Threat Modeling: Designing for Security (2014)
Part III. Managing and Addressing Threats
Part III is all about managing threats and the activities involved in threat modeling. While threats themselves are at the heart of threat modeling, the reason you threat model is so that you can deliver more secure products, services, or technologies. This part of the book focuses on the third step in the four-step framework, what to do after you've found threats and need to do something about them; but it also covers the final step: validation.
Chapters in this part include the following:
§ Chapter 7: Processing and Managing Threats describes how to start a threat modeling project, how to iterate across threats, the tables and lists you may want to use, and some scenario-specific process elements.
§ Chapter 8: Defensive Tactics and Technologies are tools you can use to address threats, ranging from simple to complex. This chapter focuses on a STRIDE breakdown of security threats and a variety of ways to address privacy.
§ Chapter 9: Trade-Offs When Addressing Threats includes risk management strategies, how to use those strategies to select mitigations, and threat-modeling specific prioritization approaches.
§ Chapter 10: Validating That Threats Are Addressed includes how to test your threat mitigations, QA'ing threat modeling, and process aspects of addressing threats. This is the last step of the four-step approach.
§ Chapter 11: Threat Modeling Tools covers the various tools that you can use to help you threat model, ranging from the generic to the specific.
Chapter 7. Processing and Managing Threats
Finding threats against arbitrary things is fun, but when you're building something with many moving parts, you need to know where to start, and how to approach it. While Part II is about the tasks you perform and the methodologies you can use to perform them, this chapter is about the processes in which those tasks are performed. Questions of “what to do when” naturally come up as you move from the specifics of looking at a particular element of a system to looking at a complete system. To the extent that these are questions of what an individual or small team does, they are addressed in this chapter; questions about what an organization does are covered in Chapter 17, “Bringing Threat Modeling to Your Organization.”
Each of the approaches covered here should work with any of the “Lego blocks” covered in Part II. In this chapter, you'll learn how to get started looking for threats, including when and where to start and how to iterate through a diagram. The chapter continues with a set of tables and lists that you might use as you threat model, and ends with a set of scenario-specific guidelines, including the importance of the vendor-customer trust boundary, threat modeling new technologies, and how to threat model an API.
Starting the Threat Modeling Project
The basic approach of “draw a diagram and use the Elevation of Privilege game to find threats” is functional, but people prefer different amounts of prescriptiveness, so this section provides some additional structure that may help you get started.
When to Threat Model
You can threat model at various times during a process, with each choice having a different value. Most important, you should threat model as you get started on a project. The act of drawing trust boundaries early on can greatly help you improve your architecture. You can also threat model as you work through features. This allows you to have smaller, more focused threat modeling projects, keeping your skills sharp and reducing the chance that you'll find big problems at the end. It is also a good idea to revisit the threat model as you get ready to deliver, to ensure that you haven't made decisions which accidentally altered the reality underlying the model.
Starting at the Beginning
Threat modeling as you get started involves modeling the system you're planning or building, finding threats against the model, and filing bugs that you'll track and manage, such as other issues discovered throughout the development process. Some of those bugs may be test cases, some might be feature work, and some may be deployment decisions. It depends on what you're threat modeling.
Working through Features
As you develop each feature, there may be a small amount of threat modeling work to do. That work involves looking deeply at the threats to that feature (and possibly refreshing or validating your understanding of the context by checking the software model). As you start work on a feature or component, it can also be a good time to work through second- or third-order threats. These are the threats in which an attacker will try to bypass the features or design elements that you put in place to block the most immediate threats. For example, if the primary threat is a car thief breaking a window, a secondary threat is them jumping the ignition. You can mitigate that with a steering-wheel lock, which is thus a second-order mitigation. There's more on this concept of ordered threats in the “Digging Deeper into Mitigations” section later in this chapter, as well as more on considering planned mitigations, and how an attacker might work around them.
Threat modeling as you work through a feature has several important value propositions. One is that if you do a small threat model as you start a component or feature, the design is probably closer to mind. In other words, you'll have a more detailed model with which to look for threats. Another is that if you find threats, they are closer to mind as you're working on that feature. Threat modeling as you work through features can also help you maintain your awareness of threats and your skills at threat modeling. (This is especially true if your project is a long one.)
