C++ Recipes: A Problem-Solution Approach (2015)
CHAPTER 11
Concurrency
CPU manufacturers have recently struggled to improve CPU frequencies at the same rate of progress as was possible in the 1990s. CPU performance improvements over time have been maintained by clever CPU design and multiple processors being included on a single chip. This means programmers today must embrace concurrent programming or multithreaded programming if they wish their programs to perform quickly on modern computer chips.
Concurrent programming can be a challenge for programmers to get right. Many pitfalls await concurrent programs, including data that gets out of sync and therefore is wrong as well as deadlocks once your tasks require the use of locks to manage access. The recipes in this chapter introduce you to some practical applications of the STL features supplied by C++ to help you write concurrent programs.
11-1. Using Threads to Execute Concurrent Tasks
Problem
You’re writing a program that is performing poorly, and you’d like to speed up execution by using multiple processors in a system.
Solution
C++ provides the thread type, which can be used to create a native operating system thread. Program threads can be run on more than a single processor and therefore allow you to write programs that can use multiple CPUs and CPU cores.
How It Works
Detecting the Number of Logical CPU Cores
The C++ thread library provides a feature set that lets programs use all the cores and CPUs available in a given computer system. The first important function supplied by the C++ threading capabilities that you should be aware of allows you to query the number of execution units the computer contains. Listing 11-1 shows the C++ thread::hardware_concurrency method.
Listing 11-1. The thread::hardware_concurrency Method
#include <iostream>
#include <thread>
using namespace std;
int main(int argc, char* argv[])
{
const unsigned int numberOfProcessors{ thread::hardware_concurrency() };
cout << "This system can run " << numberOfProcessors << " concurrent tasks" << endl;
return 0;
}
This code uses the thread::hardware_concurrency method to query the number of simultaneous threads that can be run on the computer executing the program. Figure 11-1 shows the output generated by this program on my desktop computer.
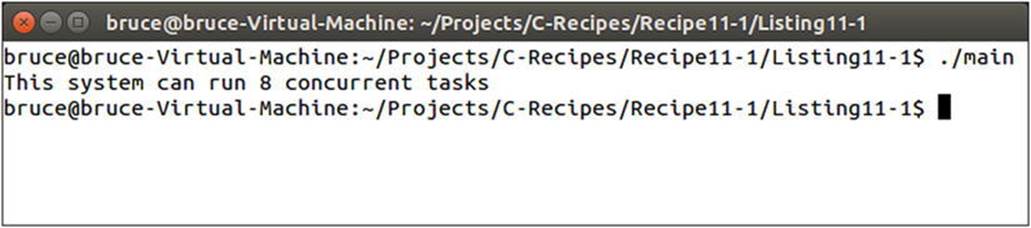
Figure 11-1. The result of calling thread::hardware_concurrency on an Intel Core i7 3770
Running the same code on a Surface Pro 2 with an Intel Core i5 4200U processor results in a value of 4 being returned, as opposed to the 8 returned by the Core i7 3770. You can see the results given by the Surface Pro 2 in Figure 11-2.
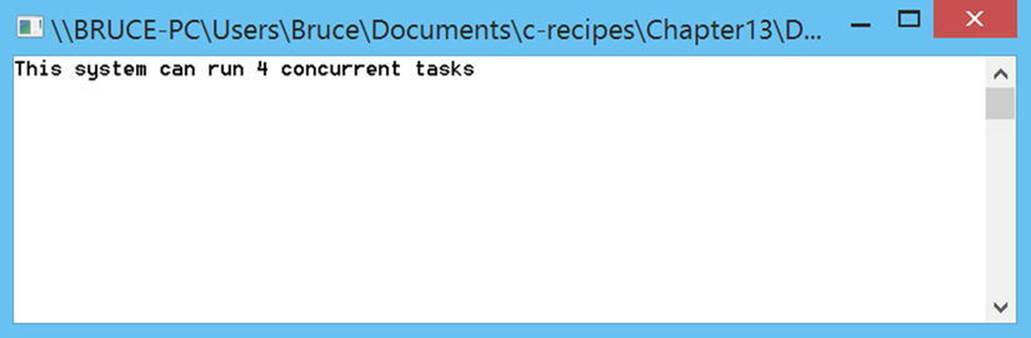
Figure 11-2. The result of running Listing 11-1 on a Surface Pro 2
Running too many threads on a computer that has too few logical cores can cause the computer to become unresponsive, so it’s important to keep this in mind when you’re creating programs.
Creating Threads
Once you know the system you’re running on might benefit from the use of concurrent execution, you can use the C++ thread class to create tasks to be run on multiple processor cores. The thread class is a portable, built-in type that allows you to write multithreaded code for any operating system.
![]() Note The thread class is a recent addition to the C++ programming language. It was added in the C++11 language spec, so you may need to check the documentation for the STL library you’re using to ensure that it supports this feature.
Note The thread class is a recent addition to the C++ programming language. It was added in the C++11 language spec, so you may need to check the documentation for the STL library you’re using to ensure that it supports this feature.
The thread constructor is simple to use and takes a function to execute on another CPU core. Listing 11-2 shows a simple thread that outputs to the console.
Listing 11-2. Creating a thread
#include <iostream>
#include <thread>
using namespace std;
void ThreadTask()
{
for (unsigned int i{ 0 }; i < 20; ++i)
{
cout << "Output from thread" << endl;
}
}
int main(int argc, char* argv[])
{
const unsigned int numberOfProcessors{ thread::hardware_concurrency() };
cout << "This system can run " << numberOfProcessors << " concurrent tasks" << endl;
if (numberOfProcessors > 1)
{
thread myThread{ ThreadTask };
cout << "Output from main" << endl;
myThread.join();
}
else
{
cout << "CPU does not have multiple cores." << endl;
}
return 0;
}
Listing 11-2 determines whether to create a thread based on the number of logical cores on the computer executing the program.
![]() Note Most operating systems allow you to run more threads than there are processors, but you might find that doing so slows your program due to the overhead of managing multiple threads.
Note Most operating systems allow you to run more threads than there are processors, but you might find that doing so slows your program due to the overhead of managing multiple threads.
If the CPU has more than one logical core, the program creates a thread object called myThread. The myThread variable is initialized with a pointer to a function. This function will be executed in the thread context and, more likely than not, on a different CPU thread than the mainfunction.
The ThreadTask function consists of a for loop that simply outputs to the console multiple times. The main function also outputs to the console. The intent is to show that both functions are running concurrently. You can see that this is true in Figure 11-3, where the output frommain occurs in the middle of the output from ThreadTask.
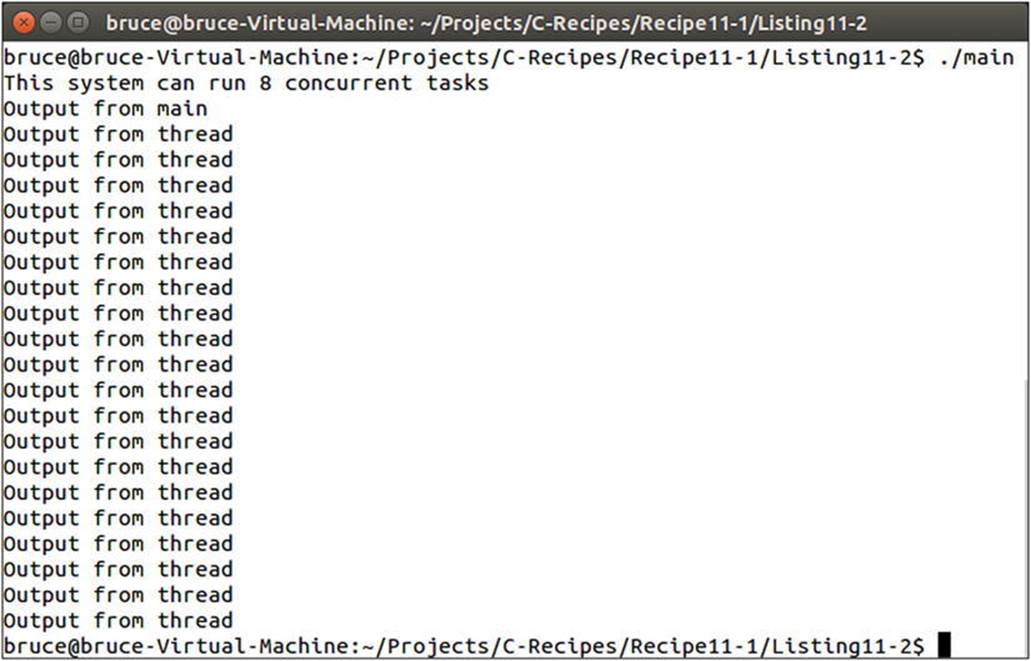
Figure 11-3. The output showing that both main and ThreadTask, from Listing 11-2, are running concurrently
Cleaning Up After Threads
The main function in Listing 11-2 immediately calls the join method on the thread. The join method is used to tell the current thread to wait for the additional thread to end execution before continuing. This is important because C++ programs are required to destroy their own threads to prevent leaks from occurring. Calling the destructor on a thread object doesn’t destroy the currently executing thread context. Listing 11-3 shows code that has been modified to not call join on myThread.
Listing 11-3. Forgetting to Call join on a thread
#include <iostream>
#include <thread>
using namespace std;
void ThreadTask()
{
for (unsigned int i{ 0 }; i < 20; ++i)
{
cout << "Output from thread" << endl;
}
}
int main(int argc, char* argv[])
{
const unsigned int numberOfProcessors{ thread::hardware_concurrency() };
cout << "This system can run " << numberOfProcessors << " concurrent tasks" << endl;
if (numberOfProcessors > 1)
{
thread myThread{ ThreadTask };
cout << "Output from main" << endl;
}
else
{
cout << "CPU does not have multiple cores." << endl;
}
return 0;
}
This code causes the myThread object to go out of scope before the ThreadTask function has completed execution. This can cause a thread leak in your program that may eventually cause the program or the operating system to become unstable. A program running on the Linux command line will fail with the error shown in Figure 11-4.
