Software Architecture for Developers: Technical leadership by coding, coaching, collaboration, architecture sketching and just enough up front design (2014)
VII. APPENDIX B: SOFTWARE GUIDEBOOK FOR TECHTRIBES.JE
This is a sample software guidebook for the techtribes.je website, which is a side-project of mine to provide a focal point for the tech, IT and digital sector in Jersey.
The code behind the techtribes.je website has been open sourced and is available on GitHub.
Introduction
This software guidebook provides an overview of the techtribes.je website. It includes a summary of the following:
1. The requirements, constraints and principles behind the website.
2. The software architecture, including the high-level technology choices and structure of the software.
3. The infrastructure architecture and how the software is deployed.
4. Operational and support aspects of the website.
Context
The techtribes.je website provides a way to find people, tribes (businesses, communities, interest groups, etc) and content related to the tech, IT and digital sector in Jersey and Guernsey. At the most basic level, it’s a content aggregator for local tweets, news, blog posts, events, talks, jobs and more. Here’s a context diagram that provides a visual summary of this:
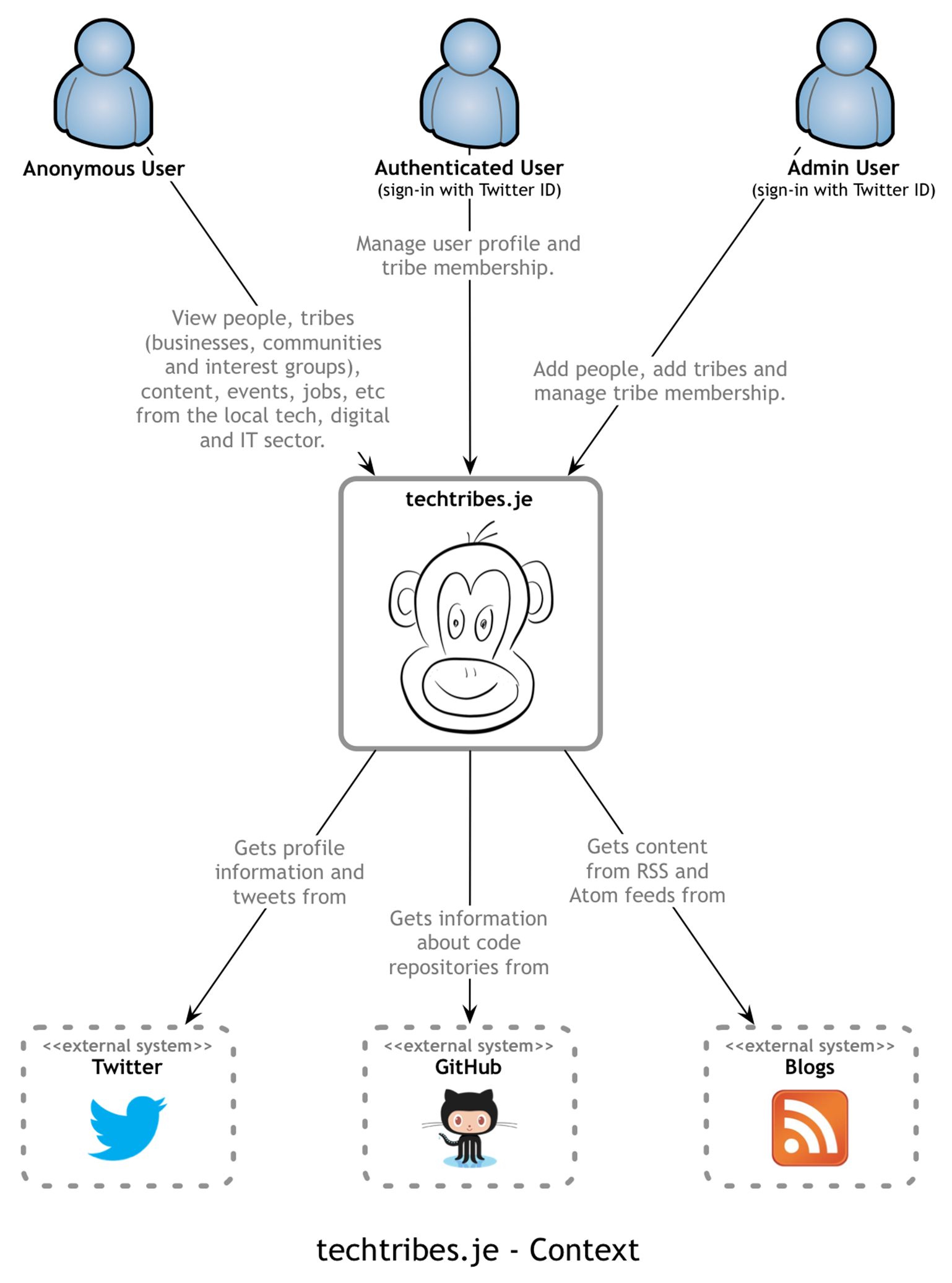
The purpose of the website is to:
1. Consolidate and share local content, helping to promote it inside and outside of the local community.
2. Encourage an open, sharing and learning culture within the local community.
Users
The techtribes.je website has three types of user:
1. Anonymous: anybody with a web browser can view content on the site.
2. Authenticated: people/tribes who have content aggregated into the website can sign-in to the website using their registered Twitter ID (if they have one) to modify some of their basic profile information.