Close to Delivery
Lastly, you should threat model as you get ready to ship by reexamining the model and checking your bugs. (Shipping here is inclusive of delivering, deploying, or going live.) Reexamining the model means ensuring that everyone still agrees it's a decent model of what you're building, and that it includes all the trust boundaries and data flows that cross them. Checking your bugs involves checking each bug that's tagged threat modeling (or however else you're tracking them), and ensuring it didn't slip through the cracks.
Time Management
So how long should all this take? The answer to that varies according to system size and complexity, the familiarity of the participants with the system, their skill in threat modeling, and even the culture of meetings in an organization. Some very rough rules of thumb are that you should be able to diagram and find threats against a “component” and decide if you need to do more enumeration in a one-hour session with an experienced threat modeler to moderate or help. For the sort of system that a small start-up might build, the end-to-end threat modeling could take a few hours to a week, or possibly longer if the data the system holds is particularly sensitive. At the larger end of the spectrum, a project to diagram the data flows of a large online service has been known to require four people working for several months. That level of effort was required to help find threat variations and alternate routes through a system that had grown to serve millions of people.
Whatever you're modeling, familiarity with threat modeling helps. If you need to refer back to this book every few minutes, your progress will be slower. One of the reasons to threat model regularly is to build skill and familiarity with the tasks and techniques. Organizational culture also plays a part. Organizations that run meetings with nowhere to sit will likely create a list of threats faster than a consensus-oriented organization that encourages exploring ideas. (Which list will be better is a separate and fascinating question.)
What to Start and (Plan to) End With
When you start looking for threats, a diagram is something between useful and essential input. Experienced modelers may be able to start without it, but will likely iterate through creating a diagram as they find threats. The diagram is likely to change as you use it to find threats; you'll discover things you missed or don't need. That's normal, and unless you run a strict waterfall approach to engineering, it's a process that evolves much like the way requirements evolve as you discover what's easy or hard to build.
Use the following two testable states to help assess when you're done:
§ You have filed bugs.
§ You have a diagram or diagrams that everyone agrees represents the system.
To be more specific, you should probably have a number of bugs that's roughly scaled to the number of things in your diagram. If you're using a data flow diagram and STRIDE, expect to have about five threats per diagram element.
Note
Originally, this text suggested that you should have: (# of processes * 6) + (# of data flows * 3) + (# of data stores * 3.5) + (# of distinct external entities *2) threats, but that requires keeping four separate counts, and is thus more work to get approximately the same answer.
You might notice that says “STRIDE” rather than “STRIDE-per-element” or “STRIDE-per-interaction,” and five turns out to match the number you get if you tally up the checkmarks in those charts. That's because those charts are derived from where the threats usually show up.
Where to Start
When you are staring at a blank whiteboard and wondering where to start, there are several commonly recommended places. Many people have recommended assets or attackers, but as you learned in Chapter 2, “Strategies for Threat Modeling,” the best starting place is a diagram that covers the system as a whole, and from there start looking at the trust boundaries. For advice on how to create diagrams, see Chapter 2.
When you assemble a group of people in a room to look for threats, you should include people who know about the software, the data flows and (if possible) threat modeling. Begin the process with the component(s) on which the participants in the room are working. You'll want to start top-down, and then work across the system, going “breadth first,” rather than delving deep into any component (“depth first”).
Finding Threats Top Down
Almost any system should be modeled from the highest-level view you can build of the entire system, for some appropriate value of “the entire system”. What constitutes an entire system is, of course, up for debate, just like what constitutes the entire Internet, the entirety of (say) Amazon's website, and so on, isn't a simple question. In such cases more scoping is needed. The ideal is probably what is within an organization's control and, to the extent possible, cross-reviews with those responsible for other components.
In contrast, bottom-up threat modeling starts from features, and then attempts to derive a coherent model from those feature-level models. This doesn't work well, but advice that implies you should do this is common, so a bit of discussion may be helpful. The reason this doesn't work is because it turns out to be very challenging to bring threat models together when they are not derived from a system-level view. As such, you should start from the highest-level view you can build of the entire system.
Microsoft's Bottom-up Experience
It may help to understand the sorts of issues that can lead to a bottom-up approach. At Microsoft in the mid-2000s, there was an explosion of bottom-up threat modeling. There were three drivers for this: specific words in the Security Development Lifecycle (SDL) threat model requirement, aspects of Microsoft's approach to function teams, and the work involved in creating top-level models. The SDL required “all new features” be threat modeled. This intersected with an approach to features whereby a particular team of developer, tester, and program manager owns a feature and collaborates to ship it. Because the team owned its feature, it was natural to ask it to add threat models to the specifications involved in producing it. As Microsoft's approach to security evolved, product security teams had diverse sets of important tasks to undertake. Creating all-up threat models was usually not near the top of the list. (Many large product diagrams have now done that work and found it worthwhile. Some of these diagrams require more than one poster-size sheet of paper.)