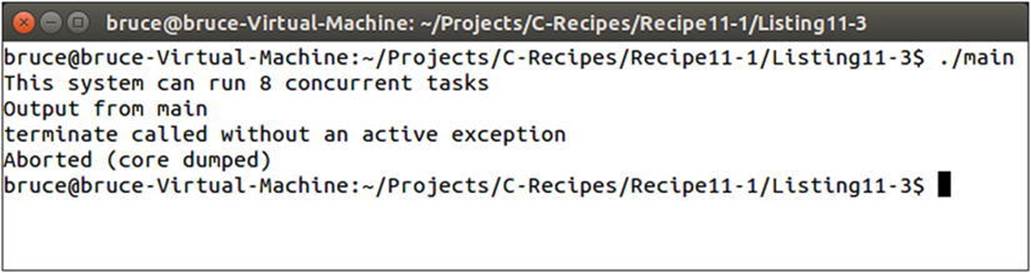
Figure 11-4. The Linux error when a thread destructor is called before completion
As you can see, this warning isn’t particularly descriptive, and there’s no guarantee that you’ll get any warning when using other operating systems and libraries. It’s therefore important to be aware of your threads' lifetimes and ensure that you’re dealing with them appropriately.
One approach is to use the join method to make the program wait for threads to finish before closing them down. C++ also provides a second option: the detach method. Listing 11-4 shows the detach method in use.
Listing 11-4. Using the detach Method
#include <iostream>
#include <thread>
using namespace std;
void ThreadTask()
{
for (unsigned int i = 0; i < 20; ++i)
{
cout << "Output from thread" << endl;
}
}
int main(int argc, char* argv[])
{
const unsigned int numberOfProcessors{ thread::hardware_concurrency() };
cout << "This system can run " << numberOfProcessors << " concurrent tasks" << endl;
if (numberOfProcessors > 1)
{
thread myThread{ ThreadTask };
cout << "Output from main" << endl;
myThread.detach();
}
else
{
cout << "CPU does not have multiple cores." << endl;
}
return 0;
}
Listing 11-4 shows that the detach method can be used in place of join. The join method causes the program to wait for a running thread to complete before continuing, but the detach method doesn’t. The detach method allows you to create threads that outlive the execution of your program. These may be useful for system tasks that need to track time over long periods; however, I’m skeptical about whether many day-to-day programs will find a use for this method. There’s also a risk that your program will leak threads that have been detached and have no way to get those tasks back. Once an execution context in a thread has been detached, you can never reattach it.
11-2. Creating thread Scope Variables
Problem
You have classes of objects that use static data in their implementations, and you’d like to use them with threads.
Solution
C++ provides the thread_local specifier to allow the computer to create an instance of the static data on a per-thread basis.
How It Works
Before I cover how to use thread_local, let’s step through a scenario where this problem can occur so you can clearly see the issue and the problem the solution itself can cause. Listing 11-5 contains a class that uses a static vector of objects to prevent many calls to new and delete.
Listing 11-5. Creating a Class that Uses Static Data to Track State
#include <cstdlib>
#include <iostream>
#include <stack>
#include <thread>
#include <vector>
using namespace std;
class MyManagedObject
{
private:
static const unsigned int MAX_OBJECTS{ 4 };
using MyManagedObjectCollection = vector < MyManagedObject > ;
static MyManagedObjectCollection s_ManagedObjects;
static stack<unsigned int> s_FreeList;
unsigned int m_Value{ 0xFFFFFFFF };
public:
MyManagedObject() = default;
MyManagedObject(unsigned int value)
: m_Value{ value }
{
}
void* operator new(size_t numBytes)
{
void* objectMemory{};
if (s_ManagedObjects.capacity() < MAX_OBJECTS)
{
s_ManagedObjects.reserve(MAX_OBJECTS);
}
if (numBytes == sizeof(MyManagedObject) &&
s_ManagedObjects.size() < s_ManagedObjects.capacity())
{
unsigned int index{ 0xFFFFFFFF };
if (s_FreeList.size() > 0)
{
index = s_FreeList.top();
s_FreeList.pop();
}
if (index == 0xFFFFFFFF)
{
s_ManagedObjects.push_back({});
index = s_ManagedObjects.size() - 1;
}
objectMemory = s_ManagedObjects.data() + index;
}
else
{
objectMemory = malloc(numBytes);
}
return objectMemory;
}
void operator delete(void* pMem)
{
const intptr_t index{
(static_cast<MyManagedObject*>(pMem) - s_ManagedObjects.data()) /
static_cast<intptr_t>(sizeof(MyManagedObject)) };
if (0 <= index && index < static_cast<intptr_t>(s_ManagedObjects.size()))
{
s_FreeList.emplace(static_cast<unsigned int>(index));
}
else
{
free(pMem);
}
}
};
MyManagedObject::MyManagedObjectCollection MyManagedObject::s_ManagedObjects{};
stack<unsigned int> MyManagedObject::s_FreeList{};
int main(int argc, char* argv[])
{
cout << hex << showbase;
MyManagedObject* pObject1{ new MyManagedObject(1) };
cout << "pObject1: " << pObject1 << endl;
MyManagedObject* pObject2{ new MyManagedObject(2) };
cout << "pObject2: " << pObject2 << endl;
delete pObject1;
pObject1 = nullptr;
MyManagedObject* pObject3{ new MyManagedObject(3) };
cout << "pObject3: " << pObject3 << endl;
pObject1 = new MyManagedObject(4);
cout << "pObject1: " << pObject1 << endl;
delete pObject2;
pObject2 = nullptr;
delete pObject3;
pObject3 = nullptr;
delete pObject1;
pObject1 = nullptr;
return 0;
}
The code in Listing 11-5 overloads the new and delete methods on the MyManagedObject class. These overloads are used to return newly created objects from an initial pool of preallocated memory. Doing this would allow you to restrict the number of a given type of object to a prearranged limit but still let you use the familiar new and delete syntax.
![]() Note The code in Listing 11-5 doesn’t actually enforce the limit; it simply falls back to dynamic allocation when the limit has been reached.
Note The code in Listing 11-5 doesn’t actually enforce the limit; it simply falls back to dynamic allocation when the limit has been reached.
The managed class works by using a constant to determine the number of preallocated objects that should exist. This number is used to initialize a vector on the first allocation. Each subsequent allocation is fulfilled from this vector until it’s exhausted. A free list of indices is maintained. If an object from the pool is released, its index is added to the top of the free stack. Objects on the free list are then reissued in the order that they were added to this stack. Figure 11-5 shows that pObject3 ends up with the same address that was used by pObject1 before it was deleted.
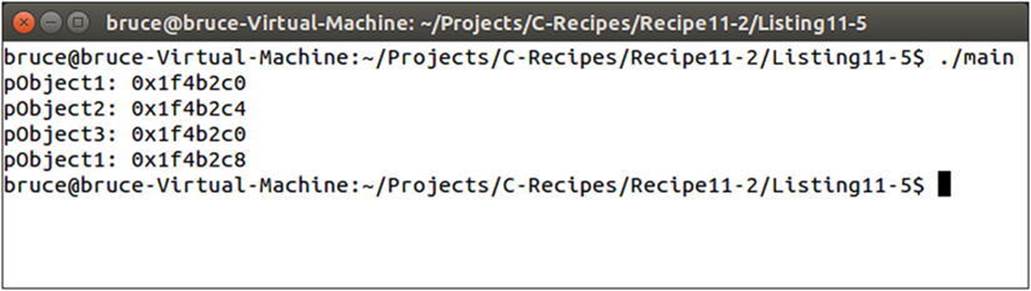
Figure 11-5. Output showing the correct operation of the MyManagedObject pool
The operation of this managed pool uses a static vector and a static stack to maintain the pool across all MyManagedObject instances. This causes problems when coupled with threads, because you can’t be sure that different threads won’t try to access these objects at the same time.
Listing 11-6 updates the code from Listing 11-5 to use a thread to also create MyManagedObject instances.
