Programming: Principles and Practice Using C++ (2014)
Part V: Appendices
A. Language Summary
“Be careful what you wish for; you might get it.”
—Traditional
This appendix summarizes key language elements of C++. The summary is very selective and specifically geared to novices who want to explore a bit beyond the sequence of topics in the book. The aim is conciseness, not completeness.
A.1 General
A.1.1 Terminology
A.1.2 Program start and termination
A.1.3 Comments
A.2 Literals
A.2.1 Integer literals
A.2.2 Floating-point-literals
A.2.3 Boolean literals
A.2.4 Character literals
A.2.5 String literals
A.2.6 The pointer literal
A.3 Identifiers
A.3.1 Keywords
A.4 Scope, storage class, and lifetime
A.4.1 Scope
A.4.2 Storage class
A.4.3 Lifetime
A.5 Expressions
A.5.1 User-defined operators
A.5.2 Implicit type conversion
A.5.3 Constant expressions
A.5.4 sizeof
A.5.5 Logical expressions
A.5.6 new and delete
A.5.7 Casts
A.6 Statements
A.7 Declarations
A.7.1 Definitions
A.8 Built-in types
A.8.1 Pointers
A.8.2 Arrays
A.8.3 References
A.9 Functions
A.9.1 Overload resolution
A.9.2 Default arguments
A.9.3 Unspecified arguments
A.9.4 Linkage specifications
A.10 User-defined types
A.10.1 Operator overloading
A.11 Enumerations
A.12 Classes
A.12.1 Member access
A.12.2 Class member definitions
A.12.3 Construction, destruction, and copy
A.12.4 Derived classes
A.12.5 Bitfields
A.12.6 Unions
A.13 Templates
A.13.1 Template arguments
A.13.2 Template instantiation
A.13.3 Template member types
A.14 Exceptions
A.15 Namespaces
A.16 Aliases
A.17 Preprocessor directives
A.17.1 #include
A.17.2 #define
A.1 General
This appendix is a reference. It is not intended to be read from beginning to end like a chapter. It (more or less) systematically describes key elements of the C++ language. It is not a complete reference, though; it is just a summary. Its focus and emphasis were determined by student questions. Often, you will need to look at the chapters for a more complete explanation. This summary does not attempt to equal the precision and terminology of the standard. Instead, it attempts to be accessible. For more information, see Stroustrup, The C++ Programming Language. The definition of C++ is the ISO C++ standard, but that document is neither intended for nor suitable for novices. Don’t forget to use your online documentation. If you look at this appendix while working on the early chapters, expect much to be “mysterious,” that is, explained in later chapters.
For standard library facilities, see Appendix B.
The standard for C++ is defined by a committee working under the auspices of the ISO (the international organization for standards) in collaboration with national standards bodies, such as INCITS (United States), BSI (United Kingdom), and AFNOR (France). The current definition is ISO/IEC 14882:2011 Standard for Programming Language C++.
A.1.1 Terminology
The C++ standard defines what a C++ program is and what the various constructs mean:
• Conforming: A program that is C++ according to the standard is called conforming (or colloquially, legal or valid).
• Implementation defined: A program can (and usually does) depend on features (such as the size of an int and the numeric value of 'a') that are only well defined on a given compiler, operating system, machine architecture, etc. The implementation-defined features are listed in the standard and must be documented in implementation documentation, and many are reflected in standard headers, such as <limits> (see §B.1.1). So, being conforming is not the same as being portable to all C++ implementations.
• Unspecified: The meaning of some constructs is unspecified, undefined, or not conforming but not requiring a diagnostic. Obviously, such features are best avoided. This book avoids them. The unspecified features to avoid include
• Inconsistent definitions in separate source files (use header files consistently; see §8.3)
• Reading and writing the same variable repeatedly in an expression (the main example is a[i]=++i;)
• Many uses of explicit type conversion (casts), especially of reinterpret_cast
A.1.2 Program start and termination
A C++ program must have a single global function called main(). The program starts by executing main(). The return type of main() is int (void is not a conforming alternative). The value returned by main() is the program’s return value to “the system.” Some systems ignore that value, but successful termination is indicated by returning zero and failure by returning a nonzero value or by an uncaught exception (but an uncaught exception is considered poor style).
The arguments to main() can be implementation defined, but every implementation must accept two versions (though only one per program):
int main(); // no arguments
int main(int argc, char* argv[]); // argv[] holds argc C-style strings
The definition of main() need not explicitly return a value. If it doesn’t, “dropping through the bottom,” it returns a zero. This is the minimal C++ program:
int main() { }
If you define a global (namespace) scope object with a constructor and a destructor, the constructor will logically be executed “before main()” and the destructor logically executed “after main()” (technically, executing those constructors is part of invoking main() and executing the destructors part of returning from main()). Whenever you can, avoid global objects, especially global objects requiring nontrivial construction and destruction.
A.1.3 Comments
What can be said in code, should be. However, C++ offers two comment styles to allow the programmer to say things that are not well expressed as code:
// this is a line comment
/*
this is a
block comment
*/
Obviously, block comments are mostly used for multi-line comments, though some people prefer single-line comments even for multiple lines:
// this is a
// multi-line comment
// expressed using three line comments
/* and this is a single line of comment expressed using a block comment */
Comments are essential for documenting the intent of code; see also §7.6.4.
A.2 Literals
Literals represent values of various types. For example, the literal 12 represents the integer value “twelve,” "Morning" represents the character string value Morning, and true represents the Boolean value true.
A.2.1 Integer literals
Integer literals come in three varieties:
• Decimal: a series of decimal digits
Decimal digits: 0, 1, 2, 3, 4, 5, 6, 7, 8, and 9
• Octal: a series of octal digits starting with 0
Octal digits: 0, 1, 2, 3, 4, 5, 6, and 7
• Hexadecimal: a series of hexadecimal digits starting with 0x or 0X
Hexadecimal digits: 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, a, b, c, d, e, f, A, B, C, D, E, and F
• Binary: a series of binary digits starting with 0b or 0B (C++14)
Binary digits: 0, 1
A suffix u or U makes an integer literal unsigned (§25.5.3), and a suffix l or L makes it long, for example, 10u and 123456UL.
C++14 also allows the use of the single quote as a digit separator in numeric literals. For example, 0b0000'0001'0010'0011 means 0b0000000100100011 and 1'000'000 means 1000000.
A.2.1.1 Number systems
We usually write out numbers in decimal notation. 123 means 1 hundred plus 2 tens plus 3 ones, or 1*100+2*10+3*1, or (using ^ to mean “to the power of”) 1*10^2+2*10^1+3*10^0. Another word for decimal is base-10. There is nothing really special about 10 here. What we have is1*base^2+2*base^1+3*base^0 where base==10. There are lots of theories about why we use base-10. One theory has been “built into” some natural languages: we have ten fingers and each symbol, such as 0, 1, and 2, that directly stands for a value in a positional number system is called a digit. Digit is Latin for “finger.”
Occasionally, other bases are used. Typically, positive integer values in computer memory are represented in base-2 (it is relatively easy to reliably represent 0 and 1 as physical states in materials), and humans dealing with low-level hardware issues sometimes use base-8 and more often base-16 to refer to the content of memory.
Consider hexadecimal. We need to name the 16 values from 0 to 15. Usually, we use 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, A, B, C, D, E, F, where A has the decimal value 10, B the decimal value 11, and so on:
A==10, B==11, C==12, D==13, E==14, F==15
We can now write the decimal value 123 as 7B using the hexadecimal notation. To see that, note that in the hexadecimal system 7B means 7*16+11, which is (decimal) 123. Conversely, hexadecimal 123 means 1*16^2+2*16+3, which is 1*256+2*16+3, which is (decimal) 291. If you have never dealt with non-decimal integer representations, we strongly recommend you try converting a few numbers to and from decimal and hexadecimal. Note that a hexadecimal digit has a very simple correspondence to a binary value:
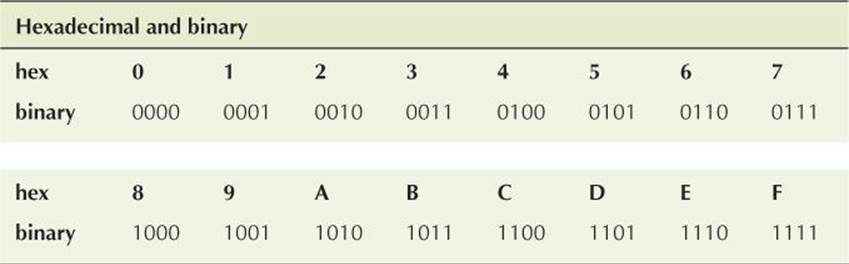
This goes a long way toward explaining the popularity of hexadecimal notation. In particular, the value of a byte is simply expressed as two hexadecimal digits.
In C++, (fortunately) numbers are decimal unless we specify otherwise. To say that a number is hexadecimal, we prefix 0X (“X for hex”), so 123==0X7B and 0X123==291. We can equivalently use a lowercase x, so we also have 123==0x7B and 0x123==291. Similarly, we can use lowercase a, b, c, d, e, and f for the hexadecimal digits. For example, 123==0x7b.
Octal is base-8. We need only eight octal digits: 0, 1, 2, 3, 4, 5, 6, 7. In C++, base-8 numbers are represented starting with a 0, so 0123 is not the decimal number 123, but 1*8^2+2*8+3, that is, 1*64+2*8+3, or (decimal) 83. Conversely, octal 83, that is, 083, is 8*8+3, which is (decimal)67. Using C++ notation, we get 0123==83 and 083==67.
Binary is base-2. We need only two digits, 0 and 1. We cannot directly represent base-2 numbers as literals in C++. Only base-8 (octal), base-10 (decimal), and base-16 (hexadecimal) are directly supported as literals and as input and output formats for integers. However, binary numbers are useful to know even if we cannot directly represent them in C++ text. For example, (decimal) 123 is
1*2^6+1*2^5+1*2^4+1*2^3+0*2^2+1*2+1
which is 1*64+1*32+1*16+1*8+0*4+1*2+1, which is (binary) 1111011.
A.2.2 Floating-point-literals
A floating-point-literal contains a decimal point (.), an exponent (e.g., e3), or a floating-point suffix (d or f). For example:
123 // int (no decimal point, suffix, or exponent)
123. // double: 123.0
123.0 // double
123 // double: 0.123
0.123 // double
1.23e3 // double: 1230.0
1.23e-3 // double: 0.00123
1.23e+3 // double: 1230.0
Floating-point-literals have type double unless a suffix indicates otherwise. For example:
1.23 // double
1.23f // float
1.23L // long double
A.2.3 Boolean literals
The literals of type bool are true and false. The integer value of true is 1 and the integer value of false is 0.
A.2.4 Character literals
A character literal is a character enclosed in single quotes, for example, 'a' and '@'. In addition, there are some “special characters”:
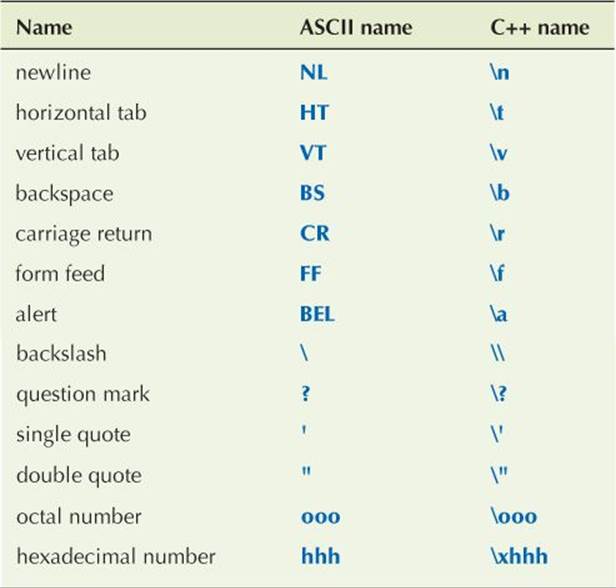
A special character is represented as its “C++ name” enclosed in single quotes, for example, '\n' (newline) and '\t' (tab).
The character set includes the following visible characters:
abcdefghijklmnopqrstuvwxyz
ABCDEFGHIJKLMNOPQRSTUVWXYZ
0123456789
!@#$%^&*()_+|~`{}[]:";'<>?,./
In portable code, you cannot rely on more visible characters. The value of a character, such as 'a' for a, is implementation dependent (but easily discovered, for example, cout << int('a')).
A.2.5 String literals
A string literal is a series of characters enclosed in double quotes, for example, "Knuth" and "King Canute". A newline cannot be part of a string; instead use the special character \n to represent newline in a string:
"King
Canute " // error: newline in string literal
"King\nCanute" // OK: correct way to get a newline into a string literal
Two string literals separated only by whitespace are taken as a single string literal. For example:
"King" "Canute" // equivalent to "KingCanute" (no space)
Note that special characters, such as \n, can appear in string literals.
A.2.6 The pointer literal
There is only one pointer literal: the null pointer, nullptr. For compatibility, any constant expression that evaluates to 0 can also be used as the null pointer. For example:
t* p1 = 0; // OK: null pointer
int* p2 = 2-2; // OK: null pointer
int* p3 = 1; // error: 1 is an int, not a pointer
int z = 0;
int* p4 = z; // error: z is not a constant
The value 0 is implicitly converted to the null pointer.
In C++ (but not in C, so beware of C headers), NULL is defined to mean 0 so that you can write
int* p4 = NULL; // (given the right definition of NULL) the null pointer
A.3 Identifiers
An identifier is a sequence of characters starting with a letter or an underscore followed by zero or more (uppercase or lowercase) letters, digits, or underscores:
int foo_bar; // OK
int FooBar; // OK
int foo bar; // error: space can’t be used in an identifier
int foo$bar; // error: $ can’t be used in an identifier
Identifiers starting with an underscore or containing a double underscore are reserved for use by the implementation; don’t use them. For example:
int _foo; // don’t
int foo_bar; // OK
int foo__bar; // don’t
int foo_; // OK
A.3.1 Keywords
Keywords are identifiers used by the language itself to express language constructs.

