Programming: Principles and Practice Using C++ (2014)
Part I: The Basics
5. Errors
“I realized that from now on a large part of my life would be spent finding and correcting my own mistakes.”
—Maurice Wilkes, 1949
In this chapter, we discuss correctness of programs, errors, and error handling. If you are a genuine novice, you’ll find the discussion a bit abstract at times and painfully detailed at other times. Can error handling really be this important? It is, and you’ll learn that one way or another before you can write programs that others are willing to use. What we are trying to do is to show you what “thinking like a programmer” is about. It combines fairly abstract strategy with painstaking analysis of details and alternatives.
5.1 Introduction
5.2 Sources of errors
5.3 Compile-time errors
5.3.1 Syntax errors
5.3.2 Type errors
5.3.3 Non-errors
5.4 Link-time errors
5.5 Run-time errors
5.5.1 The caller deals with errors
5.5.2 The callee deals with errors
5.5.3 Error reporting
5.6 Exceptions
5.6.1 Bad arguments
5.6.2 Range errors
5.6.3 Bad input
5.6.4 Narrowing errors
5.7 Logic errors
5.8 Estimation
5.9 Debugging
5.9.1 Practical debug advice
5.10 Pre- and post-conditions
5.10.1 Post-conditions
5.11 Testing
5.1 Introduction
We have referred to errors repeatedly in the previous chapters, and — having done the drills and some exercises — you have some idea why. Errors are simply unavoidable when you develop a program, yet the final program must be free of errors, or at least free of errors that we consider unacceptable for it.
There are many ways of classifying errors. For example:
![]()
• Compile-time errors: Errors found by the compiler. We can further classify compile-time errors based on which language rules they violate, for example:
• Syntax errors
• Type errors
• Link-time errors: Errors found by the linker when it is trying to combine object files into an executable program.
• Run-time errors: Errors found by checks in a running program. We can further classify run-time errors as
• Errors detected by the computer (hardware and/or operating system)
• Errors detected by a library (e.g., the standard library)
• Errors detected by user code
• Logic errors: Errors found by the programmer looking for the causes of erroneous results.
![]()
It is tempting to say that our job as programmers is to eliminate all errors. That is of course the ideal, but often that’s not feasible. In fact, for real-world programs it can be hard to know exactly what “all errors” means. If we kicked out the power cord from your computer while it executed your program, would that be an error that you were supposed to handle? In many cases, the answer is “Obviously not,” but what if we were talking about a medical monitoring program or the control program for a telephone switch? In those cases, a user could reasonably expect that something in the system of which your program was a part will do something sensible even if your computer lost power or a cosmic ray damaged the memory holding your program. The key question becomes: “Is my program supposed to detect that error?” Unless we specifically say otherwise, we will assume that your program
1. Should produce the desired results for all legal inputs
2. Should give reasonable error messages for all illegal inputs
3. Need not worry about misbehaving hardware
4. Need not worry about misbehaving system software
5. Is allowed to terminate after finding an error
Essentially all programs for which assumptions 3, 4, or 5 do not hold can be considered advanced and beyond the scope of this book. However, assumptions 1 and 2 are included in the definition of basic professionalism, and professionalism is one of our goals. Even if we don’t meet that ideal 100% of the time, it must be the ideal.
When we write programs, errors are natural and unavoidable; the question is: How do we deal with them? Our guess is that avoiding, finding, and correcting errors takes 90% or more of the effort when developing serious software. For safety-critical programs, the effort can be greater still. You can do much better for small programs; on the other hand, you can easily do worse if you’re sloppy.
Basically, we offer three approaches to producing acceptable software:
• Organize software to minimize errors.
![]()
• Eliminate most of the errors we made through debugging and testing.
• Make sure the remaining errors are not serious.
None of these approaches can completely eliminate errors by itself; we have to use all three.
Experience matters immensely when it comes to producing reliable programs, that is, programs that can be relied on to do what they are supposed to do with an acceptable error rate. Please don’t forget that the ideal is that our programs always do the right thing. We are usually able only to approximate that ideal, but that’s no excuse for not trying very hard.
5.2 Sources of errors
Here are some sources of errors:
![]()
• Poor specification: If we are not specific about what a program should do, we are unlikely to adequately examine the “dark corners” and make sure that all cases are handled (i.e., that every input gives a correct answer or an adequate error message).
• Incomplete programs: During development, there are obviously cases that we haven’t yet taken care of. That’s unavoidable. What we must aim for is to know when we have handled all cases.
• Unexpected arguments: Functions take arguments. If a function is given an argument we don’t handle, we have a problem. An example is calling the standard library square root function with -1.2: sqrt(-1.2). Since sqrt() of a double returns a double, there is no possible correct return value. §5.5.3 discusses this kind of problem.
• Unexpected input: Programs typically read data (from a keyboard, from files, from GUIs, from network connections, etc.). A program makes many assumptions about such input, for example, that the user will input a number. What if the user inputs “aw, shut up!” rather than the expected integer? §5.6.3 and §10.6 discuss this kind of problem.
• Unexpected state: Most programs keep a lot of data (“state”) around for use by different parts of the system. Examples are address lists, phone directories, and vectors of temperature readings. What if such data is incomplete or wrong? The various parts of the program must still manage. §26.3.5 discusses this kind of problem.
• Logical errors: That is, code that simply doesn’t do what it was supposed to do; we’ll just have to find and fix such problems. §6.6 and §6.9 give examples of finding such problems.
This list has a practical use. We can use it as a checklist when we are considering how far we have come with a program. No program is complete until we have considered all of these potential sources of errors. In fact, it is prudent to keep them in mind from the very start of a project, because it is most unlikely that a program that is just thrown together without thought about errors can have its errors found and removed without a serious rewrite.
5.3 Compile-time errors
When you are writing programs, your compiler is your first line of defense against errors. Before generating code, the compiler analyzes code to detect syntax errors and type errors. Only if it finds that the program completely conforms to the language specification will it allow you to proceed. Many of the errors that the compiler finds are simply “silly errors” caused by mistyping or incomplete edits of the source code. Others result from flaws in our understanding of the way parts of our program interact. To a beginner, the compiler often seems petty, but as you learn to use the language facilities — and especially the type system — to directly express your ideas, you’ll come to appreciate the compiler’s ability to detect problems that would otherwise have caused you hours of tedious searching for bugs.
As an example, we will look at some calls of this simple function:
int area(int length, int width); // calculate area of a rectangle
5.3.1 Syntax errors
What if we were to call area() like this:
int s1 = area(7; // error: ) missing
int s2 = area(7) // error: ; missing
Int s3 = area(7); // error: Int is not a type
int s4 = area('7); // error: non-terminated character (' missing)
![]()
Each of those lines has a syntax error; that is, they are not well formed according to the C++ grammar, so the compiler will reject them. Unfortunately, syntax errors are not always easy to report in a way that you, the programmer, find easy to understand. That’s because the compiler may have to read a bit further than the error to be sure that there really is an error. The effect of this is that even though syntax errors tend to be completely trivial (you’ll often find it hard to believe you have made such a mistake once you find it), the reporting is often cryptic and occasionally refers to a line further on in the program. So, for syntax errors, if you don’t see anything wrong with the line the compiler points to, also look at previous lines in the program.
Note that the compiler has no idea what you are trying to do, so it cannot report errors in terms of your intent, only in terms of what you did. For example, given the error in the declaration of s3 above, a compiler is unlikely to say
“You misspelled int; don’t capitalize the i.”
Rather, it’ll say something like
“syntax error: missing ‘;’ before identifier ‘s3’”
“‘s3’ missing storage-class or type identifiers”
“‘Int’ missing storage-class or type identifiers”
Such messages tend to be cryptic, until you get used to them, and to use a vocabulary that can be hard to penetrate. Different compilers can give very different-looking error messages for the same code. Fortunately, you soon get used to reading such stuff. After all, a quick look at those cryptic lines can be read as
“There was a syntax error before s3, and it had something to do with the type of Int or s3.”
