Algorithms Third Edition in C++ Part 5. Graph Algorithms (2006)
CHAPTER TWENTY
Minimum Spanning Trees
20.6 Comparisons and Improvements
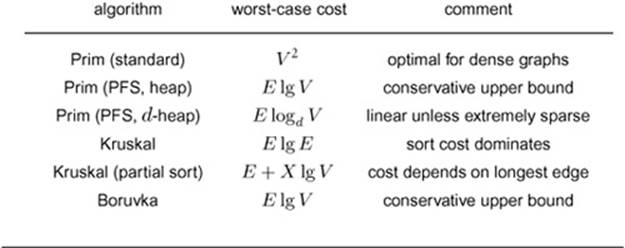
Table 20.1 summarizes the running times of the basic MST algorithms that we have considered; Table 20.2 presents the results of an empirical study comparing the algorithms. From these tables, we can conclude that the adjacency-matrix implementation of Prim’s algorithm is the method of choice for dense graphs, that all the other methods perform within a small constant factor of the best possible (the time that it takes to extract the edges) for graphs of intermediate density, and that Kruskal’s method essentially reduces the problem to sorting for sparse graphs.
In short, we might consider the MST problem to be “solved” for practical purposes. For most graphs, the cost of finding the MST is only slightly higher than the cost of extracting the graph’s edges. This rule holds except for huge graphs that are extremely sparse, but the available performance improvement over the best known algorithms even in this case is approximately a factor of 10 at best. The results in Table 20.2 are dependent on the model used to generate graphs, but they are borne out for many other graph models as well (see, for example, Exercise 20.80). Still, the theoretical results do not deny the existence of an algorithm that is guaranteed to run in linear time for all graphs; here we take a look at the extensive research on improved implementations of these methods.
First, much research has gone into developing better priority-queue implementations. The Fibonacci heap data structure, an extension of the binomial queue, achieves the theoretically optimal performance of taking constant time for decrease key operations and logarithmic time for remove the minimum operations, which behavior translates, by Property 20.8, to a running time proportional to E + V lg V for Prim’s algorithm. Fibonacci heaps are more complicated than binomial queues and are somewhat unwieldy in practice, but some simpler priority-queue implementations have similar performance characteristics ( see reference section ).
One effective approach is to use radix methods for the priority-queue implementation. Performance of such methods is typically equivalent to that of radix sorting for Kruskal’s method, or even to that of using a radix quicksort for the partial-sorting method that we discussed in Section 20.4.
Another simple early approach, proposed by D. Johnson in 1977, is one of the most effective: Implement the priority queue for Prim’s algorithm with d -ary heaps, instead of with standard binary heaps (see Figure 20.17). Program 20.10 is a complete implementation of the priority-queue interface that we have been using that is based on this method. For this priority-queue implementation, decrease key takes less than logd V steps, and remove the minimum takes time proportional to d logd V. By Property 20.8, this behavior leads to a running time proportional to Vd logd V + Elogd V for Prim’s algorithm, which is linear for graphs that are not sparse.
Table 20.1 Cost of MST algorithms
This table summarizes the cost (worst-case running time) of various MST algorithms considered in this chapter. The formulas are based on the assumptions that an MST exists (which implies that E V 1) and that there are X edges not longer than the longest edge in the MST − (see Property 20.10). These worst-case bounds may be too conservative to be useful in predicting performance on real graphs. The algorithms run in near-linear time in a broad variety of practical situations.
Property 20.12 Given a graph with V vertices and E edges, let d denote the density E/V. If d < 2 , then the running time of Prim’s algorithm is proportional to V lg V. Otherwise, we can improve the worst-case running time by a factor of lg( E/V ) by using a E/V -ary heap for the priority queue.
Proof: Continuing the discussion in the previous paragraph, the number of steps is Vd logd V + E logd V, so the running time is at most proportional to E logd V =( E lg V ) / lg d.
