C# in Depth (2012)
Part 3. C# 3: Revolutionizing data access
Chapter 9. Lambda expressions and expression trees
This chapter covers
· Lambda expression syntax
· Conversions from lambdas to delegates
· Expression tree framework classes
· Conversions from lambdas to expression trees
· Why expression trees matter
· Changes to type inference and overload resolution
In chapter 5 you saw how C# 2 made delegates much easier to use due to implicit conversions of method groups, anonymous methods, and return type and parameter variance. This is enough to make event subscription significantly simpler and more readable, but delegates in C# 2 are still too bulky to be used all the time; a page of code full of anonymous methods is painful to read, and you wouldn’t want to start putting multiple anonymous methods in a single statement on a regular basis.
One of the fundamental building blocks of LINQ is the ability to create pipelines of operations, along with any state required by those operations. These operations can express all kinds of logic about data: how to filter it, how to order it, how to join different data sources together, and much more. When LINQ queries are executed in-process, those operations are usually represented by delegates.
Statements containing several delegates are common when manipulating data with LINQ to Objects,[1] and lambda expressions in C# 3 make all of this possible without sacrificing readability. (While I’m mentioning readability, this chapter uses lambda expression and lambdainterchangeably.)
1 LINQ to Objects handles sequences of data within the same process. By contrast, providers such as LINQ to SQL offload the work to other out-of-process systems—databases, for example.
It’s all Greek to me
The term lambda expression comes from lambda calculus, also written as λ-calculus, where λ is the Greek letter lambda. This is an area of math and computer science dealing with defining and applying functions. It’s been around for a long time and is the basis of functional languages such as ML. The good news is that you don’t need to know lambda calculus to use lambda expressions in C# 3.
Executing delegates is only part of the LINQ story. To use databases and other query engines efficiently, you need a different representation of the operations in the pipeline—a way to treat code as data that can be examined programmatically. The logic within the operations can then be transformed into a different form, such as a web service call, a SQL or LDAP query—whatever’s appropriate.
Although it’s possible to build up representations of queries in a particular API, it’s usually tricky to read and it sacrifices a lot of compiler support. This is where lambdas save the day again: not only can they be used to create delegate instances, but the C# compiler can also transform them into expression trees—data structures representing the logic of the lambda expressions—so that other code can examine it. In short, lambda expressions are the idiomatic way of representing the operations in LINQ data pipelines—but we’ll take things one step at a time, examining them in a fairly isolated way before we embrace the whole of LINQ.
In this chapter we’ll look at both ways of using lambda expressions, although for the moment our coverage of expression trees will be relatively basic—we won’t create any SQL just yet. With that theory under your belt, you should be relatively comfortable with lambda expressions and expression trees by the time we hit the really impressive stuff in chapter 12.
In the final part of this chapter we’ll examine how type inference has changed for C# 3, mostly due to lambdas with implicit parameter types. This is a bit like learning how to tie shoelaces: far from exciting, but without this ability you’ll trip over yourself when you start running.
Let’s begin by seeing what lambda expressions look like. We’ll start with an anonymous method and gradually transform it into shorter and shorter forms.
9.1. Lambda expressions as delegates
In many ways, lambda expressions can be seen as an evolution of anonymous methods from C# 2. Lambda expressions can do almost everything that anonymous methods can, and they’re almost always more readable and compact.[2] In particular, the behavior of captured variables is exactly the same in lambda expressions as in anonymous methods. In the most explicit form, not much difference exists between the two, but lambda expressions have a lot of shortcuts available that make them compact in common situations. Like anonymous methods, lambda expressions have special conversion rules—the type of the expression isn’t a delegate type in itself, but it can be converted into a delegate instance in various ways, both implicitly and explicitly. The term anonymous function covers anonymous methods and lambda expressions, and in many cases the same conversion rules apply to both of them.
2 The one feature available to anonymous methods but not lambda expressions is the ability to concisely ignore parameters. Look back at section 5.4.3 for more details if you’re interested, but in practice it’s not something you’ll really miss with lambda expressions.
We’ll start with a simple example, initially expressed as an anonymous method. You’ll create a delegate instance that takes a string parameter and returns an int (which is the length of the string). First you need to choose a delegate type to use; fortunately, .NET 3.5 comes with a whole family of generic delegate types to help you out.
9.1.1. Preliminaries: Introducing the Func<...> delegate types
There are five generic Func delegate types in .NET 3.5’s System namespace. There’s nothing special about Func—it’s just handy to have some predefined generic types that are capable of handling many situations. Each delegate signature takes between zero and four parameters, the types of which are specified as type parameters.[3] The last type parameter is used for the return type in each case.
3 You may remember that you met the version without any parameters (but one type parameter) in chapter 6.
Here are the signatures of all the Func delegate types in .NET 3.5:
TResult Func<TResult>()
TResult Func<T,TResult>(T arg)
TResult Func<T1,T2,TResult>(T1 arg1, T2 arg2)
TResult Func<T1,T2,T3,TResult>(T1 arg1, T2 arg2, T3 arg3)
TResult Func<T1,T2,T3,T4,TResult>(T1 arg1, T2 arg2, T3 arg3, T4 arg4)
For example, Func<string,double,int> is equivalent to a delegate type of the form public delegate int SomeDelegate(string arg1, double arg2)
The Action<...> set of delegates provides the equivalent functionality when you want a void return type. The single parameter form of Action existed in .NET 2.0, but the rest are new to .NET 3.5. If four arguments aren’t enough for you, then .NET 4 has the answer: it expands both theAction<...> and Func<...> families to take up to 16 arguments, so Func<T1,...,T16,TResult> has an eye-watering 17 type parameters. This is primarily to help support the Dynamic Language Runtime (DLR) that you’ll meet in chapter 14, and you’re unlikely to need to deal with it directly.
For this example, you need a type that takes a string parameter and returns an int, so you can use Func<string,int>.
9.1.2. First transformation to a lambda expression
Now that you know the delegate type, you can use an anonymous method to create your delegate instance. The following listing shows this and executes the delegate instance afterward, so you can see it working.
Listing 9.1. Using an anonymous method to create a delegate instance
Func<string,int> returnLength;
returnLength = delegate (string text) { return text.Length; };
Console.WriteLine(returnLength("Hello"));
Listing 9.1 prints 5, just as you’d expect it to. I’ve separated the declaration of returnLength from the assignment to it, to keep it on one line—it’s easier to keep track of that way. The anonymous method expression is the part in bold; that’s the part you’ll convert into a lambda expression.
The most long-winded form of a lambda expression is this:
(explicitly-typed-parameter-list) => { statements }
The => part is new to C# 3 and tells the compiler that you’re using a lambda expression. Most of the time, lambda expressions are used with a delegate type that has a nonvoid return type, and the syntax is slightly less intuitive when there isn’t a result. This is another indication of the changes in idiom between C# 1 and C# 3. In C# 1, delegates were usually used for events and rarely returned anything. In LINQ they’re usually used as part of a data pipeline, taking input and returning a result to say what the projected value is, or whether the item matches the current filter, and so forth.
With the explicit parameters and statements in braces, this version looks very similar to an anonymous method. The following listing is equivalent to listing 9.1, but it uses a lambda expression.