Finding Threats “Across”
Even with a top-down approach, you want to go breadth first, and there are three different lists you can iterate “across”: A list of the trust boundaries, a list of diagram elements, or a list of threats. A structure can help you look for threats, either because you and your team like structure, or because the task feels intimidating and you want to break it down, Table 7.1 shows three approaches.
Table 7.1 Lists to Iterate Across
|
Method |
Sample Statement |
Comments |
|
Start from what goes across trust boundaries. |
″What can go wrong as foo comes across this trust boundary? |
This is likely to identify the highest-value threats. |
|
Iterate across diagram elements. |
“What can go wrong with this database file?” “What can go wrong with the logs?” |
Focusing on diagram elements may work well when a lot of teams are collaborating. |
|
Iterate across the threats. |
“Where are the spoofing threats in this diagram?” “Where are the tampering threats?” |
Making threats the focus of discussion may help you find related threats. |
Each of these approaches can be a fine way to start, as long as you don't let them become straightjackets. If you don't have a preference, try starting from what crosses trust boundaries, as threats tend to cluster there. However you iterate, ensure that you capture each threat as it comes up, regardless of the planned approach.
Digging Deeper into Mitigations
Many times threats will be mitigated by the addition of features, which can be designed, developed, tested and delivered much like other features. (Other times, mitigation might be a configuration change, or at the other end of the effort scale, require re-design.) However, mitigations are not quite like other features. An attacker will rarely try to work around the bold button and find an unintended, unsupported way to bold their text.
Finding threats is great, and to the extent that you plan to be attacked only by people who are exactly lazy enough to find a threat but not enthusiastic enough to try to bypass your mitigation, you don't need to worry about going deeper into the mitigations. (You may have to worry about a new job, but that, as they say, is beyond the scope of this book. I recommend Mike Murray's Forget the Parachute: Let Me Fly the Plane.) In this section, you'll learn about how to go deeper into the interplay of how attackers can attempt to bypass the design choices and features you put in place to make their lives harder.
The Order of Mitigation
Going back to the example of threat modeling a home from the introduction, it's easy and fun for security experts to focus on how attackers could defeat the security system by cutting the alarm wire. If you consider the window to be the attack surface, then threats include someone smashing through it and someone opening it. The smashing is addressed by re-enforced glass, which is thus “first-order” mitigation. The smashing threat is also addressed by an alarm, which is a second-order defense. But, oh no! Alarms can be defeated by cutting power. To address that third-level threat, the system designer can add more defenses. For example, alarm systems can include an alert if the line is ever dropped. Therefore, the defender can add a battery, or perhaps a cell phone or some other radio. (See how much fun this is?) These multiple layers, or orders, of attack and defense are shown in Table 7.2.
Note
If you become obsessed with the window-smashing threat and forget to put a lock on the window, or you never discover that there's a door key under the mat, you have unaddressed problems, and are likely mis-investing your resources.
Table 7.2 Threat and Mitigation “Orders” or “Layers”
|
Order |
Threat |
Mitigation |
|
1st |
Window smashing |
Reinforced glass |
|
2nd |
Window smashing |
Alarm |
|
3rd |
Cut alarm wire |
Heartbeat |
|
4th |
Fake heartbeat |
Cryptographic signal integrity |
Threat modeling should usually proceed from attack surfaces, and ensure that all first-order threats are mitigated before attention is paid to the second-order threats. Even if a methodology is in place to ensure that the full range of first-order threats is addressed, a team may run out of time to follow the methodology. Therefore, you should find threats breadth-first.
Playing Chess
It's also important to think about what an attacker will do next, given your mitigations. Maybe that means following the path to faking a heartbeat on the alarm wire, but maybe the attacker will find that door key, or maybe they'll move on to another victim. Don't think of attacks and mitigations as static. There's a dynamic interplay between them, usually driven by attackers. You might think of threats and mitigations like the black and white pieces on a chess board. The attacker can move, and when they move, their relationship to other pieces can change. As you design mitigation, ask what an attacker could do once you deliver that mitigation. How could they work around it? (This is subtly different from asking what they will do. As Nobel-prize winning physicist Niels Bohr said, “Prediction is very difficult, especially about the future.”)
