eCommerce in the Cloud (2014)
Part II. The Rise of Cloud Computing
Chapter 5. Installing Software on Newly Provisioned Hardware
The adoption of Infrastructure-as-a-Service requires a fundamental change to how software is installed and configured on newly provisioned servers. Most organizations manually install and configure software on each server. This doesn’t work when you’re quickly provisioning new servers in response to real-time traffic. Servers need to be serving HTTP requests or doing other work within minutes of being provisioned. They also need to be configured accurately, which is something humans have difficulty doing reliably.
NOTE
You can skip this chapter if you’re using only Platform-as-a-Service or Software-as-a-Service because they do all this for you. This is what you’re paying them a premium for over Infrastructure-as-a-Service.
In this chapter, we’ll discuss how to build, maintain, and monitor self-contained modular stacks of software. These stacks are called deployment units.
What Is a Deployment Unit?
When you provision capacity with Infrastructure-as-a-Service, you get raw hardware with your choice of an image. But before you can do anything with the hardware, you need to install and configure software so it can handle HTTP requests or serve whatever purpose it’s destined for, as shown in Figure 5-1.
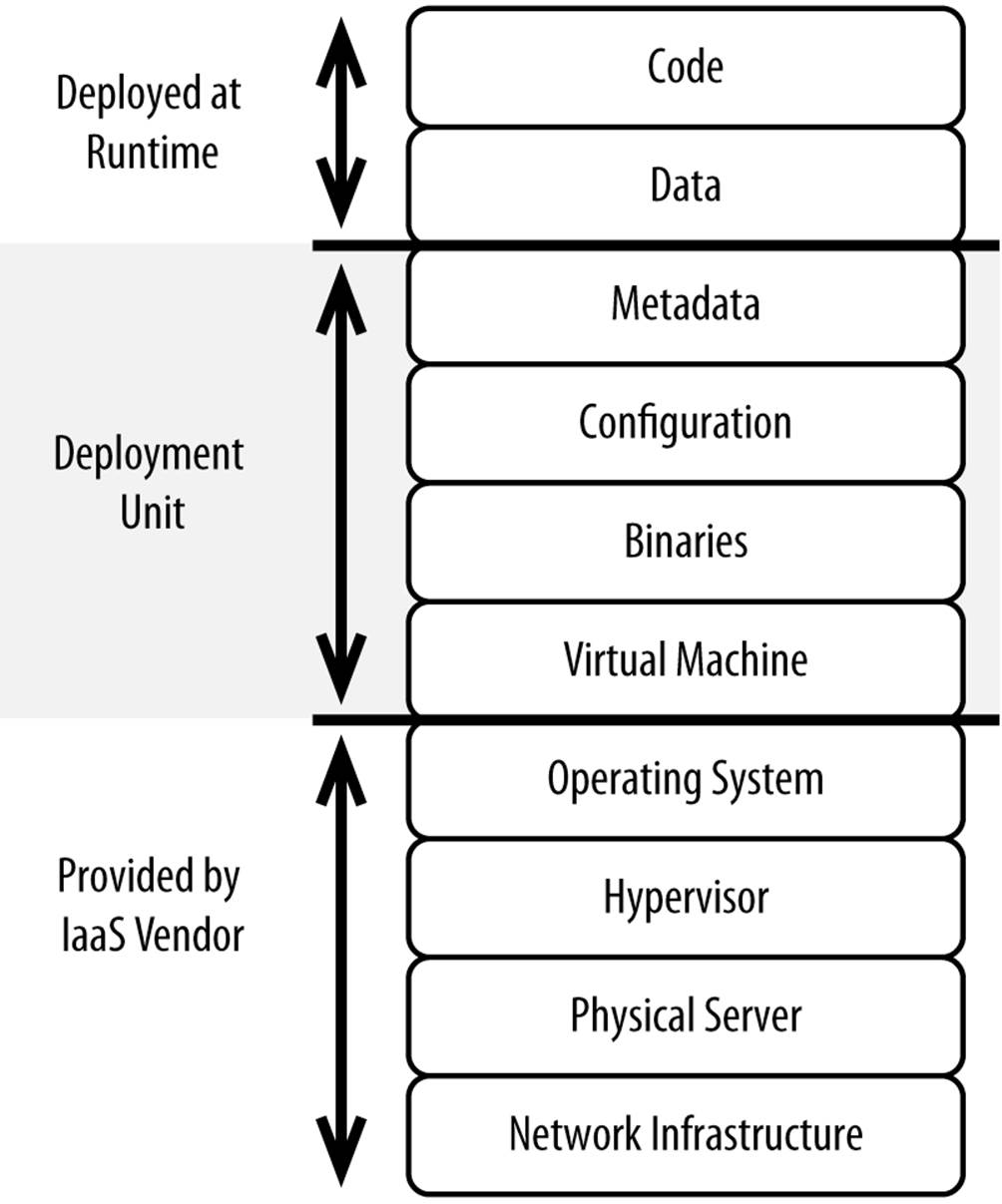
Figure 5-1. Scope of a deployment unit
Specifically, this requires installing a base image and/or doing the following:
1. Installing software from binary distributions (virtual machine, application server, caching server)
2. Configuring each of the pieces of software to work together (e.g., telling your application servers where the database is listening)
3. Setting environment variables (e.g., enabling huge pages, TCP/IP stack tuning)
4. Defining metadata (e.g., environment-specific search initialization variables)
Every environment has numerous server types. Common server types include these:
eCommerce server
ecommerce application + application server + virtual machine
Cache server
Cache grid + application server + virtual machine
Messaging server
Messaging system + application server + virtual machine
Service bus server
Service bus + application server + virtual machine
Order management server
Order management system + application server + virtual machine
Search engine server
Search engine
Database server
Database node
Each of these servers is unique, requiring potentially different binaries, configuration, and so on. What matters most is that you can build up a freshly provisioned bit of hardware within minutes and without human interaction. A single stack that is able to be deployed on a single operating system instance is considered a deployment unit for the purposes of this book.
