Programming: Principles and Practice Using C++ (2014)
Part I: The Basics
4. Computation
“If it doesn’t have
to produce correct results,
I can make it arbitrarily fast.”
—Gerald M. Weinberg
This chapter presents the basics of computation. In particular, we discuss how to compute a value from a set of operands (expression), how to choose among alternative actions (selection), and how to repeat a computation for a series of values (iteration). We also show how a particular sub-computation can be named and specified separately (a function). Our primary concern is to express computations in ways that lead to correct and well-organized programs. To help you perform more realistic computations, we introduce the vector type to hold sequences of values.
4.1 Computation
4.2 Objectives and tools
4.3 Expressions
4.3.1 Constant expressions
4.3.2 Operators
4.3.3 Conversions
4.4 Statements
4.4.1 Selection
4.4.2 Iteration
4.5 Functions
4.5.1 Why bother with functions?
4.5.2 Function declarations
4.6 vector
4.6.1 Traversing a vector
4.6.2 Growing a vector
4.6.3 A numeric example
4.6.4 A text example
4.7 Language features
4.1 Computation
![]()
From one point of view, all that a program ever does is to compute; that is, it takes some inputs and produces some output. After all, we call the hardware on which we run the program a computer. This view is accurate and reasonable as long as we take a broad view of what constitutes input and output:

The input can come from a keyboard, from a mouse, from a touch screen, from files, from other input devices, from other programs, from other parts of a program. “Other input devices” is a category that contains most really interesting input sources: music keyboards, video recorders, network connections, temperature sensors, digital camera image sensors, etc. The variety is essentially infinite.
To deal with input, a program usually contains some data, sometimes referred to as its data structures or its state. For example, a calendar program may contain lists of holidays in various countries and a list of your appointments. Some of that data is part of the program from the start; other data is built up as the program reads input and collects useful information from it. For example, the calendar program will probably build your list of appointments from the input you give it. For the calendar, the main inputs are the requests to see the months and days you ask for (probably using mouse clicks) and the appointments you give it to keep track of (probably by typing information on your keyboard). The output is the display of calendars and appointments, plus the buttons and prompts for input that the calendar program writes on your screen.
Input comes from a wide variety of sources. Similarly, output can go to a wide variety of destinations. Output can be to a screen, to files, to network connections, to other output devices, to other programs, and to other parts of a program. Examples of output devices include network interfaces, music synthesizers, electric motors, light generators, heaters, etc.
From a programming point of view the most important and interesting categories are “to/from another program” and “to/from other parts of a program.” Most of the rest of this book could be seen as discussing that last category: how do we express a program as a set of cooperating parts and how can they share and exchange data? These are key questions in programming. We can illustrate that graphically:

The abbreviation I/O stands for “input/output.” In this case, the output from one part of code is the input for the next part. What such “parts of a program” share is data stored in main memory, on persistent storage devices (such as disks), or transmitted over network connections. By “parts of a program” we mean entities such as a function producing a result from a set of input arguments (e.g., a square root from a floating-point number), a function performing an action on a physical object (e.g., a function drawing a line on a screen), or a function modifying some table within the program (e.g., a function adding a name to a table of customers).
When we say “input” and “output” we generally mean information coming into and out of a computer, but as you see, we can also use the terms for information given to or produced by a part of a program. Inputs to a part of a program are often called arguments and outputs from a part of a program are often called results.
By computation we simply mean the act of producing some outputs based on some inputs, such as producing the result (output) 49 from the argument (input) 7 using the computation (function) square (see §4.5). As a possibly helpful curiosity, we note that until the 1950s a computer was defined as a person who did computations, such as an accountant, a navigator, or a physicist. Today, we simply delegate most computations to computers (machines) of various forms, of which the pocket calculator is among the simplest.
4.2 Objectives and tools
![]()
Our job as programmers is to express computations
• Correctly
• Simply
• Efficiently
Please note the order of those ideals: it doesn’t matter how fast a program is if it gives the wrong results. Similarly, a correct and efficient program can be so complicated that it must be thrown away or completely rewritten to produce a new version (release). Remember, useful programs will always be modified to accommodate new needs, new hardware, etc. Therefore a program — and any part of a program — should be as simple as possible to perform its task. For example, assume that you have written the perfect program for teaching basic arithmetic to children in your local school, and that its internal structure is a mess. Which language did you use to communicate with the children? English? English and Spanish? What if I’d like to use it in Finland? In Kuwait? How would you change the (natural) language used for communication with a child? If the internal structure of the program is a mess, the logically simple (but in practice almost always very difficult) operation of changing the natural language used to communicate with users becomes insurmountable.
![]()
Concerns about correctness, simplicity, and efficiency become ours the minute we start writing code for others and accept the responsibility to do that well; that is, we must accept that responsibility when we decide to become professionals. In practical terms, this means that we can’t just throw code together until it appears to work; we must concern ourselves with the structure of code. Paradoxically, concerns for structure and “quality of code” are often the fastest ways of getting something to work. When programming is done well, such concerns minimize the need for the most frustrating part of programming: debugging; that is, good program structure during development can minimize the number of mistakes made and the time needed to search for such errors and to remove them.
![]()
Our main tool for organizing a program — and for organizing our thoughts as we program — is to break up a big computation into many little ones. This technique comes in two variations:
• Abstraction: Hide details that we don’t need to use a facility (“implementation details”) behind a convenient and general interface. For example, rather than considering the details of how to sort a phone book (thick books have been written about how to sort), we just call the sortalgorithm from the C++ standard library. All we need to know to sort is how to invoke (call) that algorithm, so we can write sort(b) where b refers to the phone book; sort() is a variant (§21.9) of the standard library sort algorithm (§21.8, §B.5.4) defined in std_library.h. Another example is the way we use computer memory. Direct use of memory can be quite messy, so we access it through typed and named variables (§3.2), standard library vectors (§4.6, Chapters 17-19), maps (Chapter 21), etc.
• “Divide and conquer”: Here we take a large problem and divide it into several little ones. For example, if we need to build a dictionary, we can separate that job into three: read the data, sort the data, and output the data. Each of the resulting problems is significantly smaller than the original.
![]()
Why does this help? After all, a program built out of parts is likely to be slightly larger than a program where everything is optimally merged together. The reason is that we are not very good at dealing with large problems. The way we actually deal with those — in programming and elsewhere — is to break them down into smaller problems, and we keep breaking those into even smaller parts until we get something simple enough to understand and solve. In terms of programming, you’ll find that a 1000-line program has far more than ten times as many errors as a 100-line program, so we try to compose the 1000-line program out of parts with fewer than 100 lines. For large programs, say 10,000,000 lines, applying abstraction and divide-and-conquer is not just an option, it’s an essential requirement. We simply cannot write and maintain large monolithic programs. One way of looking at the rest of this book is as a long series of examples of problems that need to be broken up into smaller parts together with the tools and techniques needed to do so.
When we consider dividing up a program, we must always consider what tools we have available to express the parts and their communications. A good library, supplying useful facilities for expressing ideas, can crucially affect the way we distribute functionality into different parts of a program. We cannot just sit back and “imagine” how best to partition a program; we must consider what libraries we have available to express the parts and their communication. It is early days yet, but not too soon to point out that if you can use an existing library, such as the C++ standard library, you can save yourself a lot of work, not just on programming but also on testing and documentation. The iostreams save us from having to directly deal with the hardware’s input/output ports. This is a first example of partitioning a program using abstraction. Every new chapter will provide more examples.