Given that, it’s not rocket science to find the problem.
 Try This
Try This
Try to compile those examples and see how the compiler responds.
5.3.2 Type errors
Once you have removed syntax errors, the compiler will start reporting type errors; that is, it will report mismatches between the types you declared (or forgot to declare) for your variables, functions, etc. and the types of values or expressions you assign to them, pass as function arguments, etc. For example:
int x0 = arena(7); // error: undeclared function
int x1 = area(7); // error: wrong number of arguments
int x2 = area("seven",2); // error: 1st argument has a wrong type
Let’s consider these errors.
1. For arena(7), we misspelled area as arena, so the compiler thinks we want to call a function called arena. (What else could it “think”? That’s what we said.) Assuming there is no function called arena(), you’ll get an error message complaining about an undeclared function. If there is a function called arena, and if that function accepts 7 as an argument, you have a worse problem: the program will compile but do something you didn’t expect it to (that’s a logical error; see §5.7).
2. For area(7), the compiler detects the wrong number of arguments. In C++, every function call must provide the expected number of arguments, of the right types, and in the right order. When the type system is used appropriately, this can be a powerful tool for avoiding run-time errors (see §14.1).
3. For area("seven",2), you might hope that the computer would look at "seven" and figure out that you meant the integer 7. It won’t. If a function needs an integer, you can’t give it a string. C++ does support some implicit type conversions (see §3.9) but not string to int. The compiler does not try to guess what you meant. What would you have expected for area("Hovel lane",2), area("7,2"), and area("sieben","zwei")?
These are just a few examples. There are many more errors that the compiler will find for you.
Try This
Try to compile those examples and see how the compiler responds. Try thinking of a few more errors yourself, and try those.
5.3.3 Non-errors
As you work with the compiler, you’ll wish that it was smart enough to figure out what you meant; that is, you’d like some of the errors it reports not to be errors. That’s natural. More surprisingly, as you gain experience, you’ll begin to wish that the compiler would reject more code, rather than less. Consider:
int x4 = area(10,-7); // OK: but what is a rectangle with a width of minus 7?
int x5 = area(10.7,9.3); // OK: but calls area(10,9)
char x6 = area(100,9999); // OK: but truncates the result
For x4 we get no error message from the compiler. From the compiler’s point of view, area (10,-7) is fine: area() asks for two integers and you gave them to it; nobody said that those arguments had to be positive.
For x5, a good compiler will warn about the truncation of the doubles 10.7 and 9.3 into the ints 10 and 9 (see §3.9.2). However, the (ancient) language rules state that you can implicitly convert a double to an int, so the compiler is not allowed to reject the call area(10.7,9.3).
The initialization of x6 suffers from a variant of the same problem as the call area(10.7,9.3). The int returned by area(100,9999), probably 999900, will be assigned to a char. The most likely result is for x6 to get the “truncated” value -36. Again, a good compiler will give you a warning even though the (ancient) language rules prevent it from rejecting the code.
As you gain experience, you’ll learn how to get the most out of the compiler’s ability to detect errors and to dodge its known weaknesses. However, don’t get overconfident: “my program compiled” doesn’t mean that it will run. Even if it does run, it typically gives wrong results at first until you find the flaws in your logic.
5.4 Link-time errors
![]()
A program consists of several separately compiled parts, called translation units. Every function in a program must be declared with exactly the same type in every translation unit in which it is used. We use header files to ensure that; see §8.3. Every function must also be defined exactly once in a program. If either of these rules is violated, the linker will give an error. We discuss how to avoid link-time errors in §8.3. For now, here is an example of a program that might give a typical linker error:
int area(int length, int width); // calculate area of a rectangle
int main()
{
int x = area(2,3);
}
Unless we somehow have defined area() in another source file and linked the code generated from that source file to this code, the linker will complain that it didn’t find a definition of area().
The definition of area() must have exactly the same types (both the return type and the argument types) as we used in our file, that is:
int area(int x, int y) { /* . . . */ } // “our” area()
Functions with the same name but different types will not match and will be ignored:
double area(double x, double y) { /* . . . */ } // not “our” area()
int area(int x, int y, char unit) { /* . . . */ } // not “our” area()
Note that a misspelled function name doesn’t usually give a linker error. Instead, the compiler gives an error immediately when it sees a call to an undeclared function. That’s good: compile-time errors are found earlier than link-time errors and are typically easier to fix.
The linkage rules for functions, as stated above, also hold for all other entities of a program, such as variables and types: there has to be exactly one definition of an entity with a given name, but there can be many declarations, and all have to agree exactly on its type. For more details, see §8.2-3.
5.5 Run-time errors
If your program has no compile-time errors and no link-time errors, it’ll run. This is where the fun really starts. When you write the program you are able to detect errors, but it is not always easy to know what to do with an error once you catch it at run time. Consider:
int area(int length, int width) // calculate area of a rectangle
{
return length*width;
}
int framed_area(int x, int y) // calculate area within frame
{
return area(x-2,y-2);
}
int main()
{
int x = -1;
int y = 2;
int z = 4;
// . . .
int area1 = area(x,y);
int area2 = framed_area(1,z);
int area3 = framed_area(y,z);
double ratio = double(area1)/area3; // convert to double to get
// floating-point division
}
We used the variables x, y, z (rather than using the values directly as arguments) to make the problems less obvious to the human reader and harder for the compiler to detect. However, these calls lead to negative values, representing areas, being assigned to area1 and area2. Should we accept such erroneous results, which violate most notions of math and physics? If not, who should detect the errors: the caller of area() or the function itself? And how should such errors be reported?
Before answering those questions, look at the calculation of the ratio in the code above. It looks innocent enough. Did you notice something wrong with it? If not, look again: area3 will be 0, so that double(area1)/area3 divides by zero. This leads to a hardware-detected error that terminates the program with some cryptic message relating to hardware. This is the kind of error that you — or your users — will have to deal with if you don’t detect and deal sensibly with run-time errors. Most people have low tolerance for such “hardware violations” because to anyone not intimately familiar with the program all the information provided is “Something went wrong somewhere!” That’s insufficient for any constructive action, so we feel angry and would like to yell at whoever supplied the program.
So, let’s tackle the problem of argument errors with area(). We have two obvious alternatives:
a. Let the caller of area() deal with bad arguments.
b. Let area() (the called function) deal with bad arguments.
5.5.1 The caller deals with errors
Let’s try the first alternative (“Let the user beware!”) first. That’s the one we’d have to choose if area() was a function in a library where we couldn’t modify it. For better or worse, this is the most common approach.
Protecting the call of area(x,y) in main() is relatively easy:
if (x<=0) error("non-positive x");
if (y<=0) error("non-positive y");
int area1 = area(x,y);
Really, the only question is what to do if we find an error. Here, we have called a function error() which we assume will do something sensible. In fact, in std_lib_facilities.h we supply an error() function that by default terminates the program with a system error message plus the string we passed as an argument to error(). If you prefer to write out your own error message or take other actions, you catch runtime_error (§5.6.2, §7.3, §7.8, §B.2.1). This approach suffices for most student programs and is an example of a style that can be used for more sophisticated error handling.