Listing 11-6. Using a thread to Create MyManagedObject Instances
#include <cstdlib>
#include <iostream>
#include <stack>
#include <thread>
#include <vector>
using namespace std;
class MyManagedObject
{
private:
static const unsigned int MAX_OBJECTS{ 8 };
using MyManagedObjectCollection = vector < MyManagedObject >;
static MyManagedObjectCollection s_ManagedObjects;
static stack<unsigned int> s_FreeList;
unsigned int m_Value{ 0xFFFFFFFF };
public:
MyManagedObject() = default;
MyManagedObject(unsigned int value)
: m_Value{ value }
{
}
void* operator new(size_t numBytes)
{
void* objectMemory{};
if (s_ManagedObjects.capacity() < MAX_OBJECTS)
{
s_ManagedObjects.reserve(MAX_OBJECTS);
}
if (numBytes == sizeof(MyManagedObject) &&
s_ManagedObjects.size() < s_ManagedObjects.capacity())
{
unsigned int index{ 0xFFFFFFFF };
if (s_FreeList.size() > 0)
{
index = s_FreeList.top();
s_FreeList.pop();
}
if (index == 0xFFFFFFFF)
{
s_ManagedObjects.push_back({});
index = s_ManagedObjects.size() - 1;
}
objectMemory = s_ManagedObjects.data() + index;
}
else
{
objectMemory = malloc(numBytes);
}
return objectMemory;
}
void operator delete(void* pMem)
{
const intptr_t index{
(static_cast<MyManagedObject*>(pMem)-s_ManagedObjects.data()) /
static_cast< intptr_t >(sizeof(MyManagedObject)) };
if (0 <= index && index < static_cast< intptr_t >(s_ManagedObjects.size()))
{
s_FreeList.emplace(static_cast<unsigned int>(index));
}
else
{
free(pMem);
}
}
};
MyManagedObject::MyManagedObjectCollection MyManagedObject::s_ManagedObjects{};
stack<unsigned int> MyManagedObject::s_FreeList{};
void ThreadTask()
{
MyManagedObject* pObject4{ new MyManagedObject(5) };
cout << "pObject4: " << pObject4 << endl;
MyManagedObject* pObject5{ new MyManagedObject(6) };
cout << "pObject5: " << pObject5 << endl;
delete pObject4;
pObject4 = nullptr;
MyManagedObject* pObject6{ new MyManagedObject(7) };
cout << "pObject6: " << pObject6 << endl;
pObject4 = new MyManagedObject(8);
cout << "pObject4: " << pObject4 << endl;
delete pObject5;
pObject5 = nullptr;
delete pObject6;
pObject6 = nullptr;
delete pObject4;
pObject4 = nullptr;
}
int main(int argc, char* argv[])
{
cout << hex << showbase;
thread myThread{ ThreadTask };
MyManagedObject* pObject1{ new MyManagedObject(1) };
cout << "pObject1: " << pObject1 << endl;
MyManagedObject* pObject2{ new MyManagedObject(2) };
cout << "pObject2: " << pObject2 << endl;
delete pObject1;
pObject1 = nullptr;
MyManagedObject* pObject3{ new MyManagedObject(3) };
cout << "pObject3: " << pObject3 << endl;
pObject1 = new MyManagedObject(4);
cout << "pObject1: " << pObject1 << endl;
delete pObject2;
pObject2 = nullptr;
delete pObject3;
pObject3 = nullptr;
delete pObject1;
pObject1 = nullptr;
myThread.join();
return 0;
}
The code in Listing 11-6 uses a thread to allocate objects from the pool concurrently with the main function. This means the static pool can be accessed simultaneously from two locations, and your program can run into problems. Two common issues are unexpected program crashes and data races.
A data race is a more subtle problem and results in unexpected memory corruption. Figure 11-6 illustrates the problem.
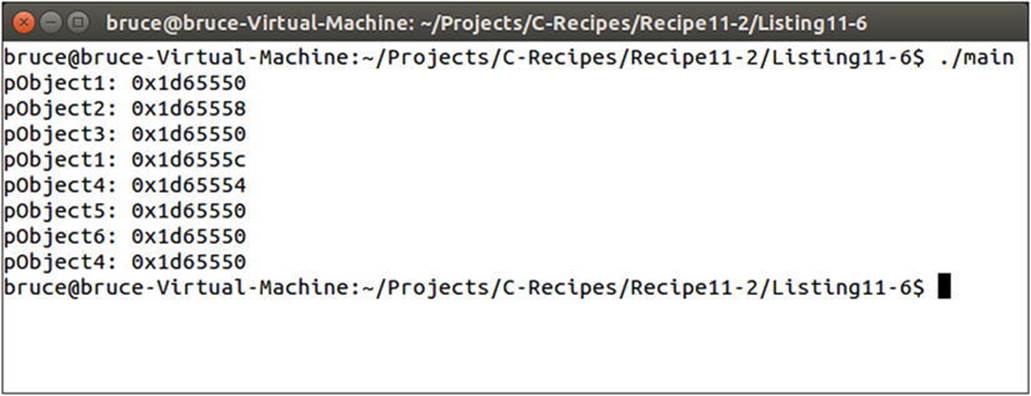
Figure 11-6. The problem caused by running into data races between threads
The problem presented by allocating objects from the same pool may be subtle and difficult to spot at first. If you look closely, you see that pObject6 and pObject3 are pointing to the same memory address. These pointers are created and initialized on different threads, and at no point do you expect them to point at the same memory address, even with object reuse in your pools. This again is a difficulty in working with threads. The associated problems are very time-sensitive and their manifestations can be altered by the conditions of the computer at the time of execution. Other programs may create threads that cause your own to be delayed slightly, so that a problem in your thread logic can manifest itself in many different ways despite having the same root cause.
C++ provides a solution to this problem: the thread_local keyword. The thread_local keyword works by telling the compiler that the static objects you’re creating should be unique for every thread you create that uses these objects. The side effect is that you don’t have a single shared instance of the static object across all classes. This is a significant departure from the normal usage of static, where there is a single shared object for all instances of the type. Listing 11-7 shows the memory-pool functions and the associated static variables updated to usethread_local.
Listing 11-7. Using thread_local
#include <cstdlib>
#include <iostream>
#include <stack>
#include <thread>
#include <vector>
using namespace std;
class MyManagedObject
{
private:
static thread_local const unsigned int MAX_OBJECTS;
using MyManagedObjectCollection = vector < MyManagedObject >;
static thread_local MyManagedObjectCollection s_ManagedObjects;
static thread_local stack<unsigned int> s_FreeList;
unsigned int m_Value{ 0xFFFFFFFF };
public:
MyManagedObject() = default;
MyManagedObject(unsigned int value)
: m_Value{ value }
{
}
void* operator new(size_t numBytes)
{
void* objectMemory{};
if (s_ManagedObjects.capacity() < MAX_OBJECTS)
{
s_ManagedObjects.reserve(MAX_OBJECTS);
}
if (numBytes == sizeof(MyManagedObject) &&
s_ManagedObjects.size() < s_ManagedObjects.capacity())
{
unsigned int index{ 0xFFFFFFFF };
if (s_FreeList.size() > 0)
{
index = s_FreeList.top();
s_FreeList.pop();
}
if (index == 0xFFFFFFFF)
{
s_ManagedObjects.push_back({});
index = s_ManagedObjects.size() - 1;
}
objectMemory = s_ManagedObjects.data() + index;
}
else
{
objectMemory = malloc(numBytes);
}
return objectMemory;
}
void operator delete(void* pMem)
{
const intptr_t index{
(static_cast<MyManagedObject*>(pMem)-s_ManagedObjects.data()) /
static_cast<intptr_t>(sizeof(MyManagedObject)) };
if (0 <= index && index < static_cast< intptr_t >(s_ManagedObjects.size()))
{
s_FreeList.emplace(static_cast<unsigned int>(index));
}
else
{
free(pMem);
}
}
};
thread_local const unsigned int MyManagedObject::MAX_OBJECTS{ 8 };thread_local MyManagedObject::MyManagedObjectCollection MyManagedObject::s_ManagedObjects{};thread_local stack<unsigned int> MyManagedObject::s_FreeList{};
void ThreadTask()
{
MyManagedObject* pObject4{ new MyManagedObject(5) };
cout << "pObject4: " << pObject4 << endl;
MyManagedObject* pObject5{ new MyManagedObject(6) };
cout << "pObject5: " << pObject5 << endl;
delete pObject4;
pObject4 = nullptr;
MyManagedObject* pObject6{ new MyManagedObject(7) };
cout << "pObject6: " << pObject6 << endl;
pObject4 = new MyManagedObject(8);
cout << "pObject4: " << pObject4 << endl;
delete pObject5;
pObject5 = nullptr;
delete pObject6;
pObject6 = nullptr;
delete pObject4;
pObject4 = nullptr;
}
int main(int argc, char* argv[])
{
cout << hex << showbase;
thread myThread{ ThreadTask };
MyManagedObject* pObject1{ new MyManagedObject(1) };
cout << "pObject1: " << pObject1 << endl;
MyManagedObject* pObject2{ new MyManagedObject(2) };
cout << "pObject2: " << pObject2 << endl;
delete pObject1;
pObject1 = nullptr;
MyManagedObject* pObject3{ new MyManagedObject(3) };
cout << "pObject3: " << pObject3 << endl;
pObject1 = new MyManagedObject(4);
cout << "pObject1: " << pObject1 << endl;
delete pObject2;
pObject2 = nullptr;
delete pObject3;
pObject3 = nullptr;
delete pObject1;
pObject1 = nullptr;
myThread.join();
return 0;
}
Listing 11-7 shows that you can specify static variables as having thread_local storage by adding the thread_local identifier to their declaration and definitions. The impact of this change is that the main function and the ThreadTask function have separates_ManagedObjects, s_FreeList, and MAX_OBJECT variables in their own execution context. Now that there are two copies of each, you have twice the number of potential objects, because as the pools have been duplicated. This may or may not be a problem for your program, but you should be careful when using thread_local and consider any unintended consequences. Figure 11-7 shows the result of running the code in Listing 11-7.
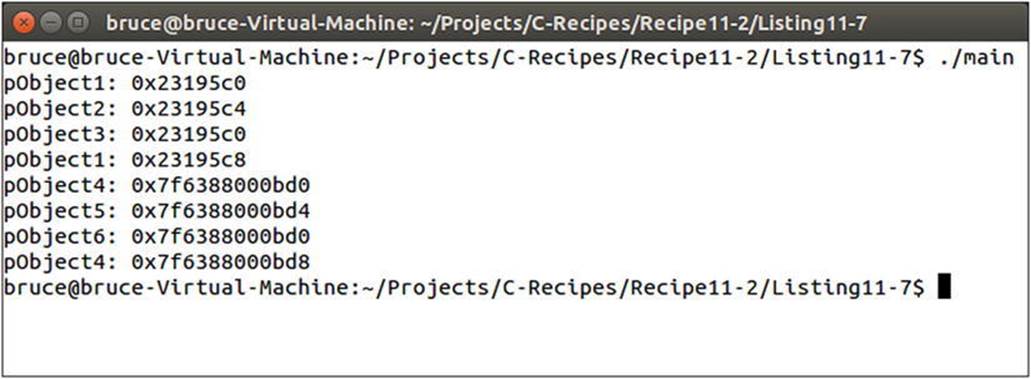
Figure 11-7. Output when using thread_local
You can see the problems when using threads. The first line of output is split between the two threads, but it should be very apparent that the two threads are being assigned values from completely separate places in memory. This proves that the compiler has made sure the staticvariables are unique for each thread in the program. You could take this further by adding even more threads to the program and seeing that they’re allocating objects from different places in memory and that at no point can two pointers on different threads be pointing to the same memory address.