Approaches to Building Deployment Units
Individual units can be built numerous ways, ranging from snapshots of entire systems (including the operating system) to scripts of various types that can be used to build each system from source. There are broadly three ways of building out individual servers. Let’s review each approach.
Building from Snapshots
Public Infrastructure-as-a-Service vendors all offer the ability to snapshot servers. These snapshots (also called images) are basically byte-level disk copies along with some metadata that can then be used as the basis for building a new server (Figure 5-2). That snapshot is installed directly on top of a hypervisor, giving you the ability to quickly build servers. You can also define bootstrap scripts that execute when the server is started up. These scripts can change network settings, update hostnames, start processes, register with the load balancer, and perform other tasks required to make the server productive.
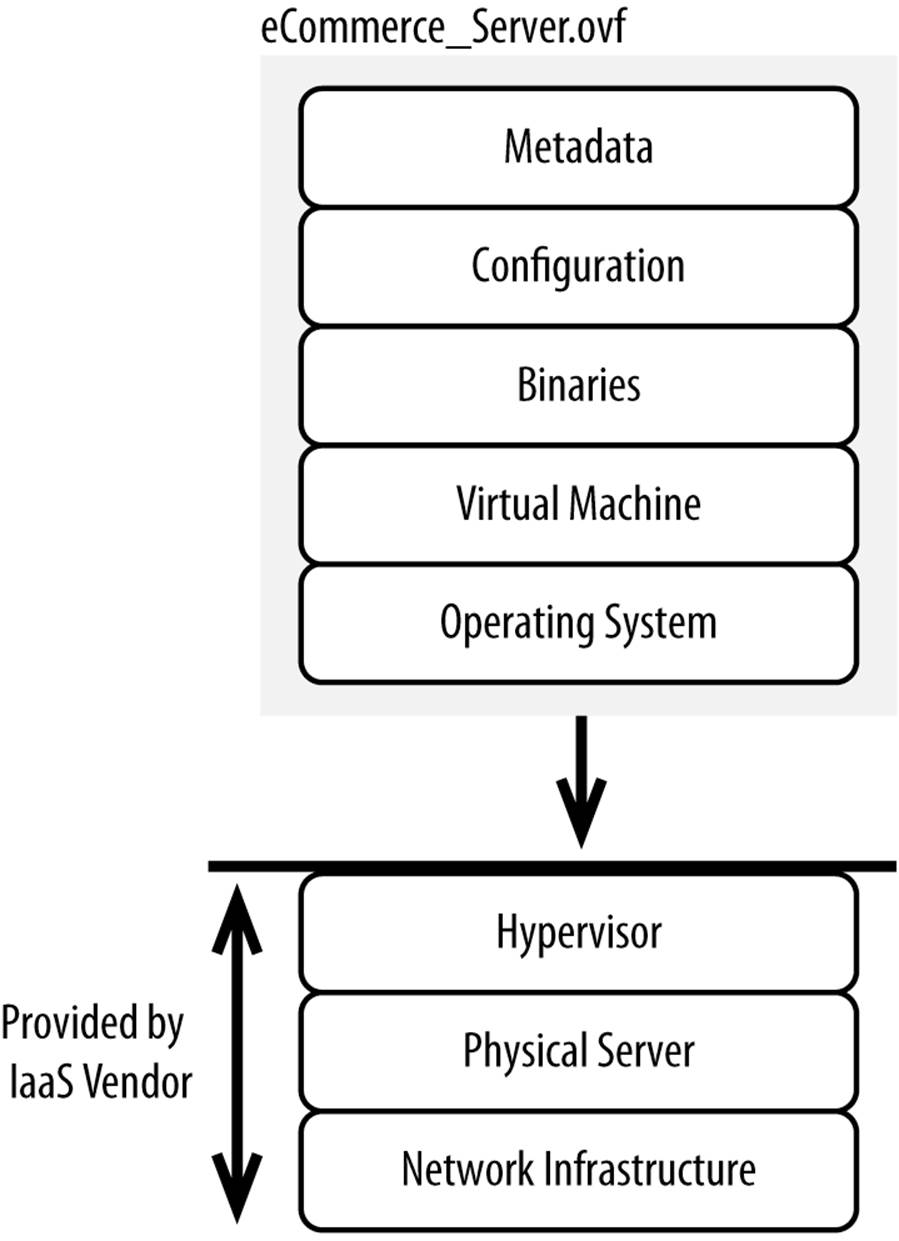
Figure 5-2. Contents of a snapshot
Common snapshot formats used by Infrastructure-as-a-Service vendors include Open Virtualization Format (OVF), RAW, ISO, and Amazon Machine Image (AMI). Again, all of these are basically byte-level disk copies along with some metadata. Individual vendors sometimes have their own proprietary formats, some of which can be used with other vendors (as is the case with AMI).
