Couchbase Essentials (2015)
Chapter 4. Advanced Views
In the previous chapter, we explored the basics of the view API in Couchbase Server. Having spent a fair bit of time discussing MapReduce, we're now ready to move on to more advanced views. In this chapter, we'll dig deep into most of the common application queries you'll likely need to build an application with Couchbase.
Querying by type
One of the most basic tasks when building applications is to find all records of a particular type. In the relational world, this effort is analogous to SELECT * FROM TableName. For example, you might need to display a list of all users in your system. For this query, we aren't concerned with any particular attribute of a document other than that it is a user document:
function (doc, meta) {
if (doc.type == "user") {
emit(null, null);
}
}
In this example, we'll simply check for the "user" type, and then emit a null key for each user document that is found. Since we didn't check for any property values other than the type, the index will contain all user documents. Again, the previous map function is similar to a SELECT * SQL query without a WHERE clause:
var view = client.GetView("users", "all_users");
foreach(var row in view)
{
var user = row.GetItem() as User;
//do something with the user
}
In the preceding C# snippet, the all_users view from the users design document is queried with no arguments. As the view object is enumerated, each document is retrieved by its key or value (performed by the GetItem() method).
You're likely wondering why we emitted a null value for the key in our map function. Recall that every row in a Couchbase view contains the ID or key from the key/value API as a part of its data structure. Therefore, it would be redundant to include a value for the key. The id property is exposed to the SDKs when they query the view over the RESTful view API:
{"id":"user_12345","key":null,"value":null}
Another point to remember is that Couchbase documents are not namespaced beyond the bucket level. There is no table analogy. As such, for a "find all" query such as the one we saw before (to find all users), some sort of convention is required to identify the type of the document. In this case, we're using the convention of having a type property with each document, as we saw in Chapter 3, Creating Secondary Indexes with Views.
Finally, it's worth mentioning again that the purpose of a view is to provide a way of accessing the original document over the key/value API. If you know a document's key from its key/value API, you wouldn't use a view to find it. You'll use views to find keys for documents when those keys are not immediately or easily known.
Nested collections
So far, we've focused on pretty simple documents. In practice, however, you're more likely to work with complex JSON structures that mirror your application's object graph. For example, consider the common Customer class. In this case, you have a Customer object, which has a collection of Address objects, as demonstrated in the following C# snippet:
public class Customer
{
public string FirstName { get; set; }
public string LastName { get; set; }
public IEnumerable<Address> Addresses { get; set; }
}
public class Address
{
public string Street { get; set; }
public string City { get; set; }
public string Province { get; set; }
public string State { get; set; }
public string Country { get; set; }
public string PostalCode { get; set; }
}
In a relational model, this object structure would translate into a one-to-many relationship between a Customers table and an Addresses table. By contrast, with document databases, you tend to store related object graphs in the same document. As such, your JSON structure would look something like this sample:
{
firstName = "Paulie",
lastName = "Walnuts",
type = "customer"
addresses = [
{
street: "20 Mulberry Street",
city: "Newark",
state: "NJ",
postalCode: "07102",
country: "US"
},
{
street: "10 Ridge Street",
city: "Orange",
state: "NJ",
postalCode: "07050",
country: "US"
}
]
}
Our JSON resembles our in-memory object graph much more closely than it does the relational equivalent. However, in the relational world, finding all customers who live in a given state or have a given postal code is possible with a straightforward query:
SELECT *
FROM Addresses a
INNER JOIN Customers c ON c.Id = a.CustomerId
WHERE State = 'NJ'
Fortunately, the map function that allows a similar query to be run is not as complex as those we've seen already. The only real difference is that we'll loop over the nested collection and emit the index values from within that loop, as follows:
function(doc, meta) {
if (doc.type == "customer" && doc.addresses) {
for(vari = 0; i<doc.addresses.length; i++) {
if (doc.addresses[i].state) {
emit(doc.addresses[i].state, null);
}
}
}
}
This map function also demonstrates that within a map multiple properties or objects from the same document may be indexed. For each address in a customer document, there will be a corresponding record in the index.
Now we can see that, since our map function is simply a JavaScript function, we can do in our map function virtually anything that we can do in JavaScript. You are able to create quite complex map functions, including having the ability to create anonymous functions.
Note
It is a common question as to whether you're able to include JavaScript libraries to be used in your map and reduce functions. Practically speaking, you aren't. You could probably manage to wedge jQuery into a map function, but that would be quite impractical.
