Professional C++ (2014)
Part IIICoding the Professional Way
Chapter 17Mastering STL Algorithms
WHAT’S IN THIS CHAPTER?
· Algorithms explained
· Lambda expressions explained
· Function objects explained
· The details of the STL algorithms
· A larger example: auditing voter registrations
WROX.COM DOWNLOADS FOR THIS CHAPTER
Please note that all the code examples for this chapter are available as a part of this chapter’s code download on the book’s website at www.wrox.com/go/proc++3e on the Download Code tab.
As Chapter 16 shows, the STL provides an impressive collection of generic data structures. Most libraries stop there. The STL, however, contains an additional assortment of generic algorithms that can, with some exceptions, be applied to elements from any container. Using these algorithms, you can find, sort, and process elements in containers, and perform a whole host of other operations. The beauty of the algorithms is that they are independent not only of the types of the underlying elements, but also of the types of the containers on which they operate. Algorithms perform their work using only the iterator interfaces.
Many of the algorithms accept a callback, which can be a function pointer or something that behaves like a function pointer, such as an object with an overloaded operator() or an inline lambda expression. Conveniently, the STL provides a set of classes that can be used to create callback objects for the algorithms. These callback objects are called function objects, or just functors.
OVERVIEW OF ALGORITHMS
The “magic” behind the algorithms is that they work on iterator intermediaries instead of on the containers themselves. In that way, they are not tied to specific container implementations. All the STL algorithms are implemented as function templates, where the template type parameters are usually iterator types. The iterators themselves are specified as arguments to the function. Templatized functions can usually deduce the template types from the function arguments, so you can generally call the algorithms as if they were normal functions, not templates.
The iterator arguments are usually iterator ranges. As Chapter 16 explains, iterator ranges are half-open for most containers such that they include the first element in the range, but exclude the last. The end iterator is really a “past-the-end” marker.
Algorithms pose certain requirements on iterators passed to it. For instance, copy_backward() is an example of an algorithm that requires a bidirectional iterator, and stable_sort() is an example of an algorithm requiring random access iterators. This means that such algorithms cannot work on containers that do not provide the necessary iterators. forward_list is an example of a container supporting only forward iterators, no bidirectional or random access iterators, thus copy_backward() and stable_sort() cannot work onforward_list.
Most algorithms are defined in the <algorithm> header file, while some numerical algorithms are defined in <numeric>. All of them are in the std namespace.
The best way to understand the algorithms is to look at some examples first. After you’ve seen how a few of them work, it’s easy to pick up the others. This section describes the find(), find_if(), and accumulate() algorithms in detail. The next sections present the lambda expressions and function objects, and discusses each of the classes of algorithms with representative samples.
The find and find_if Algorithms
find() looks for a specific element in an iterator range. You can use it on elements in any container type. It returns an iterator referring to the element found, or the end iterator of the range in case the element is not found. Note that the range specified in the call tofind() need not be the entire range of elements in a container; it could be a subset.
WARNING If find() fails to find an element, it returns an iterator equal to the end iterator specified in the function call, not the end iterator of the underlying container.
Here is an example of find(). Note that this example assumes that the user plays nice and enters valid numbers; it does not perform any error checking on the user input. Performing error checking on stream input is discussed in Chapter 12.
#include <algorithm>
#include <vector>
#include <iostream>
using namespace std;
int main()
{
int num;
vector<int> myVector;
while (true) {
cout << "Enter a number to add (0 to stop): ";
cin >> num;
if (num == 0) {
break;
}
myVector.push_back(num);
}
while (true) {
cout << "Enter a number to lookup (0 to stop): ";
cin >> num;
if (num == 0) {
break;
}
auto endIt = cend(myVector);
auto it = find(cbegin(myVector), endIt, num);
if (it == endIt) {
cout << "Could not find " << num << endl;
} else {
cout << "Found " << *it << endl;
}
}
return 0;
}
The call to find() is made with cbegin(myVector) and endIt as arguments, where endIt is defined as cend(myVector) in order to search all the elements of the vector. If you want to search in a sub range, you can change these two iterators.
Here is a sample run of the program:
Enter a number to add (0 to stop): 3
Enter a number to add (0 to stop): 4
Enter a number to add (0 to stop): 5
Enter a number to add (0 to stop): 6
Enter a number to add (0 to stop): 0
Enter a number to lookup (0 to stop): 5
Found 5
Enter a number to lookup (0 to stop): 8
Could not find 8
Enter a number to lookup (0 to stop): 0
Some containers, such as map and set, provide their own versions of find() as class methods.
WARNING If a container provides a method with the same functionality as a generic algorithm, you should use the method instead, because it’s faster. For example, the generic find() algorithm runs in linear time, even on a map, while the find()method on a map runs in logarithmic time.
find_if() is similar to find(), except that it accepts a predicate function callback instead of a simple element to match. A predicate returns true or false. The find_if() algorithm calls the predicate on each element in the range until the predicate returns true, in which case find_if()returns an iterator referring to that element. The following program reads test scores from the user, then checks if any of the scores are “perfect.” A perfect score is a score of 100 or higher. The program is similar to the previous example. Only the differences are highlighted.
bool perfectScore(int num)
{
return (num >= 100);
}
int main()
{
int num;
vector<int> myVector;
while (true) {
cout << "Enter a test score to add (0 to stop): ";
cin >> num;
if (num == 0) {
break;
}
myVector.push_back(num);
}
auto endIt = cend(myVector);
auto it = find_if(cbegin(myVector), endIt, perfectScore);
if (it == endIt) {
cout << "No perfect scores" << endl;
} else {
cout << "Found a \"perfect\" score of " << *it << endl;
}
return 0;
}
This program passes a pointer to the perfectScore() function, which the find_if() algorithm then calls on each element until it returns true.
Here is the same example but using a lambda expression. It gives you an initial idea about the power of lambda expressions. Don’t worry about their syntax; they are explained in detail later in this chapter. Note the absence of the perfectScore() function.
int num;
vector<int> myVector;
while (true) {
cout << "Enter a test score to add (0 to stop): ";
cin >> num;
if (num == 0) {
break;
}
myVector.push_back(num);
}
auto endIt = cend(myVector);
auto it = find_if(cbegin(myVector), endIt, [](int i){ return i >= 100; });
if (it == endIt) {
cout << "No perfect scores" << endl;
} else {
cout << "Found a \"perfect\" score of " << *it << endl;
}
Unfortunately, the STL provides no find_all() or equivalent algorithm that returns all instances matching a predicate. Chapter 20 shows you how to write your own find_all() algorithm.
The accumulate Algorithms
It’s often useful to calculate the sum, or some other arithmetic quantity, of all the elements in a container. The accumulate() function does just that. In its most basic form, it calculates the sum of the elements in a specified range. For example, the following function calculates the arithmetic mean of a sequence of integers in a vector. The arithmetic mean is simply the sum of all the elements divided by the number of elements.
#include <numeric>
#include <vector>
using namespace std;
double arithmeticMean(const vector<int>& nums)
{
double sum = accumulate(cbegin(nums), cend(nums), 0);
return sum / nums.size();
}
Note that accumulate() is declared in <numeric>, not in <algorithm>. The accumulate() algorithm takes as its third parameter an initial value for the sum, which in this case should be 0 (the identity for addition) to start a fresh sum.
The second form of accumulate() allows the caller to specify an operation to perform instead of the default addition. This operation takes the form of a binary callback. Suppose that you want to calculate the geometric mean, which is the product of all the numbers in the sequence to the power of the inverse of the size. In that case, you would want to use accumulate() to calculate the product instead of the sum. You could write it like this:
#include <numeric>
#include <vector>
#include <cmath>
using namespace std;
int product(int num1, int num2)
{
return num1 * num2;
}
double geometricMean(const vector<int>& nums)
{
double mult = accumulate(cbegin(nums), cend(nums), 1, product);
return pow(mult, 1.0 / nums.size());
}
Note that the product() function is passed as a callback to accumulate() and that the initial value for the accumulation is 1 (the identity for multiplication) instead of 0.
To give you a second teaser about the power of lambda expressions, the geometricMean() function could be written as follows, without using the product() function:
double geometricMeanLambda(const vector<int>& nums)
{
double mult = accumulate(cbegin(nums), cend(nums), 1,
[](int num1, int num2){ return num1 * num2; });
return pow(mult, 1.0 / nums.size());
}
Later in this chapter you learn how to use accumulate() in the geometricMean() function without writing a function callback or lambda expression.
Move Semantics with Algorithms
Just like STL containers, STL algorithms are also optimized to use move semantics at appropriate times. This can greatly speed up certain algorithms; for example, sort(). For this reason, it is highly recommended that you implement move semantics in your custom element classes that you want to store in containers. Move semantics can be added to any class by implementing a move constructor and a move assignment operator. Both should be marked as noexcept, because they should not throw exceptions. Consult the “Move Semantics” section in Chapter 10 for details on how to add move semantics to your classes.
LAMBDA EXPRESSIONS
Lambda expressions allow you to write anonymous functions inline, removing the need to write a separate function or a function object. Lambda expressions can make code easier to read and understand.
Syntax
Let’s start with a very simple lambda expression. The following example defines a lambda expression that just writes a string to the console. A lambda expression starts with square brackets [], followed by curly braces, {}, which contain the body of the lambda expression. The lambda expression is assigned to the basicLambda auto-typed variable. The second line executes the lambda expression using normal function call syntax.
auto basicLambda = []{ cout << "Hello from Lambda" << endl; };
basicLambda();
The output is as follows:
Hello from Lambda
A lambda expression can accept a parameter. Parameters are specified between parentheses and separated by commas, just as with normal functions. Here is an example using one parameter:
auto parametersLambda =
[](int value){ cout << "The value is " << value << endl; };
parametersLambda(42);
If a lambda expression does not accept any parameters, you can either specify empty parentheses or simply omit them.
