C# in Depth (2012)
Appendix B. Generic collections in .NET
There are many generic collections in .NET, and the list has grown over time. This appendix covers the most important generic collection interfaces and classes you need to know about. There are additional nongeneric collections in System .Collections,System.Collections.Specialized and System.ComponentModel, but I won’t cover those here. Likewise, I won’t mention the LINQ interfaces, such as ILookup<TKey, TValue>. This appendix is more reference than guidance—think of it as an alternative to navigating around MSDN while you’re coding. Obviously MSDN will provide more details in most cases, but the aim here is to allow you to quickly skim over the various interfaces and implementations available when choosing a particular collection to use in your code.
I haven’t indicated the thread-safety of each collection, but MSDN can provide more details. None of the normal collections support multiple concurrent writers; some support a single writer with concurrent readers. Section B.6 lists the concurrent collections that were added to .NET 4. Additionally, section B.7 discusses the read-only collection interfaces introduced in .NET 4.5.
B.1. Interfaces
Almost all the interfaces you need to know about are in the System.Collections .Generic namespace. Figure B.1 shows how the major interfaces prior to .NET 4.5 are related; I’ve included the nongeneric IEnumerable as the interface root as well. This doesn’t include the read-only interfaces in .NET 4.5, as the diagram would have been too complicated to be useful.
Figure B.1. Interfaces in System.Collections.Generic, up to .NET 4
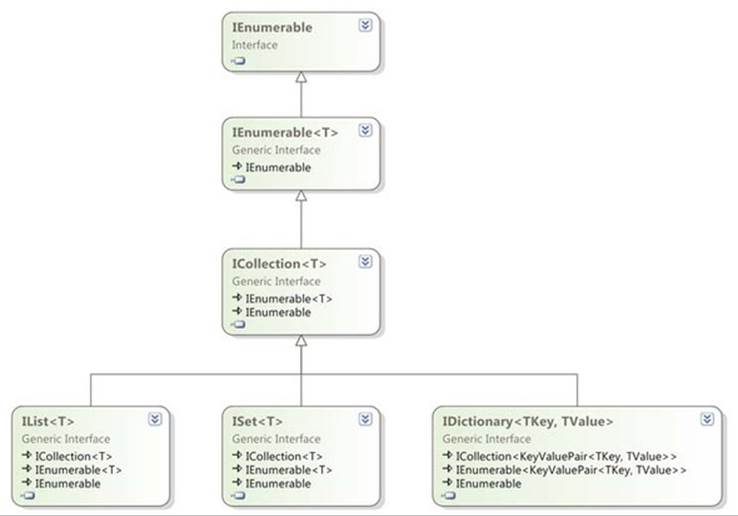
As you’ve already seen several times, the most fundamental generic collection interface is IEnumerable<T>, representing a sequence of items that can be iterated over. IEnumerable<T> allows you to ask for an iterator of type IEnumerator<T>. The separation between the iterable sequence and the iterator enables multiple iterators to run independently over the same sequence at the same time. If you want to think in database terms, a table is an IEnumerable<T>, whereas a cursor is an IEnumerator<T>. These are the only variant collection interfaces covered in this appendix, becoming IEnumerable<out T> and IEnumerator<out T> in .NET 4; all the other interfaces involve values of the element type going both in and out of members, so they have to be invariant.
Next comes ICollection<T>—this extends IEnumerable<T> but adds two properties (Count and IsReadOnly), mutation methods (Add, Remove, and Clear), CopyTo (which copies the contents to an array), and Contains (which determines if the collection contains a particular element). All the standard generic collection implementations implement this interface.
IList<T> is all about positioning: it provides an indexer, InsertAt and RemoveAt (to match Add/Remove but with positions), and IndexOf (to determine the position of an element within the collection). Iterating over an IList<T> will generally return the item at index 0, then index 1, and so on. This isn’t thoroughly documented, but it’s a reasonable assumption to make. Likewise, it’s usually expected that random access to an IList<T> by index is efficient.
