Couchbase Essentials (2015)
Chapter 3. Creating Secondary Indexes with Views
Now that we've examined Couchbase Server's key/value API, it's time to shift gears and look at its document-oriented features.
Couchbase documents
Documents in Couchbase are simply key/value pairs where the value is stored as a valid JSON document. The key/value API we learnt in Chapter 2, Using Couchbase CRUD Operations, is the same API we'll use to create JSON documents in the server. Generally, you'll use the client SDKs in combination with your platform's preferred JSON serializer, as shown in this C# snippet:
var user = new User { Name = "John" };
var json = JsonConvert.SerializeObject(user);
bucket.Upsert("jsmith", json);
In this example, the popular .NET JSON serializer is used to transform an instance of a .NET class into a valid JSON string. That string is then stored on Couchbase Server using the key/value set operation.
Similarly, to retrieve a JSON document from the server, you'll also use the key/value Get operation:
var json = bucket.Get<string>("jsmith");
var user = JsonConvert.DeserializeObject<User>(json);
In the case of retrieving a document, you'll typically retrieve the JSON string and allow your platform's JSON serializer to deserialize the JSON document into a strongly-typed object, which is a User instance in this example.
Of course, you are free to do whatever you wish with the JSON you retrieve. The Couchbase SDKs intentionally provide you with the freedom to choose your own JSON-to-object behavior. Rather than deserializing into a user-defined type as you just did, you might want to convert your JSON document into a dictionary. You also could choose to simply return the JSON document to your application. This last approach could be particularly useful when serving JSON to JavaScript-heavy applications.
Of course, being able to store JSON strings alone is not enough for a database to be considered document-oriented. For that classification, a data store must support some other document capabilities, most importantly document indexing and querying.
Couchbase indexes
We've already seen how Couchbase handles primary indexes for documents. The key in the key/value pair is the unique primary key for a document. Using the key/value API, documents may be retrieved only by this key. While this might seem limiting, there are key/value schema design patterns that help to provide flexibility. We'll explore them in Chapter 5, Introducing N1QL.
Fortunately, Couchbase as a document store provides a much more powerful approach for finding your documents. To illustrate the problem and the solution, we'll walk through a brief example. Imagine having a simple JSON document such as this:
{
"Username": "jsmith",
"Email": "jsmith@somedomain.com"
}
The key/value limitation is easy to see. Imagine we want to find a user by their username. The key/value solution might be to use the username as the key. While that would certainly work, what happens when we also want to query a user by their e-mail address? We can't have both e-mail and username as a key!
Therefore, there are key/value patterns to address this problem, and we'll discuss them briefly later on. Couchbase, with its document capabilities, provides a much more elegant solution—allowing arbitrary secondary indexes on stored JSON documents.
These secondary indexes will allow us to query our user document by username, e-mail, or any function of the two (for example, an e-mail ID with a particular domain). These indexes, which are known as views in Couchbase terms, will be created using JavaScript and MapReduce.
MapReduce
Before we can start our exploration of the Couchbase Server views, we first need to understand what MapReduce is and how we'll use it to create secondary indexes for our documents.
At its simplest, MapReduce is a programming pattern used to process large amounts of data that is typically distributed across several nodes in parallel. In the NoSQL world, MapReduce implementations may be found on many platforms from MongoDB to Hadoop, and of course Couchbase.
Even if you're new to the NoSQL landscape, it's quite possible that you've already worked with a form of MapReduce. The inspiration for MapReduce in distributed NoSQL systems was drawn from the functional programming concepts of map and reduce. While purely functional programming languages haven't quite reached mainstream status, languages such as Python, C#, and JavaScript all support map and reduce operations.
Map functions
Consider the following Python snippet:
numbers = [1, 2, 3, 4, 5]
doubled = map(lambda n: n * 2, numbers)
#doubled == [2, 4, 6, 8, 10]
These two lines of code demonstrate a very simple use of a map() function. In the first line, the numbers variable is created as a list of integers. The second line applies a function to the list to create a new mapped list. In this case, the map() function is supplied as a Python lambda, which is just an inline, unnamed function. The body of lambda multiplies each number by two.
This map() function can be made slightly more complex by doubling only odd numbers, as shown in this code:
numbers = [1, 2, 3, 4, 5]
defdouble_odd(num):
if num % 2 == 0:
return num
else:
return num * 2
doubled = map(double_odd, numbers)
#doubled == [2, 2, 6, 4, 10]
Map functions are implemented differently in each language or platform that supports them, but all follow the same pattern. An iterable collection of objects is passed to a map function. Each item of the collection is then iterated over, with the map function being applied to that iteration. The final result is a new collection where each of the original items is transformed by the map.
Reduce functions
Like maps, reduce functions also work by applying a provided function to an iterable data structure. The key difference between the two is that the reduce function works to produce a single value from the input iterable. Using Python's built-in reduce() function, we can see how to produce a sum of integers, as follows:
numbers = [1, 2, 3, 4, 5]
sum = reduce(lambda x, y: x + y, numbers)
#sum == 15
You probably noticed that unlike our map operation, the reduce lambda has two parameters (x and y in this case). The argument passed to x will be the accumulated value of all applications of the function so far, and y will receive the next value to be added to the accumulation.
Parenthetically, the order of operations can be seen as ((((1 + 2) + 3) + 4) + 5). Alternatively, the steps are shown in the following list:
1. x = 1, y = 2
2. x = 3, y = 3
3. x = 6, y = 4
4. x = 10, y = 5
5. x = 15
As this list demonstrates, the value of x is the cumulative sum of previous x and y values. As such, reduce functions are sometimes termed accumulate or fold functions. Regardless of their name, reduce functions serve the common purpose of combining pieces of a recursive data structure to produce a single value.
Couchbase MapReduce
Creating an index (or view) in Couchbase requires creating a map function written in JavaScript. When the view is created for the first time, the map function is applied to each document in the bucket containing the view. When you update a view, only new or modified documents are indexed. This behavior is known as incremental MapReduce.
You can think of a basic map function in Couchbase as being similar to a SQL CREATE INDEX statement. Effectively, you are defining a column or a set of columns, to be indexed by the server. Of course these are not columns, but rather properties of the documents to be indexed.
Basic mapping
To illustrate the process of creating a view, first imagine that we have a set of JSON documents as shown here:
var books=[
{
"id": 1,
"title": "The Bourne Identity",
"author": "Robert Ludlow"
},
{
"id": 2,
"title": "The Godfather",
"author": "Mario Puzzo"
},
{
"id": 3,
"title": "Wiseguy",
"author": "Nicholas Pileggi"
}
];
Each document contains title and author properties. In Couchbase, to query these documents by either title or author, we'd first need to write a map function. Without considering how map functions are written in Couchbase, we're able to understand the process with vanilla JavaScript:
books.map(function(book) {
return book.author;
});
In the preceding snippet, we're making use of the built-in JavaScript array's map() function. Similar to the Python snippets we saw earlier, JavaScript's map() function takes a function as a parameter and returns a new array with mapped objects. In this case, we'll have an array with each book's author, as follows:
["Robert Ludlow", "Mario Puzzo", "Nicholas Pileggi"]
At this point, we have a mapped collection that will be the basis for our author index. However, we haven't provided a means for the index to be able to refer back to the original document. If we were using a relational database, we'd have effectively created an index on the Title column with no way to get back to the row that contained it.
With a slight modification to our map function, we are able to provide the key (the id property) of the document as well in our index:
books.map(function(book) {
return [book.author, book.id];
});
In this slightly modified version, we're including the ID with the output of each author. In this way, the index has its document's key stored with its title.
[["The Bourne Identity", 1], ["The Godfather", 2], ["Wiseguy", 3]]
We'll soon see how this structure more closely resembles the values stored in a Couchbase index.
Basic reducing
Not every Couchbase index requires a reduce component. In fact, we'll see that Couchbase already comes with built-in reduce functions that will provide you with most of the reduce behavior you need. However, before relying on only those functions, it's important to understand why you'd use a reduce function in the first place.
Returning to the preceding example of the map, let's imagine we have a few more documents in our set, as follows:
var books=[
{
"id": 1,
"title": "The Bourne Identity",
"author": "Robert Ludlow"
},
{
"id": 2,
"title": "The Bourne Ultimatum",
"author": "Robert Ludlow"
},
{
"id": 3,
"title": "The Godfather",
"author": "Mario Puzzo"
},
{
"id": 4,
"title": "The Bourne Supremacy",
"author": "Robert Ludlow"
},
{
"id": 5,
"title": "The Family",
"author": "Mario Puzzo"
},
{
"id": 6,
"title": "Wiseguy",
"author": "Nicholas Pileggi"
}
];
We'll still create our index using the same map function because it provides a way of accessing a book by its author. Now imagine that we want to know how many books an author has written, or (assuming we had more data) the average number of pages written by an author.
