Designing Connected Products: UX for the Consumer Internet of Things (2015)
Chapter 11. Responsible IoT Design
BY ANN LIGHT AND CLAIRE ROWLAND[150]
This chapter looks at the factors that make products trustworthy and safe to use. Connecting up products and services brings new challenges for security, privacy, social engineering, and the environment. We argue that we should consider how our designs impact on others’ lives, and take this as seriously as we take the need for profit and competitive advantage.
This chapter introduces:
§ The challenges of securing the Internet of Things (see Security)
§ The challenges of protecting users’ privacy (see Privacy)
§ The risk that designing technology involves social engineering (see Social Engineering)
§ The environmental impact of IoT (see Mitigating the dangers of social engineering?)
This chapter addresses the following issues:
§ Why embedded devices are especially at risk from network security threats (see Why IoT Security is a Big Challenge)
§ What design requirements for usable IoT security might look like (see Design Requirements for Usable IoT Security)
§ How data that seems innocuous can be aggregated to create a privacy breach (see Aggregation)
§ What good data protection for IoT might look like (see Patterns of behavior)
§ How technology that tries to be “smart” can end up reinforcing social stereotypes (see Social Engineering)
§ Understanding the environmental impact of a connected device across its entire lifecycle (see What’s the Environmental Impact of an IoT Product?)
Security
Computer security is the degree to which a system can protect the assets it contains from unauthorized access, modification, or destruction. The “CIA triad” is a commonly used model of IT security, which defines three important aspects:
Confidentiality
Protecting information from unauthorized access—for example, through eavesdropping or spoofing (masquerading as a legitimate user). (This is related to privacy, which we’ll discuss later.)
Integrity
Protecting information from being modified or deleted by unauthorized parties (e.g., tampering with data or introducing viruses).
Availability
Protecting the system from threats that would stop it working properly, resulting in loss of access to resources (e.g., loss of power, hardware failure, or a denial of service attack).
In UX terms, a “secure” system gives the user confidence that they know who they are dealing with and that information will reach only the intended target. They can trust that interactions with the system will be honest, do them no harm, and not result in any hidden consequences.[151]
Systems can never really be assumed to be 100% “secure” or “insecure.” Effective security is a question of risk management. Determining how much and what type of security is appropriate involves considering the value of the assets, the impact of their potential loss, and the potential vulnerabilities and threats. A public air quality sensor sharing data over the open Web may not have any means to control who can access its data. But it is not “insecure” if there is no way to cause harm (e.g., as long as faking the data from the sensor has no dangerous consequences; we’ll discuss this further momentarily).
The most important defense mechanism for a system that interacts with humans is generally authentication. This means ensuring that the system and user can be confident of each other’s identity. This is often done through a shared secret. Shared secrets are often characterized as:
§ Something I know (e.g., text or graphical password; see Figure 11-1)
§ Something I have (e.g., smartcard or physical key; see Figure 11-2)
§ Something I am (e.g., biometrics like fingerprints or iris recognition; see Figure 11-3).
The first two of these place more cognitive load on the user: remembering a password or remembering to carry a key. The latter, in theory, does not.
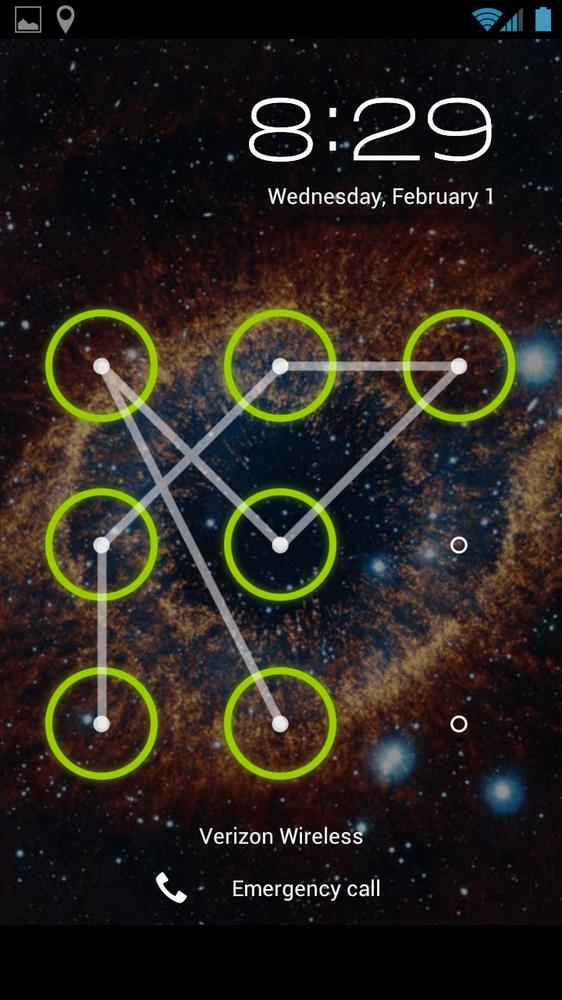
Figure 11-1. The Android unlock pattern is an example of a graphical password, or “something I know” authentication (image: Brent Rubell)

Figure 11-2. A simple house key is a basic form of “something I have” authentication
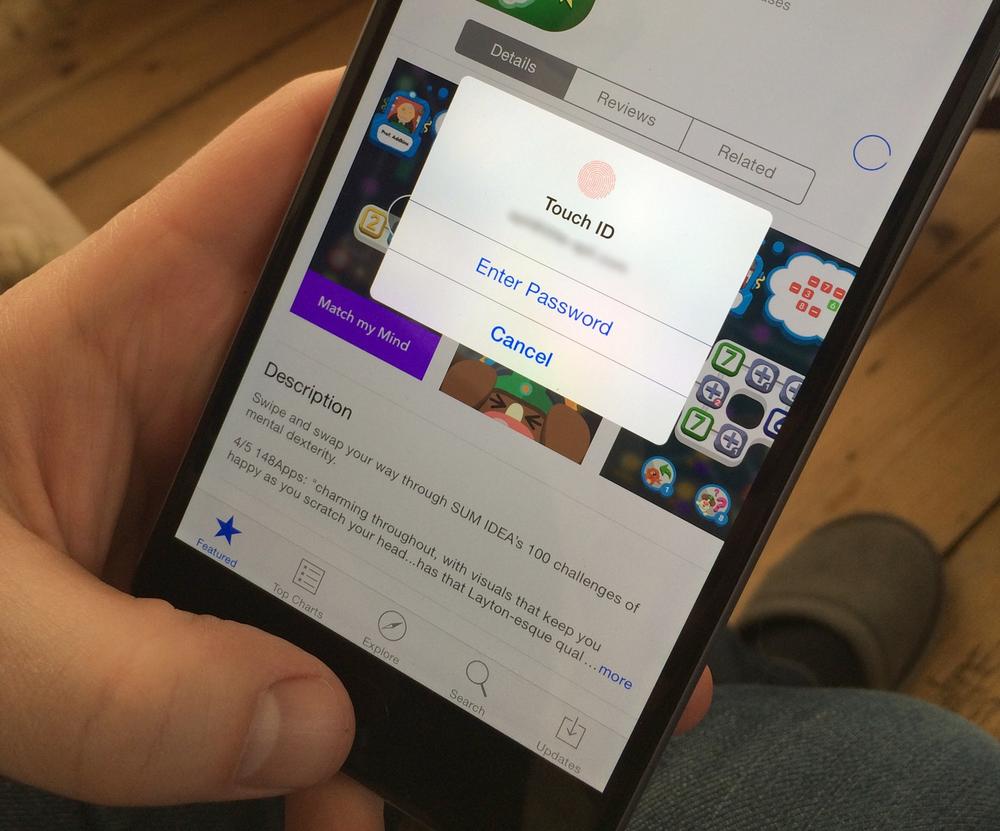
Figure 11-3. Apple TouchID fingerprint sensing is a form of “something I am” authentication
Authentication can also be required when two systems communicate without any human intervention.
Following on from authentication is authorization. A user (or another system) may be permitted to access certain data or functionality on the system, but not others.
Encryption disguises information to keep it secret, on devices, servers, or in transit over the network. Network security methods often aim to verify that information has not been observed or modified in transit (“man in the middle” attacks). A common approach is public key encryption (see Figure 11-4). Each party has a public software key, which is published, and an associated private key known only to them. To ensure confidentiality, the sender encrypts the message using the recipient’s public key. It can only be decrypted by the recipient, using their private key. The message sender also “signs” the message using their own private key. If the signature can be authenticated by the recipient using the sender’s public key, then the message has not been interfered with in transit.
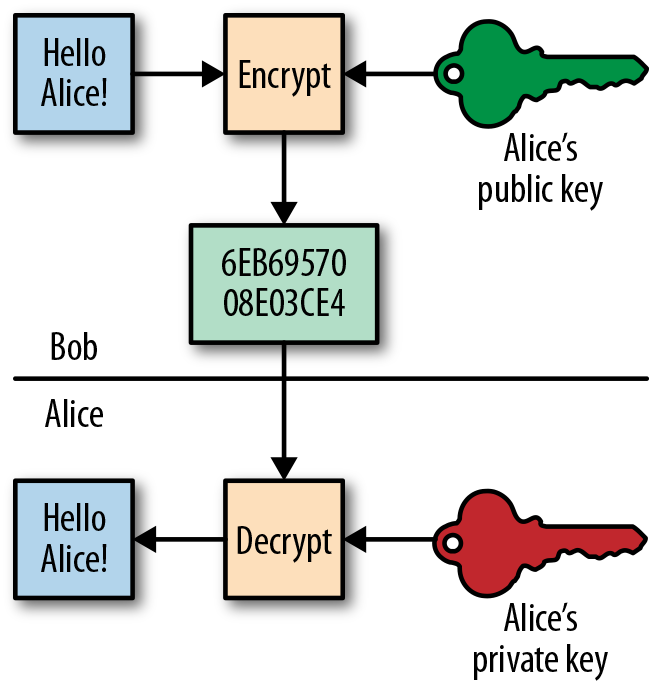
Figure 11-4. Diagram of public key encryption
Good security is a building block for privacy. If a security breach results in an unauthorized party gaining access to information, it can cause a privacy breach. But not all privacy breaches are security breaches. Parties who have legitimate access to data can cause privacy breaches by sharing it inappropriately with unauthorized third parties. These are failures to protect privacy rather than security breaches.
The UX of Security
Security and usability are often in tension. Usability seeks to make it easy for people to do things. Security measures often make it harder to do things. Both sides want to enable the right people to do things. But keeping the wrong people out adds friction to the process of getting those things done. Security is not the user’s main goal. Researcher Frank Stajano describes security as a “tax on the honest” caused by the existence of the dishonest.[152]
Computer security is often focused on minimizing the risk of malicious attacks to stored data or messages in transit. These elements don’t always have a direct impact on the UX design. The biggest UX impact is usually around trade-offs between rigorous authentication and ease of interaction.
One of the big challenges in security is getting people to use it correctly. Security measures are often complex, often designed with highly trained users in mind. The more complex they are, the less likely they are to be used properly. Sophisticated security measures used badly (because they are too confusing) are often less secure in practice than less sophisticated, more usable measures used properly. For example, truly random passwords are harder to break. But they are unmemorable to users, who write them down on notes stuck to computer monitors, or left in unlocked drawers (see Figure 11-5).

