Big Data Bootcamp: What Managers Need to Know to Profit from the Big Data Revolution (2014)
Chapter 8. The Next Billion-Dollar IPO: Big Data Entrepreneurship
Drive Data Like Billy Beane
As the General Manager of the Oakland Athletics, Billy Beane faced a problem. Beane and the Oakland A’s had to field a competitive team without the big market budget of a team like the New York Yankees. In a story made famous by the movie Moneyball and the book of the same name by Michael Lewis, Beane turned to data and statistics.
This approach is known as sabermetrics, a term coined by baseball writer and statistician Bill James. Sabermetrics is a derivative of SABR, which stands for the Society for American Baseball Research. It is “the search for objective knowledge about baseball.”1
At the time, Beane’s data-driven approach was widely criticized. It broke with years of the tradition of relying on the qualitative observations that scouts made about players. Instead it focused on using payroll to buy enough runs, not from a single player, but in aggregate, to buy wins.
Beane didn’t use Big Data as it has traditionally been defined—as working with a volume of data bigger than the volume that traditional databases can handle. But he did apply data in a novel way to achieve a powerful impact.
Rather than making decisions based purely on qualitative information, Beane used a data-driven approach. More specifically, as Nate Silver points out in his best-seller The Signal and the Noise: Why Most Predictions Fail but Some Don’t, Beane was disciplined about using the statistics that mattered, like on base percentage, rather than those that didn’t.2
Silver developed the PECOTA system, short for Player Empirical Comparison and Optimization Test Algorithm, a sabermetric system widely used for forecasting the performance of major league baseball players. The PECOTA system draws on a database of some 20,000 major league batters since World War II, as well as 15,000 minor league batters.3
Today, those who want to take a data-driven approach in their own organizations often face the same challenge that Beane faced. Taking a data-driven approach to decision making isn’t easy. But as Billy Beane showed, it does produce results.
Organizations know they need to become more data-driven, but to do so, it has to be a lot easier for them to be data-driven. Big Data Applications (BDAs) are one of the key advances that make such an approach possible. That’s one of the key reasons BDAs are poised to create tech’s next billion dollar IPOs.
Why Being Data-Driven Is Hard
Amazon, Google, IBM, and Oracle, to name a handful of the most valuable data-related companies on the planet, have shown the value of leveraging Big Data. Amazon serves billions of e-commerce transactions, Google handles billions of searches, and IBM and Oracle offer database software and applications designed for storing and working with huge amounts of data. Big Data means big dollars.
Yet baseball isn’t the only game in town that struggles to make decisions based on data. Most organizations still find making data-driven decisions difficult. In some cases, organizations simply don’t have the data. Until recently, for example, it was hard to get comprehensive data on marketing activities. It was one thing to figure out how much you were spending on marketing, but it was another to correlate that marketing investment with actual sales. Thus the age-old marketing adage, “I know that half of my advertising budget is wasted, but I’m not sure which half.”
Now, however, people are capturing data critical to understanding customers, supply chain, and machine performance, from network servers to cars to airplanes, as well as many other critical business indicators. The big challenge is no longer capturing the data, it’s making sense of it.
For decades, making sense of data has been the province of data analysts, statisticians, and PhDs. Not only did a business line manager have to wait for IT to get access to key data, she then had to wait for an analyst to pull it all together and make sense of it. The promise of BDAs is the ability not just to capture data but to act on it, without requiring a set of tools that only statisticians can use. By making data more accessible, BDAs will enable organizations, one line of business at a time, to become more data-driven.
Yet even when you have the data and the tools to act on it, doing so remains difficult. Having an opinion is easy. Having conviction is hard.
As Warren Buffet once famously said, “Be fearful when others are greedy and greedy when others are fearful.”4 Buffet is well-known for his data-driven approach to investing. Yet despite historical evidence that doing so is a bad idea, investors continue to invest on good news and sell on bad. Economists long assumed people made decisions based on logical rules, but in reality, they don’t.5
Nobel prize winning psychologist Daniel Khaneman and his colleague Amos Tversky concluded that people often behave illogically. They give more weight to losses than to gains and vivid examples often have a bigger impact on their decision making than data, even if that data is more accurate.
