Bioinformatics Data Skills (2015)
Part II. Prerequisites: Essential Skills for Getting Started with a Bioinformatics Project
Chapter 5. Git for Scientists
In Chapter 2, we discussed organizing a bioinformatics project directory and how this helps keep your work tidy during development. Good organization also facilitates automating tasks, which makes our lives easier and leads to more reproducible work. However, as our project changes over time and possibly incorporates the work of our collaborators, we face an additional challenge: managing different file versions.
It’s likely that you already use some sort of versioning system in your work. For example, you may have files with names such as thesis-vers1.docx, thesis-vers3_CD_edits.docx, analysis-vers6.R, and thesis-vers8_CD+GM+SW_edits.docx. Storing these past versions is helpful because it allows us to go back and restore whole files or sections if we need to. File versions also help us differentiate our copies of a file from those edited by a collaborator. However, this ad hoc file versioning system doesn’t scale well to complicated bioinformatics projects — our otherwise tidy project directories would be muddled with different versioned scripts, R analyses, READMEfiles, and papers.
Project organization only gets more complicated when we work collaboratively. We could share our entire directory with a colleague through a service like Dropbox or Google Drive, but we run the risk of something getting deleted or corrupted. It’s also not possible to drop an entire bioinformatics project directory into a shared directory, as it likely contains gigabytes (or more) of data that may be too large to share across a network. These tools are useful for sharing small files, but aren’t intended to manage large collaborative projects involving changing code and data.
Luckily, software engineers have faced these same issues in modern collaborative software development and developed version control systems (VCS) to manage different versions of collaboratively edited code. The VCS we’ll use in this chapter was written by Linus Torvalds and is called Git. Linus wrote Git to manage the Linux kernel (which he also wrote), a large codebase with thousands of collaborators simultaneously changing and working on files. As you can imagine, Git is well suited for project version control and collaborative work.
Admittedly, Git can be tricky to learn at first. I highly recommend you take the time to learn Git in this chapter, but be aware that understanding Git (like most topics in this book, and arguably everything in life) will take time and practice. Throughout this chapter, I will indicate when certain sections are especially advanced; you can revisit these later without problems in continuity with the rest of the book. Also, I recommend you practice Git with the example projects and code from the book to get the basic commands in the back of your head. After struggling in the beginning with Git, you’ll soon see how it’s the best version control system out there.
Why Git Is Necessary in Bioinformatics Projects
As a longtime proponent of Git, I’ve suggested it to many colleagues and offered to teach them the basics. In most cases, I find the hardest part is actually in convincing scientists they should adopt version control in their work. Because you may be wondering whether working through this chapter is worth it, I want to discuss why learning Git is definitely worth the effort. If you’re already 100% convinced, you can dive into learning Git in the next section.
Git Allows You to Keep Snapshots of Your Project
With version control systems, you create snapshots of your current project at specific points in its development. If anything goes awry, you can rewind to a past snapshot of your project’s state (called a commit) and restore files. In the fast pace of bioinformatics work, having this safeguard is very useful.
Git also helps fix a frustrating type of bug known as software regression, where a piece of code that was once working mysteriously stops working or gives different results. For example, suppose that you’re working on an analysis of SNP data. You find in your analysis that 14% of your SNPs fall in coding regions in one stretch of a chromosome. This is relevant to your project, so you cite this percent in your paper and make a commit.
Two months later, you’ve forgotten the details of this analysis, but need to revisit the 14% statistic. Much to your surprise, when you rerun the analysis code, this changes to 26%! If you’ve been tracking your project’s development by making commits (e.g., taking snapshots), you’ll have an entire history of all of your project’s changes and can pinpoint when your results changed.
Git commits allow you to easily reproduce and rollback to past versions of analysis. It’s also easy to look at every commit, when it was committed, what has changed across commits, and even compare the difference between any two commits. Instead of redoing months of work to find a bug, Git can give you line-by-line code differences across versions.
In addition to simplifying bug finding, Git is an essential part of proper documentation. When your code produces results, it’s essential that this version of code is fully documented for reproducibility. A good analogy comes from my friend and colleague Mike Covington: imagine you keep a lab notebook in pencil, and each time you run a new PCR you erase your past results and jot down the newest ones. This may sound extreme, but is functionally no different than changing code and not keeping a record of past versions.
Git Helps You Keep Track of Important Changes to Code
Most software changes over time as new features are added or bugs are fixed. It’s important in scientific computing to follow the development of software we use, as a fixed bug could mean the difference between correct and incorrect results in our own work. Git can be very helpful in helping you track changes in code — to see this, let’s look at a situation I’ve run into (and I suspect happens in labs all over the world).
Suppose a lab has a clever bioinformatician who has written a script that trims poor quality regions from reads. This bioinformatician then distributes this to all members of his lab. Two members of his lab send it to friends in other labs. About a month later, the clever bioinformatician realizes there’s a bug that leads to incorrect results in certain cases. The bioinformatician quickly emails everyone in his lab the new version and warns them of the potential for incorrect results. Unfortunately, members of the other lab may not get the message and could continue using the older buggy version of the script.
Git helps solve this problem by making it easy to stay up to date with software development. With Git, it’s easy to both track software changes and download new software versions. Furthermore, services like GitHub and Bitbucket host Git repositories on the Web, which makes sharing and collaborating on code across labs easy.
Git Helps Keep Software Organized and Available After People Leave
Imagine another situation: a postdoc moves to start her own lab, and all of her different software tools and scripts are scattered in different directories, or worse, completely lost. Disorderedly code disrupts and inconveniences other lab members; lost code leads to irreproducible results and could delay future research.
Git helps maintain both continuity in work and a full record of a project’s history. Centralizing an entire project into a repository keeps it organized. Git stores every committed change, so the entire history of a project is available even if the main developer leaves and isn’t around for questions. With the ability to roll back to past versions, modifying projects is less risky, making it easier to build off existing work.
Installing Git
If you’re on OS X, install Git through Homebrew (e.g., brew install git); on Linux, use apt-get (e.g., apt-get install git). If your system does not have a package manager, the Git website has both source code and executable versions of Git.
Basic Git: Creating Repositories, Tracking Files, and Staging and Committing Changes
Now that we’ve seen some Git concepts and how Git fits into your bioinformatics workflow, let’s explore the most basic Git concepts of creating repositories, telling Git which files to track, and staging and committing changes.
Git Setup: Telling Git Who You Are
Because Git is meant to help with collaborative editing of files, you need to tell Git who you are and what your email address is. To do this, use:
$ git config --global user.name "Sewall Wright"
$ git config --global user.email "swright@adaptivelandscape.org"
Make sure to use your own name and email, or course. We interact with Git through subcommands, which are in the format git <subcommand>. Git has loads of subcommands, but you’ll only need a few in your daily work.
Another useful Git setting to enable now is terminal colors. Many of Git’s subcommands use terminal colors to visually indicate changes (e.g., red for deletion and green for something new or modified). We can enable this with:
$ git config --global color.ui true
git init and git clone: Creating Repositories
To get started with Git, we first need to initialize a directory as a Git repository. A repository is a directory that’s under version control. It contains both your current working files and snapshots of the project at certain points in time. In version control lingo, these snapshots are known as commits. Working with Git is fundamentally about creating and manipulating these commits: creating commits, looking at past commits, sharing commits, and comparing different commits.
With Git, there are two primary ways to create a repository: by initializing one from an existing directory, or cloning a repository that exists elsewhere. Either way, the result is a directory that Git treats as a repository. Git only manages the files and subdirectories inside the repository directory — it cannot manage files outside of your repository.
Let’s start by initializing the zmays-snps/ project directory we created in Chapter 2 as a Git repository. Change into the zmays-snps/ directory and use the Git subcommand git init:
$ git init
Initialized empty Git repository in /Users/vinceb/Projects/zmays-snps/.git/
git init creates a hidden directory called .git/ in your zmays-snps/ project directory (you can see it with ls -a). This .git/ directory is how Git manages your repository behind the scenes. However, don’t modify or remove anything in this directory — it’s meant to be manipulated by Git only. Instead, we interact with our repository through Git subcommands like git init.
The other way to create a repository is through cloning an existing repository. You can clone repositories from anywhere: somewhere else on your filesystem, from your local network, or across the Internet. Nowadays, with repository hosting services like GitHub and Bitbucket, it’s most common to clone Git repositories from the Web.
Let’s practice cloning a repository from GitHub. For this example, we’ll clone the Seqtk code from Heng Li’s GitHub page. Seqtk is short for SEQuence ToolKit, and contains a well-written and useful set of tools for processing FASTQ and FASTA files. First, visit the GitHub repository and poke around a bit. All of GitHub’s repositories have this URL syntax: user/repository. Note on this repository’s page that clone URL on the righthand side — this is where you can copy the link to clone this repository.
Now, let’s switch to a directory outside of zmays-snps/. Whichever directory you choose is fine; I use a ~/src/ directory for cloning and compiling other developers’ tools. From this directory, run:
$ git clone git://github.com/lh3/seqtk.git
Cloning into 'seqtk'...
remote: Counting objects: 92, done.
remote: Compressing objects: 100% (47/47), done.
remote: Total 92 (delta 56), reused 80 (delta 44)
Receiving objects: 100% (92/92), 32.58 KiB, done.
Resolving deltas: 100% (56/56), done.
git clone clones seqtk to your local directory, mirroring the original repository on GitHub. Note that you won’t be able to directly modify Heng Li’s original GitHub repository — cloning this repository only gives you access to retrieve new updates from the GitHub repository as they’re released.
Now, if you cd into seqtk/ and run ls, you’ll see seqtk’s source:
$ cd seqtk
$ ls
Makefile README.md khash.h kseq.h seqtk.c
Despite originating through different methods, both zmays-snps/ and seqtk/ are Git repositories.
Tracking Files in Git: git add and git status Part I
Although you’ve initialized the zmays-snps/ as a Git repository, Git doesn’t automatically begin tracking every file in this directory. Rather, you need to tell Git which files to track using the subcommand git add. This is actually a useful feature of Git — bioinformatics projects contain many files we don’t want to track, including large data files, intermediate results, or anything that could be easily regenerated by rerunning a command.
Before tracking a file, let’s use the command git status to check Git’s status of the files in our repository (switch to the zmays-snps/ directory if you are elsewhere):
$ git status
# On branch master ![]()
#
# Initial commit
#
# Untracked files: ![]()
# (use "git add <file>..." to include in what will be committed)
#
# README
# data/
nothing added to commit but untracked files present (use "git add" to track)
git status tell us:
![]()
We’re on branch master, which is the default Git branch. Branches allow you to work on and switch between different versions of your project simultaneously. Git’s simple and powerful branches are a primary reason it’s such a popular version control system. We’re only going to work with Git’s default master branch for now, but we’ll learn more about branches later in this chapter.
