Software Testing Foundations: A Study Guide for the Certified Tester Exam (2014)
Chapter 2. Fundamentals of Testing
This introductory chapter will explain basic facts of software testing, covering what you will need to know to understand the following chapters. Important concepts and essential vocabulary will be explained by using an example application that will be used throughout the book. It appears frequently to illustrate and clarify the subject matter. The fundamental test process with the different testing activities will be illustrated. Psychological problems with testing will be discussed. Finally, the ISTQB Code of Tester Ethics is presented and discussed.
Throughout this book, we’ll use one example application to illustrate the software test methods and techniques presented in this book. The fundamental scenario is as follows.
Case study, “VirtualShowRoom” – VSR
A car manufacturer develops a new electronic sales support system called VirtualShowRoom (VSR). The final version of this software system will be installed at every car dealer worldwide. Customers who are interested in purchasing a new car will be able to configure their favorite model (model, type, color, extras, etc.), with or without the guidance of a salesperson.
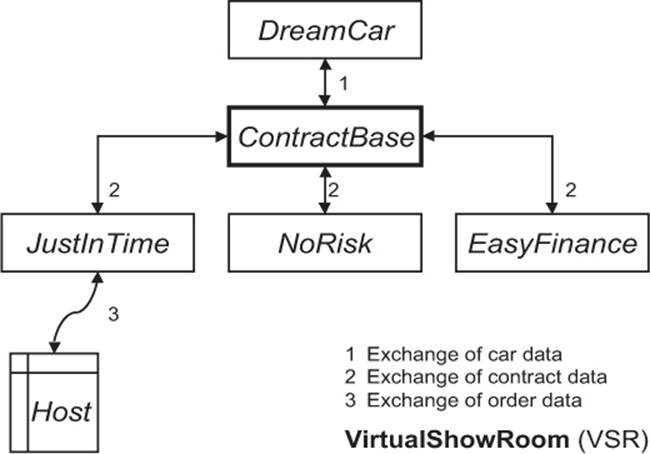
The system shows possible models and combinations of extra equipment and instantly calculates the price of the car the customer configures. A subsystem called DreamCar will provide this functionality.
When the customer has made up her mind, she will be able to calculate the most suitable financing (EasyFinance) as well as place the order online (JustIn-Time). She will even get the option to sign up for the appropriate insurance (NoRisk). Personal information and contract data about the customer is managed by the ContractBase subsystem.
Figure 2-1 shows the general architecture of this software system.
Every subsystem will be designed and developed by a separate development team. Altogether, about 50 developers and additional employees from the respective user departments are involved in working on this project. External software companies will also participate.
The VSR-System must be tested thoroughly before release. The project members assigned to test the software apply different testing techniques and methods. This book contains the basic knowledge necessary for applying them.
Figure 2–1
Architecture of the VSR-System
2.1 Terms and Motivation
Requirements
During the construction of an industry product, the parts and the final product are usually examined to make sure they fulfill the given →requirements, that is, whether the product solves the required task.
Depending on the product, there may be different requirements to the →quality of the solution. If the product has problems, corrections must be made in the production process and/or in the design of the product itself.
Software is immaterial
What generally counts for the production of industry products is also appropriate for the production or development of software. However, testing (or evaluation) of partial products and the final product is more difficult, because a software product is not a tangible physical product. Direct examination is not possible. The only way to examine the product is by reading (reviewing) the development documents and code.
The dynamic behavior of the software, however, cannot be checked this way. It must be done through →testing, by executing the software on a computer. Its behavior must be compared to the requirements. Thus, testing of software is an important and difficult task in software development. It contributes to reducing the →risk of using the software because →defects can be found in testing. Testing and test documentation are often defined in contracts, laws, or industrial or organizational standards.
Example
To identify and repair possible faults before delivery, the VSR-System from the case study example must be tested intensively before it is used. For example, if the system executes order transactions incorrectly, this could result in frustration for the customer and serious financial loss and a negative impact on the image of the dealer and the car manufacturer. Not finding such a defect constitutes a high risk during system use.
2.1.1 Error, Defect, and Bug Terminology
What is a defect, failure, or fault?
When does a system behave incorrectly, not conforming to requirements? A situation can be classified as incorrect only after we know what the correct situation is supposed to look like. Thus, a →failure means that a given requirement is not fulfilled; it is a discrepancy between the →actual result or behavior1 and the →expected result or behavior.2
A failure is present if a legitimate (user) expectation is not adequately met. An example of a failure is a product that is too difficult to use or too slow but still fulfills the →functional requirements.
In contrast to physical system failure, software failures do not occur because of aging or abrasion. They occur because of →faults in the software. Faults (or defects or →bugs) in software are present from the time the software was developed or changed yet materialize only when the software is executed, becoming visible as a failure.
Failure
To describe the event when a user experiences a problem, [IEEE 610.12] uses the term failure. However, other terms, like problem, issue, and incident, are often used. During testing or use of the software, the failure becomes visible to the →tester or user; for example, an output is wrong or the program crashes.
Fault
We have to distinguish between the occurrence of a failure and its cause. A failure is caused by a fault in the software. This fault is also called a defect or internal error. Programmer slang for a fault is bug. For example, faults can be incorrect or forgotten →statements in the program.
Defect masking
It is possible that a fault is hidden by one or more other faults in other parts of the program (→defect masking). In that case, a failure occurs only after the masking defects have been corrected. This demonstrates that corrections can have side effects.
One problem is that a fault can cause none, one, or many failures for any number of users and that the fault and the corresponding failure are arbitrarily far away from each other. A particularly dangerous example is some small corruption of stored data, which may be found a long time after it first occurred.
Error or mistake
The cause of a fault or defect is an →error or →mistake by a person—for example, defective programming by the developer. However, faults may even be caused by environmental conditions, like radiation and magnetism, that introduce hardware problems. Such problems are, however, not discussed in this book.
People err, especially under time pressure. Defects may occur, for example, by bad programming or incorrect use of program statements. Forgetting to implement a requirement leads to defective software. Another cause is changing a program part because it is complex and the programmer does not understand all consequences of the change. Infrastructure complexity, or the sheer number of system interactions, may be another cause. Using new technology often leads to defects in software, because the technology is not fully understood and thus not used correctly.
More detailed descriptions of the terms used in testing are given in the following section.
2.1.2 Testing Terms
Testing is not debugging
To be able to correct a defect or bug, it must be localized in the software. Initially, we know the effect of a defect but not the precise location in the software. Localization and correction of defects are tasks for a software developer and are often called →debugging. Repairing a defect generally increases the →quality of the product because the →change in most cases does not introduce new defects.
However, in practice, correcting defects often introduces one or more new defects. The new defects may then introduce failures for new, totally different inputs. Such unwanted side effects make testing more difficult. The result is that not only must we repeat the →test cases that have detected the defect, we must also conduct even more test cases to detect possible side effects.
Debugging is often equated with testing, but they are entirely different activities.
Debugging is the task of localizing and correcting faults. The goal of testing is the (more or less systematic) detection of failures (that indicate the presence of defects).
