C# in Depth (2012)
Part 1. Preparing for the journey
Every reader will come to this book with a different set of expectations and a different level of experience. Are you an expert looking to fill some holes, however small, in your present knowledge? Perhaps you consider yourself an average developer, with a bit of experience in using generics and lambda expressions, but a desire to better understand how they work. Maybe you’re reasonably confident with C# 2 and 3 but have no experience with C# 4 or 5.
As an author, I can’t make every reader the same—and I wouldn’t want to, even if I could. But I hope that all readers have two things in common: the desire for a deeper relationship with C# as a language, and at least a basic knowledge of C# 1. If you can bring those elements to the party, I’ll provide the rest.
The potentially huge range of skill levels is the main reason why this part of the book exists. You may already know what to expect from later versions of C#—or it could all be brand new to you. You could have a rock-solid understanding of C# 1, or you might be rusty on some of the details—some of which will become increasingly important as you learn about the later versions. By the end of part 1, I won’t have leveled the playing field entirely, but you should be able to approach the rest of the book with confidence and an idea of what’s coming later.
In the first two chapters, we’ll look both forward and back. One of the key themes of the book is evolution. Before introducing any feature into the language, the C# design team carefully considers that feature in the context of what’s already present and the general goals for the future. This brings a feeling of consistency to the language even in the midst of change. To understand how and why the language is evolving, you need to see where it’s come from and where it’s going.
Chapter 1 presents a bird’s-eye view of the rest of the book, taking a brief look at some of the biggest features of C# beyond version 1. I’ll show a progression of code from C# 1 onward, applying new features one by one until the code is almost unrecognizable from its humble beginnings. We’ll also look at some of the terminology I’ll use in the rest of the book, as well as the format for the sample code.
Chapter 2 is heavily focused on C# 1. If you’re an expert in C# 1, you can skip this chapter, but it does tackle some of the areas of C# 1 that tend to be misunderstood. Rather than try to explain the whole of the language, the chapter concentrates on features that are fundamental to the later versions of C#. From this solid base, you can move on and look at C# 2 in part 2 of the book.
Chapter 1. The changing face of C# development
This chapter covers
· An evolving example
· The composition of .NET
· Using the code in this book
· The C# language specification
Do you know what I really like about dynamic languages such as Python, Ruby, and Groovy? They suck away fluff from your code, leaving just the essence of it—the bits that really do something. Tedious formality gives way to features such as generators, lambda expressions, and list comprehensions.
The interesting thing is that few of the features that tend to give dynamic languages their lightweight feel have anything to do with being dynamic. Some do, of course—duck typing and some of the magic used in Active Record, for example—but statically typed languages don’t have to be clumsy and heavyweight.
Enter C#. In some ways, C# 1 could have been seen as a nicer version of the Java language, circa 2001. The similarities were all too clear, but C# had a few extras: properties as a first-class feature in the language, delegates and events, foreach loops, using statements, explicit method overriding, operator overloading, and custom value types, to name a few. Obviously, language preference is a personal issue, but C# 1 definitely felt like a step up from Java when I first started using it.
Since then, things have only gotten better. Each new version of C# has added significant features to reduce developer angst, but always in a carefully considered way, and with little backward incompatibility. Even before C# 4 gained the ability to use dynamic typing where it’s genuinely useful, many features traditionally associated with dynamic and functional languages had made it into C#, leading to code that’s easier to write and maintain. Similarly, while the features around asynchrony in C# 5 aren’t exactly the same as those in F#, it feels to me like there’s a definite influence.
In this book, I’ll take you through those changes one by one, in enough detail to make you feel comfortable with some of the miracles the C# compiler is now prepared to perform on your behalf. All that comes later, though—in this chapter I’ll whiz through as many features as I can, barely taking a breath. I’ll define what I mean when I talk about C# as a language compared with .NET as a platform, and I’ll offer a few important notes about the sample code for the rest of the book. Then we can dive into the details.
We won’t be looking at all the changes made to C# in this single chapter, but you’ll see generics, properties with different access modifiers, nullable types, anonymous methods, automatically implemented properties, enhanced collection initializers, enhanced object initializers, lambda expressions, extension methods, implicit typing, LINQ query expressions, named arguments, optional parameters, simpler COM interop, dynamic typing, and asynchronous functions. These will carry us from C# 1 all the way up to the latest release, C# 5. Obviously that’s a lot to get through, so let’s get started.
1.1. Starting with a simple data type
In this chapter I’ll let the C# compiler do amazing things without telling you how and barely mentioning the what or the why. This is the only time that I won’t explain how things work or try to go one step at a time. Quite the opposite, in fact—the plan is to impress rather than educate. If you read this entire section without getting at least a little excited about what C# can do, maybe this book isn’t for you. With any luck, though, you’ll be eager to get to the details of how these magic tricks work, and that’s what the rest of the book is for.
The example I’ll use is contrived—it’s designed to pack as many new features into as short a piece of code as possible. It’s also clichéd, but at least that makes it familiar. Yes, it’s a product/name/price example, the e-commerce alternative to “hello, world.” We’ll look at how various tasks can be achieved, and how, as we move forward in versions of C#, you can accomplish them more simply and elegantly than before. You won’t see any of the benefits of C# 5 until right at the end, but don’t worry—that doesn’t make it any less important.
1.1.1. The Product type in C# 1
We’ll start off with a type representing a product, and then manipulate it. You won’t see anything particularly impressive yet—just the encapsulation of a couple of properties. To make life simpler for demonstration purposes, this is also where we’ll create a list of predefined products.
Listing 1.1 shows the type as it might be written in C# 1. We’ll then move on to see how the code might be rewritten for each later version. This is the pattern we’ll follow for each of the other pieces of code. Given that I’m writing this in 2013, it’s likely that you’re already familiar with code that uses some of the features I’ll introduce, but it’s worth looking back so you can see how far the language has come.