Generally, attackers look for the weakest link they can easily find. As you consider your threats and where to go into depth, start with the weakest links. This is an area where experience, including a repertoire of real scenarios, can be very helpful. If you don't have that repertoire, a literature review can help, as you saw in Chapter 2. This interplay is a place where artful threat modeling and clever redesign can make a huge difference.
Believing that an attacker will stop because you put a mitigation in place is optimistic, or perhaps naive would be a better word. What happens several moves ahead can be important. (Attackers are tricky like that.) This differs from thinking through threat ordering in that your attacker will likely move to the “next easiest” attack available. That is, an attacker doesn't need to stick to the attack you're planning for or coding against at the moment, but rather can go anywhere in your system. The attacker gets to choose where to go, so you need to defend everywhere. This isn't really fair, but no one promised you fair.
Prioritizing
You might feel that the advice in this section about the layers of mitigations and the suggestion to find threats across first is somewhat contradictory. Which should you do first? Consider the chess game or cover everything? Covering breadth first is probably wise. As you manage the bugs and select ways to mitigate threats, you can consider the chess game and deeper threat variants. However, it's important to cover both.
The unfortunate reality is that attackers with enough interest in your technology will try to find places where you didn't have enough time to investigate or build defenses. Good requirements, along with their interplay with threats and mitigations, can help you create a target that is consistently hard to attack.
Running from the Bear
There's an old joke about Alice and Bob hiking in the woods when they come across an angry bear. Alice takes off running, while Bob pauses to put on some running shoes. Alice stops and says, “What the heck are you doing?” Bob looks at her and replies, “I don't need to outrun the bear, I just need to outrun you.”
OK, it's not a very good joke. But it is a good metaphor for bad threat modeling. You shouldn't assume that there's exactly one bear out there in the woods. There are a lot of people out there actively researching new vulnerabilities, and they publish information about not only the vulnerabilities they find, but also about their tools and techniques. Thus, more vulnerabilities are being found more efficiently than in past years. Therefore, not only are there multiple bears, but they have conferences in which they discuss techniques for eating both Alice and Bob for lunch.
Worse, many of today's attacks are largely automated, and can be scaled up nearly infinitely. It's as if the bears have machine guns. Lastly, it will get far worse as the rise of social networking empowers automated social engineering attacks (just consider the possibilities when attackers start applying modern behavior-based advertising to the malware distribution business).
If your iteration ends with “we just have to run faster than the next target,” you may well be ending your analysis early.
Tracking with Tables and Lists
Threat modeling can lead you to generate a lot of information, and good tracking mechanisms can make a big difference. Discovering what works best for you may require a bit of experimentation. This section lays out some sample lists and sample entries in such lists. These are all intended as advice, not straightjackets. If you regularly find something that you're writing on the side, give yourself a way to track it.
Tracking Threats
The first type of table to consider is one that tracks threats. There are (at least) three major ways to organize such a table, including by diagram element (see Table 7.3), by threat type (see Table 7.4), or by order of discovery (see Table 7.5). Each of these tables uses these methods to examine threats against the super-simple diagram from Chapter 1, “Dive In and Threat Model!” reprised here in Figure 7.1.
Table 7.3 A Table of Threats, Indexed by Diagram Element (excerpt)
|
Diagram Element |
Threat Type |
Threat |
Bug ID and Title |
|
Data flow (4) web server to Biz Logic |
Tampering |
Add orders without payment checks. |
4553 “need integrity controls on channel” |
|
Information disclosure |
Payment instruments in the clear |
4554 “need crypto” #PCI #p0 |
|
|
Denial of service |
Can we just accept all these inside the data center? |
4555 “Check with Alice in IT if these are acceptable”. |
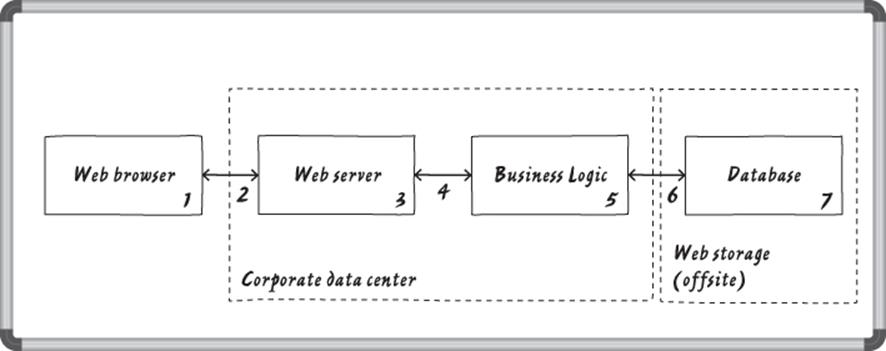
Figure 7.1 The diagram considered in threat tables
If you organize by diagram element, the column headers are Diagram Element, Threat Type, Threat, and Bug ID/Title. You can check your work by validating that the expected threats are all present in the table. For example, if you're using STRIDE-per-element, then you should have at least one tampering, information disclosure, and denial-of-service threat for each data flow. An example table for use in iterating over diagram elements is shown in Table 7.3.