IDictionary<TKey, TValue> represents a mapping from a unique key to a value for that key. The values don’t have to be unique, and may be null; keys can’t be null. Dictionaries can be regarded as collections of key/value pairs, which is why IDictionary <TKey, TValue> extendsICollection<KeyValuePair<TKey, TValue>>. Values can be retrieved with the indexer or TryGetValue; unlike the nongeneric IDictionary type, if you attempt to fetch the value for a missing key, the indexer of IDictionary<TKey, TValue> throws aKeyNotFoundException. The purpose of TryGetValue is to allow you to detect missing keys in situations where it’s expected in normal operation.
ISet<T> is a new interface in .NET 4, representing a distinct set of values. It’s been retroactively applied to HashSet<T> from .NET 3.5, and .NET 4 introduces a new implementation—SortedSet<T>.
Usually it’s fairly clear which interface (and even implementation) you want to use when implementing functionality. It can be significantly harder to decide how to expose that collection as part of an API; the more specific you are in what you return, the more your callers will be able to rely on additional functionality specified by those types. This may make the caller’s life easier, at the expense of future flexibility within your implementation. I usually prefer to use interfaces for the return types of methods and properties, rather than guaranteeing a particular implementation class. You should also think carefully before exposing a mutable collection in an API, particularly if that collection represents part of the state of the object or type. Returning either a copy or a read-only wrapper around the collection is usually preferable, unless the whole purpose of the method is to allow mutation via the returned collection.
B.2. Lists
In many ways, lists are the simplest and most natural type of collection. There are many implementations in the framework, with different abilities and performance characteristics. A few big-hitters are used all over the place, and some more esoteric ones are used for specialist situations.
B.2.1. List<T>
List<T> is the default choice for lists in most cases. It implements IList<T> and therefore ICollection<T>, IEnumerable<T>, and IEnumerable. Additionally, it implements the nongeneric ICollection and IList interfaces, boxing and unboxing as required, and performing execution-time type checks to make sure that new elements are always of a type that’s compatible with T.
Internally List<T> stores an array, and it keeps track of both the logical size of the list and the size of the backing array. Adding an element is either a simple case of setting the next value in the array, or (if the array is already full) copying the existing contents into a new, bigger array and then setting the value. This means the operation has complexity of O(1) or O(n) depending on whether the values need to be copied. The expansion strategy isn’t documented—and therefore isn’t guaranteed—but in practice the approach has always been to expand to double the newly required size. This results in an amortized complexity of O(1) for appending an item to the end of the list; sometimes it’ll be more, but that becomes increasingly rare as the list grows larger.
You can explicitly manage the size of the backing array by getting and setting the Capacity property; the TrimExcess method has the effect of making the capacity exactly equal to the current size. In practice, this is rarely necessary, but if you already know the eventual size of the list when you create it, you can pass an initial capacity into the constructor, avoiding unnecessary copying.
Removing an element from a List<T> requires all the later elements to be copied down, so its complexity is O(n – k) where k is the index of the element you’re removing; trimming the tail of a list is cheaper than removing the head. On the other hand, if you’re trying to remove an element by value instead of by index (Remove rather than RemoveAt), you’ll effectively end up with an O(n) operation wherever the element is: each element has to be either checked for equality or shuffled down.
Various methods on List<T> act as a sort of precursor to LINQ. ConvertAll projects one list into another; FindAll filters the original list into a new list containing only the values that match the specified predicate. Sort performs a sort using either the default equality comparer for the type or one specified as an argument. There’s a big difference between Sort and the OrderBy of LINQ, though: Sort modifies the contents of the original list, rather than yielding an ordered copy. Also, Sort is unstable, whereas OrderBy is stable; equal elements in the original list may be reordered when using Sort. One aspect of List<T> that isn’t supported by LINQ is binary search: if you have a list that’s already sorted in the right way for the value you’re looking for, the BinarySearch method is more efficient than using the linear IndexOf search.[1]
1 Binary search is O(log n) complexity; a linear search is O(n).
One somewhat controversial aspect of List<T> is the ForEach method. This does exactly what it sounds like—it iterates over the list and executes a delegate (specified as an argument to the method) for each value. Many developers have requested that this be added as an extension method for IEnumerable<T>, but this suggestion has been resisted so far; Eric Lippert makes the case for it being philosophically troubling on his blog (see http://mng.bz/Rur2). Calling ForEach using a lambda expression seems overkill to me; on the other hand, if you already have a delegate you want to execute on each element on the list, you might as well get ForEach to do that for you, as it’s already there.