Listing 1.1. The Product type (C# 1)
using System.Collections;
public class Product
{
string name;
public string Name { get { return name; } }
decimal price;
public decimal Price { get { return price; } }
public Product(string name, decimal price)
{
this.name = name;
this.price = price;
}
public static ArrayList GetSampleProducts()
{
ArrayList list = new ArrayList();
list.Add(new Product("West Side Story", 9.99m));
list.Add(new Product("Assassins", 14.99m));
list.Add(new Product("Frogs", 13.99m));
list.Add(new Product("Sweeney Todd", 10.99m));
return list;
}
public override string ToString()
{
return string.Format("{0}: {1}", name, price);
}
}
Nothing in listing 1.1 should be hard to understand—it’s just C# 1 code, after all. There are three limitations that it demonstrates, though:
· An ArrayList has no compile-time information about what’s in it. You could accidentally add a string to the list created in GetSampleProducts, and the compiler wouldn’t bat an eyelid.
· You’ve provided public getter properties, which means that if you wanted matching setters, they’d have to be public, too.
· There’s a lot of fluff involved in creating the properties and variables—code that complicates the simple task of encapsulating a string and a decimal.
Let’s see what C# 2 can do to improve matters.
1.1.2. Strongly typed collections in C# 2
Our first set of changes (shown in the following listing) tackles the first two items listed previously, including the most important change in C# 2: generics. The parts that are new are in bold.
Listing 1.2. Strongly typed collections and private setters (C# 2)
public class Product
{
string name;
public string Name
{
get { return name; }
private set { name = value; }
}
decimal price;
public decimal Price
{
get { return price; }
private set { price = value; }
}
public Product(string name, decimal price)
{
Name = name;
Price = price;
}
public static List<Product> GetSampleProducts()
{
List<Product> list = new List<Product>();
list.Add(new Product("West Side Story", 9.99m));
list.Add(new Product("Assassins", 14.99m));
list.Add(new Product("Frogs", 13.99m));
list.Add(new Product("Sweeney Todd", 10.99m));
return list;
}
public override string ToString()
{
return string.Format("{0}: {1}", name, price);
}
}
You now have properties with private setters (which you use in the constructor), and it doesn’t take a genius to guess that List<Product> is telling the compiler that the list contains products. Attempting to add a different type to the list would result in a compiler error, and you also don’t need to cast the results when you fetch them from the list.
The changes in C# 2 leave only one of the original three difficulties unanswered, and C# 3 helps out there.
1.1.3. Automatically implemented properties in C# 3
We’re starting off with some fairly tame features from C# 3. The automatically implemented properties and simplified initialization shown in the following listing are relatively trivial compared with lambda expressions and the like, but they can make code a lot simpler.
Listing 1.3. Automatically implemented properties and simpler initialization (C# 3)
using System.Collections.Generic;
class Product
{
public string Name { get; private set; }
public decimal Price { get; private set; }
public Product(string name, decimal price)
{
Name = name;
Price = price;
}
Product() {}
public static List<Product> GetSampleProducts()
{
return new List<Product>
{
new Product { Name="West Side Story", Price = 9.99m },
new Product { Name="Assassins", Price=14.99m },
new Product { Name="Frogs", Price=13.99m },
new Product { Name="Sweeney Todd", Price=10.99m}
};
}
public override string ToString()
{
return string.Format("{0}: {1}", Name, Price);
}
}
Now the properties don’t have any code (or visible variables!) associated with them, and you’re building the hardcoded list in a very different way. With no name and price variables to access, you’re forced to use the properties everywhere in the class, improving consistency. You now have a private parameterless constructor for the sake of the new property-based initialization. (This constructor is called for each item before the properties are set.)
In this example, you could’ve removed the public constructor completely, but then no outside code could’ve created other product instances.
1.1.4. Named arguments in C# 4
For C# 4, we’ll go back to the original code when it comes to the properties and constructor, so that it’s fully immutable again. A type with only private setters can’t be publicly mutated, but it can be clearer if it’s not privately mutable either.[1] There’s no shortcut for read-only properties, unfortunately, but C# 4 lets you specify argument names for the constructor call, as shown in the following listing, which gives you the clarity of C# 3 initializers without the mutability.
1 The C# 1 code could’ve been immutable too—I only left it mutable to simplify the changes for C# 2 and 3.
Listing 1.4. Named arguments for clear initialization code (C# 4)
using System.Collections.Generic;
public class Product
{
readonly string name;
public string Name { get { return name; } }
readonly decimal price;
public decimal Price { get { return price; } }
public Product(string name, decimal price)
{
this.name = name;
this.price = price;
}
public static List<Product> GetSampleProducts()
{
return new List<Product>
{
new Product( name: "West Side Story", price: 9.99m),
new Product( name: "Assassins", price: 14.99m),
new Product( name: "Frogs", price: 13.99m),
new Product( name: "Sweeney Todd", price: 10.99m)
};
}
public override string ToString()
{
return string.Format("{0}: {1}", name, price);
}
}
The benefits of specifying the argument names explicitly are relatively minimal in this particular example, but when a method or constructor has several parameters, it can make the meaning of the code much clearer—particularly if they’re of the same type, or if you’re passing in null for some arguments. You can choose when to use this feature, of course, only specifying the names for arguments when it makes the code easier to understand.
Figure 1.1 summarizes how the Product type has evolved so far. I’ll include a similar diagram after each task, so you can see the pattern of how the evolution of C# improves the code. You’ll notice that C# 5 is missing from all of the block diagrams; that’s because the main feature of C# 5 (asynchronous functions) is aimed at an area that really hasn’t evolved much in terms of language support. We’ll take a peek at it before too long, though.
Figure 1.1. Evolution of the Product type, showing greater encapsulation, stronger typing, and ease of initialization over time
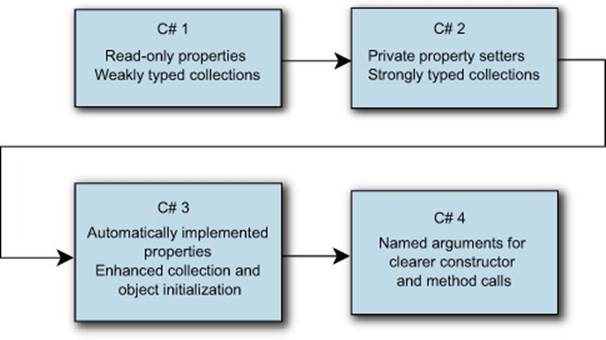
So far, the changes are relatively minimal. In fact, the addition of generics (the List<Product> syntax) is probably the most important part of C# 2, but you’ve only seen part of its usefulness so far. There’s nothing to get the heart racing yet, but we’ve only just started. Our next task is to print out the list of products in alphabetical order.
