The C++ Programming Language (2013)
Part II: Basic Facilities
13. Exception Handling
Don’t interrupt me while I’m interrupting.
– Winston S. Churchill
• Error Handling
Exceptions; Traditional Error Handling; Muddling Through; Alternative Views of Exceptions; When You Can’t Use Exceptions; Hierarchical Error Handling; Exceptions and Efficiency
• Exception Guarantees
• Resource Management
Finally
• Enforcing Invariants
• Throwing and Catching Exceptions
Throwing Exceptions; Catching Exceptions; Exceptions and Threads
• A vector Implementation
A Simple vector; Representing Memory Explicitly; Assignment; Changing Size
• Advice
13.1. Error Handling
This chapter presents error handling using exceptions. For effective error handling, the language mechanisms must be used based on a strategy. Consequently, this chapter presents the exception-safety guarantees that are central to recovery from run-time errors and the Resource Acquisition Is Initialization (RAII) technique for resource management using constructors and destructors. Both the exception-safety guarantees and RAII depend on the specification of invariants, so mechanisms for enforcement of assertions are presented.
The language facilities and techniques presented here address problems related to the handling of errors in software; the handling of asynchronous events is a different topic.
The discussion of errors focuses on errors that cannot be handled locally (within a single small function), so that they require separation of error-handling activities into different parts of a program. Such parts of a program are often separately developed. Consequently, I often refer to a part of a program that is invoked to perform a task as “a library.” A library is just ordinary code, but in the context of a discussion of error handling it is worth remembering that a library designer often cannot even know what kind of programs the library will become part of:
• The author of a library can detect a run-time error but does not in general have any idea what to do about it.
• The user of a library may know how to cope with a run-time error but cannot easily detect it (or else it would have been handled in the user’s code and not left for the library to find).
The discussion of exceptions focuses on problems that need to be handled in long-running systems, systems with stringent reliability requirements, and libraries. Different kinds of programs have different requirements, and the amount of care and effort we expend should reflect that. For example, I would not apply every technique recommended here to a two-page program written just for myself. However, many of the techniques presented here simplify code, so I would use those.
13.1.1. Exceptions
The notion of an exception is provided to help get information from the point where an error is detected to a point where it can be handled. A function that cannot cope with a problem throws an exception, hoping that its (direct or indirect) caller can handle the problem. A function that wants to handle a kind of problem indicates that by catching the corresponding exception (§2.4.3.1):
• A calling component indicates the kinds of failures that it is willing to handle by specifying those exceptions in a catch-clause of a try-block.
• A called component that cannot complete its assigned task reports its failure to do so by throwing an exception using a throw-expression.
Consider a simplified and stylized example:
void taskmaster()
{
try {
auto result = do_task();
// use result
}
catch (Some_error) {
// failure to do_task: handle problem
}
}
int do_task()
{
// ...
if (/* could perform the task */)
return result;
else
throw Some_error{};
}
The taskmaster() asks do_task() to do a job. If do_task() can do that job and return a correct result, all is fine. Otherwise, do_task() must report a failure by throwing some exception. The taskmaster() is prepared to handle a Some_error, but some other kind of exception may be thrown. For example, do_task() may call other functions to do a lot of subtasks, and one of those may throw because it can’t do its assigned subtask. An exception different from Some_error indicates a failure of taskmaster() to do its job and must be handled by whatever code invokedtaskmaster().
A called function cannot just return with an indication that an error happened. If the program is to continue working (and not just print an error message and terminate), the returning function must leave the program in a good state and not leak any resources. The exception-handling mechanism is integrated with the constructor/destructor mechanisms and the concurrency mechanisms to help ensure that (§5.2). The exception-handling mechanism:
• Is an alternative to the traditional techniques when they are insufficient, inelegant, or error-prone
• Is complete; it can be used to handle all errors detected by ordinary code
• Allows the programmer to explicitly separate error-handling code from “ordinary code,” thus making the program more readable and more amenable to tools
• Supports a more regular style of error handling, thus simplifying cooperation between separately written program fragments
An exception is an object thrown to represent the occurrence of an error. It can be of any type that can be copied, but it is strongly recommended to use only user-defined types specifically defined for that purpose. That way, we minimize the chances of two unrelated libraries using the same value, say 17, to represent different errors, thereby throwing our recovery code into chaos.
An exception is caught by code that has expressed interest in handling a particular type of exception (a catch-clause). Thus, the simplest way of defining an exception is to define a class specifically for a kind of error and throw that. For example:
struct Range_error {};
void f(int n)
{
if (n<0 || max<n) throw Range_error {};
// ...
}
If that gets tedious, the standard library defines a small hierarchy of exception classes (§13.5.2).
An exception can carry information about the error it represents. Its type represents the kind of error, and whatever data it holds represents the particular occurrence of that error. For example, the standard-library exceptions contain a string value, which can be used to transmit information such as the location of the throw (§13.5.2).
13.1.2. Traditional Error Handling
Consider the alternatives to exceptions for a function detecting a problem that cannot be handled locally (e.g., an out-of-range access) so that an error must be reported to a caller. Each conventional approach has problems, and none are general:
• Terminate the program. This is a pretty drastic approach. For example:
if (something_wrong) exit(1);
For most errors, we can and must do better. For example, in most situations we should at least write out a decent error message or log the error before terminating. In particular, a library that doesn’t know about the purpose and general strategy of the program in which it is embedded cannot simply exit() or abort(). A library that unconditionally terminates cannot be used in a program that cannot afford to crash.
• Return an error value. This is not always feasible because there is often no acceptable “error value.” For example:
int get_int(); // get next integer from input
For this input function, every int is a possible result, so there can be no integer value representing an input failure. At a minimum, we would have to modify get_int() to return a pair of values. Even where this approach is feasible, it is often inconvenient because every call must be checked for the error value. This can easily double the size of a program (§13.1.7). Also, callers often ignore the possibility of errors or simply forget to test a return value. Consequently, this approach is rarely used systematically enough to detect all errors. For example, printf()(§43.3) returns a negative value if an output or encoding error occurred, but programmers essentially never test for that. Finally, some operations simply do not have return values; a constructor is the obvious example.
• Return a legal value and leave the program in an “error state.” This has the problem that the calling function may not notice that the program has been put in an error state. For example, many standard C library functions set the nonlocal variable errno to indicate an error (§43.4, §40.3):
double d = sqrt(–1.0);
Here, the value of d is meaningless and errno is set to indicate that –1.0 isn’t an acceptable argument for a floating-point square root function. However, programs typically fail to set and test errno and similar nonlocal state consistently enough to avoid consequential errors caused by values returned from failed calls. Furthermore, the use of nonlocal variables for recording error conditions doesn’t work well in the presence of concurrency.
• Call an error-handler function. For example:
if (something_wrong) something_handler(); // and possibly continue here
This must be some other approach in disguise because the problem immediately becomes “What does the error-handling function do?” Unless the error-handling function can completely resolve the problem, the error-handling function must in turn either terminate the program, return with some indication that an error had occurred, set an error state, or throw an exception. Also, if the error-handling function can handle the problem without bothering the ultimate caller, why do we consider it an error?
Traditionally, an unsystematic combination of these approached co-exists in a program.
13.1.3. Muddling Through
One aspect of the exception-handling scheme that will appear novel to some programmers is that the ultimate response to an unhandled error (an uncaught exception) is to terminate the program. The traditional response has been to muddle through and hope for the best. Thus, exception handling makes programs more “brittle” in the sense that more care and effort must be taken to get a program to run acceptably. This is preferable, though, to getting wrong results later in the development process – or after the development process is considered complete and the program is handed over to innocent users. Where termination is unacceptable, we can catch all exceptions (§13.5.2.2). Thus, an exception terminates a program only if a programmer allows it to terminate. Typically, this is preferable to the unconditional termination that happens when a traditional incomplete recovery leads to a catastrophic error. Where termination is an acceptable response, an uncaught exception will achieve that because it turns into a call of terminate() (§13.5.2.5). Also, a noexcept specifier (§13.5.1.1) can make that desire explicit.
Sometimes, people try to alleviate the unattractive aspects of “muddling through” by writing out error messages, putting up dialog boxes asking the user for help, etc. Such approaches are primarily useful in debugging situations in which the user is a programmer familiar with the structure of the program. In the hands of nondevelopers, a library that asks the (possibly absent) user/operator for help is unacceptable. A good library doesn’t “blabber” in this way. If a user has to be informed, an exception handler can compose a suitable message (e.g., in Finnish for Finnish users or in XML for an error-logging system). Exceptions provide a way for code that detects a problem from which it cannot recover to pass the problem on to a part of the system that might be able to recover. Only a part of the system that has some idea of the context in which the program runs has any chance of composing a meaningful error message.
Please recognize that error handling will remain a difficult task and that the exception-handling mechanism – although more formalized than the techniques it replaces – is still relatively unstructured compared with language features involving only local control flow. The C++ exception-handling mechanism provides the programmer with a way of handling errors where they are most naturally handled, given the structure of a system. Exceptions make the complexity of error handling visible. However, exceptions are not the cause of that complexity. Be careful not to blame the messenger for bad news.
13.1.4. Alternative Views of Exceptions
“Exception” is one of those words that means different things to different people. The C++ exception-handling mechanism is designed to support handling of errors that cannot be handled locally (“exceptional conditions”). In particular, it is intended to support error handling in programs composed of independently developed components. Given that there is nothing particularly exceptional about a part of a program being unable to perform its given task, the word “exception” may be considered a bit misleading. Can an event that happens most times a program is run be considered exceptional? Can an event that is planned for and handled be considered an error? The answer to both questions is “yes.” “Exceptional” does not mean “almost never happens” or “disastrous.”
13.1.4.1. Asynchronous Events
The mechanism is designed to handle only synchronous exceptions, such as array range checks and I/O errors. Asynchronous events, such as keyboard interrupts and power failures, are not necessarily exceptional and are not handled directly by this mechanism. Asynchronous events require mechanisms fundamentally different from exceptions (as defined here) to handle them cleanly and efficiently. Many systems offer mechanisms, such as signals, to deal with asynchrony, but because these tend to be system-dependent, they are not described here.
13.1.4.2. Exceptions That Are Not Errors
Think of an exception as meaning “some part of the system couldn’t do what it was asked to do” (§13.1.1, §13.2).
Exception throws should be infrequent compared to function calls or the structure of the system has been obscured. However, we should expect most large programs to throw and catch at least some exceptions in the course of a normal and successful run.
