Learning Cypher (2014)
Chapter 5. Migrating from SQL
For several reasons, relational databases are probably the most used storage solutions by programmers and architects. There are a lot of stable tools for designing, monitoring, and querying. Both the relational model and the SQL language that are well-known among the programmers and are a part of most programming languages, such as Java, Ruby, Scala, C# and so on, have stable drivers that allow you to connect to common SQL databases. In the past, migrating from SQL could be a nightmare; your tools would stop working, and your application (or the persistence layer at least) would need to be completely rewritten. The whole reporting system could stop working as well. Nowadays, thanks to Cypher and to projects such as neo4j-jdbc, (http://www.neo4j.org/develop/tools/jdbc), the process is much simpler.
Migrating from a commercial SQL database such as SQL Server or Oracle to a graph database could happen due to several reasons:
· The database can't scale up any more (at least with reasonable costs), because it is bombed with write requests, and your RDBMS is blocked by transactions, locks, triggers, and indexes
· Your model changes quickly in the life cycle of the application, and you can't fit your logical model in the relational model without refactoring the database schema at every change request you submit
· You spend a lot of time deploying and updating the database schema, and you're looking for more flexibility but with the guarantee provided by ACID transactions
Irrespective of the reasons to migrate from SQL to Cypher, in this chapter, we will learn through real-world examples how to migrate a database from a SQL database to Neo4j in three steps, which are as follows:
· Migrating the schema from SQL to Neo4j
· Migrating the data from tables to Neo4j
· Migrating queries to let your application continue working, without making too many changes to your code
In this chapter, for the sake of generality, it is assumed that the interaction with the SQL database is made directly without any ORM or an abstracting layer. In Java, this means JDBC.
Anyway, it is noteworthy that for JPA, there is a driver-enabling Neo4j for Java EE (http://github.com/alexsmirnov/neo4j-connector), while for Ruby, the project Neo4j.rb (https://github.com/andreasronge/neo4j) acts as compliant ActiveModel wrapper for Neo4j.
Note
If you are using an ORM supported by Neo4j, you won't need to migrate CRUD operations, but you will still need to migrate the schema, data, and complex queries. In fact, ORMs and Active Records just reduce the frequency with which you use the underlying query languages and, foremost, save you the effort of mapping the database every time from the data model to the object model; however, you must still know your data model.
Our example
In this chapter, as an example, we will migrate a minimal bibliography store. A bibliographic store contains a huge set of publications that can be referenced.
Our example is composed of the following entities:
· Reference: This can be a book, journal or conference article
· Publisher: This can be a company, university, organization, or conference from where the article is published.
· Author: This represents the author of a publication
The following figure shows the E-R diagram of the database:
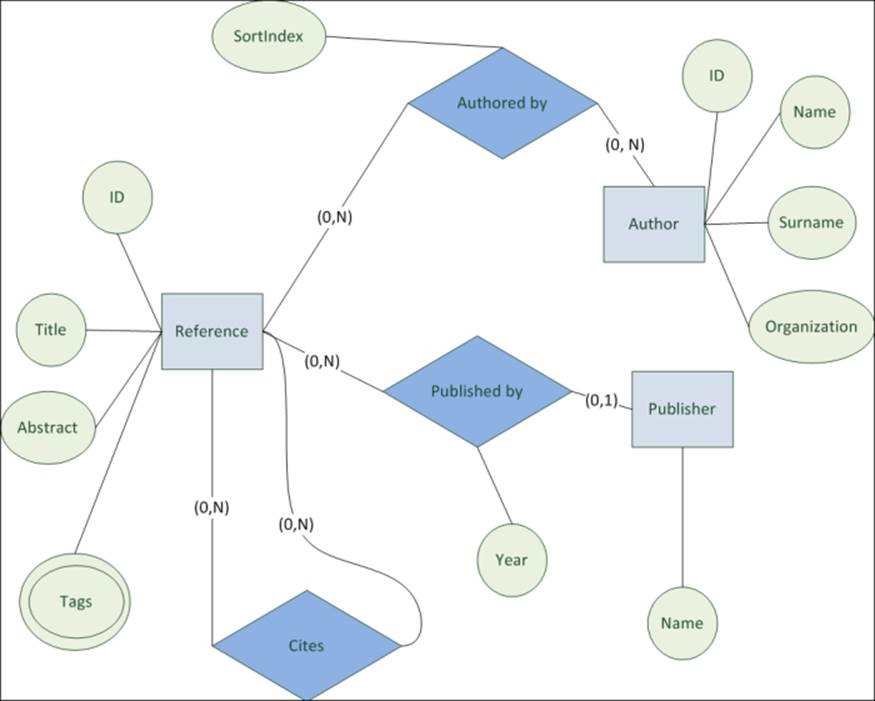
Note
An in-depth explanation of the E-R diagram would be far beyond the purpose of this book; here we can just say that the purpose of the E-R diagram is to describe a model based on entities and relationships. It shows the following features:
· Entities: These are the objects that have an independent existence and can be identified uniquely. They are represented in a box.