A test is a sample examination
Every execution3 (even using more or less random samples) of a →test object in order to examine it is testing. The →test conditions must be defined. Comparing the actual and expected behaviors of the test object serves to determine if the test object fulfills the required characteristics.4
Testing software has different purposes:
§ Executing a program to find failures
§ Executing a program to measure quality
§ Executing a program to provide confidence5
§ Analyzing a program or its documentation to prevent failures
Tests can also be performed to acquire information about the test object, which is then used as the basis for decision-making—for example, about whether one part of a system is appropriate for integration with other parts of the system. The whole process of systematically executing programs to demonstrate the correct implementation of the requirements, to increase confidence, and to detect failures is called testing. In addition, a test includes static methods, that is, static analysis of software products using tools as well as document reviews (see chapter 4).
Testing terms
Besides execution of the test object with →test data, planning, design, implementation, and analysis of the test (→test management) also belong to the →test process. A →test run or →test suite includes execution of one or more →test cases. A test case contains defined test conditions. In most cases, these are the preconditions for execution, the inputs, and the expected outputs or the expected behavior of the test object. A test case should have a high probability of revealing previously unknown faults [Myers 79].
Several test cases can often be combined to create →test scenarios, whereby the result of one test case is used as the starting point for the next test case. For example, a test scenario for a database application can contain one test case writing a date into the database, another test case changing that date, and a third test case reading the changed date from the database and deleting it. (By deleting the date, the database should be in the same state as before executing this scenario.) Then all three test cases will be executed, one after another, all in a row.
No large software system is bug free
At present, there is no known bug-free software system, and there will probably not be any in the near future (if a system has nontrivial complexity). Often the reason for a fault is that certain exceptional cases were not considered during development and testing of the software. Such faults could be the incorrectly calculated leap year or the not-considered boundary condition for time behavior or needed resources. On the other hand, there are many software systems in many different fields that operate reliably, 24/7.
Testing cannot produce absence of defects
Even if all the executed test cases do not show any further failures, we cannot safely conclude (except for very small programs) that there are no further faults or that no further test cases could find them.
Excursion: Naming tests
There are many confusing terms for different kinds of software tests. Some will be explained later in connection with the description of the different →test levels (see chapter 3). The following terms describe the different ways tests are named:
→Test objective or test type:
A test is named according to its purpose (for example, →load test).
→Test technique:
A test is named according to the technique used for specifying or executing the test (for example, →business-process-based test).
Test object:
The name of a test reflects the kind of the test object to be tested (for example, a GUI test or DB test [database test]).
Test level:
A test is named after the level of the underlying life cycle model (for example, →system test).
Test person:
A test is named after the personnel group executing the tests (for example, developer test, →user acceptance test).
Test extent:
A test is named after the level of extent (for example, partial →regression test, full test).
Thus, not every term means a new or different kind of testing. In fact, only one of the aspects is pushed to the fore. It depends on the perspective we use when we look at the actual test.
2.1.3 Software Quality
Software testing contributes to improvement of →software quality. This is done by identifying defects and subsequently correcting them. If the test cases are a reasonable sample of software use, quality experienced by the user should not be too different from quality experienced during testing.
But software quality is more than just the elimination of failures found during testing. According to the ISO/IEC Standard 9126-1 [ISO 9126], software quality comprises the following factors:
→functionality, →reliability, usability, →efficiency, →maintainability, and portability.
Testing must consider all these factors, also called →quality characteristics and →quality attributes, in order to judge the overall quality of a software product. Which quality level the test object is supposed to show for each characteristic should be defined in advance. Appropriate tests must then check to make sure these requirements are fulfilled.
Excursion: ISO/IEC 25010
In 2011 ISO/IEC Standard 9126 was replaced by ISO/IEC Standard 25010 [ISO 25010]. The current ISTQB syllabus still refers to ISO/IEC 9126. Here is a short overview of the new standard.
ISO/IEC 25010 partitions software quality into three models: quality in use model, product quality model, and data quality model. The quality in use model comprises the following characteristics: effectiveness, satisfaction, freedom from risk, and context coverage. The product quality model comprises functional sustainability, performance efficiency, compatibility, usability, reliability, security, maintainability, and portability. In this area much is like in ISO/IEC 9126. Data quality is defined in ISO/IEC 25012 [ISO 25012].
Example VirtualShowRoom
In the case of the VSR-System, the customer must define which of the quality characteristics are important. Those must be implemented in the system and then checked for. The characteristics of functionality, reliability, and usability are very important for the car manufacturer. The system must reliably provide the required functionality. Beyond that, it must be easy to use so that the different car dealers can use it without any problems in everyday life. These quality characteristics should be especially well tested in the product.
We discuss the individual quality characteristics of ISO/IEC Standard 9126-1 [ISO 9126] in the following section.
Functionality
When we talk about functionality, we are referring to all of the required capabilities of a system. The capabilities are usually described by a specific input/output behavior and/or an appropriate reaction to an input. The goal of the test is to prove that every single required capability in the system was implemented as described in the specifications. According to ISO/IEC Standard 9126-1, the functionality characteristic contains the subcharacteristics adequacy, accuracy, interoperability, correctness, and security.
An appropriate solution is achieved if every required capability is implemented in the system. Thereby it is clearly important to pay attention to, and thus to examine during testing, whether the system delivers the correct or specified outputs or effects.
Software systems must interoperate with other systems, at least with the operating system (unless the operating system is the test object itself).
Interoperability describes the cooperation between the system to be tested and other specified systems. Testing should detect trouble with this cooperation.
Adequate functionality also requires fulfilling usage-specific standards, contracts, rules, laws, and so on. Security aspects such as access control and →data security are important for many applications. Testing must show that intentional and unintentional unauthorized access to programs and data is prevented.
Reliability
Reliability describes the ability of a system to keep functioning under specific use over a specific period. In the standard, the reliability characteristic is split into maturity, →fault tolerance, and recoverability.
Maturity means how often a failure of the software occurs as a result of defects in the software.
Fault tolerance is the capability of the software product to maintain a specified level of performance or to recover from faults such as software faults, environment failures, wrong use of interface, or incorrect input.
Recoverability is the capability of the software product to reestablish a specified level of performance (fast and easily) and recover the data directly affected in case of failure. Recoverability describes the length of time it takes to recover, the ease of recovery, and the amount of work required to recover. All this should be part of the test.
Usability
Usability is very important for acceptance of interactive software systems. Users won’t accept a system that is hard to use. What is the effort required for the usage of the software for different user groups? Understandability, ease of learning, operability, and attractiveness as well as compliance to standards, conventions, style guides, and user interface regulations are aspects of usability. These quality characteristics are checked in →nonfunctional tests (see chapter 3).
Efficiency
Efficiency tests may give measurable results. An efficiency test measures the required time and consumption of resources for the execution of tasks. Resources may include other software products, the software and hardware →configuration of the system, and materials (for example, print paper, network, and storage).
Maintainability and portability
Software systems are often used over a long period on various platforms (operating system and hardware). Therefore, the last two quality criteria are very important: maintainability and portability.
Subcharacteristics of maintainability are analyzability, changeability, stability, and testability.
Subcharacteristics of portability are adaptability, ease of installation, conformity, and interchangeability. Many aspects of maintainability and portability can only be examined by →static analysis (see section 4.2).
