Big Data Bootcamp: What Managers Need to Know to Profit from the Big Data Revolution (2014)
Chapter 2. The Big Data Landscape
Infrastructure and Applications
Now that we’ve explored a few aspects of Big Data, we’ll take a look at the broader landscape of companies that are playing a role in the Big Data ecosystem. It’s easiest to think about the Big Data landscape in terms of infrastructure and applications.
The chart that follows (see Figure 2-1) is “The Big Data Landscape.” The landscape categorizes many of the players in the Big Data space. Since new entrants emerge regularly, the latest version of the landscape is always available on the web at www.bigdatalandscape.com.
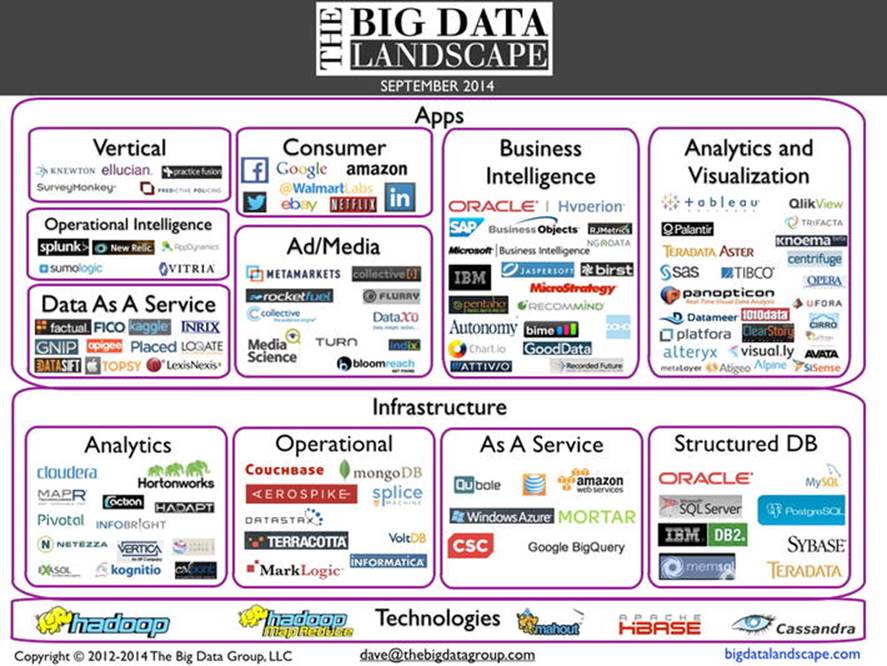
Figure 2-1. The Big Data landscape
Infrastructure is primarily responsible for storing and to some extent processing the immense amounts of data that companies are capturing. Humans and computer systems use applications to gain insights from data.
People use applications to visualize data so they can make better decisions, while computer systems use applications to serve up the right ads to the right people or to detect credit card fraud, among many other activities. Although we can’t touch on every company in the landscape, we will describe a number of them and how the ecosystem came to be.
Big Data Market Growth
Big Data is a big market. Market research firm IDC expects the Big Data market to grow to $23.8 billion a year by 2016 and that the growth rate in the space will be 31.7% annually. That doesn’t1 even include analytics software, which by itself counts for another $51 billion.
The amount of data we’re generating is growing at an astounding rate. One of the most interesting measures of this is Facebook’s growth. In October 2012, the company announced it had hit one billion users—nearly 15% of the world’s population. Facebook had more than 1.23 billion users worldwide by the end of 2013 (see Figure 2-2), adding 170 million users in the year. The company has had to develop a variety of new infrastructure and analytics technologies to keep up with its immense user growth.2
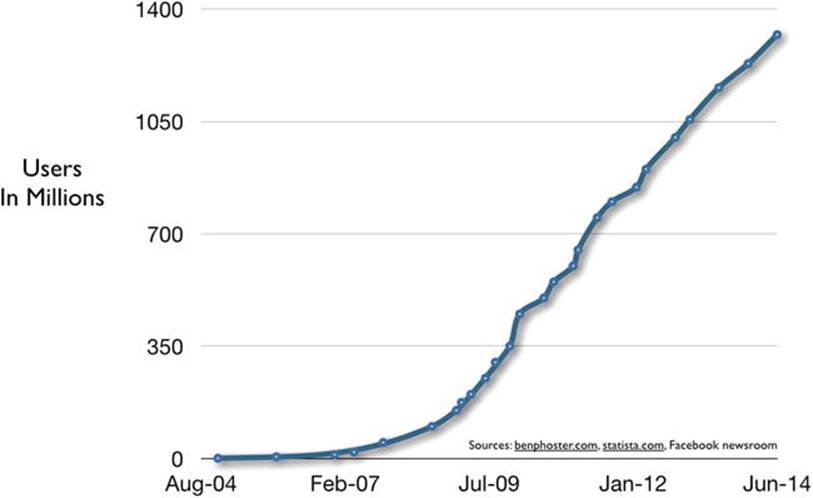
Figure 2-2. Facebook’s user growth rate
Facebook handles some 350 million photo uploads, 4.5 billion Likes, and 10 billion messages every day. That means the company stores more than 100 petabytes when it comes to the data it uses for analytics and ingests more than 500 terabytes of new data per day.3,4 That’s the equivalent of adding the data stored on roughly 2,000 Macintosh Air hard drives if they were all fully used.