B.2.2. Arrays
Arrays are in some senses the lowest level of collection in .NET. All arrays derive directly from System.Array, and they’re the only collections with direct support in the CLR. Single-dimensional arrays implement IList<T> (and the interfaces it extends) and the nongeneric IList andICollection interfaces; rectangular arrays only support the nongeneric interfaces. Arrays are always mutable in terms of their elements, but always fixed in terms of their size. All the mutating methods of the collection interfaces (such as Add and Remove) are explicitly implemented and throw NotSupportedException.
Arrays of reference types are always covariant; there’s an implicit conversion from a Stream[] reference to Object[], for example, and an explicit conversion the other way around.[2] This means that changes to the array have to be verified at execution time—the array itself knows what type it is, so if you try to store a non-Stream reference in a Stream[] by converting the array reference to an Object[] first, an ArrayTypeMismatchException will be thrown.
2 Somewhat confusingly, this also means there’s an implicit conversion from Stream[] to IList<Object>, even though IList<T> itself is invariant.
There are two different flavors of array as far as the CLR is concerned. A vector is a single-dimensional array with a lower bound of 0; anything else counts as an array. Vectors perform better and are what you almost always use in C#. An array of the form T[][] is still a vector, but with an element type of T[]; only rectangular arrays in C#, such as new string[10, 20], end up as arrays in CLR terminology. You can’t create an array with a nonzero lower bound directly in C#—you have to use Array.CreateInstance, which allows you to specify lower bounds, lengths, and the element type individually. If you create a single-dimensional array with a nonzero lower bound, you can’t then successfully cast it to T[]—the compiler will allow the cast, but it will fail at execution time.
The C# compiler has built-in support for arrays in a number of ways. Not only does it know about how to create and index them, but it also supports them directly in foreach loops; if you iterate using an expression that’s known to be an array at compile time, that iteration will use theLength property and the array indexer, rather than creating an iterator object. This is more efficient, but the performance difference is usually negligible.
Like List<T>, arrays support methods such as ConvertAll, FindAll, and BinarySearch, although in the case of arrays, these are static methods of the Array class, taking the array as the first parameter.
To come back to my first point, arrays are pretty low-level data structures. They’re important as the building blocks for many other collections, and they’re efficient in appropriate situations, but you should think twice before using them too heavily. Again, Eric has blogged on this topic, labeling them “somewhat harmful” (see http://mng.bz/3jd5). I don’t want to overstate this point, but it’s worth being aware of the shortcomings of arrays when choosing a collection type.
B.2.3. LinkedList<T>
When is a list not a list? When it’s a linked list. LinkedList<T> is a list in many ways—in particular, it’s a collection that maintains the order in which you add items—but it doesn’t implement IList<T>. This is because it doesn’t obey the implied contract of efficient access by index. It’s a classical computer science doubly linked list: it maintains a head node and a tail node, and each node has a reference to the next and previous node within the list. Each node is exposed as a LinkedListNode<T>, which is handy if you want to maintain an insertion/removal point somewhere in the middle of the list. The list explicitly maintains a size, so accessing the Count property is efficient.
Linked lists are inefficient in terms of space compared with array-backed lists, and they don’t support indexed operations, but they’re fast at inserting or removing elements at arbitrary points in the list, as long as you have a reference to the node at the relevant point. These operations have O(1) complexity, as all that’s required is fixing up the next/previous references in the surrounding nodes. Inserting or removing from the head or tail of the list is just a special case of this, where there’s always immediate access to the node you need to change. Iterating (either forward or backward) is also efficient, as it’s just a matter of following the chain of references.
Although LinkedList<T> implements the standard methods, such as Add (which adds to the tail of the list), I’d suggest using the explicit AddFirst and AddLast methods to make it clear exactly what’s going on. There are matching RemoveFirst and RemoveLast methods, and Firstand Last properties. All of these return the nodes within the list rather than the values of those nodes; the properties return a null reference if the list is empty.
B.2.4. Collection<T>, BindingList<T>, ObservableCollection<T>, and Keyed- dCollection<TKey, TItem>
Collection<T> is a member of the System.Collections.ObjectModel namespace, as are all the remaining lists we’ll look at. Like List<T>, it implements both the generic and nongeneric collection interfaces.