Figure 11-5. A random password stuck on a monitor
It’s not that users don’t care about security. No one wants their bank account to be hacked. But nonexpert users often don’t understand how things may be at risk, nor what to do to protect them. Witness the huge number of improperly secured home WiFi routers (see Figure 11-6). Nor can they foresee how their actions (such as sticking passwords on monitors) may increase risk. And if the tools are too much effort, they will try to find ways around them.

Figure 11-6. Security expert Gene Bransfield created the WarKitteh cat collar, which maps neighbors’ WiFi networks as the cat prowls the neighborhood. The collar was a Black Hat security conference demo rather than a real threat but exposed a surprising number of open and poorly secured WiFi routers[153] (image: Gene Bransfield).
Why IoT Security is a Big Challenge
If IoT is as flagrantly unsafe as our current most-IoT-like ecosystem (i.e., home WiFi routers), IoT will have fatal trustworthiness problems and might take off and then suddenly crash as an industry.
—SECURITY ENGINEER CHRIS PALMER[154]
Securing the Internet of Things is more challenging than securing the conventional Internet.
Connecting up the physical world creates the potential for malicious hacking to have “real world” consequences. In 2013, malicious hackers accessed a video baby monitor and verbally abused the child over the loudspeaker.[155] A security breach could easily put lives in danger. Cars could be remotely hijacked to disable the brakes. Pacemakers could be compromised to kill cardiac patients. And public infrastructure, like the water supply or transit system, could be hijacked to cause illness or disruption to millions:
The smart, connected fridge that will know when I’ve run out of milk and automatically place an order seems like a benign addition to my house. But when that fridge also has access to my credit card and can wirelessly unlock a door for a delivery person, it becomes less benign, especially if it depends on a security model designed for a fridge that only plugs into the power outlet.[156]
—RISK MANAGEMENT CONSULTANT CHRIS CLEARFIELD
Securing the sheer number of additional things that are newly at risk will require huge effort. The patterns we have for authenticating users over the conventional Internet may not scale. Who wants to log into their thermostat every time they want to adjust the heating?
Embedded devices themselves will often be particularly vulnerable. Low margins on hardware mean that devices are often made as cheaply as possible. Many were not historically designed with security in mind, because they simply weren’t at risk. Manufacturers may find it challenging (and expensive) to rise to the threats that come with Internet connectivity. Software installed during manufacturing may already be out of date by the time the device is purchased, and may have known vulnerabilities. As discussed in Chapter 2, many connected devices, from PVRs to smart watches to fridges, run general operating systems (often variations of Linux). This makes them vulnerable to the same, normally well-documented, exploits that work on laptops or phones.
Even if it’s possible for the user to update the security settings or software, they may be unaware that the device is at risk, unsure what to do, or they may simply not bother. Most people have a million more pressing or interesting things to do than installing security patches on tens of household devices. And they are very likely to accept default settings when setting up a device, making it very important that those defaults encourage good security choices. But this often isn’t the case.
In 2014, the website insecam.cc (now defunct) made available thousands of live feeds from home security cameras and video baby monitors. The site’s creator claimed this was done to highlight the poor security of the many cameras, which by default either did not require user authentication, or on which the default password had not been changed. The camera owners were completely unaware their daily lives were being broadcast around the world.[157]In an even more troubling example, researchers at the Department of Homeland Security identified 300 medical devices with unchangeable passwords, which could allow someone to log in and change critical settings.[158] This raises the possibility that patients’ lives could be put at risk by compromised pacemakers, defibrillators, and insulin pumps.[159]
In 2013, security researchers at Trustwave discovered a vulnerability in a (now-discontinued) Insteon home automation product that allowed home controls to be indexed by web search engines. As the system (by default) did not require authentication, users’ lights and appliances could be controlled online by anyone.[160] This is an example of the kind of issue that can occur when Internet connectivity is bolted on to a product that was previously unconnected and thus not at risk.
The same researchers also identified that the Android app used to control a $4,000 smart toilet had a hardcoded Bluetooth PIN. This meant that anyone with the app could control any of the manufacturer’s toilets as long as they were within Bluetooth range. Those with a malicious bent could stand outside the bathroom while someone else was in there, raising and lowering the lid, flushing, and activating bidet and air-dry functions.
In the case of some commonly sold products, anyone who can get onto the local WiFi network is assumed to be an authorized user. Poorly secured WiFi can therefore be an easy route to compromise a system. Smart plugs are one example: a plug attached to a heater or hair straighteners could potentially be used to start a fire.
Even industrial systems are often poorly secured. Shodan,[161] a search engine for connected devices, has been shown to be able to find many consumer and industrial devices with minimal security. Devices listed include traffic lights, security cameras, home heating systems—even nuclear power plants and particle accelerators (see Figure 11-7). In many cases, devices could be accessed using the username “admin” and password “1234”.
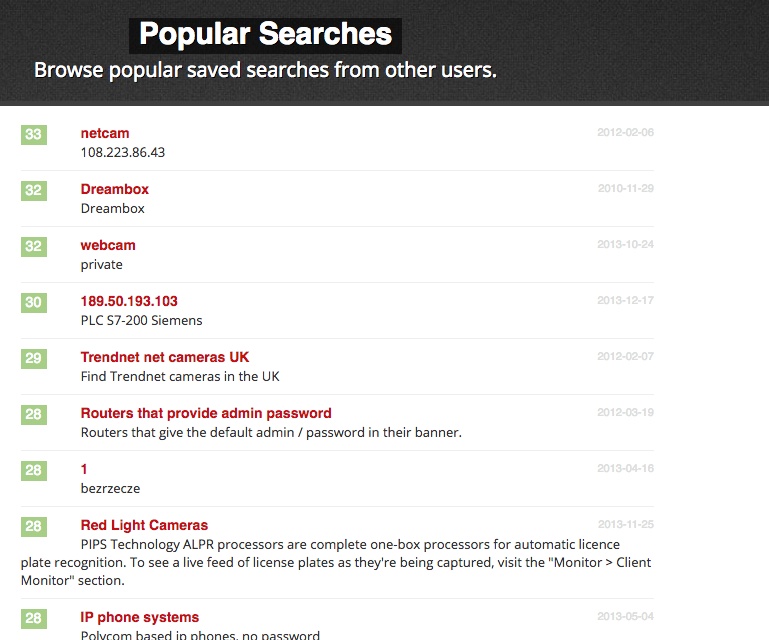
Figure 11-7. Popular Shodan searches include red light cameras with unencrypted feeds (image: shodan.io)
Some very basic, low-powered devices, like burglar alarm or temperature sensors, may not have enough onboard computing power to handle encryption. They transfer data “in the clear,” so are prone to eavesdropping attacks.
Complex interconnected networks of devices will provide many opportunities for malware to spread. Low-powered devices with less robust security might provide an entry point for criminals looking to compromise more powerful devices in the system.
Devices with no UI, or very limited UIs, may be unable to tell us when they have been compromised. A recent botnet attack co-opted 100,000 devices including WiFi routers, connected TVs, and at least one connected fridge into sending out hundreds of thousands of spam emails.[162] How is a fridge going to tell you it’s been hacked?
All of these factors amplify existing problems creating usable security. There are no easy answers to the problem of good security for connected devices, especially those that will be used by nontechnical users. IoT systems are comprised of physical devices, users, and web services, and any one of these can be compromised, either locally or over the network.
In the next section we’ll consider what some design requirements for usable IoT security might look like.
Design Requirements for Usable IoT Security
Building devices with more robust security models and securing network transmissions will solve some of these issues. But as far as the user’s concerned, these improvements aren’t visible in the system UX. In this section, we’ll focus on aspects of security that have a more direct impact on design.
To secure a conventional computer, a user might set up a login, install anti-virus software and keep it up to date. That’s just one device, but it already feels like an effort to many of us. IoT security is more challenging because it concerns systems. Functionality is distributed across networks of devices and web services. Not only do users need to authenticate themselves to the system and be authorized to do things, but devices and web services need to be able to act on behalf of the user. In a system of any complexity, it’s not practical for them to require our explicit permission for every action or type of action. Nor do we want to wade through a huge list of checkboxes to pre-approve what they can or cannot do. We need to remain safe and in control, but we also need to be able to trust that systems will employ sensible defaults and grant some of our devices a degree of autonomy.
The most secure approach is not to connect a device to anything at all. There’s a lot to be said for not connecting things (either to each other or the Internet) without a strong case for doing so. But it would be a shame for IoT to be unnecessarily limited in this way.
Limit the damage that can be caused
Security will be breached at some point, so damage limitation is important. Devices should, where possible, be designed to do no harm when compromised. But this may not always be possible. A car is of no value unless it can drive at reasonable speed, and at that speed it could cause death or injury in a collision. The car could disable itself if it knows it has been hacked, but malware is often designed to ensure the host device is unaware it has a problem.
Limiting devices to a very specific set of functionality will help prevent them being roped into unintended activities. For example, a WiFi-connected oven could be co-opted into sending spam email, sniffing the home WiFi network for sensitive details like bank account details, or compromising its functionality to endanger the user or environment (e.g., turning on the gas to cause a leak). It is safest to build it in such a way that it cannot support some of these behaviors.
A breach in one area should not enable malware or criminals to take over control of the entire system. For example, breaching the in-car entertainment system should not be a back door route to accessing the navigation system or anti-lock brakes.
Keep devices secure
Security software needs to be kept up to date, ideally with as little user intervention as possible. This can be complicated to deliver when there are multiple business partners involved in supporting a system. For example, most current Android smartphones run out-of-date software and often have security vulnerabilities. Google provides software updates to fix these issues but they are not packaged up and pushed to consumers by the carriers or handset manufacturers.[163]
Security engineer Chris Palmer proposes that if devices can’t be updated and maintained, they may need to take themselves out of service when they get too old, or at least disable any security-critical functionality.[164] Of course, devices shutting themselves down or shutting off functionality could also cause problems. The appropriate solution will vary across different devices, applications, and domains. Keeping devices in use longer through frequent software updates is more environmentally sound. But to date, the service infrastructure tends not to support this.
The physical security of devices is also an issue. If possible, product and system designers should take steps to make them less likely to be stolen or physically accessed by unauthorized parties, such as designing product housings to prevent tampering or make it apparent when the device has been tampered with (see Figure 11-8).