3. Admin: people with administrative (super-user) access to the website can manage the people, tribes and content that is aggregated into the website.
External Systems
There are three types of systems that techtribes.je integrates with. These are represented by dashed grey boxes on the context diagram.
1. Twitter: profile information and tweets from people/tribes are retrieved from Twitter for aggregation into the website. Twitter is also used to allow people/tribes to sign-in to techtribes.je with their Twitter ID.
2. GitHub: summary information about code repositories is retrieved from GitHub if people/tribes have registered a GitHub ID.
3. Blogs: content from blogs written by people/tribes is retrieved via RSS or Atom feeds for aggregation into the website.
Functional Overview
This section provides a summary of the functionality provided by the techtribes.je website.
People and Tribes
At the core of techtribes.je are people and tribes:
· People: these are people in the local tech, digital and IT sector.
· Tribes: a tribe is a group of people and there are 4 types:
o Business: a business tribe represents a local company.
o Tech: a tech tribe is a group of people with a common interest in a particular topic (e.g. Java, Raspberry Pi, SharePoint, etc).
o Media: a media tribe is an organisation who publishes local news.
o Community: a community tribe represents a local user group or other non-profit organisation.
People and tribes have some basic profile information along with a Twitter ID and one or more links to RSS/Atom feeds that techtribes.je uses to aggregate content into the website.
Content
techtribes.je aggregates and publishes a number of different types of content, all of which is associated with either a person or a tribe.
Blog posts and Tweets
The major function that techtribes.je performs is to aggregate blog posts and tweets from people and tribes, allowing users of the website to find that content in one place. Blog posts and tweets can be viewed in a number of ways on the website plus there’s also a search feature. A single, consolidated RSS feed of all blog posts is published by the website too.
News
Local tech news items are simply blog posts by media tribes. Again, these can can be viewed in a number of ways on the website.
Talks
techtribes.je publishes information about the various talks that local people do at conferences, meetups and other events. Each talk has some basic information (i.e. title, abstract, date plus event details) and is associated with a person.
Events
techtribes.je also publishes information about local tech events, meetups, user groups, etc. Each event has some basic information (i.e. title, description, date, time, event URL, etc) and is associated with a tribe.
Jobs
Finally, techtribes.je lists local tech jobs. A job has some basic information (i.e. title, description, date posted, a URL for more information, etc) and is again associated with a tribe.
Users
There are three types of users.
Anonymous Users
Anonymous users represent anybody visiting techtribes.je and they have the ability to view all of the content on the website in a number of different ways.
Authenticated Users
Local people who are listed on techtribes.je can sign-in with their Twitter ID in order to manage some basic profile information and the list of tech tribes they are a member of.
Admin Users
Admin users are simply authenticated users that have been assigned an additional role to perform some basic administration on the website. This includes adding people and tribes to the website, plus managing tribe membership.
Gaming Engine
The final major function that techtribes.je provides is a simple gaming engine to encourage local people and tribes to engage with other members of the community and share content more often.
Points
Points are awarded to people and tribes for tweeting, blogging, doing talks and organising events. The points over a seven day period are calculated on an rolling basis to produce a list of who is the most active.
Badges
In addition to points, badges are awarded to people and tribes for specific achievements. This includes simple things such as tweeting and blogging through to appearing in the top 3 on the most active list and doing a talk off-island.
Quality Attributes
This section provides information about the desired quality attributes (non-functional requirements) of the techtribes.je website.
Performance
All pages on techtribes.je should load and render in under five seconds, for fifty concurrent users.
Scalability
The techtribes.je website should be able to scale to ten times the current data volumes, as follows:
· 1000 people and tribes
· 500,000 tweets
· 10,000 news/blog posts
Security
Although most of the techtribes.je website can be viewed by anonymous users, it must provide role-based access to allow people/tribes to log-in and manage their profile. In order to reduce the operational support overhead associated with managing user credentials, all authentication must be done via a third-party mechanism such as Twitter, Facebook, Google, OpenID, etc.
Availability
Since techtribes.je is a not a mission critical system and has a limited budget, there are no strict availability targets.
Internationalisation
All user interface text will be presented in English only.