Listing 9.2. A long-winded first lambda expression, similar to an anonymous method
Func<string,int> returnLength;
returnLength = (string text) => { return text.Length; };
Console.WriteLine(returnLength("Hello"));
Again, I’ve used bold to indicate the expression used to create the delegate instance. When reading lambda expressions, it helps to think of the => part as “goes to,” so the example in listing 9.2 could be read “text goes to text.Length.” Since this is the only part of the listing that’s interesting for a while, I’ll show it alone from now on. You can replace the bold text from listing 9.2 with any of the lambda expressions listed in this section and the result will be the same.
The same rules that govern return statements in anonymous methods apply to lambdas: you can’t try to return a value from a lambda expression with a void return type, whereas if there’s a nonvoid return type, every code path has to return a compatible value.[4] It’s all pretty intuitive and rarely gets in the way.
4 Code paths throwing exceptions don’t need to return a value, of course, and neither do detectable infinite loops.
So far, we haven’t saved much space or made things particularly easy to read. Let’s start applying the shortcuts.
9.1.3. Using a single expression as the body
The form we’ve looked at so far uses a full block of code to return the value. This is flexible—you can have multiple statements, perform loops, return from different places in the block, and so on, just as with anonymous methods. But most of the time, you can easily express the whole of the body in a single expression, the value of which is the result of the lambda.[5] In these cases, you can specify just that expression, without any braces, return statements, or semicolons. The format then is
5 You can still use this syntax for a delegate with a void return type if you only need one statement. You omit the semicolon and the braces, basically.
(explicitly-typed-parameter-list) => expression
In our example, this means that the lambda expression becomes
(string text) => text.Length
That’s starting to look simpler already. Now, what about that parameter type? The compiler already knows that instances of Func<string,int> take a single string parameter, so you should be able to just name that parameter.
9.1.4. Implicitly typed parameter lists
Most of the time, the compiler can guess the parameter types without you explicitly stating them. In these cases, you can write the lambda expression as
(implicitly-typed-parameter-list) => expression
An implicitly typed parameter list is just a comma-separated list of names, without the types. You can’t mix and match for different parameters—either the whole list is explicitly typed, or it’s all implicitly typed. Also, if any of the parameters are out or ref parameters, you’re forced to use explicit typing. In our example, it’s fine, so your lambda expression is just
(text) => text.Length
That’s getting pretty short now. There’s not a lot more you could get rid of. The parentheses seem redundant, though.
9.1.5. Shortcut for a single parameter
When the lambda expression only needs a single parameter, and that parameter can be implicitly typed, C# 3 allows you to omit the parentheses, so it now has this form:
parameter-name => expression
The final form of your lambda expression is therefore
text => text.Length
You may be wondering why there are so many special cases with lambda expressions—none of the rest of the language cares whether a method has one parameter or more, for instance. Well, what sounds like a very specific case actually turns out to be extremely common, and the improvement in readability from removing the parentheses from the parameter list can be significant when there are many lambdas in a short piece of code.
It’s worth noting that you can put parentheses around the whole lambda expression if you want to, just like other expressions. Occasionally this helps readability, such as when you’re assigning the lambda to a variable or property—otherwise, the equals symbols can get confusing, at least to start with. Most of the time it’s perfectly readable without any extra syntax at all. The following listing shows this in the context of our original code.
Listing 9.3. A concise lambda expression
Func<string,int> returnLength;
returnLength = text => text.Length;
Console.WriteLine(returnLength("Hello"));
At first you may find listing 9.3 confusing to read, in the same way that anonymous methods appear strange to many developers until they get used to them. In normal use, you’d declare the variable and assign the value to it in the same expression, making it even clearer. When you are used to lambda expressions, though, you can appreciate how concise they are. It’d be hard to imagine a shorter, clearer way of creating a delegate instance.[6] You could change the variable name text to something like x, and in full LINQ that’s often useful, but longer names give valuable information to the reader.
6 That’s not to say it’s impossible. Some languages allow closures to be represented as simple blocks of code with a magic variable name to represent the common case of a single parameter.
I’ve shown this transformation over the course of a few pages, but figure 9.1 makes it clear just how much extraneous syntax you’ve saved.
Figure 9.1. Lambda syntax shortcuts

The decision of whether to use the short form for the body of the lambda expression, specifying just an expression instead of a whole block, is completely independent from the decision about whether to use explicit or implicit parameters. This example has taken us down one route of shortening the lambda, but we could’ve started off by making the parameters implicit. When you’re comfortable with lambda expressions, you won’t think about this at all—you’ll just write the shortest available form naturally.
Higher-order functions
The body of a lambda expression can itself contain a lambda expression, and this tends to be as confusing as it sounds. Alternatively, the parameter to a lambda expression can be another delegate, which is just as bad. Both of these are examples of higher-order functions. If you enjoy feeling dazed and confused, have a look at some of the downloadable source code. Although I’m being flippant, this approach is common in functional programming and can be useful. It just takes a certain degree of perseverance to get into the right mindset.
So far we’ve only dealt with a single lambda expression, putting it into different forms. Let’s look at a few examples to make things more concrete before we examine the details.
9.2. Simple examples using List<T> and events
When we look at extension methods in chapter 10, we’ll use lambda expressions all the time. Until then, List<T> and event handlers give us the best examples. We’ll start off with lists, using automatically implemented properties, implicitly typed local variables, and collection initializers for the sake of brevity. We’ll then call methods that take delegate parameters, using lambda expressions to create the delegates, of course.
9.2.1. Filtering, sorting, and actions on lists
Remember the FindAll method on List<T>—it takes a Predicate<T> and returns a new list with all the elements from the original list that match the predicate. The Sort method takes a Comparison<T> and sorts the list accordingly. Finally, the ForEach method takes an Action<T>to perform on each element.
Listing 9.4 uses lambda expressions to provide the delegate instance to each of these methods. The sample data in question is the name and year of release for various films. You print out the original list, then create and print out a filtered list of only old films, and then sort and print out the original list ordered by name. (It’s interesting to consider how much more code would’ve been required to do the same thing in C# 1.)
Listing 9.4. Manipulating a list of films using lambda expressions

The first half of listing 9.4 involves setting up the data. This code uses a named type just to make life easier—an anonymous type would’ve meant a few more hoops to jump through in this particular case.
Before you use the newly created list, you create a delegate instance ![]() , which you’ll use to print out the items of the list. You use this delegate instance three times, which is why I created a variable to hold it rather than using a separate lambda expression each time. It just prints a single element, but by passing it into List<T>.ForEach you can dump the whole list to the console. A subtle but important point is that the semicolon at the end of this statement is part of the assignment statement, not part of the lambda expression. If you were using the same lambda expression as an argument in a method call, there wouldn’t be a semicolon directly after Console.WriteLine(...).
, which you’ll use to print out the items of the list. You use this delegate instance three times, which is why I created a variable to hold it rather than using a separate lambda expression each time. It just prints a single element, but by passing it into List<T>.ForEach you can dump the whole list to the console. A subtle but important point is that the semicolon at the end of this statement is part of the assignment statement, not part of the lambda expression. If you were using the same lambda expression as an argument in a method call, there wouldn’t be a semicolon directly after Console.WriteLine(...).
