Programming: Principles and Practice Using C++ (2014)
Part V: Appendices
B. Standard Library Summary
“All complexities should, if possible, be buried out of sight.”
—David J. Wheeler
This appendix summarizes key C++ standard library facilities. The summary is selective and geared to novices who want to get an overview of the standard library facilities and explore a bit beyond the sequence of topics in the book.
B.1 Overview
B.1.1 Header files
B.1.2 Namespace std
B.1.3 Description style
B.2 Error handling
B.2.1 Exceptions
B.3 Iterators
B.3.1 Iterator model
B.3.2 Iterator categories
B.4 Containers
B.4.1 Overview
B.4.2 Member types
B.4.3 Constructors, destructors, and assignments
B.4.4 Iterators
B.4.5 Element access
B.4.6 Stack and queue operations
B.4.7 List operations
B.4.8 Size and capacity
B.4.9 Other operations
B.4.10 Associative container operations
B.5 Algorithms
B.5.1 Nonmodifying sequence algorithms
B.5.2 Modifying sequence algorithms
B.5.3 Utility algorithms
B.5.4 Sorting and searching
B.5.5 Set algorithms
B.5.6 Heaps
B.5.7 Permutations
B.5.8 min and max
B.6 STL utilities
B.6.1 Inserters
B.6.2 Function objects
B.6.3 pair and tuple
B.6.4 initializer_list
B.6.5 Resource management pointers
B.7 I/O streams
B.7.1 I/O streams hierarchy
B.7.2 Error handling
B.7.3 Input operations
B.7.4 Output operations
B.7.5 Formatting
B.7.6 Standard manipulators
B.8 String manipulation
B.8.1 Character classification
B.8.2 String
B.8.3 Regular expression matching
B.9 Numerics
B.9.1 Numerical limits
B.9.2 Standard mathematical functions
B.9.3 Complex
B.9.4 valarray
B.9.5 Generalized numerical algorithms
B.9.6 Random numbers
B.10 Time
B.11 C standard library functions
B.11.1 Files
B.11.2 The printf() family
B.11.3 C-style strings
B.11.4 Memory
B.11.5 Date and time
B.11.6 Etc.
B.12 Other libraries
B.1 Overview
This appendix is a reference. It is not intended to be read from beginning to end like a chapter. It (more or less) systematically describes key elements of the C++ standard library. It is not a complete reference, though; it is just a summary with a few key examples. Often, you will need to look at the chapters for a more complete explanation. Note also that this summary does not attempt to equal the precision and terminology of the standard. For more information, see Stroustrup, The C++ Programming Language. The complete definition is the ISO C++ standard, but that document is not intended for or suitable for novices. Don’t forget to use your online documentation.
What use is a selective (and therefore incomplete) summary? You can quickly look for a known operation or quickly scan a section to see what common operations are available. You may very well have to look elsewhere for a detailed explanation, but that’s fine: now you have a clue as to what to look for. Also, this summary contains cross-references to tutorial material in the chapters. This appendix provides a compact overview of standard library facilities. Please do not try to memorize the information here; that’s not what it is for. On the contrary, this appendix is a tool that can save you from spurious memorization.
This is a place to look for useful facilities — instead of trying to invent them yourself. Everything in the standard library (and especially everything featured in this appendix) has been useful to large groups of people. A standard library facility is almost certainly better designed, better implemented, better documented, and more portable than anything you could design and implement in a hurry. So when you can, prefer a standard library facility over “home brew.” Doing so will also make your code easier for others to understand.
If you are a sensible person, you’ll find the sheer mass of facilities intimidating. Don’t worry; ignore what you don’t need. If you are a “details person,” you’ll find much missing. However, completeness is what the expert-level guides and your online documentation offer. In either case, you’ll find much that will seem mysterious, and possibly interesting. Explore some of it!
B.1.1 Header files
The interfaces to standard library facilities are defined in headers. Use this section to gain an overview of what is available and to help guess where a facility might be defined and described:







For each of the C standard library headers, there is also a version without the initial c in its name and with a trailing .h, such as <time.h> for <ctime>. The .h versions define global names rather than names in namespace std.
Some — but not all — of the facilities defined in these headers are described in the sections below and in the chapters. If you need more information, look at your online documentation or an expert-level C++ book.
B.1.2 Namespace std
The standard library facilities are defined in namespace std, so to use them, you need an explicit qualification, a using declaration, or a using directive:
std::string s; // explicit qualification
using std::vector; // using declaration
vector<int>v(7);
using namespace std; // using directive
map<string,double> m;
In this book, we have used the using directive for std. Be very frugal with using directives; see §A.15.
B.1.3 Description style
A full description of even a simple standard library operation, such as a constructor or an algorithm, can take pages. Consequently, we use an extremely abbreviated style of presentation. For example:

We try to be mnemonic in our choice of identifiers, so b,e will be iterators specifying a range, p a pointer or an iterator, and x some value, all depending on context. In this notation, only the commentary distinguishes no result from a Boolean result, so you can confuse those if you try hard enough. For an operation returning bool, the explanation usually ends with a question mark.
Where an algorithm follows the usual pattern of returning the end of an input sequence to indicate “failure,” “not found,” etc. (§B.3.1), we do not mention that explicitly.
B.2 Error handling
The standard library consists of components developed over a period of over 40 years. Thus, their style and approaches to error handling are not consistent.
• C-style libraries consist of functions, many of which set errno to indicate that an error happened; see §24.8.
• Many algorithms operating on a sequence of elements return an iterator to the one-past-the-last element to indicate “not found” or “failure.”
• The I/O streams library relies on a state in each stream to reflect errors and may (if the user requests it) throw exceptions to indicate errors; see §10.6, §B.7.2.
• Some standard library components, such as vector, string, and bitset, throw exceptions to indicate errors.
The standard library is designed so that all facilities obey “the basic guarantee” (see §19.5.3); that is, even if an exception is thrown, no resource (such as memory) is leaked and no invariant for a standard library class is broken.
B.2.1 Exceptions
Some standard library facilities report errors by throwing exceptions:

These exceptions may be encountered in any code that directly or indirectly uses these facilities. Unless you know that no facility is used in a way that could throw an exception, it is a good idea to always catch one of the root classes of the standard library exception hierarchy (such asexception) somewhere (e.g., in main()).
We strongly recommend that you do not throw built-in types, such as ints and C-style strings. Instead, throw objects of types specifically defined to be used as exceptions. A class derived from the standard library class exception can be used for that:
class exception {
public:
exception();
exception(const exception&);
exception& operator=(const exception&);
virtual ~exception();
virtual const char* what() const;
};
The what() function can be used to obtain a string that is supposed to indicate something about the error that caused the exception.
This hierarchy of standard exception classes may help by providing a classification of exceptions:
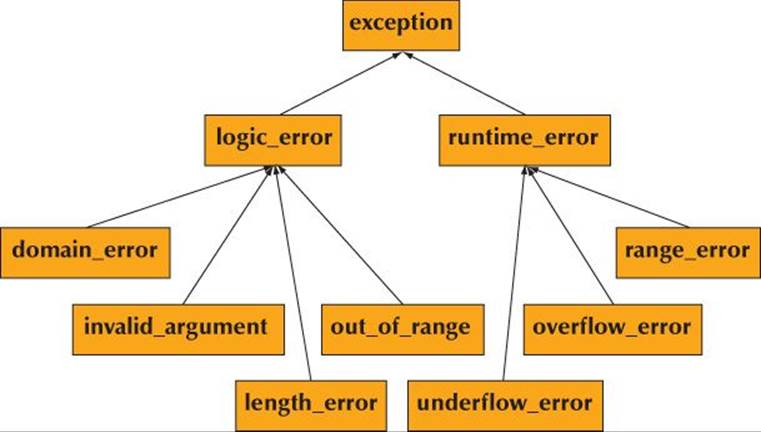
You can define an exception by deriving from a standard library exception like this:
struct My_error : runtime_error {
My_error(int x) : interesting_value{x} { }
int interesting_value;
const char* what() const override { return "My_error"; }
};
B.3 Iterators
Iterators are the glue that ties standard library algorithms to their data. Conversely, you can say that iterators are the mechanism used to minimize an algorithm’s dependence on the data structures on which it operates (§20.3):
B.3.1 Iterator model
An iterator is akin to a pointer in that it provides operations for indirect access (e.g., * for dereferencing) and for moving to a new element (e.g., ++ for moving to the next element). A sequence of elements is defined by a pair of iterators defining a half-open range [begin:end):
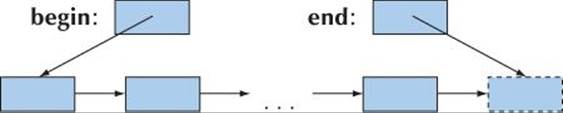
That is, begin points to the first element of the sequence and end points to one beyond the last element of the sequence. Never read from or write to *end. Note that the empty sequence has begin==end; that is, [p:p) is the empty sequence for any iterator p.
To read a sequence, an algorithm usually takes a pair of iterators (b,e) and iterates using ++ until the end is reached:
while (b!=e) { // use != rather than <
// do something
++b; // go to next element
}
Algorithms that search for something in a sequence usually return the end of the sequence to indicate “not found”; for example:
p = find(v.begin(),v.end(),x); // look for x in v
if (p!=v.end()) {
// x found at p
}
else {
// x not found in [v.begin():v.end())
}
See §20.3.
Algorithms that write to a sequence often are given only an iterator to its first element. In that case, it is the programmer’s responsibility not to write beyond the end of that sequence. For example:
template<class Iter> void f(Iter p, int n)
{
while (n>0) *p++ = --n;
}
vector<int> v(10);
f(v.begin(),v.size()); // OK
f(v.begin(),1000); // big trouble
Some standard library implementations range check — that is, throw an exception — for that last call of f(), but you can’t rely on that for portable code; many implementations don’t check.
The operations on iterators are:


Note that not every kind of iterator (§B.3.2) supports every iterator operation.
B.3.2 Iterator categories
The standard library provides five kinds of iterators (five “iterator categories”):

Logically, these iterators are organized in a hierarchy (§20.8):
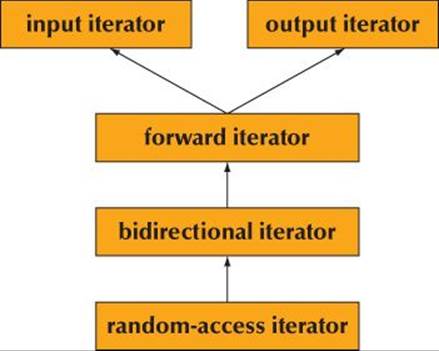
Note that since the iterator categories are not classes, this hierarchy is not a class hierarchy implemented using derivation. If you need to do something advanced with iterator categories, look for iterator_traits in an advanced reference.
Each container supplies iterators of a specified category:
• vector — random access
• list — bidirectional
• forward_list — forward
• deque — random access
• bitset — none
• set — bidirectional
• multiset — bidirectional
• map — bidirectional
• multimap — bidirectional
• unordered_set — forward
• unordered_multiset — forward
• unordered_map — forward
• unordered_multimap — forward
B.4 Containers
A container holds a sequence of objects. The elements of the sequence are of the member type called value_type. The most commonly useful containers are:


The ordered associative containers (map, set, etc.) have an optional additional template argument specifying the type used for the comparator; for example, set<K,C> uses a C to compare K values.

These containers are defined in <vector>, <list>, etc. (see §B.1.1). The sequence containers are contiguously allocated or linked lists of elements of their value_type (T in the notation used above). The associative containers are linked structures (trees) with nodes of their value_type (pair(K,V)in the notation used above). The sequence of a set, map, or multimap is ordered by its key values (K). The sequence of an unordered_* does not have a guaranteed order. A multimap differs from a map in that a key value may occur many times. Container adaptors are containers with specialized operations constructed from other containers.
If in doubt, use vector. Unless you have a solid reason not to, use vector.
A container uses an “allocator” to allocate and deallocate memory (§19.3.7). We do not cover allocators here; if necessary, see an expert-level reference. By default, an allocator uses new and delete when it needs to acquire or release memory for its elements.
Where meaningful, an access operation exists in two versions: one for const and one for non-const objects (§18.5).
This section lists the common and almost common members of the standard containers. For more details, see Chapter 20. Members that are peculiar to a specific container, such as list’s splice(), are not listed; see an expert-level reference.
Some data types provide much of what is required from a standard container, but not all. We sometimes refer to those as “almost containers.” The most interesting of those are:

B.4.1 Overview
The operations provided by the standard containers can be summarized like this:
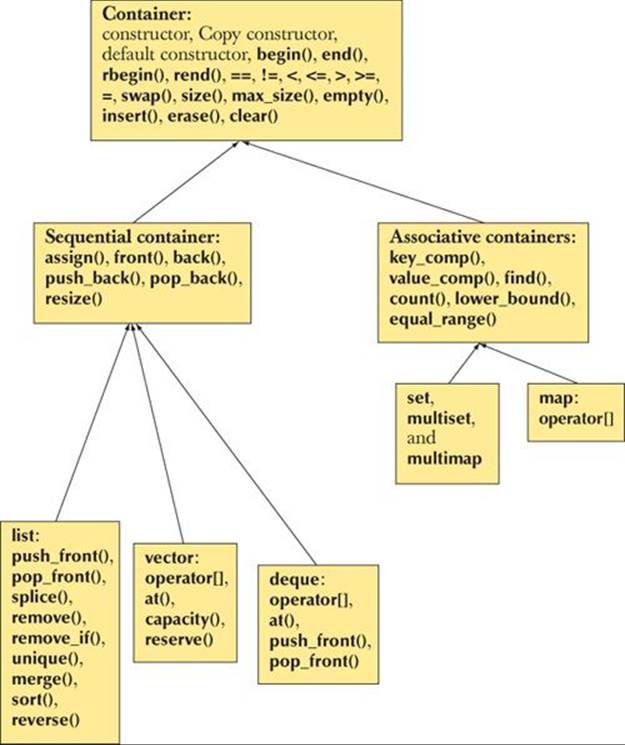
We left out array and forward_list because they are imperfect fits to the standard library ideal of interchangeability:
• array is not a handle, cannot have its number of elements changed after initialization, and must be initialized by an initializer list, rather than by a constructor.
• forward_list doesn’t support back operations. In particular, it has no size(). It is best seen as a container optimized for empty and near-empty sequences.
B.4.2 Member types
A container defines a set of member types:

B.4.3 Constructors, destructors, and assignments
Containers provide a variety of constructors and assignment operations. For a container called C (e.g., vector<double> or map<string,int>) we have:

Note that for some containers and some element types, a constructor or an element copy may throw an exception.
B.4.4 Iterators
A container can be viewed as a sequence either in the order defined by the container’s iterator or in reverse order. For an associative container, the order is based on the container’s comparison criterion (by default <):

B.4.5 Element access
Some elements can be accessed directly:

Some implementations — especially debug versions — always do range checking, but you cannot portably rely on that for correctness or on the absence of checking for performance. Where such issues are important, examine your implementations.
B.4.6 Stack and queue operations
The standard vector and deque provide efficient operations at the end (back) of their sequence of elements. In addition, list and deque provide the equivalent operations on the start (front) of their sequences:

Note that push_front() and push_back() copy an element into a container. This implies that the size of the container increases (by one). If the copy constructor of the element type can throw an exception, a push can fail.
The push_front() and push_back() operations copy their argument object into the container. For example:
vector<pair<string,int>> v;
v.push_back(make_pair("Cambridge",1209));
If first creating the object and then copying it seems awkward or potentially inefficient, we can construct the object directly in a newly allocated element slot of the sequence:
v.emplace_back("Cambridge",1209);
Emplace means “put in place” or “put in position.”
Note that pop operations do not return a value. Had they done so, a copy constructor throwing an exception could have seriously complicated the implementation. Use front() and back() (§B.4.5) to access stack and queue elements. We have not recorded the complete set of requirements here; feel free to guess (your compiler will usually tell you if you guessed wrong) and to consult more detailed documentation.
B.4.7 List operations
Containers provide list operations:

For insert() functions, the result, q, points to the last element inserted. For erase() functions, q points to the element that followed the last element erased.
B.4.8 Size and capacity
The size is the number of elements in the container; the capacity is the number of elements that a container can hold before allocating more memory:

When changing the size or the capacity, the elements may be moved to new storage locations. That implies that iterators (and pointers and references) to elements may become invalid (e.g., point to the old element locations).
B.4.9 Other operations
Containers can be copied (see §B.4.3), compared, and swapped:

When comparing containers with an operator (e.g., <), their elements are compared using the equivalent element operator (i.e., <).
B.4.10 Associative container operations
Associative containers provide lookup based on keys:

The first iterator of the pair returned by equal_range is lower_bound and the second is upper_bound. You can print the value of all elements with the key "Marian" in a multimap<string,int> like this:
string k = "Marian";
auto pp = m.equal_range(k);
if (pp.first!=pp.second)
cout << "elements with value '" << k << "':\n";
else
cout << "no element with value '" << k << "'\n";
for (auto p = pp.first; p!=pp.second; ++p)
cout << p->second << '\n';
We could equivalently have used
auto pp = make_pair(m.lower_bound(k),m.upper_bound(k));
However, that would take about twice as long to execute. The equal_range, lower_bound, and upper_bound algorithms are also provided for sorted sequences (§B.5.4). The definition of pair is in §B.6.3.
B.5 Algorithms
There are about 60 standard algorithms defined in <algorithm>. They all operate on sequences defined by a pair of iterators (for inputs) or a single iterator (for outputs).
When copying, comparing, etc. two sequences, the first is represented by a pair of iterators [b:e) but the second by just a single iterator, b2, which is considered the start of a sequence holding sufficient elements for the algorithm, for example, as many elements as the first sequence: [b2:b2+(e-b)).
Some algorithms, such as sort, require random-access iterators, whereas many, such as find, only read their elements in order so that they can make do with a forward iterator.
Many algorithms follow the usual convention of returning the end of a sequence to represent “not found.” We don’t mention that for each algorithm.
B.5.1 Nonmodifying sequence algorithms
A nonmodifying algorithm just reads the elements of a sequence; it does not rearrange the sequence and does not change the value of the elements:


Note that nothing stops the operation passed to for_each from modifying elements; that’s considered acceptable. Passing an operation that changes the elements it examines to some other algorithm (e.g., count or ==) is not acceptable.
An example (of proper use):
bool odd(int x) { return x&1; }
int n_even(const vector<int>& v) // count the number of even values in v
{
return v.size()-count_if(v.begin(),v.end(),odd);
}
B.5.2 Modifying sequence algorithms
The modifying algorithms (also called mutating sequence algorithms) can (and often do) modify the elements of their argument sequences.



A shuffle algorithm shuffles its sequence much in the way we would shuffle a pack of cards; that is, after a shuffle, the elements are in a random order, where “random” is defined by the distribution produced by the random number generator.
Please note that these algorithms do not know if their argument sequence is a container, so they do not have the ability to add or remove elements. Thus, an algorithm such as remove cannot shorten its input sequence by deleting (erasing) elements; instead, it (re)moves the elements it keeps to the front of the sequence:
template<typename Iter>
void print_digits(const string& s, Iter b, Iter e)
{
cout << s;
while (b!=e) { cout << *b; ++b; }
cout << '\n';
}
void ff()
{
vector<int> v {1,1,1, 2,2, 3, 4,4,4, 3,3,3, 5,5,5,5, 1,1,1};
print_digits("all: ",v.begin(), v.end());
auto pp = unique(v.begin(),v.end());
print_digits("head: ",v.begin(),pp);
print_digits("tail: ",pp,v.end());
pp=remove(v.begin(),pp,4);
print_digits("head: ",v.begin(),pp);
print_digits("tail: ",pp,v.end());
}
The resulting output is
all: 1112234443335555111
head: 1234351
tail: 443335555111
head: 123351
tail: 1443335555111
B.5.3 Utility algorithms
Technically, these utility algorithms are also modifying sequence algorithms, but we thought it a good idea to list them separately, lest they get overlooked.

Note that uninitialized sequences should occur only at the lowest level of programming, usually inside the implementation of containers. Elements that are targets of uninitialized_fill or uninitialized_copy must be of built-in type or uninitialized.
B.5.4 Sorting and searching
Sorting and searching are fundamental and the needs of programmers are quite varied. Comparison is by default done using the < operator, and equivalence of a pair of values a and b is determined by !(a<b)&&!(b<a) rather than requiring operator ==.