To check the completeness of Table 7.3, confirm that each element has at least one threat. If you're using STRIDE-per-element, each process should have six threats, each data flow three, each external entity two, and each data store three or four if the data store is a log.
You can also organize a table by threats, and use threats as what's being iterated “across.” If you do that, you end up with a table like the one shown in Table 7.4.
Table 7.4 A Table of Threats, Organized by Threat (excerpt)
|
Threat |
Diagram Element |
Threat |
Bug ID and Title |
|
Tampering |
Web browser (1) |
Attacker modifies our JavaScript order checker. |
4556 “Add order-checking logic to the server”. |
|
Data flow (2)from browser to server |
Failure to use HTTPS* |
4557 “Build unit tests to ensure that there are no HTTP listeners for endpoints to these data flows.” |
|
|
Web server |
Someone who tampers with the web server can attack our customers. |
4558 “Ensure all changes to server code are pulled from source control so changes are accountable”. |
|
|
Web server |
Web server can add items to orders. |
4559 “Investigate moving controls to Biz Logic, which is less accessible to attackers”. |
Table 7.5 Threats by Order of Discovery (excerpt)
|
Threat |
Diagram Element |
Threat |
Bug ID |
|
Tampering |
Web browser (1) |
Attacker modifies the JavaScript order checker. |
4556 “Add order-checking logic to the server”. |
Note
You may have noticed that Table 7.4 has two entries for web server—this is totally fine. You shouldn't let having something in a space prevent you from finding more threats against that thing, or recording additional threats that you discover.
The last way to formulate a table is by order of discovery, as shown in Table 7.5. This is the easiest to fill out, as the next threat is simply added to the next line. It is, however, the hardest to validate, because the threats will be “jumbled together.”
With three variations, the obvious question is which one should you use? If you're new to threat modeling and need structure, then either of the first two forms help you organize your approach. The third is more natural, but requires checking at the end; so as you become more comfortable threat modeling, jumping around will become natural, and therefore the third type of table will become more useful.
Making Assumptions
The key reason to track assumptions as you discover them is so that you can follow up and ensure that you're not assuming your way into a problem. To do that, you should track the following:
§ The assumption
§ The impact if it's wrong
§ Who can tell you if it's wrong
§ Who's going to follow-up
§ When they need to do so
§ A bug for tracking
Table 7.6 shows an example entry for such a table of assumptions.
Table 7.6 A Table for Recording Assumptions
|
Assumption |
Impact If Wrong |
Who to Talk to |
Who's Following Up |
Follow-Up by Date |
Bug # |
|
It's OK to ignore denial of service within the data center. |
Unhandled vulnerabilities |
Alice |
Bob |
April 15 |
4555 |
External Security Notes
Many of the documented Microsoft threat-modeling approaches have a section for “external security notes.” That name frames these notes with respect to the threat model. That is, they're notes for those outside the threat discovery process in some way, and they'll probably emerge or crystalize as you look for threats. Therefore, like tracking threats and assumptions, you want to track external security notes. You can be clearer by framing the notes in terms of two sets of audiences: your customers and those calling your APIs. One of the most illustrative forms of these notes appears in the IETF “RFC Security Considerations” section, so you'll get a brief tour of those here.
Notes for Customers
Security notes that are designed for your customers or the people using your system are generally of the form “we can't fix problem X.” Not being able to fix problem X may be acceptable, and it's more likely to be acceptable if it's not a surprise—for example, “This product is not designed to defend against the system administrator.” This sort of note is better framed as “non-requirements,” and they are discussed at length in Chapter 12, “Requirements Cookbook.”
Notes for API Callers
The right design for an API involves many trade-offs, including utility, usability, and security. Threat modeling that leads to security notes for your callers can serve two functions. First, those notes can help you understand the security implications of your design decisions before you finalize those decisions. Second, they can help your customers understand those implications.