Twitter provides another interesting measure of data growth. The company reached more than 883 million registered users as of 2013 and is handling more than 500 million tweets per day, up from 20,000 per day just five years earlier (see Figure 2-3).5
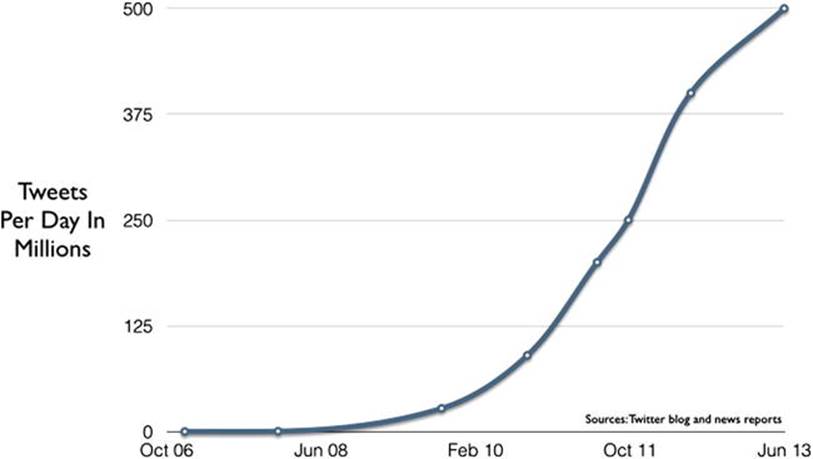
Figure 2-3. Growth of tweets on social networking site Twitter
To put this in perspective, however, this is just the data that human beings generate. Machines are generating even more data. Every time we click on a web site button, make a purchase, call someone on the phone, or do virtually any other activity, we leave a digital trail. The simple action of uploading a photo generates lots of other data: who uploaded the photo and when, who it was shared with, what tags are associated with it, and so on.
The volume of data is growing all around us: Walmart handles more than a million customer transactions every hour, and about 90 trillion emails are sent every year. Ironically, more than half of all that email, 71.8% of it, is considered spam. And the volume of business data doubles every 1.2 years, according to one estimate.6,7
To address this incredible growth, a number of new companies have emerged and a number of existing companies are repositioning themselves and their offerings around Big Data.
The Role of Open Source
Open source has played a significant role in the recent evolution of Big Data. But before we talk about that, it’s important to give some context on the role of open source more generally.
Just a few years ago, Linux became a mainstream operating system and, in combination with commodity hardware (low cost, off-the-shelf servers), it cannibalized vendors like Sun Microsystems that were once dominant. Sun, for example, was well known for its version of Unix, called Solaris, which ran on its custom SPARC hardware.
With Linux, enterprises were able to use an open source operating system on low-cost hardware to get much of the same functionality, at a much lower cost. The availability of open source database MySQL, open source web server Apache, and open source scripting language PHP, which was originally created for building web sites, also drove the popularity of Linux.
As enterprises began to use and adopt Linux for large-scale commercial use, they required enterprise-grade support and reliability. It was fine for engineers to work with open source Linux in the lab, but businesses needed a vendor they could call on for training, support, and customization. Put another way, big companies like buying from other big companies.
Among a number of vendors, Red Hat emerged as the market leader in delivering commercial support and service for Linux. The company now has a market cap of just over $10 billion. MySQL AB, a Swedish company, sponsored the development of the open source MySQL database project. Sun Microsystems acquired MySQL AB for $1 billion in early 2008 and Oracle acquired Sun in late 2009.
Both IBM and Oracle, among others, commercialized large-scale relational databases. Relational databases allow data to be stored in well-defined tables and accessed by a key. For example, an employee might be identified by an employee number, and that number would then be associated with a number of other fields containing information about the employee, such as her name, address, hire date, and position.
Such databases worked well until companies had to contend with really large quantities of unstructured data. Google had to deal with huge numbers of web pages and the relationships between links in those pages. Facebook had to contend with social graph data. The social graph is the digital representation of the relationships between people on its social network and all of the unstructured data at the end of each point in the graph, such as photos, messages, and profiles. These companies also wanted to take advantage of the lower costs of commodity hardware.
![]() Note Relational databases, the workhorses of many a large corporate IT environments, worked beautifully until companies realized they were generating far more unstructured data and needed a different solution. Enter NoSQL and graph databases, among others, which are designed for today’s diverse data environments.
Note Relational databases, the workhorses of many a large corporate IT environments, worked beautifully until companies realized they were generating far more unstructured data and needed a different solution. Enter NoSQL and graph databases, among others, which are designed for today’s diverse data environments.