Localisation
All information will be formatted for the British English locale only.
Browser compatibility
The techtribes.je website should work consistently across the following browsers:
· Safari
· Firefox
· Chrome
· Internet Explorer 8 (and above)
Constraints
This section provides information about the constraints imposed on the development of the techtribes.je website.
Budget
Since there is no formal budget for the techtribes.je website, there is a constraint to use free and open source technologies for the development. Ideally, the website should run on a single server with hosting costs of less than £20 GBP per month.
Principles
This section provides information about the principles adopted for the development of the techtribes.je website.
Package by component
To provide a simple mapping of the software architecture into the code, the package structure of the code reflects a “package by component” convention rather than “package by layer”.
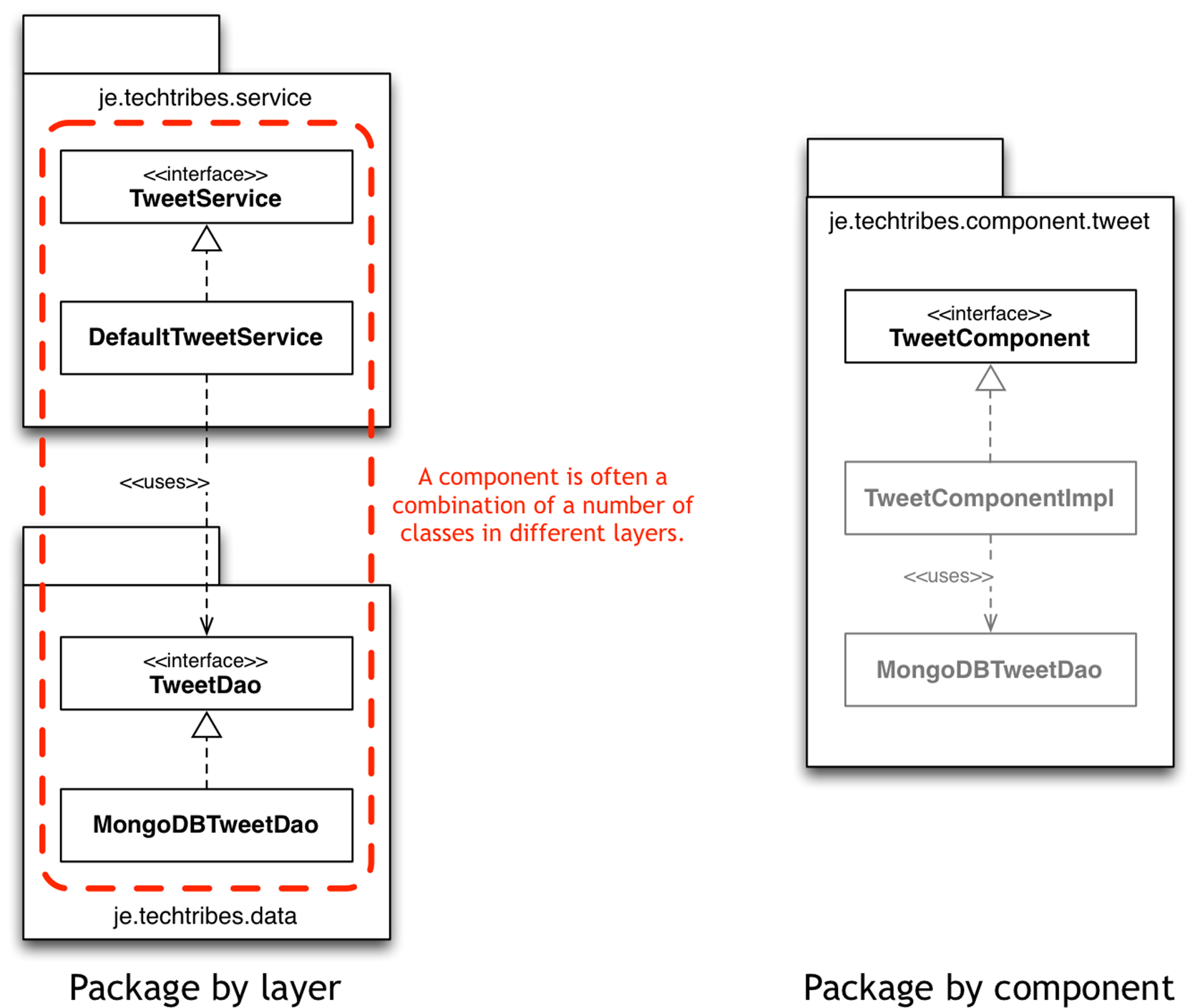
This means that the codebase is broken up into a number of components, each of which has:
· A well-defined public interface.
· Strong encapsulation (i.e. all implementation details are package protected where possible).