These notes address the question “What does someone calling your API need to do to use it in a secure way?” The notes help those callers know what threats you address (what security checks you perform), and thus you can tell them about a subset of the checks they'll need to perform. (If your security depends on not telling them about threats then you have a problem; see the section on Kerckhoffs's Principles in Chapter 16, “Threats to Cryptosystems.”) Notes to API callers are generally one of the following types:
§ Our threat model is [description]—That is, the things you worry about are… This should hopefully be obvious to readers of this book.
§ Our code will only accept input that looks like [some description]—What you'll accept is simply that—a description of what validation you'll perform, and thus what inputs you would reject. This is, at a surface level, at odds with the Internet robustness principle of “be conservative in what you send, and liberal in what you accept”; but being liberal does not require foolishness. Ideally, this description is also matched by a set of unit tests.
§ Common mistakes in using our code include [description]—This is a set of things you know callers should or should not do, and are two sides of the same coin:
§ We do not validate this property that callers might expect us to validate—In other words, what should callers check for themselves in their context, especially when they might expect you to have done something?
§ Common mistakes that our code doesn't or can't address—In other words, if you regularly see bug reports (or security issues) because your callers are not doing something, consider treating that as a design flaw and fixing it.
For an example of callers having trouble with an API, consider the strcpy function. According to the manual pages included with various flavors of unix, “strcpy does not validate that s2 will fit buffer s1,” or “strcpy requires that s1 be of at least length (s2) + 1.” These examples are carefully chosen, because as the fine manual continues, “Avoid using strcat.” (You should now use SafeStr* on Windows, strL* on unix.) The manual says this because, although notes about safer use were eventually added, the function was simply too hard to use correctly, and no amount of notes to callers was going to overcome that. If your notes to those calling your API boil down to “it is impossible to use this API without jumping through error-prone hoops,” then your API is going to need to change (or deliver some outstanding business value).
Sometimes, however, it's appropriate to use these sorts of notes to API callers—for example, “This API validates that the SignedDataBlob you pass in is signed by a valid root CA. You will still need to ensure that the OrganizationName field matches the name in the URL, as you do not pass us the URL.” That's a reasonable note, because the blob might not be associated with a URL. It might also be reasonable to have a ValidateSignatureURL() API call.
RFC Security Considerations
IETF RFCs are a form of external security notes, so it's worth looking at them as an evolved example of what such notes might contain (Rescorla, 2003). If you need a more structured form of note, this framework is a good place to start. The security considerations of a modern RFC include discussion of the following:
§ What is in scope
§ What is out of scope—and why
§ Foreseeable threats that the protocol is susceptible to
§ Residual risk to users or operators
§ Threats the protocol protects against
§ Assumptions which underlie security
Scope is reasonably obvious, and the RFC contains interesting discussion about not arbitrarily defining either foreseeable threats or residual risk as out of scope. The point about residual risk is similar to non-requirements, as covered in Chapter 12. It discusses those things that the protocol designers can't address at their level.
Scenario-Specific Elements of Threat Modeling
There are a few scenarios where the same issues with threat modeling show up again and again. These scenarios include issues with customer/vendor boundaries, threat modeling new technologies, and threat modeling an API (which is broader than just writing up external security notes). The customer/vendor trust boundary is dropped with unfortunate regularity, and how to approach an API or new technology often appears intimidating. The following sections address each scenario separately.
Customer/Vendor Trust Boundary
It is easy to assume that because someone is running your code, they trust you, and/or you can trust them. This can lead to things like Acme engineers saying, “Acme.com isn't really an external entity… ” While this may be true, it may also be wrong. Your customers may have carefully audited the code they received from you. They may believe that your organization is generally trustworthy without wanting to expose their secrets to you. You holding those secrets is a different security posture. For example, if you hold backups of their cryptographic keys, they may be subject to an information disclosure threat via a subpoena or other legal demand that you can't reveal to them. Good security design involves minimizing risk by appropriate design and enforcement of the customer/vendor trust boundary.
This applies to traditional programs such as installed software packages, and it also applies to the web. Believing that a web browser is faithfully executing the code you sent it is optimistic. The other end of an HTTPS connection might not even be a browser. If it is a browser, an attacker may have modified your JavaScript, or be altering the data sent back to you via a proxy. It is important to pay attention to the trust boundary once your code has left your trust context.