A software system cannot fulfill every quality characteristic equally well. Sometimes it is possible that meeting one characteristic results in a conflict with another one. For example, a highly efficient software system can become hard to port because the developers usually use special characteristics (or features) of the chosen platform to improve efficiency. This in turn negatively affects portability.
Prioritize quality characteristics
Quality characteristics must therefore be prioritized. The quality specification is used to determine the test intensity for the different quality characteristics. The next chapter will discuss the amount of work involved in these tests.
2.1.4 Test Effort
Complete testing is impossible
Testing cannot prove the absence of faults. In order to do this, a test would need to execute a program in every possible situation with every possible input value and with all possible conditions. In practice, a →complete or exhaustive test is not feasible. Due to combinational effects, the outcome of this is an almost infinite number of tests. Such a “testing” for all combinations is not possible.
Example
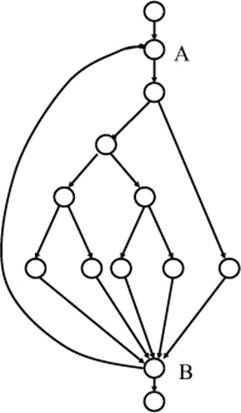
The fact that complete testing is impossible is illustrated by an example of →control flow testing [Myers 79].
A small program with an easy control flow will be tested. The program consists of four decisions (IF-instructions) that are partially nested. The control flow graph of the program is shown in figure 2-2. Between Point A and B is a loop, with a return from Point B to Point A. If the program is supposed to be exhaustively tested for the different control-flow-based possibilities, every possible flow—i.e., every possible combination of program parts—must be executed. At a loop limit of a maximum of 20 cycles and considering that all links are independent, the outcome is the following calculation, whereby 5 is the number of possible ways within the loop:
520 + 519 + 518 + ... + 51
51 test cases result from execution of every single possible way within the loop, but in each case without return to the loop starting point. If the test cases result in one single return to the loop starting point, then 5 × 5 = 52 different possibilities must be considered, and so on. The total result of this calculation is about 100 quadrillion different sequences of the program.
Figure 2–2
Control flow graph of a small program
Assuming that the test is done manually and a test case, as Myers describes [Myers 79], takes five minutes to specify, to execute, and to be analyzed, the time for this test would be one billion years. If we assume five microseconds instead of five minutes per test case, because the test mainly runs automatically, it would still last 19 years.
Test effort between 25% and 50%
Thus, in practice it is not possible to test even a small program exhaustively.
It is only possible to consider a part of all imaginable test cases. But even so, testing still accounts for a large portion of the development effort. However, a generalization of the extent of the →test effort is difficult because it depends very much on the character of the project. The following list shows some example data from projects of one large German software company. This should shed light on the spectrum of different testing efforts relative to the total budget of the development.
§ For some major projects with more than 10 person-years’ effort, coding and testing together used 40%, and a further 8% was used for the integration. At test-intensive projects (for example, →safety-critical systems), the testing effort increased to as much as 80% of the total budget.
§ In one project, the testing effort was 1.2 times as high as the coding effort, with two-thirds of the test effort used for →component testing.
§ For another project at the same software development company, the system test cost was 51.9% of the project.
Test effort is often shown as the proportion between the number of testers and the number of developers. The proportion varies from 1 tester per 10 developers to up to 3 testers per developer. The conclusion is that test efforts or the budget spent for testing vary enormously.
Defects can cause high costs
But is this high testing effort affordable and justifiable? The counter question from Jerry Weinberg is “Compared to what?” [DeMarco 93]. His question refers to the risks of faulty software systems. Risk is calculated as the probability of occurrence and the expected amount of damage.
Faults that were not found during testing can cause high costs when the software is used. The German newspaper Frankfurter Allgemeine Zeitung from January 17, 2002, had an article titled “IT system breakdowns cost many millions.” A one-hour system breakdown in the stock exchange is estimated to cost $7.8 million. When safety-critical systems fail, the lives and health of people may be in danger.
Since a full test is not possible, the testing effort must have an appropriate relation to the attainable result. “Testing should continue as long as costs of finding and correcting a defect6 are lower than the costs of failure” [Koomen 99]. Thus, the test effort is always dependent on an estimation of the application risk.
Example for a high risk in case of failure
In the case of the VSR-System, the prospective customers configure their favorite car model on the display. If the system calculates a wrong price, the customer can insist on that price. In a later stage of the VSR-System, the company plans to offer a web-based sales portal. In that case, a wrong price can lead to thousands of cars being sold for a price that’s too low. The total loss can amount to millions, depending on how much the price was miscalculated by the VSR-System. The legal view is that an online order is a valid sales contract with the quoted price.
Systems with high risks must be tested more thoroughly than systems that do not generate big losses if they fail. The risk assessment must be done for the individual system parts, or even for single error possibilities. If there is a high risk for failures by a system or subsystem, there must be a greater testing effort than for less critical (sub)systems. International standards for production of safety-critical systems use this approach to require that different test techniques be applied for software of different integrity levels.
For a producer of a computer game, saving erroneous game scores can mean a very high risk, even if no real damage is done, because the customers will not trust a defective game. This leads to high losses of sales, maybe even for all games produced by the company.
Define test intensity and test extent depending on risk
Thus, for every software program it must be decided how intensively and thoroughly it shall be tested. This decision must be made based upon the expected risk of failure of the program. Since a complete test is not possible, it is important how the limited test resources are used. To get a satisfying result, the tests must be designed and executed in a structured and systematic way. Only then is it possible to find many failures with appropriate effort and avoid →unnecessary tests that would not give more information about system quality.
Select adequate test techniques
There exist many different methods and techniques for testing software.
Every technique especially focuses on and checks particular aspects of the test object. Thus, the focus of examination for the control-flow-based test techniques is the program flow. In case of the →data flow test techniques, the examination focuses on the use and flow of data. Every test technique has its strengths and weaknesses in finding different kinds of faults. There is no test technique that is equally well suited for all aspects. Therefore, a combination of different test techniques is always necessary to detect failures with different causes.
Test of extra functionality
During the test execution phase, the test object is checked to determine if it works as required by the →specifications. It is also important—and thus naturally examined while testing—that the test object does not execute functions that go beyond the requirements. The product should provide only the required functionality.
Test case explosion
The testing effort can grow very large. Test managers face the dilemma of possible test cases and test case variants quickly becoming hundreds or thousands of tests. This problem is also called combinatorial explosion, or →test case explosion. Besides the necessary restriction in the number of test cases, the test manager normally has to fight with another problem: lack of resources.
Limited resources
Participants in every software development project will sooner or later experience a fight about resources. The complexity of the development task is underestimated, the development team is delayed, the customer pushes for an earlier release, or the project leader wants to deliver “something” as soon as possible. The test manager usually has the worst position in this “game.” Often there is only a small time window just before delivery for executing the test cases and very few testers are available to run the test. It is certain that the test manager does not have the time and resources for executing an “astronomical” amount of test cases.