These questions are not possible to answer with a map function alone. Each application of the map function knows nothing about the previous application. In other words, there is no way for you to compare or accumulate information about one author's book to another book by the same author.
Fortunately, there is a solution to this problem. As you've probably guessed, it's the use of a reduce function. As a somewhat contrived example, consider this JavaScript:
mapped = books.map(function (book) {
return ([book.id, book.author]);
});
counts = {}
reduced = mapped.reduce(function(prev, cur, idx, arr) {
var key = cur[1];
if (! counts[key]) counts[key] = 0;
++counts[key]
}, null);
This code doesn't quite reflect the way you would count books with Couchbase accurately, but it illustrates the basic idea. You look for each occurrence of a key (author) and increment a counter when it is found. With Couchbase MapReduce, the mapped structure is supplied to the reduce() function in a better format. You won't need to keep track of items in a dictionary.
Couchbase views
At this point, you should have a general sense of what MapReduce is, where it came from, and how it will affect the creation of a Couchbase Server view. So without further ado, let's see how to write our first Couchbase view.
In Chapter 1, Getting Comfortable with Couchbase, we saw that when we install Couchbase Server, we have the option of including a sample bucket. In fact, there were two to choose from. The bucket we'll use is beer-sample. If you didn't install it, don't worry. You can add it by opening the Couchbase Console and navigating to the Settings tab. Here, you'll find the option to install the bucket, as shown next:
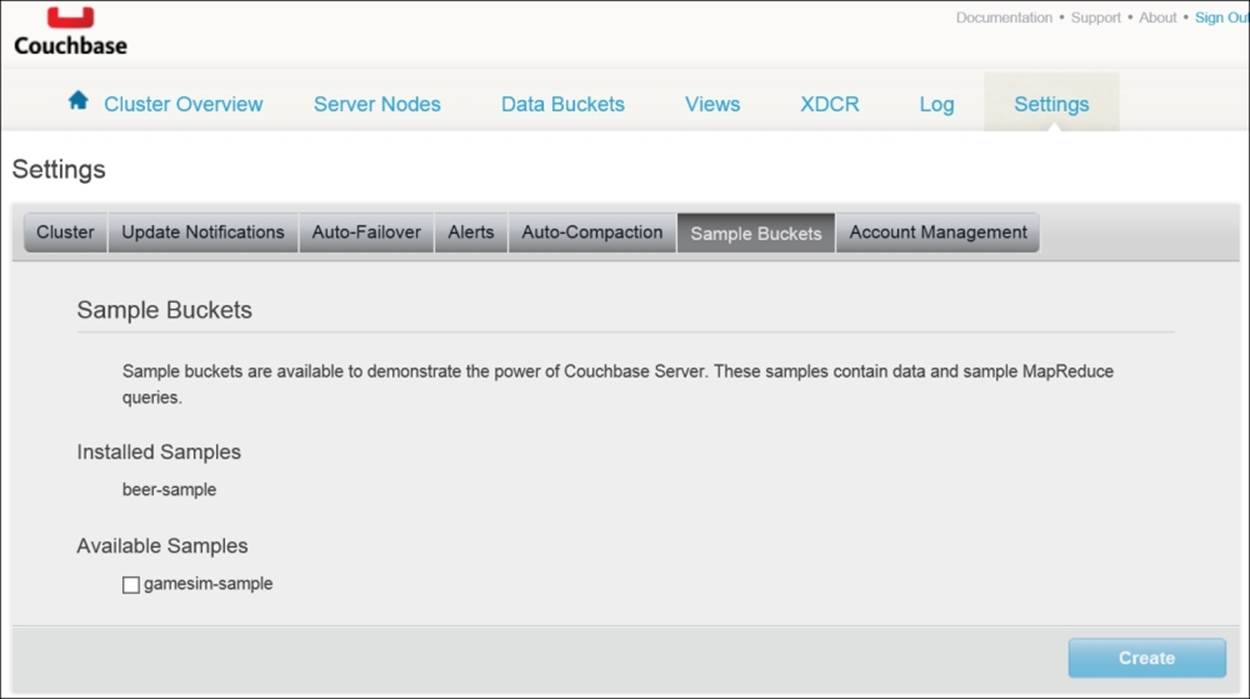
In the next sections, we'll return to the console to create our view, examine documents, and query our views. For now, however, we'll simply examine the code. First, you need to understand the document structures with which you're working. The following JSON object is a beer document (abbreviated for brevity):
{
"name": "Sundog",
"type": "beer",
"brewery_id": "new_holland_brewing_company",
"description": "Sundog is an amber ale...",
"style": "American-Style Amber/Red Ale",
"category": "North American Ale"
}
As you can see, the beer documents have several properties. We're going to create an index to let us query these documents by name. In SQL, the query would look like this:
SELECT Id FROM Beers WHERE Name = ?
You might be wondering why the SQL example includes only the Id column in its projection. We'll explore this analogy when we discuss view queries later in this chapter. For now, just know that to query a document using a view with Couchbase, the property by which you're querying must be included in an index.
To create that index, we'll write a map function. The simplest example of a map function to query beer documents by name is as follows:
function(doc) {
emit(doc.name);
}
This body of the map function has only one line. It calls the built-in Couchbase emit() function. This function is used to signal that a value should be indexed. The output of this map function will be an array of names.
The beer-sample bucket includes brewery data as well. These documents look like the following code (abbreviated for brevity):
{
"name": "Thomas Hooker Brewing",
"city": "Bloomfield",
"state": "Connecticut",
"website": "http://www.hookerbeer.com/",
"type": "brewery"
}
If we re-examine our map function, we'll see an obvious problem, both the brewery and beer documents have a name property. When this map function is applied to the documents in the bucket, it will create an index with documents from either the brewery or beer documents.
The problem is that Couchbase documents exist in a single container—the bucket. There is no namespace for a set of related documents. The solution has typically involved including a type or docType property on each document. The value of this property is used to distinguish one document from another.
In the case of the beer-sample database, beer documents have type = "beer" and brewery documents have type = "brewery". Therefore, we are easily able to modify our map function to create an index only on beer documents:
function(doc) {
if (doc.type == "beer") {
emit(doc.name);
}
}
The emit() function actually takes two arguments. The first, as we've seen, emits a value to be indexed. The second argument is an optional value and is used by the reduce function. Imagine that we want to count the number of beer types in a particular category. In SQL, we would write the following query:
SELECT Category, COUNT(*) FROM Beers GROUP BY Category
To achieve the same functionality with Couchbase Server, we'll need to use both map and reduce functions. First, let's write the map. It will create an index on the category property:
function(doc) {
if (doc.type == "beer") {
emit(doc.category, 1);
}
}
The only real difference between our category index and our name index is that we're including an argument for the value parameter of the emit() function. What we'll do with that value is simply count them. This counting will be done in our reduce function:
function(keys, values) {
return values.length;
}
In this example, the values parameter will be given to the reduce function as a list of all values associated with a particular key. In our case, for each beer category there will be a list of ones (that is, [1, 1, 1, 1, 1, 1]). Couchbase also provides a built-in _countfunction. It can be used in place of the entire reduce function in the preceding example.
Now that we've seen the basic requirements when creating an actual Couchbase view, it's time to add a view to our bucket. The easiest way to do so is to use the Couchbase Console.
Couchbase Console
In Chapter 1, Getting Comfortable with Couchbase, we skipped the Views tab in the Couchbase Web Console with the promise of returning to it in later chapters. It's just about time to fulfill that promise, but first we'll take a look at another tab we skipped—the Data Buckets tab.
