Adaptive Code via C#. Agile coding with design patterns and SOLID principles (2014)
Part I: An Agile foundation
CHAPTER 1 Introduction to Scrum
CHAPTER 2 Dependencies and layering
CHAPTER 3 Interfaces and design patterns
CHAPTER 4 Unit testing and refactoring
This part of the book gives you a grounding in Agile principles and practices.
Writing code is the central pillar of software development. However, there are many different ways to achieve the goal of working code. Even if you don’t count the selection of platform, language, and framework, there are a multitude of choices presented to a developer who is tasked with implementing even the simplest functionality.
The creation of successful software products has always been an obvious focus for the software development industry. But in recent years, developers have begun to emphasize the implementation of patterns and practices that are repeatable and have a positive effect on the quality of code. This is because the notion of code quality is no longer separate from the notion of quality in the software product. Over time, poor-quality code will degrade the quality of the product—at the very least, it will irretrievably delay the delivery of working software.
To produce high-quality software, developers must strive to ensure that their code is maintainable, readable, and tested. In addition to this, a new requirement has emerged that suggests that code should also be adaptive to change.
The chapters in this part of the book present modern software development processes and practices. These processes and practices are generally termed Agile processes and practices, which reflects their ability to change direction quickly. Agile processes suggest ways in which a software development team can elicit fast feedback and alter its focus in response, and Agile practices suggest ways in which a software development team can write code that is similarly able to change direction.
Chapter 1. Introduction to Scrum
After completing this chapter, you will be able to
![]() Assign roles to the major stakeholders in the project.
Assign roles to the major stakeholders in the project.
![]() Identify the different documents and other artifacts that Scrum requires and generates.
Identify the different documents and other artifacts that Scrum requires and generates.
![]() Measure the progress of a Scrum project on its development journey.
Measure the progress of a Scrum project on its development journey.
![]() Diagnose problems with Scrum projects and propose remedies.
Diagnose problems with Scrum projects and propose remedies.
![]() Host Scrum meetings in an effective manner for maximum benefit.
Host Scrum meetings in an effective manner for maximum benefit.
![]() Justify the use of Scrum over other methodologies, both Agile and rigid.
Justify the use of Scrum over other methodologies, both Agile and rigid.
Scrum is a project management methodology. To be more precise, it is an Agile methodology. Scrum is based on the idea of adding value to a software product in an iterative manner. The overall Scrum process is repeated—iterated—multiple times until the software product is considered complete or the process is otherwise stopped. These iterations are called sprints, and they culminate in software that is potentially releasable. All work is prioritized on the product backlog and, at the start of each sprint, the development team commits to the work that they will complete during the new iteration by placing it on the sprint backlog. The unit of work within Scrum is the story. The product backlog is a prioritized queue of pending stories, and each sprint is defined by the stories that will be developed during an iteration. Figure 1-1 shows an overview of the Scrum process.
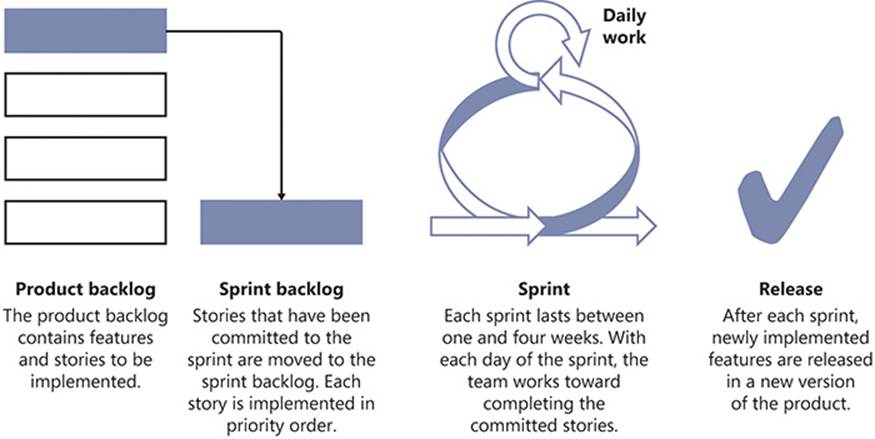
FIGURE 1-1 Scrum works like a production line for small features of a software product.
Scrum involves a mixture of documentation artifacts, roles played by people inside and outside the development team, and ceremonies—meetings that are attended by appropriate parties. Although a single chapter is not enough to explore the entirety of what Scrum offers as a project management discipline, this chapter offers enough detail to provide both a springboard to further learning and an orientation for the day-to-day practices of Scrum.
Scrum is Agile
Agile is a family of lightweight software development methods that embrace the changing requirements of customers even as the project is in progress. Agile is a reaction to the failings of more rigidly structured practices. The Agile Manifesto exemplifies the contrast. It can be found on the web at www.agilemanifesto.org.
The Agile Manifesto was signed by 17 software developers. The Agile method has grown in influence in the intervening years to the extent that experience in an Agile environment is now a common prerequisite for software development roles. Scrum is one of the most common implementations of an Agile process.
Scrum versus waterfall
In my experience, the Agile approach works better than the waterfall method of software development, and I evangelize only in favor of Agile processes. The problem with the waterfall method is its rigidity. Figure 1-2 provides a representation of the process involved in a waterfall project.
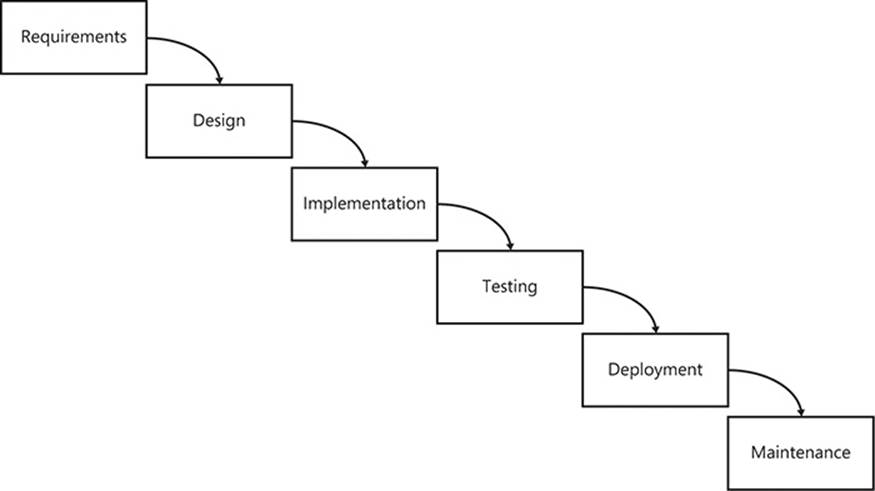
FIGURE 1-2 The waterfall development process.
Note that the output from one stage becomes the input to the next. Also note that each phase is completed before moving to the next phase. This assumes that no errors, issues, problems, or misunderstandings are discovered after a phase has completed. The arrows only point one way.
The waterfall process also assumes that there will be no changes made after a phase has completed, something that seems quite contrary to empirical and statistical evidence. Change is a natural part of life, not just of software engineering. The attitude toward change that waterfall approaches espouse is that it is expensive, undesirable, and—most damningly—avoidable. Waterfall methods assert that change can be circumnavigated by spending more time on requirements and design, so that changes simply do not occur during subsequent phases. This is preposterous, because change will always happen.
Agile responds to this fact by adopting a different approach, which welcomes change and allows everyone to adapt to any changes that occur. Although Agile—and therefore Scrum—allows for change at a process level, coding for change is one of the hardest, yet most important, tenets of modern software development. This book is dedicated to showing you how to produce code that is Agile and adaptive enough to survive change.
Waterfall methodologies are also document-centric, generating a lot of documentation that does not directly improve the software product. Agile, on the other hand, considers working software to be the most important document of a software product. The behavior of software is, after all, dictated by its source code—not by the documents that accompany that code. Furthermore, because documentation is a separate entity from the source code, it can easily fall out of sync with software.
Scrum prescribes some metrics that provide feedback on the progress of a project and its overall health, but this differs from explicative documentation about the product. Agile, in general, favors just enough documentation to avoid being irresponsible, but it does not mandate such documentation. Some code can certainly benefit from supporting documentation, providing that it is not written once and never read again. For this reason, living documents that are easy to use, such as wikis, are common tools in Scrum teams.
The rest of this chapter covers the most important aspects of Scrum in more depth, although the focus is not purely Scrum, but a common variant thereof. The aim of Scrum as a process is not only to iteratively refine the software product, but also to iteratively refine the development process. This encourages teams to adopt subtle changes to ensure that the process is working for them, given their unique situations and context.
After discussing the constituent elements of Scrum, this chapter examines its flaws. This chapter sets the scene for the rest of the book, which details how to implement code in such a way that it remains adaptive to the change that is embraced by the Scrum process. There is little point in having a process in which you claim to be able to handle change gracefully when the reality is that change is incredibly difficult to implement down at a code level.
Different forms of Scrum
Whenever a development team claims that they follow the Scrum methodology, it is common for them to mean that they follow some variant of Scrum. Pure Scrum does not include a lot of common practices that have been taken from other Agile methods, such as Extreme Programming (XP). There are three different subcategories of Scrum that progressively veer further away from the purist implementation.
Scrum and...
Common practices like writing unit tests first and pair-programming are not part of Scrum. However, they are useful and worthy additions to the process for many teams, and so they are considered complementary practices. When certain practices are added from other Agile methods such as XP or Kanban, the process becomes “Scrum and...”—that is: Scrum plus extra best practices that enhance, rather than detract from, the default Scrum process.
Scrum but...
Some development teams claim to be practicing Scrum, but they omit key aspects. Their work is ordered on a backlog that is carried into iterative sprints, and they have retrospectives and daily stand-up meetings. However, they don’t estimate in story points and instead favor real-time estimates. This sort of diluted version of Scrum is termed “Scrum but...”. Although the team is aligned with Scrum in a lot of areas, they are misaligned in one or two key areas.
Scrum not...
If a development team moves far enough away from the Scrum method, they end up doing “Scrum not...” This causes problems, particularly when team members expect an Agile methodology and the actual process in place is so different that it barely resembles Scrum at all. I find that the daily stand-up meeting is the easiest part of Scrum to adopt, but relative estimation and the positive attitude to change are much more difficult. When enough parts of the Scrum process are neglected, the process is no longer Scrum.
Roles and responsibilities
Scrum is just a process, and—I cannot stress this enough—it is only as effective as the people who follow the process. These people have roles and responsibilities that guide their actions.
Product owner
The role of product owner (sometimes called the PO) is vital. The product owner provides the link between the client or customer and the rest of the development team. Product owners take ownership of the final product and, accordingly, their responsibilities include:
![]() Deciding which features are built.
Deciding which features are built.
![]() Setting the priority of the features in terms of business value.
Setting the priority of the features in terms of business value.
![]() Accepting or rejecting “completed” work.
Accepting or rejecting “completed” work.