Figure 11-8. A hardware cryptographic security module encased in a tamper-proof housing (image: Mils Electronic)
A gateway can provide the security necessary to protect a large number of low-powered edge devices. It’s also easier to maintain one firewall for many different devices than to have to worry about securing them all individually. But any device that is open to the Internet may have vulnerabilities that could be targeted.
Make authentication easier
Users may need to authenticate themselves to devices and services. Devices and web services may also need to identify themselves to other devices and web services.
User authentication often involves passwords (“something I know”), but entering passwords to interact with many different devices would be onerous. In some cases, possession of a phone or smartcard (“something I have”) may be enough (e.g., my phone can control my home lights because it is my phone). But devices can fall into the wrong hands. Phones, keys, and smartcards can be stolen, copied, or cloned. Biometrics, a form of “something I am” (e.g., the iPhone’s fingerprint recognition, iris recognition, or even heart rate or gait analysis), can be low-friction methods of user authentication. But they are not always reliable and can increase the personal risk to users. In 2005, a violent gang of carjackers in Malaysia chopped off a victim’s finger to get around the car’s fingerprint recognition system.[165] Using more than one channel or method (e.g., Google’s two factor authentication, see Figure 11-9) is extra secure, but more hassle.
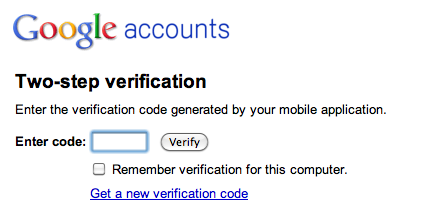
Figure 11-9. Google’s two factor authentication requires the user to use a password and a one-time code sent to their mobile via SMS (image: google.com)
In order to work together, devices need to know which other devices they can trust. Your car needs to prove that it is genuinely your car as it unlocks the garage door. You can verify the identity of the device in two ways: either ask the user to do it, or ask an independent, trusted authority to do it. You might need verification every time, or just the first time.
As Chris Palmer points out,[166] requiring the user’s agreement every time won’t be practical across more than a handful of devices. So devices have to find ways to validate each other’s identity and communicate securely. On the Web, the identity of an entity with a public name like mail.google.com can be authenticated through a certificate associated with its DNS entry. If your browser cannot find a certificate proving that the website claiming to be mail.google.com really is mail.google.com, it will flag it up as a security risk (see Figure 11-10). But users often simply click past such warnings.
But many IoT devices may not have public names and DNS entries, so cannot currently be independently validated in the same way. How does your car prove it really is your car and not a spoof device just pretending to be your car? There are currently no standards here. If some kind of third-party verification for connected devices were available, the garage door could request the car’s “papers” the first time it sees the car, then just trust it in future. Or it could ask the user for authorization on first use, then just connect in future.
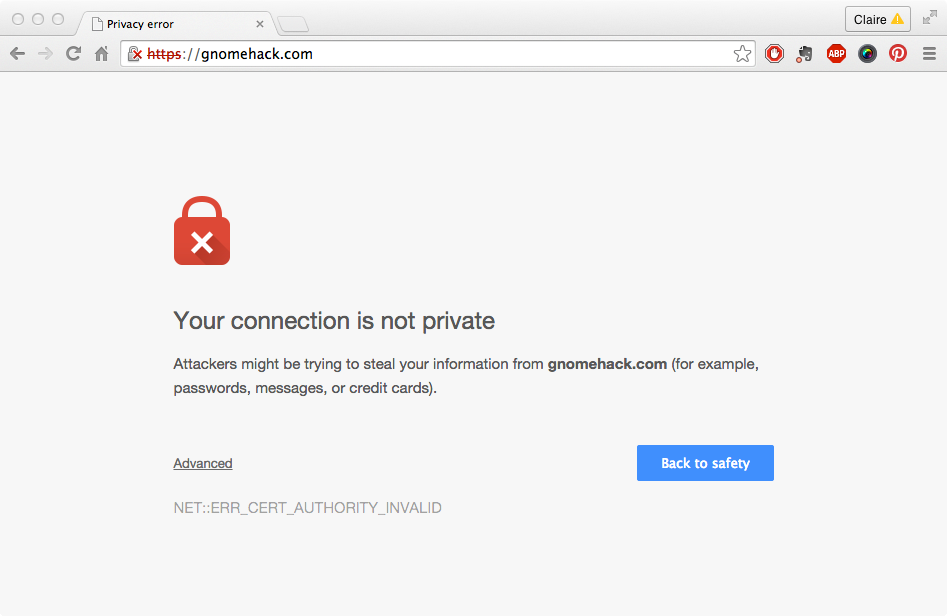
Figure 11-10. A browser certificate warning
How do we get humans involved in making these decisions without blindly accepting any request from a device wanting to connect, or clicking past any irritating warning that a device’s certificate may not be what it seems? This is a question that still troubles browser designers and won’t get any easier the more devices begin to clamor for our attention.
Keep users in control of permissions
Authenticating devices is one step, but users also have to be in control of how much those devices can do or what they can share. The clichéd Internet fridge may have your supermarket account and credit card details so it can order more milk and eggs. But it mustn’t be allowed to use those details to buy anything else that you haven’t approved. Permission control might mean devices and services have only partial access to features on other devices and services, or are granted access only for a limited time. Or a device can be bonded as a “slave” to another device and can only be controlled by it, as a smart TV might be linked only to one smartphone or tablet.
Users should of course be in control, but people don’t want to tick lots of boxes every time they get a new device to specify what it can and can’t do. Some combination of user control and low friction, sensible defaults is needed: a trade-off of transparency and effort. One possible model might be for users to treat devices like people they have hired to work for them—for example, granting them the kind of agency and trust you might give a housekeeper. Academic and commercial researchers are working on shared standards ways of enabling user authentication and access permission setting for connected devices, but there are no widely used solutions yet.
Authentication and authorization can to some extent be automated and happen without user interaction. But this doesn’t work if the user needs to determine what level of security is appropriate or how to use information appropriately.
Make the invisible visible
Devices with limited UIs can’t always tell us when they have been compromised. Is your dishwasher trying to tell you it’s been co-opted into a botnet or does it just need more rinse aid? Ways of making these invisible threats visible are needed, which requires both a way of detecting and informing the user of these threats. For example, software agents might monitor system activity and inform the user about potential security threats and available countermeasures.
Design security measures to suit user and domain needs
Security measures must be appropriate to user needs. There is no point requiring consumers to do something they are not capable of. Although not an IoT example, the One Laptop Per Child security principles are an interesting example here. These establish that the security measures on the computer must be suitable for users who cannot yet read, or choose and remember a password (see Figure 11-11).

