Adaptive Code via C#. Agile coding with design patterns and SOLID principles (2014)
Chapter 13. Other Topics
Each of the earlier chapters focused on one particular topic. Each of those topics is vast and clearly warrants a dedicated chapter. In addition, several smaller topics (while no less important) don't quite warrant a chapter all their own. This chapter is a collection of those smaller topics.
13.1. Performing Error Handling
Problem
Many security vulnerabilities are possible as a consequence of a programmer's omitting proper error handling. Developers find it extremely taxing to have to check error conditions continually. The unfortunate result is that these conditions often go forgotten.
Solution
If you have the luxury of designing an API, design it in such a way that it minimizes the amount of error handling that is required, if at all possible. In addition, try to design APIs so that failures are not potentially critical if they go unhandled.
Otherwise, appropriate exception handling can help you ensure that no errors that go unhandled will propagate dangerous error conditions. Use wrappers to convert functions that may fail with a traditional error code, so that they instead use exception handling.
Discussion
There are plenty of situations in which assuming that a function returns successfully leads to a security vulnerability. One simple example is the case of using a secure random number generator to fill a buffer with random bytes. If the return value indicates failure, it's likely that no randomness was put into the buffer. If the programmer does not check the return code, predictable data will be used.
In general, those functions that are not directly security-critical when their return value goes unchecked are often indirect security problems. (This can often happen with memory allocation functions, for example.) At the very least, such problems are often denial of service risks when they lead to a crash.
One solution to this problem is to ensure that you always check return values from functions. That approach works in theory, but it is very burdensome on the programmer and also hard to validate.
A more practical answer is to use exception handling. Using exception handling, any error conditions that the programmer does not explicitly handle will cause the program to terminate (which is generally a good idea, unless the premature termination somehow causes an insecure state).
The problem with exception handling is that it does not solve the denial of service problem. If a developer forgets to handle a particular exception, the program will generally still terminate. Of course, the entire program can be wrapped by an exception handler that restarts the program or performs a similar action.
In C++, exception handling is built into the language and should be familiar to many programmers. We will illustrate via example:
try {
somefunc( );
}
catch (MyException &e) {
// Recover from error type MyException.
}
catch (int e) {
// Recover if we got an integer exception code.
}
The try block designates code we would like to execute that may throw an exception. It also says that if the code does throw an exception, the following catch blocks may be able to handle the exception.
If an exception is not handled by one of the specified catch blocks, there may be some calling code that catches the exception. If no code wants to catch the exception, the program will abort.
In C++, the catch block used is selected based on the static type of the exception thrown. Generally, if the exception is not a primitive type, we use the & to indicate that the exception value should be passed to the handler by reference instead of being copied.
To raise an exception, we use the throw keyword:
throw 12; // Throw an integer as an error. You can throw arbitrary objects in C++.
Exception handling essentially acts as an alternate return mechanism, designed particularly for conditions that signify an abnormal state.
You can also perform exception handling in C using macros. The safe string-handling library from Recipe 3.4 includes an exception-handling library named XXL. This exception-handling library is also available separately at http://www.zork.org/xxl/.
The XXL library only allows you to throw integer exception codes. However, when throwing an exception, you may also pass arbitrary data in a void pointer. The XXL syntax attempts to look as much like C++ as possible, but is necessarily different because of the limitations of C. Here is an example:
#include "xxl.h" /* Get definitions for exception handling. */
void sample(void) {
TRY {
somefunc( );
}
CATCH(1) {
/* Handle exception code 1. */
}
CATCH(2) {
/* Handle exception code 2. */
}
EXCEPT {
/* Handle all other exceptions... if you don't do this, they get propogated up
to previous callers. */
}
FINALLY {
/* This code always gets called after an exception handler, even if no
* exception gets thrown, or you raise a new exception. Additionally, if no
* handler catches the error, this code runs before the exception gets
* propogated.
*/
}
END_TRY;
There are a number of significant differences between XXL and C++ exception handling:
§ In XXL you can only catch a compile-time constant integer, whereas in C++ you can catch based on a data type. That is, catch(2) is invalid in C++. There, you would catch on the entire integer data type, as with catch(int x). You can think of CATCH( ) in XXL as a sort of case statement in a big switch block.
§ XXL has the EXCEPT keyword, which catches any exception not explicitly caught by a catch block. The EXCEPT block must follow all CATCH( ) blocks. XXL's EXCEPT keyword is equivalent to CATCH(...) in C++.
§ XXL has a FINALLY block, which, if used, must follow any exception-handling blocks. The code in one of these blocks always runs, whether or not the exception gets caught. The only ways to avoid running such a block are to do one of the following:
§ Return from the current function.
§ Use goto to jump to a label outside the exception-handling block.
§ Break the abstraction that the XXL macros provide.
§ All of these techniques are bad form. Circumventing the XXL exception structure will cause its exception handler stack to enter an inconsistent state, resulting in unexpected and often catastrophic behavior. You should never return from within a TRY, CATCH, EXCEPT, or FINALLY block, nor should you ever use any other method, such as goto or longjmp, to jump between blocks or outside of them.
§ XXL requires you to use END_TRY. This is necessary because of the way XXL is implemented as preprocess macros; true exception handling requires handling at the language level, which is a luxury that we do not have with C.
§ The syntax for actually raising an exception differs. XXL has a THROW() macro that takes two parameters. The first is the exception code, and the second is a void *, representing arbitrary data that you might want to pass from the site of the raise to the exception handler. It is acceptable to pass in a NULL value as the second parameter if you have no need for it.
If you want to get the extra information (the void *) passed to the THROW( ) macro from within an exception handler (specifically, a CATCH(), EXCEPT, or FINALLY block), you can do so by calling EXCEPTION_INFO( ).
§ In some cases, the XXL macro set may conflict with symbols in your code. If that is the case, each also works if you prepend XXL_ to the macro. In addition, you can turn off the basic macros by defining XXL_ENFORCE_PREFIX when compiling.
Once you have an exception-handling mechanism in place, we recommend that you avoid calling functions that can return an error when they fail.
For example, consider the malloc( ) function, which can return NULL and set errno to ENOMEM when it fails (which only happens when not enough memory is available to complete the request). If you think you will simply want to bail whenever the process is out of memory, you could use the following wrapper:
#include <stdlib.h>
void *my_malloc(size_t sz) {
void *res = malloc(sz);
if (!res) {
/* We could, instead, call an out of memory handler. */
fprintf(stderr, "Critical: out of memory! Aborting.\n");
abort( );
}
return res;
}
If you prefer to give programmers the chance to handle the problem, you could throw an exception. In such a case, we recommend using the standard errno values as exception codes and using positive integers above 256 for application-specific exceptions.
#include <stdlib.h>
#include <errno.h>
#include <xxl.h>
#define EXCEPTION_OUT_OF_MEMORY (ENOMEM)
void *my_malloc(size_t sz) {
void *res = malloc(sz);
/* We pass the amount of memory requested as extra data. */
if (!res) RAISE(EXCEPTION_OUT_OF_MEMORY, (void *)sz);
return res;
}
See Also
XXL exception handling library for C: http://www.zork.org/xxl/
13.2. Erasing Data from Memory Securely
Problem
You want to minimize the exposure of data such as passwords and cryptographic keys to local attacks.
Solution
You can only guarantee that memory is erased if you declare it to be volatile at the point where you write over it. In addition, you must not use an operation such as realloc( ) that may silently move sensitive data. In any event, you might also need to worry about data being swapped to disk; see Recipe 13.3.
Discussion
Securely erasing data from memory is a lot easier in C and C++ than it is in languages where all memory is managed behind the programmer's back. There are still some nonobvious pitfalls, however.
One pitfall, particularly in C++, is that some API functions may silently move data behind the programmer's back, leaving behind a copy of the data in a different part of memory. The most prominent example in the C realm is realloc( ), which will sometimes move a piece of memory, updating the programmer's pointer. Yet the old memory location will generally still have the unaltered data, up until the point where the memory manager reallocates the data and the program overwrites the value.
Another pitfall is that functions like memset( ) may fail to wipe data because of compiler optimizations.
Compiler writers have worked hard to implement optimizations into their compilers to help make code run faster (or compile to smaller machine code). Some of these optimizations can realize significant performance gains, but sometimes they also come at a cost. One such optimization is dead-code elimination, where the optimizer attempts to identify code that does nothing and eliminate it. Only relatively new compilers seem to implement this optimization; these include the current versions of GCC and Microsoft's Visual C++ compiler, as well as some other less commonly used compilers.
Unfortunately, this optimization can cause problems when writing secure code. Most commonly, code that "erases" a piece of memory that contains sensitive information such as a password or passphrase in plaintext is often eliminated by this optimization. As a result, the sensitive information is left in memory, providing an attacker a temptation that can be difficult to ignore.