Open Couchbase Console. As a reminder, it's found at http://localhost:8091. If you're using Couchbase on a server other than your laptop, substitute that server's name for localhost. After logging in, navigate to the Data Buckets tab, as shown here:
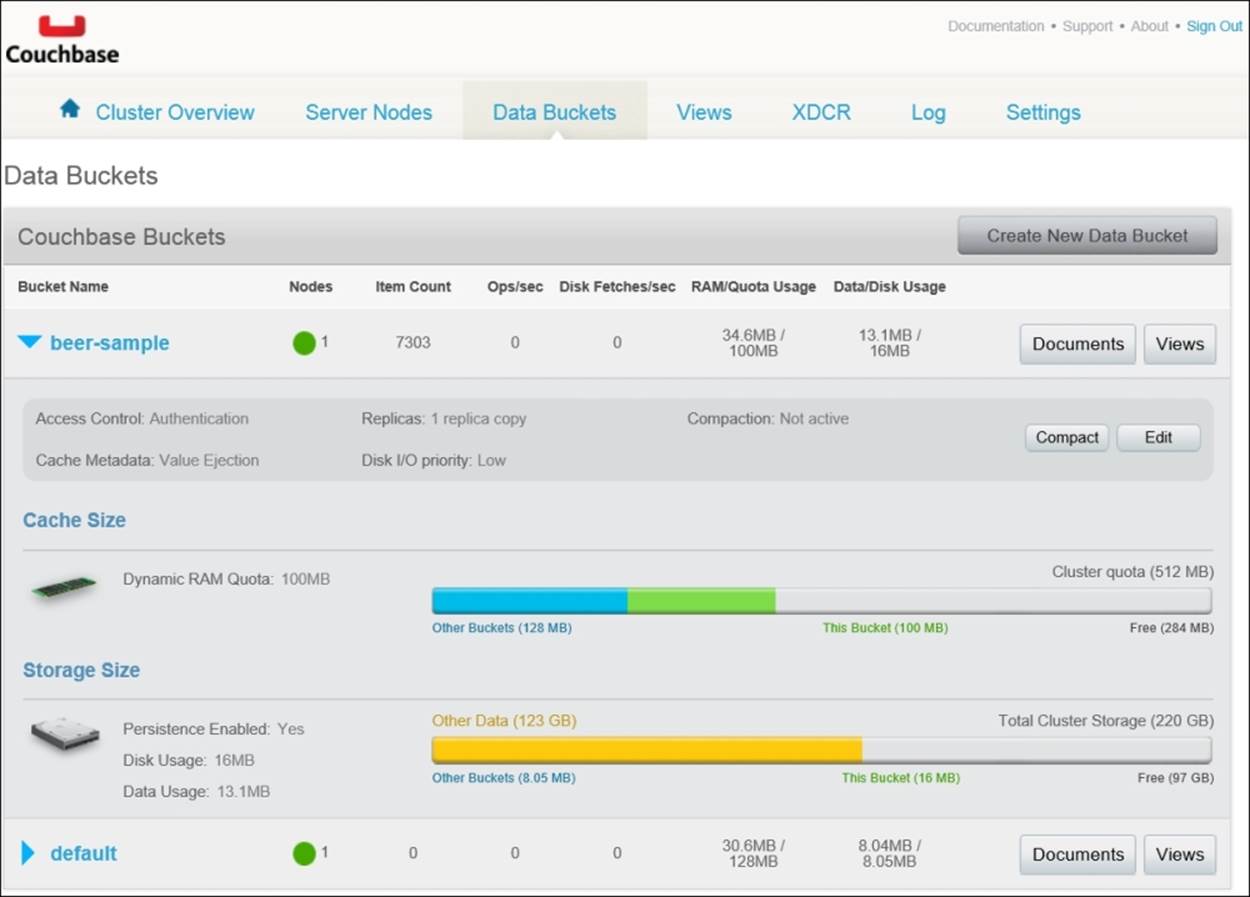
The Data Buckets tab provides you with a high-level overview of your buckets. You'll see each bucket listed with information ranging from server resource utilization to item (document) count. Feel free to explore some of the other features of this tab. This is where you are able to create and edit buckets. What we're most interested in is checking out the documents in our bucket. Click on the Documents button in the beer-sample bucket row, as shown next:
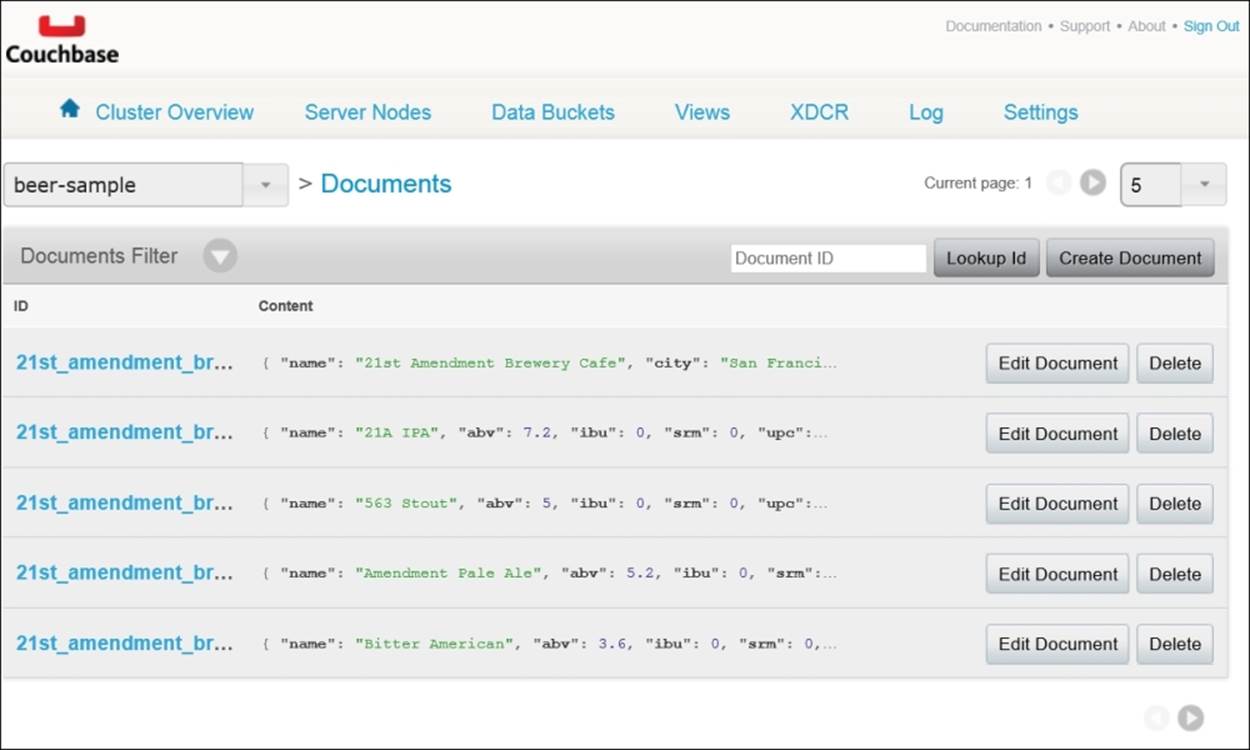
On this screen, you'll be able to browse for a document by its key or simply go through all the documents in the bucket. Select the beer-sample bucket from the drop-down menu above the list of documents. You'll then be able to browse through the sample beer and brewery documents. You're also able to edit or add documents to a bucket using additional features on this tab.
On a side note, if you followed along with an SDK in Chapter 2, Using Couchbase CRUD Operations, and looked up one of the documents you saved, you'd have noticed that you don't see JSON, but rather something that looks like what is shown in the following screenshot:
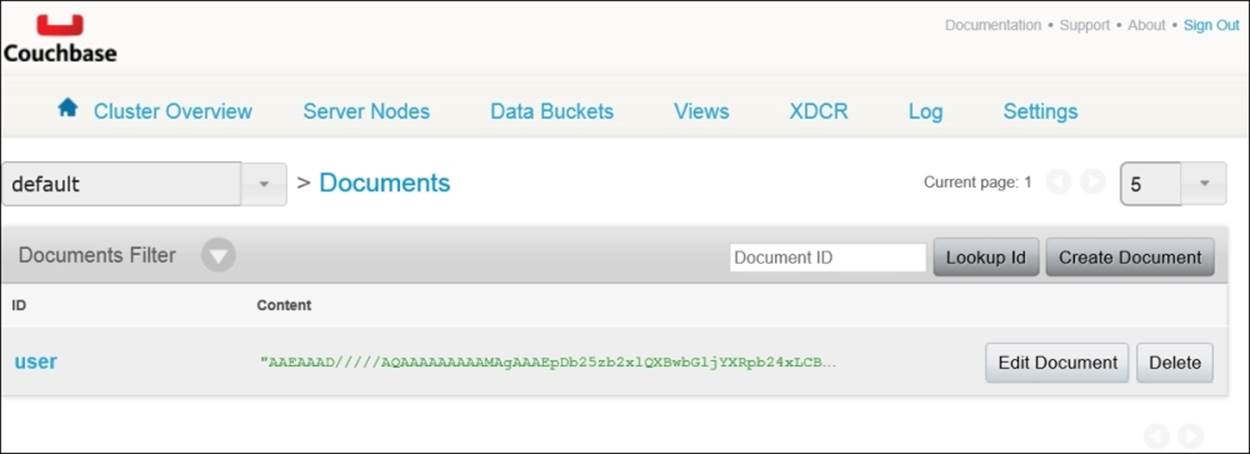
Earlier in this chapter, we learned that Couchbase Server recognizes proper JSON strings and treats them differently. Any value you store that is not JSON is treated by Couchbase Server as a byte array. Its meaning is up to your application to define. When you view a non-JSON-valued key in the document view, you'll be shown a base64 representation of that key's value.