Figure 11-11. The One Laptop Per Child security principles (image: laptop.org)[167]
Different domains (e.g., healthcare, banking, and home) may have unique requirements. The nature of the system and data, the context in which they are used, and the consequences of them being compromised may be different in each case.
Privacy
If security is a network issue, privacy is a networked data issue. It is about collecting information about other people, and making it available, as opposed to the simple exploitation of weaknesses in the system. Often privacy and security are interwoven, because a breach in security can result in a loss of privacy.
There is often no one right way to deal with privacy issues in design. Some data flows are essential to running a connected service, and with these, comes a flow of usable information that can be manipulated. It is not as easy as putting a lock on the door, which is essentially what securing your network does. Instead, it is about vetting who comes over the threshold and what they can access. Collecting only the minimum amount of personal data needed to deliver your service is an important first step.
Privacy issues are less predictable than security issues, as what counts as privacy is neither universally agreed, nor static. Privacy is dependent on contextual factors and local interpretation, as introduced in Chapter 6. In other words, one person’s notion of a privacy violation is another person’s opportunity to get a cheaper service. And privacy expectations change. At one point, there was a belief in some circles that privacy would be replaced by total transparency. Slogans such as “If you’ve got nothing to hide; you’ve got nothing to fear” implied that privacy was only an issue for the corrupt and the old-fashioned. However, since Edward Snowden’s revelations of extensive NSA data monitoring, these sentiments have swung the other way. People are taking invasive practices more seriously.
Understanding the scope of privacy concerns helps in designing a system. It is possible to mitigate some of them, alert people where necessary, and generally choose options that make the flow of data more manageable. It is also worth noting that in some parts of the world, privacy legislation affects what it is possible to do.
Information and Privacy
One important part of privacy is about controlling information: what is released and who sees what. The services in and out of homes, cars, and health devices carry enough information to embarrass and compromise their users repeatedly. It is possible to make many accurate—and inaccurate—inferences about what each user or group of users is doing and why. And some of that information may find its way to places that users were not expecting, even if they allowed the collection of the data in the first place.
Once these streams of information and related deductions leave the hands of people permitted to know these details, a privacy violation has occurred. In some cases, this is trivial, as the breach involves nothing of any consequence. But different people have different ideas about what is compromising.
There are two types of privacy breach to consider.
First, there are streams of information leaving connected devices for other destinations related to the service provider or made accessible on the journey. These streams may pass through the hands of hackers, advertisers, partner services and companies, other third parties, the NSA, and so on. We will return to these later.
Second, there are the privacy breaches that the service commits locally among users sharing the same resources or space. As more data are stored, so there is more chance of revealing socially inappropriate details to other local users or doing something that makes them feel nervous. While these may or may not count as illegal violations, they do reduce the popularity of a design. We might call these breaches tactless sharing.
Handling data with tact
The recent backlash against Google Glass has been tied to the insensitive handling of privacy in its design (among other things). Phone calls with a picture feed took more than 40 years to find their way into popular usage, partly because they threatened to give away too much about the person being phoned. (Video phone services that have taken off allow users to opt in or out of video. They are mostly used for pre-arranged calls, so that both ends can get their house in order, metaphorically or literally.) Now, wearables that record life and stream it are proving unpopular with the person on the other side of the camera. The design of Glass does not make it clear if the wearer is using the camera to record at a particular moment or not. People have likened talking to someone wearing Google Glass with having a phone held to their face (see Figure 11-12). Even if the video is not in use, wearing the glasses sets up an asymmetric relationship that makes holding a conversation potentially compromising and certainly uncomfortable.

Figure 11-12. Google Glass can disconcert those on the other side of the camera (image: Loïc Le Meur, Wikimedia Commons, CC license)
Another form of invasion is even less obvious. Teenagers sharing a house with their parents and younger siblings may go to great lengths to hide what they are doing, even if it is perfectly innocent. Home technology might well reveal what they are up to as part of helping the homeowner organize household protocols. For the teenager, that is a breach of privacy just as sending dad’s daily alcohol consumption figures to the local medical center would be, or inadvertently betraying an infidelity.
Similarly, there are ethical considerations that involve sharing data involving people considered vulnerable. Here are three sets of questions, all concerning different relations:
§ Should parents be able to monitor their children freely? For example, see Figure 11-13. Does tracking the child’s location or activity allow them more freedom (because parents trust them to be more independent) or impinge on their freedom by denying them privacy? Until what age is it OK? Should parents seek their child’s consent?

