Building Microservices (2015)
Chapter 12. Bringing It All Together
We’ve covered a fair amount in the previous chapters, from what microservices are to how to define their boundaries, and from integration technology to concerns about security and monitoring. And we even found time to work out how the role of the architect fits in. There is a lot to take in, as although microservices themselves may be small, the breadth and impact of their architecture are not. So here I’ll try to summarize some of the key points covered throughout the book.
Principles of Microservices
We discussed the role that principles can play in Chapter 2. They are statements about how things should be done, and why we think they should be done that way. They help us frame the various decisions we have to make when building our systems. You should absolutely define your own principles, but I thought it worth spelling out what I see as being the key principles for microservice architectures, which you can see summarized in Figure 12-1. These are the principles that will help us create small autonomous services that work well together. We’ve already covered everything here at least once so far, so nothing should be new, but there is value in distilling it down to its core essence.
You can choose to adopt these principles wholesale, or perhaps tweak them to make sense in your own organization. But note the value that comes from using them in combination: the whole should be greater than the sum of the parts. So if you decide to drop one of them, make sure you understand what you’ll be missing.
For each of these principles, I’ve tried to pull out some of the supporting practices that we have covered in the book. As the saying goes, there is more than one way to skin a cat: you might find your own practices to help deliver on these principles, but this should get you started.
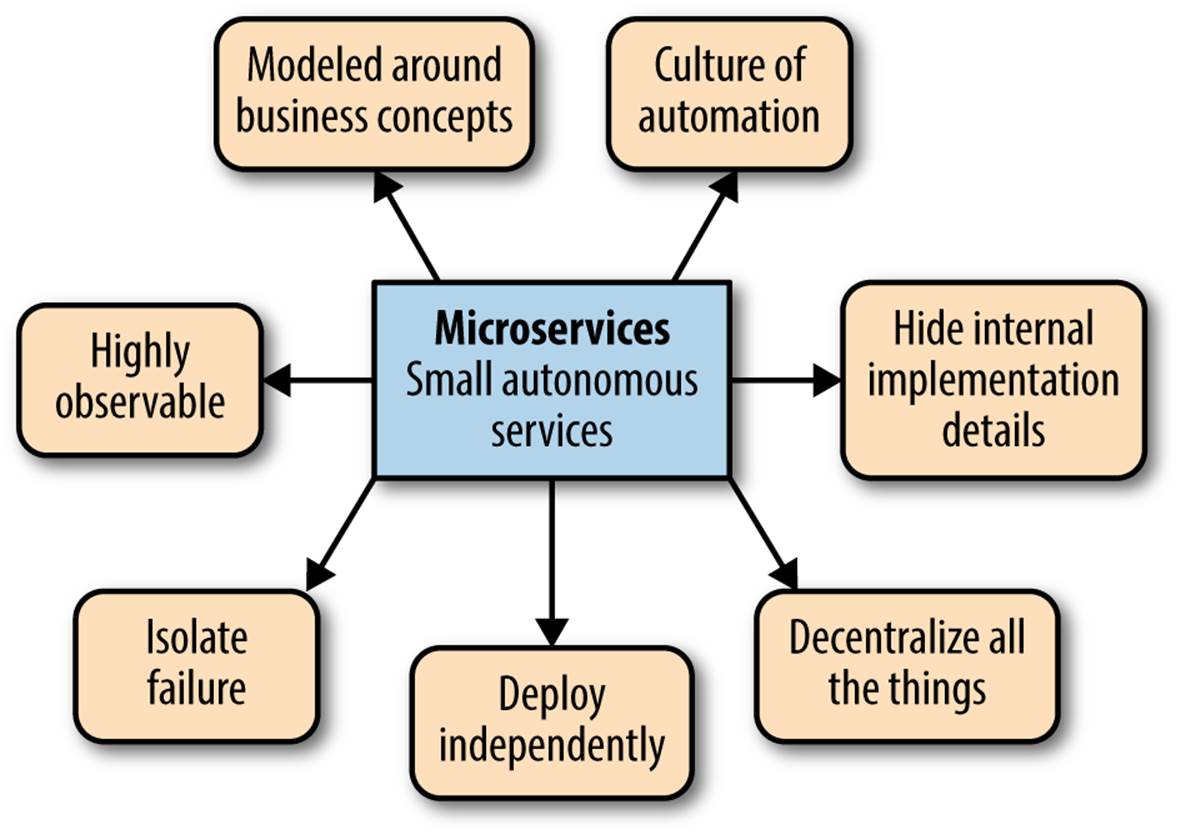
Figure 12-1. Principles of microservices
Model Around Business Concepts
Experience has shown us that interfaces structured around business-bounded contexts are more stable than those structured around technical concepts. By modeling the domain in which our system operates, not only do we attempt to form more stable interfaces, but we also ensure that we are better able to reflect changes in business processes easily. Use bounded contexts to define potential domain boundaries.
