C# 6.0 and the .NET 4.6 Framework (2015)
PART II
Core C# Programming
CHAPTER 4
Core C# Programming Constructs, Part II
This chapter picks up where the Chapter 3 left off and completes your investigation of the core aspects of the C# programming language. You will begin by examining various details regarding the construction of C# methods, exploring the out, ref, and params keywords. Along the way, you will also examine the role of optional and named parameters.
After you examine the topic of method overloading, the next task is to investigate the details behind manipulating arrays using the syntax of C# and get to know the functionality contained within the related System.Array class type.
In addition, this chapter discusses the construction of enumeration and structure types, including a fairly detailed examination of the distinction between a value type and a reference type. This chapter wraps up by examining the role of nullable data types and the related operators.
After you have completed this chapter, you will be in a perfect position to learn the object-oriented capabilities of C#, beginning in Chapter 5.
Methods and Parameter Modifiers
To begin this chapter, let’s examine the details of defining methods. Just like the Main() method (see Chapter 3), your custom methods may or may not take parameters and may or may not return values to the caller. As you will see over the next several chapters, methods can be implemented within the scope of classes or structures (as well as prototyped within interface types) and may be decorated with various keywords (e.g., static, virtual, public, new) to qualify their behavior. At this point in the text, each of your methods has followed the following basic format:
// Recall that static methods can be called directly
// without creating a class instance.
class Program
{
// static returnType MethodName(paramater list) { /* Implementation */ }
static int Add(int x, int y){ return x + y; }
}
While the definition of a method in C# is quite straightforward, you can use a handful of methods to control how arguments are passed to the method in question, as listed in Table 4-1.
Table 4-1. C# Parameter Modifiers
|
Parameter Modifier |
Meaning in Life |
|
(None) |
If a parameter is not marked with a parameter modifier, it is assumed to be passed by value, meaning the called method receives a copy of the original data. |
|
out |
Output parameters must be assigned by the method being called and, therefore, are passed by reference. If the called method fails to assign output parameters, you are issued a compiler error. |
|
ref |
The value is initially assigned by the caller and may be optionally modified by the called method (as the data is also passed by reference). No compiler error is generated if the called method fails to assign a ref parameter. |
|
params |
This parameter modifier allows you to send in a variable number of arguments as a single logical parameter. A method can have only a single params modifier, and it must be the final parameter of the method. In reality, you might not need to use the params modifier all too often; however, be aware that numerous methods within the base class libraries do make use of this C# language feature. |
To illustrate the use of these keywords, create a new Console Application project named FunWithMethods. Now, let’s walk through the role of each keyword.
The Default by Value Parameter-Passing Behavior
The default manner in which a parameter is sent into a function is by value. Simply put, if you do not mark an argument with a parameter modifier, a copy of the data is passed into the function. As explained at the end of this chapter, exactly what is copied will depend on whether the parameter is a value type or a reference type. For the time being, assume the following method within the Program class that operates on two numerical data types passed by value:
// Arguments are passed by value by default.
static int Add(int x, int y)
{
int ans = x + y;
// Caller will not see these changes
// as you are modifying a copy of the
// original data.
x = 10000;
y = 88888;
return ans;
}
Numerical data falls under the category of value types. Therefore, if you change the values of the parameters within the scope of the member, the caller is blissfully unaware, given that you are changing the values on a copy of the caller’s original data.
static void Main(string[] args)
{
Console.WriteLine("***** Fun with Methods *****\n");
// Pass two variables in by value.
int x = 9, y = 10;
Console.WriteLine("Before call: X: {0}, Y: {1}", x, y);
Console.WriteLine("Answer is: {0}", Add(x, y));
Console.WriteLine("After call: X: {0}, Y: {1}", x, y);
Console.ReadLine();
}
As you would hope, the values of x and y remain identical before and after the call to Add(), as shown in the following output, as the data points were sent in by value. Thus, any changes on these parameters within the Add() method are not seen by the caller, as the Add() method is operating on a copy of the data.
***** Fun with Methods *****
Before call: X: 9, Y: 10
Answer is: 19
After call: X: 9, Y: 10
The out Modifier
Next, you have the use of output parameters. Methods that have been defined to take output parameters (via the out keyword) are under obligation to assign them to an appropriate value before exiting the method scope (if you fail to do so, you will receive compiler errors).
To illustrate, here is an alternative version of the Add() method that returns the sum of two integers using the C# out modifier (note the physical return value of this method is now void):
// Output parameters must be assigned by the called method.
static void Add(int x, int y, out int ans)
{
ans = x + y;
}
Calling a method with output parameters also requires the use of the out modifier. However, the local variables that are passed as output variables are not required to be assigned before passing them in as output arguments (if you do so, the original value is lost after the call). The reason the compiler allows you to send in seemingly unassigned data is because the method being called must make an assignment. The following code is an example:
static void Main(string[] args)
{
Console.WriteLine("***** Fun with Methods *****");
...
// No need to assign initial value to local variables
// used as output parameters, provided the first time
// you use them is as output arguments.
int ans;
Add(90, 90, out ans);
Console.WriteLine("90 + 90 = {0}", ans);
Console.ReadLine();
}
The previous example is intended to be illustrative in nature; you really have no reason to return the value of your summation using an output parameter. However, the C# out modifier does serve a useful purpose: it allows the caller to obtain multiple outputs from a single method invocation.
// Returning multiple output parameters.
static void FillTheseValues(out int a, out string b, out bool c)
{
a = 9;
b = "Enjoy your string.";
c = true;
}
The caller would be able to invoke the FillTheseValues() method. Remember that you must use the out modifier when you invoke the method, as well as when you implement the method.
static void Main(string[] args)
{
Console.WriteLine("***** Fun with Methods *****");
...
int i; string str; bool b;
FillTheseValues(out i, out str, out b);
Console.WriteLine("Int is: {0}", i);
Console.WriteLine("String is: {0}", str);
Console.WriteLine("Boolean is: {0}", b);
Console.ReadLine();
}
Finally, always remember that a method that defines output parameters must assign the parameter to a valid value before exiting the method scope. Therefore, the following code will result in a compiler error, as the output parameter has not been assigned within the method scope:
static void ThisWontCompile(out int a)
{
Console.WriteLine("Error! Forgot to assign output arg!");
}
The ref Modifier
Now consider the use of the C# ref parameter modifier. Reference parameters are necessary when you want to allow a method to operate on (and usually change the values of) various data points declared in the caller’s scope (such as a sorting or swapping routine). Note the distinction between output and reference parameters.
· Output parameters do not need to be initialized before they passed to the method. The reason for this is that the method must assign output parameters before exiting.
· Reference parameters must be initialized before they are passed to the method. The reason for this is that you are passing a reference to an existing variable. If you don’t assign it to an initial value, that would be the equivalent of operating on an unassigned local variable.
Let’s check out the use of the ref keyword by way of a method that swaps two string variables (of course, any two data types could be used here, including int, bool, float, and so on).
// Reference parameters.
public static void SwapStrings(ref string s1, ref string s2)
{
string tempStr = s1;
s1 = s2;
s2 = tempStr;
}
This method can be called as follows:
static void Main(string[] args)
{
Console.WriteLine("***** Fun with Methods *****");
...
string str1 = "Flip";
string str2 = "Flop";
Console.WriteLine("Before: {0}, {1} ", str1, str2);
SwapStrings(ref str1, ref str2);
Console.WriteLine("After: {0}, {1} ", str1, str2);
Console.ReadLine();
}
Here, the caller has assigned an initial value to local string data (str1 and str2). After the call to SwapStrings() returns, str1 now contains the value "Flop", while str2 reports the value "Flip".
Before: Flip, Flop
After: Flop, Flip
![]() Note The C# ref keyword will be revisited later in this chapter in the section “Understanding Value Types and Reference Types.” As you will see, the behavior of this keyword changes just a bit depending on whether the argument is a value type or reference type.
Note The C# ref keyword will be revisited later in this chapter in the section “Understanding Value Types and Reference Types.” As you will see, the behavior of this keyword changes just a bit depending on whether the argument is a value type or reference type.
The params Modifier
C# supports the use of parameter arrays using the params keyword. To understand this language feature, you must (as the name implies) understand how to manipulate C# arrays. If this is not the case, you might want to return to this section after you read the section “Understanding C# Arrays” later in this chapter.
The params keyword allows you to pass into a method a variable number of identically typed parameters (or classes related by inheritance) as a single logical parameter. As well, arguments marked with the params keyword can be processed if the caller sends in a strongly typed array or a comma- delimited list of items. Yes, this can be confusing! To clear things up, assume you want to create a function that allows the caller to pass in any number of arguments and return the calculated average.