To be data-driven, not only must you have the data and figure out which data is relevant, you then have to make decisions based on that data. To do that, you must have confidence and conviction: confidence in the data, and the conviction to make decisions based on it, even when popular opinion tells you otherwise. This is called the Big Data Action Loop (see Figure 8-1).
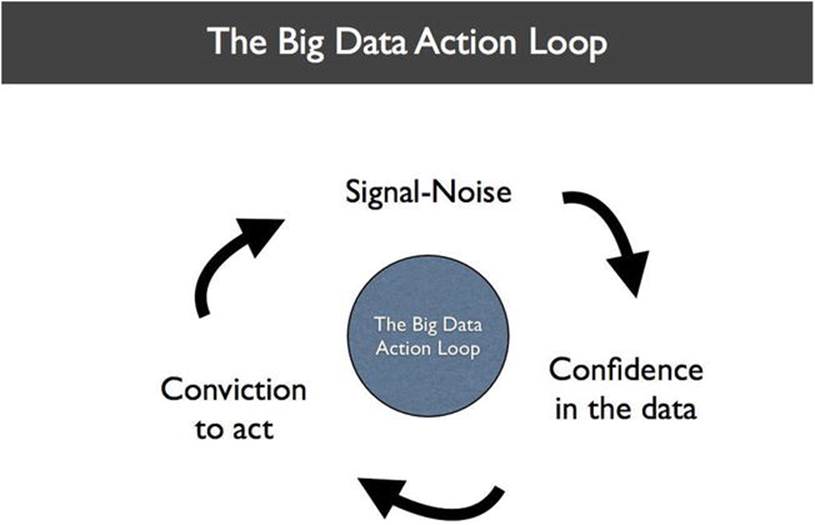
Figure 8-1. The Big Data Action Loop shows the key elements of Big Data decision-making
Hearing the Signal and Ignoring the Noise
The fact that being data-driven is so hard, both culturally and from an implementation perspective, is one of the key reasons that BDAs will play such an important role going forward. Historically, data was hard to get to and work with. Critically, data frequently wasn’t in one place. Internal company data was spread across a variety of different databases, data stores, and file servers. External data was in market reports, on the web, and in other difficult-to-access sources.
The power, and the challenge, of Big Data is that it often brings all that data together in one place. That means the potential for greater insights from larger quantities of more relevant data—what engineers refer to as signal—but also for more noise, which is data that isn’t relevant to producing insights and can even result in drawing the wrong conclusions.
Just having the data in one place doesn’t matter if computers or human beings can’t make sense of it. That is the power of BDAs. BDAs can help extract the signal from the noise. By doing so, they can give you more confidence in the data you work with, resulting in greater conviction to act on that data, either manually or automatically.
The Big Data Feedback Loop: Acting on Data
The first time you touched a hot stove and got burned, stuck your finger in an electrical outlet and got shocked, or drove over the speed limit and got a ticket, you experienced a feedback loop. Consciously or not, you ran a test, analyzed the result, and acted differently in the future. This is called the Big Data Feedback Loop (see Figure 8-2) and it is the key to building successful BDAs.