![]()
We have a list of “Untracked files,” which include everything in the root project directory. Because we haven’t told Git to track anything, Git has nothing to put in a commit if we were to try.
It’s good to get git status under your fingers, as it’s one of the most frequently used Git commands. git status describes the current state of your project repository: what’s changed, what’s ready to be included in the next commit, and what’s not being tracked. We’ll use it extensively throughout the rest of this chapter.
Let’s use git add to tell Git to track the README and data/README files in our zmays-snps/ directory:
$ git add README data/README
Now, Git is tracking both data/README and README. We can verify this by running git status again:
$ ls
README analysis data scripts
$ git status
# On branch master
#
# Initial commit
#
# Changes to be committed:
# (use "git rm --cached <file>..." to unstage)
#
# new file: README ![]()
# new file: data/README
#
# Untracked files:
# (use "git add <file>..." to include in what will be committed)
#
# data/seqs/ ![]()
![]()
Note now how Git lists README and data/README as new files, under the section “changes to be committed.” If we made a commit now, our commit would take a snapshot of the exact version of these files as they were when we added them with git add.
![]()
There are also untracked directories like data/seqs/, as we have not told Git to track these yet. Conveniently, git status reminds us we could use git add to add these to a commit.
The scripts/ and analysis/ directories are not included in git status because they are empty. The data/seqs/ directory is included because it contains the empty sequence files we created with touch in Chapter 2.
Staging Files in Git: git add and git status Part II
With Git, there’s a difference between tracked files and files staged to be included in the next commit. This is a subtle difference, and one that often causes a lot of confusion for beginners learning Git. A file that’s tracked means Git knows about it. A staged file is not only tracked, but its latest changes are staged to be included in the next commit (see Figure 5-1).
A good way to illustrate the difference is to consider what happens when we change one of the files we started tracking with git add. Changes made to a tracked file will not automatically be included in the next commit. To include these new changes, we would need to explicitly stage them — using git add again. Part of the confusion lies in the fact that git add both tracks new files and stages the changes made to tracked files. Let’s work through an example to make this clearer.
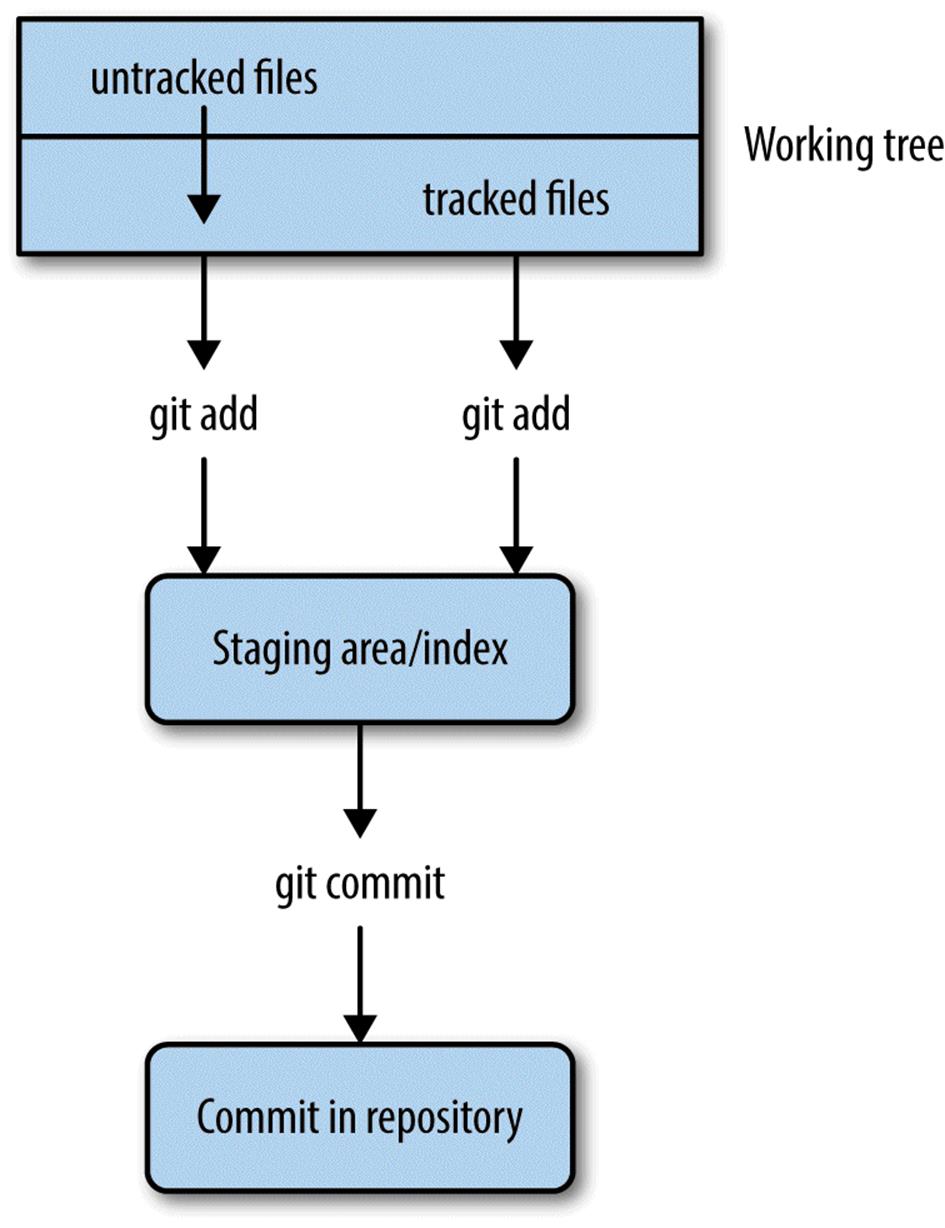
Figure 5-1. Git’s separation of the working tree (all files in your repository), the staging area (files to be included in the next commit), and committed changes (a snapshot of a version of your project at some point in time); git add on an untracked file begins tracking it and stages it, while git add on a tracked file just stages it for the next commit
From the git status output from the last section, we see that both the data/README and README files are ready to be committed. However, look what happens when we make a change to one of these tracked files and then call git status:
$ echo "Zea Mays SNP Calling Project" >> README # change file README
$ git status
# On branch master
#
# Initial commit
#
# Changes to be committed:
# (use "git rm --cached <file>..." to unstage)
#
# new file: README
# new file: data/README
#
# Changes not staged for commit:
# (use "git add <file>..." to update what will be committed)
# (use "git checkout -- <file>..." to discard changes in working directory)
#
# modified: README
#
# Untracked files:
# (use "git add <file>..." to include in what will be committed)
#
# data/seqs/
After modifying README, git status lists README under “changes not staged for commit.” This is because we’ve made changes to this file since initially tracking and staging README with git add (when first tracking a file, its current version is also staged). If we were to make a commit now, our commit would include the previous version of README, not this newly modified version.
To add these recent modifications to README in our next commit, we stage them using git add. Let’s do this now and see what git status returns:
$ git add README
$ git status
# On branch master
#
# Initial commit
#
# Changes to be committed:
# (use "git rm --cached <file>..." to unstage)
#
# new file: README
# new file: data/README
#
# Untracked files:
# (use "git add <file>..." to include in what will be committed)
#
# data/seqs/
# notebook.md
Now, README is listed under “Changes to be committed” again, because we’ve staged these changes with git add. Our next commit will include the most recent version.
Again, don’t fret if you find this confusing. The difference is subtle, and it doesn’t help that we use git add for both operations. Remember the two roles of git add:
§ Alerting Git to start tracking untracked files (this also stages the current version of the file to be included in the next commit)
§ Staging changes made to an already tracked file (staged changes will be included in the next commit)
It’s important to be aware that any modifications made to a file since the last time it was staged will not be included in the next commit unless they are staged with git add. This extra step may seem like an inconvenience but actually has many benefits. Suppose you’ve made changes to many files in a project. Two of these files’ changes are complete, but everything else isn’t quite ready. Using Git’s staging, you can stage and commit only these two complete files and keep other incomplete files out of your commit. Through planned staging, your commits can reflect meaningful points in development rather than random snapshots of your entire project directory (which would likely include many files in a state of disarray). When we learn about committing in the next section, we’ll see a shortcut to stage and commit all modified files.
git commit: Taking a Snapshot of Your Project
We’ve spoken a lot about commits, but haven’t actually made one yet. When first learning Git, the trickiest part of making a commit is understanding staging. Actually committing your staged commits is quite easy:
$ git commit -m "initial import"
2 files changed, 1 insertion(+)
create mode 100644 README
create mode 100644 data/README
This command commits your staged changes to your repository with the commit message “initial import.” Commit messages are notes to your collaborators (and yourself in the future) about what a particular commit includes. Optionally, you can omit the -m option, and Git will open up your default text editor. If you prefer to write commit messages in a text editor (useful if they are multiline messages), you can change the default editor Git uses with:
$ git config --global core.editor emacs
where emacs can be replaced by vim (the default) or another text editor of your choice.
Some Advice on Commit Messages
Commit messages may seem like an inconvenience, but it pays off in the future to have a description of how a commit changes code and what functionality is affected. In three months when you need to figure out why your SNP calling analyses are returning unexpected results, it’s much easier to find relevant commits if they have messages like “modifying SNP frequency function to fix singleton bug, refactored coverage calculation” rather than “cont” (that’s an actual commit I’ve seen in a public project). For an entertaining take on this, see xkcd’s “Git Commit” comic.
Earlier, we staged our changes using git add. Because programmers like shortcuts, there’s an easy way to stage all tracked files’ changes and commit them in one command: git commit -a -m "your commit message". The option -atells git commit to automatically stage all modified tracked files in this commit. Note that while this saves time, it also will throw all changes to tracked files in this commit. Ideally commits should reflect helpful snapshots of your project’s development, so including every slightly changed file may later be confusing when you look at your repository’s history. Instead, make frequent commits that correspond to discrete changes to your project like “new counting feature added” or “fixed bug that led to incorrect translation.”
We’ve included all changes in our commit, so our working directory is now “clean”: no tracked files differ from the version in the last commit. Until we make modifications, git status indicates there’s nothing to commit:
$ git status
# On branch master
# Untracked files:
# (use "git add <file>..." to include in what will be committed)
#
# data/seqs/
Untracked files and directories will still remain untracked (e.g., data/seqs/), and any unstaged changes to tracked files will not be included in the next commit unless added. Sometimes a working directory with unstaged changes is referred to as “messy,” but this isn’t a problem.