Note the emphasis on structure and organization: you don’t get good code just by writing a lot of statements. Why do we mention this now? At this stage you (or at least many readers) have little idea about what code is, and it will be months before you are ready to write code upon which other people could depend for their lives or livelihood. We mention it to help you get the emphasis of your learning right. It is very tempting to dash ahead, focusing on the parts of programming that — like what is described in the rest of this chapter — are concrete and immediately useful and to ignore the “softer,” more conceptual parts of the art of software development. However, good programmers and system designers know (often having learned it the hard way) that concerns about structure lie at the heart of good software and that ignoring structure leads to expensive messes. Without structure, you are (metaphorically speaking) building with mud bricks. It can be done, but you’ll never get to the fifth floor (mud bricks lack the structural strength for that). If you have the ambition to build something reasonably permanent, you pay attention to matters of code structure and organization along the way, rather than having to come back and learn them after failures.
4.3 Expressions
![]()
The most basic building block of programs is an expression. An expression computes a value from a number of operands. The simplest expression is simply a literal value, such as 10, 'a', 3.14, or "Norah".
Names of variables are also expressions. A variable represents the object of which it is the name. Consider:
// compute area:
int length = 20; // a literal integer (used to initialize a variable)
int width = 40;
int area = length*width; // a multiplication
Here the literals 20 and 40 are used to initialize the variables length and width. Then, length and width are multiplied; that is, we multiply the values found in length and width. Here, length is simply shorthand for “the value found in the object named length.” Consider also
length = 99; // assign 99 to length
Here, as the left-hand operand of the assignment, length means “the object named length,” so that the assignment expression is read “Put 99 into the object named by length.” We distinguish between length used on the left-hand side of an assignment or an initialization (“the lvalue of length” or “the object named by length”) and length used on the right-hand side of an assignment or initialization (“the rvalue of length,” “the value of the object named by length,” or just “the value of length”). In this context, we find it useful to visualize a variable as a box labeled by its name:

That is, length is the name of an object of type int containing the value 99. Sometimes (as an lvalue) length refers to the box (object) and sometimes (as an rvalue) length refers to the value in that box.
We can make more complicated expressions by combining expressions using operators, such as + and *, in just the way that we are used to. When needed, we can use parentheses to group expressions:
int perimeter = (length+width)*2; // add then multiply
Without parentheses, we’d have had to say
int perimeter = length*2+width*2;
which is clumsy, and we might even have made this mistake:
int perimeter = length+width*2; // add width*2 to length
This last error is logical and cannot be found by the compiler. All the compiler sees is a variable called perimeter initialized by a valid expression. If the result of that expression is nonsense, that’s your problem. You know the mathematical definition of a perimeter, but the compiler doesn’t.
The usual mathematical rules of operator precedence apply, so length+width*2 means length+(width*2). Similarly a*b+c/d means (a*b)+(c/d) and not a*(b+c)/d. See §A.5 for a precedence table.
The first rule for the use of parentheses is simply “If in doubt, parenthesize,” but please do learn enough about expressions so that you are not in doubt about a*b+c/d. Overuse of parentheses, as in (a*b)+(c/d), decreases readability.
Why should you care about readability? Because you and possibly others will read your code, and ugly code slows down reading and comprehension. Ugly code is not just hard to read, it is also much harder to get correct. Ugly code often hides logical errors. It is slower to read and makes it harder to convince yourself — and others — that the ugly code is correct. Don’t write absurdly complicated expressions such as
a*b+c/d*(e-f/g)/h+7 // too complicated
and always try to choose meaningful names.
4.3.1 Constant expressions
Programs typically use a lot of constants. For example, a geometry program might use pi and an inch-to-centimeter conversion program will use a conversion factor such as 2.54. Obviously, we want to use meaningful names for those constants (as we did for pi; we didn’t say 3.14159). Similarly, we don’t want to change those constants accidentally. Consequently, C++ offers the notion of a symbolic constant, that is, a named object to which you can’t give a new value after it has been initialized. For example:
constexpr double pi = 3.14159;
pi = 7; // error: assignment to constant
double c = 2*pi*r; // OK: we just read pi; we don’t try to change it
Such constants are useful for keeping code readable. You might have recognized 3.14159 as an approximation to pi if you saw it in some code, but would you have recognized 299792458? Also, if someone asked you to change some code to use pi with the precision of 12 digits for your computation, you could search for 3.14 in your code, but if someone incautiously had used 22/7, you probably wouldn’t find it. It would be much better just to change the definition of pi to use the more appropriate value:
constexpr double pi = 3.14159265359;
![]()
Consequently, we prefer not to use literals (except very obvious ones, such as 0 and 1) in most places in our code. Instead, we use constants with descriptive names. Non-obvious literals in code (outside definitions of symbolic constants) are derisively referred to as magic constants.
In some places, such as case labels (§4.4.1.3), C++ requires a constant expression, that is, an expression with an integer value composed exclusively of constants. For example:
constexpr int max = 17; // a literal is a constant expression
int val = 19;
max+2 // a constant expression (a const int plus a literal)
val+2 // not a constant expression: it uses a variable
![]()
And by the way, 299792458 is one of the fundamental constants of the universe: the speed of light in vacuum measured in meters per second. If you didn’t instantly recognize that, why would you expect not to be confused and slowed down by other literals embedded in code? Avoid magic constants!
A constexpr symbolic constant must be given a value that is known at compile time. For example:
constexpr int max = 100;
void use(int n)
{
constexpr int c1 = max+7; // OK: c1 is 107
constexpr int c2 = n+7; // error: we don’t know the value of c2
// ...
}
To handle cases where the value of a “variable” that is initialized with a value that is not known at compile time but never changes after initialization, C++ offers a second form of constant (a const):
constexpr int max = 100;
void use(int n)
{
constexpr int c1 = max+7; // OK: c1 is 107
const int c2 = n+7; // OK, but don’t try to change the value of c2
// ...
c2 = 7; // error: c2 is a const
}
Such “const variables” are very common for two reasons:
• C++98 did not have constexpr, so people used const.
• “Variables” that are not constant expressions (their value is not known at compile time) but do not change values after initialization are in themselves widely useful.
4.3.2 Operators
We just used the simplest operators. However, you will soon need more as you want to express more complex operations. Most operators are conventional, so we’ll just explain them later as needed and you can look up details if and when you find a need. Here is a list of the most common operators:

We used lval (short for “value that can appear on the left-hand side of an assignment”) where the operator modifies an operand. You can find a complete list in §A.5.
For examples of the use of the logical operators && (and), || (or), and ! (not), see §5.5.1, §7.7, §7.8.2, and §10.4.
![]()
Note that a<b<c means (a<b)<c and that a<b evaluates to a Boolean value: true or false. So, a<b<c will be equivalent to either true<c or false<c. In particular, a<b<c does not mean “Is b between a and c?” as many have naively (and not unreasonably) assumed. Thus, a<b<c is basically a useless expression. Don’t write such expressions with two comparison operations, and be very suspicious if you find such an expression in someone else’s code — it is most likely an error.
An increment can be expressed in at least three ways:
++a
a+=1
a=a+1
![]()
Which notation should we use? Why? We prefer the first version, ++a, because it more directly expresses the idea of incrementing. It says what we want to do (increment a) rather than how to do it (add 1 to a and then write the result to a). In general, a way of saying something in a program is better than another if it more directly expresses an idea. The result is more concise and easier for a reader to understand. If we wrote a=a+1, a reader could easily wonder whether we really meant to increment by 1. Maybe we just mistyped a=b+1, a=a+2, or even a=a-1; with ++a there are far fewer opportunities for such doubts. Please note that this is a logical argument about readability and correctness, not an argument about efficiency. Contrary to popular belief, modern compilers tend to generate exactly the same code from a=a+1 as for ++a when a is one of the built-in types. Similarly, we prefer a*=scale over a=a*scale.