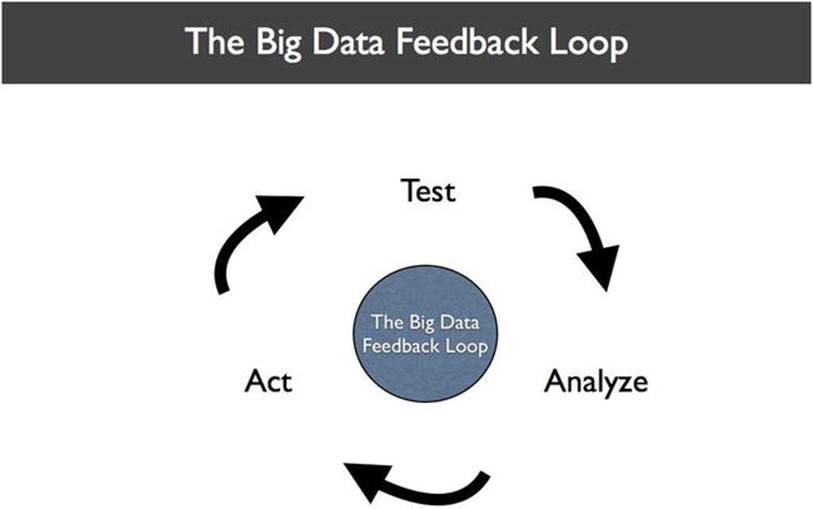
Figure 8-2. The Big Data Feedback Loop
Through testing, you found out that touching a hot stove or getting an electrical shock hurt. You found out that speeding resulted in getting an expensive ticket or getting in a car crash. Or, if you got away with it, you may have concluded that speeding was fun.
Regardless of the outcome, all of these activities gave you feedback. You incorporated this feedback into your data library and changed your future actions based on the data. If you had a fun experience speeding despite the ticket, you might have chosen to do more speeding. If you had a bad experience with a stove, you might have figured out to check if a stove was hot before touching one again in the future.
Such feedback loops are critical when it comes to Big Data. Collecting data and analyzing it isn’t enough. You have to be able to reach a set of conclusions from that data and get feedback on those conclusions to determine if they’re right or wrong. The more relevant data you can feed into your model and the more times you can get feedback on your hypotheses, the more valuable your insights are.
Historically, running such feedback loops has been slow and time consuming. Car companies, for example, collect sales data and try to draw conclusions about what pricing models or product features cause people to buy more cars. They change prices, revise features, and run the experiment again. The problem is that by the time they conclude their analysis and revise pricing and products, the environment changes. Powerful but gas-guzzling cars were out while fuel-saving cars were in. MySpace lost users while Facebook gained them. And the list goes on.
The benefit of Big Data is that in many cases you can now run the feedback loop much faster. In advertising, BDAs can figure out which ads convert the best by serving up many different ads in real time and then displaying only those that work. They can even do this on a segmented basis—determining which ads convert the best for which groups of people. This kind of A/B testing, displaying different ads to see which perform better, simply could not be done fast enough by humans to work.
Computers can run such tests at massive scale, not only choosing between different ads but actually modifying the ads themselves. They can display different fonts, colors, sizes, and images to figure out which combinations are most effective. This real-time feedback loop, the ability not just to gather massive amounts of data but to test out and act on many different approaches quickly, is one of the most powerful aspects of Big Data.
Achieving Minimum Data Scale
As people move forward with Big Data, it is becoming less a question of gathering and storing the data and more a question of what to do with it. A high-performance feedback loop requires a sufficiently large test set of customers visiting web sites, sales people calling prospects, or consumers viewing ads to be effective.
This test set is called the Minimum Data Scale (MDS; see Figure 8-3). MDS is the minimum amount of data required to run the Big Data Feedback Loop and get meaningful insights from it.
