Software Testing Foundations: A Study Guide for the Certified Tester Exam (2014)
Chapter 7. Test Tools
This chapter gives an overview of the different test tools. Topics include how to choose and introduce these tools and the preconditions for using them.
Due to the fast development of new testing tools, this chapter will undergo a major revision in the ISTQB syllabus version 2015. A reader preparing for an exam based on the new syllabus is advised to study the ISTQB syllabus in addition to this chapter.
7.1 Types of Test Tools
Why tools?
Test tools are normally used for these purposes:
§ Improving test efficiency. Manual work, such as repetitive and time-consuming tasks, can be automated. Static analysis and test execution are examples of tasks that can be automated.
§ Enabling tests. Tools may make it possible to execute tests that are impossible to do manually. This includes performance and load tests and tests of real-time inputs for control systems.
§ Improving test reliability. Reliability is improved by automating manual tasks like comparing large amounts of data or simulating program behavior.
There are tools that accomplish one single task as well as tools that have several purposes. Tools for separate test execution, test execution automation, and generating or migrating test data belong to the first group. When tools have several capabilities, they are often called tool suites. Such a suite may, for example, automate test execution, logging, and evaluation.
Test framework
Test framework is a term often used in discussions of test tools. In practice, it has at least three meanings:
§ Reusable and extensible testing libraries that can be used to build testing tools (sometimes called test harnesses)
§ The way of designing the test automation (e.g., data-driven, keyword-driven)
§ The whole process of test execution
For the purpose of the ISTQB Foundation Level syllabus, the terms test framework and test harness are used interchangeably and are defined by the first two meanings.
CAST tools
Test tools are often called CAST tools (Computer Aided Software Testing), which is derived from the term CASE tools (Computer Aided Software Engineering).
Depending on which activities or phases in the test process (see section 2.2) are supported, several tool types1 or classes may be distinguished. In most cases, special tools are available within a tool class for special platforms or application areas (e.g., performance testing tools for the testing of web applications).
Only in very few cases is the whole range of testing tools used in a project. However, the available tool types should be known. The tester should be able to decide if and when a tool may be used productively in a project.
Tool list on the Internet
A list of available test tools with suppliers can be found at [URL: Tool-List]. The following sections describe which functions the tools in the different classes provide.
7.1.1 Tools for Management and Control of Testing and Tests
Test management
Test management tools provide mechanisms for easy documentation, prioritization, listing, and maintenance of test cases. They allow the tester to document and evaluate if, when, and how often a test case has been executed. They also facilitate the documentation of the results (“OK,” “not OK”). In addition, some tools support project management within testing (e.g., timing and use of resources). They help the test manager plan the tests and keep an overview of hundreds or thousands of test cases.
Advanced test management tools support requirements-based testing. In order to do this, they capture system requirements (or import them from requirements management tools) and link them to the tests, which test the corresponding requirements. Different consistency checks may be done; for example, a test may check to see if there is at least one planned test case for every requirement.
Figure 7-1 shows what this may look like for the CarConfigurator.
Figure 7–1
Requirements-based test planning using TestBench [URL: TestBench]
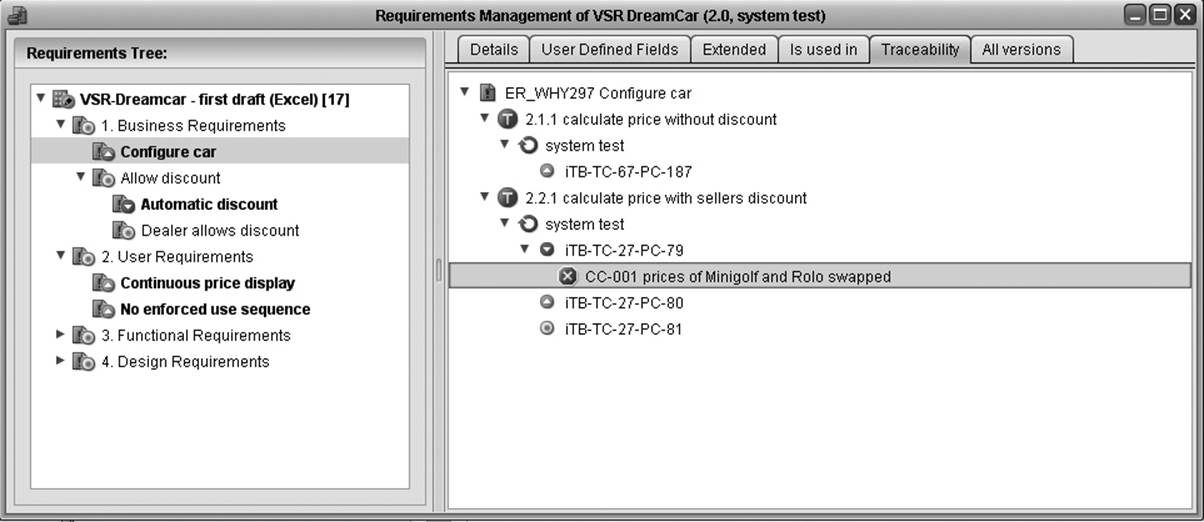
The requirement Configure car has four assigned test cases: iTB-TC-67-PC-187, iTB-TC-27-PC-79, iTB-TC-27-PC-80 and iTB-TC-27-PC-81. iTB-TC-27-PC-79 found a failure and is connected to the corresponding incident report, CC-001. Test case iTB-TC-27-PC-79 is not yet approved. Thus, the tool marks the requirement Configure car as being only “partially tested,” using a corresponding icon in the requirements tree.
