Building Microservices (2015)
Chapter 3. How to Model Services
My opponent’s reasoning reminds me of the heathen, who, being asked on what the world stood, replied, “On a tortoise.” But on what does the tortoise stand? “On another tortoise.”
Joseph Barker (1854)
So you know what microservices are, and hopefully have a sense of their key benefits. You’re probably eager now to go and start making them, right? But where to start? In this chapter, we’ll look at how to think about the boundaries of your microservices that will hopefully maximize the upsides and avoid some of the potential downsides. But first, we need something to work with.
Introducing MusicCorp
Books about ideas work better with examples. Where possible, I’ll be sharing stories from real-world situations, but I’ve found it’s also useful to have a fictional domain with which to work. Throughout the book, we’ll be returning to this domain, seeing how the concept of microservices works within this world.
So let’s turn our attention to the cutting-edge online retailer MusicCorp. MusicCorp was recently a brick-and-mortar retailer, but after the bottom dropped out of the gramophone record business it focused more and more of its efforts online. The company has a website, but feels that now is the time to double-down on the online world. After all, those iPods are just a passing fad (Zunes are way better, obviously) and music fans are quite happy to wait for CDs to arrive at their doorsteps. Quality over convenience, right? And while we’re at it, what’s this Spotify thing people keep talking about—some sort of skin treatment for teenagers?
Despite being a little behind the curve, MusicCorp has grand ambitions. Luckily, it has decided that its best chance of taking over the world is by making sure it can make changes as easily as possible. Microservices for the win!
What Makes a Good Service?
Before the team from MusicCorp tears off into the distance, creating service after service in an attempt to deliver eight-track tapes to all and sundry, let’s put the brakes on and talk a bit about the most important underlying idea we need to keep in mind. What makes a good service? If you’ve survived a failed SOA implementation, you may have some idea where I’m going next. But just in case you aren’t that (un)fortunate, I want you to focus on two key concepts: loose coupling and high cohesion. We’ll talk in detail throughout the book about other ideas and practices, but they are all for naught if we get these two thing wrong.
Despite the fact that these two terms are used a lot, especially in the context of object-oriented systems, it is worth discussing what they mean in terms of microservices.
Loose Coupling
When services are loosely coupled, a change to one service should not require a change to another. The whole point of a microservice is being able to make a change to one service and deploy it, without needing to change any other part of the system. This is really quite important.
What sort of things cause tight coupling? A classic mistake is to pick an integration style that tightly binds one service to another, causing changes inside the service to require a change to consumers. We’ll discuss how to avoid this in more depth in Chapter 4.
A loosely coupled service knows as little as it needs to about the services with which it collaborates. This also means we probably want to limit the number of different types of calls from one service to another, because beyond the potential performance problem, chatty communication can lead to tight coupling.
High Cohesion
We want related behavior to sit together, and unrelated behavior to sit elsewhere. Why? Well, if we want to change behavior, we want to be able to change it in one place, and release that change as soon as possible. If we have to change that behavior in lots of different places, we’ll have to release lots of different services (perhaps at the same time) to deliver that change. Making changes in lots of different places is slower, and deploying lots of services at once is risky—both of which we want to avoid.
So we want to find boundaries within our problem domain that help ensure that related behavior is in one place, and that communicate with other boundaries as loosely as possible.
The Bounded Context
Eric Evans’s book Domain-Driven Design (Addison-Wesley) focuses on how to create systems that model real-world domains. The book is full of great ideas like using ubiquitous language, repository abstractions, and the like, but there is one very important concept Evans introduces that completely passed me by at first: bounded context. The idea is that any given domain consists of multiple bounded contexts, and residing within each are things (Eric uses the word model a lot, which is probably better than things) that do not need to be communicated outside as well as things that are shared externally with other bounded contexts. Each bounded context has an explicit interface, where it decides what models to share with other contexts.
Another definition of bounded contexts I like is “a specific responsibility enforced by explicit boundaries.”1 If you want information from a bounded context, or want to make requests of functionality within a bounded context, you communicate with its explicit boundary using models. In his book, Evans uses the analogy of cells, where “[c]ells can exist because their membranes define what is in and out and determine what can pass.”
