The C++ Programming Language (2013)
Part II: Basic Facilities
14. Namespaces
The year is 787!
A.D.?
– Monty Python
• Composition Problems
• Namespaces
Explicit Qualification; using-Declarations; using-Directives; Argument-Dependent Lookup; Namespaces Are Open
• Modularization and Interfaces
Namespaces as Modules; Implementations; Interfaces and Implementations
• Composition Using Namespaces
Convenience vs. Safety; Namespace Aliases; Namespace Composition; Composition and Selection; Namespaces and Overloading; Versioning; Nested Namespaces; Unnamed Namespaces; C Headers
• Advice
14.1. Composition Problems
Any realistic program consists of a number of separate parts. Functions (§2.2.1, Chapter 12) and classes (§3.2, Chapter 16) provide relatively fine-grained separation of concerns, whereas “libraries,” source files, and translation units (§2.4, Chapter 15) provide coarser grain. The logical ideal is modularity, that is, to keep separate things separate and to allow access to a “module” only through a well-specified interface. C++ does not provide a single language feature supporting the notion of a module; there is no module construct. Instead, modularity is expressed through combinations of other language facilities, such as functions, classes, and namespaces, and source code organization.
This chapter and the next deal with the coarse structure of a program and its physical representation as source files. That is, these two chapters are more concerned with programming in the large than with the elegant expression of individual types, algorithms, and data structures.
Consider some of the problems that can arise when people fail to design for modularity. For example, a graphics library may provide different kinds of graphical Shapes and functions to help use them:
// Graph_lib:
class Shape { /* ... */ };
class Line : public Shape { /* ... */ };
class Poly_line: public Shape { /* ... */ }; // connected sequence of lines
class Text : public Shape { /* ... */ }; // text label
Shape operator+(const Shape&, const Shape&); // compose
Graph_reader open(const char*); // open file of Shapes
Now someone comes along with another library, providing facilities for text manipulation:
// Text_lib:
class Glyph { /* ... */ };
class Word { /* ... */ }; // sequence of Glyphs
class Line { /* ... */ }; // sequence of Words
class Text { /* ... */ }; // sequence of Lines
File* open(const char*); // open text file
Word operator+(const Line&, const Line&); // concatenate
For the moment, let us ignore the specific design issues for graphics and text manipulation and just consider the problems of using Graph_lib and Text_lib together in a program.
Assume (realistically enough) that the facilities of Graph_lib are defined in a header (§2.4.1), Graph_lib.h, and the facilities of Text_lib are defined in another header, Text_lib.h. Now, I can “innocently” #include both and try to use facilities from the two libraries:
#include "Graph_lib.h"
#include "Text_lib.h"
// ...
Just #includeing those headers causes a slurry of error messages: Line, Text, and open() are defined twice in ways that a compiler cannot disambiguate. Trying to use the libraries would give further error messages.
There are many techniques for dealing with such name clashes. For example, some such problems can be addressed by placing all the facilities of a library inside a few classes, by using supposedly uncommon names (e.g., Text_box rather than Text), or by systematically using a prefix for names from a library (e.g., gl_shape and gl_line). Each of these techniques (also known as “workarounds” and “hacks”) works in some cases, but they are not general and can be inconvenient to use. For example, names tend to become long, and the use of many different names inhibits generic programming (§3.4).
14.2. Namespaces
The notion of a namespace is provided to directly represent the notion of a set of facilities that directly belong together, for example, the code of a library. The members of a namespace are in the same scope and can refer to each other without special notation, whereas access from outside the namespace requires explicit notation. In particular, we can avoid name clashes by separating sets of declarations (e.g., library interfaces) into namespaces. For example, we might call the graph library Graph_lib:
namespace Graph_lib {
class Shape { /* ... */ };
class Line : public Shape { /* ... */ };
class Poly_line: public Shape { /* ... */ }; // connected sequence of lines
class Text : public Shape { /* ... */ }; // text label
Shape operator+(const Shape&, const Shape&); // compose
Graph_reader open(const char*); // open file of Shapes
}
Similarly, the obvious name for our text library is Text_lib:
namespace Text_lib {
class Glyph { /* ... */ };
class Word { /* ... */ }; // sequence of Glyphs
class Line { /* ... */ }; // sequence of Words
class Text { /* ... */ }; // sequence of Lines
File* open(const char*); // open text file
Word operator+(const Line&, const Line&); // concatenate
}
As long as we manage to pick distinct namespace names, such as Graph_lib and Text_lib (§14.4.2), we can now compile the two sets of declarations together without name clashes.
A namespace should express some logical structure: the declarations within a namespace should together provide facilities that unite them in the eyes of their users and reflect a common set of design decisions. They should be seen as a logical unit, for example, “the graphics library” or “the text manipulation library,” similar to the way we consider the members of a class. In fact, the entities declared in a namespace are referred to as the members of the namespace.
A namespace is a (named) scope. You can access members defined earlier in a namespace from later declarations, but you cannot (without special effort) refer to members from outside the namespace. For example:
class Glyph { /* ... */ };
class Line { /* ... */ };
namespace Text_lib {
class Glyph { /* ... */ };
class Word { /* ... */ }; // sequence of Glyphs
class Line { /* ... */ };// sequence of Words
class Text { /* ... */ };// sequence of Lines
File* open(const char*); // open text file
Word operator+(const Line&, const Line&); // concatenate
}
Glyph glyph(Line& ln, int i); // ln[i]
Here, the Word and Line in the declaration of Text_lib::operator+() refer to Text_lib::Word and Text_lib::Line. That local name lookup is not affected by the global Line. Conversely, the Glyph and Line in the declaration of the global glyph() refer to the global ::Glyph and ::Line. That (nonlocal) lookup is not affected by Text_lib’s Glyph and Line.
