Programming: Principles and Practice Using C++ (2014)
Part I: The Basics
6. Writing a Program
“Programming is understanding.”
- Kristen Nygaard
Writing a program involves gradually refining your ideas of what you want to do and how you want to express it. In this chapter and the next, we will develop a program from a first vague idea through stages of analysis, design, implementation, testing, redesign, and re-implementation. Our aim is to give you some idea of the kind of thinking that goes on when you develop a piece of code. In the process, we discuss program organization, user-defined types, and input processing.
6.1 A problem
6.2 Thinking about the problem
6.2.1 Stages of development
6.2.2 Strategy
6.3 Back to the calculator!
6.3.1 First attempt
6.3.2 Tokens
6.3.3 Implementing tokens
6.3.4 Using tokens
6.3.5 Back to the drawing board
6.4 Grammars
6.4.1 A detour: English grammar
6.4.2 Writing a grammar
6.5 Turning a grammar into code
6.5.1 Implementing grammar rules
6.5.2 Expressions
6.5.3 Terms
6.5.4 Primary expressions
6.6 Trying the first version
6.7 Trying the second version
6.8 Token streams
6.8.1 Implementing Token_stream
6.8.2 Reading tokens
6.8.3 Reading numbers
6.9 Program structure
6.1 A problem
![]()
Writing a program starts with a problem; that is, you have a problem that you’d like a program to help solve. Understanding that problem is key to a good program. After all, a program that solves the wrong problem is likely to be of little use to you, however elegant it may be. There are happy accidents when a program just happens to be useful for something for which it was never intended, but let’s not rely on such rare luck. What we want is a program that simply and cleanly solves the problem we decided to solve.
At this stage, what would be a good program to look at? A program that
• Illustrates design and programming techniques
• Gives us a chance to explore the kinds of decisions that a programmer must make and the considerations that go into such decisions
• Doesn’t require too many new programming language constructs
• Is complicated enough to require thought about its design
• Allows for many variations in its solution
• Solves an easily understood problem
• Solves a problem that’s worth solving
• Has a solution that is small enough to completely present and completely comprehend
We chose “Get the computer to do ordinary arithmetic on expressions we type in”; that is, we want to write a simple calculator. Such programs are clearly useful; every desktop computer comes with such a program, and you can even buy computers specially built to run nothing but such programs: pocket calculators.
For example, if you enter
2+3.1*4
the program should respond
14.4
Unfortunately, such a calculator program doesn’t give us anything we don’t already have available on our computer, but that would be too much to ask from a first program.
6.2 Thinking about the problem
So how do we start? Basically, think a bit about the problem and how to solve it. First think about what the program should do and how you’d like to interact with it. Later, you can think about how the program could be written to do that. Try writing down a brief sketch of an idea for a solution, and see what’s wrong with that first idea. Maybe discuss the problem and how to solve it with a friend. Trying to explain something to a friend is a marvelous way of figuring out what’s wrong with ideas, even better than writing them down; paper (or a computer) doesn’t talk back at you and challenge your assumptions. Ideally, design isn’t a lonely activity.
Unfortunately, there isn’t a general strategy for problem solving that works for all people and all problems. There are whole books that claim to help you be better at problem solving and another huge branch of literature that deals with program design. We won’t go there. Instead, we’ll present a page’s worth of suggestions for a general strategy for the kind of smaller problems an individual might face. After that, we’ll quickly proceed to try out these suggestions on our tiny calculator problem.
When reading our discussion of the calculator program, we recommend that you adopt a more than usually skeptical attitude. For realism, we evolve our program through a series of versions, presenting the reasoning that leads to each version along the way. Obviously, much of that reasoning must be incomplete or even faulty, or we would finish the chapter early. As we go along, we provide examples of the kinds of concerns and reasoning that designers and programmers deal with all the time. We don’t reach a version of the program that we are happy with until the end of the next chapter.
Please keep in mind that for this chapter and the next, the way we get to the final version of the program - the journey through partial solutions, ideas, and mistakes - is at least as important as that final version and more important than the language-technical details we encounter along the way (we will get back to those later).
6.2.1 Stages of development
Here is a bit of terminology for program development. As you work on a problem you repeatedly go through these stages:
![]()
• Analysis: Figure out what should be done and write a description of your (current) understanding of that. Such a description is called a set of requirements or a specification. We will not go into details about how such requirements are developed and written down. That’s beyond the scope of this book, but it becomes increasingly important as the size of problems increases.
• Design: Create an overall structure for the system, deciding which parts the implementation should have and how those parts should communicate. As part of the design consider which tools - such as libraries - can help you structure the program.
• Implementation: Write the code, debug it, and test that it actually does what it is supposed to do.
6.2.2 Strategy
![]()
Here are some suggestions that - when applied thoughtfully and with imagination - help with many programming projects:
• What is the problem to be solved? The first thing to do is to try to be specific about what you are trying to accomplish. This typically involves constructing a description of the problem or - if someone else gave you such a statement - trying to figure out what it really means. At this point you should take the user’s point of view (not the programmer/implementer’s view); that is, you should ask questions about what the program should do, not about how it is going to do it. Ask: “What can this program do for me?” and “How would I like to interact with this program?” Remember, most of us have lots of experience as users of computers on which to draw.
• Is the problem statement clear? For real problems, it never is. Even for a student exercise, it can be hard to be sufficiently precise and specific. So we try to clarify it. It would be a pity if we solved the wrong problem. Another pitfall is to ask for too much. When we try to figure out what we want, we easily get too greedy/ambitious. It is almost always better to ask for less to make a program easier to specify, easier to understand, easier to use, and (hopefully) easier to implement. Once it works, we can always build a fancier “version 2.0” based on our experience.
• Does the problem seem manageable, given the time, skills, and tools available? There is little point in starting a project that you couldn’t possibly complete. If there isn’t sufficient time to implement (including testing) a program that does all that is required, it is usually wise not to start. Instead, acquire more resources (especially more time) or (best of all) modify the requirements to simplify your task.
• Try breaking the program into manageable parts. Even the smallest program for solving a real problem is large enough to be subdivided.
• Do you know of any tools, libraries, etc. that might help? The answer is almost always yes. Even at the earliest stage of learning to program, you have parts of the C++ standard library. Later, you’ll know large parts of that standard library and how to find more. You’ll have graphics and GUI libraries, a matrix library, etc. Once you have gained a little experience, you will be able to find thousands of libraries by simple web searches. Remember: There is little value in reinventing the wheel when you are building software for real use. When learning to program it is a different matter; then, reinventing the wheel to see how that is done is often a good idea. Any time you save by using a good library can be spent on other parts of your problem, or on rest. How do you know that a library is appropriate for your task and of sufficient quality? That’s a hard problem. Part of the solution is to ask colleagues, to ask in discussion groups, and to try small examples before committing to use a library.
• Look for parts of a solution that can be separately described (and potentially used in several places in a program or even in other programs). To find such parts requires experience, so we provide many examples throughout this book. We have already used vector, string, andiostreams (cin and cout). This chapter gives the first complete examples of design, implementation, and use of program parts provided as user-defined types (Token and Token_stream). Chapters 8 and 13-15 present many more examples together with their design rationales. For now, consider an analogy: If we were to design a car, we would start by identifying parts, such as wheels, engine, seats, door handles, etc., on which we could work separately before assembling the complete car. There are tens of thousands of such parts of a modern car. A real-world program is no different in that respect, except of course that the parts are code. We would not try to build a car directly out of raw materials, such as iron, plastics, and wood. Nor would we try to build a major program directly out of (just) the expressions, statements, and types provided by the language. Designing and implementing such parts is a major theme of this book and of software development in general; see the discussions of user-defined types (Chapter 9), class hierarchies (Chapter 14), and generic types (Chapter 20).
• Build a small, limited version of the program that solves a key part of the problem. When we start, we rarely know the problem well. We often think we do (don’t we know what a calculator program is?), but we don’t. Only a combination of thinking about the problem (analysis) and experimentation (design and implementation) gives us the solid understanding that we need to write a good program. So, we build a small, limited version
• To bring out problems in our understanding, ideas, and tools.
• To see if details of the problem statement need changing to make the problem manageable. It is rare to find that we had anticipated everything when we analyzed the problem and made the initial design. We should take advantage of the feedback that writing code and testing give us.
Sometimes, such a limited initial version aimed at experimentation is called a prototype. If (as is likely) our first version doesn’t work or is so ugly and awkward that we don’t want to work with it, we throw it away and make another limited version based on our experience. Repeat until we find a version that we are happy with. Do not proceed with a mess; messes just grow with time.
• Build a full-scale solution, ideally by using parts of the initial version. The ideal is to grow a program from working parts rather than writing all the code at once. The alternative is to hope that by some miracle an untested idea will work and do what we want.