Let’s return for a moment to the MusicCorp business. Our domain is the whole business in which we are operating. It covers everything from the warehouse to the reception desk, from finance to ordering. We may or may not model all of that in our software, but that is nonetheless the domain in which we are operating. Let’s think about parts of that domain that look like the bounded contexts that Evans refers to. At MusicCorp, our warehouse is a hive of activity—managing orders being shipped out (and the odd return), taking delivery of new stock, having forklift truck races, and so on. Elsewhere, the finance department is perhaps less fun-loving, but still has a very important function inside our organization. These employees manage payroll, keep the company accounts, and produce important reports. Lots of reports. They probably also have interesting desk toys.
Shared and Hidden Models
For MusicCorp, we can then consider the finance department and the warehouse to be two separate bounded contexts. They both have an explicit interface to the outside world (in terms of inventory reports, pay slips, etc.), and they have details that only they need to know about (forklift trucks, calculators).
Now the finance department doesn’t need to know about the detailed inner workings of the warehouse. It does need to know some things, though—for example it needs to know about stock levels to keep the accounts up to date. Figure 3-1 shows an example context diagram. We see concepts that are internal to the warehouse, like Picker (people who pick orders), shelves that represent stock locations, and so on. Likewise, the company’s general ledger is integral to finance but is not shared externally here.
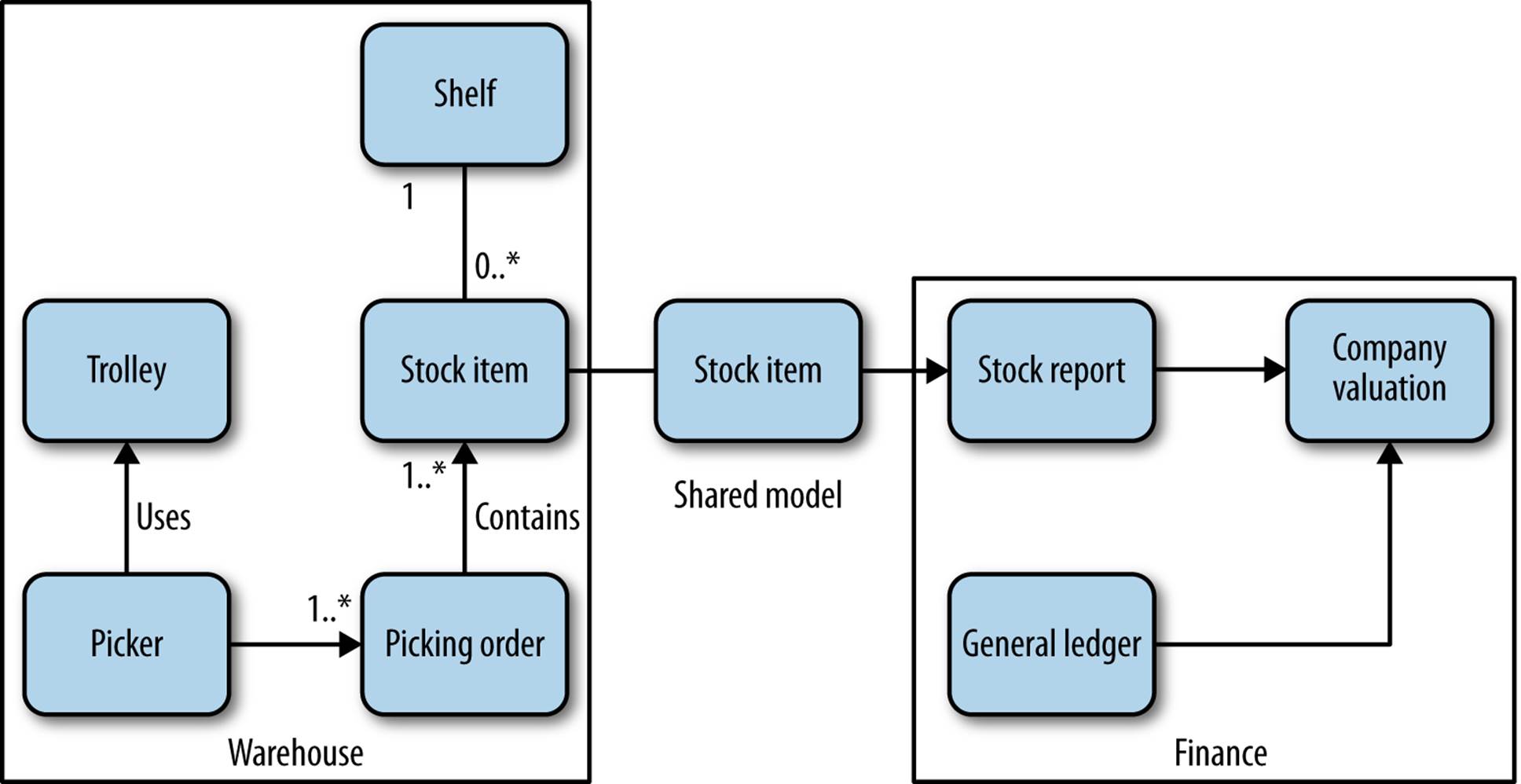
Figure 3-1. A shared model between the finance department and the warehouse
To be able to work out the valuation of the company, though, the finance employees need information about the stock we hold. The stock item then becomes a shared model between the two contexts. However, note that we don’t need to blindly expose everything about the stock item from the warehouse context. For example, although internally we keep a record on a stock item as to where it should live within the warehouse, that doesn’t need to be exposed in the shared model. So there is the internal-only representation, and the external representation we expose. In many ways, this foreshadows the discussion around REST in Chapter 4.