To refer to members of a namespace, we can use its fully qualified name. For example, if we want a glyph() that uses definitions from Text_lib, we can write:
Text_lib::Glyph glyph(Text_lib::Line& ln, int i); // ln[i]
Other ways of referring to members from outside their namespace are using-declarations (§14.2.2), using-directives (§14.2.3), and argument-dependent lookup (§14.2.4).
14.2.1. Explicit Qualification
A member can be declared within a namespace definition and defined later using the namespace-name :: member-name notation.
Members of a namespace must be introduced using this notation:
namespace namespace–name {
// declaration and definitions
}
For example:
namespace Parser {
double expr(bool); // declaration
double term(bool);
double prim(bool);
}
double val = Parser::expr(); // use
double Parser::expr(bool b) // definition
{
// ...
}
We cannot declare a new member of a namespace outside a namespace definition using the qualifier syntax (§iso.7.3.1.2). The idea is to catch errors such as misspellings and type mismatches, and also to make it reasonably easy to find all names in a namespace declaration. For example:
void Parser::logical(bool); // error: no logical() in Parser
double Parser::trem(bool); // error: no trem() in Parser (misspelling)
double Parser::prim(int); // error: Parser::prim() takes a bool argument (wrong type)
A namespace is a scope. The usual scope rules hold for namespaces. Thus, “namespace” is a very fundamental and relatively simple concept. The larger a program is, the more useful namespaces are to express logical separations of its parts. The global scope is a namespace and can be explicitly referred to using ::. For example:
int f(); // global function
int g()
{
int f; // local variable; hides the global function
f(); // error: we can't call an int
::f(); // OK: call the global function
}
Classes are namespaces (§16.2).
14.2.2. using-Declarations
When a name is frequently used outside its namespace, it can be a bother to repeatedly qualify it with its namespace name. Consider:
#include<string>
#include<vector>
#include<sstream>
std::vector<std::string> split(const std::string& s)
// split s into its whitespace-separated substrings
{
std::vector<std::string> res;
std::istringstream iss(s);
for (std::string buf; iss>>buf;)
res.push_back(buf);
return res;
}
The repeated qualification std is tedious and distracting. In particular, we repeat std::string four times in this small example. To alleviate that we can use a using-declaration to say that in this code string means std::string:
using std::string; // use "string" to mean "std::string"
std::vector<string> split(const string& s)
// split s into its whitespace-separated substrings
{
std::vector<string> res;
std::istringstream iss(s);
for (string buf; iss>>buf;)
res.push_back(buf);
return res;
}
A using-declaration introduces a synonym into a scope. It is usually a good idea to keep local synonyms as local as possible to avoid confusion.
When used for an overloaded name, a using-declaration applies to all the overloaded versions. For example:
namespace N {
void f(int);
void f(string);
};
void g()
{
using N::f;
f(789); // N::f(int)
f("Bruce"); // N::f(string)
}
For the use of using-declarations within class hierarchies, see §20.3.5.
14.2.3. using-Directives
In the split() example (§14.2.2), we still had three uses of std:: left after introducing a synonym for std::string. Often, we like to use every name from a namespace without qualification. That can be achieved by providing a using-declaration for each name from the namespace, but that’s tedious and requires extra work each time a new name is added to or removed from the namespace. Alternatively, we can use a using-directive to request that every name from a namespace be accessible in our scope without qualification. For example:
using namespace std; // make every name from std accessible
vector<string> split(const string& s)
// split s into its whitespace-separated substrings
{
vector<string> res;
istringstream iss(s);
for (string buf; iss>>buf;)
res.push_back(buf);
return res;
}
A using-directive makes names from a namespace available almost as if they had been declared outside their namespace (see also §14.4). Using a using-directive to make names from a frequently used and well-known library available without qualification is a popular technique for simplifying code. This is the technique used to access standard-library facilities throughout this book. The standard-library facilities are defined in namespace std.
Within a function, a using-directive can be safely used as a notational convenience, but care should be taken with global using-directives because overuse can lead to exactly the name clashes that namespaces were introduced to avoid. For example:
namespace Graph_lib {
class Shape { /* ... */ };
class Line : Shape { /* ... */ };
class Poly_line: Shape { /* ... */ }; // connected sequence of lines
class Text : Shape { /* ... */ }; // text label
Shape operator+(const Shape&, const Shape&); // compose
Graph_reader open(const char*); // open file of Shapes
}
namespace Text_lib {
class Glyph { /* ... */ };
class Word { /* ... */ }; // sequence of Glyphs
class Line { /* ... */ }; // sequence of Words
class Text { /* ... */ }; // sequence of Lines
File* open(const char*); // open text file
Word operator+(const Line&, const Line&); // concatenate
}
using namespace Graph_lib;
using namespace Text_lib;
Glyph gl; // Text_lib::Glyph
vector<Shape*>vs; // Graph_lib::Shape
So far, so good. In particular, we can use names that do not clash, such as Glyph and Shape. However, name clashes now occur as soon as we use one of the names that clash – exactly as if we had not used namespaces. For example:
Text txt; // error: ambiguous
File* fp = open("my_precious_data"); // error: ambiguous
Consequently, we must be careful with using-directives in the global scope. In particular, don’t place a using-directive in the global scope in a header file except in very specialized circumstances (e.g., to aid transition) because you never know where a header might be #included.