4.3.3 Conversions
We can “mix” different types in expressions. For example, 2.5/2 is a double divided by an int. What does this mean? Do we do integer division or floating-point division? Integer division throws away the remainder; for example, 5/2 is 2. Floating-point division is different in that there is no remainder to throw away; for example, 5.0/2.0 is 2.5. It follows that the most obvious answer to the question “Is 2.5/2 integer division or floating-point division?” is “Floating-point, of course; otherwise we’d lose information.” We would prefer the answer 1.25 rather than 1, and 1.25 is what we get. The rule (for the types we have presented so far) is that if an operator has an operand of type double, we use floating-point arithmetic yielding a double result; otherwise, we use integer arithmetic yielding an int result. For example:
![]()
5/2 is 2 (not 2.5)
2.5/2 means 2.5/double(2), that is, 1.25
'a'+1 means int{'a'}+1
![]()
The notations type(value) and type{value} mean “convert value to type as if you were initializing a variable of type type with the value value.” In other words, if necessary, the compiler converts (“promotes”) int operands to doubles or char operands to ints. The type{value} notation prevents narrowing (§3.9.2), but the type(value) notation does not. Once the result has been calculated, the compiler may have to convert it (again) to use it as an initializer or the right hand of an assignment. For example:
double d = 2.5;
int i = 2;
double d2 = d/i; // d2 == 1.25
int i2 = d/i; // i2 == 1
int i3 {d/i}; // error: double -> int conversion may narrow (§3.9.2)
d2 = d/i; // d2 == 1.25
i2 = d/i; // i2 == 1
Beware that it is easy to forget about integer division in an expression that also contains floating-point operands. Consider the usual formula for converting degrees Celsius to degrees Fahrenheit: f = 9/5 * c + 32. We might write
double dc;
cin >> dc;
double df = 9/5*dc+32; // beware!
Unfortunately, but quite logically, this does not represent an accurate temperature scale conversion: the value of 9/5 is 1 rather than the 1.8 we might have hoped for. To get the code mathematically correct, either 9 or 5 (or both) will have to be changed into a double. For example:
double dc;
cin >> dc;
double df = 9.0/5*dc+32; // better
4.4 Statements
An expression computes a value from a set of operands using operators like the ones mentioned in §4.3. What do we do when we want to produce several values? When we want to do something many times? When we want to choose among alternatives? When we want to get input or produce output? In C++, as in many languages, you use language constructs called statements to express those things.
So far, we have seen two kinds of statements: expression statements and declarations. An expression statement is simply an expression followed by a semicolon. For example:
a = b;
++b;
Those are two expression statements. Note that the assignment = is an operator so that a=b is an expression and we need the terminating semicolon to make a=b; a statement. Why do we need those semicolons? The reason is largely technical. Consider:
a = b ++ b; // syntax error: missing semicolon
Without the semicolon, the compiler doesn’t know whether we mean a=b++; b; or a=b; ++b;. This kind of problem is not restricted to computer languages; consider the exclamation “man eating tiger!” Who is eating whom? Punctuation exists to eliminate such problems, for example, “man-eating tiger!”
When statements follow each other, the computer executes them in the order in which they are written. For example:
int a = 7;
cout << a << '\n';
Here the declaration, with its initialization, is executed before the output expression statement.
In general, we want a statement to have some effect. Statements without effect are typically useless. For example:
1+2; // do an addition, but don’t use the sum
a*b; // do a multiplication, but don’t use the product
Such statements without effects are typically logical errors, and compilers often warn against them. Thus, expression statements are typically assignments, I/O statements, or function calls.
We will mention one more type of statement: the “empty statement.” Consider the code:
if (x == 5);
{ y = 3; }
![]()
This looks like an error, and it almost certainly is. The ; in the first line is not supposed to be there. But, unfortunately, this is a legal construct in C++. It is called an empty statement, a statement doing nothing. An empty statement before a semicolon is rarely useful. In this case, it has the unfortunate consequence of allowing what is almost certainly an error to be acceptable to the compiler, so it will not alert you to the error and you will have that much more difficulty finding it.
What will happen if this code is run? The compiler will test x to see if it has the value 5. If this condition is true, the following statement (the empty statement) will be executed, with no effect. Then the program continues to the next line, assigning the value 3 to y (which is what you wanted to have happen if x equals 5). If, on the other hand, x does not have the value 5, the compiler will not execute the empty statement (still no effect) and will continue as before to assign the value 3 to y (which is not what you wanted to have happen unless x equals 5). In other words, theif-statement doesn’t matter; y is going to get the value 3 regardless. This is a common error for novice programmers, and it can be difficult to spot, so watch out for it.
The next section is devoted to statements used to alter the order of evaluation to allow us to express more interesting computations than those we get by just executing statements in the order in which they were written.
4.4.1 Selection
In programs, as in life, we often have to select among alternatives. In C++, that is done using either an if-statement or a switch-statement.
4.4.1.1 if-statements
The simplest form of selection is an if-statement, which selects between two alternatives. For example:
int main()
{
int a = 0;
int b = 0;
cout << "Please enter two integers\n";
cin >> a >> b;
if (a<b) // condition
// 1st alternative (taken if condition is true):
cout << "max(" << a << "," << b <<") is " << b <<"\n";
else
// 2nd alternative (taken if condition is false):
cout << "max(" << a << "," << b <<") is " << a << "\n";
}
![]()
An if-statement chooses between two alternatives. If its condition is true, the first statement is executed; otherwise, the second statement is. This notion is simple. Most basic programming language features are. In fact, most basic facilities in a programming language are just new notation for things you learned in primary school — or even before that. For example, you were probably told in kindergarten that to cross the street at a traffic light, you had to wait for the light to turn green: “If the traffic light is green, go” and “If the traffic light is red, wait.” In C++ that becomes something like
if (traffic_light==green) go();
and
if (traffic_light==red) wait();
So, the basic notion is simple, but it is also easy to use if-statements in a too-simple-minded manner. Consider what’s wrong with this program (apart from leaving out the #include as usual):
// convert from inches to centimeters or centimeters to inches
// a suffix ‘i’ or ‘c’ indicates the unit of the input
int main()
{
constexpr double cm_per_inch = 2.54; // number of centimeters in
// an inch
double length = 1; // length in inches or
// centimeters
char unit = 0;
cout<< "Please enter a length followed by a unit (c or i):\n";
cin >> length >> unit;
if (unit == 'i')
cout << length << "in == " << cm_per_inch*length << "cm\n";
else
cout << length << "cm == " << length/cm_per_inch << "in\n";
}
Actually, this program works roughly as advertised: enter 1i and you get 1in == 2.54cm; enter 2.54c and you’ll get 2.54cm == 1in. Just try it; it’s good practice.
The snag is that we didn’t test for bad input. The program assumes that the user enters proper input. The condition unit=='i' distinguishes between the case where the unit is 'i' and all other cases. It never looks for a 'c'.
What if the user entered 15f (for feet) “just to see what happens”? The condition (unit == 'i') would fail and the program would execute the else part (the second alternative), converting from centimeters to inches. Presumably that was not what we wanted when we entered 'f'.
![]()
We must always test our programs with “bad” input, because someone will eventually — intentionally or accidentally — enter bad input. A program should behave sensibly even if its users don’t.