11-3. Accessing Shared Objects Using Mutual Exclusion
Problem
You have an object that you would like to be able to access on more than one thread at a time.
Solution
C++ provides mutex objects that allow you to provide mutually exclusive access to sections of code.
How It Works
A mutex can be used to synchronize threads. This is achieved by the mutex class and the methods it provides to acquire and release the mutex. A thread can be sure that no other thread is currently accessing a shared resource by waiting until it can acquire the mutex before continuing execution. The program in Listing 11-8 contains a data race: a situation in which two threads can access a shared resource at the same time and cause unstable and unexpected program behavior.
Listing 11-8. A Program Containing a Data Race
#include <cstdlib>
#include <iostream>
#include <stack>
#include <thread>
#include <vector>
using namespace std;
class MyManagedObject
{
private:
static const unsigned int MAX_OBJECTS{ 8 };
using MyManagedObjectCollection = vector < MyManagedObject >;
static MyManagedObjectCollection s_ManagedObjects;
static stack<unsigned int> s_FreeList;
unsigned int m_Value{ 0xFFFFFFFF };
public:
MyManagedObject() = default;
MyManagedObject(unsigned int value)
: m_Value{ value }
{
}
void* operator new(size_t numBytes)
{
void* objectMemory{};
if (s_ManagedObjects.capacity() < MAX_OBJECTS)
{
s_ManagedObjects.reserve(MAX_OBJECTS);
}
if (numBytes == sizeof(MyManagedObject) &&
s_ManagedObjects.size() < s_ManagedObjects.capacity())
{
unsigned int index{ 0xFFFFFFFF };
if (s_FreeList.size() > 0)
{
index = s_FreeList.top();
s_FreeList.pop();
}
if (index == 0xFFFFFFFF)
{
s_ManagedObjects.push_back({});
index = s_ManagedObjects.size() - 1;
}
objectMemory = s_ManagedObjects.data() + index;
}
else
{
objectMemory = malloc(numBytes);
}
return objectMemory;
}
void operator delete(void* pMem)
{
const intptr_t index{
(static_cast<MyManagedObject*>(pMem)-s_ManagedObjects.data()) /
static_cast<intptr_t>(sizeof(MyManagedObject)) };
if (0 <= index && index < static_cast< intptr_t >(s_ManagedObjects.size()))
{
s_FreeList.emplace(static_cast<unsigned int>(index));
}
else
{
free(pMem);
}
}
};
MyManagedObject::MyManagedObjectCollection MyManagedObject::s_ManagedObjects{};
stack<unsigned int> MyManagedObject::s_FreeList{};
void ThreadTask()
{
MyManagedObject* pObject4{ new MyManagedObject(5) };
cout << "pObject4: " << pObject4 << endl;
MyManagedObject* pObject5{ new MyManagedObject(6) };
cout << "pObject5: " << pObject5 << endl;
delete pObject4;
pObject4 = nullptr;
MyManagedObject* pObject6{ new MyManagedObject(7) };
cout << "pObject6: " << pObject6 << endl;
pObject4 = new MyManagedObject(8);
cout << "pObject4: " << pObject4 << endl;
delete pObject5;
pObject5 = nullptr;
delete pObject6;
pObject6 = nullptr;
delete pObject4;
pObject4 = nullptr;
}
int main(int argc, char* argv[])
{
cout << hex << showbase;
thread myThread{ ThreadTask };
MyManagedObject* pObject1{ new MyManagedObject(1) };
cout << "pObject1: " << pObject1 << endl;
MyManagedObject* pObject2{ new MyManagedObject(2) };
cout << "pObject2: " << pObject2 << endl;
delete pObject1;
pObject1 = nullptr;
MyManagedObject* pObject3{ new MyManagedObject(3) };
cout << "pObject3: " << pObject3 << endl;
pObject1 = new MyManagedObject(4);
cout << "pObject1: " << pObject1 << endl;
delete pObject2;
pObject2 = nullptr;
delete pObject3;
pObject3 = nullptr;
delete pObject1;
pObject1 = nullptr;
myThread.join();
return 0;
}
This program can’t prevent the code in ThreadTask and the main function from accessing the s_ManagedObjects and s_FreeList pools in the MyManagedObject class. Access to these objects can be protected by a mutex, as you can see in Listing 11-9.
Listing 11-9. Adding a Mutex to Protect Access to Shared Objects
#include <cstdlib>
#include <iostream>
#include <mutex>
#include <stack>
#include <thread>
#include <vector>
using namespace std;
class MyManagedObject
{
private:
static const unsigned int MAX_OBJECTS{ 8 };
using MyManagedObjectCollection = vector < MyManagedObject >;
static MyManagedObjectCollection s_ManagedObjects;
static stack<unsigned int> s_FreeList;
static mutex s_Mutex;
unsigned int m_Value{ 0xFFFFFFFF };
public:
MyManagedObject() = default;
MyManagedObject(unsigned int value)
: m_Value{ value }
{
}
void* operator new(size_t numBytes)
{
void* objectMemory{};
s_Mutex.lock();
if (s_ManagedObjects.capacity() < MAX_OBJECTS)
{
s_ManagedObjects.reserve(MAX_OBJECTS);
}
if (numBytes == sizeof(MyManagedObject) &&
s_ManagedObjects.size() < s_ManagedObjects.capacity())
{
unsigned int index{ 0xFFFFFFFF };
if (s_FreeList.size() > 0)
{
index = s_FreeList.top();
s_FreeList.pop();
}
if (index == 0xFFFFFFFF)
{
s_ManagedObjects.push_back({});
index = s_ManagedObjects.size() - 1;
}
objectMemory = s_ManagedObjects.data() + index;
}
else
{
objectMemory = malloc(numBytes);
}
s_Mutex.unlock();
return objectMemory;
}
void operator delete(void* pMem)
{
s_Mutex.lock();
const intptr_t index{
(static_cast<MyManagedObject*>(pMem)-s_ManagedObjects.data()) /
static_cast<intptr_t>(sizeof(MyManagedObject)) };
if (0 <= index && index < static_cast< intptr_t >(s_ManagedObjects.size()))
{
s_FreeList.emplace(static_cast<unsigned int>(index));
}
else
{
free(pMem);
}
s_Mutex.unlock();
}
};
MyManagedObject::MyManagedObjectCollection MyManagedObject::s_ManagedObjects{};
stack<unsigned int> MyManagedObject::s_FreeList{};
mutex MyManagedObject::s_Mutex;
void ThreadTask()
{
MyManagedObject* pObject4{ new MyManagedObject(5) };
cout << "pObject4: " << pObject4 << endl;
MyManagedObject* pObject5{ new MyManagedObject(6) };
cout << "pObject5: " << pObject5 << endl;
delete pObject4;
pObject4 = nullptr;
MyManagedObject* pObject6{ new MyManagedObject(7) };
cout << "pObject6: " << pObject6 << endl;
pObject4 = new MyManagedObject(8);
cout << "pObject4: " << pObject4 << endl;
delete pObject5;
pObject5 = nullptr;
delete pObject6;
pObject6 = nullptr;
delete pObject4;
pObject4 = nullptr;
}
int main(int argc, char* argv[])
{
cout << hex << showbase;
thread myThread{ ThreadTask };
MyManagedObject* pObject1{ new MyManagedObject(1) };
cout << "pObject1: " << pObject1 << endl;
MyManagedObject* pObject2{ new MyManagedObject(2) };
cout << "pObject2: " << pObject2 << endl;
delete pObject1;
pObject1 = nullptr;
MyManagedObject* pObject3{ new MyManagedObject(3) };
cout << "pObject3: " << pObject3 << endl;
pObject1 = new MyManagedObject(4);
cout << "pObject1: " << pObject1 << endl;
delete pObject2;
pObject2 = nullptr;
delete pObject3;
pObject3 = nullptr;
delete pObject1;
pObject1 = nullptr;
myThread.join();
return 0;
}
This code uses a mutex to ensure that the new and delete functions in the MyManagedObject class are only executing on a single thread at any given time. This ensures that the object pool being maintained for this class is always in a valid state and that the same addresses aren’t being given to different threads. The code requires that the lock be held for the entire execution of the functions it’s protecting. C++ provides a helper class named lock_guard that automatically locks a mutex on construction and frees the mutex on destruction. Listing 11-10 shows alock_guard in use.