When E is proportional to V1+ [epsilon1], Property 20.12 leads to a worst-case running time proportional to E/[epsilon1], and that value is linear for any constant [epsilon1]. For example, if the number of edges is proportional to V3 / 2, the cost is less than 2 E; if the number of edges is proportional to
Table 20.2 Empirical study of MST algorithms
This table shows relative timings for various algorithms for finding the MST, for random weighted graphs of various density. For low densities, Kruskal’s algorithm is best because it amounts to a fast sort. For high densities, the classical implementation of Prim’s algorithm is best because it does not incur list-processing overhead. For intermediate densities, the PFS implementation of Prim’s algorithm runs within a small factor of the time that it takes to examine each graph edge.
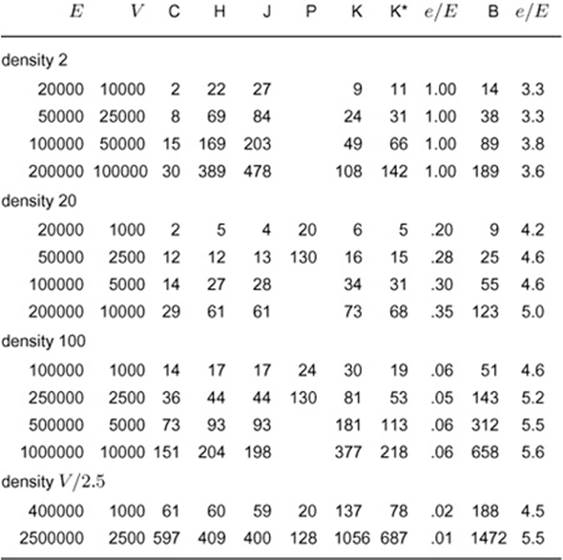
Key:
C extract edges only
H Prim’s algorithm (adjacency lists/indexed heap)
J Johnson’s version of Prim’s algorithm (d-heap priority queue)
P Prim’s algorithm (adjacency-matrix representation)
K Kruskal’s algorithm
K* Partial-sort version of Kruskal’s algorithm
B Boruvka’s algorithm
e edges examined (union operations)
V4 / 3, the cost is less than 3 E; and if the number of edges is proportional to V5 / 4, the cost is less than 4 E. For a graph with 1 million vertices, the cost is less than 6 E unless the density is less than 10.
The temptation to minimize the bound on the worst-case running time in this way needs to be tempered with the realization that the Vd logd V part of the cost is not likely to be avoided (for remove the minimum, we have to examine d successors in the heap as we sift down), but the E lg d part is not likely to be achieved (since most edges will not require a priority-queue update, as we showed in the discussion following Property 20.8).
For typical graphs such as those in the experiments in Table 20.2, decreasing d has no effect on the running time, and using a large value of d can slow down the implementation slightly. Still, the slight protection offered for worst-case performance makes the method worthwhile since it is so easy to implement. In principle, we could tune the implementation to pick the best value of d for certain types of graphs (choose the largest value that does not slow down the algorithm), but a small fixed value (such as 4, 5, or 6) will be fine except possibly for some particular huge classes of graphs that have atypical characteristics.
Using d -heaps is not effective for sparse graphs because d has to be an integer greater than or equal to 2, a condition that implies that we cannot bring the asymptotic running time lower than V lg V. Ifthe density is a small constant, then a linear-time MST algorithm would have to run in time proportional to V.
The goal of developing practical algorithms for computing the MST of sparse graphs in linear time remains elusive. A great deal of research has been done on variations of Boruvka’s algorithm as the basis for nearly linear-time MST algorithms for extremely sparse graphs ( see reference section ). Such research still holds the potential to lead us eventually to a practical linear-time MST algorithm and has even shown the existence of a randomized linear-time algorithm. While these algorithms are generally quite complicated, simplified versions of some of them may yet be shown to be useful in practice. In the meantime, we can use the basic algorithms that we have considered here to compute the MST in linear time in most practical situations, perhaps paying an extra factor of lg V for some sparse graphs.