Seeing File Differences: git diff
So far we’ve seen the Git tools needed to help you stage and commit changes in your repository. We’ve used the git status subcommand to see which files are tracked, which have changes, and which are staged for the next commit. Another subcommand is quite helpful in this process: git diff.
Without any arguments, git diff shows you the difference between the files in your working directory and what’s been staged. If none of your changes have been staged, git diff shows us the difference between your last commit and the current versions of your files. For example, if I add a line to README.md and run git diff:
$ echo "Project started 2013-01-03" >> README
$ git diff
diff --git a/README b/README
index 5483cfd..ba8d7fc 100644
--- a/README ![]()
+++ b/README
@@ -1 +1,2 @@ ![]()
Zea Mays SNP Calling Project
+Project started 2013-01-03 ![]()
This format (called a unified diff) may seem a bit cryptic at first. When Git’s terminal colors are enabled, git diff’s output is easier to read, as added lines will be green and deleted lines will be red.
![]()
This line (and the one following it) indicate there are two versions of the README file we are comparing, a and b. The --- indicates the original file — in our case, the one from our last commit. +++ indicates the changed version.
![]()
This denotes the start of a changed hunk (hunk is diff’s term for a large changed block), and indicates which line the changes start on, and how long they are. Diffs try to break your changes down into hunks so that you can easily identify the parts that have been changed. If you’re curious about the specifics, see Wikipedia’s page on the diff utility.
![]()
Here’s the meat of the change. Spaces before the line (e.g., the line that begins Zea Mays… indicates nothing was changed (and just provide context). Plus signs indicate a line addition (e.g., the line that begins Project…), and negative signs indicate a line deletion (not shown in this diff because we’ve only added a line). Changes to a line are represented as a deletion of the original line and an addition of the new line.
After we stage a file, git diff won’t show any changes, because git diff compares the version of files in your working directory to the last staged version. For example:
$ git add README
$ git diff # shows nothing
If we wanted to compare what’s been staged to our last commit (which will show us exactly what’s going into the next commit), we can use git diff --staged (in old versions of Git this won’t work, so upgrade if it doesn’t). Indeed, we can see the change we just staged:
$ git diff --staged
diff --git a/README b/README
index 5483cfd..ba8d7fc 100644
--- a/README
+++ b/README
@@ -1 +1,2 @@
Zea Mays SNP Calling Project
+Project started 2013-01-03
git diff can also be used to compare arbitrary objects in our Git commit history, a topic we’ll see in “More git diff: Comparing Commits and Files”.
Seeing Your Commit History: git log
Commits are like chains (more technically, directed acyclic graphs), with each commit pointing to its parent (as in Figure 5-2).
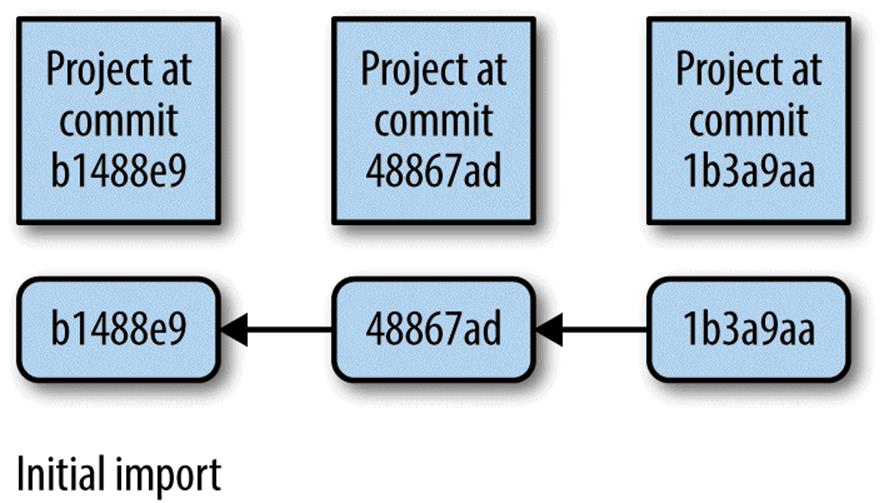
Figure 5-2. Commits in Git take discrete snapshots of your project at some point in time, and each commit (except the first) points to its parent commit; this chain of commits is your set of connected snapshots that show how your project repository evolves
We can use git log to visualize our chain of commits:
$ git log
commit 3d7ffa6f0276e607dcd94e18d26d21de2d96a460 ![]()
Author: Vince Buffalo <vsbuffaloAAAAAA@gmail.com>
Date: Mon Sep 23 23:55:08 2013 -0700
initial import
![]()
This strange looking mix of numbers and characters is a SHA-1 checksum. Each commit will have one of these, and they will depend on your repository’s past commit history and the current files. SHA-1 hashes act as a unique ID for each commit in your repository. You can always refer to a commit by its SHA-1 hash.
git log and Your Terminal Pager
git log opens up your repository’s history in your default pager (usually either the program more or less). If you’re unfamiliar with pagers, less, and more, don’t fret. To exit and get back to your prompt, hit the letter q. You can move forward by pressing the space bar, and move backward by pressing b. We’ll look at less in more detail in Chapter 7.
Let’s commit the change we made in the last section:
$ git commit -a -m "added information about project to README"
[master 94e2365] added information about project to README
1 file changed, 1 insertion(+)
Now, if we look at our commit history with git log, we see:
$ git log
commit 94e2365dd66701a35629d29173d640fdae32fa5c
Author: Vince Buffalo <vsbuffaloAAAAAA@gmail.com>
Date: Tue Sep 24 00:02:11 2013 -0700
added information about project to README
commit 3d7ffa6f0276e607dcd94e18d26d21de2d96a460
Author: Vince Buffalo <vsbuffaloAAAAAA@gmail.com>
Date: Mon Sep 23 23:55:08 2013 -0700
initial import
As we continue to make and commit changes to our repository, this chain of commits will grow. If you want to see a nice example of a longer Git history, change directories to the seqtk repository we cloned earlier and call git log.
Moving and Removing Files: git mv and git rm
When Git tracks your files, it wants to be in charge. Using the command mv to move a tracked file will confuse Git. The same applies when you remove a file with rm. To move or remove tracked files in Git, we need to use Git’s version of mv and rm: git mv and git rm.
For example, our README file doesn’t have an extension. This isn’t a problem, but because the README file might later contain Markdown, it’s not a bad idea to change its extension to .md. You can do this using git mv:
$ git mv README README.md
$ git mv data/README data/README.md
Like all changes, this isn’t stored in your repository until you commit it. If you ls your files, you can see your working copy has been renamed:
$ ls
README.md analysis data notebook.md scripts
Using git status, we see this change is staged and ready to be committed:
$ git status
# On branch master
# Changes to be committed:
# (use "git reset HEAD <file>..." to unstage)
#
# renamed: README -> README.md
# renamed: data/README -> data/README.md
#
# Untracked files:
# (use "git add <file>..." to include in what will be committed)
#
# data/seqs/
git mv already staged these commits for us; git add is only necessary for staging modifications to the contents of files, not moving or removing files. Let’s commit these changes:
$ git commit -m "added markdown extensions to README files"
[master e4feb22] added markdown extensions to README files
2 files changed, 0 insertions(+), 0 deletions(-)
rename README => README.md (100%)
rename data/{README => README.md} (100%)
Note that even if you change or remove a file and commit it, it still exists in past snapshots. Git does its best to make everything recoverable. We’ll see how to recover files later on in this chapter.
Telling Git What to Ignore: .gitignore
You may have noticed that git status keeps listing which files are not tracked. As the number of files in your bioinformatics project starts to increase (this happens quickly!) this long list will become a burden.
Many of the items in this untracked list may be files we never want to commit. Sequencing data files are a great example: they’re usually much too large to include in a repository. If we were to commit these large files, collaborators cloning your repository would have to download these enormous data files. We’ll talk about other ways of managing these later, but for now, let’s just ignore them.
Suppose we wanted to ignore all FASTQ files (with the extension .fastq) in the data/seqs/ directory. To do this, create and edit the file .gitignore in your zmays-snps/ repository directory, and add:
data/seqs/*.fastq
Now, git status gives us:
$ git status
# On branch master
# Untracked files:
# (use "git add <file>..." to include in what will be committed)
#
# .gitignore
It seems we’ve gotten rid of one annoyance (the data/seqs/ directory in “Untracked files”) but added another (the new .gitignore). Actually, the best way to resolve this is to add and commit your .gitignore file. It may seem counterintuitive to contribute a file to a project that’s merely there to tell Git what to ignore. However, this is a good practice; it saves collaborators from seeing a listing of untracked files Git should ignore. Let’s go ahead and stage the .gitignore file, and commit this and the filename changes we made earlier:
$ git add .gitignore
$ git commit -m "added .gitignore"
[master c509f63] added .gitignore
1 file changed, 1 insertion(+)
create mode 100644 .gitignore
What should we tell .gitignore to ignore? In the context of a bioinformatics project, here are some guidelines:
Large files
These should be ignored and managed by other means, as Git isn’t designed to manage really large files. Large files slow creating, pushing, and pulling commits. This can lead to quite a burden when collaborators clone your repository.
Intermediate files
Bioinformatics projects are often filled with intermediate files. For example, if you align reads to a genome, this will create SAM or BAM files. Even if these aren’t large files, these should probably be ignored. If a data file can easily be reproduced by rerunning a command (or better yet, a script), it’s usually preferable to just store how it was created. Ultimately, recording and storing how you created an intermediate file in Git is more important than the actual file. This also ensures reproducibility.
Text editor temporary files
Text editors like Emacs and Vim will sometimes create temporary files in your directory. These can look like textfile.txt~ or #textfile.txt#. There’s no point in storing these in Git, and they can be an annoyance when viewing progress with git status. These files should always be added to .gitignore. Luckily, .gitignore takes wildcards, so these can be ignored with entries like *~ and \#*\#.
Temporary code files
Some language interpreters (e.g., Python) produce temporary files (usually with some sort of optimized code). With Python, these look like overlap.pyc.
We can use a global .gitignore file to universally ignore a file across all of our projects. Good candidates of files to globally ignore are our text editor’s temporary files or files your operating system creates (e.g., OS X will sometimes create hidden files named .DS_Store in directories to store details like icon position). GitHub maintains a useful repository of global .gitignore suggestions.