14.2.4. Argument-Dependent Lookup
A function taking an argument of user-defined type X is more often than not defined in the same namespace as X. Consequently, if a function isn’t found in the context of its use, we look in the namespaces of its arguments. For example:
namespace Chrono {
class Date { /* ... */ };
bool operator==(const Date&, const std::string&);
std::string format(const Date&); // make string representation
// ...
}
void f(Chrono::Date d, int i)
{
std::string s = format(d); // Chrono::format()
std::string t = format(i); // error: no format() in scope
}
This lookup rule (called argument-dependent lookup or simply ADL) saves the programmer a lot of typing compared to using explicit qualification, yet it doesn’t pollute the namespace the way a using-directive (§14.2.3) can. It is especially useful for operator operands (§18.2.5) and template arguments (§26.3.5), where explicit qualification can be quite cumbersome.
Note that the namespace itself needs to be in scope and the function must be declared before it can be found and used.
Naturally, a function can take arguments from more than one namespace. For example:
void f(Chrono::Date d, std::string s)
{
if (d == s) {
// ...
}
else if (d == "August 4, 1914") {
// ...
}
}
In such cases, we look for the function in the scope of the call (as ever) and in the namespaces of every argument (including each argument’s class and base classes) and do the usual overload resolution (§12.3) of all functions we find. In particular, for the call d==s, we look for operator==in the scope surrounding f(), in the std namespace (where == is defined for string), and in the Chrono namespace. There is a std::operator==(), but it doesn’t take a Date argument, so we use Chrono::operator==(), which does. See also §18.2.5.
When a class member invokes a named function, other members of the same class and its base classes are preferred over functions potentially found based on the argument types (operators follow a different rule; §18.2.1, §18.2.5). For example:
namespace N {
struct S { int i };
void f(S);
void g(S);
void h(int);
}
struct Base {
void f(N::S);
};
struct D : Base {
void mf();
void g(N::S x)
{
f(x); // call Base::f()
mf(x); // call D::mf()
h(1); // error: no h(int) available
}
};
In the standard, the rules for argument-dependent lookup are phrased in terms of associated namespaces (§iso.3.4.2). Basically:
• If an argument is a class member, the associated namespaces are the class itself (including its base classes) and the class’s enclosing namespaces.
• If an argument is a member of a namespace, the associated namespaces are the enclosing namespaces.
• If an argument is a built-in type, there are no associated namespaces.
Argument-dependent lookup can save a lot of tedious and distracting typing, but occasionally it can give surprising results. For example, the search for a declaration of a function f() does not have a preference for functions in a namespace in which f() is called (the way it does for functions in a class in which f() is called):
namespace N {
template<class T>
void f(T, int); // N::f()
class X { };
}
namespace N2 {
N::X x;
void f(N::X, unsigned);
void g()
{
f(x,1); // calls N::f(X,int)
}
}
It may seem obvious to choose N2::f(), but that is not done. Overload resolution is applied and the best match is found: N::f() is the best match for f(x,1) because 1 is an int rather than an unsigned. Conversely, examples have been seen where a function in the caller’s namespace is chosen but the programmer expected a better function from a known namespace to be used (e.g., a standard-library function from std). This can be most confusing. See also §26.3.6.
14.2.5. Namespaces Are Open
A namespace is open; that is, you can add names to it from several separate namespace declarations. For example:
namespace A {
int f(); // now A has member f()
}
namespace A {
int g(); // now A has two members, f() and g()
}
That way, the members of a namespace need not be placed contiguously in a single file. This can be important when converting older programs to use namespaces. For example, consider a header file written without the use of namespaces:
// my header:
void mf(); // my function
void yf(); // your function
int mg(); // my function
// ...
Here, we have (unwisely) just added the declarations needed without concerns of modularity. This can be rewritten without reordering the declarations:
// my header:
namespace Mine {
void mf(); // my function
// ...
}
void yf(); // your function (not yet put into a namespace)
namespace Mine {
int mg(); // my function
// ...
}
When writing new code, I prefer to use many smaller namespaces (see §14.4) rather than putting really major pieces of code into a single namespace. However, that is often impractical when converting major pieces of software to use namespaces.
Another reason to define the members of a namespace in several separate namespace declarations is that sometimes we want to distinguish parts of a namespace used as an interface from parts used to support easy implementation; §14.3 provides an example.
A namespace alias (§14.4.2) cannot be used to re-open a namespace.
14.3. Modularization and Interfaces
Any realistic program consists of a number of separate parts. For example, even the simple “Hello, world!” program involves at least two parts: the user code requests Hello, world! to be printed, and the I/O system does the printing.