Figure 20.17 2-, 3-, and 4-ary heaps
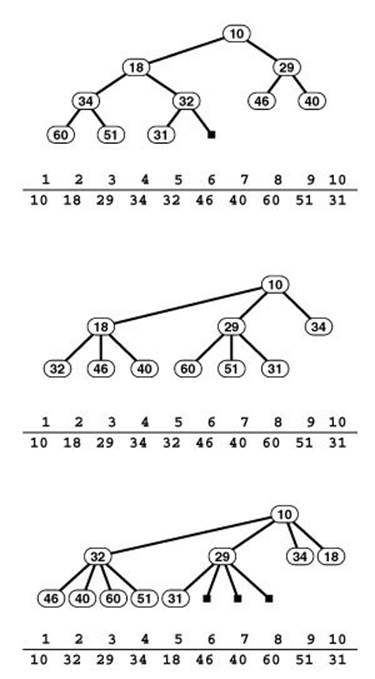
When we store a standard binary heap-ordered complete tree in an array (top), we use implicit links to take us from a node i down the tree to its children 2 i and 2 i + 1 and up the tree to its parent i/ 2. In a 3-ary heap (center), implicit links for i are to its children 3 i 1, 3 i, and 3 i + 1 and to its parent − [floorleft] ( i +1) / 3 [floorright]; and in a 4-ary heap (bottom), implicit links for i are to its children 4 i − 2, 4 i 1, 4 i, and 4 i +1 and to its parent −[floorleft] ( i +2) / 4. Increasing the branching factor in [floorright] an implicit heap implementation can be valuable in applications, like Prim’s algorithm, that require a significant number of decrease key operations.
Program 20.10 Multiway heap PQ implementation
This class uses multiway heaps to implement the indirect priority-queue interface that we use in this book. It is based on changing Program 9.12 to have the constructor take a reference to a vector of priorities, to implement getmin and lower instead of delmax and change, and to generalize fixUp and fixDown so that they maintain a d -way heap (so remove the minimumtakes time proportional to d logd V, but decrease key requires less than logd V steps).

Exercises
• 20.71 [V. Vyssotsky] Develop an implementation of the algorithm discussed in Section 20.2 that builds the MST by adding edges one at a time and deleting the longest edges on the cycle formed (see Exercise 20.33). Use a parent-link representation of a forest of MST subtrees. Hint:Reverse pointers when traversing paths in trees.
• 20.72 Run empirical tests to compare the running time of your implementation in Exercise 20.71 with that of Kruskal’s algorithm, for various weighted graphs (see Exercises 20.9–14). Check whether randomizing the order in which the edges are considered affects your results.
• 20.73 Describe how you would find the MST of a graph so large that only V edges can fit into main memory at once.
• 20.74 Develop a priority-queue implementation for which remove the minimum and find the minimum are constant-time operations, and for which decrease key takes time proportional to the logarithm of the priority-queue size. Compare your implementation with 4-heaps when you use Prim’s algorithm to find the MST of sparse graphs, for various weighted graphs (see Exercises 20.9–14).
20.75 Run empirical studies to compare the performance of various priority-queue implementations when used in Prim’s algorithm for various weighted graphs (see Exercises 20.9–14). Consider d -heaps for various values of d, binomial queues, the STL priority_queue, balanced trees, and any other data structure that you think might be effective.
20.76 Develop an implementation that generalizes Boruvka’s algorithm to maintain a generalized queue containing the forest of MST subtrees. (Using Program 20.9 corresponds to using a FIFO queue.) Experiment with other generalized-queue implementations, for various weighted graphs (see Exercises 20.9–14).
• 20.77 Develop a generator for random connected cubic graphs (each vertex of degree 3) that have random weights on the edges. Fine-tune for this case the MST algorithms that we have discussed, then determine which is the fastest.
• 20.78 For V = 106, plot the ratio of the upper bound on the cost for Prim’s algorithm with d -heaps to E as a function of the density d, for d in the range from 1 to 100.
• 20.79 Table 20.2 suggests that the standard implementation of Kruskal’s algorithm is significantly faster than the partial-sort implementation for low-density graphs. Explain this phenomenon.
• 20.80 Run an empirical study, in the style of Table 20.2, for random complete graphs that have Gaussian weights (see Exercise 20.18).
All materials on the site are licensed Creative Commons Attribution-Sharealike 3.0 Unported CC BY-SA 3.0 & GNU Free Documentation License (GFDL)
If you are the copyright holder of any material contained on our site and intend to remove it, please contact our site administrator for approval.
© 2016-2026 All site design rights belong to S.Y.A.