Requirements management
Tools for requirements management store and manage information about requirements. They allow testers to prioritize requirements and to follow their implementation status.
In a narrow sense, they are not testing tools, but they are very useful for defining a test based on requirements (see section 3.7.1) and for planning the test; for example, the test could be oriented on the implementation status of a requirement. For this purpose, requirements management tools are usually able to exchange information with test management tools. Thus, it is possible to seamlessly interconnect requirements, tests, and test results. For every requirement the corresponding tests can be found and vice versa. The tools also help to find inconsistencies or holes in the requirements, and they can identify requirements without test cases; that is, requirements that otherwise might go untested.
Incident management
A tool for incident, problem, or failure management is nearly indispensable for a test manager. As described in section 6.6, incident management tools are used to document, manage, distribute, and statistically evaluate incident and failure messages. Better tools of this class support problem status models capable of being individually tailored. The whole work process may be defined, from the incident discovery through correction until the regression test has been executed. Every project member will be guided through the process corresponding to his role in the team.
Configuration management
Configuration management tools (see section 6.7) are, strictly speaking, not testing tools. They make it possible to keep track of different versions and builds of the software to be tested as well as documentation and testware. It is thus easier to trace which test results belong to a test run for a certain test object of a certain version.
Tool integration
Integrating test tools with test tools and with other tools is getting more and more important. The test management tool is the key for this:
§ Requirements are imported from the requirements management tool and used for test planning. The test status for every requirement can be watched and traced in the requirements management tool or the test management tool.
§ From the test management tool, test execution tools (for example, → test robots) are started and supplied with test scripts. The test results are automatically sent back and archived.
§ The test management tool is coupled with the incident management tool. Thus, a plan for retest can be generated; that is, a list of all test cases necessary to verify which defects have been successfully corrected in the latest test object version.
§ Finally, through configuration management, every code change is connected to the triggering incident or the change request causing it.
Such a tool chain makes it possible to completely trace the test status from the requirements through the test cases and test results to the incident reports and code changes.
Generation of test reports and test documents
Both test management and incident management tools include extensive analysis and reporting features, including the possibility to generate the complete test documentation (test plan, test specification, test summary report) from the data maintained by the tool.
Usually, the format and contents of such documents can be individually adjusted. Thus the generated test documents will be easy to seamlessly integrate into the existing documentation workflow.
The collected data can be evaluated quantitatively in many ways. For example, it is very easy to determine how many test cases have been run and how many of them were successful or how often the tests have found failures or faults of a certain category. Such information helps to assess the progress of the testing and to manage the test process.
7.1.2 Tools for Test Specification
In order to make test cases reproducible, the pre- and postconditions as well as test input data and expected results need to be specified.
Test data generators
So-called test (data) generators can support the test designer in generating test data. According to [Fewster 99], several approaches can be distinguished, depending on the test basis used for deriving the test data:
§ Database-based test data generators process database schemas and are able to produce test databases from these schemas. Alternatively, they perform dedicated filtering of database contents and thus produce test data. A similar process is the generation of test data from files in different data formats.
§ Code-based test data generators produce test data by analyzing the test object’s source code. A drawback and limitation is that no expected results can be generated (a test oracle is needed for this) and that only existing code can be covered (as with all white box methods). Faults caused by missing program instructions (missing code) remain undetected. The use of code as a test basis for testing the code itself is in general a very poor foundation. However, this approach may be used to generate a regression or platform test of an existing and reliable system, where the test result is collected for the existing system and platform and the generated test is then re-executed on other platforms or new versions.