You can build libraries of these snapshots and then specify which snapshot you want to build your server from when you provision your new server. The snapshot-based approach works well for the following:
Quickly building servers
The time from when you provision the hardware to when it’s useful is governed by how quickly the bytes can be written to a filesystem. It typically takes no more than a few minutes before a server is built with the machine image of your choice. This is helpful when you need to scale up very quickly because of an unanticipated spike in traffic.
Capturing intricate changes
Some software requires intricate installations. There may be lengthy configuration files, changes to file permissions, and special operating system users. It’s rare that you can simply install an applications server from binary and deploy a package of code to it.
Being able to test
Like code, snapshots can be tested for functionality, security, and performance.
Archiving audit trails
You can easily archive snapshots for auditing and compliance purposes. If there was ever an incident, you could quickly go back and show the state of each server in an environment.
A downside of this approach is that it has no ability to handle patching and routine maintenance on its own. Without the introduction of software that handles this, you’ll have to do the following:
1. Apply changes to live systems.
2. Snapshot each of the live servers that runs a unique image.
3. Swap out the images on each of the affected live servers.
Or you’ll have to apply the updates manually to each server, which probably isn’t even feasible. More on this topic in .
Building from Archives
While a snapshot is a clone of an entire live operating system and its contents, an archive (e.g., .tar, .zip, .rar) is a collection of directories and files. You provision new resources from an Infrastructure-as-a-Service vendor and then extract the directories and files on to your local filesystem. The archive can contain scripts or other means required to change file permissions, configure the software to run in your environment, and so on. Compression may also be included to reduce the amount of data that must be transferred. The contents of an archive are depicted in Figure 5-3.
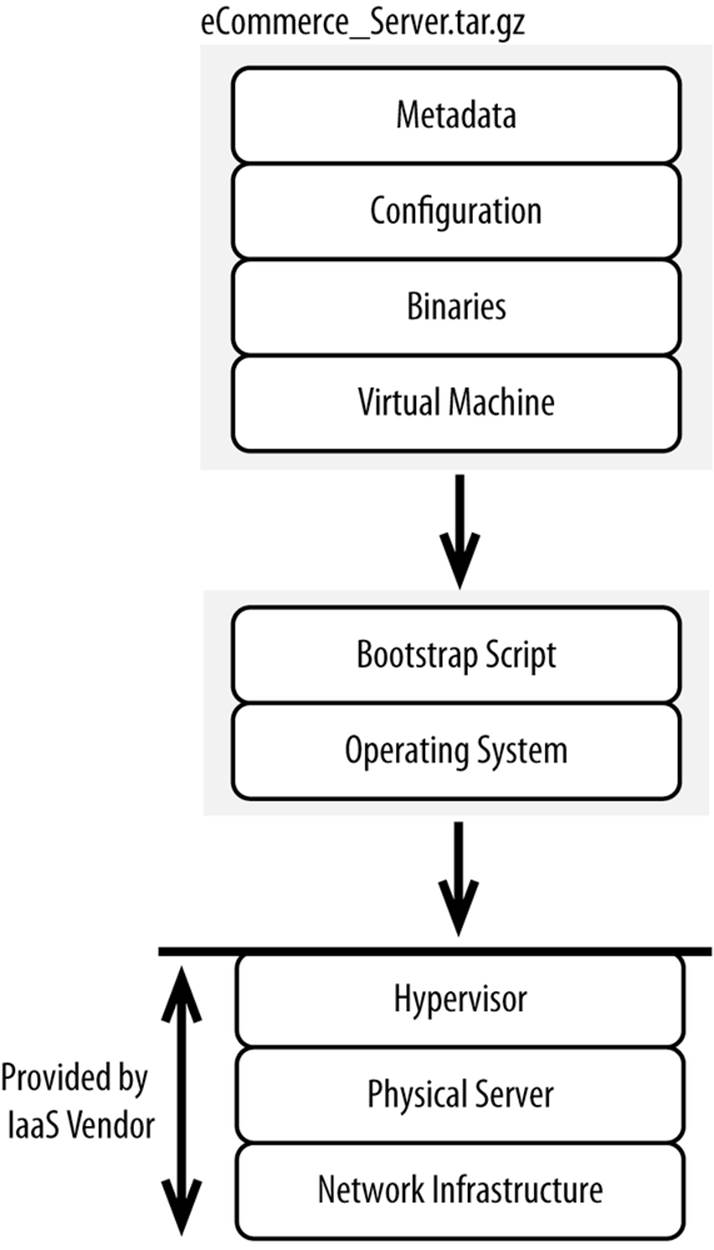
Figure 5-3. What’s capable of being included in an archive
This approach works by being able to isolate the changes you make to a base filesystem image. In other words, all of the changes you make to a base filesystem should be captured either in the directories and files in your archive or through a manual script that can be replayed after the files are written. If you install all of your software under a single root directory (e.g., /opt/YourCompany), it’s pretty easy to archive that root directory.
Once you provision a new server, you’ll have to get the archive to that new server, extract it to the local filesystem, and run any scripts you need to generally initialize the environment. Since you can’t do this manually, it’s a great idea to create a bootstrap script to pull the latest archive and extract it. You can bake this bootstrap script into a snapshot, which you can use as the baseline for new servers.
This approach works best for software shipped in zip distributions or software that can be fully installed under a given root (e.g., /opt/YourCompany). Applications that sprawl files across a filesystem, set environment variables, or change file permissions, do not work well as you have to capture the changes made and then replay them manually in a script. Most software today is shipped through a zip distribution or is able to be fully installed under a given root, so it shouldn’t be an issue.