So companies like Google, Yahoo!, Facebook, and others developed their own solutions for storing and processing vast quantities of data. In the operating system and database markets, Linux emerged as an open source version of Unix and MySQL as an open source alternative to databases like Oracle. Today, much the same thing is happening in the Big Data world.
Apache Hadoop, an open source distributed computing platform for storing large quantities of data via the Hadoop Distributed File System (HDFS)—and dividing operations on that data into small fragments via a programming model called MapReduce—was derived from technologies originally built at Google and Yahoo!.
Other open source technologies have emerged around Hadoop. Apache Hive provides data warehousing capabilities, including data extract/transform/load (ETL), a process for extracting data from a variety of sources, transforming it to fit operational needs (including ensuring the quality of the data), and loading it into the target database. Apache HBase provides real-time read-write access to very large structured tables on top of Hadoop. It is modeled on Google’s8 BigTable. Meanwhile, Apache Cassandra provides fault-tolerant data storage by replicating data.
Historically, such capabilities were only available from commercial software vendors, typically on specialized hardware. Linux made the capabilities of Unix available on commodity hardware, drastically reducing the cost of computing. In much the same way, open source Big Data technologies are making data storage and processing capabilities that were previously only available to companies like Google or from commercial vendors available to everyone on commodity hardware.
The widespread availability of low-cost Big Data technology reduces the up-front cost of working with Big Data and has the potential to make Big Data accessible to a much larger number of potential users. Closed-source vendors point out that while open source software is free to adopt, it can be costly to maintain, especially at scale.
That said, the fact that open source is free to get started with has made it an appealing option for many. Some commercial vendors have adopted “freemium” business models to compete. Products are free to use on a personal basis or for a limited amount of data, but customers are required to pay for departmental or larger data usage.
Those enterprises that adopt open source technologies over time require commercial support for them, much as they did with Linux. Companies like Cloudera, Hortonworks, and MapR are addressing that need for Hadoop, while companies like DataStax are doing the same for Cassandra. By the same token, LucidWorks is performing such a role for Apache Lucerne, an open source text search engine used for indexing and searching large quantities of web pages and documents.
![]() Note Even though companies like Cloudera and Hortonworks provide products built on open source software (like Hadoop, Hive, Pig, and others), companies will always need commercially packaged, tested versions along with support and training. Hence Intel’s recent infusion of $900 million into Cloudera.
Note Even though companies like Cloudera and Hortonworks provide products built on open source software (like Hadoop, Hive, Pig, and others), companies will always need commercially packaged, tested versions along with support and training. Hence Intel’s recent infusion of $900 million into Cloudera.
Enter the Cloud
Two other market trends are occurring in parallel. First, the volume of data is increasing—doubling almost every year. We are generating more data in the form of photos, tweets, likes, and emails. Our data has data associated with it. What’s more, machines are generating data in the form of status updates and other information from servers, cars, airplanes, mobile phones, and other devices.
As a result, the complexity of working with all that data is increasing. More data means more data to integrate, understand, and try to get insights from. It also means higher risks around data security and data privacy. And while companies historically viewed internal data such as sales figures and external data like brand sentiment or market research numbers separately, they now want to integrate those kinds of data to take advantage of the resulting insights.
Second, enterprises are moving computing and processing to the cloud. This means that instead of buying hardware and software and installing it in their own data centers and then maintaining that infrastructure, they’re now getting the capabilities they want on demand over the Internet. As mentioned, Software as a Service (SaaS) company Salesforce.com pioneered the delivery of applications over the web with its “no software” model for customer relationship management (CRM). The company has continued to build out an ecosystem of offerings to complement its core CRM solution. The SaaS model has gained momentum with a number of other companies offering cloud-based services targeted at business users.
Meanwhile, Amazon paved the way for infrastructure on demand with Amazon Web Services (AWS), the company’s extremely popular cloud-based computing and storage offering. Amazon launched AWS in 2002 with the idea that it could make a profit on the infrastructure required to run the Amazon.com store. The company has continued to add on-demand infrastructure services that allow developers to bring up new servers, storage, and databases quickly.9,10
Amazon has also introduced Big Data-specific services, including Amazon Elastic MapReduce (EMR), an Amazon cloud-based version of the open source Hadoop MapReduce offering. Amazon Redshift is a data-warehousing on-demand solution that Amazon expects will cost as little as $1,000 per terabyte per year, less than a tenth of what companies typically pay for on-premise data-warehousing, which can run to more than $20,000 per terabyte annually. Meanwhile, Amazon Glacier provides low-cost digital archiving services at $0.01 per gigabyte per month or about $120 per terabyte per year.11
Amazon has two primary advantages over other providers. It has a very well-known consumer brand. The company also benefits from the economies of scale it gets from supporting the Amazon.com web site as well as from serving so many customers on its infrastructure. Other technology market leaders also offer cloud infrastructure services, including Google with its Google Cloud Platform and Microsoft with Windows Azure, but Amazon has paved the way and grabbed pole position with AWS.