While these documents are technically accessible to views, practically speaking you're highly unlikely to ever use a non-JSON record in your views. You could decode a base64 value in JavaScript, but we'll work with the assumption that you don't want to do so.
Tip
A common problem new Couchbase developers encounter is that they didn't provide proper JSON to the server, and they are unable to retrieve expected documents when querying a view. Checking for a base64-encoded string in the Documents page is a good way to eliminate bad JSON.
We're now ready to explore the Views tab, as shown here:
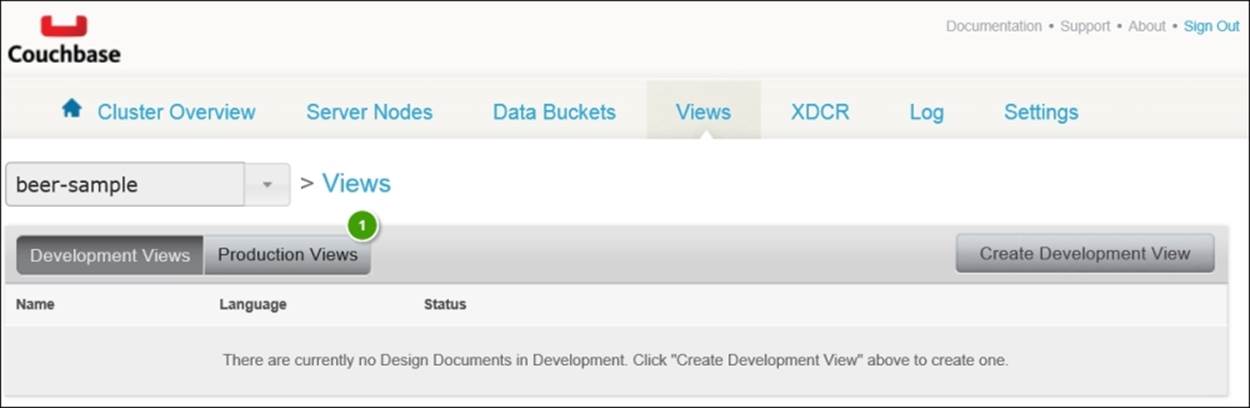
Development views
If you have a bucket with millions of documents, you probably won't want to trigger index creation with every tweak of your view definition during development. To allow developers to build views iteratively and quickly, Couchbase Server includes development views.
Unlike production views, development views are applied only to a subset of data from the bucket. Therefore, you are safely able to test a view definition against your production systems. Your application won't accidentally query one of these views either, because you must explicitly turn development views on for your chosen SDK.
After you've developed and tested your development view, you are able to promote it to production. At that time, the full bucket is indexed. In the Couchbase Console, you're able to edit only development views. Your production views are read-only.
The Couchbase REST admin API does allow you to work around this safety check by creating a view outside the confines of the console. You might choose to manage your views this way because it allows you to work more easily with source control or server automation tools.
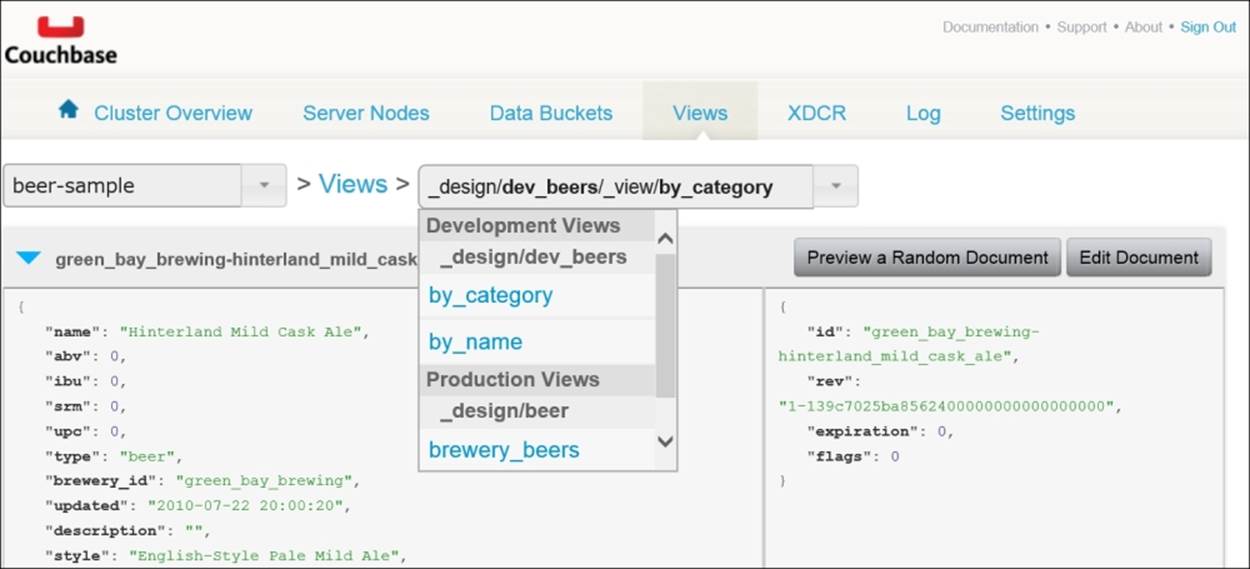
We'll focus only on the Couchbase Console to create our views. To get started, click on the Create Development View button. You're then taken to a page where, at the top, there are dropdowns with your buckets and views in those buckets. Select the beer-sample bucket. This sample bucket includes three predefined views, as shown next. We'll create our own view rather than examining these.
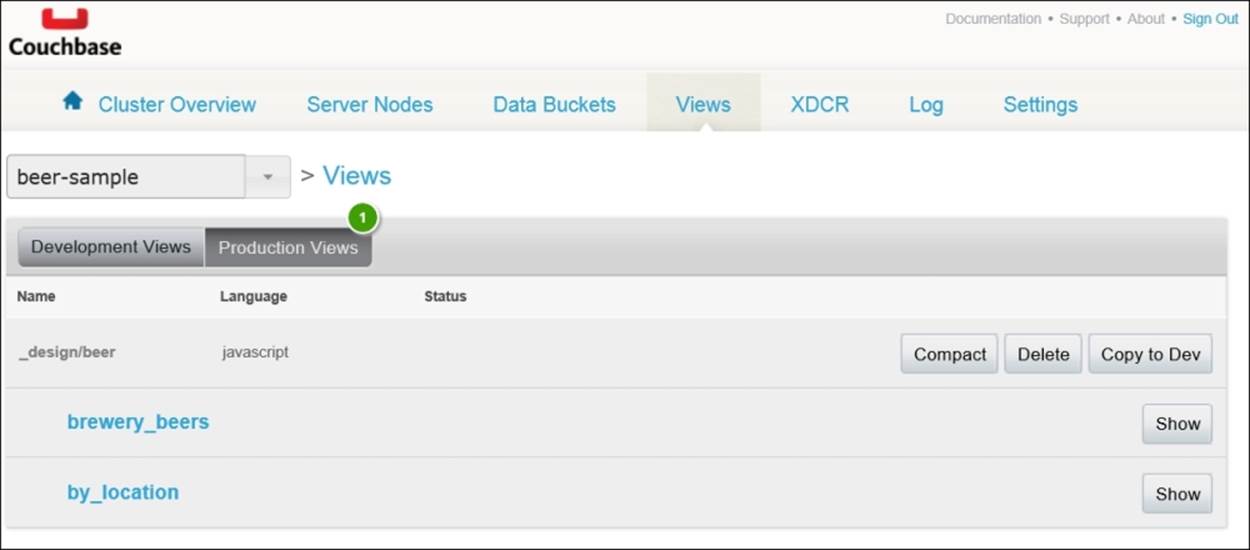
Design documents
With the beer-sample bucket selected, click on the Create Development View button (ensure that Development Views is selected). In addition to providing a view name, you'll be prompted to provide a design document name, as shown here:
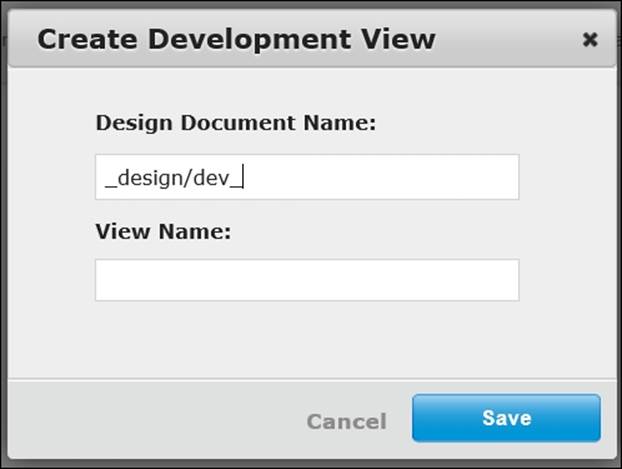
Naming a Development View
Views are defined in special documents on the server, known as a design documents. These documents are named with a prefix of _design/ followed by any meaningful name you choose. Additionally, development design documents will be named with a dev_prefix.