A lambda expression can return a value. The return type is specified following an arrow, called a trailing return type. The following example defines a lambda expression accepting two parameters and returning the sum:
auto returningLambda = [](int a, int b) -> int { return a + b; };
int sum = returningLambda(11, 22);
The return type can be omitted even if the lambda expression does return something. If the return type is omitted, the compiler deduces the return type of the lambda expression according to the same rules as for function return type deduction (see Chapter 1). In the previous example, the return type can be omitted as follows:
auto returningLambda = [](int a, int b){ return a + b; };
int sum = returningLambda(11, 22);
A lambda expression can capture variables from its enclosing scope. For example, the following lambda expression captures the variable data so that it can be used in its body.
double data = 1.23;
auto capturingLambda = [data]{ cout << "Data = " << data << endl; };
The square brackets part is called the lambda capture block. It allows you to specify how you want to capture variables from the enclosing scope. Capturing a variable means that the variable becomes available inside the body of the lambda expression. Specifying an empty capture block, [], means that no variables from the enclosing scope are captured. When you just write the name of a variable in the capture block as in the preceding example, then you are capturing that variable by value.
The compiler transforms a lambda expression into some kind of functor. Chapter 14 explains what a functor is. The captured variables become data members of this functor. Variables captured by value are copied into data members of the functor. These data members have the same constness as the captured variables. In the preceding capturingLambda example, the functor gets a non-const data member called data, because the captured variable, data, is non-const. However, in the following example, the functor gets a constdata member called data, because the captured variable is const.
const double data = 1.23;
auto capturingLambda = [data]{ cout << "Data = " << data << endl; };
A functor always has an implementation of the function call operator. For a lambda expression, this function call operator is marked as const by default. That means that even if you capture a non-const variable by value in a lambda expression, the lambda expression will not be able to modify the copy. You can mark the function call operator as non-const by specifying the lambda expression as mutable as follows:
double data = 1.23;
auto capturingLambda =
[data] () mutable { data *= 2; cout << "Data = " << data << endl; };
In this example, the non-const variable data is captured by value, thus the functor gets a non-const data member that is a copy of data. Because of the mutable keyword, the function call operator is marked as non-const, thus the body of the lambda expression can modify its copy of data. Note that if you specify mutable, then you have to specify the parentheses for the parameters even if they are empty.
You can prefix the name of a variable with & to capture it by reference. The following example captures the variable data by reference so that the lambda expression can directly change data in the enclosing scope:
double data = 1.23;
auto capturingLambda = [&data]{ data *= 2; };
When you capture a variable by reference, you have to make sure that the reference is still valid at the time the lambda expression is executed.
There are two ways to capture all variables from the enclosing scope:
· [=] captures all variables by value
· [&] captures all variables by reference
 It is also possible to selectively decide which variables to capture and how, by specifying a capture list with an optional capture default. Variables prefixed with & are captured by reference. Variables without a prefix are captured by value. The capture default should be the first element in the capture list and be either & or =. Here are some capture block examples:
It is also possible to selectively decide which variables to capture and how, by specifying a capture list with an optional capture default. Variables prefixed with & are captured by reference. Variables without a prefix are captured by value. The capture default should be the first element in the capture list and be either & or =. Here are some capture block examples:
· [&x] captures only x by reference and nothing else.
· [x] captures only x by value and nothing else.
· [=, &x, &y] captures by value by default, except variables x and y, which are captured by reference.
· [&, x] captures by reference by default, except variable x, which is captured by value.
· [&x, &x] is illegal because identifiers cannot be repeated.
· [this] captures the surrounding object. In the body of the lambda expression you can access this object, even without using this->.
WARNING It is not recommended to capture all variables from the enclosing scope with [=], [&], or with a capture default, even though it is possible. Instead, you should selectively capture only what’s needed.
Full Syntax
The complete syntax of a lambda expression is as follows:
[capture_block](parameters) mutable exception_specification attribute_specifier
-> return_type {body}
A lambda expression contains the following parts:
· Capture block: specifies how variables from the enclosing scope are captured and made available in the body of the lambda.
· Parameters: (optional) a list of parameters for the lambda expression. You can omit this list only if you do not need any parameters and you do not specify mutable, an exception specification, attribute specifier, or a return type. The parameter list is similar to the parameter list for normal functions.
· Mutable: (optional) marks the lambda expression as mutable; see previous section.
· exception_specification: (optional) can be used to specify which exceptions the body of the lambda expression can throw.
· attribute_specifier: (optional) can be used to specify attributes for the lambda expression. Attributes are explained in Chapter 10.
· return_type: (optional) the type of the returned value. If this is omitted, the compiler deduces the return type according to the same rules as for function return type deduction; see Chapter 1.
Generic Lambda Expressions
Starting with C++14 it is possible to use auto type deduction for parameters of lambda expressions instead of explicitly specifying concrete types for them. To specify auto type deduction for a parameter, the type is simply specified as auto. The type deduction rules are the same as those for template argument deduction.
The following example defines a generic lambda expression called isGreaterThan100. This single lambda expression is used with the find_if() algorithm, once for a vector of integers and once for a vector of doubles.
vector<int> ints{ 11, 55, 101, 200 };
vector<double> doubles{ 11.1, 55.5, 200.2 };
// Define a generic lambda to find values > 100.
auto isGreaterThan100 = [](auto i){ return i > 100; };
// Use the generic lambda with the vector of integers.
auto it1 = find_if(cbegin(ints), cend(ints), isGreaterThan100);
if (it1 != cend(ints)) {
cout << "Found a value > 100: " << *it1 << endl;
}
// Use exactly the same generic lambda with the vector of doubles.
auto it2 = find_if(cbegin(doubles), cend(doubles), isGreaterThan100);
if (it2 != cend(doubles)) {
cout << "Found a value > 100: " << *it2 << endl;
}
Lambda Capture Expressions
C++14 adds support for lambda capture expressions to initialize capture variables with any kind of expression. It can be used to introduce variables in the lambda expression that are not at all captured from the enclosing scope. For example, the following code creates a lambda expression. Inside this lambda expression there are two variables available; one called myCapture, initialized to the string “Pi:” using a lambda capture expression, and one called pi, which is captured by value from the enclosing scope. Note that non-reference capture variables such as myCapture that are initialized with a capture initializer are copy constructed, which means that const qualifiers are stripped.
double pi = 3.1415;
auto myLambda = [myCapture = "Pi: ", pi]{ std::cout << myCapture << pi; };
A lambda capture variable can be initialized with any kind of expression, and also with std::move(). This is important for objects that cannot be copied, only moved; for example, unique_ptr. By default, capturing by value uses copy semantics, so it’s impossible to capture a unique_ptr by value in a lambda expression. Using a lambda capture expression, it is possible to capture it by moving. For example:
auto myPtr = std::make_unique<double>(3.1415);
auto myLambda = [p = std::move(myPtr)]{ std::cout << *p; };
It’s allowed to have the same name for the capture variable as the name in the enclosing scope. The previous example can be written as follows:
auto myPtr = std::make_unique<double>(3.1415);
auto myLambda = [myPtr = std::move(myPtr)]{ std::cout << *myPtr; };
Lambda Expressions as Return Type
std::function defined in the <functional> header file is a polymorphic function wrapper and is similar to a function pointer. It can be bound to anything that can be called (functors, member function pointers, function pointers, and lambdas) as long as the arguments and return type are compatible with those of the wrapper. A wrapper for a function that returns a double and takes two integers as parameters can be defined as follows:
function<double(int, int)> myWrapper;
By using std::function, lambda expressions can be given a name and can be returned from functions. Take a look at the following definition:
function<int(void)> multiplyBy2Lambda(int x)
{
return [x]{ return 2*x; };
}
The body of this function creates a lambda expression that captures the variable x from the enclosing scope by value and returns an integer that is two times the value passed to multiplyBy2Lambda(). The return type of the multiplyBy2Lambda() function isfunction<int(void)>, which is a function accepting no arguments and returning an integer. The lambda expression defined in the body of the function exactly matches this prototype. The variable x is captured by value and thus a copy of the value of x is bound to the xin the lambda expression before the lambda is returned from the function.
C++14 supports function return type deduction (see Chapter 1), which allows you to write the multiplyBy2Lambda() function as follows:
auto multiplyBy2Lambda(int x)
{
return [x]{ return 2 * x; };
}
The function can be called as follows:
function<int(void)> fn = multiplyBy2Lambda(5);
cout << fn() << endl;
You can use the auto keyword to make this much easier:
auto fn = multiplyBy2Lambda(5);
cout << fn() << endl;
The output will be 10.
The multiplyBy2Lambda() example captures the variable x by value, [x]. Suppose the function is rewritten to capture the variable by reference, [&x], as follows. This will not work because the lambda expression will be executed later in the program, not anymore in the scope of the multiplyBy2Lambda() function at which point the reference to x is not valid anymore:
function<int(void)> multiplyBy2Lambda(int x)
{
return [&x]{ return 2*x; }; // BUG!
}
Lambda Expressions as Parameters
You can write your own functions that accept lambda expressions as parameters. This can, for example, be used to implement callbacks. The following code implements a testCallback() function that accepts a vector of integers and a callback function. The implementation iterates over all the elements in the given vector and calls the callback function for each element. The callback function accepts the current element from the vector as an int argument and returns a Boolean. If the callback returns false, the iteration is stopped.
void testCallback(const vector<int>& vec,
const function<bool(int)>& callback)
{
for (const auto& i : vec) {
// Call callback. If it returns false, stop iteration.
if (!callback(i)) {
break;
}
// Callback did not stop iteration, so print value
cout << i << " ";
}
cout << endl;
}
The testCallback() function can be tested as follows. First, a vector with 10 elements is created. Then the testCallback() function is called with a small lambda expression as a callback function. This lambda expression returns true for values that are less than 6.
vector<int> vec{ 1, 2, 3, 4, 5, 6, 7, 8, 9, 10 };
testCallback(vec, [](int i){return i < 6;});
The output of this example is:
1 2 3 4 5
Examples with STL Algorithms
This section demonstrates lambda expressions with two STL algorithms. More examples follow later in this chapter.
count_if
The following example uses the count_if() algorithm to count the number of elements in the given vector that satisfy a certain condition. The condition is given in the form of a lambda expression, which captures the value variable from its enclosing scope by value.
vector<int> vec{ 1, 2, 3, 4, 5, 6, 7, 8, 9 };
int value = 3;
int cnt = count_if(cbegin(vec), cend(vec),
[value](int i){ return i > value; });
cout << "Found " << cnt << " values > " << value << endl;
The output is as follows:
Found 6 values > 3
The example can be extended to demonstrate capturing variables by reference. The following lambda expression counts the number of times it is called by incrementing a variable in the enclosing scope that is captured by reference:
vector<int> vec = { 1, 2, 3, 4, 5, 6, 7, 8, 9 };
int value = 3;
int cntLambdaCalled = 0;
int cnt = count_if(cbegin(vec), cend(vec),
[value, &cntLambdaCalled](int i){ ++cntLambdaCalled; return i > value; });
cout << "The lambda expression was called " << cntLambdaCalled
<< " times." << endl;
cout << "Found " << cnt << " values > " << value << endl;
The output is as follows:
The lambda expression was called 9 times.