The first list you print out is just the original one without any modifications ![]() . You then find all the films in your list that were made before 1960 and print those out
. You then find all the films in your list that were made before 1960 and print those out ![]() . This is done with another lambda expression, which is executed for each film in the list—it only has to determine whether a single film should be included in the filtered list. The source code uses the lambda expression as a method argument, but really the compiler has created a method like this:
. This is done with another lambda expression, which is executed for each film in the list—it only has to determine whether a single film should be included in the filtered list. The source code uses the lambda expression as a method argument, but really the compiler has created a method like this:
private static bool SomeAutoGeneratedName(Film film)
{
return film.Year < 1960;
}
The method call to FindAll is then effectively this:
films.FindAll(new Predicate<Film>(SomeAutoGeneratedName))
The lambda expression support here is just like the anonymous method support in C# 2; it’s all cleverness on the part of the compiler. (In fact, the Microsoft compiler is even smarter in this case—it realizes it can get away with reusing the delegate instance if the code is ever called again, so it caches it.)
Sorting the list is also achieved using a lambda expression ![]() , which compares any two films using their names. I have to confess that explicitly calling CompareTo yourself is a bit ugly. In the next chapter you’ll see how the OrderBy extension method allows you to express ordering in a neater way.
, which compares any two films using their names. I have to confess that explicitly calling CompareTo yourself is a bit ugly. In the next chapter you’ll see how the OrderBy extension method allows you to express ordering in a neater way.
Let’s look at another example, this time using lambda expressions with event handling.
9.2.2. Logging in an event handler
If you think back to chapter 5, in section 5.9 you saw an easy way of using anonymous methods to log which events were occurring, but you could only use a compact syntax because you didn’t mind losing the parameter information. What if you wanted to log both the nature of the event andinformation about its sender and arguments? Lambda expressions enable this in a neat way, as shown in the following listing.
Listing 9.5. Logging events using lambda expressions
static void Log(string title, object sender, EventArgs e)
{
Console.WriteLine("Event: {0}", title);
Console.WriteLine(" Sender: {0}", sender);
Console.WriteLine(" Arguments: {0}", e.GetType());
foreach (PropertyDescriptor prop in
TypeDescriptor.GetProperties(e))
{
string name = prop.DisplayName;
object value = prop.GetValue(e);
Console.WriteLine(" {0}={1}", name, value);
}
}
...
Button button = new Button { Text = "Click me" };
button.Click += (src, e) => Log("Click", src, e);
button.KeyPress += (src, e) => Log("KeyPress", src, e);
button.MouseClick += (src, e) => Log("MouseClick", src, e);
Form form = new Form { AutoSize = true, Controls = { button } };
Application.Run(form);
Listing 9.5 uses lambda expressions to pass the event name and parameters to the Log method, which logs details of the event. You don’t log the details of the event source, beyond whatever its ToString override returns, because an overwhelming amount of information is associated with controls. But you use reflection over property descriptors to show the details of the EventArgs instance passed to you.
Here’s some sample output from when you click the button:
Event: Click
Sender: System.Windows.Forms.Button, Text: Click me
Arguments: System.Windows.Forms.MouseEventArgs
Button=Left
Clicks=1
X=53
Y=17
Delta=0
Location={X=53,Y=17}
Event: MouseClick
Sender: System.Windows.Forms.Button, Text: Click me
Arguments: System.Windows.Forms.MouseEventArgs
Button=Left
Clicks=1
X=53
Y=17
Delta=0
Location={X=53,Y=17}
All of this is possible without lambda expressions, of course, but it’s a lot neater than it would’ve been otherwise.
Now that you’ve seen lambdas being converted into delegate instances, it’s time to look at expression trees, which represent lambda expressions as data instead of code.
9.3. Expression trees
The idea of code as data is an old one, but it hasn’t been used much in popular programming languages. You could argue that all .NET programs use the concept, because the IL code is treated as data by the JIT, which then converts it into native code to run on your CPU. That’s deeply hidden though, and although libraries that manipulate IL programmatically exist, they’re not widely used.
Expression trees in .NET 3.5 provide an abstract way of representing some code as a tree of objects. It’s like CodeDOM but operating at a slightly higher level. The primary use of expression trees is in LINQ, and later in this section you’ll see how crucial expression trees are to the whole LINQ story.
C# 3 provides built-in support for converting lambda expressions to expression trees, but before we cover that, let’s explore how they fit into the .NET Framework without using any compiler tricks.
9.3.1. Building expression trees programmatically
Expression trees aren’t as mystical as they sound, although some of the uses they’re put to look like magic. As the name suggests, they’re trees of objects, where each node in the tree is an expression in itself. Different types of expressions represent the different operations that can be performed in code: binary operations, such as addition; unary operations, such as taking the length of an array; method calls; constructor calls; and so forth.
The System.Linq.Expressions namespace contains the various classes that represent expressions. All of them derive from the Expression class, which is abstract and mostly consists of static factory methods to create instances of other expression classes. It exposes two properties, though:
· The Type property represents the .NET type of the evaluated expression—you can think of it like a return type. The type of an expression that fetches the Length property of a string would be int, for example.
· The NodeType property returns the kind of expression represented as a member of the ExpressionType enumeration, with values such as LessThan, Multiply, and Invoke. To use the same example, in myString.Length the property access part would have a node type ofMemberAccess.
There are many classes derived from Expression, and some of them can have many different node types. BinaryExpression, for instance, represents any operation with two operands: arithmetic, logic, comparisons, array indexing, and the like. This is where the NodeType property is important, as it distinguishes between different kinds of expressions that are represented by the same class.
I don’t intend to cover every expression class or node type—there are far too many, and MSDN does a perfectly good job of explaining them (see http://mng.bz/3vW3). Instead, we’ll try to get a general feel for what you can do with expression trees.
Let’s start off by creating one of the simplest possible expression trees, adding two constant integers together. The following listing creates an expression tree to represent 2+3.
Listing 9.6. A simple expression tree, adding 2 and 3
Expression firstArg = Expression.Constant(2);
Expression secondArg = Expression.Constant(3);
Expression add = Expression.Add(firstArg, secondArg);
Console.WriteLine(add);
Running listing 9.6 will produce the output (2 + 3), which demonstrates that the various expression classes override ToString to produce human-readable output. Figure 9.2 depicts the tree generated by the code.
Figure 9.2. Graphical representation of the expression tree created by listing 9.6
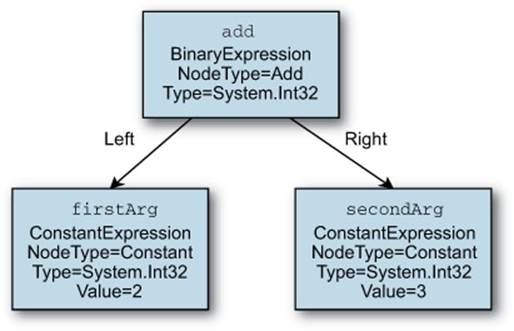
It’s worth noting that the leaf expressions are created first in the code: you build expressions from the bottom up. This is enforced by the fact that expressions are immutable—once you’ve created an expression, it’ll never change, so you can cache and reuse expressions at will.
Now that you’ve built up an expression tree, it’s time to execute it.