6.3 Back to the calculator!
How do we want to interact with the calculator? That’s easy: we know how to use cin and cout, but graphical user interfaces (GUIs) are not explained until Chapter 16, so we’ll stick to the keyboard and a console window. Given expressions as input from the keyboard, we evaluate them and write out the resulting value to the screen. For example:
Expression: 2+2
Result: 4
Expression: 2+2*3
Result: 8
Expression: 2+3-25/5
Result: 0
The expressions, e.g., 2+2 and 2+2*3, should be entered by the user; the rest is produced by the program. We chose to output Expression: to prompt the user. We could have chosen Please enter an expression followed by a newline but that seemed verbose and pointless. On the other hand, a pleasantly short prompt, such as >, seemed too cryptic. Sketching out such examples of use early on is important. They provide a very practical definition of what the program should minimally do. When discussing design and analysis, such examples of use are called use cases.
When faced with the calculator problem for the first time, most people come up with a first idea like this for the main logic of the program:
read_a_line
calculate // do the work
write_result
This kind of “scribbles” clearly isn’t code; it’s called pseudo code. We tend to use it in the early stages of design when we are not yet certain exactly what our notation means. For example, is “calculate” a function call? If so, what would be its arguments? It is simply too early to answer such questions.
6.3.1 First attempt
At this point, we are not really ready to write the calculator program. We simply haven’t thought hard enough, but thinking is hard work and - like most programmers - we are anxious to write some code. So let’s take a chance, write a simple calculator, and see where it leads us. The first idea is something like
#include "std_lib_facilities.h"
int main()
{
cout << "Please enter expression (we can handle + and -): ";
int lval = 0;
int rval;
char op;
int res;
cin>>lval>>op>>rval; // read something like 1 + 3
if (op=='+')
res = lval + rval; // addition
else if (op=='-')
res = lval - rval; // subtraction
cout << "Result: " << res << '\n';
keep_window_open();
return 0;
}
That is, read a pair of values separated by an operator, such as 2+2, compute the result (in this case 4), and print the resulting value. We chose the variable names lval for left-hand value and rval for right-hand value.
This (sort of) works! So what if this program isn’t quite complete? It feels great to get something running! Maybe this programming and computer science stuff is easier than the rumors say. Well, maybe, but let’s not get too carried away by an early success. Let’s
1. Clean up the code a bit
2. Add multiplication and division (e.g., 2*3)
3. Add the ability to handle more than one operand (e.g., 1+2+3)
In particular, we know that we should always check that our input is reasonable (in our hurry, we “forgot”) and that testing a value against many constants is best done by a switch-statement rather than an if-statement.
The “chaining” of operations, such as 1+2+3+4, we will handle by adding the values as they are read; that is, we start with 1, see +2 and add 2 to 1 (getting an intermediate result 3), see +3 and add that 3 to our intermediate result (3), and so on. After a few false starts and after correcting a few syntax and logic errors, we get
#include "std_lib_facilities.h"
int main()
{
cout << "Please enter expression (we can handle +, -, *, and /)\n";
cout << "add an x to end expression (e.g., 1+2*3x): ";
int lval = 0;
int rval;
cin>>lval; // read leftmost operand
if (!cin) error("no first operand");
for (char op; cin>>op; ) { // read operator and right-hand operand
// repeatedly
if (op!='x') cin>>rval;
if (!cin) error("no second operand");
switch(op) {
case '+':
lval += rval; // add: lval = lval + rval
break;
case '-':
lval -= rval; // subtract: lval = lval - rval
break;
case '*':
lval *= rval; // multiply: lval = lval * rval
break;
case '/':
lval /= rval; // divide: lval = lval / rval
break;
default: // not another operator: print result
cout << "Result: " << lval << '\n';
keep_window_open();
return 0;
}
}
error("bad expression");
}
This isn’t bad, but then we try 1+2*3 and see that the result is 9 and not the 7 our arithmetic teachers told us was the right answer. Similarly, 1-2*3 gives -3 rather than the -5 we expected. We are doing the operations in the wrong order: 1+2*3 is calculated as (1+2)*3 rather than as the conventional 1+(2*3). Similarly, 1-2*3 is calculated as (1-2)*3 rather than as the conventional 1-(2*3). Bummer! We might consider the convention that “multiplication binds tighter than addition” as a silly old convention, but hundreds of years of convention will not disappear just to simplify our programming.
6.3.2 Tokens
So (somehow), we have to “look ahead” on the line to see if there is a * (or a /). If so, we have to (somehow) adjust the evaluation order from the simple and obvious left-to-right order. Unfortunately, trying to barge ahead here, we immediately hit a couple of snags:
1. We don’t actually require an expression to be on one line. For example:
1
+
2
works perfectly with our code so far.
2. How do we search for a * (or a /) among digits, plusses, minuses, and parentheses on several input lines?
3. How do we remember where a * was?
4. How do we handle evaluation that’s not strictly left-to-right (e.g., 1+2*3)?
Having decided to be super-optimists, we’ll solve problems 1-3 first and not worry about 4 until later.
Also, we’ll ask around for help. Surely someone will know a conventional way of reading “stuff,” such as numbers and operators, from input and storing it in a way that lets us look at it in convenient ways. The conventional and very useful answer is “tokenize”: first input characters are read and assembled into tokens, so if you type in
45+11.5/7
the program should produce a list of tokens representing
45
+
11.5
/
7
![]()
A token is a sequence of characters that represents something we consider a unit, such as a number or an operator. That’s the way a C++ compiler deals with its source. Actually, “tokenizing” in some form or another is the way most analysis of text starts. Following the example of C++ expression, we see the need for three kinds of tokens:
• Floating-point-literals: as defined by C++, e.g., 3.14, 0.274e2, and 42
• Operators: e.g., +, -, *, /, %
• Parentheses: (, )
The floating-point-literals look as if they may become a problem: reading 12 seems much easier than reading 12.3e-3, but calculators do tend to do floating-point arithmetic. Similarly, we suspect that we’ll have to accept parentheses to have our calculator deemed useful.
How do we represent such tokens in our program? We could try to keep track of where each token started (and ended), but that gets messy (especially if we allow expressions to span line boundaries). Also, if we keep a number as a string of characters, we later have to figure out what its value is; that is, if we see 42 and store the characters 4 and 2 somewhere, we then later have to figure out that those characters represent the numerical value 42 (i.e., 4*10+2). The obvious - and conventional - solution is to represent each token as a (kind,value) pair. The kind tells us if a token is a number, an operator, or a parenthesis. For a number, and in this example only for a number, we use its numerical value as its value.
![]()
So how do we express the idea of a (kind,value) pair in code? We define a type Token to represent tokens. Why? Remember why we use types: they hold the data we need and give us useful operations on that data. For example, ints hold integers and give us addition, subtraction, multiplication, division, and remainder, whereas strings hold sequences of characters and give us concatenation and subscripting. The C++ language and its standard library give us many types such as char, int, double, string, vector, and ostream, but not a Token type. In fact, there is a huge number of types - thousands or tens of thousands - that we would like to have, but the language and its standard library do not supply them. Among our favorite types that are not supported are Matrix (see Chapter 24), Date (see Chapter 9), and infinite precision integers (try searching the web for “Bignum”). If you think about it for a second, you’ll realize that a language cannot supply tens of thousands of types: who would define them, who would implement them, how would you find them, and how thick would the manual have to be? Like most modern languages, C++ escapes that problem by letting us define our own types (user-defined types) when we need them.
6.3.3 Implementing tokens
What should a token look like in our program? In other words, what would we like our Token type to be? A Token must be able to represent operators, such as + and -, and numeric values, such as 42 and 3.14. The obvious implementation is something that can represent what “kind” a token is and hold the numeric value for tokens that have one:

There are many ways that this idea could be represented in C++ code. Here is the simplest that we found useful:
class Token { // a very simple user-defined type
public:
char kind;
double value;
};
A Token is a type (like int or char), so it can be used to define variables and hold values. It has two parts (called members): kind and value. The keyword class means “user-defined type”; it indicates that a type with zero or more members is being defined. The first member, kind, is a character,char, so that it conveniently can hold '+' and '*' to represent + and *. We can use it to make types like this:
Token t; // t is a Token
t.kind = '+'; // t represents a +
Token t2; // t2 is another Token
t2.kind = '8'; // we use the digit 8 as the “kind” for numbers
t2.value = 3.14;
We use the member access notation, object_name . member_name, to access a member. You can read t.kind as “t’s kind” and t2.value as “t2’s value.” We can copy Tokens just as we can copy ints:
Token tt = t; // copy initialization
if (tt.kind != t.kind) error("impossible!");
t = t2; // assignment
cout << t.value; // will print 3.14
Given Token, we can represent the expression (1.5+4)*11 using seven tokens like this:

Note that for simple tokens, such as +, we don’t need the value, so we don’t use its value member. We needed a character to mean “number” and picked '8' just because '8' obviously isn’t an operator or a punctuation character. Using '8' to mean “number” is a bit cryptic, but it’ll do for now.