Found 6 values > 3
generate
The generate() algorithm requires an iterator range and replaces the values in that range with the values returned from the function given as a third argument. The following example uses the generate() algorithm together with a lambda expression to put the numbers 2, 4, 8, 16, and so on in the vector:
vector<int> vec(10);
int value = 1;
generate(begin(vec), end(vec), [&value]{ value *= 2; return value; });
for (const auto& i : vec) {
cout << i << " ";
}
The output is as follows:
2 4 8 16 32 64 128 256 512 1024
FUNCTION OBJECTS
You can overload the function call operator in a class such that objects of the class can be used in place of function pointers. These objects are called function objects, or just functors.
Many of the STL algorithms, such as find_if() and a version of accumulate(), require a function pointer as one of the parameters. When you use these functions, you can pass a functor instead of a lambda expression or function pointer. C++ provides several predefined functor classes, defined in the <functional> header file, that perform the most commonly used callback operations.
Functor classes often consist of simple one-line expressions. The clumsiness of having to create a function or functor class, give it a name that does not conflict with other names, and then use this name is considerable overhead for what is fundamentally a simple concept. In these cases, using anonymous (unnamed) functions represented by lambda expressions is a big convenience. Their syntax is easier and can make your code easier to understand. They are discussed in the previous sections. However, this section explains functors and how to use the predefined functor classes because you will likely encounter them at some point.
NOTE It is recommended to use lambda expressions, if possible, instead of function objects because lambdas are easier to use and easier to understand.
Arithmetic Function Objects
C++ provides functor class templates for the five binary arithmetic operators: plus, minus, multiplies, divides, and modulus. Additionally, unary negate is supplied. These classes are templatized on the type of the operands and are wrappers for the actual operators. They take one or two parameters of the template type, perform the operation, and return the result. Here is an example using the plus class template:
plus<int> myPlus;
int res = myPlus(4, 5);
cout << res << endl;
This example is silly, because there’s no reason to use the plus class template when you could just use operator+ directly. The benefit of the arithmetic function objects is that you can pass them as callbacks to algorithms, which you cannot do directly with the arithmetic operators. For example, the implementation of the geometricMean() function earlier in this chapter used the accumulate() function with a function pointer to the product() callback to multiply two integers. You could rewrite it to use the predefined multipliesfunction object:
double geometricMean(const vector<int>& nums)
{
double mult = accumulate(cbegin(nums), cend(nums), 1, multiplies<int>());
return pow(mult, 1.0 / nums.size());
}
The expression multiplies<int>() creates a new object of the multiplies functor template class, instantiating it with the int type.
The other arithmetic function objects behave similarly.
WARNING The arithmetic function objects are just wrappers around the arithmetic operators. If you use the function objects as callbacks in algorithms, make sure that the objects in your container implement the appropriate operation, such asoperator* or operator+.
Transparent Operator Functors
C++14 adds support for transparent operator functors, which allow you to omit the template type argument. For example, you can just specify multiplies<>() instead of multiplies<int>():
double geometricMeanTransparent(const vector<int>& nums)
{
double mult = accumulate(cbegin(nums), cend(nums), 1, multiplies<>());
return pow(mult, 1.0 / nums.size());
}
A very important feature of these transparent operators is that they are heterogeneous. That is, they are not only more concise than the non-transparent functors, but they also have real functional advantages. For instance, the following code uses the transparent operator functor and uses 1.1, a double, as the initial value, while the vector contains integers. accumulate() will calculate the result as a double and result will be 6.6:
vector<int> nums{ 1, 2, 3 };
double result = accumulate(cbegin(nums), cend(nums), 1.1, multiplies<>());
If this code uses a non-transparent operator functor as follows, then accumulate() will calculate the result as an integer, and result will be 6. When you compile this code, the compiler will give you warnings about possible loss of data.
vector<int> nums{ 1, 2, 3 };
double result = accumulate(cbegin(nums), cend(nums), 1.1, multiplies<int>());
NOTE It’s recommended to always use the transparent operator functors.
Comparison Function Objects
In addition to the arithmetic function object classes, the C++ language provides all the standard comparisons: equal_to, not_equal_to, less, greater, less_equal, and greater_equal. You’ve already seen less in Chapter 16 as the default comparison for elements in thepriority_queue and the associative containers. Now you can learn how to change that criterion. Here’s an example of a priority_queue using the default comparison operator: less.
priority_queue<int> myQueue;
myQueue.push(3);
myQueue.push(4);
myQueue.push(2);
myQueue.push(1);
while (!myQueue.empty()) {
cout << myQueue.top() << " ";
myQueue.pop();
}
The output from the program is:
4 3 2 1
As you can see, the elements of the queue are removed in descending order, according to the less comparison. You can change the comparison to greater by specifying it as the comparison template argument. The priority_queue template definition looks like this:
template <class T, class Container = vector<T>, class Compare = less<T> >;
Unfortunately, the Compare type parameter is last, which means that in order to specify it you must also specify the container. If you want to use a priority_queue that sorts the elements in ascending order using greater, then you need to change the definition of thepriority_queue in the previous example to the following:
priority_queue<int, vector<int>, greater<>> myQueue;
The output now is as follows:
1 2 3 4
If your compiler does not yet support the transparent operator functors, then you need this definition:
priority_queue<int, vector<int>, greater<int>> myQueue;
Several algorithms that you learn about later in this chapter require comparison callbacks, for which the predefined comparators come in handy.
Logical Function Objects
C++ provides function object classes for the three logical operations: logical_not (operator!), logical_and (operator&&), and logical_or (operator||). These logical operations deal only with values true and false. Bitwise function objects are covered in the next section.
Logical functors can, for example, be used to implement an allTrue() function that checks if all the Boolean flags in a container are true:
bool allTrue(const vector<bool>& flags)
{
return accumulate(begin(flags), end(flags), true, logical_and<>());
}
Similarly, the logical_or functor can be used to implement an anyTrue() function that returns true if there is at least one Boolean flag in a container true:
bool anyTrue(const vector<bool>& flags)
{
return accumulate(begin(flags), end(flags), false, logical_or<>());
}
If your compiler does not yet support the transparent operator functors then you need to use logical_and<bool> and logical_or<bool> in the previous functions.
Bitwise Function Objects
C++ has function objects for all the bitwise operations: bit_and (operator&), bit_or (operator|), and bit_xor (operator^). C++14 adds bit_not (operator~). These bitwise functors can, for example, be used together with the transform() algorithm (discussed later in this chapter) to perform bitwise operations on all elements in a container.
Function Object Adapters
When you try to use the basic function objects provided by the standard, it often feels as if you’re trying to put a square peg into a round hole. For example, you can’t use the less function object with find_if() to find an element smaller than some value becausefind_if() passes only one argument to its callback each time instead of two. The function adapters attempt to rectify this problem and others. They provide a modicum of support for functional composition, or combining functions together to create the exact behavior you need.
Binders
Binders can be used to bind parameters of functions to certain values. For this you use std::bind(), defined in <functional>, which allows you to bind arguments of a function in a flexible way. You can bind function arguments to fixed values and you can even rearrange function arguments in a different order. It is best explained with an example.
Suppose you have a function called func() accepting two arguments:
void func(int num, const string& str)
{
cout << "func(" << num << ", " << str << ")" << endl;
}
The following code demonstrates how you can use bind() to bind the second argument of func() to a fixed value, myString. The result is stored in f1(). The auto keyword is used to remove the need to specify the exact return type, which can become complicated. Arguments that are not bound to specific values should be specified as _1, _2, _3, and so on. These are defined in the std::placeholders namespace. In the definition of f1(), the _1 specifies where the first argument to f1() needs to go when func() is called. After this,f1() can be called with just a single integer argument.
string myString = "abc";
auto f1 = bind(func, placeholders::_1, myString);
f1(16);
The output is:
func(16, abc)
bind() can also be used to rearrange the arguments, as shown in the following code. The _2 specifies where the second argument to f2() needs to go when func() is called. In other words, the f2() binding means that the first argument to f2() will become the second argument to func(), and the second argument to f2() will become the first argument to func().
auto f2 = bind(func, placeholders::_2, placeholders::_1);
f2("Test", 32);
The output is as follows:
func(32, Test)
The <functional> header defines the std::ref() and std::cref() helper functions. These can be used to bind references or const references, respectively. For example, suppose you have the following function:
void increment(int& value) { ++value; }
If you call this function as follows, then the value of index becomes 1:
int index = 0;
increment(index);
If you use bind() to call it as follows, then the value of index is not increment because a copy of index is made and a reference to this copy is binded to the first parameter of the increment() function:
int index = 0;
auto incr = bind(increment, index);
incr();
Using std::ref() to pass a proper reference correctly increments index:
int index = 0;
auto incr = bind(increment, ref(index));
incr();
There is a small issue with binding parameters in combination with overloaded functions. Suppose you have the following two overloaded functions called overloaded(). One accepts an integer and the other accepts a floating point number:
void overloaded(int num) {}
void overloaded(float f) {}
If you want to use bind() with these overloaded functions, you need to explicitly specify which of the two overloads you want to bind. The following will not compile:
auto f3 = bind(overloaded, placeholders::_1); // ERROR
If you want to bind the parameters of the overloaded function accepting a floating point argument, you need the following syntax:
auto f4 = bind((void(*)(float))overloaded, placeholders::_1); // OK
Another example of bind() is to use the find_if() algorithm to find the first element in a sequence that is greater than or equal to 100. To solve this problem earlier in this chapter, a pointer to a perfectScore() function is passed to find_if(). This can be rewritten using the comparison functor greater_equal and bind(). The following code uses bind() to bind the second parameter of greater_equal to a fixed value of 100:
// Code for inputting scores into the vector omitted, similar as earlier.
auto endIter = end(myVector);
auto it = find_if(begin(myVector), endIter,
bind(greater_equal<>(), placeholders::_1, 100));
if (it == endIter) {
cout << "No perfect scores" << endl;
} else {
cout << "Found a \"perfect\" score of " << *it << endl;
}
WARNING Before C++11 there was bind2nd() and bind1st(). Both have been deprecated by C++11. Use lambda expressions or bind() instead.
