The C++ Programming Language (2013)
Part IV: The Standard Library
33. STL Iterators
The reason that STL containers and algorithms work so well together is that they know nothing of each other.
– Alex Stepanov
• Introduction
• Iterator Model
Iterator Categories; Iterator Traits; Iterator Operations
• Iterator Adaptors
Reverse Iterators; Insert Iterators; Move Iterator
• Range Access Functions
• Function Objects
• Function Adaptors
bind(); mem_fn(); function
• Advice
33.1. Introduction
This chapter presents the STL iterators and utilities, notably standard-library function objects. The STL consists of the iterator, container, algorithm, and function object parts of the standard library. The rest of the STL is presented in Chapter 31 and Chapter 32.
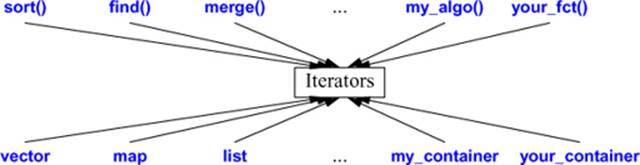
Iterators are the glue that ties standard-library algorithms to their data. Conversely, you can say that iterators are the mechanism used to minimize an algorithm’s dependence on the data structures on which it operates:
33.1.1. Iterator Model
An iterator is akin to a pointer in that it provides operations for indirect access (e.g., * for dereferencing) and for moving to point to a new element (e.g., ++ for moving to the next element). A sequence is defined by a pair of iterators defining a half-open range [begin:end):

That is, begin points to the first element of the sequence, and end points to the one-beyond-the-last element of the sequence. Never read from or write to *end. Note that the empty sequence has begin==end; that is, [p:p) is the empty sequence for any iterator p.
To read a sequence, an algorithm usually takes a pair of iterators (b,e) and iterates using ++ until the end is reached:
while (b!=e) { // use != rather than <
// do something
++b; // go to next element
}
The reason to use != rather than < for testing whether we have reached the end is partially because that is the more precise statement of what we are testing for and partially because only random-access iterators support <.
Algorithms that search for something in a sequence usually return the end of the sequence to indicate “not found”; for example:
auto p = find(v.begin(),v.end(),x); // look for x in v
if (p!=v.end()) {
// x found at p
}
else {
// x not found in [v.begin():v.end())
}
Algorithms that write to a sequence often are given only an iterator to its first element. In that case, it is the programmer’s responsibility not to write beyond the end of that sequence. For example:
template<typename Iter>
void forward(Iter p, int n)
{
while (n>0)
*p++ = ––n;
}
void user()
{
vector<int> v(10);
forward(v.begin(),v.size()); // OK
forward(v.begin(),1000); // big trouble
}
Some standard-library implementations range check – that is, throw an exception for that last call of forward() – but you can’t rely on that for portable code: many implementations don’t check. For a simple and safe alternative use an insert iterator (§33.2.2).
33.1.2. Iterator Categories
The standard library provides five kinds of iterators (five iterator categories):
• Input iterator : We can iterate forward using ++ and read each element (repeatedly) using *. We can compare input iterators using == and !=. This is the kind of iterator that istream offers; see §38.5.
• Output iterator: We can iterate forward using ++ and write an element once only using *. This is the kind of iterator that ostream offers; see §38.5.
• Forward iterator: We can iterate forward repeatedly using ++ and read and write (unless the elements are const) elements repeatedly using *. If a forward iterator points to a class object, we can use –> to refer to a member. We can compare forward iterators using == and !=. This is the kind of iterator forward_list offers (§31.4).
• Bidirectional iterator: We can iterate forward (using ++) and backward (using ––) and read and write (unless the elements are const) elements repeatedly using *. If a bidirectional iterator points to a class object, we can use –> to refer to a member. We can compare bidirectional iterators using == and !=. This is the kind of iterator that list, map, and set offer (§31.4).
• Random-access iterator: We can iterate forward (using ++ or +=) and backward (using – or –=) and read and write (unless the elements are const) elements repeatedly using * or []. If a random-access iterator points to a class object, we can use –> to refer to a member. We can subscript a random-access iterator using [], add an integer using +, and subtract an integer using –. We can find the distance between two random-access iterators to the same sequence by subtracting one from the other. We can compare random-access iterators using ==, !=, <, <=, >, and >=. This is the kind of iterator that vector offers (§31.4).
Logically, these iterators are organized in a hierarchy (§iso.24.2):
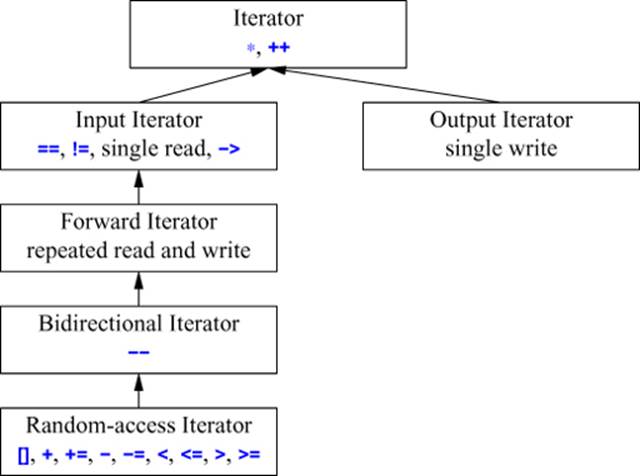
The iterator categories are concepts (§24.3) rather than classes, so this hierarchy is not a class hierarchy implemented using derivation. If you need to do something advanced with iterator categories, use iterator_traits (directly or indirectly).
33.1.3. Iterator Traits
In <iterator>, the standard library provides a set of type functions that allow us to write code specialized for specific properties of an iterator:

The iterator tags are types used to select among algorithms based on the type of an iterator. For example, a random-access iterator can go directly to an element:
template<typename Iter>
void advance_helper(Iter p, int n, random_access_iterator_tag)
{
p+=n;
}
On the other hand, a forward iterator must get to the nth element by moving one step at a time (e.g., following links on a list):
template<typename Iter>
void advance_helper(Iter p, int n, forward_iterator_tag)
{
if (0<n)
while (n––) ++p;
else if (n<0)
while (n++) ––p;
}
Given these helpers, advance() can consistently use the optimal algorithm:
template<typename Iter>
void advance(Iter p, int n) // use the optimal algorithm
{
advance_helper(p,n,typename iterator_traits<Iter>::iterator_category{});
}
Typically, advance() and/or advance_helper() will be inlined to ensure that no run-time overhead is introduced by this tag dispatch technique. Variants of this technique are pervasive in the STL.
The key properties of an iterator are described by the aliases in iterator_traits:
template<typename Iter>
struct iterator_traits {
using value_type = typename Iter::value_type;
using difference_type = typename Iter::difference_type;
using pointer = typename Iter::pointer; // pointer type
using reference = typename Iter::reference; // reference type
using iterator_category = typename Iter::iterator_category; // (tag)
};
For an iterator that does not have these member types (e.g., an int*), we provide a specialization of iterator_traits:
template<typename T>
struct iterator_traits<T*>{ // specialization for pointers
using difference_type = ptrdiff_t;
using value_type = T;
using pointer = T*;
using reference = T& reference;
using iterator_category = random_access_iterator_tag;
};
We cannot in general say:
template<typename Iter>
typename Iter::value_type read(Iter p, int n) // not general
{
// ... do some checking ...
return p[n];
{
This is an error waiting to happen. Calling this read() with a pointer argument would be an error. The compiler would catch it, but the error messages might be voluminous and obscure. Instead, we can write:
template<typename Iter>
typename iterator_traits<Iter>::value_type read(Iter p, int n) // more general
{
// ... do some checking ...
return p[n];
{
The idea is that to find a property of an iterator, you look in its iterator_traits (§28.2.4), rather than at the iterator itself. To avoid directly referring to the iterator_traits, which after all is just an implementation detail, we can define an alias. For example:
template<typename Iter>
using Category<Iter> = typename std::iterator_traits<Iter>::iterator_category;
template<typename Iter>
using Difference_type<Iter> = typename std::iterator_traits<Iter>::difference_type;
So, if we want to know the type of the difference between two iterators (pointing to the same sequence), we have some choices:
tempate<typename Iter>
void f(Iter p, Iter q)
{
Iter::difference_type d1 = distance(p,q); // syntax error: "typename" missing
typename Iter::difference_type d2 = distance(p,q); // doesn't work for pointers, etc.
typename iterator_traits<Iter>::distance_type d3 = distance(p,q); // OK, but ugly
Distance_type<Iter> d4 = distance(p,q); // OK, much better
auto d5 = distance(p,q); // OK, if you don't need to mention the type explicitly
// ...
}
I recommend the last two alternatives.
The iterator template simply bundles the key properties of an iterator into a struct for the convenience of iterator implementers and provides a few defaults:
template<typename Cat, typename T, typename Dist = ptrdiff_t, typename Ptr = T*, typename Ref = T&>
struct iterator {
using value_type = T;
using difference_type = Dist ; // type used by distance()
using pointer = Ptr; // pointer type
using reference = Ref; // reference type
using iterator_category = Cat; // category (tag)
};
33.1.4. Iterator Operations
Depending on its category (§33.1.2), an iterator provides some or all of these operations:

A ++p returns a reference to p, whereas p++ must return a copy of p holding the old value. Thus, for more complicated iterators, ++p is likely to be more efficient than p++.
The following operations work for every iterator for which they can be implemented, but they may work more efficiently for random-access iterators (see §33.1.2):

In each case, if p is not a random-access iterator, the algorithm will take n steps.
33.2. Iterator Adaptors
In <iterator>, the standard library provides adaptors to generate useful related iterator types from a given iterator type:

Iterators for iostreams are described in §38.5.
33.2.1. Reverse Iterator
Using an iterator we can traverse a sequence [b:e) from b to e. If the sequence allows bidirectional access, we can also traverse the sequence in reverse order, from e to b. An iterator that does that is called a reverse_iterator. A reverse_iterator iterates from the end of the sequence defined by its underlying iterator to the beginning of that sequence. To get a half-open sequence, we must consider b–1 as one past the end and e–1 as the start of the sequence: [e–1, b–1). Thus, the fundamental relation between a reverse iterator and its corresponding iterator is &*(reverse_iterator(p))==&*(p–1). In particular, if v is a vector, v.rbegin() points to its last element, v[v.size()–1]. Consider:

This sequence can be viewed like this using a reverse_iterator:

The definition of reverse_iterator looks something like this:
template<typename Iter>
class reverse_iterator
: public iterator<Iterator_category<Iter>,
Value_type<Iter>,
Difference_type<Iter>,
Pointer<Iter>,
Reference<Iter>> {
public:
using iterator_type = Iter;
reverse_iterator(): current{} { }
explicit reverse_iterator(Iter p): current{p} { }
template<typename Iter2>
reverse_iterator(const reverse_iterator<Iter2>& p) :current(p.base()) { }
Iter base() const { return current; } // current iterator value
reference operator*() const { tmp = current; return *––tmp; }
pointer operator–>() const;
reference operator[](difference_type n) const;
reverse_iterator& operator++() { ––current; return *this; } // note: not ++
reverse_iterator operator++(int) { reverse_iterator t = current; ––current; return t; }
reverse_iterator& operator––() { ++current; return *this; } // note: not ––
reverse_iterator operator––(int) { reverse_iterator t = current; ++current; return t; }
reverse_iterator operator+(difference_type n) const;
reverse_iterator& operator+=(difference_type n);
reverse_iterator operator–(difference_type n) const;
reverse_iterator& operator–=(difference_type n);
// ...
protected:
Iterator current; // current points to the element after the one *this refers to
private:
// ...
iterator tmp; // for temporaries that need to outlive a function scope
};
A reverse_iterator<Iter> has the same member types and operations as Iter. In particular, if Iter is a random-access operator, its reverse_iterator<Iter> has [], +, and <. For example:
void f(vector<int>& v, list<char>& lst)
{
v.rbegin()[3] = 7; // OK: random-access iterator
lst.rbegin()[3] = '4'; // error: bidirectional iterator doesn't support []
*(next(lst.rbegin(),3)) = '4'; // OK!
}
I use next() to move the iterator because (like []) + wouldn’t work for a bidirectional iterator, such as list<char>::iterator.
Reverse iterators allow us to use algorithms in a way that views a sequence in the reverse order. For example, to find the last occurrence of an element in a sequence, we can apply find() to its reverse sequence:
auto ri = find(v.rbegin(),v.rend(),val); // last occurrence
Note that C::reverse_iterator is not the same type as C::iterator. So, if I wanted to write a find_last() algorithm using a reverse sequence, I would have to decide which type of iterator to return:
template<typename C, typename Val>
auto find_last(C& c, Val v) –> decltype(c.begin()) // use C's iterator in the interface
{
auto ri = find(c.rbegin(),c.rend(),v);
if (ri == c.rend()) return c.end(); // use c.end() to indicate "not found"
return prev(ri.base());
}
For a reverse_iterator, ri.base() returns an iterator pointing one beyond the position pointed to by ri. So, to get an iterator pointing to the same element as the reverse iterator ri, I have to return ri.base()–1. However, my container may be a list that does not support – for its iterators, so I useprev() instead.
A reverse iterator is a perfectly ordinary iterator, so I could write the loop explicitly:
template<typename C, Val v>
auto find_last(C& c, Val v) –> decltype(c.begin())
{
for (auto p = c.rbegin(); p!=c.rend(); ++p) // view sequence in reverse order
if (*p==v) return ––p.base();
return c.end(); // use c.end() to indicate "not found"
}
The equivalent code searching backward using a (forward) iterator is:
template<typename C>
auto find_last(C& c, Val v) –> decltype(c.begin())
{
for (auto p = c.end(); p!=c.begin(); ) // search backward from end
if (*––p==v) return p;
return c.end(); // use c.end() to indicate "not found"
}
As for the earlier definitions of find_last(), this version requires at least a bidirectional iterator.
33.2.2. Insert Iterators
Producing output through an iterator into a container implies that elements following the one pointed to by the iterator can be overwritten. This implies the possibility of overflow and consequent memory corruption. For example:
void f(vector<int>& vi)
{
fill_n(vi.begin(),200,7); // assign 7 to vi[0]..[199]
}
If vi has fewer than 200 elements, we are in trouble.
In <iterator>, the standard library provides a solution in the form of an inserter: when written to, an inserter inserts a new element into a sequence rather than overwriting an existing element. For example:
void g(vector<int>& vi)
{
fill_n(back_inserter(vi),200,7); // add 200 7s to the end of vi
}
When writing to an element through an insert iterator, the iterator inserts its value rather than overwriting the element pointed to. So, a container grows by one element each time a value is written to it through an insert iterator. Inserters are as simple and efficient as they are useful.
There are three insert iterators:
• insert_iterator inserts before the element pointed to using insert().
• front_insert_iterator inserts before the first element of a sequence using push_front().
• back_insert_iterator inserts after the last element of the sequence using push_back().
An inserter is usually constructed by a call to a helper function:

The iterator passed to inserter() must be an iterator into the container. For a sequence container, that implies that it must be a bidirectional iterator (so that you can insert before it). For example, you can’t use inserter() to make an iterator to insert into a forward_list. For an associative container, where that iterator is only used as a hint for where to insert, a forward iterator (e.g., as provided by an unordered_set) can be acceptable.
An inserter is an output iterator:


The front_insert_iterator and back_insert_iterator differ in that their constructors don’t require an iterator. For example:
vector<string> v;
back_insert_iterator<v> p;
You cannot read through an inserter.
33.2.3. Move Iterator
A move iterator is an iterator where reading from the pointed-to element moves rather than copies. We usually make a move iterator from another iterator using a helper function:

A move iterator has the same operations as the iterator from which it is made. For example, we can do ––p if the move iterator p was made from a bidirectional iterator. A move iterator’s operator*() simply returns an rvalue reference (§7.7.2) to the element pointed to: std::move(q). For example:
vector<string> read_strings(istream&);
auto vs = read_strings(cin); // get some strings
vector<string> vs2;
copy(vs,back_inserter(vs2)); // copy strings from vs into vs2
vector<string> vs3;
copy(vs2,make_move_iterator(back_inserter(vs3))); // move strings from vs2 into vs3
This assumes that a container version of std::copy() has been defined.
33.3. Range Access Functions
In <iterator>, the standard library provides a nonmember begin() and end() functions for containers:

These functions are very simple:
template<typename C>
auto begin(C& c) –> decltype(c.begin());
template<typename C>
auto begin(const C& c) –> decltype(c.begin());
template<typename C>
auto end(C& c) –> decltype(c.end());
template<typename C>
auto end(const C& c) –> decltype(c.end());
template<typename T, size_t N> // for built-in arrays
auto begin(T (&array)[N]) –> T*;
template<typename T, size_t N>
auto end(T (&array)[N]) –> T*;
These functions are used by the range-for-statement (§9.5.1) but can of course also be used directly by users. For example:
template<typename Cont>
void print(Cont& c)
{
for(auto p=begin(c); p!=end(c); ++p)
cout << *p << '\n';
}
void f()
{
vector<int> v {1,2,3,4,5};
print(v);
int a[] {1,2,3,4,5};
print(a);
}
Had I said c.begin() and c.end(), the call print(a) would have failed.
A user-defined container with member begin() and end() automatically gets nonmember versions when <iterator> is #included. To provide nonmember begin() and end() for a container, My_container, that doesn’t have them, I have to write something like:
template<typename T>
Iterator<My_container<T>> begin(My_container<T>& c)
{
return Iterator<My_container<T>>{&c[0]}; // iterator to first element
}
template<typename T>
Iterator<My_container<T>> end(My_container<T>& c)
{
return Iterator<My_container<T>>{&c[0]+c.size()}; // iterator to last element
}
Here, I assume that passing the address of the first element is a way to create an iterator to the first element of My_container and that My_container has a size().
33.4. Function Objects
Many of the standard algorithms take function objects (or functions) as arguments to control the way they work. Common uses are comparison criteria, predicates (functions returning bool), and arithmetic operations. In <functional>, the standard library supplies a few common function objects:
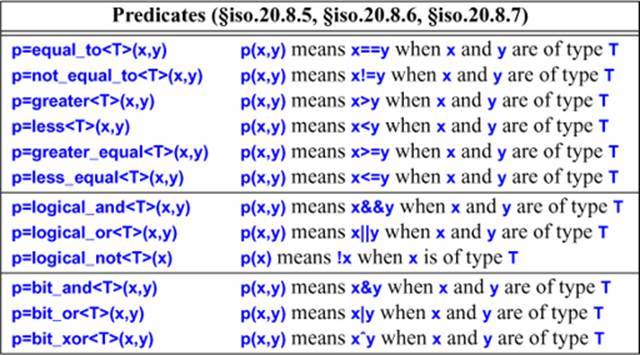
For example:
vector<int> v;
// ...
sort(v.begin(),v.end(),greater<int>{}); // sort v into decreasing order
Such predicates are roughly equivalent to simple lambdas. For example:
vector<int> v;
// ...
sort(v.begin(),v.end(),[](int a, int b) { return a>b; }); // sort v into decreasing order
Note that logical_and and logical_or always evaluate both their arguments (&& and || do not).

33.5. Function Adaptors
A function adaptor takes a function as argument and returns a function object that can be used to invoke the original function.

The bind() and mem_fn() adaptors do argument binding, also called Currying or partial evaluation. These binders, and their deprecated predecessors (such as bind1st(), mem_fun(), and mem_fun_ref()), were heavily used in the past, but most uses seem to be more easily expressed using lambdas (§11.4).
33.5.1. bind()
Given a function and a set of arguments, bind() produces a function object that can be called with “the remaining” arguments, if any, of the function. For example:
double cube(double);
auto cube2 = bind(cube,2);
A call cube2() will invoke cube with the argument 2, that is, cube(2). We don’t have to bind every argument of a function. For example:
using namespace placeholders;
void f(int,const string&);
auto g = bind(f,2,_1); // bind f()'s first argument to 2
f(2,"hello");
g("hello"); // also calls f(2,"hello");
The curious _1 argument to the binder is a placeholder telling bind() where arguments to the resulting function object should go. In this case, g()’s (first) argument is used as f()’s second argument.
The placeholders are found in the (sub)namespace std::placeholders that is part of <functional>. The placeholder mechanism is very flexible. Consider:
f(2,"hello");
bind(f)(2,"hello"); // also calls f(2,"hello");
bind(f,_1,_2)(2,"hello"); // also calls f(2,"hello");
bind(f,_2,_1)("hello",2); // reverse order of arguments: also calls f(2,"hello");
auto g = [](const string& s, int i) { f(i,s); } // reverse order of arguments
g("hello",2); // also calls f(2,"hello");
To bind arguments for an overloaded function, we have to explicitly state which version of the function we want to bind:
int pow(int,int);
double pow(double,double); // pow() is overloaded
auto pow2 = bind(pow,_1,2); // error: which pow()?
auto pow2 = bind((double(*)(double,double))pow,_1,2); // OK (but ugly)
Note that bind() takes ordinary expressions as arguments. This implies that references are dereferenced before bind() gets to see them. For example:
void incr(int& i)
{
++i;
}
void user()
{
int i = 1;
incr(i); // i becomes 2
auto inc = bind(incr,_1);
inc(i); // i stays 2; inc(i) incremented a local copy of i
}
To deal with that, the standard library provides yet another pair of adaptors:

This solves the “reference problem” for bind():
void user()
{
int i = 1;
incr(i); // i becomes 2
auto inc = bind(incr,_1);
inc(ref(i)); // i becomes 3
}
This ref() is needed to pass references as arguments to threads because thread constructors are variadic templates (§42.2.2).
So far, I either used the result of bind() immediately or assigned it to a variable declared using auto. This saves me the bother of specifying the return type of a call of bind(). That can be useful because the return type of bind() varies with the type of function to be called and the argument values stored. In particular, the returned function object is larger when it has to hold values of bound parameters. However, we sometimes want to be specific about the types of the arguments required and the type of result returned. If so, we can specify them for a function (§33.5.3).
33.5.2. mem_fn()
The function adaptor mem_fn(mf) produces a function object that can be called as a nonmember function. For example:
void user(Shape* p)
{
p–>draw();
auto draw = mem_fn(&Shape::draw);
draw(p);
}
The major use of mem_fn() is when an algorithm requires an operation to be called as a nonmember function. For example:
void draw_all(vector<Shape*>& v)
{
for_each(v.begin(),v.end(),mem_fn(&Shape::draw));
}
Thus, mem_fn() can be seen as a mapping from the object-oriented calling style to the functional one.
Often, lambdas provide a simple and general alternative to binders. For example:
void draw_all(vector<Shape*>& v)
{
for_each(v.begin(),v.end(),[](Shape* p) { p–>draw(); });
}
33.5.3. function
A bind() can be used directly, and it can be used to initialize an auto variable. In that, bind() resembles a lambda.
If we want to assign the result of bind() to a variable with a specific type, we can use the standard-library type function. A function is specified with a specific return type and a specific argument type.


For example:
int f(double);
function<int(double)> fct {f}; // initialize to f
int g(int);
void user()
{
fct = [](double d) { return round(d); }; // assign lambda to fct
fct = f; // assign function to fct
fct = g; // error: incorrect return type
}
The target functions are provided for the rare cases where someone wants to examine a function, rather than simply call it as usually intended.
The standard-library function is a type that can hold any object you can invoke using the call operator () (§2.2.1, §3.4.3, §11.4, §19.2.2). That is, an object of type function is a function object. For example:
int round(double x) { return static_cast<double>(floor(x+0.5)); } // conventional 4/5 rounding
function<int(double)> f; // f can hold anything that can be called with a double and return an int
enum class Round_style { truncate, round };
struct Round { // function object carrying a state
Round_style s;
Round(Round_style ss) :s(ss) { }
int operator()(double x) const { return (s==Round_style::round) ? (x+0.5) : x; };
};
void t1()
{
f = round;
cout << f(7.6) << '\n'; // call through f to the function round
f = Round(Round_style::truncate);
cout << f(7.6) << '\n'; // call the function object
Round_style style = Round_style::round;
f = [style] (double x){ return (style==Round_style::round) ? x+0.5 : x; };
cout << f(7.6) << '\n'; // call the lambda
vector<double> v {7.6};
f = Round(Round_style::round);
std::transform(v.begin(),v.end(),v.begin(),f); // pass to algorithm
cout << v[0] << '\n'; // transformed by the lambda
}
We get 8, 8, 7, and 8.
Obviously, functions are useful for callbacks, for passing operations as arguments, etc.
33.6. Advice
[1] An input sequence is defined by a pair of iterators; §33.1.1.
[2] An output sequence is defined by a single iterator; avoid overflow; §33.1.1.
[3] For any iterator p, [p:p] is the empty sequence; §33.1.1.
[4] Use the end of a sequence to indicate “not found”; §33.1.1.
[5] Think of iterators as more general and often better behaved pointers; §33.1.1.
[6] Use iterator types, such as list<char>::iterator, rather than pointers to refer to elements of a container; §33.1.1.
[7] Use iterator_traits to obtain information about iterators; §33.1.3.
[8] You can do compile-time dispatch using iterator_traits; §33.1.3.
[9] Use iterator_traits to select an optimal algorithm based on an iterator’s category; §33.1.3.
[10] iterator_traits are an implementation detail; prefer to use them implicitly; §33.1.3.
[11] Use base() to extract an iterator from a reverse_iterator; §33.2.1.
[12] You can use an insert iterator to add elements to a container; §33.2.2.
[13] A move_iterator can be used to make copy operations into move operations; §33.2.3.
[14] Make sure that your containers can be traversed using a range-for; §33.3.
[15] Use bind() to create variants of functions and function objects; §33.5.1.
[16] Note that bind() dereferences references early; use ref() if you want to delay dereferencing; §33.5.1.
[17] A mem_fn() or a lambda can be used to convert the p–>f(a) calling convention into f(p,a); §33.5.2.
[18] Use function when you need a variable that can hold a variety of callable objects; §33.5.3.