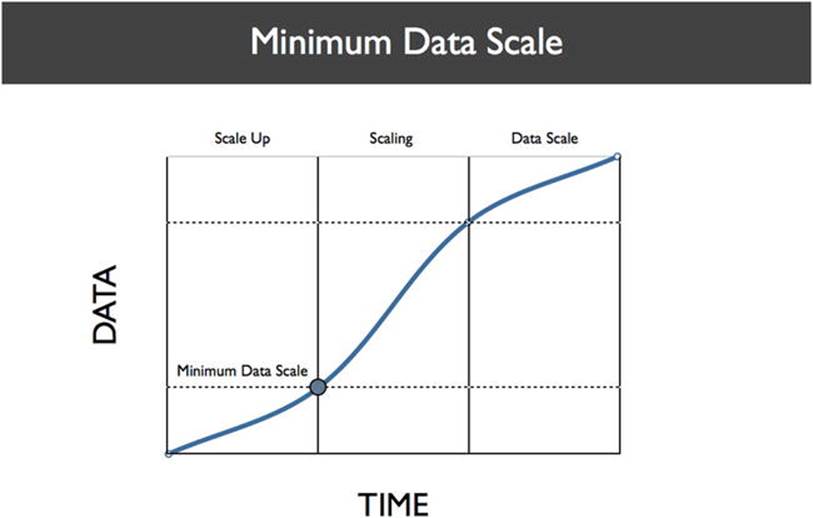
Figure 8-3. The Minimum Data Scale is the minimum amount of data required to derive meaningful conclusions from data
MDS means that a company has enough visitors to its web site, viewers of its advertisements, or sales prospects that it can derive meaningful conclusions and make decisions based on the data. When a company has enough data points to reach MDS, it can use BDAs to tell sales people whom to call next, decide which ad to serve for the highest conversion rate, or recommend the right movie or book.
When that data set becomes so large that it is a source of competitive advantage, it means a company has achieved what early PayPal and LinkedIn analytics guru Mike Greenfield refers to as Data Scale.6 Companies like Amazon, Facebook, Google, PayPal, LinkedIn, and others have all achieved Data Scale.
Creating Big Data Applications
Successful BDAs run part or all of the Big Data Feedback Loop. Some BDAs—powerful analytics and visualization applications, for example—get the data in one place and make it viewable so that humans can decide what to do. Others test new approaches and decide what to do next automatically, as in the case of ad serving or web site optimization.
The BDAs of today can’t help significantly in reaching global maximums. For instance, they can’t invent the next iPhone or build the next Facebook. But they can fully optimize the local maximum. They can serve up the right ads, optimize web pages, tell sales people whom to call, and even guide those sales people in what to say during each call.
It is this combination of Data Scale and applications—Big Data Applications—that will fuel tomorrow’s billion dollar IPOs.
The Rise of the Big Data Asset: The Heart of a Big Data Startup
The large volume of data that a company collects is the company’s Big Data Asset. Companies that use this asset to their advantage will become more valuable than those that don’t. They will be able to charge more and pay less, prioritize one prospect over another, convert more customers, and ultimately, retain more customers.
This has two major implications. First, when it comes to startups, there is a massive opportunity to build the applications that make such competitive advantage possible, as out-of-the-box solutions. Enterprises won’t have to build these capabilities on their own; they’ll get them as applications that are ready to use right away.
Second, companies—both startups and gorillas—that consider data and the ability to act on it a core asset will have a significant competitive advantage over those that don’t.
As an example, PayPal and Square are battling it out to disrupt the traditional payments space. The winner will understand its customers better and reach them more efficiently. Both companies have access to massive quantities of transaction data. The one that can act on this data more effectively will come out on top.
![]() Tip You want to build a billion-dollar company? Pay a lot of attention to the creation and nurturing of your Big Data Asset. It is the shiny feature that will attract investors and buyers.
Tip You want to build a billion-dollar company? Pay a lot of attention to the creation and nurturing of your Big Data Asset. It is the shiny feature that will attract investors and buyers.
What It Takes to Build a Billion Dollar Company
With all the opportunities in Big Data, what determines the difference between building a small company and building a big one?
As Cameron Myhrvold, founding partner of venture capital firm Ignition Partners, told me, building a billion dollar company doesn’t just mean picking a big market. It means picking the right market. Fast food in China is a huge market. But that doesn’t make it a good market. It’s highly competitive and a tough market to crack.
Building a billion dollar company means riding a big wave. Big Data, cloud, mobile, and social are all clichés for a reason—because they’re big waves. Companies that ride those waves are more likely to succeed than the ones that don’t. Of course, it’s more than that. It’s building specific products that align with those waves to deliver must-have value to customers.