If we didn’t need separate error messages about each argument, we would simplify:
if (x<=0 || y<=0) error("non-positive area() argument"); // || means “or”
int area1 = area(x,y);
To complete protecting area() from bad arguments, we have to deal with the calls through framed_area(). We could write
if (z<=2)
error("non-positive 2nd area() argument called by framed_area()");
int area2 = framed_area(1,z);
if (y<=2 || z<=2)
error("non-positive area() argument called by framed_area()");
int area3 = framed_area(y,z);
This is messy, but there is also something fundamentally wrong. We could write this only by knowing exactly how framed_area() used area(). We had to know that framed_area() subtracted 2 from each argument. We shouldn’t have to know such details! What if someone modifiedframed_area() to use 1 instead of 2? Someone doing that would have to look at every call of framed_area() and modify the error-checking code correspondingly. Such code is called “brittle” because it breaks easily. This is also an example of a “magic constant” (§4.3.1). We could make the code less brittle by giving the value subtracted by framed_area() a name:
constexpr int frame_width = 2;
int framed_area(int x, int y) // calculate area within frame
{
return area(x-frame_width,y-frame_width);
}
That name could be used by code calling framed_area():
if (1-frame_width<=0 || z-frame_width<=0)
error("non-positive argument for area() called by framed_area()");
int area2 = framed_area(1,z);
if (y-frame_width<=0 || z-frame_width<=0)
error("non-positive argument for area() called by framed_area()");
int area3 = framed_area(y,z);
Look at that code! Are you sure it is correct? Do you find it pretty? Is it easy to read? Actually, we find it ugly (and therefore error-prone). We have more than trebled the size of the code and exposed an implementation detail of framed_area(). There has to be a better way!
Look at the original code:
int area2 = framed_area(1,z);
int area3 = framed_area(y,z);
It may be wrong, but at least we can see what it is supposed to do. We can keep this code if we put the check inside framed_area().
5.5.2 The callee deals with errors
Checking for valid arguments within framed_area() is easy, and error() can still be used to report a problem:
int framed_area(int x, int y) // calculate area within frame
{
constexpr int frame_width = 2;
if (x-frame_width<=0 || y-frame_width<=0)
error("non-positive area() argument called by framed_area()");
return area(x-frame_width,y-frame_width);
}
This is rather nice, and we no longer have to write a test for each call of framed_area(). For a useful function that we call 500 times in a large program, that can be a huge advantage. Furthermore, if anything to do with the error handling changes, we only have to modify the code in one place.
Note something interesting: we almost unconsciously slid from the “caller must check the arguments” approach to the “function must check its own arguments” approach (also called “the callee checks” because a called function is often called “a callee”). One benefit of the latter approach is that the argument-checking code is in one place. We don’t have to search the whole program for calls. Furthermore, that one place is exactly where the arguments are to be used, so all the information we need is easily available for us to do the check.
Let’s apply this solution to area():
int area(int length, int width) // calculate area of a rectangle
{
if (length<=0 || width <=0) error("non-positive area() argument");
return length*width;
}
This will catch all errors in calls to area(), so we no longer need to check in framed_area(). We might want to, though, to get a better — more specific — error message.
Checking arguments in the function seems so simple, so why don’t people do that always? Inattention to error handling is one answer, sloppiness is another, but there are also respectable reasons:
• We can’t modify the function definition: The function is in a library that for some reason can’t be changed. Maybe it’s used by others who don’t share your notions of what constitutes good error handling. Maybe it’s owned by someone else and you don’t have the source code. Maybe it’s in a library where new versions come regularly so that if you made a change, you’d have to change it again for each new release of the library.
• The called function doesn’t know what to do in case of error: This is typically the case for library functions. The library writer can detect the error, but only you know what is to be done when an error occurs.
• The called function doesn’t know where it was called from: When you get an error message, it tells you that something is wrong, but not how the executing program got to that point. Sometimes, you want an error message to be more specific.
• Performance: For a small function the cost of a check can be more than the cost of calculating the result. For example, that’s the case with area(), where the check also more than doubles the size of the function (that is, the number of machine instructions that need to be executed, not just the length of the source code). For some programs, that can be critical, especially if the same information is checked repeatedly as functions call each other, passing information along more or less unchanged.
So what should you do? Check your arguments in a function unless you have a good reason not to.
![]()
After examining a few related topics, we’ll return to the question of how to deal with bad arguments in §5.10.
5.5.3 Error reporting
Let’s consider a slightly different question: Once you have checked a set of arguments and found an error, what should you do? Sometimes you can return an “error value.” For example:
// ask user for a yes-or-no answer;
// return 'b' to indicate a bad answer (i.e., not yes or no)
char ask_user(string question)
{
cout << question << "? (yes or no)\n";
string answer = " ";
cin >> answer;
if (answer =="y" || answer=="yes") return 'y';
if (answer =="n" || answer=="no") return 'n';
return 'b'; // ‘b’ for “bad answer”
}
// calculate area of a rectangle;
// return -1 to indicate a bad argument
int area(int length, int width)
{
if (length<=0 || width <=0) return -1;
return length*width;
}
That way, we can have the called function do the detailed checking, while letting each caller handle the error as desired. This approach seems like it could work, but it has a couple of problems that make it unusable in many cases:
• Now both the called function and all callers must test. The caller has only a simple test to do but must still write that test and decide what to do if it fails.
• A caller can forget to test. That can lead to unpredictable behavior further along in the program.
• Many functions do not have an “extra” return value that they can use to indicate an error. For example, a function that reads an integer from input (such as cin’s operator >>) can obviously return any int value, so there is no int that it could return to indicate failure.
The second case above — a caller forgetting to test — can easily lead to surprises. For example:
int f(int x, int y, int z)
{
int area1 = area(x,y);
if (area1<=0) error("non-positive area");
int area2 = framed_area(1,z);
int area3 = framed_area(y,z);
double ratio = double(area1)/area3;
// . . .
}
Do you see the errors? This kind of error is hard to find because there is no obvious “wrong code” to look at: the error is the absence of a test.
Try This
Test this program with a variety of values. Print out the values of area1, area2, area3, and ratio. Insert more tests until all errors are caught. How do you know that you caught all errors? This is not a trick question; in this particular example you can give a valid argument for having caught all errors.
There is another solution that deals with that problem: using exceptions.
5.6 Exceptions
Like most modern programming languages, C++ provides a mechanism to help deal with errors: exceptions. The fundamental idea is to separate detection of an error (which should be done in a called function) from the handling of an error (which should be done in the calling function) while ensuring that a detected error cannot be ignored; that is, exceptions provide a mechanism that allows us to combine the best of the various approaches to error handling we have explored so far. Nothing makes error handling easy, but exceptions make it easier.
![]()
The basic idea is that if a function finds an error that it cannot handle, it does not return normally; instead, it throws an exception indicating what went wrong. Any direct or indirect caller can catch the exception, that is, specify what to do if the called code used throw. A function expresses interest in exceptions by using a try-block (as described in the following subsections) listing the kinds of exceptions it wants to handle in the catch parts of the try-block. If no caller catches an exception, the program terminates.
We’ll come back to exceptions much later (Chapter 19) to see how to use them in slightly more advanced ways.
5.6.1 Bad arguments
Here is a version of area() using exceptions:
class Bad_area { }; // a type specifically for reporting errors from area()
// calculate area of a rectangle;
// throw a Bad_area exception in case of a bad argument
int area(int length, int width)
{
if (length<=0 || width<=0) throw Bad_area{};
return length*width;
}
That is, if the arguments are OK, we return the area as always; if not, we get out of area() using the throw, hoping that some catch will provide an appropriate response. Bad_area is a new type we define with no other purpose than to provide something unique to throw from area() so that somecatch can recognize it as the kind of exception thrown by area(). User-defined types (classes and enumeration) will be discussed in Chapter 9. The notation Bad_area{} means “Make an object of type Bad_area with the default value,” so throw Bad_area{} means “Make an object of typeBad_area and throw it.”
We can now write
int main()
try {
int x = -1;
int y = 2;
int z = 4;
// . . .
int area1 = area(x,y);
int area2 = framed_area(1,z);
int area3 = framed_area(y,z);
double ratio = area1/area3;
}
catch (Bad_area) {
cout << "Oops! bad arguments to area()\n";
}
First note that this handles all calls to area(), both the one in main() and the two through framed_area(). Second, note how the handling of the error is cleanly separated from the detection of the error: main() knows nothing about which function did a throw Bad_area{}, and area() knows nothing about which function (if any) cares to catch the Bad_area exceptions it throws. This separation is especially important in large programs written using many libraries. In such programs, nobody can “just deal with an error by putting some code where it’s needed,” because nobody would want to modify code in both the application and in all of the libraries.