You can create a global .gitignore file in ~/.gitignore_global and then configure Git to use this with the following:
git config --global core.excludesfile ~/.gitignore_global
A repository should store everything required to replicate a project except large datasets and external programs. This includes all scripts, documentation, analysis, and possibly even a final manuscript. Organizing your repository this way means that all of your project’s dependencies are in one place and are managed by Git. In the long run, it’s far easier to have Git keep track of your project’s files, than try to keep track of them yourself.
Undoing a Stage: git reset
Recall that one nice feature of Git is that you don’t have to include messy changes in a commit — just don’t stage these files. If you accidentally stage a messy file for a commit with git add, you can unstage it with git reset. For example, suppose you add a change to a file, stage it, but decide it’s not ready to be committed:
$ echo "TODO: ask sequencing center about adapters" >> README.md
$ git add README.md
$ git status
# On branch master
# Changes to be committed:
# (use "git reset HEAD <file>..." to unstage)
#
# new file: README.md
#
With git status, we can see that our change to README.md is going to be included in the next commit. To unstage this change, follow the directions git status provides:
$ git reset HEAD README.md
$ git status
# On branch master
# Changes not staged for commit:
# (use "git add <file>..." to update what will be committed)
# (use "git checkout -- <file>..." to discard changes in working
directory)
#
# modified: README.md
#
The syntax seems a little strange, but all we’re doing is resetting our staging area (which Git calls the index) to the version at HEAD for our README.md file. In Git’s lingo, HEAD is an alias or pointer to the last commit on the current branch (which is, as mentioned earlier, the default Git branch called master). Git’s reset command is a powerful tool, but its default action is to just reset your index. We’ll see additional ways to use git reset when we learn about working with commit histories.
Collaborating with Git: Git Remotes, git push, and git pull
Thus far, we’ve covered the very basics of Git: tracking and working with files, staging changes, making commits, and looking at our commit history. Commits are the foundation of Git — they are the snapshots of our project as it evolves. Commits allow you to go back in time and look at, compare, and recover past versions, which are all topics we look at later in this chapter. In this section, we’re going to learn how to collaborate with Git, which at its core is just about sharing commits between your repository and your collaborators’ repositories.
The basis of sharing commits in Git is the idea of a remote repository, which is just a version of your repository hosted elsewhere. This could be a shared departmental server, your colleague’s version of your repository, or on a repository hosting service like GitHub or Bitbucket. Collaborating with Git first requires we configure our local repository to work with our remote repositories. Then, we can retrieve commits from a remote repository (a pull) and send commits to a remote repository (a push).
Note that Git, as a distributed version control system, allows you to work with remote repositories any way you like. These workflow choices are up to you and your collaborators. In this chapter, we’ll learn an easy common workflow to get started with: collaborating over a shared central repository.
Let’s take a look at an example: suppose that you’re working on a project you wish to share with a colleague. You start the project in your local repository. After you’ve made a few commits, you want to share your progress by sharing these commits with your collaborator. Let’s step through the entire workflow before seeing how to execute it with Git:
1. You create a shared central repository on a server that both you and your collaborator have access to.
2. You push your project’s initial commits to this repository (seen in (a) in Figure 5-3).
3. Your collaborator then retrieves your initial work by cloning this central repository (seen in (b) in Figure 5-3).
4. Then, your collaborator makes her changes to the project, commits them to her local repository, and then pushes these commits to the central repository (seen in (a) in Figure 5-4).
5. You then pull in the commits your collaborator pushed to the central repository (seen in (b) in Figure 5-4). The commit history of your project will be a mix of both you and your collaborator’s commits.
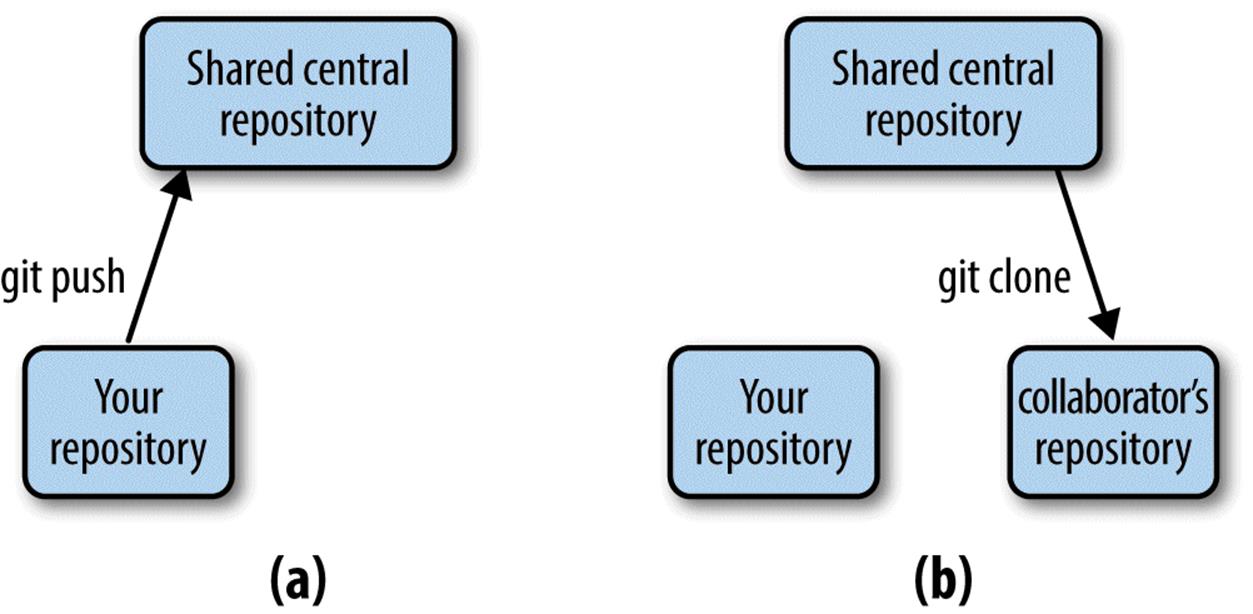
Figure 5-3. After creating a new shared central repository, you push your project’s commits (a); your collaborator can retrieve your project and its commits by cloning this central repository (b)
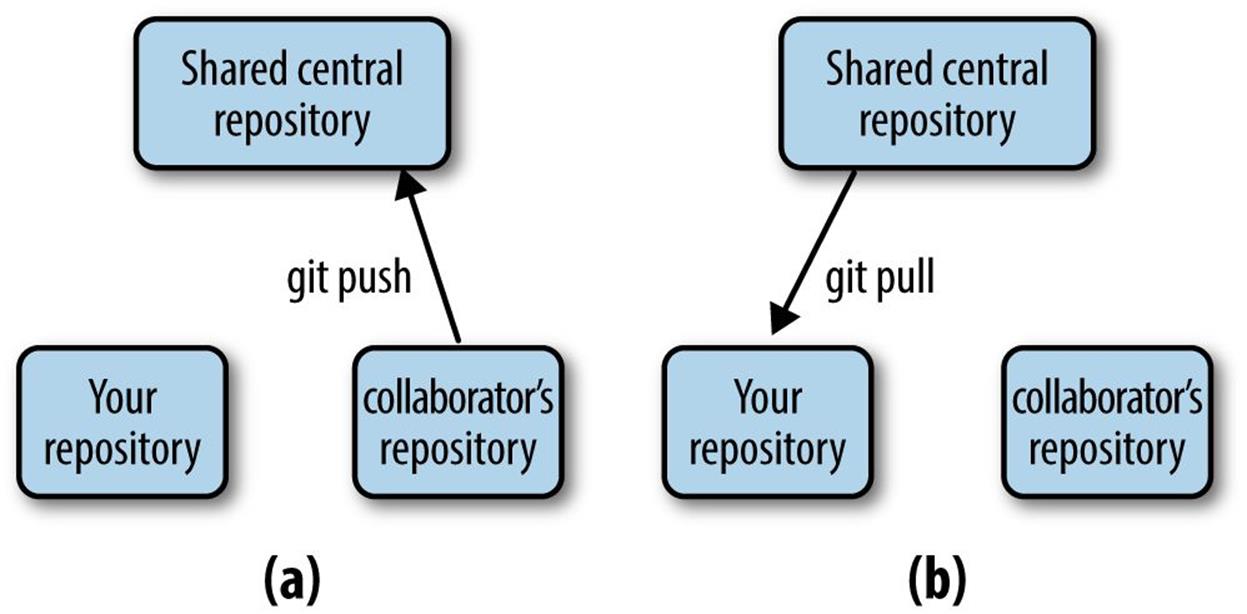
Figure 5-4. After making and committing changes, your collaborator pushes them to the central repository (a); to retrieve your collaborator’s new commits, you pull them from the central repository (b)
This process then repeats: you and your collaborator work independently in your own local repositories, and when either of you have commits to share, you push them to the central repository. In many cases, if you and your collaborator work on different files or different sections of the same file, Git can automatically figure out how best to merge these changes. This is an amazing feature of collaborating with Git: you and your collaborator can work on the same project simultaneously. Before we dive into how to do this, there is one caveat to discuss.
It’s important to note that Git cannot always automatically merge code and documents. If you and your collaborator are both editing the same section of the same file and both of you commit these changes, this will create a merge conflict. Unfortunately, one of you will have to resolve the conflicting files manually. Merge conflicts occur when you (or your collaborator) pull in commits from the central repository and your collaborator’s (or your) commits conflict with those in the local repository. In these cases, Git just isn’t smart enough to figure out how to reconcile you and your collaborator’s conflicting versions.
Most of us are familiar with this process when we collaboratively edit manuscripts in a word processor. If you write a manuscript and send it to all your collaborators to edit, you will need to manually settle sections with conflicting edits. Usually, we get around this messy situation through planning and prioritizing which coauthors will edit first, and gradually incorporating changes. Likewise, good communication and planning with your collaborators can go far in preventing Git merge conflicts, too. Additionally, it’s helpful to frequently push and pull commits to the central repository; this keeps all collaborators synced so everyone’s working with the newest versions of files.
Creating a Shared Central Repository with GitHub
The first step of our workflow is to create a shared central repository, which is what you and your collaborator(s) share commits through. In our examples, we will use GitHub, a web-based Git repository hosting service. Bitbucket is another Git repository hosting service you and your collaborators could use. Both are excellent; we’ll use GitHub because it’s already home to many large bioinformatics projects like Biopython and Samtools.