If an exception is expected and caught so that it has no bad effects on the behavior of the program, then how can it be an error? Only because the programmer thinks of it as an error and of the exception-handling mechanisms as tools for handling errors. Alternatively, one might think of the exception-handling mechanisms as simply another control structure, an alternative way of returning a value to a caller. Consider a binary tree search function:
void fnd(Tree* p, const string& s)
{
if (s == p–>str) throw p; // found s
if (p–>left) fnd(p–>left,s);
if (p–>right) fnd(p–>right,s);
}
Tree* find(Tree* p, const string& s)
{
try {
fnd(p,s);
}
catch (Tree* q) { // q->str==s
return q;
}
return 0;
}
This actually has some charm, but it should be avoided because it is likely to cause confusion and inefficiencies. When at all possible, stick to the “exception handling is error handling” view. When this is done, code is clearly separated into two categories: ordinary code and error-handling code. This makes code more comprehensible. Furthermore, the implementations of the exception mechanisms are optimized based on the assumption that this simple model underlies the use of exceptions.
Error handling is inherently difficult. Anything that helps preserve a clear model of what is an error and how it is handled should be treasured.
13.1.5. When You Can’t Use Exceptions
Use of exceptions is the only fully general and systematic way of dealing with errors in a C++ program. However, we must reluctantly conclude that there are programs that for practical and historical reasons cannot use exceptions. For example:
• A time-critical component of an embedded system where an operation must be guaranteed to complete in a specific maximum time. In the absence of tools that can accurately estimate the maximum time for an exception to propagate from a throw to a catch, alternative error-handling methods must be used.
• A large old program in which resource management is an ad hoc mess (e.g., free store is unsystematically “managed” using “naked” pointers, news, and deletes), rather than relying on some systematic scheme, such as resource handles (e.g., string and vector; §4.2, §4.4).
In such cases, we are thrown back onto “traditional” (pre-exception) techniques. Because such programs arise in a great variety of historical contexts and in response to a variety of constraints, I cannot give a general recommendation for how to handle them. However, I can point to two popular techniques:
• To mimic RAII, give every class with a constructor an invalid() operation that returns some error_code. A useful convention is for error_code==0 to represent success. If the constructor fails to establish the class invariant, it ensures that no resource is leaked and invalid() returns a nonzero error_code. This solves the problem of how to get an error condition out of a constructor. A user can then systematically test invalid() after each construction of an object and engage in suitable error handling in case of failure. For example:
void f(int n)
{
my_vector<int> x(n);
if (x.invalid()) {
// ... deal with error ...
}
// ...
}
• To mimic a function either returning a value or throwing an exception, a function can return a pair<Value,Error_code> (§5.4.3). A user can then systematically test the error_code after each function call and engage in suitable error handling in case of failure. For example:
void g(int n)
{
auto v = make_vector(n); // return a pair
if (v.second) {
// ... deal with error ...
}
auto val = v.first;
// ...
}
Variations of this scheme have been reasonably successful, but they are clumsy compared to using exceptions in a systematic manner.
13.1.6. Hierarchical Error Handling
The purpose of the exception-handling mechanisms is to provide a means for one part of a program to inform another part that a requested task could not be performed (that an “exceptional circumstance” has been detected). The assumption is that the two parts of the program are written independently and that the part of the program that handles the exception often can do something sensible about the error.
To use handlers effectively in a program, we need an overall strategy. That is, the various parts of the program must agree on how exceptions are used and where errors are dealt with. The exception-handling mechanisms are inherently nonlocal, so adherence to an overall strategy is essential. This implies that the error-handling strategy is best considered in the earliest phases of a design. It also implies that the strategy must be simple (relative to the complexity of the total program) and explicit. Something complicated would not be consistently adhered to in an area as inherently tricky as error recovery.
Successful fault-tolerant systems are multilevel. Each level copes with as many errors as it can without getting too contorted and leaves the rest to higher levels. Exceptions support that view. Furthermore, terminate() supports this view by providing an escape if the exception-handling mechanism itself is corrupted or if it has been incompletely used, thus leaving exceptions uncaught. Similarly, noexcept provides a simple escape for errors where trying to recover seems infeasible.
Not every function should be a firewall. That is, not every function can test its preconditions well enough to ensure that no errors could possibly stop it from meeting its postcondition. The reasons that this will not work vary from program to program and from programmer to programmer. However, for larger programs:
[1] The amount of work needed to ensure this notion of “reliability” is too great to be done consistently.
[2] The overhead in time and space is too great for the system to run acceptably (there will be a tendency to check for the same errors, such as invalid arguments, over and over again).
[3] Functions written in other languages won’t obey the rules.
[4] This purely local notion of “reliability” leads to complexities that actually become a burden to overall system reliability.
However, separating the program into distinct subsystems that either complete successfully or fail in well-defined ways is essential, feasible, and economical. Thus, major libraries, subsystems, and key interface functions should be designed in this way. Furthermore, in most systems, it is feasible to design every function to ensure that it always either completes successfully or fails in a well-defined manner.
Usually, we don’t have the luxury of designing all of the code of a system from scratch. Therefore, to impose a general error-handling strategy on all parts of a program, we must take into account program fragments implemented using strategies different from ours. To do this we must address a variety of concerns relating to the way a program fragment manages resources and the state in which it leaves the system after an error. The aim is to have the program fragment appear to follow the general error-handling strategy even if it internally follows a different strategy.
Occasionally, it is necessary to convert from one style of error reporting to another. For example, we might check errno and possibly throw an exception after a call to a C library or, conversely, catch an exception and set errno before returning to a C program from a C++ library:
void callC() // Call a C function from C++; convert errno to a throw
{
errno = 0;
c_function();
if (errno) {
// ... local cleanup, if possible and necessary ...
throw C_blewit(errno);
}
}
extern "C" void call_from_C() noexcept // Call a C++ function from C; convert a throw to errno
{
try {
c_plus_plus_function();
}
catch (...) {
// ... local cleanup, if possible and necessary ...
errno = E_CPLPLFCTBLEWIT;
}
}
In such cases, it is important to be systematic enough to ensure that the conversion of error-reporting styles is complete. Unfortunately, such conversions are often most desirable in “messy code” without a clear error-handling strategy and therefore difficult to be systematic about.
Error handling should be – as far as possible – hierarchical. If a function detects a run-time error, it should not ask its caller for help with recovery or resource acquisition. Such requests set up cycles in the system dependencies. That in turn makes the program hard to understand and introduces the possibility of infinite loops in the error-handling and recovery code.
13.1.7. Exceptions and Efficiency
In principle, exception handling can be implemented so that there is no run-time overhead when no exception is thrown. In addition, this can be done so that throwing an exception isn’t all that expensive compared to calling a function. Doing so without adding significant memory overhead while maintaining compatibility with C calling sequences, debugger conventions, etc., is possible, but hard. However, please remember that the alternatives to exceptions are not free either. It is not unusual to find traditional systems in which half of the code is devoted to error handling.
Consider a simple function f() that appears to have nothing to do with exception handling:
void f()
{
string buf;
cin>>buf;
// ...
g(1);
h(buf);
}
However, g() or h() may throw an exception, so f() must contain code ensuring that buf is destroyed correctly in case of an exception.
Had g() not thrown an exception, it would have had to report its error some other way. Consequently, the comparable code using ordinary code to handle errors instead of exceptions isn’t the plain code above, but something like:
bool g(int);
bool h(const char*);
char* read_long_string();
bool f()
{
char* s = read_long_string();
// ...
if (g(1)) {
if (h(s)) {
free(s);
return true;
}
else {
free(s);
return false;
}
}
else {
free(s);
return false;
}
}
Using a local buffer for s would simplify the code by eliminating the calls to free(), but then we’d have range-checking code instead. Complexity tends to move around rather than just disappear.
People don’t usually handle errors this systematically, though, and it is not always critical to do so. However, when careful and systematic handling of errors is necessary, such housekeeping is best left to a computer, that is, to the exception-handling mechanisms.
The noexcept specifier (§13.5.1.1) can be most helpful in improving generated code. Consider:
void g(int) noexcept;
void h(const string&) noexcept;
Now, the code generated for f() can possibly be improved.
No traditional C function throws an exception, so most C functions can be declared noexcept. In particular, a standard-library implementer knows that only a few standard C library functions (such as atexit() and qsort()) can throw, and can take advantage of that fact to generate better code.
Before declaring a “C function” noexcept, take a minute to consider if it could possibly throw an exception. For example, it might have been converted to use the C++ operator new, which can throw bad_alloc, or it might call a C++ library that throws an exception.
As ever, discussions about efficiency are meaningless in the absence of measurements.
13.2. Exception Guarantees
To recover from an error – that is, to catch an exception and continue executing a program – we need to know what can be assumed about the state of the program before and after the attempted recovery action. Only then can recovery be meaningful. Therefore, we call an operation exception-safe if that operation leaves the program in a valid state when the operation is terminated by throwing an exception. However, for that to be meaningful and useful, we have to be precise about what we mean by “valid state.” For practical design using exceptions, we must also break down the overly general “exception-safe” notion into a few specific guarantees.
When reasoning about objects, we assume that a class has a class invariant (§2.4.3.2, §17.2.1). We assume that this invariant is established by its constructor and maintained by all functions with access to the object’s representation until the object is destroyed. So, by valid state we mean that a constructor has completed and the destructor has not yet been entered. For data that isn’t easily viewed as an object, we must reason similarly. That is, if two pieces of nonlocal data are assumed to have a specific relationship, we must consider that an invariant and our recovery action must preserve it. For example:
namespace Points { // (vx[i],vy[i]) is a point for all i
vector<int> vx;
vector<int> vy;
};
Here it is assumed that vx.size()==vy.size() is (always) true. However, that was only stated in a comment, and compilers do not read comments. Such implicit invariants can be very hard to discover and maintain.
Before a throw, a function must place all constructed objects in valid states. However, such a valid state may be one that doesn’t suit the caller. For example, a string may be left as the empty string or a container may be left unsorted. Thus, for complete recovery, an error handler may have to produce values that are more appropriate/desirable for the application than the (valid) ones existing at the entry to a catch-clause.
The C++ standard library provides a generally useful conceptual framework for design for exception-safe program components. The library provides one of the following guarantees for every library operation:
• The basic guarantee for all operations: The basic invariants of all objects are maintained, and no resources, such as memory, are leaked. In particular, the basic invariants of every built-in and standard-library type guarantee that you can destroy an object or assign to it after every standard-library operation (§iso.17.6.3.1).