Figure 11-13. A child wearing an Amber Alert GPS tag (image: Amber Alert)
§ At what point does it become acceptable to monitor your aging parent? Is counting beers, checking insulin levels, and locking the liquor cabinet a necessary precaution or an outrageous intrusion into someone’s private life?
§ What is the difference between an emergency alarm to be pressed by users if they feel ill and one that is wired to alert the local doctor if irregularities are detected by the monitor? And how is it different again if the aging parent is no longer well enough to give consent to surveillance?
The configuration of tools can leave these issues wide open, steer one way or the other, or give people the means to work out their own custom path.
Tact is required in considering local privacy for connected objects; a poor choice will affect take-up. By tact, we mean that what counts as intrusive is context-dependent, determined by who is present and what the situation is, so we need to err on the side of giving people discretion to go about their business, whatever that may mean to them. What counts as tactful in different cultures will vary. One way of finding out what people think is to ask them (see Chapter 6). Bear in mind that people are particularly bad at anticipating privacy concerns. Ask a range of people about the specifics of their experience in different contexts. Consider tacit awareness of others and what happens when this becomes loudly signposted. It is best not to use hypothetical or generalized scenarios. And never assume that one person can speak for a whole household.
In 2004, the concept of “contextual integrity”[168] was introduced to draw attention to how images and the like can be compromised when they are viewed (and, of course, posted) out of context. It has been particularly useful to explain the discomfort that results when intimate pictures that were taken with consent for use privately are then circulated on the Web. It is easy to see that a similar violation is possible in the era of IoT, when data is used out of its original context.
Collecting and distributing data
As the designer of a connected product, some information will be necessary to you to provide a good service. The more that tools and products are expected to infer users’ wishes from their behavior, the more information you will need to manipulate. Some of that information may also have to be given to third parties so that multiple services can interoperate. As products become more complicated, they will manage more and more information about people and their lifestyles, overseen by you as part of service provision. This brings responsibilities as well as opportunities with it.
At a recent conference discussing the future of IoT,[169] panelists noted that new sensing devices could be flagging up health issues before the person affected knows about them. They then got to arguing about how such insights could be used. One declared that any company not using its collected data to the full would be in danger of losing competitive advantage. Others were more optimistic about a self-regulating industry. There followed a disagreement about how ethical companies are likely to be, regardless of what is identified as best consumer practice.
Let’s take their question further. A service provider that knows the user is ill before the user themselves does has various choices. They can tell the person; tell the doctor; tell the insurance company; or keep quiet. Each has different ethical implications.
Telling the individual may be awkward: What and how much do you say? Will they understand the implications of the diagnosis? Will it scare them more than help them? Will they understand how you know? Even a message telling them to visit their doctor is scary coming from a device.
Telling the doctor may overcome some of these problems, but telling the doctor is a breach of privacy unless it is an accepted part of the service. Should it be? Did you think you were building a medical aid when you made a system to help runners monitor their heart rate and blood flow? What does it say in the small print (that no one reads) about the limits of your responsibility? Is this the finite liability that your lawyers recommended? How might liability change as knowledge of medical conditions increases rapidly through such monitoring and correlation of conditions?
As for telling the insurance company, this might be lucrative for you as the service provider if you happen to have an arrangement or be owned by the same parent company as the insurer. But does the user know who will be informed of their health condition and what the implications are?
Different countries have different healthcare systems, not all insurance based. But health insurance companies across the world have an interest in health diagnostics tools. If they provide data to their clients to help them live longer and claim less, that offers a win-win situation. If everyone knows who is seeing what, there are likely to be fewer privacy implications. If the tool becomes a way of ensuring that the company is protected from risk, even if the client isn’t, then users might think twice about a digital service that “leaked” such information. There would have to be some reward for parting with this highly personal data, especially if it resulted in higher premiums. Among other things, the challenge in each case is the right degree of transparency so that users can make an informed judgment in their interests.
The fridge with advertising, mentioned in Chapter 4, is a good example of how this trade-off might work. A free fridge that promoted food products to users based on what they eat would have to know a lot about them. It would be sending that information to the supermarket that issued the fridge. In this way, the supermarket would have millions of user profiles and could implement cost-effective just-in-time ordering, reduce wasted food and innovate with products that are sure to sell. Only people who are prepared to buy their ad-free fridge at full cost (see Chapter 4) would be buying real privacy about their food consumption. Otherwise, there would be a permanent spy in the kitchen. But it would be a known spy and one that could be informed as needed about changes to household life.
Aggregation
One of the hardest things for people to understand is the way that innocuous information can be combined to give insight into beliefs, behavior, and choices. Connected product systems can use multiple data sources to make inferences about the world, especially where things are supposed to respond to context, hierarchies of user permissions, and contradictory inputs. For instance, it may be useful to the system to know which member of the family is opening the door at any moment. Keys can be customized to give this information, allowing a whole series of adaptations to take place based on other data held about each individual, from setting room temperature and TV channel to denying access to parts of the house. Just as our swipe cards at work hold this kind of differentiating information, so too can our homes. And this could be enhanced by network knowledge that the person at the door has had a difficult day, is running a fever, or wants to impress their date. The house might perform differently according to this knowledge, but handing over this information to the house is an act of trust that this won’t be abused then or later.
Computer rules of great subtlety and complexity can be written to govern points of intersection between data types and make sense of them. In some fields, rules are being shown to outdo human judgment in aggregating many different variables to come up with a likely deduction, such as fraud detection and tumor identification. Seemingly innocent revelations over the years can result in unexpected (and sometimes unwelcome) insights, available to anyone holding multiple streams of data that can be combined and analyzed—and the power to aggregate them.
A classic story of inference that invades privacy is given by Professor Andrew Monk[170] in talking about care for older people. He describes research in a care home where elderly residents were asked if they minded having sensors attached to their beds (see Figure 11-14) and to the sinks in their bathrooms. These would record if they got out of bed for periods in the night and whether they had turned off the tap. In both cases, the residents were quite happy for this information to be gathered and given to the wardens in the home. The same residents were then asked if they would mind the wardens knowing if they got up in the night to use the toilet. Most were unhappy about the idea. They did not see that the combination of the two sensors would allow anyone scanning the data to infer this information. They had no sense that a simple program could scan for intersections in the data and conclude—without any human intervention—that they had been up for a pee.