Consider the desk calculator example from §10.2. It can be viewed as composed of five parts:
[1] The parser, doing syntax analysis: expr(), term(), and prim()
[2] The lexer, composing tokens out of characters: Kind, Token, Token_stream, and ts
[3] The symbol table, holding (string,value) pairs: table
[4] The driver: main() and calculate()
[5] The error handler: error() and number_of_errors
This can be represented graphically:
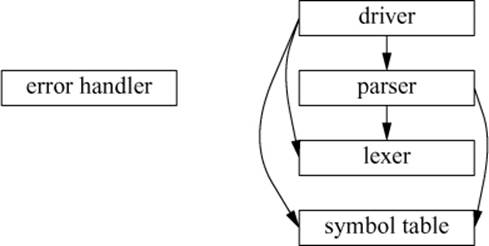
where an arrow means “using.” To simplify the picture, I have not represented the fact that every part relies on error handling. In fact, the calculator was conceived as three parts, with the driver and error handler added for completeness.
When one module uses another, it doesn’t need to know everything about the module used. Ideally, most of the details of a module are unknown to its users. Consequently, we make a distinction between a module and its interface. For example, the parser directly relies on the lexer’s interface (only), rather than on the complete lexer. The lexer simply implements the services advertised in its interface. This can be presented graphically like this:
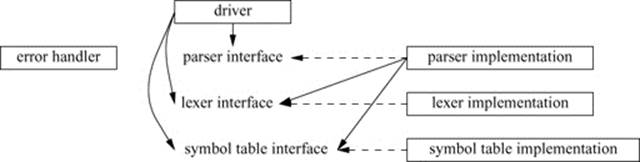
A dashed line means “implements.” I consider this to be the real structure of the program, and our job as programmers is to represent this faithfully in code. That done, the code will be simple, efficient, comprehensible, maintainable, etc., because it will directly reflect our fundamental design.
The following subsections show how the logical structure of the desk calculator program can be made clear, and §15.3 shows how the program source text can be physically organized to take advantage of it. The calculator is a tiny program, so in “real life” I wouldn’t bother using namespaces and separate compilation (§2.4.1, §15.1) to the extent done here. Making the structure of the calculator explicit is simply an illustration of techniques useful for larger programs without drowning in code. In real programs, each “module” represented by a separate namespace will often have hundreds of functions, classes, templates, etc.
Error handling permeates the structure of a program. When breaking up a program into modules or (conversely) when composing a program out of modules, we must take care to minimize dependencies between modules caused by error handling. C++ provides exceptions to decouple the detection and reporting of errors from the handling of errors (§2.4.3.1, Chapter 13).
There are many more notions of modularity than the ones discussed in this chapter and the next. For example, we might use concurrently executing and communicating tasks (§5.3, Chapter 41) or processes to represent important aspects of modularity. Similarly, the use of separate address spaces and the communication of information between address spaces are important topics not discussed here. I consider these notions of modularity largely independent and orthogonal. Interestingly, in each case, separating a system into modules is easy. The hard problem is to provide safe, convenient, and efficient communication across module boundaries.
14.3.1. Namespaces as Modules
A namespace is a mechanism for expressing logical grouping. That is, if some declarations logically belong together according to some criteria, they can be put in a common namespace to express that fact. So we can use namespaces to express the logical structure of our calculator. For example, the declarations of the parser from the desk calculator (§10.2.1) may be placed in a namespace Parser:
namespace Parser {
double expr(bool);
double prim(bool get) { /* ... */ }
double term(bool get) { /* ... */ }
double expr(bool get) { /* ... */ }
}
The function expr() must be declared first and then later defined to break the dependency loop described in §10.2.1.
The input part of the desk calculator could also be placed in its own namespace:
namespace Lexer {
enum class Kind : char { /* ... */ };
class Token { /* ... */ };
class Token_stream { /* ... */ };
Token_stream ts;
}
The symbol table is extremely simple:
namespace Table {
map<string,double> table;
}
The driver cannot be completely put into a namespace because the language rules require main() to be a global function:
namespace Driver {
void calculate() { /* ... */ }
}
int main() { /* ... */ }
The error handler is also trivial:
namespace Error {
int no_of_errors;
double error(const string& s) { /* ... */ }
}
This use of namespaces makes explicit what the lexer and the parser provide to a user. Had I included the source code for the functions, this structure would have been obscured. If function bodies are included in the declaration of a realistically sized namespace, you typically have to wade through screenfuls of information to find what services are offered, that is, to find the interface.
An alternative to relying on separately specified interfaces is to provide a tool that extracts an interface from a module that includes implementation details. I don’t consider that a good solution. Specifying interfaces is a fundamental design activity, a module can provide different interfaces to different users, and often an interface is designed long before the implementation details are made concrete.
Here is a version of the Parser with the interface separated from the implementation:
namespace Parser {
double prim(bool);
double term(bool);
double expr(bool);
}
double Parser::prim(bool get) { /* ... */ }
double Parser::term(bool get) { /* ... */ }
double Parser::expr(bool get) { /* ... */ }
Note that as a result of separating the implementation from the interface, each function now has exactly one declaration and one definition. Users will see only the interface containing declarations. The implementation – in this case, the function bodies – will be placed “somewhere else” where a user need not look.
Ideally, every entity in a program belongs to some recognizable logical unit (“module”). Therefore, every declaration in a nontrivial program should ideally be in some namespace named to indicate its logical role in the program. The exception is main(), which must be global in order for the compiler to recognize it as special (§2.2.1, §15.4).