• The strong guarantee for key operations: in addition to providing the basic guarantee, either the operation succeeds, or it has no effect. This guarantee is provided for key operations, such as push_back(), single-element insert() on a list, and uninitialized_copy().
• The nothrow guarantee for some operations: in addition to providing the basic guarantee, some operations are guaranteed not to throw an exception. This guarantee is provided for a few simple operations, such as swap() of two containers and pop_back().
Both the basic guarantee and the strong guarantee are provided on the condition that
• user-supplied operations (such as assignments and swap() functions) do not leave container elements in invalid states,
• user-supplied operations do not leak resources, and
• destructors do not throw exceptions (§iso.17.6.5.12).
Violating a standard-library requirement, such as having a destructor exit by throwing an exception, is logically equivalent to violating a fundamental language rule, such as dereferencing a null pointer. The practical effects are also equivalent and often disastrous.
Both the basic guarantee and the strong guarantee require the absence of resource leaks. This is necessary for every system that cannot afford resource leaks. In particular, an operation that throws an exception must not only leave its operands in well-defined states but must also ensure that every resource that it acquired is (eventually) released. For example, at the point where an exception is thrown, all memory allocated must be either deallocated or owned by some object, which in turn must ensure that the memory is properly deallocated. For example:
void f(int i)
{
int* p = new int[10];
// ...
if (i<0) {
delete[] p; // delete before the throw or leak
throw Bad();
}
// ...
}
Remember that memory isn’t the only kind of resource that can leak. I consider anything that has to be acquired from another part of the system and (explicitly or implicitly) given back to be a resource. Files, locks, network connections, and threads are examples of system resources. A function may have to release those or hand them over to some resource handler before throwing an exception.
The C++ language rules for partial construction and destruction ensure that exceptions thrown while constructing subobjects and members will be handled correctly without special attention from standard-library code (§17.2.3). This rule is an essential underpinning for all techniques dealing with exceptions.
In general, we must assume that every function that can throw an exception will throw one. This implies that we must structure our code so that we don’t get lost in a rat’s nest of complicated control structures and brittle data structures. When analyzing code for potential errors, simple, highly structured, “stylized” code is the ideal; §13.6 includes a realistic example of such code.
13.3. Resource Management
When a function acquires a resource – that is, it opens a file, allocates some memory from the free store, acquires a mutex, etc. – it is often essential for the future running of the system that the resource be properly released. Often that “proper release” is achieved by having the function that acquired it release it before returning to its caller. For example:
void use_file(const char* fn) // naive code
{
FILE* f = fopen(fn,"r");
// ... use f ...
fclose(f);
}
This looks plausible until you realize that if something goes wrong after the call of fopen() and before the call of fclose(), an exception may cause use_file() to be exited without fclose() being called. Exactly the same problem can occur in languages that do not support exception handling. For example, the standard C library function longjmp() can cause the same problem. Even an ordinary return-statement could exit use_file without closing f.
A first attempt to make use_file() fault-tolerant looks like this:
void use_file(const char* fn) // clumsy code
{
FILE* f = fopen(fn,"r");
try {
// ... use f ...
}
catch (...) { // catch every possible exception
fclose(f);
throw;
}
fclose(f);
}
The code using the file is enclosed in a try-block that catches every exception, closes the file, and rethrows the exception.
The problem with this solution is that it is verbose, tedious, and potentially expensive. Worse still, such code becomes significantly more complex when several resources must be acquired and released. Fortunately, there is a more elegant solution. The general form of the problem looks like this:
void acquire()
{
// acquire resource 1
// ...
// acquire resource n
// ... use resources ...
// release resource n
// ...
// release resource 1
}
It is typically important that resources are released in the reverse order of their acquisition. This strongly resembles the behavior of local objects created by constructors and destroyed by destructors. Thus, we can handle such resource acquisition and release problems using objects of classes with constructors and destructors. For example, we can define a class File_ptr that acts like a FILE*:
class File_ptr {
FILE* p;
public:
File_ptr(const char* n, const char* a) // open file n
: p{fopen(n,a)}
{
if (p==nullptr) throw runtime_error{"File_ptr: Can't open file"};
}
File_ptr(const string& n, const char* a) // open file n
:File_ptr{n.c_str(),a}
{ }
explicit File_ptr(FILE* pp) // assume ownership of pp
:p{pp}
{
if (p==nullptr) throw runtime_error("File_ptr: nullptr"};
}
// ... suitable move and copy operations ...
~File_ptr() { fclose(p); }
operator FILE*() { return p; }
};
We can construct a File_ptr given either a FILE* or the arguments required for fopen(). In either case, a File_ptr will be destroyed at the end of its scope and its destructor will close the file. File_ptr throws an exception if it cannot open a file because otherwise every operation on the file handle would have to test for nullptr. Our function now shrinks to this minimum:
void use_file(const char* fn)
{
File_ptr f(fn,"r");
// ... use f ...
}
The destructor will be called independently of whether the function is exited normally or exited because an exception is thrown. That is, the exception-handling mechanisms enable us to remove the error-handling code from the main algorithm. The resulting code is simpler and less error-prone than its traditional counterpart.
This technique for managing resources using local objects is usually referred to as “Resource Acquisition Is Initialization” (RAII; §5.2). This is a general technique that relies on the properties of constructors and destructors and their interaction with exception handling.
It is often suggested that writing a “handle class” (a RAII class) is tedious so that providing a nicer syntax for the catch(...) action would provide a better solution. The problem with that approach is that you need to remember to “catch and correct” the problem wherever a resource is acquired in an undisciplined way (typically dozens or hundreds of places in a large program), whereas the handler class need be written only once.
An object is not considered constructed until its constructor has completed. Then and only then will stack unwinding (§13.5.1) call the destructor for the object. An object composed of subobjects is constructed to the extent that its subobjects have been constructed. An array is constructed to the extent that its elements have been constructed (and only fully constructed elements are destroyed during unwinding).
A constructor tries to ensure that its object is completely and correctly constructed. When that cannot be achieved, a well-written constructor restores – as far as possible – the state of the system to what it was before creation. Ideally, a well-designed constructor always achieves one of these alternatives and doesn’t leave its object in some “half-constructed” state. This can be simply achieved by applying the RAII technique to the members.
Consider a class X for which a constructor needs to acquire two resources: a file x and a mutex y (§5.3.4). This acquisition might fail and throw an exception. Class X’s constructor must never complete having acquired the file but not the mutex (or the mutex and not the file, or neither). Furthermore, this should be achieved without imposing a burden of complexity on the programmer. We use objects of two classes, File_ptr and std::unique_lock (§5.3.4), to represent the acquired resources. The acquisition of a resource is represented by the initialization of the local object that represents the resource:
class Locked_file_handle {
File_ptr p;
unique_lock<mutex> lck;
public:
X(const char* file, mutex& m)
: p{file,"rw"}, // acquire "file"
lck{m} // acquire "m"
{}
// ...
};
Now, as in the local object case, the implementation takes care of all of the bookkeeping. The user doesn’t have to keep track at all. For example, if an exception occurs after p has been constructed but before lck has been, then the destructor for p but not for lck will be invoked.
This implies that where this simple model for acquisition of resources is adhered to, the author of the constructor need not write explicit exception-handling code.
The most common resource is memory, and string, vector, and the other standard containers use RAII to implicitly manage acquisition and release. Compared to ad hoc memory management using new (and possibly also delete), this saves lots of work and avoids lots of errors.
When a pointer to an object, rather than a local object, is needed, consider using the standard-library types unique_ptr and shared_ptr (§5.2.1, §34.3) to avoid leaks.
13.3.1. Finally
The discipline required to represent a resource as an object of a class with a destructor have bothered some. Again and again, people have invented “finally” language constructs for writing arbitrary code to clean up after an exception. Such techniques are generally inferior to RAII because they are ad hoc, but if you really want ad hoc, RAII can supply that also. First, we define a class that will execute an arbitrary action from its destructor.
template<typename F>
struct Final_action {
Final_action(F f): clean{f} {}
~Final_action() { clean(); }
F clean;
};
The “finally action” is provided as an argument to the constructor.
Next, we define a function that conveniently deduces the type of an action:
template<class F>
Final_action<F> finally(F f)
{
return Final_action<F>(f);
}
Finally, we can test finally():
void test()
// handle undiciplined resource acquisition
// demonstrate that arbitrary actions are possible
{
int* p = new int{7}; // probably should use a unique_ptr (§5.2)
int* buf = (int*)malloc(100*sizeof(int)); // C-style allocation
auto act1 = finally([&]{ delete p;
free(buf); // C-style deallocation
cout<< "Goodby, Cruel world!\n";
}
);
int var = 0;
cout << "var = " << var << '\n';
// nested block:
{
var = 1;
auto act2 = finally([&]{ cout<< "finally!\n"; var=7; });
cout << "var = " << var << '\n';
} // act2 is invoked here
cout << "var = " << var << '\n';
}// act1 is invoked here
This produced:
var = 0
var = 1
finally!
var = 7
Goodby, Cruel world!
In addition, the memory allocated and pointed to by p and buf is appropriately deleted and free()d.
It is generally a good idea to place a guard close to the definition of whatever it is guarding. That way, we can at a glance see what is considered a resource (even if ad hoc) and what is to be done at the end of its scope. The connection between finally() actions and the resources they manipulate is still ad hoc and implicit compared to the use of RAII for resource handles, but using finally() is far better than scattering cleanup code around in a block.
Basically, finally() does for a block what the increment part of a for-statement does for the for-statement (§9.5.2): it specifies the final action at the top of a block where it is easy to be seen and where it logically belongs from a specification point of view. It says what is to be done upon exit from a scope, saving the programmer from trying to write code at each of the potentially many places from which the thread of control might exit the scope.
13.4. Enforcing Invariants
When a precondition for a function (§12.4) isn’t met, the function cannot correctly perform its task. Similarly, when a constructor cannot establish its class invariant (§2.4.3.2, §17.2.1), the object is not usable. In those cases, I typically throw exceptions. However, there are programs for which throwing an exception is not an option (§13.1.5), and there are people with different views of how to deal with the failure of a precondition (and similar conditions):
• Just don’t do that: It is the caller’s job to meet preconditions, and if the caller doesn’t do that, let bad results occur – eventually those errors will be eliminated from the system through improved design, debugging, and testing.