A.4 Scope, storage class, and lifetime
Every name in C++ (with the lamentable exception of preprocessor names; see §A.17) exists in a scope; that is, the name belongs to a region of text in which it can be used. Data (objects) are stored in memory somewhere; the kind of memory used to store an object is called its storage class.The lifetime of an object is from the time it is first initialized until it is finally destroyed.
A.4.1 Scope
There are five kinds of scopes (§8.4):
• Global scope: A name is in global scope unless it is declared inside some language construct (e.g., a class or a function).
• Namespace scope: A name is in a namespace scope if it is defined within a namespace and not inside some language construct (e.g., a class or a function). Technically, the global scope is a namespace scope with “the empty name.”
• Local scope: A name is in a local scope if it is declared inside a function (this includes function parameters).
• Class scope: A name is in a class scope if it is the name of a member of a class.
• Statement scope: A name is in a statement scope if it is declared in the (. . .) part of a for-, while-, switch-, or if-statement.
The scope of a variable extends (only) to the end of the statement in which it is defined. For example:
for (int i = 0; i<v.size(); ++i) {
// i can be used here
}
if (i < 27) // the i from the for-statement is not in scope here
Class and namespace scopes have names, so that we can refer to a member from “elsewhere.” For example:
void f(); // in global scope
namespace N {
void f() // in namespace scope N
{
int v; // in local scope
::f(); // call the global f()
}
}
void f()
{
N::f(); // call N’s f()
}
What would happen if you called N::f() or ::f()? See also §A.15.
A.4.2 Storage class
There are three storage classes (§17.4):
• Automatic storage: Variables defined in functions (including function parameters) are placed in automatic storage (i.e., “on the stack”) unless explicitly declared to be static. Automatic storage is allocated when a function is called and deallocated when a call returns; thus, if a function is (directly or indirectly) called by itself, multiple copies of automatic data can exist: one for each call (§8.5.8).
• Static storage: Variables declared in global and namespace scope are stored in static storage, as are variables explicitly declared static in functions and classes. The linker allocates static storage “before the program starts running.”
• Free store (heap): Objects created by new are allocated in the free store.
For example:
vector<int> vg(10); // constructed once at program start (“before main()”)
vector<int>* f(int x)
{
static vector<int> vs(x); // constructed in first call of f() only
vector<int> vf(x+x); // constructed in each call of f()
for (int i=1; i<10; ++i) {
vector<int> vl(i); // constructed in each iteration
// . . .
} // v1 destroyed here (in each iteration)
return new vector<int>(vf); // constructed on free store as a copy of vf
} // vf destroyed here
void ff()
{
vector<int>* p = f(10); // get vector from f()
// . . .
delete p; // delete the vector from f
}
The statically allocated variables vg and vs are destroyed at program termination (“after main()”), provided they have been constructed.
Class members are not allocated as such. When you allocate an object somewhere, the non-static members are placed there also (with the same storage class as the class object to which they belong).
Code is stored separately from data. For example, a member function is not stored in each object of its class; one copy is stored with the rest of the code for the program.
See also §14.3 and §17.4.
A.4.3 Lifetime
Before an object can be (legally) used, it must be initialized. This initialization can be explicit using an initializer or implicit using a constructor or a rule for default initialization of built-in types. The lifetime of an object ends at a point determined by its scope and storage class (e.g., see §17.4and §B.4.2):
• Local (automatic) objects are constructed if/when the thread of execution gets to them and are destroyed at end of scope.
• Temporary objects are created by a specific sub-expression and destroyed at the end of their full expression. A full expression is an expression that is not a sub-expression of some other expression.
• Namespace objects and static class members are constructed at the start of the program (“before main()”) and destroyed at the end of the program (“after main()”).
• Local static objects are constructed if/when the thread of execution gets to them and (if constructed) are destroyed at the end of the program.
• Free-store objects are constructed by new and optionally destroyed using delete.
A temporary variable bound to a local or namespace reference “lives” as long as the reference. For example:
const char* string_tbl[] = { "Mozart", "Grieg", "Haydn", "Chopin" };
const char* f(int i) { return string_tbl[i]; }
void g(string s){}
void h()
{
const string& r = f(0); // bind temporary string to r
g(f(1)); // make a temporary string and pass it
string s = f(2); // initialize s from temporary string
cout << "f(3): " << f(3) // make a temporary string and pass it
<<" s: " << s
<< " r: " << r << '\n';
}
The result is
f(3): Chopin s: Haydn r: Mozart
The string temporaries generated for the calls f(1), f(2), and f(3) are destroyed at the end of the expression in which they were created. However, the temporary generated for f(0) is bound to r and “lives” until the end of h().
A.5 Expressions
This section summarizes C++’s operators. We use abbreviations that we find mnemonic, such as m for a member name, T for a type name, p for an expression yielding a pointer, x for an expression, v for an lvalue expression, and lst for an argument list. The result type of the arithmetic operations is determined by “the usual arithmetic conversions” (§A.5.2.2). The descriptions in this section are of the built-in operators, not of any operator you might define on your own, though when you define your own operators, you are encouraged to follow the semantic rules described for built-in operations (§9.6).