Negators
The negators are functions similar to the binders but they complement the result of a predicate. For example, if you want to find the first element in a sequence of test scores less than 100, you could apply the not1() negator adapter to the result of perfectScore() like this:
// Code for inputting scores into the vector omitted, similar as earlier.
auto endIter = end(myVector);
function<bool(int)> f = perfectScore;
auto it = find_if(begin(myVector), endIter, not1(f));
if (it == endIter) {
cout << "All perfect scores" << endl;
} else {
cout << "Found a \"less-than-perfect\" score of " << *it << endl;
}
Note that in this example you could have used the find_if_not() algorithm. The function not1() complements the result of every call to the predicate it takes as an argument. The “1” in not1() refers to the fact that its operand must be a unary function (one that takes a single argument). If its operand is a binary function (takes two arguments), you must use not2() instead.
As you can see, using functors and adapters can become complicated. My advice is to use lambda expressions instead of functors if possible. For example, the previous find_if() call using the not1() negator can be written more elegantly using a lambda expression:
auto it = find_if(begin(myVector), endIter, [](int i){ return i < 100; });
Calling Member Functions
If you have a container of objects, you sometimes want to pass a pointer to a class method as the callback to an algorithm. For example, you might want to find the first empty string in a vector of strings by calling empty() on each string in the sequence. However, if you just pass a pointer to string::empty() to find_if(), the algorithm has no way to know that it received a pointer to a method instead of a normal function pointer or functor. The code to call a method pointer is different from that to call a normal function pointer, because the former must be called in the context of an object.
C++ provides a conversion function called mem_fn() that you can call on a method pointer before passing it to an algorithm. The following example demonstrates this. Note that you have to specify the method pointer as &string::empty. The &string:: part is not optional.
void findEmptyString(const vector<string>& strings)
{
auto endIter = end(strings);
auto it = find_if(begin(strings), endIter, mem_fn(&string::empty));
if (it == endIter) {
cout << "No empty strings!" << endl;
} else {
cout << "Empty string at position: "
<< static_cast<int>(it - begin(strings)) << endl;
}
}
mem_fn() generates a function object that serves as the callback for find_if(). Each time it is called back, it calls the empty() method on its argument.
mem_fn() works exactly the same when you have a container of pointers to objects instead of objects themselves. For example:
void findEmptyString(const vector<string*>& strings)
{
auto endIter = end(strings);
auto it = find_if(begin(strings), endIter, mem_fn(&string::empty));
// Remainder of function omitted because it is the same as earlier
}
mem_fn() is not the most intuitive way to implement the findEmptyString() function. Using lambda expressions, it can be implemented in a much more readable and elegant way. Here is the implementation using a lambda expression working on a container of objects:
void findEmptyString(const vector<string>& strings)
{
auto endIter = end(strings);
auto it = find_if(begin(strings), endIter,
[](const string& str){ return str.empty(); });
// Remainder of function omitted because it is the same as earlier
}
Similarly, the following uses a lambda expression working on a container of pointers to objects:
void findEmptyString(const vector<string*>& strings)
{
auto endIter = end(strings);
auto it = find_if(begin(strings), endIter,
[](const string* str){ return str->empty(); });
// Remainder of function omitted because it is the same as earlier
}
Writing Your Own Function Objects
You can write your own function objects to perform more specific tasks than those provided by the predefined functors and if you need to do something more complex than suitable for lambda expressions. If you want to be able to use the function adapters with these custom functors, you must supply certain typedefs. The easiest way to do that is to derive your function object classes from either unary_function or binary_function, depending on whether they take one or two arguments. These two classes, defined in <functional>, are templatized on the parameter and return types of the “function” they provide. For example:
class myIsDigit : public unary_function<char, bool>
{
public:
bool operator() (char c) const { return ::isdigit(c) != 0; }
};
bool isNumber(const string& str)
{
auto endIter = end(str);
auto it = find_if(begin(str), endIter, not1(myIsDigit()));
return (it == endIter);
}
Note that the overloaded function call operator of the myIsDigit class must be const in order to pass objects of it to find_if().
WARNING The algorithms are allowed to make multiple copies of function object predicates and call different ones for different elements. The function call operator needs to be const; thus, you cannot write functors such that they count on any internal state to the object being consistent between calls.
Before C++11, a class defined locally in the scope of a function could not be used as a template argument. This limitation has been removed. The following example demonstrates this:
bool isNumber(const string& str)
{
class myIsDigit : public unary_function<char, bool>
{
public:
bool operator() (char c) const { return ::isdigit(c) != 0; }
};
auto endIter = end(str);
auto it = find_if(begin(str), endIter, not1(myIsDigit()));
return (it == endIter);
}
NOTE As you can see from previous examples, lambda expressions allow you to write more readable and more elegant code. I recommend you use simple lambda expressions instead of function objects, and use function objects only when they need to do more complicated things.
ALGORITHM DETAILS
Chapter 15 lists all available STL algorithms, divided into different categories. Most of the algorithms are defined in the <algorithm> header file, but a few are located in <numeric> and in <utility>. They are all in the std namespace. This chapter cannot discuss all available algorithms, so it picks a number of categories and provides examples of those. Once you know how to use these, you should have no problems with the other algorithms. Consult a Standard Library Reference — for example http://www.cppreference.com/ orhttp://www.cplusplus.com/reference/ — for a full reference of all the algorithms.
Iterators
First, a few more words on iterators. There are five types of iterators: input, output, forward, bidirectional, and random-access. These are described in Chapter 16. There is no formal class hierarchy of these iterators, because the implementations for each container are not part of the standard hierarchy. However, one can deduce a hierarchy based on the functionality they are required to provide. Specifically, every random access iterator is also bidirectional, every bidirectional iterator is also forward, and every forward iterator is also input and output. Figure 17-1 shows such hierarchy. Dotted lines are used because the figure is not a real class hierarchy.
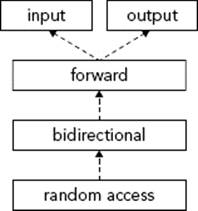
FIGURE 17-1
The standard way for the algorithms to specify what kind of iterators they need is to use the following names for the iterator template arguments: InputIterator, OutputIterator, ForwardIterator, BidirectionalIterator, and RandomAccessIterator. These names are just names: They don’t provide binding type checking. Therefore, you could, for example, try to call an algorithm expecting a RandomAccessIterator by passing a bidirectional iterator. The template doesn’t do type checking, so it would allow this instantiation. However, the code in the function that uses the random-access iterator capabilities would fail to compile on the bidirectional iterator. Thus, the requirement is enforced, just not where you would expect. The error message can therefore be somewhat confusing. For example, attempting to use the generic sort() algorithm, which requires a random-access iterator, on a list, which provides only a bidirectional iterator, gives a cryptic error of 32 lines in Visual C++ 2013, of which the first two lines are:
...\vc\include\algorithm(3157): error C2784: 'unknown-type std::operator -(std::move_iterator<_RanIt> &,const std::move_iterator<_RanIt2> &)' : could not deduce template argument for 'std::move_iterator<_RanIt> &' from 'std::_List_iterator<std::_List_val<std::_List_simple_types<int>>>'
...\vc\include\xutility(1969) : see declaration of 'std::operator -'
Non-Modifying Sequence Algorithms
The non-modifying sequence algorithms include functions for searching elements in a range, comparing two ranges to each other, and includes a number of utility algorithms.
Search Algorithms
You’ve already seen two examples of using search algorithms: find() and find_if(). The STL provides several other variations of the basic find() algorithm that work on sequences of elements. The section “Search Algorithms” in Chapter 15 describes the different search algorithms that are available, including their complexity.
All the algorithms use default comparisons of operator== or operator<, but also provide overloaded versions that allow you to specify a comparison callback.
Here are examples of some of the search algorithms:
// The list of elements to be searched
vector<int> myVector = { 5, 6, 9, 8, 8, 3 };
auto beginIter = cbegin(myVector);
auto endIter = cend(myVector);
// Find the first element that does not satisfy the given lambda expression
auto it = find_if_not(beginIter, endIter, [](int i){ return i < 8; });
if (it != endIter) {
cout << "First element not < 8 is " << *it << endl;
}
// Find the min and max elements in the vector
auto res = minmax_element(beginIter, endIter);
cout << "min is " << *(res.first) << " and max is " << *(res.second) << endl;
// Find the min and max elements in the vector
it = min_element(beginIter, endIter);
auto it2 = max_element(beginIter, endIter);
cout << "min is " << *it << " and max is " << *it2 << endl;
// Find the first pair of matching consecutive elements
it = adjacent_find(beginIter, endIter);
if (it != endIter) {
cout << "Found two consecutive equal elements with value " << *it << endl;
}
// Find the first of two values
vector<int> targets = { 8, 9 };
it = find_first_of(beginIter, endIter, cbegin(targets), cend(targets));
if (it != endIter) {
cout << "Found one of 8 or 9: " << *it << endl;
}
// Find the first subsequence
vector<int> sub = { 8, 3 };
it = search(beginIter, endIter, cbegin(sub), cend(sub));
if (it != endIter) {
cout << "Found subsequence {8,3}" << endl;
} else {
cout << "Unable to find subsequence {8,3}" << endl;
}
// Find the last subsequence (which is the same as the first in this example)
it2 = find_end(beginIter, endIter, cbegin(sub), cend(sub));
if (it != it2) {
cout << "Error: search and find_end found different subsequences "
<< "even though there is only one match." << endl;
}
// Find the first subsequence of two consecutive 8s
it = search_n(beginIter, endIter, 2, 8);
if (it != endIter) {
cout << "Found two consecutive 8s" << endl;
} else {
cout << "Unable to find two consecutive 8s" << endl;
}
Here is the output:
First element not < 8 is 9
min is 3 and max is 9
min is 3 and max is 9
Found two consecutive equal elements with value 8
Found one of 8 or 9: 9
Found subsequence {8,3}
Found two consecutive 8s
NOTE Remember that some of the containers have equivalent methods. If that’s the case, it’s recommended to use the methods instead of the generic algorithms, because the methods are more efficient.