· Attributes: These are the values whose existence depends on an entity; an attribute does not make sense alone and must be related to an entity. They are represented in a circle linked to an entity. An attribute has a multiple cardinality if it can have multiple values. In this case, the attribute is represented in a double circle, like the Tags attribute in the previous diagram..
· Relations: This is the relation between entities. They are represented in a diamond.
This application is similar to a book store. The difference is that it can contain much more data such as articles, websites, blog posts and so on. However, the most important difference is that you can have huge number of relationships:
· A reference can be published by a publisher
· An author may have worked on many references
· A reference can be cited in many other references
It's important to understand the domain we are migrating because we will change the persistence model extensively; however, the domain model will remain the invariant part and will continue to be the basis of the new data layer. In the next step, we will migrate the schema of this database to Neo4j.
Migrating the schema
The database schema in a relational database defines tables, attributes (columns), primary and foreign keys, as well as indexes. To create these schema elements in relational databases, you will need a Data Description Language (DDL).
Note
In the code provided at the Packt Publishing website (http://www.packtpub.com/), you will find the complete code to create and query the database.
The queries shown in this chapter are slightly different from the ones provided with the code. In fact, the complete code uses the Apache Derby (a famous embedded SQL database) and, just as most relational databases, has its own dialect. For generality, the SQL code shown in the chapter, is SQL ANSI, which is the standard SQL.
Moreover, the SQL queries in this chapter are written in lowercase to better differentiate them from the Cypher queries. As you know, both SQL and Cypher are case insensitive.
For example, the following CREATE TABLE SQL query creates a table of the reference entries in the database:
create table ReferenceEntries(
ID int not null primary key,
TITLE varchar(200) not null,
ABSTRACTTEXT varchar(1000) not null,
PUBLISHEDBY varchar(200)
references PUBLISHERS(NAME)
on delete set null
on update restrict,
PublishedYear int)
The table has a primary key (ID), a non-nullable property (title), and the column that contains the abstract. This table also references the publisher and the data of this relation (the year). This relation is present here and not in a new table because it's a one-to-one relation.
As you know, representing an E-R diagram in SQL is not straightforward. For example, to represent the reference entity, we need another table, one that stores the tags of a reference entry because SQL does not allow multivalue attributes:
create table EntryTags(
ReferenceId int references ReferenceEntries(ID),
Tag VARCHAR(50) )
Note that this table does not need a primary key (though it could have one) because it does not store entities.
The following diagram shows all tables used in our application to represent the aforementioned E-R diagram:
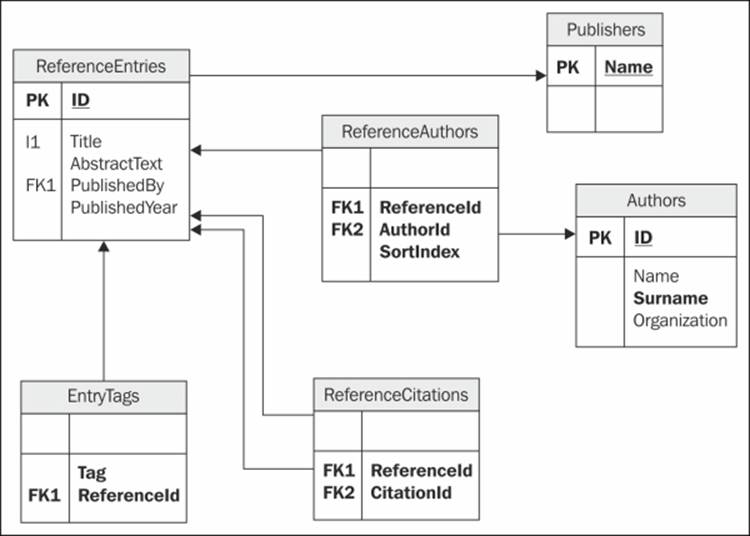
What do we need to migrate this schema? Even though Neo4j essentially is considered schema-less, it is still better to consider designing the graph model in advance by making the following important choices:
· Determining the type of labels and the number of labels to use in our graph database
· Determining the properties that need unique assertions
· Determining the properties that need indexing
· Determining the relationships to consider between the nodes
I think that the best approach is to start from the E-R diagram of the database. If you do not have an E-R diagram for your database, you could easily write one; however, for this, you should know the domain of the application. In the next sections, we will answer the questions that just arose.
Labels
Since entities are objects that are not defined by their attributes but have an identity of their own, you must be able to identify them in the graph. For each entity in the E-R diagram, create a label.
Therefore, in our example database to migrate, we have the following labels:
· Author
· Reference
· Publisher
Note that the entities in a E-R model don't match one-to-one with tables because many relations (and surely many-to-many relations) are mapped in tables. So, it's better to create the Neo4j model from a more real model (like the E-R model) rather than from the table-based model, This prevents the risk of introducing complexity and limitations of RDBMS in the Neo4j graph.
Just like when you translate from an E-R model into SQL, you can merge two entities that have a one-to-one relationship in a single label. Of course, this choice depends on the domain of your application and the usage of your database.