New Technologies
From mobile to cloud to industrial control systems to the emergent “Internet of Things,” technologists are constantly creating new and exciting technologies. Sometimes these technologies genuinely involve new threat categories. More often, the same threats manifest themselves. Models of threats that are intended to elicit or organize thinking about skilled threat modelers (such as STRIDE in its mnemonic form) can help in threat modeling these new technologies. Such models of threats enable skilled practitioners to find many of the threats that can occur even as the new technologies are being imagined.
As your threat elicitation technique moves from the abstract to the detailed, changes in the details of both the technologies and the threats may inhibit your ability to apply the technique.
From a threat-modeling perspective, the most important thing that designers of new technologies can do is clearly define and communicate the trust relationships by drawing their trust boundaries. What's essential is not just identification, but also communication. For example, in the early web, the trust model was roughly as shown in Figure 7.2.
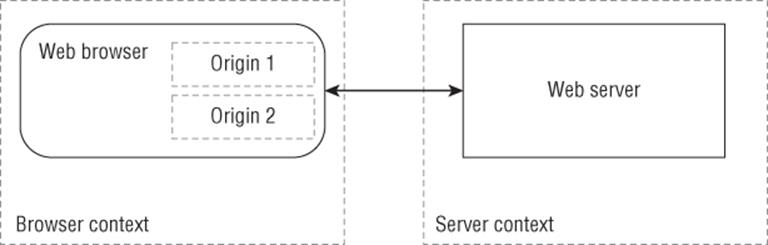
Figure 7.2 The early web threat model
In that model, servers and clients both ran code, and what passed between them via HTTP was purely data in the form of HTML and images. (As a model, this is simplified; early web browsers supported more than HTTP, including gopher and FTP.) However, the boundaries were clearly drawable. As the web evolved and web developers pushed the boundary of what was possible with the browser's built-in functionality, a variety of ways for the server to run code on the client were added, including JavaScript, Java, ActiveX, and Flash. This was an active transformation of the security model, which now looks more like Figure 7.3.
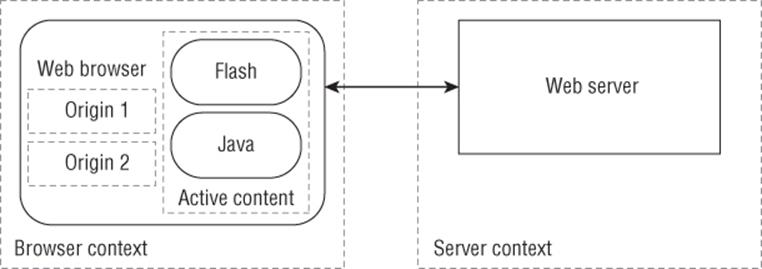
Figure 7.3 The evolved web threat model
In this model, content from the server has dramatically more access to the browser, leading to two new categories of threats. One is intra-page threats, whereby code from different servers can attack other information in the browser. The other is escape threats, whereby code from the server can find a way to influence what's happening on the client computer. In and of themselves, these changes are neither good nor bad. The new technologies created a dramatic transformation of what's possible on the web for both web developers and web attackers. The transformation of the web would probably have been accomplished with more security if boundaries had been clearly identified. Thus, those using new technology will get substantial security benefits from its designers by defining, communicating, and maintaining clear trust boundaries.
Threat Modeling an API
API threat models are generally very similar. Each API has a low trust side, regardless of whether it is called from a program running on the local machine or called by anonymous parties on the far side of the Internet. On a local machine, the low trust side is more often clear: The program running as a normal user is running at a low trust level compared to the kernel. (It may also be running at the same trust level as other code running with the same user ID, but with the introduction of things like AppContainer on Windows and Mac OS sandbox, two programs running with the same UID may not be fully equivalent. Each should treat the other as being untrusted.) In situations where there's a clear “lower trust” side, that unprivileged code has little to do, except ensure that data is validated for the context in which that data will be used. If it really is at a lower trust level, then it will have a hard time defending itself from a malicious kernel, and should generally not try. This applies only to relationships like that of a program to a kernel, where there's a defined hierarchy of privilege. Across the Internet, each side must treat the other as untrusted. The “high trust” side of the API needs to do the following seven things for security:
§ Perform all security checks inside the trust boundary. A system has a trust boundary because the other side is untrusted or less trusted. To allow the less trusted side to perform security checks for you is missing the point of having a boundary. It is often useful to test input before sending it (for example, a user might fill out a long web form, miss something, and then get back an error message). However, that's a usability feature, not a security feature. You must test inside the trust boundary. Additionally, for networked APIs/restful APIs/protocol endpoints, it is important to consider authentication, authorization, and revocation.