Comparison Algorithms
You can compare entire ranges of elements in three different ways: equal(), mismatch(), and lexicographical_compare(). These algorithms have the advantage that you can compare ranges in different containers. For example, you can compare the contents of a vectorwith the contents of a list. In general, these work best with sequential containers. They work by comparing the values in corresponding positions of the two collections to each other.
· equal() returns true if all corresponding elements are equal. It requires both containers to have the same number of elements.
· mismatch() returns iterators, one iterator for each of the collections, to indicate where in the range the corresponding elements mismatched.
· lexicographical_compare() deals with the situation where the two ranges may contain different numbers of elements. It returns true if the first unequal element in the first range is less than its corresponding element in the second range, or, if the first range has fewer elements than the second and all elements in the first range are equal to their corresponding initial subsequence in the second set. “lexicographical_compare” gets its name because it resembles the rules for comparing strings, but extends this set of rules to deal with objects of any type.
NOTE If you want to compare the elements of two containers of the same type, you can use operator== or operator< instead of equal() or lexicographical_compare(). The algorithms are useful primarily for comparing sequences of elements from different container types.
Here are some examples of these algorithms:
// Function template to populate a container of ints.
// The container must support push_back().
template<typename Container>
void populateContainer(Container& cont)
{
int num;
while (true) {
cout << "Enter a number (0 to quit): ";
cin >> num;
if (num == 0) {
break;
}
cont.push_back(num);
}
}
int main()
{
vector<int> myVector;
list<int> myList;
cout << "Populate the vector:" << endl;
populateContainer(myVector);
cout << "Populate the list:" << endl;
populateContainer(myList);
// compare the two containers
if (myList.size() == myVector.size() &&
equal(cbegin(myVector), cend(myVector), cbegin(myList))) {
cout << "The two containers have equal elements" << endl;
} else {
if (myList.size() < myVector.size()) {
cout << "Sorry, the list is not long enough." << endl;
return 1;
} else {
// If the containers were not equal, find out why not
auto miss = mismatch(cbegin(myVector), cend(myVector),
cbegin(myList));
cout << "The following initial elements are the same in "
<< "the vector and the list:" << endl;
for (auto i = cbegin(myVector); i != miss.first; ++i) {
cout << *i << '\t';
}
cout << endl;
}
}
// Now order them.
if (lexicographical_compare(cbegin(myVector), cend(myVector),
cbegin(myList), cend(myList))) {
cout << "The vector is lexicographically first." << endl;
} else {
cout << "The list is lexicographically first." << endl;
}
return 0;
}
Here is a sample run of the program:
Populate the vector:
Enter a number (0 to quit): 5
Enter a number (0 to quit): 6
Enter a number (0 to quit): 7
Enter a number (0 to quit): 0
Populate the list:
Enter a number (0 to quit): 5
Enter a number (0 to quit): 6
Enter a number (0 to quit): 9
Enter a number (0 to quit): 8
Enter a number (0 to quit): 0
The following initial elements are the same in the vector and the list:
5 6
The vector is lexicographically first.
C++14 adds a version of equal() and mismatch() accepting four iterators: begin and end iterators for the first container, and begin and end iterators for the second container. Using these versions of equal() and mismatch() the tests in the previous example to check whether the size of myList is equal to or less than the size of myVector are not needed anymore:
if (equal(cbegin(myVector), cend(myVector), cbegin(myList), cend(myList))) {
cout << "The two containers have equal elements" << endl;
} else {
// If the containers were not equal, find out why not
auto miss = mismatch(cbegin(myVector), cend(myVector),
cbegin(myList), cend(myList));
cout << "The following initial elements are the same in "
<< "the vector and the list:" << endl;
for (auto i = cbegin(myVector); i != miss.first; ++i) {
cout << *i << '\t';
}
cout << endl;
}
Utility Algorithms
The non-modifying utility algorithms are: all_of(), any_of(), none_of(), count(), and count_if(). Here are examples of the first three algorithms. An example of count_if() is given earlier in this chapter.
// all_of()
vector<int> vec2 = { 1, 1, 1, 1 };
if (all_of(cbegin(vec2), cend(vec2), [](int i){ return i == 1; })) {
cout << "All elements are == 1" << endl;
} else {
cout << "Not all elements are == 1" << endl;
}
// any_of()
vector<int> vec3 = { 0, 0, 1, 0 };
if (any_of(cbegin(vec3), cend(vec3), [](int i){ return i == 1; })) {
cout << "At least one element == 1" << endl;
} else {
cout << "No elements are == 1" << endl;
}
// none_of()
vector<int> vec4 = { 0, 0, 0, 0 };
if (none_of(cbegin(vec4), cend(vec4), [](int i){ return i == 1; })) {
cout << "All elements are != 1" << endl;
} else {
cout << "Some elements are == 1" << endl;
}
The output is as follows:
All elements are == 1
At least one element == 1
All elements are != 1
Modifying Sequence Algorithms
The STL provides a variety of modifying sequence algorithms that perform tasks such as copying elements from one range to another, removing elements, or reversing the order of elements in a range.
The modifying algorithms all have the concept of source and destination ranges. The elements are read from the source range and added to or modified in the destination range. The source and destination ranges can often be the same, in which case the algorithm is said to operate in place.
WARNING Ranges from maps and multimaps cannot be used as destinations of modifying algorithms. These algorithms overwrite entire elements, which in a map consist of key/value pairs. However, maps and multimaps mark the key const, so it cannot be assigned to. The same holds for set and multiset. Your alternative is to use an insert iterator, described in Chapter 20.
The section “Modifying Sequence Algorithms” in Chapter 15 lists all available modifying algorithms with a description. This section provides code examples for a number of those algorithms. If you understand how to use the algorithms explained in this section, you should have no problems using the other algorithms for which no examples are given.
transform
The transform() algorithm applies a callback to each element in a range and expects the callback to generate a new element, which it stores in the destination range specified. The source and destination ranges can be the same if you want transform() to replace each element in a range with the result from the call to the callback. The parameters are a begin and end iterator of the source sequence, a begin iterator of the destination sequence, and the callback. For example, you could add 100 to each element in a vector like this:
vector<int> myVector;
populateContainer(myVector);
cout << "The vector contents are:" << endl;
for (const auto& i : myVector) { cout << i << " "; }
cout << endl;
transform(begin(myVector), end(myVector), begin(myVector),
[](int i){ return i + 100;});
cout << "The vector contents are:" << endl;
for (const auto& i : myVector) { cout << i << " "; }
Another form of transform() calls a binary function on pairs of elements in a range. It requires a begin and end iterator of the first range, a begin iterator of the second range, and a begin iterator of the destination range. The following example creates two vectors and uses transform() to calculate the sum of pairs of elements and store the result back in the first vector:
vector<int> vec1;
cout << "Vector1:" << endl;
populateContainer(vec1);
cout << "Vector2:" << endl;
vector<int> vec2;
populateContainer(vec2);
if (vec2.size() < vec1.size())
{
cout << "Vector2 should be at least the same size as vector1." << endl;
return 1;
}
// Create a lambda to print a container
auto printContainer = [](const auto& container) {
for (auto& i : container) { cout << i << " "; }
cout << endl;
};
cout << "Vector1: "; printContainer(vec1);
cout << "Vector2: "; printContainer(vec2);
transform(begin(vec1), end(vec1), begin(vec2), begin(vec1),
[](int a, int b){return a + b;});
cout << "Vector1: "; printContainer(vec1);
cout << "Vector2: "; printContainer(vec2);
The output could look as follows:
Vector1:
Enter a number (0 to quit): 1
Enter a number (0 to quit): 2
Enter a number (0 to quit): 0
Vector2:
Enter a number (0 to quit): 11
Enter a number (0 to quit): 22
Enter a number (0 to quit): 33
Enter a number (0 to quit): 0
Vector1: 1 2
Vector2: 11 22 33
Vector1: 12 24
Vector2: 11 22 33
NOTE transform() and the other modifying algorithms often return an iterator referring to the past-the-end value of the destination range. The examples in this book usually ignore that return value.
copy
The copy() algorithm allows you to copy elements from one range to another, starting with the first element and proceeding to the last element in the range. The source and destination ranges must be different, but they can overlap. Note that copy() doesn’t insertelements into the destination range. It just overwrites whatever elements were there already. Thus, you can’t use copy() directly to insert elements into a container, only to overwrite elements that were previously in a container.
NOTE Chapter 20 describes how to use iterator adapters to insert elements into a container or stream with copy().