1.2. Sorting and filtering
In this section, we won’t change the Product type at all—instead, we’ll take the sample products and sort them by name, and then find the expensive ones. Neither of these tasks is exactly difficult, but you’ll see how much simpler they become over time.
1.2.1. Sorting products by name
The easiest way to display a list in a particular order is to sort the list and then run through it, displaying items. In .NET 1.1, this involved using ArrayList.Sort, and optionally providing an IComparer implementation to specify a particular comparison. You could make the Product type implement IComparable, but that would only allow you to define one sort order, and it’s not a stretch to imagine that you might want to sort by price at some stage, as well as by name.
The following listing implements IComparer, and then sorts the list and displays it.
Listing 1.5. Sorting an ArrayList using IComparer (C# 1)
class ProductNameComparer : IComparer
{
public int Compare(object x, object y)
{
Product first = (Product)x;
Product second = (Product)y;
return first.Name.CompareTo(second.Name);
}
}
...
ArrayList products = Product.GetSampleProducts();
products.Sort(new ProductNameComparer());
foreach (Product product in products)
{
Console.WriteLine (product);
}
The first thing to spot in listing 1.5 is that you had to introduce an extra type to help with the sorting. That’s not a disaster, but it’s a lot of code if you only want to sort by name in one place. Next, look at the casts in the Compare method. Casts are a way of telling the compiler that you know more information than it does, and that usually means there’s a chance you’re wrong. If the ArrayList you returned from GetSampleProducts did contain a string, that’s where the code would go bang—where the comparison tries to cast the string to a Product.
You also have a cast in the code that displays the sorted list. It’s not obvious, because the compiler puts it in automatically, but the foreach loop implicitly casts each element of the list to Product. Again, that cast could fail at execution time, and once more generics come to the rescue in C# 2. The following listing shows the previous code with the use of generics as the only change.
Listing 1.6. Sorting a List<Product> using IComparer<Product> (C# 2)
class ProductNameComparer : IComparer<Product>
{
public int Compare(Product x, Product y)
{
return x.Name.CompareTo(y.Name);
}
}
...
List<Product> products = Product.GetSampleProducts();
products.Sort(new ProductNameComparer());
foreach (Product product in products)
{
Console.WriteLine(product);
}
The code for the comparer in listing 1.6 is simpler because you’re given products to start with. No casting is necessary. Similarly, the invisible cast in the foreach loop is effectively gone now. The compiler still has to consider the conversion from the source type of the sequence to the target type of the variable, but it knows that in this case both types are Product, so it doesn’t need to emit any code for the conversion.
That’s an improvement, but it’d be nice if you could sort the products by simply specifying the comparison to make, without needing to implement an interface to do so. The following listing shows how to do precisely this, telling the Sort method how to compare two products using a delegate.
Listing 1.7. Sorting a List<Product> using Comparison<Product> (C# 2)
List<Product> products = Product.GetSampleProducts();
products.Sort(delegate(Product x, Product y)
{ return x.Name.CompareTo(y.Name); }
);
foreach (Product product in products)
{
Console.WriteLine(product);
}
Behold the lack of the ProductNameComparer type. The statement in bold font creates a delegate instance, which you provide to the Sort method in order to perform the comparisons. You’ll learn more about this feature (anonymous methods) in chapter 5.
You’ve now fixed all the problems identified in the C# 1 version. That doesn’t mean that C# 3 can’t do better, though. First, you’ll replace the anonymous method with an even more compact way of creating a delegate instance, as shown in the following listing.
Listing 1.8. Sorting using Comparison<Product> from a lambda expression (C# 3)
List<Product> products = Product.GetSampleProducts();
products.Sort((x, y) => x.Name.CompareTo(y.Name));
foreach (Product product in products)
{
Console.WriteLine(product);
}
You’ve gained even more strange syntax (a lambda expression), which still creates a Comparison<Product> delegate, just as listing 1.7 did, but this time with less fuss. You didn’t have to use the delegate keyword to introduce it, or even specify the types of the parameters.
There’s more, though: with C# 3, you can easily print out the names in order without modifying the original list of products. The next listing shows this using the OrderBy method.
Listing 1.9. Ordering a List<Product> using an extension method (C# 3)
List<Product> products = Product.GetSampleProducts();
foreach (Product product in products.OrderBy(p => p.Name))
{
Console.WriteLine (product);
}
In this listing, you appear to be calling an OrderBy method on the list, but if you look in MSDN, you’ll see that it doesn’t even exist in List<Product>. You’re able to call it due to the presence of an extension method, which you’ll see in more detail in chapter 10. You’re not actually sorting the list “in place” anymore, just retrieving the contents of the list in a particular order. Sometimes you’ll need to change the actual list; sometimes an ordering without any other side effects is better.
The important point is that this code is much more compact and readable (once you understand the syntax, of course). We wanted the list ordered by name, and that’s exactly what the code says. It doesn’t say to sort by comparing the name of one product with the name of another, like the C# 2 code did, or to sort by using an instance of another type that knows how to compare one product with another. It just says to order by name. This simplicity of expression is one of the key benefits of C# 3. When the individual pieces of data querying and manipulation are so simple, larger transformations can remain compact and readable in one piece of code. That, in turn, encourages a more data-centric way of looking at the world.
You’ve seen more of the power of C# 2 and 3 in this section, with a lot of (as yet) unexplained syntax, but even without understanding the details you can see the progress toward clearer, simpler code. Figure 1.2 shows that evolution.
Figure 1.2. Features involved in making sorting easier in C# 2 and 3

That’s it for sorting.[2] Let’s do a different form of data manipulation now—querying.
2 C# 4 does provide one feature that can be relevant when sorting, called generic variance, but giving an example here would require too much explanation. You can find the details near the end of chapter 13.
1.2.2. Querying collections
Your next task is to find all the elements of the list that match a certain criterion—in particular, those with a price greater than $10. The following listing shows how, in C# 1, you need to loop around, testing each element and printing it out when appropriate.
Listing 1.10. Looping, testing, printing out (C# 1)
ArrayList products = Product.GetSampleProducts();
foreach (Product product in products)
{
if (product.Price > 10m)
{
Console.WriteLine(product);
}
}
This code is not difficult to understand. But it’s worth bearing in mind how intertwined the three tasks are—looping with foreach, testing the criterion with if, and then displaying the product with Console.WriteLine. The dependency is obvious because of the nesting.