Though you can use Collection<T> on its own, it’s more commonly used as a base class. It always acts as a wrapper to another list: you either specify one in the constructor, or a new List<T> will be created behind the scenes. All mutating actions on the collection go through protected virtual methods (InsertItem, SetItem, RemoveItem, and ClearItems); derived classes can intercept these methods, raising events or providing other custom behavior. The wrapped list is accessible to derived classes via the Items property. If this list is read-only, the public mutating methods throw an exception rather than calling the virtual methods; you don’t need to recheck this when you override them.
BindingList<T> and ObservableCollection<T> derive from Collection<T> in order to provide binding capabilities. BindingList<T> has been available since .NET 2.0, but ObservableCollection<T> was introduced with Windows Presentation Foundation (WPF). Of course, you don’t have to use them for data binding in user interfaces—you may have your own reasons to be interested in changes to a list. In that case, you should see which collection provides notifications in a more useful form when you’re deciding which to use. Note that you’ll only be notified of changes that occur through the wrapper; if the underlying list is shared with other code that may modify it on its own, that won’t raise any events in the wrapper.
KeyedCollection<TKey, TItem> is a sort of hybrid between a list and a dictionary, allowing an item to be fetched by key as well as by index. Unlike normal dictionaries, the key should be effectively embedded within the item, rather than being independent. In many cases this is natural; for example, you might have a Customer type with a CustomerID property. KeyedCollection<,> is an abstract class; derived classes implement the GetKeyForItem method to provide a way of extracting a key from any item added to the collection. In our customer scenario, theGetKeyForItem method would just return the ID for the given customer. Just like a dictionary, the key must be unique within the collection—attempting to add another item with the same key will fail with an exception. Although null keys aren’t permitted, GetKeyForItem can returnnull (if the key type is a reference type), in which case the key will be ignored (and the item won’t be fetchable by its key).
B.2.5. ReadOnlyCollection<T> and ReadOnlyObservableCollection<T>
Our final two lists are more wrappers, providing read-only access even when the underlying list is mutable. Again, both generic and nongeneric collection interfaces are implemented. A mixture of explicit and implicit interface implementation is used so that callers using a compile-time expression of the concrete type will be discouraged from using mutating operations that will fail.
ReadOnlyObservableCollection<T> derives from ReadOnlyCollection<T> and implements the same INotifyCollectionChanged and INotifyPropertyChanged interfaces as ObservableCollection<T>. A ReadOnlyObservableCollection<T> instance can only be constructed with an ObservableCollection<T> backing list. Even though the collection is still read-only for callers, they can observe changes made elsewhere to the backing list.
Though usually I’d advise using an interface when deciding the return type of methods in an API, it can be useful to deliberately expose ReadOnlyCollection<T> to provide a clear indication to callers that they won’t be able to modify the returned collection. But you’ll still need to document whether the underlying collection could be changed elsewhere, or whether it’s effectively constant.
B.3. Dictionaries
The choices for dictionaries in the framework are much more limited than those of lists. There are only three mainstream nonconcurrent implementations of IDictionary <TKey, TValue>, although it’s also implemented by ExpandoObject (as you saw in chapter 14),ConcurrentDictionary (which we’ll look at along with the other concurrent collections), and RouteValueDictionary (used for routing web requests, particularly in ASP.NET MVC).
Just as a reminder, the primary purpose of a dictionary is to provide an efficient lookup from a key to a value.
B.3.1. Dictionary<TKey, TValue>
Unless you have specialist requirements, Dictionary<TKey, TValue> is the default choice of dictionary in much the same way that List<T> is the default list implementation. It uses a hash table to implement an efficient lookup, although this means that the efficiency of the dictionary depends on how good your hashing function is. You can either use the default hashing and equality functions (calls to Equals and GetHashCode within the key objects themselves) or specify an IEqualityComparer<TKey> as a constructor argument.
The simplest use case is to implement a dictionary with string keys, which uses the keys in a case-insensitive way, as shown in the following code:

Although the keys within a dictionary have to be unique, the hash codes don’t. It’s perfectly acceptable for two unequal keys to have the same hash; this is known as a hash collision, and although it reduces the efficiency of the dictionary slightly, it’ll still function correctly. The dictionary willfail if the keys are mutable and change their hash codes after they’ve been inserted into the dictionary. Mutable dictionary keys are almost always a bad idea, but if you absolutely have to use them, make sure you don’t change them after insertion.