If you were to prototype this method to take an array of doubles, this would force the caller to first define the array, then fill the array, and finally pass it into the method. However, if you define CalculateAverage() to take a params of double[] data types, the caller can simply pass a comma- delimited list of doubles. The .NET runtime will automatically package the set of doubles into an array of type double behind the scenes.
// Return average of "some number" of doubles.
static double CalculateAverage(params double[] values)
{
Console.WriteLine("You sent me {0} doubles.", values.Length);
double sum = 0;
if(values.Length == 0)
return sum;
for (int i = 0; i < values.Length; i++)
sum += values[i];
return (sum / values.Length);
}
This method has been defined to take a parameter array of doubles. What this method is in fact saying is, “Send me any number of doubles (including zero), and I’ll compute the average.” Given this, you can call CalculateAverage() in any of the following ways:
static void Main(string[] args)
{
Console.WriteLine("***** Fun with Methods *****");
...
// Pass in a comma-delimited list of doubles…
double average;
average = CalculateAverage(4.0, 3.2, 5.7, 64.22, 87.2);
Console.WriteLine("Average of data is: {0}", average);
// …or pass an array of doubles.
double[] data = { 4.0, 3.2, 5.7 };
average = CalculateAverage(data);
Console.WriteLine("Average of data is: {0}", average);
// Average of 0 is 0!
Console.WriteLine("Average of data is: {0}", CalculateAverage());
Console.ReadLine();
}
If you did not make use of the params modifier in the definition of CalculateAverage(), the first invocation of this method would result in a compiler error, as the compiler would be looking for a version of CalculateAverage() that took five double arguments.
![]() Note To avoid any ambiguity, C# demands a method support only a single params argument, which must be the final argument in the parameter list.
Note To avoid any ambiguity, C# demands a method support only a single params argument, which must be the final argument in the parameter list.
As you might guess, this technique is nothing more than a convenience for the caller, given that the array is created by the CLR as necessary. By the time the array is within the scope of the method being called, you are able to treat it as a full-blown .NET array that contains all the functionality of the System.Array base class library type. Consider the following output:
You sent me 5 doubles.
Average of data is: 32.864
You sent me 3 doubles.
Average of data is: 4.3
You sent me 0 doubles.
Average of data is: 0
Defining Optional Parameters
C# allows you to create methods that can take optional arguments. This technique allows the caller to invoke a single method while omitting arguments deemed unnecessary, provided the caller is happy with the specified defaults.
![]() Note As you will see in Chapter 16, a key motivation for adding optional arguments to C# is to simplify interacting with COM objects. Several Microsoft object models (e.g., Microsoft Office) expose their functionality via COM objects, many of which were written long ago to make use of optional parameters, which earlier versions of C# did not support.
Note As you will see in Chapter 16, a key motivation for adding optional arguments to C# is to simplify interacting with COM objects. Several Microsoft object models (e.g., Microsoft Office) expose their functionality via COM objects, many of which were written long ago to make use of optional parameters, which earlier versions of C# did not support.
To illustrate working with optional arguments, assume you have a method named EnterLogData() , which defines a single optional parameter.
static void EnterLogData(string message, string owner = "Programmer")
{
Console.Beep();
Console.WriteLine("Error: {0}", message);
Console.WriteLine("Owner of Error: {0}", owner);
}
Here, the final string argument has been assigned the default value of "Programmer", via an assignment within the parameter definition. Given this, you can call EnterLogData() from within Main() in two manners.
static void Main(string[] args)
{
Console.WriteLine("***** Fun with Methods *****");
...
EnterLogData("Oh no! Grid can’t find data");
EnterLogData("Oh no! I can’t find the payroll data", "CFO");
Console.ReadLine();
}
Because the first invocation of EnterLogData() did not specify a second string argument, you would find that the programmer is the one responsible for losing data for the grid, while the CFO misplaced the payroll data (as specified by the second argument in the second method call).
One important thing to be aware of is that the value assigned to an optional parameter must be known at compile time and cannot be resolved at runtime (if you attempt to do so, you’ll receive compile-time errors!). To illustrate, assume you want to update EnterLogData() with the following extra optional parameter:
// Error! The default value for an optional arg must be known
// at compile time!
static void EnterLogData(string message,
string owner = "Programmer", DateTime timeStamp = DateTime.Now)
{
Console.Beep();
Console.WriteLine("Error: {0}", message);
Console.WriteLine("Owner of Error: {0}", owner);
Console.WriteLine("Time of Error: {0}", timeStamp);
}
This will not compile because the value of the Now property of the DateTime class is resolved at runtime, not compile time.
![]() Note To avoid ambiguity, optional parameters must always be packed onto the end of a method signature. It is a compiler error to have optional parameters listed before nonoptional parameters.
Note To avoid ambiguity, optional parameters must always be packed onto the end of a method signature. It is a compiler error to have optional parameters listed before nonoptional parameters.
Invoking Methods Using Named Parameters
Another language feature found in C# is support for named arguments. To be honest, at first glance, this language construct might appear to do little more than result in confusing code. And to continue being completely honest, this could be the case! Similar to optional arguments, including support for named parameters is partially motivated by the desire to simplify the process of working with the COM interoperability layer (again, see Chapter 16).
Named arguments allow you to invoke a method by specifying parameter values in any order you choose. Thus, rather than passing parameters solely by position (as you will do in most cases), you can choose to specify each argument by name using a colon operator. To illustrate the use of named arguments, assume you have added the following method to the Program class:
static void DisplayFancyMessage(ConsoleColor textColor,
ConsoleColor backgroundColor, string message)
{
// Store old colors to restore after message is printed.
ConsoleColor oldTextColor = Console.ForegroundColor;
ConsoleColor oldbackgroundColor = Console.BackgroundColor;
// Set new colors and print message.
Console.ForegroundColor = textColor;
Console.BackgroundColor = backgroundColor;
Console.WriteLine(message);
// Restore previous colors.
Console.ForegroundColor = oldTextColor;
Console.BackgroundColor = oldbackgroundColor;
}
Now, the way DisplayFancyMessage() was written, you would expect the caller to invoke this method by passing two ConsoleColor variables followed by a string type. However, using named arguments, the following calls are completely fine:
static void Main(string[] args)
{
Console.WriteLine("***** Fun with Methods *****");
...
DisplayFancyMessage(message: "Wow! Very Fancy indeed!",
textColor: ConsoleColor.DarkRed,
backgroundColor: ConsoleColor.White);
DisplayFancyMessage(backgroundColor: ConsoleColor.Green,
message: "Testing...",
textColor: ConsoleColor.DarkBlue);
Console.ReadLine();
}
One minor “gotcha” regarding named arguments is that if you begin to invoke a method using positional parameters, you must list them before any named parameters. In other words, named arguments must always be packed onto the end of a method call. The following code is an example:
// This is OK, as positional args are listed before named args.
DisplayFancyMessage(ConsoleColor.Blue,
message: "Testing...",
backgroundColor: ConsoleColor.White);
// This is an ERROR, as positional args are listed after named args.
DisplayFancyMessage(message: "Testing...",
backgroundColor: ConsoleColor.White,
ConsoleColor.Blue);
This restriction aside, you might still be wondering when you would ever want to use this language feature. After all, if you need to specify three arguments to a method, why bother flipping around their position?
Well, as it turns out, if you have a method that defines optional arguments, this feature can actually be really helpful. Assume DisplayFancyMessage() has been rewritten to now support optional arguments, as you have assigned fitting defaults.
static void DisplayFancyMessage(ConsoleColor textColor = ConsoleColor.Blue,
ConsoleColor backgroundColor = ConsoleColor.White,
string message = "Test Message")
{
...
}
Given that each argument has a default value, named arguments allow the caller to specify only the parameters for which they do not want to receive the defaults. Therefore, if the caller wants the value "Hello!" to appear in blue text surrounded by a white background, they can simply specify the following:
DisplayFancyMessage(message: "Hello!");
Or, if the caller wants to see “Test Message” print out with a green background containing blue text, they can invoke DisplayFancyMessage().
DisplayFancyMessage(backgroundColor: ConsoleColor.Green);
As you can see, optional arguments and named parameters tend to work hand in hand. To wrap up your examination of building C# methods, I need to address the topic of method overloading.
![]() Source Code The FunWithMethods application is located in the Chapter 4 subdirectory.