Token is an example of a C++ user-defined type. A user-defined type can have member functions (operations) as well as data members. There can be many reasons for defining member functions. Here, we’ll just provide two member functions to give us a more convenient way of initializing Tokens:
class Token {
public:
char kind; // what kind of token
double value; // for numbers: a value
};
We can now initialize (“construct”) Token objects. For example:
Token t1 {'+'}; // initialize t1 so that t1.kind = ‘+’
Token t2 {'8',11.5}; // initialize t2 so that t2.kind = ‘8’ and t2.value = 11.5
For more about initializing class objects, see §9.4.2 and §9.7.
6.3.4 Using tokens
So, maybe now we can complete our calculator! However, maybe a small amount of planning ahead would be worthwhile. How would we use Tokens in the calculator? We can read input into a vector of Tokens:
Token get_token(); // function to read a token from cin
vector<Token> tok; // we’ll put the tokens here
int main()
{
while (cin) {
Token t = get_token();
tok.push_back(t);
}
// . . .
}
Now we can read an expression first and evaluate later. For example, for 11*12, we get

We can look at that to find the multiplication and its operands. Having done that, we can easily perform the multiplication because the numbers 11 and 12 are stored as numeric values and not as strings.
Now let’s look at more complex expressions. Given 1+2*3, tok will contain five Tokens:

Now we could find the multiply operation by a simple loop:
for (int i = 0; i<tok.size(); ++i) {
if (tok[i].kind=='*') { // we found a multiply!
double d = tok[i-1].value*tok[i+1].value;
// now what?
}
}
Yes, but now what? What do we do with that product d? How do we decide in which order to evaluate the sub-expressions? Well, + comes before * so we can’t just evaluate from left to right. We could try right-to-left evaluation! That would work for 1+2*3 but not for 1*2+3. Worse still, consider 1+2*3+4. This example has to be evaluated “inside out”: 1+(2*3)+4. And how will we handle parentheses, as we eventually will have to do? We seem to have hit a dead end. We need to back off, stop programming for a while, and think about how we read and understand an input string and evaluate it as an arithmetic expression.
![]()
So, this first enthusiastic attempt to solve the problem (writing a calculator) ran out of steam. That’s not uncommon for first tries, and it serves the important role of helping us understand the problem. In this case, it even gave us the useful notion of a token, which itself is an example of the notion of a (name,value) pair that we will encounter again and again. However, we must always make sure that such relatively thoughtless and unplanned “coding” doesn’t steal too much time. We should do very little programming before we have done at least a bit of analysis (understanding the problem) and design (deciding on an overall structure of a solution).
 Try This
Try This
On the other hand, why shouldn’t we be able to find a simple solution to this problem? It doesn’t seem to be all that difficult. If nothing else, trying would give us a better appreciation of the problem and the eventual solution. Consider what you might do right away. For example, look at the input 12.5+2. We could tokenize that, decide that the expression was simple, and compute the answer. That may be a bit messy, but straightforward, so maybe we could proceed in this direction and find something that’s good enough! Consider what to do if we found both a + and a * in the line 2+3*4. That too can be handled by “brute force.” How would we deal with a complicated expression, such as 1+2*3/4%5+(6-7*(8))? And how would we deal with errors, such as 2+*3 and 2&3? Consider this for a while, maybe doodling a bit on a piece of paper trying to outline possible solutions and interesting or important input expressions.
6.3.5 Back to the drawing board
Now, we will look at the problem again and try not to dash ahead with another half-baked solution. One thing that we did discover was that having the program (calculator) evaluate only a single expression was tedious. We would like to be able to compute several expressions in a single invocation of our program; that is, our pseudo code grows to
while (not_finished) {
read_a_line
calculate // do the work
write_result
}
Clearly this is a complication, but when we think about how we use calculators, we realize that doing several calculations is very common. Could we let the user invoke our program several times to do several calculations? We could, but program startup is unfortunately (and unreasonably) slow on many modern operating systems, so we’d better not rely on that.
As we look at this pseudo code, our early attempts at solutions, and our examples of use, several questions - some with tentative answers - arise:
1. If we type in 45+5/7, how do we find the individual parts 45, +, 5, /, and 7 in the input? (Tokenize!)
2. What terminates an input expression? A newline, of course! (Always be suspicious of “of course”: “of course” is not a reason.)
3. How do we represent 45+5/7 as data so that we can evaluate it? Before doing the addition we must somehow turn the characters 4 and 5 into the integer value 45 (i.e., 4*10+5). (So tokenizing is part of the solution.)
4. How do we make sure that 45+5/7 is evaluated as 45+(5/7) and not as (45+5)/7?
5. What’s the value of 5/7? About .71, but that’s not an integer. Based on experience with calculators, we know that people would expect a floating-point result. Should we also allow floating-point inputs? Sure!
6. Can we have variables? For example, could we write
v=7
m=9
v*m
Good idea, but let’s wait until later. Let’s first get the basics working.
![]()
Possibly the most important decision here is the answer to question 6. In §7.8, you’ll see that if we had said yes we’d have almost doubled the size of the initial project. That would have more than doubled the time needed to get the initial version running. Our guess is that if you really are a novice, it would have at least quadrupled the effort needed and most likely pushed the project beyond your patience. It is most important to avoid “feature creep” early in a project. Instead, always first build a simple version, implementing the essential features only. Once you have something running, you can get more ambitious. It is far easier to build a program in stages than all at once. Saying yes to question 6 would have had yet another bad effect: it would have made it hard to resist the temptation to add further “neat features” along the line. How about adding the usual mathematical functions? How about adding loops? Once we start adding “neat features” it is hard to stop.
From a programmer’s point of view, questions 1, 3, and 4 are the most bothersome. They are also related, because once we have found a 45 or a +, what do we do with them? That is, how do we store them in our program? Obviously, tokenizing is part of the solution, but only part.
![]()
What would an experienced programmer do? When we are faced with a tricky technical question, there often is a standard answer. We know that people have been writing calculator programs for at least as long as there have been computers taking symbolic input from a keyboard. That is at least for 50 years. There has to be a standard answer! In such a situation, the experienced programmer consults colleagues and/or the literature. It would be silly to barge on, hoping to beat 50 years of experience in a morning.
6.4 Grammars
There is a standard answer to the question of how to make sense of expressions: first input characters are read and assembled into tokens (as we discovered). So if you type in
45+11.5/7
the program should produce a list of tokens representing
45
+
11.5
/
7
A token is a sequence of characters that represents something we consider a unit, such as a number or an operator.
![]()
After tokens have been produced, the program must ensure that complete expressions are understood correctly. For example, we know that 45+11.5/7 means 45+(11.5/7) and not (45+11.5)/7, but how do we teach the program that useful rule (division “binds tighter” than addition)? The standard answer is that we write a grammar defining the syntax of our input and then write a program that implements the rules of that grammar. For example:
// a simple expression grammar:
Expression:
Term
Expression "+" Term // addition
Expression "-" Term // subtraction
Term:
Primary
Term "*" Primary // multiplication
Term "/" Primary // division
Term "%" Primary // remainder (modulo)
Primary:
Number
"(" Expression ")" // grouping
Number:
floating-point-literal
This is a set of simple rules. The last rule is read “A Number is a floating-point-literal.” The next-to-last rule says, “A Primary is a Number or '(' followed by an Expression followed by ')'.” The rules for Expression and Term are similar; each is defined in terms of one of the rules that follow.
As seen in §6.3.2, our tokens - as borrowed from the C++ definition - are
• floating-point-literal (as defined by C++, e.g., 3.14, 0.274e2, or 42)
• +, -, *, /, % (the operators)
• (, ) (the parentheses)
From our first tentative pseudo code to this approach, using tokens and a grammar is actually a huge conceptual jump. It’s the kind of jump we hope for but rarely manage without help. This is what experience, the literature, and Mentors are for.
At first glance, a grammar probably looks like complete nonsense. Technical notation often does. However, please keep in mind that it is a general and elegant (as you will eventually appreciate) notation for something you have been able to do since middle school (or earlier). You have no problem calculating 1-2*3 and 1+2-3 and 3*2+4/2. It seems hardwired in your brain. However, could you explain how you do it? Could you explain it well enough for someone who had never seen conventional arithmetic to grasp? Could you do so for every combination of operators and operands? To articulate an explanation in sufficient detail and precisely enough for a computer to understand, we need a notation - and a grammar is a most powerful and conventional tool for that.
How do you read a grammar? Basically, given some input, you start with the “top rule,” Expression, and search through the rules to find a match for the tokens as they are read. Reading a stream of tokens according to a grammar is called parsing, and a program that does that is often called a parser or a syntax analyzer. Our parser reads the tokens from left to right, just like we type them and read them. Let’s try something really simple: Is 2 an expression?
1. An Expression must be a Term or end with a Term. That Term must be a Primary or end with a Primary. That Primary must start with a ( or be a Number. Obviously, 2 is not a (, but a floating-point-literal, which is a Number, which is a Primary.