AWS has seen incredible growth. The service was expected to bring in $3.2 billion in revenue for the company in 2013. As of June, 2012, Amazon was storing more than a trillion objects in its Simple Storage Service (S3) and was adding more than 40,000 new objects per second. That number is up from just 2.9 billion objects stored as of the end of 2006 and 262 billion at the end of 2010. Major companies like Netflix, Dropbox, and others run their business on AWS.12,13
Amazon continues to broaden its infrastructure-on-demand offerings, adding services for IP routing, email sending, and a host of Big Data related services. In addition to offering its own infrastructure on demand, Amazon also works with an ecosystem of partners to offer their infrastructure products. Thus, the headline for any new infrastructure startup thinking about building a public cloud offering may well be the following: find a way to partner with Amazon or expect the company to come out with a competitive offering.
With cloud services, customers pay only for what they use. This makes it significantly easier to get new Big Data projects up and running. Companies are no longer constrained by the often expensive up-front costs typically associated with buying, deploying, and managing server and storage infrastructure.
We can store and analyze the massive quantities of data associated with Big Data initiatives much more quickly and cost effectively than in the past. With cloud-based Big Data infrastructure, it is possible to go from planning to insights in days instead of months or years. This in turn means more innovation at both startups and big companies in the area of Big Data as well as far easier access to data-driven insights.
![]() Note Affordable cloud-based Big Data infrastructure means companies can go from design to product, or from hypothesizing to discovering insights, in days instead of months or years.
Note Affordable cloud-based Big Data infrastructure means companies can go from design to product, or from hypothesizing to discovering insights, in days instead of months or years.
Overcoming the Challenges of the Cloud
Of course, many are still skeptical of taking advantage of public cloud infrastructure. Historically, there have been three major potential issues with public cloud services. First, technologists at large enterprises felt that such services were not secure and that in-house infrastructure was more secure. Second, many large vendors simply didn’t offer Internet/cloud-based versions of their software. Companies had to buy the hardware and run the software themselves or hire a third party to do so. Finally, it was difficult to get large volumes of data from in-house systems into the cloud.
While the first challenge remains true for certain government agencies and enterprises subject to compliance requirements, the widespread adoption of services like Salesforce for managing customer data and Box, Dropbox, and Google Drive for storing files illustrates that many companies are now comfortable having third-party vendors store their confidential information. Simply put, businesses are adopting far more applications delivered over the net than they have in the past.
First it was customer data, then HR data. Today, the market values Workday, a web-based provider of HR management solutions, at nearly $9 billion. Over time, enterprises will migrate more and more of their business applications and data to the cloud.
The third challenge, moving massive amounts of data to the cloud, remains an issue. Many experts feel that when it comes to really high volume data, data is subject to a sort of gravitational pull. They believe that data that starts on-premise, at a company, will remain there, while data that starts in the cloud will stay there.
But as more line-of-business applications become available over the net, more data will start in the cloud and will stay there. In addition, companies are emerging to provide technologies that speed up the transfer of large quantities of data. Aspera, for example, has focused on accelerating file transfer speeds, particularly for large audio and video files. Companies like Netflix and Amazon use Aspera to transfer files at up to 10 times traditional speeds.
With the cloud, companies get a host of other advantages: they spend less time maintaining and deploying hardware and software, and they can scale on-demand. If a company needs more computing resources or storage, that’s not a matter of months but of minutes. What’s more, enterprises with installed software have traditionally lagged behind in terms of using the latest version of the software. With applications that come over the net, users can be on the latest version as soon as it’s available.
Of course, there are tradeoffs. Companies are at the mercy of the public cloud provider they choose to work with regarding costs. But competition between cloud vendors has continued to push prices down. Once a company has built and deployed applications on top of a particular cloud vendor, switching platforms can be challenging. Although the underlying infrastructures are similar, scripts for deploying new application builds, hooks into platform-specific services, and network configurations are all based on the chosen platform.
![]() Note Most companies tend to stick with the public cloud platform they initially choose. That’s one reason the battle for cloud customers is more intense than ever.
Note Most companies tend to stick with the public cloud platform they initially choose. That’s one reason the battle for cloud customers is more intense than ever.
Customers also depend on such providers to deliver reliable service. Amazon has suffered a few major high-profile outages that have caused some to question whether relying on its service makes sense. One such outage caused movie-streaming provider Netflix to lose service on Christmas Eve and Christmas Day 2012, traditionally a very popular time for watching movies. Yet in general, cloud-based infrastructure services have continued to become more transparent about their service availability and have added enterprise-grade service and support options to meet the requirements of business customers. In many cases, providers like Amazon, Google, and Microsoft may deliver infrastructure that is more reliable, secure, and cost-effective than many enterprises can deliver themselves, due to the incredible scale at which these providers operate.
Cloud providers will continue to introduce more infrastructure-on-demand capabilities. As they compete with each other and reduce prices, even more businesses will take advantage of such offerings. Startups will introduce new, innovative Big Data applications built on top of these infrastructure services and enterprises and consumers will both benefit.