• Terminate the program: Violating a precondition is a serious design error, and the program must not proceed in the presence of such errors. Hopefully, the total system can recover from the failure of one component (that program) – eventually such failures may be eliminated from the system through improved design, debugging, and testing.
Why would anyone choose one of these alternatives? The first approach often relates to the need for performance: systematically checking preconditions can lead to repeated tests of logically unnecessary conditions (for example, if a caller has correctly validated data, millions of tests in thousands of called functions may be logically redundant). The cost in performance can be significant. It may be worthwhile to suffer repeated crashes during testing to gain that performance. Obviously, this assumes that you eventually get all critical precondition violations out of the system. For some systems, typically systems completely under the control of a single organization, that can be a realistic aim.
The second approach tends to be used in systems where complete and timely recovery from a precondition failure is considered infeasible. That is, making sure that recovery is complete imposes unacceptable complexity on the system design and implementation. On the other hand,termination of a program is considered acceptable. For example, it is not unreasonable to consider program termination acceptable if it is easy to rerun the program with inputs and parameters that make repeated failure unlikely. Some distributed systems are like this (as long as the program that terminates is only a part of the complete system), and so are many of the small programs we write for our own consumption.
Realistically, many systems use a mix of exceptions and these two alternative approaches. All three share a common view that preconditions should be defined and obeyed; what differs is how enforcement is done and whether recovery is considered feasible. Program structure can be radically different depending on whether (localized) recovery is an aim. In most systems, some exceptions are thrown without real expectation of recovery. For example, I often throw an exception to ensure some error logging or to produce a decent error message before terminating or re-initializing a process (e.g., from a catch(...) in main()).
A variety of techniques are used to express checks of desired conditions and invariants. When we want to be neutral about the logical reason for the check, we typically use the word assertion, often abbreviated to an assert. An assertion is simply a logical expression that is assumed to betrue. However, for an assertion to be more than a comment, we need a way of expressing what happens if it is false. Looking at a variety of systems, I see a variety of needs when it comes to expressing assertions:
• We need to choose between compile-time asserts (evaluated by the compiler) and run-time asserts (evaluated at run time).
• For run-time asserts we need a choice of throw, terminate, or ignore.
• No code should be generated unless some logical condition is true. For example, some runtime asserts should not be evaluated unless the logical condition is true. Usually, the logical condition is something like a debug flag, a level of checking, or a mask to select among asserts to enforce.
• Asserts should not be verbose or complicated to write (because they can be very common).
Not every system has a need for or supports every alternative.
The standard offers two simple mechanisms:
• In <cassert>, the standard library provides the assert(A) macro, which checks its assertion, A, at run time if and only if the macro NDEBUG (“not debugging”) is not defined (§12.6.2). If the assertion fails, the compiler writes out an error message containing the (failed) assertion, the source file name, and the source file line number and terminates the program.
• The language provides static_assert(A,message), which unconditionally checks its assertion, A, at compile time (§2.4.3.3). If the assertion fails, the compiler writes out the message and the compilation fails.
Where assert() and static_assert() are insufficient, we could use ordinary code for checking. For example:
void f(int n)
// n should be in [1:max)
{
if (2<debug_level && (n<=0 || max<n)
throw Assert_error("range problem");
// ...
}
However, using such “ordinary code” tends to obscure what is being tested. Are we:
• Evaluating the conditions under which we test? (Yes, the 2<debug_level part.)
• Evaluating a condition that is expected to be true for some calls and not for others? (No, because we are throwing an exception – unless someone is trying to use exceptions as simply another return mechanism; §13.1.4.2.)
• Checking a precondition which should never fail? (Yes, the exception is simply our chosen response.)
Worse, the precondition testing (or invariant testing) can easily get dispersed in other code and thus be harder to spot and easier to get wrong. What we would like is a recognizable mechanism for checking assertions. What follows here is a (possibly slightly overelaborate) mechanism for expressing a variety of assertions and a variety of responses to failures. First, I define mechanisms for deciding when to test and deciding what to do if an assertion fails:
namespace Assert {
enum class Mode { throw_, terminate_, ignore_ };
constexpr Mode current_mode = CURRENT_MODE;
constexpr int current_level = CURRENT_LEVEL;
constexpr int default_level = 1;
constexpr bool level(int n)
{ return n<=current_level; }
struct Error : runtime_error {
Error(const string& p) :runtime_error(p) {}
};
// ...
}
The idea is to test whenever an assertion has a “level” lower than or equal to current_level. If an assertion fails, current_mode is used to choose among three alternatives. The current_level and current_mode are constants because the idea is to generate no code whatsoever for an assertion unless we have made a decision to do so. Imagine CURRENT_MODE and CURRENT_LEVEL to be set in the build environment for a program, possibly as compiler options.
The programmer will use Assert::dynamic() to make assertions:
namespace Assert {
// ...
string compose(const char* file, int line, const string& message)
// compose message including file name and line number
{
ostringstream os ("(");
os << file << "," << line << "):" << message;
return os.str();
}
template<bool condition =level(default_level), class Except = Error>
void dynamic(bool assertion, const string& message ="Assert::dynamic failed")
{
if (assertion)
return;
if (current_mode == Assert_mode::throw_)
throw Except{message};
if (current_mode == Assert_mode::terminate_)
std::terminate();
}
template<>
void dynamic<false,Error>(bool, const string&) // do nothing
{
}
void dynamic(bool b, const string& s) // default action
{
dynamic<true,Error>(b,s);
}
void dynamic(bool b) // default message
{
dynamic<true,Error>(b);
}
}
I chose the name Assert::dynamic (meaning “evaluate at run time”) to contrast with static_assert (meaning “evaluate at compile time”; §2.4.3.3).
Further implementation trickery could be used to minimize the amount of code generated. Alternatively, we could do more of the testing at run time if more flexibility is needed. This Assert is not part of the standard and is presented primarily as an illustration of the problems and the implementation techniques. I suspect that the demands on an assertion mechanism vary too much for a single one to be used everywhere.
We can use Assert::dynamic like this:
void f(int n)
// n should be in [1:max)
{
Assert::dynamic<Assert::level(2),Assert::Error>(
(n<=0 || max<n), Assert::compose(__FILE__,__LINE__,"range problem");
// ...
}
The __FILE__ and __LINE__ are macros that expand at their point of appearance in the source code (§12.6.2). I can’t hide them from the user’s view by placing them inside the implementation of Assert where they belong.
Assert::Error is the default exception, so we need not mention it explicitly. Similarly, if we are willing to use the default assertion level, we don’t need to mention the level explicitly:
void f(int n)
// n should be in [1:max)
{
Assert::dynamic((n<=0 || max<n),Assert::compose(__FILE__,__LINE__,"range problem");
// ...
}
I do not recommend obsessing about the amount of text needed to express an assertion, but by using a namespace directive (§14.2.3) and the default message, we can get to a minimum:
void f(int n)
// n should be in [1:max)
{
dynamic(n<=0||max<n);
// ...
}
It is possible to control the testing done and the response to testing through build options (e.g., controlling conditional compilation) and/or through options in the program code. That way, you can have a debug version of a system that tests extensively and enters the debugger and a production version that does hardly any testing.
I personally favor leaving at least some tests in the final (shipping) version of a program. For example, with Assert the obvious convention is that assertions marked as level zero will always be checked. We never find the last bug in a large program under continuous development and maintenance. Also, even if all else works perfectly, having a few “sanity checks” left to deal with hardware failures can be wise.
Only the builder of the final complete system can decide whether a failure is acceptable or not. The writer of a library or reusable component usually does not have the luxury of terminating unconditionally. I interpret that to mean that for general library code, reporting an error – preferably by throwing an exception – is essential.
As usual, destructors should not throw, so don’t use a throwing Assert() in a destructor.
13.5. Throwing and Catching Exceptions
This section presents exceptions from a language-technical point of view.
13.5.1. Throwing Exceptions
We can throw an exception of any type that can be copied or moved. For example:
class No_copy {
No_copy(const No_copy&) = delete; // prohibit copying (§17.6.4)
};
class My_error {
// ...
};
void f(int n)
{
switch (n) {
case 0: throw My_error{}; // OK
case 1: throw No_copy{}; // error: can't copy a No_copy
case 2: throw My_error; // error: My_error is a type, rather than an object
}
}
The exception object caught (§13.5.2) is in principle a copy of the one thrown (though an optimizer is allowed to minimize copying); that is, a throw x; initializes a temporary variable of x’s type with x. This temporary may be further copied several times before it is caught: the exception is passed (back) from called function to calling function until a suitable handler is found. The type of the exception is used to select a handler in the catch-clause of some try-block. The data in the exception object – if any – is typically used to produce error messages or to help recovery. The process of passing the exception “up the stack” from the point of throw to a handler is called stack unwinding . In each scope exited, the destructors are invoked so that every fully constructed object is properly destroyed. For example:
void f()
{
string name {"Byron"};
try {
string s = "in";
g();
}
catch (My_error) {
// ...
}
}
void g()
{
string s = "excess";
{
string s = "or";
h();
}
}
void h()
{
string s = "not";
throw My_error{};
string s2 = "at all";
}
After the throw in h(), all the strings that were constructed are destroyed in the reverse order of their construction: "not", "or", "excess", "in", but not "at all", which the thread of control never reached, and not "Byron", which was unaffected.
Because an exception is potentially copied several times before it is caught, we don’t usually put huge amounts of data in it. Exceptions containing a few words are very common. The semantics of exception propagation are those of initialization, so objects of types with move semantics (e.g., strings) are not expensive to throw. Some of the most common exceptions carry no information; the name of the type is sufficient to report the error. For example:
struct Some_error { };
void fct()
{
// ...
if (something_wrong)
throw Some_error{};
}
There is a small standard-library hierarchy of exception types (§13.5.2) that can be used either directly or as base classes. For example:
struct My_error2 : std::runtime_error {
const char* what() const noexcept { return "My_error2"; }
};
The standard-library exception classes, such as runtime_error and out_of_range, take a string argument as a constructor argument and have a virtual function what() that will regurgitate that string. For example:
void g(int n) // throw some exception
{
if (n)
throw std::runtime_error{"I give up!"};
else
throw My_error2{};
}
void f(int n) // see what exception g() throws
{
try {
void g(n);
}
catch (std::exception& e) {
cerr << e.what() << '\n';
}
}
13.5.1.1. noexcept Functions
Some functions don’t throw exceptions and some really shouldn’t. To indicate that, we can declare such a function noexcept. For example:
double compute(double) noexcept; // may not throw an exception
Now no exception will come out of compute().