Your design document may contain one or more view definitions. Typically, you're likely to have one design document for each document type (for example, one beer design document and one brewery document). However, our sample design document contains views for both breweries and beers.
Tip
While adhering to the convention of one design document per document type is a good place to start, there are other factors that you must consider. Specifically, when you make any change to a design document, it triggers a re-indexing of all views defined within that design document. Therefore, it's best to segment views based on the likelihood of one document being updated.
Creating a view
Now that we know what design documents are, we're ready to create our first view. In the dialog box that appeared when you clicked on Create Development View, name the design document _design/dev_beers.
A useful convention for naming views is to prefix them with by_ and complete the name with the indexed fields. So, for the new view we're about to create (which indexes beer documents by their name property), set the name of the view to by_name.
After you've provided the design document name and view name, you'll see your view listed on the page. To edit this view, you could click on either the Edit button or the name of the view. Then you'll be presented with a simple editor in which you'll create your views, as shown next:
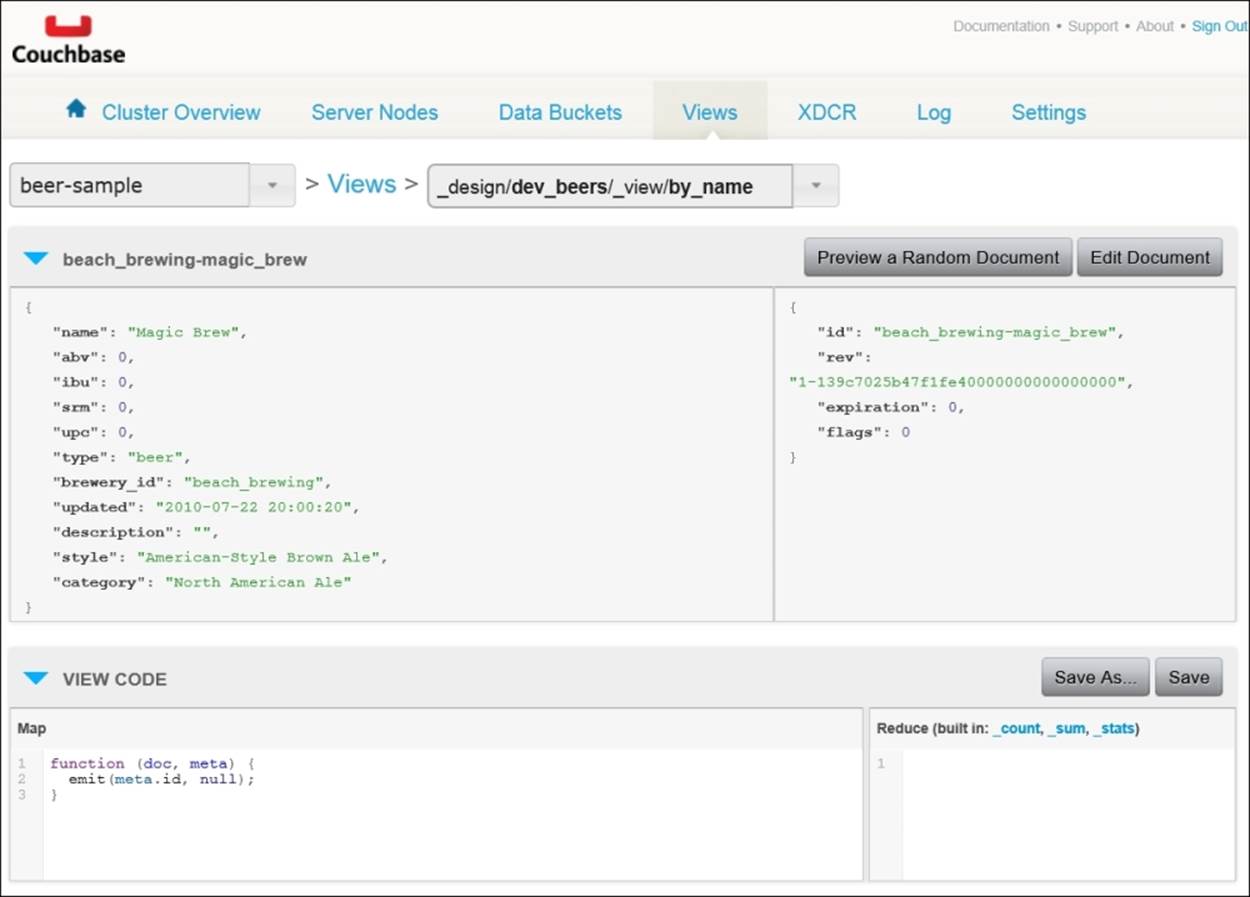
The default view that appears includes a map function. This map function looks slightly different from those we previously walked through. While it's mostly the same map function, notice the additional meta parameter. This optional parameter provides you with a way to access document metadata in your map function. Each document in Couchbase has a few fields of associated metadata. You can see these fields in the panel above the code editor (under Preview a Random Document).
More often than not, the only metadata field your views will be concerned with is the id field. This field is the key from the key/value API that is associated with a document. It's important to understand that the key is not part of the document, but rather a means of storing and retrieving the document.
The window that you see by default when you create a new view creates an index on document keys using the meta argument's id property. It might seem redundant to create a secondary index on the primary index. However, should you wish to perform range queries (that is, find all keys from A to C), then you'll need this index.
To create our view, we'll reuse the map function we wrote earlier in this chapter:
function(doc, meta) {
if (doc.type == "beer") {
emit(doc.name, null);
}
}
After you've modified the map function to use this code, click on Save to start the process of indexing the documents. Once the map function is saved, we are able to test our view by clicking on the Show Results button under the code editor, as shown here:
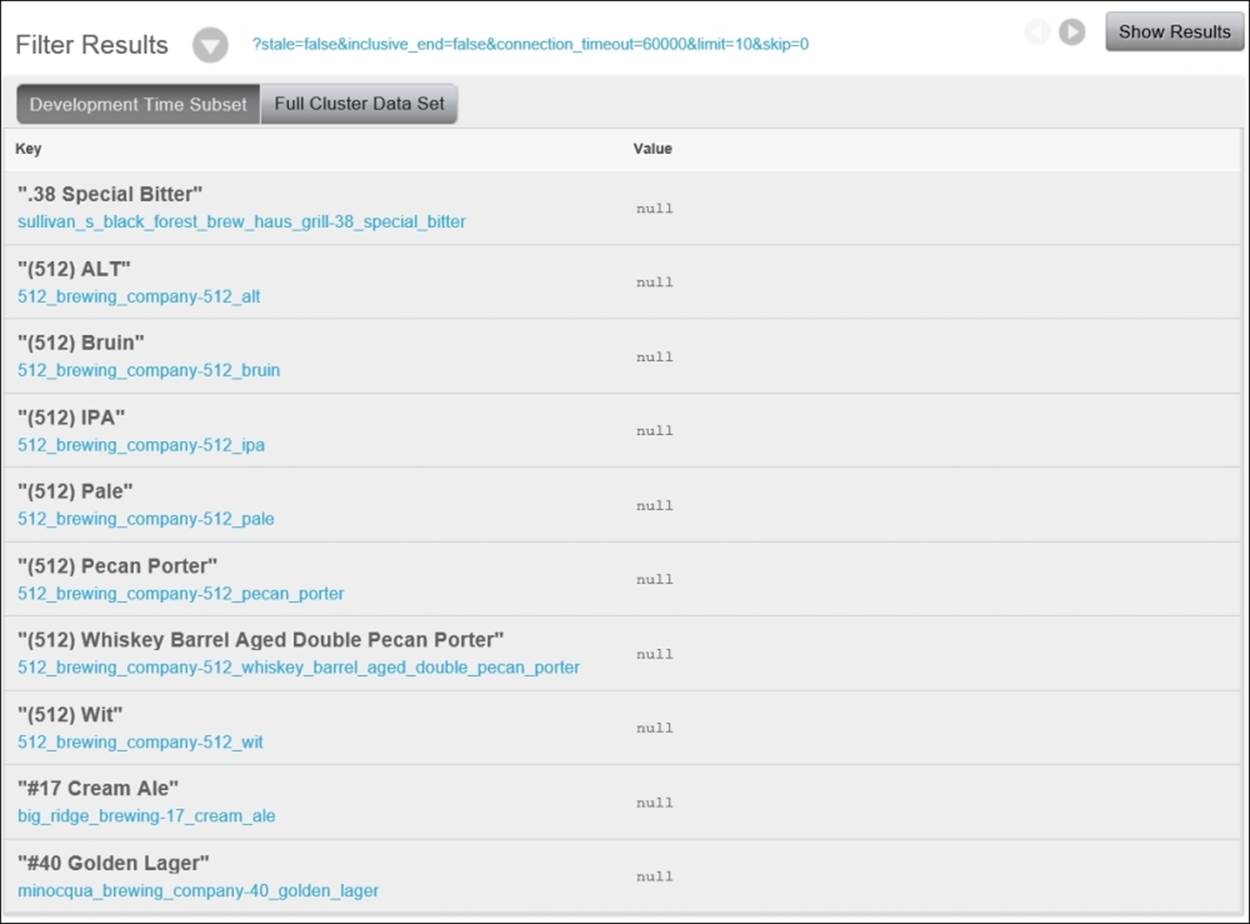
The result you'll see is simply a list of every document that was included in the index. The key parameter in the index is the document's name property, ordered using Unicode collation. The value is null in this case because we did not include a second argument to our call to emit(). Notice that the document's id property is included under each of the index keys.