The following listing demonstrates how C# 2 lets you flatten things out a bit.
Listing 1.11. Separating testing from printing (C# 2)
List<Product> products = Product.GetSampleProducts();
Predicate<Product> test = delegate(Product p) { return p.Price > 10m; };
List<Product> matches = products.FindAll(test);
Action<Product> print = Console.WriteLine;
matches.ForEach(print);
The test variable is initialized using the anonymous method feature you saw in the previous section. The print variable initialization uses another new C# 2 feature called method group conversions that makes it easier to create delegates from existing methods.
I’m not going to claim that this code is simpler than the C# 1 code, but it is a lot more powerful.[3]
3 In some ways, this is cheating. You could’ve defined appropriate delegates in C# 1 and called them within the loop. The FindAll and ForEach methods in .NET 2.0 just encourage you to consider separation of concerns.
In particular, the technique of separating the two concerns like this makes it very easy to change the condition you’re testing for and the action you take on each of the matches independently. The delegate variables involved (test and print) could be passed into a method, and that same method could end up testing radically different conditions and taking radically different actions. Of course, you could put all the testing and printing into one statement, as shown in the following listing.
Listing 1.12. Separating testing from printing redux (C# 2)
List<Product> products = Product.GetSampleProducts();
products.FindAll(delegate(Product p) { return p.Price > 10;})
.ForEach(Console.WriteLine);
In some ways, this version is better, but the delegate(Product p) is getting in the way, as are the braces. They’re adding noise to the code, which hurts readability. I still prefer the C# 1 version in cases where I only ever want to use the same test and perform the same action. (It may sound obvious, but it’s worth remembering that there’s nothing stopping you from using the C# 1 code with a later compiler version. You wouldn’t use a bulldozer to plant tulip bulbs, which is the kind of overkill used in the last listing.)
The next listing shows how C# 3 improves matters dramatically by removing a lot of the fluff surrounding the actual logic of the delegate.
Listing 1.13. Testing with a lambda expression (C# 3)
List<Product> products = Product.GetSampleProducts();
foreach (Product product in products.Where(p => p.Price > 10))
{
Console.WriteLine(product);
}
The combination of the lambda expression putting the test in just the right place and a well-named method means you can almost read the code out loud and understand it without thinking. You still have the flexibility of C# 2—the argument to Where could come from a variable, and you could use an Action<Product> instead of the hardcoded Console.WriteLine call if you wanted to.
This task has emphasized what you already knew from sorting—anonymous methods make writing a delegate simple, and lambda expressions are even more concise. In both cases, that brevity means that you can include the query or sort operation inside the first part of the foreach loop without losing clarity.
Figure 1.3 summarizes the changes we’ve just looked at. C# 4 doesn’t offer anything to simplify this task any further.
Figure 1.3. Anonymous methods and lambda expressions in C# 2 and 3 aid separation of concerns and readability.

Now that you’ve displayed the filtered list, let’s consider a change to your initial assumptions about the data. What happens if you don’t always know the price of a product? How can you cope with that within the Product class?
1.3. Handling an absence of data
We’ll look at two different forms of missing data. First we’ll deal with the scenario where you genuinely don’t have the information, and then see how you can actively remove information from method calls, using default values.
1.3.1. Representing an unknown price
I won’t present much code this time, but I’m sure it’ll be a familiar problem to you, especially if you’ve done a lot of work with databases. Imagine your list of products contains not just products on sale right now, but ones that aren’t available yet. In some cases, you may not know the price. If decimal were a reference type, you could just use null to represent the unknown price, but since it’s a value type, you can’t. How would you represent this in C# 1?
There are three common alternatives:
· Create a reference type wrapper around decimal.
· Maintain a separate Boolean flag indicating whether the price is known.
· Use a “magic value” (decimal.MinValue, for example) to represent the unknown price.
I hope you’ll agree that none of these holds much appeal. Time for a little magic: you can solve the problem by adding a single character in the variable and property declarations. .NET 2.0 makes matters a lot simpler by introducing the Nullable<T> structure, and C# 2 provides some additional syntactic sugar that lets you change the property declaration to this block of code:
decimal? price;
public decimal? Price
{
get { return price; }
private set { price = value; }
}
The constructor parameter changes to decimal?, and then you can pass in null as the argument, or say Price = null; within the class. The meaning of the null changes from “a special reference that doesn’t refer to any object” to “a special value of any nullable type representing the absence of other data,” where all reference types and all Nullable<T>-based types count as nullable types.
That’s a lot more expressive than any of the other solutions. The rest of the code works as is—a product with an unknown price will be considered to be less expensive than $10, due to the way nullable values are handled in greater-than comparisons. To check whether a price is known, you can compare it with null or use the HasValue property, so to show all the products with unknown prices in C# 3, you’d write the following code.
Listing 1.14. Displaying products with an unknown price (C# 3)
List<Product> products = Product.GetSampleProducts();
foreach (Product product in products.Where(p => p.Price == null))
{
Console.WriteLine(product.Name);
}
The C# 2 code would be similar to that in listing 1.12, but you’d need to check for null in the anonymous method:
List<Product> products = Product.GetSampleProducts();
products.FindAll(delegate(Product p) { return p.Price == null; })
.ForEach(Console.WriteLine);
C# 3 doesn’t offer any changes here, but C# 4 has a feature that’s at least tangentially related.
1.3.2. Optional parameters and default values
Sometimes you don’t want to tell a method everything it needs to know, such as when you almost always use the same value for a particular parameter. Traditionally the solution has been to overload the method in question, but C# 4 introduced optional parameters to make this simpler.
In the C# 4 version of the Product type, you have a constructor that takes the name and the price. You can make the price a nullable decimal, just as in C# 2 and 3, but let’s suppose that most of the products don’t have prices. It would be nice to be able to initialize a product like this:
Product p = new Product("Unreleased product");
Prior to C# 4, you would’ve had to introduce a new overload in the Product constructor for this purpose. C# 4 allows you to declare a default value (in this case, null) for the price parameter:
public Product(string name, decimal? price = null)
{
this.name = name;
this.price = price;
}
You always have to specify a constant value when you declare an optional parameter. It doesn’t have to be null; that just happens to be the appropriate default in this situation. The requirement that the default value is a constant applies to any type of parameter, although for reference types other than strings you are limited to null as the only constant value available.