9.3.2. Compiling expression trees into delegates
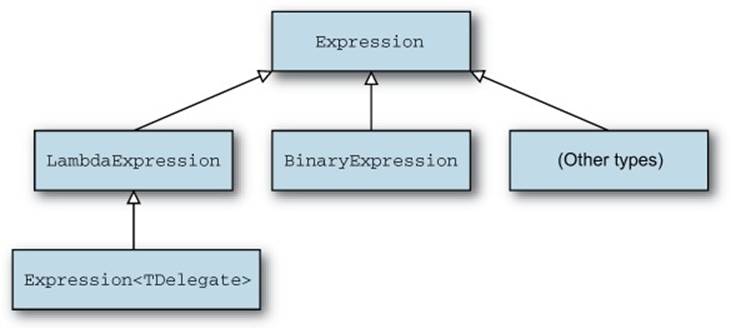
One of the types derived from Expression is LambdaExpression. The generic class Expression<TDelegate> then derives from LambdaExpression. It’s all slightly confusing—figure 9.3 shows the type hierarchy to make things clearer.
Figure 9.3. Type hierarchy from Expression<TDelegate> up to Expression
The difference between Expression and Expression<TDelegate> is that the generic class is statically typed to indicate what kind of expression it is, in terms of return type and parameters. Obviously, this is expressed by the TDelegate type parameter, which must be a delegate type. For instance, the simple addition expression takes no parameters and returns an integer—this is matched by the signature of Func<int>, so you could use an Expression<Func<int>> to represent the expression in a statically typed manner. You do this using the Expression.Lambdamethod, which has a number of overloads. The examples we’ve looked at use the generic method, which uses a type parameter to indicate the type of delegate we wanted to represent. See MSDN for alternatives.
So, what’s the point of doing this? Well, LambdaExpression has a Compile method that creates a delegate of the appropriate type; Expression<TDelegate> has another method by the same name, but statically typed to return a delegate of type TDelegate. This delegate can now be executed in the normal manner, as if it had been created using a normal method or any other means. The following listing shows this in action, with the same expression as before.
Listing 9.7. Compiling and executing an expression tree
Expression firstArg = Expression.Constant(2);
Expression secondArg = Expression.Constant(3);
Expression add = Expression.Add(firstArg, secondArg);
Func<int> compiled = Expression.Lambda<Func<int>>(add).Compile();
Console.WriteLine(compiled());
Arguably, listing 9.7 is one of the most convoluted ways of printing out 5 that you could ask for. At the same time, it’s also rather impressive. You’re programmatically creating some logical blocks and representing them as normal objects, and then asking the framework to compile the whole thing into real code that can be executed. You may never need to use expression trees this way, or even build them up programmatically at all, but it’s useful background information that will help you understand how LINQ works.
As I said at the beginning of this section, expression trees aren’t too far removed from CodeDOM—Snippy compiles and executes C# code that’s been entered as plain text, for instance. But two significant differences exist between CodeDOM and expression trees.
First, in .NET 3.5, expression trees were only able to represent single expressions. They weren’t designed for whole classes, methods, or even just statements. This has changed somewhat in .NET 4, where they’re used to support dynamic typing—you can now create blocks, assign values to variables, and so on. But there are still significant restrictions compared with CodeDOM.
Second, C# supports expression trees directly in the language, through lambda expressions. Let’s take a look at that now.
9.3.3. Converting C# lambda expressions to expression trees
As you’ve already seen, lambda expressions can be converted to appropriate delegate instances, either implicitly or explicitly. That’s not the only conversion that’s available. You can also ask the compiler to build an expression tree from your lambda expression, creating an instance ofExpression<TDelegate> at execution time. For example, the following listing shows a much shorter way of creating the “return 5” expression, compiling it, and then invoking the resulting delegate.
Listing 9.8. Using lambda expressions to create expression trees
Expression<Func<int>> return5 = () => 5;
Func<int> compiled = return5.Compile();
Console.WriteLine(compiled());
In the first line of listing 9.8, the () => 5 part is the lambda expression. You don’t need any casts because the compiler can verify everything as it goes. You could’ve written 2+3 instead of 5, but the compiler would’ve optimized the addition away for you. The important point to take away is that the lambda expression has been converted into an expression tree.
There are limitations
Not all lambda expressions can be converted to expression trees. You can’t convert a lambda with a block of statements (even just one return statement) into an expression tree—it has to be in the form that evaluates a single expression, and that expression can’t contain assignments. This restriction applies even in .NET 4 with its extended abilities for expression trees. Although these are the most common restrictions, they’re not the only ones—the full list isn’t worth describing here, as this issue comes up so rarely. If there’s a problem with an attempted conversion, you’ll find out at compile time.
Let’s look at a more complicated example to see how things work, particularly with respect to parameters. This time you’ll write a predicate that takes two strings and checks to see if the first one begins with the second. The code is simple when written as a lambda expression.
Listing 9.9. Demonstration of a more complicated expression tree
Expression<Func<string, string, bool>> expression =
(x, y) => x.StartsWith(y);
var compiled = expression.Compile();
Console.WriteLine(compiled("First", "Second"));
Console.WriteLine(compiled("First", "Fir"));
The expression tree itself is more complicated, especially by the time you’ve converted it into an instance of LambdaExpression. The next listing shows how it could be built in code.
Listing 9.10. Building a method call expression tree in code

As you can see, listing 9.10 is considerably more involved than the version with the C# lambda expression. But it does make it more obvious exactly what’s involved in the tree and how parameters are bound.
You start off by working out everything you need to know about the method call that forms the body of the final expression ![]() : the target of the method (the string you’re calling StartsWith on); the method itself (as a MethodInfo); and the list of arguments (in this case, just the one). It so happens that your method target and argument will both be parameters passed into the expression, but they could be other types of expressions—constants, the results of other method calls, property evaluations, and so forth.
: the target of the method (the string you’re calling StartsWith on); the method itself (as a MethodInfo); and the list of arguments (in this case, just the one). It so happens that your method target and argument will both be parameters passed into the expression, but they could be other types of expressions—constants, the results of other method calls, property evaluations, and so forth.
After building the method call as an expression ![]() , you then need to convert it into a lambda expression
, you then need to convert it into a lambda expression ![]() , binding the parameters as you go. You reuse the same ParameterExpression values you created as information for the method call: the order in which they’re specified when creating the lambda expression is the order in which they’ll be picked up when you eventually call the delegate.
, binding the parameters as you go. You reuse the same ParameterExpression values you created as information for the method call: the order in which they’re specified when creating the lambda expression is the order in which they’ll be picked up when you eventually call the delegate.
Figure 9.4 shows the same final expression tree graphically. To be picky, even though it’s still called an expression tree, the fact that you reuse the parameter expressions (and you have to—creating a new one with the same name and attempting to bind parameters that way causes an exception at execution time) means that it’s not really a tree in the purest sense.