This approach can be better than the snapshot-based approach because you’re dealing with relatively small archives all self-contained under a root (e.g., /opt/YourCompany). As with the snapshot-based approach, the downside is having no real ability to handle patching and routine maintenance. We’ll discuss an alternative in .
Building from Source
Rather than installing software and then taking a snapshot of a whole server or a directory, you can build an entire stack of software from source. Source in this case refers to actual source code or precompiled binaries. This approach involves scripting out your environments, including what must be installed, in what order, and with what parameters. An agent installed on an operating system then runs the script, downloading, installing, and configuring as required (see Figure 5-4).
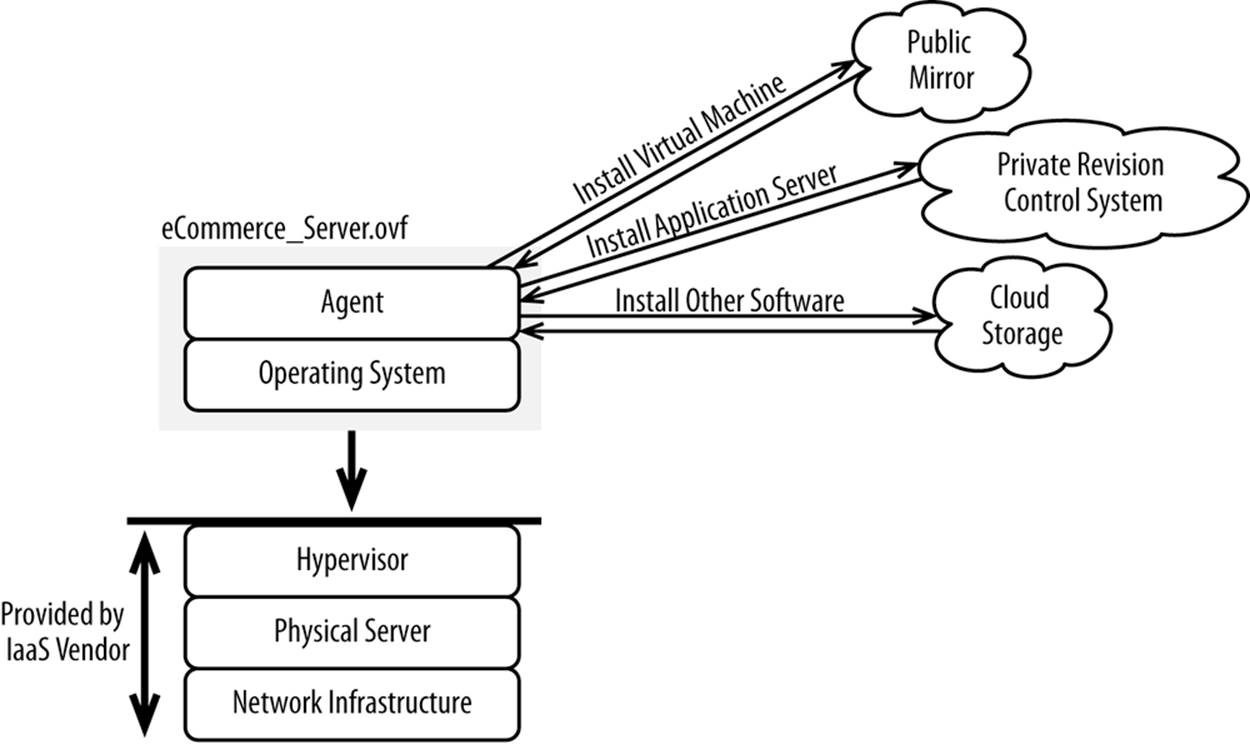
Figure 5-4. Building from source
Numerous commercial and open source products on the market allow you to:
§ Download binaries
§ Execute installers
§ Detect failures in installations
§ Configure software (e.g., updating properties/XML files)
§ Issue arbitrary commands to the operating system
§ Push arbitrary files
§ Execute scripts and report the output
§ Define hierarchal relationships between components with either declarative or procedural dependency models
§ Execute the same script across different platforms and operating systems
All of these activities are typically done through a lightweight agent installed on each server, with the agent communicating with a central management server either within or outside of an Infrastructure-as-a-Service cloud. Here’s how you would install JDK 8 using Chef, a popular configuration management tool:
# install jdk8
java_ark "jdk" do
url 'http://download.oracle.com/otn-pub/java/jdk/8-b132/jdk-8-linux-x64.bin'
checksum 'a8603fa62045ce2164b26f7c04859cd548ffe0e33bfc979d9fa73df42e3b3365'
app_home '/usr/local/java/default'
bin_cmds ["java", "javac"]
action :install
end
For more information, please read Learning Chef by Seth Vargo and Mischa Taylor (O’Reilly).
Many software vendors have contributed to these projects to make it exceptionally easy to install their products. Of course, shell scripting is always an option, but that is far more challenging because it lacks so many of the capabilities of purpose-built solutions.
Many of these systems have full support for scripting, allowing you to customize the installation of each product. For example, you can see how many vCPUs are available and then change how many threads you allocate to a load balancer. You can fine-tune your software to run well on its target server. When you snapshot a live system, it’s just that: a static snapshot. Building from source is the most robust approach but it adds substantial overhead to the development and deployment process. For this to work properly, you need to build out fairly lengthy scripts, even for simple environments. It’s a lot of work to maintain them, especially for software that’s complex to install.