As a key stakeholder to the success of the project, the PO must be available to the team and be able to communicate the vision clearly. The long-term goal of the project should be clear to the development team, with changes in focus propagated throughout the team in a timely manner. In short-term sprint planning, the product owner sets out what will be developed and when. Product owners determine the features that will be needed along the road to making a release of the software, and they set the priorities for the product backlog.
Although the product owner’s role is key, he or she does not have unlimited influence over the process. The product owner cannot influence how much the team commits to for a sprint, because this is determined by the team itself based on its velocity. Product owners also do not dictatehow work is done—the development team has control over the details of how it implements a certain story at a technical level. When a sprint is underway, the product owner cannot change the sprint goals, alter acceptance criteria, or add or remove stories. After the goals are decided and the stories committed to the sprint during sprint planning, the sprint in progress becomes immutable. Any changes must wait until the next sprint—unless the change is to cancel the sprint or project in its entirety and start again. This allows the development team to retain total focus on achieving the sprint goal without moving the goalposts.
Throughout the sprint, as stories progress and are completed, the product owner will be asked to verify how a feature works or comment on a task that is in progress. It is important that product owners be able to devote some time during the sprint to liaise with the development team, in case the unexpected occurs and confusion arises. In this way, by the end of the sprint, the product owner is not presented with “completed” stories that deviate from their initial vision. Product owners do, however, get to decide whether a story meets the acceptance criteria supplied and whether it is considered complete and can be demonstrated at the end of the sprint.
Scrum master
The Scrum master (SM) shields the team from any external distractions during the sprint and tackles any of the impediments that the team flags during the daily Scrum meeting. This keeps the team fully functional and productive for the duration of the sprint, allowing it to focus wholly on the sprint goals.
Just as the product owner owns the product—what is to be done—the Scrum master owns the process—the framework surrounding how it is to be done. Thus it is the Scrum master’s responsibility to ensure that the process is being followed by the team. Although the Scrum master can make some suggestions for improving the process (such as switching from a four-week sprint duration to a two-week duration), the Scrum master’s authority is limited. Scrum masters cannot, for instance, specify how the team should implement a story, beyond ensuring that it follows the Scrum process.
As owners of the process, Scrum masters also own the daily Scrum meeting. The Scrum master ensures the team’s attendance and takes notes throughout in case any actionable items are uncovered. The team is not, however, reporting to the Scrum master during the Scrum meeting; they are informing everyone present of their progress.
Development team
Ideally, an Agile team consists of generalizing specialists. That is, each member of the team should be multidisciplinary—capable of operating effectively on several different technologies, but with an aptitude, preference, or specialization in a certain area. For example, a team could consist of four developers, each of whom is capable of working very competently on ASP.NET MVC, Windows Workflow, and Windows Communication Foundation (WCF). However, two of the developers specialize in Windows Forms, and the remaining pair prefer to work with Windows Presentation Foundation (WPF) and Microsoft SQL Server.
Having a cross-functional team prevents siloes where one person—the “web person,” the “database person,” or the “WPF person”—has sole knowledge of how that part of the application works. Siloes are bad for everyone involved, and there should be heavy emphasis placed on breaking down siloes wherever possible. In Scrum, the code is owned by the team collectively. Siloes are bad for the business because it makes them depend too heavily on a single resource to provide value in a certain area. And the individuals themselves suffer because they become entrenched in roles that “only they can do.”
Software testers are responsible for maintaining the quality of the software while it is being developed. Before a story is started, the testers might discuss automated test plans for verifying that the implementation of a story meets all of the acceptance criteria. They might work with the developers to implement those test plans, or they might write such tests themselves. After a story is implemented, the developer can submit it for testing, and the test analyst will verify that it is working as required.
Pigs and chickens
Each role of the Scrum process can be categorized as a pig or a chicken. These characterizations relate to the following story: A chicken approaches his friend, the pig, and says, “Hello pig, I’ve had an idea. I think we should open a restaurant!” At first, the pig is enthusiastic and enquires, “What should we call it?” The chicken replies, “We could call it Ham ‘n’ Eggs.” The pig ponders this briefly before exclaiming in outrage, “No way! I’d be committed, but you’d only contribute!”
This fun allegory merely highlights the level of involvement that certain members need to have in a project. Pigs are entirely committed to a project and will be accountable for its outcome, whereas chickens merely contribute and are involved in a more peripheral manner. The product owner, the Scrum master and the development team are all pigs inasmuch as they are committed to the delivery of the product. Most often, customers are merely contributing chickens. Similarly, executive management will contribute to the project, so they are also considered chickens rather than pigs.
Artifacts
Throughout the lifetime of any software project, many documents, graphs, diagrams, charts, and metrics are created, reviewed, analyzed, and dissected. In this respect, a Scrum project is no different from any other. However, Scrum documents are distinct from documents of other types of project management in their type and purpose. A key difference between all Agile processes and more rigid processes is the relative importance of documentation. Structured Systems Analysis and Design Methodology (SSADM), for example, places a heavy emphasis on writing lots of documentation. This is referred to pejoratively as Big Design Up Front (BDUF): the errant belief that all fear, uncertainty, and doubt can be eliminated from a project if sufficient attention is paid to documentation. Agile processes aim to reduce the amount of documentation produced to only that which is absolutely necessary for the project to succeed. Instead, Agile favors the idea that the code—which is highly authoritative documentation—can be deployed, run, and used at any time. It also prefers that all stakeholders communicate with each other directly rather than write documents that might never be read by their most important audience. Documentation is still important to an Agile project, but its importance does not supersede that of working software or communication.
The Scrum board
Central to the daily workings of a Scrum project is the Scrum board. There should be a generous amount of wall space reserved for the Scrum board—if the board is too small, the temptation is to omit important details. Wall space might well be at a premium in your office, but there are tricks that you can use. Perhaps that large, neglected whiteboard could be repurposed as a Scrum board. With the aid of magnets, metal filing cabinets can double as the Scrum board. If your office is rented or you otherwise cannot deface the walls, “magic” whiteboards—which are simply wipe-clean sheets of static paper—are ideal. Try to identify a suitable place that could perform this function in your office. Whatever you choose, however you designate it, if it doesn’t feel right after a couple of iterations, feel free to change it. Physical Scrum boards are an absolute must. There is nothing that can replace the visceral experience of standing in front of a Scrum board. Though digital Scrum tools have their uses, I believe that they are complementary, rather than primary, to the Scrum process. Figure 1-3 shows an example of a typical Scrum board.
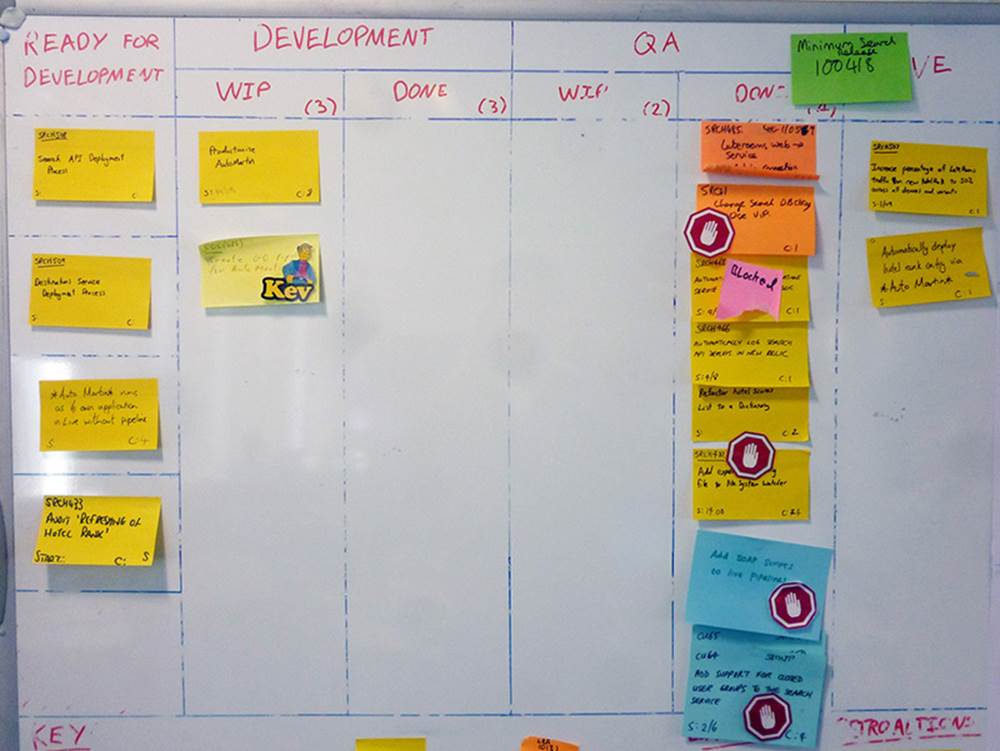
FIGURE 1-3 A Scrum board is a snapshot of the state of the work currently in development.
A Scrum board is a hive of information. It holds a lot of details, and discerning what is happening might be daunting. The rest of this section explains each aspect in detail.
Cards
The primary items on the Scrum board are the cards. The cards represent different elements of progress for a software product—from a physical release of the software down to the smallest distinct task. Each of these card types is typically represented by a different color, for clarity. Due to space constraints, the Scrum board usually shows only the stories, tasks, defects, and technical debt associated with the current sprint.
![]() Tip
Tip
Colors alone might not be sufficient for the requirements of everyone on the team. For example, consider coupling colors with distinct shapes for team members who can’t distinguish colors.
Hierarchy of composition
Figure 1-4 shows how the cards on a Scrum board are related. Note that it is implied that a product is composed of many tasks. Even the most complex software can be distilled into a finite list of discrete tasks that must be performed, each paving the way to completion.
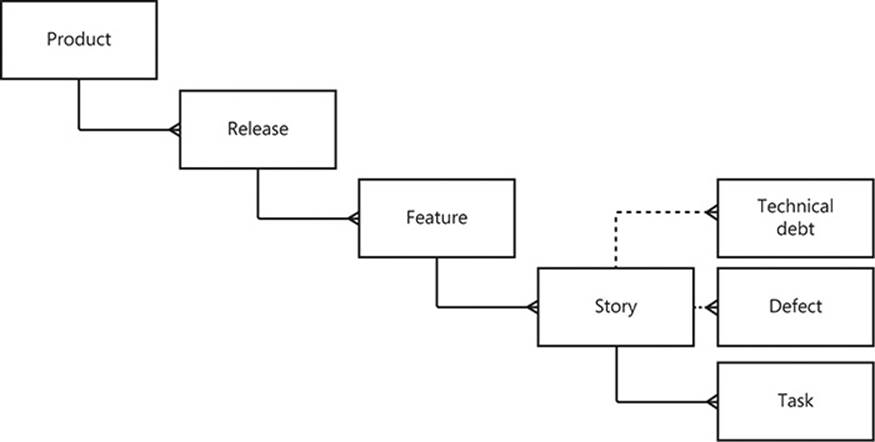
FIGURE 1-4 The cards on the Scrum board represent different parts of an aggregated product.