In many programming languages, sorting tends to follow byte order. If you sort a set of strings, most default implementations would follow ASCII ordering, which orders uppercase letters before lowercase variants. By contrast, Unicode collation orders variants of the same letter next to each other, as we have already discussed in a previous section.
Tip
If you're unfamiliar with Unicode collation, you can think of it as being "not quite alphabetical." Though A will always be ordered before B, so will À. In other words, variations of letters will be ordered together before the next letter and its variations. Additionally, lowercase letters and their variants will precede uppercase variants. Numeric values will precede all letter variants.
Before we move on to running queries against our views, let's walk through our earlier MapReduce example where we tried to count beer types by category. Start by clicking on the Views tab, where you'll now see you have the ability to add a view to your existing design document, as shown here:
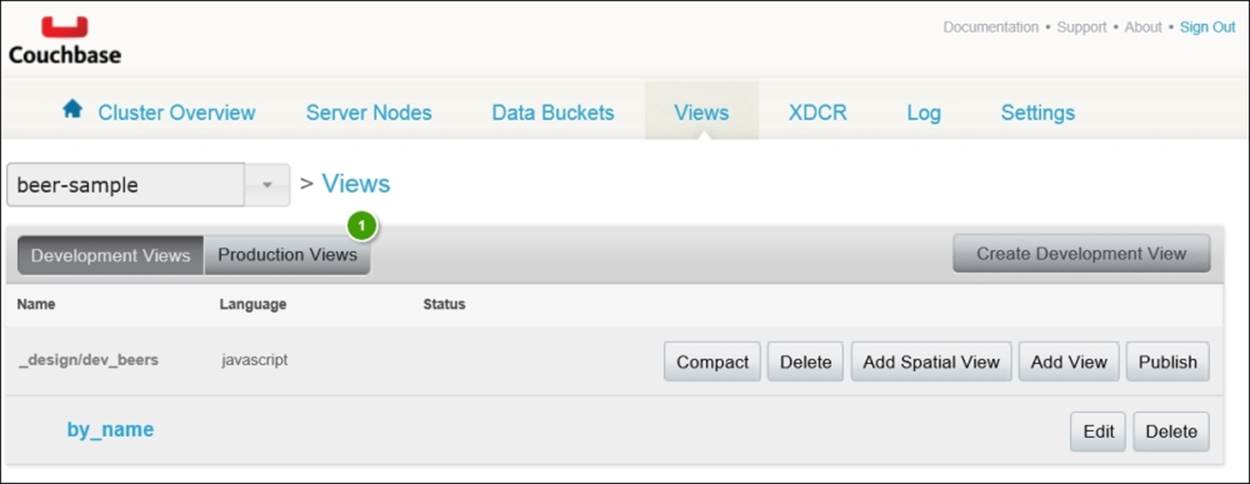
Click on Add View in the line where the dev_beers design document is shown. Name this view by_category. Click on Edit next to the new view to return to the view editor page. Modify the map function so that it looks like this snippet:
function(doc, meta) {
if (doc.type == "beer" &&doc.category) {
emit(doc.category, 1);
}
}
Tip
This map function is the similar to the function we wrote earlier in this chapter, but it now includes a safety check so that beers without a category are not indexed. Without the null check, the index would contain numerous documents that do not have a category. Checking for a property's existence is a common practice when creating views.
Once you've modified the view code, click on Save. Then click on Show Results. The grid should look similar to that of our by_name index, but with the addition of 1 to the value for each indexed document, as shown next:
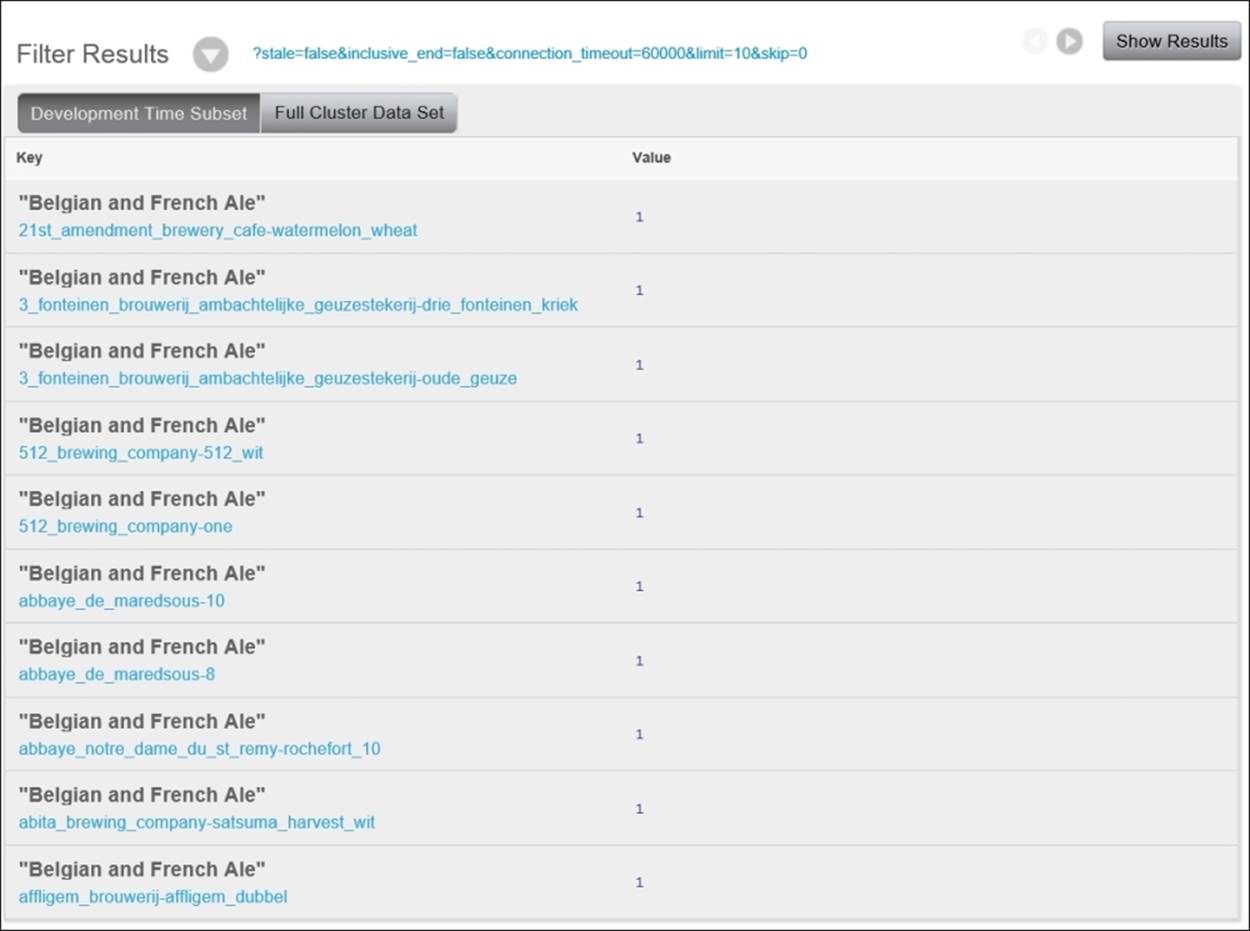