The exact details of the implementation of the hash table are unspecified and may change over time, but one important aspect can cause confusion: there’s no ordering guarantee within Dictionary<TKey, TValue>, even though it might appear that way. If you add items to a dictionary and then iterate over it, you may see the items come out in the insertion order, but please don’t rely on it. It’s somewhat unfortunate that as a quirk of the implementation, simply adding entries without ever deleting any tends to preserve order—an implementation that happened to scramble the order naturally would probably cause less confusion.
Like List<T>, Dictionary<TKey, TValue> keeps its entries in an array and expands this when it needs to, leading to amortized O(1) expansion. Access by key is also O(1) assuming a reasonable hash; if all the keys have the same hash code, you’ll end up with O(n) access because the dictionary has to check each key in turn for equality. In most practical scenarios, this isn’t an issue.
B.3.2. SortedList<TKey, TValue> and SortedDictionary<TKey, TValue>
A casual observer might imagine that a class named SortedList<,> would be a list... but no. Both of these types are actually dictionaries, and neither implements IList<T> at all. It might be more informative for them to be named ListBackedSortedDictionary andTreeBackedSortedDictionary, but it’s too late to change now.
There’s a lot of commonality between these two classes: both use an IComparer <TKey> instead of an IEqualityComparer<TKey> to compare keys, and both maintain the keys in a sorted fashion, based on that comparison. Both have O(log n) performance when finding values, effectively performing a binary search. But their internal data structures are very different: SortedList<,> maintains an array of entries that’s kept sorted, whereas SortedDictionary<,> uses a red-black tree structure (see the Wikipedia entry at http://mng.bz/K1S4). This leads to significant differences in insertion and removal times as well as memory efficiency. If you’re creating a dictionary from mostly sorted data, a SortedList<,> will populate efficiently; if you imagine the steps involved in keeping a List<T> sorted, you can see that adding a single item to the end of the list is cheap (O(1) if you ignore expansion), whereas adding items randomly is expensive, because it involves copying existing items (O(n) in the worst case). Adding items to the balanced tree in a SortedDictionary<,> is always fairly cheap (O(log n) complexity), but it involves a separate tree node on the heap for each entry, leading to more overhead and memory fragmentation than the array of key/value entry structures in a SortedList<,>.
Both collections expose their keys and values as separate collections, and in both cases the returned collection is live in that it’ll change as the underlying dictionary changes. But the collections exposed by a SortedList<,> implement IList<T>, so you can effectively access entries by sorted key index if you really want to.
I don’t want to put you off too much with all this talk of complexity. Unless you have a very large amount of data, you probably don’t need to worry much about which implementation you use. If you are likely to have vast numbers of entries in your dictionary, you should carefully analyze the performance characteristics of both collections to work out which one to use.
B.3.3. ReadOnlyDictionary<TKey, TValue>
Once you’re familiar with ReadOnlyCollection<T>, which we discussed in section B.2.5, ReadOnlyDictionary<TKey, TValue> should hold no surprises for you. Again, it’s simply a wrapper around an existing collection (an IDictionary<TKey, TValue> this time) that hides all mutating operations behind explicit interface implementation and throws a NotSupportedException if they’re called anyway.
As with the read-only lists, this really is just a wrapper; if the underlying collection (the one passed to the constructor) is modified, those modifications will be visible through the wrapper.
B.4. Sets
Prior to .NET 3.5, there was no public set collection in the framework at all. When developers needed something to represent a set in .NET 2.0, they’d typically use a -Dictionary<,>, using the set items as keys and providing dummy values. This situation was improved somewhat withHashSet<T> in .NET 3.5, and now .NET 4 has added a SortedSet<T> and a common ISet<T> interface. Although logically a set interface could consist merely of Add/Remove/Contains operations, ISet<T> specifies a number of other operations to manipulate the set (ExceptWith,IntersectWith, SymmetricExceptWith, and UnionWith) and to test for various more complex conditions (SetEquals, Overlaps, IsSubsetOf, IsSupersetOf, IsProperSubsetOf, and IsProperSupersetOf). The parameters for all of these methods are expressed in terms ofIEnumerable<T> rather than ISet<T>, which is initially surprising, but it means that sets interact with LINQ in a natural way.