5.6.2 Range errors
Most real-world code deals with collections of data; that is, it uses all kinds of tables, lists, etc. of data elements to do a job. In the context of C++, we often refer to “collections of data” as containers. The most common and useful standard library container is the vector we introduced in §4.6. A vector holds a number of elements, and we can determine that number by calling the vector’s size() member function. What happens if we try to use an element with an index (subscript) that isn’t in the valid range [0:v.size())? The general notation [low:high) means indices from low tohigh-1, that is, including low but not high:

Before answering that question, we should pose another question and answer it:
“Why would you do that?” After all, you know that a subscript for v should be in the range [0,v.size()), so just be sure that’s so!
As it happens, that’s easy to say but sometimes hard to do. Consider this plausible program:
vector<int> v; // a vector of ints
for (int i; cin>>I; )
v.push_back(i); // get values
for (int i = 0; i<=v.size(); ++i) // print values
cout << "v[" << i <<"] == " << v[i] << '\n';
Do you see the error? Please try to spot it before reading on. It’s not an uncommon error. We have made such errors ourselves — especially late at night when we were tired. Errors are always more common when you are tired or rushed. We use 0 and size() to try to make sure that i is always in range when we do v[i].
![]()
Unfortunately, we made a mistake. Look at the for-loop: the termination condition is i<=v.size() rather than the correct i<v.size(). This has the unfortunate consequence that if we read in five integers we’ll try to write out six. We try to read v[5], which is one beyond the end of the vector. This kind of error is so common and “famous” that it has several names: it is an example of an off-by-one error, a range error because the index (subscript) wasn’t in the range required by the vector, and a bounds error because the index was not within the limits (bounds) of the vector.
Why didn’t we use a range-for-statement to express that loop? With a range-for, we cannot get the end of the loop wrong. However, for this loop, we wanted not only the value of each element but also the indices (subscripts). A range-for doesn’t give that without extra effort.
Here is a simpler version that produces the same range error as the loop:
vector<int> v(5);
int x = v[5];
However, we doubt that you’d have considered that realistic and worth serious attention.
So what actually happens when we make such a range error? The subscript operation of vector knows the size of the vector, so it can check (and the vector we are using does; see §4.6 and §19.4). If that check fails, the subscript operation throws an exception of type out_of_range. So, if the off-by-one code above had been part of a program that caught exceptions, we would at least have gotten a decent error message:
int main()
try {
vector<int> v; // a vector of ints
for (int x; cin>>x; )
v.push_back(x); // set values
for (int i = 0; i<=v.size(); ++i) // print values
cout << "v[" << i <<"] == " << v[i] << '\n';
} catch (out_of_range) {
cerr << "Oops! Range error\n";
return 1;
} catch (...) { // catch all other exceptions
cerr << "Exception: something went wrong\n";
return 2;
}
Note that a range error is really a special case of the argument errors we discussed in §5.5.2. We didn’t trust ourselves to consistently check the range of vector indices, so we told vector’s subscript operation to do it for us. For the reasons we outline, vector’s subscript function (calledvector::operator[]) reports finding an error by throwing an exception. What else could it do? It has no idea what we would like to happen in case of a range error. The author of vector couldn’t even know what programs his or her code would be part of.
5.6.3 Bad input
We’ll postpone the detailed discussion of what to do with bad input until §10.6. However, once bad input is detected, it is dealt with using the same techniques and language features as argument errors and range errors. Here, we’ll just show how you can tell if your input operations succeeded. Consider reading a floating-point number:
double d = 0;
cin >> d;
We can test if the last input operation succeeded by testing cin:
if (cin) {
// all is well, and we can try reading again
}
else {
// the last read didn’t succeed, so we take some other action
}
There are several possible reasons for that input operation’s failure. The one that should concern you right now is that there wasn’t a double for >> to read.
During the early stages of development, we often want to indicate that we have found an error but aren’t yet ready to do anything particularly clever about it; we just want to report the error and terminate the program. Later, maybe, we’ll come back and do something more appropriate. For example:
double some_function()
{
double d = 0;
cin >> d;
if (!cin) error("couldn't read a double in 'some_function()'");
// do something useful
}
The condition !cin (“not cin,” that is, cin is not in a good state) means that the previous operation on cin failed.
The string passed to error() can then be printed as a help to debugging or as a message to the user. How can we write error() so as to be useful in a lot of programs? It can’t return a value because we wouldn’t know what to do with that value; instead error() is supposed to terminate the program after getting its message written. In addition, we might want to take some minor action before exiting, such as keeping a window alive long enough for us to read the message. That’s an obvious job for an exception (see §7.3).
![]()
The standard library defines a few types of exceptions, such as the out_of_range thrown by vector. It also supplies runtime_error which is pretty ideal for our needs because it holds a string that can be used by an error handler. So, we can write our simple error() like this:
void error(string s)
{
throw runtime_error(s);
}
When we want to deal with runtime_error we simply catch it. For simple programs, catching runtime_error in main() is ideal:
int main()
try {
// . . . our program . . .
return 0; // 0 indicates success
}
catch (runtime_error& e) {
cerr << "runtime error: " << e.what() << '\n';
keep_window_open();
return 1; // 1 indicates failure
}
The call e.what() extracts the error message from the runtime_error. The & in
catch(runtime_error& e) {
is an indicator that we want to “pass the exception by reference.” For now, please treat this as simply an irrelevant technicality. In §8.5.4-6, we explain what it means to pass something by reference.
Note that we used cerr rather than cout for our error output: cerr is exactly like cout except that it is meant for error output. By default both cerr and cout write to the screen, but cerr isn’t optimized so it is more resilient to errors, and on some operating systems it can be diverted to a different target, such as a file. Using cerr also has the simple effect of documenting that what we write relates to errors. Consequently, we use cerr for error messages.
As it happens, out_of_range is not a runtime_error, so catching runtime_error does not deal with the out_of_range errors that we might get from misuse of vectors and other standard library container types. However, both out_of_range and runtime_error are “exceptions,” so we can catchexception to deal with both:
int main()
try {
// our program
return 0; // 0 indicates success
}
catch (exception& e) {
cerr << "error: " << e.what() << '\n';
keep_window_open();
return 1; // 1 indicates failure
}
catch (...) {
cerr << "Oops: unknown exception!\n";
keep_window_open();
return 2; // 2 indicates failure
}
We added catch(...) to handle exceptions of any type whatsoever.
Dealing with exceptions of both type out_of_range and type runtime_error through a single type exception, said to be a common base (supertype) of both, is a most useful and general technique that we will explore in Chapters 13-16.
Note again that the return value from main() is passed to “the system” that invoked the program. Some systems (such as Unix) often use that value, whereas others (such as Windows) typically ignore it. A zero indicates successful completion and a nonzero return value from main()indicates some sort of failure.
When you use error(), you’ll often wish to pass two pieces of information along to describe the problem. In that case, just concatenate the strings describing those two pieces of information. This is so common that we provide a second version of error() for that:
void error(string s1, string s2)
{
throw runtime_error(s1+s2);
}
This simple error handling will do for a while, until our needs increase significantly and our sophistication as designers and programmers increases correspondingly. Note that we can use error() independently of how many function calls we have done on the way to the error: error() will find its way to the nearest catch of runtime_error, typically the one in main(). For examples of the use of exceptions and error(), see §7.3 and §7.7. If you don’t catch an exception, you’ll get a default system error (an “uncaught exception” error).
Try This
To see what an uncaught exception error looks like, run a small program that uses error() without catching any exceptions.