TIP
If you have to SSH into a server to do anything manually, your automation has failed.
Monitoring the Health of a Deployment Unit
Regardless of whether your servers are in a public Infrastructure-as-a-Service cloud or in your own data centers managed by your own administrators, the health of each deployment unit must be thoroughly interrogated. Individual deployment units should be considered disposable. The health of a deployment unit is best evaluated by querying the uppermost stack of software, as shown in Figure 5-5.
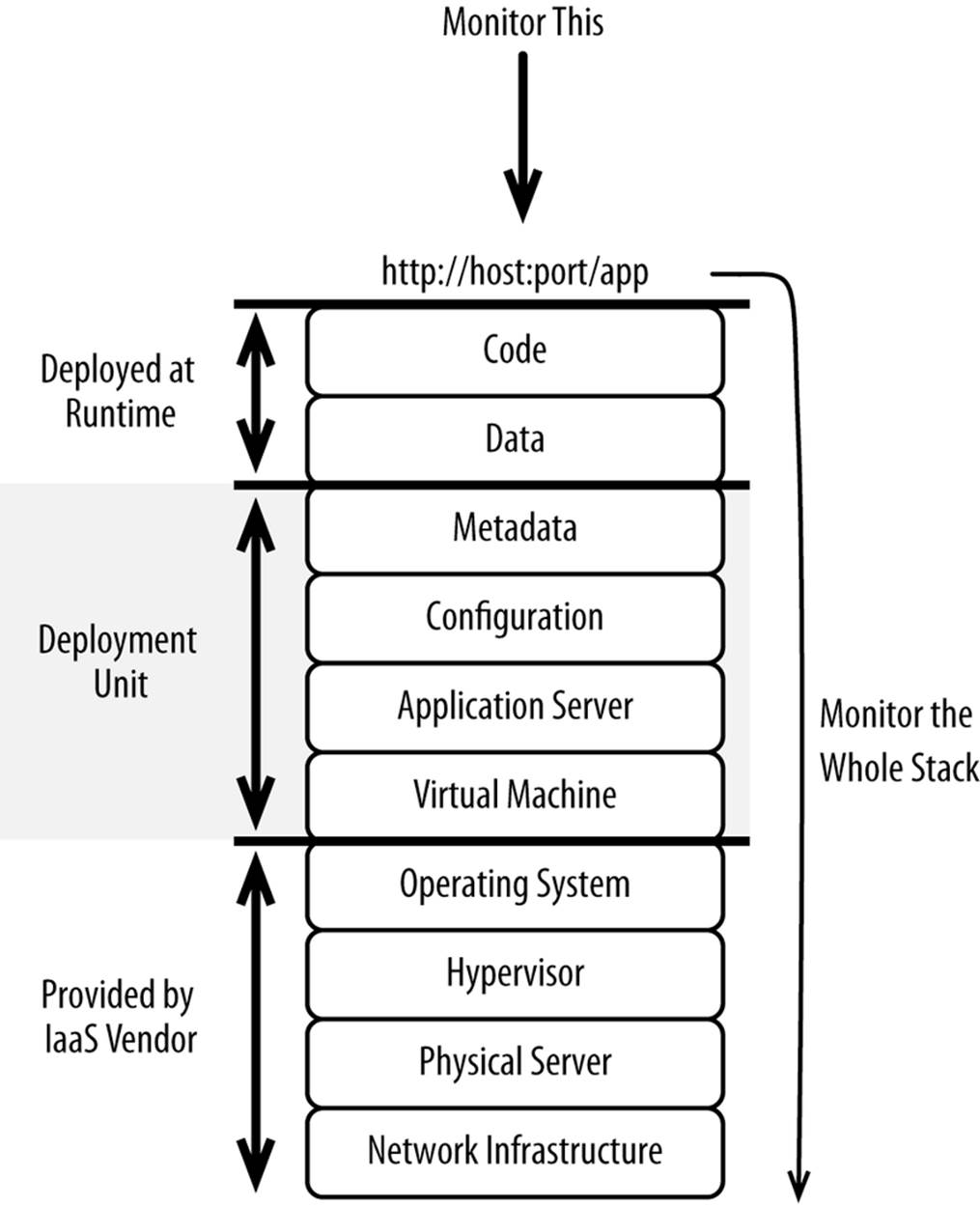
Figure 5-5. What needs to be monitored
Bad servers should be immediately pulled from the load balancer to prevent customers from having a poor experience. This is especially important with cloud environments where there may be interference from noisy neighbors.
Traditional health checking has been very superficial, with its scope limited to the health of individual components (e.g., filesystem, memory, network, CPU) and whether the specified HTTP port responds to a TCP ping (see Figure 5-6).