B.4.1. HashSet<T>
A HashSet<T> is effectively a Dictionary<,> without the values. It has the same performance characteristics, and again you can specify an IEqualityComparer<T> to customize how items are compared. Again, you must not rely on a HashSet<T> maintaining the order in which you add values.
One additional feature supported by HashSet<T> is the RemoveWhere method, which removes any entry that matches a given predicate. This allows you to prune a set without worrying about the normal prohibition against modifying a collection while you iterate over it.
B.4.2. SortedSet<T> (.NET 4)
Just like the previous HashSet<T> comparison with Dictionary<,>, a SortedSet<T> is like a valueless SortedDictionary<,>. It maintains a red-black tree of values, providing O(log n) complexity for addition, removal, and containment checking. When you iterate over the set, the values will be yielded in a sorted order.
It provides the same RemoveWhere method as HashSet<T> (despite this not being in the interface) and additionally provides properties (Min and Max) to return the minimum and maximum values. A more intriguing method is GetViewBetween, which returns another SortedSet<T>offering a view on the original set between a lower and upper bound, both of which are inclusive. This is a mutable, live view—changes to the view are reflected in the original set, and vice versa. The following example demonstrates this:

Although GetViewBetween is convenient, it’s not entirely free: operations on the view may be more expensive than expected, in order to keep internal consistency. In particular, accessing the Count property of a view is an O(n) operation if the underlying set has changed since the last tree walk. Like all powerful tools, this should be used with care.
One final feature of SortedSet<T>: it exposes a Reverse() method that allows you to iterate over it in reverse order. This isn’t used by Enumerable.Reverse(), which buffers the contents of the sequence it’s called on. If you know you’ll want to access a sorted set in reverse order, it may be useful to keep an expression of type SortedSet<T> instead of using a more general interface type, so that you can access this more efficient implementation.
B.5. Queue<T> and Stack<T>
Queues and stacks are staples of every computer science course. They’re sometimes referred to as FIFO (first in, first out) and LIFO (last in, first out) structures, respectively. The basic idea is the same for both data structures: you add items to the collection, and at some other point you remove them. The difference is the order in which they’re removed: a queue acts like a queue in a shop, where the first person to join the queue is the first to be served; a stack acts like a stack of plates where the last plate placed on the top is the first to be taken off it. One common use for queues and stacks is to maintain a list of work items still to be processed.
Just as with LinkedList<T>, although you can use the normal collection interface methods to access queues and stacks, I recommend using the class-specific ones to make your code clearer.
B.5.1. Queue<T>
Queue<T> is implemented with a circular buffer: essentially it maintains an array, with an index remembering the next slot to add an item into, and another index remembering the next slot to take an item from. If the add index catches up with the remove index, the contents are copied into a larger array.
Queue<T> provides the Enqueue and Dequeue methods to add and remove items; a Peek method allows you to see what item will be dequeued next, without actually removing it. Both Dequeue and Peek throw InvalidOperationException if they’re called on an empty queue. Iterating over the queue yields values in the order they’d be dequeued.
B.5.2. Stack<T>
The Stack<T> implementation is even simpler than Queue<T>—you can think of it as being just like a List<T>, but with a Push method to add a new item to the end of the list, Pop to remove the final item, and Peek to look at the final item without removing it. Again, Pop and Peekthrow InvalidOperationException when called on an empty stack. Iterating over the stack yields values in the order they’d be popped—so the most recently added value is yielded first.
B.6. Concurrent collections (.NET 4)
As part of Parallel Extensions in .NET 4, there are several new collections in a new System.Collections.Concurrent namespace. These are designed to be safe in the face of concurrent operations from multiple threads, with relatively little locking. The namespace also contains three classes that are used for partitioning collections for parallel operations, but we won’t be looking at those here.