Figure 9.4. Graphical representation of an expression tree that calls a method and uses parameters from a lambda expression
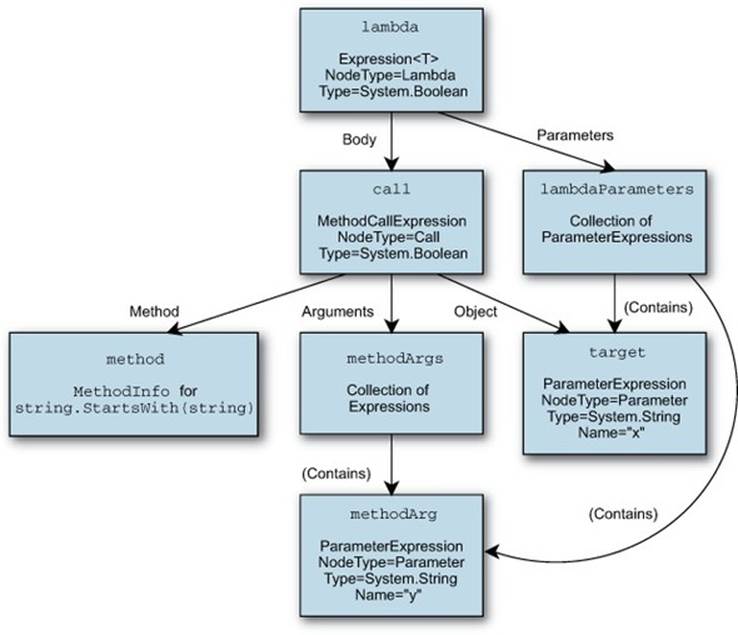
Glancing at the complexity of figure 9.4 and listing 9.10 without trying to look at the details, you’d be forgiven for thinking that you were doing something really complicated, when in fact it’s just a single method call. Imagine what the expression tree for a genuinely complex expression would look like—and then be grateful that C# 3 can create expression trees from lambda expressions!
For one final way of looking at the same idea, Visual Studio 2010 and 2012 provide a built-in visualizer for expression trees.[7] This can be useful if you’re trying to work out how to build up an expression tree in code, and you want to get an idea of what it should look like; write a lambda expression that does what you want with some dummy data, look at the visualization in the debugger, and then work out how to build similar trees with the information you have in your real code. The visualizer relies on changes within .NET 4, so it won’t work with projects targeting .NET 3.5. Figure 9.5 shows the visualization for the StartsWith example.
7 If you’re using Visual Studio 2008, you can download some sample code from MSDN to build a similar visualizer (see http://mng.bz/g6xd), but obviously it’s easier to use the one shipped with Visual Studio if you have a recent enough version.
Figure 9.5. Debugger visualization of an expression tree
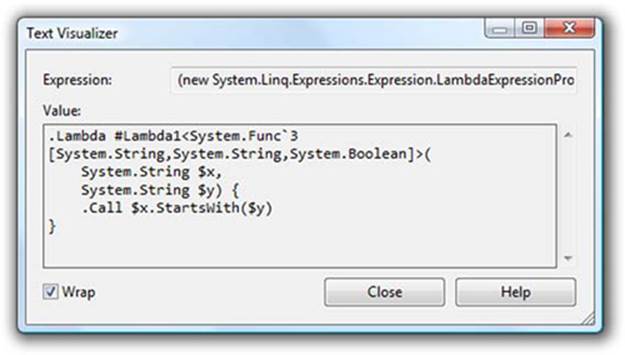
The .Lambda and .Call parts of the visualization correspond to your calls to Expression.Lambda and Expression.Call; $x and $y correspond to the parameter expressions. The visualization is the same whether the expression tree has been built up explicitly through code or using a lambda expression conversion.
One small point to note is that although the C# compiler builds expression trees in the compiled code using code similar to listing 9.10, it has one shortcut up its sleeve: it doesn’t need to use normal reflection to get the MethodInfo for string.StartsWith. Instead, it uses the method equivalent of the typeof operator. This is only available in IL, not in C# itself, and the same operator is used to create delegate instances from method groups.
Now that you’ve seen how expression trees and lambda expressions are linked, let’s take a brief look at why they’re so useful.
9.3.4. Expression trees at the heart of LINQ
Without lambda expressions, expression trees would have relatively little value. They’d be an alternative to CodeDOM in cases where you only wanted to model a single expression instead of whole statements, methods, types, and so forth, but the benefit would still be limited.
The reverse is also true to a limited extent: without expression trees, lambda expressions would certainly be less useful. Having a more compact way of creating delegate instances would still be welcome, and the shift toward a more functional mode of development would still be viable. Lambda expressions are particularly effective when combined with extension methods, as you’ll see in the next chapter, but with expression trees in the picture as well, things get a lot more interesting.
What do you get when you combine lambda expressions, expression trees, and extension methods? The answer is, “the language side of LINQ,” pretty much. The extra syntax you’ll see in chapter 11 is icing on the cake, but the story would still have been compelling with just those three ingredients. For a long time you could have either nice compile-time checking or the ability to tell another platform to run some code, usually expressed as text (SQL queries being the most obvious example). But you couldn’t do both at the same time.
By combining lambda expressions that provide compile-time checks with expression trees that abstract the execution model away from the desired logic, you can have the best of both worlds, within reason. At the heart of out-of-process LINQ providers is the idea that you can produce an expression tree from a familiar source language (C#, in this case) and use the result as an intermediate format that can then be converted into the native language of the target platform—SQL, for example. In some cases, there may not be a simple native language so much as a native API, making different web service calls depending on what the expression represents, perhaps. Figure 9.6 shows the different paths of LINQ to Objects and LINQ to SQL.
Figure 9.6. Both LINQ to Objects and LINQ to SQL start with C# code and end with query results. The ability to execute the code remotely comes through expression trees.
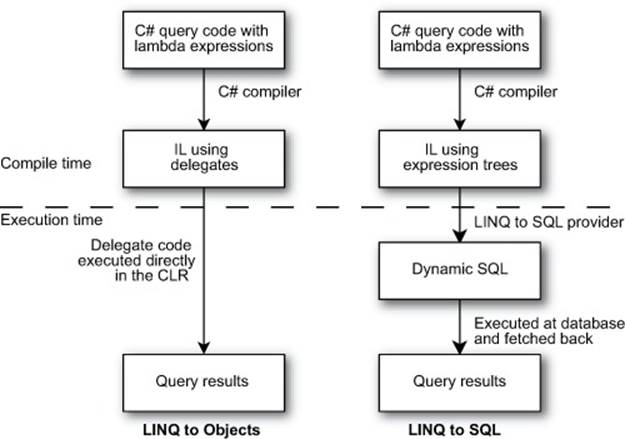
In some cases, the conversion may try to perform all the logic on the target platform, whereas other cases may use the compilation facilities of expression trees to execute some of the expression locally and some elsewhere. We’ll look at some of the details of this conversion step in chapter 12, but you should bear this end goal in mind as we explore extension methods and LINQ syntax in chapters 10 and 11.
Not all checking can be done by the compiler
When expression trees are examined by some sort of converter, some cases generally have to be rejected. For instance, although it’s possible to convert a call to string.StartsWith into a similar SQL expression, a call to string.IsInterned doesn’t make sense in a database environment. Expression trees allow a large amount of compile-time safety, but the compiler can only check that the lambda expression can be converted into a valid expression tree; it can’t make sure that the expression tree will be suitable for its eventual use.
Although the most common uses of expression trees are related to LINQ, that’s not always the case...
9.3.5. Expression trees beyond LINQ
Bjarne Stroustrup once said, “I wouldn’t like to build a tool that could only do what I had been able to imagine for it.” Though expression trees were introduced into .NET primarily for LINQ, both the community and Microsoft have found other uses for them since then. This section is far from comprehensive, but it might give you a few ideas of where expression trees might help you.
Optimizing the Dynamic Language Runtime
We’ll see a lot more of the Dynamic Language Runtime (DLR) in chapter 14, when we talk about dynamic typing in C#, but expression trees are a core part of the architecture. They have three properties that make them attractive to the DLR:
· They’re immutable, so you can cache them safely.