Declaring a function noexcept can be most valuable for a programmer reasoning about a program and for a compiler optimizing a program. The programmer need not worry about providing try-clauses (for dealing with failures in a noexcept function) and an optimizer need not worry about control paths from exception handling.
However, noexcept is not completely checked by the compiler and linker. What happens if the programmer “lied” so that a noexcept function deliberately or accidentally threw an exception that wasn’t caught before leaving the noexcept function? Consider:
double compute(double x) noexcept;
{
string s = "Courtney and Anya";
vector<double> tmp(10);
// ...
}
The vector constructor may fail to acquire memory for its ten doubles and throw a std::bad_alloc. In that case, the program terminates. It terminates unconditionally by invoking std::terminate() (§30.4.1.3). It does not invoke destructors from calling functions. It is implementation-defined whether destructors from scopes between the throw and the noexcept (e.g., for s in compute()) are invoked. The program is just about to terminate, so we should not depend on any object anyway. By adding a noexcept specifier, we indicate that our code was not written to cope with athrow.
13.5.1.2. The noexcept Operator
It is possible to declare a function to be conditionally noexcept. For example:
template<typename T>
void my_fct(T& x) noexcept(Is_pod<T>());
The noexcept(Is_pod<T>()) means that My_fct may not throw if the predicate Is_pod<T>() is true but may throw if it is false. I may want to write this if my_fct() copies its argument. I know that copying a POD does not throw, whereas other types (e.g., a string or a vector) may.
The predicate in a noexcept() specification must be a constant expression. Plain noexcept means noexcept(true).
The standard library provides many type predicates that can be useful for expressing the conditions under which a function may throw an exception (§35.4).
What if the predicate we want to use isn’t easily expressed using type predicates only? For example, what if the critical operation that may or may not throw is a function call f(x)? The noexcept() operator takes an expression as its argument and returns true if the compiler “knows” that it cannot throw and false otherwise. For example:
template<typename T>
void call_f(vector<T>& v) noexcept(noexcept(f(v[0]))
{
for (auto x : v)
f(x);
}
The double mention of noexcept looks a bit odd, but noexcept is not a common operator.
The operand of noexcept() is not evaluated, so in the example we do not get a run-time error if we pass call_f() with an empty vector.
A noexcept(expr) operator does not go to heroic lengths to determine whether expr can throw; it simply looks at every operation in expr and if they all have noexcept specifications that evaluate to true, it returns true. A noexcept(expr) does not look inside definitions of operations used in expr.
Conditional noexcept specifications and the noexcept() operator are common and important in standard-library operations that apply to containers. For example (§iso.20.2.2):
template<class T, size_t N>
void swap(T (&a)[N], T (&b)[N]) noexcept(noexcept(swap(*a, *b)));
13.5.1.3. Exception Specifications
In older C++ code, you may find exception specifications. For example:
void f(int) throw(Bad,Worse); // may only throw Bad or Worse exceptions
void g(int) throw(); // may not throw
An empty exception specification throw() is defined to be equivalent to noexcept (§13.5.1.1). That is, if an exception is thrown, the program terminates.
The meaning of a nonempty exception specification, such as throw(Bad,Worse), is that if the function (here f()) throws any exception that is not mentioned in the list or publicly derived from an exception mentioned there, an unexpected handler is called. The default effect of an unexpected exception is to terminate the program (§30.4.1.3). A nonempty throw specification is hard to use well and implies potentially expensive run-time checks to determine if the right exception is thrown. This feature has not been a success and is deprecated. Don’t use it.
If you want to dynamically check which exceptions are thrown, use a try-block.
13.5.2. Catching Exceptions
Consider:
void f()
{
try {
throw E{};
}
catch(H) {
// when do we get here?
}
}
The handler is invoked:
[1] If H is the same type as E
[2] If H is an unambiguous public base of E
[3] If H and E are pointer types and [1] or [2] holds for the types to which they refer
[4] If H is a reference and [1] or [2] holds for the type to which H refers
In addition, we can add const to the type used to catch an exception in the same way that we can add it to a function parameter. This doesn’t change the set of exceptions we can catch; it only restricts us from modifying the exception caught.
In principle, an exception is copied when it is thrown (§13.5). The implementation may apply a wide variety of strategies for storing and transmitting exceptions. It is guaranteed, however, that there is sufficient memory to allow new to throw the standard out-of-memory exception,bad_alloc (§11.2.3).
Note the possibility of catching an exception by reference. Exception types are often defined as part of class hierarchies to reflect relationships among the kinds of errors they represent. For examples, see §13.5.2.3 and §30.4.1.1. The technique of organizing exception classes into hierarchies is common enough for some programmers to prefer to catch every exception by reference.
The {} in both the try-part and a catch-clause of a try-block are real scopes. Consequently, if a name is to be used in both parts of a try-block or outside it, that name must be declared outside the try-block. For example:
void g()
{
int x1;
try {
int x2 = x1;
// ...
}
catch (Error) {
++x1; // OK
++x2; // error: x2 not in scope
int x3 = 7;
// ...
}
catch(...) {
++x3; // error: x3 not in scope
// ...
}
++x1; // OK
++x2; // error: x2 not in scope
++x3; // error: x3 not in scope
}
The “catch everything” clause, catch(...), is explained in §13.5.2.2.
13.5.2.1. Rethrow
Having caught an exception, it is common for a handler to decide that it can’t completely handle the error. In that case, the handler typically does what can be done locally and then throws the exception again. Thus, an error can be handled where it is most appropriate. This is the case even when the information needed to best handle the error is not available in a single place, so that the recovery action is best distributed over several handlers. For example:
void h()
{
try {
// ... code that might throw an exception ...
}
catch (std::exception& err) {
if (can_handle_it_completely) {
// ... handle it ...
return;
}
else {
// ... do what can be done here ...
throw; // rethrow the exception
}
}
}
A rethrow is indicated by a throw without an operand. A rethrow may occur in a catch-clause or in a function called from a catch-clause. If a rethrow is attempted when there is no exception to rethrow, std::terminate() (§13.5.2.5) will be called. A compiler can detect and warn about some, but not all, such cases.
The exception rethrown is the original exception caught and not just the part of it that was accessible as an exception. For example, had an out_of_range been thrown, h() would catch it as a plain exception, but throw; would still rethrow it as an out_of_range. Had I written throw err;instead of the simpler throw;, the exception would have been sliced (§17.5.1.4) and h()’s caller could not have caught it as an out_of_range.
13.5.2.2. Catch Every Exception
In <stdexcept>, the standard library provides a small hierarchy of exception classes with a common base exception (§30.4.1.1). For example:
void m()
{
try {
// ... do something ...
}
catch (std::exception& err) { // handle every standard-library exception
// ... cleanup ...
throw;
}
}
This catches every standard-library exception. However, the standard-library exceptions are just one set of exception types. Consequently, you cannot catch every exception by catching std::exception. If someone (unwisely) threw an int or an exception from some application-specific hierarchy, it would not be caught by the handler for std::exception&.
However, we often need to deal with every kind of exception. For example, if m() is supposed to leave some pointers in the state in which it found them, then we can write code in the handler to give them acceptable values. As for functions, the ellipsis, ..., indicates “any argument” (§12.2.4), so catch(...) means “catch any exception.” For example:
void m()
{
try {
// ... something ...
}
catch(...) { // handle every exception
// ... cleanup ...
throw;
}
}
13.5.2.3. Multiple Handlers
A try-block may have multiple catch-clauses (handlers). Because a derived exception can be caught by handlers for more than one exception type, the order in which the handlers are written in a try-statement is significant. The handlers are tried in order. For example:
void f()
{
try {
// ...
}
catch (std::ios_base::failure) {
// ... handle any iostream error (§30.4.1.1) ...
}
catch (std::exception& e) {
// ... handle any standard-library exception (§30.4.1.1) ...
}
catch (...) {
// ... handle any other exception (§13.5.2.2) ...
}
}
The compiler knows the class hierarchy, so it can warn about many logical mistakes. For example:
void g()
{
try {
// ...
}
catch (...) {
// ... handle every exception (§13.5.2.2) ...
}
catch (std::exception& e) {
// ... handle any standard library exception (§30.4.1.1) ...
}
catch (std::bad_cast) {
// ... handle dynamic_cast failure (§22.2.1) ...
}
}
Here, the exception is never considered. Even if we removed the “catch-all” handler, bad_cast wouldn’t be considered because it is derived from exception. Matching exception types to catch-clauses is a (fast) run-time operation and is not as general as (compile-time) overload resolution.
13.5.2.4. Function try-Blocks
The body of a function can be a try-block. For example:
int main()
try
{
// ... do something ...
}
catch (...} {
// ... handle exception ...
}
For most functions, all we gain from using a function try-block is a bit of notational convenience. However, a try-block allows us to deal with exceptions thrown by base-or-member initializers in constructors (§17.4). By default, if an exception is thrown in a base-or-member initializer, the exception is passed on to whatever invoked the constructor for the member’s class. However, the constructor itself can catch such exceptions by enclosing the complete function body – including the member initializer list – in a try-block. For example:
class X {
vector<int> vi;
vector<string> vs;
// ...
public:
X(int,int);
// ...
};
X::X(int sz1, int sz2)
try
:vi(sz1), // construct vi with sz1 ints
vs(sz2), // construct vs with sz2 strings
{
// ...
}
catch (std::exception& err) { // exceptions thrown for vi and vs are caught here
// ...
}
So, we can catch exceptions thrown by member constructors. Similarly, we can catch exceptions thrown by member destructors in a destructor (though a destructor should never throw). However, we cannot “repair” the object and return normally as if the exception had not happened: an exception from a member constructor means that the member may not be in a valid state. Also, other member objects will either not be constructed or already have had their destructors invoked as part of the stack unwinding.
The best we can do in a catch-clause of a function try-block for a constructor or destructor is to throw an exception. The default action is to rethrow the original exception when we “fall off the end” of the catch-clause (§iso.15.3).
There are no such restrictions for the try-block of an ordinary function.
13.5.2.5. Termination
There are cases where exception handling must be abandoned for less subtle error-handling techniques. The guiding principles are:
• Don’t throw an exception while handling an exception.