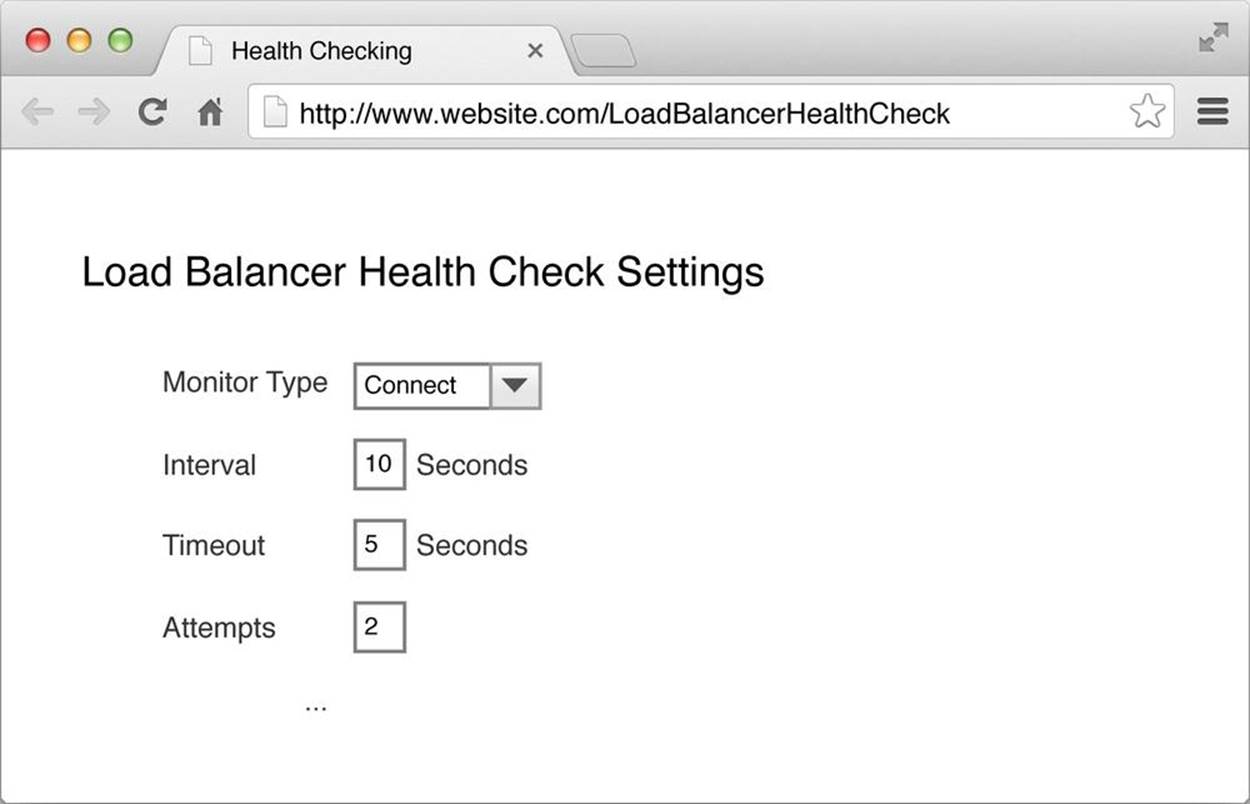
Figure 5-6. Basic health check
This is of no use: an application server could respond to a TCP ping, with, for example, an HTTP 500 error because the application server couldn’t establish a connection to the database. Testing TCP pings tests only the lower levels of the stack, not whether anything is actually working.
A better, and perhaps the most common approach is shown in Figure 5-7.
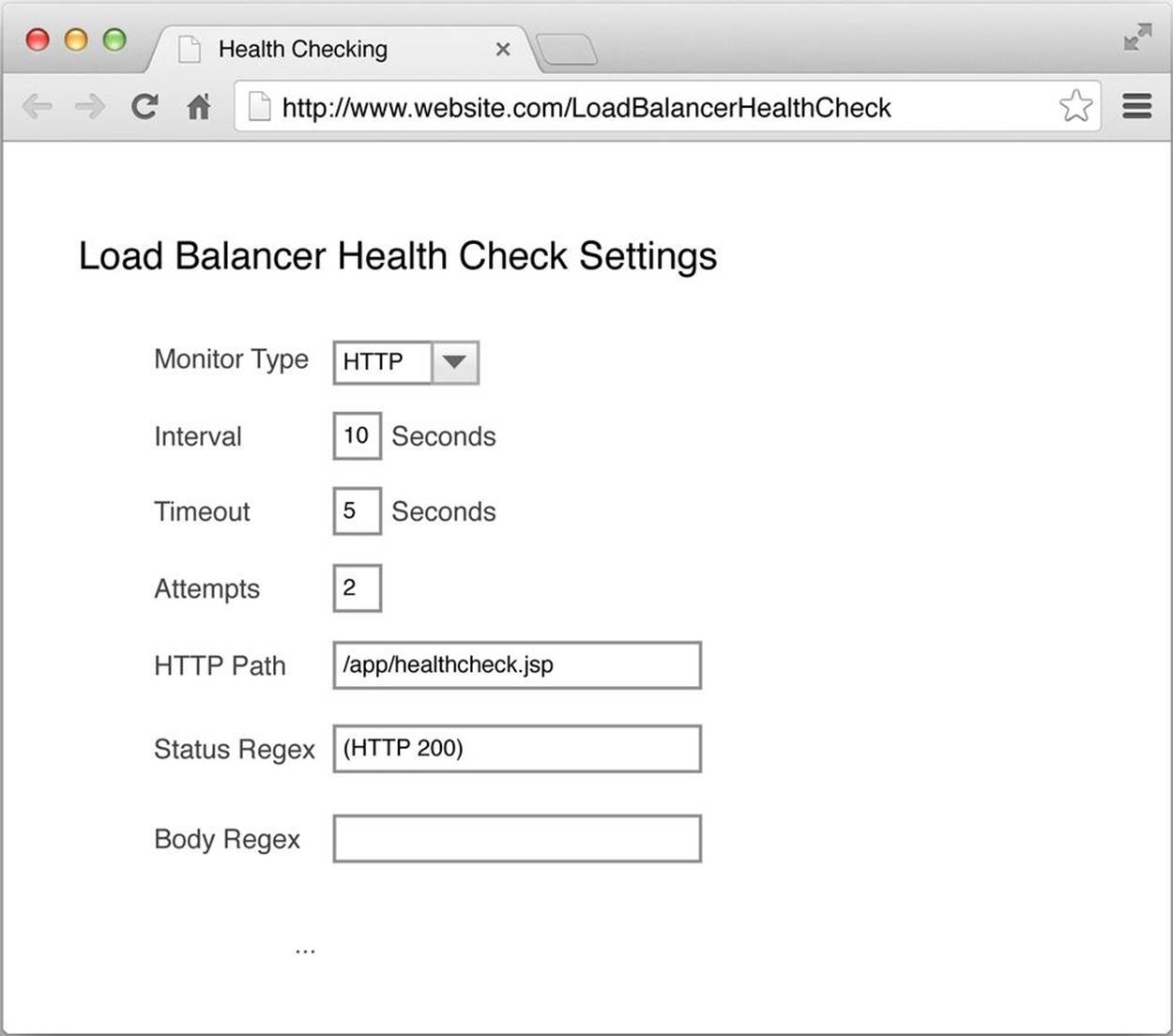
Figure 5-7. Better health check
With this approach, you’re verifying that the home page or another functionally rich page actually responds with an HTTP 200 response code. This is slightly better, but it can’t evaluate the health of the entire application and the services (e.g., database, cache grid, messaging) required to fully deliver the entire application. Home pages, for example, tend to be fairly static and heavily cached.