It's not always right to nest related entities as we just did with customer addresses. There are times when it will make more sense to store a related record in its own document. For example, you probably wouldn't want to nest products purchased by a customer within the customer record. Instead, you would likely store a reference to a product document's key. In Chapter 6, Designing a Schema-less Data Mode, we'll explore these patterns in more detail.
Range queries
We've seen the basics of key range queries but haven't fully explored how they work. Understanding range queries is critical in order to understand how to perform a number of common query tasks. We'll start by revisiting a basic range query. We'll use a simple document structure, as shown here:
{
"firstName": "Hank",
"lastName": "Moody",
"type": "user"
},
{
"firstName": "Karen",
"lastName": "Van Der Beek",
"type": "user"
},
{
"firstName": "Becca",
"lastName": "Moody-Smith",
"type": "user"
}
In this example, we have three documents. We'll start by writing the map function, which will allow us to perform queries by last name. This is our standard view definition with a check on type and for the existence of a lastName property:
function (doc, meta) {
if (doc.type == "user" && doc.lastName) {
emit(doc.lastName, null);
}
}
As a refresher, to find a user by the last name, we'll simply provide the value "Moody" as a view parameter (including the quotes). That is a basic key search. But what if we wanted to find all Moody records, even those with a hyphenated last name? In this case, we can use a range query.
To query a view by a range, there are two parameters to be set, startkey and endkey. Even with that knowledge in mind, it might still not be obvious what values to provide for these parameters. The startkey parameter represents the lower bounds of the range, and the endkey parameter represents the upper bounds. It might be obvious how you'd perform a range query on integers, but how do you perform a range query on words?
Deliberately taking a naïve approach, we'll start by using "M" and "N" as our arguments for startkey and endkey, respectively. While with our limited dataset we'd certainly get both the Moody records, we'd also get any document with a last name starting with the letter M.
As a second step, we could change startkey to "Moody". While this would eliminate documents such as one with a last name of Matthews, it would leave records such as Morissette. The question then becomes, what are the values greater than Moody? More specifically, we want to find values greater than Moody followed by a hyphen, and any other name. Before we look at the answer, let's first revisit the notion of Unicode collation.
When we compare strings in most programming languages, we tend to rely on ASCII or byte order. In byte order, A is less than (or ordered before) a, but greater than B. By contrast, with Unicode Collation, a is less than A and less than B, which is greater than b. Additionally, accented variants are also grouped together with letters. For example, a is less than à, and A is less than Ă. The following example illustrates the basics of Unicode sorting:
1 < 5 < a < à < A < Ă < c < ç < C
Now that we have understood how view results are sorted, we can solve the problem of ending our range query. What we want is a value that will always be higher than any last name starting with Moody followed by a hyphen. This value should also be less than any value that could be greater than Moody followed by a hyphen.
With Couchbase server, the practice is to create an upper bound that starts with the values you hope to match, but suffixes that value with some high-order value. For example, one approach would be to set startkey to "Moody" and endkey to "Moody-ZZZZ". While this approach is likely to catch most documents, what about last names starting with Ȥ, or any other accented Z character?
A better approach is to select a boundary outside the likely realm of possible values for a name. Usually, this approach involves using the value at the end of the Unicode Collation table, which is \u02ad. Therefore, if we want to capture all "Moody-?" names, we'd use an endkey parameter of "Moody-\u02ad".
Tip
Note that in this example, the last name moody would not be part of the query results because m is less than M. To address this issue, we can either change the query to have a start range of moody or modify the map function to emit all lowercase keys.
It's also worth mentioning that this type of query is effectively a "starts with" or LIKE "A%" query. In other words, it provides a means of searching for all documents that start with a particular string. There is no comparable "ends with" query.
Multiple keys per document
The preceding map function we just wrote has a limitation—it will identify only those last names where the desired name appears before the hyphen. Therefore, the last name Van Der Beek-Moody would not be found. To address this issue, we could query a second time, with the startkey and endkey parameters reversed from our previous query. However, there is a better way.
There is no rule that a document must have only one key per row in an index. Therefore, we can rewrite our index to emit an index row for every possible last name. In this example, a possible last name is anything appearing before or after a hyphen:
function(doc, meta) {
if (doc.type == "user" && doc.lastName) {
var parts = doc.lastName.split("-");
for(vari = 0; i<parts.length; i++) {
emit(parts[i], null);
}
}
}
In this new map function, we use JavaScript's string split() function to return each of the names contained in a last name. For each match name we find, we send it to the index. Now the document with a last name of Moody-Smith will have two rows in the index, one for Moody and one for Smith. The Van Der Beek-Moody document will also have two rows.