§ Interface-based test data generators analyze the test object’s interface and identify the interface parameter domains and use. For example, equivalence class partitioning and boundary value analysis can be used to derive test data from these domains. Tools are available for analyzing different kinds of interfaces, ranging from application programming interfaces (APIs) to graphical user interfaces (GUIs). The tool is able to identify which data fields are contained in a screen (e.g., numeric field, date) and generate test data covering the respective value ranges (e.g., by applying boundary value analysis). Here, too, the problem is that no expected results can be generated. However, the tools are very well suited for automatic generation of negative tests because specific target values are of no importance here; what is important is whether the test object produces an error message or not.
§ Specification-based test data generators use a specification to derive test data and corresponding expected results. A precondition is that the specification is available in a formal notation. For example, a UML message sequence chart may describe a method-calling sequence. This approach is called model-based testing (MBT). The UML model is designed using a CASE tool and is then imported to the test generator. The test generator generates test scripts, which are then passed on to a suitable test execution tool.
Test designer’s creativity cannot be replaced
Test tools cannot work miracles. Specifying tests is a very challenging task, requiring not only a comprehensive understanding of the test object but also creativity and intuition. A test data generator can apply certain rules (e.g., boundary value analysis) for systematic test generation. However, it cannot judge whether the generated test cases are suitable, important, or irrelevant. The test designer must still perform this creative analytical task. The corresponding expected result must be determined and added manually too.
7.1.3 Tools for Static Testing
Static analysis can be executed on source code or on specifications before there are executable programs. Tools for static testing can therefore be helpful to find faults in early phases of the development cycle (i.e., the left branch of the generic V-model in figure 3-1). Faults can be detected and fixed soon after being introduced and thus dynamic testing will be less riddled with problems, which decreases costs and development time.
Tools for review support
Reviews are structured manual examinations using the principle that four eyes find more defects than two (see section 4.1.2). Review support tools help to plan, execute, and evaluate reviews. They store information about planned and executed review meetings, meeting participants, and findings and their resolution and results. Even review aids like checklists can be provided online and maintained. The collected data from many reviews may be evaluated and compared. This helps to better estimate review resources and to plan reviews but also to uncover typical weaknesses in the development process and specifically prevent them.
Tools for review support are especially useful when large, geographically distributed projects use several teams. Online reviews can be useful here and even may be the only possibility.
Static analysis
Static analyzers provide measures of miscellaneous characteristics of the program code, such as the cyclomatic number and other code metrics (see section 4.2). Such data are useful for identifying complex areas in the code, which tend to be defect prone and risky and should thus be reviewed. These tools can also check that safety- and security-related coding requirements have been followed. Finally, they can identify portability issues in the code.
Additionally, static analyzers can be used to find inconsistencies and defects in the source code. These are, for example, data flow and control flow anomalies, violation of programming standards, and broken or invalid links in website code.
Analyzers list all “suspicious” areas, whether there are really problems or not, causing the output lists to grow very long. Therefore, most tools are configurable; that is, it is possible to control the breadth and depth of analysis. When analyzing for the first time, the tools should be set to be less thorough. A more thorough analysis may be done later. In order to make such tools acceptable for developers, it is essential to configure them according to project-specific needs.
Model checker
Source code is not the only thing that may be analyzed for certain characteristics. Even a specification can be analyzed if it is written in a formal notation or if it is a formal model. The corresponding analysis tools are called model checkers. They “read” the model structure and check different static characteristics of these models. During checking, they may find problems such as missing states, state transitions, and other inconsistencies in a model. The specification-based test generators discussed in section 7.1.2 are often extensions of static model checkers. Such tools are very interesting for developers if they generate test cases.
7.1.4 Tools for Dynamic Testing
Tools reduce mechanical test work
When talking about test tools in general, we often mean tools for automatic execution of dynamic tests. They reduce the mechanical work involved in test execution. Such tools send input data to the test object, record its reaction, and document test execution. In most cases the tools run on the same hardware as the test object. However, this influences the test object because the test tool uses memory and machine resources. The test object may thus react differently. This is called the tool effect. This must be remembered when evaluating the test. These tools must be coupled to the test interface of the test object. They are therefore quite different, depending on the test level in which they are used.