· They’re composable, so you can build complex behavior out of simple building blocks.
· They can be compiled into delegates that are JIT-compiled into native code as normal.
The DLR has to make decisions about how to handle various expressions where the meaning can change subtly based on different rules. Expression trees allow these rules (and the results) to be transformed into code that’s close to what you’d write by hand if you knew all the rules and results you’d seen so far. It’s a powerful concept, and one that allows dynamic code to execute surprisingly quickly.
Refactor-proof references to members
In section 9.3.3 I mentioned that the compiler can emit references to MethodInfo values much like the typeof operator can. Unfortunately, C# doesn’t have the same ability, which means the only way of telling one piece of general-purpose, reflection-based code to “use the property calledBirthDate defined in my type” has previously been to use a string literal and make sure that if you change the name of the property, you also change the literal. Using C# 3, you can build an expression tree representing a property reference using a lambda expression. The method can then dissect the expression tree, work out the property you mean, and do whatever it likes with the information. It can also compile the expression tree into a delegate and use it directly, of course.
As an example of how this might be used, you could write this:
serializationContext.AddProperty(x => x.BirthDate);
The serialization context would then know that you wanted to serialize the BirthDate property, and it could record appropriate metadata and retrieve the value. (Serialization is just one area where you may want a property or method reference; it’s fairly common within reflection-driven code.) If you refactor the BirthDate property to call it DateOfBirth, the lambda expression will change too. Of course, it’s not foolproof—there’s no compile-time check that the expression really evaluates a simple property; that has to be an execution-time check in the AddPropertycode.
It’s possible that one day C# will gain the ability to do this within the language itself. Such an operator has already been named: infoof, pronounced either “info-of” or “in-foof,” depending on your level of light-heartedness. This has been on the C# team’s possible-feature list for a while, and unsurprisingly Eric Lippert has blogged about it (see http://mng.bz/24y7), but it hasn’t made the cut yet. Maybe in C# 6.
Simpler reflection
The final use I want to mention before we delve into the murky depths of type inference is also about reflection. As I mentioned in chapter 3, arithmetic operators don’t play nicely with generics, which makes it hard to write generic code to (say) add up a series of values. Marc Gravell used expression trees to great effect to provide a generic Operator class and a nongeneric helper class, allowing you to write code such as this:
T runningTotal = initialValue;
foreach (T item in values)
{
runningTotal = Operator.Add(runningTotal, item);
}
This will even work in cases where the values are a different type than the running total—adding a whole sequence of TimeSpan values to a DateTime, for example. It’s possible to do this in C# 2, but it’s significantly more fiddly due to the ways that operators are exposed via reflection, particularly for the primitive types. Expression trees allow the implementation of this magic to be quite clean, and the fact that they’re compiled to normal IL, which is then JIT-compiled, gives great performance.
These are just some examples, and no doubt there are many developers busy working on completely different uses. But they mark an end to our direct coverage of lambda expressions and expression trees. You’ll see a good deal more of them when we look at LINQ, but before we go any further, there are a few changes to C# that need some explanation. These are changes to type inference and how the compiler selects between overloaded methods.
9.4. Changes to type inference and overload resolution
The steps involved in type inference and overload resolution were altered in C# 3 to accommodate lambda expressions and to make anonymous methods more useful. This may not count as a new feature of C# as such, but it can be important to understand what the compiler is going to do. If you find details like this tedious and irrelevant, feel free to skip to the chapter summary, but remember that this section exists, so you can read it if you run across a compilation error related to this topic and can’t understand why your code doesn’t work. (Alternatively, you might want to come back to this section if you find your code does compile, but you don’t think it should!)
Even within this section, I won’t go into every nook and cranny—that’s what the language specification is for; the details are in the C# 5 specification, section 7.5.2 (“Type inference”). Instead, I’ll give an overview of the new behavior, providing examples of common cases. The primary reason for changing the specification is to allow lambda expressions to work in a concise fashion, which is why I’ve included the topic in this particular chapter.
Let’s first look a little deeper at what problems you’d have run into if the C# team had stuck with the old rules.
9.4.1. Reasons for change: streamlining generic method calls
Type inference occurs in a few situations. You’ve already seen it apply to implicitly typed arrays, and it’s also required when you try to implicitly convert a method group to a delegate type. This can be particularly confusing when the conversion occurs when you’re using a method group as an argument to another method. With overloading of the method being called, and overloading of methods within the method group, and the possibility of generic methods getting involved, the set of potential conversions may be enormous.
By far the most common situation for type inference is when you’re calling a generic method without specifying any type arguments. This happens all the time in LINQ—the way that query expressions work depends heavily on this ability. It’s all handled so smoothly that it’s easy to ignore how much the compiler has to work out on your behalf, all for the sake of making your code clearer and more concise.
The rules were reasonably straightforward in C# 2, although method groups and anonymous methods weren’t always handled as well as you might’ve liked. The type inference process didn’t deduce any information from them, leading to situations where the desired behavior was obvious to developers but not to the compiler. Life is more complicated in C# 3 due to lambda expressions. If you call a generic method using a lambda expression with an implicitly typed parameter list, the compiler needs to work out what types you’re talking about before it can check the lambda expression’s body.
This is much easier to see in code than in words. The following listing gives an example of the kind of issue I’m referring to: calling a generic method using a lambda expression.
Listing 9.11. Example of code requiring the new type inference rules
static void PrintConvertedValue<TInput,TOutput>
(TInput input, Converter<TInput,TOutput> converter)
{
Console.WriteLine(converter(input));
}
...
PrintConvertedValue("I'm a string", x => x.Length);
The PrintConvertedValue method in listing 9.11 simply takes an input value and a delegate that can convert that value into a different type. It’s completely generic—it makes no assumptions about the type parameters TInput and TOutput. Now, look at the types of the arguments you’re calling it with in the bottom line of the listing. The first argument is clearly a string, but what about the second? It’s a lambda expression, so you need to convert it into a Converter<TInput,TOutput>, and that means you need to know the types of TInput and TOutput.
Remember from section 3.3.2 that the type inference rules of C# 2 were applied to each argument individually, with no way of using the types inferred from one argument to another. In this case, these rules would’ve stopped you from finding the types of TInput and TOutput for the second argument, so the code in listing 9.11 would’ve failed to compile.
Our eventual goal is to understand what makes listing 9.11 compile in C# 3 (and it does, I promise you), but we’ll start with something more modest.
9.4.2. Inferred return types of anonymous functions
The following listing shows another example of some code that looks like it should compile but doesn’t under the type inference rules of C# 2.
Listing 9.12. Attempting to infer the return type of an anonymous method

Compiling listing 9.12 under C# 2 gives an error like this:
error CS0411: The type arguments for method
'Snippet.WriteResult<T>(Snippet.MyFunc<T>)' cannot be inferred from the
usage. Try specifying the type arguments explicitly.
You can fix the error in two ways—either specify the type argument explicitly (as suggested by the compiler) or cast the anonymous method to a concrete delegate type:
WriteResult<int>(delegate { return 5; });
WriteResult((MyFunc<int>)delegate { return 5; });
Both of these work, but they’re ugly. You might like the compiler to perform the same kind of type inference as for nondelegate types, using the type of the returned expression to infer the type of T. That’s exactly what C# 3 does for both anonymous methods and lambda expressions, but there’s one catch. Although in many cases only one return statement is involved, there can sometimes be more.