Product
At the top of the Scrum food chain is the software product that is being built. Examples of products are bountiful: integrated development environments, web applications, accounting software, social media apps, and many more. This is the software that you are developing and the product you intend to deliver.
Teams usually work toward only one product at a time, but sometimes teams are responsible for delivering multiple products.
Release
For every product that you develop, there will be multiple releases. A release is a version of the software that end users can purchase or use as a service. Sometimes a release is made only to address defects, but a release could also be intended to provide value-add features to key clients or to make a beta version of the software available as a sneak preview.
Web applications are often implicitly versioned with only a single deployment that supersedes all prior releases. In fact, the Google Chrome web browser is an interesting example. Although it is a desktop application, it is deployed as a stream of micro-releases that are seamlessly deployed to desktops without the usual fanfare that accompanies rival browsers. Internet Explorer 8, 9, and 10 each had their own advertisements on television, but Chrome does not follow this pattern—Google simply advertises the browser itself, irrespective of version. And iterative releases like this are becoming more common. Scrum can direct this release pattern by focusing on the potential to deliver working software after every sprint.
Minimum viable release
The first release can be aligned to a minimum viable release (MVR)—the basic set of features that are deemed sufficient to fulfill the fundamental requirements. For accounting software, for example, this feature set could be limited to the ability to create new clients, add transactions (both deposits and withdrawals) to their accounts, and present a total. The idea here is to bootstrap the project so that it becomes self-funding as soon as possible. Although this is unlikely to occur as a result of the MVR, the hope is that the MVR will at least bring in some revenue to offset the ongoing costs of development. Not only this, but that first deployment, even if it targets a restricted client base, is likely to provide vital feedback that can influence the direction of the software. This is the nature of Scrum—and Agile in general—constantly evolving the software product with the knowledge that all software is subject to change.
Regardless of the intent of the release or how it is deployed (or even how often), ideally a single product will survive several releases.
Feature
Each release is made up of one or more features that were previously not present in the software. The most significant difference between version 1.0 and version 2.0 of any piece of software is the addition of new features that the team believes will generate sufficient interest to persuade new users to make a purchase and existing users to upgrade.
The term minimum marketable feature (MMF) is useful to delineate features and compose a release. The following is a list of example features that are generic enough to be applied to many different projects, yet specific enough to be real-world features:
![]() Exporting application data to a portable XML-based format
Exporting application data to a portable XML-based format
![]() Servicing webpage requests within 0.5 seconds
Servicing webpage requests within 0.5 seconds
![]() Archiving historical data for future reference
Archiving historical data for future reference
![]() Copying and pasting text
Copying and pasting text
![]() Sharing files across a network with colleagues
Sharing files across a network with colleagues
Features are marketable if they have some value for the customer. When distilled down to the smallest amount of functionality possible while still retaining its value, the feature is also minimal.
Epics/features vs. MMFs vs. themes
You might be more used to the term epic rather than feature when talking about Scrum, but I have taken the liberty of switching this out for my preferred term. Epics and features are often considered “large stories”: that is, stories that are much larger than MMFs and that cannot be delivered in a single sprint.
Features are also similar to Scrum themes in that they serve to group stories that fulfill a common goal.
Features can be broadly grouped into three categories for each release: required, preferred, and desired. These are mutually exclusive options that reflect the overall priority assigned to each feature. Typically, the development team is instructed to work on all required features before tackling the preferred features, with the desired features being addressed only if time allows. As you might have guessed, these categories—and, indeed, the features themselves—are always changeable. They can be canceled, reprioritized, altered, and superseded at any time, with the team expected to switch focus gracefully (with the proviso, however, that deadlines and funding might also change in kind). Everything in Scrum is a moveable feast, and this book is aimed to help you deal with that reality.
User story
The user story is probably the Scrum artifact that most people are familiar with, but ironically, it is not prescribed by Scrum. User stories are an artifact of Extreme Programming, but they have been co-opted by Scrum because they are so commonly used. User stories are specified by using the following template:
“As a [user role], I want to [verb-centric behavior], so that [user value added].”
The square brackets denote parameterization that distinguishes one user story from another. A concrete example should illuminate further:
“As an unauthenticated but registered user, I want to reset my password, so that I can log on to the system if I forget my password.”
There are many things to note about this user story. First of all, there is not nearly enough detail to actually implement the behavior required. Note that the user story is written from the perspective of a user. Although this would seem to be obvious, this point is missed by many and, too often, stories are wrongly written from the perspective of developers. This is why the first part of the template—As a [user role]—is so important. Similarly, the [user value added] portion is just as important because, without this, it is easy to lose sight of the underlying reason that the user story exists. This is usually what ties the user story is to its parent feature; the example just given could belong to a feature such as “Forgotten user credentials are recoverable.” And the story would probably be grouped with the story in which the user has forgotten his or her logon name and the story in which the user has forgotten both logon name and password.
Given that this user story is not sufficient to begin development, what is its value? A user story represents a conversation that is yet to occur between the development team and the customer. When it comes time to implement the story, the developers assigned to it will start by taking the story to the customer and talking through the customer’s requirements. This analysis phase will produce several acceptance criteria that must be adhered to throughout the lifetime of the user story, so that the user story can be deemed complete.
After the requirements have been gathered, the developers convene and lay out some design ideas to meet these requirements. This phase might include user interface mockups that use Balsamiq, Microsoft Visio, or some other tool. Some technical design concepts will detail how the existing code base must be altered to meet these new requirements, often using Unified Modeling Language (UML) diagrams.
After the design is ratified, the team can start to break the user story down into tasks and then work toward implementing the story by performing these tasks. When they reach a point when they are satisfied that the story is working as required, they can hand it over to be acceptance tested. This final phase of quality assurance (QA) double-checks the working software against the acceptance criteria and either approves or rejects it. When it is approved, the user story is complete.
Let’s recap for a minute. With a user story for guidance, developers gathered requirements in an analysis phase, generated a design, implemented a working solution, and then tested this against the acceptance criteria. This sounds a lot like waterfall development methodologies! Indeed, that’s the whole point of user stories—to perform the entire software development life cycle, in miniature, for each story. This helps to prevent any wasted effort because it is not until the user story is ready to be taken from the Scrum board and implemented that the developers can be sure it is still relevant to the software product.
User stories are the main focus of work in Scrum; they hold the incentive that Scrum provides for team members: story points. The team assigns each user story its own story point score during sprint planning and, after the user story is complete, the story points are considered to be earned and are deducted from the sprint total. Story points are explained in further detail later in this chapter.
Task
There is a unit of work smaller than a user story—the task. Stories can be broken down into more manageable tasks, which can then be split between the developers assigned to the story. I prefer to wait until the story is taken off the board before I split it into tasks, but I have also seen this done as part of sprint planning.
Although user stories must incorporate a full vertical slice of functionality, tasks can be split at the layer level to take advantage of developer specializations within the team. For example, if a new field is required on an existing form, there will probably need to be changes to the user interface, business logic, and data access layers. You could divide this into three tasks that target these three layers and assign each to the relevant specialist: the WPF developer, the core C# expert, and the database guru, respectively. Of course, if you are lucky enough to have a team of generalizing specialists, anyone should really be able to volunteer for any task. This allows everyone to work on various parts of the code, which improves their understanding in addition to boosting their job satisfaction.
The vertical slice
When I was growing up, every Christmas my father would make trifle. This is a traditional English dessert that is made from various layers. At the bottom there is sliced fruit; then there are layers of sponge cake, jelly, and custard; and on top is whipped cream. My brother used to dig his spoon all the way through the layers, whereas I would eat each layer in turn.
Well-designed software is layered just like a trifle. The bottom layer is dedicated to data access, with layers in between for object-relational mappers, domain models, services, and controllers—with the user interface on top. Much like eating trifle, there are two ways to slice any part of a layered application: vertically and horizontally.
By slicing horizontally, you take each layer and implement what is required of those layers as a whole. But there is no guarantee that each slice will align at the same time. The user interface might allow the user to interact with certain features that layers below have not yet implemented. The net effect is that the client cannot use the application until a significant proportion of each layer has been completed. This delays the important feedback loop that Agile methods give you and increases the likelihood that you will build more than is needed—or simply the wrong thing.
Slicing vertically is what you should aim for. Each user story should incorporate functionality at each layer and should be tethered at the top to the user interface. This way, you can demonstrate the functionality to the user and receive feedback quickly. This also avoids writing user stories that are developer-centric, such as, “I want to be able to query the database for customers who have not paid this month.” This sounds too much like a task; the story could be about generating a report on the outstanding unpaid accounts.
It is important to note that the user stories are the bearers of story points and that these do not transfer down to their constituent tasks. A five-point story that is broken into three distinct tasks is not composed of two one-point tasks and a three-point task. This is because there is neither incentive nor credit for partially completed work. Unless the story—as a whole—is proven complete by the QA process before the end of the sprint, the points that it contains are not claimed, even in part. The story remains in progress until the next sprint, when ideally it will be completed early in the iteration. If a story takes too long to complete and remains in progress for a long time—more than a full sprint’s length—then it was probably too big in the first place and should have been sliced into smaller, more manageable stories.
Technical debt
Technical debt is a very interesting concept, but it is easily misunderstood. Technical debt is a metaphor for the design and architectural compromises that have been made during a story’s journey across the Scrum board. Technical debt has its own section later in this chapter.
Defect
A defect card is created whenever acceptance criteria are not met on a previously complete user story. This highlights the need for automated acceptance testing: each batch of tests written for a story forms a suite of regression tests to ensure that no future work is able to introduce a breaking change.
Defect cards, like technical debt, do not have story points assigned to them, thus removing the incentive to create defects and technical debt—something that developers want to avoid even if full eradication of defects and technical debt is unattainable.
All software has defects. That is just a fact of software development, and no amount of planning or diligence will ever account for the fallibility of humans. Defects can be broadly categorized as A, B, or C: apocalyptic defects, behavioral errors, and cosmetic issues.
Apocalyptic defects result in an outright crash of the application or otherwise prevent the continuation of the user’s work. An uncaught exception is the classic example because the program must terminate and be restarted or—in a web scenario—the webpage must be reloaded. These defects should be assigned the highest priority and should be fixed before a release of the software.
Behavioral errors are often not quite as serious but can infuriate users. These types of errors could be even more damaging than simply crashing the application. Imagine erroneous currency conversion logic that rounds data badly. Whether the algorithm favors the customer or the business, someone is going to lose money. Of course, not all logic errors are quite this serious, but it is easy to understand why they should be given medium-priority to high-priority.
Cosmetic issues are typically problems with the user interface—badly aligned images, a window that doesn’t expand to full screen gracefully, or an image on the web that never loads. These issues do not affect the use of the software, just its appearance. Although these issues are often given a lower priority, it is still important to remember that appearances count toward the user’s expectations of the software. If the user interface is badly designed with buttons that don’t work and images that don’t load, users are less inclined to trust the internal workings of that software. Conversely, a shiny user interface with plenty of bells and whistles might convince users that your software is just as well designed internally. A common trick for projects that have developed a poor reputation is to redesign the user interface—perhaps even rebranding the entire product—to improve perceptions and reset expectations.