Debuggers
Debuggers make it possible to execute a program or part of a program line by line. They also support stopping the program at every statement to set and read variables. Debuggers are mainly analysis tools for the developers, used to reproduce failures and analyze their causes. But even during testing, debuggers can be useful to force certain test situations, which normally requires a lot of work. Debuggers can also be used as a test interface at the component level.
Test drivers and test frameworks
Products or tailor-made tools that interact with the test object through its programming interface are called test drivers or test frameworks. This is especially important for test objects without a user interface, that is, impossible to test manually. Test drivers are mainly necessary in component and integration testing and for special tasks in system testing. Generic test drivers or test harness generators are also available. These analyze the programming interface of the test object and generate a test frame. Test framework generators are thus made for specific programming languages and development environments. The generated test frame contains the necessary initializations and call sequences to control the test object. Even dummies or stubs may be generated. Additionally, functions are provided to capture test execution and expected and actual results. Test frame (generators) considerably reduce the work necessary for programming the test environment. Different generic test frameworks are freely available on the Internet [URL: xunit].
Simulators
If performing a system test in its operational environment or using the final system is not possible or demands a disproportionately great effort (e.g., airplane control robustness test in the airplane itself), simulators can be used. A simulator simulates the actual application environment as comprehensively and realistically as possible.
Test robots
Should the user interface of a software system directly serve as the test interface, so-called test robots can be used. These tools have traditionally been called →capture/replay tools or →capture/playback tools, which almost completely explains their way of functioning. A test robot works somewhat like a video recorder: The tool logs all manual tester inputs (keyboard inputs and mouse clicks). These inputs are then saved as a test script. The tester can repeat the test script automatically by “playing it back.” This principle sounds very tempting and easy, but in practice, there are traps.
Excursion: On the functioning of capture/playback tools
Capture
In capture mode, the capture/playback tool logs keyboard input and mouse clicks. The tool not only records the x-/y-coordinates of the mouse clicks but also the events (e.g., pressButton (“Start”)) triggered in the graphical user interface (GUI) as well as the object’s attributes (object name, color, text, x/y position, etc.) necessary to recognize the selected object.
Result comparisons
To determine if the program under test is performing correctly, the tester can include checkpoints, that is, comparisons between expected and actual results (either during test recording or during script editing).
Thus, layout properties of user interface controls (e.g., color, position, and button size) can be verified as well as functional properties of the test object (value of a screen field, contents of a message box, output values and texts, etc.).
Replay
The captured test scripts can be replayed and therefore, in principle, be repeated as often as desired. Should a discrepancy in values occur at a checkpoint, “the test fails.” The test robot then writes an appropriate notice in the test log. Because of their capability to perform automated comparisons of actual and expected values, test robot tools are extraordinarily well suited for regression test automation.
Problem: GUI changes
However, one problem exists: If, in the course of program correction or program extension, the test object’s GUI is changed between two test runs, the original script may not “suit” the new GUI layout. The script, no longer being synchronized to the application, may stop and abort the automated test run. Test robot tools offer a certain robustness against such GUI layout changes because they recognize the object itself and its properties, instead of just x/y positions on the screen. This is why, for example, during replay of the test script, buttons will be recognized again, even if their position has moved.
Test programming
Test scripts are usually written in scripting languages. These scripting languages are similar to common programming languages (BASIC, C, and Java) and offer their well-known general language properties (decisions, loops, procedure calls, etc.). With these properties it is possible to implement even complex test runs or to edit and enhance captured scripts. In practice, this editing of captured scripts is nearly always necessary because capturing usually does not deliver scripts capable for regression testing. The following example illustrates this.
Example: Automated test of VSR-ContractBase
The tester will test the VSR subsystem for contract management by examining whether sales contracts are properly filed and retrieved. For test automation purposes, the tester may record the following interaction sequence:
Call screen "contract data';
Enter data for customer "Miller";
Set checkpoint;
Store "Miller" contract in contract database;
Clear screen "contract data";
Read "Miller" contract from contract database;
Compare checkpoint with screen contents;
A successful check indicates that the contract read from the database corresponds to the contract previously filed, which leads to the conclusion that the system correctly files contracts. But, when replaying this script, the tester is surprised to find that the script has stopped unexpectedly. What happened?
Problem: Regression test capability
When the script is played a second time, upon trying to store the “Miller” contract, the test object reacts in a different way than during the first run. The “Miller” contract already exists in the contract database, and the test object ends the attempt to file the contract for the second time by reporting as follows:
"Contract already exists.