Here is an improved version:
// convert from inches to centimeters or centimeters to inches
// a suffix ‘i’ or ‘c’ indicates the unit of the input
// any other suffix is an error
int main()
{
constexpr double cm_per_inch = 2.54; // number of centimeters in
// an inch
double length = 1; // length in inches or
// centimeters
char unit = ' '; // a space is not a unit
cout<< "Please enter a length followed by a unit (c or i):\n";
cin >> length >> unit;
if (unit == 'i')
cout << length << "in == " << cm_per_inch*length << "cm\n";
else if (unit == 'c')
cout << length << "cm == " << length/cm_per_inch << "in\n";
else
cout << "Sorry, I don't know a unit called '" << unit << "'\n";
}
We first test for unit=='i' and then for unit=='c' and if it isn’t (either) we say, “Sorry.” It may look as if we used an “else-if-statement,” but there is no such thing in C++. Instead, we combined two if-statements. The general form of an if-statement is
if ( expression ) statement else statement
That is, an if, followed by an expression in parentheses, followed by a statement, followed by an else, followed by a statement. What we did was to use an if-statement as the else part of an if-statement:
if ( expression ) statement else if ( expression ) statement else statement
For our program that gives this structure:
if (unit == 'i')
. . . // 1st alternative
else if (unit == 'c')
. . . // 2nd alternative
else
. . . // 3rd alternative
![]()
In this way, we can write arbitrarily complex tests and associate a statement with each alternative. However, please remember that one of the ideals for code is simplicity, rather than complexity. You don’t demonstrate your cleverness by writing the most complex program. Rather, you demonstrate competence by writing the simplest code that does the job.
 Try This
Try This
Use the example above as a model for a program that converts yen, euros, and pounds into dollars. If you like realism, you can find conversion rates on the web.
4.4.1.2 switch-statements
Actually, the comparison of unit to 'i' and to 'c' is an example of the most common form of selection: a selection based on comparison of a value against several constants. Such selection is so common that C++ provides a special statement for it: the switch-statement. We can rewrite our example as
int main()
{
constexpr double cm_per_inch = 2.54; // number of centimeters in
// an inch
double length = 1; // length in inches or
// centimeters
char unit = 'a';
cout<< "Please enter a length followed by a unit (c or i):\n";
cin >> length >> unit;
switch (unit) {
case 'i':
cout << length << "in == " << cm_per_inch*length << "cm\n";
break;
case 'c':
cout << length << "cm == " << length/cm_per_inch << "in\n";
break;
default:
cout << "Sorry, I don't know a unit called '" << unit << "'\n";
break;
}
}
![]()
The switch-statement syntax is archaic but still clearer than nested if-statements, especially when we compare against many constants. The value presented in parentheses after the switch is compared to a set of constants. Each constant is presented as part of a case label. If the value equals the constant in a case label, the statement for that case is chosen. Each case is terminated by a break. If the value doesn’t match any of the case labels, the statement identified by the default label is chosen. You don’t have to provide a default, but it is a good idea to do so unless you are absolutely certain that you have listed every alternative. If you don’t already know, programming will teach you that it’s hard to be absolutely certain (and right) about anything.
4.4.1.3 Switch technicalities
Here are some technical details about switch-statements:
1. The value on which we switch must be of an integer, char, or enumeration (§9.5) type. In particular, you cannot switch on a string.
2. The values in the case labels must be constant expressions (§4.3.1). In particular, you cannot use a variable in a case label.
3. You cannot use the same value for two case labels.
4. You can use several case labels for a single case.
5. Don’t forget to end each case with a break. Unfortunately, the compiler probably won’t warn you if you forget.
For example:
int main() // you can switch only on integers, etc.
{
cout << "Do you like fish?\n";
string s;
cin >> s;
switch (s) { // error: the value must be of integer, char, or enum type
case "no":
// . . .
break;
case "yes":
// . . .
break;
}
}
To select based on a string you have to use an if-statement or a map (Chapter 21).
A switch-statement generates optimized code for comparing against a set of constants. For larger sets of constants, this typically yields more efficient code than a collection of if-statements. However, this means that the case label values must be constants and distinct. For example:
int main() // case labels must be constants
{
// define alternatives:
int y = 'y'; // this is going to cause trouble
constexpr char n = 'n';
constexpr char m = '?';
cout << "Do you like fish?\n";
char a;
cin >> a;
switch (a) {
case n:
// . . .
break;
case y: // error: variable in case label
// . . .
break;
case m:
// . . .
break;
case 'n': // error: duplicate case label (n’s value is ‘n’)
// . . .
break;
default:
// . . .
break;
}
}
Often you want the same action for a set of values in a switch. It would be tedious to repeat the action so you can label a single action by a set of case labels. For example:
int main() // you can label a statement with several case labels
{
cout << "Please enter a digit\n";
char a;
cin >> a;
switch (a) {
case '0': case '2': case '4': case '6': case '8':
cout << "is even\n";
break;
case '1': case '3': case '5': case '7': case '9':
cout << "is odd\n";
break;
default:
cout << "is not a digit\n";
break;
}
}
![]()
The most common error with switch-statements is to forget to terminate a case with a break. For example:
int main() // example of bad code (a break is missing)
{
constexpr double cm_per_inch = 2.54; // number of centimeters in
// an inch
double length = 1; // length in inches or
// centimeters
char unit = 'a';
cout << "Please enter a length followed by a unit (c or i):\n";
cin >> length >> unit;
switch (unit) {
case 'i':
cout << length << "in == " << cm_per_inch*length << "cm\n";
case 'c':
cout << length << "cm == " << length/cm_per_inch << "in\n";
}
}
Unfortunately, the compiler will accept this, and when you have finished case 'i' you’ll just “drop through” into case 'c', so that if you enter 2i the program will output
2in == 5.08cm
2cm == 0.787402in
You have been warned!
Try This
Rewrite your currency converter program from the previous Try this to use a switch-statement. Add conversions from yuan and kroner. Which version of the program is easier to write, understand, and modify? Why?
4.4.2 Iteration
We rarely do something only once. Therefore, programming languages provide convenient ways of doing something several times. This is called repetition or — especially when you do something to a series of elements of a data structure — iteration.
4.4.2.1 while-statements
As an example of iteration, consider the first program ever to run on a stored-program computer (the EDSAC). It was written and run by David Wheeler in the computer laboratory in Cambridge University, England, on May 6, 1949, to calculate and print a simple list of squares like this:
0 0
1 1
2 4
3 9
4 16
. . .
98 9604
99 9801
Each line is a number followed by a “tab” character ('\t'), followed by the square of the number. A C++ version looks like this:
// calculate and print a table of squares 0-99
int main()
{
int i = 0; // start from 0
while (i<100) {
cout << i << '\t' << square(i) << '\n';
++i; // increment i (that is, i becomes i+1)
}
}
The notation square(i) simply means the square of i. We’ll later explain how it gets to mean that (§4.5).
No, this first modern program wasn’t actually written in C++, but the logic was as is shown here:
• We start with 0.
• We see if we have reached 100, and if so we are finished.
• Otherwise, we print the number and its square, separated by a tab ('\t'), increase the number, and try again.
Clearly, to do this we need
• A way to repeat some statement (to loop)
• A variable to keep track of how many times we have been through the loop (a loop variable or a control variable), here the int called i
• An initializer for the loop variable, here 0
• A termination criterion, here that we want to go through the loop 100 times
• Something to do each time around the loop (the body of the loop)
The language construct we used is called a while-statement. Just following its distinguishing keyword, while, it has a condition “on top” followed by its body:
while (i<100) // the loop condition testing the loop variable i
{
cout << i << '\t' << square(i) << '\n';
++i ; // increment the loop variable i
}
The loop body is a block (delimited by curly braces) that writes out a row of the table and increments the loop variable, i. We start each pass through the loop by testing if i<100. If so, we are not yet finished and we can execute the loop body. If we have reached the end, that is, if i is 100, we leave the while-statement and execute what comes next. In this program the end of the program is next, so we leave the program.