14.3.2. Implementations
What will the code look like once it has been modularized? That depends on how we decide to access code in other namespaces. We can always access names from “our own” namespace exactly as we did before we introduced namespaces. However, for names in other namespaces, we have to choose among explicit qualification, using-declarations, and using-directives.
Parser::prim() provides a good test case for the use of namespaces in an implementation because it uses each of the other namespaces (except Driver). If we use explicit qualification, we get:
double Parser::prim(bool get) // handle primaries
{
if (get) Lexer::ts.get();
switch (Lexer::ts.current().kind) {
case Lexer::Kind::number: // floating-point constant
{ double v = Lexer::ts.current().number_value;
Lexer::ts.get();
return v;
}
case Lexer::Kind::name:
{ double& v = Table::table[Lexer::ts.current().string_value];
if (Lexer::ts.get().kind == Lexer::Kind::assign) v = expr(true); // '=' seen: assignment
return v;
}
case Lexer::Kind::minus: // unary minus
return -prim(true);
case Lexer::Kind::lp:
{ double e = expr(true);
if (Lexer::ts.current().kind != Lexer::Kind::rp) return Error::error(" ')' expected");
Lexer::ts.get(); // eat ')'
return e;
}
default:
return Error::error("primary expected");
}
}
I count 14 occurrences of Lexer::, and (despite theories to the contrary) I don’t think the more explicit use of modularity has improved readability. I didn’t use Parser:: because that would be redundant within namespace Parser.
If we use using-declarations, we get:
using Lexer::ts; // saves eight occurrences of "Lexer::"
using Lexer::Kind; // saves six occurrences of "Lexer::"
using Error::error; // saves two occurrences of "Error::"
using Table::table; // saves one occurrence of "Table::"
double prim(bool get) // handle primaries
{
if (get) ts.get();
switch (ts.current().kind) {
case Kind::number: // floating-point constant
{ double v = ts.current().number_value;
ts.get();
return v;
}
case Kind::name:
{ double& v = table[ts.current().string_value];
if (ts.get().kind == Kind::assign) v = expr(true); // '=' seen: assignment
return v;
}
case Kind::minus: // unary minus
return -prim(true);
case Kind::lp:
{ double e = expr(true);
if (ts.current().kind != Kind::rp) return error("')' expected");
ts.get(); // eat ')'
return e;
}
default:
return error("primary expected");
}
}
My guess is that the using-declarations for Lexer:: were worth it, but that the value of the others was marginal.
If we use using-directives, we get:
using namespace Lexer; // saves fourteen occurrences of "Lexer::"
using namespace Error; // saves two occurrences of "Error::"
using namespace Table; // saves one occurrence of "Table::"
double prim(bool get) // handle primaries
{
// as before
}
The using-declarations for Error and Table don’t buy much notationally, and it can be argued that they obscure the origins of the formerly qualified names.
So, the tradeoff among explicit qualification, using-declarations, and using-directives must be made on a case-by-case basis. The rules of thumb are:
[1] If some qualification is really common for several names, use a using-directive for that namespace.
[2] If some qualification is common for a particular name from a namespace, use a using-declaration for that name.
[3] If a qualification for a name is uncommon, use explicit qualification to make it clear from where the name comes.
[4] Don’t use explicit qualification for names in the same namespace as the user.
14.3.3. Interfaces and Implementations
It should be clear that the namespace definition we used for Parser is not the ideal interface for Parser to present to its users. Instead, that Parser declares the set of declarations that is needed to write the individual parser functions conveniently. The Parser’s interface to its users should be far simpler:
namespace Parser {// user interface
double expr(bool);
}
We see the namespace Parser used to provide two things:
[1] The common environment for the functions implementing the parser
[2] The external interface offered by the parser to its users
Thus, the driver code, main(), should see only the user interface.
The functions implementing the parser should see whichever interface we decided on as the best for expressing those functions’ shared environment. That is:
namespace Parser { // implementer interface
double prim(bool);
double term(bool);
double expr(bool);
using namespace Lexer; // use all facilities offered by lexer
using Error::error;
using Table::table;
}
or graphically:
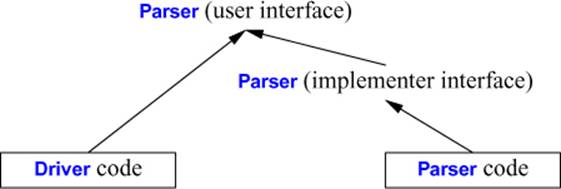
The arrows represent “relies on the interface provided by” relations.
We could give the user’s interface and the implementer’s interface different names, but (because namespaces are open; §14.2.5) we don’t have to. The lack of separate names need not lead to confusion because the physical layout of the program (see §15.3.2) naturally provides separate (file) names. Had we decided to use a separate implementation namespace, the design would not have looked different to users:
namespace Parser {// user interface
double expr(bool);
}
namespace Parser_impl { // implementer interface
using namespace Parser;
double prim(bool);
double term(bool);
double expr(bool);
using namespace Lexer; // use all facilities offered by Lexer
using Error::error;
using Table::table;
}
or graphically:
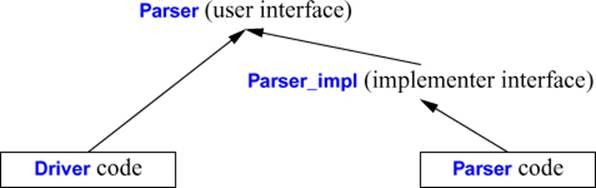
For larger programs, I lean toward introducing _impl interfaces.
