Algorithms Third Edition in C++ Part 5. Graph Algorithms (2006)
CHAPTER SEVENTEEN
Graph Properties and Types
17.6 Graph Generators
To develop further appreciation for the diverse nature of graphs as combinatorial structures, we now consider detailed examples of the types of graphs that we use later to test the algorithms that we study. Some of these examples are drawn from applications. Others are drawn from mathematical models that are intended both to have properties that we might find in real graphs and to expand the range of input trials available for testing our algorithms.
To make the examples concrete, we present them as client functions of Program 17.1, so that we can put them to immediate use when we test implementations of the graph algorithms that we consider. In addition, we consider the implementation of io::scan from Program 17.4, which reads a sequence of pairs of arbitrary names from standard input and builds a graph with vertices corresponding to the names and edges corresponding to the pairs.
The implementations that we consider in this section are based upon the interface of Program 17.1, so they function properly, in theory, for any graph representation. In practice, however, some combinations of interface and representation can have unacceptably poor performance, as we shall see.
Program 17.12 Random graph generator (random edges)
This function adds random edges to a graph by generating E random pairs of integers, interpreting the integers as vertex labels and the pairs of vertex labels as edges. It leaves the decision about the treatment of parallel edges and self-loops to the implementation of the insert member function of Graph. This method is generally not suitable for generating huge dense graphs because of the number of parallel edges that it generates.
static void randE(Graph &G, int E)
{
for (int i = 0;i<E; i++)
{
int v = int(G.V()*rand()/(1.0+RAND_MAX));
int w = int(G.V()*rand()/(1.0+RAND_MAX));
G.insert(Edge(v,w));
}
}
As usual, we are interested in having “random problem instances,” both to exercise our programs with arbitrary inputs and to get an idea of how the programs might perform in real applications. For graphs, the latter goal is more elusive than for other domains that we have considered, although it is still a worthwhile objective. We shall encounter various different models of randomness, starting with these two.
Random edges This model is simple to implement, as indicated by the generator given in Program 17.12. For a given number of vertices V, we generate random edges by generating pairs of numbers between 0 and V − 1. The result is likely to be a random multigraph with self-loops. A given pair could have two identical numbers (hence, self-loops could occur); and any pair could be repeated multiple times (hence, parallel edges could occur). Program 17.12 generates edges until the graph is known to have E edges, leaving to the implementation the decision of whether to eliminate parallel edges. If parallel edges are eliminated, the number of edges generated is substantially higher than then number of edges used (E) for dense graphs (see Exercise 17.62); so this method is normally used for sparse graphs.
Figure 17.12 Two random graphs

Both of these random graphs have 50 vertices. The sparse graph at the top has 50 edges, while the dense graph at the bottom has 500 edges. The sparse graph is not connected, with each vertex connected only to a few others; the dense graph is certainly connected, with each vertex connected to 20 others, on the average. These diagrams also indicate the difficulty of developing algorithms that can draw arbitrary graphs (the vertices here are placed in random position).
Program 17.13 Random graph generator (random graph)
Like Program 17.12, this function generates random pairs of integers between 0 and V-1 to add random edges to a graph, but it uses a different probabilistic model where each possible edge occurs independently with some probability p. The value of p is calculated such that the expected number of edges (pV (V − 1)/2) is equal to E. The number of edges in any particular graph generated by this code will be close to E but is unlikely to be precisely equal to E. This method is primarily suitable for dense graphs, because its running time is proportional to V2.
static void randG(Graph &G, int E)
{ double p = 2.0*E/G.V()/(G.V()-1);
for (int i = 0; i < G.V(); i++)
for (int j = 0; j < i; j++)
if (rand() < p*RAND_MAX)
G.insert(Edge(i, j));
}
Random graph The classic mathematical model for random graphs is to consider all possible edges and to include each in the graph with a fixed probability p. If we want the expected number of edges in the graph to be E, we can choose p = 2E/V (V − 1). Program 17.13 is a function that uses this model to generate random graphs. This model precludes duplicate edges, but the number of edges in the graph is only equal to E on the average. This implementation is well-suited for dense graphs, but not for sparse graphs, since it runs in time proportional to V (V − 1)/2 to generate just E =pV (V - 1)/2 edges. That is, for sparse graphs, the running time of Program 17.13 is quadratic in the size of the graph (see Exercise 17.68).