5.6.4 Narrowing errors
In §3.9.2 we saw a nasty kind of error: when we assign a value that’s “too large to fit” to a variable, it is implicitly truncated. For example:
int x = 2.9;
char c = 1066;
![]()
Here x will get the value 2 rather than 2.9, because x is an int and ints don’t have values that are fractions of an integer, just whole integers (obviously). Similarly, if we use the common ASCII character set, c will get the value 42 (representing the character *), rather than 1066, because there is no char with the value 1066 in that character set.
In §3.9.2 we saw how we could protect ourselves against such narrowing by testing. Given exceptions (and templates; see §19.3) we can write a function that tests and throws a runtime_error exception if an assignment or initialization would lead to a changed value. For example:
int x1 = narrow_cast<int>(2.9); // throws
int x2 = narrow_cast<int>(2.0); // OK
char c1 = narrow_cast<char>(1066); // throws
char c2 = narrow_cast<char>(85); // OK
The < . . . > brackets are the same as are used for vector<int>. They are used when we need to specify a type, rather than a value, to express an idea. They are called template arguments. We can use narrow_cast when we need to convert a value and we are not sure “if it will fit”; it is defined instd_lib_facilities.h and implemented using error(). The word cast means “type conversion” and indicates the operation’s role in dealing with something that’s broken (like a cast on a broken leg). Note that a cast doesn’t change its operand; it produces a new value (of the type specified in the < . . . >) that corresponds to its operand value.
5.7 Logic errors
Once we have removed the initial compiler and linker errors, the program runs. Typically, what happens next is that no output is produced or that the output that the program produces is just wrong. This can occur for a number of reasons. Maybe your understanding of the underlying program logic is flawed; maybe you didn’t write what you thought you wrote; or maybe you made some “silly error” in one of your if-statements, or whatever. Logic errors are usually the most difficult to find and eliminate, because at this stage the computer does what you asked it to. Your job now is to figure out why that wasn’t really what you meant. Basically, a computer is a very fast moron. It does exactly what you tell it to do, and that can be most humbling.
Let us try to illustrate this with a simple example. Consider this code for finding the lowest, highest, and average temperature values in a set of data:
int main()
{
vector<double> temps; // temperatures
for (double temp; cin>>temp; ) // read and put into temps
temps.push_back(temp);
double sum = 0;
double high_temp = 0;
double low_temp = 0;
for (int x : temps)
{
if(x > high_temp) high_temp = x; // find high
if(x < low_temp) low_temp = x; // find low
sum += x; // compute sum
}
cout << "High temperature: " << high_temp<< '\n';
cout << "Low temperature: " << low_temp << '\n';
cout << "Average temperature: " << sum/temps.size() << '\n';
}
We tested this program by entering the hourly temperature values from the weather center in Lubbock, Texas, for February 16, 2004 (Texas still uses Fahrenheit):
-16.5, -23.2, -24.0, -25.7, -26.1, -18.6, -9.7, -2.4,
7.5, 12.6, 23.8, 25.3, 28.0, 34.8, 36.7, 41.5,
40.3, 42.6, 39.7, 35.4, 12.6, 6.5, -3.7, -14.3
The output was
High temperature: 42.6
Low temperature: -26.1
Average temperature: 9.3
A naive programmer would conclude that the program works just fine. An irresponsible programmer would ship it to a customer. It would be prudent to test it again with another set of data. This time use the temperatures from July 23, 2004:
76.5, 73.5, 71.0, 73.6, 70.1, 73.5, 77.6, 85.3,
88.5, 91.7, 95.9, 99.2, 98.2, 100.6, 106.3, 112.4,
110.2, 103.6, 94.9, 91.7, 88.4, 85.2, 85.4, 87.7
This time, the output was
High temperature: 112.4
Low temperature: 0.0
Average temperature: 89.2
Oops! Something is not quite right. Hard frost (0.0°F is about -18°C) in Lubbock in July would mean the end of the world! Did you spot the error? Since low_temp was initialized at 0.0, it would remain 0.0 unless one of the temperatures in the data was below zero.
Try This
Get this program to run. Check that our input really does produce that output. Try to “break” the program (i.e., get it to give wrong results) by giving it other input sets. What is the least amount of input you can give it to get it to fail?
Unfortunately, there are more errors in this program. What would happen if all of the temperatures were below zero? The initialization for high_temp has the equivalent problem to low_temp: high_temp will remain at 0.0 unless there is a higher temperature in the data. This program wouldn’t work for the South Pole in winter either.
These errors are fairly typical; they will not cause any errors when you compile the program or cause wrong results for “reasonable” inputs. However, we forgot to think about what we should consider “reasonable.” Here is an improved program:
int main()
{
double sum = 0;
double high_temp = -1000; // initialize to impossibly low
double low_temp = 1000; // initialize to “impossibly high”
int no_of_temps = 0;
for (double temp; cin>>temp; ) { // read temp
++no_of_temps; // count temperatures
sum += temp; // compute sum
if (temp > high_temp) high_temp = temp; // find high
if (temp < low_temp) low_temp = temp; // find low
}
cout << "High temperature: " << high_temp<< '\n';
cout << "Low temperature: " << low_temp << '\n';
cout << "Average temperature: " << sum/no_of_temps << '\n';
}
Does it work? How would you be certain? How would you precisely define “work”? Where did we get the values 1000 and -1000? Remember that we warned about “magic constants” (§5.5.1). Having 1000 and -1000 as literal values in the middle of the program is bad style, but are the values also wrong? Are there places where the temperatures go below -1000°F (-573°C)? Are there places where the temperatures go above 1000°F (538°C)?
Try This
Look it up. Check some information sources to pick good values for the min_temp (the “minimum temperature”) and max_temp (the “maximum temperature”) constants for our program. Those values will determine the limits of usefulness of our program.
5.8 Estimation
Imagine you have written a program that does a simple calculation, say, computing the area of a hexagon. You run it and it gives the area -34.56. You just know that’s wrong. Why? Because no shape has a negative area. So, you fix that bug (whatever it was) and get 21.65685. Is that right? That’s harder to say because we don’t usually keep the formula for the area of a hexagon in our heads. What we must do before making fools of ourselves by delivering a program that produces ridiculous results is just to check that the answer is plausible. In this case, that’s easy. A hexagon is much like a square. We scribble our regular hexagon on a piece of paper and eyeball it to be about the size of a 3-by-3 square. Such a square has the area 9. Bummer, our 21.65685 can’t be right! So we work over our program again and get 10.3923. Now, that just might be right!
![]()
The general point here has nothing to do with hexagons. The point is that unless we have some idea of what a correct answer will be like — even ever so approximately — we don’t have a clue whether our result is reasonable. Always ask yourself this question:
1. Is this answer to this particular problem plausible?
You should also ask the more general (and often far harder) question:
2. How would I recognize a plausible result?
Here, we are not asking, “What’s the exact answer?” or “What’s the correct answer?” That’s what we are writing the program to tell us. All we want is to know that the answer is not ridiculous. Only when we know that we have a plausible answer does it make sense to proceed with further work.
Estimation is a noble art that combines common sense and some very simple arithmetic applied to a few facts. Some people are good at doing estimates in their heads, but we prefer scribbles “on the back of an envelope” because we find we get confused less often that way. What we call estimation here is an informal set of techniques that are sometimes (humorously) called guesstimation because they combine a bit of guessing with a bit of calculation.
Try This
Our hexagon was regular with 2cm sides. Did we get that answer right? Just do the “back of the envelope” calculation. Take a piece a paper and scribble on it. Don’t feel that’s beneath you. Many famous scientists have been greatly admired for their ability to come up with an approximate answer using a pencil and the back of an envelope (or a napkin). This is an ability — a simple habit, really — that can save us a lot of time and confusion.