Note that members can themselves nest, so that you can get N::C::m; see also §8.7.

The typeid operator and its uses are not covered in this book; see an expert-level reference. Note that casts do not modify their argument. Instead, they produce a result of their type, which somehow corresponds to the argument value; see §A.5.7.

Note that the object(s) pointed to by p in delete p and delete[] p must be allocated using new; see §A.5.6. Note that (T)x is far less specific — and therefore more error-prone — than the more specific cast operators; see §A.5.7.

Not covered in this book; see an expert-level reference.

The effect of x/y and x%y is undefined if y==0. The effect of x%y is implementation defined if x or y is negative.


For the (built-in) use of >> and << for shifting bits, see §25.5.4. When their leftmost operators are iostreams, these operators are used for I/O; see Chapters 10 and 11.

The result of a relational operator is a bool.

Note that x!=y is !(x==y). The result of an equality operator is a bool.

Note that & (like ^, |, ~, >>, and <<) delivers a set of bits. For example, if a and b are unsigned chars, a&b is an unsigned char with each bit being the result of applying & to the corresponding bits in a and b; see §A.5.5.




See §A.5.5.

For example:
template<class T> T& max(T& a, T& b) { return (a>b)?a:b; }
The “question mark colon operator” is explained in §8.4.
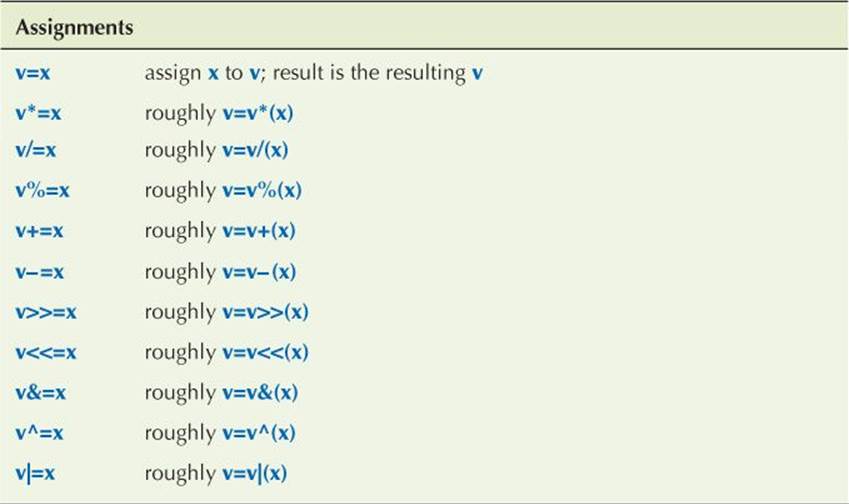
By “roughly v=v*(x)” we mean that v*=x has that value except that v is evaluated only once. For example, v[++i]*=7+3 means (++i, v[i]=v[i]*(7+3)) rather than (v[++i]=v[++i]*(7+3)) (which would be undefined; see §8.6.1).

The type of a throw expression is void.

Each box holds operators with the same precedence. Operators in higher boxes have higher precedence than operators in lower boxes. For example, a+b*c means a+(b*c) rather than (a+b)*c because * has higher precedence than +. Similarly, *p++ means *(p++), not (*p)++. Unary operators and assignment operators are right-associative; all others are left-associative. For example, a=b=c means a=(b=c) and a+b+c means (a+b)+c.
An lvalue is an expression that identifies an object that could in principle be modified (but obviously an lvalue that has a const type is protected against modification by the type system) and have its address taken. The complement to lvalue is rvalue, that is, an expression that identifies something that may not be modified or have its address taken, such as a value returned from a function (&f(x) is an error because f(x) is an rvalue).
A.5.1 User-defined operators
The rules defined here are for built-in types. If a user-defined operator is used, an expression is simply transformed into a call of the appropriate user-defined operator function, and the rules for function call determine what happens. For example:
class Mine { /* . . . */ };
bool operator==(Mine, Mine);
void f(Mine a, Mine b)
{
if (a==b) { // a==b means operator==(a,b)
// . . .
}
}
A user-defined type is a class (§A.12, Chapter 9) or an enumeration (§A.11, §9.5).
A.5.2 Implicit type conversion
Integral and floating-point types (§A.8) can be mixed freely in assignments and expressions. Wherever possible, values are converted so as not to lose information. Unfortunately, value-destroying conversions are also performed implicitly.
A.5.2.1 Promotions
The implicit conversions that preserve values are commonly referred to as promotions. Before an arithmetic operation is performed, integral promotion is used to create ints out of shorter integer types. This reflects the original purpose of these promotions: to bring operands to the “natural” size for arithmetic operations. In addition, float to double is considered a promotion.
Promotions are used as part of the usual arithmetic conversions (see §A.5.2.2).
A.5.2.2 Conversions
The fundamental types can be converted into each other in a bewildering number of ways. When writing code, you should always aim to avoid undefined behavior and conversions that quietly throw away information (see §3.9 and §25.5.3). A compiler can warn about many questionable conversions.
• Integral conversions: An integer can be converted to another integer type. An enumeration value can be converted to an integer type. If the destination type is unsigned, the resulting value is simply as many bits from the source as will fit in the destination (high-order bits are thrown away if necessary). If the destination type is signed, the value is unchanged if it can be represented in the destination type; otherwise, the value is implementation defined. Note that bool and char are integer types.
• Floating-point conversions: A floating-point value can be converted to another floating-point type. If the source value can be exactly represented in the destination type, the result is the original numeric value. If the source value is between two adjacent destination values, the result is one of those values. Otherwise, the behavior is undefined. Note that float to double is considered a promotion.
• Pointer and reference conversions: Any pointer to an object type can be implicitly converted to a void* (§17.8, §27.3.5). A pointer (reference) to a derived class can be implicitly converted to a pointer (reference) to an accessible and unambiguous base (§14.3). A constant expression (§A.5, §4.3.1) that evaluates to 0 can be implicitly converted to any pointer type. A T* can be implicitly converted to a const T*. Similarly, a T& can be implicitly converted to a const T&.
• Boolean conversions: Pointers, integrals, and floating-point values can be implicitly converted to bool. A nonzero value converts to true; a zero value converts to false.
• Floating-to-integer conversions: When a floating-point value is converted to an integer value, the fractional part is discarded. In other words, conversion from a floating-point type to an integer type truncates. The behavior is undefined if the truncated value cannot be represented in the destination type. Conversions from integer to floating types are as mathematically correct as the hardware allows. Loss of precision occurs if an integral value cannot be represented exactly as a value of the floating type.
• Usual arithmetic conversions: These conversions are performed on the operands of a binary operator to bring them to a common type, which is then used as the type of the result:
1. If either operand is of type long double, the other is converted to long double. Otherwise, if either operand is double, the other is converted to double. Otherwise, if either operand is float, the other is converted to float. Otherwise, integral promotions are performed on both operands.
2. Then, if either operand is unsigned long, the other is converted to unsigned long. Otherwise, if one operand is a long int and the other is an unsigned int, then if a long int can represent all the values of an unsigned int, the unsigned int is converted to a long int; otherwise, both operands are converted to unsigned long int. Otherwise, if either operand is long, the other is converted to long. Otherwise, if either operand is unsigned, the other is converted to unsigned. Otherwise, both operands are int.
Obviously, it is best not to rely too much on complicated mixtures of types, so as to minimize the need for implicit conversions.
A.5.2.3 User-defined conversions
In addition to the standard promotions and conversions, a programmer can define conversions for user-defined types. A constructor that takes a single argument defines a conversion from its argument type to its type. If the constructor is explicit (see §18.4.1), the conversion happens only when the programmer explicitly requires the conversion. Otherwise, the conversion can be implicit.
A.5.3 Constant expressions
A constant expression is an expression that can be evaluated at compile time. For example:
const int a = 2.7*3;
const int b = a+3;
constexpr int a = 2.7*3;
constexpr int b = a+3;
A const can be initialized with an expression involving variables. A constexpr must be initialized by a constant expression. Constant expressions are required in a few places, such as array bounds, case labels, enumerator initializers, and int template arguments. For example:
int var = 7;
switch (x) {
case 77: // OK
case a+2: // OK
case var: // error (var is not a constant expression)
// . . .
};
A function declared constexpr can be used in a constant expression.
A.5.4 sizeof
In sizeof(x), x can be a type or an expression. If x is an expression, the value of sizeof(x) is the size of the resulting object. If x is a type, sizeof(x) is the size of an object of type x. Sizes are measured in bytes. By definition, sizeof(char)==1.
A.5.5 Logical expressions
C++ provides logical operators for integer types:


The bitwise operators do their operation on each bit of their operands, whereas the logical operators (&& and ||) treat a 0 as the value false and anything else as the value true. The definitions of the operations are:

A.5.6 new and delete
Memory on the free store (dynamic store, heap) is allocated using new and deallocated (“freed”) using delete (for individual objects) or delete[] (for an array). If memory is exhausted, new throws a bad_alloc exception. A successful new operation allocates at least 1 byte and returns a pointer to the allocated object. The type of object allocated is specified after new. For example:
int* p1 = new int; // allocate an (uninitialized) int
int* p2 = new int(7); // allocate an int initialized to 7
int* p3 = new int[100]; // allocate 100 (uninitialized) ints
// . . .
delete p1; // deallocate individual object
delete p2;
delete[] p3; // deallocate array
If you allocate objects of a built-in type using new, they will not be initialized unless you specify an initializer. If you allocate objects of a class with a constructor using new, a constructor is called; the default constructor is called unless you specify an initializer (§17.4.4).
A delete invokes the destructor, if any, for its operand. Note that a destructor may be virtual (§A.12.3.1).
A.5.7 Casts
There are four type-conversion operators:

The dynamic cast is typically used for class hierarchy navigation where p is a pointer to a base class and D is derived from that base. It returns 0 if v is not a D*. If you want dynamic_cast to throw an exception (bad_cast) instead of returning 0, cast to a reference instead of to a pointer. The dynamic cast is the only cast that relies on run-time checking.
Static cast is used for “reasonably well-behaved conversions,” that is, where v could have been the result of an implicit conversion from a T; see §17.8.
Reinterpret cast is used for reinterpreting a bit pattern. It is not guaranteed to be portable. In fact, it is best to assume that every use of reinterpret_cast is non-portable. A typical example is an int-to-pointer conversion to get a machine address into a program; see §17.8 and §25.4.1.
The C-style and functional casts can perform any conversion that can be achieved by a static_cast or a reinterpret_cast, combined with a const_cast.
Casts are best avoided. In most cases, consider their use a sign of poor programming. Exceptions to this rule are presented in §17.8 and §25.4.1. The C-style cast and function-style casts have the nasty property that you don’t have to understand exactly what the cast is doing (§27.3.4). Prefer the named casts when you cannot avoid an explicit type conversion.
A.6 Statements
Here is a grammar for C++’s statements (opt means “optional”):
statement:
declaration
{ statement-listopt }
try { statement-listopt } handler-list
expressionopt ;
selection-statement
iteration-statement
labeled-statement
control-statement
selection-statement:
if ( condition ) statement
if ( condition ) statement else statement
switch ( condition ) statement
iteration-statement:
while ( condition ) statement
do statement while ( expression ) ;
for ( for-init-statement conditionopt ; expressionopt ) statement
for ( declaration : expression ) statement
labeled-statement:
case constant-expression : statement
default : statement
identifier : statement
control-statement:
break ;
continue ;
return expressionopt ;
goto identifier ;
statement-list:
statement statement-listopt
condition:
expression
type-specifier declarator = expression
for-init-statement:
expressionopt ;
type-specifier declarator = expression ;
handler-list:
catch ( exception-declaration ) { statement-listopt }
handler-list handler-listopt
Note that a declaration is a statement and that there is no assignment statement or procedure call statement; assignments and function calls are expressions. More information:
• Iteration (for and while); see §4.4.2.
• Selection (if, switch, case, and break); see §4.4.1. A break “breaks out of” the nearest enclosing switch-statement, while-statement, do-statement, or for-statement; that is, the next statement executed will be the statement following that enclosing statement.
• Expressions; see §A.5, §4.3.
• Declarations; see §A.6, §8.2.
• Exceptions (try and catch); see §5.6, §19.4.
Here is an example concocted simply to demonstrate a variety of statements (what does it do?):
int* f(int p[], int n)
{
if (p==0) throw Bad_p(n);
vector<int> v;
int x;
while (cin>>x) {
if (x==terminator) break; // exit while loop
v.push_back(x);
}
for (int i = 0; i<v.size() && i<n; ++i) {
if (v[i]==*p)
return p;
else
++p;
}
return 0;
}
A.7 Declarations
A declaration consists of three parts:
• The name of the entity being declared
• The type of the entity being declared
• The initial value of the entity being declared (optional in most cases)
We can declare
• Objects of built-in types and user-defined types (§A.8)
• User-defined types (classes and enumerations) (§A.10-11, Chapter 9)
• Templates (class templates and function templates) (§A.13)
• Aliases (§A.16)
• Namespaces (§A.15, §8.7)
• Functions (including member functions and operators) (§A.9, Chapter 8)
• Enumerators (values for enumerations) (§A.11, §9.5)
• Macros (§A.17.2, §27.8)
The initializer can be a { }-delimited list of expressions with zero or more elements (§3.9.2, §9.4.2, §18.2). For example:
vector<int> v {a,b,c,d};
int x {y*z};
If the type of the object in a definition is auto, the object must be initialized and the type is the type of the initializer (§13.3, §21.2). For example:
auto x = 7; // x is an int
const auto pi = 3.14; // pi is a double
for (const auto& x : v) // x is a reference to an element of v
A.7.1 Definitions
A declaration that initializes, sets aside memory, or in other ways provides all the information necessary for using a name in a program is called a definition. Each type, object, and function in a program must have exactly one definition. Examples:
double f(); // a declaration
double f() { /* . . . */ }; // (also) a definition
extern const int x; // a declaration
int y; // (also) a definition
int z = 10; // a definition with an explicit initializer
A const must be initialized. This is achieved by requiring an initializer for a const unless it has an explicit extern in its declaration (so that the initializer must be on its definition elsewhere) or it is of a type with a default constructor (§A.12.3). Class members that are consts must be initialized in every constructor using a member initializer (§A.12.3).
A.8 Built-in types
C++ has a host of fundamental types and types constructed from fundamental types using modifiers:

Here, T indicates “some type,” so you can have a long unsigned int, a long double, an unsigned char, and a const char * (pointer to constant char). However, this system is not perfectly general; for example, there is no short double (that would have been a float), no signed bool (that would have been meaningless), no short long int (that would have been redundant), and no long long long long int. A long long is guaranteed to hold at least 64 bits.
The floating-point types are float, double, and long double. They are C++’s approximation of real numbers.
The integer types (sometimes called integral types) are bool, char, short, int, long, and long long and their unsigned variants. Note that an enumeration type or value can often be used where an integer type or value is needed.
The sizes of built-in types are discussed in §3.8, §17.3.1, and §25.5.1. Pointers and arrays are discussed in Chapters 17 and 18. References are discussed in §8.5.4-6.
A.8.1 Pointers
A pointer is an address of an object or a function. Pointers are stored in variables of pointer types. A valid object pointer holds the address of an object:
int x = 7;
int* pi = &x; // pi points to x
int xx = *pi; // *pi is the value of the object pointed to by pi, that is, 7
An invalid pointer is a pointer that does not hold the value of an object:
int* pi2; // uninitialized
*pi2 = 7; // undefined behavior
pi2 = nullptr; // the null pointer (pi2 is still invalid)
*pi2 = 7; // undefined behavior
pi2 = new int(7); // now pi2 is valid
int xxx = *pi2; // fine: xxx becomes 7
We try to have invalid pointers hold the null pointer (nullptr) so that we can test it:
if (p2 == nullptr) { // “if invalid”
// don’t use *p2
}
Or simply
if (p2) { // “if valid”
// use *p2
}
See §17.4 and §18.6.4.
The operations on a (non-void) object pointer are:

Note that any form of pointer arithmetic (e.g., ++p and p+=7) is allowed only for pointers into an array and that the effect of dereferencing a pointer pointing outside the array is undefined (and most likely not checked by the compiler or the language run-time system). The comparisons <, <=,>, and >= can also be used for pointers of the same type into the same object or array.
The only operations on a void* pointer are copying (assignment or initialization), casting (type conversion), and comparison (==, !=, <, <=, >, and >=).
A pointer to function (§27.2.5) can only be copied and called. For example:
using Handle_type = void (*)(int);
void my_handler(int);
Handle_type handle = my_handler;
handle(10); // equivalent to my_handler(10)
A.8.2 Arrays
An array is a fixed-length contiguous sequence of objects (elements) of a given type:
int a[10]; // 10 ints
If an array is global, its elements will be initialized to the appropriate default value for the type. For example, the value of a[7] will be 0. If the array is local (a variable declared in a function) or allocated using new, elements of built-in types will be uninitialized and elements of class types will be initialized as required by the class’s constructors.
The name of an array is implicitly converted to a pointer to its first element. For example:
int* p = a; // p points to a[0]
An array or a pointer to an element of an array can be subscripted using the [ ] operator. For example:
a[7] = 9;
int xx = p[6];
Array elements are numbered starting with 0; see §18.6.
Arrays are not range checked, and since they are often passed as pointers, the information to range check them is not reliably available to users. Prefer vector.
The size of an array is the sum of the sizes of its elements. For example:
int a[max]; // sizeof(a); that is, sizeof(int)*max
You can define and use an array of an array (a two-dimensional array), an array of an array of an array, etc. (multidimensional arrays). For example:
double da[100][200][300]; // 300 elements of type
// 200 elements of type
// 100 type double
da[7][9][11] = 0;
Nontrivial uses of multidimensional arrays are subtle and error-prone; see §24.4. If you have a choice, prefer a Matrix library (such as the one in Chapter 24).
A.8.3 References
A reference is an alias (alternative name) for an object:
int a = 7;
int& r = a;
r = 8; // a becomes 8
References are most common as function parameters, where they are used to avoid copying:
void f(const string& s);
// . . .
f("this string could be somewhat costly to copy, so we use a reference");
See §8.5.4-6.
A.9 Functions
A function is a named piece of code taking a (possibly empty) set of arguments and optionally returning a value. A function is declared by giving the return type followed by its name followed by the parameter list:
char f(string, int);
So, f is a function taking a string and an int returning a char. If the function is just being declared, the declaration is terminated by a semicolon. If the function is being defined, the argument declaration is followed by the function body:
char f(string s, int i) { return s[i]; }
The function body must be a block (§8.2) or a try-block (§5.6.3).
A function declared to return a value must return a value (using the return-statement):
char f(string s, int i) { char c = s[i]; } // error: no value returned
The main() function is the odd exception to that rule (§A.1.2). Except for main(), if you don’t want to return a value, declare the function void; that is, use void as the “return type”:
void increment(int& x) { ++x; } // OK: no return value required
A function is called using the call operator (application operator), ( ), with an acceptable list of arguments:
char x1 = f(1,2); // error: f()’s first argument must be a string
string s = "Battle of Hastings";
char x2 = f(s); // error: f() requires two arguments
char x3 = f(s,2); // OK
For more information about functions, see Chapter 8.
A function definition can be prefixed with constexpr. In that case, it must be simple enough for the compiler to evaluate when called with constant expression arguments. A constexpr function can be used in a constant expression (§8.5.9).
A.9.1 Overload resolution
Overload resolution is the process of choosing a function to call based on a set of arguments. For example:
void print(int);
void print(double);
void print(const std::string&);
print(123); // use print(int)
print(1.23); // use print(double)
print("123"); // use print(const string&)
It is the compiler’s job to pick the right function according to the language rules. Unfortunately, in order to cope with complicated examples, the language rules are quite complicated. Here we present a simplified version.
Finding the right version to call from a set of overloaded functions is done by looking for a best match between the type of the argument expressions and the parameters (formal arguments) of the functions. To approximate our notions of what is reasonable, a series of criteria is tried in order:
1. Exact match, that is, match using no or only trivial conversions (for example, array name to pointer, function name to pointer to function, and T to const T)
2. Match using promotions, that is, integral promotions (bool to int, char to int, short to int, and their unsigned counterparts; see §A.8) and float to double
3. Match using standard conversions, for example, int to double, double to int, double to long double, Derived* to Base* (§14.3), T* to void* (§17.8), int to unsigned int (§25.5.3)
4. Match using user-defined conversions (§A.5.2.3)
5. Match using the ellipsis . . . in a function declaration (§A.9.3)
If two matches are found at the highest level where a match is found, the call is rejected as ambiguous. The resolution rules are this elaborate primarily to take into account the elaborate rules for built-in numeric types (§A.5.3).
For overload resolution based on multiple arguments, we first find the best match for each argument. If one function is at least as good a match as all other functions for every argument and is a better match than all other functions for one argument, that function is chosen; otherwise the call is ambiguous. For example:
void f(int, const string&, double);
void f(int, const char*, int);
f(1,"hello",1); // OK: call f(int, const char*, int)
f(1,string("hello"),1.0); // OK: call f(int, const string&, double)
f(1, "hello",1.0); // error: ambiguous
In the last call, the "hello" matches const char* without a conversion and const string& only with a conversion. On the other hand, 1.0 matches double without a conversion, but int only with a conversion, so neither f() is a better match than the other.
If these simplified rules don’t agree with what your compiler says and what you thought reasonable, please first consider if your code is more complicated than necessary. If so, simplify your code; if not, consult an expert-level reference.
A.9.2 Default arguments
A general function sometimes needs more arguments than are needed for the most common cases. To handle that, a programmer may provide default arguments to be used if a caller of a function doesn’t specify an argument. For example:
void f(int, int=0, int=0);
f(1,2,3);
f(1,2); // calls f(1,2,0)
f(1); // calls f(1,0,0)
Only trailing arguments can be defaulted and left out in a call. For example:
void g(int, int =7, int); // error: default for non-trailing argument
f(1,,1); // error: second argument missing
Overloading can be an alternative to using default arguments (and vice versa).
A.9.3 Unspecified arguments
It is possible to specify a function without specifying the number or types of its arguments. This is indicated by an ellipsis (. . .), meaning “and possibly more arguments.” For example, here is the declaration of and some calls to what is arguably the most famous C function, printf() (§27.6.1, §B.11.2):
void printf(const char* format ...); // takes a format string and maybe more
int x = 'x';
printf("hello, world!");
printf("print a char '%c'\n",x); // print the int x as a char
printf("print a string \"%s\"",x); // shoot yourself in the foot
The “format specifiers” in the format string, such as %c and %s, determine if and how further arguments are used. As demonstrated, this can lead to nasty type errors. In C++, unspecified arguments are best avoided.
A.9.4 Linkage specifications
C++ code is often used in the same program as C code; that is, parts of a program are written in C++ (and compiled by a C++ compiler) and other parts in C (and compiled by a C compiler). To ease that, C++ offers linkage specifications for the programmer to say that a function obeys C linkage conventions. A C linkage specification can be placed in front of a function declaration:
extern "C" void callable_from_C(int);
Alternatively it can apply to all declarations in a block:
extern "C" {
void callable_from_C(int);
int and_this_one_also(double, int*);
/* . . . */
}
For details of use, see §27.2.3.