These models are well-studied and are not difficult to implement, but they do not necessarily generate graphs with properties similar to the ones that we see in practice. In particular, graphs that model maps, circuits, schedules, transactions, networks, and other practical situations are usually not only sparse but also exhibit a locality property—edges are much more likely to connect a given vertex to vertices in a particular set than to vertices that are not in the set. We might consider many different ways of modeling locality, as illustrated in the following examples.
k-neighbor graph The graph depicted at the top in Figure 17.13 is drawn from a simple modification to a random-edges graph generator, where we randomly pick the first vertex v, then randomly pick the second from among those whose indices are within a fixed constant k of v (wrapping around from V − 1 to 0, when the vertices are arranged in a circle as depicted). Such graphs are easy to generate and certainly exhibit locality not found in random graphs.
Euclidean neighbor graph The graph depicted at the bottom in Figure 17.13 is drawn from a generator that generates V points in the plane with random coordinates between 0 and 1, and then generates edges connecting any two points within distance d of one another. If d is small, the graph is sparse; if d is large, the graph is dense (see Exercise 17.74). This graph models the types of graphs that we might expect when we process graphs from maps, circuits, or other applications where vertices are associated with geometric locations. They are easy to visualize, exhibit properties of algorithms in an intuitive manner, and exhibit many of the structural properties that we find in such applications.
One possible defect in this model is that the graphs are not likely to be connected when they are sparse; other difficulties are that the graphs are unlikely to have high-degree vertices and that they do not have any long edges. We can change the models to handle such situations, if desired, or we can consider numerous similar examples to try to model other situations (see, for example, Exercises 17.72 and 17.73).
Or, we can test our algorithms on real graphs. In many applications, there is no shortage of problem instances drawn from actual data that we can use to test our algorithms. For example, huge graphs drawn from actual geographic data are easy to find; two more examples are listed in the next two paragraphs. The advantage of working with real data instead of a random graph model is that we can see solutions to real problems as algorithms evolve. The disadvantage is that we may lose the benefit of being able to predict the performance of our algorithms through mathematical analysis. We return to this topic when we are ready to compare several algorithms for the same task, at the end of Chapter 18.
Transaction graph Figure 17.14 illustrates a tiny piece of a graph that we might find in a telephone company’s computers. It has a
Figure 17.13 Random neighbor graphs
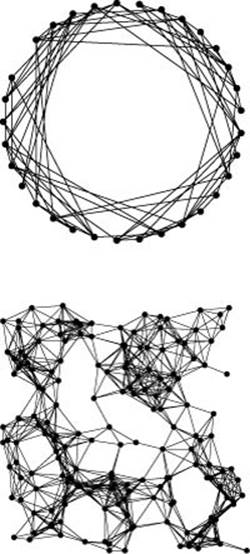
These figures illustrate two models of sparse graphs. The neighbor graph at the top has 33 vertices and 99 edges, with each edge restricted to connect vertices whose indices differ by less than 10 (modulo V ). The Euclidean neighbor graph at the bottom models the types of graphs that we might find in applications where vertices are tied to geometric locations. Vertices are random points in the plane; edges connect any pair of vertices within a specified distance d of each other. This graph is sparse (177 vertices and 1001 edges); by adjusting d, we can generate graphs of any desired density.
Figure 17.14 Transaction graph

A sequence of pairs of numbers like this one might represent a list of telephone calls in a local exchange, or financial transfers between accounts, or any similar situation involving transactions between entities with unique identifiers. The graphs are hardly random—some phones are far more heavily used than others and some accounts are far more active than others.
Program 17.14 Building a graph from pairs of symbols
This implementation of the scan function from Program 17.4 uses a symbol table to build a graph by reading pairs of symbols from standard input. The symbol-table ADT function index associates an integer with each symbol: on unsuccessful search in a table of size N it adds the symbol to the table with associated integer N+1; on successful search, it simply returns the integer previously associated with the symbol. Any of the symbol-table methods in Part 4 can be adapted for this use; for example, see Program 17.15.
#include “ST.cc”
template <class Graph>
void IO<Graph>::scan(Graph &G)
{ string v, w;
ST st;
while (cin >> v >> w)
G.insert(Edge(st.index(v), st.index(w)));
}
vertex defined for each phone number, and an edge for each pair i and j with the property that i made a telephone call to j within some fixed period. This set of edges represents a huge multigraph. It is certainly sparse, since each person places calls to only a tiny fraction of the available telephones. It is representative of many other applications. For example, a financial institution’s credit card and merchant account records might have similar information.