Card sharp
A lot of options are available for customizing and personalizing the cards on the Scrum board.
Color scheme
Any color scheme will suffice for the cards, but there are a few that, in my experience, make the most sense. Index cards are ideal for features and user stories, whereas sticky notes make excellent task, defect, and technical debt cards because they can be stuck to a relevant story. Here are my recommendations:
![]() Features: green index cards
Features: green index cards
![]() User stories: white index cards
User stories: white index cards
![]() Tasks: yellow sticky notes
Tasks: yellow sticky notes
![]() Defects: red/pink sticky notes
Defects: red/pink sticky notes
![]() Technical debt: purple/blue sticky notes
Technical debt: purple/blue sticky notes
Note that user stories and tasks, being the most common kinds of cards you will create, use the most commonly available index cards and sticky notes. The last thing you need is to run out of index cards, so try to use the most commonly available colors.
Who creates cards?
The simple answer to the question, “Who can create the cards?” is: anyone. This does, of course, come with some conditions. Though anyone can create a card, its validity, priority, criticality, and other such states are not something that should be decided by one person alone. All feature and story cards should be verified by the product owner, but task, defect, and technical debt cards are entirely the domain of the development team.
Avatars
Much like the avatars found online in forums, on blogs, and on Twitter, these are miniature representations of the various members of the team. Feel free to allow your team members to express themselves through their avatars, because it certainly adds a sense of fun to the Scrum process. Of course, steer them away from anything likely to cause offense, but there should be a sense of distinct identity for each person’s avatar.
Over the course of an iteration, these avatars will be moved around a lot and will be handled on a daily basis. Because you have index-card stories and sticky-note tasks already on the board, these avatars should be no bigger than 2-inch squares. Laminating them will also help to protect them from becoming dog-eared or torn, and reusable adhesive or a little piece of tape should hold them in place.
Swimlanes
Scrum boards have vertical lines drawn on them to demarcate the swimlanes. Each swimlane can contain multiple user story cards to denote the progress of that story throughout its development life cycle. From left to right, the basic swimlanes are Backlog, In Progress, QA, and Done.
A story in the backlog has been “committed to” for the sprint and should—unless canceled—be taken from the board and work on it should begin. This column can be ordered by priority so that the top item is always the next one that should be implemented.
After the story is taken from the backlog and a conversation has taken place with the product owner about the scope and requirements, the card is returned—with newly derived tasks—to the In Progress swimlane. At this point, the avatars of all team members involved in the story should also be attached. The story now counts toward any swimlane limits that might be associated with the in-progress phase. For example, you might require that only three user stories be in progress at a time, thus coercing the team to complete already-started stories in preference to those that have not yet been started. Remember: there is no incentive for partially completed work.
After analysis, design, and implementation have been carried out for a story, it is considered “developer complete” and can be moved to the Quality Assurance (QA) swimlane. Ideally, the QA environment should mirror the production environment as closely as possible, to avoid any environmental errors that can occur from even minor differences in deployment. The test analysts will assess the story in conjunction with the acceptance criteria. In essence, they try to break the story and prove that the code does not behave in the manner in which it ought. Typically, they attempt to provide unusual and erroneous input to certain operations, ensuring that validation works correctly. They might even look for security loopholes to ensure that malicious end users cannot gain access above their specified privilege level. When it is fully complete, the user story is moved across to the Done swimlane. Any story points associated with the story are then claimed, and the sprint burndown chart (which shows the progress of the sprint) can be amended. These artifacts are covered in more detail later.
Horizontal swimlanes
The Scrum board can be further split by using horizontal swimlanes. These swimlanes can be used to group the stories by feature, so that everyone can see at a glance where effort is being concentrated, and thus where bottlenecks need to be alleviated.
One special swimlane at the top of the board is the Fast-Track lane, into which any very high priority tasks can be placed. Team members can be instructed to “swarm” on a fast-track item so that it is completed as quickly as possible, often to the detriment of any other outstanding work. Swarming ensures that the team stops what they are doing to collaborate on a problem or task that has overriding priority. It is a useful tool and should be used sparingly, when such a priority occurs. Apocalyptic defects found in production are the most common fast-track items.
Technical debt
The term technical debt deserves further explanation. Throughout the course of implementing a user story, it is likely that certain compromises will need to be made between the “ideal code” and code that is good enough to meet the deadline. This is not to say that poor design should be willingly tolerated (nor actively encouraged) in order to hit a deadline, but that there is value in doing something simpler now, with a view to improving it later.
Good and bad technical debt
Debt is likely to accrue gradually over the lifetime of a project. It is termed debt because that is a great metaphor for how it should be viewed. There is nothing wrong with certain types of financial debt. If, for example, you have the option of spreading the payments for a car over 12 months and these payments are interest-free, you are in debt, but this could be a good decision if you need the car for commuting and cannot afford the payment in full. The car will allow you to generate the revenue necessary to pay for it, because you can now get to work on time.
Of course, some debt is bad. If you take out a credit card and pay for something extravagant without first calculating how you will repay the debt, you can end up in a cycle of balance transfers, trying to keep interest payments at a minimum. This will, in hindsight, look like a bad financial decision based around bad debt. The key is to look carefully at the options and decide whether the debt is worth taking on or whether you should just pay up front.
The tradeoff is the same in software. You could implement a suboptimal solution now and meet a deadline or spend the extra time now to improve the design, perhaps missing the deadline. There is no right answer that fits all situations, just guidelines for detecting good and bad technical debt.
The technical debt quadrant
Martin Fowler, a prominent Agile evangelist, defined a technical debt quadrant for categorizing the concessions and compromises that might be needed to mark a story as done. The two axes that divide a plane into quadrants, x and y, correspond to the questions, “Are we accruing this technical debt for the correct reasons?” and “Are we aware of alternatives to avoid this technical debt?”, respectively.
If you answer “Yes” to the former question, you are adding prudent technical debt: you can point to valid reasons for adding it, and your conscience is clear. If you answer “No,” then this debt is reckless and you would be better advised to deal with this debt now, rather than allow it to accumulate.
For the latter question, an affirmative answer means that you have considered the alternatives and decided to take the debt. A negative answer indicates that you cannot think of other alternatives.
The results of these questions generate four possible scenarios, as shown in Figure 1-5:
![]() Reckless, deliberate This type of debt is the most poisonous. It is equivalent to saying something like, “We don’t have time for design,” which indicates a very unhealthy working environment. A decision such as this should alert everyone that the team is not adaptive, and is marching steadily toward inevitable failure.
Reckless, deliberate This type of debt is the most poisonous. It is equivalent to saying something like, “We don’t have time for design,” which indicates a very unhealthy working environment. A decision such as this should alert everyone that the team is not adaptive, and is marching steadily toward inevitable failure.
![]() Reckless, inadvertent This type of debt is most likely created by a lack of experience. It is the result of not knowing best practices in modern software engineering. It is likely that the code is a mess, much like in the previous case, but the developer did not know any better and therefore could not find any other options. Education is the answer here: as long as developers are willing to learn, they can stop introducing this kind of technical debt.
Reckless, inadvertent This type of debt is most likely created by a lack of experience. It is the result of not knowing best practices in modern software engineering. It is likely that the code is a mess, much like in the previous case, but the developer did not know any better and therefore could not find any other options. Education is the answer here: as long as developers are willing to learn, they can stop introducing this kind of technical debt.
![]() Prudent, inadvertent This occurs when you follow best practices but it turns out that there was a better way of doing something, and “now you know how you should have done it.” This is similar to the previous case, but all of the developers were in agreement at the time that there was no better way of solving the problem.
Prudent, inadvertent This occurs when you follow best practices but it turns out that there was a better way of doing something, and “now you know how you should have done it.” This is similar to the previous case, but all of the developers were in agreement at the time that there was no better way of solving the problem.
![]() Prudent, deliberate This is the most acceptable type of debt. All of the choices have been considered, and you know exactly what you are doing—and why—by allowing this debt to remain. It is most commonly associated with a late decision to “ship now and deal with the consequences.”
Prudent, deliberate This is the most acceptable type of debt. All of the choices have been considered, and you know exactly what you are doing—and why—by allowing this debt to remain. It is most commonly associated with a late decision to “ship now and deal with the consequences.”

FIGURE 1-5 The technical debt quadrant, as explained by Martin Fowler, helps developers visualize the four different categories of debt.
Repaying debt
Technical debt is not directly associated with any story points, yet the debt must be repaid despite the lack of direct incentive. It is best to try to attach a technical debt card to a story and refactor the code so that the new design is implemented along with associated new behavior. The next time that a story is taken from the board, check whether any of the code that will be edited has a technical debt attached, and try to tackle the two together.
Digital Scrum boards
A digital Scrum board, unless constantly projected on a wall, hides some of the most important information about a project. By being open with this information and displaying it for the whole company to see, you invite questions about process that otherwise would not be asked. Being transparent with process is a huge benefit, especially when you are implementing Scrum for the first time in a company. It encourages buy-in from important stakeholders that you would do well to involve in the process.
It is a cliché, but people really do fear change. Fear is just a natural reaction to the unknown. By educating people on what you are doing and what certain charts mean (and why their wall is now covered in dozens of index cards), you foster a spirit of collaboration and communication that really is priceless. Being required to explain these things to a layman can also be helpful to you, because in doing so you might come to understand the process better yourself.
As with all tools, the best ones are high-touch and low-resistance. They will be used very often, and there will be no barriers to their use. When a tool becomes even mildly inconvenient to use, it will gradually be more and more neglected. What was initially used often and diligently kept up to date will no longer be tended, and it will rapidly fall behind reality.
The definition of done
Every project needs a definition of done (DoD). This is the standard that every user story must adhere to in order to be considered done. How many times have you heard these lines from a developer?
“It’s done, I just have to test it....”
“It’s done, but I found a defect that I need to fix....”
“It’s done, but I’m not 100-percent happy with the design, so I’m going to change the interface....”
I have used these myself in the past. If the story truly was done, there would be no caveats, conditions, or clauses required. These examples are what developers say when they need to buy themselves a little more time due to a bad estimate or an unforeseen problem. Everyone must agree on a definition of “done” and stick to it. If a user story doesn’t meet the criteria, it can’t possibly be done. Story points are never claimed until the story meets the definition of done.
What goes into a definition of done? That is entirely up to you, your team, and how stringent you want your quality assurance process to be. However, the following demonstrates a stock DoD as a starting point.
In order to claim that a user story is done, you must:
![]() Unit-test all code to cover its success and failure paths, with all tests passing.
Unit-test all code to cover its success and failure paths, with all tests passing.
![]() Ensure that all code is submitted to the Continuous Integration builds and compiles—without errors—with all tests passing.
Ensure that all code is submitted to the Continuous Integration builds and compiles—without errors—with all tests passing.
![]() Verify behavior against the acceptance criteria with the product owner.
Verify behavior against the acceptance criteria with the product owner.
![]() Peer-review code by a developer who did not work on the story.