Overwrite the contract Y/N?"
The test object now expects keyboard input. Because keyboard input is missing in the captured test script, the automated test stops.
The two test runs have different preconditions. Because the captured script relies on a certain precondition (“Miller” contract not in the database), the test case is not good enough for regression test. This problem can be corrected by programming a case decision or by deleting the contract from the database as the final “cleanup action” of the test case.
As seen in the example, it is crucial to edit the scripts by programming. Thus, implementing such test automation requires programming skills. When comprehensive and long-lived automation is required, a well-founded test architecture must be chosen; that is, the test scripts must be modularized.
Excursion: Test automation architectures
A good structure for the test scripts helps to minimize the cost for creating and maintaining automated tests. A good structure also supports dividing the work between test automators (knowing the test tool) and testers (knowing the application/business domain).
Data-driven testing
Often, a test procedure (test script) shall be repeated many times with different data. In the previous example, not only the contract of Mr. Miller should be stored and managed, but the contracts of many other customers as well.
An obvious step to structure the test script and minimize the effort is to separate test data and test procedure. Usually the test data are exported into a table or spreadsheet file. Naturally, expected results must also be stored. The test script reads a test data line, executes the →test procedure with these test data, and repeats this process with the next test data line. If additional test data are necessary, they are just added to the test data table without changing the script. Even testers without programming skills can extend these tests and maintain them to a certain degree. This approach is called data-driven testing.
Command- or keyword-driven testing
In extensive test automation projects, an extra requirement is reusing certain test procedures. For example, if contract handling should be tested, not only for buying new cars but also for buying used cars, it would be useful to run the script from the previous example without changes for both areas. Thus, the test steps are encapsulated in a procedure named, for example, check_contract (customer). The procedure can then be called via its name and reused in other tests without changes.
With correct granularity and correspondingly well-chosen test procedure names, it is possible to achieve a situation where every execution sequence available for the system user is mapped to such a procedure or command. So that the procedures can be used without programmer know-how, an architecture is implemented to make the procedures callable through spreadsheet tables. The (business) tester will then (analogous to the data-driven test) work only with tables of commands or keywords and test data. Specialized test automation programmers have to implement the commands. This approach is called command-, keyword-, or action-word-driven testing.
The spreadsheet-based approach is only partly scalable. With large lists of keywords and complex test runs, the tables become incomprehensible. Dependencies between commands, and between commands and their parameters, are very difficult to trace. The effort to maintain the tables grows disproportionately as the tables grow.
Interaction-driven tests
The newest generation of test tools (for an example, see [URL: TestBench]) implement an object-oriented management of test modules using a database. You can retrieve test modules (so-called interactions) from the database by dragging and dropping them into new test sequences. The necessary test data (even complex data structures) are automatically included. If any module is changed, every area using this module is easy to find and can be selected. This considerably reduces the test maintenance effort. Even very large repositories can be used efficiently and without losing overview.
Comparators
→Comparators (a further tool class) are used to identify differences between expected and actual results. Comparators typically function with standard file and database formats, detecting differences between data files containing expected and actual data. Test robots usually include integrated comparator functions operating with terminal contents, GUI objects, or screen content copies. These tools usually offer filtering mechanisms that skip data or data fields that are irrelevant to the comparison. For example, this is necessary when date/time information is contained in the test object’s file or screen output. Because this information differs from test run to test run, the comparator would wrongly interpret this change as a difference between expected and actual outcome.
Dynamic analysis
During test execution, tools for dynamic analysis acquire additional information on the internal state of the software being tested. This may be, for instance, information on allocation, usage, and release of memory. Thus, memory leaks, wrong pointer allocation, or pointer arithmetic problems can be detected.
Coverage analysis
Coverage analyzers provide structural test coverage values that are measured during test execution (see section 5.2). For this purpose, prior to execution, an instrumentation component of the tool inserts measurement code into the test object (instrumentation). If such measurement code is executed during a test run, the corresponding program fragment is logged as “covered.” After test execution, the coverage log is analyzed and a coverage statistic is created. Most tools provide simple coverage metrics, such as statement coverage and branch coverage (see sections 5.2.1and 5.2.2). When interpreting measurement results, it is important to bear in mind that different coverage tools may give different coverage results and that some coverage metrics may be defined differently depending on the actual tool.