Sometimes we may encounter models with the same name that have very different meanings in different contexts too. For example, we might have the concept of a return, which represents a customer sending something back. Within the context of the customer, a return is all about printing a shipping label, dispatching a package, and waiting for a refund. For the warehouse, this could represent a package that is about to arrive, and a stock item that needs to be restocked. It follows that within the warehouse we store additional information associated with the return that relates to the tasks to be carried out; for example, we may generate a restock request. The shared model of the return becomes associated with different processes and supporting entities within each bounded context, but that is very much an internal concern within the context itself.
Modules and Services
By thinking clearly about what models should be shared, and not sharing our internal representations, we avoid one of the potential pitfalls that can result in tight coupling (the opposite of what we want). We have also identified a boundary within our domain where all like-minded business capabilities should live, giving us the high cohesion we want. These bounded contexts, then, lend themselves extremely well to being compositional boundaries.
As we discussed in Chapter 1, we have the option of using modules within a process boundary to keep related code together and attempt to reduce the coupling to other modules in the system. When you’re starting out on a new codebase, this is probably a good place to begin. So once you have found your bounded contexts in your domain, make sure they are modeled within your codebase as modules, with shared and hidden models.
These modular boundaries then become excellent candidates for microservices. In general, microservices should cleanly align to bounded contexts. Once you become very proficient, you may decide to skip the step of keeping the bounded context modeled as a module within a more monolithic system, and jump straight for a separate service. When starting out, however, keep a new system on the more monolithic side; getting service boundaries wrong can be costly, so waiting for things to stabilize as you get to grips with a new domain is sensible. We’ll discuss this more in Chapter 5, along with techniques to help break apart existing systems into microservices.
So, if our service boundaries align to the bounded contexts in our domain, and our microservices represent those bounded contexts, we are off to an excellent start in ensuring that our microservices are loosely coupled and strongly cohesive.
Premature Decomposition
At ThoughtWorks, we ourselves experienced the challenges of splitting out microservices too quickly. Aside from consulting, we also create a few products. One of them is SnapCI, a hosted continuous integration and continuous delivery tool (we’ll discuss those concepts later in Chapter 6). The team had previously worked on another similar tool, Go-CD, a now open source continuous delivery tool that can be deployed locally rather than being hosted in the cloud.
Although there was some code reuse very early on between the SnapCI and Go-CD projects, in the end SnapCI turned out to be a completely new codebase. Nonetheless, the previous experience of the team in the domain of CD tooling emboldened them to move more quickly in identifying boundaries, and building their system as a set of microservices.
After a few months, though, it became clear that the use cases of SnapCI were subtly different enough that the initial take on the service boundaries wasn’t quite right. This led to lots of changes being made across services, and an associated high cost of change. Eventually the team merged the services back into one monolithic system, giving them time to better understand where the boundaries should exist. A year later, the team was then able to split the monolithic system apart into microservices, whose boundaries proved to be much more stable. This is far from the only example of this situation I have seen. Prematurely decomposing a system into microservices can be costly, especially if you are new to the domain. In many ways, having an existing codebase you want to decompose into microservices is much easier than trying to go to microservices from the beginning.