Adopt a Culture of Automation
Microservices add a lot of complexity, a key part of which comes from the sheer number of moving parts we have to deal with. Embracing a culture of automation is one key way to address this, and front-loading effort to create the tooling to support microservices can make a lot of sense.Automated testing is essential, as ensuring our services still work is a more complex process than with monolithic systems. Having a uniform command-line call to deploy the same way everywhere can help, and this can be a key part of adopting continuous delivery to give us fast feedback on the production quality of each check-in.
Consider using environment definitions to help you specify the differences from one environment to another, without sacrificing the ability to use a uniform deployment method. Think about creating custom images to speed up deployment, and embracing the creation of fully automatedimmutable servers to make it easier to reason about your systems.
Hide Internal Implementation Details
To maximize the ability of one service to evolve independently of any others, it is vital that we hide implementation details. Modeling bounded contexts can help, as this helps us focus on those models that should be shared, and those that should be hidden. Services should also hide their databases to avoid falling into one of the most common sorts of coupling that can appear in traditional service-oriented architectures, and use data pumps or event data pumps to consolidate data across multiple services for reporting purposes.
Where possible, pick technology-agnostic APIs to give you freedom to use different technology stacks. Consider using REST, which formalizes the separation of internal and external implementation details, although even if using remote procedure calls (RPCs), you can still embrace these ideas.
Decentralize All the Things
To maximize the autonomy that microservices make possible, we need to constantly be looking for the chance to delegate decision making and control to the teams that own the services themselves. This process starts with embracing self-service wherever possible, allowing people to deploy software on demand, making development and testing as easy as possible, and avoiding the need for separate teams to perform these activities.
Ensuring that teams own their services is an important step on this journey, making teams responsible for the changes that are made, ideally even having them decide when to release those changes. Making use of internal open source ensures that people can make changes on services owned by other teams, although remember that this requires work to implement. Align teams to the organization to ensure that Conway’s law works for you, and help your team become domain experts in the business-focused services they are creating. Where some overarching guidance is needed, try to embrace a shared governance model where people from each team collectively share responsibility for evolving the technical vision of the system.
This principle can apply to architecture too. Avoid approaches like enterprise service bus or orchestration systems, which can lead to centralization of business logic and dumb services. Instead, prefer choreography over orchestration and dumb middleware, with smart endpoints to ensure that you keep associated logic and data within service boundaries, helping keep things cohesive.
Independently Deployable
We should always strive to ensure that our microservices can and are deployed by themselves. Even when breaking changes are required, we should seek to coexist versioned endpoints to allow our consumers to change over time. This allows us to optimize for speed of release of new features, as well as increasing the autonomy of the teams owning these microservices by ensuring that they don’t have to constantly orchestrate their deployments. When using RPC-based integration, avoid tightly bound client/server stub generation such as that promoted by Java RMI.