7.1.5 Tools for Nonfunctional Test
Load and performance test
There is tool support for nonfunctional tests, especially for load and performance tests. Load test tools generate a synthetic load (i.e., parallel database queries, user transactions, or network traffic). They are used for executing volume, stress, or performance tests. Tools for performance tests measure and log the response time behavior of the system being tested depending on the load input. Depending on how the measurement is performed and on the tools being used, the time behavior of the test object may vary (probe effect or tool effect). This must be remembered when interpreting the measurement results. In order to successfully use such tools and evaluate the test results, experience with performance tests is crucial. The necessary measurement elements are called monitors.
Monitors
Load or performance tests are necessary when a software system has to execute a large number of parallel requests or transactions within a certain maximum response time. Real-time systems and, normally, client/server systems as well as web-based applications must fulfill such requirements. Performance tests can measure the increase in response time correlated to increasing load (for example, increasing number of users) as well as the system’s maximum capacity when the increased load leads to unacceptable latency due to overload. Used as an analysis resource, performance test tools generally supply the tester with extensive charts, reports, and diagrams representing the system’s response time and transaction behavior relative to the load applied as well as information on performance bottlenecks. Should the performance test indicate that overload already occurs under everyday load conditions, the system must be tuned (for example, by hardware extension or optimization of performance-critical software components).
Testing of security
Tools for testing access control and data security try to detect security vulnerabilities. Exploiting these, unauthorized persons may possibly get access to the system. Virus scanners and firewalls can also be seen as part of this tool category, mainly because the protocols generated by such tools deliver evidence of security deficiencies.
Data Quality Assessment
In system testing, especially in data conversion or migration projects, tools may be used to check the data. Before and after conversion or migration, the data must be checked to make sure they are correct and complete or conform to certain syntactical or semantic rules.
Example: Data quality in the VSR-System
Various aspects of data quality are relevant to the VSR-System:
§ The DreamCar subsystem includes various car model and accessory variants. Even if the software works correctly, the user may experience problems if their data concerning specific cars or accessories is incorrect or missing. In this case, the user cannot successfully create a configuration or, worse still, is able to create a configuration that is impossible to produce. The customer happily expects his new car and later learns that it cannot be delivered. Such situations guarantee customer disappointment.
§ NoRisk helps the sales office calculate matching insurance costs for any car. If some of the data is obsolete, the cost of insurance will be wrongly priced. This is a risk, especially if the resulting quote is too expensive, which would encourage customers to seek an alternative insurance provider. The customer could decide not to sign an insurance contract at the car dealer and instead look for insurance at home through the Internet.
§ ContractBase is used to document complete customer histories, including contracts, repairs, and so on. The prices can be shown in euros, even if they were actually transacted in an older European currency. When older currencies were converted to euros, were the data correctly converted or has the customer really paid the shown amount?
§ During advertising campaigns, the car dealer regularly sends out special offers and invites existing customers to attend new product presentations. The system contains all necessary address data as well as further data, such as, for example, the age of the customer’s current car. However, the special advertising will get to the right customer with the right information only if the data are complete and consistent. Does the VSR-System prevent such problems at input time? For example, does the zip code match the actual town or road? Does the system assure that all fields relevant for marketing are filled in (for example, the age of the used car and not the contract date for its purchase)?
These examples illustrate that data accuracy is largely the responsibility of the customer or system user. But the system supplier can support “good” data quality. Conversion programs need to be bug free and traceable. There should be reasonable checks of input data for consistency and plausibility and many other similar measures.
7.2 Selection and Introduction of Test Tools
Some elementary tools (e.g., comparators, coverage analyzers) are included in typical operating system environments (e.g., UNIX) as a standard feature. In these cases, the tester can assemble the necessary tool support using simple, available means. Naturally, the capabilities of such standard tools are limited, so it is sometimes useful to buy more advanced commercial test tools.
As described earlier, special tools are commercially available for every phase in the test process, supporting the tester in executing the phase-specific tasks or performing these tasks themselves. The tools range from test planning and test specification tools, supporting the tester in his creative test development process, to test drivers and test robots able to automate the mechanical test execution tasks.
When contemplating the acquisition of test tools, automation tools for test execution should not be the first and only choice.
“Automating ... faster chaos”
The area in which tool support may be advantageous strongly depends on the respective project environment and the maturity level of the development and test process. Test execution automation is not a very good idea in a chaotic project environment, where “programming on the fly” is common practice, documentation does not exist or is inconsistent, and tests are performed in an unstructured way (if at all). A tool can never replace a nonexistent process or compensate for a sloppy procedure. “It is far better to improve the effectiveness of testing first than to improve the efficiency of poor testing. Automating chaos just gives faster chaos” [Fewster 99, p. 11].