Functions like memset( ) do useful work, so why would dead-code elimination passes remove them? Many compilers implement such functions as built-ins, which means that the compiler has knowledge of what the function does. In addition, situations in which such calls would be eliminated are restricted to times when the compiler can be sure that the data written by these functions is never read again. For example:
int get_and_verify_password(char *real_password) {
int result;
char *user_password[64];
/* WARNING * WARNING * WARNING * WARNING * WARNING * WARNING * WARNING
*
* This is an example of unsafe code. In particular, note the use of memset( ),
* which is exactly what we are discussing as being a problem in this recipe.
*/
get_password_from_user_somehow(user_password, sizeof(user_password));
result = !strcmp(user_password, real_password);
memset(user_password, 0, strlen(user_password));
return result;
}
In this example, the variable user_password exists solely within the function get_and_verify_password( ). After the memset( ), it's never used again, and because memset( ) only writes the data, the compiler can "safely" remove it.
Several solutions to this particular problem exist, but the code that we've provided here is the most correct when used with a compiler that conforms to at least the ANSI/ISO 9899-1990 standard, which includes any modern C compiler. The key is the use of the volatile keyword, which essentially instructs the compiler not to optimize out expressions that involve the variable because there may be side effects unknown to the compiler. A commonly cited example of this is a variable that may be modified by hardware, such as a real-time clock.
It's proper to declare any variable containing sensitive information as volatile. Unfortunately, many programmers are unaware of what this keyword means, so it is frequently omitted. In addition, simply declaring a variable as volatile may not be enough. Whether or not it is enough often depends on how aggressive a particular compiler is in performing dead-code elimination. Early implementations of dead-code elimination optimizations were probably far less aggressive than current ones, and logically you can safely assume that they will perhaps get more aggressive in the future. It is best to protect code from any current optimizing compiler, as well as any that may be used in the future.
If simply declaring a variable as volatile may not be enough, what more must be done? The answer is to replace calls to functions like memcpy( ), memmove( ), and memset( ) with handwritten versions. These versions may perform less well, but they will ensure their expected behavior. The solution we have provided above does just that. Notice the use of the volatile keyword on each function's argument list. An important difference between these functions and typical implementations is the use of that keyword. When memset( ) is called, the volatile qualifier on the buffer passed into it is lost. Further, many compilers have built-in implementations of these functions so that the compiler may perform heavier optimizing because it knows exactly what the functions do.
Here is code that implements three different methods of writing data to a buffer that a compiler may try to optimize away. The first is spc_memset( ) , which acts just like the standard memset( ) function, except that it guarantees the write will not be optimized away if the destination is never used. Then we implement spc_memcpy( ) and spc_memmove( ) , which are also analogs of the appropriate standard library functions.
#include <stddef.h>
volatile void *spc_memset(volatile void *dst, int c, size_t len) {
volatile char *buf;
for (buf = (volatile char *)dst; len; buf[--len] = c);
return dst;
}
volatile void *spc_memcpy(volatile void *dst, volatile void *src, size_t len) {
volatile char *cdst, *csrc;
cdst = (volatile char *)dst;
csrc = (volatile char *)src;
while (len--) cdst[len] = csrc[len];
return dst;
}
volatile void *spc_memmove(volatile void *dst, volatile void *src, size_t len) {
size_t i;
volatile char *cdst, *csrc;
cdst = (volatile char *)dst;
csrc = (volatile char *)src;
if (csrc > cdst && csrc < cdst + len)
for (i = 0; i < len; i++) cdst[i] = csrc[i];
else
while (len--) cdst[len] = csrc[len];
return dst;
}
If you're writing code for Windows using the latest Platform SDK, you can use SecureZeroMemory( ) instead of spc_memset( ) to zero memory. SecureZeroMemory( ) is actually implemented as a macro to RtlSecureMemory( ) , which is implemented as an inline function in the same way thatspc_memset( ) is implemented, except that it only allows a buffer to be filled with zero bytes instead of a value of the caller's choosing as spc_memset( ) does.
13.3. Preventing Memory from Being Paged to Disk
Problem
Your program stores sensitive data in memory, and you want to prevent that data from ever being written to disk.
Solution
On Unix systems, the mlock( ) system call is often implemented in such a way that locked memory is never swapped to disk; however, the system call does not necessarily guarantee this behavior. On Windows, VirtualLock( ) can be used to achieve the desired behavior; locked memory will never be swapped to disk.
Discussion
WARNING
The solutions presented here are not foolproof methods. Given enough time and resources, someone will eventually be able to extract the data from the program's memory. The best you can hope for is to make it so difficult to do that an attacker deems it not worth the time.
All modern operating systems have virtual memory managers. Among other things, virtual memory enables the operating system to make more memory available to running programs by swapping the contents of physical memory to disk. When a program must store sensitive data in memory, it risks having the information written to disk when the operating system runs low on physical memory.
On Windows systems, the VirtualLock( ) API function allows an application to "lock" virtual memory into physical memory. The function guarantees that successfully locked memory will never be swapped to disk. However, preventing memory from swapping can have a significant negative performance impact on the system as a whole. Therefore, the amount of memory that can be locked is severely limited.
On Unix systems, the POSIX 1003.1b standard for real-time extensions introduces an optional system call, mlock( ) , which is intended to guarantee that locked memory is always resident in physical memory. However, contrary to popular belief, it does not guarantee that locked memory will never be swapped to disk. On the other hand, most current implementations are implemented in such a way that locked memory will not be swapped to disk. The Linux implementation in particular does make the guarantee, but this is nonstandard (and thus nonportable) behavior!
Because the mlock( ) system call is an optional part of the POSIX standard, a feature test macro named _POSIX_MEMLOCK_RANGE should be defined in the unistd.h header file if the system call is available. Unfortunately, there is no sure way to know whether the system call will actually prevent the memory it locks from being swapped to disk.
On all modern hardware architectures, memory is broken up and managed by the hardware in fixed-size chunks called pages. On Intel x86 systems, the page size is 4,096 bytes. Most architectures use a similar page size, but never assume that the page size is a specific size. Because the hardware manages memory with page-sized granularity, operating system virtual memory managers must do the same. Therefore, memory can only be locked in a multiple of the hardware's page size, whether you're using VirtualLock( ) on Windows or mlock( ) on Unix.
VirtualLock( ) does not require that the address at which to begin locking is page-aligned, and most implementations of mlock( ) don't either. In both cases, the starting address is rounded down to the nearest page boundary. However, the POSIX standard does not require this behavior, so for maximum portability, you should always ensure that the address passed to mlock( ) is page-aligned.
Both Windows and Unix memory locking limit the maximum number of pages that may be locked by a single process at any one time. In both cases, the limit can be adjusted, but if you need to lock more memory than the default maximum limits, you probably need to seriously reconsider what you are doing. Locking large amounts of memory can—and, most probably, will—have a negative impact on overall system performance, affecting all running programs.
The mlock( ) system call on Unix imposes an additional limitation over VirtualLock( ) on Window: the process making the call must have superuser privileges. In addition, when fork( ) is used by a process that has locked memory, the copy of the memory in the newly created process will not be locked. In other words, child processes do not inherit memory locks.
13.4. Using Variable Arguments Properly
Problem
You need a way to protect a function that accepts a variable number of arguments from reading more arguments than were passed to the function.
Solution
Our solution for dealing with a variable number of arguments is actually two solutions. The interface for both solutions is identical, however. Instead of calling va_arg( ), you should call spc_next_varg( ) , listed later in this section. Note, however, that the signature for the two functions is different. The code:
my_int_arg = va_arg(ap, int);
becomes:
spc_next_varg(ap, int, my_int_arg);
The biggest difference from using variable argument functions is how you need to make the calls when using this solution. If you can guarantee that your code will be compiled only by GCC and will always be running on an x86 processor (or another processor to which you can port the first solution), you can make calls to the function using spc_next_varg( ) in the normal way. Otherwise, you will need to use the VARARG_CALL_x macros, where x is the number of arguments that you will be passing to the function, including both fixed and variable.