The interface offered to implementers is larger than the interface offered to users. Had this interface been for a realistically sized module in a real system, it would change more often than the interface seen by users. It is important that the users of a module (in this case, Driver usingParser) be insulated from such changes.
14.4. Composition Using Namespaces
In larger programs, we tend to use many namespaces. This section examines technical aspects of composing code out of namespaces.
14.4.1. Convenience vs. Safety
A using-declaration adds a name to a local scope. A using-directive does not; it simply renders names accessible in the scope in which they were declared. For example:
namespace X {
int i, j, k;
}
int k;
void f1()
{
int i = 0;
using namespace X; // make names from X accessible
i++; // local i
j++; // X::j
k++; // error: X's k or the global k?
::k++; // the global k
X::k++; // X's k
}
void f2()
{
int i = 0;
using X::i; // error: i declared twice in f2()
using X::j;
using X::k; // hides global k
i++;
j++; // X::j
k++; // X::k
}
A locally declared name (declared either by an ordinary declaration or by a using-declaration) hides nonlocal declarations of the same name, and any illegal overloading of the name is detected at the point of declaration.
Note the ambiguity error for k++ in f1(). Global names are not given preference over names from namespaces made accessible in the global scope. This provides significant protection against accidental name clashes, and – importantly – ensures that there are no advantages to be gained from polluting the global namespace.
When libraries declaring many names are made accessible through using-directives, it is a significant advantage that clashes of unused names are not considered errors.
14.4.2. Namespace Aliases
If users give their namespaces short names, the names of different namespaces will clash:
namespace A {// short name, will clash (eventually)
// ...
}
A::String s1 = "Grieg";
A::String s2 = "Nielsen";
However, long namespace names can be impractical in real code:
namespace American_Telephone_and_Telegraph { // too long
// ...
}
American_Telephone_and_Telegraph::String s3 = "Grieg";
American_Telephone_and_Telegraph::String s4 = "Nielsen";
This dilemma can be resolved by providing a short alias for a longer namespace name:
// use namespace alias to shorten names:
namespace ATT = American_Telephone_and_Telegraph;
ATT::String s3 = "Grieg";
ATT::String s4 = "Nielsen";
Namespace aliases also allow a user to refer to “the library” and have a single declaration defining what library that really is. For example:
namespace Lib = Foundation_library_v2r11;
// ...
Lib::set s;
Lib::String s5 = "Sibelius";
This can immensely simplify the task of replacing one version of a library with another. By using Lib rather than Foundation_library_v2r11 directly, you can update to version “v3r02” by changing the initialization of the alias Lib and recompiling. The recompile will catch source-level incompatibilities. On the other hand, overuse of aliases (of any kind) can lead to confusion.
14.4.3. Namespace Composition
Often, we want to compose an interface out of existing interfaces. For example:
namespace His_string {
class String { /* ... */ };
String operator+(const String&, const String&);
String operator+(const String&, const char*);
void fill(char);
// ...
}
namespace Her_vector {
template<class T>
class Vector { /* ... */ };
// ...
}
namespace My_lib {
using namespace His_string;
using namespace Her_vector;
void my_fct(String&);
}
Given this, we can now write the program in terms of My_lib:
void f()
{
My_lib::String s = "Byron"; // finds My_lib::His_string::String
// ...
}
using namespace My_lib;
void g(Vector<String>& vs)
{
// ...
my_fct(vs[5]);
// ...
}
If an explicitly qualified name (such as My_lib::String) isn’t declared in the namespace mentioned, the compiler looks in namespaces mentioned in using-directives (such as His_string).
Only if we need to define something do we need to know the real namespace of an entity:
void My_lib::fill(char c) // error: no fill() declared in My_lib
{
// ...
}
void His_string::fill(char c) // OK: fill() declared in His_string
{
// ...
}
void My_lib::my_fct(String& v)// OK: String is My_lib::String, meaning His_string::String
{
// ...
}
Ideally, a namespace should
[1] express a logically coherent set of features,
[2] not give users access to unrelated features, and
[3] not impose a significant notational burden on users.
Together with the #include mechanism (§15.2.2), the composition techniques presented here and in the following subsections provide strong support for this.
14.4.4. Composition and Selection
Combining composition (by using-directives) with selection (by using-declarations) yields the flexibility needed for most real-world examples. With these mechanisms, we can provide access to a variety of facilities in such a way that we resolve name clashes and ambiguities arising from their composition. For example:
namespace His_lib {
class String { /* ... */ };
template<class T>
class Vector { /* ... */ };
// ...
}
namespace Her_lib {
template<class T>
class Vector { /* ... */ };
class String { /* ... */ };
// ...
}
namespace My_lib {
using namespace His_lib; // everything from His_lib
using namespace Her_lib; // everything from Her_lib
using His_lib::String; // resolve potential clash in favor of His_lib
using Her_lib::Vector; // resolve potential clash in favor of Her_lib
template<class T>
class List { /* ... */ }; // additional stuff
// ...
}
When looking into a namespace, names explicitly declared there (including names declared by using-declarations) take priority over names made accessible in another scope by a using-directive (see also §14.4.1). Consequently, a user of My_lib will see the name clashes for String andVector resolved in favor of His_lib::String and Her_lib::Vector. Also, My_lib::List will be used by default independently of whether His_lib or Her_lib is providing a List.