Here is a simple example of copy() that uses the resize() method on a vector to ensure that there is enough space in the destination container. It copies all elements from vec1 to vec2:
vector<int> vec1, vec2;
populateContainer(vec1);
vec2.resize(vec1.size());
copy(cbegin(vec1), cend(vec1), begin(vec2));
for (const auto& i : vec2) { cout << i << " "; }
There is also a copy_backward() algorithm, which copies the elements from the source backward to the destination. In other words, it starts with the last element of the source and puts it in the last position in the destination range and moves backward after each copy. The preceding example can be modified to use copy_backward() instead of copy(), as follows. Note that you need to specify end(vec2) as a third argument instead of begin(vec2):
copy_backward(cbegin(vec1), cend(vec1), end(vec2));
This results in exactly the same output.
copy_if() works by having an input range specified by two iterators, an output destination specified by one iterator, and a predicate (function or lambda expression). The function or lambda expression is executed for each element that is a candidate to be copied. If the returned value is true, the element is copied and the destination iterator is incremented; if the value is false the element is not copied and the destination iterator is not incremented. Thus, the destination may hold fewer elements than the source range. For some containers, because they must have already created space to hold the maximum possible number of elements (remember, copy does not create or extend containers, merely replaces the existing elements), it might be desirable to remove the space “beyond” where the last element was copied to. To facilitate this, copy_if() returns an iterator to the one-past-the-last-copied element in the destination range. This can be used to determine how many elements should be removed from the destination container. The following example demonstrates this by copying only the even numbers to vec2:
vector<int> vec1, vec2;
populateContainer(vec1);
vec2.resize(vec1.size());
auto endIterator = copy_if(cbegin(vec1), cend(vec1),
begin(vec2), [](int i){ return i % 2 == 0; });
vec2.erase(endIterator, end(vec2));
for (const auto& i : vec2) { cout << i << " "; }
copy_n() copies n elements from the source to the destination. The first parameter of copy_n() is the start iterator. The second parameter of copy_n() is an integer specifying the number of elements to copy and the third parameter is the destination iterator. Thecopy_n() algorithm does not perform any bounds checking, so you must make sure that the start iterator, incremented by the number of elements to copy, does not exceed the end() of the collection or your program will have undefined behavior. The following is an example:
vector<int> vec1, vec2;
populateContainer(vec1);
size_t cnt = 0;
cout << "Enter number of elements you want to copy: ";
cin >> cnt;
cnt = min(cnt, vec1.size());
vec2.resize(cnt);
copy_n(cbegin(vec1), cnt, begin(vec2));
for (const auto& i : vec2) { cout << i << " "; }
move
There are two move-related algorithms: move() and move_backward(). They both use move semantics discussed in Chapter 10. You have to provide a move assignment operator in your element classes if you want to use these algorithms on containers with elements of your own types, as demonstrated in the following example. The main() function creates a vector with three MyClass objects and then moves those elements from vecSrc to vecDst. Note that the code includes two different uses of move(). The move() function accepting a single argument converts an lvalue into an rvalue, while move() accepting three arguments is the STL move() algorithm to move elements between containers. Consult Chapter 10 for details on implementing move assignment operators and the use of the single parameter version of std::move().
class MyClass
{
public:
MyClass() = default;
MyClass(const MyClass& src) = default;
MyClass(const string& str) : mStr(str) {}
// Move assignment operator
MyClass& operator=(MyClass&& rhs) noexcept {
if (this == &rhs)
return *this;
mStr = std::move(rhs.mStr);
cout << "Move operator= (mStr=" << mStr << ")" << endl;
return *this;
}
string getString() const {return mStr;}
private:
string mStr;
};
int main()
{
vector<MyClass> vecSrc {MyClass("a"), MyClass("b"), MyClass("c")};
vector<MyClass> vecDst(vecSrc.size());
move(begin(vecSrc), end(vecSrc), begin(vecDst));
for (const auto& c : vecDst) { cout << c.getString() << " "; }
return 0;
}
The output is as follows:
Move operator= (mStr=a)
Move operator= (mStr=b)
Move operator= (mStr=c)
a b c
NOTE Chapter 10 explains that source objects in a move operation are reset because the target object takes ownership of the resources of the source object. For the previous example, this means that you should not use the elements from vecSrcanymore after the move operation.
move_backward() uses the same move mechanism as move() but it moves the elements starting from the last to the first element.
replace
The replace() and replace_if() algorithms replace elements in a range matching a value or predicate, respectively, with a new value. Take replace_if() as an example. Its first and second parameters specify the range of elements in your container. The third parameter is a function or lambda expression that returns true or false. If it returns true, the value in the container is replaced with the value given as fourth parameter; if it returns false, it leaves the original value.
For example, you might want to replace all values less than a lower limit with the value of the lower limit and replace all values greater than an upper limit with the value of the upper limit. This is called “clamping” values to a range. In audio applications, this is known as “clipping.” For example, audio signals are often limited to integers in the range of -32K to +32K. The following example demonstrates clipping by first calling replace_if() to replace all values less than -32K with -32K and then calling it a second time to replace all values greater than 32K with 32K:
vector<int> vec;
populateContainer(vec);
int low = -32768;
int up = 32767;
replace_if(begin(vec), end(vec), [low](int i){ return i < low; }, low);
replace_if(begin(vec), end(vec), [up](int i){ return i > up; }, up);
for (const auto& i : vec) { cout << i << " "; }
There are also variants of replace() called replace_copy() and replace_copy_if() that copy the results to a different destination range. They are similar to copy(), in that the destination range must already be large enough to hold the new elements.
remove
Suppose you have a range of elements and you want to remove elements matching a certain condition. The first solution that you might think of is to check the documentation to see if your container has an erase() method and then iterate over all the elements and call erase() for each element that matches the condition. The vector is an example of a container that has such an erase() method. However, if applied to the vector container, this solution is very inefficient as it will cause a lot of memory operations to keep the vectorcontiguous in memory, resulting in a quadratic complexity (see Chapter 4). This solution is also error-prone, because you need to be careful that you keep your iterators valid after a call to erase(). The correct solution for this problem is the so-called remove-erase-idiom, which runs in linear time and is explained in this section.
Algorithms have access only to the iterator abstraction, not to the container. Thus the remove algorithms cannot really remove them from the underlying container. Instead, the algorithms work by replacing the elements that match the given value or predicate with the next element that does not match the given value or predicate. The result is that the range becomes partitioned into two sets: the elements to be kept and elements to be removed. An iterator is returned that points to the first element in the range of elements to be removed. If you want to actually erase these elements from the container, you must use the remove() algorithm, then call erase() on the container to erase all the elements from the returned iterator up to the end of the range. This is the remove-erase-idiom. Here is an example of a function that removes empty strings from a vector of strings:
void removeEmptyStrings(vector<string>& strings)
{
auto it = remove_if(begin(strings), end(strings),
[](const string& str){ return str.empty(); });
// Erase the removed elements.
strings.erase(it, end(strings));
}
int main()
{
vector<string> myVector = {"", "one", "", "two", "three", "four"};
for (auto& str : myVector) { cout << "\"" << str << "\" "; }
cout << endl;
removeEmptyStrings(myVector);
for (auto& str : myVector) { cout << "\"" << str << "\" "; }
cout << endl;
return 0;
}
The output is as follows:
"" "one" "" "two" "three" "four"
"one" "two" "three" "four"
The remove_copy() and remove_copy_if() variations of remove() do not change the source range. Instead they copy all kept elements to a different destination range. They are similar to copy(), in that the destination range must already be large enough to hold the new elements.
NOTE The remove() family of functions are stable in that they maintain the order of elements remaining in the container even while moving the retained elements toward the beginning.
unique
The unique() algorithm is a special case of remove() that removes all duplicate contiguous elements. The list container provides its own unique() method that implements the same semantics. You should generally use unique() on sorted sequences, but nothing prevents you from running it on unsorted sequences.
The basic form of unique() runs in place, but there is also a version of the algorithm called unique_copy() that copies its results to a new destination range.
Chapter 16 shows an example of the list::unique() algorithm, so an example of the general form here is omitted.
reverse
The reverse() algorithm reverses the order of the elements in a range. The first element in the range is swapped with the last, the second with the second-to-last, and so on.
The basic form of reverse() runs in place and requires two arguments: a start and end iterator for the range. There is also a version of the algorithm called reverse_copy() that copies its results to a new destination range and requires three arguments: a start and end iterator for the source range and a start iterator for the destination range. The destination range must already be large enough to hold the new elements.
shuffle
shuffle() rearranges the elements of a range in a random order with a linear complexity. It’s useful for implementing tasks like shuffling a deck of cards. shuffle() requires a start and end iterator for the range that you want to shuffle and a uniform random number generator object that specifies how the random numbers should be generated. Random number generators are discussed in detail in Chapter 19.
Operational Algorithms
There is only one algorithm in this category: for_each(). It executes a callback on each element of the range. You can use it with simple function callbacks or lambda expressions for things like printing every element in a container. for_each() is mentioned here because you might encounter it in existing code; however, it’s often easier and more readable to use a simple range-based for loop instead of for_each().
Following is an example using a lambda expression, printing the elements from a map:
map<int, int> myMap = { { 4, 40 }, { 5, 50 }, { 6, 60 } };
for_each(cbegin(myMap), cend(myMap), [](const pair<int, int>& p)
{ cout << p.first << "->" << p.second << endl;});
The output is as follows:
4->40
5->50
6->60
In C++14 you can use a generic lambda expression using the auto keyword:
for_each(cbegin(myMap), cend(myMap), [](const auto& p)
{ cout << p.first << "->" << p.second << endl; });
Without lambda expressions, you have to write a separate function and pass a pointer to it to for_each().
The following example shows how to use the for_each() algorithm and a lambda expression to calculate the sum and the product of a range of elements at the same time. Note that the lambda expression explicitly captures only those variables it needs. It captures them by reference; otherwise, changes made to sum and prod in the lambda expression would not be visible outside the lambda.
vector<int> myVector;
populateContainer(myVector);
int sum = 0;
int prod = 1;
for_each(cbegin(myVector), cend(myVector),
[&sum, &prod](int i){
sum += i;
prod *= i;
});
cout << "The sum is " << sum << endl;
cout << "The product is " << prod << endl;
This example can also be written with a functor in which you accumulate information that you can retrieve after for_each() has finished processing each element. For example, you could calculate both the sum and product of elements in one pass by writing a functorSumAndProd that tracks both at the same time:
class SumAndProd : public unary_function<int, void>
{
public:
SumAndProd() : mSum(0), mProd(1) {}
void operator()(int elem);
int getSum() const { return mSum; }
int getProduct() const { return mProd; }
private:
int mSum;
int mProd;
};
void SumAndProd::operator()(int elem)
{
mSum += elem;
mProd *= elem;
}
int main()
{
vector<int> myVector;
populateContainer(myVector);
SumAndProd func;
func = for_each(cbegin(myVector), cend(myVector), func);
cout << "The sum is " << func.getSum() << endl;
cout << "The product is " << func.getProduct() << endl;
return 0;
}
You might be tempted to ignore the return value of for_each(), yet still try to read information from func after the call. However, that doesn’t work because the functor is moved into the for_each(), and at the end, it is moved back out of the for_each(). You must capture the return value in order to ensure correct behavior.