Source Code The FunWithMethods application is located in the Chapter 4 subdirectory.
Understanding Method Overloading
Like other modern object-oriented languages, C# allows a method to be overloaded. Simply put, when you define a set of identically named methods that differ by the number (or type) of parameters, the method in question is said to be overloaded.
To understand why overloading is so useful, consider life as an old-school Visual Basic 6.0 (VB6) developer. Assume you are using VB6 to build a set of methods that return the sum of various incoming data types (Integers, Doubles, and so on). Given that VB6 does not support method overloading, you would be required to define a unique set of methods that essentially do the same thing (return the sum of the arguments).
’ VB6 code examples.
Public Function AddInts(ByVal x As Integer, ByVal y As Integer) As Integer
AddInts = x + y
End Function
Public Function AddDoubles(ByVal x As Double, ByVal y As Double) As Double
AddDoubles = x + y
End Function
Public Function AddLongs(ByVal x As Long, ByVal y As Long) As Long
AddLongs = x + y
End Function
Not only can code such as this become tough to maintain, but the caller must now be painfully aware of the name of each method. Using overloading, you are able to allow the caller to call a single method named Add(). Again, the key is to ensure that each version of the method has a distinct set of arguments (methods differing only by return type are not unique enough).
![]() Note As explained in Chapter 9, it is possible to build generic methods that take the concept of overloading to the next level. Using generics, you can define type placeholders for a method implementation that are specified at the time you invoke the member in question.
Note As explained in Chapter 9, it is possible to build generic methods that take the concept of overloading to the next level. Using generics, you can define type placeholders for a method implementation that are specified at the time you invoke the member in question.
To check this out firsthand, create a new Console Application project named MethodOverloading. Now, consider the following class definition:
// C# code.
class Program
{
static void Main(string[] args)
{
}
// Overloaded Add() method.
static int Add(int x, int y)
{ return x + y; }
static double Add(double x, double y)
{ return x + y; }
static long Add(long x, long y)
{ return x + y; }
}
The caller can now simply invoke Add() with the required arguments, and the compiler is happy to comply, given that the compiler is able to resolve the correct implementation to invoke with the provided arguments.
static void Main(string[] args)
{
Console.WriteLine("***** Fun with Method Overloading *****\n");
// Calls int version of Add()
Console.WriteLine(Add(10, 10));
// Calls long version of Add()
Console.WriteLine(Add(900000000000, 900000000000));
// Calls double version of Add()
Console.WriteLine(Add(4.3, 4.4));
Console.ReadLine();
}
The Visual Studio IDE provides assistance when calling overloaded methods to boot. When you type in the name of an overloaded method (such as your good friend Console.WriteLine()), IntelliSense will list each version of the method in question. Note that you are able to cycle through each version of an overloaded method using the up and down arrow keys shown in Figure 4-1.
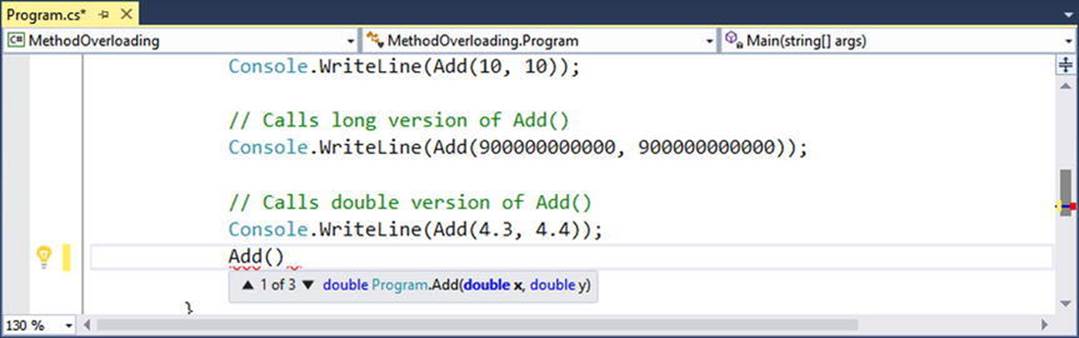
Figure 4-1. Visual Studio IntelliSense for overloaded methods
![]() Source Code The MethodOverloading application is located in the Chapter 4 subdirectory.
Source Code The MethodOverloading application is located in the Chapter 4 subdirectory.
That wraps up the initial examination of building methods using the syntax of C#. Next, let’s check out how to build and manipulate arrays, enumerations, and structures.
Understanding C# Arrays
As I would guess you are already aware, an array is a set of data items, accessed using a numerical index. More specifically, an array is a set of contiguous data points of the same type (an array of ints, an array of strings, an array of SportsCars, and so on). Declaring, filling, and accessing an array with C# is quite straightforward. To illustrate, create a new Console Application project (named FunWithArrays) that contains a helper method named SimpleArrays(), invoked from within Main().
class Program
{
static void Main(string[] args)
{
Console.WriteLine("***** Fun with Arrays *****");
SimpleArrays();
Console.ReadLine();
}
static void SimpleArrays()
{
Console.WriteLine("=> Simple Array Creation.");
// Create an array of ints containing 3 elements indexed 0, 1, 2
int[] myInts = new int[3];
// Create a 100 item string array, indexed 0 - 99
string[] booksOnDotNet = new string[100];
Console.WriteLine();
}
}
Look closely at the previous code comments. When declaring a C# array using this syntax, the number used in the array declaration represents the total number of items, not the upper bound. Also note that the lower bound of an array always begins at 0. Thus, when you write int[] myInts = new int[3], you end up with an array holding three elements, indexed at positions 0, 1, 2.
After you have defined an array variable, you are then able to fill the elements index by index, as shown here in the updated SimpleArrays() method:
static void SimpleArrays()
{
Console.WriteLine("=> Simple Array Creation.");
// Create and fill an array of 3 Integers
int[] myInts = new int[3];
myInts[0] = 100;
myInts[1] = 200;
myInts[2] = 300;
// Now print each value.
foreach(int i in myInts)
Console.WriteLine(i);
Console.WriteLine();
}
![]() Note Do be aware that if you declare an array but do not explicitly fill each index, each item will be set to the default value of the data type (e.g., an array of bools will be set to false or an array of ints will be set to 0).
Note Do be aware that if you declare an array but do not explicitly fill each index, each item will be set to the default value of the data type (e.g., an array of bools will be set to false or an array of ints will be set to 0).
C# Array Initialization Syntax
In addition to filling an array element by element, you are also able to fill the items of an array using C# array initialization syntax. To do so, specify each array item within the scope of curly brackets ({}). This syntax can be helpful when you are creating an array of a known size and want to quickly specify the initial values. For example, consider the following alternative array declarations:
static void ArrayInitialization()
{
Console.WriteLine("=> Array Initialization.");
// Array initialization syntax using the new keyword.
string[] stringArray = new string[]
{ "one", "two", "three" };
Console.WriteLine("stringArray has {0} elements", stringArray.Length);
// Array initialization syntax without using the new keyword.
bool[] boolArray = { false, false, true };
Console.WriteLine("boolArray has {0} elements", boolArray.Length);
// Array initialization with new keyword and size.
int[] intArray = new int[4] { 20, 22, 23, 0 };
Console.WriteLine("intArray has {0} elements", intArray.Length);
Console.WriteLine();
}
Notice that when you make use of this “curly-bracket” syntax, you do not need to specify the size of the array (seen when constructing the stringArray variable), given that this will be inferred by the number of items within the scope of the curly brackets. Also notice that the use of the new keyword is optional (shown when constructing the boolArray type).