Navigate to http://github.com and sign up for an account. After your account is set up, you’ll be brought to the GitHub home page, which is a newsfeed for you to follow project development (this newsfeed is useful to follow how bioinformatics software you use changes over time). On the main page, there’s a link to create a new repository. After you’ve navigated to the Create a New Repository page, you’ll see you need to provide a repository name, and you’ll have the choice to initialize with a README.md file (GitHub plays well with Markdown), a .gitignore file, and a license (to license your software project). For now, just create a repository named zmays-snps. After you’ve clicked the “Create repository” button, GitHub will forward you to an empty repository page — the public frontend of your project.
There are a few things to note about GitHub:
§ Public repositories are free, but private repositories require you to pay. Luckily, GitHub has a special program for educational users. If you need private repositories without cost, Bitbucket has a different pricing scheme and provides some for free. Or, you can set up your own internal Git repository on your network if you have shared server space. Setting up your own Git server is out of the scope of this book, but see “Git on the Server - Setting Up the Server” in Scott Chacon and Ben Straub’s free online book Pro Git for more information. If your repository is public, anyone can see the source (and even clone and develop their own versions of your repository). However, other users don’t have access to modify your GitHub repository unless you grant it to them.
§ If you’re going to use GitHub for collaboration, all participating collaborators need a GitHub account.
§ By default, you are the only person who has write (push) access to the repository you created. To use your remote repository as a shared central repository, you’ll have to add collaborators in your GitHub repository’s settings. Collaborators are GitHub users who have access to push their changes to your repository on GitHub (which modifies it).
§ There are other common GitHub workflows. For example, if you manage a lab or other group, you can set up an organization account. You can create repositories and share them with collaborators under the organization’s name. We’ll discuss other GitHub workflows later in this chapter.
Authenticating with Git Remotes
GitHub uses SSH keys to authenticate you (the same sort we generated in “Quick Authentication with SSH Keys”). SSH keys prevent you from having to enter a password each time you push or pull from your remote repository. Recall in “Quick Authentication with SSH Keys” we generated two SSH keys: a public key and a private key. Navigate to your account settings on GitHub, and in account settings, find the SSH keys tab. Here, you can enter your public SSH key (remember, don’t share your private key!) by using cat ~/.ssh/id_rsa.pub to view it, copying it to your clipboard, and pasting it into GitHub’s form. You can then try out your SSH public key by using:
$ ssh -T git@github.com
Hi vsbuffalo! You've successfully authenticated, but
GitHub does not provide shell access.
If you’re having troubles with this, consult GitHub’s “Generating SSH Keys” article.
GitHub allows you to use to HTTP as a protocol, but this is typically only used if your network blocks SSH. By default, HTTP asks for passwords each time you try to pull and push (which gets tiresome quickly), but there are ways around this — see GitHub’s “Caching Your GitHub Password in Git” article.
Connecting with Git Remotes: git remote
Now, let’s configure our local repository to use the GitHub repository we’ve just created as a remote repository. We can do this with git remote add:
$ git remote add origin git@github.com:username/zmays-snps.git
In this command, we specify not only the address of our Git repository (git@github.com:username/zmays-snps.git), but also a name for it: origin. By convention, origin is the name of your primary remote repository. In fact, earlier when we cloned Seqtk from GitHub, Git automatically added the URL we cloned from as a remote named origin.
Now if you enter git remote -v (the -v makes it more verbose), you see that our local Git repository knows about the remote repository:
$ git remote -v
origin git@github.com:username/zmays-snps.git (fetch)
origin git@github.com:username/zmays-snps.git (push)
Indeed, origin is now a repository we can push commits to and fetch commits from. We’ll see how to do both of these operations in the next two sections.
It’s worth noting too that you can have multiple remote repositories. Earlier, we mentioned that Git is a distributed version control system; as a result, we can have many remote repositories. We’ll come back to how this is useful later on. For now, note that you can add other remote repositories with different names. If you ever need to delete an unused remote repository, you can with git remote rm <repository-name>.
Pushing Commits to a Remote Repository with git push
With our remotes added, we’re ready to share our work by pushing our commits to a remote repository. Collaboration on Git is characterized by repeatedly pushing your work to allow your collaborators to see and work on it, and pulling their changes into your own local repository. As you start collaborating, remember you only share the commits you’ve made.
Let’s push our initial commits from zmays-snps into our remote repository on GitHub. The subcommand we use here is git push <remote-name> <branch>. We’ll talk more about using branches later, but recall from “Tracking Files in Git: git add and git status Part I” that our default branch name is master. Thus, to push our zmays-snps repository’s commits, we do this:
$ git push origin master
Counting objects: 14, done.
Delta compression using up to 2 threads.
Compressing objects: 100% (9/9), done.
Writing objects: 100% (14/14), 1.24 KiB | 0 bytes/s, done.
Total 14 (delta 0), reused 0 (delta 0)
To git@github.com:vsbuffalo/zmays-snps.git
* [new branch] master -> master
That’s it — your collaborator now has access to all commits that were on your master branch through the central repository. Your collaborator retrieves these commits by pulling them from the central repository into her own local repository.
Pulling Commits from a Remote Repository with git pull
As you push new commits to the central repository, your collaborator’s repository will go out of date, as there are commits on the shared repository she doesn’t have in her own local repository. She’ll need to pull these commits in before continuing with her work. Collaboration on Git is a back-and-forth exchange, where one person pushes their latest commits to the remote repository, other collaborators pull changes into their local repositories, make their own changes and commits, and then push these commits to the central repository for others to see and work with.
To work through an example of this exchange, we will clone our own repository to a different directory, mimicking a collaborator’s version of the project. Let’s first clone our remote repository to a local directory named zmay-snps-barbara/. This directory name reflects that this local repository is meant to represent our colleague Barbara’s repository. We can clone zmays-snps from GitHub to a local directory named zmays-snps-barbara/ as follows:
$ git clone git@github.com:vsbuffalo/zmays-snps.git zmays-snps-barbara
Cloning into 'zmays-snps-barbara'...
remote: Counting objects: 14, done.
remote: Compressing objects: 100% (9/9), done.
remote: Total 14 (delta 0), reused 14 (delta 0)
Receiving objects: 100% (14/14), done.
Checking connectivity... done
Now, both repositories have the same commits. You can verify this by using git log and seeing that both have the same commits. Now, in our original zmay-snps/ local repository, let’s modify a file, make a commit, and push to the central repository:
$ echo "Samples expected from sequencing core 2013-01-10" >> README.md
$ git commit -a -m "added information about samples"
[master 46f0781] added information about samples
1 file changed, 1 insertion(+)
$ git push origin master
Counting objects: 5, done.
Delta compression using up to 2 threads.
Compressing objects: 100% (3/3), done.
Writing objects: 100% (3/3), 415 bytes | 0 bytes/s, done.
Total 3 (delta 0), reused 0 (delta 0)
To git@github.com:vsbuffalo/zmays-snps.git
c509f63..46f0781 master -> master
Now, Barbara’s repository (zmays-snps-barbara) is a commit behind both our local zmays-snps repository and the central shared repository. Barbara can pull in this change as follows:
$ # in zmays-snps-barbara/
$ git pull origin master
remote: Counting objects: 5, done.
remote: Compressing objects: 100% (3/3), done.
remote: Total 3 (delta 0), reused 3 (delta 0)
Unpacking objects: 100% (3/3), done.
From github.com:vsbuffalo/zmays-snps
* branch master -> FETCH_HEAD
c509f63..46f0781 master -> origin/master
Updating c509f63..46f0781
Fast-forward
README.md | 1 +
1 file changed, 1 insertion(+)
We can verify that Barbara’s repository contains the most recent commit using git log. Because we just want a quick image of the last few commits, I will use git log with some helpful formatting options:
$ # in zmays-snps-barbara/
$ git log --pretty=oneline --abbrev-commit
46f0781 added information about samples
c509f63 added .gitignore
e4feb22 added markdown extensions to README files
94e2365 added information about project to README
3d7ffa6 initial import
Now, our commits are in both the central repository and Barbara’s repository.
Working with Your Collaborators: Pushing and Pulling
Once you grow a bit more acquainted with pushing and pulling commits, it will become second nature. I recommend practicing this with fake repositories with a labmate or friend to get the hang of it. Other than merge conflicts (which we cover in the next section), there’s nothing tricky about pushing and pulling. Let’s go through a few more pushes and pulls so it’s extremely clear.
In the last section, Barbara pulled our new commit into her repository. But she will also create and push her own commits to the central repository. To continue our example, let’s make a commit from Barbara’s local repository and push it to the central repository. Because there is no Barbara (Git is using the account we made at the beginning of this chapter to make commits), I will modify git log’s output to show Barbara as the collaborator. Suppose she adds the following line to the README.md:
$ # in zmays-snps-barbara/ -- Barbara's version
$ echo "\n\nMaize reference genome version: refgen3" >> README.md
$ git commit -a -m "added reference genome info"
[master 269aa09] added reference genome info
1 file changed, 3 insertions(+)
$ git push origin master
Counting objects: 5, done.
Delta compression using up to 2 threads.
Compressing objects: 100% (3/3), done.
Writing objects: 100% (3/3), 390 bytes | 0 bytes/s, done.
Total 3 (delta 1), reused 0 (delta 0)
To git@github.com:vsbuffalo/zmays-snps.git
46f0781..269aa09 master -> master
Now Barbara’s local repository and the central repository are two commits ahead of our local repository. Let’s switch to our zmays-snps repository, and pull these new commits in. We can see how Barbara’s commits changed README.md with cat:
$ # in zmays-snps/ -- our version
$ git pull origin master
From github.com:vsbuffalo/zmays-snps
* branch master -> FETCH_HEAD
Updating 46f0781..269aa09
Fast-forward
README.md | 3 +++
1 file changed, 3 insertions(+)
$ cat README.md
Zea Mays SNP Calling Project
Project started 2013-01-03
Samples expected from sequencing core 2013-01-10
Maize reference genome version: refgen3
If we were to look at the last two log entries, they would look as follows:
$ git log -n 2
commit 269aa09418b0d47645c5d077369686ff04b16393
Author: Barbara <barbara@barbarasmaize.com>
Date: Sat Sep 28 22:58:55 2013 -0700
added reference genome info
commit 46f0781e9e081c6c9ee08b2d83a8464e9a26ae1f
Author: Vince Buffalo <vsbuffaloAAAAAA@gmail.com>
Date: Tue Sep 24 00:31:31 2013 -0700
added information about samples
This is what collaboration looks like in Git’s history: a set of sequential commits made by different people. Each is a snapshot of their repository and the changes they made since the last commit. All commits, whether they originate from your collaborator’s or your repository, are part of the same history and point to their parent commit.