The most comprehensive way of health checking is to build a dynamic page that exercises the basic functionality of an application. If all tests are successful, it writes PASS. If there was an error, it writes FAIL. Then, configure the load balancer to search for an HTTP 200 response code and PASS. Figure 5-8 shows how you configure your load balancer.
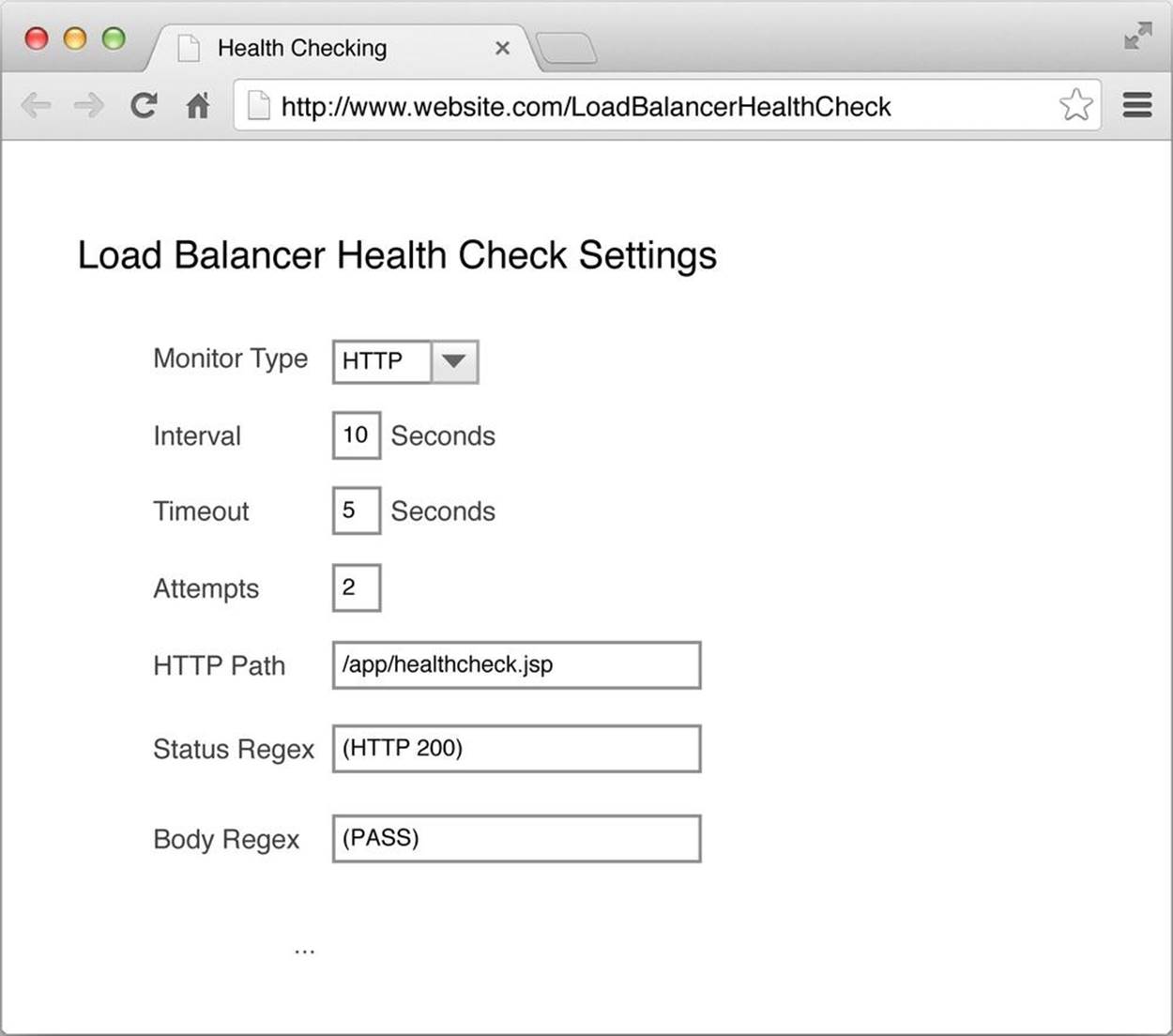
Figure 5-8. Best health check
Tests performed on this page can include:
§ Querying the cache grid for a product
§ Adding a product to the shopping cart
§ Writing a new order to a database and then deleting it
§ Querying the service bus for inventory availability
§ Executing a query against the search engine
These few tests are far more comprehensive than any arbitrary page or URL you select. It’s very important that the load balancer you choose has the ability to look at both the HTTP response header and the body of the response.