Often, making an estimate involves coming up with estimates of data that are needed for a proper calculation, but that we don’t yet have. Imagine you have to test a program that estimates driving times between cities. Is a driving time of 15 hours and 33 minutes plausible for New York City to Denver? From London to Nice? Why or why not? What data do you have to “guess” to answer these questions? Often, a quick web search can be most helpful. For example, 2000 miles is not a bad guess on the road distance from New York City to Denver, and it would be hard (and illegal) to maintain an average speed of 130m/hr, so 15 hours is not plausible (15*130 is just a bit less than 2000). You can check: we overestimated both the distance and the average speed, but for a check of plausibility we don’t have to be exactly right; we just have to guess well enough.
Try This
Estimate those driving times. Also, estimate the corresponding flight times (using ordinary commercial air travel). Then, try to verify your estimates by using appropriate sources, such as maps and timetables. We’d use online sources.
5.9 Debugging
When you have written (drafted?) a program, it’ll have errors. Small programs do occasionally compile and run correctly the first time you try. But if that happens for anything but a completely trivial program, you should at first be very, very suspicious. If it really did run correctly the first time, go tell your friends and celebrate — because this won’t happen every year.
So, when you have written some code, you have to find and remove the errors. That process is usually called debugging and the errors bugs. The term bug is often claimed to have originated from a hardware failure caused by insects in the electronics in the days when computers were racks of vacuum tubes and relays filling rooms. Several people have been credited with the discovery and the application of the word bug to errors in software. The most famous of those is Grace Murray Hopper, the inventor of the COBOL programming language (§22.2.2.2). Whoever invented the term more than 50 years ago, bug is evocative and ubiquitous. The activity of deliberately searching for errors and removing them is called debugging.
Debugging works roughly like this:
1. Get the program to compile.
2. Get the program to link.
3. Get the program to do what it is supposed to do.
Basically, we go through this sequence again and again: hundreds of times, thousands of times, again and again for years for really large programs. Each time something doesn’t work we have to find what caused the problem and fix it. I consider debugging the most tedious and time-wasting aspect of programming and will go to great lengths during design and programming to minimize the amount of time spent hunting for bugs. Others find that hunt thrilling and the essence of programming — it can be as addictive as any video game and keep a programmer glued to the computer for days and nights (I can vouch for that from personal experience also).
Here is how not to debug:
![]()
while (the program doesn't appear to work) { // pseudo code
Randomly look through the program for something that "looks odd"
Change it to look better
}
Why do we bother to mention this? It’s obviously a poor algorithm with little guarantee of success. Unfortunately, that description is only a slight caricature of what many people find themselves doing late at night when feeling particularly lost and clueless, having tried “everything else.”
The key question in debugging is
How would I know if the program actually worked correctly?
![]()
If you can’t answer that question, you are in for a long and tedious debug session, and most likely your users are in for some frustration. We keep returning to this point because anything that helps answer that question minimizes debugging and helps produce correct and maintainable programs. Basically, we’d like to design our programs so that bugs have nowhere to hide. That’s typically too much to ask for, but we aim to structure programs to minimize the chance of error and maximize the chance of finding the errors that do creep in.
5.9.1 Practical debug advice
![]()
Start thinking about debugging before you write the first line of code. Once you have a lot of code written it’s too late to try to simplify debugging.
Decide how to report errors: “Use error() and catch exception in main()” will be your default answer in this book.
![]()
Make the program easy to read so that you have a chance of spotting the bugs:
• Comment your code well. That doesn’t simply mean “Add a lot of comments.” You don’t say in English what is better said in code. Rather, you say in the comments — as clearly and briefly as you can — what can’t be said clearly in code:
• The name of the program
• The purpose of the program
• Who wrote this code and when
• Version numbers
• What complicated code fragments are supposed to do
• What the general design ideas are
• How the source code is organized
• What assumptions are made about inputs
• What parts of the code are still missing and what cases are still not handled
• Use meaningful names.
• That doesn’t simply mean “Use long names.”
• Use a consistent layout of code.
• Your IDE tries to help, but it can’t do everything and you are the one responsible.
• The style used in this book is a reasonable starting point.
• Break code into small functions, each expressing a logical action.
• Try to avoid functions longer than a page or two; most functions will be much shorter.
• Avoid complicated code sequences.
• Try to avoid nested loops, nested if-statements, complicated conditions, etc. Unfortunately, you sometimes need those, but remember that complicated code is where bugs can most easily hide.
• Use library facilities rather than your own code when you can.
• A library is likely to be better thought out and better tested than what you could produce as an alternative while busily solving your main problem.
This is pretty abstract just now, but we’ll show you example after example as we go along.
![]()
Get the program to compile. Obviously, your compiler is your best help here. Its error messages are usually helpful — even if we always wish for better ones — and, unless you are a real expert, assume that the compiler is always right; if you are a real expert, this book wasn’t written for you. Occasionally, you will feel that the rules the compiler enforces are stupid and unnecessary (they rarely are) and that things could and ought to be simpler (indeed, but they are not). However, as they say, “a poor craftsman curses his tools.” A good craftsman knows the strengths and weaknesses of his tools and adjusts his work accordingly. Here are some common compile-time errors:
• Is every string literal terminated?
cout << "Hello, << name << '\n'; // oops!
• Is every character literal terminated?
cout << "Hello, " << name << '\n; // oops!
• Is every block terminated?
int f(int a)
{
if (a>0) { /* do something */ else { /* do something else */ }
} // oops!
• Is every set of parentheses matched?
if (a<=0 // oops!
x = f(y);
The compiler generally reports this kind of error “late”; it doesn’t know you meant to type a closing parenthesis after the 0.
• Is every name declared?
• Did you include needed headers (for now, #include "std_lib_facilities.h")?
• Is every name declared before it’s used?
• Did you spell all names correctly?
int count; /* . . . */ ++Count; // oops!
char ch; /* . . . */ Cin>>c; // double oops!
• Did you terminate each expression statement with a semicolon?
x = sqrt(y)+2 // oops!
z = x+3;
We present more examples in this chapter’s drills. Also, keep in mind the classification of errors from §5.2.
After the program compiles and links, next comes what is typically the hardest part: figuring out why the program doesn’t do what it’s supposed to. You look at the output and try to figure out how your code could have produced that. Actually, first you often look at a blank screen (or window), wondering how your program could have failed to produce any output. A common first problem with a Windows console-mode program is that the console window disappears before you have had a chance to see the output (if any). One solution is to call keep_window_open() from our std_lib_facilities.h at the end of main(). Then the program will ask for input before exiting and you can look at the output produced before giving it the input that will let it close the window.
When looking for a bug, carefully follow the code statement by statement from the last point that you are sure it was correct. Pretend you’re the computer executing the program. Does the output match your expectations? Of course not, or you wouldn’t be debugging.
• Often, when you don’t see the problem, the reason is that you “see” what you expect to see rather than what you wrote. Consider:
for (int i = 0; i<=max; ++j) { // oops! (twice)
for (int i=0; 0<max; ++i); // print the elements of v
cout << "v[" << i << "]==" << v[i] << '\n';
// ...
}
This last example came from a real program written by experienced programmers (we expect it was written very late some night).
• Often when you do not see the problem, the reason is that there is too much code being executed between the point where the program produced the last good output and the next output (or lack of output). Most programming environments provide a way to execute (“step through”) the statements of a program one by one. Eventually, you’ll learn to use such facilities, but for simple problems and simple programs, you can just temporarily put in a few extra output statements (using cerr) to help you see what’s going on. For example:
int my_fct(int a, double d)
{
int res = 0;
cerr << "my_fct(" << a << "," << d << ")\n";
// . . . misbehaving code here . . .
cerr << "my_fct() returns " << res << '\n';
return res;
}
• Insert statements that check invariants (that is, conditions that should always hold; see §9.4.3) in sections of code suspected of harboring bugs. For example:
int my_complicated_function(int a, int b, int c)
// the arguments are positive and a < b < c
{
if (!(0<a && a<b && b<c)) // ! means “not” and && means “and”
error("bad arguments for mcf");
// . . .