Peer-review code by a developer who did not work on the story.
![]() Document just enough to communicate intent.
Document just enough to communicate intent.
![]() Reject reckless technical debt.
Reject reckless technical debt.
Feel free to remove, amend, or append any rules, but be strict with this definition. If one story cannot meet all criteria, you either ensure that this story can meet all criteria or drop prohibitive criteria from the definition of done altogether. For example, if you feel that code reviews are arcane or pedantic, feel free to omit that criterion from your DoD.
Charts and metrics
There are several charts that can be used to monitor the progress of a Scrum project. Scrum charts can indicate the health and historical progress of a Scrum project, in addition to predicting probable future achievement. All of these charts should be displayed prominently by the Scrum board in a size sufficient to be read from a few feet away. This shows the team that these metrics are not being used behind their back, that they are not a way of measuring their progress for the consumption of management. Instead, be very up front about how progress is measured, and make it clear that these charts are not being made for performance reasons, but to diagnose problems with the project as a whole.
On a related note, try to avoid measuring anything on a personal level—such as story points achieved per developer. This conveys a poor message to the team: that they can sacrifice team progress for personal progress. Developers will readily attach themselves to such measurements and try to save face by monopolizing larger stories, trying to achieve points all by themselves. Be careful what you incentivize.
![]() Caution
Caution
Be wary of what you measure—there is an “observer effect.” For instance, for some metrics, the act of measuring is not possible without first altering that which is measured. Take, for example, measuring tire pressure on a car. It is very difficult to measure the pressure without first letting a little air out of the tire, thus altering the pressure. This same principle applies quite aptly to human nature, too. When the team knows that they are going to be measured by some criteria, they will do whatever they can to improve their statistics to look good. This is not to say that you are managing a group of Machiavellian troublemakers, but when the team realizes that story points will be used to measure their progress, they might be inclined to assign higher points for the same effort. Use triangulation (which is covered in the “Sprint retrospective” section later in this chapter) to reconcile estimated effort with actual effort.
Story points
Story points are intended to incentivize the team to add business value with every sprint. Story points are assigned to user stories by the whole development team during the sprint planning meeting (see the “Sprint planning” section later in this chapter). A story point is a measure of relative effort required to implement the behavior that the user story represents. This is the inclusive effort required to fulfill the entire software life cycle—requirements analysis, technical design, and code implementation with unit testing, plus quality assurance against acceptance criteria and deployment to a staging environment. Although every story should already be small enough to fit comfortably inside a sprint, stories might still vary significantly in size.
At one end of the scale is a “one-point story” which requires minimal effort to implement. An interesting and important fact about story points is that they are absolutely meaningless outside of the team that assigned them. A one-point story for one team might be a three-point story for another team. What occurs over multiple sprints is a consensus on the approximate effort required for a story.
One thing that a story point definitely does not represent is effort measured in absolute terms—days, hours, or any other temporal measurement. Story points do, very roughly, correspond to a historical range of times, as shown in Figure 1-6. In this chart, the vertical bars represent estimated times, and the horizontal dashes attached to the bars represent actual effort spent on a story of the corresponding number of points.
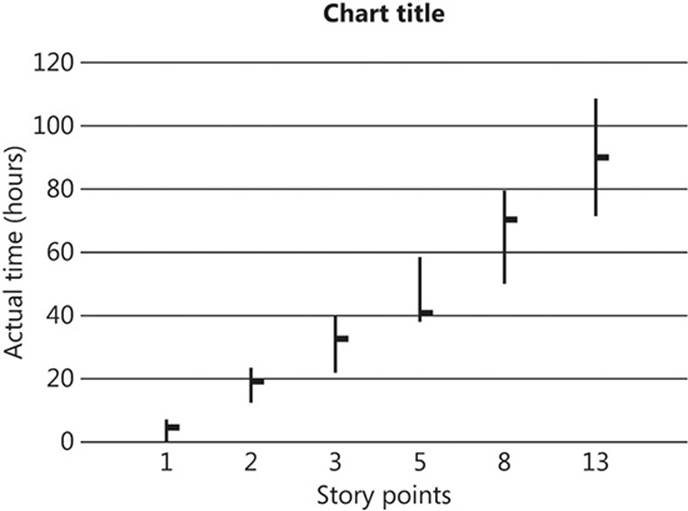
FIGURE 1-6 Min/max/average chart showing correlation between estimated effort and actual effort.
The main takeaway from this chart is that larger stories have correspondingly larger ranges—the larger a story is assumed to be, the harder it is to accurately predict how long it will take to complete.
Velocity
Over multiple sprints, it is possible to calculate a running average of the achieved story points. Let’s say that a team has completed three sprints, meeting the definition of done on stories totaling 8, 12, and 11 story points. This is a running total of 31 and a running average of 10 points. This can be said to be the team’s velocity, and it can be used in two ways.
First, a team’s velocity can form a ceiling for how many points a team should commit to for the next sprint. If the team is averaging 10 points per sprint, committing to more than that amount for a single iteration would be more than just optimistic—it would be setting them up for a morale-sapping failure. It is better to set an achievable goal and meet or exceed it than to set an unrealistic goal and fall short. If the team took these 10 points and actually implemented 11, it would feed into a new velocity of 11: (12 + 11 + 11) / 3. This is the Scrum feedback loop in action.
A second use for the velocity is to analyze problems with delivery. If the velocity of a team drops by a significant percentage for one sprint, this probably indicates that something bad happened during that sprint that needs to be rectified. Perhaps the stories were too large and their true scale was underestimated, thus keeping them in progress for a long time and requiring them to survive for more than one sprint. Alternatively, a simpler explanation could be possible—that too many key staff members were on vacation (or ill) all at once and progress naturally slowed. On the other hand, perhaps too much time was spent refactoring existing, working code, with not enough emphasis on introducing new behavior to the system. Whatever the reason, a 25-percent drop in velocity is not always disastrous, but it could be indicative of further problems to come that you should address as soon as possible. Week-after-week reductions in velocity—protracted deceleration—is a definite problem and probably points to code that is not adaptive to change; something that this book will help you address.
Sprint burndown chart
At the start of each sprint, a two-dimensional Cartesian graph is created and placed by the Scrum board. The total number of story points is charted along the y-axis, and the number of working days is plotted along the x-axis. A straight diagonal line (also known as the line of best fit) is then drawn to show the ideal progression of the sprint, as shown in Figure 1-7.
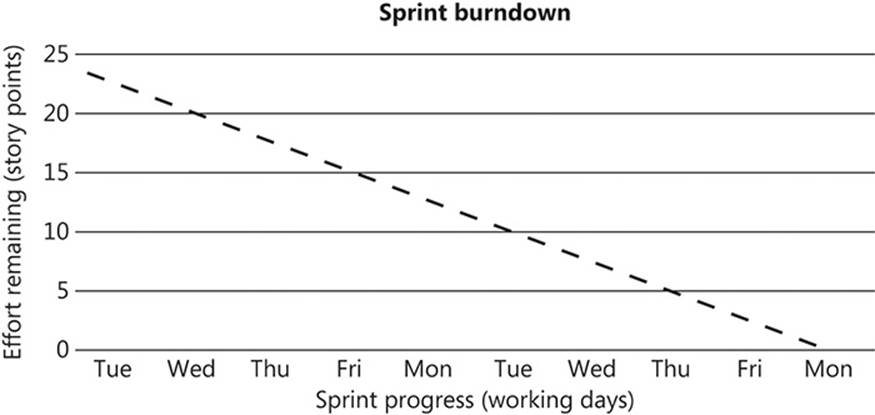
FIGURE 1-7 A sprint burndown chart at the beginning of a sprint. The straight line shows the “line of best fit” to the sprint goal (23 story points, in this example).
At each morning’s stand-up Scrum meeting, the points associated with any completed user stories are claimed and deducted from the current remaining total. As illustrated in Figure 1-8, this shows the actual progress of the sprint against the necessary progress in order to achieve the sprint goal.
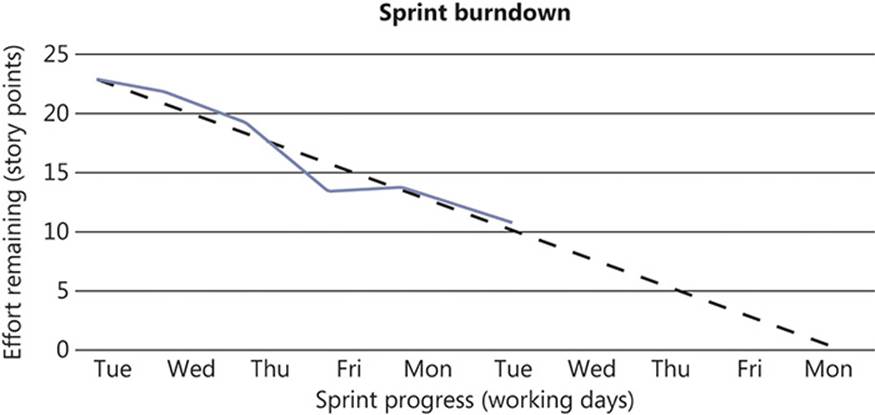
FIGURE 1-8 A sprint burndown chart partway through a sprint. In this instance, the team is sticking closely to the “path of perfection,” although no progress was made between Friday and Monday of the first week.
Drawing the actual-progress line and required line in different colors helps differentiate the two. If at any time during the sprint the actual line is above the required line, the chart is indicating that there is a problem and that the amount of work that will be delivered is less than planned. Conversely, if the actual line is below the required line, the project is ahead of schedule. It is likely that during the course of a sprint, the actual line will oscillate above and below the line somewhat, without indicating any real problems. It is the larger divergences that need to be explained.
Burndown charts are useful when there is a fixed amount of work required in a fixed amount of time. Under these conditions, it is not possible to dip below the x-axis. (When y=0, you have completed all work assigned.)
Feature burnup chart
Just as the sprint burndown chart tracks progress at story level throughout a sprint, the feature burnup chart shows the progress of completed features as they are implemented. At the end of each sprint, it is possible that a new feature might have been implemented in its entirety. The best thing about this graph is that it is impossible to fake the delivery of completed features without having symptoms manifest quite quickly. The idea is to watch this graph increase linearly over time, ideally without significant plateaus. Figure 1-9 shows an example of a good feature burnup chart.