In those situations, manual testing must first be organized. This means, initially, that a systematic test process must be defined, introduced, and adhered to. Next, thought can be given to the question, Which process steps can be supported by tools? What can be done to enhance the productivity or quality by using tools? When introducing testing tools from the different explained categories, it is recommended to adhere to the following order of introduction:
Observe the order of tool introduction
1. Incident management
2. Configuration management
3. Test planning
4. Test execution
5. Test specification
Remember the learning curve
Take into account the necessary time to learn a new tool and to establish its use. Due to the learning curve, productivity may even decline for some time instead of increasing, as would be desired. It is therefore risky to introduce a new tool during “hot” project phases, hoping to solve personnel bottlenecks then and there by introducing a misunderstood kind of automation.
7.2.1 Cost Effectiveness of Tool Introduction
Introducing a new tool brings with it selection, acquisition, and maintenance costs. In addition, costs may arise for hardware acquisition or updates and employee training. Depending on tool complexity and the number of workstations to be equipped with the tool, the amount invested can rapidly grow large. The time frame in which the new test tool will start to pay back is interesting, as with every investment.
Make a cost-benefit analysis
Test execution automation tools offer a good possibility for estimating the amount of effort saved when comparing an automated test to a manually executed test. The extra test programming effort must, of course, be taken into account. This typically results in a negative cost-benefit balance after only one automated test run. The achieved savings per test run accumulate only after further automated regression test runs (figure 7–2).
Figure 7–2
The life cycle of a test case
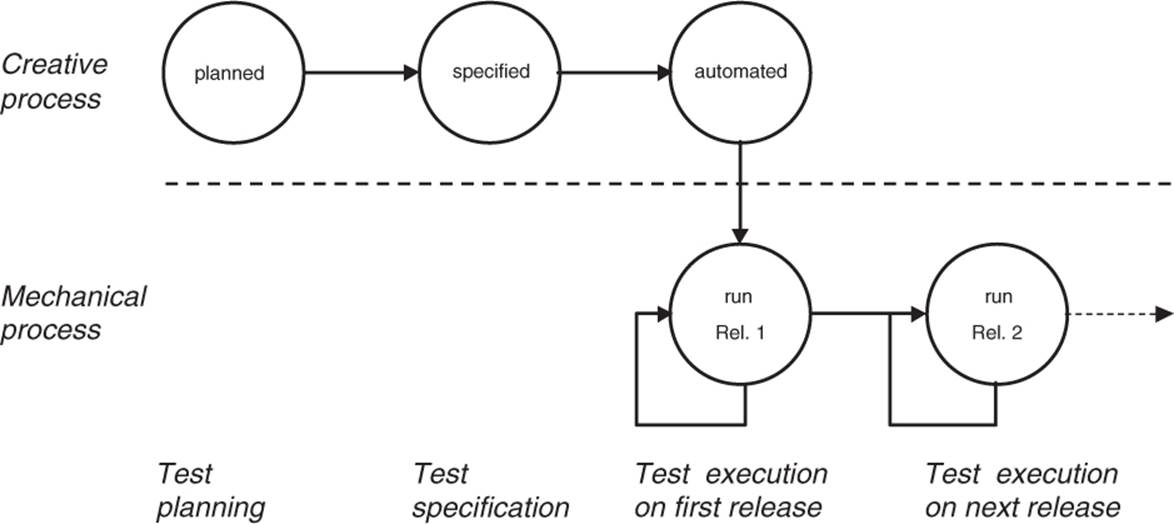
The balance will become positive after a certain number of regression test cycles. It is difficult to give an exact estimate of the time for payback. Breakeven will be achieved only if the tests are designed and programmed for easy use in regression testing and easy maintenance. If tests are easy to repeat and maintain, a positive balance is definitely possible from the third test cycle onward for capture/replay tools. Of course, this calculation makes sense only when manual execution is possible at all. However, many tests cannot be run in a purely manual way (e.g., performance tests). They have to be run automatically.
Evaluate the influence on test quality
Merely discussing the level of test effort does not suffice. Test quality improvement by applying a new test tool that results in detecting and eliminating more faults, or results in more trustworthiness of the test, must also be taken into account. Development, support, and maintenance costs will decrease, at least in the medium term. The savings potential is significantly higher for this case and therefore more interesting.