WARNING
This monitoring is not to take the place of more comprehensive system-level monitoring—rather, it’s to tell the load balancer whether a given unit is healthy enough to continue serving traffic. Standard system-level monitoring is required and expected, though outside the scope of this book.
Make sure you don’t overdo your health checking, as frequent monitoring can add work to your system without providing a clear benefit.
Lifecycle Management
Every one of your servers has its own stack of software, patches, configuration, and code. Once a server is provisioned and built, it must be updated as you make changes to the baseline. Being able to quickly push updates to production helps to ensure that servers stay up, making it easier to debug problems, all while reducing labor costs. In addition, you will likely have to be able to push through emergency configuration and security-related changes (Figure 5-9).
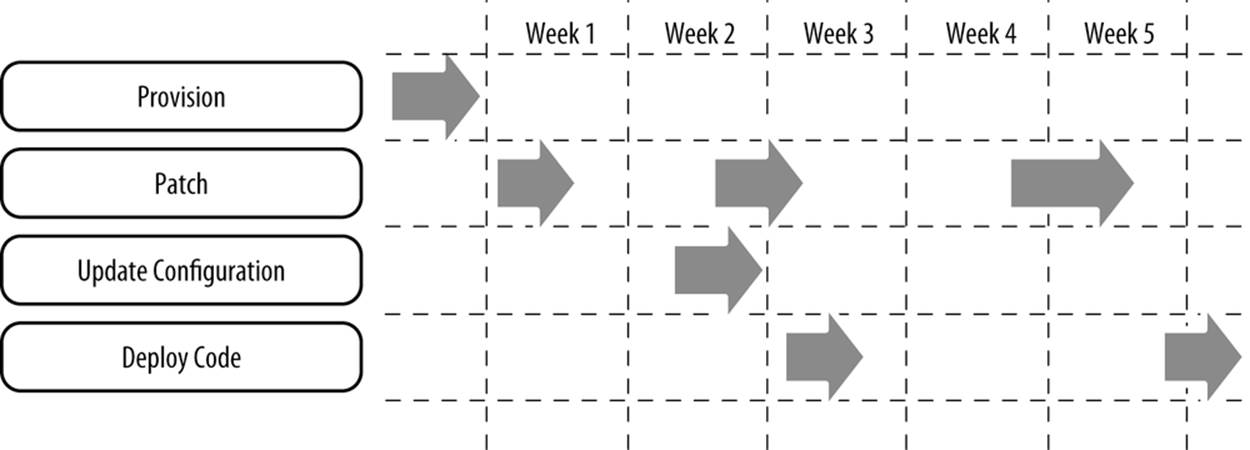
Figure 5-9. Lifecycle of each server
Often a single logical change (e.g., applying a patch or deploying new code) requires executing many, if not all, of the following actions:
§ Updating files on a filesystem
§ Arbitrarily executing commands against a shell script and monitoring the results
§ Making configuration changes (through updating configuration files or executing commands through the shell)
All running servers, as well as your reference snapshot if you use a snapshot-based approach, must be updated as you advance your baseline of software, patches, configuration, and code. Again, you can’t do this by hand, so you have to automate the process.
The approach outlined in is often used for both initial installation and ongoing lifecycle management. Because an agent is always running on each server, you can push any files or make any configuration changes you want. You can even use it for deploying new builds. But the snapshot-based approaches (either full images or archives) lack agents. They’re static snapshots and therefore need supplemental software to handle a lifecycle.
Once you do pick a solution and start to use it, make sure you stage your changes and test them with a limited set of customers before you roll the changes out across an entire environment. You can just apply the changes to a handful of servers, monitor their health, and then roll out the changes across the entire environment. Or if your changes are more substantial, you can even build a separate parallel production environment and instruct your load balancer to direct a small amount of traffic to the new environment. When you’re satisfied with the results, you can have your load balancer cut all of your traffic over to your new production environment and then decommission your old servers. This can get very complicated, but the payoff can be substantial.
Summary
In this chapter we discussed three approaches for installing software on hardware, followed by how to monitor each stack of software. While building and monitoring deployment units is a fundamental prerequisite to adopting cloud, virtualization is perhaps even more of a basic building block.
All materials on the site are licensed Creative Commons Attribution-Sharealike 3.0 Unported CC BY-SA 3.0 & GNU Free Documentation License (GFDL)
If you are the copyright holder of any material contained on our site and intend to remove it, please contact our site administrator for approval.
© 2016-2026 All site design rights belong to S.Y.A.