2. That Primary (the Number 2) isn’t preceded by a /, *, or %, so it is a complete Term (rather than the end of a /, *, or % expression).
3. That Term (the Primary 2) isn’t preceded by a + or -, so it is a complete Expression (rather than the end of a + or - expression).
So yes, according to our grammar, 2 is an expression. We can illustrate the progression through the grammar like this:

This represents the path we followed through the definitions. Retracing our path, we can say that 2 is an Expression because 2 is a floating-point-literal, which is a Number, which is a Primary, which is a Term, which is an Expression.
Let’s try something a bit more complicated: Is 2+3 an Expression? Naturally, much of the reasoning is the same as for 2:
1. An Expression must be a Term or end with a Term, which must be a Primary or end with a Primary, and a Primary must start with a ( or be a Number. Obviously 2 is not a (, but it is a floating-point-literal, which is a Number, which is a Primary.
2. That Primary (the Number 2) isn’t preceded by a /, *, or %, so it is a complete Term (rather than the end of a /, *, or % expression).
3. That Term (the Primary 2) is followed by a +, so it is the end of the first part of an Expression and we must look for the Term after the +. In exactly the same way as we found that 2 was a Term, we find that 3 is a Term. Since 3 is not followed by a + or a - it is a complete Term (rather than the first part of a + or - Expression). Therefore, 2+3 matches the Expression+Term rule and is an Expression.
Again, we can illustrate this reasoning graphically (leaving out the floating-point-literal to Number rule to simplify):
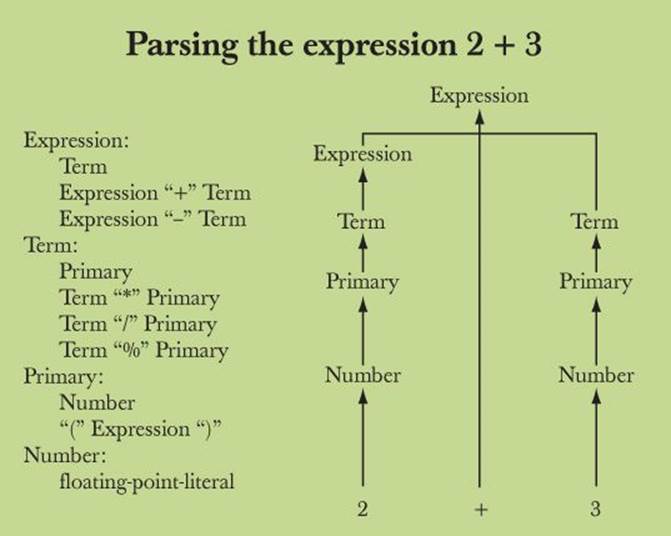
This represents the path we followed through the definitions. Retracing our path, we can say that 2+3 is an Expression because 2 is a term which is an Expression, 3 is a Term, and an Expression followed by + followed by a Term is an Expression.
The real reason we are interested in grammars is that they can solve our problem of how to correctly parse expressions with both + and *, so let’s try 45+11.5*7. However, “playing computer” following the rules in detail as we did above is tedious, so let’s skip some of the intermediate steps that we have already gone through for 2 and 2+3. Obviously, 45, 11.5, and 7 are all floating-point-literals which are Numbers, which are Primarys, so we can ignore all rules below Primary. So we get:
1. 45 is an Expression followed by a +, so we look for a Term to finish the Expression+Term rule.
2. 11.5 is a Term followed by *, so we look for a Primary to finish the Term*Primary rule.
3. 7 is Primary, so 11.5*7 is a Term according to the Term*Primary rule. Now we can see that 45+11.5*7 is an Expression according to the Expression+Term rule. In particular, it is an Expression that first does the multiplication 11.5*7 and then the addition 45+11.5*7, just as if we had written 45+(11.5*7).
Again, we can illustrate this reasoning graphically (again leaving out the floating-point-literal to Number rule to simplify):
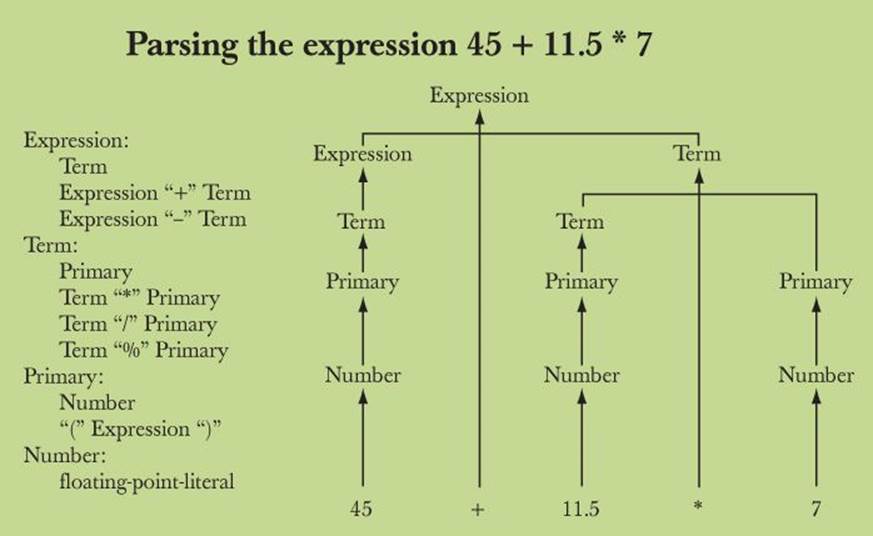
Again, this represents the path we followed through the definitions. Note how the Term*Primary rule ensures that 11.5 is multiplied by 7 rather than added to 45.
You may find this logic hard to follow at first, but many humans do read grammars, and simple grammars are not hard to understand. However, we were not really trying to teach you to understand 2+2 or 45+11.5*7. Obviously, you knew that already. We were trying to find a way for the computer to “understand” 45+11.5*7 and all the other complicated expressions you might give it to evaluate. Actually, complicated grammars are not fit for humans to read, but computers are good at it. They follow such grammar rules quickly and correctly with the greatest of ease. Following precise rules is exactly what computers are good at.
6.4.1 A detour: English grammar
If you have never before worked with grammars, we expect that your head is now spinning. In fact, it may be spinning even if you have seen a grammar before, but take a look at the following grammar for a very small subset of English:
Sentence:
Noun Verb // e.g., C++ rules
Sentence Conjunction Sentence // e.g., Birds fly but fish swim
Conjunction:
"and"
"or"
"but"
Noun:
"birds"
"fish"
"C++"
Verb:
"rules"
"fly"
"swim"
A sentence is built from parts of speech (e.g., nouns, verbs, and conjunctions). A sentence can be parsed according to these rules to determine which words are nouns, verbs, etc. This simple grammar also includes semantically meaningless sentences such as “C++ fly and birds rules,” but fixing that is a different matter belonging in a far more advanced book.
Many have been taught/shown such rules in middle school or in foreign language class (e.g., English classes). These grammar rules are very fundamental. In fact, there are serious neurological arguments for such rules being hardwired into our brains!
Now look at a parsing tree as we used above for expressions, but used here for simple English:
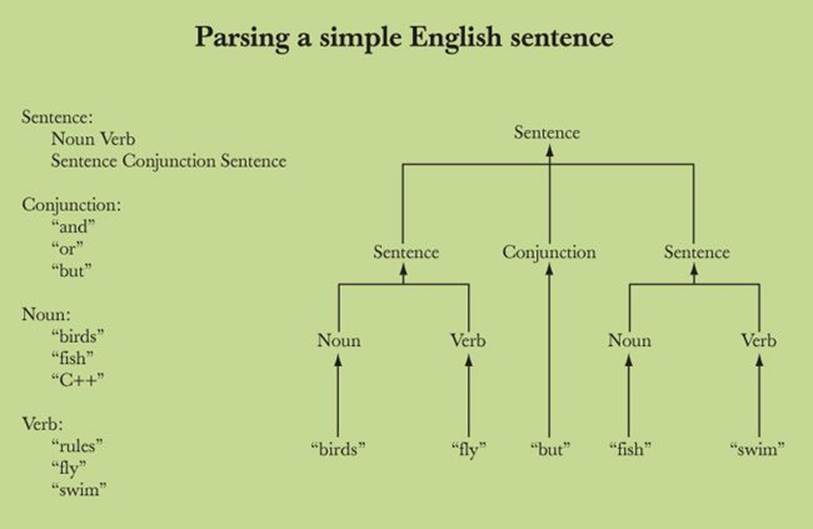
This is not all that complicated. If you had trouble with §6.4, then please go back and reread it from the beginning; it may make more sense the second time through!