Figure 1.4 summarizes the evolution we’ve looked at across different versions of C#.
Figure 1.4. Options for working with missing data

So far the features have been useful, but perhaps nothing to write home about. Next we’ll look at something rather more exciting: LINQ.
1.4. Introducing LINQ
LINQ (Language-Integrated Query) is at the heart of the changes in C# 3. As its name suggests, LINQ is all about queries—the aim is to make it easy to write queries against multiple data sources with consistent syntax and features, in a readable and composable fashion.
Whereas the features in C# 2 are arguably more about fixing annoyances in C# 1 than setting the world on fire, almost everything in C# 3 builds toward LINQ, and the result is rather special. I’ve seen features in other languages that tackle some of the same areas as LINQ, but nothing quite so well-rounded and flexible.
1.4.1. Query expressions and in-process queries
If you’ve seen any LINQ code before, you’ve probably seen query expressions that allow you to use a declarative style to create queries on various data sources. The reason none of this chapter’s examples have used query expressions so far is that the examples have all been simpler withoutusing the extra syntax. That’s not to say you couldn’t use it anyway—the following listing, for example, is equivalent to listing 1.13.
Listing 1.15. First steps with query expressions: filtering a collection
List<Product> products = Product.GetSampleProducts();
var filtered = from Product p in products
where p.Price > 10
select p;
foreach (Product product in filtered)
{
Console.WriteLine(product);
}
Personally, I find the earlier listing easier to read—the only benefit to this query expression version is that the where clause is simpler. I’ve snuck in one extra feature here—implicitly typed local variables, which are declared using the var contextual keyword. These allow the compiler to infer the type of a variable from the value that it’s initially assigned—in this case, the type of filtered is IEnumerable<Product>. I’ll use var fairly extensively in the rest of the examples in this chapter; it’s particularly useful in books, where space in listings is at a premium.
But if query expressions are no good, why does everyone make such a fuss about them, and about LINQ in general? The first answer is that although query expressions aren’t particularly beneficial for simple tasks, they’re very good for more complicated situations that would be hard to read if written out in the equivalent method calls (and would be fiendish in C# 1 or 2). Let’s make things a little harder by introducing another type—Supplier.
Each supplier has a Name (string) and a SupplierID (int). I’ve also added SupplierID as a property in Product and adapted the sample data appropriately. Admittedly that’s not a very object-oriented way of giving each product a supplier—it’s much closer to how the data would be represented in a database. It does make this particular feature easier to demonstrate for now, but you’ll see in chapter 12 that LINQ allows you to use a more natural model too.
Now let’s look at the code (listing 1.16) that joins the sample products with the sample suppliers (obviously based on the supplier ID), applies the same price filter as before to the products, sorts by supplier name and then product name, and prints out the name of both the supplier and the product for each match. That was a mouthful, and in earlier versions of C# it would’ve been a nightmare to implement. In LINQ, it’s almost trivial.
Listing 1.16. Joining, filtering, ordering, and projecting (C# 3)
List<Product> products = Product.GetSampleProducts();
List<Supplier> suppliers = Supplier.GetSampleSuppliers();
var filtered = from p in products
join s in suppliers
on p.SupplierID equals s.SupplierID
where p.Price > 10
orderby s.Name, p.Name
select new { SupplierName = s.Name, ProductName = p.Name };
foreach (var v in filtered)
{
Console.WriteLine("Supplier={0}; Product={1}",
v.SupplierName, v.ProductName);
}
You might have noticed that this looks remarkably like SQL. Indeed, the reaction of many people on first hearing about LINQ (but before examining it closely) is to reject it as merely trying to put SQL into the language for the sake of talking to databases. Fortunately, LINQ has borrowed the syntax and some ideas from SQL, but as you’ve seen, you needn’t be anywhere near a database in order to use it. None of the code you’ve seen so far has touched a database at all. Indeed, you could be getting data from any number of sources: XML, for example.
1.4.2. Querying XML
Suppose that instead of hardcoding your suppliers and products, you’d used the following XML file:
<?xml version="1.0"?>
<Data>
<Products>
<Product Name="West Side Story" Price="9.99" SupplierID="1" />
<Product Name="Assassins" Price="14.99" SupplierID="2" />
<Product Name="Frogs" Price="13.99" SupplierID="1" />
<Product Name="Sweeney Todd" Price="10.99" SupplierID="3" />
</Products>
<Suppliers>
<Supplier Name="Solely Sondheim" SupplierID="1" />
<Supplier Name="CD-by-CD-by-Sondheim" SupplierID="2" />
<Supplier Name="Barbershop CDs" SupplierID="3" />
</Suppliers>
</Data>
The file is simple enough, but what’s the best way of extracting the data from it? How do you query it? Join on it? Surely it’s going to be somewhat harder than what you did in listing 1.16, right? The following listing shows how much work you have to do in LINQ to XML.
Listing 1.17. Complex processing of an XML file with LINQ to XML (C# 3)
XDocument doc = XDocument.Load("data.xml");
var filtered = from p in doc.Descendants("Product")
join s in doc.Descendants("Supplier")
on (int)p.Attribute("SupplierID")
equals (int)s.Attribute("SupplierID")
where (decimal)p.Attribute("Price") > 10
orderby (string)s.Attribute("Name"),
(string)p.Attribute("Name")
select new
{
SupplierName = (string)s.Attribute("Name"),
ProductName = (string)p.Attribute("Name")
};
foreach (var v in filtered)
{
Console.WriteLine("Supplier={0}; Product={1}",
v.SupplierName, v.ProductName);
}
This approach isn’t quite as straightforward, because you need to tell the system how it should understand the data (in terms of what attributes should be used as what types), but it’s not far off. In particular, there’s an obvious relationship between each part of the two listings. If it weren’t for the line-length limitations of books, you’d see an exact line-by-line correspondence between the two queries.
Impressed yet? Not quite convinced? Let’s put the data where it’s much more likely to be—in a database.
1.4.3. LINQ to SQL
There’s some work involved in letting LINQ to SQL know what to expect in what table, but it’s all fairly straightforward and much of it can be automated. We’ll skip straight to the querying code, which is shown in the following listing. If you want to see the details ofLinqDemoDataContext, they’re all in the downloadable source code.