The loop variable for a while-statement must be defined and initialized outside (before) the while-statement. If we fail to define it, the compiler will give us an error. If we define it, but fail to initialize it, most compilers will warn us, saying something like “local variable i not set,” but would be willing to let us execute the program if we insisted. Don’t insist! Compilers are almost certainly right when they warn about uninitialized variables. Uninitialized variables are a common source of errors. In this case, we wrote
int i = 0; // start from 0
so all is well.
Basically, writing a loop is simple. Getting it right for real-world problems can be tricky, though. In particular, it can be hard to express the condition correctly and to initialize all variables so that the loop starts correctly.
Try This
The character 'b' is char('a'+1), 'c' is char('a'+2), etc. Use a loop to write out a table of characters with their corresponding integer values:
a 97
b 98
. . .
z 122
4.4.2.2 Blocks
Note how we grouped the two statements that the while had to execute:
while (i<100) {
cout << i << '\t' << square(i) << '\n';
++i ; // increment i (that is, i becomes i+1)
}
![]()
A sequence of statements delimited by curly braces { and } is called a block or a compound statement. A block is a kind of statement. The empty block { } is sometimes useful for expressing that nothing is to be done. For example:
if (a<=b) { // do nothing
}
else { // swap a and b
int t = a;
a = b;
b = t;
}
4.4.2.3 for-statements
Iterating over a sequence of numbers is so common that C++, like most other programming languages, has a special syntax for it. A for-statement is like a while-statement except that the management of the control variable is concentrated at the top where it is easy to see and understand. We could have written the “first program” like this:
// calculate and print a table of squares 0-99
int main()
{
for (int i = 0; i<100; ++i)
cout << i << '\t' << square(i) << '\n';
}
This means “Execute the body with i starting at 0 incrementing i after each execution of the body until we reach 100.” A for-statement is always equivalent to some while-statement. In this case
for (int i = 0; i<100; ++i)
cout << i << '\t' << square(i) << '\n';
means
{
int i = 0; // the for-statement initializer
while (i<100) { // the for-statement condition
cout << i << '\t' << square(i) << '\n'; // the for-statement body
++i; // the for-statement increment
}
}
![]()
Some novices prefer while-statements and some novices prefer for-statements. However, using a for-statement yields more easily understood and more maintainable code whenever a loop can be defined as a for-statement with a simple initializer, condition, and increment operation. Use awhile-statement only when that’s not the case.
![]()
Never modify the loop variable inside the body of a for-statement. That would violate every reader’s reasonable assumption about what a loop is doing. Consider:
int main()
{
for (int i = 0; i<100; ++i) { // for i in the [0:100) range
cout << i << '\t' << square(i) << '\n';
++i; // what's going on here? It smells like an error!
}
}
Anyone looking at this loop would reasonably assume that the body would be executed 100 times. However, it isn’t. The ++i in the body ensures that i is incremented twice each time around the loop so that we get an output only for the 50 even values of i. If we saw such code, we would assume it to be an error, probably caused by a sloppy conversion from a while-statement. If you want to increment by 2, say so:
// calculate and print a table of squares of even numbers in the [0:100) range
int main()
{
for (int i = 0; i<100; i+=2)
cout << i << '\t' << square(i) << '\n';
}
![]()
Please note that the cleaner, more explicit version is shorter than the messy one. That’s typical.
Try This
Rewrite the character value example from the previous Try this to use a for-statement. Then modify your program to also write out a table of the integer values for uppercase letters and digits.
There is also a simpler “range-for-loop” for traversing collections of data, such as vectors; see §4.6.
4.5 Functions
In the program above, what was square(i)? It is a call of a function. In particular, it is a call of the function called square with the argument i. A function is a named sequence of statements. A function can return a result (also called a return value). The standard library provides a lot of useful functions, such as the square root function sqrt() that we used in §3.4. However, we write many functions ourselves. Here is a plausible definition of square:
int square(int x) // return the square of x
{
return x*x;
}
The first line of this definition tells us that this is a function (that’s what the parentheses mean), that it is called square, that it takes an int argument (here, called x), and that it returns an int (the type of the result always comes first in a function declaration); that is, we can use it like this:
int main()
{
cout << square(2) << '\n'; // print 4
cout << square(10) << '\n'; // print 100
}
We don’t have to use the result of a function call, but we do have to give a function exactly the arguments it requires. Consider:
square(2); // probably a mistake: unused return value
int v1 = square(); // error: argument missing
int v2 = square; // error: parentheses missing
int v3 = square(1,2); // error: too many arguments
int v4 = square("two"); // error: wrong type of argument - int expected
![]()
Many compilers warn against unused results, and all give errors as indicated. You might think that a computer should be smart enough to figure out that by the string "two" you really meant the integer 2. However, a C++ compiler deliberately isn’t that smart. It is the compiler’s job to do exactly what you tell it to do after verifying that your code is well formed according to the definition of C++. If the compiler guessed about what you meant, it would occasionally guess wrong, and you — or the users of your program — would be quite annoyed. You’ll find it hard enough to predict what your code will do without having the compiler “help you” by second-guessing you.
The function body is the block (§4.4.2.2) that actually does the work.
{
return x*x; // return the square of x
}
For square, the work is trivial: we produce the square of the argument and return that as our result. Saying that in C++ is easier than saying it in English. That’s typical for simple ideas. After all, a programming language is designed to state such simple ideas simply and precisely.
The syntax of a function definition can be described like this:
type identifier ( parameter-list ) function-body
That is, a type (the return type), followed by an identifier (the name of the function), followed by a list of parameters in parentheses, followed by the body of the function (the statements to be executed). The list of arguments required by the function is called a parameter list and its elements are called parameters (or formal arguments). The list of parameters can be empty, and if we don’t want to return a result we give void (meaning “nothing”) as the return type. For example:
void write_sorry() // take no argument; return no value
{
cout << "Sorry\n";
}
The language-technical aspects of functions will be examined more closely in Chapter 8.
4.5.1 Why bother with functions?
![]()
We define a function when we want a separate computation with a name because doing so
• Makes the computation logically separate
• Makes the program text clearer (by naming the computation)
• Makes it possible to use the function in more than one place in our program
• Eases testing
We’ll see many examples of each of those reasons as we go along, and we’ll occasionally mention a reason. Note that real-world programs use thousands of functions, some even hundreds of thousands of functions. Obviously, we would never be able to write or understand such programs if their parts (e.g., computations) were not clearly separated and named. Also, you’ll soon find that many functions are repeatedly useful and you’d soon tire of repeating equivalent code. For example, you might be happy writing x*x and 7*7 and (x+7)*(x+7), etc. rather than square(x) andsquare(7) and square(x+7), etc. However, that’s only because square is a very simple computation. Consider square root (called sqrt in C++): you prefer to write sqrt(x) and sqrt(7) and sqrt(x+7), etc. rather than repeating the (somewhat complicated and many lines long) code for computing square root. Even better: you don’t have to even look at the computation of square root because knowing that sqrt(x) gives the square root of x is sufficient.
In §8.5 we will address many function technicalities, but for now, we’ll just give another example.
If we had wanted to make the loop in main() really simple, we could have written
void print_square(int v)
{
cout << v << '\t' << v*v << '\n';
}
int main()
{
for (int i = 0; i<100; ++i) print_square(i);
}
Why didn’t we use the version using print_square()? That version is not significantly simpler than the version using square(), and note that
• print_square() is a rather specialized function that we could not expect to be able to use later, whereas square() is an obvious candidate for other uses
• square() hardly requires documentation, whereas print_square() obviously needs explanation
The underlying reason for both is that print_square() performs two logically separate actions:
• It prints.
• It calculates a square.
Programs are usually easier to write and to understand if each function performs a single logical action. Basically, the square() version is the better design.