This approach is far more powerful because it allows us to perform a key query rather than a key range query. To find all Moody documents, we simply set the key parameter's value to "Moody" (with the quotes). Regardless of where Moody appears in the last name, it will be found by our query.
As another example, consider a blog post document where the post includes a set of tags. You want to be able to locate all the posts with the same tag:
{
"title" : "About Couchbase Views",
"body" : "Views are secondary indexes...",
"type" : "post",
"tags" : ["couchbase", "nosql", "views"]
}
In this example, the tags property is an array of strings. The map function used to index these tags will be similar to the function we just wrote to index last names in our user documents:
function(doc, meta) {
if (doc.type == "post" && doc.tags && doc.tags,length) {
for(vari = 0; i<doc.tags.length; i++) {
emit(doc.tags[i], null);
}
}
}
Since our tags were already stored in an array, all we need to do is iterate over those values and emit them to the index. Note that we'll also verify that our document has a tags property and that the tags property has a length property. This test will ensure that even if the document has a tags property, it is also an enumerable property, such as an array.
As another example of this approach to indexing documents, consider the goal of indexing the words in a document's title property. Our goal is to create a simple text index:
function(doc, meta) {
if (doc.type == "post" && doc.title) {
var words = doc.title.split(" ");
for(vari = 0; i<words.length; i++) {
emit(doc.words[i], null);
}
}
}
Simply splitting the words in the title and emitting them to an index allows us to query for documents by words in the post's title. Of course, if a true full-text index is what you need, you'd likely want to use a full-text search tool such as Elasticsearch. Fortunately, the Couchbase team supplies an Elasticsearch plugin. It can be used to push data from a Couchbase cluster to an Elasticsearch cluster. The plugin is available for download at http://www.couchbase.com/nosql-databases/downloads.
The final example of emitting multiple keys per document demonstrates how to emulate an OR query. Using our user documents, we'll emit an index that includes both first and last names. In SQL, this query would be similar to the following:
SELECT *
FROM Users
WHERE LastName = 'Moody' OR FirstName = 'Hank'
For the map function, we'll simply add an extra call to emit so that both first and last names are sent:
function(doc, meta) {
if (doc.type == "user" && doc.firstName && doc.lastName) {
emit(doc.firstName, null);
emit(doc.lastName, null);
}
}
The index will consist of two rows for each user document, one for the first name and one for the last name. To run an OR query, you would use the keys parameter, supplying an array of the values that you want to search, for example ["Hank", "Moody"].
Querying a view by keys yields all the documents that match the supplied keys. Keys that don't match are ignored (much like OR). One thing to keep in mind is that in this approach, you aren't specifying whether a key is a first name or last name, as would be the case with SQL. We'll learn how to enhance this view in the next section.
Tip
It's good practice to check for null any and all properties being emitted to an index. Such checks make it safer to perform actions on your emitted properties, or to have reduce functions that won't encounter unexpected null values. The following snippet could break your indexing if lastName were null:
emit(doc.lastName.toLowerCase(),null);
Compound indexes
Writing an AND query requires a different approach than what we used for our OR query. If you wanted to perform the analogue of a SQL query with multiple values in a WHERE clause, you'd need to structure your view keys in such a way as to allow your application to supply multiple values as one key parameter value:
SELECT *
FROM Users
WHERE LastName = 'Soprano' AND FirstName = 'Tony'
In the preceding SQL statement, we are able to have values for both LastName and FirstName. One approach would be to create a delimited key in our index like this:
function(doc, meta) {
if (doc.type == "user" && doc.firstName && doc.lastName) {
emit(doc.lastName + "," + doc.firstName, null);
}
}
This map function emits a key in the form of "Soprano,Tony" to the index. When querying the index, the client application would concatenate the last name, a comma, and the first name. The resulting string would be provided as the argument for the key parameter.
Obviously, it's not optimal to concatenate a set of values in order to run a query. Fortunately, as we saw briefly in Chapter 3, Creating Secondary Indexes with Views, Couchbase views support compound indexes. Recall that compound indexes are simply array keys. With this change in mind, we could rewrite the last name and first name indexes in this way:
function(doc, meta) {
if (doc.type == "user" && doc.firstName && doc.lastName) {
emit([doc.lastName, doc.firstName], null);
}
}
In this version of the map function, we have an array key where the last name is the first element and the first name is the second element. With this change, when a client queries for a combination of first and last names, the key parameter is used. The key to search on will be a valid JSON array, for example, ["Moody", "Hank"]. On the client side, no concatenation is required.