Listing 11-10. Using a lock_guard
#include <cstdlib>
#include <iostream>
#include <mutex>
#include <stack>
#include <thread>
#include <vector>
using namespace std;
class MyManagedObject
{
private:
static const unsigned int MAX_OBJECTS{ 8 };
using MyManagedObjectCollection = vector < MyManagedObject >;
static MyManagedObjectCollection s_ManagedObjects;
static stack<unsigned int> s_FreeList;
static mutex s_Mutex;
unsigned int m_Value{ 0xFFFFFFFF };
public:
MyManagedObject() = default;
MyManagedObject(unsigned int value)
: m_Value{ value }
{
}
void* operator new(size_t numBytes)
{
lock_guard<mutex> lock{ s_Mutex };
void* objectMemory{};
if (s_ManagedObjects.capacity() < MAX_OBJECTS)
{
s_ManagedObjects.reserve(MAX_OBJECTS);
}
if (numBytes == sizeof(MyManagedObject) &&
s_ManagedObjects.size() < s_ManagedObjects.capacity())
{
unsigned int index{ 0xFFFFFFFF };
if (s_FreeList.size() > 0)
{
index = s_FreeList.top();
s_FreeList.pop();
}
if (index == 0xFFFFFFFF)
{
s_ManagedObjects.push_back({});
index = s_ManagedObjects.size() - 1;
}
objectMemory = s_ManagedObjects.data() + index;
}
else
{
objectMemory = malloc(numBytes);
}
return objectMemory;
}
void operator delete(void* pMem)
{
lock_guard<mutex> lock{ s_Mutex };
const intptr_t index{
(static_cast<MyManagedObject*>(pMem)-s_ManagedObjects.data()) /
static_cast<intptr_t>(sizeof(MyManagedObject)) };
if (0 <= index && index < static_cast<intptr_t>(s_ManagedObjects.size()))
{
s_FreeList.emplace(static_cast<unsigned int>(index));
}
else
{
free(pMem);
}
}
};
MyManagedObject::MyManagedObjectCollection MyManagedObject::s_ManagedObjects{};
stack<unsigned int> MyManagedObject::s_FreeList{};
mutex MyManagedObject::s_Mutex;
void ThreadTask()
{
MyManagedObject* pObject4{ new MyManagedObject(5) };
cout << "pObject4: " << pObject4 << endl;
MyManagedObject* pObject5{ new MyManagedObject(6) };
cout << "pObject5: " << pObject5 << endl;
delete pObject4;
pObject4 = nullptr;
MyManagedObject* pObject6{ new MyManagedObject(7) };
cout << "pObject6: " << pObject6 << endl;
pObject4 = new MyManagedObject(8);
cout << "pObject4: " << pObject4 << endl;
delete pObject5;
pObject5 = nullptr;
delete pObject6;
pObject6 = nullptr;
delete pObject4;
pObject4 = nullptr;
}
int main(int argc, char* argv[])
{
cout << hex << showbase;
thread myThread{ ThreadTask };
MyManagedObject* pObject1{ new MyManagedObject(1) };
cout << "pObject1: " << pObject1 << endl;
MyManagedObject* pObject2{ new MyManagedObject(2) };
cout << "pObject2: " << pObject2 << endl;
delete pObject1;
pObject1 = nullptr;
MyManagedObject* pObject3{ new MyManagedObject(3) };
cout << "pObject3: " << pObject3 << endl;
pObject1 = new MyManagedObject(4);
cout << "pObject1: " << pObject1 << endl;
delete pObject2;
pObject2 = nullptr;
delete pObject3;
pObject3 = nullptr;
delete pObject1;
pObject1 = nullptr;
myThread.join();
return 0;
}
Using a lock_guard means you don’t have to worry about calling unlock on the mutex for yourself. It also conforms to the Resource Allocation Is Initialization (RAII) pattern that many C++ developers try to follow.
11-4. Creating Threads that Wait for Events
Problem
You would like to create a thread that waits for another event in your program.
Solution
C++ provides the condition_variable class that can be used to signal that an event has occurred to a waiting thread.
How It Works
A condition_variable is another C++ construct that wraps a complex behavior into a simple object interface. It’s common in multithreaded programming to create threads that you would like to have wait for some event to occur in another thread. This is common in a producer/consumer situation, where one thread may be creating tasks and another thread is auctioning or carrying out those tasks. A condition variable is perfect in these scenarios.
A condition_variable requires a mutex to be effective. It works by waiting for some condition to become true and then attempting to acquire a lock on the mutex protecting a shared resource. Listing 11-11 uses a mutex, a unique_lock, and a condition_variable to communicate between threads when a producer thread has queued work for two consumer threads.
Listing 11-11. Using a condition_variable to Wake a Thread
#include <condition_variable>
#include <cstdlib>
#include <functional>
#include <iostream>
#include <mutex>
#include <thread>
#include <stack>
#include <vector>
using namespace std;
class MyManagedObject
{
private:
static const unsigned int MAX_OBJECTS{ 8 };
using MyManagedObjectCollection = vector < MyManagedObject >;
static MyManagedObjectCollection s_ManagedObjects;
static stack<unsigned int> s_FreeList;
static mutex s_Mutex;
unsigned int m_Value{ 0xFFFFFFFF };
public:
MyManagedObject() = default;
MyManagedObject(unsigned int value)
: m_Value{ value }
{
}
unsigned int GetValue() const { return m_Value; }
void* operator new(size_t numBytes)
{
lock_guard<mutex> lock{ s_Mutex };
void* objectMemory{};
if (s_ManagedObjects.capacity() < MAX_OBJECTS)
{
s_ManagedObjects.reserve(MAX_OBJECTS);
}
if (numBytes == sizeof(MyManagedObject) &&
s_ManagedObjects.size() < s_ManagedObjects.capacity())
{
unsigned int index{ 0xFFFFFFFF };
if (s_FreeList.size() > 0)
{
index = s_FreeList.top();
s_FreeList.pop();
}
if (index == 0xFFFFFFFF)
{
s_ManagedObjects.push_back({});
index = s_ManagedObjects.size() - 1;
}
objectMemory = s_ManagedObjects.data() + index;
}
else
{
objectMemory = malloc(numBytes);
}
return objectMemory;
}
void operator delete(void* pMem)
{
lock_guard<mutex> lock{ s_Mutex };
const intptr_t index{
(static_cast<MyManagedObject*>(pMem)-s_ManagedObjects.data()) /
static_cast<intptr_t>(sizeof(MyManagedObject)) };
if (0 <= index && index < static_cast<intptr_t>(s_ManagedObjects.size()))
{
s_FreeList.emplace(static_cast<unsigned int>(index));
}
else
{
free(pMem);
}
}
};
MyManagedObject::MyManagedObjectCollection MyManagedObject::s_ManagedObjects{};
stack<unsigned int> MyManagedObject::s_FreeList{};
mutex MyManagedObject::s_Mutex;
using ProducerQueue = vector < unsigned int > ;
void ThreadTask(
reference_wrapper<condition_variable> condition,
reference_wrapper<mutex> queueMutex,
reference_wrapper<ProducerQueue> queueRef,
reference_wrapper<bool> die)
{
ProducerQueue& queue{ queueRef.get() };
while (!die.get() || queue.size())
{
unique_lock<mutex> lock{ queueMutex.get() };
function<bool()> predicate{
[&queue]()
{
return !queue.empty();
}
};
condition.get().wait(lock, predicate);
unsigned int numberToCreate{ queue.back() };
queue.pop_back();
cout << "Creating " <<
numberToCreate <<
" objects on thread " <<
this_thread::get_id() << endl;
for (unsigned int i = 0; i < numberToCreate; ++i)
{
MyManagedObject* pObject{ new MyManagedObject(i) };
}
}
}
int main(int argc, char* argv[])
{
condition_variable condition;
mutex queueMutex;
ProducerQueue queue;
bool die{ false };
thread myThread1{ ThreadTask, ref(condition), ref(queueMutex), ref(queue), ref(die) };
thread myThread2{ ThreadTask, ref(condition), ref(queueMutex), ref(queue), ref(die) };
queueMutex.lock();
queue.emplace_back(300000);
queue.emplace_back(400000);
queueMutex.unlock();
condition.notify_all();
this_thread::sleep_for( 10ms );
while (!queueMutex.try_lock())
{
cout << "Main waiting for queue access!" << endl;
this_thread::sleep_for( 100ms );
}
queue.emplace_back(100000);
queue.emplace_back(200000);
this_thread::sleep_for( 1000ms );
condition.notify_one();
this_thread::sleep_for( 1000ms );
condition.notify_one();
this_thread::sleep_for( 1000ms );
queueMutex.unlock();
die = true;
cout << "main waiting for join!" << endl;
myThread1.join();
myThread2.join();
return 0;
}
This code contains a complex scenario using the C++ language’s multithreading capabilities. The first aspect of this example that you need to understand is the method used to pass variables from main into the threads. When the thread object is created, you can think of the values you pass to it as being passed into a function by value. In effect, this causes your threads to receive copies of variables and not the variables themselves. This causes difficulty when you’re trying to share objects between threads, because changes in one aren’t reflected in the other. You can overcome this limitation by using the reference_wrapper template. A reference_wrapper essentially stores a pointer to the object you’re trying to share between threads, but it helps overcome the problem where you would normally have to account for a null pointer by ensuring that the value can’t be null. When you pass the variable into the thread constructor, you actually pass the variable into the ref function, which in turn passes a reference_wrapper containing your object to thread. When the thread constructor makes a copy of the values you passed to it, you receive a copy of the reference_wrapper and not a copy of the object itself. You could achieve the same result by using pointers to objects, but this built-in C++ method is much simpler and provides more safety. The ThreadTask function retrieves the shared objects from theirreference_wrapper instances using the get method supplied by the reference_wrapper template.
The ThreadTask function is used by two different threads in the program, and therefore the use of reference_wrapper is essential to ensure that the two instances share the same mutex and condition_variable along with main. Each instance uses a unique_lock to wrap the behavior of the mutex. Curiously, a unique_lock automatically locks a mutex when it’s constructed, but the code in Listing 11-11 never calls unlock on the mutex. The unlock call is carried out by the wait method in the first instance. Thecondition_variable::wait method unlocks the mutex and waits for a signal from another thread that it should continue. Unfortunately, this waiting isn’t completely reliable, because some operating systems can decide to unblock threads without the appropriate signal being sent. For this reason, it’s a good idea to have a backup plan—and the wait method provides this by taking a predicate parameter. The predicate takes a variable that can be called like a function. The code in Listing 11-11 provides a closure that determines whether the queue is empty. When thethread wakes, because it has been signaled to wake either by the program or by the operating system, it first checks to see if the predicate is true before attempting to reacquire the lock on the supplied mutex. If the predicate is true, the wait function calls lock and returns; doing so allows the thread's function to continue execution. The ThreadTask function creates the appropriate number of objects before starting over due to the while loop. At the end of each iteration of the while loop, the unique_lock wrapper for the mutex goes out of scope; its destructor callsunlock on the mutex, allowing other threads to be unblocked.