Big Data Infrastructure
With the context of open source and Big Data in the cloud in mind, we’ll now take a look at some of the companies playing key roles in the infrastructure and applications spaces.
In the larger context, investors had until recently put a relatively small amount of capital to work in Big Data infrastructure. Their investments in Hadoop-related companies Cloudera, Hortonworks, and MapR, and in NoSQL companies MongoDB, Couchbase, and others, totaled less than a billion through the end of 2013. In early 2014, however, Intel and Cloudera made headlines when Intel invested a whopping $900 million into Cloudera.
Cloudera has been the most visible of all of the new Big Data infrastructure companies. Cloudera sells tools and consulting services that help companies run Hadoop. Its investors include Accel Partners, Ignition Partners, In-Q-Tel, Intel, Greylock Partners, and Meritech Capital Partners. Cloudera was founded by the marquee team of Mike Olson, Amr Awadallah, who worked with Hadoop at Yahoo!, Jeff Hammerbacher, who had worked with it at Facebook, and Christophe Bisciglia from Google.14,15
It is interesting to note that Google first published a paper describing Google MapReduce and Google File System, from which Hadoop is derived, all the way back in 2004. That goes to show just how long it takes for technologies used in large consumer companies like Google and Yahoo! to make their way into the enterprise.16
Cloudera competitor Hortonworks was spun out of Yahoo! Its engineers have contributed more than 80% of the code for Apache Hadoop. MapR focuses on delivering a higher-performance version of Hadoop with its M5 offering, which tries to address the biggest knock on Hadoop: the long time it takes to process data.
At the same time as these companies are delivering and supporting Hadoop in the enterprise, other companies are emerging to deliver Hadoop in the cloud. Qubole, Nodeable, and Platfora are three companies in the cloud Hadoop space. The challenge for these companies will be standing out from native Big Data cloud processing offerings such as Amazon’s own EMR offering.
What, exactly, does Hadoop do? Hadoop was designed to perform batch-based operations across very large data sets. In the traditional Hadoop model, engineers design jobs that are processed in parallel across hundreds or thousands of servers. The individual results are pulled back together to produce the result. As a very simple example, a Hadoop MapReduce job might be used to count the number of occurrences of words in various documents. If there were millions of documents, it would be difficult to perform such a calculation on a single machine. Hadoop breaks the task into smaller jobs that each machine can execute. The results of each individual counting job are added together to produce the final count.
The challenge is that running such jobs can consume a lot of time, which is not ideal when analysts and other business users want to query data in real time. New additions to Hadoop such as the Cloudera Impala project promise to make Hadoop more responsive, not just for batch processing, but for near real-time analytics applications as well. Of course, such innovations make Cloudera a desirable acquisition target (before or after going public), either for Intel, as a follow on to its investment, or for an existing large analytics or data-warehousing provider such as EMC, HP, IBM, or Oracle, among others.17
![]() Note No more waiting days or weeks for analyses to be run and interpreted. Big Data infrastructure and applications are making real-time analysis possible for the first time ever.
Note No more waiting days or weeks for analyses to be run and interpreted. Big Data infrastructure and applications are making real-time analysis possible for the first time ever.
Big Data Applications
We use a wide variety of Big Data Applications (BDAs) every day, often without even thinking of them as BDAs. Facebook, Google, LinkedIn, Netflix, Pandora, and Twitter are just a few of the applications that use large amounts of data to give us insights and keep us entertained.
While we’ll continue to see innovation in Big Data infrastructure, much of the interest going forward in Big Data will be in BDAs that take advantage of the vast amounts of data being generated and the low-cost computing power available to process it. Here are a few examples:
· Facebook stores and uses Big Data in the form of user profiles, photos, messages, and advertisements. By analyzing such data, the company is better able to understand its users and figure out what content to show them.
· Google crawls billions of web pages and has a vast array of other Big Data sources such as Google Maps, which contains an immense amount of data including physical street locations, satellite imagery, on-street photos, and even inside views of many buildings.
· LinkedIn hosts hundreds of millions of online resumes as well as the knowledge about how people are connected with each other. The company uses all that data to suggest the subset of people with whom we might want to connect. LinkedIn also uses that data to show us relevant updates about our friends and colleagues.
· Internet radio service Pandora uses some 450 song attributes to figure out what songs to recommend. The company employs musicologists who characterize the attributes of virtually every new song that comes out and store its characteristics as part of the Music Genome Project.18 The company has more than 900,000 songs from more than 90,000 artists in its database.
· Netflix is well-known for its movie prediction algorithms, which enable it to suggest to movie viewers what movie to watch next. The company relies on a group of about 40 human taggers to makes notes on more than 100 attributes, from storyline to tone, that define each movie.19
· Twitter handles more than 500 million tweets per day. Companies like Topsy (recently acquired by Apple), a data analytics startup that performs real-time analysis of tweets, are using such data sources to build applications on top of Twitter and other platforms.