Grouping keys
The real power of composite keys isn't the ability to search in multiple fields, but the ability to perform grouping with aggregation. To illustrate this point, we'll revisit the blog post document with a new property for published date:
{
"title": "Composite Keys with Couchbase Views ",
"body": "Composite keys are arrays...",
"publishedDate": "2014-09-17",
"type": "post"
}
Let's imagine that we want to display both a list of posts by year and month and the count of posts by year and month. By writing a view that uses compound keys and grouping methods, we are able to achieve both. Starting with the map function, we'll emit the year and month as values in our composite (array) key:
function(doc, meta) {
if (doc.type == "post" &&doc.publishedDate) {
emit(dateToArray(doc.publishedDate), null);
}
}
As always, we first check the type of the document and verify that it contains a publishedDate property. We then use the built-in dateToArray function provided by Couchbase. This is quite useful because JSON doesn't define a date type.
This function will take a document date string and provide the constituent pieces as items in an array, for example 2014-09-17 becomes [2014, 9, 17, 0, 0, 0]. Then we can see that each of our keys will be an array of integers, starting with the year, followed by the month, then the day, and then the time components.
We'll start by getting a count of posts by year. To do so, we'll need to add a reduce function to our view. We'll simply use the built-in _count function. Additionally, we'll need to make use of the group_level parameter. If we provide 1 as an argument to group_level, the view results will be grouped by the first item of the array index. In SQL, you could think of this behavior as a SELECT COUNT(*) statement:
SELECT Year, Count(*)
FROM posts
GROUP BY Year
As you can probably guess, to get a count of posts by month, we'd simply change the group_level to 2. It's important to understand that group levels are always inclusive of the elements in earlier positions in the array. In other words, when you group results at level 2(that is, month), level 1 (year) is always considered. In SQL, grouping at level 2 would be analogous to the following statement:
SELECT Year, Month, Count(*)
FROM posts
GROUP BY Year, Month
If you wanted to group results by months across all years, you will need to write a separate view that emits the month as the first element in the array. In this case, you will not be able to use the built-in dateToArray helper function directly in the emit call. You can use the result of the dateToArray function, but you should omit the year when emitting the key.
When you supply a group level, the keys against which you would perform range queries are no longer the fully emitted arrays, but rather the arrays at the specified level, for example at level 2, [2014,3,23,0,0,0] becomes [2014,3]. At group level 1, the index includes only the year.
You query compound keys with range arguments. You provide startkey and endkey, as we saw earlier in this chapter. However, with compound keys, you will provide arrays as the values passed to these parameters. If you wanted to find the count of posts by month for the first half of a year, you could provide a startkey value of [2014] and an endkey value of [2014,6,99].
Assuming you're familiar with the Gregorian calendar, you probably noticed that the upper bound of date was not valid —June has only 30 days. This value illustrates an important aspect of how composite keys are treated when queried. Specifically, queries are not performed against arrays but rather concatenated strings (from the array values) are used.
Recall the discussion earlier in this chapter about Unicode collation. Compound key queries are compared in the same way. While it seems that we've created a set of keys as integer arrays, Couchbase actually maintains those keys as strings. More specifically, Couchbase Server will treat all the array characters as elements in the strings, including brackets and commas. Additionally, single digits will be padded with a leading zero.
Therefore, when you set the startkey and endkey parameters to [2014] and [2014,6,99] respectively, the actual comparison is made by comparing the strings passed to these parameters to the ["2014"] and ["2014","06","31"] key parameter strings. In this case, [2014]will always be less than any date with a month, including January 1, and also 99 will always be greater than any possible day of June ("06") will always be less than July ("07").
If we omit the group_level parameter entirely but leave the key ranges in place, we'll be provided with an ungrouped list of all posts over that time period. Instead, if we want to get a list of posts for a given month, we should again leave the group_level parameter, but supply a shorter range for our startkey and endkey parameters. In both of our ungrouped cases, it is also necessary to add set the reduce parameter to false.
Emitting values
Up until this point, we've written most of our map functions to emit null for the value side of our key/value views. We've also learnt that it's best to use views as a means to retrieve a document via the key/value API. However, there are exceptions to this rule.