![]() Note The use of unique_lock in Listing 11-11 is technically inefficient. Holding the lock for longer than it takes to retrieve the number of objects to be created from the queue essentially serializes the creation of the objects by causing all threads to synchronize while one thread is creating objects. This example is poorly designed on purpose to show how these objects can be used in practice.
Note The use of unique_lock in Listing 11-11 is technically inefficient. Holding the lock for longer than it takes to retrieve the number of objects to be created from the queue essentially serializes the creation of the objects by causing all threads to synchronize while one thread is creating objects. This example is poorly designed on purpose to show how these objects can be used in practice.
Whereas the ThreadTask function is used in two threads to consume jobs from queue, the main function is a producer thread that adds jobs to queue. It begins by creating the two consumer threads that will carry out its tasks. Once the threads are created, the main function carries on with the task of adding jobs to queue. It lock the mutex, adds two jobs—one to create 300,000 objects and another to create 400,000 objects—and unlocks the mutex. It then calls notify_all on the condition_variable. The condition_variable object stores a list of threads that are waiting for a signal to continue; the notify_all method wakes all of these threads so they can carry out work. The main function then uses try_lock to show that it can’t add tasks while the threads are busy. In normal code, you could call lock; but this is an example of how to make a thread wait for a certain amount of time and how the try_lock method can be used to conditionally execute code if the mutex can’t be locked. More tasks are added to queue once try_lock returns true and before the mutex is unlocked again. Thenotify_one function is then used to wake a single thread at a time to show that it’s possible to write code with finer control over threads. The second thread must also be awakened, or the program will stall on the join calls indefinitely.
Figure 11-8 shows the output generated by running this code. You see that main can be blocked while waiting for access to the mutex and that both threads are used to consume tasks from queue.
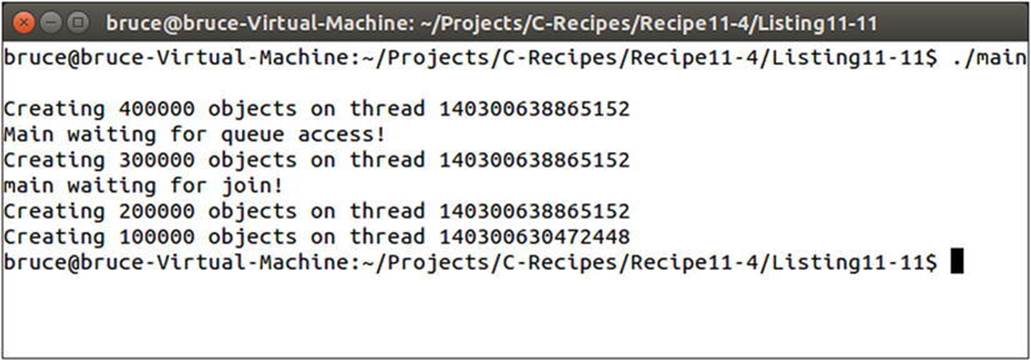
Figure 11-8. Output showing multiple threads being awakened by a condition variable
11-5. Retrieving Results from a Thread
Problem
You would like to create a thread that is capable of returning a result.
Solution
C++ provides promise and future objects that can be used to transfer data between threads.
How It Works
Using the promise and future Classes
Transferring data from a worker thread back to the thread that begins a task can be a complicated process. You must ensure mutually exclusive access to the memory set aside to store the result as well as handle all the signaling between threads. These signals include having the workingthread specifying when the result of the thread operation is available as well as having the scheduling thread wait for that result to be available. Modern C++ solves this problem using the promise template.
A promise template can be specialized with a thread task return type. This creates a contract between threads that allows the transfer of this type of object from one to another. A promise contains a future. This means a promise can fulfil its name: it essentially promises to provide a value of its specialized type to the holder of its future at some point in the future. There is no requirement for a promise to be used on more than a single thread, but promises are thread-safe and perfect for this job. Alternate uses for promise/future pairs could be to retrieve results from asynchronous operations such as HTTP requests. Listing 11-12 shows the use of a promise on a single thread.
Listing 11-12. Using a promise on One Thread
#include <future>
#include <iostream>
using namespace std;
using FactorialPromise = promise< long long >;
long long Factorial(unsigned int value)
{
return value == 1
? 1
: value * Factorial(value - 1);
}
int main(int argc, char* argv[])
{
using namespace chrono;
FactorialPromise promise;
future<long long> taskFuture{ promise.get_future() };
promise.set_value(Factorial(3));
cout << "Factorial result was " << taskFuture.get() << endl;
return 0;
}
Listing 11-12 shows the use of a promise to provide storage for a value that can be calculated later and retrieved in the future. You could use this for long-running tasks such as loading data from a file or retrieving information from a server. A program can continue rendering a UI or a progress bar while the promise hasn’t been fulfilled.
The promise is initialized with a default constructor, and you can use the get_future method to get the future into which the promise places its value. The set_value method on the promise sets the value on the future, and the get method on the future provides access to the value.
It can be a little difficult to see the separation of concerns between the promise and the future when they’re used close together as in Listing 11-12. Listing 11-13 overcomes this issue by moving the promise to another thread.
Listing 11-13. Moving a promise to a Second Thread
#include <future>
#include <iostream>
using namespace std;
using FactorialPromise = promise< long long > ;
long long Factorial(unsigned int value)
{
this_thread::sleep_for(chrono::seconds(2));
return value == 1
? 1
: value * Factorial(value - 1);
}
void ThreadTask(FactorialPromise& threadPromise, unsigned int value)
{
threadPromise.set_value(Factorial(value));
}
int main(int argc, char* argv[])
{
using namespace chrono;
FactorialPromise promise;
future<long long> taskFuture{ promise.get_future() };
thread taskThread{ ThreadTask, std::move(promise), 3 };
while (taskFuture.wait_until(system_clock::now() + seconds(1)) != future_status::ready)
{
cout << "Still Waiting!" << endl;
}
cout << "Factorial result was " << taskFuture.get() << endl;
taskThread.join();
return 0;
}
In Listing 11-13, the promise and future objects are initialized the same way as in Listing 11-12; however, the Factorial function is called from a thread using the ThreadTask function. Some additional lines show how you can use a future to wait for completion without necessarily blocking a thread. The Factorial method has a sleep_for call that causes the calculation of the Factorial to take much longer than usual. This allows for the example of the future::wait_until method. This method waits either until the supplied absolute time or until the promise has been fulfilled and the future’s value can be retrieved. The wait_until method takes an absolute system time to wait; this can be supplied easily using the system_clock::now method with a suitable duration, in this case one second. If the loop that prints “Still Waiting!” wasn’t present, then the call to get on the future would be a blocking call. This would cause your thread to stall until the set_value method had been called on the promise. Sometimes this behavior is suitable, and other times it isn’t. It depends on the requirements of the software you’re writing.
The use of a promise and a future directly relies on you managing your own thread function. Sometimes this can be overkill, as is the case in Listing 11-13. The ThreadTask function has only one job: to call set_value on the promise. C++ provides the packaged_tasktemplate, which removes the need for you to create your own thread function. A packaged_task constructor takes the function to call as a parameter; a corresponding thread constructor that can take a packaged_task. A thread constructed in this way can automatically call the method in the supplied packaged_task and call set_value on its internal promise. Listing 11-14 shows the use of a packaged_task.
Listing 11-14. Using a packaged_task
#include <future>
#include <iostream>
using namespace std;
long long Factorial(unsigned int value)
{
this_thread::sleep_for(chrono::seconds(2));
return value == 1
? 1
: value * Factorial(value - 1);
}
int main(int argc, char* argv[])
{
using namespace chrono;
packaged_task<long long(unsigned int)> task{ Factorial };
future<long long> taskFuture{ task.get_future() };
thread taskThread{ std::move(task), 3 };
while (taskFuture.wait_until(system_clock::now() + seconds(1)) != future_status::ready)
{
cout << "Still Waiting!" << endl;
}
cout << "Factorial result was " << taskFuture.get() << endl;
taskThread.join();
return 0;
}
Listing 11-14 shows that the ThreadTask function is no longer needed when using a packaged_task. The packaged_task constructor takes a function pointer as a parameter. The packaged_task template also supplies a get_future method and is passed to a threadusing move semantics.
Although a packaged task removes the need for a thread function, you must still create your own thread manually. C++ supplies a fourth level of abstraction that prevents you from having to worry about threads. Listing 11-15 uses the async function to call a function asynchronously.
Listing 11-15. Using async to Call Functions
#include <future>
#include <iostream>
using namespace std;
long long Factorial(unsigned int value)
{
cout << "ThreadTask thread: " << this_thread::get_id() << endl;
return value == 1
? 1
: value * Factorial(value - 1);
}
int main(int argc, char* argv[])
{
using namespace chrono;
cout << "main thread: " << this_thread::get_id() << endl;
auto taskFuture1 = async(Factorial, 3);
cout << "Factorial result was " << taskFuture1.get() << endl;
auto taskFuture2 = async(launch::async, Factorial, 3);
cout << "Factorial result was " << taskFuture2.get() << endl;
auto taskFuture3 = async(launch::deferred, Factorial, 3);
cout << "Factorial result was " << taskFuture3.get() << endl;
auto taskFuture4 = async(launch::async | launch::deferred, Factorial, 3);
cout << "Factorial result was " << taskFuture4.get() << endl;
return 0;
}
Listing 11-15 shows the different possible combinations of the async function and its overloaded version, which takes the launch enum as a parameter. The first call to async is the simplest: you call async and pass it a function and the parameters for that function. The asyncfunction returns a future that can be used to get the value returned from the function supplied to async. There is no guarantee, however, that the function will be called on another thread. All async guarantees is that the function will be called sometime between where you create the object and when you call get on the future.