· A Spring configuration file called component.xml to configure and wire the component together into the rest of the system.
Automated testing
The strategy for automated testing is to use automated unit and component tests.
· Unit tests: These are fast running, very small tests that operate on a single class or method in isolation. See the techtribes-core unit tests for some examples.
· Component tests: Rather than mocking out database connections to test component internals, components are tested as single units to avoid breaking encapsulation. See the techtribes-core component tests for some examples.
Configuration
All configuration needed by components is externalised into a Java .properties file, which is held outside of the deployment files created by the build process. This means that builds can be migrated from development, testing and into production without change.
Spring Autowiring
Spring autowiring is only used in the web-tier part of techtribes.je (techtribes-web), to inject components into the Spring MVC controllers.
Software Architecture
This section provides an overview of the techtribes.je software architecture.
Containers
The following diagram shows the logical containers that make up the techtribes.je system. The diagram does not represent the physical number and location of containers - please see the infrastructure and deployment sections for this information.
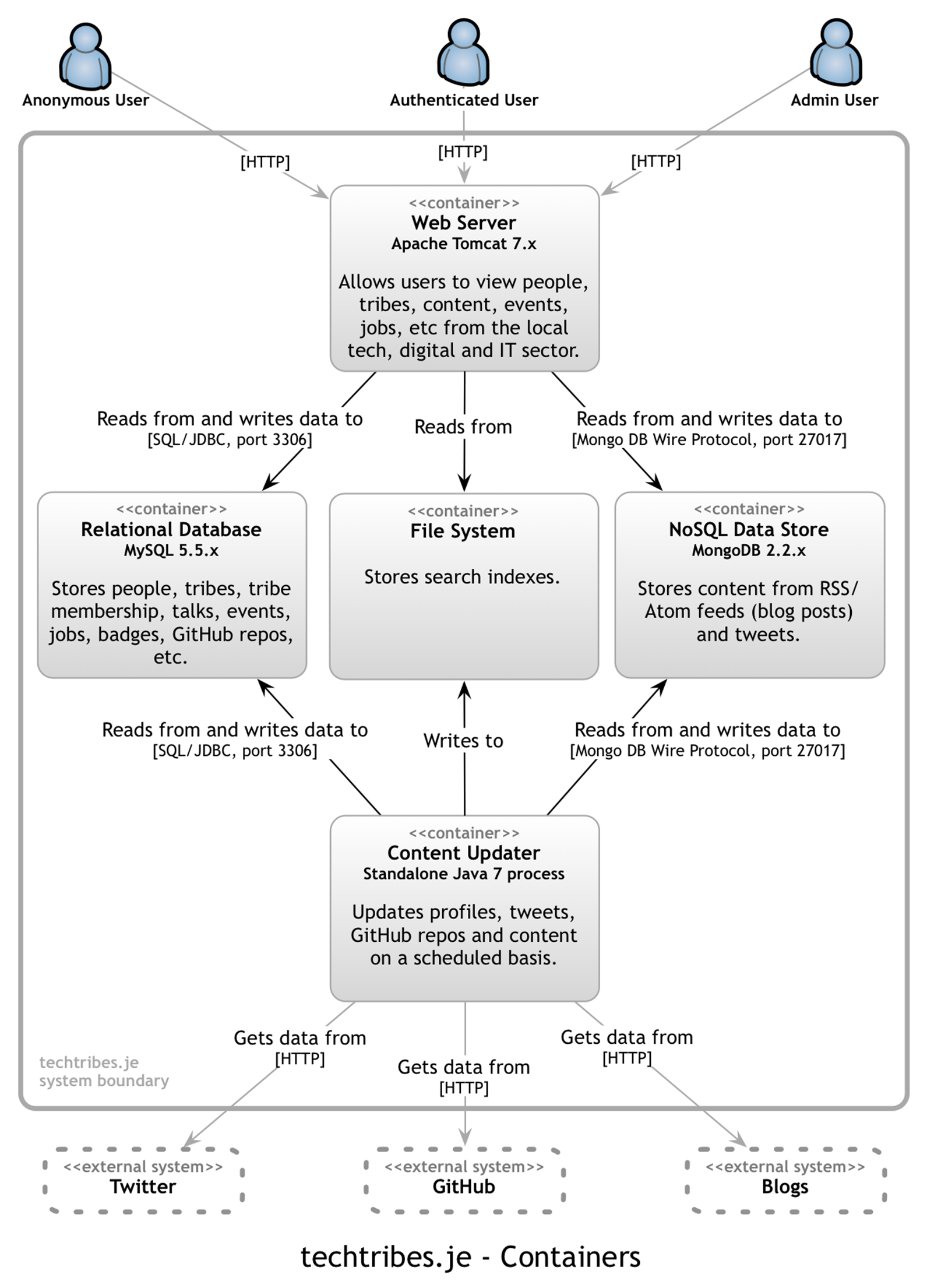
· Web Server: an Apache Tomcat 7 web server that is the single point of access for the techtribes.je website from the Internet.