Business Capabilities
When you start to think about the bounded contexts that exist in your organization, you should be thinking not in terms of data that is shared, but about the capabilities those contexts provide the rest of the domain. The warehouse may provide the capability to get a current stock list, for example, or the finance context may well expose the end-of-month accounts or let you set up payroll for a new recruit. These capabilities may require the interchange of information—shared models—but I have seen too often that thinking about data leads to anemic, CRUD-based (create, read, update, delete) services. So ask first “What does this context do?”, and then “So what data does it need to do that?”
When modeled as services, these capabilities become the key operations that will be exposed over the wire to other collaborators.
Turtles All the Way Down
At the start, you will probably identify a number of coarse-grained bounded contexts. But these bounded contexts can in turn contain further bounded contexts. For example, you could decompose the warehouse into capabilities associated with order fulfillment, inventory management, or goods receiving. When considering the boundaries of your microservices, first think in terms of the larger, coarser-grained contexts, and then subdivide along these nested contexts when you’re looking for the benefits of splitting out these seams.
I have seen these nested contexts remaining hidden to other, collaborating microservices to great effect. To the outside world, they are still making use of business capabilities in the warehouse, but they are unaware that their requests are actually being mapped transparently to two or more separate services, as you can see in Figure 3-2. Sometimes, you will decide it makes more sense for the higher-level bounded context to not be explicitly modeled as a service boundary, as in Figure 3-3, so rather than a single warehouse boundary, you might instead split out inventory, order fulfillment, and goods receiving.
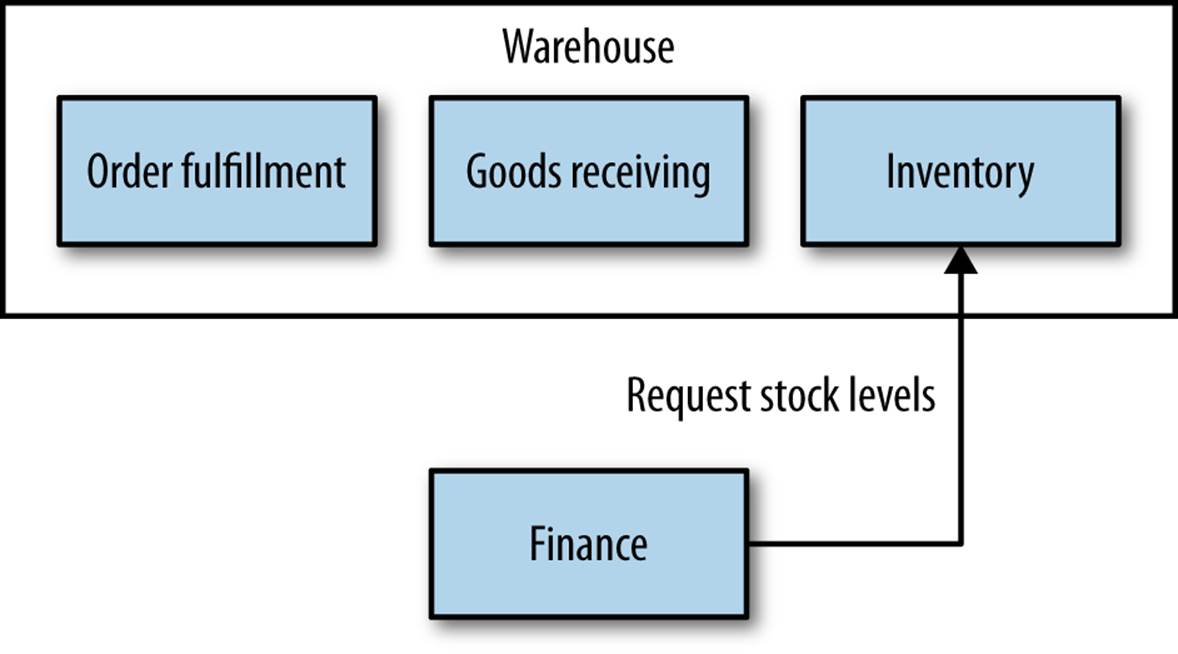
Figure 3-2. Microservices representing nested bounded contexts hidden inside the warehouse
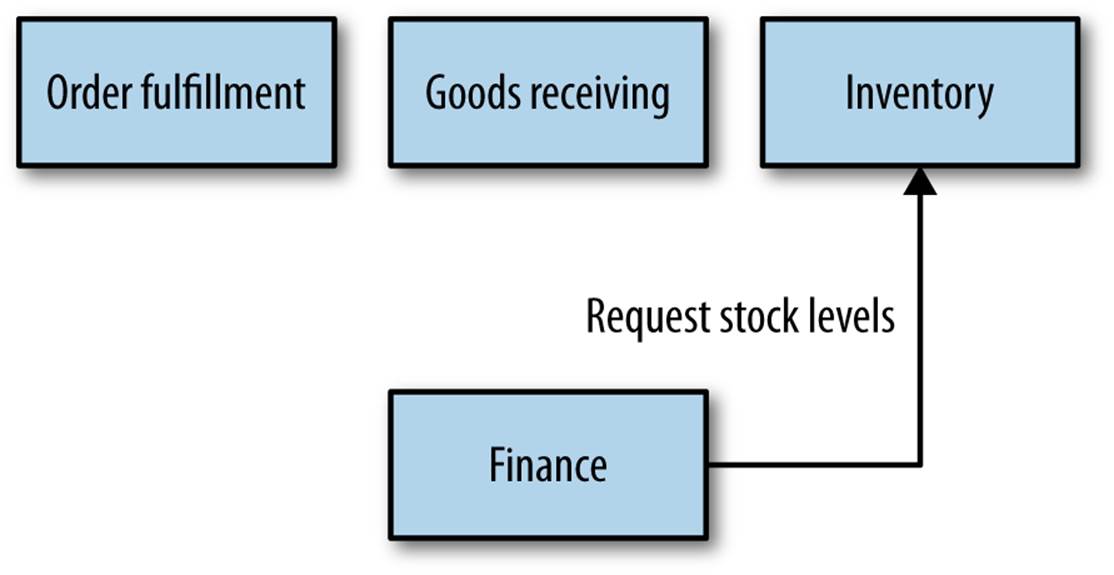
Figure 3-3. The bounded contexts inside the warehouse being popped up into their own top-level contexts
In general, there isn’t a hard-and-fast rule as to what approach makes the most sense. However, whether you choose the nested approach over the full separation approach should be based on your organizational structure. If order fulfillment, inventory management, and goods receiving are managed by different teams, they probably deserve their status as top-level microservices. If, on the other hand, all of them are managed by one team, then the nested model makes more sense. This is because of the interplay of organizational structures and software architecture, which we will discuss toward the end of the book in Chapter 10.