}
• If that doesn’t have any effect, insert invariants in sections of code not suspected of harboring bugs; if you can’t find a bug, you are almost certainly looking in the wrong place.
A statement that states (asserts) an invariant is called an assertion (or just an assert).
![]()
Interestingly enough, there are many effective ways of programming. Different people successfully use dramatically different techniques. Many differences in debugging technique come from differences in the kinds of programs people work on; others seem to have to do with differences in the ways people think. To the best of our knowledge, there is no one best way to debug. One thing should always be remembered, though: messy code can easily harbor bugs. By keeping your code as simple, logical, and well formatted as possible, you decrease your debug time.
5.10 Pre- and post-conditions
![]()
Now, let us return to the question of how to deal with bad arguments to a function. The call of a function is basically the best point to think about correct code and to catch errors: this is where a logically separate computation starts (and ends on the return). Look at what we did in the piece of advice above:
int my_complicated_function(int a, int b, int c)
// the arguments are positive and a < b < c
{
if (!(0<a && a<b && b<c)) // ! means “not” and && means “and”
error("bad arguments for mcf");
// . . .
}
First, we stated (in a comment) what the function required of its arguments, and then we checked that this requirement held (throwing an exception if it did not).
This is a good basic strategy. A requirement of a function upon its argument is often called a pre-condition: it must be true for the function to perform its action correctly. The question is just what to do if the pre-condition is violated (doesn’t hold). We basically have two choices:
1. Ignore it (hope/assume that all callers give correct arguments).
2. Check it (and report the error somehow).
Looking at it this way, argument types are just a way of having the compiler check the simplest pre-conditions for us and report them at compile time. For example:
int x = my_complicated_function(1, 2, "horsefeathers");
Here, the compiler will catch that the requirement (“pre-condition”) that the third argument be an integer was violated. Basically, what we are talking about here is what to do with the requirements/pre-conditions that the compiler can’t check.
![]()
Our suggestion is to always document pre-conditions in comments (so that a caller can see what a function expects). A function with no comments will be assumed to handle every possible argument value. But should we believe that callers read those comments and follow the rules? Sometimes we have to, but the “check the arguments in the callee” rule could be stated, “Let a function check its pre-conditions.” We should do that whenever we don’t see a reason not to. The reasons most often given for not checking pre-conditions are:
• Nobody would give bad arguments.
• It would slow down my code.
• It is too complicated to check.
The first reason can be reasonable only when we happen to know “who” calls a function — and in real-world code that can be very hard to know.
The second reason is valid far less often than people think and should most often be ignored as an example of “premature optimization.” You can always remove checks if they really turn out to be a burden. You cannot easily gain the correctness they ensure or get back the nights’ sleep you lost looking for bugs those tests could have caught.
The third reason is the serious one. It is easy (once you are an experienced programmer) to find examples where checking a pre-condition would take significantly more work than executing the function. An example is a lookup in a dictionary: a pre-condition is that the dictionary entries are sorted — and verifying that a dictionary is sorted can be far more expensive than a lookup. Sometimes, it can also be difficult to express a pre-condition in code and to be sure that you expressed it correctly. However, when you write a function, always consider if you can write a quick check of the pre-conditions, and do so unless you have a good reason not to.
Writing pre-conditions (even as comments) also has a significant benefit for the quality of your programs: it forces you to think about what a function requires. If you can’t state that simply and precisely in a couple of comment lines, you probably haven’t thought hard enough about what you are doing. Experience shows that writing those pre-condition comments and the pre-condition tests helps you avoid many design mistakes. We did mention that we hated debugging; explicitly stating pre-conditions helps in avoiding design errors as well as catching usage errors early. Writing
int my_complicated_function(int a, int b, int c)
// the arguments are positive and a < b < c
{
if (!(0<a && a<b && b<c)) // ! means “not” and && means “and”
error("bad arguments for mcf");
// . . .
}
saves you time and grief compared with the apparently simpler
int my_complicated_function(int a, int b, int c)
{
// . . .
}
5.10.1 Post-conditions
Stating pre-conditions helps us improve our design and catch usage errors early. Can this idea of explicitly stating requirements be used elsewhere? Yes, one more place immediately springs to mind: the return value! After all, we typically have to state what a function returns; that is, if we return a value from a function we are always making a promise about the return value (how else would a caller know what to expect?). Let’s look at our area function (from §5.6.1) again:
// calculate area of a rectangle;
// throw a Bad_area exception in case of a bad argument
int area(int length, int width)
{
if (length<=0 || width <=0) throw Bad_area();
return length*width;
}
It checks its pre-condition, but it doesn’t state it in the comment (that may be OK for such a short function) and it assumes that the computation is correct (that’s probably OK for such a trivial computation). However, we could be a bit more explicit:
int area(int length, int width)
// calculate area of a rectangle;
// pre-conditions: length and width are positive
// post-condition: returns a positive value that is the area
{
if (length<=0 || width <=0) error("area() pre-condition");
int a = length*width;
if (a<=0) error("area() post-condition");
return a;
}
We couldn’t check the complete post-condition, but we checked the part that said that it should be positive.
Try This
Find a pair of values so that the pre-condition of this version of area holds, but the post-condition doesn’t.
Pre- and post-conditions provide basic sanity checks in code. As such they are closely connected to the notion of invariants (§9.4.3), correctness (§4.2, §5.2), and testing (Chapter 26).
5.11 Testing
How do we know when to stop debugging? Well, we keep debugging until we have found all the bugs — or at least we try to. How do we know that we have found the last bug? We don’t. “The last bug” is a programmers’ joke: there is no such creature; we never find “the last bug” in a large program. By the time we might have, we are busy modifying the program for some new use.
![]()
![]()
In addition to debugging we need a systematic way to search for errors. This is called testing and we’ll get back to that in §7.3, the exercises in Chapter 10, and in Chapter 26. Basically, testing is executing a program with a large and systematically selected set of inputs and comparing the results to what was expected. A run with a given set of inputs is called a test case. Realistic programs can require millions of test cases. Basically, systematic testing cannot be done by humans typing in one test after another, so we’ll have to wait a few chapters before we have the tools necessary to properly approach testing. However, in the meantime, remember that we have to approach testing with the attitude that finding errors is good. Consider:
Attitude 1: I’m smarter than any program! I’ll break that @#$%^ code!
Attitude 2: I polished this code for two weeks. It’s perfect!
Who do you think will find more errors? Of course, the very best is an experienced person with a bit of “attitude 1” who coolly, calmly, patiently, and systematically works through the possible failings of the program. Good testers are worth their weight in gold.
We try to be systematic in choosing our test cases and always try both correct and incorrect inputs. §7.3 gives the first example of this.
 Drill
Drill
Below are 25 code fragments. Each is meant to be inserted into this “scaffolding”:
#include "std_lib_facilities.h"
int main()
try {
<<your code here>>
keep_window_open();
return 0;
}
catch (exception& e) {
cerr << "error: " << e.what() << '\n';
keep_window_open();
return 1;
}
catch (...) {
cerr << "Oops: unknown exception!\n";
keep_window_open();
return 2;
}
Each has zero or more errors. Your task is to find and remove all errors in each program. When you have removed those bugs, the resulting program will compile, run, and write “Success!” Even if you think you have spotted an error, you still need to enter the (original, unimproved) program fragment and test it; you may have guessed wrong about what the error is, or there may be more errors in a fragment than you spotted. Also, one purpose of this drill is to give you a feel for how your compiler reacts to different kinds of errors. Do not enter the scaffolding 25 times — that’s a job for cut and paste or some similar “mechanical” technique. Do not fix problems by simply deleting a statement; repair them by changing, adding, or deleting a few characters.