By adopting a one-service-per-host model, you reduce side effects that could cause deploying one service to impact another unrelated service. Consider using blue/green or canary release techniques to separate deployment from release, reducing the risk of a release going wrong. Useconsumer-driven contracts to catch breaking changes before they happen.
Remember that it should be the norm, not the exception, that you can make a change to a single service and release it into production, without having to deploy any other services in lock-step. Your consumers should decide when they update themselves, and you need to accommodate this.
Isolate Failure
A microservice architecture can be more resilient than a monolithic system, but only if we understand and plan for failures in part of our system. If we don’t account for the fact that a downstream call can and will fail, our systems might suffer catastrophic cascading failure, and we could find ourselves with a system that is much more fragile than before.
When using network calls, don’t treat remote calls like local calls, as this will hide different sorts of failure mode. So make sure if you’re using client libraries that the abstraction of the remote call doesn’t go too far.
If we hold the tenets of antifragility in mind, and expect failure will occur anywhere and everywhere, we are on the right track. Make sure your timeouts are set appropriately. Understand when and how to use bulkheads and circuit breakers to limit the fallout of a failing component. Understand what the customer-facing impact will be if only one part of the system is misbehaving. Know what the implications of a network partition might be, and whether sacrificing availability or consistency in a given situation is the right call.
Highly Observable
We cannot rely on observing the behavior of a single service instance or the status of a single machine to see if the system is functioning correctly. Instead, we need a joined-up view of what is happening. Use semantic monitoring to see if your system is behaving correctly, by injectingsynthetic transactions into your system to simulate real-user behavior. Aggregate your logs, and aggregate your stats, so that when you see a problem you can drill down to the source. And when it comes to reproducing nasty issues or just seeing how your system is interacting in production, use correlation IDs to allow you to trace calls through the system.
When Shouldn’t You Use Microservices?
I get asked this question a lot. My first piece of advice would be that the less well you understand a domain, the harder it will be for you to find proper bounded contexts for your services. As we discussed previously, getting service boundaries wrong can result in having to make lots of changes in service-to-service collaboration—an expensive operation. So if you’re coming to a monolithic system for which you don’t understand the domain, spend some time learning what the system does first, and then look to identify clean module boundaries prior to splitting out services.
Greenfield development is also quite challenging. It isn’t just that the domain is also likely to be new; it’s that it is much easier to chunk up something you have than something you don’t! So again, consider starting monolithic first and break things out when you’re stable.
Many of the challenges you’re going to face with microservices get worse with scale. If you mostly do things manually, you might be OK with 1 or 2 services, but 5 or 10? Sticking with old monitoring practices where you just look at stats like CPU and memory likewise might work OK for a few services, but the more service-to-service collaboration you do, the more painful this will become. You’ll find yourself hitting these pain points as you add more services, and I hope the advice in this book will help you see some of these problems coming, and give you some concrete tips for how to deal with them. I spoke before about REA and Gilt taking a while to build the tooling and practices to manage microservices well, prior to being able to use them in any large quantity. These stories just reinforce to me the importance of starting gradually so you understand your organization’s appetite and ability to change, which will help you properly adopt microservices.
Parting Words
Microservice architectures give you more options, and more decisions to make. Making decisions in this world is a far more common activity than in simpler, monolithic systems. You won’t get all of these decisions right, I can guarantee that. So, knowing we are going to get some things wrong, what are our options? Well, I would suggest finding ways to make each decision small in scope; that way, if you get it wrong, you only impact a small part of your system. Learn to embrace the concept of evolutionary architecture, where your system bends and flexes and changes over time as you learn new things. Think not of big-bang rewrites, but instead of a series of changes made to your system over time to keep it supple.
Hopefully by now I’ve shared with you enough information and experiences to help you decide if microservices are for you. If they are, I hope you think of this as a journey, not a destination. Go incrementally. Break your system apart piece by piece, learning as you go. And get used to it: in many ways, the discipline to continually change and evolve our systems is a far more important lesson to learn than any other I have shared with you through this book. Change is inevitable. Embrace it.