In the case of the intArray declaration, again recall the numeric value specified represents the number of elements in the array, not the value of the upper bound. If there is a mismatch between the declared size and the number of initializers (whether you have too many or too few initializers), you are issued a compile-time error. The following is an example:
// OOPS! Mismatch of size and elements!
int[] intArray = new int[2] { 20, 22, 23, 0 };
Implicitly Typed Local Arrays
In Chapter 3, you learned about the topic of implicitly typed local variables. Recall that the var keyword allows you to define a variable, whose underlying type is determined by the compiler. In a similar vein, the var keyword can be used to define implicitly typed local arrays. Using this technique, you can allocate a new array variable without specifying the type contained within the array itself (note you must use the new keyword when using this approach).
static void DeclareImplicitArrays()
{
Console.WriteLine("=> Implicit Array Initialization.");
// a is really int[].
var a = new[] { 1, 10, 100, 1000 };
Console.WriteLine("a is a: {0}", a.ToString());
// b is really double[].
var b = new[] { 1, 1.5, 2, 2.5 };
Console.WriteLine("b is a: {0}", b.ToString());
// c is really string[].
var c = new[] { "hello", null, "world" };
Console.WriteLine("c is a: {0}", c.ToString());
Console.WriteLine();
}
Of course, just as when you allocate an array using explicit C# syntax, the items in the array’s initialization list must be of the same underlying type (e.g., all ints, all strings, or all SportsCars). Unlike what you might be expecting, an implicitly typed local array does not default toSystem.Object; thus, the following generates a compile-time error:
// Error! Mixed types!
var d = new[] { 1, "one", 2, "two", false };
Defining an Array of Objects
In most cases, when you define an array, you do so by specifying the explicit type of item that can be within the array variable. While this seems quite straightforward, there is one notable twist. As you will come to understand in Chapter 6, System.Object is the ultimate base class to every type (including fundamental data types) in the .NET type system. Given this fact, if you were to define an array of System.Object data types, the subitems could be anything at all. Consider the following ArrayOfObjects() method (which again can be invoked from Main()for testing):
static void ArrayOfObjects()
{
Console.WriteLine("=> Array of Objects.");
// An array of objects can be anything at all.
object[] myObjects = new object[4];
myObjects[0] = 10;
myObjects[1] = false;
myObjects[2] = new DateTime(1969, 3, 24);
myObjects[3] = "Form & Void";
foreach (object obj in myObjects)
{
// Print the type and value for each item in array.
Console.WriteLine("Type: {0}, Value: {1}", obj.GetType(), obj);
}
Console.WriteLine();
}
Here, as you are iterating over the contents of myObjects, you print the underlying type of each item using the GetType() method of System.Object, as well as the value of the current item. Without going into too much detail regarding System.Object.GetType() at this point in the text, simply understand that this method can be used to obtain the fully qualified name of the item (Chapter 15 examines the topic of type information and reflection services in detail). The following output shows the result of calling ArrayOfObjects():
=> Array of Objects.
Type: System.Int32, Value: 10
Type: System.Boolean, Value: False
Type: System.DateTime, Value: 3/24/1969 12:00:00 AM
Type: System.String, Value: Form & Void
Working with Multidimensional Arrays
In addition to the single-dimension arrays you have seen thus far, C# also supports two varieties of multidimensional arrays. The first of these is termed a rectangular array, which is simply an array of multiple dimensions, where each row is of the same length. To declare and fill a multidimensional rectangular array, proceed as follows:
static void RectMultidimensionalArray()
{
Console.WriteLine("=> Rectangular multidimensional array.");
// A rectangular MD array.
int[,] myMatrix;
myMatrix = new int[3,4];
// Populate (3 * 4) array.
for(int i = 0; i < 3; i++)
for(int j = 0; j < 4; j++)
myMatrix[i, j] = i * j;
// Print (3 * 4) array.
for(int i = 0; i < 3; i++)
{
for(int j = 0; j < 4; j++)
Console.Write(myMatrix[i, j] + "\t");
Console.WriteLine();
}
Console.WriteLine();
}
The second type of multidimensional array is termed a jagged array. As the name implies, jagged arrays contain some number of inner arrays, each of which may have a different upper limit. Here’s an example:
static void JaggedMultidimensionalArray()
{
Console.WriteLine("=> Jagged multidimensional array.");
// A jagged MD array (i.e., an array of arrays).
// Here we have an array of 5 different arrays.
int[][] myJagArray = new int[5][];
// Create the jagged array.
for (int i = 0; i < myJagArray.Length; i++)
myJagArray[i] = new int[i + 7];
// Print each row (remember, each element is defaulted to zero!).
for(int i = 0; i < 5; i++)
{
for(int j = 0; j < myJagArray[i].Length; j++)
Console.Write(myJagArray[i][j] + " ");
Console.WriteLine();
}
Console.WriteLine();
}
The output of calling each of the RectMultidimensionalArray() and JaggedMultidimensionalArray() methods within Main() is shown next:
=> Rectangular multidimensional array:
0 0 0 0
0 1 2 3
0 2 4 6
=> Jagged multidimensional array:
0 0 0 0 0 0 0
0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0
Arrays As Arguments or Return Values
After you have created an array, you are free to pass it as an argument or receive it as a member return value. For example, the following PrintArray() method takes an incoming array of ints and prints each member to the console, while the GetStringArray() method populates an array of strings and returns it to the caller:
static void PrintArray(int[] myInts)
{
for(int i = 0; i < myInts.Length; i++)
Console.WriteLine("Item {0} is {1}", i, myInts[i]);
}
static string[] GetStringArray()
{
string[] theStrings = {"Hello", "from", "GetStringArray"};
return theStrings;
}
These methods may be invoked as you would expect:
static void PassAndReceiveArrays()
{
Console.WriteLine("=> Arrays as params and return values.");
// Pass array as parameter.
int[] ages = {20, 22, 23, 0} ;
PrintArray(ages);
// Get array as return value.
string[] strs = GetStringArray();
foreach(string s in strs)
Console.WriteLine(s);
Console.WriteLine();
}
At this point, you should feel comfortable with the process of defining, filling, and examining the contents of a C# array variable. To complete the picture, let’s now examine the role of the System.Array class.
The System.Array Base Class
Every array you create gathers much of its functionality from the System.Array class. Using these common members, you are able to operate on an array using a consistent object model. Table 4-2 gives a rundown of some of the more interesting members (be sure to check the .NET Framework 4.6 SDK documentation for full details).
Table 4-2. Select Members of System.Array
|
Member of Array Class |
Meaning in Life |
|
Clear() |
This static method sets a range of elements in the array to empty values (0 for numbers, null for object references, false for Booleans). |
|
CopyTo() |
This method is used to copy elements from the source array into the destination array. |
|
Length |
This property returns the number of items within the array. |
|
Rank |
This property returns the number of dimensions of the current array. |
|
Reverse() |
This static method reverses the contents of a one-dimensional array. |
|
Sort() |
This static method sorts a one-dimensional array of intrinsic types. If the elements in the array implement the IComparer interface, you can also sort your custom types (see Chapter 9). |
Let’s see some of these members in action. The following helper method makes use of the static Reverse() and Clear() methods to pump out information about an array of string types to the console:
static void SystemArrayFunctionality()
{
Console.WriteLine("=> Working with System.Array.");
// Initialize items at startup.
string[] gothicBands = {"Tones on Tail", "Bauhaus", "Sisters of Mercy"};
// Print out names in declared order.
Console.WriteLine("-> Here is the array:");
for (int i = 0; i < gothicBands.Length; i++)
{
// Print a name.
Console.Write(gothicBands[i] + ", ");
}
Console.WriteLine("\n");
// Reverse them...
Array.Reverse(gothicBands);
Console.WriteLine("-> The reversed array");
// ... and print them.
for (int i = 0; i < gothicBands.Length; i++)
{
// Print a name.
Console.Write(gothicBands[i] + ", ");
}
Console.WriteLine("\n");
// Clear out all but the first member.
Console.WriteLine("-> Cleared out all but one...");
Array.Clear(gothicBands, 1, 2);
for (int i = 0; i < gothicBands.Length; i++)
{
// Print a name.
Console.Write(gothicBands[i] + ", ");
}
Console.WriteLine();
}
If you invoke this method from within Main(), you will get the output shown here:
=> Working with System.Array.
-> Here is the array:
Tones on Tail, Bauhaus, Sisters of Mercy,
-> The reversed array
Sisters of Mercy, Bauhaus, Tones on Tail,
-> Cleared out all but one...
Sisters of Mercy, , ,
Notice that many members of System.Array are defined as static members and are, therefore, called at the class level (for example, the Array.Sort() and Array.Reverse() methods). Methods such as these are passed in the array you want to process. Other members ofSystem.Array (such as the Length property) are bound at the object level; thus, you are able to invoke the member directly on the array.
![]() Source Code The FunWithArrays application is located in the Chapter 4 subdirectory.
Source Code The FunWithArrays application is located in the Chapter 4 subdirectory.
Understanding the enum Type
Recall from Chapter 1 that the .NET type system is composed of classes, structures, enumerations, interfaces, and delegates. To begin exploration of these types, let’s check out the role of the enumeration (or simply, enum) using a new Console Application project named FunWithEnums.
![]() Note Do not confuse the term enum with enumerator; they are completely different concepts. An enum is a custom data type of name-value pairs. An enumerator is a class or structure that implements a .NET interface named IEnumerable. Typically, this interface is implemented on collection classes, as well as the System.Array class. As you will see later in Chapter 8, objects that support IEnumerable can work within the foreach loop.