C doesn’t offer function overloading, so you can put a C linkage specification on at most one version of a C++ overloaded function.
A.10 User-defined types
There are two ways for a programmer to define a new (user-defined) type: as a class (class, struct, or union; see §A.12) and as an enumeration (enum; see §A.11).
A.10.1 Operator overloading
A programmer can define the meaning of most operators to take operands of one or more user-defined types. It is not possible to change the standard meaning of an operator for built-in types or to introduce a new operator. The name of a user-defined operator (“overloaded operator”) is the operator prefixed by the keyword operator; for example, the name of a function defining + is operator +:
Matrix operator+(const Matrix&, const Matrix&);
For examples, see std::ostream (Chapters 10-11), std::vector (Chapters 17-19, §B.4), std::complex (§B.9.3), and Matrix (Chapter 24).
All but the following operators can be user-defined:
?: . .* :: sizeof typeid alignas noexcept
Functions defining the following operators must be members of a class:
= [ ] ( ) ->
All other operators can be defined as member functions or as freestanding functions.
Note that every user-defined type has = (assignment and initialization), & (address of), and , (comma) defined by default.
Be restrained and conventional with operator overloading.
A.11 Enumerations
An enumeration defines a type with a set of named values (enumerators):
enum Color { green, yellow, red }; // “plain” enumeration
enum class Traffic_light { yellow, red, green }; // scoped enumeration
The enumerators of an enum class are in the scope of the enumeration, whereas the enumerators of a “plain” enum are exported to the scope of the enum. For example:
Color col = red; // OK
Traffic_light tl = red; // error: cannot convert integer value
// (i.e., Color::red) to Traffic_light
By default the value of the first enumerator is 0, so that Color::green==0, and the values increase by one, so that Color’s yellow==1 and red==2. It is also possible to explicitly define the value of an enumerator:
enum Day { Monday=1, Tuesday, Wednesday };
Here, we get Monday==1, Tuesday==2, and Wednesday==3.
Enumerators and enumeration values of a “plain” enum implicitly convert to integers, but integers do not implicitly convert to enumeration types:
int x = green; // OK: implicit Color-to-int conversion
Color c = green; // OK
c = 2; // error: no implicit int-to-Color conversion
c = Color(2); // OK: (unchecked) explicit conversion
int y = c; // OK: implicit Color-to-int conversion
Enumerators and enumeration values of an enum class do not convert to integers, and integers do not implicitly convert to enumeration types:
int x = Traffic_light::green; // error: no implicit Traffic_light-to-int conversion
Traffic_light c = green; // error: no implicit int-to-Traffic_light conversion
For a discussion of the uses of enumerations, see §9.5.
A.12 Classes
A class is a type for which the user defines the representation of its objects and the operations allowed on those objects:
class X {
public:
// user interface
private:
// implementation
};
A variable, function, or type defined within a class declaration is called a member of the class. See Chapter 9 for class technicalities.
A.12.1 Member access
A public member can be accessed by users; a private member can be accessed only by the class’s own members:
class Date {
public:
// . . .
int next_day();
private:
int y, m, d;
};
void Date::next_day() { return d+1; } // OK
void f(Date d)
{
int nd = d.d+1; // error: Date::d is private
// . . .
}
A struct is a class where members are by default public:
struct S {
// members (public unless explicitly declared private)
};
For more details of member access, including a discussion of protected, see §14.3.4.
Members of an object can be accessed through a variable or referenced using the . (dot) operator or through a pointer using the -> (arrow) operator:
struct Date {
int d, m, y;
int day() const { return d; } // defined in-class
int month() const; // just declared; defined elsewhere
int year() const; // just declared; defined elsewhere
};
Date x;
x.d = 15; // access through variable
int y = x.day(); // call through variable
Date* p = &x;
p->m = 7; // access through pointer
int z = p->month(); // call through pointer
Members of a class can be referred to using the :: (scope resolution) operator:
int Date::year() const { return y; } // out-of-class definition
Within a member function, we can refer to other members by their unqualified name:
struct Date {
int d, m, y;
int day() const { return d; }
// . . .
};
Such unqualified names refer to the member of the object for which the member function was called:
void f(Date d1, Date d2)
{
d1.day(); // will access d1.d
d2.day(); // will access d2.d
// . . .
}
A.12.1.1 The this pointer
If we want to be explicit when referring to the object for which the member function is called, we can use the predefined pointer this:
struct Date {
int d, m, y;
int month() const { return this->m; }
// . . .
};
A member function declared const (a const member function) cannot modify the value of a member of the object for which it is called:
struct Date {
int d, m, y;
int month() const { ++m; } // error: month() is const
// . . .
};
For more information about const member functions, see §9.7.4.
A.12.1.2 Friends
A function that is not a member of a class can be granted access to all members through a friend declaration. For example:
// needs access to Matrix and Vector members:
Vector operator*(const Matrix&, const Vector&);
class Vector {
friend
Vector operator*(const Matrix&, const Vector&); // grant access
// . . .
};
class Matrix {
friend
Vector operator*(const Matrix&, const Vector&); // grant access
// . . .
};
As shown, this is usually done for functions that need to access two classes. Another use of friend is to provide an access function that should not be called using the member access syntax. For example:
class Iter {
public:
int distance_to(const iter& a) const;
friend int difference(const Iter& a, const Iter& b);
// . . .
};
void f(Iter& p, Iter& q)
{
int x = p.distance_to(q); // invoke using member syntax
int y = difference(p,q); // invoke using “mathematical syntax”
// . . .
}
Note that a function declared friend cannot also be declared virtual.
A.12.2 Class member definitions
Class members that are integer constants, functions, or types can be defined/initialized either in-class (§9.7.3) or out-of-class (§9.4.4):
struct S {
int c = 1;
int c2;
void f() { }
void f2();
struct SS { int a; };
struct SS2;
};
The members that were not defined in-class must be defined “elsewhere”:
int S::c2 = 7;
void S::f2() { }
struct S::SS2 { int m; };
If you want to initialize a data member with a value specified by the creator of an object, do it in a constructor.
Function members do not occupy space in an object:
struct S {
int m;
void f();
};
Here, sizeof(S)==sizeof(int). That’s not actually guaranteed by the standard, but it is true for all implementations we know of. But note that a class with a virtual function has one “hidden” member to allow virtual calls (§14.3.1).
A.12.3 Construction, destruction, and copy
You can define the meaning of initialization for an object of a class by defining one or more constructors. A constructor is a member function with the same name as its class and no return type:
class Date {
public:
Date(int yy, int mm, int dd) :y{yy}, m{mm}, d{dd} { }
// . . .
private:
int y,m,d;
};
Date d1 {2006,11,15}; // OK: initialization done by the constructor
Date d2; // error: no initializers
Date d3 {11,15}; // error: bad initializers (three initializers required)
Note that data members can be initialized by using an initializer list in the constructor (a base and member initializer list). Members will be initialized in the order in which they are declared in the class.
Constructors are typically used to establish a class’s invariant and to acquire resources (§9.4.2-3).
Class objects are constructed “from the bottom up,” starting with base class objects (§14.3.1) in declaration order, followed by members in declaration order, followed by the code in the constructor itself. Unless the programmer does something really strange, this ensures that every object is constructed before use.
Unless declared explicit, a single-argument constructor defines an implicit conversion from its argument type to its class:
class Date {
public:
Date(const char*);
explicit Date(long); // use an integer encoding of Date
// . . .
};
void f(Date);
Date d1 = "June 5, 1848"; // OK
f("June 5, 1848"); // OK
Date d2 = 2007*12*31+6*31+5; // error: Date(long) is explicit
f(2007*12*31+6*31+5); // error: Date(long) is explicit
Date d3(2007*12*31+6*31+5); // OK
Date d4 = Date{2007*12*31+6*31+5}; // OK
f(Date{2007*12*31+6*31+5}); // OK