Imagine that we've augmented our user documents to include an e-mail address, like this:
{
"firstName": "Sam",
"lastName": "Malone",
"email": "sam@example.com",
"type": "user"
}
Now consider the task of creating some sort of scheduled job that needs to send a weekly e-mail to all users. We've already seen how to write the "select all users" query. Therefore, we know how to iterate over the set of users and retrieve the original user document to get this new e-mail property. However, this isn't necessarily the most efficient way to do so.
If we have millions of user documents, we'd be querying both the view and key/value API millions of times. By emitting the e-mail address as the value in our index, we can turn our index into what is called a Covering Index in the SQL world. Such an index is able to answer a query with the index data alone:
//the map function for a view named by_lastname
function(doc, meta) {
if (doc.type == "user" && doc.email&&doc.lastName) {
emit(doc.lastName, doc.email);
}
}
In this code snippet, our by_lastname view has been re-purposed to include e-mail as a value. In doing so, some space on disk is saved by not having an entirely separate index for e-mail. Also, some resources are saved by not having an extra indexing job on the server.
In deciding whether to include a value with your view, space and data freshness will be the important factors. If you are including large chunks of your document in your index, you'd instead want to use the key/value lookup pattern. Similarly, if the data you are emitting to your view needs to be fully up to date, you should again use the key/value lookup, even if the data stored is small.
It's also worth noting that values (as well as keys) do not need to be primitive types or strings. It is possible (and sometimes desirable) to emit a JSON structure. For example, imagine our user document is much larger than the small snippet we've seen. We're frequently going to query user documents through views, but we'll need to access the full document less frequently:
function(doc, meta) {
if (doc.type == "user"&&doc.email&&doc.firstName&&doc.lastName)
{
emit(doc.email, { "firstName": doc.firstName, "lastName": doc.lastName });
}
}
In the preceding map function, we assume a use case where we'll frequently look up a user by e-mail and then retrieve their first and last names. Again, storing values with your index when you're not reducing the amount of data retrieved generally comes at a cost. It's far more common to emit a value with a reduce function.
Imagine we have a set of order documents where each order includes a price:
{
"customerId" : "123456",
"products": [
{
"product": "fender_telecaster",
"price": 1249.99
},
{
"product": "line6_spider",
"price": 299.99
}
],
"type": "order"
}
If we wanted to calculate a total of all purchases by a customer, we would emit the price as a value and use the built-in _sum function as our reduce function:
function(doc, meta) {
if (doc.type == "order" && doc.products&&doc.products.length) {
for(vari = 0; i<doc.products.length; i++) {
emit(doc.customerId, doc.products[i].price);
}
}
}
This map function emits a separate index row for each product purchased in a specific order. Alternatively, we could have computed the order total in our loop and emitted a single row with just that order's total.
When we query this view, we need to include the group parameter as well as the reduce parameter (both true). The result will be similar to the following SQL statement. In the relational world, we'd have a separate table for line items unlike our document, which nests each ordered product within the order document:
SELECT CustomerId, SUM(Price)
FROM OrderItems
GROUP BY CustomerId
Querying with beer-sample
So far, we've explored a wide variety of view queries. For some more concrete examples, we'll turn now to the beer-sample bucket. If you followed along in Chapter 3, Creating Secondary Indexes with Views, you should already have a design document created in this bucket. If so, then feel free to reuse that document. If not, then you'll need to create a new document.
Start by returning to the Views tab on the Couchbase Web Console. Select the beer-sample bucket to retrieve the current set (if any) of views within the dev_beers design document. If you did not follow along in the previous chapter, refer to the Creating a viewsection in Chapter 3, Creating Secondary Indexes with Views to get started. The following screenshot shows the Couchbase Console's Views tab:
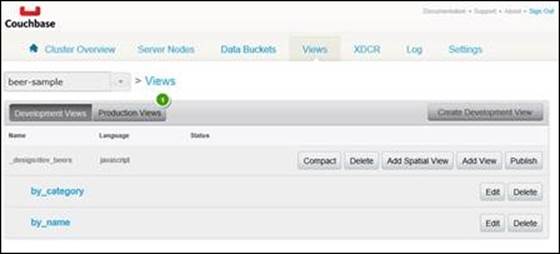
The Couchbase Console Views tab
Querying all documents by type
We'll start by revisiting the first view we looked at in this chapter — querying for all documents of a given type. Our first approach was to create an index with null keys and values for all user documents. This approach works well for organizing your design documents in a manner similar to your application's business objects.