Note Do not confuse the term enum with enumerator; they are completely different concepts. An enum is a custom data type of name-value pairs. An enumerator is a class or structure that implements a .NET interface named IEnumerable. Typically, this interface is implemented on collection classes, as well as the System.Array class. As you will see later in Chapter 8, objects that support IEnumerable can work within the foreach loop.
When building a system, it is often convenient to create a set of symbolic names that map to known numerical values. For example, if you are creating a payroll system, you might want to refer to the type of employees using constants such as vice president, manager, contractor, and grunt. C# supports the notion of custom enumerations for this very reason. For example, here is an enumeration named EmpType (you can define this in the same file as your Program class, right before the class definition):
// A custom enumeration.
enum EmpType
{
Manager, // = 0
Grunt, // = 1
Contractor, // = 2
VicePresident // = 3
}
The EmpType enumeration defines four named constants, corresponding to discrete numerical values. By default, the first element is set to the value zero (0), followed by an n+1 progression. You are free to change the initial value as you see fit. For example, if it made sense to number the members of EmpType as 102 through 105, you could do so as follows:
// Begin with 102.
enum EmpType
{
Manager = 102,
Grunt, // = 103
Contractor, // = 104
VicePresident // = 105
}
Enumerations do not necessarily need to follow a sequential ordering and do not need to have unique values. If (for some reason or another) it makes sense to establish your EmpType as shown here, the compiler continues to be happy:
// Elements of an enumeration need not be sequential!
enum EmpType
{
Manager = 10,
Grunt = 1,
Contractor = 100,
VicePresident = 9
}
Controlling the Underlying Storage for an enum
By default, the storage type used to hold the values of an enumeration is a System.Int32 (the C# int); however, you are free to change this to your liking. C# enumerations can be defined in a similar manner for any of the core system types (byte, short, int, or long). For example, if you want to set the underlying storage value of EmpType to be a byte rather than an int, you can write the following:
// This time, EmpType maps to an underlying byte.
enum EmpType : byte
{
Manager = 10,
Grunt = 1,
Contractor = 100,
VicePresident = 9
}
Changing the underlying type of an enumeration can be helpful if you are building a .NET application that will be deployed to a low-memory device and need to conserve memory wherever possible. Of course, if you do establish your enumeration to use a byte as storage, each value must be within its range! For example, the following version of EmpType will result in a compiler error, as the value 999 cannot fit within the range of a byte:
// Compile-time error! 999 is too big for a byte!
enum EmpType : byte
{
Manager = 10,
Grunt = 1,
Contractor = 100,
VicePresident = 999
}
Declaring enum Variables
Once you have established the range and storage type of your enumeration, you can use it in place of so- called magic numbers. Because enumerations are nothing more than a user-defined data type, you are able to use them as function return values, method parameters, local variables, and so forth. Assume you have a method named AskForBonus(), taking an EmpType variable as the sole parameter. Based on the value of the incoming parameter, you will print out a fitting response to the pay bonus request.
class Program
{
static void Main(string[] args)
{
Console.WriteLine("**** Fun with Enums *****");
// Make an EmpType variable.
EmpType emp = EmpType.Contractor;
AskForBonus(emp);
Console.ReadLine();
}
// Enums as parameters.
static void AskForBonus(EmpType e)
{
switch (e)
{
case EmpType.Manager:
Console.WriteLine("How about stock options instead?");
break;
case EmpType.Grunt:
Console.WriteLine("You have got to be kidding...");
break;
case EmpType.Contractor:
Console.WriteLine("You already get enough cash...");
break;
case EmpType.VicePresident:
Console.WriteLine("VERY GOOD, Sir!");
break;
}
}
}
Notice that when you are assigning a value to an enum variable, you must scope the enum name (EmpType) to the value (Grunt). Because enumerations are a fixed set of name-value pairs, it is illegal to set an enum variable to a value that is not defined directly by the enumerated type.
static void ThisMethodWillNotCompile()
{
// Error! SalesManager is not in the EmpType enum!
EmpType emp = EmpType.SalesManager;
// Error! Forgot to scope Grunt value to EmpType enum!
emp = Grunt;
}
The System.Enum Type
The interesting thing about .NET enumerations is that they gain functionality from the System.Enum class type. This class defines a number of methods that allow you to interrogate and transform a given enumeration. One helpful method is the static Enum.GetUnderlyingType(), which, as the name implies, returns the data type used to store the values of the enumerated type (System.Byte in the case of the current EmpType declaration).
static void Main(string[] args)
{
Console.WriteLine("**** Fun with Enums *****");
// Make a contractor type.
EmpType emp = EmpType.Contractor;
AskForBonus(emp);
// Print storage for the enum.
Console.WriteLine("EmpType uses a {0} for storage",
Enum.GetUnderlyingType(emp.GetType()));
Console.ReadLine();
}
If you were to consult the Visual Studio object browser, you would be able to verify that the Enum.GetUnderlyingType() method requires you to pass in a System.Type as the first parameter. As fully examined in Chapter 15, Type represents the metadata description of a given .NET entity.
One possible way to obtain metadata (as shown previously) is to use the GetType() method, which is common to all types in the .NET base class libraries. Another approach is to use the C# typeof operator. One benefit of doing so is that you do not need to have a variable of the entity you want to obtain a metadata description of.
// This time use typeof to extract a Type.
Console.WriteLine("EmpType uses a {0} for storage",
Enum.GetUnderlyingType(typeof(EmpType)));
Dynamically Discovering an enum’s Name/Value Pairs
Beyond the Enum.GetUnderlyingType() method, all C# enumerations support a method named ToString(), which returns the string name of the current enumeration’s value. The following code is an example:
static void Main(string[] args)
{
Console.WriteLine("**** Fun with Enums *****");
EmpType emp = EmpType.Contractor;
AskForBonus(emp);
// Prints out "emp is a Contractor".
Console.WriteLine("emp is a {0}.", emp.ToString());
Console.ReadLine();
}
If you are interested in discovering the value of a given enumeration variable, rather than its name, you can simply cast the enum variable against the underlying storage type. The following is an example:
static void Main(string[] args)
{
Console.WriteLine("**** Fun with Enums *****");
EmpType emp = EmpType.Contractor;
...
// Prints out "Contractor = 100".
Console.WriteLine("{0} = {1}", emp.ToString(), (byte)emp);
Console.ReadLine();
}
![]() Note The static Enum.Format() method provides a finer level of formatting options by specifying a desired format flag. Consult the .NET Framework 4.6 SDK documentation for full details of the System.Enum.Format() method.
Note The static Enum.Format() method provides a finer level of formatting options by specifying a desired format flag. Consult the .NET Framework 4.6 SDK documentation for full details of the System.Enum.Format() method.
System.Enum also defines another static method named GetValues(). This method returns an instance of System.Array. Each item in the array corresponds to a member of the specified enumeration. Consider the following method, which will print out each name-value pairwithin any enumeration you pass in as a parameter:
// This method will print out the details of any enum.
static void EvaluateEnum(System.Enum e)
{
Console.WriteLine("=> Information about {0}", e.GetType().Name);
Console.WriteLine("Underlying storage type: {0}",
Enum.GetUnderlyingType(e.GetType()));
// Get all name/value pairs for incoming parameter.
Array enumData = Enum.GetValues(e.GetType());
Console.WriteLine("This enum has {0} members.", enumData.Length);
// Now show the string name and associated value, using the D format
// flag (see Chapter 3).
for(int i = 0; i < enumData.Length; i++)
{
Console.WriteLine("Name: {0}, Value: {0:D}",
enumData.GetValue(i));
}
Console.WriteLine();
}
To test this new method, update your Main() method to create variables of several enumeration types declared in the System namespace (as well as an EmpType enumeration for good measure). The following code is an example:
static void Main(string[] args)
{
Console.WriteLine("**** Fun with Enums *****");
...
EmpType e2 = EmpType.Contractor;
// These types are enums in the System namespace.
DayOfWeek day = DayOfWeek.Monday;
ConsoleColor cc = ConsoleColor.Gray;
EvaluateEnum(e2);
EvaluateEnum(day);
EvaluateEnum(cc);
Console.ReadLine();
}
Some partial output is shown here:
=> Information about DayOfWeek
Underlying storage type: System.Int32
This enum has 7 members.