B.6.1. IProducerConsumerCollection<T> and BlockingCollection<T>
Three of the new collections implement the new IProducerConsumerCollection<T> interface, which is designed to be used with BlockingCollection<T>. When describing queues and stacks, I mentioned that they’re often used to store work items for later processing; the producer/consumer pattern is a way of executing these work items concurrently. Sometimes there’s a single producer thread creating work and multiple consumer threads executing the work items. In other cases, the consumers can also be producers; for example, a web crawler may process a web page and discover more links to be crawled later.
IProducerConsumerCollection<T> acts as an abstraction for the data storage of the producer/consumer pattern, and BlockingCollection<T> wraps this in an easy-to-use form and also provides the ability to limit how many items can be buffered at any one time.BlockingCollection<T> assumes that nothing else will be adding to the wrapped collection directly; all the interested parties should use the wrapper for both adding and removing work items. The constructor overloads that don’t take an IProducerConsumerCollection<T>parameter use a ConcurrentQueue<T> for backing storage.
The IProducerConsumerCollection<T> only provides three particularly interesting methods: ToArray, TryAdd, and TryTake. ToArray copies the current contents of the collection to a new array; this is a snapshot of the collection at the point when the method is called. TryAdd andTryTake both follow the normal TryXXX pattern, returning a Boolean value to indicate success or failure, and they do what you’d expect: attempt to add an item to the collection, or attempt to remove one from the collection. Allowing an efficient failure mode reduces the need for locking. In a Queue<T>, for example, you’d want to hold a lock in order to combine the operations of “test whether there are any items in the queue” and “dequeue an item if there is one”—otherwise Dequeue could throw an exception.
BlockingCollection<T> layers blocking behavior on top of these nonblocking methods, with a host of overloads to allow timeouts and cancellation tokens to be specified. Usually you won’t need to use BlockingCollection<T> or IProducerConsumerCollection<T> directly; you’ll call other parts of Parallel Extensions that’ll use them for you. It’s worth knowing they’re there, though, in case you need your own custom behavior.
B.6.2. ConcurrentBag<T>, ConcurrentQueue<T>, and ConcurrentStack<T>
The framework comes with three implementations of IProducerConsumerCollection<T>. Essentially, they differ in terms of the order in which items are retrieved; the queue and stack act as you’d expect them to from their nonconcurrent equivalents, whereas ConcurrentBag<T>doesn’t guarantee any ordering.
All three implement IEnumerable<T> in a thread-safe way. The iterator returned by GetEnumerator() will iterate over a snapshot of the collection; you can modify the collection while you’re iterating, and the changes won’t be seen within the iterator. All three also offer a TryPeekmethod that’s similar to TryTake, but that doesn’t remove a value from the collection. Unlike TryTake, this method isn’t specified in IProducerConsumerCollection<T>.
B.6.3. ConcurrentDictionary<TKey, TValue>
ConcurrentDictionary<TKey, TValue> implements the standard IDictionary <TKey, TValue> interface (whereas none of the concurrent collections implements IList<T>) and is essentially a thread-safe hash-based dictionary. It supports multiple threads reading and writing concurrently, and also allows thread-safe iteration, although unlike the three collections from the previous section, modifications made to the dictionary while iterating may or may not be reflected in the iterator.
There’s more to it than just thread-safe access. Whereas normal dictionary implementations basically offer add-or-update via the indexer, and add-or-throw via the Add method, ConcurrentDictionary<TKey, TValue> offers a veritable smorgasbord of options. You can update the value associated with a key based on its previous value, get a value based on a key or add it if the key wasn’t present beforehand, conditionally update a value only if it was what you expected it to be before, and many other possibilities, all of which act atomically. It’s all bewildering to start with, but Stephen Toub of the Parallel Extensions team has a blog post giving details of when you should use which method (see http://mng.bz/WMdW).
B.7. Read-only interfaces (.NET 4.5)
.NET 4.5 introduced three new collection interfaces: IReadOnlyCollection<T>, IReadOnlyList<T>, and IReadOnlyDictionary<TKey, TValue>. As I write this, they’re not widely used—but it’s worth being aware of them, mostly so you know what they’re not. Figure B.2 shows how they relate to each other and to the IEnumerable interfaces.