Over the past few years, numerous web companies have sprung up. Some of the most successful ones, like Facebook and Twitter, are Big Data companies disguised as consumer companies. They store immense amounts of data. They maintain extensive social graphs that represent how we are connected to each other and to other entities such as brands. Such companies have built-in systems for optimizing what content and which ads they show to each user.
Now there are multiple billion dollar opportunities to bring these kinds of capabilities to enterprises as out-of-the-box solutions in the form of Big Data Applications.
For enterprises, historically, such data sophistication required buying hardware and software and layering custom development on top. Enterprise software products were the basis for such implementations. But they brought with them time-consuming integrations and expensive consulting in order to make sophisticated data analytics capabilities available to end-users. Even then, only experienced analysts could use the systems that companies developed to generate reports, visualizations, and insights.
Now, these kinds of capabilities are available via off-the-shelf BDAs. Operational intelligence for IT infrastructure no longer requires custom scripts—applications from companies like Splunk, a company currently valued at more than $6 billion, make such functionality readily available. Data visualization no longer requires complex programming in languages like R. Instead, business users can create interactive visualizations using products from companies like Tableau Software, which is valued at nearly $5 billion. Both of these Big Data companies just went public in the last few years.
More Big Data companies are gearing to go public soon. Big Data companies AppDynamics and New Relic both process billions of events per month and are expected to file in 2014. Palantir, a data analytics company, recently raised capital at a $9 billion valuation and estimates indicate the company may be doing as much as $1 billion a year in revenue.
Given all the opportunity, perhaps the biggest challenge in reaching a billion for any startup that is able to get meaningful traction is the high likelihood of getting acquired.
When it comes to big vendors in the enterprise space, these days there are a lot of potential acquirers. There are the traditional ultra big, with market caps approaching or more than $100B: Cisco, IBM, Intel, Microsoft, Oracle, and SAP, with a mix of hardware and software offerings.
There are the big players that have an evolving or emerging role in the enterprise, like Amazon, Apple, and Google. There is the $20B–$50B group, like Dell, HP, EMC, Salesforce, and VMWare.
Finally, there are those companies in the sub $10B range (NetApp is just north of that), like BMC, Informatica, Workday, NetSuite, ServiceNow, Software AG, TIBCO, Splunk, and others. This group is a mix of the new, like Workday, ServiceNow, and Splunk, and the older, like BMC and TIBCO. The smaller ones are potential takeover targets for the big. Cisco or IBM might be interested in Splunk, while Oracle or HP might want to buy TIBCO.
Existing public companies that can bulk up by adding more BDAs to their portfolios will do so. Expect Salesforce and Oracle to keep on buying. Salesforce will continue to build out a big enough and comprehensive enough ecosystem that it can’t easily be toppled. Oracle will add more cloud offerings so that it can offer Big Data however customers want it, be that on-premise or in the cloud.
Companies like TIBCO and Software AG will keep buying as well. Both companies have been building their cash war chests, likely with an eye toward expanding their portfolios and adding non-organic revenue.
What does that mean for entrepreneurs trying to build the next billion dollar public company? It means they need a great story, great revenue growth, or both. Splunk, for example, started out as a centralized way to view log files. It turned into the Oracle of machine data. That story certainly helped, as did the company’s growth.
The small will look to bulk up and the big will look to stay relevant, ramp earnings, and leverage the immense scale of their enterprise sales organizations. That means that entrepreneurs with successful products and revenue growth that want to surpass a billion in market cap will have to work hard not to get taken out too early.
![]() Tip If you are a tech entrepreneur looking for a great exit, don’t sell too soon—nor too late. It’s a fine line between taking the time to increase your valuation and waiting too long to sell or go public.
Tip If you are a tech entrepreneur looking for a great exit, don’t sell too soon—nor too late. It’s a fine line between taking the time to increase your valuation and waiting too long to sell or go public.
Investment Trends: Opportunities Abound
When it comes to Big Data, we are already seeing a host of new applications being built. The BDAs we’ve seen so far are just the tip of the iceberg. Many are focused on line-of-business issues. But many more will emerge to disrupt entire spaces and industries.