· Content Updater: a standalone Java 7 application that updates information from Twitter, GitHub and blogs.
· Relational Database: a MySQL database that stores the majority of the data behind the techtribes.je website.
· NoSQL Data Store: a MongoDB database that stores the tweets and blog posts.
· File System: the file system stores Lucene search indexes.
Components - Content Updater
The following diagram shows the components that make up the standalone Content Updater.
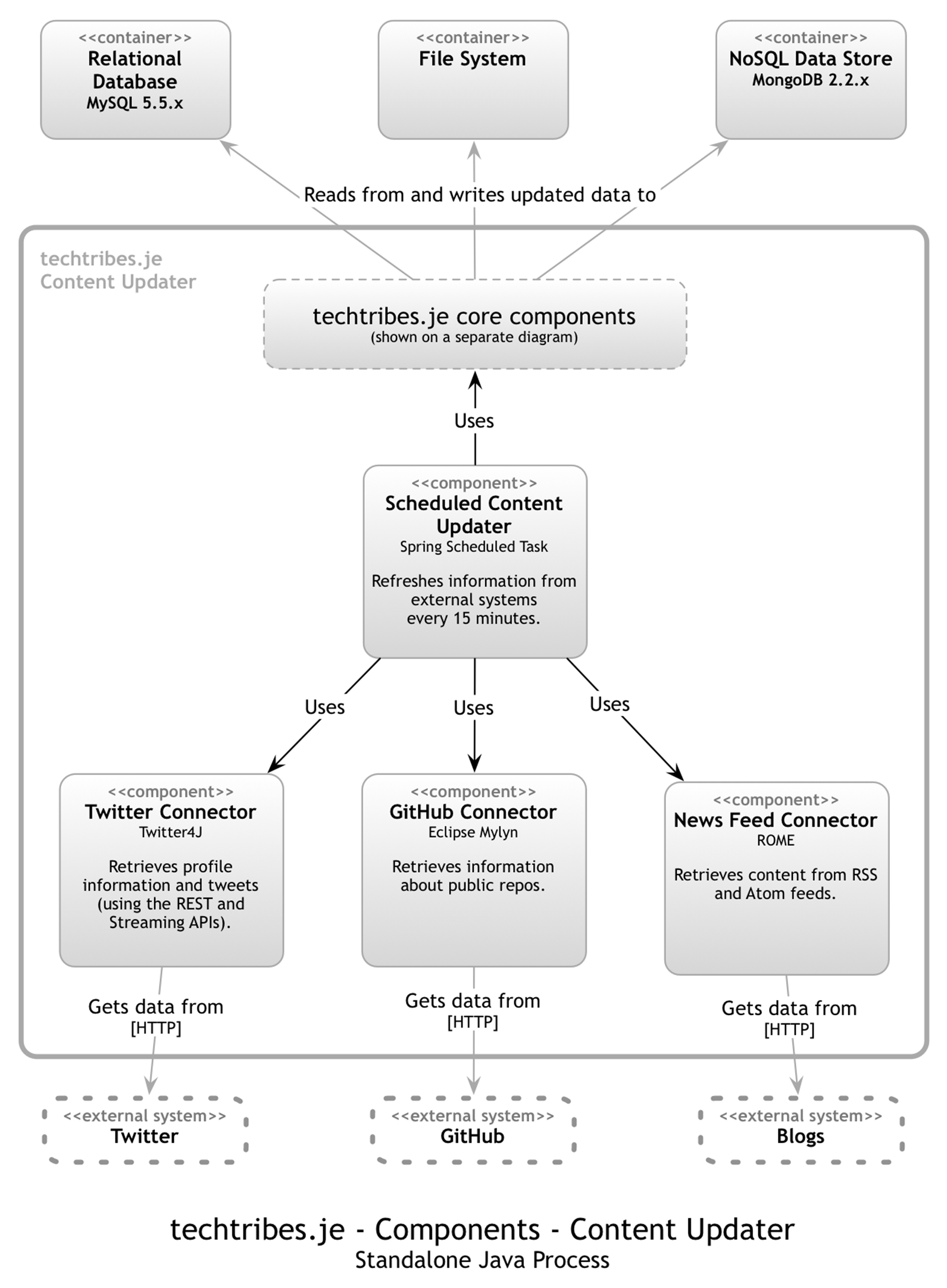
In addition to some core components (detailed later), the standalone Content Updater process consists of the following components:
· Scheduled Content Updater: This component orchestrates the update of information from Twitter, GitHub and blogs on a scheduled basis (i.e. every fifteen minutes). It also recalculates the “recent activity” and awards badges once per hour. It’s a Spring Bean that uses the Spring scheduling annotations. See je.techtribes.component.scheduledcontentupdater for the code.