Figure 11-14. An under-mattress sensor, such as this one made by Emfit, can be used to track whether the occupant has got out of bed (image: Emfit)
A more everyday example of data mining involves analysis of household purchases. A supermarket loyalty card can reveal family preferences and other superficial characteristics. Prolonged analysis over time can reveal if a baby is due, impending divorce, menstrual cycles, and other more intimate details. Added information from local devices, like notice of a fall in blood sugar, could be used to make inferences about the state of someone’s mood, health, and/or hunger level at time of shopping and thus promote more effective selling. Once this is combined with household data from a smart home and medical, social, and financial data from other sources, a strong picture of each of us will be available to those who want to know about us. That will mostly be marketers (and possibly some government agencies). And they will have a very full grasp of our aggregated tendencies, which can be taken back to each of us as individuals.
The collective intelligence service Hunch.com, which ceased in 2014, showed just how much could be correlated, even without access to our home and health data. Hugo Liu, Hunch’s chief scientist, could ask someone one question and then present them with a whole profile of tastes and behaviors. He once did this to members of a panel that Ann had co-convened and they were stunned by how accurately he could “interpret” them. It was a great party trick, but it made the point that competent cross-referenced inferences about our tastes and lifestyles already exist and all that is needed is to add sensors to know when and where to apply them. YouGov in the UK has a similar profiling service online that can build a rich set of demographics and preferences based around an interest in a single brand, person, or thing (see Figure 11-15).
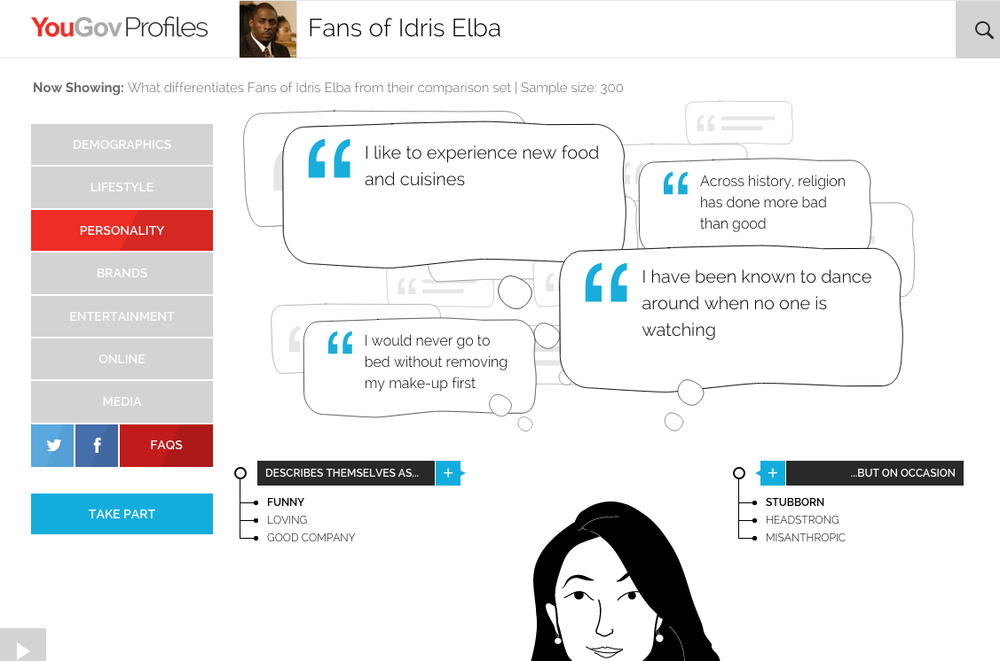
Figure 11-15. Fans of the actor Idris Elba have an above-average propensity to dance when no one else is watching (image: YouGov)[171]
Patterns of behavior
Privacy is mostly about information, though patterns of information flow are also relevant because these give access to patterns of behavior. A crude example would be turning off most of your network when you leave to go on holiday. Even the dip in energy consumption that your smart meter is picking up tells the story. That dip gives as much information as leaving a note for the milkman saying you don’t need milk for the next week, as people used to do in more trusting times. It puts your home at risk by indicating you are absent, which is a security matter, but, taken over the year, it also reveals that you go away, when and for how long, how regularly you go, and so on. The only thing it doesn’t indicate is where you have headed, but that is probably easy to establish by combining this data with recent buying patterns.
Legal Issues, Consent, and Data Protection
Different parts of the world take different attitudes to this data management responsibility. An American friend recently asked for credit to buy a large consumer electronics item. She spent several minutes on the phone to the technology company negotiating with them about the state of her finances. In Europe, the company would put in a call to a credit ratings company to get a rating for the individual and accept or deny her credit, but the firm itself would have less access to her financial information. In Europe, this information would be deemed private and legislation controls its distribution.
In the USA
In the United States, there is no single, comprehensive national law regulating the collection and use of personal data. There is piecemeal legislation, and security breaches in recent years have led to the field of privacy becoming one of the fastest growing areas of legal regulation. But there are gaps, overlaps, and even contradictions in the many federal and state laws and self-regulated systems that are intended to protect individuals.
Security-related privacy laws exist that control use of information linking name, Social Security number, driver’s details, home, telephone, email, and financial information, but only in some states. For instance, California has introduced the legal right for young people “to be forgotten” online. And recently a free mobile app that shared users’ geolocation and unique device identification with advertisers without providing notice or obtaining consent was prosecuted. The regulators are not without ambition, but there is too much complexity in the US situation to begin to cover it here.
In Europe
By contrast, Europe has long had a centralized approach to data protection. At the time of writing, a new regulation is being introduced into the European Union (EU) that will supersede the current Data Protection Directive, active since 1995. In Europe, privacy is a human right and data protection is upheld more stringently than in much of the world.
Even passing information out of the EU is controlled, with a duty on service providers to ensure that the receiving country has similar protective legislation in place or contractual protections. This has implications for the siting of servers and so on. While online service providers have historically argued that resources are being reached from countries outside the EU (and so outside its jurisdiction), this is a more difficult argument to make when the data is associated with embodied objects that exist within the union’s boundaries. The EU advises that any equipment located in an EU state is under the jurisdiction of European data protection laws and recent legal rulings have given individuals the right to be governed by the laws where they live.
Relatedly, the “right to be forgotten and to erasure” is being discussed in Europe at the moment. This is proving highly controversial. If and when enacted, it would allow people to request the removal of information that they deem compromising to the life they are living now—for example, information that is old or lapsed, or that pertains to a person’s juvenile years.
Principles of data management for privacy
The OECD, in 1980, produced seven principles that underpin the EU system. They are also endorsed in the United States, though not legislated for. The OECD principles are:
Notice
Data subjects should be given notice when their data is being collected
Purpose
Data should only be used for the purpose stated and not for any other purposes
Consent
Data should not be disclosed without the data subject’s consent
Security
Collected data should be kept secure from any potential abuses
Disclosure
Data subjects should be informed as to who is collecting their data
Access
Data subjects should be allowed to access their data and make corrections to any inaccurate data
Accountability
Data subjects should have a way to hold data collectors accountable for not following these principles
And Europe is leading again with IoT regulation. Already, there are extensive recommendations about what IoT services need to do to honor data protection, issued by the EU’s Article 29 Working Party (and well summarized by lawyer Giulio Coraggio).[172] This includes making a privacy impact assessment of new IoT technologies. In Coraggio’s view, service providers need to identify carefully roles and responsibilities in the processing of personal data by everyone involved in providing a service and the equipment to support it so that liabilities are well understood. He points out that any data—even if it originates from “things”—can be considered as personal data if it is able to reveal information about the personal life of individuals.
Showing the range of aspects that the working party has considered, two examples of the many new guidelines are:
§ Information published by IoT devices on social platforms should not become public or be indexed by search engines by default
§ IoT device owners and users should not be economically penalized or have degraded access to the capabilities of their devices if they decide not to provide consent
The second of these already has people scratching their heads. Implicit in this is the requirement to be able to handle data so that consent for release is not needed, as clearly some flow of information will be essential to provide “the capabilities of their devices” (i.e., services).
Privacy settings and informed consent
There is no legal breach of privacy if consent for the use of the information in the way that it is being used has been given.
Twenty years ago, at the outset of ubiquitous computing, Victoria Bellotti and Abigail Sellen[173] of Xerox PARC argued for design capable of:
§ Empowering people to stipulate what information they project and who can get hold of it (control)
§ Informing people when and what information about them is being captured and to whom the information is being made available (feedback)
At the time, control still seemed plausible. Ethically, it is now debateable whether people are capable of giving informed consent in many of the cases we discuss here, as we have shown how hard it is to understand possible uses of data. It is also impossible to make absolute commitments for data that has been distributed to third parties. Both their plans and the plans of those to whom they may pass it are outside the designer’s control. It is similarly difficult to predict what data combinations might result from developments in a smart home as it takes in new nodes and features. Even a small device may have a stake in sharing this outside the boundaries of the original terms.
Put simply, getting informed consent is a minefield. It may be better to try and avoid the need for it.
“Privacy by Design and Privacy by Default”[174]
One way of overcoming the problem of consent and data privacy is to store all data in the local system, where it belongs to the user, and only take the minimum of processed and anonymized information back into the service to provide necessary functionality. By anonymized, we mean data that cannot identify its source either in content or pattern. (It is no use just changing or deleting names if it is possible to work out who is being referred to by correlating with location, patterns of connection, etc.) In 2010, Privacy by Design was recognized as the global privacy standard by the International Conference of Data Protection and Privacy Commissioners. This can support tact in the moment, minimize long-term misuse of data, and reduce the potential for unpleasant repercussions after the event.
For instance, research is going on into dynamic privacy settings. “While driving to a client, Bob [the boss] may access [staff member] Alice’s destination and her estimated arrival time, but not Alice’s exact position. When Alice is at a client, Bob can know Alice’s exact location. At the same time, all incoming calls for Alice should be blocked in order to not disturb the meeting. After work, Bob should not get any information about Alice’s whereabouts.”[175] In this example, privacy and application blocking are linked, to “better motivate privacy relevance” and provide a more efficient meeting. But, importantly, this acknowledges that Alice’s role as employee has privacy-sensitive context features. It matters where she is and whether she is on duty or not. And the description recognizes that granularity changes (preciseness of location) affect her privacy.
Privacy at source sits in tension with some providers’ business models, which rely on gathering, aggregating, and trading in data. Bruce Sterling’s essay on “The Struggle for the Internet of Things”[176] relates how centralized IoT information could become if the big five super-companies he identifies start to manage every interaction users have with all their devices. If this is the future of the Internet of Things, then mass surveillance is a critical part of the plan. But even monetizing every interaction (as they may hope to do) does not require that precise knowledge of who is doing what is centrally stored and mined for individuals’ details, even while it is being analyzed for trends, relationships, and patterns.
It is perhaps optimistic or naïve to point out alternatives to expecting users to part with all their movements, actions, and desires to those with the resources to dig through this information. Certainly, there is unlikely to be any symmetry: government and big business will know about everyone’s lives, but little information will come back the other way. However, there is a strong lobby, led by Canada, for de-identification of data before it is released. There are critiques of this system, such as the argument that data can be re-identified (and we cannot predict how clever applications for re-identification will become in the future). But on the whole, some thought to how much information you need to take—and in what form—is a good way to approach privacy issues. True (or “deep”) anonymization affords privacy. There is also a strong ethical argument for erasing data that is no longer necessary, rather than stockpiling it.
Such measures need to be implemented at design time and respond to context. For instance, the geographical location of devices (and their users) can be related to their current function in deciding what level of privacy is a basic right. And however data management is approached, a transparent and informative method of communicating with users is necessary. The current model of long, obscure End User Licensing Agreements (EULAs) that no one reads is insufficient to meet high standards of consent.
Social Engineering
Privacy affects the present and shows signs of impacting our futures too, as new functions change what we understand by it. From this we can see that connecting up devices and creating new infrastructures has the potential to alter society at a more global level. It is capable of changing the culture around us. This change has a long-term trajectory and it is even more nebulous to consider in designing than privacy issues. Nonetheless, we raise the matter here, in the context of responsible design, because it gives something to think about in constructing the new world of connected things. There are likely to be unintended consequences.
This is because we can never know the full range of impacts possible when we introduce the means to alter relationships in society. And the Internet of Things is predicated on altering relations. After all, things will be communicating their whereabouts, state, and ability to support our needs. And we will be controlling them, displaced in space and time. We may not intend to be changing behavior with our designs, but over the longer term and the wider context, change is going to happen—related to how technology has been implemented.
To give an example, let’s look at the implications of the personalized gathering and filtering of information that IoT enables.
In the early days of the Web, there was considerable concern about the “Daily Me” (a term we owe to MIT Media Lab founder Nicholas Negroponte; see Figure 11-16). This was a customized online news service that showed to you only what you were interested in and it was criticized for being too individualistic. More recently, bubbling in search results and social media has fueled the argument that we are fragmenting our cultures and losing access to the common experience that, among other things, encourages empathy and compassion. Bubbling is the tendency to show you what you want to see out of all possible feeds, based on previous choices, location, and other contextual factors. It builds “echo chambers” and keeps people within them. It is used to produce relevant results, but is accused of exploiting the human desire for confirmatory bias and reinforcing existing perspectives.
Figure 11-16. Zite.com (recently acquired by Flipboard) is a news aggregator based around preferences, similar to the concept of the Daily Me
With IoT, this filtering is no longer limited to online contexts. Now there are vending machines in Japan that will not sell prohibited goods to minors because they can read networked data. There are nearly six million vending machines in Japan, worth almost US$60 billion a year in trade (see Figure 11-17).