For example:
vector<int> v {3,1,4,2};
list<double> lst {0.5,1.5,3,2.5}; // lst is in order
sort(v.begin(),v.end()); // put v in order
vector<double> v2;
merge(v.begin(),v.end(),lst.begin(),lst.end(),back_inserter(v2));
for (auto x : v2) cout << x << ", ";
For inserters, see §B.6.1. The output is
0.5, 1, 1.5, 2, 2, 2.5, 3, 4,
The equal_range, lower_bound, and upper_bound algorithms are used just like their equivalents for associative containers; see §B.4.10.
B.5.5 Set algorithms
These algorithms treat a sequence as a set of elements and provide the basic set operations. The input sequences are supposed to be sorted and the output sequences are also sorted:

B.5.6 Heaps
A heap is a data structure that keeps the element with highest value first. The heap algorithms allow a programmer to treat a random-access sequence as a heap:

The point of a heap is to provide fast addition of elements and fast access to the element with the highest value. The main use of heaps is to implement priority queues.
B.5.7 Permutations
Permutations are used to generate combinations of elements of a sequence. For example, the permutations of abc are abc, acb, bac, bca, cab, and cba.
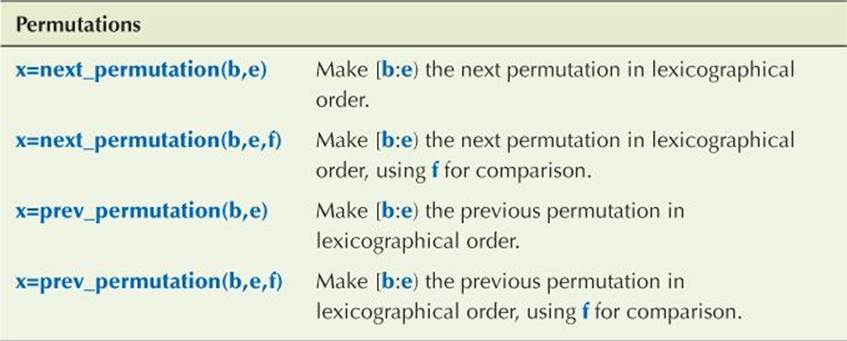
The return value (x) for next_permutation is false if [b:e) already contains the last permutation (cba in the example); in that case, it returns the first permutation (abc in the example). The return value for prev_permutation is false if [b:e) already contains the first permutation (abc in the example); in that case, it returns the last permutation (cba in the example).
B.5.8 min and max
Value comparisons are useful in many contexts:

B.6 STL utilities
The standard library provides a few facilities for making it easier to use standard library algorithms.
B.6.1 Inserters
Producing output through an iterator into a container implies that elements pointed to by the iterator and following it can be overwritten. This also implies the possibility of overflow and consequent memory corruption. For example:
void f(vector<int>& vi)
{
fill_n(vi.begin(), 200,7 ); // assign 7 to vi[0]..[199]
}
If vi has fewer than 200 elements, we are in trouble.
In <iterator>, the standard library provides three iterators to deal with this problem by adding (inserting) elements to a container rather than overwriting old elements. Three functions are provided for generating those inserting iterators:

For inserter(c,p), p must be a valid iterator for the container c. Naturally, a container grows by one element each time a value is written to it through an insert iterator. When written to, an inserter inserts a new element into a sequence using push_back(x), c.push_front(), or insert() rather than overwriting an existing element. For example:
void g(vector<int>& vi)
{
fill_n(back_inserter(vi), 200,7 ); // add 200 7s to the end of vi
}
B.6.2 Function objects
Many of the standard algorithms take function objects (or functions) as arguments to control the way they work. Common uses are comparison criteria, predicates (functions returning bool), and arithmetic operations. In <functional>, the standard library supplies a few common function objects.
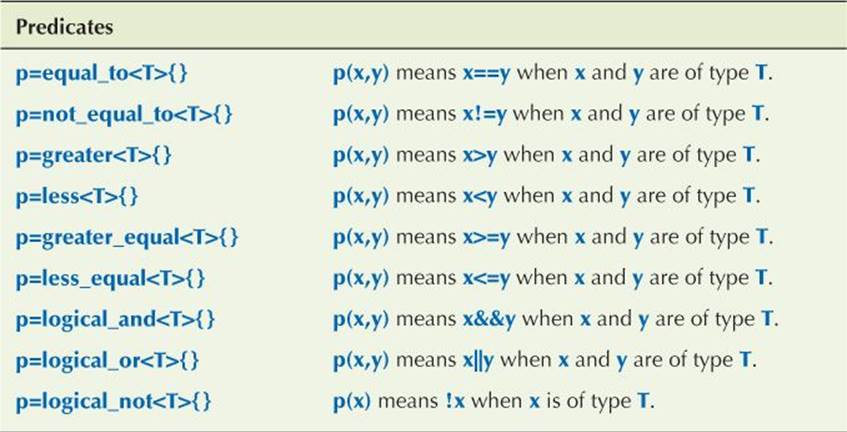
For example:
vector<int> v;
// . . .
sort(v.begin(),v.end(),greater<int>{}); // sort v in decreasing order
Note that logical_and and logical_or always evaluate both their arguments (whereas && and || do not).
Also, a lambda expression (§15.3.3) is often an alternative to a simple function object:
sort(v.begin(),v.end(),[](int x, int y) { return x>y;}); // sort v in decreasing order


Note that function is a template, so that you can define variables of type function<T> and assign callable objects to such variables. For example:
int f1(double);
function<int(double)> fct {f1}; // initialize to f1
int x = fct(2.3); // call f1(2.3)
function<int(double)> fun; // fun can hold any int(double)
fun = f1;
B.6.3 pair and tuple
In <utility>, the standard library provides a few “utility components,” including pair:
template <class T1, class T2>
struct pair {
typedef T1 first_type;
typedef T2 second_type;
T1 first;
T2 second;
// . . . copy and move operations . . .
};
template <class T1, class T2>
constexpr pair<T1,T2> make_pair(T1 x, T2 y) { return pair<T1,T2>{x,y}; }
The make_pair() function makes the use of pairs simple. For example, here is the outline of a function that returns a value and an error indicator:
pair<double,error_indicator> my_fct(double d)
{
errno = 0; // clear C-style global error indicator
// . . . do a lot of computation involving d computing x . . .
error_indicator ee = errno;
errno = 0; // clear C-style global error indicator
return make_pair(x,ee);
}
This example of a useful idiom can be used like this:
pair<int,error_indicator> res = my_fct(123.456);
if (res.second==0) {
// . . . use res.first . . .
}
else {
// oops: error
}
We use pair when we need exactly two elements and don’t care to define a specific type. If we need zero or more elements, we can use a tuple from <tuple>:
template <typename... Types>
struct tuple {
explicit constexpr tuple(const Types& ...); // construct from N values
template<typename... Atypes>
explicit constexpr tuple(const Atypes&& ...); // construct from N values
// . . . copy and move operations . . .
};
template <class... Types>
constexpr tuple<Types...> make_tuple(Types&&...); // construct tuple
// from N values
The tuple implementation uses a feature beyond the scope of this book, variadic templates. This is what those ellipses (. . .) refer to. However, we can use tuples much as we do pairs. For example:
auto t0 = make_tuple(); // no elements
auto t1 = make_tuple(123.456); // one element of type double
auto t2 = make_tuple(123.456, 'a'); // two elements of types double and char
auto t3 = make_tuple(12,'a',string{"How?"}); // three elements of types int,
// char, and string
A tuple can have many elements, so we can’t just use first and second to access them. Instead, a function get is used:
auto d = get<0>(t1); // the double
auto n = get<0>(t3); // the int
auto c = get<1>(t3); // the char
auto s = get<2>(t3); // the string
The subscript for get is provided as a template argument. As can be seen from the example, tuple subscripting is zero-based.
Tuples are mostly used in generic programming.
B.6.4 initializer_list
In <initializer_list>, we find the definition of initializer_list:
template<typename T>
class initializer_list {
public:
initializer_list() noexcept;
size_t size() const noexcept; // number of elements
const T* begin() const noexcept; // first element
const T* end() const noexcept; // one-past-last element
// . . .
};
When the compiler sees a { } initializer list with elements of type X, that list is used to construct an initializer_list<X> (§14.2.1, §18.2). Unfortunately, initializer_list does not support the subscript operator ([ ]).
B.6.5 Resource management pointers
A built-in pointer does not indicate whether it represents ownership of the object it points to. That can seriously complicate programming (§19.5). The resource management pointers unique_ptr and shared_ptr are defined in <memory> to deal with that problem:
• unique_ptr (§19.5.4) represents exclusive ownership; there can be only one unique_ptr to an object and the object is deleted when its unique_ptr is destroyed.
• shared_ptr represents shared ownership; there can be many shared_ptrs to an object, and the object is deleted when its last shared_ptr is destroyed.