6.4.2 Writing a grammar
How did we pick those expression grammar rules? “Experience” is the honest answer. The way we do it is simply the way people usually write expression grammars. However, writing a simple grammar is pretty straightforward: we need to know how to
![]()
1. Distinguish a rule from a token
2. Put one rule after another (sequencing)
3. Express alternative patterns (alternation)
4. Express a repeating pattern (repetition)
5. Recognize the grammar rule to start with
Different textbooks and different parser systems use different notational conventions and different terminology. For example, some call tokens terminals and rules non-terminals or productions. We simply put tokens in (double) quotes and start with the first rule. Alternatives are put on separate lines. For example:
List:
"{" Sequence "}"
Sequence:
Element
Element " ," Sequence
Element:
"A"
"B"
So a Sequence is either an Element or an Element followed by a Sequence using a comma for separation. An Element is either the letter A or the letter B. A List is a Sequence in “curly brackets.” We can generate these Lists (how?):
{ A }
{ B }
{ A,B }
{A,A,A,A,B }
However, these are not Lists (why not?):
{ }
A
{ A,A,A,A,B
{A,A,C,A,B }
{ A B C }
{A,A,A,A,B, }
This sequence rule is not one you learned in kindergarten or have hardwired into your brain, but it is still not rocket science. See §7.4 and §7.8.1 for examples of how we work with a grammar to express syntactic ideas.
6.5 Turning a grammar into code
There are many ways of getting a computer to follow a grammar. We’ll use the simplest one: we simply write one function for each grammar rule and use our type Token to represent tokens. A program that implements a grammar is often called a parser.
6.5.1 Implementing grammar rules
To implement our calculator, we need four functions: one to read tokens plus one for each rule in our grammar:
get_token() // read characters and compose tokens
// uses cin
expression() // deal with + and -
// calls term() and get_token()
term() // deal with *, /, and %
// calls primary() and get_token()
primary() // deal with numbers and parentheses
// calls expression() and get_token()
![]()
Note: Each function deals with a specific part of an expression and leaves everything else to other functions; this radically simplifies each function. This is much like a group of humans dealing with problems by letting each person handle problems in his or her own specialty, handing all other problems over to colleagues.
What should these functions actually do? Each function should call other grammar functions according to the grammar rule it is implementing and get_token() where a token is required in a rule. For example, when primary() tries to follow the (Expression) rule, it must call
get_token() // to deal with ( and )
expression() // to deal with Expression
What should such parsing functions return? How about the answer we really wanted? For example, for 2+3, expression() could return 5. After all, the information is all there. That’s what we’ll try! Doing so will save us from answering one of the hardest questions from our list: “How do I represent 45+5/7 as data so that I can evaluate it?” Instead of storing a representation of 45+5/7 in memory, we simply evaluate it as we read it from input. This little idea is really a major breakthrough! It will keep the program at a quarter of the size it would have been had we hadexpression() return something complicated for later evaluation. We just saved ourselves about 80% of the work.
The “odd man out” is get_token(): because it deals with tokens, not expressions, it can’t return the value of a sub-expression. For example, + and ( are not expressions. So, it must return a Token. We conclude that we want
// functions to match the grammar rules:
Token get_token() // read characters and compose tokens
double expression() // deal with + and -
double term() // deal with *, /, and %
double primary() // deal with numbers and parentheses
6.5.2 Expressions
Let’s first write expression(). The grammar looks like this:
Expression:
Term
Expression '+' Term
Expression '-' Term
Since this is our first attempt to turn a set of grammar rules into code, we’ll proceed through a couple of false starts. That’s the way it usually goes with new techniques, and we learn useful things along the way. In particular, a novice programmer can learn a lot from looking at the dramatically different behavior of similar pieces of code. Reading code is a useful skill to cultivate.
6.5.2.1 Expressions: first try
Looking at the Expression '+' Term rule, we try first calling expression(), then looking for + (and -) and then term():
double expression()
{
double left = expression(); // read and evaluate an Expression
Token t = get_token(); // get the next token
switch (t.kind) { // see which kind of token it is
case '+':
return left + term(); // read and evaluate a Term,
// then do an add
case '-':
return left - term(); // read and evaluate a Term,
// then do a subtraction
default:
return left; // return the value of the Expression
}
}
It looks good. It is almost a trivial transcription of the grammar. It is quite simple, really: first read an Expression and then see if it is followed by a + or a -, and if it is, read the Term.
Unfortunately, that doesn’t really make sense. How do we know where the expression ends so that we can look for a + or a -? Remember, our program reads left to right and can’t peek ahead to see if a + is coming. In fact, this expression() will never get beyond its first line: expression()starts by calling expression() which starts by calling expression() and so on “forever.” This is called an infinite recursion and will in fact terminate after a short while when the computer runs out of memory to hold the “never-ending” sequence of calls of expression(). The term recursion is used to describe what happens when a function calls itself. Not all recursions are infinite, and recursion is a very useful programming technique (see §8.5.8).
6.5.2.2 Expressions: second try
So what do we do? Every Term is an Expression, but not every Expression is a Term; that is, we could start looking for a Term and look for a full Expression only if we found a + or a -. For example:
double expression()
{
double left = term(); // read and evaluate a Term
Token t = get_token(); // get the next token
switch (t.kind) { // see which kind of token that is
case '+':
return left + expression(); // read and evaluate an Expression,
// then do an add
case '-':
return left - expression(); // read and evaluate an Expression,
// then do a subtraction
default:
return left; // return the value of the Term
}
}
This actually - more or less - works. We have tried it in the finished program and it parses every correct expression we throw at it (and no illegal ones). It even correctly evaluates most expressions. For example, 1+2 is read as a Term (with the value 1) followed by + followed by anExpression (which happens to be a Term with the value 2) and gives the answer 3. Similarly, 1+2+3 gives 6. We could go on for quite a long time about what works, but to make a long story short: How about 1-2-3? This expression() will read the 1 as a Term, then proceed to read 2-3 as anExpression (consisting of the Term 2 followed by the Expression 3). It will then subtract the value of 2-3 from 1. In other words, it will evaluate 1-(2-3). The value of 1-(2-3) is 2 (positive two). However, we were taught (in primary school or even earlier) that 1-2-3 means (1-2)-3 and therefore has the value -4 (negative four).
![]()
So we got a very nice program that just didn’t do the right thing. That’s dangerous. It is especially dangerous because it gives the right answer in many cases. For example, 1+2+3 gives the right answer (6) because 1+(2+3) equals (1+2)+3. What fundamentally, from a programming point of view, did we do wrong? We should always ask ourselves this question when we have found an error. That way we might avoid making the same mistake again, and again, and again.
Fundamentally, we just looked at the code and guessed. That’s rarely good enough! We have to understand what our code is doing and we have to be able to explain why it does the right thing.
Analyzing our errors is often also the best way to find a correct solution. What we did here was to define expression() to first look for a Term and then, if that Term is followed by a + or a -, look for an Expression. This really implements a slightly different grammar:
Expression:
Term
Term '+' Expression // addition
Term '-' Expression // subtraction
The difference from our desired grammar is exactly that we wanted 1-2-3 to be the Expression 1-2 followed by - followed by the Term 3, but what we got here was the Term 1 followed by - followed by the Expression 2-3; that is, we wanted 1-2-3 to mean (1-2)-3 but we got 1-(2-3).
Yes, debugging can be tedious, tricky, and time-consuming, but in this case we are really working through rules you learned in primary school and learned to apply without too much trouble. The snag is that we have to teach the rules to a computer - and a computer is a far slower learner than you are.
Note that we could have defined 1-2-3 to mean 1-(2-3) rather than (1-2)-3 and avoided this discussion altogether. Often, the trickiest programming problems come when we must match conventional rules that were established by and for humans long before we started using computers.
6.5.2.3 Expressions: third time lucky
So, what now? Look again at the grammar (the correct grammar in §6.5.2): any Expression starts with a Term and such a Term can be followed by a + or a -. So, we have to look for a Term, see if it is followed by a + or a -, and keep doing that until there are no more plusses or minuses. For example:
double expression()
{
double left = term(); // read and evaluate a Term
Token t = get_token(); // get the next token
while (t.kind=='+' || t.kind=='-') { // look for a + or a -
if (t.kind == '+')
left += term(); // evaluate Term and add
else
left -= term(); // evaluate Term and subtract
t = get_token();
}
return left; // finally: no more + or -; return the answer
}
This is a bit messier: we had to introduce a loop to keep looking for plusses and minuses. We also got a bit repetitive: we test for + and - twice and twice call get_token(). Because it obscures the logic of the code, let’s just get rid of the duplication of the test for + and -:
double expression()
{
double left = term(); // read and evaluate a Term
Token t = get_token(); // get the next token
while (true) {
switch (t.kind) {
case '+':
left += term(); // evaluate Term and add
t = get_token();
break;
case '-':
left -= term(); // evaluate Term and subtract
t = get_token();
break;
default:
return left; // finally: no more + or -; return the answer
}
}
}
Note that - except for the loop - this is actually rather similar to our first try (§6.5.2.1). What we have done is to remove the mention of expression() within expression() and replace it with a loop. In other words, we translated the Expression in the grammar rules for Expression into a loop looking for a Term followed by a + or a -.