However, it is expected that the test manager delivers trustworthy results and makes sure the software is sufficiently tested. Only if the test manager has a well-planned, efficient strategy is there is a chance to fulfill this challenge successfully. A fundamental test process is required. Besides the adherence to a fundamental test process, further →quality assurance activities must be accomplished, such as, for example, →reviews (see section 4.1.2). Additionally, a test manager should learn from earlier projects and improve the development and testing process.
The next section describes a fundamental test process typically used for the development and testing of systems like the VSR-System.
2.2 The Fundamental Test Process
Excursion Life cycle models
To accomplish a structured and controllable software development effort, software development models and →development processes are used. Many different models exist. Examples are the waterfall model [Boehm 73], [Boehm 81], the general V-model7 [Boehm 79], and the German V-model XT [URL: V-model XT]). Furthermore, there are the spiral model, different incremental or evolutionary models, and the agile, or lightweight, methods like XP (Extreme Programming [Beck 00]) and SCRUM [Beedle 01], which are popular nowadays (for example, see [Bleek 08]). Development of object-oriented software systems often uses the rational unified process [Jacobson 99].
All of these models define a systematic, orderly way of working during the project. In most cases, phases or design steps are defined. They have to be completed with a result in the form of a document. A phase completion, often called a →milestone, is achieved when the required documents are completed and conform to the given quality criteria. Usually, →roles dedicated to specific tasks in software development are defined. Project staff has to accomplish these tasks. Sometimes, the models even define the techniques and processes to be used in a particular phase. With the aid of these models, detailed planning of resource usage (time, personnel, infrastructure, etc.) can be performed. In a project, the development models define the collective and mandatory tasks and their chronological sequence.
Testing appears in each of these life cycle models, but with very different meanings and to a different extent. In the following, some models will be briefly discussed from the view of testing.
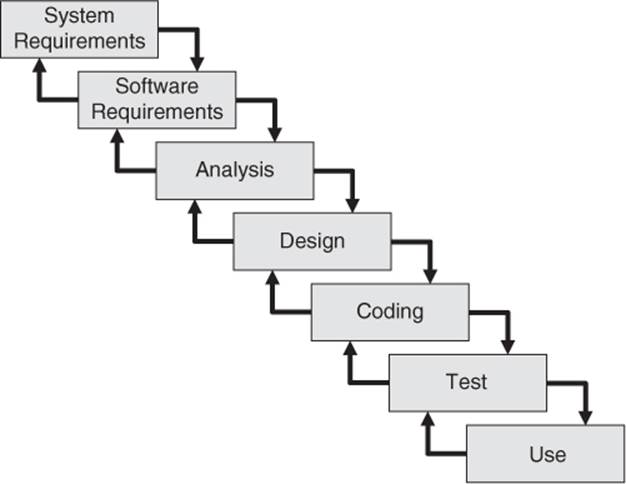
The waterfall model: Testing as “final inspection”
The first fundamental model was the waterfall model (see figure 2-3, shown with the originally defined phases [Royce 70]8). It is impressively simple and very well known. Only when one development phase is completed will the next one be initiated.
Between adjacent phases only, there are feedback loops that allow, if necessary, required revisions in the previous phase. The crucial disadvantage of this model is that testing is understood as a “one time” action at the end of the project just before the release to operation. The test is seen as a “final inspection,” an analogy to a manufacturing inspection before handing over the product to the customer.
The general V-model
An enhancement of the waterfall model is the general V-model ([Boehm 79], [IEEE/IEC 12207]), where the constructive activities are decomposed from the testing activities (see chapter 3,figure 3-1). The model has the form of a V. The constructive activities, from requirements definition to implementation, are found on the downward branch of the V. The test execution activities on the ascending branch are organized by test levels and matched to the appropriate abstraction level on the opposite side’s constructive activity. The general V-model is common and frequently used in practice.
Figure 2–3
Waterfall-model
The description of tasks in the process models discussed previously is not sufficient as an instruction on how to perform structured tests in software projects. In addition to embedding testing in the whole development process, a more detailed process for the testing tasks themselves is needed (see figure 2-4). This means that the “content” of the development task testing must be split into smaller subtasks, as follows: →test planning and control, test analysis and design, test implementation and execution, evaluation of test →exit criteria and reporting, and test closure activities. Although illustrated sequentially, the activities in the test process may overlap or take place concurrently. Test activities also need to be adjusted to the individual needs of each project. The test process described here is a generic one. The listed subtasks form a fundamental test process and are described in more detail in the following sections.
Figure 2–4
ISTQB fundamental test process
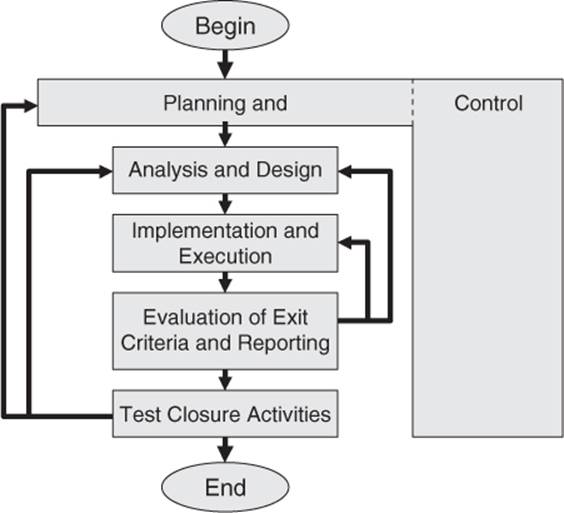
2.2.1 Test Planning and Control
Execution of such a substantial task as testing must not take place without a plan. Planning of the test process starts at the beginning of the software development project. As with all planning, during the course of the project the previous plans must be regularly checked, updated, and adjusted.
Resource planning
The mission and objectives of testing must be defined and agreed upon as well as the resources necessary for the test process. Which employees are needed for the execution of which tasks and when? How much time is needed, and which equipment and utilities must be available? These questions and many more must be answered during planning, and the result should be documented in the →test plan (see chapter 6). Necessary training programs for the employees should be prepared. An organizational structure with the appropriate test management must be arranged or adjusted if necessary.
Test control is the monitoring of the test activities and comparing what actually happens during the project with the plan. It includes reporting the status of deviations from the plan and taking any actions necessary to meet the planned goals in the new situation. The test plan must be updated to the changed situation.
Part of the test management tasks is administrating and maintaining the test process, the →test infrastructure, and the →testware. Progress tracking can be based on appropriate reporting from the employees as well as data automatically generated from tools. Agreements about these topics must be made early.
Determination of the test strategy
The main task of planning is to determine the →test strategy or approach (see section 6.4). Since an exhaustive test is not possible, priorities must be set based on risk assessment. The test activities must be distributed to the individual subsystems, depending on the expected risk and the severity of failure effects. Critical subsystems must get greater attention, thus be tested more intensively. For less critical subsystems, less extensive testing may be sufficient. If no negative effects are expected in the event of a failure, testing could even be skipped on some parts. However, this decision must be made with great care. The goal of the test strategy is the optimal distribution of the tests to the “right” parts of the software system.
Example for a test strategy
The VSR-System consists of the following subsystems:
§ DreamCar allows the individual configuration of a car and its extra equipment.