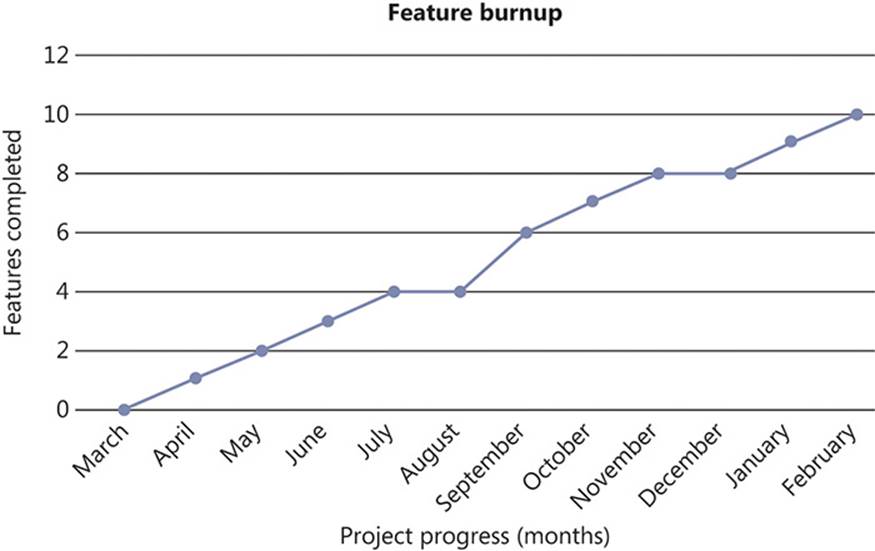
FIGURE 1-9 The feature burnup chart covering an adjusted calendar year for a healthy project making consistent progress.
Although the gradient might be shallow, this graph implies that the team has found a good rhythm to their development and is consistently delivering features at a fairly predictable rate. Though there are slight deviations from a perfectly straight line, these are nothing to worry about.
On the other hand, the burnup chart shown in Figure 1-10 shows that a definite issue has occurred during development. The team started very strongly, delivering lots of features extremely quickly, but they have since stalled and only delivered two completed features over the past eight months.
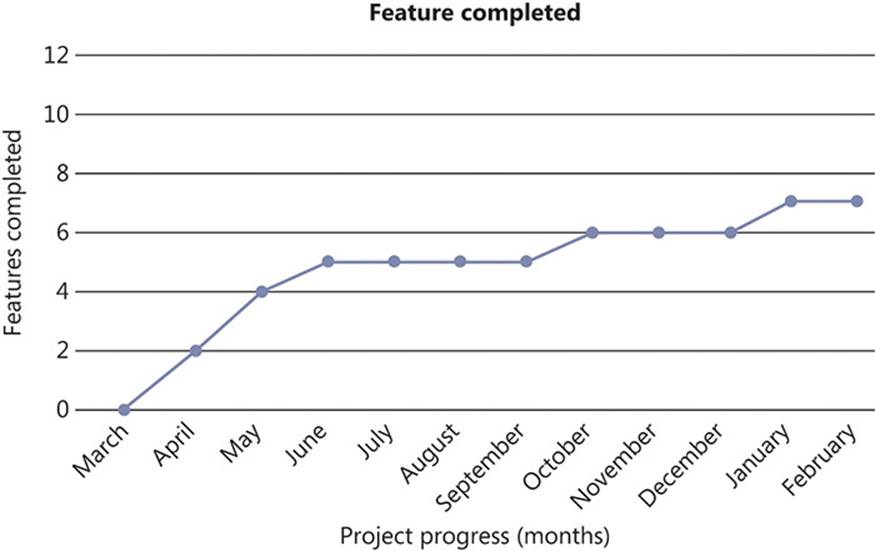
FIGURE 1-10 The feature burnup chart covering an adjusted calendar year for a project that has stalled.
The problem here is quite clear: the code was not adaptive to change. The initial dash from the starting line could indicate a lack of unit testing and neglect for layering or other best practices. By omitting these details, the team managed to complete features early. However, as the code base became bloated and disorganized, progress began to slow down significantly and the amount of features delivered ground to a halt. A progression like this is likely to be accompanied by an increase in the amount of defects and bad—reckless—technical debt. Eventually, if the project continues to follow this path, it would probably be better to start over—the refactoring effort required to get it back on track would outweigh the benefits. If the problem was caught early enough, of course, the team and project could recover. However, it is probably best to start with Agile development practices in place from the outset, rather than trying to crowbar them in to a brownfield project.
![]() Note
Note
Brownfield here means a project that is already in progress. It is the opposite of a greenfield project, which is a new project. The terms are taken from the construction industry.
Backlogs
A backlog is a list of pending items that are yet to be addressed. These items are waiting for their time to be taken from the backlog and acted on until they are complete. Each item in the list has an assigned priority and an estimated required effort, and the list is ordered first by priority and then by effort.
Two backlogs are maintained in Scrum, each with its own distinct purpose: the product backlog and the sprint backlog.
Product backlog
At any point during a product’s life, the product backlog contains features that are waiting to be implemented. These features have not been committed to a sprint, so the development team is not actively working on the items on this backlog. However, the development team—or its key representatives—will have spent time estimating the effort required on these features. This helps to prioritize the items on the product backlog so that it remains in priority order.
The priority of each item is primarily dictated by the value that implementing the feature would represent to the business. This business value must be determined by the owner of the product backlog: the product owner. This person represents the business to the development team and can speak authoritatively for it. The product owner’s knowledge of the business and its working practices is vital for correctly assigning the business value intrinsic to any particular feature. If two items on the product backlog have the same relative business value, their priority is decided based on the relative effort required. Given two features of high business value, if one is estimated to be small and another estimated to be large, it makes business sense to implement the small feature first. This is because smaller features pose less of a risk; the probable range of time required to implement a small feature will not vary as much as that of a larger feature. Also, the return on investment (ROI) is larger for a feature that requires less effort than for one of equal value that requires more.
When the business wants to release a new version of the product, the product backlog can be consulted to determine which features are most valuable to the release. This can occur in one of two ways: either the business sets an absolute deadline for the release and commits to the amount of work likely to be accomplished in that timeframe, given the effort estimates attached; or the business selects the features that are required for the release and the likely release date is determined from the estimates.
Aside from features, the product backlog can also contain defects that must be fixed but that have not yet found their way into a sprint. Just like features, defects will have some assigned business value. The estimate of effort required for a defect is difficult to ascertain, because there is less known about the cause of defects and some time might be required to find an estimate.
The product backlog should reflect the open nature of Agile reporting. It should be visible to everyone so that anyone can contribute ideas, offer suggestions, or indicate possible surprises along the way. It is also important that this list remain authoritative, containing the true state of the product backlog at any time. Poor decisions are often made due to poor information, and an out-of-date product backlog could be disastrous if key release-planning decisions are ill-informed.
Sprint backlog
The sprint backlog contains all of the user stories that are to be completed in the coming sprint. At the start of the sprint, the team selects enough work to fill a sprint based on their current velocity and the relative size of the user stories that are yet to be developed. After the stories are committed to the sprint, the team can start to break down each story into tasks that have real-world time estimates in hours. Each individual then elects to implement enough tasks to fill his or her time during the sprint.
The sprint backlog and all of the time estimates are owned by the team. No one outside of the development team can add items to the sprint backlog, nor can they reliably estimate the relative effort or absolute hours required to complete work. The team alone is responsible for the sprint backlog, but they must take work from the product backlog in priority order.
The sprint
The iterations of a Scrum project are called sprints. Sprints should last between one and four weeks, with two-week sprints commonly favored. A shorter sprint might leave too little time to accomplish the sprint goals, and a longer sprint might cause the team to lose focus.
Sprints are generally referred to by their index number, starting with sprint zero. Sprint zero is intended to prepare the development environment for the whole team, and to carry out some preliminary planning meetings before the first actual sprint begins. There will probably not be any points associated with sprint zero, but a lot can be achieved in those first weeks to make the transition to Scrum easier during subsequent sprints.
The temptation is to align sprints to the working week by starting them on a Monday and ending them on a Friday. The trouble with this is that the sprint retrospective (which will be covered shortly) involves quite a lot of time in meetings, and there is nothing more energy-sapping than sitting in meetings on a Friday afternoon. Some people also tend to leave early on Fridays, and concentration levels are likely to dip before the weekend. Similarly, no one looks forward to starting their week with meetings, so it is perhaps best to avoid this and start your sprints around midweek: Tuesday, Wednesday, or Thursday.
The following is an explanation of all of the meetings that form part of each sprint, in order, unless otherwise stated.
Release planning
At some point before the sprint begins, the release of the software must be planned. This involves the customer and the product owner deciding on a release date and prioritizing and sizing the features that are to be included.
Feature estimation
Features can involve a lot of effort, even on the smaller end of the scale. Thus, any attempts to accurately predict the amount of effort required will likely be off by a wide margin. For this reason, feature effort can be stated in common T-shirt sizes:
![]() Extra-large (XL)
Extra-large (XL)
![]() Large (L)
Large (L)
![]() Medium (M)
Medium (M)
![]() Small (S)
Small (S)
![]() Extra-small (XS)
Extra-small (XS)
Feature priority
It might be difficult to predict how many features can fit into a release, which is why feature priority is so important. For a specific release, all features can be given one of three priorities:
![]() Required (R)
Required (R)
![]() Preferred (P)
Preferred (P)
![]() Desired (D)
Desired (D)
Required features form part of the Minimum Viable Release. Preferred features are the features that should be tackled if any time is available before the deadline looms. Desired features are the lowest priority, those features that are not essential—but that the customer would certainly like to have implemented—for this release, anyway.
In addition, business stakeholders should number the features so that the development team can be sure to implement each feature in priority order.
Sprint planning
The expected outcome of sprint planning is to estimate user stories. As with all parts of the Scrum process, there are variations of the story estimation process. This section discusses planning poker, which is one of the more common ways to generate discussion, and affinity estimation, a quicker way to estimate the relative size of stories. Affinity estimation is better when there are a large number of stories to estimate. For an individual sprint, it is possible to use planning poker if there are only a few stories to estimate or to use affinity estimation if there are a larger number of stories or if time is short.
Planning poker
The planning poker session involves the whole development team—business analysts, developers, and test analysts—including the Scrum master and the product owner. For every user story that is currently on the product backlog, a small scope explanation is given, and then everyone is asked to vote on its size in story points.
In order to avoid a lot of small-scale differences, it is best to limit the voting options. For example, a common choice is a modified Fibonacci scale: 1, 2, 3, 5, 8, 13, 20, 40, and 100. Regardless of the scale chosen, the choices should be limited overall and the gaps between the options should increase in size as the number of points goes up. At the lower end of the scale, zero can be added to represent “no work required,” for a story that requires a negligible amount of work. At the upper end of the scale, team members can vote that a story is too big to implement within a sprint and must be vertically split further before being taken off the board to develop.
A few decks of playing cards double well as voting cards, but you can also fashion voting cards from spare index cards or even just scribble numbers on pieces of scrap paper. When it comes time to vote, everyone should show their cards at the same time, to avoid being influenced by the choices of others. It is unlikely that consensus will be achieved all the time, and there could be some large divergences between individual estimates. This is perfectly normal—there is sure to be a couple of outliers who deviate from the average vote. These voters should be asked to justify their choice in light of the general consensus. For example, if someone votes a 1 when the average vote was 8, that person would be asked—politely, of course—to explain why they think the story requires that much less effort. Similarly, voters who vote above the average should be asked to explain their reasons, too. All that is occurring here is that a discussion is generated about how much effort the team believes is required to carry a story to its conclusion.