6.5.3 Terms
The grammar rule for Term is very similar to the Expression rule:
Term:
Primary
Term '*' Primary
Term '/' Primary
Term '%' Primary
Consequently, the code should be very similar also. Here is a first try:
double term()
{
double left = primary();
Token t = get_token();
while (true) {
switch (t.kind) {
case '*':
left *= primary();
t = get_token();
break;
case '/':
left /= primary();
t = get_token();
break;
case '%':
left %= primary();
t = get_token();
break;
default:
return left;
}
}
}
![]()
Unfortunately, this doesn’t compile: the remainder operation (%) is not defined for floating-point numbers. The compiler kindly tells us so. When we answered question 5 in §6.3.5 - “Should we also allow floating-point inputs?” - with a confident “Sure!” we actually hadn’t thought the issue through and fell victim to feature creep. That always happens! So what do we do about it? We could at run time check that both operands of % are integers and give an error if they are not. Or we could simply leave % out of our calculator. Let’s take the simplest choice for now. We can always add % later; see §7.5.
After we eliminate the % case, the function works: terms are correctly parsed and evaluated. However, an experienced programmer will notice an undesirable detail that makes term() unacceptable. What would happen if you entered 2/0? You can’t divide by zero. If you try, the computer hardware will detect it and terminate your program with a somewhat unhelpful error message. An inexperienced programmer will discover this the hard way. So, we’d better check and give a decent error message:
double term()
{
double left = primary();
Token t = get_token();
while (true) {
switch (t.kind) {
case '*':
left *= primary();
t = get_token();
break;
case '/':
{ double d = primary();
if (d == 0) error("divide by zero");
left /= d;
t = get_token();
break;
}
default:
return left;
}
}
}
Why did we put the statements handling / into a block? The compiler insists. If you want to define and initialize variables within a switch-statement, you must place them inside a block.
6.5.4 Primary expressions
The grammar rule for primary expressions is also simple:
Primary:
Number
'(' Expression ')'
The code that implements it is a bit messy because there are more opportunities for syntax errors:
double primary()
{
Token t = get_token();
switch (t.kind) {
case '(': // handle ‘(‘ expression ‘)’
{ double d = expression();
t = get_token();
if (t.kind != ')') error("')' expected");
return d;
}
case '8': // we use ‘8’ to represent a number
return t.value; // return the number’s value
default:
error("primary expected");
}
}
Basically there is nothing new compared to expression() and term(). We use the same language primitives, the same way of dealing with Tokens, and the same programming techniques.
6.6 Trying the first version
To run these calculator functions, we need to implement get_token() and provide a main(). The main() is trivial: we just keep calling expression() and printing out its result:
int main()
try {
while (cin)
cout << expression() << '\n';
keep_window_open();
}
catch (exception& e) {
cerr << e.what() << '\n';
keep_window_open ();
return 1;
}
catch (...) {
cerr << "exception \n";
keep_window_open ();
return 2;
}
The error handling is the usual “boilerplate” (§5.6.3). Let us postpone the description of the implementation of get_token() to §6.8 and test this first version of the calculator.
Try This
This first version of the calculator program (including get_token()) is available as file calculator00.cpp. Get it to run and try it out.
Unsurprisingly, this first version of the calculator doesn’t work quite as we expected. So we shrug and ask, “Why not?” or rather, “So, why does it work the way it does?” and “What does it do?” Type a 2 followed by a newline. No response. Try another newline to see if it’s asleep. Still no response. Type a 3 followed by a newline. No response! Type a 4 followed by a newline. It answers 2! Now the screen looks like this:
2
3
4
2
We carry on by typing 5+6. The program responds with a 5, so that the screen looks like this:
2
3
4
2
5+6
5
Unless you have programmed before, you are most likely very puzzled! In fact, even an experienced programmer might be puzzled. What’s going on here? At this point, you try to get out of the program. How do you do this? We “forgot” to program an exit command, but an error will cause the program to exit, so you type an x and the program prints Bad token and exits. Finally, something worked as planned!
However, we forgot to distinguish between input and output on the screen. Before we try to solve the main puzzle, let’s just fix the output to better see what we are doing. Adding an = to indicate output will do for now:
while (cin) cout << "="<< expression() << '\n'; // version 1
Now, entering the exact sequence of characters as before, we get
2
3
4
= 2
5+6
= 5
x
Bad token
Strange! Try to figure out what the program did. We tried another few examples, but let’s just look at this. This is a puzzle:
Why didn’t the program respond after the first 2 and 3 and the newlines?
Why did the program respond with 2, rather than 4, after we entered 4?
Why did the program answer 5, rather than 11, after 5+6?
There are many possible ways of proceeding from such mysterious results. We’ll examine some of those in the next chapter, but here, let’s just think. Could the program be doing bad arithmetic? That’s most unlikely; the value of 4 isn’t 2, and the value of 5+6 is 11 rather than 5. Consider what happens when we enter 1 2 3 4+5 6+7 8+9 10 11 12 followed by a newline. We get
1 2 3 4+5 6+7 8+9 10 11 12
= 1
= 4
= 6
= 8
= 10
Huh? No 2 or 3. Why 4 and not 9 (that is, 4+5)? Why 6 and not 13 (that is, 6+7)? Look carefully: the program is outputting every third token! Maybe the program “eats” some of our input without evaluating it? It does. Consider expression():
double expression()
{
double left = term(); // read and evaluate a Term
Token t = get_token(); // get the next token
while (true) {
switch (t.kind) {
case '+':
left += term(); // evaluate Term and add
t = get_token();
break;
case '-':
left -= term(); // evaluate Term and subtract
t = get_token();
break;
default:
return left; // finally: no more + or -; return the answer
}
}
}
When the Token returned by get_token() is not a + or a - we just return. We don’t use that token and we don’t store it anywhere for any other function to use later. That’s not smart. Throwing away input without even determining what it is can’t be a good idea. A quick look shows that term()has exactly the same problem. That explains why our calculator ate two tokens for each that it used.
Let us modify expression() so that it doesn’t “eat” tokens. Where would we put that next token (t) when the program doesn’t need it? We could think of many elaborate schemes, but let’s jump to the obvious answer (“obvious” once you see it): that token is going to be used by some other function that is reading tokens from the input, so let’s put the token back into the input stream so that it can be read again by some other function! Actually, you can put characters back into an istream, but that’s not really what we want. We want to deal with tokens, not mess with characters. What we want is an input stream that deals with tokens and that you can put an already read token back into.
So, assume that we have a stream of tokens - a “Token_stream” - called ts. Assume further that a Token_stream has a member function get() that returns the next token and a member function putback(t) that puts a token t back into the stream. We’ll implement that Token_stream in §6.8 as soon as we have had a look at how it needs to be used. Given Token_stream, we can rewrite expression() so that it puts a token that it does not use back into the Token_stream:
double expression()
{
double left = term(); // read and evaluate a Term
Token t = ts.get(); // get the next Token from the Token stream
while (true) {
switch (t.kind) {
case '+':
left += term(); // evaluate Term and add
t = ts.get();
break;
case '-':
left -= term(); // evaluate Term and subtract
t = ts.get();
break;
default:
ts.putback(t); // put t back into the token stream
return left; // finally: no more + or -; return the answer
}
}
}
In addition, we must make the same change to term():
double term()
{
double left = primary();
Token t = ts.get(); // get the next Token from the Token stream
while (true) {
switch (t.kind) {
case '*':
left *= primary();
t = ts.get();
break;
case '/':
{ double d = primary();
if (d == 0) error("divide by zero");
left /= d;
t = ts.get();
break;
}
default:
ts.putback(t); // put t back into the Token stream
return left;
}
}
}
For our last parser function, primary(), we just need to change get_token() to ts.get(); primary() uses every token it reads.
6.7 Trying the second version
So, we are ready to test our second version. This second version of the calculator program (including Token_stream) is available as file calculator01.cpp. Get it to run and try it out. Type 2 followed by a newline. No response. Try another newline to see if it’s asleep. Still no response. Type a 3followed by a newline and it answers 2. Try 2+2 followed by a newline and it answers 3. Now your screen looks like this:
2
3
=2
2+2
=3
Hmm. Maybe our introduction of putback() and its use in expression() and term() didn’t fix the problem. Let’s try another test:
2 3 4 2+3 2*3
= 2
= 3
= 4
= 5
Yes! These are correct answers! But the last answer (6) is missing. We still have a token-look-ahead problem. However, this time the problem is not that our code “eats” characters, but that it doesn’t get any output for an expression until we enter the following expression. The result of an expression isn’t printed immediately; the output is postponed until the program has seen the first token of the next expression. Unfortunately, the program doesn’t see that token until we hit Return after the next expression. The program isn’t really wrong; it is just a bit slow responding.