§ ContractBase manages all customer information and contract data.
§ JustInTime implements the ability to place online orders (within the first expansion stage by the dealer).
§ EasyFinance calculates an optimal method of financing for the customer.
§ NoRisk provides the ability to purchase appropriate insurance.
Naturally, the five subsystems should not be tested with identical intensity. The result of a discussion with the VSR-System client is that incorrect behavior of the DreamCar and ContractBase subsystems will have the most harmful effects. Because of this, the test strategy dictates that these two subsystems must be tested more intensively.
The possibility to place orders online, provided by the subsystem JustInTime, is found to be less critical because the order can, in the worst case, still be passed on in other ways (via fax, for example). But it is important that the order data must not be altered or get lost in the JustInTimesubsystem. Thus, this aspect should be tested more intensively.
For the other two subsystems, NoRisk and EasyFinance, the test strategy defines that all of their main functions (computing a rate, recording and placing contracts, saving and printing contracts, etc.) must be tested. Because of time constraints, it is not possible to cover all conceivable contract variants for financing and insuring a car. Thus, it is decided to concentrate the test around the most commonly occurring rate combinations. Combinations that occur less frequently get a lower priority (see sections 6.2 and 6.4).
With these first thoughts about the test strategy for the VSR-System, it is clear that it is reasonable to choose the level of intensity for testing whole subsystems as well as single aspects of a system.
Define test intensity for subsystems and different aspects
The intensity of testing depends very much on the test techniques that are used and the →test coverage that must be achieved. Test coverage serves as a test exit criterion. Besides →coverage criteria referring to source code structure (for example, statement coverage; see section 5.2), it is possible to define meeting the customer requirements as an exit criterion. It may be demanded that all functions must be tested at least once or, for example, that at least 70% of the possible transactions in a system are executed. Of course, the risk in case of failure should be considered when the exit criteria, and thus the intensity of the tests, are defined. Once all test exit criteria9 are defined, they may be used after executing the test cases to decide if the test process can be finished.
Prioritization of the tests
Because software projects are often run under severe time pressure, it is reasonable to appropriately consider the time aspect during planning. The prioritization of tests guarantees that the critical software parts are tested first in case time constraints do not allow executing all the planned tests (see section 6.2).
Tool support
If the necessary tool support (see chapter 7) does not exist, selection and acquisition of tools must be initiated early. Existing tools must be evaluated if they are updated. If parts of the test infrastructure have to be developed, this can be prepared. →Test harnesses (or →test beds), where subsystems can be executed in isolation, must often be programmed. They must be created soon enough to be ready after the respective test objects are programmed. If frameworks—such as Junit [URL: xunit]—shall be applied, their usage should be announced early in the project and should be tried in advance.
2.2.2 Test Analysis and Design
Review the test basis
The first task is to review the →test basis, i.e., the specification of what should be tested. The specification should be concrete and clear enough to develop test cases. The basis for the creation of a test can be the specification or architecture documents, the results of risk analysis, or other documents produced during the software development process.
For example, a requirement may be too imprecise in defining the expected output or the expected behavior of the system. No test cases can then be developed. →Testability of this requirement is insufficient. Therefore it must be reworked. Determining the →preconditions and requirements to test case design should be based on an analysis of the requirements, the expected behavior, and the structure of the test object.
Check testability
As with analyzing the basis for a test, the test object itself also has to fulfill certain requirements to be simple to test. Testability has to be checked. This process includes checking the ease with which interfaces can be addressed (interface openness) and the ease with which the test object can be separated into smaller, more easily testable units. These issues need to be addressed during development and the test object should be designed and programmed accordingly. The results of this analysis are also used to state and prioritize the test conditions based on the general objectives of the test. The test conditions state exactly what shall be tested. This may be a function, a component, or some quality characteristic.
Consider the risk
The test strategy determined in the test plan defines which test techniques shall be used. The test strategy is dependent on requirements for reliability and safety. If there is a high risk of failure for the software, very thorough testing should be planned. If the software is less critical, testing may be less formal.
In the →test specification, the test cases are then developed using the test techniques specified. Techniques planned previously are used, as well as techniques chosen based on an analysis of possible complexity in the test object.
Traceability is important
It is important to ensure →traceability between the specifications to be tested and the tests themselves. It must be clear which test cases test which requirements and vice versa. Only this way is it possible to decide which requirements are to be or have been tested, how intensively and with which test cases. Even the traceability of requirement changes to the test cases and vice versa should be verified.
Logical and concrete test cases
Specification of the test cases takes place in two steps. →Logical test cases have to be defined first. After that, the logical test cases can be translated into concrete, physical test cases, meaning the actual inputs are selected (→concrete test cases). Also, the opposite sequence is possible: from concrete to the general logical test cases. This procedure must be used if a test object is specified insufficiently and test specification must be done in a rather experimental way (→exploratory testing, see section 5.3). Development of physical test cases, however, is part of the next phase, test implementation.
The test basis guides the selection of logical test cases with all test techniques. The test cases can be determined from the test object’s specification (→black box test design techniques) or be created by analyzing the source code (→white box test design techniques). It becomes clear that the activity called →test case specification can take place at totally different times during the software development process. This depends on the chosen test techniques, which are found in the test strategy. The process models shown at the beginning of section 2.2 represent the test execution phases only. Test planning, analysis, and design tasks can and should take place in parallel with earlier development activities.
Test cases comprise more than just the test data
For each test case, the initial situation (precondition) must be described. It must be clear which environmental conditions must be fulfilled for the test. Furthermore, before →test execution, it must be defined which results and behaviors are expected. The results include outputs, changes to global (persistent) data and states, and any other consequences of the test case.
Test oracle
To define the expected results, the tester must obtain the information from some adequate source. In this context, this is often called an oracle, or →test oracle. A test oracle is a mechanism for predicting the expected results. The specification can serve as a test oracle. There are two main possibilities:
§ The tester derives the expected data based on the specification of the test object.
§ If functions doing the reverse action are available, they can be run after the test and then the result is verified against the original input. An example of this scenario is encryption and decryption of data.
See also chapter 5 for more information about predicting the expected results.
Test cases for expected and unexpected inputs
Test cases can be differentiated by two criteria:
§ First are test cases for examining the specified behavior, output, and reaction. Included here are test cases that examine specified handling of exception and error cases (→negative test). But it is often difficult to create the necessary preconditions for the execution of these test cases (for example, capacity overload of a network connection).
§ Next are test cases for examining the reaction of test objects to invalid and unexpected inputs or conditions, which have no specified →exception handling.
Example for test cases
The following example is intended to clarify the difference between logical and concrete (physical) test cases.
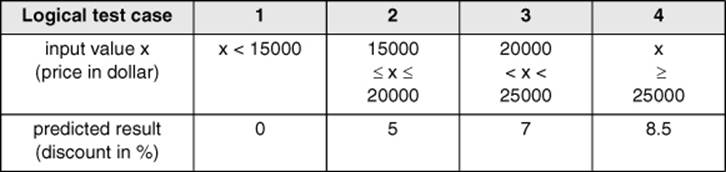
Using the sales software, the car dealer is able to define discount rules for his salespeople: With a price of less than $15.000, no discount shall be given. For a price of $20.000, 5% is OK. If the price is below $25.000, a 7% discount is possible. For higher prices, 8.5% can be granted.