The overloaded version of async gives you more control. Passing launch::async guarantees that the function will be called on another thread as soon as possible. This may not necessarily be a brand-new thread. The implementer of async is free to use any thread they choose. This may mean having a pool of threads that can be reused if they’re available. The deferred option, on the other hand, tells the returned future to evaluate the supplied function when get is called. This isn’t a concurrent process and causes the thread calling get to block, but again this is implementation specific and not the same across all C++ libraries. You have to check the documentation for your library or test your code by running and checking execution times and thread IDs.
The final call to async passes both async and deferred using an or. This is the same as calling async without specifying an execution policy and lets the implementation decide whether async or deferred should be used. Figure 11-9 shows the result of each call to async.
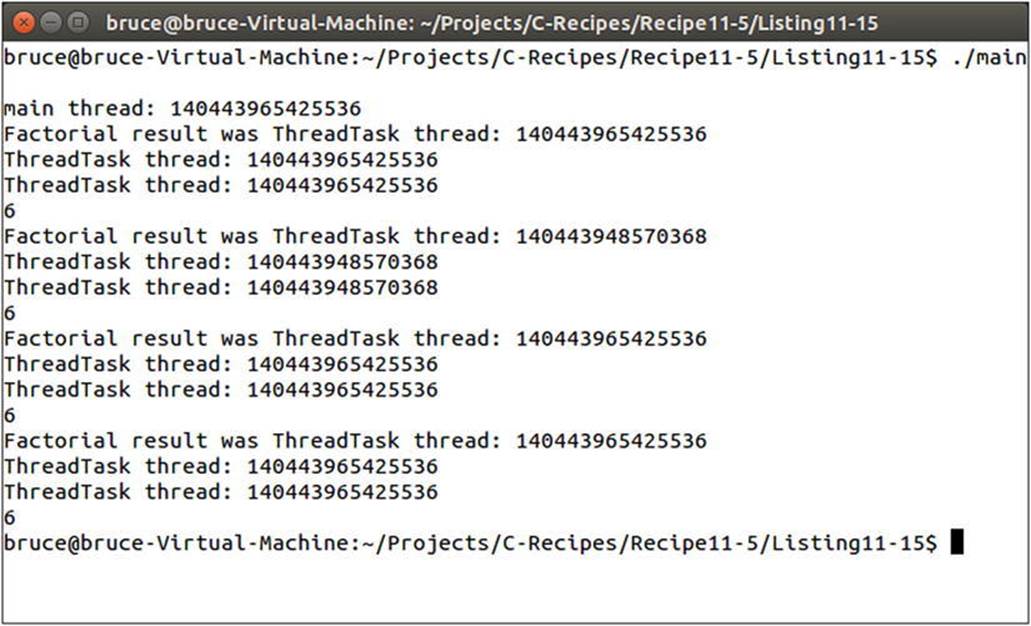
Figure 11-9. The thread IDs used when calling async
As you can see, the library uses the main thread for every call except the one explicitly marked as async. Be sure to test your programs on all platforms and libraries in use to ensure that you’re seeing the behavior you expect.
11-6. Synchronizing Queued Messages between Threads
Problem
You have a thread that you would like to live for the entire duration of your program and respond to messages it’s sent.
Solution
You can use a combination of function, bind, condition_variable, mutex, and unique_lock to create a double-buffered message queue to transfer work from one thread to another.
How It Works
Many programs benefit from separating their display logic from their business logic (or, in video games, separating simulation from rendering) and running them on different CPU cores. Ultimately, these tasks can usually be carried out independently of each other as long as you can define a well-structured boundary between the systems and develop a method for transferring data from one thread to the other. One such approach is to create a double buffer of messages or commands. The business-logic thread can add commands to the queue while the display logic thread is reading commands from the queue. Double-buffering the queue allows you to reduce the number of sync points that exist between the threads in an effort to increase throughput on both. The producer thread carries out work and queues a lot of tasks into one side of the buffer while the consumer thread is busy working through the last set of tasks to be queued. The only time delays occur on either thread is when one is finished and waiting for the other. Listing 11-16 shows the class definition for a double-buffered message queue.
Listing 11-16. Creating a Double-Buffered Message Queue
#include <future>
#include <iostream>
using namespace std;
template <typename T>
class MessageQueue
{
private:
using Queue = vector < T > ;
using QueueIterator = typename Queue::iterator;
Queue m_A;
Queue m_B;
Queue* m_Producer{ &m_A };
Queue* m_Consumer{ &m_B };
QueueIterator m_ConsumerIterator{ m_B.end() };
condition_variable& m_MessageCondition;
condition_variable m_ConsumptionFinished;
mutex m_MutexProducer;
mutex m_MutexConsumer;
unsigned int m_SwapCount{ 0 };
public:
MessageQueue(condition_variable& messageCondition)
: m_MessageCondition{ messageCondition }
{
}
unsigned int GetCount() const
{
return m_SwapCount;
}
void Add(T&& operation)
{
unique_lock<mutex> lock{ m_MutexProducer };
m_Producer->insert(m_Producer->end(), std::move(operation));
}
void BeginConsumption()
{
m_MutexConsumer.lock();
}
T Consume()
{
T operation;
if (m_Consumer->size() > 0)
{
operation = *m_ConsumerIterator;
m_ConsumerIterator = m_Consumer->erase(m_ConsumerIterator);
assert(m_ConsumerIterator == m_Consumer->begin());
}
return operation;
}
void EndConsumption()
{
assert(m_Consumer->size() == 0);
m_MutexConsumer.unlock();
m_ConsumptionFinished.notify_all();
}
unsigned int Swap()
{
unique_lock<mutex> lockB{ m_MutexConsumer };
m_ConsumptionFinished.wait(
lockB,
[this]()
{
return m_Consumer->size() == 0;
}
);
unique_lock<mutex> lockA{ m_MutexProducer };
Queue* temp{ m_Producer };
m_Producer = m_Consumer;
m_Consumer = temp;
m_ConsumerIterator = m_Consumer->begin();
m_MessageCondition.notify_all();
return m_SwapCount++;
}
};
The class template shown in Listing 11-16 is a functional message queue containing a double buffer for passing objects from one thread to another. It consists of two vectors, m_A and m_B, that are accessed through the pointers m_Producer and m_Consumer. The class, when used properly, allows for nonblocking access across the Add and Consume methods. If you were simply adding from one thread and consuming from another, you could buffer a lot of work without ever having to synchronize the threads. The only time the two threads require synchronization is when the producer thread would like to synchronize work into the consumer thread. This is handled in the Swap method. The Swap method uses the m_ConsumptionFinished condition_variable to wait for the m_Consumer queue to be empty. Thecondition_variable here is notified by the EndConsumption method. This implementation relies on the consumer thread exhausting the queued objects before informing the queue that it has finished. Not doing so would result in a deadlock.
The Add method works by taking an rvalue reference to an object to be moved to the other thread. An rvalue reference is used to ensure that the object being sent to the other thread is invalidated in the current thread after being moved to the queue. This helps to prevent data races where the producer thread could be left a valid reference to data being sent to another thread. Every object added goes at the end of the queue so that objects can be consumed in order by the consumer. The Consume method pulls objects from the beginning of the queue using a copyoperation and then removes the original object from the queue. The Swap method simply switches the m_Producer and m_Consumer pointers; it does this under the protection of both mutexes and therefore can be confident that the switch is occurring when all producer and consumerthreads should be able to handle it. Swap also sets m_ConsumerIterator to the correct queue and issues a notify to all threads waiting for the swap operation to be complete.
To show this queue in action, the example in Listing 11-17 uses an object to maintain a running total of some arithmetic operations. The main function acts as a producer that adds operations to be completed to the queue, and a thread is created that receives these operations and carries them out.
Listing 11-17. A Working MessageQueue Example
#include <cassert>
#include <future>
#include <iostream>
#include <vector>
using namespace std;
class RunningTotal
{
private:
int m_Value{ 0 };
bool m_Finished{ false };
public:
RunningTotal& operator+=(int value)
{
m_Value += value;
return *this;
}
RunningTotal& operator-=(int value)
{
m_Value -= value;
return *this;
}
RunningTotal& Finish()
{
m_Finished = true;
return *this;
}
int operator *() const throw(int)
{
if (!m_Finished)
{
throw m_Value;
}
return m_Value;
}
};
template <typename T>
class MessageQueue
{
private:
using Queue = vector < T > ;
using QueueIterator = typename Queue::iterator;
Queue m_A;
Queue m_B;
Queue* m_Producer{ &m_A };
Queue* m_Consumer{ &m_B };
QueueIterator m_ConsumerIterator{ m_B.end() };
condition_variable& m_MessageCondition;
condition_variable m_ConsumptionFinished;
mutex m_MutexProducer;
mutex m_MutexConsumer;
unsigned int m_SwapCount{ 0 };
public:
MessageQueue(condition_variable& messageCondition)
: m_MessageCondition{ messageCondition }
{
}
unsigned int GetCount() const
{
return m_SwapCount;
}
void Add(T&& operation)
{
unique_lock<mutex> lock{ m_MutexProducer };
m_Producer->insert(m_Producer->end(), std::move(operation));
}
void BeginConsumption()
{
m_MutexConsumer.lock();
}
T Consume()
{
T operation;
if (m_Consumer->size() > 0)
{
operation = *m_ConsumerIterator;
m_ConsumerIterator = m_Consumer->erase(m_ConsumerIterator);
assert(m_ConsumerIterator == m_Consumer->begin());
}
return operation;
}
void EndConsumption()
{
assert(m_Consumer->size() == 0);
m_MutexConsumer.unlock();
m_ConsumptionFinished.notify_all();
}
unsigned int Swap()
{
unique_lock<mutex> lockB{ m_MutexConsumer };
m_ConsumptionFinished.wait(
lockB,
[this]()
{
return m_Consumer->size() == 0;
}
);
unique_lock<mutex> lockA{ m_MutexProducer };
Queue* temp{ m_Producer };
m_Producer = m_Consumer;
m_Consumer = temp;
m_ConsumerIterator = m_Consumer->begin();
m_MessageCondition.notify_all();
return m_SwapCount++;
}
};
using RunningTotalOperation = function < RunningTotal&() > ;
using RunningTotalMessageQueue = MessageQueue < RunningTotalOperation > ;
int Task(reference_wrapper<mutex> messageQueueMutex,
reference_wrapper<condition_variable> messageCondition,
reference_wrapper<RunningTotalMessageQueue> messageQueueRef)
{
int result{ 0 };
RunningTotalMessageQueue& messageQueue = messageQueueRef.get();
unsigned int currentSwapCount{ 0 };
bool finished{ false };
while (!finished)
{
unique_lock<mutex> lock{ messageQueueMutex.get() };
messageCondition.get().wait(
lock,
[&messageQueue, ¤tSwapCount]()
{
return currentSwapCount != messageQueue.GetCount();
}
);
messageQueue.BeginConsumption();
currentSwapCount = messageQueue.GetCount();
while (RunningTotalOperation operation{ messageQueue.Consume() })
{
RunningTotal& runningTotal = operation();
try
{
result = *runningTotal;
finished = true;
break;
}
catch (int param)
{
// nothing to do, not finished yet!