Unless a class has bases or members that require explicit arguments, and unless the class has other constructors, a default constructor is automatically generated. This default constructor initializes each base or member that has a default constructor (leaving members without default constructors uninitialized). For example:
struct S {
string name, address;
int x;
};
This S has an implicit constructor S{} that initializes name and address, but not x. In addition, a class without a constructor can be initialized using an initializer list:
S s1 {"Hello!"}; // s1 becomes { "Hello! ",0}
S s2 {"Howdy!", 3};
S* p = new S{"G'day!"}; // *p becomes {"G'day",0};
As shown, trailing unspecified values become the default value (here, 0 for the int).
A.12.3.1 Destructors
You can define the meaning of an object being destroyed (e.g., going out of scope) by defining a destructor. The name of a destructor is ~ (the complement operator) followed by the class name:
class Vector { // vector of doubles
public:
explicit Vector(int s) : sz{s}, p{new double[s]} { } // constructor
~Vector() { delete[] p; } // destructor
// . . .
private:
int sz;
double* p;
};
void f(int ss)
{
Vector v(s);
// . . .
} // v will be destroyed upon exit from f(); Vector’s destructor will be called for v
Destructors that invoke the destructors of members of a class can be generated by the compiler, and if a class is to be used as a base class, it usually needs a virtual destructor; see §17.5.2.
A destructor is typically used to “clean up” and release resources.
Class objects are destructed “from the top down” starting with the code in the destructor itself, followed by members in declaration order, followed by the base class objects in declaration order, that is, in reverse order of construction.
A.12.3.2 Copying
You can define the meaning of copying an object of a class:
class Vector { // vector of doubles
public:
explicit Vector(int s) : sz{s}, p{new double[s]} { } // constructor
~Vector() { delete[] p; } // destructor
Vector(const Vector&); // copy constructor
Vector& operator=(const Vector&); // copy assignment
// . . .
private:
int sz;
double* p;
};
void f(int ss)
{
Vector v(ss);
Vector v2 = v; // use copy constructor
// . . .
v = v2; // use copy assignment
// . . .
}
By default (that is, unless you define a copy constructor and a copy assignment), the compiler will generate copy operations for you. The default meaning of copy is memberwise copy; see also §14.2.4 and §18.3.
A.12.3.3 Moving
You can define the meaning of moving an object of a class:
class Vector { // vector of doubles
public:
explicit Vector(int s) : sz{s}, p{new double[s]} { } // constructor
~Vector() { delete[] p; } // destructor
Vector(Vector&&); // move constructor
Vector& operator=(Vector&&); // move assignment
// . . .
private:
int sz;
double* p;
};
Vector f(int ss)
{
Vector v(ss);
// . . .
return v; // use move constructor
}
By default (that is, unless you define a copy constructor and a copy assignment), the compiler will generate move operations for you. The default meaning of move is memberwise move; see also §18.3.4.
A.12.4 Derived classes
A class can be defined as derived from other classes, in which case it inherits the members of the classes from which it is derived (its base classes):
struct B {
int mb;
void fb() { };
};
class D : B {
int md;
void fd();
};
Here B has two members, mb and fb(), whereas D has four members, mb, fb(), md, and fd().
Like members, bases can be public or private:
Class DD : public B1, private B2 {
// . . .
};
So, the public members of B1 become public members of DD, whereas the public members of B2 become private members of DD. A derived class has no special access to members of its bases, so DD does not have access to the private members of B1 or B2.
A class with more than one direct base class (such as DD) is said to use multiple inheritance.
A pointer to a derived class, D, can be implicitly converted to a pointer to its base class, B, provided B is accessible and is unambiguous in D. For example:
struct B { };
struct B1: B { }; // B is a public base of B1
struct B2: B { }; // B is a public base of B2
struct C { };
struct DD : B1, B2, private C { };
DD* p = new DD;
B1* pb1 = p; // OK
B* pb = p; // error: ambiguous: B1::B or B2::B
C* pc = p; // error: DD::C is private
Similarly, a reference to a derived class can be implicitly converted to an unambiguous and accessible base class.
For more information about derived classes, see §14.3. For more information about protected, see an expert-level textbook or reference.
A.12.4.1 Virtual functions
A virtual function is a member function that defines a calling interface to functions of the same name taking the same argument types in derived classes. When calling a virtual function, the function invoked by the call will be the one defined for the most derived class. The derived class is said to override the virtual function in the base class.
class Shape {
public:
virtual void draw(); // virtual means “can be overridden”
virtual ~Shape() { } // virtual destructor
// . . .
};
class Circle : public Shape {
public:
void draw(); // override Shape::draw
~Circle(); // override Shape::~Shape()
// . . .
};
Basically, the virtual functions of a base class (here, Shape) define a calling interface for the derived class (here, Circle):
void f(Shape& s)
{
// . . .
s.draw();
}
void g()
{
Circle c{Point{0,0}, 4};
f(c); // will call Circle’s draw
}
Note that f() doesn’t know about Circles, only about Shapes. An object of a class with a virtual function contains one extra pointer to allow it to find the set of overriding functions; see §14.3.
Note that a class with virtual functions usually needs a virtual destructor (as Shape has); see §17.5.2.
The wish to override a base class’s virtual function can be made explicit using the override suffix. For example:
class Square : public Shape {
public:
void draw() override; // override Shape::draw
~Circle() override; // override Shape::~Shape()
void silly() override; // error: Shape does not have a virtual Shape::silly()
// . . .
};
A.12.4.2 Abstract classes
An abstract class is a class that can be used only as a base class. You cannot make an object of an abstract class:
Shape s; // error: Shape is abstract
class Circle : public Shape {
public:
void draw(); // override Shape::draw
// . . .
};
Circle c{p,20}; // OK: Circle is not abstract
The most common way of making a class abstract is to define at least one pure virtual function. A pure virtual function is a virtual function that requires overriding:
class Shape {
public:
virtual void draw() = 0; // =0 means “pure”
// . . .
};
See §14.3.5.
The rarer, but equally effective, way of making a class abstract is to declare all its constructors protected (§14.2.1).
A.12.4.3 Generated operations
When you define a class, it will by default have several operations defined for its objects:
• Default constructor
• Copy operations (copy assignment and copy initialization)
• Move operations (move assignment and move initialization)
• Destructor
Each is (again by default) defined to apply recursively to each of its base classes and members. Construction is done “bottom-up,” that is, bases before members. Destruction is done “top-down,” that is, members before bases. Members and bases are constructed in order of appearance and destroyed in the opposite order. That way, constructor and destructor code always relies on well-defined base and member objects. For example:
struct D : B1, B2 {
M1 m1;
M2 m2;
};
Assuming that B1, B2, M1, and M2 are defined, we can now write
D f()
{
D d; // default initialization
D d2 = d; // copy initialization
d = D{}; // default initialization followed by copy assignment
return d; // d is moved out of f()
} // d and d2 are destroyed here
For example, the default initialization of d invokes four default constructors (in order): B1::B1(), B2::B2(), M1::M1(), and M2::M2(). If one of those doesn’t exist or can’t be called, the construction of d fails. At the return, four move constructors are invoked (in order): B1::B1(), B2::B2(),M1::M1(), and M2::M2(). If one of those doesn’t exist or can’t be called, the return fails. The destruction of d invokes four destructors (in order): M2::~M2(), M1::~M1(), B2::~B2(), and B1::~B1(). If one of those doesn’t exist or can’t be called, the destruction of d fails. Each of these constructors and destructors can be either user-defined or generated.
The implicit (compiler-generated) default constructor is not defined (generated) if a class has a user-defined constructor.
A.12.5 Bitfields
A bitfield is a mechanism for packing many small values into a word or to match an externally imposed bit-layout format (such as a device register). For example:
struct PPN { // R6000 Physical Page Number
unsigned int PFN : 22 ; // Page Frame Number
int : 3 ; // unused
unsigned int CCA : 3 ; // Cache Coherency Algorithm
bool nonreachable : 1 ;
bool dirty : 1 ;
bool valid : 1 ;
bool global : 1 ;
};
Packing the bitfields into a word left to right leads to a layout of bits in a word like this (see §25.5.5):