From this, the following cases can be derived:
|
Price |
< 15.000 discount = 0% |
|
15.000 |
≤ price ≤ 20.000 discount = 5% |
|
20.000 |
< price < 25.000 discount = 7% |
|
price |
≥ 25.000 discount = 8.5% |
It becomes obvious that the text has room for interpretation10, which may be misunderstood. With more formal, mathematical description, this will not happen. However, the discounts are clearly stated. From the more formal statement (above), table 2-1 can be developed.
Table 2–1
Table with logical test cases
To execute the test cases, the logical test cases must be converted into concrete test cases. Concrete inputs must be chosen (see table 2-2) Special preconditions or conditions are not given for these test cases.
Table 2–2
Table with concrete test cases

The values chosen here shall only serve to illustrate the difference between logical and concrete test cases. No explicit test method has been used for designing them. We do not claim that the program is tested well enough with these four test cases. For example, there are no test cases for wrong inputs, such as, for example, negative prices. More detailed descriptions of methods for designing test cases are given in chapter 5.
In parallel to the described test case specification, it is important to decide on and prepare the test infrastructure and the necessary environment to execute the test object. To prevent delays during test execution, the test infrastructure should already be assembled, integrated, and verified as much as possible at this time.
2.2.3 Test Implementation and Execution
Here, logical test cases must be transformed into concrete test cases; all the details of the environment (test infrastructure and test framework) must be set up. The tests must be run and logged.
When the test process has advanced and there is more clarity about technical implementation, the logical test cases are converted into concrete ones. These test cases can then be used without further modifications or additions for executing the test, if the defined →preconditions for the respective test case are fulfilled. The mutual traceability between test cases and specifications must be checked and, if necessary, updated.
Test case execution
In addition to defining test cases, one must describe how the tests will be executed. The priority of the test cases (see section 6.2.3), decided during test planning, must be taken into account. If the test developer executes the tests himself, additional, detailed descriptions may not be necessary.
The test cases should also be grouped into →test suites or test scenarios for efficient test execution and easier understanding.
Test harness
In many cases specific test harnesses, →drivers, →simulators, etc. must be programmed, built, acquired, or set up as part of the test environment before the test cases can be executed. Because failures may also be caused by faults in the test harness, the →test environment must be checked to make sure it’s working correctly.
When all preparatory tasks for the test have been accomplished, test execution can start immediately after programming and delivery of the subsystems to testing. Test execution may be done manually or with tools using the prepared sequences and scenarios.
Checking for completeness
First, the parts to be tested are checked for completeness. The test object is installed in the available test environment and tested for its ability to start and do the main processing.
Examination of the main functions
The recommendation is to start test execution with the examination of the test object’s main functionality (→smoke test). If →failures or →deviations from the expected result show up at this time, it is foolish to continue testing. The failures or deviations should be corrected first. After the test object passes this test, everything else is tested. Such a sequence should be defined in the test approach.
Tests without a log are of no value
Test execution must be exactly and completely logged. This includes logging which test runs have been executed with which results (pass or failure). On the one hand, the testing done must be comprehensible to people not directly involved (for example, the customer) on the basis of these →test logs. On the other hand, the execution of the planned tests must be provable. The test log must document who tested which parts, when, how intensively, and with what results.
Reproducibility is important
Besides the test object, quite a number of documents and pieces of information belong to each test execution: test environment, input data, test logs, etc. The information related to a test case or test run must be maintained in such a way that it is possible to easily repeat the test later with the same input data and conditions. The testware must be subjected to →configuration management (see also section 6.7).
Failure found?
If a difference shows up between expected and actual results during test execution, it must be decided when evaluating the test logs if the difference really indicates a failure. If so, the failure must be documented. At first, a rough analysis of possible causes must be made. This analysis may require the tester to specify and execute additional test cases.
The cause for a failure can also be an erroneous or inexact test specification, problems with the test infrastructure or the test case, or an incorrect test execution. The tester must examine carefully if any of these possibilities apply. Nothing is more detrimental to the credibility of a tester than reporting a supposed failure whose cause is actually a test problem. But the fear of this possibility should not result in potential failures not being reported, i.e., the testers starting to self-censor their results. This could be fatal as well.
In addition to reporting discrepancies between expected and real results, test coverage should be measured (see section 2.2.4). If necessary, the use of time should also be logged. The appropriate tools for this purpose should be used (see chapter 7).
Correction may lead to new faults
Based on the →severity of a failure (see section 6.6.3), a decision must be made about how to prioritize fault corrections. After faults are corrected, the tester must make sure the fault has really been corrected and that no new faults have been introduced (see section 3.7.4). New testing activities result from the action taken for each incident—for example, reexecution of a test that previously failed in order to confirm a defect fix, execution of a corrected test, and/or regression tests. If necessary, new test cases must be specified to examine the modified or new source code. It would be convenient to correct faults and retest corrections individually to avoid unwanted interactions of the changes. In practice, this is not often possible. If the test is not executed by the developer, but instead by independent testers, a separate correction of individual faults is not practical or possible. It would take a prohibitive amount of effort to report every failure in isolation to the developer and continue testing only after corrections are made. In this case, several defects are corrected together and then a new software version is installed for new testing.
The most important test cases first
In many projects, there is not enough time to execute all specified test cases. When that happens, a reasonable selection of test cases must be made to make sure that as many critical failures as possible are detected. Therefore, test cases should be prioritized. If the tests end prematurely, the best possible result should be achieved. This is called →risk-based testing (see section 6.4.3).
Furthermore, an advantage of assigning priority is that important test cases are executed first, and thus important problems are found and corrected early. An equal distribution of the limited test resources on all test objects of the project is not reasonable. Critical and uncritical program parts are then tested with the same intensity. Critical parts would be tested insufficiently, and resources would be wasted on uncritical parts for no reason.
2.2.4 Test Evaluation and Reporting11
End of test?
During test evaluation and reporting, the test object is assessed against the set test exit criteria specified during planning. This may result in normal termination of the tests if all criteria are met, or it may be decided that additional test cases should be run or that the criteria were too hard.
It must be decided whether the test exit criteria defined in the test plan are fulfilled.
Considering the risk, an adequate exit criterion must be determined for each test technique used. For example, it could be specified that a test is considered good enough after execution of 80% of the test object statements. However, this would not be a very high requirement for a test. Appropriate tools should be used to collect such measures, or →metrics, in order to decide when a test should end (see section 7.1.4).
If at least one test exit criterion is not fulfilled after all tests are executed, further tests must be executed. Attention should be paid to ensure that the new test cases better cover the respective exit criteria. Otherwise, the extra test cases just result in additional work but no improvement concerning the end of testing.
Is further effort justifiable?
A closer analysis of the problem can also show that the necessary effort to fulfill the exit criteria is not appropriate. In that situation, further tests are canceled. Such a decision must, naturally, consider the associated risk.