After the justifications have been aired, a revote might be necessary because other people could have been persuaded that their vote was actually too big or too small and that the outlier was in fact correct. Eventually, consensus should be achieved, with all parties agreeing on a suitable number of story points. Each story should be estimated until the number of points assigned reaches the team’s current velocity, which is the maximum amount of work that the team should commit to in each sprint.
Avoiding Parkinson’s Law
Parkinson’s Law states:
“Work expands so as to fill the time available for its completion.”
—Cyril Northcote Parkinson
When you untether the estimates of stories from real-world time, there is less likelihood of succumbing to Parkinson’s Law. The focus should remain on completing the story—that is, on meeting the definition of done—as quickly as possible.
Affinity estimation
Affinity estimation is provided as a counterpoint to planning poker, which can take a significant amount of time to generate estimates if there are a lot of stories. Rather than entering into a discussion for each story, the team picks two stories from the top of the product backlog and then decides which is the smaller of the two. The smaller is placed on the left side of a table and the larger on the right.
The team then proceeds to take a single story from the product backlog and places it where they believe it should go on the spectrum between the existing smaller and larger stories. It could feasibly be placed to the left of the smaller story, indicating that it is smaller still; to the right of the larger, indicating that it is larger still; on top of the small or large story, indicating that it is roughly the same; or anywhere in between the two stories. This process then continues for each story on the product backlog, until there is no more room in the sprint for extra work.
With the stories grouped together by relative size, the team can start at the leftmost group and proceed toward the rightmost group, allocating points to the stories according to the modified Fibonacci sequence. If there are many stories to estimate, or if time is scarce, this is a good way of achieving a ballpark estimate of relative size.
Daily Scrum
Although there are several meetings that will last a couple of hours, the Scrum process itself is only really visible day to day at the daily Scrum, or “stand-up meeting.”
The team should gather around the Scrum board in a horseshoe shape and each person, in turn, should address the whole team. The daily Scrum should not last longer than 15 minutes. To focus the meeting, everyone should answer these three questions:
![]() What did you do yesterday?
What did you do yesterday?
![]() What will you do today?
What will you do today?
![]() What impediments do you face?
What impediments do you face?
The key issues that the daily stand-up meeting addresses are yesterday’s actual progress and today’s estimated progress. In discussing what you did yesterday, refer to the Scrum board and feel free to move cards across from one swimlane to another or move your avatar from one card to another, thus keeping the Scrum board current. Outline what you worked on and how the day went. If you do not have anything to do at this point, notify the Scrum master and request a new work item. Impediments include anything that might prevent you from completing your goal for the day. Because you will refer back to what you claim you will be doing today in tomorrow’s daily Scrum, it is important to enumerate anything that might prevent you from achieving what you plan to do. The impediment could be directly work related, as in, “I will not be able to continue if the network keeps going down like it did yesterday,” or it might be a personal matter, as in “I have an appointment with the dentist at 14:00, so I’m unlikely to complete everything.” Regardless, the Scrum master should be taking notes so that she knows how everyone is progressing with their stories.
Niko-niko calendar
A “niko-niko calendar”—also sometimes referred to as a “mood board” (in Japanese, “niko-niko” has a meaning close to “smiley”)— provides a good barometer of how the team feels about their progress during the sprint. A table is drawn by the Scrum board, with the days of the sprint across the top and the names of the team members down the side, as shown in Figure 1-11.
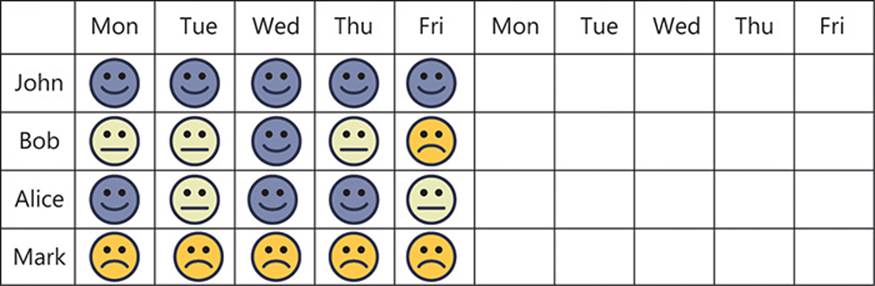
FIGURE 1-11 A niko-niko calendar quickly shows who is having a good sprint and who is not.
At the Scrum meeting, each person is asked to place one of three stickers on the board—green, yellow, or red—in their square for the previous day. Each sticker corresponds to an overall summary of how the previous day went: good, okay, or bad, respectively. This will quickly show when team members are having consecutive frustrating days and require help, which they might not otherwise seek.
This is just another metric to improve the feedback loop. If all of your team members are consistently feeling bad about their work, perhaps morale needs to be boosted. Or if one of the team is consistently unhappy but the rest of the team is happy, this could indicate that someone is being left behind or doesn’t feel like he/she fits in. Worst of all, if the whole team feels happy when sprints are running late, the code is in a mess, and clients are knocking down the door for their money back—the team has stopped caring!
After everyone has spoken, the meeting is over. One thing to be vigilant against is tangential conversations. It is extremely tempting to try to talk through problems during the Scrum. If someone mentions an impediment of some weird and wonderful behavior in the code base, all of the developers will likely want to hypothesize about the possible causes. Be aware of who needs to be present for such conversations—do the test analysts really need to listen to a discussion on why Microsoft Visual Studio is using the coders’ entire available RAM? No, most likely not. Make a note of the problem and ask the appropriate people to take the discussion offline (after the meeting).
Sprint demo
A sprint demo is a key event to put in the sprint calendar. It is a showcase of all of the completed stories—those that have met the definition of done during the sprint—in action in a real environment. The entire development team should be present, and you could also invite other stakeholders to the meeting, such as management or sales team representatives. Anyone who might have an interest in the project’s progress should be free to attend. This further fosters an openness that all projects should have.
Collect all of the completed user stories from the Scrum board and, for each one, explain its scope and what it was intended to achieve as part of the project as a whole. Refer to the feature to which the story belongs, and the change in application behavior that has occurred as a result of its implementation. Proceed to demonstrate this behavior by using a real deployment of the system. Invite questions from the audience, but do be careful about off-topic issues or getting sidetracked by irrelevance. Keep the conversation focused, and offer to talk to people individually after the demo has completed. Any suggestions for improvements should feed back into the product backlog so that they are correctly prioritized and scheduled. It sometimes feels that improvements suggested in the demo are suddenly the most important things to be done, but this is rarely a reflection of reality.
The demo should not be feared, but it certainly incentivizes progress. No one wants to cancel a demo because nothing has been completed, but resist the temptation to circumvent the definition of done just to demonstrate something. By being honest about progress, you will not have to hide any problems. Instead, point to the charts and metrics to explain probable causes for the reduced output.
Specifying a time before the demo when code will be locked is also a good idea, to prevent those tempting last-minute changes to try to claim more points. Dedicate a realistic amount of time before the demo to set up the environment and ensure that everyone is ready, and guard against throwing reckless technical debt into the code for a short-term boost.
Discipline is the ability to consistently choose perpetual benefit over fleeting temptation.
Mike Alexander, Fitness Expert
Sprint retrospective
When the sprint demo is complete, it is time to take stock of the iteration and gauge opinions about its overall success. For some team members, the sprint might have been a resounding success, whereas for others, it might have been an absolute disaster. The sprint retrospective can help you distill the elements that went well into actions that bear repeating and isolate problems so that they can be dealt with. The output from the sprint retrospective should not be written once and forever forgotten. It should be referred to at the end of the next sprint to ensure that requisite changes were made and that mistakes were not repeated.
The following questions should be asked of the team during the retrospective:
![]() What went well?
What went well?
![]() What went badly?
What went badly?
![]() What do we need to start doing?
What do we need to start doing?
![]() What do we need to stop doing?
What do we need to stop doing?
![]() What do we need to continue doing?
What do we need to continue doing?
![]() Did we experience any surprises during the sprint?
Did we experience any surprises during the sprint?
Starting with the positive, ask each team member to elaborate on what they felt went well about the sprint. Perhaps they were very happy with the progress that was made, or with the quality of the work that was produced.
Next, ask them to explain what went badly in the sprint. Perhaps some tasks were more difficult and involved than first anticipated, thus causing an otherwise simple story to be delayed. Whatever the problem, it is certain that some kind of resolution can be found. There is nothing wrong with candidness, as long as it is accompanied by objectivity. No one should be accusatory against other team members, and all criticism should be given constructively and received gracefully. The goal is an improvement of the process and the product.
It could be that there are certain things that the team does not currently do that should be introduced to the process. Perhaps there are not yet any formal unit tests to accompany the code, and the team believes that this should be introduced at this stage. As with all suggestions, the Scrum master should be actively taking notes to take action later.
Equally, there could be things that the team is doing that they feel should be stopped. Prime examples are to stop unplanned digressions in meetings and to stop moving stories into the In Progress lane when there is plenty of work already there. This latter problem is quite common and can be solved by putting capacity limits on certain swimlanes. By enforcing that no more than three stories can be in progress at a time, team members are encouraged to help finish work that has already begun rather than start something afresh.
Some things that went well will yield actions that bear repeating. If the sprint demo went well and it was decided that this was due to good preparation beforehand, make a note to continue to do this. It is quite surprising how quickly good habits can be forgotten and bad habits take their place.
Finally, the team should recall any surprises—good or bad—that were revealed during the sprint. Any bad surprise should result in an action item to avoid such an occurrence in the future, whereas a good surprise could result in behavior that bears repeating.
At least one action item from the retrospective should be prioritized for the next sprint. The outcomes of this meeting should not be forgotten; they should be acted on.
Story point triangulation
Some of the stories during the sprint might have required more or less effort than was estimated by the team during the sprint planning meeting. Taking 5 or 10 minutes at the end of the sprint retrospective to triangulate the estimated stories with the actual effort expended can be rewarding.
After a couple of sprints, there will be statistics available for how long each story actually took in comparison to its story point estimate. For example, you might have a table something like Table 1-1.
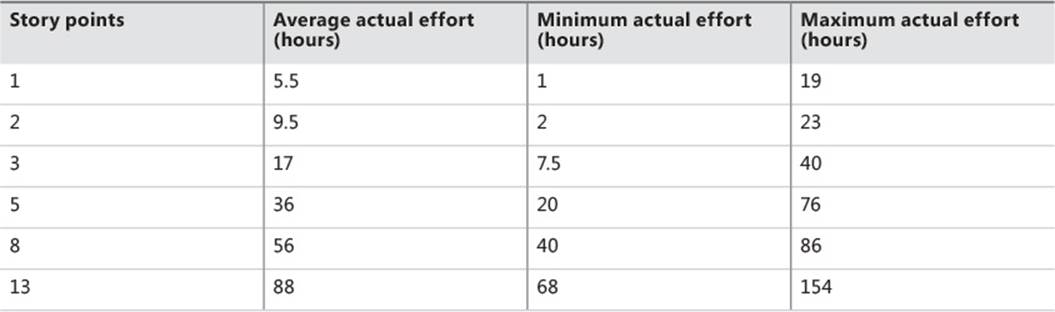
TABLE 1-1 Statistics for the average, minimum, and maximum actual effort compared to user story estimates on a hypothetical project
If a one-point story for a sprint actually took 60 hours to complete, it was probably closer to an eight-point story. As long as there were no mitigating circumstances—such as a lack of developer resources because of absence—the estimate can be safely deemed to have been erroneous. If you claim the eight story points instead, your velocity will not suffer as a result, and the amount of stories that the team can commit to does not decrease.