To summarize:
§ Tools may support the creative testing tasks. They help the tester to improve test quality.
§ Mechanical test execution may be automated. This reduces test effort or makes it possible to run more tests with the same test effort. However, more tests do not necessarily mean better test quality.
§ In both cases, without good test procedures or well-established test methods, tools do not lead to the desired cost reduction.
7.2.2 Tool Selection
After a decision is made about which test task a tool shall support, the actual selection (and evaluation) of the tool starts. As explained earlier, the investment can be very large. It is, therefore, best to proceed carefully and in a well-planned way. The selection process consists of the following five steps:
1. Requirements specification for the tool
2. Market research (creating a list of possible candidates)
3. Tool demonstrations
4. Evaluation of the tools on the short list
5. Review of the results and selection of the tool
For the first step, requirements specification, the following criteria may be relevant:
Selection criteria
§ Quality of interaction with the potential test objects
§ Tester know-how regarding the tool or method
§ Possibility of integration into the existing development environment
§ Possibility of integration with other already used testing tools
§ Platform for using the tool
§ Possibilities for integration with tools from the same supplier
§ Manufacturer’s service, reliability, and market position
§ License conditions, price, maintenance costs
These and possible further individual criteria are compiled in a list and then weighted according to their relative importance. Absolutely indispensable criteria are identified and marked as knock-out criteria.
Market research and short-listing
Parallel to creating a catalogue of criteria, market research takes place: A list is created, listing the available products of the tool category of interest. Product information is requested from suppliers or collected from the Internet. Based on these materials, the suppliers of the preferred candidates are invited to demonstrate their respective tools. A relatively reliable impression of the respective company and its service philosophy can be gained from these demonstrations. The best vendors will then be taken into the final evaluation process, where primarily the following points need to be verified:
§ Does the tool work with the test objects and the development environment?
§ Are the features and quality characteristics that caused the respective tool to be considered for final evaluation fulfilled in reality? (Marketing can promise a lot.)
§ Is the supplier’s support staff able to provide qualified information and help even with nonstandard questions (before and after purchase2)?
7.2.3 Tool Introduction
After a tool is selected, it must be introduced into the organization. Normally the first step is to launch a pilot project (proof of concept). This should show that the expected benefits will be achieved in real projects. People other than the ones who helped in selecting the tool should execute the pilot project. Otherwise, the evaluation results could introduce bias.
Pilot operation
Pilot operation should deliver additional knowledge of the technical details of the tool as well as experiences with the practical use of the tool and experiences about its usage environment. It should thus become apparent whether, and to what extent, there exists a need for training and where, if necessary, the test process should be changed. Furthermore, rules and conventions for general use should be developed. These may be naming conventions for files and test cases, rules for structuring the tests, and so on. If test drivers or test robots are introduced, it can be determined during the pilot project if it is reasonable to build test libraries. This should facilitate reuse of certain tests and test modules outside the project.
Because the new tool will always generate additional workload in the beginning, the introduction of a tool requires strong and ongoing commitment of the new users and stakeholders.
Coaching and training measures are important.
Success factors
There are some important success factors during rollout:
§ Introduce the tool stepwise.
§ Integrate the tool’s support with the processes.
§ Implement user training and continuous coaching.
§ Make available rules and suggestions for applying the tool.
§ Collect usage experiences and make them available to all users (hints, tricks, FAQs, etc.).
§ Monitor tool acceptance and gather and evaluate cost-benefit data.
Successful tool introduction follows these six steps:
1. Execute a pilot project.
2. Evaluate the pilot project experiences.
3. Adapt the processes and implement rules for usage.
4. Train the users.
5. Introduce the tool stepwise.
6. Offer coaching.
This chapter pointed out many of the difficulties and the additional effort involved when selecting and using tools for supporting the test process.
This is not meant to create the impression that using tools is not worthwhile.
On the contrary, in larger projects, testing without the support of appropriate tools is not feasible. However, a careful tool introduction is necessary, otherwise the expensive tool quickly becomes “shelfware”; that is, it falls into disuse.
7.3 Summary
§ Tools are available for every phase of the test process, helping the tester automate test activities or improve the quality of these activities.
§ Use of a test tool is beneficial only when the test process is defined and controlled.
§ Test tool selection must be a careful and well-managed process because introducing a test tool may incur large investments.
§ Information, training, and coaching must support the introduction of the selected tool. This helps to assure the future users’ acceptance and hence the continued application of the tool.