#include <stdarg.h>
#include <stdio.h>
#if defined(_ _GNUC_ _) && defined(i386)
/* NOTE: This is valid only using GCC on an x86 machine */
#define spc_next_varg(ap, type, var) \
do { \
unsigned int _ _frame; \
_ _frame = *(unsigned int *)_ _builtin_frame_address(0); \
if ((unsigned int)(ap) = = _ _frame - 16) { \
fprintf(stderr, "spc_next_varg( ) called too many times!\n"); \
abort( ); \
} \
(var) = va_arg((ap), (type)); \
} while (0)
#define VARARG_CALL_1(func, a1) \
func((a1))
#define VARARG_CALL_2(func, a1, a2) \
func((a1), (a2))
#define VARARG_CALL_3(func, a1, a2, a3) \
func((a1), (a2), (a3))
#define VARARG_CALL_4(func, a1, a2, a3, a4) \
func((a1), (a2), (a3), (a4))
#define VARARG_CALL_5(func, a1, a2, a3, a4, a5) \
func((a1), (a2), (a3), (a4), (a5))
#define VARARG_CALL_6(func, a1, a2, a3, a4, a5, a6) \
func((a1), (a2), (a3), (a4), (a5), (a6))
#define VARARG_CALL_7(func, a1, a2, a3, a4, a5, a6, a7) \
func((a1), (a2), (a3), (a4), (a5), (a6), (a7))
#define VARARG_CALL_8(func, a1, a2, a3, a4, a5, a6, a7, a8) \
func((a1), (a2), (a3), (a4), (a5), (a6), (a7), (a8))
#else
/* NOTE: This should work on any machine with any compiler */
#define VARARG_MAGIC 0xDEADBEEF
#define spc_next_varg(ap, type, var) \
do { \
(var) = va_arg((ap), (type)); \
if ((int)(var) = = VARARG_MAGIC) { \
fprintf(stderr, "spc_next_varg( ) called too many times!\n"); \
abort( ); \
} \
} while (0)
#define VARARG_CALL_1(func, a1) \
func((a1), VARARG_MAGIC)
#define VARARG_CALL_2(func, a1, a2) \
func((a1), (a2), VARARG_MAGIC)
#define VARARG_CALL_3(func, a1, a2, a3) \
func((a1), (a2), (a3), VARARG_MAGIC)
#define VARARG_CALL_4(func, a1, a2, a3, a4) \
func((a1), (a2), (a3), (a4), VARARG_MAGIC)
#define VARARG_CALL_5(func, a1, a2, a3, a4, a5) \
func((a1), (a2), (a3), (a4), (a5), VARARG_MAGIC)
#define VARARG_CALL_6(func, a1, a2, a3, a4, a5, a6) \
func((a1), (a2), (a3), (a4), (a5), (a6), VARARG_MAGIC)
#define VARARG_CALL_7(func, a1, a2, a3, a4, a5, a6, a7) \
func((a1), (a2), (a3), (a4), (a5), (a6), (a7), VARARG_MAGIC)
#define VARARG_CALL_8(func, a1, a2, a3, a4, a5, a6, a7, a8) \
func((a1), (a2), (a3), (a4), (a5), (a6), (a7), (a8), VARARG_MAGIC)
#endif
Discussion
Both C and C++ allow the definition of functions that take a variable number of arguments. The header file stdarg.h defines three macros,[1] va_start( ) , va_arg( ) , and va_end( ) , that can be used to obtain the arguments in the variable argument list. First, you must call the macro va_start( ), possibly followed by an arbitrary number of calls to va_arg( ), and finally, you must call va_end( ).
A function that takes a variable number of arguments does not know the number of arguments present or the type of each argument in the argument list; the function must therefore have some other way of knowing how many arguments should be present, so as to not make too many calls tova_arg( ). In fact, the ANSI C standard does not define the behavior that occurs should va_arg( ) be called too many times. Often, the behavior is to keep returning data from the stack until a hardware exception occurs, which will crash your program, of course.
Calling va_arg( ) too many times can have disastrous effects. In Recipe 13.2, we discussed format string attacks against the printf family of functions. One particularly dangerous format specifier is %n, which causes the number of bytes written so far to the output destination (whether it's a string via sprintf( ), or a file via fprintf( )) to be written into the next argument in the variable argument list. For example:
int x;
printf("hello, world%n\n", &x);
In this example code, the integer value 12 would be written into the variable x. Imagine what would happen if no argument were present after the format string, and the return address were the next thing on the stack: an attacker could overwrite the return address, possibly resulting in arbitrary code execution.
There is no easy way to protect the printf family of functions against this type of attack, except to properly sanitize input that could eventually make its way down into a call to one of the printf family of functions. However, it is possible to protect variable argument functions that you write against possible mistakes that would leave the code vulnerable to such an attack.
The first solution we've presented is compiler- and processor-specific because it makes use of a GCC-specific built-in function, _ _builtin_frame_address( ) , and of knowledge of how the stack is organized on an x86 based processor to determine where the arguments pushed by the caller end. With a small amount of effort, this solution can likely be ported to some other processors as well, but the non-x86 systems on which we have tested do not work (in particular, this trick does not work on Apple Mac G3 or G4 systems). This solution also requires that you do not compile your program using the optimization option to omit the frame pointer, -fomit-frame-pointer, because it depends on having the frame pointer available.
The second solution we have presented should work with any compiler and processor combination. It works by adding an extra argument passed to the function that is a "magic" value. When spc_next_varg( ) gets the next argument by calling va_arg( ) itself, it checks to see whether the value of the argument matches the "magic" value. The need to add this extra "magic" argument is the reason for the VARARG_CALL_x macros. We have chosen a magic value of 0xDEADBEEF here, but if a legitimate argument with that value might be used, it can easily be changed to something else. Certainly, the code provided here could also be easily modified to allow different "magic" values to be used for different function calls.
Finally, note that both implementations of spc_next_varg( ) print an error message to stderr and call abort( ) to terminate the program immediately. Handling this error condition differently in your own program may take the form of throwing an exception if you are using the code in C++, or calling a special handler function. Anything except allowing the function to proceed can be done here. The error should not necessarily be treated as fatal, but it certainly is serious.
See Also
Recipe 3.2
[1] The ANSI C standard dictates that va_start( ), va_arg( ), and va_end( ) must be macros. However, it does not place any requirements on their expansion. Some implementations may simply expand the macros to built-in function calls (GCC does this). Others may be expressions performing pointer arithmetic (Microsoft Visual C++ does this). Others still may provide some completely different kind of implementation for the macros.
13.5. Performing Proper Signal Handling
Problem
Your program needs to handle asynchronous signals.
Solution
On Unix systems, it is often necessary to perform some amount of signal handling. In particular, if a program receives a termination signal, it is often desirable to perform some kind of cleanup before terminating the program—flushing in-memory caches to disk, recording the event to a log file, and so on. Unfortunately, many programmers do not perform their signal handling safely, which of course leads to possible security vulnerabilities. Even more unfortunate is that there is no cookie-cutter solution to writing safe signal handlers. Fortunately, following some easy guidelines will help you write more secure signal-handling code.
Do not share signal handlers.
Several signals are normally used to terminate a program, including SIGTERM, SIGQUIT, and SIGINT (to name but a few). It is far too common to see code like this:
signal(SIGINT, signal_handler);
signal(SIGTERM, signal_handler);
signal(SIGQUIT, signal_handler);
Such code is unsafe because while signal_handler( ) is handling a SIGTERM that has been delivered to the process, a SIGINT could be delivered to the same function. Most programmers have a tendency to write their signal handlers in a non-reentrant fashion because the same signal will not be delivered to the process again until the first handler returns. In addition, many programmers write their code under the false assumption that no signals can be delivered while a signal handler is running, which is not true.
Do as little work as is possible in a signal handler.
Only a small number of system functions are safe to call from a signal handler. Worse, the list is different on different operating systems. Worse still, many operating systems do not document which functions are safe, and which are not. In general, it is a good idea to set a flag in a signal handler, and do nothing else. Never make calls to dynamic memory allocation functions such as malloc( ) or free( ), or any other functions that may make calls to those functions. This includes calls to functions like syslog( )—which we'll discuss in more detail later in this chapter (seeRecipe 13.11)—for a variety of reasons, including the fact that it often makes calls to malloc( ) internally.
Note that on many systems, system functions like malloc( ) and free( ) are re-entrant, and can be called safely from multiple threads, but this type of reentrancy is not the same as what is required for use by a signal handler! For thread safety, these functions usually use a mutex to protect themselves. But what happens if a signal is delivered to a thread while that thread is in the process of running malloc( )? The simple answer is that the behavior is undefined. On some systems, this might cause a deadlock because the same thread is trying to acquire the same mutex more than once. On other systems, the acquisition of the mutex may fail, and malloc( ) proceeds normally, resulting in a double release of the mutex. On still other systems, there could be no multithreaded protection at all, and the heap could become corrupted. Many other possibilities exist as well, but these three alone should scare you enough to make the point.
If you must perform more complex operations in a signal handler than we are recommending here, you should block signal delivery during any nonatomic operations that may be impacted by operations performed in a signal handler. In addition, you should block signal delivery inside all signal handlers.
We strongly recommend against performing complex operations in a signal handler. If you feel that it's necessary, be aware that it can be done but is error-prone and will negatively affect program performance.
As an example of what you must do to safely use malloc( ) (whether directly or indirectly) from inside a signal handler, note that any time malloc( ) needs to be called inside or outside the signal handler, signal delivery will need to be blocked before the call to malloc( ) and unblocked again after the call. Changing the signal delivery often incurs a context switch from user mode to kernel mode; when such switching is done so frequently, it can quickly add up to a significant decrease in performance. In addition, because you may never be certain which functions may call malloc( ) under the covers, you may need to protect everything, which can easily result in forgotten protections in places.
Discussion
As we have already mentioned, there is unfortunately no cookie-cutter solution to writing safe signal handlers. The code presented here is simply an example of how signal handlers can be properly written. A much more detailed discussion of signal handling, which includes real-world examples of how improperly written signal handlers can be exploited, can be found in Michal Zalewski's paper, "Delivering Signals for Fun and Profit," which is available at http://www.netsys.com/library/papers/signals.txt. Another excellent source of information regarding the proper way to write signal handlers is Advanced Programming in the Unix Environment by W. Richard Stevens (Addison Wesley).