Name: Sunday, Value: 0
Name: Monday, Value: 1
Name: Tuesday, Value: 2
Name: Wednesday, Value: 3
Name: Thursday, Value: 4
Name: Friday, Value: 5
Name: Saturday, Value: 6
As you will see over the course of this text, enumerations are used extensively throughout the .NET base class libraries. For example, ADO.NET makes use of numerous enumerations to represent the state of a database connection (e.g., opened or closed) or the state of a row in aDataTable (e.g., changed, new, or detached). Therefore, when you make use of any enumeration, always remember that you are able to interact with the name-value pairs using the members of System.Enum.
![]() Source Code The FunWithEnums project is located under the Chapter 4 subdirectory.
Source Code The FunWithEnums project is located under the Chapter 4 subdirectory.
Understanding the Structure (aka Value Type)
Now that you understand the role of enumeration types, let’s examine the use of .NET structures (or simply structs). Structure types are well suited for modeling mathematical, geometrical, and other “atomic” entities in your application. A structure (such as an enumeration) is a user-defined type; however, structures are not simply a collection of name-value pairs. Rather, structures are types that can contain any number of data fields and members that operate on these fields.
![]() Note If you have a background in OOP, you can think of a structure as a “lightweight class type,” given that structures provide a way to define a type that supports encapsulation but cannot be used to build a family of related types. When you need to build a family of related types through inheritance, you will need to make use of class types.
Note If you have a background in OOP, you can think of a structure as a “lightweight class type,” given that structures provide a way to define a type that supports encapsulation but cannot be used to build a family of related types. When you need to build a family of related types through inheritance, you will need to make use of class types.
On the surface, the process of defining and using structures is simple, but as they say, the devil is in the details. To begin understanding the basics of structure types, create a new project named FunWithStructures. In C#, structures are defined using the struct keyword. Define a new structure named Point, which defines two member variables of type int and a set of methods to interact with said data.
struct Point
{
// Fields of the structure.
public int X;
public int Y;
// Add 1 to the (X, Y) position.
public void Increment()
{
X++; Y++;
}
// Subtract 1 from the (X, Y) position.
public void Decrement()
{
X--; Y--;
}
// Display the current position.
public void Display()
{
Console.WriteLine("X = {0}, Y = {1}", X, Y);
}
}
Here, you have defined your two integer fields (X and Y) using the public keyword, which is an access control modifier (Chapter 5 furthers this discussion). Declaring data with the public keyword ensures the caller has direct access to the data from a given Point variable (via the dot operator).
![]() Note It is typically considered bad style to define public data within a class or structure. Rather, you will want to define private data, which can be accessed and changed using public properties. These details will be examined in Chapter 5.
Note It is typically considered bad style to define public data within a class or structure. Rather, you will want to define private data, which can be accessed and changed using public properties. These details will be examined in Chapter 5.
Here is a Main() method that takes the Point type out for a test-drive:
static void Main(string[] args)
{
Console.WriteLine("***** A First Look at Structures *****\n");
// Create an initial Point.
Point myPoint;
myPoint.X = 349;
myPoint.Y = 76;
myPoint.Display();
// Adjust the X and Y values.
myPoint.Increment();
myPoint.Display();
Console.ReadLine();
}
The output is as you would expect.
***** A First Look at Structures *****
X = 349, Y = 76
X = 350, Y = 77
Creating Structure Variables
When you want to create a structure variable, you have a variety of options. Here, you simply create a Point variable and assign each piece of public field data before invoking its members. If you do not assign each piece of public field data (X and Y in this case) before using the structure, you will receive a compiler error.
// Error! Did not assign Y value.
Point p1;
p1.X = 10;
p1.Display();
// OK! Both fields assigned before use.
Point p2;
p2.X = 10;
p2.Y = 10;
p2.Display();
As an alternative, you can create structure variables using the C# new keyword, which will invoke the structure’s default constructor. By definition, a default constructor does not take any arguments. The benefit of invoking the default constructor of a structure is that each piece of field data is automatically set to its default value.
// Set all fields to default values
// using the default constructor.
Point p1 = new Point();
// Prints X=0,Y=0.
p1.Display();
It is also possible to design a structure with a custom constructor. This allows you to specify the values of field data upon variable creation, rather than having to set each data member field by field. Chapter 5 will provide a detailed examination of constructors; however, to illustrate, update the Point structure with the following code:
struct Point
{
// Fields of the structure.
public int X;
public int Y;
// A custom constructor.
public Point(int XPos, int YPos)
{
X = XPos;
Y = YPos;
}
...
}
With this, you could now create Point variables, as follows:
// Call custom constructor.
Point p2 = new Point(50, 60);
// Prints X=50,Y=60.
p2.Display();
As mentioned, working with structures on the surface is quite simple. However, to deepen your understanding of this type, you need to explore the distinction between a .NET value type and a .NET reference type.
![]() Source Code The FunWithStructures project is located in the Chapter 4 subdirectory.
Source Code The FunWithStructures project is located in the Chapter 4 subdirectory.
Understanding Value Types and Reference Types
![]() Note The following discussion of value types and reference types assumes that you have a background in object-oriented programming. If this is not the case, you might want to skip to the “Understanding C# Nullable Types” section of this chapter and return to this section after you have read Chapters 5 and 6.
Note The following discussion of value types and reference types assumes that you have a background in object-oriented programming. If this is not the case, you might want to skip to the “Understanding C# Nullable Types” section of this chapter and return to this section after you have read Chapters 5 and 6.
Unlike arrays, strings, or enumerations, C# structures do not have an identically named representation in the .NET library (that is, there is no System.Structure class) but are implicitly derived from System.ValueType. Simply put, the role of System.ValueType is to ensure that the derived type (e.g., any structure) is allocated on the stack, rather than the garbage-collected heap. Simply put, data allocated on the stack can be created and destroyed quickly, as its lifetime is determined by the defining scope. Heap-allocated data, on the other hand, is monitored by the .NET garbage collector and has a lifetime that is determined by a large number of factors, which will be examined in Chapter 13.
Functionally, the only purpose of System.ValueType is to override the virtual methods defined by System.Object to use value-based, versus reference-based, semantics. As you might know, overriding is the process of changing the implementation of a virtual (or possibly abstract) method defined within a base class. The base class of ValueType is System.Object. In fact, the instance methods defined by System.ValueType are identical to those of System.Object.
// Structures and enumerations implicitly extend System.ValueType.
public abstract class ValueType : object
{
public virtual bool Equals(object obj);
public virtual int GetHashCode();
public Type GetType();
public virtual string ToString();
}
Given that value types are using value-based semantics, the lifetime of a structure (which includes all numerical data types [int, float], as well as any enum or structure) is predictable. When a structure variable falls out of the defining scope, it is removed from memory immediately.
// Local structures are popped off
// the stack when a method returns.
static void LocalValueTypes()
{
// Recall! "int" is really a System.Int32 structure.
int i = 0;
// Recall! Point is a structure type.
Point p = new Point();
} // "i" and "p" popped off the stack here!
Value Types, References Types, and the Assignment Operator
When you assign one value type to another, a member-by-member copy of the field data is achieved. In the case of a simple data type such as System.Int32, the only member to copy is the numerical value. However, in the case of your Point, the X and Y values are copied into the new structure variable. To illustrate, create a new Console Application project named ValueAndReferenceTypes and then copy your previous Point definition into your new namespace. Next, add the following method to your Program type:
// Assigning two intrinsic value types results in
// two independent variables on the stack.
static void ValueTypeAssignment()
{
Console.WriteLine("Assigning value types\n");
Point p1 = new Point(10, 10);
Point p2 = p1;
// Print both points.
p1.Display();
p2.Display();
// Change p1.X and print again. p2.X is not changed.
p1.X = 100;
Console.WriteLine("\n=> Changed p1.X\n");
p1.Display();
p2.Display();
}
Here, you have created a variable of type Point (named p1) that is then assigned to another Point (p2). Because Point is a value type, you have two copies of the MyPoint type on the stack, each of which can be independently manipulated. Therefore, when you change the value ofp1.X, the value of p2.X is unaffected.
Assigning value types
X = 10, Y = 10
X = 10, Y = 10
=> Changed p1.X
X = 100, Y = 10
X = 10, Y = 10
In stark contrast to value types, when you apply the assignment operator to reference types (meaning all class instances), you are redirecting what the reference variable points to in memory. To illustrate, create a new class type named PointRef that has the same members as the Pointstructures, beyond renaming the constructor to match the class name.
// Classes are always reference types.
class PointRef
{
// Same members as the Point structure...