§ When reading, ensure that all data is copied in before validation for purpose (see next bullet). The low, or untrusted side, can't be trusted to validate data. Nor can it be trusted to not change data under its control after you've checked it. There is an entire genus of security flaws called TOCTOU (“time of check, time of use”) in which this pattern is violated. The data that you take from the low side needs to be copied into secured memory, validated for some purpose, and then used without further reference to the data on the low side.
§ Know what purpose the data will be put to, and validate that it matches what the rest of your system expects from it. Knowing what the data will be used for enables you to check it for that purpose—for example, ensure an IPv4 address is four octets, or that an e-mail address matches some regular expression (an e-mail regular expression is an easily grasped example, but sending e-mail to the address is better [Celis, 2006]). If the API is a pass-through (for example, listening on a socket), then you may be restricted to validating length, length to a C-style string, or perhaps nothing at all. In that case, your documentation should be very clear that you are doing minimal or no validation, and callers should be cautious.
§ Ensure that your messages enable troubleshooting without giving away secrets. Trusted code will often know things that untrusted code should not. You need to balance the capability to debug problems with returning too much data. For example, if you have a database connection, you might want to return an error like “can't connect to server instance with username dba password dfug90845b4j,” but anyone who connected then now knows the DBA's password. Oops! Messages of the form “An error of type Xoccurred. This is instance Y in the error log Z” are helpful enough to a systems administrator, who can search for Y in Z while only disclosing the existence of the logs to the attacker. Even better are errors that include information about who to contact. Messages that merely say “Contact your system administrator” are deeply frustrating.
§ Document what security checks you perform, and the checks you expect callers to perform for themselves. Very few APIs take unconstrained input. The HTTP interface is a web interface: It expects a verb (GET, POST, HEAD) and data. For a GET orHEAD, the data is a URL, an HTTP version, and a set of HTTP headers. Old-fashioned CGI programs knew that the web server would pass them a set of headers as environment variables and then a set of name-value pairs. The environment variables were not always unique, leading to a number of bugs. What a CGI could rely on could be documented, but the diverse set of attacks and assumptions that people could read into it was not documentable.
§ Ensure that any cryptographic function runs in a constant time. All your crypto functions should run in constant time from the perspective of the low trust side. It should be obvious that cryptographic keys (except the public portion of asymmetric systems) are a critical subset of the things you should not expose to low. Crypto keys are usually both a stepping stone asset and a thing you want to protect asset. See also Chapter 16 on threats to cryptosystems.
§ Handle the unique security demands of your API. While the preceding issues show up with great consistency, you're hopefully building a new API to deliver new value, and that API may also bring new risks that you should consider. Sometimes it's useful to use the “rogue insider” model to help ask “what could we do wrong with this?”
In addition to the preceding checklist, it may be helpful to look to similar or competitive APIs and see what security changes they've executed, although the security changes may not be documented as such.
Summary
There are a set of tools and techniques that you can use to help threat modeling fit with other development, architecture, or technology deployments. Threat modeling tasks that use these tools happen at the start of a project, as you're working through features, and as you're close to delivery.
Threat modeling should start with the creation of a software diagram (or updating the diagram from the previous release). It should end with a set of security bugs being filed, so that the normal development process picks up and manages those bugs.
When you're creating the diagram, start with the broadest description you can, and add details as appropriate. Work top down, and as you do, at each level of the diagram(s), work across something: trust boundaries, software elements or your threat discovery technique.
As you look to create mitigations, be aware that attackers may try to bypass those mitigations. You want to mitigate the most accessible (aka “first order”) threats first, and then mitigate attacks against your mitigations. You have to consider your threats and mitigations not as a static environment, but as a game where the attacker can move pieces, and possibly cheat.
As you go through these analyses, you'll want to track discoveries, including threats, assumptions, and things your customers need to know. Customers here include your customers, who need to understand what your goals and non-goals are, and API callers, who need to understand what security checks you perform, and what checks they need to perform.
There are some scenario-specific call outs: It is important to respect the customer/vendor security boundary; new technologies can and should be threat modeled, especially with respect to all the trust boundaries, not just the customer/vendor one; all APIs have very similar threat models, although there may be new and interesting security properties of your new and interesting API.