Take note of the fact that at this point, each category appears in our results, once for each beer with which it's associated. To find the count of beers grouped by category, we'll need to add a reduce function to our view. For this example, simply use the built-in _countfunction in the reduce editor. After you've made that change, click on Save and then on Show Results. You can see the following result:
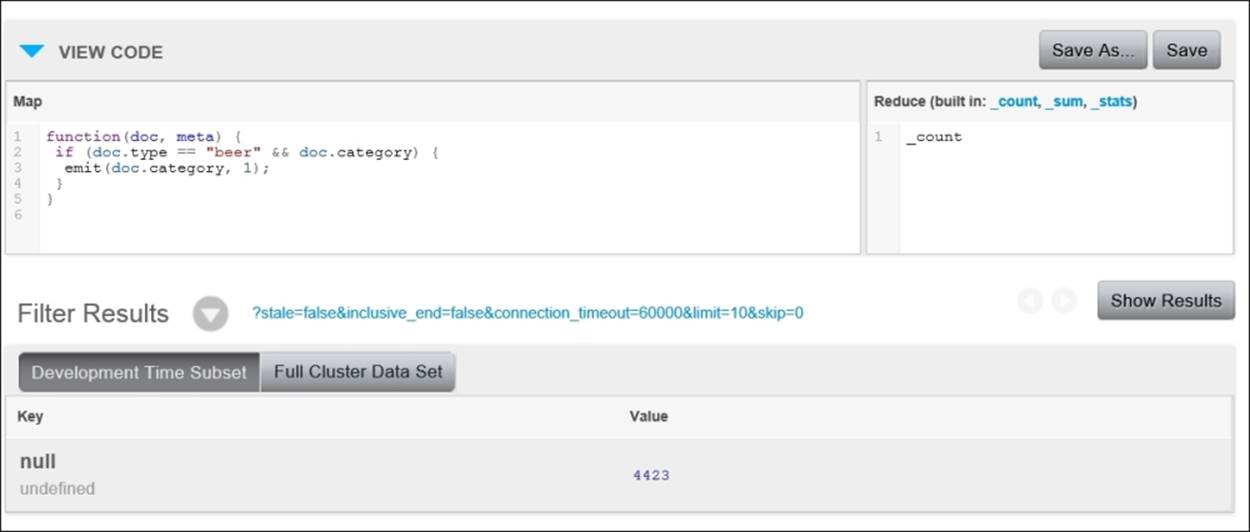
The results you see might not be what you expected. We've said all along that our goal was to provide a count of beers grouped by category. Instead, what we're seeing is the equivalent of a SQL COUNT query without a GROUP BY clause:
SELECT COUNT(*) FROM Beers
To understand how we group our results, we'll have to explore the view query API, which we'll do in the next section.
Tip
Downloading the example code
You can download the example code files for all Packt books you have purchased from your account at http://www.packtpub.com. If you purchased this book elsewhere, you can visit http://www.packtpub.com/support and register to have the files e-mailed directly to you.
Querying views
An important distinction to make at this point is that views are not queries, but means of querying for documents. You'll run queries against the view index in order to find the original documents. It is a common misconception that the views you write are actual queries.
Couchbase views have an API that supports a variety of search options, from an exact key search to a key range search. Continuing to use the Couchbase Console, we'll explore the various parameters we are able to use as we query our views. Begin by clicking on the down arrow next to the Filter Results text above the results panel.
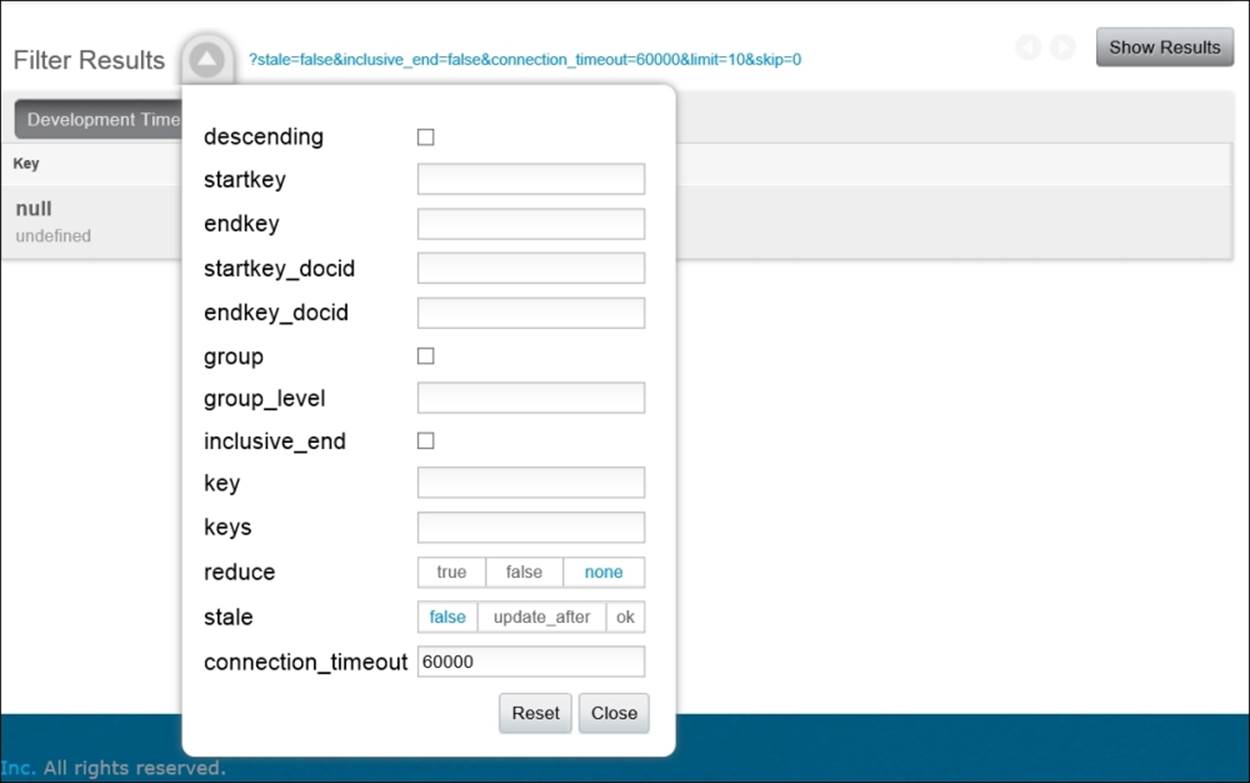
Filtering views
Grouping
To continue with the reduce example, check the box next to group and click on Close. Click on Show Results again, and you'll now see that the results are grouped by the name of the category, as shown here:
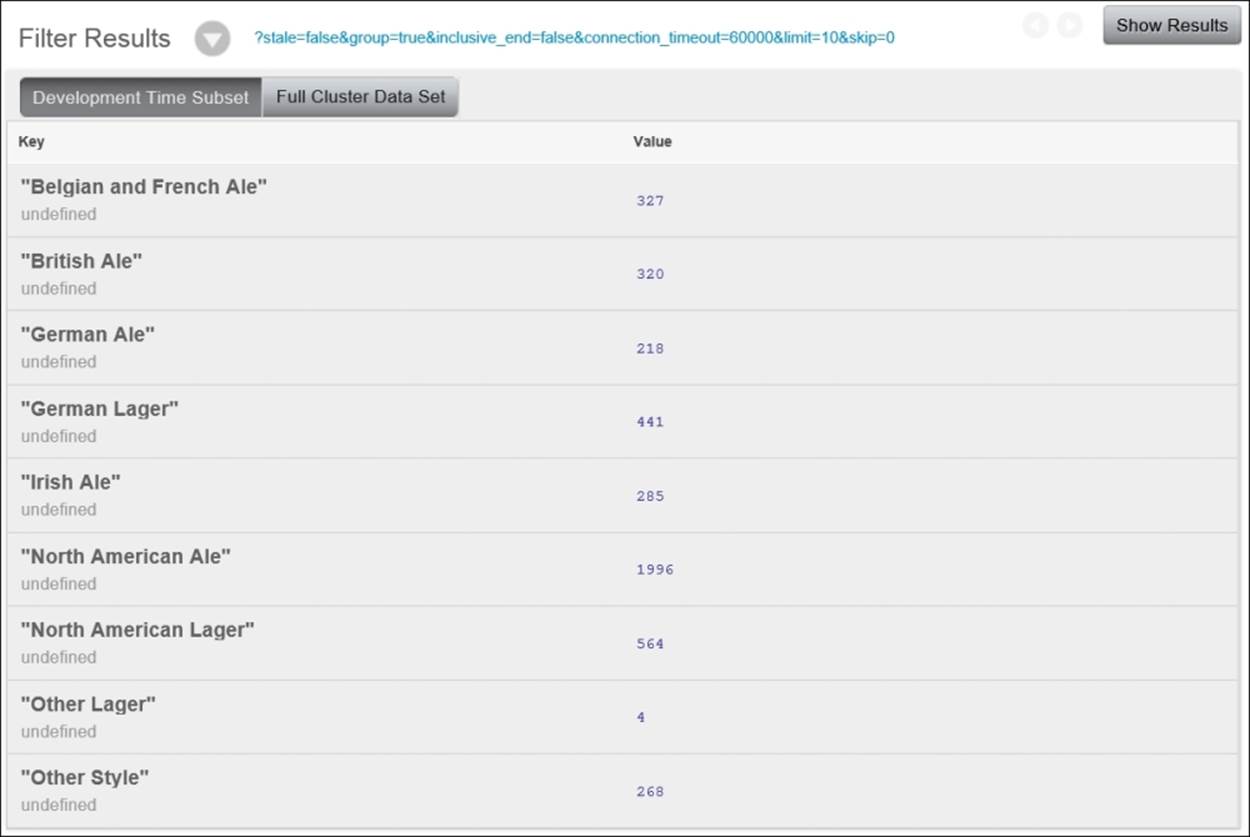
There's an additional parameter called group_level under the group option. This parameter takes an integer argument and is meant to be used with composite (array) keys. Our map function produces only a single-value key, so we'll avoid exploring this option untilChapter 4, Advanced Views.