Another option would be to create a single view which will allow you to search for all documents of any type. To achieve this goal, we'll simply emit each document's type property to the keys of the index:
function (doc, meta) {
if (doc.type) {
emit(doc.type, null);
}
}
With this version of our SELECT * view, every document with a type property will have a corresponding row in the index. When we want to query for all beers, we simply provide the key property as "beer", or the "brewery" parameter for breweries. This is shown in the following screenshot:
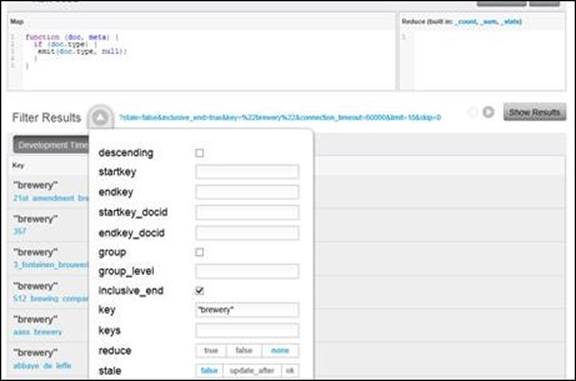
Finding all brewery documents
Counting breweries by location
Brewery documents in the beer-sample bucket contain address information. With these properties, we're able to write a view to count the number of breweries in a country, state, or province, down to the postal code level. Because the sample data often lack postal codes, we'll stop at the city level.
Our map function will be fairly straightforward. We'll emit an array as the key where the values of the array are the document's country, city, state, and code properties. The following map function produces keys such as ["Belgium","Hainaut","Binche"] and["Canada","Quebec","Chambly"]:
function(dsoc, meta) {
if (doc.type == "brewery" &&doc.country&&doc.state&&doc.city)
{
emit([doc.country, doc.state, doc.city], null);
}
}
To get a count of breweries by country, we first need to add a reduce function. Just as we have done before, we'll use the built-in _count function. After saving the view with the reduce function in place, we'll need to set the group_level parameter to 1, as shown here:
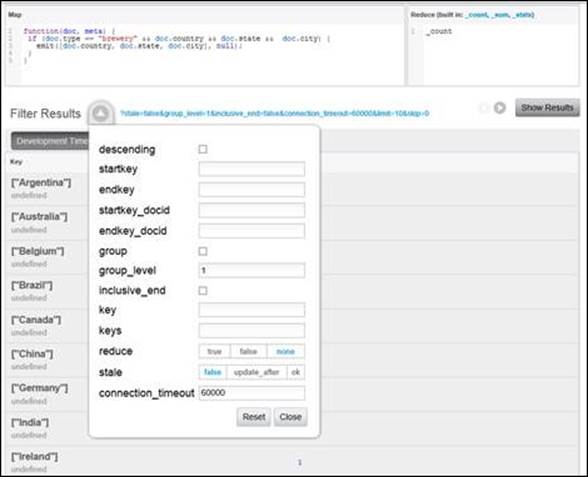
Breweries counted by country
Similarly, we could set the group_level parameter to 2 or 3 to get a count of breweries by province or city, respectively, as shown in the following screenshot. Recall that group_level is always inclusive of the previous levels. We can't count breweries in Connecticut without including the United States. Similarly, we can't count breweries in Hartford without including both Connecticut and the United States.
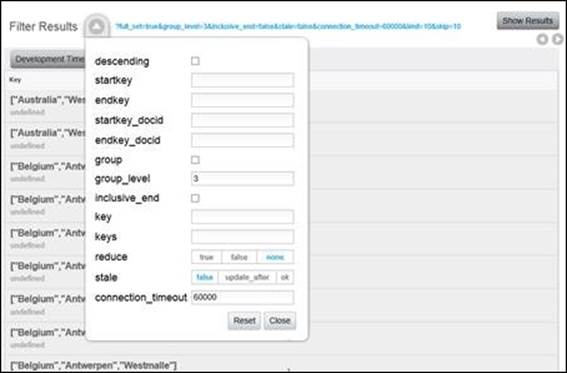
Tip
If you're a beer aficionado, you might find the sample data to be lacking in some of your favorite brews. This is because the source of the brewery data was the Open Beer Database, which is no longer maintained. Moreover, many of the documents have incomplete address components. Keep these limitations in mind as you pull back results that suggest Ireland has only one brewery.
If we want to find out how many breweries exist for a specific city, we will need to provide startkey and endkey. The approach we'll take will be the same as the approach we used to find blog posts by a specific month. For the startkey parameter, we'll provide an exact country and state, for example, ["United States", "Massachusetts"].