Big Data applications are emerging to improve our personal lives as well. Education startup Knewton uses Big Data to create dynamic learning experiences as well as to understand which students are likely to drop out so that advisors can help them stay in school. Healthcare startup Practice Fusion is improving patient experiences by making it easier for doctors to work with patient medical records. SurveyMonkey is turning responses to millions of surveys into data that markets and product designers can use to better understand their customers and clients.
Such applications are just the tip of the iceberg when it comes to Big Data Applications. Enterprises have historically built and maintained their own infrastructure for processing Big Data and in many cases developed custom applications for analyzing that data. All that is starting to change across a variety of areas, from serving existing customers better using operational intelligence tools to delivering more relevant ads online. More and more businesses will continue to take advantage of pre-built, cloud-based applications to meet their needs.
Online Advertising Applications
To determine which ad to show you, companies use algorithmic solutions to process huge volumes of data in real time. These algorithmic approaches combine a variety of rules that tell computers what to do with real-time data about what is happening in the market and data about whether you (or users similar to you) have shown an interest in related content in the past. For example, an algorithmic advertising bidding algorithm might determine that you had recently visited an automotive web site and that ad space for auto ads is available at a desirable price. Based on this information, the bidding algorithm would acquire the ad space and show you a relevant car ad.
Using this kind of automated analysis, computer programs can figure out which ad is most relevant to you and how much to pay (or charge) for particular ad impressions. Vendors in this space include Collective, DataXu, Metamarkets, Rocket Fuel, Turn, and a number of others.
These vendors truly operate at Big Data scale. The Turn platform processes some 100 billion data events daily and stores some 20 trillion attributes.20 The Rocket Fuel platform currently handles some 43.2 billion queries per day.21 Meanwhile, Admeld (now part of Google) works with publishers to help them optimize their ad inventory. Instead of providing just basic ad services, these companies use advanced algorithms to analyze a variety of attributes across a range of data sources to optimize ad delivery.
Marketers will continue to shift more dollars to online advertising, which suggests that this category is likely to witness growth and consolidation. Mobile advertising and mobile analytics presents one of the largest potential growth markets because of the increasingly amount of time consumers and business users now spend on their mobile devices.
Companies like Flurry (recently acquired by Yahoo!) provide analytics capabilities that allow mobile app developers to measure consumer behavior and monetize their audiences more effectively. At the same time, the mobile area is also one of the most complex due to the amount of control that Amazon, Apple, Google, and hardware vendors like Samsung exert in the space.
Sales and Marketing Applications
Salesforce.com changed the way companies did Customer Relationship Management (CRM) by introducing its hosted “no software” model for CRM as an alternative to PeopleSoft and other offerings that had to be installed, customized, and run on-premise.
More recently, marketing automation companies like Eloqua (now a part of Oracle), Marketo (now public), and HubSpot have systematized the way companies do lead management, demand generation, and email marketing.
But today’s marketers face a new set of challenges. They have to manage and understand customer campaigns and interactions across a large number of channels.
Today’s marketers need to ensure that a company is optimizing its web pages so they get indexed in Google and Bing and are easy for potential customers to find. They need to have a regular presence on social media channels such as Facebook, Twitter, and Google Plus. This is not just because these are the venues where people are spending time getting entertained and receiving information, but also because of Google’s increasing emphasis on social media as a way to gauge the importance of a particular piece of content.
As Patrick Moran, Chief Marketing Officer at application performance monitoring company New Relic, points out, marketers also need to factor in a variety of other sources of data to understand their customers fully. This includes actual product usage data, lead sources, and trouble ticket information. Such data can give marketers significant insight into which customers are most valuable so they can look for other potential customers with similar attributes. They can also determine which marketing activities are most likely to result in prospects converting into customers.
All of this means a lot of data for marketers to visualize and act on. As Brian Kardon, chief marketing officer of Lattice Engines, and formerly of Eloqua and Forrester Research, suggests, marketing in the future will be in large part about algorithms. Trading on Wall Street was once the purview of humans, until computer-run algorithmic trading took its place. Kardon envisions a similar future for marketing, a future in which algorithms analyze all of these data sources to find useful patterns and tell marketers what to do next.22
![]() Note Cloud-based sales and marketing software now allows companies to analyze any bit of data streaming into the company, including product usage, online behavior, trouble ticket information, and more. Marketers need to be on their toes to implement the technologies necessary to use such data before competitors do.
Note Cloud-based sales and marketing software now allows companies to analyze any bit of data streaming into the company, including product usage, online behavior, trouble ticket information, and more. Marketers need to be on their toes to implement the technologies necessary to use such data before competitors do.
Such software will likely tell marketers which campaigns to run, which emails to send, what blog posts to write, and when and what to tweet. It won’t stop there, however.
Ultimately, Big Data marketing applications will not only analyze all these data sources but perform much of the work to optimize marketing campaigns based on the data. Companies like BloomReach and Content Analytics are already heading down this path with algorithm-based software that helps e-commerce companies optimize their web sites for highest conversion and visibility.