Finally, why did we use square(i) rather than simply i*i in the first version of the problem? Well, one of the purposes of functions is to simplify code by separating out complicated calculations as named functions, and for the 1949 version of the program there was no hardware that directly implemented “multiply.” Consequently, in the 1949 version of the program, i*i was actually a fairly complicated calculation, similar to what you’d do by hand using a piece of paper. Also, the writer of that original version, David Wheeler, was the inventor of the function (then called a subroutine) in modern computing, so it seemed appropriate to use it here.
Try This
Implement square() without using the multiplication operator; that is, do the x*x by repeated addition (start a variable result at 0 and add x to it x times). Then run some version of “the first program” using that square().
4.5.2 Function declarations
Did you notice that all the information needed to call a function was in the first line of its definition? For example:
int square(int x)
Given that, we know enough to say
int x = square(44);
We don’t really need to look at the function body. In real programs, we most often don’t want to look at a function body. Why would we want to look at the body of the standard library sqrt() function? We know it calculates the square root of its argument. Why would we want to see the body of our square() function? Of course we might just be curious. But almost all of the time, we are just interested in knowing how to call a function — seeing the definition would just be distracting. Fortunately, C++ provides a way of supplying that information separate from the complete function definition. It is called a function declaration:
int square(int); // declaration of square
double sqrt(double); // declaration of sqrt
Note the terminating semicolons. A semicolon is used in a function declaration instead of the body used in the corresponding function definition:
int square(int x) // definition of square
{
return x*x;
}
So, if you just want to use a function, you simply write — or more commonly #include — its declaration. The function definition can be elsewhere. We’ll discuss where that “elsewhere” might be in §8.3 and §8.7. This distinction between declarations and definitions becomes essential in larger programs where we use declarations to keep most of the code out of sight to allow us to concentrate on a single part of a program at a time (§4.2).
4.6 vector
To do just about anything of interest in a program, we need a collection of data to work on. For example, we might need a list of phone numbers, a list of members of a football team, a list of courses, a list of books read over the last year, a catalog of songs for download, a set of payment options for a car, a list of the weather forecasts for the next week, a list of prices for a camera in different web stores, etc. The possibilities are literally endless and therefore ubiquitous in programs. We’ll get to see a variety of ways of storing collections of data (a variety of containers of data; see Chapters 20 and 21). Here we will start with one of the simplest, and arguably the most useful, ways of storing data: a vector.
![]()
A vector is simply a sequence of elements that you can access by an index. For example, here is a vector called v:
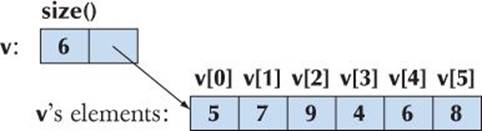
That is, the first element has index 0, the second index 1, and so on. We refer to an element by subscripting the name of the vector with the element’s index, so here the value of v[0] is 5, the value of v[1] is 7, and so on. Indices for a vector always start with 0 and increase by 1. This should look familiar: the standard library vector is simply the C++ standard library’s version of an old and well-known idea. I have drawn the vector so as to emphasize that it “knows its size”; that is, a vector doesn’t just store its elements, it also stores its size.
We could make such a vector like this:
vector<int> v = {5, 7, 9, 4, 6, 8}; // vector of 6 ints
We see that to make a vector we need to specify the type of the elements and the initial set of elements. The element type comes after vector in angle brackets (< >), here <int>. Here is another example:
vector<string> philosopher
= {"Kant", "Plato", "Hume", "Kierkegaard"}; // vector of 4 strings
Naturally, a vector will only accept elements of its declared element type:
philosopher[2] = 99; // error: trying to assign an int to a string
v[2] = "Hume"; // error: trying to assign a string to an int
We can also define a vector of a given size without specifying the element values. In that case, we use the (n) notation where n is the number of elements, and the elements are given a default value according to the element type. For example:
vector<int> vi(6); // vector of 6 ints initialized to 0
vector<string> vs(4); // vector of 4 strings initialized to “”
The string with no characters "" is called the empty string.
Please note that you cannot simply refer to a nonexistent element of a vector:
vi[20000] = 44; // run-time error
We will discuss run-time errors and subscripting in the next chapter.
4.6.1 Traversing a vector
A vector “knows” its size, so we can print the elements of a vector like this:
vector<int> v = {5, 7, 9, 4, 6, 8};
for (int i=0; i<v.size(); ++i)
cout << v[i] << '\n';
The call v.size() gives the number of elements of the vector called v. In general, v.size() gives us the ability to access elements of a vector without accidentally referring to an element outside the vector’s range. The range for a vector v is [0:v.size()). That’s the mathematical notation for a half-open sequence of elements. The first element of v is v[0] and the last v[v.size()-1]. If v.size==0, v has no elements, that is, v is an empty vector. This notion of half-open sequences is used throughout C++ and the C++ standard library (§17.3, §20.3).
The language takes advantage of the notion of a half-open sequence to provide a simple loop over all the elements of a sequence, such as the elements of a vector. For example:
vector<int> v = {5, 7, 9, 4, 6, 8};
for (int x : v) // for each x in v
cout << x << '\n';
This is called a range-for-loop because the word range is often used to mean the same as “sequence of elements.” We read for (int x : v) as “for each int x in v” and the meaning of the loop is exactly like the equivalent loop over the subscripts [0:v.size()). We use the range-for-loop for simple loops over all the elements of a sequence looking at one element at a time. More complicated loops, such as looking at every third element of a vector, looking at only the second half of a vector, or comparing elements of two vectors, are usually better done using the more complicated and more general traditional for-statement (§4.4.2.3).
4.6.2 Growing a vector
![]()
Often, we start a vector empty and grow it to its desired size as we read or compute the data we want in it. The key operation here is push_back(), which adds a new element to a vector. The new element becomes the last element of the vector. For example:

Note the syntax for a call of push_back(). It is called a member function call; push_back() is a member function of vector and must be called using this dot notation:
member-function-call:
object_name.member-function-name ( argument-list )
The size of a vector can be obtained by a call to another of vector’s member functions: size(). Initially v.size() was 0, and after the third call of push_back(), v.size() has become 3.
If you have programmed before, you will note that a vector is similar to an array in C and other languages. However, you need not specify the size (length) of a vector in advance, and you can add as many elements as you like. As we go along, you’ll find that the C++ standard vector has other useful properties.
4.6.3 A numeric example
Let’s look at a more realistic example. Often, we have a series of values that we want to read into our program so that we can do something with them. The “something” could be producing a graph of the values, calculating the mean and median, finding the largest element, sorting them, combining them with other data, searching for “interesting” values, comparing them to other data, etc. There is no limit to the range of computations we might perform on data, but first we need to get it into our computer’s memory. Here is the basic technique for getting an unknown — possibly large — amount of data into a computer. As a concrete example, we chose to read in floating-point numbers representing temperatures:
// read some temperatures into a vector
int main()
{
vector<double> temps; // temperatures
for (double temp; cin>>temp; ) // read into temp
temps.push_back(temp); // put temp into vector
// . . . do something . . .
}
So, what goes on here? First we declare a vector to hold the data:
vector<double> temps; // temperatures
This is where the type of input we expect is mentioned. We read and store doubles.
Next comes the actual read loop:
for (double temp; cin>>temp; ) // read into temp
temps.push_back(temp); // put temp into vector
We define a variable temp of type double to read into. The cin>>temp reads a double, and that double is pushed into the vector (placed at the back). We have seen those individual operations before. What’s new here is that we use the input operation, cin>>temp, as the condition for a for-statement. Basically, cin>>temp is true if a value was read correctly and false otherwise, so that for-statement will read all the doubles we give it and stop when we give it anything else. For example, if you typed
1.2 3.4 5.6 7.8 9.0 |
then temps would get the five elements 1.2, 3.4, 5.6, 7.8, 9.0 (in that order, for example, temps[0]==1.2). We used the character '|' to terminate the input — anything that isn’t a double can be used. In §10.6 we discuss how to terminate input and how to deal with errors in input.