Usually, I prefer to leave a name unchanged when including it into a new namespace. Then, I don’t have to remember two different names for the same entity. However, sometimes a new name is needed or simply nice to have. For example:
namespace Lib2 {
using namespace His_lib; // everything from His_lib
using namespace Her_lib; // everything from Her_lib
using His_lib::String; // resolve potential clash in favor of His_lib
using Her_lib::Vector; // resolve potential clash in favor of Her_lib
using Her_string = Her_lib::String; // rename
template<class T>
using His_vec = His_lib::Vector<T>; // rename
template<class T>
class List { /* ... */ }; // additional stuff
// ...
}
There is no general language mechanism for renaming, but for types and templates, we can introduce aliases with using (§3.4.5, §6.5).
14.4.5. Namespaces and Overloading
Function overloading (§12.3) works across namespaces. This is essential to allow us to migrate existing libraries to use namespaces with minimal source code changes. For example:
// old A.h:
void f(int);
// ...
// old B.h:
void f(char);
// ...
// old user.c:
#include "A.h"
#include "B.h"
void g()
{
f('a'); // calls the f() from B.h
}
This program can be upgraded to a version using namespaces without changing the actual code:
// new A.h:
namespace A {
void f(int);
// ...
}
// new B.h:
namespace B {
void f(char);
// ...
}
// new user.c:
#include "A.h"
#include "B.h"
using namespace A;
using namespace B;
void g()
{
f('a'); // calls the f() from B.h
}
Had we wanted to keep user.c completely unchanged, we would have placed the using-directives in the header files. However, it is usually best to avoid using-directives in header files, because putting them there greatly increases the chances of name clashes.
This overloading rule also provides a mechanism for extending libraries. For example, people often wonder why they have to explicitly mention a sequence to manipulate a container using a standard-library algorithm. For example:
sort(v.begin(),v.end());
Why not write:
sort(v);
The reason is the need for generality (§32.2), but manipulating a container is by far the most common case. We can accommodate that case like this:
#include<algorithm>
namespace Estd {
using namespace std;
template<class C>
void sort(C& c) { std::sort(c.begin(),c.end()); }
template<class C, class P>
void sort(C& c, P p) { std::sort(c.begin(),c.end(),p); }
}
Estd (my “extended std”) provides the frequently wanted container versions of sort(). Those are of course implemented using std::sort() from <algorithm>. We can use it like this:
using namespace Estd;
template<class T>
void print(const vector<T>& v)
{
for (auto& x : v)
cout << v << ' ';
cout << '\n';
}
void f()
{
std::vector<int> v {7, 3, 9, 4, 0, 1};
sort(v);
print(v);
sort(v,[](int x, int y) { return x>y; });
print(v);
sort(v.begin(),v.end());
print(v);
sort(v.begin(),v.end(),[](int x, int y) { return x>y; });
print(v);
}
The namespace lookup rules and the overloading rules for templates ensure that we find and invoke the correct variants of sort() and get the expected output:
0 1 3 4 7 9
9 7 4 3 1 0
0 1 3 4 7 9
9 7 4 3 1 0
If we removed the using namespace std; from Estd, this example would still work because std’s sort()s would be found by argument-dependent lookup (§14.2.4). However, we would then not find the standard sort()s for our own containers defined outside std.
14.4.6. Versioning
The toughest test for many kinds of interfaces is to cope with a sequence of new releases (versions). Consider a widely used interface, say, an ISO C++ standard header. After some time, a new version is defined, say, the C++11 version of the C++98 header. Functions may have been added, classes renamed, proprietary extensions (that should never have been there) removed, types changed, templates modified. To make life “interesting” for the implementer, hundreds of millions of lines of code are “out there” using the old header, and the implementer of the new version cannot ever see or modify them. Needless to say, breaking such code will cause howls of outrage, as will the absence of a new and better version. The namespace facilities described so far can be used to handle this problem with very minor exceptions, but when large amounts of code are involved, “very minor” still means a lot of code. Consequently, there is a way of selecting between two versions that simply and obviously guarantees that a user sees exactly one particular version. This is called an inline namespace:
namespace Popular {
inline namespace V3_2 { // V3_2 provides the default meaning of Popular
double f(double);
int f(int);
template<class T>
class C { /* ... */ };
}
namespace V3_0 {
// ...
}
namespace V2_4_2 {
double f(double);
template<class T>
class C { /* ... */ };
}
}
Here, Popular contains three subnamespaces, each defining a version. The inline specifies that V3_2 is the default meaning of Popular. So we can write:
using namespace Popular;
void f()
{
f(1); // Popular::V3_2::f(int)
V3_0::f(1); // Popular::V3_0::f(double)
V2_4_2::f(1); // Popular::V2_4_2::f(double)
}
template<class T>
Popular::C<T*> { /* ... */ };
This inline namespace solution is intrusive; that is, to change which version (subnamespace) is the default requires modification of the header source code. Also, naively using this way of handling versioning would involve a lot of replication (of common code in the different versions). However, that replication can be minimized using #include tricks. For example:
// file V3_common:
// ... lots of declarations ...