• Don’t throw an exception that can’t be caught.
If the exception-handling implementation catches you doing either, it will terminate your program.
If you managed to have two exceptions active at one time (in the same thread, which you can’t), the system would have no idea which of the exceptions to try to handle: your new one or the one it was already trying to handle. Note that an exception is considered handled immediately upon entry into a catch-clause. Rethrowing an exception (§13.5.2.1) or throwing a new exception from within a catch-clause is considered a new throw done after the original exception has been handled. You can throw an exception from within a destructor (even during stack unwinding) as long as you catch it before it leaves the destructor.
The specific rules for calling terminate() are (§iso.15.5.1)
• When no suitable handler was found for a thrown exception
• When a noexcept function tries to exit with a throw
• When a destructor invoked during stack unwinding tries to exit with a throw
• When code invoked to propagate an exception (e.g., a copy constructor) tries to exit with a throw
• When someone tries to rethrow (throw;) when there is no current exception being handled
• When a destructor for a statically allocated or thread-local object tries to exit with a throw
• When an initializer for a statically allocated or thread-local object tries to exit with a throw
• When a function invoked as an atexit() function tries to exit with a throw
In such cases, the function std::terminate() is called. In addition, a user can call terminate() if less drastic approaches are infeasible.
By “tries to exit with a throw,” I mean that an exception is thrown somewhere and not caught so that the run-time system tries to propagate it from a function to its caller.
By default, terminate() will call abort() (§15.4.3). This default is the correct choice for most users – especially during debugging. If that is not acceptable, the user can provide a terminate handler function by a call std::set_terminate() from <exception>:
using terminate_handler = void(*)(); // from <exception>
[[noreturn]] void my_handler() // a terminate handler cannot return
{
// handle termination my way
}
void dangerous() // very!
{
terminate_handler old = set_terminate(my_handler);
// ...
set_terminate(old); // restore the old terminate handler
}
The return value is the previous function given to set_terminate().
For example, a terminate handler could be used to abort a process or maybe to re-initialize a system. The intent is for terminate() to be a drastic measure to be applied when the error recovery strategy implemented by the exception-handling mechanism has failed and it is time to go to another level of a fault tolerance strategy. If a terminate handler is entered, essentially nothing can be assumed about a program’s data structures; they must be assumed to be corrupted. Even writing an error message using cerr must be assumed to be hazardous. Also, note that as dangerous()is written, it is not exception-safe. A throw or even a return before set_terminate(old) will leave my_handler in place when it wasn’t meant to be. If you must mess with terminate(), at least use RAII (§13.3).
A terminate handler cannot return to its caller. If it tries to, terminate() will call abort().
Note that abort() indicates abnormal exit from the program. The function exit() can be used to exit a program with a return value that indicates to the surrounding system whether the exit is normal or abnormal (§15.4.3).
It is implementation-defined whether destructors are invoked when a program is terminated because of an uncaught exception. On some systems, it is essential that the destructors are not called so that the program can be resumed from the debugger. On other systems, it is architecturally close to impossible not to invoke the destructors while searching for a handler.
If you want to ensure cleanup when an otherwise uncaught exception happens, you can add a catch-all handler (§13.5.2.2) to main() in addition to handlers for exceptions you really care about. For example:
int main()
try {
// ...
}
catch (const My_error& err) {
// ... handle my error ...
}
catch (const std::range_error&)
{
cerr << "range error: Not again!\n";
}
catch (const std::bad_alloc&)
{
cerr << "new ran out of memory\n";
}
catch (...) {
// ...
}
This will catch every exception, except those thrown by construction and destruction of namespace and thread-local variables (§13.5.3). There is no way of catching exceptions thrown during initialization or destruction of namespace and thread-local variables. This is another reason to avoid global variables whenever possible.
When an exception is caught, the exact point where it was thrown is generally not known. This represents a loss of information compared to what a debugger might know about the state of a program. In some C++ development environments, for some programs, and for some people, it might therefore be preferable not to catch exceptions from which the program isn’t designed to recover.
See Assert (§13.4) for an example of how one might encode the location of a throw into the thrown exception.
13.5.3. Exceptions and Threads
If an exception is not caught on a thread (§5.3.1, §42.2), std::terminate() (§13.5.2.5) is called. So, if we don’t want an error in a thread to stop the whole program, we must catch all errors from which we would like to recover and somehow report them to a part of the program that is interested in the results of the thread. The “catch-all” construct catch(...) (§13.5.2.2) comes in handy for that.
We can transfer an exception thrown on one thread to a handler on another thread using the standard-library function current_exception() (§30.4.1.2). For example:
try {
// ... do the work ...
}
catch(...) {
prom.set_exception(current_exception());
}
This is the basic technique used by packaged_task to handle exceptions from user code (§5.3.5.2).
13.6. A vector Implementation
The standard vector provides splendid examples of techniques for writing exception-safe code: its implementation illustrates problems that occur in many contexts and solutions that apply widely.
Obviously, a vector implementation relies on many language facilities provided to support the implementation and use of classes. If you are not (yet) comfortable with C++’s classes and templates, you may prefer to delay studying this example until you have read Chapter 16, Chapter 25, and Chapter 26. However, a good understanding of the use of exceptions in C++ requires a more extensive example than the code fragments so far in this chapter.
The basic tools available for writing exception-safe code are:
• The try-block (§13.5).
• The support for the “Resource Acquisition Is Initialization” technique (§13.3).
The general principles to follow are to
• Never let go of a piece of information before its replacement is ready for use.
• Always leave objects in valid states when throwing or rethrowing an exception.
That way, we can always back out of an error situation. The practical difficulty in following these principles is that innocent-looking operations (such as <, =, and sort()) might throw exceptions. Knowing what to look for in an application takes experience.
When you are writing a library, the ideal is to aim at the strong exception-safety guarantee (§13.2) and always to provide the basic guarantee. When writing a specific program, there may be less concern for exception safety. For example, if I write a simple data analysis program for my own use, I’m usually quite willing to have the program terminate in the unlikely event of memory exhaustion.
Correctness and basic exception safety are closely related. In particular, the techniques for providing basic exception safety, such as defining and checking invariants (§13.4), are similar to the techniques that are useful to get a program small and correct. It follows that the overhead of providing the basic exception-safety guarantee (§13.2) – or even the strong guarantee – can be minimal or even insignificant.
13.6.1. A Simple vector
A typical implementation of vector (§4.4.1, §31.4) will consist of a handle holding pointers to the first element, one-past-the-last element, and one-past-the-last allocated space (§31.2.1) (or the equivalent information represented as a pointer plus offsets):
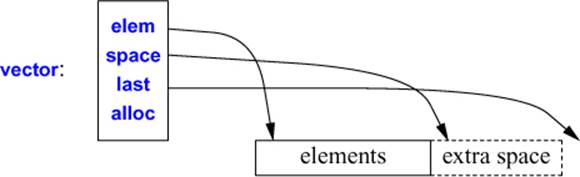
In addition, it holds an allocator (here, alloc), from which the vector can acquire memory for its elements. The default allocator (§34.4.1) uses new and delete to acquire and release memory.
Here is a declaration of vector simplified to present only what is needed to discuss exception safety and avoidance of resource leaks:
template<class T, class A = allocator<T>>
class vector {
private:
T* elem; // start of allocation
T* space; // end of element sequence, start of space allocated for possible expansion
T* last; // end of allocated space
A alloc; // allocator
public:
using size_type = unsigned int; // type used for vector sizes
explicit vector(size_type n, const T& val = T(), const A& = A());
vector(const vector& a); // copy constructor
vector& operator=(const vector& a); // copy assignment
vector(vector&& a); // move constructor
vector& operator=(vector&& a); // move assignment
~vector();
size_type size() const { return space–elem; }
size_type capacity() const { return last–elem; }
void reserve(size_type n); // increase capacity to n
void resize(size_type n, const T& = {}); // increase size to n
void push_back(const T&); // add an element at the end
// ...
};
Consider first a naive implementation of the constructor that initializes a vector to n elements initialized to val:
template<class T, class A>
vector<T,A>::vector(size_type n, const T& val, const A& a) // warning: naive implementation
:alloc{a} // copy the allocator
{
elem = alloc.allocate(n); // get memory for elements (§34.4)
space = last = elem+n;
for (T* p = elem; p!=last; ++p)
a.construct(p,val); // construct copy of val in *p (§34.4)
}
There are two potential sources of exceptions here:
[1] allocate() may throw an exception if no memory is available.
[2] T’s copy constructor may throw an exception if it can’t copy val.
What about the copy of the allocator? We can imagine that it throws, but the standard specifically requires that it does not do that (§iso.17.6.3.5). Anyway, I have written the code so that it wouldn’t matter if it did.
In both cases of a throw, no vector object is created, so vector’s destructor is not called (§13.3).
When allocate() fails, the throw will exit before any resources are acquired, so all is well.
When T’s copy constructor fails, we have acquired some memory that must be freed to avoid memory leaks. Worse still, the copy constructor for T might throw an exception after correctly constructing a few elements but before constructing them all. These T objects may own resources that then would be leaked.
To handle this problem, we could keep track of which elements have been constructed and destroy those (and only those) in case of an error:
template<class T, class A>
vector<T,A>::vector(size_type n, const T& val, const A& a) // elaborate implementation
:alloc{a} // copy the allocator
{
elem = alloc.allocate(n); // get memory for elements
iterator p;
try {
iterator end = elem+n;
for (p=elem; p!=end; ++p)
alloc.construct(p,val); // construct element (§34.4)
last = space = p;
}
catch (...) {
for (iterator q = elem; q!=p; ++q)
alloc.destroy(q); // destroy constructed elements
alloc.deallocate(elem,n); // free memory
throw; // rethrow
}
}
Note that the declaration of p is outside the try-block; otherwise, we would not be able to access it in both the try-part and the catch-clause.
The overhead here is the overhead of the try-block. In a good C++ implementation, this overhead is negligible compared to the cost of allocating memory and initializing elements. For implementations where entering a try-block incurs a cost, it may be worthwhile to add a test if (n)before the try to explicitly handle the (very common) empty vector case.