cout << "Total not yet finished, current is: " << param << endl;
}
}
messageQueue.EndConsumption();
}
return result;
}
int main(int argc, char* argv[])
{
RunningTotal runningTotal;
mutex messageQueueMutex;
condition_variable messageQueueCondition;
RunningTotalMessageQueue messageQueue(messageQueueCondition);
auto myFuture = async(launch::async,
Task,
ref(messageQueueMutex),
ref(messageQueueCondition),
ref(messageQueue));
messageQueue.Add(bind(&RunningTotal::operator+=, &runningTotal, 3));
messageQueue.Swap();
messageQueue.Add(bind(&RunningTotal::operator-=, &runningTotal, 100));
messageQueue.Add(bind(&RunningTotal::operator+=, &runningTotal, 100000));
messageQueue.Add(bind(&RunningTotal::operator-=, &runningTotal, 256));
messageQueue.Swap();
messageQueue.Add(bind(&RunningTotal::operator-=, &runningTotal, 100));
messageQueue.Add(bind(&RunningTotal::operator+=, &runningTotal, 100000));
messageQueue.Add(bind(&RunningTotal::operator-=, &runningTotal, 256));
messageQueue.Swap();
messageQueue.Add(bind(&RunningTotal::Finish, &runningTotal));
messageQueue.Swap();
cout << "The final total is: " << myFuture.get() << endl;
return 0;
}
This code represents a complex use of many modern C++ language features. Let’s break the source into smaller examples to show how individual tasks are executed on a long-running helper thread. Listing 11-18 covers the RunningTotal class.
Listing 11-18. The RunningTotal Class
class RunningTotal
{
private:
int m_Value{ 0 };
bool m_Finished{ false };
public:
RunningTotal& operator+=(int value)
{
m_Value += value;
return *this;
}
RunningTotal& operator-=(int value)
{
m_Value -= value;
return *this;
}
RunningTotal& Finish()
{
m_Finished = true;
return *this;
}
int operator *() const throw(int)
{
if (!m_Finished)
{
throw m_Value;
}
return m_Value;
}
};
The RunningTotal class in Listing 11-18 is a simple object that represents a long-running store of data. In a proper program, this class could be an interface to a web server, database, or rendering engine that exposes methods to update its state. For the purposes of this example, the class simply wraps an int that keeps track of the results of the operations and a bool that determines when the calculations are complete. These values are manipulated using an overridden += operator, -= operator, and * operator. There is also a Finished method that sets them_Finished Boolean to true.
The main function is responsible for instantiating the RunningTotal object as well as the message queue and the consumer thread. It can be seen in Listing 11-19.
Listing 11-19. The main Function
#include <future>
#include <iostream>
using namespace std;
using RunningTotalOperation = function < RunningTotal&() >;
using RunningTotalMessageQueue = MessageQueue < RunningTotalOperation > ;
int main(int argc, char* argv[])
{
RunningTotal runningTotal;
mutex messageQueueMutex;
condition_variable messageQueueCondition;
RunningTotalMessageQueue messageQueue(messageQueueCondition);
auto myFuture = async(launch::async,
Task,
ref(messageQueueMutex),
ref(messageQueueCondition),
ref(messageQueue));
messageQueue.Add(bind(&RunningTotal::operator+=, &runningTotal, 3));
messageQueue.Swap();
messageQueue.Add(bind(&RunningTotal::operator-=, &runningTotal, 100));
messageQueue.Add(bind(&RunningTotal::operator+=, &runningTotal, 100000));
messageQueue.Add(bind(&RunningTotal::operator-=, &runningTotal, 256));
messageQueue.Swap();
messageQueue.Add(bind(&RunningTotal::operator-=, &runningTotal, 100));
messageQueue.Add(bind(&RunningTotal::operator+=, &runningTotal, 100000));
messageQueue.Add(bind(&RunningTotal::operator-=, &runningTotal, 256));
messageQueue.Swap();
messageQueue.Add(bind(&RunningTotal::Finish, &runningTotal));
messageQueue.Swap();
cout << "The final total is: " << myFuture.get() << endl;
return 0;
}
The first piece of important code in Listing 11-19 is the type aliases before main. These are used to create types that represent the message queue you’ll be using and the type of objects the message queue contains. In this case, I have created a type that you ca n use to carry out operations on the RunningTotal class. This type alias is created using the C++ function object, which allows you to create a representation of a function to be called later. This type requires that you specify the signature type of the function in the template—and you may be surprised to see that the signature is described without parameters. This means the functors stored in the queue won’t have parameters passed to them directly. This would normally cause issues for operations such as += and -= that need parameters; but the bind function comes to the rescue. You can see several uses of bind in the main function. All of these examples of bind are used to bind a method pointer to a method instance of that type. The second parameter passed to bind when using a method pointer should always be the instance of the object on which the method will be called. Any subsequent parameters are automatically passed to the function when the functor is executed. This automatic passing of bound parameters is why you don’t need to specify any parameter types in the type alias and why you can use a single queue to represent functions that have different signatures.
main creates a thread using the async function and queues several operations to be carried out on the thread along with multiple swaps. The last piece of the example is the Task function, which is executed on the second thread; see Listing 11-20.
Listing 11-20. The Task Function
#include <future>
#include <iostream>
using namespace std;
int Task(reference_wrapper<mutex> messageQueueMutex,
reference_wrapper<condition_variable> messageCondition,
reference_wrapper<RunningTotalMessageQueue> messageQueueRef)
{
int result{ 0 };
RunningTotalMessageQueue& messageQueue = messageQueueRef.get();
unsigned int currentSwapCount{ 0 };
bool finished{ false };
while (!finished)
{
unique_lock<mutex> lock{ messageQueueMutex.get() };
messageCondition.get().wait(
lock,
[&messageQueue, ¤tSwapCount]()
{
return currentSwapCount != messageQueue.GetCount();
}
);
messageQueue.BeginConsumption();
currentSwapCount = messageQueue.GetCount();
while (RunningTotalOperation operation{ messageQueue.Consume() })
{
RunningTotal& runningTotal = operation();
try
{
result = *runningTotal;
finished = true;
break;
}
catch (int param)
{
// nothing to do, not finished yet!
cout << "Total not yet finished, current is: " << param << endl;
}
}
messageQueue.EndConsumption();
}
return result;
}
The Task function loops until the finished bool has been set to true. It waits for the messageCondition condition_variable to be signaled before continuing work, and it uses the lambda to ensure that a swap has actually occurred in case the thread was awakened by the operating system rather than by a notify call.
Once the thread has been kicked and there is work to be carried out, it calls the BeginConsumption method on the queue. This has the effect of locking the queue’s Swap method until all the current jobs in the thread have been completed. The currentSwapCount variable is updated to ensure that the condition_variable can guarantee safety the next time the loop is entered. A second while loop is responsible for pulling each of the functors from the queue until the queue is empty. This is where the bound function objects created by main are executed. The thread itself doesn’t know the substance of the work it’s carrying out; it simply responds to the requests that have been queued in the main function.
The * operator is used after every operation to test whether the Finished command has been sent. The RunningTotal::operator* method will throw an int exception containing the current value stored if the Finished method hasn’t been called. You can see how this is used in the Task function with the try...catch block. The result variable, finished bool, and break statements are executed only in the event that the operator* returns a value rather than throwing the value. The current total is printed to the console each time an operation completes that doesn’t mark the operations as finished. You can see the result of this code in Figure 11-10.
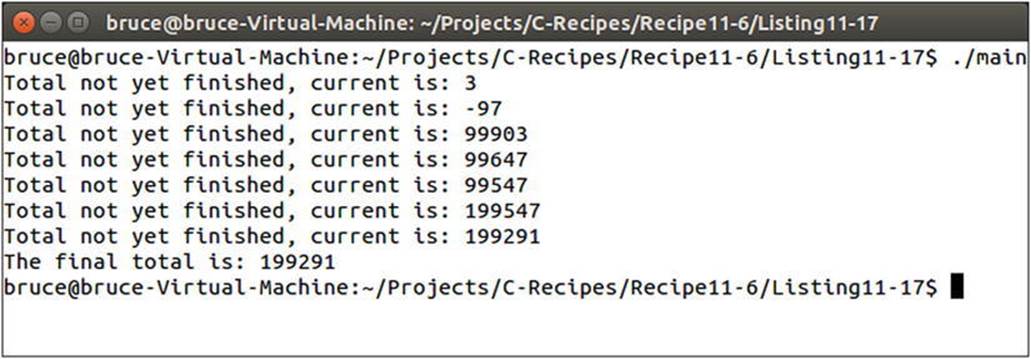
Figure 11-10. The output showing a working message queue in actions