Of course, the creative part of marketing will remain critical, and marketers will still make the big picture decisions about where to invest and how to position relative to their competition. But BDAs will play a huge role in automating much of the manual work currently associated with online marketing.
Visualization Applications
As access to data becomes more democratized, visualization becomes ever more important. There are many companies in the visualization space, so in this section we’ll highlight just a few of them. Tableau Software is well known for its interactive and easy-to-use visualization software. The company’s technology came out of research at Stanford University. The company recently completed a successful public offering.
QlikTech offers its popular QlikView visualization product, which some 26,000 companies use around the world. The company went public in 2010 and is valued at about $2.3 billion as of February, 2014. There are a host of other recent entrants. SiSense performs huge amounts of data crunching on computers as small as laptops and delivers visualizations as output.
While not strictly a visualization company, Palantir is well known for its Big Data software and has a strong customer base in government and financial services. There are also offerings from large enterprise vendors, including IBM, Microsoft, Oracle, SAS, SAP, and TIBCO.
More and more companies are adding tools for embedding interactive visualizations into web sites. Publishers now use such visualizations to provide readers with greater insights into data.
Enterprise collaboration and social networking companies like Yammer emerged to make business communication, both internally and externally, more social. Expect to see similar social capabilities become a standard part of nearly every data analytics and visualization offering.
Given the importance of visualization as a way to understand large data sets and complex relationships, new tools will continue to emerge. The challenge and opportunity for such tools is to help people see data in ways that provide greater insights, as well as to help them take meaningful action based on those insights.
Business Intelligence Applications
Much of the history of data analysis has been in business intelligence (BI). Organizations rely on BI to organize and analyze large quantities of corporate data with the goal of helping managers make better decisions. For example, by analyzing sales and supply chain data, managers might be able to decide on better pricing approaches in the future.
Business intelligence was first referenced in a 1958 article by an IBM researcher, and the company has continued to break new ground with technical advances like algorithmic trading and IBM Watson. Other major vendors, including SAP, SAS, and Oracle, all offer business intelligence products. MicroStrategy remains one of the few large-scale, independent players in the space. It has a market cap of about a billion dollars and has recently introduced compelling mobile offerings to the market.23
Domo, a cloud-based business intelligence software company, is a relatively recent entrant into the market. Domo was founded by Josh James, the founder and former CEO of analytics leader Omniture (now Adobe). Other well-known players in the space include GoodData and Birst. However, the hosted BI space has proven difficult to crack due to the challenge of getting companies to move mission-critical company data into the cloud and the amount of customization traditionally required. But as with other areas, that is starting to change. Users want to be able to access and work with the same data on their desktops, tablets, and mobile phones, which means that more data will need to move into the cloud for it to be easily accessed and shared.
Operational Intelligence
By performing searches and looking at charts, companies can understand the cause of server failures and other infrastructure issues. Rather than building their own scripts and software to understand infrastructure failures, enterprises are starting to rely on newer operational intelligence companies like Splunk. The company provides both an on-premise and cloud-based version of its software, which IT engineers use to analyze the vast amounts of log data that servers, networking equipment, and other devices generate.
Sumo Logic and Loggly are more recent entrants in the space, and large vendors such as TIBCO (which acquired LogLogic) and HP (which acquired ArcSight) and existing player Vitria all have offerings as well. Meanwhile, AppDynamics and New Relic provide web offerings that enable engineers to understand issues at the application layer.
Data as a Service
Straddling both Big Data infrastructure and applications is the Data as a Service category. Historically, companies have faced a challenge in obtaining Big Data sets. It was often hard to get up-to-date data or to get it over the Internet. Now, however, data as a service providers come in a variety of forms. Dun & Bradstreet provides web programming interfaces for financial, address, and other forms of data, while FICO provides financial data. Huge volumes of streaming data, such as the tweet streams that Twitter provides, are among the most interesting new data sources.
These data sources allow others to build compelling applications based on them. New applications can predict the outcomes of presidential elections with very high accuracy or help companies understand how large numbers of consumers feel about their brands. There are also companies that deliver vertical-specific data through service interfaces. BlueKai provides data related to consumer profiles, INRIX provides traffic data, and LexisNexis provides legal data.
Data Cleansing
Perhaps one of the most unglamorous yet critical areas when it comes to working with data is that of data cleansing and integration. Companies like Informatica have long played a dominant role in this space. Internal and external data can be stored in a wide range of formats and can include errors and duplicate records. Such data often needs to be cleansed before it can be used or before multiple data sources can be used together.
At its simplest level, data cleansing involves tasks like removing duplicate records and normalizing address fields. Companies like Trifacta, funded by well-known venture capital firms Andreessen Horowitz and Greylock, are bringing to market new applications for cleansing data and working with diverse data sources. Data cleansing as a cloud service, perhaps through a combination of machine-based algorithms and crowdsourcing, presents an interesting and as yet mostly unexplored market opportunity.