A bitfield need not have a name, but if it doesn’t, you can’t access it.
Surprisingly, packing many small values into a single word does not necessarily save space. In fact, using one of those values often wastes space compared to using a char or an int to represent even a single bit. The reason is that it takes several instructions (which have to be stored in memory somewhere) to extract a bit from a word and to write a single bit of a word without modifying other bits of a word. Don’t try to use bitfields to save space unless you need lots of objects with tiny data fields.
A.12.6 Unions
A union is a class where all members are allocated starting at the same address. A union can hold only one element at a time, and when a member is read it must be the same as was last written. For example:
union U {
int x;
double d;
}
U a;
a.x = 7;
int x1 = a.x; // OK
a.d = 7.7;
int x2 = a.x; // oops
The rule requiring consistent reads and writes is not checked by the compiler. You have been warned.
A.13 Templates
A template is a class or a function parameterized by a set of types and/or integers:
template<typename T>
class vector {
public:
// . . .
int size() const;
private:
int sz;
T* p;
};
template<class T>
int vector<T>::size() const
{
return sz;
}
In a template argument list, class means type; typename is an equivalent alternative. A member function of a template class is implicitly a template function with the same template arguments as its class.
Integer template arguments must be constant expressions:
template<typename T, int sz>
class Fixed_array {
public:
T a[sz];
// . . .
int size() const { return sz; };
};
Fixed_array<char,256> x1; // OK
int var = 226;
Fixed_array<char,var> x2; // error: non-const template argument
A.13.1 Template arguments
Arguments for a template class are specified whenever its name is used:
vector<int> v1; // OK
vector v2; // error: template argument missing
vector<int,2> v3; // error: too many template arguments
vector<2> v4; // error: type template argument expected
Arguments for template functions are typically deduced from the function arguments:
template<class T>
T find(vector<T>& v, int i)
{
return v[i];
}
vector<int> v1;
vector<double> v2;
// . . .
int x1 = find(v1,2); // find()’s T is int
int x2 = find(v2,2); // find()’s T is double
It is possible to define a template function for which it is not possible to deduce its template arguments from its function arguments. In that case we must specify the missing template arguments explicitly (exactly as for class templates). For example:
template<class T, class U> T* make(const U& u) { return new T{u}; }
int* pi = make<int>(2);
Node* pn = make<Node>(make_pair("hello",17));
This works if a Node can be initialized by a pair<const char *,int> (§B.6.3). Only trailing template arguments can be left out of an explicit argument specialization (to be deduced).
A.13.2 Template instantiation
A version of a template for a specific set of template arguments is called a specialization. The process of generating specializations from a template and a set of arguments is called template instantiation. Usually, the compiler generates a specialization from a template and a set of template arguments, but the programmer can also define a specific specialization. This is usually done when a general template is unsuitable for a particular set of arguments. For example:
template<class T> struct Compare { // general compare
bool operator()(const T& a, const T& b) const
{
return a<b;
}
};
template<> struct Compare<const char*> { // compare C-style strings
bool operator()(const char* a, const char* b) const
{
return strcmp(a,b)==0;
}
};
Compare<int> c2; // general compare
Compare<const char*> c; // C-style string compare
bool b1 = c2(1,2); // use general compare
bool b2 = c("asd","dfg"); // use C-style string compare
For functions, the rough equivalent is achieved through overloading:
template<class T> bool compare(const T& a, const T& b)
{
return a<b;
}
bool compare (const char* a, const char* b) // compare C-style strings
{
return strcmp(a,b)==0;
}
bool b3 = compare(2,3); // use general compare
bool b4 = compare("asd","dfg"); // use C-style string compare
Separate compilation of templates (i.e., keeping declarations only in header files and unique definitions in .cpp files) does not work portably, so if a template needs to be used in several .cpp files, put its complete definition in a header file.
A.13.3 Template member types
A template can have members that are types and members that are not types (such as data members and member functions). This means that in general, it can be hard to tell whether a member name refers to a type or to a non-type. For language-technical reasons, the compiler has to know, so occasionally we must tell it. For that, we use the keyword typename. For example:
template<class T> struct Vec {
typedef T value_type; // a member type
static int count; // a data member
// . . .
};
template<class T> void my_fct(Vec<T>& v)
{
int x = Vec<T>::count; // by default member names
// are assumed to refer to non-types
v.count = 7; // a simpler way to refer to a non-type member
typename Vec<T>::value_type xx = x; // typename is needed here
// . . .
}
For more information about templates, see Chapter 19.
A.14 Exceptions
An exception is used (with a throw statement) to tell a caller about an error that cannot be handled locally. For example, move Bad_size out of Vector:
struct Bad_size {
int sz;
Bad_size(int s) : ss{s} { }
};
class Vector {
Vector(int s) { if (s<0 || maxsize<s) throw Bad_size{s}; }
// . . .
};
Usually, we throw a type that is defined specifically to represent a particular error. A caller can catch an exception:
void f(int x)
{
try {
Vector v(x); // may throw
// . . .
}
catch (Bad_size bs) {
cerr << "Vector with bad size (" << bs.sz << ")\n";
// . . .
}
}
A “catch all” clause can be used to catch every exception:
try {
// . . .
} catch (. . .) { // catch all exceptions
// . . .
}
Usually, the RAII (“Resource Acquisition Is Initialization”) technique is better (simpler, easier, more reliable) than using lots of explicit trys and catches; see §19.5.
A throw without an argument (i.e., throw;) re-throws the current exception. For example:
try {
// . . .
} catch (Some_exception& e) {
// do local cleanup
throw; // let my caller do the rest
}
You can define your own types for use as exceptions. The standard library defines a few exception types that you can also use; see §B.2.1. Never use a built-in type as an exception (someone else might have done that and your exceptions might be confused with those).
When an exception is thrown, the run-time support system for C++ searches “up the call stack” for a catch-clause with a type that matches the type of the object thrown; that is, it looks through try-statements in the function that threw, then through the function that called the function that threw, then through the function that called the function that called, etc., until it finds a match. If it doesn’t find a match, the program terminates. In each function encountered in this search of a matching catch-clause and in each scope on the way, destructors are called to clean up. This process is called stack unwinding.
An object is considered constructed once its constructor has completed and will then be destroyed during unwinding or any other exit from its scope. This implies that partially constructed objects (with some members or bases constructed and some not), arrays, and variables in a scope are correctly handled. Sub-objects are destroyed if and only if they have been constructed.
Do not throw an exception so that it leaves a destructor. This implies that a destructor should not fail. For example:
X::~X() { if (in_a_real_mess()) throw Mess{}; } // never do this!
The primary reason for this Draconian advice is that if a destructor throws (and doesn’t itself catch the exception) during unwinding, we wouldn’t know which exception to handle. It is worthwhile to go to great lengths to avoid a destructor exiting by a throw because we know of no systematic way of writing correct code where that can happen. In particular, no standard library facility is guaranteed to work if that happens.
A.15 Namespaces
A namespace groups related declarations together and is used to prevent name clashes:
int a;
namespace Foo {
int a;
void f(int i)
{
a+= i; // that’s Foo’s a (Foo::a)
}
}
void f(int);
int main()
{
a = 7; // that’s the global a (::a)
f(2); // that’s the global f (::f)
Foo::f(3); // that’s Foo’s f
::f(4); // that’s the global f (::f)
}
Names can be explicitly qualified by their namespace name (e.g., Foo::f(3)) or by :: (e.g., ::f(2)), indicating the global scope.
All names from a namespace (here, the standard library namespace, std) can be made accessible by a single namespace directive:
using namespace std;
Be restrained in the use of using directives. The notational convenience offered by a using directive is achieved at the cost of potential name clashes. In particular, avoid using directives in header files. A single name from a namespace can be made available by a namespace declaration:
using Foo::g;
g(2); // that’s Foo’s g (Foo::g)
For more information about namespaces, see §8.7.
A.16 Aliases
We can define an alias for a name; that is, we can define a symbolic name that means exactly the same as what it refers to (for most uses of the name):
using Pint = int*; // Pint means pointer to int
namespace Long_library_name { /* . . . */ }
namespace Lib = Long_library_name; // Lib means Long_library_name
int x = 7;
int& r = x; // r means x
A reference (§8.5.5, §A.8.3) is a run-time mechanism, referring to objects. The using (§20.5) and namespace aliases are compile-time mechanisms, referring to names. In particular, a using does not introduce a new type, just a new name for a type. For example:
using Pchar = char*; // Pchar is a name for char*
Pchar p = "Idefix"; // OK: p is a char*
char* q = p; // OK: p and q are both char*s
int x = strlen(p); // OK: p is a char*
Older code uses the keyword typedef (§27.3.1) rather than the (C++) using notation to define a type alias. For example:
typedef char* Pchar; // Pchar is a name for char*
A.17 Preprocessor directives
Every C++ implementation includes a preprocessor. In principle, the preprocessor runs before the compiler proper and transforms the source code we wrote into what the compiler sees. In reality, this action is integrated into the compiler and uninteresting except when it causes problems. Every line starting with # is a preprocessor directive.
A.17.1 #include
We have used the preprocessor extensively to include headers. For example:
#include "file.h"
This is a directive that tells the preprocessor to include the contents of file.h at the point of the source text where the directive occurs. For standard headers, we can also use < . . . > instead of " . . . ". For example:
#include<vector>
That is the recommended notation for standard header inclusion.
A.17.2 #define
The preprocessor implements a form of character manipulation called macro substitution. For example, we can define a name for a character string:
#define FOO bar
Now, whenever FOO is seen, bar will be substituted:
int FOO = 7;
int FOOL = 9;
Given that, the compiler will see
int bar = 7;
int FOOL = 9;
Note that the preprocessor knows enough about C++ names not to replace the FOO that’s part of FOOL.
You can also define macros that take parameters:
#define MAX(x,y) (((x)>(y))?(x) : (y))
And we can use it like this:
int xx = MAX(FOO+1,7);
int yy = MAX(++xx,9);
This will expand to
int xx = (((bar+1)>( 7))?(bar+1) : (7));
int yy = (((++xx)>( 9))?(++xx) : (9));
Note how the parentheses were necessary to get the right result for FOO+1. Also note that xx was incremented twice in a very non-obvious way. Macros are immensely popular — primarily because C programmers have few alternatives to using them. Common header files define thousands of macros. You have been warned!
If you must use macros, the convention is to name them using ALL_CAPITAL_LETTERS. No ordinary name should be in all capital letters. Don’t depend on others to follow this sound advice. For example, we have found a macro called max in an otherwise reputable header file.
See also §27.8.
All materials on the site are licensed Creative Commons Attribution-Sharealike 3.0 Unported CC BY-SA 3.0 & GNU Free Documentation License (GFDL)
If you are the copyright holder of any material contained on our site and intend to remove it, please contact our site administrator for approval.
© 2016-2026 All site design rights belong to S.Y.A.