To limit the scope of our input variable, temp, to the loop, we used a for-statement, rather than a while-statement:
double temp;
while (cin>>temp) // read
temps.push_back(temp); // put into vector
// ... temp might be used here ...
As usual, a for-loop shows what is going on “up front” so that the code is easier to understand and accidental errors are harder to make.
Once we get data into a vector we can easily manipulate it. As an example, let’s calculate the mean and median temperatures:
// compute mean and median temperatures
int main()
{
vector<double> temps; // temperatures
for (double temp; cin>>temp; ) // read into temp
temps.push_back(temp); // put temp into vector
// compute mean temperature:
double sum = 0;
for (int x : temps) sum += x;
cout << "Average temperature: " << sum/temps.size() << '\n';
// compute median temperature:
sort(temps); // sort temperatures
cout << "Median temperature: " << temps[temps.size()/2] << '\n';
}
We calculate the average (the mean) by simply adding all the elements into sum, and then dividing the sum by the number of elements (that is, temps.size()):
// compute average temperature:
double sum = 0;
for (int x : temps) sum += x;
cout << "Average temperature: " << sum/temps.size() << '\n';
Note how the += operator comes in handy.
To calculate a median (a value chosen so that half of the values are lower and the other half are higher) we need to sort the elements. For that, we use a variant of the standard library sort algorithm, sort():
// compute median temperature:
sort(temps); // sort temperatures
cout << "Median temperature: " << temps[temps.size()/2] << '\n';
We will explain the standard library algorithms much later (Chapter 20). Once the temperatures are sorted, it’s easy to find the median: we just pick the middle element, the one with index temps.size()/2. If you feel like being picky (and if you do, you are starting to think like a programmer), you could observe that the value we found may not be a median according to the definition we offered above. Exercise 2 at the end of this chapter is designed to solve that little problem.
4.6.4 A text example
We didn’t present the temperature example because we were particularly interested in temperatures. Many people — such as meteorologists, agronomists, and oceanographers — are very interested in temperature data and values based on it, such as means and medians. However, we are not. From a programmer’s point of view, what’s interesting about this example is its generality: the vector and the simple operations on it can be used in a huge range of applications. It is fair to say that whatever you are interested in, if you need to analyze data, you’ll use vector (or a similar data structure; see Chapter 21). As an example, let’s build a simple dictionary:
// simple dictionary: list of sorted words
int main()
{
vector<string> words;
for(string temp; cin>>temp; ) // read whitespace-separated words
words.push_back(temp); // put into vector
cout << "Number of words: " << words.size() << '\n';
sort(words); // sort the words
for (int i = 0; i<words.size(); ++i)
if (i==0 || words[i-1]!=words[i]) // is this a new word?
cout << words[i] << "\n";
}
If we feed some words to this program, it will write them out in order without repeating a word. For example, given
a man a plan a canal panama
it will write
a
canal
man
panama
plan
How do we stop reading string input? In other words, how do we terminate the input loop?
for (string temp; cin>>temp; ) // read
words.push_back(temp); // put into vector
When we read numbers (in §4.6.2), we just gave some input character that wasn’t a number. We can’t do that here because every (ordinary) character can be read into a string. Fortunately, there are characters that are “not ordinary.” As mentioned in §3.5.1, Ctrl+Z terminates an input stream under Windows and Ctrl+D does that under Unix.
Most of this program is remarkably similar to what we did for the temperatures. In fact, we wrote the “dictionary program” by cutting and pasting from the “temperature program.” The only thing that’s new is the test
if (i==0 || words[i-1]!=words[i]) // is this a new word?
If you deleted that test the output would be
a
a
a
canal
man
panama
plan
We didn’t like the repetition, so we eliminated it using that test. What does the test do? It looks to see if the previous word we printed is different from the one we are about to print (words[i-1]!=words[i]) and if so, we print that word; otherwise, we do not. Obviously, we can’t talk about a previous word when we are about to print the first word (i==0), so we first test for that and combine those two tests using the || (or) operator:
if (i==0 || words[i-1]!=words[i]) // is this a new word?
Note that we can compare strings. We use != (not equals) here; == (equals), < (less than), <= (less than or equal), > (greater than), and >= (greater than or equal) also work for strings. The <, >, etc. operators use the usual lexicographical ordering, so "Ape" comes before "Apple" and"Chimpanzee".
Try This
Write a program that “bleeps” out words that you don’t like; that is, you read in words using cin and print them again on cout. If a word is among a few you have defined, you write out BLEEP instead of that word. Start with one “disliked word” such as
string disliked = “Broccoli”;
When that works, add a few more.
4.7 Language features
The temperature and dictionary programs used most of the fundamental language features we presented in this chapter: iteration (the for-statement and the while-statement), selection (the if-statement), simple arithmetic (the ++ and += operators), comparisons and logical operators (the ==, !=, and || operators), variables, and functions (e.g., main(), sort(), and size()). In addition, we used standard library facilities, such as vector (a container of elements), cout (an output stream), and sort() (an algorithm).
![]()
If you count, you’ll find that we actually achieved quite a lot with rather few features. That’s the ideal! Each programming language feature exists to express a fundamental idea, and we can combine them in a huge (really, infinite) number of ways to write useful programs. This is a key notion: a computer is not a gadget with a fixed function. Instead it is a machine that we can program to do any computation we can think of, and given that we can attach computers to gadgets that interact with the world outside the computer, we can in principle get it to do anything.
 Drill
Drill
Go through this drill step by step. Do not try to speed up by skipping steps. Test each step by entering at least three pairs of values — more values would be better.
1. Write a program that consists of a while-loop that (each time around the loop) reads in two ints and then prints them. Exit the program when a terminating '|' is entered.
2. Change the program to write out the smaller value is: followed by the smaller of the numbers and the larger value is: followed by the larger value.
3. Augment the program so that it writes the line the numbers are equal (only) if they are equal.
4. Change the program so that it uses doubles instead of ints.
5. Change the program so that it writes out the numbers are almost equal after writing out which is the larger and the smaller if the two numbers differ by less than 1.0/100.
6. Now change the body of the loop so that it reads just one double each time around. Define two variables to keep track of which is the smallest and which is the largest value you have seen so far. Each time through the loop write out the value entered. If it’s the smallest so far, write the smallest so far after the number. If it is the largest so far, write the largest so far after the number.
7. Add a unit to each double entered; that is, enter values such as 10cm, 2.5in, 5ft, or 3.33m. Accept the four units: cm, m, in, ft. Assume conversion factors 1m == 100cm, 1in == 2.54cm, 1ft == 12in. Read the unit indicator into a string. You may consider 12 m (with a space between the number and the unit) equivalent to 12m (without a space).
8. Reject values without units or with “illegal” representations of units, such as y, yard, meter, km, and gallons.
9. Keep track of the sum of values entered (as well as the smallest and the largest) and the number of values entered. When the loop ends, print the smallest, the largest, the number of values, and the sum of values. Note that to keep the sum, you have to decide on a unit to use for that sum; use meters.
10. Keep all the values entered (converted into meters) in a vector. At the end, write out those values.
11. Before writing out the values from the vector, sort them (that’ll make them come out in increasing order).
Review
1. What is a computation?
2. What do we mean by inputs and outputs to a computation? Give examples.
3. What are the three requirements a programmer should keep in mind when expressing computations?
4. What does an expression do?
5. What is the difference between a statement and an expression, as described in this chapter?
6. What is an lvalue? List the operators that require an lvalue. Why do these operators, and not the others, require an lvalue?