A final point about for_each() is that your lambda or callback is allowed to take its argument by reference and modify it. That has the effect of changing values in the actual iterator range. The voter registration example later in this chapter shows a use of this capability.
Partition Algorithms
partition_copy() copies elements from a source to two different destinations. The specific destination for each element is selected based on the result of a predicate, either true or false. The returned value of partition_copy() is a pair of iterators: one iterator referring to one-past-the-last-copied element in the first destination range, and one iterator referring to one-past-the-last-copied element in the second destination range. These returned iterators can be used in combination with erase() to remove excess elements from the two destination ranges, just as with the copy_if() example earlier. The following example asks the user to enter a number of integers, which are then partitioned into two destination vectors; one for the even numbers and one for the odd numbers:
vector<int> vec1, vecOdd, vecEven;
populateContainer(vec1);
vecOdd.resize(vec1.size());
vecEven.resize(vec1.size());
auto pairIters = partition_copy(cbegin(vec1), cend(vec1),
begin(vecEven), begin(vecOdd),
[](int i){ return i % 2 == 0; });
vecEven.erase(pairIters.first, end(vecEven));
vecOdd.erase(pairIters.second, end(vecOdd));
cout << "Even numbers: ";
for (const auto& i : vecEven) { cout << i << " "; }
cout << endl << "Odd numbers: ";
for (const auto& i : vecOdd) { cout << i << " "; }
The output can be as follows:
Enter a number (0 to quit): 11
Enter a number (0 to quit): 22
Enter a number (0 to quit): 33
Enter a number (0 to quit): 44
Enter a number (0 to quit): 0
Even numbers: 22 44
Odd numbers: 11 33
The partition() algorithm sorts a sequence such that all elements for which a predicate returns true are before all elements for which it returns false, without preserving the original order of the elements within each partition. The following example demonstrates how to partition a vector into all even numbers followed by all odd numbers.
vector<int> vec;
populateContainer(vec);
partition(begin(vec), end(vec), [](int i){ return i % 2 == 0; });
cout << "Partitioned result: ";
for (const auto& i : vec) { cout << i << " "; }
The output can be as follows:
Enter a number (0 to quit): 55
Enter a number (0 to quit): 44
Enter a number (0 to quit): 33
Enter a number (0 to quit): 22
Enter a number (0 to quit): 11
Enter a number (0 to quit): 0
Partitioned result: 22 44 33 55 11
A couple of other partition algorithms are available. See Chapter 15 for a list.
Sorting Algorithms
The STL provides several variations of sorting algorithms. A “sorting algorithm” reorders the contents of a container such that an ordering is maintained between sequential elements of the collection. Thus, it applies only to sequential collections. Sorting is not relevant to associative containers because they already maintain elements in a sorted order. Sorting is not relevant to the unordered associative containers either because they have no concept of ordering. Some containers, such as list and forward_list, provide their own sorting methods because these can be implemented more efficiently than a general sort mechanism. Consequently, the general sorting algorithms are most useful for vectors, deques, and arrays.
The sort() function sorts a range of elements in O(N log N) time in the general case. Following the application of sort() to a range, the elements in the range are in nondecreasing order (lowest to highest), according to operator<. If you don’t like that order, you can specify a different comparison callback such as greater.
A variant of sort(), called stable_sort(), maintains the relative order of equal elements in the range. However, because it needs to maintain relative order of equal elements in the range, it is less efficient than the sort() algorithm.
Here is an example:
vector<int> vec;
cout << "Enter values:" << endl;
populateContainer(vec);
sort(begin(vec), end(vec));
There is also is_sorted() and is_sorted_until(); is_sorted() returns true if the given range is sorted, while is_sorted_until() returns an iterator in the given range such that everything before this iterator is sorted.
Binary Search Algorithms
There are several search algorithms that work only on sequences that are sorted or that are at least partitioned on the element that is searched for. This could, for example, be achieved by applying partition(). These algorithms are: binary_search(), lower_bound(), upper_bound(), and equal_range(). Examples of sorted sequences are vectors whose contents are sorted, map, multimap, set, and multiset. The lower_bound(), upper_bound(), and equal_range() algorithms are similar to their method equivalents on the map and setcontainers. See Chapter 16 for an example on how to use them.
The binary_search() algorithm finds a matching element in logarithmic time instead of linear time. It requires a start and end iterator specifying the range, a value to search, and optionally a comparison callback. It returns true if the value is found in the specified range, false otherwise. The following example demonstrates this algorithm:
vector<int> vec;
cout << "Enter values:" << endl;
populateContainer(vec);
// Sort the container
sort(begin(vec), end(vec));
while (true) {
int num;
cout << "Enter a number to find (0 to quit): ";
cin >> num;
if (num == 0) {
break;
}
if (binary_search(cbegin(vec), cend(vec), num)) {
cout << "That number is in the vector." << endl;
} else {
cout << "That number is not in the vector." << endl;
}
}
Set Algorithms
The set algorithms work on any sorted iterator range. The includes() algorithm implements standard subset determination, checking if all the elements of one sorted range are included in another sorted range, in any order.
The set_union(), set_intersection(), set_difference(), and set_symmetric_difference() algorithms implement the standard semantics of those operations. In set theory, the result of union is all the elements in either set. The result of intersection is all the elements, which are in both sets. The result of difference is all the elements in the first set but not the second. The result of symmetric difference is the “exclusive or” of sets: all the elements in one, but not both, sets.
WARNING Make sure that your result range is large enough to hold the result of the operations. For set_union() and set_symmetric_difference(), the result is at most the sum of the sizes of the two input ranges. For set_intersection(), the result is at most the minimum size of the two input ranges, and for set_difference() it’s at most the size of the first range.
WARNING You can’t use iterator ranges from associative containers, including sets, to store the results because they don’t allow changes to their keys.
Here are examples of how to use these algorithms:
vector<int> vec1, vec2, result;
cout << "Enter elements for set 1:" << endl;
populateContainer(vec1);
cout << "Enter elements for set 2:" << endl;
populateContainer(vec2);
// set algorithms work on sorted ranges
sort(begin(vec1), end(vec1));
sort(begin(vec2), end(vec2));
cout << "Set 1: ";
for (const auto& i : vec1) { cout << i << " "; }
cout << endl;
cout << "Set 2: ";
for (const auto& i : vec2) { cout << i << " "; }
cout << endl;
if (includes(cbegin(vec1), cend(vec1), cbegin(vec2), cend(vec2))) {
cout << "The second set is a subset of the first." << endl;
}
if (includes(cbegin(vec2), cend(vec2), cbegin(vec1), cend(vec1))) {
cout << "The first set is a subset of the second" << endl;
}
result.resize(vec1.size() + vec2.size());
auto newEnd = set_union(cbegin(vec1), cend(vec1), cbegin(vec2),
cend(vec2), begin(result));
cout << "The union is: ";
for_each(begin(result), newEnd, [](int i){ cout << i << " "; });
cout << endl;
newEnd = set_intersection(cbegin(vec1), cend(vec1), cbegin(vec2),
cend(vec2), begin(result));
cout << "The intersection is: ";
for_each(begin(result), newEnd, [](int i){ cout << i << " "; });
cout << endl;
newEnd = set_difference(cbegin(vec1), cend(vec1), cbegin(vec2),
cend(vec2), begin(result));
cout << "The difference between set 1 and set 2 is: ";
for_each(begin(result), newEnd, [](int i){ cout << i << " "; });
cout << endl;
newEnd = set_symmetric_difference(cbegin(vec1), cend(vec1),
cbegin(vec2), cend(vec2), begin(result));
cout << "The symmetric difference is: ";
for_each(begin(result), newEnd, [](int i){ cout << i << " "; });
cout << endl;
Here is a sample run of the program:
Enter elements for set 1:
Enter a number (0 to quit): 5
Enter a number (0 to quit): 6
Enter a number (0 to quit): 7
Enter a number (0 to quit): 8
Enter a number (0 to quit): 0
Enter elements for set 2:
Enter a number (0 to quit): 8
Enter a number (0 to quit): 9
Enter a number (0 to quit): 10
Enter a number (0 to quit): 0
Set 1: 5 6 7 8
Set 2: 8 9 10
The union is: 5 6 7 8 9 10
The intersection is: 8
The difference between set 1 and set 2 is: 5 6 7
The symmetric difference is: 5 6 7 9 10
The merge() function allows you to merge two sorted ranges together, while maintaining the sorted order. The result is a sorted range containing all the elements of the two source ranges. It works in linear time. The following parameters are required:
· start and end iterator of first source range
· start and end iterator of second source range
· start iterator of destination range
· optionally, a comparison callback
Without merge(), you could still achieve the same effect by concatenating the two ranges and applying sort() to the result, but that would be less efficient [O(N log N) instead of linear].
WARNING Always ensure that you supply a big enough destination range to store the result of the merge!