#include <stdio.h>
#include <signal.h>
#include <unistd.h>
int sigint_received = 0;
int sigterm_received = 0;
int sigquit_received = 0;
void handle_sigint(int sig) { sigint_received = 1; }
void handle_sigterm(int sig) { sigterm_received = 1; }
void handle_sigquit(int sig) { sigquit_received = 1; }
static void setup_signal_handler(int sig, void (*handler)( )) {
#if _POSIX_VERSION > 198800L
struct sigaction action;
action.sa_handler = handler;
sigemptyset(&(action.sa_mask));
sigaddset(&(action.sa_mask), sig);
action.sa_flags = 0;
sigaction(sig, &action, 0);
#else
signal(sig, handler);
#endif
}
static int signal_was_caught(void)
{
if (sigint_received) printf("SIGINT received!\n");
if (sigterm_received) printf("SIGTERM received!\n");
if (sigquit_received) printf("SIGQUIT received!\n");
return (sigint_received || sigterm_received || sigquit_received);
}
int main(int argc, char *argv[ ]) {
char buffer[80];
setup_signal_handler(SIGINT, handle_sigint);
setup_signal_handler(SIGTERM, handle_sigterm);
setup_signal_handler(SIGQUIT, handle_sigquit);
/* The main loop of this program simply reads input from stdin, and
* throws it away. It's useless functionality, but the point is to
* illustrate signal handling, and fread is a system call that will
* be interrupted by signals, so it works well for example purposes
*/
while (!feof(stdin)) {
fread(buffer, 1, sizeof(buffer), stdin);
if (signal_was_caught( )) break;
}
return (sigint_received || sigterm_received || sigquit_received);
}
This code clearly illustrates both points made in Section 13.5.2. Separate signal handlers are used for each signal that we want to handle: SIGINT, SIGTERM, and SIGQUIT. For each signal handler, a global flag is set to nonzero to indicate that the signal was caught. Later, when the system call—fread( ) in this case—returns, the flags are checked and fully handled. (It is true that fread( ) itself is not really a system call, but it is a wrapper around the read( ) system call.)
In the function setup_signal_handler( ) , we use sigaction( ) to set up our signal handlers, rather than signal( ), if it is available. On most modern Unix systems, sigaction( ) is available and should be used. One problem with signal( ) is that on some platforms it is subject to race conditions because it is implemented as a wrapper around sigaction( ). Another problem is that on some systems—most notably those that are BSD-derived—some system calls are restarted when interrupted by a signal, which is typically not the behavior we want. In this particular example, it certainly is not because we won't get the opportunity to check our flags until after the call to fread( ) completes, which could be a long time. Using sigaction( ) without the nonportable SA_RESTART flag will disable this behavior and cause fread( ) to return immediately with the global errno set to EINTR.
The function signal_was_caught( ) is used to check each of the signal flags and print an appropriate message if one of the signals was received. It is, in fact, possible that more than one signal could have been received, so all the flags are checked. Immediately after the call to fread( ), we callsignal_was_caught( ) to do the signal tests and immediately break out of our loop and exit if any one of the signals was received.
See Also
§ "Delivering Signals for Fun and Profit" by Michal Zalewski: http://www.netsys.com/library/papers/signals.txt
§ Advanced Programming in the Unix Environment by W. Richard Stevens (Addison Wesley)
§ Recipe 13.11
13.6. Protecting against Shatter Attacks on Windows
Problem
You are developing software that will run on Windows, and you want to protect your program against shatter attacks.
Solution
In December 2002, Microsoft issued security bulletin MS02-071 (http://www.microsoft.com/technet/treeview/?url=/technet/security/bulletin/MS02-071.asp), along with a patch for Windows NT 4.0, Windows 2000, and Windows XP that addresses the issue described in this recipe. Use that patch to prevent shatter attacks.
In addition, services running with elevated privileges should never use any of the Windows user interface APIs. In particular, windows (even invisible ones) and message loops should be avoided.
The primary consequence of the shatter attack is local elevation of privileges, which means that it is only an issue on versions of Windows that have privileges. In other words, Windows 95, Windows 98, and Windows ME are not affected.
Discussion
In August 2002, Chris Paget released a white paper (http://security.tombom.co.uk/shatter.html) describing a form of attack against event-driven systems that he termed a shatter attack. In particular, Paget's paper targeted Microsoft's Win32 API. Paget was not the first to discover the vulnerabilities he described in his paper, but his paper reached the widest audience, and the name he gave the attack has since stuck. Indeed, Microsoft has been aware of the problems Paget describes since at least 1994.
In an event-driven system, all communication is done by way of messages. Devices (such as a keyboard or a mouse, for example) send messages to applications, and applications send messages to each other. The attack works by sending either unexpected messages (typically a series of messages that is expected in a particular order, but when received in a different order, the recipient will behave erratically) or malformed messages. The effect can be a denial of service—causing the victim application to crash, for example—or it can be more serious, allowing an attacker to inject code into the application and execute it, which could potentially result in privilege escalation.
Most event-driven systems are susceptible in varying degrees to these types of attack, but Microsoft's Win32 is particularly susceptible for two reasons. The first reason is that messages are used not only for notification, but also for control. For example, it is possible to cause a button to be clicked by sending it the appropriate message. The second reason is that it is impossible for the recipient of a message to determine the message's origin. Because of this, an attacker can easily impersonate another application, a device, the window manager, or the system. An application has no way of knowing whether a message to shut down the system has come from the system or from a malicious application.
There is one Win32 message that is of particular interest: WM_TIMER . This message is normally generated by the system as a result of calling the API function SetTimer( ). A timer is created with a timeout, and every time that timeout occurs, the message is sent to the window that requested the timer. What is interesting about this message, though, is that its parameters may contain an address. If an address is present, Windows (if it has not been patched) will jump to that address without performing any kind of validation to determine whether or not it is reasonable to do so. An attacker can take advantage of these facts to jump to an invalid address to force an application crash (denial of service), or to jump to an address known to contain code that an attacker has injected into the recipient's address space (by way of an edit control, for example). Such attacks could do any number of mischievous things, such as create a command window with elevated privileges.
The patch that Microsoft has issued to address the problem prevents WM_TIMER messages containing addresses that have not been registered with SetTimer( ) from being processed. In addition, Longhorn goes a step further by refusing to start a service that interacts with the desktop.
See Also
§ Microsoft Security Bulletin MS02-071: http://www.Microsoft.com/technet/treeview/?url=/technet/security/bulletin/MS02-071.asp
§ "Shatter Attacks—How to Break Windows" by Chris Paget: http://security.tombom.co.uk/shatter.html
13.7. Guarding Against Spawning Too Many Threads
Problem
You need to prevent too many threads from being spawned, a problem that could potentially result in a denial of service owing to exhausted system resources.
Solution
A common mistake in writing multithreaded programs is to create a new thread every time a new task is initiated; this is often overkill. Often, a "pool" of threads can be used to perform simple tasks. A set number of threads are created when the program initializes, and these threads exist for the lifetime of the process. Whenever a task needs to be performed on another thread, the task can be queued. When a thread is available, it can perform the task, then go back to waiting for another task to perform.
On Windows 2000 and greater, there is a new API function called QueueUserWorkItem( ) that essentially implements the same functionality as that presented in this recipe. Unfortunately, that function does not exist on older versions of Windows. Our solution has the advantage of being portable to such older systems. However, if you are writing code that is guaranteed always to be running on a system that supports the API, you may wish to use it instead. Regardless of whether you use the API or the code we present in this recipe, the concepts are the same, and the bulk of our discussion still applies.
Discussion
Suppose that the program using thread spawns is a network server, and it spawns a new thread for each connection it receives, an attacker can quickly flood the server with false or incomplete connections. The result is either that the server runs out of available threads and cannot create any more, or that it cannot create them fast enough to service the incoming requests. Either way, legitimate connections can no longer get through, and system resources are exhausted.
The proper way to handle a program using an arbitrary number of threads is to generate a "pool" of threads in advance, which solves two problems. First, it removes the thread creation time, which can be expensive because of the cost of accepting a new connection. Second, it prevents system resources from being exhausted because too many threads have been spawned.
We can effectively map threads that would otherwise be spawned to tasks. Normally when a thread is spawned, a function to serve as its entry point is specified along with a pointer to void as an argument that can be any application-specific data to be passed to the thread's entry point. We'll mirror these semantics in our tasks and create a function, spc_threadpool_schedule( ) to schedule a new task. The task will be stored at the end of a list so that tasks will be run in the order they are scheduled. When a new task is scheduled, the system will signal a condition object, which pooled threads will wait on when they have no tasks to run. Figure 13-1 illustrates the sequence of events that occurs in each pooled thread.
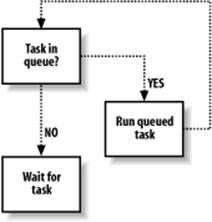
Figure 13-1. Actions carried out by pooled threads
Notice that the number of tasks that can be scheduled is not restricted. As long as there is sufficient memory to create a new task structure, tasks will be scheduled. Depending on how the thread pool is to be used, it may be desirable to limit the number of tasks that can be scheduled at any one time. For example, in a network server that schedules each connection as a task, you may want to immediately limit the number of connections until all of the already scheduled connections have been run.