Function call graph We can associate a graph with any computer program with functions as vertices and an edge connecting X and Y whenever function X calls function Y. We can instrument the program to create such a graph (or have a compiler do it). Two completely different graphs are of interest: the static version, where we create edges at compile time corresponding to the function calls that appear in the program text of each function; and a dynamic version, where we create edges at run time when the calls actually happen. We use static function call graphs to study program structure and dynamic ones to study program behavior. These graphs are typically huge and sparse.
In applications such as these, we face massive amounts of data, so we might prefer to study the performance of algorithms on real
Program 17.15 Symbol indexing for vertex names
This implementation of symbol-table indexing for string keys (which is described in the commentary for Program 17.14) accomplishes the task by adding an index field to each node in an existence-table TST (see Program 15.8). The index associated with each key is kept in the index field in the node corresponding to its end-of-string character.
We use the characters in the search key to move down the TST, as usual. When we reach the end of the key, we set its index if necessary and also set the private data member val, which is returned to the caller after all recursive calls to the function have returned.

Figure 17.15 Degrees-of-separation graph
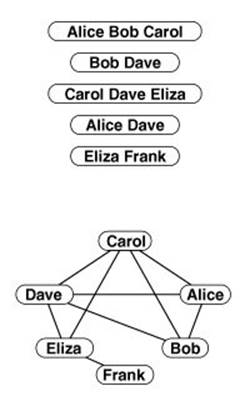
The graph at the bottom is defined by the groups at the top, with one vertex for each person and an edge connecting a pair of people whenever they are in the same group. Shortest path lengths in the graph correspond to degrees of separation. For example, Frank is three degrees of separation from Alice and Bob.
sample data rather than on random models. We might choose to try to avoid degenerate situations by randomly ordering the edges or by introducing randomness in the decision making in our algorithms, but that is a different matter from generating a random graph. Indeed, in many applications, learning the properties of the graph structure is a goal in itself.
In several of these examples, vertices are natural named objects, and edges appear as pairs of named objects. For example, a transaction graph might be built from a sequence of pairs of telephone numbers, and a Euclidean graph might be built from a sequence of pairs of cities or towns.Program 17.14 is an implementation of the scan function in Program 17.4, which we can use to build a graph in this common situation. For the client’s convenience, it takes the set of edges as defining the graph and deduces the set of vertex names from their use in edges. Specifically, the program reads a sequence of pairs of symbols from standard input, uses a symbol table to associate the vertex numbers 0 to V − 1 to the symbols (where V is the number of different symbols in the input), and builds a graph by inserting the edges, as in Programs 17.12 and 17.13. We could adapt any symbol-table implementation to support the needs of Program 17.14; Program 17.15 is an example that uses ternary search trees (TSTs) (see Chapter 14). These programs make it easy for us to test our algorithms on real graphs that may not be characterized accurately by any probabilistic model.
Program 17.14 is also significant because it validates the assumption we have made in all of our algorithms that the vertex names are integers between 0 and V − 1. If we have a graph that has some other set of vertex names, then the first step in representing the graph is to use Program 17.15to map the vertex names to integers between 0 and V − 1.
Some graphs are based on implicit connections among items. We do not focus on such graphs, but we note their existence in the next few examples and devote a few exercises to them. When faced with processing such a graph, we can certainly write a program to construct explicit graphs by enumerating all the edges; but there also may be solutions to specific problems that do not require that we enumerate all the edges and therefore can run in sublinear time.
Degrees-of-separation graph Consider a collection of subsets drawn from V items. We define a graph with one vertex corresponding to each element in the union of the subsets and edges between two vertices if both vertices appear in some subset (see Figure 17.15). If desired, the graph might be a multigraph, with edge labels naming the appropriate subsets. All items incident on a given item v are said to be 1 degree of separation from v. Otherwise, all items incident on any item that is i degrees of separation from v (that are not already known to be i or fewer degrees of separation from v) are (i+1) degrees of separation from v. This construction has amused people ranging from mathematicians (Erdös number) to movie buffs (separation from Kevin Bacon).