How can we fix this? One obvious solution is to require a “print command.” So, let’s accept a semicolon after an expression to terminate it and trigger output. And while we are at it, let’s add an “exit command” to allow for graceful exit. The character q (for “quit”) would do nicely for an exit command. In main(), we have
while (cin) cout << "=" << expression() << '\n'; // version 1
We can change that to the messier but more useful
double val = 0;
while (cin) {
Token t = ts.get();
if (t.kind == 'q') break; // ‘q’ for “quit”
if (t.kind == ';') // ‘;’ for “print now”
cout << "=" << val << '\n';
else
ts.putback(t);
val = expression();
}
Now the calculator is actually usable. For example, we get
2;
= 2
2+3;
= 5
3+4*5;
= 23
q
At this point we have a good initial version of the calculator. It’s not quite what we really wanted, but we have a program that we can use as the base for making a more acceptable version. Importantly, we can now correct problems and add features one by one while maintaining a working program as we go along.
6.8 Token streams
Before further improving our calculator, let us show the implementation of Token_stream. After all, nothing - nothing at all - works until we get correct input. We implemented Token_stream first of all but didn’t want too much of a digression from the problems of calculation before we had shown a minimal solution.
Input for our calculator is a sequence of tokens, just as we showed for (1.5+4)*11 above (§6.3.3). What we need is something that reads characters from the standard input, cin, and presents the program with the next token when it asks for it. In addition, we saw that we - that is, our calculator program - often read a token too many, so that we must be able to put it back for later use. This is typical and fundamental; when you see 1.5+4 reading strictly left to right, how could you know that the number 1.5 had been completely read without reading the +? Until we see the +we might be on our way to reading 1.55555. So, we need a “stream” that produces a token when we ask for one using get() and where we can put a token back into the stream using putback(). Everything we use in C++ has a type, so we have to start by defining the type Token_stream.
You probably noticed the public: in the definition of Token in §6.3.3. There, it had no apparent purpose. For Token_stream, we need it and must explain its function. A C++ user-defined type often consists of two parts: the public interface (labeled public:) and the implementation details (labeled private:). The idea is to separate what a user of a type needs for convenient use from the details that we need in order to implement the type, but that we’d rather not have users mess with:
class Token_stream {
public:
// user interface
private:
// implementation details
// (not directly accessible to users of Token_stream)
};
![]()
Obviously, users and implementers are often just us “playing different roles,” but making the distinction between the (public) interface meant for users and the (private) implementation details used only by the implementer is a powerful tool for structuring code. The public interface should contain (only) what a user needs, which is typically a set of functions. The private implementation contains what is necessary to implement those public functions, typically data and functions dealing with messy details that the users need not know about and shouldn’t directly use.
Let’s elaborate the Token_stream type a bit. What does a user want from it? Obviously, we want get() and putback() functions - that’s why we invented the notion of a token stream. The Token_stream is to make Tokens out of characters that it reads for input, so we need to be able to make a Token_stream and to define it to read from cin. Thus, the simplest Token_stream looks like this:
class Token_stream {
public:
Token_stream(); // make a Token_stream that reads from cin
Token get(); // get a Token
void putback(Token t); // put a Token back
private:
// implementation details
};
That’s all a user needs to use a Token_stream. Experienced programmers will wonder why cin is the only possible source of characters, but we decided to take our input from the keyboard. We’ll revisit that decision in a Chapter 7 exercise.
Why do we use the “verbose” name putback() rather than the logically sufficient put()? We wanted to emphasize the asymmetry between get() and putback(); this is an input stream, not something that you can also use for general output. Also, istream has a putback() function: consistency in naming is a useful property of a system. It helps people remember and helps people avoid errors.
We can now make a Token_stream and use it:
Token_stream ts; // a Token_stream called ts
Token t = ts.get(); // get next Token from ts
// . . .
ts.putback(t); // put the Token t back into ts
That’s all we need to write the rest of the calculator.
6.8.1 Implementing Token_stream
Now, we need to implement those three Token_stream functions. How do we represent a Token_stream? That is, what data do we need to store in a Token_stream for it to do its job? We need space for any token we put back into the Token_stream. To simplify, let’s say we can put back at most one token at a time. That happens to be sufficient for our program (and for many, many similar programs). That way, we just need space for one Token and an indicator of whether that space is full or empty:
class Token_stream {
public:
Token get(); // get a Token (get() is defined in §6.8.2)
void putback(Token t); // put a Token back
private:
bool full {false}; // is there a Token in the buffer?
Token buffer; // here is where we keep a Token put back using putback()
};
Now we can define (“write”) the two member functions. The putback() is easy, so we will define it first. The putback() member function puts its argument back into the Token_stream’s buffer:
void Token_stream::putback(Token t)
{
buffer = t; // copy t to buffer
full = true; // buffer is now full
}
The keyword void (meaning “nothing”) is used to indicate that putback() doesn’t return a value.
When we define a member of a class outside the class definition itself, we have to mention which class we mean the member to be a member of. We use the notation
class_name :: member_name
for that. In this case, we define Token_stream’s member putback.
Why would we define a member outside its class? The main answer is clarity: the class definition (primarily) states what the class can do. Member function definitions are implementations that specify how things are done. We prefer to put them “elsewhere” where they don’t distract. Our ideal is to have every logical entity in a program fit on a screen. Class definitions typically do that if the member function definitions are placed elsewhere, but not if they are placed within the class definition (“in-class”).
If we wanted to make sure that we didn’t try to use putback() twice without reading what we put back in between (using get()), we could add a test:
void Token_stream::putback(Token t)
{
if (full) error("putback() into a full buffer");
buffer = t; // copy t to buffer
full = true; // buffer is now full
}
The test of full checks the pre-condition “There is no Token in the buffer.”
Obviously, a Token_stream should start out empty. That is, full should be false until after the first call of get(). We achieve that by initializing the member full right in the definition of Token_stream.
6.8.2 Reading tokens
All the real work is done by get(). If there isn’t already a Token in Token_stream::buffer, get() must read characters from cin and compose them into Tokens:
Token Token_stream::get()
{
if (full) { // do we already have a Token ready?
full = false; // remove Token from buffer
return buffer;
}
char ch;
cin >> ch; // note that >> skips whitespace (space, newline, tab, etc.)
switch (ch) {
case ';': // for “print”
case 'q': // for “quit”
case '(': case ')': case '+': case '-': case '*': case '/':
return Token{ch}; // let each character represent itself
case '.':
case '0': case '1': case '2': case '3': case '4':
case '5': case '6': case '7': case '8': case '9':
{ cin.putback(ch); // put digit back into the input stream
double val;
cin >> val; // read a floating-point number
return Token{'8',val}; // let ‘8’ represent “a number”
}
default:
error("Bad token");
}
}
Let’s examine get() in detail. First we check if we already have a Token in the buffer. If so, we can just return that:
if (full) { // do we already have a Token ready?
full = false; // remove Token from buffer
return buffer;
}
Only if full is false (that is, there is no token in the buffer) do we need to mess with characters. In that case, we read a character and deal with it appropriately. We look for parentheses, operators, and numbers. Any other character gets us the call of error() that terminates the program:
default:
error("Bad token");
The error() function is described in §5.6.3 and we make it available in std_lib_facilities.h.
We had to decide how to represent the different kinds of Tokens; that is, we had to choose values for the member kind. For simplicity and ease of debugging, we decided to let the kind of a Token be the parentheses and operators themselves. This leads to extremely simple processing of parentheses and operators:
case '(': case ')': case '+': case '-': case '*': case '/':
return Token{ch}; // let each character represent itself
To be honest, we had forgotten ';' for “print” and 'q' for “quit” in our first version. We didn’t add them until we needed them for our second solution.
6.8.3 Reading numbers
Now we just have to deal with numbers. That’s actually not that easy. How do we really find the value of 123? Well, that’s 100+20+3, but how about 12.34, and should we accept scientific notation, such as 12.34e5? We could spend hours or days to get this right, but fortunately, we don’t have to. Input streams know what C++ literals look like and how to turn them into values of type double. All we have to do is to figure out how to tell cin to do that for us inside get():
case '.':
case '0': case '1': case '2': case '3': case '4':
case '5': case '6': case '7': case '8': case '9':
{ cin.putback(ch); // put digit back into the input stream
double val;
cin >> val; // read a floating-point number
return Token{'8',val}; // let ‘8’ represent “a number”
}
We - somewhat arbitrarily - chose '8' to represent “a number” in a Token.
How do we know that a number is coming? Well, if we guess from experience or look in a C++ reference (e.g., Appendix A), we find that a numeric literal must start with a digit or . (the decimal point). So, we test for that. Next, we want to let cin read the number, but we have already read the first character (a digit or dot), so just letting cin loose on the rest will give a wrong result. We could try to combine the value of the first character with the value of “the rest” as read by cin; for example, if someone typed 123, we would get 1 and cin would read 23 and we’d have to add100 to 23. Yuck! And that’s a trivial case. Fortunately (and not by accident), cin works much like Token_stream in that you can put a character back into it. So instead of doing any messy arithmetic, we just put the initial character back into cin and then let cin read the whole number.