For an endkey value, we'll need to supply a value that is greater than all possible city values in Massachusetts. In this case, it would probably be safe to use a startkey value such as ["United States", "Massachusetts", "ZZZZ"] since no city in Massachusetts (or anywhere else) is ever likely to be given a value greater than "ZZZZ". However, it's safer to use an endkey value in the form of ["United States", "Massachusetts", "\u02ad"], as \u02ad will always be greater than any city name. The following screenshot demonstrates this example:
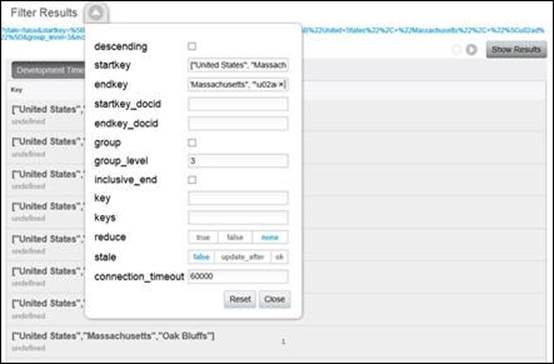
Counting breweries by state
While we are unable to reuse this view to query for breweries by country or state, it may be used to find breweries in a particular city. To accomplish this task, simply remove the reduce parameter (or set it to false) and perform a key query, such as ["United States", "Massachusetts", "Cambridge"], as shown here:
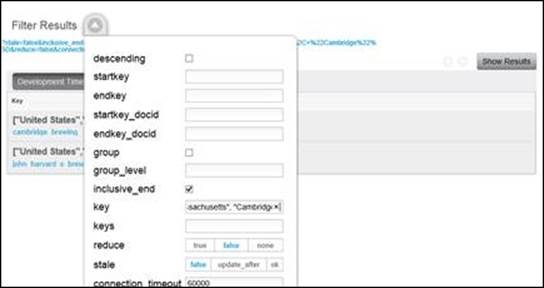
Finding breweries by city
This type of view is useful to work with any set of hierarchical properties. With this example, we could have a page that shows a list of countries with brewery counts. Clicking on a country could then display a list of states, provinces and their brewery counts. Then, clicking on a state would show a list of cities and brewery counts. Finally, clicking on a city would show all the breweries in that city.
Finding beer documents by brewery
To understand how to look up a beer name by its brewery, we first need to examine the relationship between the two types of documents. Recall that Couchbase Server does not support foreign keys and there is no referential integrity between documents. However, it is common to create a relationship by adding a property to a foreign document.
Each beer document contains a brewery_id property, and it is the meta.id property of a brewery document. Again, the meta.id value is the key from the key/value API. By including this property on beer documents, it's possible to write a simple map function to search for beer names by their brewery, as follows:
function(doc, meta) {
if (doc.type == "beer" && doc.brewery_id) {
emit(doc.brewery_id, null);
}
}
Keep in mind that there are no joins in Couchbase Server. When you query this view with a key value such as "pivzavod_baltika", you cannot get both the brewery and its beer document in a single lookup. Typically with Couchbase Server, you'll perform multiple Getoperations to retrieve related documents.
Collated views
Though Couchbase Server does not support joins, there is a technique commonly used to find documents with a parent-child relationship. This technique is known as a collated view because it relies on Couchbase Server's Unicode collation. Before we dig into how we can build a collated view, it's useful to understand the goal.
We've already seen that Unicode collation guarantees that the index will be ordered by its key in a predictable and consumable way. In the previous section, we saw how to create an index of beer names where the key was the brewery's ID. That map function provides part of the solution—it orders all of a brewery's beer documents together.
The other part of the solution is to add the brewery document to the index alongside the beer documents. Specifically, we want a row with the brewery followed by each of its beer names. This technique is not obvious at first, so we'll take it piece by piece:
function(doc, meta) {
if (doc.type == "brewery") {
emit(meta.id);
}
}
The preceding map function is fairly straightforward. We simply check for brewery documents and emit their meta.id value to the index. To add beer documents, we'll first modify the map function slightly, as follows:
function(doc, meta) {
if (doc.type == "brewery") {
emit(meta.id);
} else if (doc.type == "beer" && doc.brewery_id) {
emit(doc.brewery_id);
}
}
We've added a second condition to our map function. Now if we encounter a beer document, we'll emit its brewery_id value as the key. At this point, we have an index entirely consisting of brewery IDs.