Figure B.2. Read-only interfaces in .NET 4.5
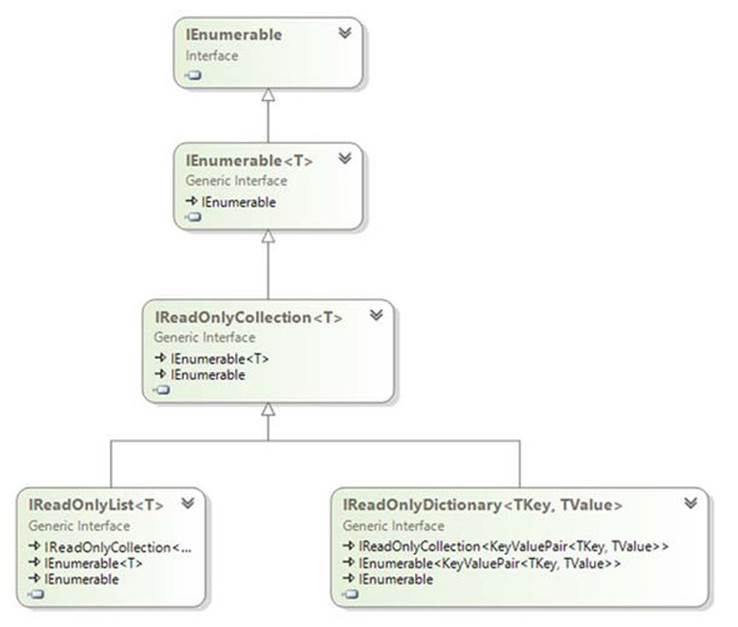
If you thought that ReadOnlyCollection<T> was stretching the truth with its name, these interfaces are even more sneaky. They don’t just allow for mutations to be made by other code; they even allow mutations through the very same object, if that happens to be a mutable collection. For example, List<T> implements IReadOnlyList<T> even though it’s clearly not a read-only collection.
That’s not to say the interfaces aren’t useful, of course. In particular, both IReadOnlyCollection<T> and IReadOnlyList<T> are covariant in T, just like IEnumerable <T> but exposing more operations. Unfortunately IReadOnlyDictionary<TKey, TValue> is invariant in both type parameters, partly due to it implementing -IEnumerable<KeyValuePair<TKey, TValue>>—which is invariant because KeyValuePair<TKey, TValue> is a struct, which is therefore invariant in itself. Additionally, the covariance of IReadOnlyList<T> means that it can’t expose any methods accepting a T, such as Contains and IndexOf. The big benefit is that it does expose an indexer to fetch items by index.
I can’t see myself using these interfaces much right now, but in the future I think they’ll be very important. In late 2012, Microsoft released their first preview of a NuGet package of immutable collections, called Microsoft.Bcl.Immutable. A BCL team blog post (http://mng.bz/Xlqd) gives more details, but fundamentally it does what it says on the tin: fully immutable collections, along with freezable (mutable until they’re frozen) collections. Of course, if the element type is mutable (such as StringBuilder), then this only gets you so far, but I’m still excited about it, for all the normal reasons that immutability is helpful.
B.8. Summary
The .NET Framework contains a rich set of collections (although not a particularly rich collection of sets). These have been gradually growing, along with the rest of the framework, although the most commonly used collections are likely to be List<T> and Dictionary<TKey, TValue>for some time to come.
There are certainly data structures that could be added in the future, but the benefit always has to be weighed against the cost of adding something to the core framework. Maybe we’ll see explicitly tree-based APIs in the future, rather than them being an implementation detail of existing collections. Maybe we’ll see Fibonacci heaps, weak-reference caches, and the like—but as you’ve seen, there’s already a lot for developers to take in, and there’s a risk of information overload.
If there’s a particular data structure you need for your project, it’s worth looking online for an open source implementation; Wintellect’s Power Collections have a -particularly strong history as an alternative to the built-in collections (http://-powercollections.codeplex.com). But in most cases, the framework is likely to be adequate for your needs. Hopefully this appendix has expanded your horizons slightly in terms of what’s available out of the box.
All materials on the site are licensed Creative Commons Attribution-Sharealike 3.0 Unported CC BY-SA 3.0 & GNU Free Documentation License (GFDL)
If you are the copyright holder of any material contained on our site and intend to remove it, please contact our site administrator for approval.
© 2016-2026 All site design rights belong to S.Y.A.