Listing 1.18. Applying a query expression to a SQL database (C# 3)
using (LinqDemoDataContext db = new LinqDemoDataContext())
{
var filtered = from p in db.Products
join s in db.Suppliers
on p.SupplierID equals s.SupplierID
where p.Price > 10
orderby s.Name, p.Name
select new { SupplierName = s.Name, ProductName = p.Name };
foreach (var v in filtered)
{
Console.WriteLine("Supplier={0}; Product={1}",
v.SupplierName, v.ProductName);
}
}
By now, this should be looking incredibly familiar. Everything below the join line is cut and pasted directly from listing 1.16 with no changes.
That’s impressive enough, but if you’re performance-conscious, you may be wondering why you’d want to pull down all the data from the database and then apply these .NET queries and orderings. Why not get the database to do it? That’s what it’s good at, isn’t it? Well, indeed—and that’s exactly what LINQ to SQL does. The code in listing 1.18 issues a database request, which is basically the query translated into SQL. Even though you’ve expressed the query in C# code, it’s been executed as SQL.
You’ll see later that there’s a more relation-oriented way of approaching this kind of join when the schema and the entities know about the relationship between suppliers and products. The result is the same, though, and it shows just how similar LINQ to Objects (the in-memory LINQ operating on collections) and LINQ to SQL can be.
LINQ is extremely flexible—you can write your own provider to talk to a web service or translate a query into your own specific representation. In chapter 13, we’ll look at how broad the term LINQ really is, and how it can go beyond what you might expect in terms of querying collections.
1.5. COM and dynamic typing
Next, I’d like to demonstrate some features that are specific to C# 4. Whereas LINQ was the major focus of C# 3, interoperability was the biggest theme in C# 4. This includes working with both the old technology of COM and also the brave new world of dynamic languages executing on theDynamic Language Runtime (DLR). We’ll start by exporting the product list to an Excel spreadsheet.
1.5.1. Simplifying COM interoperability
There are various ways of making data available to Excel, but using COM to control it gives you the most power and flexibility. Unfortunately, previous incarnations of C# made it quite difficult to work with COM; VB had much better support. C# 4 largely rectifies that situation.
The following listing shows some code to save your data to a new spreadsheet.
Listing 1.19. Saving data to Excel using COM (C# 4)
var app = new Application { Visible = false };
Workbook workbook = app.Workbooks.Add();
Worksheet worksheet = app.ActiveSheet;
int row = 1;
foreach (var product in Product.GetSampleProducts()
.Where(p => p.Price != null))
{
worksheet.Cells[row, 1].Value = product.Name;
worksheet.Cells[row, 2].Value = product.Price;
row++;
}
workbook.SaveAs(Filename: "demo.xls",
FileFormat: XlFileFormat.xlWorkbookNormal);
app.Application.Quit();
This may not be quite as nice as you’d like, but it’s a lot better than it would’ve been using earlier versions of C#. In fact, you already know about some of the C# 4 features shown here—but there are a couple of others that aren’t so obvious. Here’s the full list:
· The SaveAs call uses named arguments.
· Various calls omit arguments for optional parameters—in particular, SaveAs would normally have an extra 10 arguments!
· C# 4 can embed the relevant parts of the primary interop assembly (PIA) into the calling code, so you no longer need to deploy the PIA separately.
· In C# 3, the assignment to worksheet would fail without a cast, because the type of the ActiveSheet property is represented as object. When using the embedded PIA feature, the type of ActiveSheet becomes dynamic, which leads to an entirely different feature.
Additionally, C# 4 supports named indexers when working with COM—a feature not demonstrated in this example.
I’ve already mentioned the final feature: dynamic typing in C# using the dynamic type.
1.5.2. Interoperating with a dynamic language
Dynamic typing is such a big topic that the entirety of chapter 14 is dedicated to it. I’ll just show you one small example of what it can do here.
Suppose your products aren’t stored in a database, or in XML, or in memory. They’re accessible via a web service of sorts, but you only have Python code to access it, and that code uses the dynamic nature of Python to build results without declaring a type containing all the properties you need to access on each result. Instead, the results let you ask for any property, and try to work out what you mean at execution time. In a language like Python, there’s nothing unusual about that. But how can you access your results from C#?
The answer comes in the form of dynamic—a new type[4] that the C# compiler allows you to use dynamically. If an expression is of type dynamic, you can call methods on it, access properties, pass it around as a method argument, and so on—and most of the normal binding process happens at execution time instead of compile time. You can implicitly convert a value from dynamic to any other type (which is why the worksheet cast in listing 1.19 worked) and do all kinds of other fun stuff.
4 Sort of, anyway. It’s a type as far as the C# compiler is concerned, but the CLR doesn’t know anything about it.
This behavior can also be useful even within pure C# code, with no interop involved, but it’s fun to see it working with other languages. The following listing shows how you can get the list of products from IronPython and print it out. This includes all the setup code to run the Python code in the same process.
Listing 1.20. Running IronPython and extracting properties dynamically (C# 4)
ScriptEngine engine = Python.CreateEngine();
ScriptScope scope = engine.ExecuteFile("FindProducts.py");
dynamic products = scope.GetVariable("products");
foreach (dynamic product in products)
{
Console.WriteLine("{0}: {1}", product.ProductName, product.Price);
}
Both products and product are declared to be dynamic, so the compiler is happy to let you iterate over the list of products and print out the properties, even though it doesn’t know whether it’ll work. If you make a typo, using product.Name instead of product.ProductName, for example, that would only show up at execution time.
This is completely contrary to the rest of C#, which is statically typed. But dynamic typing only comes into play when expressions with a type of dynamic are involved; most C# code is likely to remain statically typed throughout.
1.6. Writing asynchronous code without the heartache
Finally you get to see C# 5’s big feature: asynchronous functions, which allow you to pause code execution without blocking a thread.
This topic is big—really big—but I’ll give you just a snippet for now. As I’m sure you’re aware, there are two golden rules when it comes to threading in Windows Forms: you mustn’t block the UI thread, and you mustn’t access UI elements on any other thread, except in a few well-specified ways. The following listing shows a single method that handles a button click in a Windows Forms application and displays information about a product, given its ID.