The main part of this constructor is a repeat of the implementation of std::uninitialized_fill():
template<class For, class T>
void uninitialized_fill(For beg, For end, const T& x)
{
For p;
try {
for (p=beg; p!=end; ++p)
::new(static_cast<void* >(&*p)) T(x); // construct copy of x in *p (§11.2.4)
}
catch (...) {
for (For q = beg; q!=p; ++q)
(&*q)–>~T(); // destroy element (§11.2.4)
throw; // rethrow (§13.5.2.1)
}
}
The curious construct &p takes care of iterators that are not pointers. In that case, we need to take the address of the element obtained by dereference to get a pointer. Together with the explicitly global ::new, the explicit cast to void* ensures that the standard-library placement function (§17.2.4) is used to invoke the constructor, and not some user-defined operator new() for T*s. The calls to alloc.construct() in the vector constructors are simply syntactic sugar for this placement new. Similarly, the alloc.destroy() call simply hides explicit destruction (like (&*xq)–>~T()). This code is operating at a rather low level where writing truly general code can be difficult.
Fortunately, we don’t have to invent or implement uninitialized_fill(), because the standard library provides it (§32.5.6). It is often essential to have initialization operations that either complete successfully, having initialized every element, or fail, leaving no constructed elements behind. Consequently, the standard library provides uninitialized_fill(), uninitialized_fill_n(), and uninitialized_copy() (§32.5.6), which offer the strong guarantee (§13.2).
The uninitialized_fill() algorithm does not protect against exceptions thrown by element destructors or iterator operations (§32.5.6). Doing so would be prohibitively expensive and probably impossible.
The uninitialized_fill() algorithm can be applied to many kinds of sequences. Consequently, it takes a forward iterator (§33.1.2) and cannot guarantee to destroy elements in the reverse order of their construction.
Using uninitialized_fill(), we can simplify our constructor:
template<class T, class A>
vector<T,A>::vector(size_type n, const T& val, const A& a) // still a bit messy
:alloc(a) // copy the allocator
{
elem = alloc.allocate(n); // get memory for elements
try {
uninitialized_fill(elem,elem+n,val); // copy elements
space = last = elem+n;
}
catch (...) {
alloc.deallocate(elem,n); // free memory
throw; // rethrow
}
}
This is a significant improvement on the first version of this constructor, but the next section demonstrates how to further simplify it.
The constructor rethrows a caught exception. The intent is to make vector transparent to exceptions so that the user can determine the exact cause of a problem. All standard-library containers have this property. Exception transparency is often the best policy for templates and other “thin” layers of software. This is in contrast to major parts of a system (“modules”) that generally need to take responsibility for all exceptions thrown. That is, the implementer of such a module must be able to list every exception that the module can throw. Achieving this may involve grouping exceptions into hierarchies (§13.5.2) and using catch(...) (§13.5.2.2).
13.6.2. Representing Memory Explicitly
Experience shows that writing correct exception-safe code using explicit try-blocks is more difficult than most people expect. In fact, it is unnecessarily difficult because there is an alternative: The “Resource Acquisition Is Initialization” technique (§13.3) can be used to reduce the amount of code that must be written and to make the code more stylized. In this case, the key resource required by the vector is memory to hold its elements. By providing an auxiliary class to represent the notion of memory used by a vector, we can simplify the code and decrease the chances of accidentally forgetting to release it:
template<class T, class A = allocator<T> >
struct vector_base { // memory structure for vector
A alloc; // allocator
T* elem; // start of allocation
T* space; // end of element sequence, start of space allocated for possible expansion
T* last; // end of allocated space
vector_base(const A& a, typename A::size_type n)
: alloc{a}, elem{alloc.allocate(n)}, space{elem+n}, last{elem+n} { }
~vector_base() { alloc.deallocate(elem,last–elem); }
vector_base(const vector_base&) = delete; // no copy operations
vector_base& operator=(const vector_base&) = delete;
vector_base(vector_base&&); // move operations
vector_base& operator=(vector_base&&);
};
As long as elem and last are correct, vector_base can be destroyed. Class vector_base deals with memory for a type T, not objects of type T. Consequently, a user of vector_base must construct all objects explicitly in the allocated space and later destroy all constructed objects in avector_base before the vector_base itself is destroyed.
The vector_base is designed exclusively to be part of the implementation of vector. It is always hard to predict where and how a class will be used, so I made sure that a vector_base can’t be copied and also that a move of a vector_base properly transfers ownership of the memory allocated for elements:
template<class T, class A>
vector_base<T,A>::vector_base(vector_base&& a)
: alloc{a.alloc},
elem{a.elem},
space{a.space},
last{a.space}
{
a.elem = a.space = a.last = nullptr; // no longer owns any memory
}
template<class T, class A>
vector_base<T,A>::& vector_base<T,A>::operator=(vector_base&& a)
{
swap(*this,a);
return *this;
}
This definition of the move assignment uses swap() to transfer ownership of any memory allocated for elements. There are no objects of type T to destroy: vector_base deals with memory and leaves concerns about objects of type T to vector.
Given vector_base, vector can be defined like this:
template<class T, class A = allocator<T> >
class vector {
vector_base<T,A> vb; // the data is here
void destroy_elements();
public:
using size_type = unsigned int;
explicit vector(size_type n, const T& val = T(), const A& = A());
vector(const vector& a); // copy constructor
vector& operator=(const vector& a); // copy assignment
vector(vector&& a); // move constructor
vector& operator=(vector&& a); // move assignment
~vector() { destroy_elements(); }
size_type size() const { return vb.space–vb.elem; }
size_type capacity() const { return vb.last–vb.elem; }
void reserve(size_type); // increase capacity
void resize(size_type, T = {}); // change the number of elements
void clear() { resize(0); } // make the vector empty
void push_back(const T&); // add an element at the end
// ...
};
template<class T, class A>
void vector<T,A>::destroy_elements()
{
for (T* p = vb.elem; p!=vb.space; ++p)
p–>~T(); // destroy element (§17.2.4)
vb.space=vb.elem;
}
The vector destructor explicitly invokes the T destructor for every element. This implies that if an element destructor throws an exception, the vector destruction fails. This can be a disaster if it happens during stack unwinding caused by an exception and terminate() is called (§13.5.2.5). In the case of normal destruction, throwing an exception from a destructor typically leads to resource leaks and unpredictable behavior of code relying on reasonable behavior of objects. There is no really good way to protect against exceptions thrown from destructors, so the library makes no guarantees if an element destructor throws (§13.2).
Now the constructor can be simply defined:
template<class T, class A>
vector<T,A>::vector(size_type n, const T& val, const A& a)
:vb{a,n} // allocate space for n elements
{
uninitialized_fill(vb.elem,vb.elem+n,val);// make n copies of val
}
The simplification achieved for this constructor carries over to every vector operation that deals with initialization or allocation. For example, the copy constructor differs mostly by using uninitialized_copy() instead of uninitialized_fill():
template<class T, class A>
vector<T,A>::vector(const vector<T,A>& a)
:vb{a.alloc,a.size()}
{
uninitialized_copy(a.begin(),a.end(),vb.elem);
}
This style of constructor relies on the fundamental language rule that when an exception is thrown from a constructor, subobjects (including bases) that have already been completely constructed will be properly destroyed (§13.3). The uninitialized_fill() algorithm and its cousins (§13.6.1) provide the equivalent guarantee for partially constructed sequences.
The move operations are even simpler:
template<class T, class A>
vector<T,A>::vector(vector&& a) // move constructor
:vb{move(a.vb)} // transfer ownership
{
}
The vector_base move constructor will set the argument’s representation to “empty.”
For the move assignment, we must take care of the old value of the target:
template<class T, class A>
vector<T,A>::& vector<T,A>::operator=(vector&& a) // move assignment
{
clear(); // destroy elements
swap(*this,a); // transfer ownership
}
The clear() is strictly speaking redundant because I could assume that the rvalue a would be destroyed immediately after the assignment. However, I don’t know if some programmer has been playing games with std::move().
13.6.3. Assignment
As usual, assignment differs from construction in that an old value must be taken care of. First consider a straightforward implementation:
template<class T, class A>
vector<T,A>& vector<T,A>::operator=(const vector& a) // offers the strong guarantee (§13.2)
{
vector_base<T,A> b(alloc,a.size()); // get memory
uninitialized_copy(a.begin(),a.end(),b.elem); // copy elements
destroy_elements(); // destroy old elements
swap(vb,b); // transfer ownership
return *this; // implicitly destroy the old value
}
This vector assignment provides the strong guarantee, but it repeats a lot of code from constructors and destructors. We can avoid repetition:
template<class T, class A>
vector<T,A>& vector<T,A>::operator=(const vector& a) // offers the strong guarantee (§13.2)
{
vector temp {a}; // copy allocator
std::swap(*this,temp); // swap representations
return *this;
}
The old elements are destroyed by temp’s destructor, and the memory used to hold them is deallocated by temp’s vector_base’s destructor.
The reason that the standard-library swap() (§35.5.2) works for vector_bases is that we defined vector_base move operations for swap() to use.
The performance of the two versions ought to be equivalent. Essentially, they are just two different ways of specifying the same set of operations. However, the second implementation is shorter and doesn’t replicate code from related vector functions, so writing the assignment that way ought to be less error-prone and lead to simpler maintenance.
Note that I did not test for self-assignment, such as v=v. This implementation of = works by first constructing a copy and then swapping representations. This obviously handles self-assignment correctly. I decided that the efficiency gained from the test in the rare case of self-assignment was more than offset by its cost in the common case where a different vector is assigned.
In either case, two potentially significant optimizations are missing:
[1] If the capacity of the vector assigned to is large enough to hold the assigned vector, we don’t need to allocate new memory.
[2] An element assignment may be more efficient than an element destruction followed by an element construction.
Implementing these optimizations, we get:
template<class T, class A>
vector<T,A>& vector<T,A>::operator=(const vector& a) // optimized, basic guarantee (§13.2) only
{
if (capacity() < a.size()) { // allocate new vector representation:
vector temp {a}; // copy allocator
swap(*this,temp); // swap representations
return *this; // implicitly destroy the old value
}
if (this == &a) return *this; // optimize self assignment
size_type sz = size();
size_type asz = a.size();
vb.alloc = a.vb.alloc; // copy the allocator
if (asz<=sz) {
copy(a.begin(),a.begin()+asz,vb.elem);
for (T* p = vb.elem+asz; p!=vb.space; ++p) // destroy surplus elements (§16.2.6)
p–>~T();
}
else {
copy(a.begin(),a.begin()+sz,vb.elem);
uninitialized_copy(a.begin()+sz,a.end(),vb.space); // construct extra elements
}
vb.space = vb.elem+asz;
return *this;
}
These optimizations are not free. Obviously, the complexity of the code is far higher. Here, I also test for self-assignment. However, I do so mostly to show how it is done because here it is only an optimization.