#include <stdlib.h>
#ifndef WIN32
#include <pthread.h>
#else
#include <windows.h>
#endif
typedef void (*spc_threadpool_fnptr)(void *);
typedef struct _spc_threadpool_task {
spc_threadpool_fnptr fnptr;
void *arg;
struct _spc_threadpool_task *next;
} spc_threadpool_task;
typedef struct {
int size;
int destroy;
#ifndef WIN32
pthread_t *tids;
pthread_cond_t cond;
#else
HANDLE *tids;
HANDLE cond;
#endif
spc_threadpool_task *tasks;
spc_threadpool_task *tail;
} spc_threadpool_t;
#ifndef WIN32
#define SPC_ACQUIRE_MUTEX(mtx) pthread_mutex_lock(&(mtx))
#define SPC_RELEASE_MUTEX(mtx) pthread_mutex_unlock(&(mtx))
#define SPC_CREATE_COND(cond) pthread_cond_init(&(cond), 0)
#define SPC_DESTROY_COND(cond) pthread_cond_destroy(&(cond))
#define SPC_SIGNAL_COND(cond) pthread_cond_signal(&(cond))
#define SPC_BROADCAST_COND(cond) pthread_cond_broadcast(&(cond))
#define SPC_WAIT_COND(cond, mtx) pthread_cond_wait(&(cond), &(mtx))
#define SPC_CLEANUP_PUSH(func, arg) pthread_cleanup_push(func, arg)
#define SPC_CLEANUP_POP(exec) pthread_cleanup_pop(exec)
#define SPC_CREATE_THREAD(t, f, arg) (!pthread_create(&(t), 0, (f), (arg)))
static pthread_mutex_t threadpool_mutex = PTHREAD_MUTEX_INITIALIZER;
#else
#define SPC_ACQUIRE_MUTEX(mtx) WaitForSingleObjectEx((mtx), INFINITE, FALSE)
#define SPC_RELEASE_MUTEX(mtx) ReleaseMutex((mtx))
#define SPC_CREATE_COND(cond) (cond) = CreateEvent(0, TRUE, FALSE, 0)
#define SPC_DESTROY_COND(cond) CloseHandle((cond))
#define SPC_SIGNAL_COND(cond) SetEvent((cond))
#define SPC_BROADCAST_COND(cond) PulseEvent((cond))
#define SPC_WAIT_COND(cond, mtx) spc_win32_wait_cond((cond), (mtx))
#define SPC_CLEANUP_PUSH(func, arg) { void (*_ _spc_func)(void *) = (func); \
void *_ _spc_arg = (arg)
#define SPC_CLEANUP_POP(exec) if ((exec)) _ _spc_func(_ _spc_arg); } \
do { } while (0)
#define SPC_CREATE_THREAD(t, f, arg) ((t) = CreateThread(0, 0, (f), (arg), 0, 0))
static HANDLE threadpool_mutex = 0;
#endif
#ifdef WIN32
static void spc_win32_wait_cond(HANDLE cond, HANDLE mutex) {
HANDLE handles[2];
handles[0] = cond;
handles[1] = mutex;
ResetEvent(cond);
ReleaseMutex(mutex);
WaitForMultipleObjectsEx(2, handles, TRUE, INFINITE, FALSE);
}
#endif
int spc_threadpool_schedule(spc_threadpool_t *pool, spc_threadpool_fnptr fnptr,
void *arg) {
spc_threadpool_task *task;
SPC_ACQUIRE_MUTEX(threadpool_mutex);
if (!pool->tids) {
SPC_RELEASE_MUTEX(threadpool_mutex);
return 0;
}
if (!(task = (spc_threadpool_task *)malloc(sizeof(spc_threadpool_task)))) {
SPC_RELEASE_MUTEX(threadpool_mutex);
return 0;
}
task->fnptr = fnptr;
task->arg = arg;
task->next = 0;
if (pool->tail) pool->tail->next = task;
else pool->tasks = task;
pool->tail = task;
SPC_SIGNAL_COND(pool->cond);
SPC_RELEASE_MUTEX(threadpool_mutex);
return 1;
}
Each pooled thread will normally run in a loop that waits for new tasks to be scheduled. When a new task is scheduled, it will be removed from the list of scheduled tasks and run. When there are no scheduled tasks, the threads will be put to sleep, waiting on the condition thatspc_threadpool_schedule( ) will signal when a new task is scheduled. Note that pthread_cond_wait( ) is a cancellation point. If the thread is cancelled while it is waiting for the condition to be signaled, the guard mutex will be locked. As a result, we need to push a cleanup handler to undo that so that other threads will successfully die when they are cancelled as well. (The importance of this behavior will become apparent shortly.)
static void cleanup_worker(void *arg) {
spc_threadpool_t *pool = (spc_threadpool_t *)arg;
if (pool->destroy && !--pool->destroy) {
SPC_DESTROY_COND(pool->cond);
free(pool);
}
SPC_RELEASE_MUTEX(threadpool_mutex);
}
#ifndef WIN32
static void *worker_thread(void *arg) {
#else
static DWORD WINAPI worker_thread(LPVOID arg) {
#endif
int done = 0;
spc_threadpool_t *pool = (spc_threadpool_t *)arg;
spc_threadpool_task *task;
while (!done) {
SPC_ACQUIRE_MUTEX(threadpool_mutex);
if (!pool->tids || pool->destroy) {
cleanup_worker(arg);
return 0;
}
SPC_CLEANUP_PUSH(cleanup_worker, arg);
if (pool->tids) {
if (!pool->tasks) SPC_WAIT_COND(pool->cond, threadpool_mutex);
if ((task = pool->tasks) != 0)
if (!(pool->tasks = task->next)) pool->tail = 0;
} else done = 1;
SPC_CLEANUP_POP(1);
if (!done && task) {
task->fnptr(task->arg);
free(task);
}
}
return 0;
}
Before any tasks can be scheduled, the pool of threads to run them needs to be created. This is done by making a call to spc_threadpool_init( ) and specifying the number of threads that will be in the pool. Be careful not to make the size of the pool too small. It is better for it to be too big than not big enough. Ideally, you would like to have scheduled tasks remain scheduled for as short a time as possible. Finding the right size for the thread pool will likely take some tuning, and it is probably a good idea to make it a configurable option in your program.
If there is a problem creating any of the threads to be part of the pool, any already created threads are canceled, and the initialization function will return failure. Successive attempts can be made to initialize the pool without any leakage of resources.
spc_threadpool_t *spc_threadpool_init(int pool_size) {
int i;
spc_threadpool_t *pool;
#ifdef WIN32
if (!threadpool_mutex) threadpool_mutex = CreateMutex(NULL, FALSE, 0);
#endif
if (!(pool = (spc_threadpool_t *)malloc(sizeof(spc_threadpool_t))))
return 0;
#ifndef WIN32
pool->tids = (pthread_t *)malloc(sizeof(pthread_t) * pool_size);
#else
pool->tids = (HANDLE *)malloc(sizeof(HANDLE) * pool_size);
#endif
if (!pool->tids) {
free(pool);
return 0;
}
SPC_CREATE_COND(pool->cond);
pool->size = pool_size;
pool->destroy = 0;
pool->tasks = 0;
pool->tail = 0;
SPC_ACQUIRE_MUTEX(threadpool_mutex);
for (i = 0; i < pool->size; i++) {
if (!SPC_CREATE_THREAD(pool->tids[i], worker_thread, pool)) {
pool->destroy = i;
free(pool->tids);
pool->tids = 0;
SPC_RELEASE_MUTEX(threadpool_mutex);
return 0;
}
}
SPC_RELEASE_MUTEX(threadpool_mutex);
return pool;
}
Finally, when the thread pool is no longer needed, it can be cleaned up by calling spc_threadpool_cleanup( ) . All of the threads in the pool will be cancelled, and any scheduled tasks will be destroyed without being run.
void spc_threadpool_cleanup(spc_threadpool_t *pool) {
spc_threadpool_task *next;
SPC_ACQUIRE_MUTEX(threadpool_mutex);
if (pool->tids) {
while (pool->tasks) {
next = pool->tasks->next;
free(pool->tasks);
pool->tasks = next;
}
free(pool->tids);
pool->tids = 0;
}
pool->destroy = pool->size;
SPC_BROADCAST_COND(pool->cond);
SPC_RELEASE_MUTEX(threadpool_mutex);
}
13.8. Guarding Against Creating Too Many Network Sockets
Problem
You need to limit the number of network sockets that your program can create.
Solution
Limiting the number of sockets that can be created in an application is a good way to mitigate potential denial of service attacks by preventing an attacker from creating too many open sockets for your program to be able to handle. Imposing a limit on sockets is a simple matter of maintaining a count of the number of sockets that have been created so far. To do this, you will need to appropriately wrap three socket functions. The first two functions that need to be wrapped, socket( ) and accept( ), are used to obtain new socket descriptors, and they should be modified to increment the number of sockets when they're successful. The third function, close( ) (closesocket( ) on Windows), is used to dispose of an existing socket descriptor, and it should be modified to decrement the number of sockets when it's successful.