Big enterprises have shown more and more willingness to give smaller vendors a shot—because they need the innovation that these smaller companies bring to the table.
Historically, vendors and customers were both reliant on and at odds with each other. Customers wanted flexibility but couldn’t switch due to their heavy custom development and integration investments, while vendors wanted to drive lock-in.
On the other hand, large customers needed comprehensive solutions. Even if they didn’t have the best technology in every area, it meant that the CIO or CEO of a big customer could call the CEO of a big vendor and get an answer or an issue resolved.
In a time of crisis such as a system outage, data problems, or other issues, one C could call another C and make things happen. In a world of many complex and interconnected systems—such as flight scheduling, baggage routing, package delivery, and so on—that was and is critical. But nimble startups are bringing a level of innovation and speed to the table that big vendors just can’t match. They’re creating their services in the cloud using off-the-shelf building blocks. They’re getting to market faster, with easy-to-use consumer-like interfaces that larger, traditional vendors struggle to match. As a result, big and small buyers alike are becoming customers of a variety of new Big Data startups that offer functionality and speed that traditional vendors can’t match.
There are many opportunities for new applications, both broad and niche. Take the police department of Santa Cruz, California as an example. By analyzing historical arrest records, the police department is able to predict areas where crime will happen. The department can send police officers to areas where crime is likely to happen, which has been shown to reduce crime rates. That is, just having officers in the area at the right time of day or day of week (based on the historical analysis) results in a reduction in crime. The police department of Santa Cruz is assisted by PredPol, a company that is specifically working with this kind of Big Data to make it useful for that specific purpose.
The point is not that investors should back or entrepreneurs should start a hundred predictive policing companies. Rather, it is that, as Myhrvold put it, Big Data is driving the creation of a whole new set of applications. It also means that Big Data isn’t just for big companies. If the city of Santa Cruz is being shaped by Big Data, Big Data is going to impact organizations of all sizes as well as our own personal lives, from how we live and love to how we learn. Big Data is no longer only the domain of big companies that have large data analyst and engineering staffs.
The infrastructure is readily available, and as you saw in Chapter 6, much of it is available in the cloud. It’s easy to spin up and get started. Lots of public data sets are available to work with. As a result, entrepreneurs will create tons of BDAs. The challenge for entrepreneurs and investors will be to find interesting combinations of data, both public and private, and combine them in specific applications that deliver real value to lots of people over the next few years.
Data from review site Yelp, sentiment data from Twitter, government data about weather patterns—putting these kinds of data sources together could result in some very compelling applications. Banks might better determine who to lend to, while a company picking its next store location might have better insight as to where to locate it.
Big returns, at least when it comes to venture capital, are about riding big waves. As Apple, Facebook, Google, and other big winners have shown, quite often it’s not about being first. It’s about delivering the best product that rides the wave most successfully.
The other waves investors are betting on are cloud, mobile, and social. Mobile, of course, is disrupting where, when, and how people consume media, interact, and do business. Cloud is making computing and storage resources readily available. And social is changing the way we communicate. Any one of these is a compelling wave to ride.
For entrepreneurs looking to build and investors looking to back the next billion dollar opportunity, it really comes down to three things.
First, it is about choosing the right market—not just a big market. The best markets are ones that have the potential to grow rapidly. Second, it is about riding a wave, be it Big Data, cloud, mobile, or social. Third, as Gus Tai, a general partner at Trinity Ventures, put it, it is about being comfortable with a high level of ambiguity.
If the path is perfectly clear, then the opportunity is, by definition, too small. Clear paths are a lot more comfortable. We can see them. But opportunities that can be the source of a billion new dollars in value are inherently ambiguous. That requires entrepreneurs and investors who are willing to step out of their comfort zones. The next wave of billion dollar Big Data entrepreneurs will be building BDAs where the path is ambiguous, but the goal is crystal clear.