The usual pointer operations, such as *, ->, ==, and <, can be used for unique_ptrs. Additionally, a unique_ptr can be defined to use a delete action different from plain delete.

The usual pointer operations, such as *, ->, ==, and <, can be used for shared_ptrs. Additionally, a shared_ptr can be defined to use a delete action different from plain delete.
There is also a weak_ptr for breaking loops of shared_ptrs.
B.7 I/O streams
The I/O stream library provides formatted and unformatted buffered I/O of text and numeric values. The definitions for I/O stream facilities are found in <istream>, <ostream>, etc.; see §B.1.1.
An ostream converts typed objects to a stream of characters (bytes):
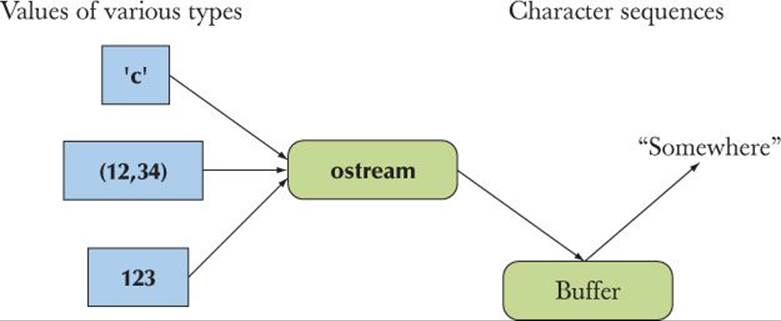
An istream converts a stream of characters (bytes) to typed objects:
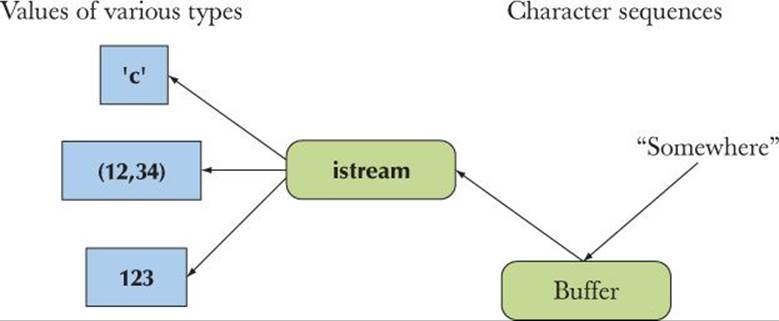
An iostream is a stream that can act as both an istream and an ostream. The buffers in the diagrams are “stream buffers” (streambufs). Look them up in an expert-level textbook if you ever need to define a mapping from an iostream to a new kind of device, file, or memory.
There are three standard streams:

B.7.1 I/O streams hierarchy
An istream can be connected to an input device (e.g., a keyboard), a file, or a string. Similarly, an ostream can be connected to an output device (e.g., a text window), a file, or a string. The I/O stream facilities are organized in a class hierarchy:
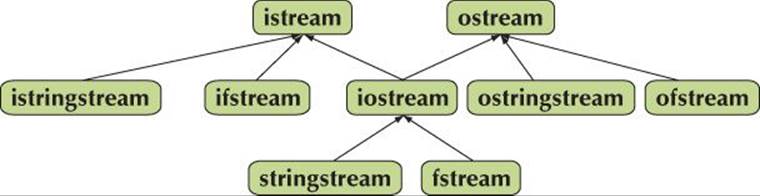
A stream can be opened either by a constructor or by an open() call:

For file streams, the file name is a C-style string.
You can open a file in one of several modes:

In each case, the exact effect of opening a file may depend on the operating system, and if an operating system cannot honor a request to open a file in a certain way, the result will be a stream that is not in the good() state.
An example:
void my_code(ostream& os); // my code can use any ostream
ostringstream os; // o for “output”
ofstream of("my_file");
if (!of) error("couldn't open 'my_file' for writing");
my_code(os); // use a string
my_code(of); // use a file
See §11.3.
B.7.2 Error handling
An iostream can be in one of four states:

By using s.exceptions(), a programmer can request an iostream to throw an exception if it turns from good() into another state (see §10.6).
Any operation attempted on a stream that is not in the good() state has no effect; it is a “no op.”
An iostream can be used as a condition. In that case, the condition is true (succeeds) if the state of the iostream is good(). That is the basis for the common idiom for reading a stream of values:
for (X buf; cin>>buf; ) { // buf is an “input buffer” for holding one value of type X
// . . . do something with buf . . .
}
// we get here when >> couldn’t read another X from cin
B.7.3 Input operations
Input operations are found in <istream> except for the ones reading into a string; those are found in <string>:

Unless otherwise stated, an istream operation returns a reference to its istream, so that we can “chain” operations, for example, cin>>x>>y;.

The get() and getline() functions place a 0 at the end of the characters (if any) written to p[0] . . . ; getline() removes the terminator (t) from the input, if found, whereas get() does not. A read(p,n) does not write a 0 to the array after the characters read. Obviously, the formatted input operators are simpler to use and less error-prone than the unformatted ones.
B.7.4 Output operations
Output operations are found in <ostream> except for the ones writing out a string; those are found in <string>:

Unless otherwise stated, an ostream operation returns a reference to its ostream, so that we can “chain” operations, for example, cout << x<<y;.
B.7.5 Formatting
The format of stream I/O is controlled by a combination of object type, stream state, locale information (see <locale>), and explicit operations. Chapters 10 and 11 explain much of this. Here, we just list the standard manipulators (operations modifying the state of a stream) because they provide the most straightforward way of modifying formatting.
Locales are beyond the scope of this book.
B.7.6 Standard manipulators
The standard library provides manipulators corresponding to the various format states and state changes. The standard manipulators are defined in <ios>, <istream>, <ostream>, <iostream>, and <iomanip> (for manipulators that take arguments):