1. Cout << "Success!\n";
2. cout << "Success!\n;
3. cout << "Success" << !\n"
4. cout << success << '\n';
5. string res = 7; vector<int> v(10); v[5] = res; cout << "Success!\n";
6. vector<int> v(10); v(5) = 7; if (v(5)!=7) cout << "Success!\n";
7. if (cond) cout << "Success!\n"; else cout << "Fail!\n";
8. bool c = false; if (c) cout << "Success!\n"; else cout << "Fail!\n";
9. string s = "ape"; boo c = "fool"<s; if (c) cout << "Success!\n";
10. string s = "ape"; if (s=="fool") cout << "Success!\n";
11. string s = "ape"; if (s=="fool") cout < "Success!\n";
12. string s = "ape"; if (s+"fool") cout < "Success!\n";
13. vector<char> v(5); for (int i=0; 0<v.size(); ++i) ; cout << "Success!\n";
14. vector<char> v(5); for (int i=0; i<=v.size(); ++i) ; cout << "Success!\n";
15. string s = "Success!\n"; for (int i=0; i<6; ++i) cout << s[i];
16. if (true) then cout << "Success!\n"; else cout << "Fail!\n";
17. int x = 2000; char c = x; if (c==2000) cout << "Success!\n";
18. string s = "Success!\n"; for (int i=0; i<10; ++i) cout << s[i];
19. vector v(5); for (int i=0; i<=v.size(); ++i) ; cout << "Success!\n";
20. int i=0; int j = 9; while (i<10) ++j; if (j<i) cout << "Success!\n";
21. int x = 2; double d = 5/(x-2); if (d==2*x+0.5) cout << "Success!\n";
22. string<char> s = "Success!\n"; for (int i=0; i<=10; ++i) cout << s[i];
23. int i=0; while (i<10) ++j; if (j<i) cout << "Success!\n";
24. int x = 4; double d = 5/(x-2); if (d=2*x+0.5) cout << "Success!\n";
25. cin << "Success!\n";
Review
1. Name four major types of errors and briefly define each one.
2. What kinds of errors can we ignore in student programs?
3. What guarantees should every completed project offer?
4. List three approaches we can take to eliminate errors in programs and produce acceptable software.
5. Why do we hate debugging?
6. What is a syntax error? Give five examples.
7. What is a type error? Give five examples.
8. What is a linker error? Give three examples.
9. What is a logic error? Give three examples.
10. List four potential sources of program errors discussed in the text.
11. How do you know if a result is plausible? What techniques do you have to answer such questions?
12. Compare and contrast having the caller of a function handle a run-time error vs. the called function’s handling the run-time error.
13. Why is using exceptions a better idea than returning an “error value”?
14. How do you test if an input operation succeeded?
15. Describe the process of how exceptions are thrown and caught.
16. Why, with a vector called v, is v[v.size()] a range error? What would be the result of calling this?
17. Define pre-condition and post-condition; give an example (that is not the area() function from this chapter), preferably a computation that requires a loop.
18. When would you not test a pre-condition?
19. When would you not test a post-condition?
20. What are the steps in debugging a program?
21. Why does commenting help when debugging?
22. How does testing differ from debugging?
Terms
argument error
assertion
catch
compile-time error
container
debugging
error
exception
invariant
link-time error
logic error
post-condition
pre-condition
range error
requirement
run-time error
syntax error
testing
throw
type error
Exercises
1. If you haven’t already, do the Try this exercises from this chapter.
2. The following program takes in a temperature value in Celsius and converts it to Kelvin. This code has many errors in it. Find the errors, list them, and correct the code.
double ctok(double c) // converts Celsius to Kelvin
{
int k = c + 273.15;
return int
}
int main()
{
double c = 0; // declare input variable
cin >> d; // retrieve temperature to input variable
double k = ctok("c"); // convert temperature
Cout << k << '/n' ; // print out temperature
}
3. Absolute zero is the lowest temperature that can be reached; it is -273.15°C, or 0K. The above program, even when corrected, will produce erroneous results when given a temperature below this. Place a check in the main program that will produce an error if a temperature is given below -273.15°C.
4. Do exercise 3 again, but this time handle the error inside ctok().
5. Add to the program so that it can also convert from Kelvin to Celsius.
6. Write a program that converts from Celsius to Fahrenheit and from Fahrenheit to Celsius (formula in §4.3.3). Use estimation (§5.8) to see if your results are plausible.
7. Quadratic equations are of the form
a · x2 + b · x + c = 0
To solve these, one uses the quadratic formula:
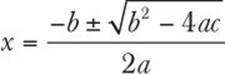
There is a problem, though: if b2-4ac is less than zero, then it will fail. Write a program that can calculate x for a quadratic equation. Create a function that prints out the roots of a quadratic equation, given a, b, c. When the program detects an equation with no real roots, have it print out a message. How do you know that your results are plausible? Can you check that they are correct?
8. Write a program that reads and stores a series of integers and then computes the sum of the first N integers. First ask for N, then read the values into a vector, then calculate the sum of the first N values. For example:
“Please enter the number of values you want to sum:”
3
“Please enter some integers (press '|' to stop):”
12 23 13 24 15 |
“The sum of the first 3 numbers ( 12 23 13 ) is 48.”
Handle all inputs. For example, make sure to give an error message if the user asks for a sum of more numbers than there are in the vector.
9. Modify the program from exercise 8 to write out an error if the result cannot be represented as an int.
10. Modify the program from exercise 8 to use double instead of int. Also, make a vector of doubles containing the N-1 differences between adjacent values and write out that vector of differences.
11. Write a program that writes out the first so many values of the Fibonacci series, that is, the series that starts with 1 1 2 3 5 8 13 21 34. The next number of the series is the sum of the two previous ones. Find the largest Fibonacci number that fits in an int.
12. Implement a little guessing game called (for some obscure reason) “Bulls and Cows.” The program has a vector of four different integers in the range 0 to 9 (e.g., 1234 but not 1122) and it is the user’s task to discover those numbers by repeated guesses. Say the number to be guessed is 1234 and the user guesses 1359; the response should be “1 bull and 1 cow” because the user got one digit (1) right and in the right position (a bull) and one digit (3) right but in the wrong position (a cow). The guessing continues until the user gets four bulls, that is, has the four digits correct and in the correct order.
13. The program is a bit tedious because the answer is hard-coded into the program. Make a version where the user can play repeatedly (without stopping and restarting the program) and each game has a new set of four digits. You can get four random digits by calling the random number generator randint(10) from std_lib_facilities.h four times. You will note that if you run that program repeatedly, it will pick the same sequence of four digits each time you start the program. To avoid that, ask the user to enter a number (any number) and call srand(n) where n is the number the user entered before calling randint(10). Such an n is called a seed, and different seeds give different sequences of random numbers.
14. Read (day-of-the-week,value) pairs from standard input. For example:
Tuesday 23 Friday 56 Tuesday -3 Thursday 99
Collect all the values for each day of the week in a vector<int>. Write out the values of the seven day-of-the-week vectors. Print out the sum of the values in each vector. Ignore illegal days of the week, such as Funday, but accept common synonyms such as Mon and monday. Write out the number of rejected values.
Postscript
![]()
Do you think we overemphasize errors? As novice programmers we would have thought so. The obvious and natural reaction is “It simply can’t be that bad!” Well, it is that bad. Many of the world’s best brains have been astounded and confounded by the difficulty of writing correct programs. In our experience, good mathematicians are the people most likely to underestimate the problem of bugs, but we all quickly exceed our natural capacity for writing programs that are correct the first time. You have been warned! Fortunately, after 50 years or so, we have a lot of experience in organizing code to minimize problems, and techniques to find the bugs that we — despite our best efforts — inevitably leave in our programs as we first write them. The techniques and examples in this chapter are a good start.
All materials on the site are licensed Creative Commons Attribution-Sharealike 3.0 Unported CC BY-SA 3.0 & GNU Free Documentation License (GFDL)
If you are the copyright holder of any material contained on our site and intend to remove it, please contact our site administrator for approval.
© 2016-2026 All site design rights belong to S.Y.A.