Listing 1.21. Displaying products in Windows Forms using an asynchronous function
private async void CheckProduct(object sender, EventArgs e)
{
try
{
productCheckButton.Enabled = false;
string id = idInput.Text;
Task<Product> productLookup = directory.LookupProductAsync(id);
Task<int> stockLookup = warehouse.LookupStockLevelAsync(id);
Product product = await productLookup;
if (product == null)
{
return;
}
nameValue.Text = product.Name;
priceValue.Text = product.Price.ToString("c");
int stock = await stockLookup;
stockValue.Text = stock.ToString();
}
finally
{
productCheckButton.Enabled = true;
}
}
The full method is a little longer than the one shown in listing 1.22, displaying status messages and clearing the results at the start, but this listing contains all the important parts. The new parts of syntax are in bold—the method has the new async modifier, and there are two awaitexpressions.
If you squint and ignore those for the moment, you can probably understand the general flow of the code. It starts off performing lookups on both the product directory and warehouse to find out the product details and current stock. The method then waits until it has the product information, and quits if the directory has no entry for the given ID. Otherwise, it fills in the UI elements for the name and price, and then waits to get the stock information, and displays that too.
Both the product and stock lookups are asynchronous—they could be database operations or web service calls. It doesn’t matter—when you await the results, you’re not actually blocking the UI thread, even though all the code in the method runs on that thread. When the results come back, the method continues from where it left off. The example also demonstrates that normal flow control (try/finally) operates exactly as you’d expect it to. The really surprising thing about this method is that it has managed to achieve exactly the kind of asynchrony you want without any of the normal messing around starting other threads or BackgroundWorkers, calling Control .BeginInvoke, or attaching callbacks to asynchronous events. Of course you still need to think—asynchrony doesn’t become easy using async/await, but it becomes less tedious, with far less boilerplate code to distract you from the inherent complexity you’re trying to control.
Are you dizzy yet? Relax, I’ll slow down considerably for the rest of the book. In particular, I’ll explain some of the corner cases, going into more detail about why various features were introduced, and giving some guidance as to when it’s appropriate to use them.
So far I’ve been showing you features of C#. Some of these features require library assistance, and some of them require runtime assistance. I’ll say this sort of thing a lot, so let’s clear up what I mean.
1.7. Dissecting the .NET platform
When it was originally introduced, .NET was used as a catchall term for a vast range of technologies coming from Microsoft. For instance, Windows Live ID was called .NET Passport, despite there being no clear relationship between that and what you currently know as .NET. Fortunately, things have calmed down somewhat since then. In this section, we’ll look at the various parts of .NET.
In several places in this book, I’ll refer to three different kinds of features: features of C# as a language, features of the runtime that provides the “engine,” if you will, and features of the .NET framework libraries. This book is heavily focused on the language of C#, and I’ll generally only discuss runtime and framework features when they relate to features of C# itself. Often features will overlap, but it’s important to understand where the boundaries lie.
1.7.1. C#, the language
The language of C# is defined by its specification, which describes the format of C# source code, including both syntax and behavior. It doesn’t describe the platform that the compiler output will run on, beyond a few key points where the two interact. For instance, the C# language requires a type called System.IDisposable, which contains a method called Dispose. These are required in order to define the using statement. Likewise, the platform needs to be able to support (in one form or another) both value types and reference types, along with garbage collection.
In theory, any platform that supports the required features could have a C# compiler targeting it. For example, a C# compiler could legitimately produce output in a form other than the Intermediate Language (IL), which is the typical output at the time of this writing. A runtime could interpret the output of a C# compiler, or convert it all to native code in one step rather than JIT-compiling it. Though these options are relatively uncommon, they do exist in the wild; for example, the Micro Framework uses an interpreter, as can Mono (http://mono-project.net). At the other end of the spectrum, ahead-of-time compilation is used by NGen and by Xamarin.iOS (http://xamarin.com/ios)—a platform for building applications for the iPhone and other iOS devices.
1.7.2. Runtime
The runtime aspect of the .NET platform is the relatively small amount of code that’s responsible for making sure that programs written in IL execute according to the Common Language Infrastructure (CLI) specification (ECMA-335 and ISO/IEC 23271), partitions I to III. The runtime part of the CLI is called the Common Language Runtime (CLR). When I refer to the CLR in the rest of the book, I mean Microsoft’s implementation.
Some elements of the C# language never appear at the runtime level, but others cross the divide. For instance, enumerators aren’t defined at a runtime level, and neither is any particular meaning attached to the IDisposable interface, but arrays and delegates are important to the runtime.
1.7.3. Framework libraries
Libraries provide code that’s available to your programs. The framework libraries in .NET are largely built as IL themselves, with native code used only where necessary. This is a mark of the strength of the runtime: your own code isn’t expected to be a second-class citizen—it can provide the same kind of power and performance as the libraries it utilizes. The amount of code in the libraries is much greater than that of the runtime, in the same way that there’s much more to a car than the engine.
The framework libraries are partially standardized. Partition IV of the CLI specification provides a number of different profiles (compact and kernel) and libraries. Partition IV comes in two parts—a general textual description of the libraries identifying, among other things, which libraries are required within which profiles, and another part containing the details of the libraries themselves in XML format. This is the same form of documentation produced when you use XML comments within C#.
There’s much within .NET that’s not within the base libraries. If you write a program that only uses libraries from the specification, and uses them correctly, you should find that your code works flawlessly on any implementation—Mono, .NET, or anything else. But in practice, almost any program of any size will use libraries that aren’t standardized—Windows Forms or ASP.NET, for instance. The Mono project has its own libraries that aren’t part of .NET, such as GTK#, and it implements many of the nonstandardized libraries.
The term .NET refers to the combination of the runtime and libraries provided by Microsoft, and it also includes compilers for C# and VB.NET. It can be seen as a whole development platform built on top of Windows. Each aspect of .NET is versioned separately, which can be a source of confusion. Appendix C gives a quick rundown of which version of what came out when and with what features.
If that’s all clear, I have one last bit of housekeeping to go through before we really start diving into C#.
1.8. Making your code super awesome
I apologize for the misleading heading. This section (in itself) will not make your code super awesome. It won’t even make it refreshingly minty. It will help you make the most of this book, though—and that’s why I wanted to make sure you actually read it. There’s more of this sort of thing in the front matter (the bit before page 1), but I know that many readers skip over that, heading straight for the meat of the book. I can understand that, so I’ll make this as quick as possible.