Data Privacy
As we move more data to the cloud and publish more information about ourselves on the net, data privacy and security remains a growing concern. Facebook has beefed up the control that users have over which information they share. Google has added layers of security and encryption to make its data centers more secure. Recent large-scale losses of consumer data at retailers like Target have also raised awareness around data security and privacy for both consumers and businesses.
As with any new technology, Big Data offers many potential benefits, but it also poses a variety of risks. It brings with it the need for well-thought-out policies around the kinds of data we store and how we use that data. As an example, anonymous data may not be as anonymous as it seems. In one study, analysts were able to look at anonymized movie-watching data and determine, by looking at reviews from users who had posted on the Internet Movie Database (IMDB), which users had watched which movies.
In the future, BDAs may emerge that not only let us decide which data to share, but also help us to understand the hidden implications of sharing personal information, whether that information identifies us personally or not.
Landscape Futures
Data and the algorithms designed to make use of it are becoming a fundamental and distinguishing competitive asset for companies, both consumer- and business-focused.
File sharing and collaboration solutions Box and Dropbox may well be considered BDAs given the huge volume of files they store. More and more BDAs are emerging that are vertical focused. As mentioned in chapters to come, those like Opower take the data from power meters and help consumers and businesses understand their power consumption and then use energy more efficiently.
Nest, which was recently acquired by Google for $3.2 billion, is a learning thermostat that understands consumer behavior and applies algorithms to the data it collects so that it can better heat and cool homes. Some of these BDA companies will be acquired, while others will follow in the footsteps of QlikTech, Tableau, and Splunk and go public as they seek to build leading, independent BDA companies. What’s clear is that the market’s appetite for Big Data is just beginning.
![]() Note The market’s appetite for Big Data is just beginning.
Note The market’s appetite for Big Data is just beginning.
As more BDAs come to market, where does that leave infrastructure providers? When it comes to cloud-based infrastructure, it’s likely that Amazon will have a highly competitive offering in virtually every area. And for those areas where it doesn’t, the larger open source infrastructure vendors may jump in to provide cloud-based offerings. If history is any predictor, it’s likely that big enterprise players, from Cisco to EMC, IBM, and Oracle, will continue to be extremely active acquirers of these vendors. Intel’s $900 million investment in Cloudera shows that it is extremely serious about Big Data.
Going forward, expect even more BDAs to emerge that enhance our work and our personal lives. Some of those applications will help us better understand information. But many of them won’t stop there. BDAs will improve our ability to reach the right customers and to serve those customers effectively once we do. But they won’t stop there. BDAs at the intersection of Big Data and mobile will improve the quality of care we receive when we visit the doctor’s office. Someday, BDAs may even enable self-driving cars to take care of our daily commutes. No matter the application, the Big Data landscape is sure to be a source of profound innovation in the years ahead.
____________________
1http://gigaom.com/2013/01/08/idc-says-big-data-will-be-24b-market-in-2016-i-say-its-bigger/
2http://www.theguardian.com/technology/2014/feb/04/facebook-10-years-mark-zuckerberg
3http://www.digitaltrends.com/social-media/according-to-facebook-there-are-350-million-photos-uploaded-on-the-social-network-daily-and-thats-just-crazy/#!Cht6e
4http://us.gizmodo.com/5937143/what-facebook-deals-with-everyday-27-billion-likes-300-million-photos-uploaded-and-500-terabytes-of-data
5http://twopcharts.com/twitteractivitymonitor
6http://www.securelist.com/en/analysis/204792243/Spam_in_July_2012
7http://knowwpcarey.com/article.cfm?cid=25&aid=1171
8http://en.wikipedia.org/wiki/Extract,_transform,_load
9http://phx.corporate-ir.net/phoenix.zhtml?c=176060&p=irol-corporateTimeline
10http://en.wikipedia.org/wiki/Amazon_Web_Services#cite_note-1
11http://www.informationweek.com/software/information-management/amazon-redshift-leaves-on-premises-openi/240143912
12http://www.informationweek.com/cloud/infrastructure-as-a-service/amazon-web-services-revenue-new-details/d/d-id/1112068?
13http://aws.typepad.com/aws/2012/06/amazon-s3-the-first-trillion-objects.html
14The author is an investor in Ignition Partners.
15http://www.xconomy.com/san-francisco/2010/11/04/is-cloudera-the-next-oracle-ceo-mike-olson-hopes-so/2/
16http://static.googleusercontent.com/external_content/untrusted_dlcp/research.google.com/en/us/archive/mapreduce-osdi04.pdf
17http://blog.cloudera.com/blog/2012/10/cloudera-impala-real-time-queries-in-apache-hadoop-for-real/
18http://www.time.com/time/magazine/article/0,9171,1992403,00.html
19http://consumerist.com/2012/07/09/how-does-netflix-categorize-movies/
20http://www.turn.com/whyturn
21http://www.slideshare.net/HusetMarkedsforing/rtb-update-4-dominic-trigg-rocket-fuel
22http://www.b2bmarketinginsider.com/strategy/real-time-marketing-trading-room-floor
23http://en.wikipedia.org/wiki/Business_intelligence