Because new commits build on top of the commit history, it’s helpful to do the following to avoid problems:
§ When pulling in changes, it helps to have your project’s changes committed. Git will error out if a pull would change a file that you have uncommitted changes to, but it’s still helpful to commit your important changes before pulling.
§ Pull often. This complements the earlier advice: planning and communicating what you’ll work on with your collaborators. By pulling in your collaborator’s changes often, you’re in a better position to build on your collaborators’ changes. Avoid working on older, out-of-date commits.
Merge Conflicts
Occasionally, you’ll pull in commits and Git will warn you there’s a merge conflict. Resolving merge conflicts can be a bit tricky — if you’re struggling with this chapter so far, you can bookmark this section and return to it when you encounter a merge conflict in your own work.
Merge conflicts occur when Git can’t automatically merge your repository with the commits from the latest pull — Git needs your input on how best to resolve a conflict in the version of the file. Merge conflicts seem scary, but the strategy to solve them is always the same:
1. Use git status to find the conflicting file(s).
2. Open and edit those files manually to a version that fixes the conflict.
3. Use git add to tell Git that you’ve resolved the conflict in a particular file.
4. Once all conflicts are resolved, use git status to check that all changes are staged. Then, commit the resolved versions of the conflicting file(s). It’s also wise to immediately push this merge commit, so your collaborators see that you’ve resolved a conflict and can continue their work on this new version accordingly.
As an example, let’s create a merge conflict between our zmays-snps repository and Barbara’s zmays-snps-barbara repository. One common situation where merge conflicts arise is to pull in a collaborator’s changes that affect a file you’ve made and committed changes to. For example, suppose that Barbara changed README.md to something like the following (you’ll have to do this in your text editor if you’re following along):
Zea Mays SNP Calling Project
Project started 2013-01-03
Samples expected from sequencing core 2013-01-10
Maize reference genome version: refgen3, downloaded 2013-01-04 from
http://maizegdb.org into `/share/data/refgen3/`.
After making these edits to README.md, Barbara commits and pushes these changes. Meanwhile, in your repository, you also changed the last line:
Zea Mays SNP Calling Project
Project started 2013-01-03
Samples expected from sequencing core 2013-01-10
We downloaded refgen3 on 2013-01-04.
You commit this change, and then try to push to the shared central repository. To your surprise, you get the following error message:
$ git push origin master
To git@github.com:vsbuffalo/zmays-snps.git
! [rejected] master -> master (fetch first)
error: failed to push some refs to 'git@github.com:vsbuffalo/zmays-snps.git'
hint: Updates were rejected because the remote contains work that you do
hint: not have locally. This is usually caused by another repository pushing
hint: to the same ref. You may want to first integrate the remote changes
hint: (e.g., 'git pull ...') before pushing again.
hint: See the 'Note about fast-forwards' in 'git push --help' for details.
Git rejects your push attempt because Barbara has already updated the central repository’s master branch. As Git’s message describes, we need to resolve this by integrating the commits Barbara has pushed into our own local repository. Let’s pull in Barbara’s commit, and then try pushing as the message suggests (note that this error is not a merge conflict — rather, it just tells us we can’t push to a remote that’s one or more commits ahead of our local repository):
$ git pull origin master
remote: Counting objects: 5, done.
remote: Compressing objects: 100% (2/2), done.
remote: Total 3 (delta 1), reused 3 (delta 1)
Unpacking objects: 100% (3/3), done.
From github.com:vsbuffalo/zmays-snps
* branch master -> FETCH_HEAD
269aa09..dafce75 master -> origin/master
Auto-merging README.md
CONFLICT (content): Merge conflict in README.md
Automatic merge failed; fix conflicts and then commit the result.
This is the merge conflict. This message isn’t very helpful, so we follow the first step of the merge strategy by checking everything with git status:
$ git status
# On branch master
# You have unmerged paths.
# (fix conflicts and run "git commit")
#
# Unmerged paths:
# (use "git add <file>..." to mark resolution)
#
# both modified: README.md
#
no changes added to commit (use "git add" and/or "git commit -a")
git status tells us that there is only one file with a merge conflict, README.md (because we both edited it). The second step of our strategy is to look at our conflicting file(s) in our text editor:
Zea Mays SNP Calling Project
Project started 2013-01-03
Samples expected from sequencing core 2013-01-10
<<<<<<< HEAD ![]()
We downloaded refgen3 on 2013-01-04.
======= ![]()
Maize reference genome version: refgen3, downloaded 2013-01-04 from
http://maizegdb.org into `/share/data/refgen3/`.
>>>>>>> dafce75dc531d123922741613d8f29b894e605ac ![]()
Notice Git has changed the content of this file in indicating the conflicting lines.
![]()
This is the start of our version, the one that’s HEAD in our repository. HEAD is Git’s lingo for the latest commit (technically, HEAD points to the latest commit on the current branch).
![]()
Indicates the end of HEAD and beginning of our collaborator’s changes.
![]()
This final delimiter indicates the end of our collaborator’s version, and the different conflicting chunk. Git does its best to try to isolate the conflicting lines, so there can be many of these chunks.
Now we use step two of our merge conflict strategy: edit the conflicting file to resolve all conflicts. Remember, Git raises merge conflicts when it can’t figure out what to do, so you’re the one who has to manually resolve the issue. Resolving merge conflicts in files takes some practice. After resolving the conflict in README.md, the edited file would appear as follows:
Zea Mays SNP Calling Project
Project started 2013-01-03
Samples expected from sequencing core 2013-01-10
We downloaded the B73 reference genome (refgen3) on 2013-01-04 from
http://maizegdb.org into `/share/data/refgen3/`.
I’ve edited this file so it’s a combination of both versions. We’re happy now with our changes, so we continue to the third step of our strategy — using git add to declare this conflict has been resolved:
$ git add README.md
Now, the final step in our strategy — check git status to ensure all conflicts are resolved and ready to be merged, and commit them:
$ git status
git status
# On branch master
# All conflicts fixed but you are still merging.
# (use "git commit" to conclude merge)
#
# Changes to be committed:
#
# modified: README.md
#
$ git commit -a -m "resolved merge conflict in README.md"
[master 20041ab] resolved merge conflict in README.md
That’s it: our merge conflict is resolved! With our local repository up to date, our last step is to share our merge commit with our collaborator. This way, our collaborators know of the merge and can continue their work from the new merged version of the file.
After pushing our merge commit to the central repository with git push, let’s switch to Barbara’s local repository and pull in the merge commit:
$ git pull origin master
remote: Counting objects: 10, done.
remote: Compressing objects: 100% (4/4), done.
remote: Total 6 (delta 2), reused 5 (delta 2)
Unpacking objects: 100% (6/6), done.
From github.com:vsbuffalo/zmays-snps
* branch master -> FETCH_HEAD
dafce75..20041ab master -> origin/master
Updating dafce75..20041ab
Fast-forward
README.md | 2 +-
1 file changed, 1 insertion(+), 1 deletion(-)
Using git log we see that this is a special commit — a merge commit:
commit cd72acf0a81cdd688cb713465cb774320caeb2fd
Merge: f9114a1 d99121e
Author: Vince Buffalo <vsbuffaloAAAAAA@gmail.com>
Date: Sat Sep 28 20:38:01 2013 -0700
resolved merge conflict in README.md
Merge commits are special, in that they have two parents. This happened because both Barbara and I committed changes to the same file with the same parent commit. Graphically, this situation looks like Figure 5-5.
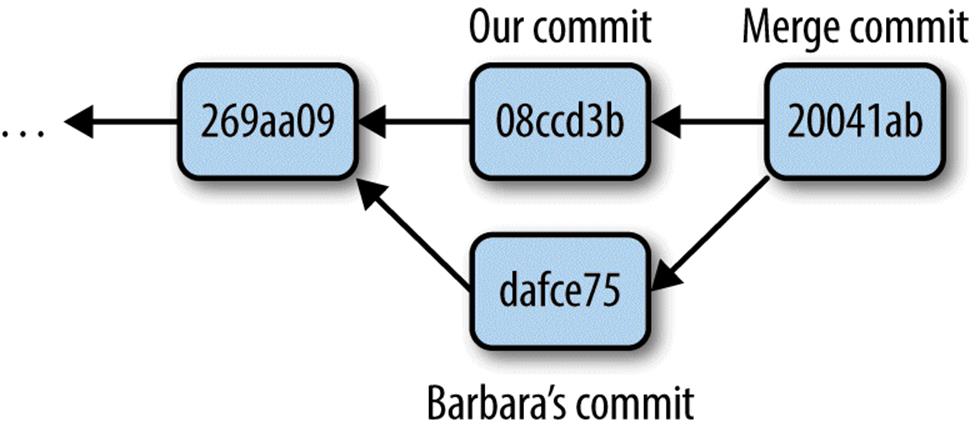
Figure 5-5. A merge commit has two parents — in this case, Barbara’s version and our version; merge commits resolve conflicts between versions
We can also see the same story through git log with the option --graph, which draws a plain-text graph of your commits:
* commit 20041abaab156c39152a632ea7e306540f89f706
|\ Merge: 08ccd3b dafce75
| | Author: Vince Buffalo <vsbuffaloAAAAAA@gmail.com>
| | Date: Sat Sep 28 23:13:07 2013 -0700
| |
| | resolved merge conflict in README.md
| |
| * commit dafce75dc531d123922741613d8f29b894e605ac
| | Author: Vince Buffalo <vsbuffaloAAAAAA@gmail.com>
| | Date: Sat Sep 28 23:09:01 2013 -0700
| |
| | added ref genome download date and link
| |
* | commit 08ccd3b056785513442fc405f568e61306d62d4b
|/ Author: Vince Buffalo <vsbuffaloAAAAAA@gmail.com>
| Date: Sat Sep 28 23:10:39 2013 -0700
|
| added reference download date
Merge conflicts are intimidating at first, but following the four-step strategy introduced at the beginning of this section will get you through it. Remember to repeatedly check git status to see what needs to be resolved, and use git add to stage edited files as you resolve the conflicts in them. At any point, if you’re overwhelmed, you can abort a merge with git merge --abort and start over (but beware: you’ll lose any changes you’ve made).
There’s one important caveat to merging: if your project’s code is spread out across a few files, resolving a merge conflict does not guarantee that your code works. Even if Git can fast-forward your local repository after a pull, it’s still possible your collaborator’s changes may break something (such is the danger when working with collaborators!). It’s always wise to do some sanity checks after pulling in code.