Another reason to prefer the nested approach could be to chunk up your architecture to simplify testing. For example, when testing services that consume the warehouse, I don’t have to stub each service inside the warehouse context, just the more coarse-grained API. This can also give you a unit of isolation when considering larger-scoped tests. I may, for example, decide to have end-to-end tests where I launch all services inside the warehouse context, but for all other collaborators I might stub them out. We’ll explore more about testing and isolation in Chapter 7.
Communication in Terms of Business Concepts
The changes we implement to our system are often about changes the business wants to make to how the system behaves. We are changing functionality—capabilities—that are exposed to our customers. If our systems are decomposed along the bounded contexts that represent our domain, the changes we want to make are more likely to be isolated to one, single microservice boundary. This reduces the number of places we need to make a change, and allows us to deploy that change quickly.
It’s also important to think of the communication between these microservices in terms of the same business concepts. The modeling of your software after your business domain shouldn’t stop at the idea of bounded contexts. The same terms and ideas that are shared between parts of your organization should be reflected in your interfaces. It can be useful to think of forms being sent between these microservices, much as forms are sent around an organization.
The Technical Boundary
It can be useful to look at what can go wrong when services are modeled incorrectly. A while back, a few colleagues and I were working with a client in California, helping the company adopt some cleaner code practices and move more toward automated testing. We’d started with some of the low-hanging fruit, such as service decomposition, when we noticed something much more worrying. I can’t go into too much detail as to what the application did, but it was a public-facing application with a large, global customer base.
The team, and system, had grown. Originally one person’s vision, the system had taken on more and more features, and more and more users. Eventually, the organization decided to increase the capacity of the team by having a new group of developers based in Brazil take on some of the work. The system got split up, with the front half of the application being essentially stateless, implementing the public-facing website, as shown in Figure 3-4. The back half of the system was simply a remote procedure call (RPC) interface over a data store. Essentially, imagine you’d taken a repository layer in your codebase and made this a separate service.