An example of such a case may be the treatment of an exceptional situation. With the available test environment, it may not be possible to introduce or simulate this situation. The appropriate source code for treating it can then not be executed and tested. In such cases, other examination techniques should be used, such as, for example, static analysis (see section 4.2).
Dead code
A further case of not meeting test exit criteria may occur if the specified criterion is impossible to fulfill in the specific case. If, for example, the test object contains →dead code, then this code cannot be executed. Thus, 100% statement coverage is not possible because this would also include the unreachable (dead) code. This possibility must be considered in order to avoid further senseless tests trying to fulfill the criterion. An impossible criterion is often a hint to possible inconsistent or imprecise requirements or specifications. For example, it would certainly make sense to investigate why the program contains instructions that cannot be executed. Doing this allows further faults to be found so their corresponding failures can be prevented.
If further tests are planned, the test process must be resumed, and it must be decided at which point the test process will be reentered. Sometimes it is even necessary to revise the test plan because additional resources are needed. It is also possible that the test specifications must be improved in order to fulfill the required exit criterion.
Further criteria for the determination of the test’s end
In addition to test coverage criteria, other criteria can be used to define the test’s end. A possible criterion is the failure rate. Figure 2-5 shows the average number of new failures per testing hour over 10 weeks. In the 1st week, there was an average of two new failures per testing hour. In the 10th week, it is fewer than one failure per two hours. If the failure rate falls below a given threshold (e.g., fewer than one failure per testing hour), it will be assumed that more testing is not economically justified and the test can be ended.
Figure 2–5
Failure rate
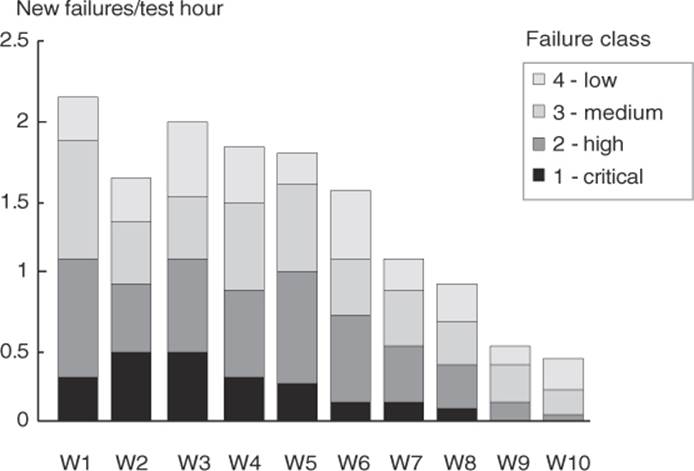
When deciding to stop testing this way it must be considered that some failures can have very different effects. Classifying and differentiating failures according to their impact to the stakeholders (i.e., failure severity) is therefore reasonable and should generally be considered (see section 6.6.3).
Consider several test cycles
The failures found during the test should be repaired, after which a new test becomes necessary. If further failures occur during the new test, new test cycles may be necessary. Not planning such correction and testing cycles by assuming that no failures will occur while testing is unrealistic. Because it can be assumed that testing finds failures, additional faults must be removed and retested in a further →test cycle. If this cycle is ignored, then the project will be delayed. The required effort for defect correction and the following cycles is difficult to calculate. Historical data from previous, similar projects can help. The project plan should provide for the appropriate time buffers and personnel resources.
End criteria in practice: Time and cost
In practice, the end of a test is often defined by factors that have no direct connection to the test: time and costs. If these factors lead to stopping the test activities, it is because not enough resources were provided in the project plan or the effort for an adequate test was underestimated.
Successful testing saves costs
Even if testing consumed more resources than planned, it nevertheless results in savings due to elimination of faults in the software. Faults delivered in the product mostly cause higher costs when found during operation (see section 6.3.1).
Test summary report
When the test criteria are fulfilled or a deviation from them is clarified, a →test summary report should be written for the stakeholders, which may include the project manager, the test manager, and possibly the customer. In lower-level tests (component tests), this may just take the form of a message to the project manager about meeting the criteria. In higher-level tests, a formal report may be required.
2.2.5 Test Closure Activities
Learning from experience
It is a pity that these activities, which should be executed during this final phase in the test process, are often left out. The experience gathered during the test work should be analyzed and made available for future projects. Of interest are deviations between planning and execution for the different activities as well as the assumed causes. For example, the following data should be recorded:
§ When was the software system released?
§ When was the test finished or terminated?
§ When was a milestone reached or a maintenance release completed?
Important information for evaluation can be extracted by asking the following questions:
§ Which planned results were achieved and when—if at all?
§ Which unexpected events happened (reasons and how they were met)?
§ Are there any open problems and →change requests? Why were they not implemented?
§ How was user acceptance after deploying the system?
The evaluation of the test process—i.e., a critical evaluation of the executed tasks in the test process, taking into account the resources used and the achieved results—will probably show possibilities for improvement. If these findings are used in subsequent projects, continuous process improvement is achieved. Detailed hints for analysis and improvement of the test processes can be found in [Pol 98] and [Black 03].
Archiving testware
A further closure activity is the “conservation” of the testware for the future. Software systems are used for a long time. During this time, failures not found during testing will occur. Additionally, customers require changes. Both of these lead to changes to the program, and the changed program must be tested in every case. A major part of the test effort during →maintenance can be avoided if the testware (test cases, test logs, test infrastructure, tools, etc.) is still available. The testware should be delivered to the organization responsible for maintenance. It can then be adapted instead of being constructed from scratch, and it can also be successfully used for projects having similar requirements, after adaptation. The test material needs to be archived. Sometimes this is necessary in order to provide legal evidence of the testing done.
2.3 The Psychology of Testing
Errare humanum est
People make mistakes, but they do not like to admit them! One goal of testing software is to find discrepancies between the software and the specifications, or customer needs. The failures found must be reported to the developers. This section describes how the psychological problems occurring in connection with this can be dealt with.
The tasks of developing software are often seen as constructive actions. The tasks of examining documents and software are seen as destructive actions. The attitudes of those involved relating to their job often differ due to this perception. But these differences are not justifiable, because “testing is an extremely creative and intellectually challenging task” [Myers 79, p.15].
Developer test
“Can the developer test his own program?” is an important and frequently asked question. There is no universally valid answer. If the tester is also the author of the program, she must examine her own work very critically. Only very few people are able to keep the necessary distance to a self-created product. Who really likes to detect and show their own mistakes? Developers would rather not find any defects in their own program text.
The main weakness of developer tests is that developers who have to test their own programs will tend to be too optimistic. There is the danger of forgetting reasonable test cases or, because they are more interested in programming than in testing, only testing superficially.
Blindness to one’s own mistakes
If a developer implemented a fundamental design error—for example, if she misunderstood the task—then she will not find this using her own tests. The proper test case will not even come to mind. One possibility to decrease this problem of “blindness to one’s own errors” is to work together in pairs and let a colleague test the programs.
On the other hand, it is advantageous to have a deep knowledge of one’s own test object. Time is saved because it is not necessary to learn the test object. Management has to decide when saving time is an advantage over blindness to one’s own errors. This must be decided depending on the criticality of the test object and the associated failure risk.