The copy() algorithm (§32.5.1) does not offer the strong exception-safety guarantee. Thus, if T::operator=() throws an exception during copy(), the vector being assigned to need not be a copy of the vector being assigned, and it need not be unchanged. For example, the first five elements might be copies of elements of the assigned vector and the rest unchanged. It is also plausible that an element – the element that was being copied when T::operator=() threw an exception – ends up with a value that is neither the old value nor a copy of the corresponding element in the vector being assigned. However, if T::operator=() leaves its operands in valid states before it throws (as it should), the vector is still in a valid state – even if it wasn’t the state we would have preferred.
The standard-library vector assignment offers the (weaker) basic exception-safety guarantee of this last implementation – and its potential performance advantages. If you need an assignment that leaves the vector unchanged if an exception is thrown, you must either use a library implementation that provides the strong guarantee or provide your own assignment operation. For example:
template<class T, class A>
void safe_assign(vector<T,A>& a, const vector<T,A>& b) // simple a = b
{
vector<T,A> temp{b}; // copy the elements of b into a temporary
swap(a,temp);
}
Alternatively, we could simply use call-by-value (§12.2):
template<class T, class A>
void safe_assign(vector<T,A>& a, vector<T,A> b) // simple a = b (note: b is passed by value)
{
swap(a,b);
}
I never can decide if this last version is simply beautiful or too clever for real (maintainable) code.
13.6.4. Changing Size
One of the most useful aspects of vector is that we can change its size to suit our needs. The most popular functions for changing size are v.push_back(x), which adds an x at the end of v, and v.resize(s), which makes s the number of elements in v.
13.6.4.1. reserve()
The key to a simple implementation of such functions is reserve(), which adds free space at the end for the vector to grow into. In other words, reserve() increases the capacity() of a vector. If the new allocation is larger than the old, reserve() needs to allocate new memory and move the elements into it. We could try the trick from the unoptimized assignment (§13.6.3):
template<class T, class A>
void vector<T,A>::reser ve(size_type newalloc) // flawed first attempt
{
if (newalloc<=capacity()) return; // never decrease allocation
vector<T,A> v(capacity()); // make a vector with the new capacity
copy(elem,elem+size(),v.begin()) // copy elements
swap(*this,v); // install new value
} // implicitly release old value
This has the nice property of providing the strong guarantee. However, not all types have a default value, so this implementation is flawed. Furthermore, looping over the elements twice, first to default construct and then to copy, is a bit odd. So let us optimize:
template<class T, class A>
void vector<T,A>::reserve(size_type newalloc)
{
if (newalloc<=capacity()) return; // never decrease allocation
vector_base<T,A> b {vb.alloc,newalloc}; // get new space
uninitialized_move(elem,elem+size(),b.elem); // move elements
swap(vb,b); // install new base
} // implicitly release old space
The problem is that the standard library doesn’t offer uninitialized_move(), so we have to write it:
template<typename In, typename Out>
Out uninitialized_move(In b, In e, Out oo)
{
for (; b!=e; ++b,++oo) {
new(static_cast<void*>(&*oo)) T{move(*b)}; // move construct
b–>~T(); // destroy
}
return b;
}
In general, there is no way of recovering the original state from a failed move, so I don’t try to. This uninitialized_move() offers only the basic guarantee. However, it is simple and for the vast majority of cases it is fast. Also, the standard-library reserve() only offers the basic guarantee.
Whenever reserve() may have moved the elements, any iterators into the vector may have been invalidated (§31.3.3).
Remember that a move operation should not throw. In the rare cases where the obvious implementation of a move might throw, we typically go out of our way to avoid that. A throw from a move operation is rare, unexpected, and damaging to normal reasoning about code. If at all possible avoid it. The standard-library move_if_noexcept() operations may be of help here (§35.5.1).
The explicit use of move() is needed because the compiler doesn’t know that elem[i] is just about to be destroyed.
13.6.4.2. resize()
The vector member function resize() changes the number of elements. Given reserve(), the implementation resize() is fairly simple. If the number of elements increases, we must construct the new elements. Conversely, if the number of elements decrease, we must destroy the surplus elements:
template<class T, class A>
void vector<T,A>::resize(size_type newsize, const T& val)
{
reserve(newsize);
if (size()<newsize)
uninitialized_fill(elem+size(),elem+newsize,val); // construct new elements: [size():newsize)
else
destroy(elem.size(),elem+newsize); // destroy surplus elements: [newsize:size())
vb.space = vb.last = vb.elem+newsize;
}
There is no standard destroy(), but that easily written:
template<typename In>
void destroy(In b, In e)
{
for (; b!=e; ++b) // destroy [b:e)
b–>~T();
}
13.6.4.3. push_back()
From an exception-safety point of view, push_back() is similar to assignment in that we must take care that the vector remains unchanged if we fail to add a new element:
template< class T, class A>
void vector<T,A>::push_back(const T& x)
{
if (capacity()==size()) // no more free space; relocate:
reserve(sz?2*sz:8); // grow or start with 8
vb.alloc.construct(&vb.elem[size()],val); // add val at end
++vb.space; // increment size
}
Naturally, the copy constructor used to initialize *space might throw an exception. If that happens, the value of the vector remains unchanged, with space left unincremented. However, reserve() may already have reallocated the existing elements.
This definition of push_back() contains two “magic numbers” (2 and 8). An industrial-strength implementation would not do that, but it would still have values determining the size of the initial allocation (here, 8) and the rate of growth (here, 2, indicating a doubling in size each time thevector would otherwise overflow). As it happens, these are not unreasonable or uncommon values. The assumption is that once we have seen one push_back() for a vector, we will almost certainly see many more. The factor two is larger than the mathematically optimal factor to minimize average memory use (1.618), so as to give better run-time performance for systems where memories are not tiny.
13.6.4.4. Final Thoughts
Note the absence of try-blocks in the vector implementation (except for the one hidden inside uninitialized_copy()). The changes in state were done by carefully ordering the operations so that if an exception is thrown, the vector remains unchanged or at least valid.
The approach of gaining exception safety through ordering and the RAII technique (§13.3) tends to be more elegant and more efficient than explicitly handling errors using try-blocks. More problems with exception safety arise from a programmer ordering code in unfortunate ways than from lack of specific exception-handling code. The basic rule of ordering is not to destroy information before its replacement has been constructed and can be assigned without the possibility of an exception.
Exceptions introduce possibilities for surprises in the form of unexpected control flows. For a piece of code with a simple local control flow, such as the reserve(), safe_assign(), and push_back() examples, the opportunities for surprises are limited. It is relatively simple to look at such code and ask, “Can this line of code throw an exception, and what happens if it does?” For large functions with complicated control structures, such as complicated conditional statements and nested loops, this can be hard. Adding try-blocks increases this local control structure complexity and can therefore be a source of confusion and errors (§13.3). I conjecture that the effectiveness of the ordering approach and the RAII approach compared to more extensive use of try-blocks stems from the simplification of the local control flow. Simple, stylized code is easier to understand, easier to get right, and easier to generate good code for.
This vector implementation is presented as an example of the problems that exceptions can pose and of techniques for addressing those problems. The standard does not require an implementation to be exactly like the one presented here. However, the standard does require the exception-safety guarantees as provided by the example.
13.7. Advice
[1] Develop an error-handling strategy early in a design; §13.1.
[2] Throw an exception to indicate that you cannot perform an assigned task; §13.1.1.
[3] Use exceptions for error handling; §13.1.4.2.
[4] Use purpose-designed user-defined types as exceptions (not built-in types); §13.1.1.
[5] If you for some reason cannot use exceptions, mimic them; §13.1.5.
[6] Use hierarchical error handling; §13.1.6.
[7] Keep the individual parts of error handling simple; §13.1.6.
[8] Don’t try to catch every exception in every function; §13.1.6.
[9] Always provide the basic guarantee; §13.2, §13.6.
[10] Provide the strong guarantee unless there is a reason not to; §13.2, §13.6.
[11] Let a constructor establish an invariant, and throw if it cannot; §13.2.
[12] Release locally owned resources before throwing an exception; §13.2.
[13] Be sure that every resource acquired in a constructor is released when throwing an exception in that constructor; §13.3.
[14] Don’t use exceptions where more local control structures will suffice; §13.1.4.
[15] Use the “Resource Acquisition Is Initialization” technique to manage resources; §13.3.
[16] Minimize the use of try-blocks; §13.3.
[17] Not every program needs to be exception-safe; §13.1.
[18] Use “Resource Acquisition Is Initialization” and exception handlers to maintain invariants; §13.5.2.2.
[19] Prefer proper resource handles to the less structured finally; §13.3.1.
[20] Design your error-handling strategy around invariants; §13.4.
[21] What can be checked at compile time is usually best checked at compile time (using static_assert); §13.4.
[22] Design your error-handling strategy to allow for different levels of checking/enforcement; §13.4.
[23] If your function may not throw, declare it noexcept; §13.5.1.1
[24] Don’t use exception specification; §13.5.1.3.
[25] Catch exceptions that may be part of a hierarchy by reference; §13.5.2.
[26] Don’t assume that every exception is derived from class exception; §13.5.2.2.
[27] Have main() catch and report all exceptions; §13.5.2.2, §13.5.2.4.
[28] Don’t destroy information before you have its replacement ready; §13.6.
[29] Leave operands in valid states before throwing an exception from an assignment; §13.2.
[30] Never let an exception escape from a destructor; §13.2.
[31] Keep ordinary code and error-handling code separate; §13.1.1, §13.1.4.2.
[32] Beware of memory leaks caused by memory allocated by new not being released in case of an exception; §13.3.
[33] Assume that every exception that can be thrown by a function will be thrown; §13.2.
[34] A library shouldn’t unilaterally terminate a program. Instead, throw an exception and let a caller decide; §13.4.
[35] A library shouldn’t produce diagnostic output aimed at an end user. Instead, throw an exception and let a caller decide; §13.1.3.
All materials on the site are licensed Creative Commons Attribution-Sharealike 3.0 Unported CC BY-SA 3.0 & GNU Free Documentation License (GFDL)
If you are the copyright holder of any material contained on our site and intend to remove it, please contact our site administrator for approval.
© 2016-2026 All site design rights belong to S.Y.A.