The following listing is a slightly modified version of listing 9.12, where the anonymous method sometimes returns an integer and sometimes returns an object.
Listing 9.13. Code returning an integer or an object depending on the time of day

The compiler uses the same logic to determine the return type in this situation as it does for implicitly typed arrays, as described in section 8.4. It forms a set of all the types from the return statements in the body of the anonymous function[8] (in this case, int and object) and checks to see if exactly one of the types can be implicitly converted to from all the others. There’s an implicit conversion from int to object (via boxing) but not from object to int, so the inference succeeds with object as the inferred return type. If there are no types matching that criterion (or more than one), no return type can be inferred and you’ll get a compilation error.
8 Returned expressions that don’t have a type, such as null or another lambda expression, aren’t included in this set. Their validity is checked later, once a return type has been determined, but they don’t contribute to that decision.
Now you know how to work out the return type of an anonymous function, but what about lambda expressions where the parameter types can be implicitly defined?
9.4.3. Two-phase type inference
The details of type inference in C# 3 are much more complicated than they are for C# 2. It’s rare that you’ll need to reference the specification for the exact behavior, but if you do, I recommend you write down all the type parameters, arguments, and so forth on a piece of paper, and then follow the specification step by step, carefully noting down every action it requires. You’ll end up with a sheet full of fixed and unfixed type variables, with a different set of bounds for each of them. A fixed type variable is one that the compiler has decided the value of; otherwise it’s unfixed. A bound is a piece of information about a type variable. In addition to a bunch of notes, I suspect you’ll get a headache; this stuff isn’t pretty.
I’ll present a more fuzzy way of thinking about type inference—one that’s likely to serve just as well as knowing the specification and that will be a lot easier to understand. The fact is, if the compiler doesn’t perform type inference in exactly the way you want it to, it’ll almost certainly result in a compilation error rather than code that builds but doesn’t behave properly. If your code doesn’t build, try giving the compiler more information—it’s as simple as that. But here’s roughly what’s changed for C# 3.
The first big difference is that the method arguments work as a team in C# 3. In C# 2, every argument was used to try to pin down some type parameters exactly, and the compiler would complain if any two arguments came up with different results for a particular type parameter, even if they were compatible. In C# 3, arguments can contribute pieces of information—types that must be implicitly convertible to the final fixed value of a particular type variable. The logic used to come up with that fixed value is the same as for inferred return types and implicitly typed arrays.
The following listing shows an example of this without using any lambda expressions or even anonymous methods.
Listing 9.14. Flexible type inference combining information from multiple arguments
static void PrintType<T>(T first, T second)
{
Console.WriteLine(typeof(T));
}
...
PrintType(1, new object());
Although the code in listing 9.14 is syntactically valid in C# 2, it wouldn’t build; type inference would fail, because the first parameter would decide that T must be int and the second parameter would decide that T must be object. In C# 3, the compiler determines that T should be objectin exactly the same way that it did for the inferred return type in listing 9.13. In fact, the inferred return type rules are effectively one example of the more general process in C# 3.
The second change is that type inference is now performed in two phases. The first phase deals with normal arguments where the types involved are known to begin with. This includes anonymous functions where the parameter list is explicitly typed.
The second phase then kicks in, where implicitly typed lambda expressions and method groups have their types inferred. The idea is to see whether any of the information the compiler has pieced together so far is enough to work out the parameter types of the lambda expression (or method group). If it is, the compiler can then examine the body of the lambda expression and work out the inferred return type which is often another of the type parameters it’s looking for. If the second phase gives some more information, the compiler goes through it again, repeating until either it runs out of clues or it’s worked out all the type parameters involved.
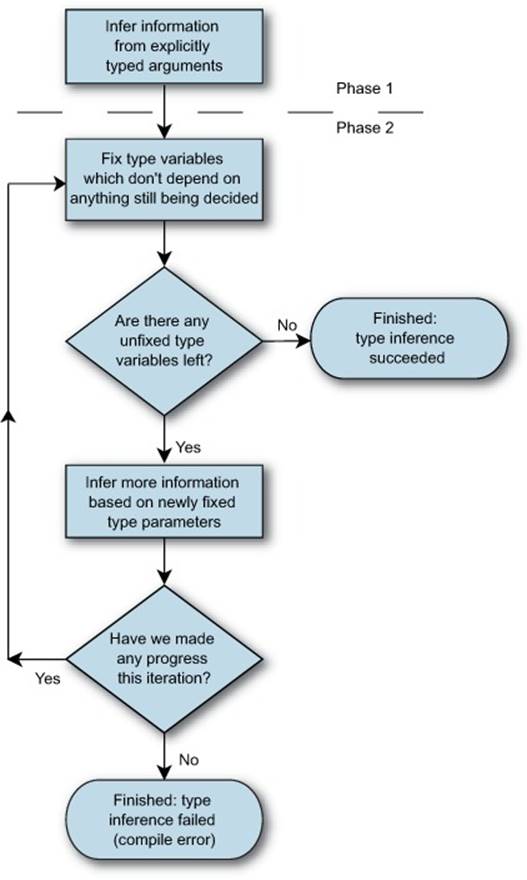
Figure 9.7 shows this in flowchart form, but please bear in mind that this is a heavily simplified version of the algorithm.
Figure 9.7. The two-phase type inference flow
Let’s look at two examples to show how it works. First we’ll take the code we started the section with—listing 9.11:
static void PrintConvertedValue<TInput,TOutput>
(TInput input, Converter<TInput,TOutput> converter)
{
Console.WriteLine(converter(input));
}
...
PrintConvertedValue("I'm a string", x => x.Length);
The type parameters you need to work out here are TInput and TOutput. The steps performed are as follows:
1. Phase 1 begins.
2. The first parameter is of type TInput, and the first argument is of type string. You infer that there must be an implicit conversion from string to TInput.
3. The second parameter is of type Converter<TInput,TOutput>, and the second argument is an implicitly typed lambda expression. No inference is performed—you don’t have enough information.
4. Phase 2 begins.
5. TInput doesn’t depend on any unfixed type parameters, so it’s fixed to string.
6. The second argument now has a fixed input type but an unfixed output type. You can consider it to be (string x) => x.Length and infer the return type as int. Therefore an implicit conversion must take place from int to TOutput.
7. Phase 2 repeats.
8. TOutput doesn’t depend on anything unfixed, so it’s fixed to int.
9. There are now no unfixed type parameters, so inference succeeds.
Complicated, eh? Still, it does the job—the result is what you’d want (TInput=string, TOutput=int), and everything compiles without any problems.
The importance of phase 2 repeating is best shown with another example. Listing 9.15 shows two conversions being performed, with the output of the first one becoming the input of the second. Until you’ve worked out the output type of the first conversion, you don’t know the input type of the second, so you can’t infer its output type either.
Listing 9.15. Multistage type inference
static void ConvertTwice<TInput,TMiddle,TOutput>
(TInput input,
Converter<TInput,TMiddle> firstConversion,
Converter<TMiddle,TOutput> secondConversion)
{
TMiddle middle = firstConversion(input);
TOutput output = secondConversion(middle);
Console.WriteLine(output);
}
...