7. What is a constant expression?
8. What is a literal?
9. What is a symbolic constant and why do we use them?
10. What is a magic constant? Give examples.
11. What are some operators that we can use for integers and floating-point values?
12. What operators can be used on integers but not on floating-point numbers?
13. What are some operators that can be used for strings?
14. When would a programmer prefer a switch-statement to an if-statement?
15. What are some common problems with switch-statements?
16. What is the function of each part of the header line in a for-loop, and in what sequence are they executed?
17. When should the for-loop be used and when should the while-loop be used?
18. How do you print the numeric value of a char?
19. Describe what the line char foo(int x) means in a function definition.
20. When should you define a separate function for part of a program? List reasons.
21. What can you do to an int that you cannot do to a string?
22. What can you do to a string that you cannot do to an int?
23. What is the index of the third element of a vector?
24. How do you write a for-loop that prints every element of a vector?
25. What does vector<char> alphabet(26); do?
26. Describe what push_back() does to a vector.
27. What do vector’s member functions begin(), end(), and size() do?
28. What makes vector so popular/useful?
29. How do you sort the elements of a vector?
Terms
abstraction
begin()
computation
conditional statement
declaration
definition
divide and conquer
else
end()
expression
for-statement
range-for-statement
function
if-statement
increment
input
iteration
loop
lvalue
member function
output
push_back()
repetition
rvalue
selection
size()
sort()
statement
switch-statement
vector
while-statement
Exercises
1. If you haven’t already, do the Try this exercises from this chapter.
2. If we define the median of a sequence as “a number so that exactly as many elements come before it in the sequence as come after it,” fix the program in §4.6.3 so that it always prints out a median. Hint: A median need not be an element of the sequence.
3. Read a sequence of double values into a vector. Think of each value as the distance between two cities along a given route. Compute and print the total distance (the sum of all distances). Find and print the smallest and greatest distance between two neighboring cities. Find and print the mean distance between two neighboring cities.
4. Write a program to play a numbers guessing game. The user thinks of a number between 1 and 100 and your program asks questions to figure out what the number is (e.g., “Is the number you are thinking of less than 50?”). Your program should be able to identify the number after asking no more than seven questions. Hint: Use the < and <= operators and the if-else construct.
5. Write a program that performs as a very simple calculator. Your calculator should be able to handle the four basic math operations — add, subtract, multiply, and divide — on two input values. Your program should prompt the user to enter three arguments: two double values and a character to represent an operation. If the entry arguments are 35.6, 24.1, and '+', the program output should be The sum of 35.6 and 24.1 is 59.7. In Chapter 6 we look at a much more sophisticated simple calculator.
6. Make a vector holding the ten string values "zero", "one", . . . "nine". Use that in a program that converts a digit to its corresponding spelled-out value; e.g., the input 7 gives the output seven. Have the same program, using the same input loop, convert spelled-out numbers into their digit form; e.g., the input seven gives the output 7.
7. Modify the “mini calculator” from exercise 5 to accept (just) single-digit numbers written as either digits or spelled out.
8. There is an old story that the emperor wanted to thank the inventor of the game of chess and asked the inventor to name his reward. The inventor asked for one grain of rice for the first square, 2 for the second, 4 for the third, and so on, doubling for each of the 64 squares. That may sound modest, but there wasn’t that much rice in the empire! Write a program to calculate how many squares are required to give the inventor at least 1000 grains of rice, at least 1,000,000 grains, and at least 1,000,000,000 grains. You’ll need a loop, of course, and probably an int to keep track of which square you are at, an int to keep the number of grains on the current square, and an int to keep track of the grains on all previous squares. We suggest that you write out the value of all your variables for each iteration of the loop so that you can see what’s going on.
9. Try to calculate the number of rice grains that the inventor asked for in exercise 8 above. You’ll find that the number is so large that it won’t fit in an int or a double. Observe what happens when the number gets too large to represent exactly as an int and as a double. What is the largest number of squares for which you can calculate the exact number of grains (using an int)? What is the largest number of squares for which you can calculate the approximate number of grains (using a double)?
10. Write a program that plays the game “Rock, Paper, Scissors.” If you are not familiar with the game do some research (e.g., on the web using Google). Research is a common task for programmers. Use a switch-statement to solve this exercise. Also, the machine should give random answers (i.e., select the next rock, paper, or scissors randomly). Real randomness is too hard to provide just now, so just build a vector with a sequence of values to be used as “the next value.” If you build the vector into the program, it will always play the same game, so maybe you should let the user enter some values. Try variations to make it less easy for the user to guess which move the machine will make next.
11. Create a program to find all the prime numbers between 1 and 100. One way to do this is to write a function that will check if a number is prime (i.e., see if the number can be divided by a prime number smaller than itself) using a vector of primes in order (so that if the vector is calledprimes, primes[0]==2, primes[1]==3, primes[2]==5, etc.). Then write a loop that goes from 1 to 100, checks each number to see if it is a prime, and stores each prime found in a vector. Write another loop that lists the primes you found. You might check your result by comparing yourvector of prime numbers with primes. Consider 2 the first prime.
12. Modify the program described in the previous exercise to take an input value max and then find all prime numbers from 1 to max.
13. Create a program to find all the prime numbers between 1 and 100. There is a classic method for doing this, called the “Sieve of Eratosthenes.” If you don’t know that method, get on the web and look it up. Write your program using this method.
14. Modify the program described in the previous exercise to take an input value max and then find all prime numbers from 1 to max.
15. Write a program that takes an input value n and then finds the first n primes.
16. In the drill, you wrote a program that, given a series of numbers, found the max and min of that series. The number that appears the most times in a sequence is called the mode. Create a program that finds the mode of a set of positive integers.
17. Write a program that finds the min, max, and mode of a sequence of strings.
18. Write a program to solve quadratic equations. A quadratic equation is of the form
ax2 + bx + c = 0
If you don’t know the quadratic formula for solving such an expression, do some research. Remember, researching how to solve a problem is often necessary before a programmer can teach the computer how to solve it. Use doubles for the user inputs for a, b, and c. Since there are two solutions to a quadratic equation, output both x1 and x2.
19. Write a program where you first enter a set of name-and-value pairs, such as Joe 17 and Barbara 22. For each pair, add the name to a vector called names and the number to a vector called scores (in corresponding positions, so that if names[7]=="Joe" then scores[7]==17). Terminate input with NoName 0. Check that each name is unique and terminate with an error message if a name is entered twice. Write out all the (name,score) pairs, one per line.
20. Modify the program from exercise 19 so that when you enter a name, the program will output the corresponding score or name not found.
21. Modify the program from exercise 19 so that when you enter an integer, the program will output all the names with that score or score not found.
Postscript
From a philosophical point of view, you can now do everything that can be done using a computer — the rest is details! Among other things, this shows the value of “details” and the importance of practical skills, because clearly you have barely started as a programmer. But we are serious. The tools presented in this chapter do allow you to express every computation: you have as many variables (including vectors and strings) as you want, you have arithmetic and comparisons, and you have selection and iteration. Every computation can be expressed using those primitives. You have text and numeric input and output, and every input or output can be expressed as text (even graphics). You can even organize your computations as sets of named functions. What is left for you to do is “just” to learn to write good programs, that is, to write programs that are correct, maintainable, and reasonably efficient. Importantly, you must try to learn to do so with a reasonable amount of effort.
All materials on the site are licensed Creative Commons Attribution-Sharealike 3.0 Unported CC BY-SA 3.0 & GNU Free Documentation License (GFDL)
If you are the copyright holder of any material contained on our site and intend to remove it, please contact our site administrator for approval.
© 2016-2026 All site design rights belong to S.Y.A.