· Twitter Connector: This component is responsible for connecting to Twitter in order to refresh profile information and retrieve tweets. It’s a Spring Bean that uses the Twitter4J library. Both of the REST and streaming APIs are used. See je.techtribes.component.twitterconnector for the code.
· GitHub Connector: This component is responsible for connecting to GitHub in order to refresh repository information. It’s a Spring Bean that uses the Eclipse Mylyn GitHub connector. See je.techtribes.component.githubconnector for the code.
· News Feed Connector: This component is responsible for connecting to RSS/Atom feeds in order to refresh the news and blog posts aggregated into the techtribes.je website. It’s a Spring Bean that uses the ROME library. See je.techtribes.component.newsfeedconnector for the code.
Components - Core
The following diagram shows the common components that are used by the Web Server and the standalone Content Updater.
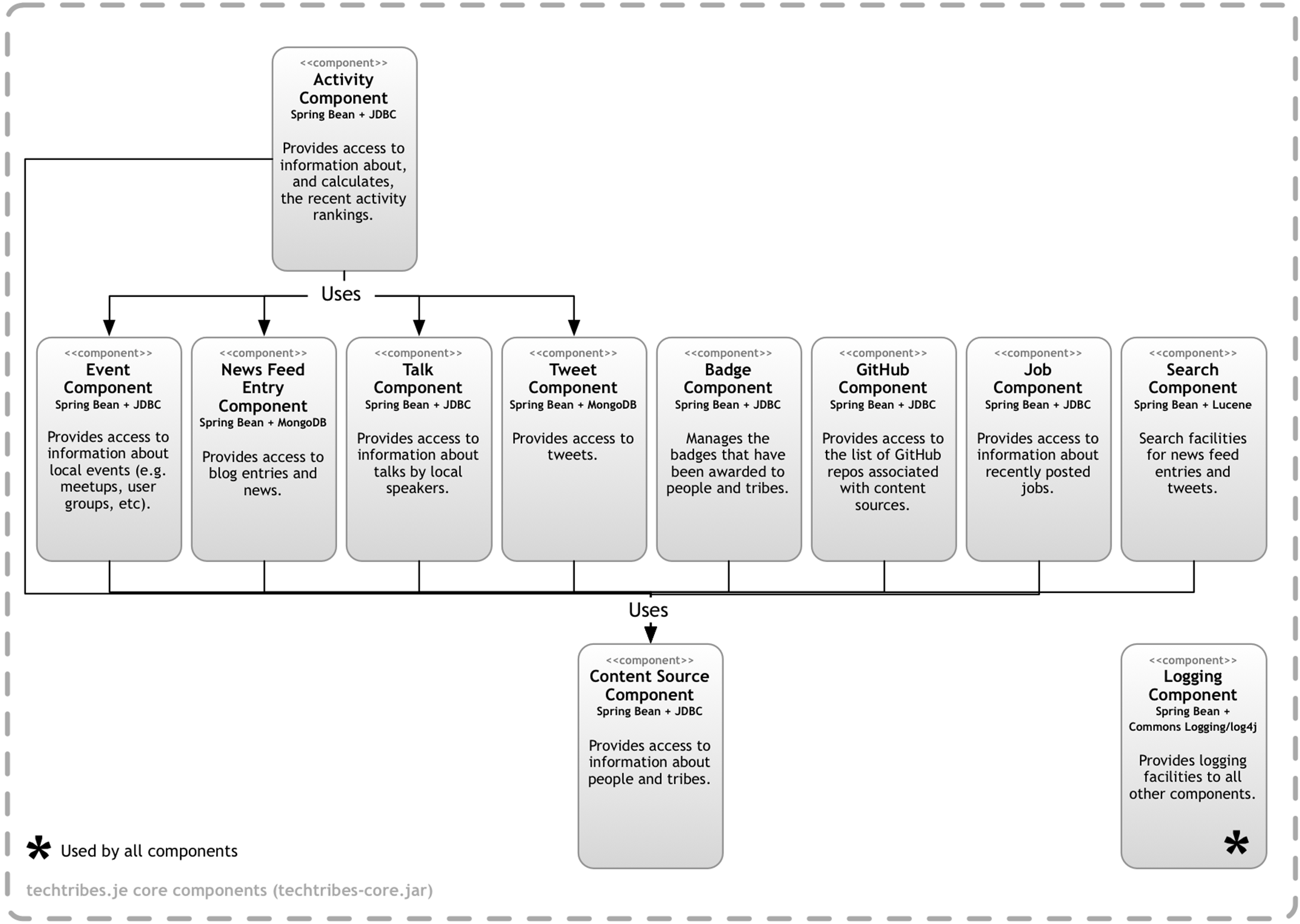
Here is a brief summary of each core component:
· Content Source Component: This component provides access to information about people and tribes (together, referred to as “content sources”), which are stored in MySQL. See je.techtribes.component.contentsource for the code.