Focus on the stories that are significantly out of range. If a one-point story fits into the range for a two-point or three-point story, it is unlikely to make a significant difference to take more points.
Scrum calendar
For clarity, a calendar showing the typical Scrum meetings over the course of a sprint is shown in Table 1-2.
TABLE 1-2 A possible calendar for organizing the Scrum meetings of a sprint for a hypothetical project
Observe that almost a whole day is dedicated to the end of a sprint and the beginning of a new sprint. This is called Sprint Handover Day and, to maintain concentration levels, it is sometimes split between two consecutive days: an afternoon and the following morning. The sprint demo and retrospective would then be held Tuesday afternoon, and the sprint planning meeting would be moved to Wednesday morning.
Another interesting point is the timing of the daily Scrum. If it is too early in the day, attendance can be a problem because people could be delayed by traffic or otherwise waylaid. Similarly, if it is too late, dragging people from their desks when they are already involved in a task is also difficult.
These meetings can be added to Microsoft Outlook or some other calendar program, with the relevant people attached as attendees.
Problems with Scrum and Agile
Agile processes are not a miracle solution, destined to turn every failing project to profitability and success. The aim of any software development process is to create repeatable success when delivering software, but that software still needs to be written. No amount of documentation can remove the fact that a software product is the result of working source code.
This book teaches developers how to create software solutions that are adaptive. This means that they are resilient to the sort of change to which all software is subjected. It is irrational to assume that the first attempt at a solution will meet all of the needs of the customer, so change is inevitable. Agile processes—and Scrum is no exception—aim to embrace this change and seek to ensure that customers are allowed to make alterations to the behavior of the software as it is developed. Otherwise, they would be forced to accept a substandard solution that misses the mark.
Maladaptive code
Code that is not adaptive is maladaptive. If code is maladaptive, it does not readily lend itself to change. The estimates that the team assigned to various tasks could be significantly different from reality because the code takes much longer to change than it really should. Changing the code might also result in the introduction of defects that will eventually take further time, effort, and resources to be fixed.
Rigidity
Code can display a few different signs of rigidity, each of which needs to be addressed so that changes don’t become increasingly difficult, limiting the number of features that can be delivered.
Lack of abstractions
An abstraction hides the details of something, showing instead a much simpler representation. Abstractions are all around us. The steering wheel in your car abstracts the mechanical implementation that eventually turns the wheels in either direction. In fact, there are two common types of steering: rack-and-pinion steering and recirculating-ball steering. In either implementation, the end result is that both of the wheels turn to match how much you have turned the steering wheel, in relative terms. Also, the left and right wheels do not turn the same amount. Because the inside wheel traces a circle of smaller radius than the outside wheel, it must turn more tightly than the outside wheel.
Of course, you do not need to know any of this to drive a car. Sure, it might help you diagnose problems or explain how it works, but as an everyday driver, all this is extraneous information that is not vital to you. The abstraction hides as many details as it can and gives you just enough to get by.
In software, abstractions are key. The user interface does not need to know what storage medium is being used to house the user’s input. In fact, if it does know this, there is a lack of abstraction, and the user interface becomes hopelessly obsessed with details that it need not and should not be concerned with.
Code with sufficient abstractions will be better organized, easier to understand and communicate to others, and easier to maintain, and it will contain fewer errors.
Mixed responsibilities
Often, code gradually grows organically from something small, perhaps even trivial, to something much bigger and more important. Incremental changes are made, one on top of the other, until some critical point is reached when a single change can have many related and unpredictable consequences.
This sort of code contains methods, classes, and possibly even whole modules that have no single discernable purpose. Instead, each fulfills several different responsibilities that cannot be easily separated. In this code, a change that should only take a few hours to complete can easily end up taking a day or more of wrestling with the side-effects that one change has on another, ostensibly unrelated, area of the code.
To avoid this, ensure that code at every level—methods, classes, and modules—focuses on one well-defined responsibility.
Untestability
Unit testing has been an established practice for many years now. It is a reliable method of ensuring code correctness that should feel entirely natural to many developers. However, it takes constant discipline and diligence to ensure that code remains testable over the long term.
If code is untestable, it is untested. If code is untested, it will contain defects. There is no quantum state indeterminacy at play here: you must simply assume that untested code contains defects. That is the level of suspicion with which you should treat such code.
The following concepts, and testability in general, are discussed in further detail in Chapter 4, “Unit testing and refactoring.”
Skyhooks vs. cranes
Daniel C. Dennett wrote in his 1995 book, “Darwin’s Dangerous Idea” [emphasis mine]:
“A skyhook is ... an exception to the principle that all design, and apparent design, is ultimately the result of mindless, motiveless mechanicity. A crane, in contrast, is a subprocess or special feature of a design process that can be demonstrated to permit the local speeding up of the basic, slow process of natural selection, and that can be demonstrated to be itself the predictable (or retrospectively explicable) product of the basic process.”
Daniel C. Dennett, Darwin’s Dangerous Idea: Evolution and the Meaning of Life, 1995 [Simon & Schuster]
Sidestepping the religiosity of the content, put simply, a skyhook is a way to explain something without reference to a prior antecedent. Conversely, cranes have explicable antecedents—perhaps until arriving at some primary axiom.
This is a useful analogy in programming, too. Skyhooks are indicative of a deeper problem. All skyhooks should be replaced with appropriate cranes.
The presence of a skyhook in code is difficult to replace with a fake implementation, thereby reducing testability. Examples of skyhooks are:
![]() Static methods
Static methods
![]() Static classes (including singletons)
Static classes (including singletons)
![]() Object construction that uses new
Object construction that uses new
![]() Extension methods
Extension methods
Each of these make testing more difficult1 by hindering your ability to inject mocks into your code; they are skyhooks and thus they are undesirable. Each is used ex nihilo—from nothing.
1 Difficult, though not impossible. Some mocking frameworks, such as TypeMock (www.typemock.com), are able to mock skyhooks. However, this should only be considered if the skyhooks are in third-party, unchangeable code.
Luckily, each of these can be replaced with a suitable crane, such as the following, that will facilitate some kind of external injection (that is, it can be used ex materia—from something).
![]() Interfaces
Interfaces
![]() Dependency injections
Dependency injections
![]() Inversion of control
Inversion of control
![]() Factories
Factories
In subsequent chapters of this book, each of these “cranes” of programming are explained in more detail.
Metrics
Source code has been subject to many different metrics through the years, each attempting to reduce the complexity of code down to numbers that indicate the health—or otherwise—of the project as a whole.
This might seem rather reductive, but metrics have evolved somewhat since middle-management obsessed over source lines of code (SLOC). Although SLOC correlates well to the effort required—it takes longer to write more lines of code than it does to write fewer—it does not necessarily correlate to the level of functionality of a system. Nor, indeed, is it a reliable measure of a developer’s productivity.
Cum hoc ergo propter hoc
The Latin phrase cum hoc ergo propter hoc translates to “With this, therefore because of this.” This is an example of a logical fallacy: a mistake in reasoning. It is the misapprehension that, because an event statistically occurs in conjunction with some other event, one of those events occurs because of the other. Sometimes this is quoted as, “Correlation does not imply causation.”
It is important to remember that, with all of these metrics, there is merely a statistical correlation between a desirable value for the metric and the nebulous goal of “good code.”
Unit test coverage
Unit test coverage is a measurement of the percentage of the code that is covered by unit tests. This ranges from 0 percent, indicating that none of the code is covered by any tests, to 100 percent, where every line of code is covered by at least one unit test. Typically, coverage of 80 percent is considered a minimum acceptable level.
In addition to the unit tests, unit test coverage tools should be run by the continuous integration server, which will compile the code every time it is committed to source control. This will allow you to gain fast feedback on any movements in code coverage.
Test coverage is somewhat misleading, because it is a quantitative measure of the unit tests, as opposed to a qualitative measure. It is easy to increase code coverage with any tests, as opposed to the right tests.
If test coverage is below 80 percent—or whatever your chosen benchmark is—then it can be incrementally increased over time toward your overall coverage goal. With each increase, the continuous integration build should be configured to fail if the coverage percentage slips backward. This means that no new production code can be added without accompanying unit tests, otherwise the coverage percentage would be diluted and would decline.
Cyclomatic complexity
Cyclomatic complexity is a measure of the number of paths that exist in the code. With each additional branch in the code—if statements, loops, or switch statements—the cyclomatic complexity increases. As Figure 1-12 shows, a simple if statement and inner loop can be modeled as a graph As the figure shows, the total number of paths through the statement and loop is equal to the cyclomatic complexity of the code.
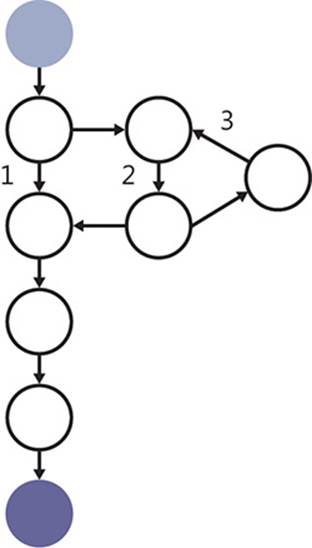
FIGURE 1-12 Each extra path through the code adds further complexity.
The edge labeled 1 is the case when the if statement has a false condition, thus its body is not executed. Edge 2 is when the if statement’s body is executed, but the contained loop is not. Edge 3 is the case when both the if statement and loop are executed.
As cyclomatic complexity increases, the testing effort required in order to gain unit test code coverage on each branch also increases. Therefore, it is best to keep branching, thus cyclomatic complexity, low to avoid extra test code.
There is also a statistical correlation between high complexity and defect count. That is, code with more branching tends to have more defects.
Conclusion
This chapter has served as an introduction to the Scrum process. If you have never worked on a Scrum project, I hope that your interest has now been piqued sufficiently to do so. On the other hand, if you do work on a Scrum project, perhaps there were some new ideas in this chapter that you want to use.
Though there is admittedly a lot of ground still not covered in this chapter with respect to Scrum, the rest of the book is dedicated more to the developer’s point of view of an Agile project. However, there are plenty of resources available for learning more about Scrum and discovering whether it is a good fit for your company and your projects.
Scrum projects, like any software projects, are vulnerable to failure. Spotting when something is going wrong is a significant part of the battle, but spotting why it is happening can be even harder. The internal machinations of the code might be designed in a way that makes change very difficult—no matter what process is in place for managing this change. The rest of this book will provide advice and guidelines for ensuring that code is adaptive from the bottom up, making change easier and allowing you to focus solely on adding business value with every sprint.