![]() Note Clear paths to opportunity are not the ones you should be seeking. Others will see them too. Instead, look for opportunities that look foggy or ambiguous from a distance. One area ripe for innovation: making heretofore inaccessible data useful. Think Zillow, AccuWeather, and other companies that make use of large quantities of hard-to-access data.
Note Clear paths to opportunity are not the ones you should be seeking. Others will see them too. Instead, look for opportunities that look foggy or ambiguous from a distance. One area ripe for innovation: making heretofore inaccessible data useful. Think Zillow, AccuWeather, and other companies that make use of large quantities of hard-to-access data.
Big Data “Whitespace” You Can Fill In
Big Data is opening up a number of new areas for entrepreneurship and investment. Products that make data more accessible, that allow analysis and insight development without requiring you to be a statistician, engineer, or data analyst are one major opportunity area. Just as Facebook has made it easier to share photos, new analytics products will make it far easier not just to run analysis but also to share the results with others and learn from such collaborations.
The ability to pull together diverse internal data sources in one place or to combine public and private data sources also opens up new opportunities for product creation and investment. New data combinations could lead to improved credit scoring, better urban planning, and the ability for companies to understand and act on market changes faster than their competition.
There will also be new information and data service businesses. Although lots of data is now on the web—from school performance metrics to weather information to U.S. Census data—lots of this data remains hard to access in its native form.
Real estate web site Zillow consolidated massive amounts of real estate data and made it easy to access. The company went beyond for-sale listings by compiling home sales data that was stored in individual courthouses around the country. Services like Zillow will emerge in other categories. Gathering data, normalizing it, and presenting it in a fashion that makes it easily accessible is difficult. But information services is an area ripe for disruption exactly because accessing such data is so hard.
Innovative data services could also emerge as a result of new data that we generate. Since smartphones come with GPS, motion sensors, and built-in Internet connectivity, they are the perfect option for generating new location-specific data at a low cost.
Developers are already building applications to detect road abnormalities, such as potholes, based on vibrations that phones detect when vehicles move across uneven road surfaces. That is just the first of a host of new BDAs based on collecting data using low-cost sensors built into devices like smartphones.
Big Data Business Models
To get the most value from such whitespace opportunities ultimately requires the financial markets to understand not just Big Data businesses, but subscription business models as well.
Although Splunk is primarily sold via a traditional licensed software plus service model, the company charges based on the amount of data indexed per day. As a result, investors can easily value Splunk on the volume of data companies manage with it. In the case of Splunk, revenue is tied directly to data volume. (Splunk also offers a term license, wherein the company charges a yearly fee.)
For most cloud-based offerings, however, valuations are not so simple. As Tien Tzuo, former Chief Marketing Officer of Salesforce.com and CEO of cloud-based billing company Zuora, points out, financial managers still don’t fully appreciate the value of subscription businesses.
This is important because companies will use subscription models to monetize many future BDAs. Tzuo suggests that such models are about building and monetizing recurring customer relationships. That’s in contrast to their historical licensed-software and on-premise hardware counterparts, which were “about building and shipping units for discrete one-time transactions.”7 As Tzuo puts it, knowing that someone will give you a $100 once is less valuable than knowing that that person will give you a $100 a year for the next eight years, as they do in subscription businesses.
In the years ahead, companies that have subscription models will be well-positioned to hold onto their customers and maintain steady revenue streams. They won’t have to rely on convincing existing customers to upgrade to new software versions in addition to the already hard job of acquiring new customers. Instead they’ll simply be able to focus on delivering value.
Apple effectively has the best of both in today’s world: repeat one-time purchases in the form of iPads, iPhones, and Macs combined with on-going revenue from the purchase of digital goods like songs and music. That said, even Apple with its incredible brand loyalty may soon need to change to a subscription-based business model. Companies like Spotify are making subscription-based music a viable alternative to one-time purchases.