The following example demonstrates merge().
vector<int> vectorOne, vectorTwo, vectorMerged;
cout << "Enter values for first vector:" << endl;
populateContainer(vectorOne);
cout << "Enter values for second vector:" << endl;
populateContainer(vectorTwo);
// Sort both containers
sort(begin(vectorOne), end(vectorOne));
sort(begin(vectorTwo), end(vectorTwo));
// Make sure the destination vector is large enough to hold the values
// from both source vectors.
vectorMerged.resize(vectorOne.size() + vectorTwo.size());
merge(cbegin(vectorOne), cend(vectorOne), cbegin(vectorTwo),
cend(vectorTwo), begin(vectorMerged));
cout << "Merged vector: ";
for (const auto& i : vectorMerged) { cout << i << " "; }
cout << endl;
Minimum/Maximum Algorithms
The min() and max() algorithms compare two or more elements of any type using operator< or a user-supplied binary predicate, returning a const reference to the smallest or largest element, respectively. The minmax() algorithm returns a pair containing the minimum and maximum value of two or more elements. These algorithms do not take iterator parameters. There is also min_element(), max_element(), and minmax_element() that work on iterator ranges.
The following program gives some examples:
int x = 4, y = 5;
cout << "x is " << x << " and y is " << y << endl;
cout << "Max is " << max(x, y) << endl;
cout << "Min is " << min(x, y) << endl;
// Using max() and min() on more than two values
int x1 = 2, x2 = 9, x3 = 3, x4 = 12;
cout << "Max of 4 elements is " << max({ x1, x2, x3, x4 }) << endl;
cout << "Min of 4 elements is " << min({ x1, x2, x3, x4 }) << endl;
// Using minmax()
auto p2 = minmax({ x1, x2, x3, x4 });
cout << "Minmax of 4 elements is <"
<< p2.first << "," << p2.second << ">" << endl;
// Using minmax_element()
vector<int> vec{ 11, 33, 22 };
auto result = minmax_element(cbegin(vec), cend(vec));
cout << "minmax_element() result: <"
<< *result.first << "," << *result.second << ">" << endl;
Here is the program output:
x is 4 and y is 5
Max is 5
Min is 4
Max of 4 elements is 12
Min of 4 elements is 2
Minmax of 4 elements is <2,12>
minmax_element() result: <11,33>
NOTE Sometimes you might encounter non-standard macros to find the minimum and maximum. For example, the GNU C Library (glibc) has macros MIN() and MAX(), while the Windows.h header file defines min() and max() macros. Because these are macros, they potentially evaluate one of their arguments twice; whereas std::min() and std::max() evaluate each argument exactly once. Make sure you always use the C++ versions, std::min() and std::max().
Numerical Processing Algorithms
You’ve already seen an example of one numerical processing algorithm: accumulate(). The following sections give examples of two more numerical algorithms.
inner_product
inner_product(), defined in <numeric>, calculates the inner product of two sequences. For example, the inner product in the following example is calculated as (1*9)+(2*8)+(3*7)+(4*6):
vector<int> v1{ 1, 2, 3, 4 };
vector<int> v2{ 9, 8, 7, 6 };
cout << inner_product(cbegin(v1), cend(v1), cbegin(v2), 0) << endl;
The output is 70.
iota
The iota() algorithm, defined in the <numeric> header file, generates a sequence of values in the specified range starting with the specified value and applying operator++ to generate each successive value. The following example shows how to use this algorithm on avector of integers, but note that it works on any element type that implements operator++:
vector<int> vec(10);
iota(begin(vec), end(vec), 5);
for (auto& i : vec) { cout << i << " "; }
The output is as follows:
5 6 7 8 9 10 11 12 13 14
ALGORITHMS EXAMPLE: AUDITING VOTER REGISTRATIONS
Voter fraud can be a problem everywhere. People sometimes attempt to register and vote in two or more different voting districts. Additionally, some people, for example convicted felons, are ineligible to vote, but occasionally attempt to register and vote anyway. Using your newfound algorithm skills, you could write a simple voter registration auditing function that checks the voter rolls for certain anomalies.
The Voter Registration Audit Problem Statement
The voter registration audit function should audit the voters’ information. Assume that voter registrations are stored by district in a map that maps district names to a list of voters. Your audit function should take this map and a list of convicted felons as parameters, and should remove all convicted felons from the lists of voters. Additionally, the function should find all voters who are registered in more than one district and should remove those names from all districts. Voters with duplicate registrations must have all their registrations removed, and therefore become ineligible to vote. For simplicity, assume that the list of voters is simply a list of string names. A real application would obviously require more data, such as address and party affiliation.
The auditVoterRolls Function
The auditVoterRolls() function works in three steps:
1. Find all the duplicate names in all the registration lists by making a call to getDuplicates().
2. Combine the set of duplicates and the list of convicted felons.
3. Remove from every voter list all the names found in the combined set of duplicates and convicted felons. The approach taken here is to use for_each() to process each list in the map, applying a lambda expression to remove the offending names from each list.
The following type aliases are used in the code:
using VotersMap = map<string, list<string>>;
using DistrictPair = pair<const string, list<string>>;
Here’s the implementation of auditVoterRolls():
// Expects a map of string/list<string> pairs keyed on district names
// and containing lists of all the registered voters in those districts.
// Removes from each list any name on the convictedFelons list and
// any name that is found on any other list.
void auditVoterRolls(VotersMap& votersByDistrict,
const list<string>& convictedFelons)
{
// get all the duplicate names
set<string> toRemove = getDuplicates(votersByDistrict);
// combine the duplicates and convicted felons -- we want
// to remove names on both lists from all voter rolls
toRemove.insert(cbegin(convictedFelons), cend(convictedFelons));
// Now remove all the names we need to remove using
// nested lambda expressions and the remove-erase-idiom
for_each(begin(votersByDistrict), end(votersByDistrict),
[&toRemove](DistrictPair& district) {
auto it = remove_if(begin(district.second),
end(district.second), [&toRemove](const string& name) {
return (toRemove.count(name) > 0);
});
district.second.erase(it, end(district.second));
});
}
The getDuplicates Function
The getDuplicates() function must find any name that is on more than one voter registration list. There are several different approaches one could use to solve this problem. To demonstrate the adjacent_find() algorithm, this implementation combines the lists from each district into one big list and sorts it. At that point, any duplicate names between the different lists will be next to each other in the big list. getDuplicates() can then use the adjacent_find() algorithm on the big, sorted list to find all consecutive duplicates and store them in a set called duplicates. Here is the implementation:
// Returns a set of all names that appear in more than one list in
// the map.
set<string> getDuplicates(const VotersMap& votersByDistrict)
{
// Collect all the names from all the lists into one big list
list<string> allNames;
for (auto& district : votersByDistrict) {
allNames.insert(end(allNames), begin(district.second),
end(district.second));
}
// sort the list -- use the list version, not the general algorithm,
// because the list version is faster
allNames.sort();
// Now it's sorted, all duplicate names will be next to each other.
// Use adjacent_find() to find instances of two or more identical names
// next to each other.
// Loop until adjacent_find() returns the end iterator.
set<string> duplicates;
for (auto lit = cbegin(allNames); lit != cend(allNames); ++lit) {
lit = adjacent_find(lit, cend(allNames));
if (lit == cend(allNames)) {
break;
}
duplicates.insert(*lit);
}
return duplicates;
}
In this implementation, allNames is of type list<string>. That way, this example can show you how to use the sort() and adjacent_find() algorithms.
Another solution is to change the type of allNames to set<string>, which results in a more compact implementation, because a set doesn’t allow duplicates. This new solution loops over all lists and tries to insert each name into allNames. When this insert fails, it means that there is already an element with that name in allNames, so the name is added to duplicates.
set<string> getDuplicates(const VotersMap& votersByDistrict)
{
set<string> allNames;
set<string> duplicates;
for (auto& district : votersByDistrict) {
for (auto& name : district.second) {
if (!allNames.insert(name).second) {
duplicates.insert(name);
}
}
}
return duplicates;
}
Testing the auditVoterRolls Function
That’s the complete implementation of the voter roll audit functionality. Here is a small test program:
// Initialize map using uniform initialization
VotersMap voters = {
{"Orange", {"Amy Aardvark", "Bob Buffalo",
"Charles Cat", "Dwayne Dog"}},
{"Los Angeles", {"Elizabeth Elephant", "Fred Flamingo",
"Amy Aardvark"}},
{"San Diego", {"George Goose", "Heidi Hen", "Fred Flamingo"}}
};
list<string> felons = {"Bob Buffalo", "Charles Cat"};
// Local lambda expression to print a district
auto printDistrict = [](const DistrictPair& district) {
cout << district.first << ":";
for (auto& str : district.second) {
cout << " {" << str << "}";
}
cout << endl;
};
cout << "Before Audit:" << endl;
for_each(cbegin(voters), cend(voters), printDistrict);
cout << endl;
auditVoterRolls(voters, felons);
cout << "After Audit:" << endl;
for_each(cbegin(voters), cend(voters), printDistrict);
cout << endl;
The output of the program is:
Before Audit:
Los Angeles: {Elizabeth Elephant} {Fred Flamingo} {Amy Aardvark}
Orange: {Amy Aardvark} {Bob Buffalo} {Charles Cat} {Dwayne Dog}
San Diego: {George Goose} {Heidi Hen} {Fred Flamingo}
After Audit:
Los Angeles: {Elizabeth Elephant}
Orange: {Dwayne Dog}
San Diego: {George Goose} {Heidi Hen}
SUMMARY
This chapter concludes the basic STL functionality. It provided an overview of the various algorithms and function objects available for your use. It also showed you how to use lambda expressions, which make it often easier to understand what your code is doing. I hope that you have gained an appreciation for the usefulness of the STL containers, algorithms, and function objects. If not, think for a moment about rewriting the voter registration audit example without the STL. You would need to write your own linked-list and map classes, and your own searching, removing, iterating, and other algorithms. The program would be much longer, more error-prone, harder to debug, and more difficult to maintain.
The next chapters discuss a couple of other aspects of the C++ Standard Library. Chapter 18 discusses regular expressions. Chapter 19 covers a number of additional library utilities available for you to use, and Chapter 20 gives a taste of some more advanced features, such as allocators, iterator adapters, and writing your own algorithms.
All materials on the site are licensed Creative Commons Attribution-Sharealike 3.0 Unported CC BY-SA 3.0 & GNU Free Documentation License (GFDL)
If you are the copyright holder of any material contained on our site and intend to remove it, please contact our site administrator for approval.
© 2016-2026 All site design rights belong to S.Y.A.