Key queries
To continue our examination of the different view query options, let's return to our by_name view. Scroll up to the top of the page and select this view from the drop-down list. You can see this in the following screenshot:
Once the page has refreshed with the by_name view, return to the Filter Results section and expand the dialog. For our first query, we'll search for beer types with names starting with the letters B and C. To do so, enter "B" in the startkey field and "D" in the endkeyfield. Note that the quotes around your start and end keys must be included.
Close the dialog and click on Show Results again. You'll see that the first beer types shown have names starting with the letter B. You can click all over the list to see the results that were returned as part of our view query.
Tip
Note that if you page through the list, you might not find a beer starting with C. The reason is that the results view panel limits your results to only 100 records.
Range queries such as these are useful when we don't know exactly what we're looking for. However, we'll often want to search for a document by an exact match on an indexed property. To achieve this result, simply supply a string value to the key parameter, such as "Three Philosophers" or "(512) ALT". Similarly, if you want to search on multiple keys in one query, you can supply an array to the keys parameter, such as ["Three Philosophers", "(512) ALT"].
Eventual consistency
We'll explore the parameters that we saw in the previous section, along with other parameters, in more detail in the next chapter. One last parameter we'll examine now is the stale option. You've already learned that views are incrementally updated, which means your query might be against a stale view. In other words, if a document was modified, the current state of the index might not have considered that change yet.
This delay between the time a document is modified and the time it is indexed is known as eventual consistency. In other words, the right or current value for a document will eventually be made consistent in the view index. In many cases this might be acceptable, but for others it's not. Fortunately, with Couchbase you can tune your consistency requirements for views.
By default, querying a view will trigger an update to the index after the results of the query are returned. This is done by the update_after argument, which may be supplied to the stale parameter. If you need a fully consistent answer, then set the stale value to false. If stale data is permissible, set the stale value to ok. This last option will not force an update of the view index.
Tip
Prior to Couchbase Server 3.0, a document had to be made to persist in the disk before it could be considered for an index. This meant that true consistency between in-memory documents and view indexes required a combination of key/value operation with astale value of false. Couchbase Server 3.0 introduces new stream-based views. Built on the new Data Change Protocol (DCP), streamed views may be made consistent by setting stale to false. This setting considers in-memory changes.
Couchbase SDKs and views
For another perspective on your view, click on the link right above the grid of results. This link will lead to a JSON view of our index:
{
"total_rows": 5891,
"rows": [
{
"id": "sullivan_s_black_forest_brew_haus_grill",
"key": ".38 Special Bitter",
"value": null
},
{
"id": "512_brewing_company-512_alt",
"key": "(512) ALT",
"value": null
},
{
"id": "512_brewing_company-512_bruin",
"key": "(512) Bruin",
"value": null
}
]
}
The client libraries will use this JSON when querying a view. This view also introduces an important element of the Couchbase Server view API—the fact that it's HTTP-based. Unlike the key/value API, which is a binary protocol, views are queried over a RESTful API, with parameter values supplied as query string arguments. Being able to see the JSON that your client library sees is useful not only for debugging but also for understanding how you'll work with views through your SDK.
Unlike documents, which reside in memory (when available), view indexes are stored in the disk. Therefore, it's more expensive to query a view than to retrieve a document by its key. As such, it is best practice to think of an index as a means to retrieve the document's key. Once the key is found, you'll then use the key/value API to retrieve the original document.
Tip
It is a common mistake to output the original document as a part of the map function by supplying doc as the value argument to emit(). Doing so means storing a copy of your document with the index, which will not be kept in sync with the doc argument in the memory.
As you can see in the previous JSON, each record in the index provides your SDK with three values. The first parameter, "id", is the key for a document to use with the key/value API. The second parameter, "key", is the key that was indexed. Your queries are made against this key. The third parameter, "value", is the value you output, typically to be used with reduce.
To see how you can use an SDK to query a view, consider the following C# snippet:
var query = bucket.CreateQuery("dev_beers", "by_name");
var result = bucket.Query<dynamic>(query);
foreach (var item in result.Rows)
{
Console.WriteLine(item.Key);
}
In this example, the client SDK will query the view (without arguments) and get back an enumerable View object. As the view is iterated over, the GetItem() method uses the index row's id property to query for the original document via the key/value API. The Java SDK has a similar approach:
View view = client.getView("beer", "brewery_beers");
Query query = new Query();
query.setKeys("[\"Three Philosophers\",\"(512) ALT\"]");
ViewResponse response = client.query(view, query);
for (ViewRow row : response) {
System.out.println(row.getDocument());
}
Each SDK adheres to roughly the same pattern. First, you get access to a view object of some type and set any parameters you need to set. Then you iterate over the results, getting the original document by the ID value found in the index.
For better performance, you should consider using the multi-get operations. To do so, you should first aggregate the set of id values into some enumerable structure, and then pass that set of IDs to the multi-get operation of the SDK. The following C# snippet demonstrates how to create a list of IDs from the view results and then supply those IDs to a multi-get operation:
var query = bucket.CreateQuery("dev_beers", "by_name");
var result = bucket.Query<dynamic>(query);
var ids = result.Rows.Select(r =>r.Id).ToList();
var beers = bucket.Get<dynamic>(ids);
Summary
We covered a lot of ground in this chapter. In the beginning, you saw Couchbase only as a key/value store. Since then, you learned that Couchbase is a very capable document store as well, treating JSON documents as first-class citizens.
You learned the purpose of secondary indexes in a key/value store. We dug deep into MapReduce, both in terms of its history in functional languages and as a tool for NoSQL and big data systems.
As far as Couchbase MapReduce is concerned, we only scratched the surface. While you learned how to develop, test, and query views, the queries covered so far were simple. Couchbase view queries are capable of a lot more, which you will see as we move forward.
In the next chapter, we'll cover MapReduce in detail. We will have to start exploring more complex views, with a special focus on queries you're probably used to in SQL. From complex keys to simulating joins, you'll soon see that Couchbase views can be used for a lot more than simple queries.
All materials on the site are licensed Creative Commons Attribution-Sharealike 3.0 Unported CC BY-SA 3.0 & GNU Free Documentation License (GFDL)
If you are the copyright holder of any material contained on our site and intend to remove it, please contact our site administrator for approval.
© 2016-2026 All site design rights belong to S.Y.A.