// Be sure to change your constructor name to PointRef!
public PointRef(int XPos, int YPos)
{
X = XPos;
Y = YPos;
}
}
Now, use your PointRef type within the following new method. Note that beyond using the PointRef class, rather than the Point structure, the code is identical to the ValueTypeAssignment() method.
static void ReferenceTypeAssignment()
{
Console.WriteLine("Assigning reference types\n");
PointRef p1 = new PointRef(10, 10);
PointRef p2 = p1;
// Print both point refs.
p1.Display();
p2.Display();
// Change p1.X and print again.
p1.X = 100;
Console.WriteLine("\n=> Changed p1.X\n");
p1.Display();
p2.Display();
}
In this case, you have two references pointing to the same object on the managed heap. Therefore, when you change the value of X using the p1 reference, p2.X reports the same value. Assuming you have called this new method within Main(), your output should look like the following:
Assigning reference types
X = 10, Y = 10
X = 10, Y = 10
=> Changed p1.X
X = 100, Y = 10
X = 100, Y = 10
Value Types Containing Reference Types
Now that you have a better feeling for the basic differences between value types and reference types, let’s examine a more complex example. Assume you have the following reference (class) type that maintains an informational string that can be set using a custom constructor:
class ShapeInfo
{
public string infoString;
public ShapeInfo(string info)
{
infoString = info;
}
}
Now assume that you want to contain a variable of this class type within a value type named Rectangle. To allow the caller to set the value of the inner ShapeInfo member variable, you also provide a custom constructor. Here is the complete definition of the Rectangle type:
struct Rectangle
{
// The Rectangle structure contains a reference type member.
public ShapeInfo rectInfo;
public int rectTop, rectLeft, rectBottom, rectRight;
public Rectangle(string info, int top, int left, int bottom, int right)
{
rectInfo = new ShapeInfo(info);
rectTop = top; rectBottom = bottom;
rectLeft = left; rectRight = right;
}
public void Display()
{
Console.WriteLine("String = {0}, Top = {1}, Bottom = {2}, " +
"Left = {3}, Right = {4}",
rectInfo.infoString, rectTop, rectBottom, rectLeft, rectRight);
}
}
At this point, you have contained a reference type within a value type. The million-dollar question now becomes, what happens if you assign one Rectangle variable to another? Given what you already know about value types, you would be correct in assuming that the integer data (which is indeed a structure—System.Int32) should be an independent entity for each Rectangle variable. But what about the internal reference type? Will the object’s state be fully copied, or will the reference to that object be copied? To answer this question, define the following method and invoke it from Main():
static void ValueTypeContainingRefType()
{
// Create the first Rectangle.
Console.WriteLine("-> Creating r1");
Rectangle r1 = new Rectangle("First Rect", 10, 10, 50, 50);
// Now assign a new Rectangle to r1.
Console.WriteLine("-> Assigning r2 to r1");
Rectangle r2 = r1;
// Change some values of r2.
Console.WriteLine("-> Changing values of r2");
r2.rectInfo.infoString = "This is new info!";
r2.rectBottom = 4444;
// Print values of both rectangles.
r1.Display();
r2.Display();
}
The output can be seen in the following:
-> Creating r1
-> Assigning r2 to r1
-> Changing values of r2
String = This is new info!, Top = 10, Bottom = 50, Left = 10, Right = 50
String = This is new info!, Top = 10, Bottom = 4444, Left = 10, Right = 50
As you can see, when you change the value of the informational string using the r2 reference, the r1 reference displays the same value. By default, when a value type contains other reference types, assignment results in a copy of the references. In this way, you have two independent structures, each of which contains a reference pointing to the same object in memory (i.e., a shallow copy). When you want to perform a deep copy, where the state of internal references is fully copied into a new object, one approach is to implement the ICloneable interface (as you will do in Chapter 8).
![]() Source Code The ValueAndReferenceTypes project is located in the Chapter 4 subdirectory.
Source Code The ValueAndReferenceTypes project is located in the Chapter 4 subdirectory.
Passing Reference Types by Value
Reference types or value types can, obviously, be passed as parameters to methods. However, passing a reference type (e.g., a class) by reference is quite different from passing it by value. To understand the distinction, assume you have a simple Person class defined in a new Console Application project named RefTypeValTypeParams, defined as follows:
class Person
{
public string personName;
public int personAge;
// Constructors.
public Person(string name, int age)
{
personName = name;
personAge = age;
}
public Person(){}
public void Display()
{
Console.WriteLine("Name: {0}, Age: {1}", personName, personAge);
}
}
Now, what if you create a method that allows the caller to send in the Person object by value (note the lack of parameter modifiers, such as out or ref)?
static void SendAPersonByValue(Person p)
{
// Change the age of "p"?
p.personAge = 99;
// Will the caller see this reassignment?
p = new Person("Nikki", 99);
}
Notice how the SendAPersonByValue() method attempts to reassign the incoming Person reference to a new Person object, as well as change some state data. Now let’s test this method using the following Main() method:
static void Main(string[] args)
{
// Passing ref-types by value.
Console.WriteLine("***** Passing Person object by value *****");
Person fred = new Person("Fred", 12);
Console.WriteLine("\nBefore by value call, Person is:");
fred.Display();
SendAPersonByValue(fred);
Console.WriteLine("\nAfter by value call, Person is:");
fred.Display();
Console.ReadLine();
}
The following is the output of this call:
***** Passing Person object by value *****
Before by value call, Person is:
Name: Fred, Age: 12
After by value call, Person is:
Name: Fred, Age: 99
As you can see, the value of personAge has been modified. This behavior seems to fly in the face of what it means to pass a parameter “by value.” Given that you were able to change the state of the incoming Person, what was copied? The answer: a copy of the reference to the caller’s object. Therefore, as the SendAPersonByValue() method is pointing to the same object as the caller, it is possible to alter the object’s state data. What is not possible is to reassign what the reference is pointing to.
Passing Reference Types by Reference
Now assume you have a SendAPersonByReference() method, which passes a reference type by reference (note the ref parameter modifier).
static void SendAPersonByReference(ref Person p)
{
// Change some data of "p".
p.personAge = 555;
// "p" is now pointing to a new object on the heap!
p = new Person("Nikki", 999);
}
As you might expect, this allows complete flexibility of how the callee is able to manipulate the incoming parameter. Not only can the callee change the state of the object, but if it so chooses, it may also reassign the reference to a new Person object. Now ponder the following updatedMain() method:
static void Main(string[] args)
{
// Passing ref-types by ref.
Console.WriteLine("***** Passing Person object by reference *****");
...
Person mel = new Person("Mel", 23);
Console.WriteLine("Before by ref call, Person is:");
mel.Display();
SendAPersonByReference(ref mel);
Console.WriteLine("After by ref call, Person is:");
mel.Display();
Console.ReadLine();
}
Notice the following output:
***** Passing Person object by reference *****
Before by ref call, Person is:
Name: Mel, Age: 23
After by ref call, Person is:
Name: Nikki, Age: 999
As you can see, an object named Mel returns after the call as an object named Nikki, as the method was able to change what the incoming reference pointed to in memory. The golden rule to keep in mind when passing reference types is the following:
· If a reference type is passed by reference, the callee may change the values of the object’s state data, as well as the object it is referencing.
· If a reference type is passed by value, the callee may change the values of the object’s state data but not the object it is referencing.
![]() Source Code The RefTypeValTypeParams project is located in the Chapter 4 subdirectory.
Source Code The RefTypeValTypeParams project is located in the Chapter 4 subdirectory.
Final Details Regarding Value Types and Reference Types
To wrap up this topic, consider the information in Table 4-3, which summarizes the core distinctions between value types and reference types.
Table 4-3. Value Types and Reference Types Comparison
|
Intriguing Question |
Value Type |
Reference Type |
|
Where are objects allocated? |
Allocated on the stack. |
Allocated on the managed heap. |
|
How is a variable represented? |
Value type variables are local copies. |
Reference type variables are pointing to the memory occupied by the allocated instance. |
|
What is the base type? |
Implicitly extends System.ValueType. |
Can derive from any other type (except System. ValueType), as long as that type is not “sealed” (more details on this in Chapter 6). |
|
Can this type function as a base to other types? |
No. Value types are always sealed and cannot be inherited from. |
Yes. If the type is not sealed, it may function as a base to other types. |
|
What is the default parameter passing behavior? |
Variables are passed by value (i.e., a copy of the variable is passed into the called function). |
For reference types, the reference is copied by value. |
|
Can this type override System.Object.Finalize()? |
No. |
Yes, indirectly (more details on this in Chapter 13). |
|
Can I define constructors for this type? |
Yes, but the default constructor is reserved (i.e., your custom constructors must all have arguments). |
But, of course! |
|
When do variables of this type die? |
When they fall out of the defining scope. |
When the object is garbage collected. |
Despite their differences, value types and reference types both have the ability to implement interfaces and may support any number of fields, methods, overloaded operators, constants, properties, and events.