![]()
Please note how we again and again avoid doing complicated work and instead find simpler solutions - often relying on library facilities. That’s the essence of programming: the continuing search for simplicity. Sometimes that’s - somewhat facetiously - expressed as “Good programmers are lazy.” In that sense (and only in that sense), we should be “lazy”; why write a lot of code if we can find a way of writing far less?
6.9 Program structure
Sometimes, the proverb says, it’s hard to see the forest for the trees. Similarly, it is easy to lose sight of a program when looking at all its functions, classes, etc. So, let’s have a look at the program with its details omitted:
#include "std_lib_facilities.h"
class Token { /* . . . */ };
class Token_stream { /* . . . */ };
void Token_stream::putback(Token t) { /* . . . */ }
Token Token_stream::get() { /* . . . */ }
Token_stream ts; // provides get() and putback()
double expression() // declaration so that primary() can call expression()
double primary() { /* . . . */ } // deal with numbers and parentheses
double term() { /* . . . */ } // deal with * and /
double expression() { /* . . . */ } // deal with + and -
int main() { /* . . . */ } // main loop and deal with errors
![]()
The order of the declarations is important. You cannot use a name before it has been declared, so ts must be declared before ts.get() uses it, and error() must be declared before the parser functions because they all use it. There is an interesting loop in the call graph: expression() calls term()which calls primary() which calls expression().
We can represent that graphically (leaving out calls to error() - everyone calls error()):
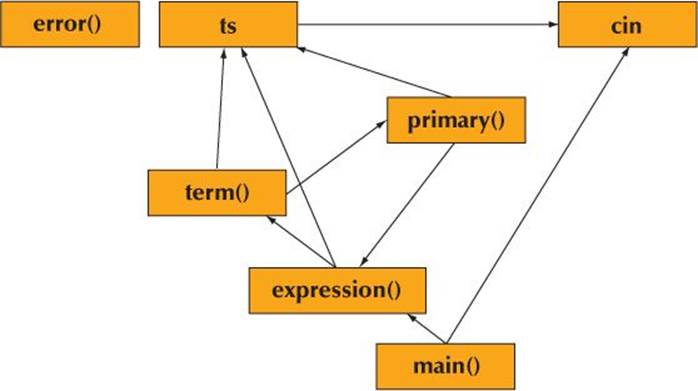
This means that we can’t just define those three functions: there is no order that allows us to define every function before it is used. We need at least one declaration that isn’t also a definition. We chose to declare (“forward declare”) expression().
But does this work? It does, for some definition of “work.” It compiles, runs, correctly evaluates expressions, and gives decent error messages. But does it work in a way that we like? The unsurprising answer is “Not really.” We tried the first version in §6.6 and removed a serious bug. This second version (§6.7) is not much better. But that’s fine (and expected). It is good enough for its main purpose, which is to be something that we can use to verify our basic ideas and get feedback from. As such, it is a success, but try it: it’ll (still) drive you nuts!
 Try This
Try This
Get the calculator as presented above to run, see what it does, and try to figure out why it works as it does.
 Drill
Drill
This drill involves a series of modifications of a buggy program to turn it from something useless into something reasonably useful.
1. Take the calculator from the file calculator02buggy.cpp. Get it to compile. You need to find and fix a few bugs. Those bugs are not in the text in the book. Find the three logic errors deviously inserted in calculator02buggy.cpp and remove them so that the calculator produces correct results.
2. Change the character used as the exit command from q to x.
3. Change the character used as the print command from ; to =.
4. Add a greeting line in main():
"Welcome to our simple calculator.
Please enter expressions using floating-point numbers."
5. Improve that greeting by mentioning which operators are available and how to print and exit.
Review
1. What do we mean by “Programming is understanding”?
2. The chapter details the creation of a calculator program. Write a short analysis of what the calculator should be able to do.
3. How do you break a problem up into smaller manageable parts?
4. Why is creating a small, limited version of a program a good idea?
5. Why is feature creep a bad idea?
6. What are the three main phases of software development?
7. What is a “use case”?
8. What is the purpose of testing?
9. According to the outline in the chapter, describe the difference between a Term, an Expression, a Number, and a Primary.
10. In the chapter, an input was broken down into its component Terms, Expressions, Primarys, and Numbers. Do this for (17+4)/(5-1).
11. Why does the program not have a function called number()?
12. What is a token?
13. What is a grammar? A grammar rule?
14. What is a class? What do we use classes for?
15. How can we provide a default value for a member of a class?
16. In the expression function, why is the default for the switch-statement to “put back” the token?
17. What is “look-ahead”?
18. What does putback() do and why is it useful?
19. Why is the remainder (modulus) operation, %, difficult to implement in the term()?
20. What do we use the two data members of the Token class for?
21. Why do we (sometimes) split a class’s members into private and public members?
22. What happens in the Token_stream class when there is a token in the buffer and the get() function is called?
23. Why were the ';' and 'q' characters added to the switch-statement in the get() function of the Token_stream class?
24. When should we start testing our program?
25. What is a “user-defined type”? Why would we want one?
26. What is the interface to a C++ “user-defined type”?
27. Why do we want to rely on libraries of code?
Terms
analysis
class
class member
data member
design
divide by zero
grammar
implementation
interface
member function
parser
private
prototype
pseudo code
public
syntax analyzer
token
use case
Exercises
1. If you haven’t already, do the Try this exercises from this chapter.
2. Add the ability to use {} as well as () in the program, so that {(4+5)*6} / (3+4) will be a valid expression.
3. Add a factorial operator: use a suffix ! operator to represent “factorial.” For example, the expression 7! means 7 * 6 * 5 * 4 * 3 * 2 * 1. Make ! bind tighter than * and /; that is, 7*8! means 7*(8!) rather than (7*8)!. Begin by modifying the grammar to account for a higher-level operator. To agree with the standard mathematical definition of factorial, let 0! evaluate to 1. Hint: The calculator functions deal with doubles, but factorial is defined only for ints, so just for x!, assign the x to an int and calculate the factorial of that int.
4. Define a class Name_value that holds a string and a value. Rework exercise 19 in Chapter 4 to use a vector<Name_value> instead of two vectors.
5. Add the article the to the “English” grammar in §6.4.1, so that it can describe sentences such as “The birds fly but the fish swim.”
6. Write a program that checks if a sentence is correct according to the “English” grammar in §6.4.1. Assume that every sentence is terminated by a full stop (.) surrounded by whitespace. For example, birds fly but the fish swim . is a sentence, but birds fly but the fish swim (terminating dot missing) and birds fly but the fish swim. (no space before dot) are not. For each sentence entered, the program should simply respond “OK” or “not OK.” Hint: Don’t bother with tokens; just read into a string using >>.
7. Write a grammar for bitwise logical expressions. A bitwise logical expression is much like an arithmetic expression except that the operators are ! (not), ~ (complement), & (and), | (or), and ^ (exclusive or). Each operator does its operation to each bit of its integer operands (see §25.5).! and ~ are prefix unary operators. A ^ binds tighter than a | (just as * binds tighter than +) so that x|y^z means x|(y^z) rather than (x|y)^z. The & operator binds tighter than ^ so that x^y&z means x^(y&z).
8. Redo the “Bulls and Cows” game from exercise 12 in Chapter 5 to use four letters rather than four digits.
9. Write a program that reads digits and composes them into integers. For example, 123 is read as the characters 1, 2, and 3. The program should output 123 is 1 hundred and 2 tens and 3 ones. The number should be output as an int value. Handle numbers with one, two, three, or four digits. Hint: To get the integer value 5 from the character '5' subtract '0', that is, '5'-'0'==5.
10. A permutation is an ordered subset of a set. For example, say you wanted to pick a combination to a vault. There are 60 possible numbers, and you need three different numbers for the combination. There are P(60,3) permutations for the combination, where P is defined by the formula
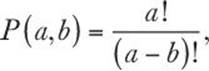
where ! is used as a suffix factorial operator. For example, 4! is 4*3*2*1.
Combinations are similar to permutations, except that the order of the objects doesn’t matter. For example, if you were making a “banana split” sundae and wished to use three different flavors of ice cream out of five that you had, you wouldn’t care if you used a scoop of vanilla at the beginning or the end; you would still have used vanilla. The formula for combinations is
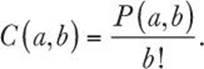
Design a program that asks users for two numbers, asks them whether they want to calculate permutations or combinations, and prints out the result. This will have several parts. Do an analysis of the above requirements. Write exactly what the program will have to do. Then, go into the design phase. Write pseudo code for the program, and break it into sub-components. This program should have error checking. Make sure that all erroneous inputs will generate good error messages.
Postscript
Making sense of input is one of the fundamental programming activities. Every program somehow faces that problem. Making sense of something directly produced by a human is among the hardest problems. For example, many aspects of voice recognition are still a research problem. Simple variations of this problem, such as our calculator, cope by using a grammar to define the input.