· News Feed Entry Component: This component provides access to news and blog posts, which are stored in MongoDB. See je.techtribes.component.newsfeedentry for the code.
· Tweet Component: This component provides access to tweets, which are stored in MongoDB. See je.techtribes.component.tweet for the code.
· Talk Component: This component provides access to information about talks by local speakers, which are stored in MySQL. See je.techtribes.component.talk for the code.
· Event Component: This component provides access to information about local events (e.g. meetups, seminars, coding dojos, etc), which are stored in MySQL. See je.techtribes.component.event for the code.
· Job Component: This component provides access to information about local job openings, which are stored in MySQL. See je.techtribes.component.job for the code.
· GitHub Component: This component provides access to information about code repositories belonging to local people/tribes, which are stored in MySQL. See je.techtribes.component.github for the code.
· Search Component: This component provides search facilities across the news, blog posts and tweets. Apache Lucene is used for the indexing and searching. See je.techtribes.component.search for the code.
· Activity Component: This component provides access to the “recent activity” information, which is stored in MySQL and calculated by the Content Updater component. See je.techtribes.component.activity for the code.
· Badge Component: This component provides access to the badges that have been awarded to people/tribes as a result of their activity. See je.techtribes.component.badge for the code.
· Logging Component: This is a simple wrapper around Commons Logging and log4j. It’s used by all other components. See je.techtribes.component.log for the code.
Infrastructure Architecture
This section provides information about the infrastructure architecture of the techtribes.je website.
Live environment
The live environment is very simple; it’s a single Cloud Server at Rackspace, hosted in the London region as follows:
· Operating System: Ubuntu 12.04 LTS (Precise Pangolin)
· Flavour: 1024 MB RAM, 40 GB Disk
· Server Type: Next Generation Server
The credentials for the Rackspace dashboard are:
· Username: ********
· Password: ********
Deployment
This section provides information about the mapping between the software architecture and the infrastructure architecture.
Software
The live environment is a single Rackspace cloud server and therefore all of the following software is installed on the server via the Ubuntu Advanced Packaging Tool (apt).
· Java 7 (Open JDK) (this needs to be patched with the Java Cryptography Extension (JCE) Unlimited Strength Jurisdiction Policy Files so that authentication via Twitter works)
· Apache Tomcat 7
· MySQL 5.x
· MongoDB 2.2.x
Building techtribes.je
To avoid the “it works on my machine” syndrome, plus to ensure that builds are clean and repeatable, all releases are built by a continuous integration server - the free edition of TeamCity. The build.xml script does all of the heavy lifting of compiling, running the automated tests and creating a release package.