Discussion
To limit the number of sockets that can be created, the first step is to call spc_socketpool_init( ) to initialize the socket pool code. On Unix, this does nothing, but it is required on Windows to initialize two synchronization objects. Once the socket pool code is initialized, the next step is to callspc_socketpool_setlimit( ) with the maximum number of sockets to allow. In our implementation, any limit less than or equal to zero disables limiting sockets but causes them still to be counted. We have written the code to be thread-safe and to allow the wrapped functions to block when no sockets are available. If the limit is adjusted to allow more sockets when the old limit has already been reached, we cause all threads waiting for sockets to be awakened by signaling a condition object using pthread_cond_broadcast( ) on Unix or PulseEvent( ) on Windows.
#include <errno.h>
#include <sys/types.h>
#ifndef WIN32
#include <sys/socket.h>
#include <pthread.h>
#else
#include <windows.h>
#include <winsock.h>
#endif
#ifndef WIN32
#define SPC_ACQUIRE_MUTEX(mtx) pthread_mutex_lock(&(mtx))
#define SPC_RELEASE_MUTEX(mtx) pthread_mutex_unlock(&(mtx))
#define SPC_CREATE_COND(cond) (!pthread_cond_init(&(cond), 0))
#define SPC_DESTROY_COND(cond) pthread_cond_destroy(&(cond))
#define SPC_SIGNAL_COND(cond) pthread_cond_signal(&(cond))
#define SPC_BROADCAST_COND(cond) pthread_cond_broadcast(&(cond))
#define SPC_WAIT_COND(cond, mtx) pthread_cond_wait(&(cond), &(mtx))
#define SPC_CLEANUP_PUSH(func, arg) pthread_cleanup_push(func, arg)
#define SPC_CLEANUP_POP(exec) pthread_cleanup_pop(exec)
#define closesocket(sock) close((sock))
#define SOCKET_ERROR -1
#else
#define SPC_ACQUIRE_MUTEX(mtx) WaitForSingleObjectEx((mtx), INFINITE, FALSE)
#define SPC_RELEASE_MUTEX(mtx) ReleaseMutex((mtx))
#define SPC_CREATE_COND(cond) ((cond) = CreateEvent(0, TRUE, FALSE, 0))
#define SPC_DESTROY_COND(cond) CloseHandle((cond))
#define SPC_SIGNAL_COND(cond) SetEvent((cond))
#define SPC_BROADCAST_COND(cond) PulseEvent((cond))
#define SPC_WAIT_COND(cond, mtx) spc_win32_wait_cond((cond), (mtx))
#define SPC_CLEANUP_PUSH(func, arg) { void (*_ _spc_func)(void *) = func; \
void *_ _spc_arg = arg;
#define SPC_CLEANUP_POP(exec) if ((exec)) _ _spc_func(_ _spc_arg); } \
do { } while (0)
#endif
static int socketpool_used = 0;
static int socketpool_limit = 0;
#ifndef WIN32
static pthread_cond_t socketpool_cond = PTHREAD_COND_INITIALIZER;
static pthread_mutex_t socketpool_mutex = PTHREAD_MUTEX_INITIALIZER;
#else
static HANDLE socketpool_cond, socketpool_mutex;
#endif
#ifdef WIN32
static void spc_win32_wait_cond(HANDLE cond, HANDLE mutex) {
HANDLE handles[2];
handles[0] = cond;
handles[1] = mutex;
ResetEvent(cond);
ReleaseMutex(mutex);
WaitForMultipleObjectsEx(2, handles, TRUE, INFINITE, FALSE);
}
#endif
int spc_socketpool_init(void) {
#ifdef WIN32
if (!SPC_CREATE_COND(socketpool_cond)) return 0;
if (!(socketpool_mutex = CreateMutex(0, FALSE, 0))) {
CloseHandle(socketpool_cond);
return 0;
}
#endif
return 1;
}
int spc_socketpool_setlimit(int limit) {
SPC_ACQUIRE_MUTEX(socketpool_mutex);
if (socketpool_limit > 0 && socketpool_used >= socketpool_limit) {
if (limit <= 0 || limit > socketpool_limit)
SPC_BROADCAST_COND(socketpool_cond);
}
socketpool_limit = limit;
SPC_RELEASE_MUTEX(socketpool_mutex);
return 1;
}
The wrappers for the accept( ) and socket( ) calls are very similar, and they really differ only in the arguments they accept. Our wrappers add an extra argument that indicates whether the functions should wait for a socket to become available if one is not immediately available. Any nonzero value will cause the functions to wait until a socket becomes available. A value of zero will cause the functions to return immediately with errno set to EMFILE if there are no available sockets. Should the actual wrapped functions return any kind of error, the wrapper functions will return that error immediately without incrementing the socket count.
static void socketpool_cleanup(void *arg) {
SPC_RELEASE_MUTEX(socketpool_mutex);
}
int spc_socketpool_accept(int sd, struct sockaddr *addr, int *addrlen, int block) {
int avail = 1, new_sd = -1;
SPC_ACQUIRE_MUTEX(socketpool_mutex);
SPC_CLEANUP_PUSH(socketpool_cleanup, 0);
if (socketpool_limit > 0 && socketpool_used >= socketpool_limit) {
if (!block) {
avail = 0;
errno = EMFILE;
} else {
while (socketpool_limit > 0 && socketpool_used >= socketpool_limit)
SPC_WAIT_COND(socketpool_cond, socketpool_mutex);
}
}
if (avail && (new_sd = accept(sd, addr, addrlen)) != -1)
socketpool_used++;
SPC_CLEANUP_POP(1);
return new_sd;
}
int spc_socketpool_socket(int domain, int type, int protocol, int block) {
int avail = 1, new_sd = -1;
SPC_ACQUIRE_MUTEX(socketpool_mutex);
SPC_CLEANUP_PUSH(socketpool_cleanup, 0);
if (socketpool_limit > 0 && socketpool_used >= socketpool_limit) {
if (!block) {
avail = 0;
errno = EMFILE;
} else {
while (socketpool_limit > 0 && socketpool_used >= socketpool_limit)
SPC_WAIT_COND(socketpool_cond, socketpool_mutex);
}
}
if (avail && (new_sd = socket(domain, type, protocol)) != -1)
socketpool_used++;
SPC_CLEANUP_POP(1);
return new_sd;
}
When a socket that was obtained using spc_socketpool_accept( ) or spc_socketpool_socket( ) is no longer needed, close it by calling spc_socketpool_close( ) . Do not call spc_socketpool_close( ) with file or socket descriptors that were not obtained from one of the wrapper functions; otherwise, the socket count will become corrupted. This implementation does not keep a list of the actual descriptors that have been allocated, so it is the responsibility of the caller to do so. If a socket being closed makes room for another socket to be created, the condition that the accept( )and socket( ) wrapper functions wait on will be signaled.
int spc_socketpool_close(int sd) {
if (closesocket(sd) = = SOCKET_ERROR) return -1;
SPC_ACQUIRE_MUTEX(socketpool_mutex);
if (socketpool_limit > 0 && socketpool_used = = socketpool_limit)
SPC_SIGNAL_COND(socketpool_cond);
socketpool_used--;
SPC_RELEASE_MUTEX(socketpool_mutex);
return 0;
}
13.9. Guarding Against Resource Starvation Attacks on Unix
Problem
You need to prevent resource starvation attacks against your application.
Solution
The operating system does not trust the applications that it allows to run. For this reason, the operating system imposes limits on certain resources. The limitations are imposed to prevent an application from using up all of the available system resources, thus denying other running applications the ability to run. The default limits are usually set much higher than they need to be, which ends up allowing any given application to use up far more resources than it ordinarily should.
Unix provides a mechanism by which an application can self-impose restrictive limits on the resources that it uses. It's a good idea for the programmer to lower the limits to a point where the application can run comfortably, but if something unexpected happens (such as a memory leak or, more to the point, a denial of service attack), the limits cause the application to begin failing without bringing down the rest of the system with it.
Discussion
Operating system resources are difficult for an application to control; the pooling approach used in threads and sockets is difficult to implement when the application does not explicitly allocate and destroy its own resources. System resources such as memory, CPU time, disk space, and open file descriptors are best managed using system quotas. The programmer can never be sure that system quotas are enabled when the application is running; therefore, it pays to be defensive and to write code that is reasonably aware of system resource management.
The most basic advice will be long familiar from lectures on good programming practice:
§ Avoid the use of system calls when possible.
§ Minimize the number of filesystem reads and writes.
§ Steer away from CPU-intensive or "tight" loops.
§ Avoid allocating large buffers on the stack.
The ambitious programmer may wish to replace library and operating system resource management subsystems, by such means as writing a memory allocator that enforces a maximum memory usage per thread, or writing a scheduler tied to the system clock which pauses or stops threads and processes with SIGSTOP signals after a specified period of time. While these are viable solutions and should be considered for any large-scale project, they greatly increase development time and are likely to introduce new bugs into the system.