Figure 11-17. A “smart” connected vending machine in Japan (image: Cameron Stone/camknows via Flickr)
Further, some machines use sensors to estimate the age, gender, and “type” of the person approaching the machine[177] and make recommendations accordingly. “For instance, for a young girl, the machine might recommend a sugar-free drink, while for an athletic young male it might recommend water or an energy drink, all based on market research and information collected from the machines themselves. The vending machines will also recommend drinks based on the time of day, season and temperature.”[178]
Extrapolate this and the connected world that a young woman experiences is markedly different from that of a young man. This would be true even if we only draw on the current marketing trends in play in the world, used to inform these machines’ behavior now. But, this is not a static situation. The difference in experience serves to emphasize different patterns of taste and so the divergence, which was once subtle, can subsequently become quite extreme. Girls may never even see that beer is for sale. Boys will only be offered the chance to do “things that men do,” whatever version of masculinity has become enshrined in the information provided to the system. Now imagine that this is extended to one’s identity as an ethnic minority too. If you are recognizably of a discernible minority, you will be presented with choices that reflect existing tastes and trends in that community. It is easy to see how this will encourage segregation rather than assimilation, divergence rather than equality.
Similarly, simple choices may matter for years to come. If you buy a health drink, you access a profile of yourself as concerned about fitness, so you see healthier options—and you live a healthier life. What you are offered by your smart environment takes you down one path, rather than another.
We are not advocating any particular way of living, but rather raising questions as to how we refrain from inadvertently introducing infrastructure so specific to how we live now that we prevent future societies pursuing a different track. Connecting up products produces particular relations, which are then potentially amplified, using correlational data, to offer normative choices back to users, in the hope of pleasing them. Clearly, this penalizes outliers and rebels. But it also results in a shift toward articulated norms for the majority. These norms will be much the same as those that are underpinning advertising already, but they will be imported into the fabric of homes and other new and intimate contexts. They will become linked to who we are as well as what we do. This tendency has been discussed in the context of the Semantic Web, with recommendations as to how to avoid closing down options.[179]
If we take this concern about reinforcing stereotypes back into the connected home, we see other potential points of tension. None of these are things that designers can legislate upon; all are things that could be considered in designing for connecting up products. For instance, what are the politics of the permission hierarchies in place to run the smart home? Who says what should happen and who can override others? How will this differ from the democracy of the visible switch, which anyone can flick and thereby undo someone else’s choice? We need only look at the history of control of the TV remote to see that new systems disturb this democracy (see Figure 11-18). When the whole of life is administered by remote control panels that only some people can override (and may be invisible to others sharing the space), the politics of permission will be a live issue in many households, just as control of the TV was before people got their own sets.
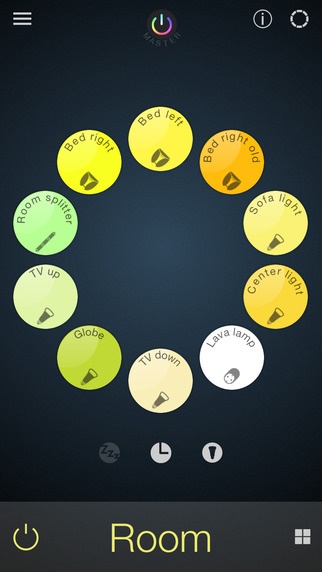
Figure 11-18. A new generation of remote controls will introduce new power struggles into the household (image: iConnect Hue)
There is always the danger that such mechanisms impact most on the least powerful and most vulnerable. A particular field that is already contentious is care for the elderly. At its best, IoT technology can be a great enabler. At its worst, IoT technology can support the imprisoning of older people in safe, dull environments, without the need of much social intervention to manage their everyday functions. Sensory information about the neighborhood is reduced through environmentally controlled boundaries, and if the windows are not automated to reflect the weather, then a button reduces the effort of opening them, thereby removing need for the movements that keep muscles ticking over. Because safer options exist, when residents choose risk, excitement, or undue physical exercise, they become a cause of concern for their care givers, in case they expose them to litigation.
And abuse can take other forms. While the new car clubs employ IoT technology to make hyperlocal use of shared resources possible, the same remote management tools are being used to penalize people with auto loans who are deemed a risk by their lenders. The New York Times[180] recently ran a story about people who had their cars repossessed remotely by lenders, who were able to interrupt the starter on the car if they were concerned about late payment. This disconnection happened sometimes while the client was driving—there is one story of a woman caught without power in the middle of a major road (see Figure 11-19). None of these drivers had yet defaulted on payment; they were merely a few days late. Such an aggressive protection of assets is not restricted to cars, but cars are particularly an issue, both because the crude use of remote disconnection could potentially be fatal, and because so often the car is a lifeline for families with vulnerable dependents. Manufacturers argue that tools such as this mitigate risk and make it viable for lenders to offer loans to consumers who might otherwise not qualify for credit at all. But disconnection without warning is far swifter than current forms of retrieval, and leads to subprime borrowers being penalized more readily for minor late payments than their better-off counterparts. Vehicles have GPS tracking fitted too, thus both safety and privacy are potentially compromised.
A final situation we can consider when we think about social engineering might sound futuristic, but it is being discussed as autonomous systems start to find a niche in the market. There is already speculation about what should happen ethically and legally when a networked machine is acting on a person’s instructions but using its own “initiative” in choosing how to carry them out.

Figure 11-19. A GPS tracking unit with the ability to disable a car’s starter motor (image by thematthatter on Instructables.com, shared under a CC license)
You may want to consider driverless vehicles on roads to grasp the import of this, as they overcome the problems of interacting with other cars, pedestrians, and cyclists. But, before finishing this section, we might also contemplate briefly what the next wave of systems brings with it. The field of artificial intelligence has been working for years to create systems that adapt their behavior to new situations by “learning” about them. These systems are not just interacting with a set of conditions by choosing a good path of action in response, they are adapting to the conditions they find repeatedly by altering their potential for future behavior based on their experiences—as people do. Ethicists have already begun discussion about how responsibility for this unspecified behavior can be assigned, whether it is reasonable to hold designers responsible for the actions of a system that could not be debugged in every possible situation, and what the ethical, social, and legal implications of coexisting with learning networks might be. Autonomous systems, especially those with the power to learn, are theoretically unpredictable, even if they never actually do anything controversial at all. Should current trends continue, there will be an added layer of complexity to designing people’s relationship with technology that hangs on how far and how safely the technical tools can adapt.
Mitigating the dangers of social engineering?
One way of avoiding the worst of these scenarios is to use methods that mean you design with your users as well as for them, listening to them and mitigating their concerns (see Chapter 6). But even participatory design[181] will not tackle all the bigger trends that are subterraneously shaping choices of how technologies are implemented. Some aspects of these relations will only be held up to the light as new forms of interaction make them visible. That argues for systems that can be reconfigured easily as we all learn about what they enable.
So it also behooves those with responsibility for design to take their power seriously and design systems that are easy to use, easy to escape from, and do not lock people in, either literally through malfunction, or figuratively, through a desire for short-term gain. And as more automation and machine learning is incorporated, there is also a need to acknowledge that it is not always possible to predict what a system will do as it grows and learns.
In summary, the long-term trajectory for connected products is one that impacts on the local control of ordinary people, and eventually, on identity and self-determination. Yet, no dystopia is assured, any more than a utopian new world can be forecast. What we can predict is that there will never be a dull moment for anyone interested in the ethical aspects of implementing these technologies.
Environment
On first impression, there seems to be a theme of environmental awareness running through the current crop of consumer IoT systems. Smart meters will help us understand our energy impact, and devices such as smart thermostats will help us waste less of it. Sensors monitoring air and water quality and radiation can help us better understand our impact on the planet (see Figure 11-20).