Each of these operations returns a reference to its first (stream) operand, s. For example:
cout << 1234 << ',' << hex << 1234 << ',' << oct << 1234 << endl;
produces
1234,4d2,2322
and
cout << '(' << setw(4) << setfill('#') << 12 << ") (" << 12 << ")\n";
produces
(##12) (12)
To explicitly set the general output format for floating-point numbers use
b.setf(ios_base::fmtflags(0), ios_base::floatfield)
See Chapter 11.
B.8 String manipulation
The standard library offers character classification operations in <cctype>, strings with associated operations in <string>, regular expression matching in <regex>, and support for C-style strings in <cstring>.
B.8.1 Character classification
The characters from the basic execution character set can be classified like this:

In addition, the standard library provides two useful functions for getting rid of case differences:

Extended character sets, such as Unicode, are supported but are beyond the scope of this book.
B.8.2 String
The standard library string class, string, is a specialization of a general string template basic_string for the character type char; that is, string is a sequence of chars:



B.8.3 Regular expression matching
The regular expression facilities are found in <regex>. The main functions are
• Searching for a string that matches a regular expression in an (arbitrarily long) stream of data — supported by regex_search()
• Matching a regular expression against a string (of known size) — supported by regex_match()
• Replacement of matches — supported by regex_replace(); not described in this book; see an expert-level text or manual
The result of a regex_search() or a regex_match() is a collection of matches, typically represented as an smatch:
regex row("^[\\w ]+( \\d+)( \\d+)( \\d+)$"); // data line
while (getline(in,line)) { // check data line
smatch matches;
if (!regex_match(line, matches, row))
error("bad line", lineno);
// check row:
int field1 = from_string<int>(matches[1]);
int field2 = from_string<int>(matches[2]);
int field3 = from_string<int>(matches[3]);
// . . .
}
The syntax of regular expressions is based on characters with special meaning (Chapter 23):

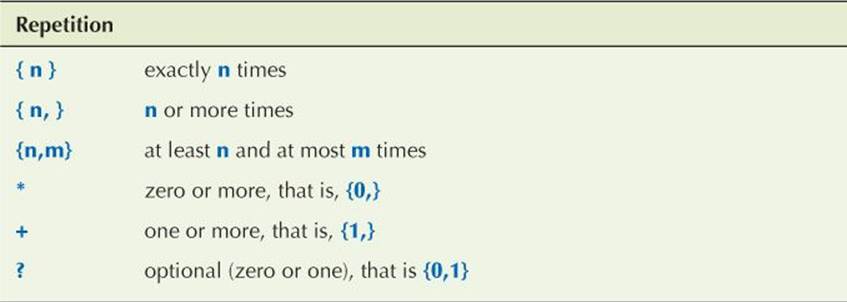

Several character classes are supported by shorthand notation:

B.9 Numerics
The C++ standard library provides the most basic building blocks for mathematical (scientific, engineering, etc.) calculations.
B.9.1 Numerical limits
Each C++ implementation specifies properties of the built-in types, so that programmers can use those properties to check against limits, set sentinels, etc.
From <limits>, we get numeric_limits<T> for each built-in or library type T. In addition, a programmer can define numeric_limits<X> for a user-defined numeric type X. For example:
class numeric_limits<float> {
public:
static const bool is_specialized = true;
static constexpr int radix = 2; // base of exponent (in this case, binary)
static constexpr int digits = 24; // number of radix digits in mantissa
static constexpr int digits10 = 6; // number of base-10 digits in mantissa
static constexpr bool is_signed = true;
static constexpr bool is_integer = false;
static constexpr bool is_exact = false;
static constexpr float min() { return 1.17549435E-38F; } // example value
static constexpr float max() { return 3.40282347E+38F; } // example value
static constexpr float lowest() { return -3.40282347E+38F; } // example value
static constexpr float epsilon() { return 1.19209290E-07F; } // example value
static constexpr float round_error() { return 0.5F; } // example value
static constexpr float infinity() { return /* some value */; }
static constexpr float quiet_NaN() { return /* some value */; }
static constexpr float signaling_NaN() { return /* some value */; }
static constexpr float denorm_min() { return min(); }
static constexpr int min_exponent = -125; // example value
static constexpr int min_exponent10 = -37; // example value
static constexpr int max_exponent = +128; // example value
static constexpr int max_exponent10 = +38; // example value
static constexpr bool has_infinity = true;
static constexpr bool has_quiet_NaN = true;
static constexpr bool has_signaling_NaN = true;
static constexpr float_denorm_style has_denorm = denorm_absent;
static constexpr bool has_denorm_loss = false;
static constexpr bool is_iec559 = true; // conforms to IEC-559
static constexpr bool is_bounded = true;
static constexpr bool is_modulo = false;
static constexpr bool traps = true;
static constexpr bool tinyness_before = true;
static constexpr float_round_style round_style = round_to_nearest;
};
From <limits.h> and <float.h>, we get macros specifying key properties of integers and floating-point numbers, including:

B.9.2 Standard mathematical functions
The standard library provides the most common mathematical functions (defined in <cmath> and <complex>):
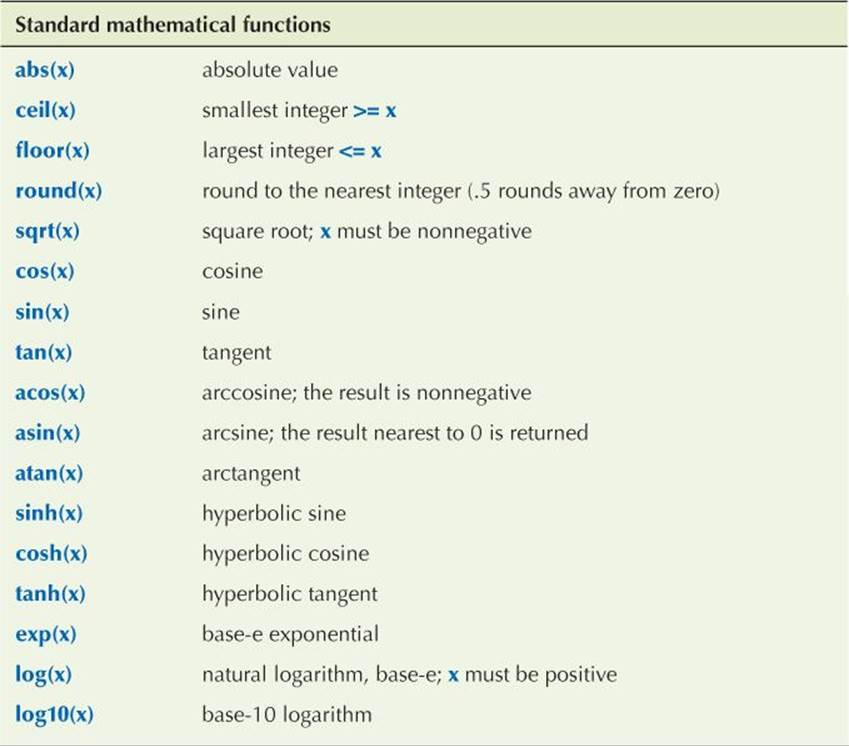
There are versions taking float, double, long double, and complex arguments. For each function, the return type is the same as the argument type.
If a standard mathematical function cannot produce a mathematically valid result, it sets the variable errno.
B.9.3 Complex
The standard library provides complex number types complex<float>, complex<double>, and complex<long double>. A complex<Scalar> where Scalar is some other type supporting the usual arithmetic operations usually works but is not guaranteed to be portable.
template<class Scalar> class complex {
// a complex is a pair of scalar values, basically a coordinate pair
Scalar re, im;
public:
constexpr complex(const Scalar & r, const Scalar & i) :re{r}, im{i} { }
constexpr complex(const Scalar & r) :re{r}, im(Scalar{}} { }
constexpr complex() :re{Scalar{}}, im{Scalar{}} { }
Scalar real() { return re; } // real part
Scalar imag() { return im; } // imaginary part
// operators: = += -= *= /=
};
In addition to the members of complex, <complex> offers a host of useful operations:

The standard mathematical functions (see §B.9.2) are also available for complex numbers. Note: complex does not provide < or %; see also §24.9.
B.9.4 valarray
The standard valarray is a single-dimensional numerical array; that is, it provides arithmetic operations for an array type (much like Matrix in Chapter 24) plus support for slices and strides.
B.9.5 Generalized numerical algorithms
These algorithms from <numeric> provide general versions of common operations on sequences of numerical values:

For example:
vector<int> v(100);
iota(v.begin(),v.end(),0); // v=={1, 2,3,4,5 . . . 100}
B.9.6 Random numbers
In <random>, the standard library provides random number engines and distributions (§24.7). By default use the default_random_engine, which is chosen for wide applicability and low cost.
Distributions include:

A distribution can be called with an engine as its argument. For example:
uniform_real_distribution<> dist;
default_random_engine engn;
for (int i = 0; i<10; ++i)
cout << dist(engn) << ' ';
B.10 Time
In <chrono>, the standard library provides facilities for timing. A clock counts time in number of clock ticks and reports the current point in time as the result of a call of now(). Three clocks are defined:
• system_clock: the default system clock
• steady_clock: a clock, c, for which c.now()<=c.now() for consecutive calls of now() and the time between clock ticks is constant
• high_resolution_clock: the highest-resolution clock available on a system
A number of clock ticks for a given clock is converted into a conventional unit of time, such as seconds, milliseconds, and nanoseconds, by the function duration_cast<>(). For example:
auto t = steady_clock::now();
// . . . do something . . .
auto d = steady_clock::now()-t; // something took d time units
cout << "something took "
<< duration_cast<milliseconds>(d).count() << "ms";
This will print the time that “something” took in milliseconds. See also §26.6.1.
B.11 C standard library functions
The standard library for the C language is with very minor modifications incorporated into the C++ standard library. The C standard library provides quite a few functions that have proved useful over the years in a wide variety of contexts — especially for relatively low-level programming. Here, we have organized them into a few conventional categories:
• C-style I/O
• C-style strings
• Memory
• Date and time
• Etc.
There are more C standard library functions than we present here; see a good C textbook, such as Kernighan and Ritchie, The C Programming Language (K&R), if you need to know more.
B.11.1 Files
The <stdio> I/O system is based on “files.” A file (a FILE*) can refer to a file or to one of the standard input and output streams, stdin, stdout, and stderr. The standard streams are available by default; other files need to be opened:

A “mode” is a string containing one or more directives specifying how a file is to be opened:

There may be (and usually are) more options on a specific system. Some options can be combined; for example, fopen("foo","rb") tries to open a file called foo for binary reading. The I/O modes should be the same for stdio and iostreams (§B.7.1).
B.11.2 The printf() family
The most popular C standard library functions are the I/O functions. However, we recommend iostreams because that library is type-safe and extensible. The formatted output function, printf(), is widely used (also in C++ programs) and widely imitated in other programming languages:

For each version, n is the number of characters written or a negative number if the output failed. The return value from printf() is essentially always ignored.
The declaration of printf() is
int printf(const char* format . . .);
In other words, it takes a C-style string (typically a string literal) followed by an arbitrary number of arguments of arbitrary type. The meaning of those “extra arguments” is controlled by conversion specifications, such as %c (print as character) and %d (print as decimal integer), in the format string. For example:
int x = 5;
const char* p = "asdf";
printf("the value of x is '%d' and the value of p is '%s'\n",x,p);
A character following a % controls the handling of an argument. The first % applies to the first “extra argument” (here, %d applies to x), the second % to the second “extra argument” (here, %s applies to p), and so on. In particular, the output of that call to printf() is
the value of x is '5' and the value of p is 'asdf'
followed by a newline.
In general, the correspondence between a % conversion directive and the type to which it is applied cannot be checked, and when it can, it usually is not. For example:
printf("the value of x is '%s' and the value of p is '%d'\n",x,p); // oops
The set of conversion specifications is quite large and provides a great degree of flexibility (and possibilities for confusion). Following the %, there may be:
- an optional minus sign that specifies left adjustment of the converted value in the field.
+ an optional plus sign that specifies that a value of a signed type will always begin with a + or — sign.
0 an optional zero that specifies that leading zeros are used for padding of a numeric value. If — or a precision is specified, this 0 is ignored.
# an optional # that specifies that floating-point values will be printed with a decimal point even if no nonzero digits follow, that trailing zeros will be printed, that octal values will be printed with an initial 0, and that hexadecimal values will be printed with an initial 0x or 0X.
d an optional digit string specifying a field width; if the converted value has fewer characters than the field width, it will be blank-padded on the left (or right, if the left-adjustment indicator has been given) to make up the field width; if the field width begins with a zero, zero padding will be done instead of blank padding.
. an optional period that serves to separate the field width from the next digit string.
dd an optional digit string specifying a precision that specifies the number of digits to appear after the decimal point, for e- and f-conversion, or the maximum number of characters to be printed from a string.
* a field width or precision may be * instead of a digit string. In this case, an integer argument supplies the field width or precision.
h an optional character h, specifying that a following d, o, x, or u corresponds to a short integer argument.
l an optional character l (the letter l), specifying that a following d, o, x, or u corresponds to a long integer argument.
L an optional character L, specifying that a following e, E, g, G, or f corresponds to a long double argument.
% indicating that the character % is to be printed; no argument is used.
c a character that indicates the type of conversion to be applied. The conversion characters and their meanings are:
d The integer argument is converted to decimal notation.
i The integer argument is converted to decimal notation.
o The integer argument is converted to octal notation.
x The integer argument is converted to hexadecimal notation.
X The integer argument is converted to hexadecimal notation.
f The float or double argument is converted to decimal notation in the style [-]ddd.ddd. The number of ds after the decimal point is equal to the precision for the argument. If necessary, the number is rounded. If the precision is missing, six digits are given; if the precision is explicitly 0 and # isn’t specified, no decimal point is printed.
e The float or double argument is converted to decimal notation in the scientific style [-]d.ddde+dd or [-]d.ddde-dd, where there is one digit before the decimal point and the number of digits after the decimal point is equal to the precision specification for the argument. If necessary, the number is rounded. If the precision is missing, six digits are given; if the precision is explicitly 0 and # isn’t specified, no digits and no decimal point are printed.
E Like e, but with an uppercase E used to identify the exponent.
g The float or double argument is printed in style d, in style f, or in style e, whichever gives the greatest precision in minimum space.
G Like g, but with an uppercase E used to identify the exponent.
c The character argument is printed. Null characters are ignored.
s The argument is taken to be a string (character pointer), and characters from the string are printed until a null character or until the number of characters indicated by the precision specification is reached; however, if the precision is 0 or missing, all characters up to a null are printed.
p The argument is taken to be a pointer. The representation printed is implementation dependent.
u The unsigned integer argument is converted to decimal notation.
n The number of characters written so far by the call of printf(), fprintf(), or sprintf() is written to the int pointed to by the pointer-to-int argument.
In no case does a nonexistent or small field width cause truncation of a field; padding takes place only if the specified field width exceeds the actual width.
Because C does not have user-defined types in the sense that C++ has, there are no provisions for defining output formats for user-defined types, such as complex, vector, or string.
The C standard output, stdout, corresponds to cout. The C standard input, stdin, corresponds to cin. The C standard error output, stderr, corresponds to cerr. This correspondence between C standard I/O and C++ I/O streams is so close that C-style I/O and I/O streams can share a buffer. For example, a mix of cout and stdout operations can be used to produce a single output stream (that’s not uncommon in mixed C and C++ code). This flexibility carries a cost. For better performance, don’t mix stdio and iostream operations for a single stream and callios_base::sync_with_stdio(false) before the first I/O operation.
The stdio library provides a function, scanf(), that is an input operation with a style that mimics printf(). For example:
int x;
char s[buf_size];
int i = scanf("the value of x is '%d' and the value of s is '%s'\n",&x,s);
Here, scanf() tries to read an integer into x and a sequence of non-whitespace characters into s. Non-format characters specify that the input should contain that character. For example,
the value of x is '123' and the value of s is 'string '\n"
will read 123 into x and string followed by a 0 into s. If the call of scanf() succeeds, the result value (i in the call above) will be the number of argument pointers assigned to (hopefully 2 in the example); otherwise, EOF. This way of specifying input is error-prone (e.g., what would happen if you forgot the space after string on that input line?). All arguments to scanf() must be pointers. We strongly recommend against the use of scanf().
So what can we do for input if we are obliged to use stdio? One popular answer is, “Use the standard library function gets()”:
// very dangerous code:
char s[buf_size];
char* p = gets(s); // read a line into s
The call p=gets(s) reads characters into s until a newline or an end of file is encountered and a 0 character is placed after the last character written to s. If an end of file is encountered or if an error occurred, p is set to NULL (that is, 0); otherwise it is set to s. Never use gets(s) or its rough equivalent (scanf("%s",s))! For years, they were the favorites of virus writers: by providing an input that overflows the input buffer (s in the example), a program can be corrupted and a computer potentially taken over by an attacker. The sprintf() function suffers similar buffer-overflow problems.
The stdio library also provides simple and useful character read and write functions:

Note that the result of these functions is an int (not a char, or EOF couldn’t be returned). For example, this is a typical C-style input loop:
int ch; /* not char ch; */
while ((ch=getchar())!=EOF) { /* do something */ }
Don’t do two consecutive ungetc()s on a stream. The result of that is undefined and (therefore) non-portable.
There are more stdio functions; see a good C textbook, such as K&R, if you need to know more.
B.11.3 C-style strings
A C-style string is a zero-terminated array of chars. This notion of a string is supported by a set of functions defined in <cstring> (or <string.h>; note: not <string>) and <cstdlib>. These functions operate on C-style strings through char* pointers (const char* pointers for memory that’s only read):

Note that in C++, strchr() and strstr() are duplicated to make them type-safe (they can’t turn a const char* into a char* the way the C equivalents can); see also §27.5.
An extraction function looks into its C-style string argument for a conventionally formatted representation of a number, such as "124" and " 1.4". If no such representation is found, the extraction function returns 0. For example:
int x = atoi("fortytwo"); /* x becomes 0 */
B.11.4 Memory
The memory manipulation functions operate on “raw memory” (no type known) through void* pointers (const void* pointers for memory that’s only read):

Note that malloc(), etc. do not invoke constructors and free() doesn’t invoke destructors. Do not use these functions for types with constructors or destructors. Also, memset() should never be used for any type with a constructor.
The mem* functions are found in <cstring> and the allocation functions in <cstdlib>.
See also §27.5.2.
B.11.5 Date and time
In <ctime>, you can find several types and functions related to date and time:

struct tm is defined like this:
struct tm {
int tm_sec; // second of minute [0:61]; 60 and 61 represent leap seconds
int tm_min; // minute of hour [0,59]
int tm_hour; // hour of day [0,23]
int tm_mday; // day of month [1,31]
int tm_mon; // month of year [0,11]; 0 means January (note: not [1:12])
int tm_year; // year since 1900; 0 means year 1900, and 102 means 2002
int tm_wday; // days since Sunday [0,6]; 0 means Sunday
int tm_yday; // days since January 1 [0,365]; 0 means January 1
int tm_isdst; // hours of Daylight Savings Time
};
Date and time functions:
clock_t clock(); // number of clock ticks since the start of the program
time_t time(time_t* pt); // current calendar time
double difftime(time_t t2, time_t t1); // t2-t1 in seconds
tm* localtime(const time_t* pt); // local time for the *pt
tm* gmtime(const time_t* pt); // Greenwich Mean Time (GMT) tm for *pt, or 0
time_t mktime(tm* ptm); // time_t for *ptm, or time_t(-1)
char* asctime(const tm* ptm); // C-style string representation for *ptm
char* ctime(const time_t* t) { return asctime(localtime(t)); }
An example of the result of a call of asctime() is "Sun Sep 16 01:03:52 1973\n".
An amazing zoo of formatting options for tm is provided by a function called strftime(). Look it up if you need it.
B.11.6 Etc.
In <cstdlib> we find:

The comparison function (cmp) used by qsort() and bsearch() must have the type
int (*cmp)(const void* p, const void* q);
That is, no type information is known to the sort function that simply “sees” its array as a sequence of bytes. The integer returned is
• Negative if *p is considered less than *q
• Zero if *p is considered equal to *q
• Positive if *p is considered greater than *q
Note that exit() and abort() do not invoke destructors. If you want destructors called for constructed automatic and static objects (§A.4.2), throw an exception.
For more standard library functions see K&R or some other reputable C language reference.
B.12 Other libraries
Looking through the standard library facilities, you’ll undoubtedly have failed to find something you could use. Compared to the challenges faced by programmers and the number of libraries available in the world, the C++ standard library is minute. There are many libraries for
• Graphical user interfaces
• Advanced math
• Database access
• Networking
• XML
• Date and time
• File system manipulation
• 3D graphics
• Animation
• Etc.
However, such libraries are not part of the standard. You can find them by searching the web or by asking friends and colleagues. Please don’t get the idea that the only useful libraries are those that are part of the standard library.