Twenty years ago, it was hard for investors to imagine investing exclusively in software businesses. Now such investments are the norm. As a result, it’s not hard to envision that despite today’s skepticism, 20 years hence most software businesses will be subscription businesses. At a minimum, their pricing will be aligned with actual usage in some way: more data, more cost; less data, less cost.
What such businesses will need to figure out, however, is how to offer cost predictability alongside flexibility and agility. Due to the ease with which customers can spin up more instances or store more data, cloud costs can be wildly unpredictable and therefore difficult to budget for and manage.
A number of different usage-based models exist, particularly for cloud offerings. These include charging based on data volume; number of queries, as in the case of some analytics offerings; or on a subscription basis. Customers who take advantage of such offerings don’t need to maintain their own hardware, power, and engineering maintenance resources. More capacity is available when customers need it, less when they don’t.
The cost of such flexibility, however, is less predictability around cost. In most cases, such offerings should be less expensive than traditional software. Customers only pay for what they use.
It’s easy to run over your mobile phone minutes and get an unexpectedly large bill. Similarly, customers can overuse and over-spend on usage-based software offerings without realizing it.
Such ambiguity has slowed the adoption of some subscription-based services, because CFOs and CIOs rightly demand predictability when it comes to budgeting. Vendors will need to introduce better controls and built-in usage policies so that buyers can more easily manage their expenditures. They’ll need to make it easier not just to scale up, but to scale down as well, with little to no engineering effort.
Just over 20 years ago, limited partners—like the managers of university endowments and corporate and municipal pension funds—considering putting capital into venture capital funds thought that investing in software was a radical idea, says Mark Gorenberg, Managing Partner of Hummer Winblad Ventures. Previously they had invested primarily in hardware companies that developed computer chips, networking equipment, and the like. Investors even viewed hardware companies like Cisco that developed a lot of software that ran on such hardware primarily as hardware companies.
The limited partners of the time wondered if there would be any more companies like Microsoft. Now, of course, investing in telecom and hardware is out of favor, and investing in software is the norm. For a long time, in business-to-business (B2B) software, that has meant investing in installed, on-premise software. That’s software that companies sell, and then charge for implementing, supporting, and upgrading. It requires vendors to fight an on-going battle of convincing existing customers to upgrade to new versions just to maintain their existing revenue base.
Today’s markets still tend to undervalue subscription-based businesses. Although vendors have much work to do in making subscription and data-based pricing models easier to manage and budget, it is not hard to envision a world 20 years from now in which most pricing is subscription-based. That would mean that instead of financial managers discounting subscription-based companies, they would instead discount companies that still sell on a traditional licensed software and service model.
In such a future, those that had adjusted and moved to subscription models aligned with customer usage would be buying up and consolidating those that hadn’t, instead of the reverse. If there is one truism of the tech industry, it is that while it takes the gorillas a long, long time to fall, there is always a new, nimble startup that emerges to become the next gorilla. For cynics who claim that such things won’t happen, just remember that we have short memories. You need look back no further than at the housing booms and busts or the dot-com crash.
As a result, there will always be another billion dollar company, and the great thing about B2B companies is that there is typically room for a few in each area (unlike with consumer companies like Facebook, which tend to be winner-take-all endeavors). With the waves of Big Data, cloud, mobile, and social setting the stage, the next 20 years of information technology are sure to be even more exciting and valuable than the last 20.
____________________
1http://seanlahman.com/baseball-archive/sabermetrics/sabermetric-manifesto/
2http://bigdata.pervasive.com/Blog/Big-Data-Blog/EntryId/1123/It-s-Not-about-being-Data-Driven.aspx
3http://en.wikipedia.org/wiki/PECOTA
4http://www.nytimes.com/2008/10/17/opinion/17buffett.html?_r=0
5http://www.nytimes.com/2002/11/05/health/a-conversation-with-daniel-kahneman-on-profit-loss-and-the-mysteries-of-the-mind.html
6http://numeratechoir.com/2012/05/
7http://allthingsd.com/20121128/wall-street-loves-workday-but-doesnt-understand-subscription-businesses/