Independent test team
An independent testing team is beneficial for test quality and comprehensiveness. Further information on the formation of independent test teams can be found in section 6.1.1. The tester can look at the test object without bias. It is not the tester’s own product, and the tester does not necessarily share possible developer assumptions and misunderstandings. The tester must, however, acquire the necessary knowledge about the test object in order to create test cases, which takes time. But the tester typically has more testing knowledge. A developer does not have this knowledge and must acquire it (or rather should have acquired it before, because the necessary time is often not unavailable during the project).
Failure reporting
The tester must report the failures and discrepancies observed to the author and/or to management. The way this reporting is done can contribute to cooperation between developers and testers. If it’s not done well, it may negatively influence the important communication of these two groups. To prove other people’s mistakes is not an easy job and requires diplomacy and tact.
Often, failures found during testing are not reproducible in the development environment for the developers. Thus, in addition to a detailed description of failures, the test environment must be documented in detail so that differences in the environments can be detected, which can be the cause for the different behavior.
It must be defined in advance what constitutes a failure or discrepancy. If it is not clearly visible from the requirements or specifications, the customer, or management, is asked to make a decision. A discussion between the involved staff, developer, and tester as to whether this is a fault or not is not helpful. The often heard reaction of developers against any critique is, “It’s not a bug, it’s a feature!” That’s not helpful either.
Mutual comprehension
Mutual knowledge of their respective tasks improves cooperation between tester and developer. Developers should know the basics of testing and testers should have a basic knowledge of software development. This eases the understanding of the mutual tasks and problems.
The conflicts between developer and tester exist in a similar way at the management level. The test manager must report the →test results to the project manager and is thus often the messenger bringing bad news. The project manager then must decide whether there still is a chance to meet the deadline and possibly deliver software with known problems or if delivery should be delayed and additional time used for corrections. This decision depends on the severity of the failures and the possibility to work around the faults in the software.
2.4 General Principles of Testing
During the last 40 years, several principles for testing have become accepted as general rules for test work.
Principle 1:
Testing shows the presence of defects, not their absence.
Testing can show that the product fails, i.e., that there are defects. Testing cannot prove that a program is defect free. Adequate testing reduces the probability that hidden defects are present in the test object. Even if no failures are found during testing, this is no proof that there are no defects.
Principle 2:
Exhaustive testing is impossible.
It’s impossible to run an exhaustive test that includes all possible values for all inputs and their combinations combined with all different preconditions. Software, in normal practice, would require an “astronomically” high number of test cases. Every test is just a sample. The test effort must therefore be controlled, taking into account risk and priorities.
Principle 3:
Testing activities should start as early as possible.
Testing activities should start as early as possible in the software life cycle and focus on defined goals. This contributes to finding defects early.
Principle 4:
Defect clustering.
Defects are not evenly distributed; they cluster together. Most defects are found in a few parts of the test object. Thus if many defects are detected in one place, there are normally more defects nearby. During testing, one must react flexibly to this principle.
Principle 5:
The pesticide paradox.
Insects and bacteria become resistant to pesticides. Similarly, if the same tests are repeated over and over, they tend to loose their effectiveness: they don’t discover new defects. Old or new defects might be in program parts not executed by the test cases. To maintain the effectiveness of tests and to fight this “pesticide paradox,” new and modified test cases should be developed and added to the test. Parts of the software not yet tested, or previously unused input combinations will then become involved and more defects may be found.
Principle 6:
Testing is context dependent.
Testing must be adapted to the risks inherent in the use and environment of the application. Therefore, no two systems should be tested in the exactly same way. The intensity of testing, test exit criteria, etc. should be decided upon individually for every software system, depending on its usage environment. For example, safety-critical systems require different tests than e-commerce applications.
Principle 7:
No failures means the system is useful is a fallacy.
Finding failures and repairing defects does not guarantee that the system meets user expectations and needs. Early involvement of the users in the development process and the use of prototypes are preventive measures intended to avoid this problem.
2.5 Ethical Guidelines
This section presents the Code of Tester Ethics as presented in the ISTQB Foundation Syllabus of 2011.
Dealing with critical information
Testers often have access to confidential and privileged information. This may be real, not scrambled production data used as a basis for test data, or it may be productivity data about employees. Such data or documents must be handled appropriately and must not get into the wrong hands or be misused.
For other aspects of testing work, moral or ethical rules can be applicable as well. ISTQB has based its code of ethics on the ethics from the Association for Computing Machinery (ACM) and the Institute of Electrical and Electronics Engineers (IEEE). The ISTQB code of ethics12 is as follows:
§ PUBLIC
»Certified software testers shall act consistently with the public interest.«
§ CLIENT AND EMPLOYER
»Certified software testers shall act in a manner that is in the best interest of their client and employer, consistent with the public interest.«
§ PRODUCT
»Certified software testers shall ensure that the deliverables they provide (on the products and systems they test) meet the highest professional standards possible.«
§ JUDGMENT
»Certified software testers shall maintain integrity and independence in their professional judgment.«
§ MANAGEMENT
»Certified software test managers and leaders shall subscribe to and promote an ethical approach to the management of software testing.«
§ PROFESSION
»Certified software testers shall advance the integrity and reputation of the profession consistent with the public interest.«
§ COLLEAGUES
»Certified software testers shall be fair to and supportive of their colleagues, and promote cooperation with software developers.«
§ SELF
»Certified software testers shall participate in lifelong learning regarding the practice of their profession and shall promote an ethical approach to the practice of the profession.«
Ethical codes are meant to enhance public discussion about certain questions and values. Ideally, they serve as a guideline for individual responsible action. They state a “moral obligation,” not a legal one. Certified testers must know the ISTQB code of ethics, which serve as a guide for daily work.
2.6 Summary
§ Technical terms in the domain of software testing are often defined and used very differently, which can result in misunderstanding. Knowledge of the standards (e.g., [BS 7925-1], [IEEE 610.12], [ISO 9126]) and terminology associated with software testing is therefore an important part of the education of the Certified Tester. This book’s glossary compiles the relevant terms.
§ Tests are important tasks for →quality assurance in software development. The international standard ISO 9126-1 [ISO 9126] defines appropriate quality characteristics.
§ The fundamental test process consists of the following phases: planning and control, analysis and design, implementation and execution, evaluation of exit criteria and reporting, and test closure activities. A test can be finished when previously defined exit criteria are fulfilled.
§ A test case consists of input, expected results, and the list of defined preconditions under which the test case must run as well as the specified →postconditions. When the test case is executed, the test object shows a certain behavior. If the expected result and actual result differ, there is a failure. The expected results should be defined before test execution and during test specification (using a test oracle).
§ People make mistakes, but they do not like to admit them! Because of this, psychological aspects play an important role in testing.
§ The seven principles for testing must always be kept in mind during testing.
§ Certified testers should know the ISTQB’s ethical guidelines, which are helpful in the course of their daily work.
All materials on the site are licensed Creative Commons Attribution-Sharealike 3.0 Unported CC BY-SA 3.0 & GNU Free Documentation License (GFDL)
If you are the copyright holder of any material contained on our site and intend to remove it, please contact our site administrator for approval.
© 2016-2026 All site design rights belong to S.Y.A.