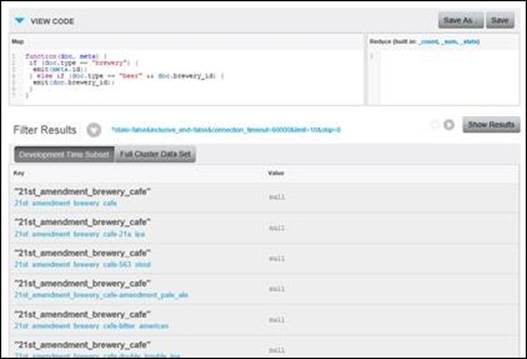
The beginning of a collated view
As we can see in the previous figure, our index consists of a brewery, followed by its beer names. In fact, all our beer names and breweries will appear in the index as brewery first and beer second. A client application can now query the view by brewery ID and build a set of parent-child objects.
Though it seems like we're done with our map function, we still have one final change to make. Even though our breweries correctly appear before the beer documents, it's only because of the way the beer keys were created in the beer-sample bucket.
Each beer's key (or meta.id) is prefixed with its brewery's key. Therefore, the brewery key will always be less than the beer key, for example the "21st_amendment_brewery_cafe" brewery key will always be less than its beer's keys (such as " 21st_amendment_brewery_cafe-21a_ipa"). Couchbase Server sorts results by the document's ID as a sort of tie-breaker for the same key in an index.
To fix our map function, we need to provide a means of forcing our parent rows to be emitted before any of its children rows, regardless of the meta.id value for its children. If we convert our keys to composite keys, we are easily able to enforce this ordering:
function(doc, meta) {
if (doc.type == "brewery") {
emit([meta.id, 0]);
} else if (doc.type == "beer" && doc.brewery_id) {
emit([doc.brewery_id, 1]);
}
}
With this new map function in place, we emit 0 after the brewery's meta.id value, and 1 after the beer's brewery_id value. We've now guaranteed that all beer names will appear together immediately following their brewery. Moreover, the query to find a brewery with its beers simply requires startkey and endkey with the brewery_id value, followed by 0 and 1 respectively. The following screenshot demonstrates this example:
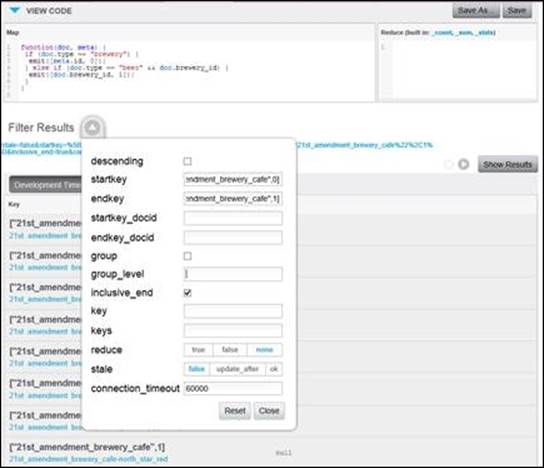
Finding a brewery and its beer names
Summary
Following the background information in Chapter 3, Creating Secondary Indexes with Views, you now saw a more complete picture of Couchbase views. You learned how a document can be indexed in virtually any way imaginable with JavaScript. Moreover, you now know that you can index a document in multiple ways within the same view.
Reviewing range queries led you to explore Unicode collation and some tricks to find your data. You also saw how you are able to parse collections within documents to create several indexed values from a single document field.
Then we explored compound indexes in some detail. You learned that these indexes provide so much more than grouping. We can use them to query multiple properties and to create an index that yields parent-child relationships.
Along the way, we alluded to some important topics. While discussing collated views, we touched on the importance of key (meta.id) selection for our documents. We also broached the subject of document relationships. These topics will resurface in more detail inChapter 6, Designing a Schema-less Data Model, when we discuss schema design.
Before we move on to schema design, we're going to take a look at N1QL, an exciting new query language that is currently being developed by the Couchbase engineering team. Though it uses views behind the scenes, it offers a simpler approach to querying by providing a rich language to find data in a Couchbase bucket.
All materials on the site are licensed Creative Commons Attribution-Sharealike 3.0 Unported CC BY-SA 3.0 & GNU Free Documentation License (GFDL)
If you are the copyright holder of any material contained on our site and intend to remove it, please contact our site administrator for approval.
© 2016-2026 All site design rights belong to S.Y.A.