Understanding C# Nullable Types
To wrap up this chapter, let’s examine the role of nullable data type using a final Console Application project named NullableTypes. As you know, C# data types have a fixed range and are represented as a type in the System namespace. For example, the System.Boolean data type can be assigned a value from the set {true, false}. Now, recall that all the numerical data types (as well as the Boolean data type) are value types. Value types can never be assigned the value of null, as that is used to establish an empty object reference.
static void Main(string[] args)
{
// Compiler errors!
// Value types cannot be set to null!
bool myBool = null;
int myInt = null;
// OK! Strings are reference types.
string myString = null;
}
C# supports the concept of nullable data types. Simply put, a nullable type can represent all the values of its underlying type, plus the value null. Thus, if you declare a nullable bool, it could be assigned a value from the set {true, false, null}. This can be extremely helpful when working with relational databases, given that it is quite common to encounter undefined columns in database tables. Without the concept of a nullable data type, there is no convenient manner in C# to represent a numerical data point with no value.
To define a nullable variable type, the question mark symbol (?) is suffixed to the underlying data type. Do note that this syntax is legal only when applied to value types. If you attempt to create a nullable reference type (including strings), you are issued a compile-time error. Like a non-nullable variable, local nullable variables must be assigned an initial value before you can use them.
static void LocalNullableVariables()
{
// Define some local nullable variables.
int? nullableInt = 10;
double? nullableDouble = 3.14;
bool? nullableBool = null;
char? nullableChar = ’a’;
int?[] arrayOfNullableInts = new int?[10];
// Error! Strings are reference types!
// string? s = "oops";
}
In C#, the ? suffix notation is a shorthand for creating an instance of the generic System.Nullable<T> structure type. Although you will not examine generics until Chapter 9, it is important to understand that the System.Nullable<T> type provides a set of members that all nullable types can make use of.
For example, you are able to programmatically discover whether the nullable variable indeed has been assigned a null value using the HasValue property or the != operator. The assigned value of a nullable type may be obtained directly or via the Value property. In fact, given that the ? suffix is just a shorthand for using Nullable<T>, you could implement your LocalNullableVariables() method as follows:
static void LocalNullableVariablesUsingNullable()
{
// Define some local nullable types using Nullable<T>.
Nullable<int> nullableInt = 10;
Nullable<double> nullableDouble = 3.14;
Nullable<bool> nullableBool = null;
Nullable<char> nullableChar = ’a’;
Nullable<int>[] arrayOfNullableInts = new Nullable<int>[10];
}
Working with Nullable Types
As stated, nullable data types can be particularly useful when you are interacting with databases, given that columns in a data table may be intentionally empty (e.g., undefined). To illustrate, assume the following class, which simulates the process of accessing a database that has a table containing two columns that may be null. Note that the GetIntFromDatabase() method is not assigning a value to the nullable integer member variable, while GetBoolFromDatabase() is assigning a valid value to the bool? member.
class DatabaseReader
{
// Nullable data field.
public int? numericValue = null;
public bool? boolValue = true;
// Note the nullable return type.
public int? GetIntFromDatabase()
{ return numericValue; }
// Note the nullable return type.
public bool? GetBoolFromDatabase()
{ return boolValue; }
}
Now, assume the following Main() method, which invokes each member of the DatabaseReader class and discovers the assigned values using the HasValue and Value members, as well as using the C# equality operator (not equal, to be exact):
static void Main(string[] args)
{
Console.WriteLine("***** Fun with Nullable Data *****\n");
DatabaseReader dr = new DatabaseReader();
// Get int from "database".
int? i = dr.GetIntFromDatabase();
if (i.HasValue)
Console.WriteLine("Value of ’i’ is: {0}", i.Value);
else
Console.WriteLine("Value of ’i’ is undefined.");
// Get bool from "database".
bool? b = dr.GetBoolFromDatabase();
if (b != null)
Console.WriteLine("Value of ’b’ is: {0}", b.Value);
else
Console.WriteLine("Value of ’b’ is undefined.");
Console.ReadLine();
}
The Null Coalescing Operator
The next aspect to be aware of is any variable that might have a null value (i.e., a reference-type variable or a nullable value-type variable) can make use of the C# ?? operator, which is formally termed the null coalescing operator. This operator allows you to assign a value to a nullable type if the retrieved value is in fact null. For this example, assume you want to assign a local nullable integer to 100 if the value returned from GetIntFromDatabase() is null (of course, this method is programmed to always return null, but I am sure you get the general idea).
static void Main(string[] args)
{
Console.WriteLine("***** Fun with Nullable Data *****\n");
DatabaseReader dr = new DatabaseReader();
...
// If the value from GetIntFromDatabase() is null,
// assign local variable to 100.
int myData = dr.GetIntFromDatabase() ?? 100;
Console.WriteLine("Value of myData: {0}", myData);
Console.ReadLine();
}
The benefit of using the ?? operator is that it provides a more compact version of a traditional if/else condition. However, if you want, you could have authored the following functionally equivalent code to ensure that if a value comes back as null, it will indeed be set to the value 100:
// Long-hand notation not using ?? syntax.
int? moreData = dr.GetIntFromDatabase();
if (!moreData.HasValue)
moreData = 100;
Console.WriteLine("Value of moreData: {0}", moreData);
The Null Conditional Operator
When you are writing software, it is common to check incoming parameters, values returned from type members (methods, properties, indexers) against the value null. For example, let’s assume you have a method that takes a string array as a single parameter. To be safe, you might want to test for null before proceeding. In that way, you will not get a runtime error if the array is empty. The following would be a traditional way to perform such a check:
static void TesterMethod(string[] args)
{
// We should check for null before accessing the array data!
if (args != null)
{
Console.WriteLine($"You sent me {args.Length} arguments.");
}
}
Here, you use a conditional scope to ensure that the Length property of the string array will not be accessed if the array is null. If the caller failed to make an array of data and called your method like so, you are still safe and will not trigger a runtime error:
TesterMethod(null);
With the current release of the C# language, it is now possible to leverage the null conditional operator token (a question mark placed after a variable type but before an access operator) to simplify the previous error checking. Rather than explicitly building a conditional statement to check for null, you can now write the following:
static void TesterMethod(string[] args)
{
// We should check for null before accessing the array data!
Console.WriteLine($"You sent me {args?.Length} arguments.");
}
In this case, you are not using a conditional statement. Rather, you are suffixing the ? operator directly after the string array variable. If this is null, its call to the Length property will not throw a runtime error. If you want to print an actual value, you could leverage the null coalescing operator to assign a default value as so:
Console.WriteLine($"You sent me {args?.Length ?? 0} arguments.");
There are some additional areas of coding where the new C# 6.0 null conditional operator will be quite handy, especially when working with delegates and events. However, since those topics are not addressed until later in the book (see Chapter 10), you will hold on any additional use cases. With this, your initial investigation of the C# programming language is complete! In Chapter 5, you will begin to dig into the details of object-oriented development.
![]() Source Code The NullableTypes application is located in the Chapter 4 subdirectory.
Source Code The NullableTypes application is located in the Chapter 4 subdirectory.
Summary
This chapter began with an examination of several C# keywords that allow you to build custom methods. Recall that by default parameters are passed by value; however, you may pass a parameter by reference if you mark it with ref or out. You also learned about the role of optional or named parameters and how to define and invoke methods taking parameter arrays.
After you investigated the topic of method overloading, the bulk of this chapter examined several details regarding how arrays, enumerations, and structures are defined in C# and represented within the .NET base class libraries. Along the way, you examined several details regarding value types and reference types, including how they respond when passing them as parameters to methods and how to interact with nullable data types and variables that might be null (e.g., reference-type variables and nullable value-type variables) using the ? and ?? operators.
All materials on the site are licensed Creative Commons Attribution-Sharealike 3.0 Unported CC BY-SA 3.0 & GNU Free Documentation License (GFDL)
If you are the copyright holder of any material contained on our site and intend to remove it, please contact our site administrator for approval.
© 2016-2026 All site design rights belong to S.Y.A.