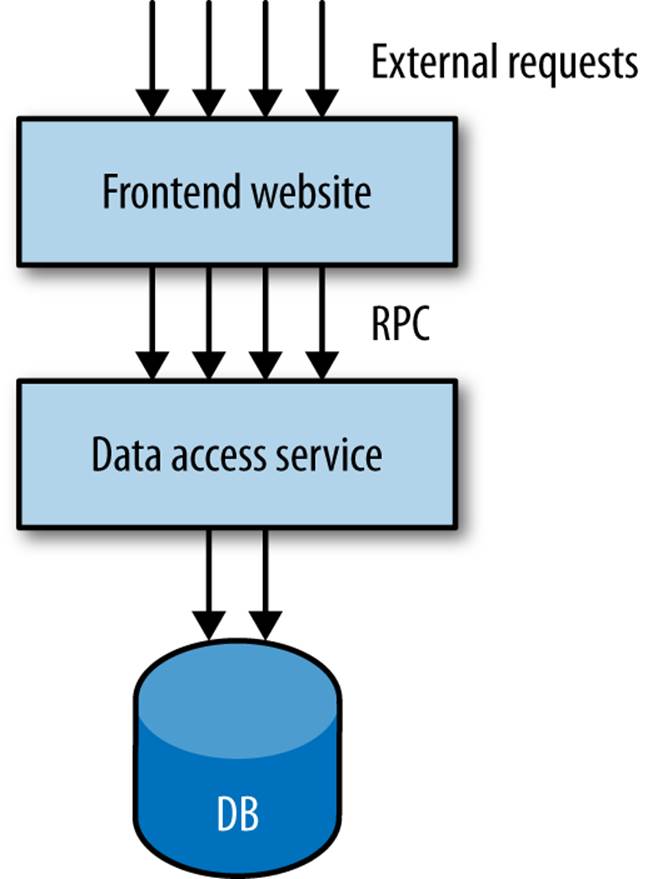
Figure 3-4. A service boundary split across a technical seam
Changes frequently had to be made to both services. Both services spoke in terms of low-level, RPC-style method calls, which were overly brittle (we’ll discuss this futher in Chapter 4). The service interface was also very chatty too, resulting in performance issues. This resulted in the need for elaborate RPC-batching mechanisms. I called this onion architecture, as it had lots of layers and made me cry when we had to cut through it.
Now on the face of it, the idea of splitting the previously monolithic system along geographical/organizational lines makes perfect sense, as we’ll expand on in Chapter 10. Here, however, rather than taking a vertical, business-focused slice through the stack, the team picked what was previously an in-process API and made a horizontal slice.
Making decisions to model service boundaries along technical seams isn’t always wrong. I have certainly seen this make lots of sense when an organization is looking to achieve certain performance objectives, for example. However, it should be your secondary driver for finding these seams, not your primary one.
Summary
In this chapter, you’ve learned a bit about what makes a good service, and how to find seams in our problem space that give us the dual benefits of both loose coupling and high cohesion. Bounded contexts are a vital tool in helping us find these seams, and by aligning our microservices to these boundaries we ensure that the resulting system has every chance of keeping those virtues intact. We’ve also got a hint about how we can subdivide our microservices further, something we’ll explore in more depth later. And we also introduced MusicCorp, the example domain that we will use throughout this book.
The ideas presented in Eric Evans’s Domain-Driven Design are very useful to us in finding sensible boundaries for our services, and I’ve just scratched the surface here. I recommend Vaughn Vernon’s book Implementing Domain-Driven Design (Addison-Wesley) to help you understand the practicalities of this approach.
Although this chapter has been mostly high-level, we need to get much more technical in the next. There are many pitfalls associated with implementing interfaces between services that can lead to all sorts of trouble, and we will have to take a deep dive into this topic if we are to keep our systems from becoming a giant, tangled mess.
1 http://bit.ly/bounded-context-explained
All materials on the site are licensed Creative Commons Attribution-Sharealike 3.0 Unported CC BY-SA 3.0 & GNU Free Documentation License (GFDL)
If you are the copyright holder of any material contained on our site and intend to remove it, please contact our site administrator for approval.
© 2016-2026 All site design rights belong to S.Y.A.