ConvertTwice("Another string",
text => text.Length,
length => Math.Sqrt(length));
The first thing to notice is that the method signature appears to be pretty horrific. It’s not too bad when you stop being scared and just look at it carefully, and certainly the example usage makes it more obvious. You take a string and perform a conversion on it—the same conversion as before, just a length calculation. You then take that length (an int) and find its square root (a double).
Phase 1 of type inference tells the compiler that there must be a conversion from string to TInput. The first time through phase 2, TInput is fixed to string and you infer that there must be a conversion from int to TMiddle. The second time through phase 2, TMiddle is fixed to intand you infer that there must be a conversion from double to TOutput. The third time through phase 2, TOutput is fixed to double and type inference succeeds. When type inference has finished, the compiler can look at the code within the lambda expression properly.
Checking the body of a lambda expression
The body of a lambda expression cannot be checked until the input parameter types are known. The lambda expression x => x.Length is valid if x is an array or a string, but invalid in many other cases. This isn’t a problem when the parameter types are explicitly declared, but with an implicit parameter list, the compiler needs to wait until it’s performed the relevant type inference before it can try to work out what the lambda expression means.
These examples have shown only one change working at a time, but in practice there can be several pieces of information about different type variables, potentially discovered in different iterations of the process. In an effort to save your sanity (and mine), I won’t present any more complicated examples—hopefully you understand the general mechanism, even if the exact details are hazy.
Although it may seem as if this kind of situation will occur so rarely that it’s not worth having such complex rules to cover it, in fact it’s common in C# 3, particularly with LINQ. You could easily use type inference extensively without thinking about it—it’s likely to become second nature to you. If it fails and you wonder why, you can always revisit this section and the language specification.
We need to cover one more change, but you’ll be glad to hear it’s easier than type inference. Let’s look at method overloading.
9.4.4. Picking the right overloaded method
Overloading occurs when there are multiple methods available with the same name but different signatures. Sometimes it’s obvious which method is appropriate, because it’s the only one with the right number of parameters, or it’s the only one where all the arguments can be converted into the corresponding parameter types.
The tricky bit comes when there are multiple methods that could be the right one. The rules in section 7.5.3 of the specification (“Overload Resolution”) are quite complicated (yes, again), but the key part is the way that each argument type is converted into the parameter type.[9] For instance, consider these method signatures as if they were both declared in the same type:
9 I’m assuming that all the methods are declared in the same class. When inheritance is involved as well, it becomes even more complicated. That aspect hasn’t changed in C# 3, though.
void Write(int x)
void Write(double y)
The meaning of a call to Write(1.5) is obvious, because there’s no implicit conversion from double to int, but a call to Write(1) is trickier. There is an implicit conversion from int to double, so both methods are possible. At that point, the compiler considers the conversion fromint to int and from int to double. A conversion from any type to itself is defined to be better than any conversion to a different type, so the Write(int x) method is better than Write(double y) for this particular call.
When there are multiple parameters, the compiler has to make sure there’s a best method to use. One method is better than another if all the argument conversions involved are at least as good as the corresponding conversions in the other method, and at least one conversion is strictly better. As a simple example, suppose you had this:
void Write(int x, double y)
void Write(double x, int y)
A call to Write(1, 1) would be ambiguous, and the compiler would force you to add a cast to at least one of the parameters to make it clear which method you meant to call. Each overload has one better argument conversion, so neither of them is the best method.
That logic still applies to C# 3, but with one extra rule about anonymous functions, which never specify a return type. In this case, the inferred return type (as described in section 9.4.2) is used in the better-conversion rules.
Let’s look at an example of the kind of situation that needs the new rule. The following listing contains two methods with the name Execute and a call using a lambda expression.
Listing 9.16. Sample of overloading choice influenced by delegate return type
static void Execute(Func<int> action)
{
Console.WriteLine("action returns an int: " + action());
}
static void Execute(Func<double> action)
{
Console.WriteLine("action returns a double: " + action());
}
...
Execute(() => 1);
The call to Execute in listing 9.16 could’ve been written with an anonymous method or a method group instead—the same rules are applied whatever kind of conversion is involved. Which Execute method should be called? The overloading rules say that when two methods are both applicable after performing conversions on the arguments, those argument conversions are examined to see which one is better. The conversions here aren’t from a normal .NET type to the parameter type—they’re from a lambda expression to two different delegate types. Which conversion is better?
Surprisingly enough, the same situation in C# 2 would result in a compilation error—there was no language rule covering this case. In C# 3, the method with the Func<int> parameter would be chosen. The extra rule that has been added can be paraphrased this way:
If an anonymous function can be converted to two delegate types that have the same parameter list but different return types, the delegate conversions are judged by the conversions from the inferred return type to the delegates’ return types.
That’s pretty much gibberish without referring to an example. Let’s look back at listing 9.16 where you’re converting from a lambda expression with no parameters and an inferred return type of int to either Func<int> or Func<double>. The parameter lists are the same (empty) for both delegate types, so the rule applies. You then just need to find the better conversion: int to int, or int to double. This puts you in more familiar territory; as you saw earlier, the int to int conversion is better. Listing 9.16 therefore prints out action returns an int: 1.
9.4.5. Wrapping up type inference and overload resolution
This section has been pretty heavy. I would’ve loved to have made it simpler, but it’s a fundamentally complicated topic. The terminology involved doesn’t make it any easier, especially as parameter type and type parameter mean completely different things! Congratulations if you made it through and actually understood it all. Don’t worry if you didn’t; hopefully next time you read through the section, it’ll shed more light on the topic—particularly after you’ve run into situations where it’s relevant to your own code. For the moment, here are the most important points:
· Anonymous functions (anonymous methods and lambda expressions) have inferred return types based on the types of all the return statements.
· Lambda expressions can only be understood by the compiler when the types of all the parameters are known.
· Type inference no longer requires that each argument independently come to exactly the same conclusion about type parameters, as long as the results stay compatible.
· Type inference is now multistage: the inferred return type of one anonymous function can be used as a parameter type for another.
· Finding the best overloaded method when anonymous functions are involved takes the inferred return type into account.
Even that short list is pretty daunting in terms of the sheer density of technical terms. Again, don’t fret if it doesn’t all make sense. In my experience things just work the way you want them to most of the time.
9.5. Summary
In C# 3, lambda expressions almost entirely replace anonymous methods. Anonymous methods are supported for the sake of backward compatibility, but idiomatic, freshly written C# 3 code will contain few of them.
You’ve seen how lambda expressions are more than just a compact syntax for delegate creation. They can be converted into expression trees, subject to some limitations. The expression trees can then be processed by other code, possibly performing equivalent actions in different execution environments. Without this ability, LINQ would be restricted to in-process queries.
Our discussion of type inference and overloading was a necessary evil to some extent; very few people actually enjoy discussing the sort of rules that are required, but it’s important to have at least a passing understanding of what’s going on. Before we all feel too sorry for ourselves, spare a thought for the poor language designers who have to live and breathe this kind of thing, making sure the rules are consistent and don’t fall apart in nasty situations. Then pity the testers who have to try to break the implementation.
That’s it in terms of describing lambda expressions, but you’ll see a lot more of them in the rest of the book. For instance, the next chapter is all about extension methods. Superficially, they’re completely separate from lambda expressions, but in reality the two features are often used together.