For complex merge conflicts, you may want to use a merge tool. Merge tools help visualize merge conflicts by placing both versions side by side, and pointing out what’s different (rather than using Git’s inline notation that uses inequality and equal signs). Some commonly used merge tools include Meld and Kdiff.
More GitHub Workflows: Forking and Pull Requests
While the shared central repository workflow is the easiest way to get started collaborating with Git, GitHub suggests a slightly different workflow based on forking repositories. When you visit a repository owned by another user on GitHub, you’ll see a “fork” link. Forking is an entirely GitHub concept — it is not part of Git itself. By forking another person’s GitHub repository, you’re copying their repository to your own GitHub account. You can then clone your forked version and continue development in your own repository. Changes you push from your local version to your remote repository do not interfere with the main project. If you decide that you’ve made changes you want to share with the main repository, you can request that your commits are pulled using a pull request (another feature of GitHub).
This is the workflow GitHub is designed around, and it works very well with projects with many collaborators. Development primarily takes place in contributors’ own repositories. A developer’s contributions are only incorporated into the main project when pulled in. This is in contrast to a shared central repository workflow, where collaborators can push their commits to the main project at their will. As a result, lead developers can carefully control what commits are added to the project, which prevents the hassle of new changes breaking functionality or creating bugs.
Using Git to Make Life Easier: Working with Past Commits
So far in this chapter we’ve created commits in our local repository and shared these commits with our collaborators. But our commit history allows us to do much more than collaboration — we can compare different versions of files, retrieve past versions, and tag certain commits with helpful messages.
After this point, the material in this chapter becomes a bit more advanced. Readers can skip ahead to Chapter 6 without a loss of continuity. If you do skip ahead, bookmark this section, as it contains many tricks used to get out of trouble (e.g., restoring files, stashing your working changes, finding bugs by comparing versions, and editing and undoing commits). In the final section, we’ll also cover branching, which is a more advanced Git workflow — but one that can make your life easier.
Getting Files from the Past: git checkout
Anything in Git that’s been committed is easy to recover. Suppose you accidentally overwrite your current version of README.md by using > instead of >>. You see this change with git status:
$ echo "Added an accidental line" > README.md
$ cat README.md
Added an accidental line
$ git status
# On branch master
# Changes not staged for commit:
# (use "git add <file>..." to update what will be committed)
# (use "git checkout -- <file>..." to discard changes in working
directory)
#
# modified: README.md
#
no changes added to commit (use "git add" and/or "git commit -a")
This mishap accidentally wiped out the previous contents of README.md! However, we can restore this file by checking out the version in our last commit (the commit HEAD points to) with the command git checkout -- <file>. Note that you don’t need to remember this command, as it’s included in git status messages. Let’s restore README.md:
$ git checkout -- README.md
$ cat README.md
Zea Mays SNP Calling Project
Project started 2013-01-03
Samples expected from sequencing core 2013-01-10
We downloaded the B72 reference genome (refgen3) on 2013-01-04 from
http://maizegdb.org into `/share/data/refgen3/`.
But beware: restoring a file this way erases all changes made to that file since the last commit! If you’re curious, the cryptic -- indicates to Git that you’re checking out a file, not a branch (git checkout is also used to check out branches; commands with multiple uses are common in Git).
By default, git checkout restores the file version from HEAD. However, git checkout can restore any arbitrary version from commit history. For example, suppose we want to restore the version of README.md one commit before HEAD. The past three commits from our history looks like this (using some options to make git log more concise):
$ git log --pretty=oneline --abbrev-commit -n 3
20041ab resolved merge conflict in README.md
08ccd3b added reference download date
dafce75 added ref genome download date and link
Thus, we want to restore README.md to the version from commit 08ccd3b. These SHA-1 IDs (even the abbreviated one shown here) function as absolute references to your commits (similar to absolute paths in Unix like/some/dir/path/file.txt). We can always refer to a specific commit by its SHA-1 ID. So, to restore README.md to the version from commit 08ccd3b, we use:
$ git checkout 08ccd3b -- README.md
$ cat README.md
Zea Mays SNP Calling Project
Project started 2013-01-03
Samples expected from sequencing core 2013-01-10
We downloaded refgen3 on 2013-01-04.
If we restore to get the most recent commit’s version, we could use:
$ git checkout 20041ab -- README.md
$ git status
# On branch master
nothing to commit, working directory clean
Note that after checking out the latest version of the README.md file from commit 20041ab, nothing has effectively changed in our working directory; you can verify this using git status.
Stashing Your Changes: git stash
One very useful Git subcommand is git stash, which saves any working changes you’ve made since the last commit and restores your repository to the version at HEAD. You can then reapply these saved changes later. git stash is handy when we want to save our messy, partial progress before operations that are best performed with a clean working directory — for example, git pull or branching (more on branching later).
Let’s practice using git stash by first adding a line to README.md:
$ echo "\\nAdapter file: adapters.fa" >> README.md
$ git status
# On branch master
# Changes not staged for commit:
# (use "git add <file>..." to update what will be committed)
# (use "git checkout -- <file>..." to discard changes in working
directory)
#
# modified: README.md
#
no changes added to commit (use "git add" and/or "git commit -a")
Then, let’s stash this change using git stash:
$ git stash
Saved working directory and index state WIP on master: 20041ab
resolved merge conflict in README.md
HEAD is now at 20041ab resolved merge conflict in README.md
Stashing our working changes sets our directory to the same state it was in at the last commit; now our project directory is clean.
To reapply the changes we stashed, use git stash pop:
$ git stash pop
# On branch master
# Changes not staged for commit:
# (use "git add <file>..." to update what will be committed)
# (use "git checkout -- <file>..." to discard changes in working
# directory)
#
# modified: README.md
#
no changes added to commit (use "git add" and/or "git commit -a")
Dropped refs/stash@{0} (785dad46104116610d5840b317f05465a5f07c8b)
Note that the changes stored with git stash are not committed; git stash is a separate way to store changes outside of your commit history. If you start using git stash a lot in your work, check out other useful stash subcommands like git stash apply and git stash list.
More git diff: Comparing Commits and Files
Earlier, we used git diff to look at the difference between our working directory and our staging area. But git diff has many other uses and features; in this section, we’ll look at how we can use git diff to compare our current working tree to other commits.
One use for git diff is to compare the difference between two arbitrary commits. For example, if we wanted to compare what we have now (at HEAD) to commit dafce75:
$ git diff dafce75
diff --git a/README.md b/README.md
index 016ed0c..9491359 100644
--- a/README.md
+++ b/README.md
@@ -3,5 +3,7 @@ Project started 2013-01-03
Samples expected from sequencing core 2013-01-10
-Maize reference genome version: refgen3, downloaded 2013-01-04 from
+We downloaded the B72 reference genome (refgen3) on 2013-01-04 from
http://maizegdb.org into `/share/data/refgen3/`.
+
+Adapter file: adapters.fa
SPECIFYING REVISIONS RELATIVE TO HEAD
Like writing out absolute paths in Unix, referring to commits by their full SHA-1 ID is tedious. While we can reduce typing by using the abbreviated commits (the first seven characters of the full SHA-1 ID), there’s an easier way: relative ancestry references. Similar to using relative paths in Unix like ./ and ../, Git allows you to specify commits relative to HEAD (or any other commit, with SHA-1 IDs).
The caret notation (^) represents the parent commit of a commit. For example, to refer to the parent of the most recent commit on the current branch (HEAD), we’d use HEAD^ (commit 08ccd3b in our examples).
Similarly, if we’d wanted to refer to our parent’s parent commit (dafce75 in our example), we use HEAD^^. Our example repository doesn’t have enough commits to refer to the parent of this commit, but if it did, we could use HEAD^^^. At a certain point, using this notation is no easier than copying and pasting a SHA-1, so a succinct alternative syntax exists: git HEAD~<n>, where <n> is the number of commits back in the ancestry of HEAD (including the last one). Using this notation, HEAD^^ is the same as HEAD~2.
Specifying revisions becomes more complicated with merge commits, as these have two parents. Git has an elaborate language to specify these commits. For a full specification, enter git rev-parse --help and see the “Specifying Revisions” section of this manual page.
Using git diff, we can also view all changes made to a file between two commits. To do this, specify both commits and the file’s path as arguments (e.g., git diff <commit> <commit> <path>). For example, to compare our version of README.md across commits 269aa09 and 46f0781, we could use either:
$ git diff 46f0781 269aa09 README.md
# or
$ git diff HEAD~3 HEAD~2 README.md
This second command utilizes the relative ancestry references explained in “Specifying Revisions Relative to HEAD”.
How does this help? Git’s ability to compare the changes between two commits allows you to find where and how a bug entered your code. For example, if a modified script produces different results from an earlier version, you can use git diff to see exactly which lines differ across versions. Git also has a tool called git bisect to help developers find where exactly bugs entered their commit history. git bisect is out of the scope of this chapter, but there are some good examples in git bisect --help.
Undoing and Editing Commits: git commit --amend
At some point, you’re bound to accidentally commit changes you didn’t mean to or make an embarrassing typo in a commit message. For example, suppose we were to make a mistake in a commit message:
$ git commit -a -m "added adpters file to readme"
[master f4993e3] added adpters file to readme
1 file changed, 2 insertions(+)
We could easily amend our commit with:
$ git commit --amend
git commit --amend opens up your last commit message in your default text editor, allowing you to edit it. Amending commits isn’t limited to just changing the commit message though. You can make changes to your file, stage them, and then amend these staged changes with git commit --amend. In general, unless you’ve made a mistake, it’s best to just use separate commits.
It’s also possible to undo commits using either git revert or the more advanced git reset (which if used improperly can lead to data loss). These are more advanced topics that we don’t have space to cover in this chapter, but I’ve listed some resources on this issue in this chapter’s README file on GitHub.
Working with Branches
Our final topic is probably Git’s greatest feature: branching. If you’re feeling overwhelmed so far by Git (I certainly did when I first learned it), you can move forward to Chapter 6 and work through this section later.
Branching is much easier with Git than in other version control systems — in fact, I switched to Git after growing frustrated with another version control system’s branching model. Git’s branches are virtual, meaning that branching doesn’t require actually copying files in your repository. You can create, merge, and share branches effortlessly with Git. Here are some examples of how branches can help you in your bioinformatics work:
§ Branches allow you to experiment in your project without the risk of adversely affecting the main branch, master. For example, if in the middle of a variant calling project you want to experiment with a new pipeline, you can create a new branch and implement the changes there. If the new variant caller doesn’t work out, you can easily switch back to the master branch — it will be unaffected by your experiment.
