're a more process-intensive shop.
Table 10.2 Overall Threat Modeling Bug Tracking (Example)
|
Bug ID |
Threat |
Risk Management Approach |
Technique/Building Blocks |
Done? |
|
1234 |
Criminals sending money orders |
Avoid |
Don't accept checks/ACH/money orders. |
Yes! |
|
4556 |
Orders not checked at server |
Address |
Fix now. |
Check with Alice. |
|
1235 |
People will mistype URL, visit phishing site. |
Accept |
Document in security advice page, advising bookmark, since we can't fix the browsers. |
Yes |
|
1236 |
People will order things they don't want. |
Transfer |
Terms of service state that all orders are final. |
Yes |
Table 10.2 shows the following:
§ Bug ID
§ Threat
§ Risk management approach
§ Risk management technique or building blocks
§ Is it done?
§ Test IDs if you have test code (optional).
In tracking accepted risks, the key deliverable is an understanding of the risks you're accepting, so that executives can have a single view. You might choose to sort such a table by bug ID, cost, or the business owner who has accepted the risk. Of course, as you've learned, putting a dollar value on threats can be challenging. If you do put a cost on threats, then unlike most of the other tables, the accepted risks table can actually be summarized or totaled.
As shown in Table 10.3, you should track at least the following:
§ Bug ID
§ Threat
§ Cost or impact estimate
§ Who made the estimate and how (optional)
§ Why the risk is accepted
§ Who accepted it
§ The sign off procedure that was followed (optional)
Table 10.3 Accepted Risks (Example)
|
Bug ID |
Threat |
Cost/Impact Estimate |
Reason to Accept |
Business Sign-Off From |
|
1237 |
A janitor will plug a keylogger into the CEO's desktop. |
High |
The CEO still has a desktop. |
IT director |
|
1238 |
||||
|
… |
… |
… |
… |
|
|
Total |
(above) |
$1,000,000 |
Charlene, Dave |
The “transferred to” column may or may not be needed. You may find that all risks are transferred to the customer, but you might find that some risks are transferred to other parties. For example, if your product has a file-sharing feature, risk may be transferred to copyright owners; or if your product has a messaging feature, you may create a new channel for spam. Of course, in practice, those risks may fall on your customers.
If you want to track to whom it's transferred, you can do so as shown in Table 10.4, which includes the following:
§ Bug ID
§ Threat
§ Why you can't fix it
§ To whom it's transferred (optional)
§ The way it's being transferred
§ Whether the transfer mechanism is completed
Table 10.4 Transferred Risks (Example)
|
Bug ID |
Threat |
Reason We Can't Fix |
Form of Transfer |
Done? |
|
1238 |
Insiders |
Need an admin role |
Non-requirements, presented in security operations guide |
Yes |
|
1239 |
Buffer overflow in our custom document format |
After careful redesign and fuzzing, residual risks exist. |
Warning on opening document |
No—requires user testing. |
Summary
Like everything else in the development of software or the deployment of systems, threat models can be subjected to a quality assurance process. It's important to “close the loop” and ensure that threats have been appropriately handled. Those tasks may fall outside what's normally thought of as threat modeling. How you handle them will vary according to your organization.
Thus, there's a need to integrate threat model testing into your test process, and to test that each threat is addressed. You'll also want to look for variants and second- or third-order attacks as you test for threats.
When you perform quality assurance, you'll want to confirm that the software model conforms to what you ended up building, deploying or acquiring. Modeling the architecture of software you acquire involves a different process than software you create in-house. In addition, you should verify that each task and process associated with threat modeling was completed, and check the threat model bugs to ensure that each was handled appropriately.
There's an interesting overlap between “the security mindset” and the way many testers approach their work. This may lead to an interesting career opportunity for testers. Also, at larger organizations, this offers an opportunity for security and testers to create a virtuous circle of mutual reinforcement.
The term “validated” is, by itself, a red flag for security analysis and testing. Without a clear statement of what the validation is for, it is impossible to test whether it's correct, and whether the assumption (or group of assumptions) is accurate or shared by everyone touching the supposedly validated data. “The exact purpose data is being validated” is often left as an assumption, rather than being made explicit. There are many others, and all of them should be validated as you threat model, and tested at an appropriate time.
All materials on the site are licensed Creative Commons Attribution-Sharealike 3.0 Unported CC BY-SA 3.0 & GNU Free Documentation License (GFDL)
If you are the copyright holder of any material contained on our site and intend to remove it, please contact our site administrator for approval.
© 2016-2026 All site design rights belong to S.Y.A.