1.8.1. Presenting full programs as snippets
One of the challenges when writing a book about a computer language (other than scripting languages) is that complete programs—ones that the reader can compile and run with no source code other than what’s presented—get long pretty quickly. I wanted to get around this, to provide you with code that you could easily type in and experiment with. I believe that actually trying something is a much better way of learning than just reading about it.
With the right assembly references and the right using directives, you can accomplish a lot with a fairly short amount of C# code, but the killer is the fluff involved in writing those using directives, declaring a class, and declaring a Main method before you’ve written the first line of usefulcode. My examples are mostly in the form of snippets, which ignore the fluff that gets in the way of simple programs, concentrating on the important parts. The snippets can be run directly in a small tool I’ve built, called Snippy.
If a snippet doesn’t contain an ellipsis (...), then all of the code should be considered to be the body of the Main method of a program. If there is an ellipsis, then everything before it is treated as declarations of methods and nested types, and everything after the ellipsis goes in the Mainmethod. For example, consider this snippet:
static string Reverse(string input)
{
char[] chars = input.ToCharArray();
Array.Reverse(chars);
return new string(chars);
}
...
Console.WriteLine(Reverse("dlrow olleH"));
This is expanded by Snippy into the following:
using System;
public class Snippet
{
static string Reverse(string input)
{
char[] chars = input.ToCharArray();
Array.Reverse(chars);
return new string(chars);
}
[STAThread]
static void Main()
{
Console.WriteLine(Reverse("dlrow olleH"));
}
}
In reality, Snippy includes far more using directives, but the expanded version was already getting long. Note that the containing class will always be called Snippet, and any types declared within the snippet will be nested within that class.
There are more details about how to use Snippy on the book’s website (http://mng.bz/Lh82), along with all the examples as both snippets and expanded versions in Visual Studio solutions. Additionally, there’s support for LINQPad (http://www.linqpad.net)—a similar tool developed by Joe Albahari, with particularly helpful features for exploring LINQ.
Next, let’s look at what’s wrong with the code we’ve just seen.
1.8.2. Didactic code isn’t production code
It’d be lovely if you could take all the examples from this book and use them directly in your own applications with no further thought involved...but I strongly suggest you don’t. Most examples are presented to demonstrate a specific point—and that’s usually the limit of the intent. Most snippets don’t include argument validation, access modifiers, unit tests, or documentation. They may also fail when used outside their intended context.
For example, let’s consider the body of the method previously shown for reversing a string. I use this code several times in the course of the book:
char[] chars = input.ToCharArray();
Array.Reverse(chars);
return new string(chars);
Leaving aside argument validation, this succeeds in reversing the sequence of UTF-16 code points within a string, but in some cases that’s not good enough. For example, if a single displayed glyph is composed of an e followed by a combining character representing an acute accent, you don’t want to switch the sequence of the code points; the accent will end up on the wrong character. Or suppose your string contains a character outside the basic multilingual plane, formed from a surrogate pair—reordering the code points will lead to a string that’s effectively invalid UTF-16. Fixing these problems would lead to much more complicated code, distracting from the point it’s meant to be demonstrating.
You’re welcome to use the code from the book, but please bear this section in mind if you do so—it’d be much better to take inspiration from it than to copy it verbatim and assume it’ll meet your particular requirements.
Finally, there’s another book you should download in order to make the absolute most of this one.
1.8.3. Your new best friend: the language specification
I’ve tried extremely hard to be accurate in this book, but I’d be amazed if there were no errors at all—indeed, you’ll find a list of known errors on the book’s website (http://mng.bz/m1Hh). If you think you’ve found a mistake, I’d be grateful if you could email me (skeet@pobox.com) or add a note on the author forum (http://mng.bz/TQmF). But you may not want to wait for me to get back to you, or you may have a question that isn’t covered in the book. Ultimately, the definitive source for the intended behavior of C# is the language specification.
There are two important forms of the spec—the international standard from ECMA, and the Microsoft specification. As I write this, the ECMA specification (ECMA-334 and ISO/IEC 23270) only covers C# 2, despite being the fourth edition. It’s unclear whether or when this will be updated, but the Microsoft version is complete and freely available. This book’s website has links to all the available versions of both specification flavors (http://mng.bz/8s38), and Visual Studio ships with a copy too.[5] When I refer to sections of the specification within this book, I’ll use numbering from the Microsoft C# 5 specification, even when I’m talking about earlier versions of the language. I strongly recommend that you download this version and have it on hand whenever you find yourself eager to check out a weird corner case.
5 The exact location of the specification will depend on your system, but on my Visual Studio 2012 Professional installation, it’s in C:\Program Files (x86)\Microsoft Visual Studio 11.0\VC#\Specifications\1033.
One of my aims is to make the spec mostly redundant for developers—to provide a more developer-oriented form covering everything you’re likely to see in everyday code, without the huge level of detail required by compiler authors. Having said that, it’s extremely readable as specifications go, and you shouldn’t be daunted by it. If you find the spec interesting, there are annotated versions available for C# 3 and C# 4. Both contain fascinating comments from the C# team and other contributors. (Disclaimer: I’m one of the “other contributors” for the C# 4 edition...but all the othercomments are great!)
1.9. Summary
In this chapter, I’ve shown (but not explained) some of the features that are tackled in depth in the rest of the book. There are plenty more that I haven’t shown here, and many of the features you’ve seen so far have further subfeatures associated with them. Hopefully what you’ve seen here has whetted your appetite for the rest of the book.
Although features have taken up most of the chapter, we’ve also looked at some areas that should help you get the most out of the book. I’ve clarified what I mean when I refer to the language, runtime, and libraries, and I’ve also explained how code will be laid out in the book.
There’s one more area we need to cover before we dive into the features of C# 2, and that’s C# 1. Obviously, as an author I have no idea how knowledgeable you are about C# 1, but I do have some understanding of which areas of C# often cause conceptual problems. Some of these areas are critical to getting the most out of the later versions of C#, so in the next chapter I’ll go over them in some detail.
All materials on the site are licensed Creative Commons Attribution-Sharealike 3.0 Unported CC BY-SA 3.0 & GNU Free Documentation License (GFDL)
If you are the copyright holder of any material contained on our site and intend to remove it, please contact our site administrator for approval.
© 2016-2026 All site design rights belong to S.Y.A.