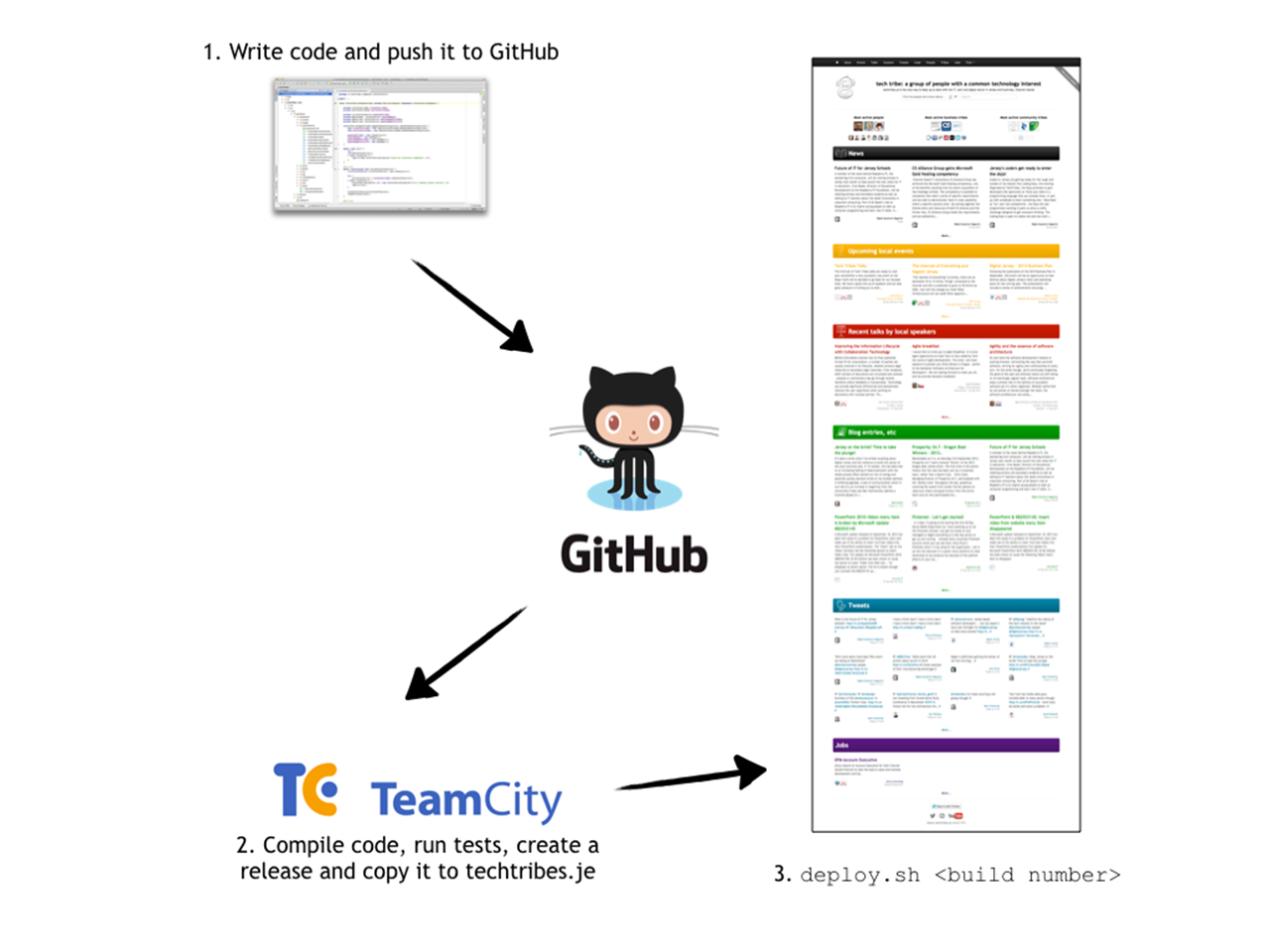
The final part of the build script, if the build is successful, is to securely copy the release up to the techtribes.je Rackspace server.
Deploying techtribes.je
All of the techtribes.je software is installed underneath ~techtribesje/builds, with a subdirectory per release. There are a number of scripts in GitHub that are used to unpack a release, switch version via symlinks and restart processes.
Deploying a new version, or rolling back to an old version, is as simple as running:
1 ~/bin/deploy.sh XYZ
(where XYZ is the number of the build created by the TeamCity continuous integration server)
Configuration
The configuration files for the web server and content updater can be found at:
· /etc/techtribesje-web.properties
· /etc/techtribesje-updater.properties
Operation and Support
This section provides information about the operational and support aspects of the techtribes.je website.
Starting MySQL
MySQL is installed as a service, and should be running after a server restart. You can check this by using the following command:
1 sudo netstat -tap | grep mysql
If you need to start MySQL, you can use the following command:
1 sudo service mysql start
Starting MongoDB
MongoDB is also installed as a service, and should be running after a server restart. You can check this by using the following commands:
1 sudo netstat -tap | grep mongo
2 tail /var/log/mongodb/mongodb.log
If you need to start MongoDB, you can use the following command:
1 sudo service mongodb start
Starting the Web Server
Apache Tomcat is also installed as a service, and should be running after a server restart. You can check this by using the following commands:
1 ps -Af | grep tomcat
2 tail /var/lib/tomcat7/logs/catalina.out
If you need to start Tomcat, you can use the following command:
1 ~techtribesje/bin/start-tomcat.sh
Starting the Content Updater
The Content Updater is a standalone Java process that needs to be started manually after a server restart. You can do this with the following command (where XYZ is the build number):
1 ~techtribesje/bin/start-updater.sh XYZ
You can check the log file with the following command:
1 ~techtribesje/bin/updater-logs.sh XYZ
Monitoring
The only monitoring on the techtribes.je website is Pingdom, which is configured to test that the website is still accessible every 5 minutes. An e-mail is sent if the web server is detected to be unavailable.
Backups
Both the MySQL and MongoDB databases are backed-up daily via a cron job at 3am GMT. You can check that this is scheduled with the following command:
1 crontab -l
You should see something like this:
1 0 3 * * * /home/techtribesje/bin/backup-data.sh > /dev/null
This shell script takes an export of the MySQL and MongoDB databases, copying them to a folder that is synced by Dropbox.
1. If multiple Java EE web applications or .NET websites are part of the same software system, they are usually executed in separate classloaders or AppDomains so I show them as separate containers because they are independent and require inter-process communication (e.g. remote method invocation, SOAP, REST, etc) to collaborate.↩