Figure 11-20. The Lapka organic matter sensor detects levels of nitrates in fruit and vegetables (image: Alex Washburn/CC license)
But look a little deeper, and there are valid concerns. The tech industry scramble to turn out the next big product used to mean ones and zeros, but now more hardware is being manufactured. As Allison Arieff points out, the maker movement is enthused by the potential of home 3D printing, but fails to consider that it uses 50–100 times more energy than injection molding and increases the use of plastics.[182]
And in the past, our nonconnected devices were thrown away only when they stopped working and were uneconomic to repair. But the lifecycle of computing devices is far shorter. Devices that still technically work become obsolete much more quickly. Will IoT result in us making, buying, and throwing away more stuff?
This need not always be the case. Connectivity can recast products as shared services, such as reducing the need for car ownership among occasional drivers through car clubs (see Figure 11-21). It can enable better use of the resources we have, such as through smart car parking schemes that reduce the amount of fuel drivers burn (and pollution they create) driving around looking for spaces.

Figure 11-21. Car clubs, such as Zipcar, have been shown to reduce car ownership (image: Zipcar)[183]
But it’s hard to understand what the true positive or negative environmental impact may be of the systems we create. In this section, we look at factors that may affect the impact of IoT systems, and what designers’ responsibilities may be.
What’s the Environmental Impact of an IoT Product?
Ethically, we should ask ourselves how our systems may be doing both good and harm. Standards and certification bodies provide limited information and legal controls on some aspects of products. But assessing this accurately requires us to look at the environmental impact of a product over its entire lifetime. For that, no complete picture is available.
Manufacturing
The first impact of manufacturing is in resources. Electronic devices tend to contain more precious and rare earth metals (e.g., copper, gold, palladium, and platinum). These are valuable resources yet often lost when old products are not recycled (only 1% of cellphones in the United States are recycled[184]). Mining them consumes a considerable amount of energy and has environmental consequences. For example, radioactive waste (thorium) is a by-product of rare earth metal mining. In some cases, such as tantalum (mined from coltan and used in capacitors), ethical questions have been raised about the corporate responsibility of the mining companies. Tantalum is even classified as a conflict resource due to links between coltan smuggling and warfare in the Democratic Republic of Congo.
Electronics also contain materials that are toxic to humans and the environment, such as lead and cadmium in printed circuit boards, brominated flame retardants used in PCBs and plastic casings, and PVC coatings on cables and casings which release dioxins and furans when burned. Any product sold or imported into the European Union must comply with the Restriction of Hazardous Substances Directive (RoHs), which restricts the use of toxins such as lead, mercury, and cadmium. But even when individual devices contain lower levels of toxins, a large quantity of discarded devices can still be highly toxic.
Manufacturing devices also consumes energy and creates greenhouse gases (this is described as the device’s “embodied energy/carbon”). Nest addresses this up front on their blog, claiming that it takes 8 weeks for their thermostat to become carbon neutral by offsetting the energy involved in manufacturing and distribution.[185] But devices that do not reduce the user’s overall energy consumption cannot claim the same virtuous effect.
Usage
During usage, the device should make efficient use of energy (for many embedded devices that run on batteries, this is not just an environmental concern but essential to the normal functioning of the system). Energy Star, a program of the US Environmental Protection Agency, sets globally used standards for energy efficiency in consumer product specifications.
The total energy consumed by the product also includes the energy required to provide the Internet service. In 2010, data center electricity consumption accounted for an estimated 1.3% of all electricity use in the world, and 2% of all electricity use in the United States.[186] Google themselves claim that doing a search consumes 0.0003kWh of energy,[187] the equivalent of running a 60w lightbulb for 17 seconds. That might not seem like much, but across billions of potential users and devices, the energy consumption of an Internet service would be huge.
Maintenance and upgradeability
In theory, providing a device with Internet connectivity ought to extend its lifespan. It should be relatively easy to deliver software or firmware updates that improve the device’s functionality and performance and keep it in service for longer. You could even charge for software updates in lieu of new hardware. However, in practice, increases in functionality tend to make ever-increasing demands on hardware, which is usually manufactured to a tight budget and may not have the additional processing power, memory, or UI capabilities to handle very many future upgrades. At some point, the old devices may no longer be powerful enough to support the latest and greatest software. It can also become uneconomic for manufacturers or service providers to continue to support software updates and security patches to a large number of older versions of devices out in the field (as we saw earlier in the Security section).
A nonconnected home lighting or heating system might be expected to last 10–20 years (or more, in the case of lighting), but its connected equivalent is likely to become obsolete much faster. Even if it doesn’t fail, it may no longer offer us the new functionality we have come to expect from such systems. And products are explicitly designed for planned obsolescence: companies want us to buy new things.
Disposal
Finally, there is disposal: retiring devices at the end of their lives. This creates waste, some of which is highly toxic. Electronic waste represents 2% of America’s waste in landfills, but is responsible for 70% of the heavy metals in that waste.[188] Chemicals from landfill leach into the groundwater. Very few PCs and smartphones are currently recycled. According to the US Environmental Protection Agency, fewer than 10% of the 141 million mobile phones discarded in the United States in 2009 were recycled.[189] In the European Union, the Waste Electrical and Electronic Equipment Directive (WEEE) mandates that it is the responsibility of the producer or distributor to make provision for the collection and recycling of electronic equipment placed on the market after 2005 (see Figure 11-22).

Figure 11-22. E-waste waiting for recycling at a specialist processing facility in Kent, UK (image: SWEEP Kuusakoski)
Recycling helps recover valuable materials such as metals, but it’s not a perfect solution. In Cradle to Cradle, William McDonough and Michael Braungart argue that recycling is generally downcycling: converting materials into lower-quality materials with a more limited range of uses.[190] The universal recycling symbol (Figure 11-23) may be a loop, but this is misleading. We should really be designing materials that can be recycled into equally high-quality materials.

Figure 11-23. The universal recycling symbol implies that materials can be recycled into equivalent materials, which is not the case (image: C Buckley via WikiCommons)
What Can Designers Do?
IoT products may offer the promise of reduced energy consumption, better understanding of the world, and more efficient use of resources. But if we approach creating connected products the way we’ve approached everything else, we’re at risk of accelerating the destruction of our environment through burning resources making disposable junk. We need to reduce the impact of the systems we create and not add to the damage.
We can say “no” to making pointless stuff that will end up in landfill in six months. We can design things that reduce consumption by reducing waste, or supporting usage, not just ownership. We can consider the materials we use, and how things are made and design for end of life and the next life of materials, not just this one. We can choose responsible hosting companies who try to conserve energy and invest in renewable power. We can design for upgradeability and longevity through software updates (see Figure 11-24).
That may sound idealistic, but it’s not intended to deny the need for most products to make money, or our desire to have good products in our lives. William McDonough and Michael Braungart propose a triple bottom line approach to business strategy based on economy (making money), equity (providing value and treating people fairly), and ecology (not harming the environment). The intention is to help the world prosper through consuming. Taking nature as inspiration, a production process in which everything is used and returned to the cycle can do good instead of harm. But there are no easy answers.

Figure 11-24. The Fairphone smartphone uses conflict-free minerals and is designed for repairability and upgradeability[191] (image: Fairphone)
Summary
Embedded devices are especially vulnerable to security threats such as eavesdropping or malware. They may not have been designed with security in mind, and keeping security software up to date, if they have any at all, may be difficult or impossible. They may also lack ways of indicating when they have been compromised. Security is often complex to use, and in tension with usability, as it creates barriers to the user instead of making things easier.
Usable security for IoT is a major challenge, and will need to focus on limiting the damage that can be done when a system is compromised as well as making it easier for users and devices to authenticate themselves and for users to set permissions controlling what devices and applications can do.
Privacy is a many-headed problem in smart contexts. Systems may reveal information about others’ behavior to people who share the same space. Providing a service requires that potentially compromising personal information is gathered and aggregated, leaving people open to privacy violations from service providers and third parties. And data can be combined and mined for details that are not obvious to those providing it. To cooperate with data protection legislation and protect users, Privacy by Design is a means to take the minimum data needed, work with it in anonymous form, and delete it as soon as practicable.
Meanwhile, systems that treat us differently according to the details they hold about us can produce unanticipated social consequences by amplifying differences along stereotypical lines. The new services may contribute to unintended social engineering. The best way to resist this is to work with users to identify likely problems and build in flexibility at outset, but effects may be hard to predict ahead of implementation.
Energy and environmental monitoring are strong themes in IoT. But there are real risks that the technology rush will have a damaging environmental impact through the consumption of resources and creation of more e-waste. Designers need to consider the environmental impact of a product across its entire lifecycle, taking into account manufacturing and materials, energy consumption during usage, designing for maintenance and upgradeability, and ensuring high-quality materials can be recovered through recycling at end of life.