§ If you’re developing software, branches allow you to develop new features or bug fixes without affecting the working production version, the master branch. Once the feature or bug fix is complete, you can merge it into the master branch, incorporating the change into your production version.
§ Similarly, branches simplify working collaboratively on repositories. Each collaborator can work on their own separate branches, which prevents disrupting the master branch for other collaborators. When a collaborator’s changes are ready to be shared, they can be merged into the master branch.
Creating and Working with Branches: git branch and git checkout
As a simple example, let’s create a new branch called readme-changes. Suppose we want to make some edits to README.md, but we’re not sure these changes are ready to be incorporated into the main branch, master.
To create a Git branch, we use git branch <branchname>. When called without any arguments, git branch lists all branches. Let’s create the readme-changes branch and check that it exists:
$ git branch readme-changes
$ git branch
* master
readme-changes
The asterisk next to master is there to indicate that this is the branch we’re currently on. To switch to the readme-changes branch, use git checkout readme-changes:
$ git checkout readme-changes
Switched to branch 'readme-changes'
$ git branch
master
* readme-changes
Notice now that the asterisk is next to readme-changes, indicating this is our current branch. Now, suppose we edit our README.md section extensively, like so:
# Zea Mays SNP Calling Project
Project started 2013-01-03.
## Samples
Samples downloaded 2013-01-11 into `data/seqs`:
data/seqs/zmaysA_R1.fastq
data/seqs/zmaysA_R2.fastq
data/seqs/zmaysB_R1.fastq
data/seqs/zmaysB_R2.fastq
data/seqs/zmaysC_R1.fastq
data/seqs/zmaysC_R2.fastq
## Reference
We downloaded the B72 reference genome (refgen3) on 2013-01-04 from
http://maizegdb.org into `/share/data/refgen3/`.
Now if we commit these changes, our commit is added to the readme-changes branch. We can verify this by switching back to the master branch and seeing that this commit doesn’t exist:
$ git commit -a -m "reformatted readme, added sample info" ![]()
[readme-changes 6e680b6] reformatted readme, added sample info
1 file changed, 12 insertions(+), 3 deletions(-)
$ git log --abbrev-commit --pretty=oneline -n 3 ![]()
6e680b6 reformatted readme, added sample info
20041ab resolved merge conflict in README.md
08ccd3b added reference download date
$ git checkout master ![]()
Switched to branch 'master'
$ git log --abbrev-commit --pretty=oneline -n 3 ![]()
20041ab resolved merge conflict in README.md
08ccd3b added reference download date
dafce75 added ref genome download date and link
![]()
Our commit, made on the branch readme-changes.
![]()
The commit we just made (6e680b6).
![]()
Switching back to our master branch.
![]()
Our last commit on master is 20041ab. Our changes to README.md are only on the readme-changes branch, and when we switch back to master, Git swaps our files out to those versions on that branch.
Back on the master branch, suppose we add the adapters.fa file, and commit this change:
$ git branch
* master
readme-changes
$ echo ">adapter-1\\nGATGATCATTCAGCGACTACGATCG" >> adapters.fa
$ git add adapters.fa
$ git commit -a -m "added adapters file"
[master dd57e33] added adapters file
1 file changed, 2 insertions(+)
create mode 100644 adapters.fa
Now, both branches have new commits. This situation looks like Figure 5-6.
Figure 5-6. Our two branches (within Git, branches are represented as pointers at commits, as depicted here), the master and readme-changes branches have diverged, as they point to different commits (our HEAD points to master, indicating this is the current branch we’re on)
Another way to visualize this is with git log. We’ll use the --branches option to specify we want to see all branches, and -n 2 to only see these last commits:
$ git log --abbrev-commit --pretty=oneline --graph --branches -n2
* dd57e33 added adapters file
| * 6e680b6 reformatted readme, added sample info
|/
Merging Branches: git merge
With our two branches diverged, we now want to merge them together. The strategy to merge two branches is simple. First, use git checkout to switch to the branch we want to merge the other branch into. Then, use git merge <otherbranch> to merge the other branch into the current branch. In our example, we want to merge the readme-changes branch into master, so we switch to master first. Then we use:
$ git merge readme-changes
Merge made by the 'recursive' strategy.
README.md | 15 ++++++++++++---
1 file changed, 12 insertions(+), 3 deletions(-)
There wasn’t a merge conflict, so git merge opens our text editor and has us write a merge commit message. Once again, let’s use git log to see this:
$ git log --abbrev-commit --pretty=oneline --graph --branches -n 3
* e9a81b9 Merge branch 'readme-changes'
|\
| * 6e680b6 reformatted readme, added sample info
* | dd57e33 added adapters file
|/
Bear in mind that merge conflicts can occur when merging branches. In fact, the merge conflict we encountered in “Merge Conflicts” when pulling in remote changes was a conflict between two branches; git pull does a merge between a remote branch and a local branch (more on this in “Branches and Remotes”). Had we encountered a merge conflict when running git merge, we’d follow the same strategy as in “Merge Conflicts” to resolve it.
When we’ve used git log to look at our history, we’ve only been looking a few commits back — let’s look at the entire Git history now:
$ git log --abbrev-commit --pretty=oneline --graph --branches
* e9a81b9 Merge branch 'readme-changes'
|\
| * 6e680b6 reformatted readme, added sample info
* | dd57e33 added adapters file
|/
* 20041ab resolved merge conflict in README.md
|\
| * dafce75 added ref genome download date and link
* | 08ccd3b added reference download date
|/
* 269aa09 added reference genome info
* 46f0781 added information about samples
* c509f63 added .gitignore
* e4feb22 added markdown extensions to README files
* 94e2365 added information about project to README
* 3d7ffa6 initial import
Note that we have two bubbles in our history: one from the merge conflict we resolved after git pull, and the other from our recent merge of the readme-changes branch.
Branches and Remotes
The branch we created in the previous section was entirely local — so far, our collaborators are unable to see this branch or its commits. This is a nice feature of Git: you can create and work with branches to fit your workflow needs without having to share these branches with collaborators. In some cases, we do want to share our local branches with collaborators. In this section, we’ll see how Git’s branches and remote repositories are related, and how we can share work on local branches with collaborators.
Remote branches are a special type of local branch. In fact, you’ve already interacted with these remote branches when you’ve pushed to and pulled from remote repositories. Using git branch with the option --all, we can see these hidden remote branches:
$ git branch --all
* master
readme-changes
remotes/origin/master
remotes/origin/master is a remote branch — we can’t do work on it, but it can be synchronized with the latest commits from the remote repository using git fetch. Interestingly, a git pull is nothing more than a git fetch followed by a git merge. Though a bit technical, understanding this idea will greatly help you in working with remote repositories and remote branches. Let’s step through an example.
Suppose that Barbara is starting a new document that will detail all the bioinformatics methods of your project. She creates a new-methods branch, makes some commits, and then pushes these commits on this branch to our central repository:
$ git push origin new-methods
Counting objects: 4, done.
Delta compression using up to 2 threads.
Compressing objects: 100% (2/2), done.
Writing objects: 100% (3/3), 307 bytes | 0 bytes/s, done.
Total 3 (delta 1), reused 0 (delta 0)
To git@github.com:vsbuffalo/zmays-snps.git
* [new branch] new-methods -> new-methods
Back in our repository, we can fetch Barbara’s latest branches using git fetch <remotename>. This creates a new remote branch, which we can see with git branch --all:
$ git fetch origin
remote: Counting objects: 4, done.
remote: Compressing objects: 100% (1/1), done.
remote: Total 3 (delta 1), reused 3 (delta 1)
Unpacking objects: 100% (3/3), done.
From github.com:vsbuffalo/zmays-snps
= [up to date] master -> origin/master
* [new branch] new-methods -> origin/new-methods
$ git branch --all
* master
new-methods
remotes/origin/master
remotes/origin/new-methods
git fetch doesn’t change any of your local branches; rather, it just synchronizes your remote branches with the newest commits from the remote repositories. If after a git fetch we wanted to incorporate the new commits on our remote branch into our local branch, we would use a git merge. For example, we could merge Barbara’s new-methods branch into our master branch with git merge origin/new-methods, which emulates a git pull.
However, Barbara’s branch is just getting started — suppose we want to develop on the new-methods branch before merging it into our master branch. We cannot develop on remote branches (e.g., our remotes/origin/new-methods), so we need to make a new branch that starts from this branch:
$ git checkout -b new-methods origin/new-methods
Branch new-methods set up to track remote branch new-methods from origin.
Switched to a new branch 'new-methods'
Here, we’ve used git checkout to simultaneously create and switch a new branch using the -b option. Note that Git notified us that it’s tracking this branch. This means that this local branch knows which remote branch to push to and pull from if we were to just use git push or git pull without arguments. If we were to commit a change on this branch, we could then push it to the remote with git push:
$ echo "\\n(1) trim adapters\\n(2) quality-based trimming" >> methods.md
$ git commit -am "added quality trimming steps"
[new-methods 5f78374] added quality trimming steps
1 file changed, 3 insertions(+)
$ git push
Counting objects: 5, done.
Delta compression using up to 2 threads.
Compressing objects: 100% (3/3), done.
Writing objects: 100% (3/3), 339 bytes | 0 bytes/s, done.
Total 3 (delta 1), reused 0 (delta 0)
To git@github.com:vsbuffalo/zmays-snps.git
6364ebb..9468e38 new-methods -> new-methods
Development can continue on new-methods until you and your collaborator decide to merge these changes into master. At this point, this branch’s work has been incorporated into the main part of the project. If you like, you can delete the remote branch with git push origin :new-methods and your local branch with git branch -d new-methods.
Continuing Your Git Education
Git is a massively powerful version control system. This chapter has introduced the basics of version control and collaborating through pushing and pulling, which is enough to apply to your daily bioinformatics work. We’ve also covered some basic tools and techniques that can get you out of trouble or make working with Git easier, such as git checkout to restore files, git stash to stash your working changes, and git branch to work with branches. After you’ve mastered all of these concepts, you may want to move on to more advanced Git topics such as rebasing (git rebase), searching revisions (git grep), and submodules. However, none of these topics are required in daily Git use; you can search out and learn these topics as you need them. A great resource for these advanced topics is Scott Chacon and Ben Straub’s Pro Git book.
All materials on the site are licensed Creative Commons Attribution-Sharealike 3.0 Unported CC BY-SA 3.0 & GNU Free Documentation License (GFDL)
If you are the copyright holder of any material contained on our site and intend to remove it, please contact our site administrator for approval.
© 2016-2025 All site design rights belong to S.Y.A.