Interval graph Consider a collection of V intervals on the real line (pairs of real numbers). We define a graph with one vertex corresponding to each interval, with edges between vertices if the corresponding intervals intersect (have any points in common).
de Bruijn graph Suppose that V is a power of 2. We define a digraph with one vertex corresponding to each nonnegative integer less than V, with edges from each vertex i to 2i and (2i +1) mod lg V. These graphs are useful in the study of the sequence of values that can occur in a fixed-length shift register for a sequence of operations where we repeatedly shift all the bits one position to the left, throw away the leftmost bit, and fill the rightmost bit with 0 or 1. Figure 17.16 depicts thedeBruijn graphs with 8, 16, 32, and 64 vertices.
The various types of graphs that we have considered in this section have a wide variety of different characteristics. However, they all look the same to our programs: They are simply collections of edges. As we saw in Chapter 1, learning even the simplest facts about them can be a computational challenge. In this book, we consider numerous ingenious algorithms that have been developed for solving practical problems related to many types of graphs.
Based just on the few examples presented in this section, we can see that graphs are complex combinatorial objects, far more complex than those underlying other algorithms that we studied in Parts 1 through 4. In many instances, the graphs that we need to consider in applications are difficult or impossible to characterize. Algorithms that perform well on random graphs are often of limited applicability because it is often difficult to be persuaded that random graphs have
Figure 17.16 de Bruijn graphs
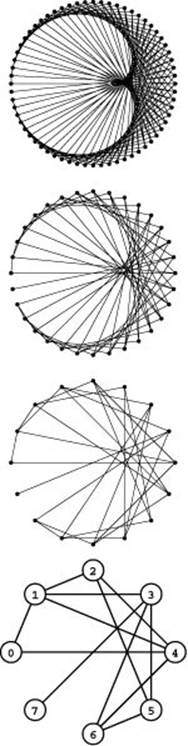
A de Bruijn digraph of order n has 2n vertices with edges from i to 2i mod n and (2i+1) mod 2n, for all i. Pictured here are the underlying undirected de Bruijn graphs of order 6, 5, 4, and 3 (top to bottom).
structural characteristics the same as those of the graphs that arise in applications. The usual approach to overcome this objection is to design algorithms that perform well in the worst case. While this approach is successful in some instances, it falls short (by being too conservative) in others.
While we are often not justified in assuming that performance studies on graphs generated from one of the random graph models that we have discussed will give information sufficiently accurate to allow us to predict performance on real graphs, the graph generators that we have considered in this section are useful in helping us to test implementations and to understand our algorithms’ performance. Before we even attempt to predict performance for applications, we must at least verify any assumptions that we might have made about the relationship between the application’s data and whatever models or sample data we may have used. While such verfication is wise when we are working in any applications domain, it is particularly important when we are processing graphs, because of the broad variety of types of graphs that we encounter.
Exercises
• 17.61 When we use Program 17.12 to generate random graphs of density αV, what fraction of edges produced are self-loops?
• 17.62 Calculate the expected number of parallel edges produced when we use Program 17.12 to generate random graphs with V vertices of density. Use the result of your calculation to draw plots showing the fraction of parallel edges produced as a function of, for V =10, 100, and 1000.
17.63 Use an STL map to develop an alternate implemention of the ST class of Program 17.15.
• 17.64 Find a large undirected graph somewhere online—perhaps based on network-connectivity information, or a separation graph defined by coauthors in a set of bibliographic lists or by actors in movies.
• 17.65 Write a program that generates sparse random graphs for a well-chosen set of values of V and E, and prints the amount of space that it used for the graph representation and the amount of time that it took to build it. Test your program with a sparse-graph class (Program 17.9) and with the random-graph generator (Program 17.12), so that you can do meaningful empirical tests on graphs drawn from this model.
• 17.66 Write a program that generates dense random graphs for a well-chosen set of values of V and E, and prints the amount of space that it used for the graph representation and the amount of time that it took to build it. Test your
program with a dense-graph class (Program 17.7) and with the random-graph generator (Program 17.13), so that you can do meaningful empirical tests on graphs drawn from this model.
• 17.67 Give the standard deviation of the number of edges produced by Program 17.13.
• 17.68 Write a program that produces each possible graph with precisely the same probability as does Program 17.13, but uses time and space proportional to only V + E, not V2. Test your program as described in Exercise 17.65.
• 17.69 Write a program that produces each possible graph with precisely the same probability as does Program 17.12, but uses time proportional to E, even when the density is close to 1. Test your program as described in Exercise 17.66.