Instead, you may wish to voluntarily submit to the resource limits enforced by system quotas, thereby in effect "enabling" quotas for the application. This can be done with the setrlimit( ) function, which allows the resources listed in Table 13-1 to be limited. Note, however, that not all systems implement all resource limits listed in this table. Exceeding any of these limits will cause runtime errors such as ENOMEM when attempting to allocate memory after RLIMIT_DATA has been reached. On BSD-derived systems, two exceptions are RLIMIT_CPU and RLIMIT_FSIZE, which raise theSIGXCPU and SIGXFSZ signals, respectively.
Table 13-1. Resources that may be limited with setrlimit( )
|
Resource |
Description |
|
RLIMIT_CORE |
Maximum size in bytes of a core file (see Recipe 1.9) |
|
RLIMIT_CPU |
Maximum amount of CPU time in seconds |
|
RLIMIT_DATA |
Maximum size in bytes of .data, .bss, and the heap |
|
RLIMIT_FSIZE |
Maximum size in bytes of a file |
|
RLIMIT_NOFILE |
Maximum number of open files per process |
|
RLIMIT_NPROC |
Maximum number of child processes per user ID |
|
RLIMIT_RSS |
Maximum resident set size in bytes |
|
RLIMIT_STACK |
Maximum size in bytes of the process stack |
|
RLIMIT_VMEM |
Maximum size in bytes of mapped memory |
The setrlimit( ) function has the following syntax:
struct rlimit
{
rlim_t rlim_cur;
rlim_t rlim_max;
};
int setrlimit(int resource, const struct rlimit *rlim);
The resource parameter is one of the constants listed in Table 13-1. The programmer may increase or decrease the rlim_cur field at will; increasing the rlim_max field requires root privileges. For this reason, it is important to read the rlimit structure before modifying it in order to preserve therlim_max field, thus allowing the system call to complete successfully. The current settings for rlim_cur and rlim_max can be obtained with the getrlimit( ) function, which has a similar signature to setrlimit( ):
int getrlimit(int resource, struct rlimit *rlim);
We've implemented a function here called spc_rsrclimit( ) that can be used to conveniently adjust the resource limits for the process that calls it. It does nothing more than make the necessary calls to getrlimit( ) and setrlimit( ). Note that the signal handlers have been left unimplemented because they will be application-specific.
#include <sys/types.h>
#include <sys/time.h>
#include <sys/resource.h>
static int resources[ ] = {
RLIMIT_CPU, RLIMIT_DATA, RLIMIT_STACK, RLIMIT_FSIZE,
#ifdef RLIMIT_NPROC
RLIMIT_NPROC,
#endif
#ifdef RLIMIT_NOFILE
RLIMIT_NOFILE,
#endif
#ifdef RLIMIT_OFILE
RLIMIT_OFILE,
#endif
-1
};
void spc_rsrclimit(int max_cpu, int max_data, int max_stack, int max_fsize,
int max_proc, int max_files) {
int limit, *resource;
struct rlimit r;
for (resource = resources; *resource >= 0; resource++) {
switch (*resource) {
case RLIMIT_CPU: limit = max_cpu; break;
case RLIMIT_DATA: limit = max_data; break;
case RLIMIT_STACK: limit = max_stack; break;
case RLIMIT_FSIZE: limit = max_fsize; break;
#ifdef RLIMIT_NPROC
case RLIMIT_NPROC: limit = max_proc; break;
#endif
#ifdef RLIMIT_NOFILE
case RLIMIT_NOFILE: limit = max_files; break;
#endif
#ifdef RLIMIT_OFILE
case RLIMIT_OFILE: limit = max_files; break;
#endif
}
getrlimit(*resource, &r);
r.rlim_cur = (limit < r.rlim_max ? limit : r.rlim_max);
setrlimit(*resource, &r);
}
}
See Also
Recipe 1.9
13.10. Guarding Against Resource Starvation Attacks on Windows
Problem
You need to prevent resource starvation attacks against your application.
Solution
As we noted in the previous recipe, the operating system does not trust the applications that it allows to run. For this reason, the operating system imposes limits on certain resources. The limitations are imposed to prevent an application from using up all of the available system resources, thus denying other running applications the ability to run. The default limits are usually set much higher than they need to be, which ends up allowing any given application to use up far more resources than it ordinarily should.
Windows 2000 and newer versions provide a mechanism by which applications can self-impose restrictive limits on the resources that it uses. It's a good idea for the programmer to lower the limits to a point where the application can run comfortably, but if something unexpected happens (such as a memory leak or, more to the point, a denial of service attack), the limits cause the application to terminate without bringing down the rest of the system with it.
Discussion
Operating system resources are difficult for an application to control; the pooling approach used in threads and sockets is difficult to implement when the application does not explicitly allocate and destroy its own resources. System resources, such as memory and CPU time, are best managed using system quotas. The programmer can never be sure that system quotas are enabled when the application is running; therefore, it pays to be defensive and write code that is reasonably aware of system resource management.
The most basic advice will be long familiar from lectures on good programming practice:
§ Avoid the use of system calls when possible.
§ Minimize the number of filesystem reads and writes.
§ Steer away from CPU-intensive or "tight" loops.
§ Avoid allocating large buffers on the stack.
The ambitious programmer may wish to replace library and operating system resource management subsystems, by such means as writing a memory allocator that enforces a maximum memory usage per thread, or writing a scheduler tied to the system clock which pauses or stops threads and processes after a specified period of time. While these are viable solutions and should be considered for any large-scale project, they greatly increase development time and will likely introduce new bugs into the system.
Instead, you may wish to voluntarily submit to the resource limits enforced by system quotas, thereby in effect "enabling" quotas for the application. This can be done on Windows using job objects . Job objects are created to hold and control processes, imposing limits on them that do not exist on processes outside of the job object. Various restrictions may be imposed upon processes running within a job object, including limiting CPU time, memory usage, and access to the user interface. Here, we are only interested in restricting resource utilization of processes within a job, which will cause any process exceeding any of the imposed limits to be terminated by the operating system.
The first step in using job objects on Windows is to create a job control object. This is done by calling CreateJobObject( ) , which requires a set of security attributes in a SECURITY_ATTRIBUTES structure and a name for the job object. The job object may be created without a name, in which case other processes cannot open it, making the job object private to the process that creates it and its children. If the job object is created successfully, CreateJobObject( ) returns a handle to the object; otherwise, it returns NULL, and GetLastError( ) can be used to determine what caused the failure.
With a handle to a job object in hand, restrictions can be placed on the processes that run within the job using the SetInformationJobObject( ) function, which has the following signature:
BOOL SetInformationJobObject(HANDLE hJob, JOBOBJECTINFOCLASS JobObjectInfoClass,
LPVOID lpJobObjectInfo, DWORD cbJobObjectInfoLength);
This function has the following arguments:
hJob
Handle to a job object created with CreateJobObject( ), or opened by name with OpenJobObject( ).
JobObjectInfoClass
Predefined constant value used to specify the type of restriction to place on the job object. Several constants are defined, but we are only interested in two of them: JobObjectBasicLimitInformation and JobObjectExtendedLimitInformation.
lpJobObjectInfo
Pointer to a filled-in structure that is either a JOBOBJECT_BASIC_LIMIT_INFORMATION or a JOBOBJECT_EXTENDED_LIMIT_INFORMATION, depending on the value specified for JobObjectInfoClass.
cbJobObjectInfoLength
Length of the structure pointed to by lpJobObjectInfo in bytes.
For the two job object information classes that we are interested in, two data structures are defined. The interesting fields in each structure are:
typedef struct _JOBOBJECT_BASIC_LIMIT_INFORMATION {
LARGE_INTEGER PerProcessUserTimeLimit;
LARGE_INTEGER PerJobUserTimeLimit;
DWORD LimitFlags;
DWORD ActiveProcessLimit;
} JOBOBJECT_BASIC_LIMIT_INFORMATION;
typedef struct _JOBOBJECT_EXTENDED_LIMIT_INFORMATION {
JOBOBJECT_BASIC_LIMIT_INFORMATION BasicLimitInformation;
SIZE_T ProcessMemoryLimit;
SIZE_T JobMemoryLimit;
} JOBOBJECT_EXTENDED_LIMIT_INFORMATION;
Note that the structures as presented here are incomplete. Each one contains several other members that are of no interest to us in this recipe. In the JOBOBJECT_BASIC_LIMIT_INFORMATION structure, the LimitFlags member is treated as a set of flags that control which other structure members are used by SetInformationJobObject( ) . The flags that can be set for LimitFlags that are of interest within the context of this recipe are:
JOB_OBJECT_LIMIT_ACTIVE_PROCESS
Sets the ActiveProcessLimit member in the JOBOBJECT_BASIC_LIMIT_INFORMATION structure to the number of processes to be allowed in the job object.