// file V3_2:
namespace V3_2 { // V3_2 provides the default meaning of Popular
double f(double);
int f(int);
template<class T>
class C { /* ... */ };
#include "V3_common"
}
// file V3_0.h:
namespace V3_0 {
#include "V3_common"
}
// file Popular.h:
namespace Popular {
inline
#include "V3_2.h"
#include "V3_0.h"
#include "V2_4_2.h"
}
I do not recommend such intricate use of header files unless it is really necessary. The example above repeatedly violates the rules against including into a nonlocal scope and against having a syntactic construct span file boundaries (the use of inline); see §15.2.2. Sadly, I have seen worse.
In most cases, we can achieve versioning by less intrusive means. The only example I can think of that is completely impossible to do by other means is the specialization of a template explicitly using the namespace name (e.g., Popular::C<T*>). However, in many important cases “in most cases” isn’t good enough. Also, a solution based on a combination of other techniques is less obviously completely right.
14.4.7. Nested Namespaces
One obvious use of namespaces is to wrap a complete set of declarations and definitions in a separate namespace:
namespace X {
// ... all my declarations ...
}
The list of declarations will, in general, contain namespaces. Thus, nested namespaces are allowed. This is allowed for practical reasons, as well as for the simple reason that constructs ought to nest unless there is a strong reason for them not to. For example:
void h();
namespace X {
void g();
// ...
namespace Y {
void f();
void ff();
// ...
}
}
The usual scope and qualification rules apply:
void X::Y::ff()
{
f(); g(); h();
}
void X::g()
{
f(); // error: no f() in X
Y::f(); // OK
}
void h()
{
f(); // error: no global f()
Y::f(); // error: no global Y
X::f(); // error: no f() in X
X::Y::f(); // OK
}
For examples of nested namespaces in the standard library, see chrono (§35.2) and rel_ops (§35.5.3).
14.4.8. Unnamed Namespaces
It is sometimes useful to wrap a set of declarations in a namespace simply to protect against the possibility of name clashes. That is, the aim is to preserve locality of code rather than to present an interface to users. For example:
#include "header.h"
namespace Mine {
int a;
void f() { /* ... */ }
int g() { /* ... */ }
}
Since we don’t want the name Mine to be known outside a local context, it simply becomes a bother to invent a redundant global name that might accidentally clash with someone else’s names. In that case, we can simply leave the namespace without a name:
#include "header.h"
namespace {
int a;
void f() { /* ... */ }
int g() { /* ... */ }
}
Clearly, there has to be some way of accessing members of an unnamed namespace from outside the unnamed namespace. Consequently, an unnamed namespace has an implied using-directive. The previous declaration is equivalent to
namespace $$$ {
int a;
void f() { /* ... */ }
int g() { /* ... */ }
}
using namespace $$$;
where $$$ is some name unique to the scope in which the namespace is defined. In particular, unnamed namespaces in different translation units are different. As desired, there is no way of naming a member of an unnamed namespace from another translation unit.
14.4.9. C Headers
Consider the canonical first C program:
#include <stdio.h>
int main()
{
printf("Hello, world!\n");
}
Breaking this program wouldn’t be a good idea. Making standard libraries special cases isn’t a good idea either. Consequently, the language rules for namespaces are designed to make it relatively easy to take a program written without namespaces and turn it into a more explicitly structured one using namespaces. In fact, the calculator program (§10.2) is an example of this.
One way to provide the standard C I/O facilities in a namespace would be to place the declarations from the C header stdio.h in a namespace std:
// cstdio:
namespace std {
int printf(const char* ... );
// ...
}
Given this <cstdio>, we could provide backward compatibility by adding a using-directive:
// stdio.h:
#include<cstdio>
using namespace std;
This <stdio.h> makes the Hello, world! program compile. Unfortunately, the using-directive makes every name from namespace std accessible in the global namespace. For example:
#include<vector> // carefully avoids polluting the global namespace
vector v1; // error: no "vector" in global scope
#include<stdio.h> // contains a "using namespace std;"
vector v2; // oops: this now works
So the standard requires that <stdio.h> place only names from <cstdio> in the global scope. This can be done by providing a using-declaration for each declaration in <cstdio>:
// stdio.h:
#include<cstdio>
using std::printf;
// ...
Another advantage is that the using-declaration for printf() prevents a user from (accidentally or deliberately) defining a nonstandard printf() in the global scope. I consider nonlocal using-directives primarily a transition tool. I also use them for essential foundation libraries, such as the ISO C++ standard library (std). Most code referring to names from other namespaces can be expressed more clearly with explicit qualification and using-declarations.
The relationship between namespaces and linkage is described in §15.2.5.
14.5. Advice
[1] Use namespaces to express logical structure; §14.3.1.
[2] Place every nonlocal name, except main(), in some namespace; §14.3.1.
[3] Design a namespace so that you can conveniently use it without accidentally gaining access to unrelated namespaces; §14.3.3.
[4] Avoid very short names for namespaces; §14.4.2.
[5] If necessary, use namespace aliases to abbreviate long namespace names; §14.4.2.
[6] Avoid placing heavy notational burdens on users of your namespaces; §14.2.2, §14.2.3.
[7] Use separate namespaces for interfaces and implementations; §14.3.3.
[8] Use the Namespace::member notation when defining namespace members; §14.4.
[9] Use inline namespaces to support versioning; §14.4.6.
[10] Use using-directives for transition, for foundational libraries (such as std), or within a local scope; §14.4.9.
[11] Don’t put a using-directive in a header file; §14.2.3.