• 17.70 Write a program that produces, with equal likelihood, each of the possible graphs with V vertices and E edges (see Exercise 17.9). Test your program as described in Exercise 17.65 (for low densities) and as described in Exercise 17.66 (for high densities).
• 17.71 Write a program that generates random graphs by connecting vertices arranged in a ![]() -by-
-by-![]() grid to their neighbors (see Figure 1.2), with k extra edges connecting each vertex to a randomly chosen destination vertex (each destination vertex equally likely). Determine how to set ksuch that the expected number of edges is E. Test your program as described in Exercise 17.65.
grid to their neighbors (see Figure 1.2), with k extra edges connecting each vertex to a randomly chosen destination vertex (each destination vertex equally likely). Determine how to set ksuch that the expected number of edges is E. Test your program as described in Exercise 17.65.
17.72 Write a program that generates random digraphs by randomly connecting vertices arranged in a ![]() -by-
-by-![]() grid to their neighbors, with each of the possible edges occurring with probability p (see Figure 1.2). Determine how to set p such that the expected number of edges is E. Test your program as described in Exercise 17.65.
grid to their neighbors, with each of the possible edges occurring with probability p (see Figure 1.2). Determine how to set p such that the expected number of edges is E. Test your program as described in Exercise 17.65.
• 17.73 Augment your program from Exercise 17.72 to add R extra random edges, computed as in Program 17.12. For large R, shrink the grid so that the total number of edges remains about V.
17.74 Write a program that generates V random points in the plane, then builds a graph consisting of edges connecting all pairs of points within a given distance d of one another (see Figure 17.13 and Program 3.20). Determine how to set d such that the expected number of edges is E. Test your program as described in Exercise 17.65 (for low densities) and as described in Exercise 17.66 (for high densities).
• 17.75 Write a program that generates V random intervals in the unit interval, all of length d, then builds the corresponding interval graph. Determine how to set d such that the expected number of edges is E. Test your program as described in Exercise 17.65 (for low densities) and as described in Exercise 17.66 (for high densities). Hint: Use a BST.
• 17.76 Write a program that chooses V vertices and E edges at random from the real graph that you found for Exercise 17.64. Test your program as described in Exercise 17.65 (for low densities) and as described in Exercise 17.66 (for high densities).
• 17.77 One way to define a transportation system is with a set of sequences of vertices, each sequence defining a path connecting the vertices. For example, the sequence 0-9-3-2 defines the edges 0-9, 9-3, and 3-2. Write a program that builds a graph from an input file consisting of one sequence per line, using symbolic names. Develop input suitable to allow you to use your program to build a graph corresponding to the Paris metro system.
17.78 Extend your solution to Exercise 17.77 to include vertex coordinates, along the lines of Exercise 17.60, so that you can work with graphical representations.
• 17.79 Apply the transformations described in Exercises 17.34 through 17.37 to various graphs (see Exercises 17.63–76), and tabulate the number of vertices and edges removed by each transformation.
• 17.80 Implement a constructor for Program 17.1 that allows clients to build separation graphs without having to call a function for each implied edge. That is, the number of function calls required for a client to build a graph should be proportional to the sum of the sizes of the groups. Develop an efficient implementation of this modified ADT (based on data structures involving groups, not implied edges).
17.81 Give a tight upper bound on the number of edges in any separation graph with N different groups of k people.
• 17.82 Draw graphs in the style of Figure 17.16 that, for V = 8, 16, and 32, have V vertices numbered from 0 to V − 1 and an edge connecting each vertex i with [floorleft]i/ 2[floorright].
17.83 Modify the ADT interface in Program 17.1 to allow clients to use symbolic vertex names and edges to be pairs of instances of a generic Vertex type. Hide the vertex-index representation and the symbol-table ADT usage completely from clients.
17.84 Add a function to the ADT interface from Exercise 17.83 that supports a join operation for graphs, and provide implementations for the adjacency-matrix and adjacency-lists representations. Note: Any vertex or edge in either graph should be in the join, but vertices that are in both graphs appear only once in the join, and you should remove parallel edges.
All materials on the site are licensed Creative Commons Attribution-Sharealike 3.0 Unported CC BY-SA 3.0 & GNU Free Documentation License (GFDL)
If you are the copyright holder of any material contained on our site and intend to remove it, please contact our site administrator for approval.
© 2016-2026 All site design rights belong to S.Y.A.