JOB_OBJECT_LIMIT_JOB_TIME
Sets the PerJobUserTimeLimit member in the JOBOBJECT_BASIC_LIMIT_INFORMATION structure to the combined amount of time all processes in the job may spend executing in user space. In other words, the time each process in the job spends executing in user space is totaled, and any process that causes this limit to be exceeded will be terminated. The limit is specified in units of 100 nanoseconds.
JOB_OBJECT_LIMIT_PROCESS_TIME
Sets the PerProcessUserTimeLimit member in the JOBOBJECT_BASIC_LIMIT_INFORMATION structure to the amount of time a process in the job may spend executing in user space. When a process exceeds the limit, it will be terminated. The limit is specified in units of 100 nanoseconds.
JOB_OBJECT_LIMIT_JOB_MEMORY
Sets the JobMemoryLimit member in the JOBOBJECT_EXTENDED_LIMIT_INFORMATION structure to the maximum amount of memory that all processes in the job may commit. When the combined total of committed memory of all processes in the job exceeds this limit, processes will be terminated as they attempt to commit more memory. The limit is specified in units of bytes.
JOB_OBJECT_LIMIT_PROCESS_MEMORY
Sets the ProcessMemoryLimit member in the JOBOBJECT_EXTENDED_LIMIT_INFORMATION structure to the maximum amount of memory that a process in the job may commit. When a process attempts to commit memory exceeding this limit, it will be terminated. The limit is specified in units of bytes.
Once a job object has been created and restrictions have been placed on it, processes can be assigned to the job by calling AssignProcessToJobObject( ) , which has the following signature:
BOOL AssignProcessToJobObject(HANDLE hJob, HANDLE hProcess);
This function has the following arguments:
hJob
Handle to the job object to assign the process.
hProcess
Handle of the process to be assigned.
If the assignment is successful, the AssignProcessToJobObject( )returns TRUE; otherwise, it returns FALSE, and the reason for the failure can be determined by calling GetLastError( ). Note that when a process exceeds one of the set limits, it is terminated immediately without being given the opportunity to perform any cleanup.
13.11. Following Best Practices for Audit Logging
Problem
You want to record activity and/or errors in your program for later review.
Solution
On Unix systems, syslog is the system audit logging facility. Windows also has its own built-in facility for audit logging that differs significantly from syslog on Unix.
WARNING
The syslog( ) function is susceptible to a format string attack if used improperly. See Recipe 3.2 for more information.
Discussion
We cannot overstate the importance of audit logging for security and, more importantly, for forensics. Unfortunately, most existing logging infrastructures severely lack any kind of security. It is generally trivial for attackers to cover their tracks by modifying or deleting any logs that would betray their presence or indicate how they managed to infiltrate your system. A number of things can be done to raise the bar, making it much more difficult for the would-be attacker to invalidate your logs. (We acknowledge, however, that no solution is perfect.)
Network logging
One such possibility involves logging to a network server that is dedicated to storing the logs of other machines on the network. The Unix syslog utility provides a simple interface for configuring logging to a network server instead of writing the log files on the local system, but the system administrator must do the configuration. Configuration cannot be done programmatically by individual programs using the service to make log entries.
If the server that is responsible for audit logging is configured properly, it can make an attacker's job of scrubbing your logs considerably more difficult, but it doesn't provide any real guarantees that your log files will not be altered or deleted by an attacker. Your audit log server should be configured to accept remote logging connections and nothing else. Any other access to the log files should require physical access to the machine. This makes it significantly more difficult for an attacker to gain access to your logs. If you need remote access to view your log files, a service like ssh is reasonably safe to enable as long as it is properly configured,[2] but it does increase the risk of the log files being compromised.
One final point regarding logging to a remote server using syslog: syslog sends log entries to the server over a UDP port without any kind of encryption or authentication. As a side effect of using a connectionless protocol, syslog is also notorious for losing log entries, particularly on heavily loaded systems.
Ideally, syslog would support making entries using an SSL-enabled TCP connection with authentication, but because it does not, system administrators should take steps to protect the log entries in transit to the logging server. One possible way to do this is to use a virtual private network (VPN) between the logging server and all network hosts that will be using it. Other possibilities include signing and encrypting the log entries in your programs before sending the entries to syslog, but this can be very difficult to do correctly. In an ideal world, the syslog daemon would handle encryption and signatures for you.
An alternative to using the stock syslog implementation that is included as part of most Unix distributions is to use syslog-ng , produced by Balabit IT Security LTD in Budapest, available under the GPL from http://www.balabit.com/products/syslog_ng/. It provides support for a variety of different network protocols, including both UDP and TCP; however, it does not support any kind of encryption or authentication. Before making the decision to use syslog-ng, you should be aware that it has had a few security vulnerabilities in recent history.
The audit logging service that is a part of Windows makes no provision for network logging. Every system stores its logs locally. In addition, log files are stored in a proprietary binary format that is not documented. At least in theory, it is possible to make the Windows logging service relay log entries to a centralized server, but to do so would require a program external to the logging service that listens for logging notifications and forwards them to the logging server. Logging to a remote server in this manner would cause a record to be kept in two locations: one on the local machine, and the other on the remote server.
Unfortunately, this solution is not likely to work very well in practice, because the Windows logging service depends upon local DLLs to supply the messages that you see when you view the logs. When a program wants to make log entries using the Windows logging service, it must first register a DLL that contains logging information with the logging service. When log entries are made, only a small amount of information is stored; this information includes a timestamp, an integer value representing the log message, and possibly some additional "metadata" that makes up the variable portion of the log message. The full textual message is never stored; instead, the DLLs that have been registered with the logging service provide the message on demand when the logs are viewed.
Logging to CD-R
On the surface, the idea of logging to read-only media sounds like a good idea, but in practice, it does not usually work out very well. There are a surprising number of serious problems with logging to CD-R. In fact, we recommend against it; we feel that the problems greatly outweigh the benefits.
One of the primary problems with logging to CD-R is the lack of hardware and software support for doing so. In order to write log entries out to CD-R in real time, writing must be done in what is known as packet-writing mode . Packet-writing mode allows data to be written to the CD-R incrementally instead of all at once. Most available hardware does not support packet-writing mode for CD-R. As a direct consequence of this, most operating systems do not have support for it either.
Perhaps the most obvious problem with logging to CD-R is that it requires constant monitoring and manual intervention. CD-R media is small, holding only roughly 660MB. A busy system could fill this up quite quickly, so someone must keep a close eye on the logging system, being prepared to swap media when necessary. In most environments, having someone around to swap CDs is not an effective use of resources. More importantly, if a busy system can fill up the media quickly under normal conditions, imagine what an attacker could do!
Other problems with packet-writing mode are performance and reliability. Because operating in packet-writing mode is slow, a busy system is very likely going to fall well behind the activity that is going on in real time. Reliability is also an issue. If an error of some kind occurs, there is a high probability that any data written to the CD-R will be lost. In addition, if an attacker were to reboot the system before the CD-R was finalized, all of the data on that CD-R would be lost.
If you still want to log to CD-R in "real time," be sure that you don't rely solely on CD-R copies. You should also keep local copies on the system's hard drive and log to a network server if you can.
Signing and encrypting log entries
Signing and encrypting entries made to log files can help ensure the integrity of the logs that are generated. Ideally, the logging server would be responsible for performing the cryptographic operations on all entries submitted to it, but neither syslog nor the Windows logging service provide built-in support for either signing or encrypting log entries. It is possible, however, to sign and/or encrypt the entries before submitting them to the logging server.
On Unix systems that use syslog, there is no guarantee that entries will be written to log files in the order in which they are submitted by a program. This is a side effect of using datagram sockets for communication between clients and the server. With this in mind, make sure that you include all of the information required to decrypt or verify the signature on a log entry in a single entry. Note also that other clients could possibly make log entries in between multiple entries being made from your program, which is something that can also happen with the Windows logging service.
Signing and encrypting log entries will prevent an attacker from modifying the log entries undetected, but it will not prevent an attacker from deleting the log entries or replacing them with garbage or captured log entries. There is no way to really prevent an attacker from deleting the contents of a log file or making the contents unreadable. The best you can do is to set things up in such a way that you can determine when log files have been manipulated, but signing and encrypting alone will not do this for you.
To be able to determine whether log entries have been deleted or modified in some way, you can employ a MAC with a sequential nonce. For each log entry that is made, increment the nonce by one. The log entries can then be checked to ensure that all nonces are accounted for and that no duplicates have been inserted into the log file.
See Also
syslog-ng by Balabit IT Security LTD: http://www.balabit.com/products/syslog_ng/
[2] In particular, protocol 1, root logins, and password authentication should be disabled. Any user accounts on the machine should not share their names with any other names on your network, making it more difficult for an attacker to guess an account name and password if he has compromised the rest of your network and has access to your password files. In general, your logging machine should share as little in common as possible with all other systems on your network.
All materials on the site are licensed Creative Commons Attribution-Sharealike 3.0 Unported CC BY-SA 3.0 & GNU Free Documentation License (GFDL)
If you are the copyright holder of any material contained on our site and intend to remove it, please contact our site administrator for approval.
© 2016-2026 All site design rights belong to S.Y.A.