To clarify, consider a diagram with two entities, Person and Personal Account, each with their attributes and sharing a one-to-one relationship between them. This means that creating or deleting a person will always result in creating or deleting a bank account and vice versa:
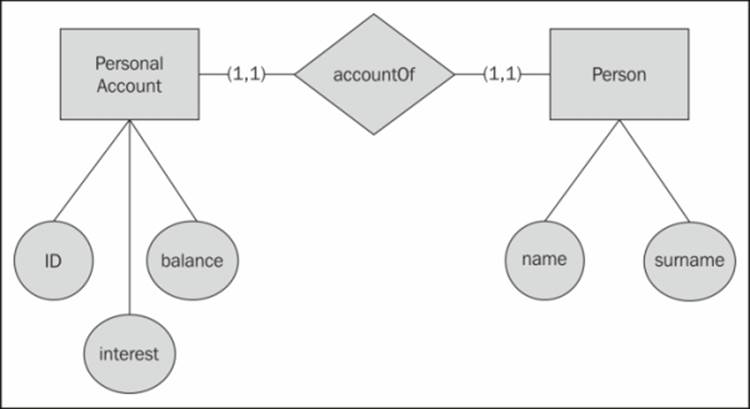
The E-R diagram of a one-to-one relationship
In this case, you could decide to put everything inside the Person label:
On the other hand, you could put two labels in the database (Person and Personal bank account) and a relationship between them. In this case, you can decide later whether most of Person nodes will also have the PersonalAccount label because even Neo4j allows self-loops:
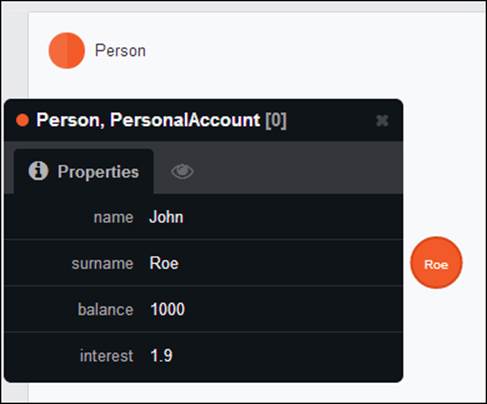
Of course this approach, though being very flexible, would affect all your queries and their performance because you will always need to visit a relationship to get the account information of a person. In fact, you can't say that the data in these labels are in the same node of a priori. The best approach depends on the usage of the database—if your application reads the PersonalAccount data every time it accesses the Person data, then they should be merged.
Indexes and constraints
Now, let's go to the second and third question about indexes and constraints. We can ignore attributes now because Neo4j is schema-less. But, we can define the uniqueness constraints. In the previous chapter, we had seen how these constraints are useful to preserve database integrity, and improve performances of queries. For example, for the reference label:
CREATE CONSTRAINT ON (r:Reference)
ASSERT r.id IS UNIQUE
The same constraint can be created for authors:
CREATE CONSTRAINT ON (r:Author)
ASSERT r.id IS UNIQUE
Considering, our model publishers don't have an ID but are referenced by name, we can create a constraint on the name:
CREATE CONSTRAINT ON (r:Publisher)
ASSERT r.name IS UNIQUE
Then, we can create an index on the properties most used for searching. We mustn't create indexes for properties that have a constraint already defined, because a constraint implies an index automatically as we learnt in the previous chapter. But, for example, the title property will be surely used for searching:
CREATE INDEX ON :Reference(title)
Also, tags are likely to be used for searching:
CREATE INDEX ON :Reference(tags)
While, authors could be searched by surname:
CREATE INDEX ON :Author(surname)
Publishers nowadays don't need any index, because the name is already indexed by the constraint we defined in the preceding code.
Tip
Note that by using SQL databases, you have to create one more table to express multi-valued attributes such as the tags of the reference. By using Neo4j, this is not necessary because you can have array properties on nodes and relationships. Anyway, you can still create a separate tag node for each tag and link it to the reference through a relation if you should find that such a model performs better in your situation. Yet, this choice would neither be driven by data model nor by database limitations, but only by performance or applicative considerations.
To summarize, the answer to the second and third questions are:
· Create a uniqueness constraint on properties that are the primary keys of the SQL model
· Create an index on properties that are used for searching, and probably have an index on the SQL database
Relationships
The last question is which relationships to use. Since relationships in Neo4j are complex structures with properties and types, you don't have to create anything like relation tables as we did in SQL to describe many-to-many relations or relations with attributes. The consequence is that relationships between entities of the E-R model can be expressed directly as Neo4j relationships in the graph.
In our application, we have these relationships:
· AuthoredBy
· Cites
· PublishedBy
In my opinion, the resulting Neo4j database has a far more natural look than its SQL ancestor, especially if we compare them to the E-R diagram. The reason is that this domain fits the graph model more naturally than the table model. In this case, querying and data manipulation also looks easier, it will be clearer in the next sections of this chapter. The old motto "use the right tool for the job" is still valid. In fact, SQL is still a very good choice for data that doesn't have too many multiple entity relations.
Migrating the data
To migrate the data, you have to convert SQL data to graph data. This is a long-lasting activity of the process and probably awkward as well. Because you have to migrate data from SQL, you must read data using ad hoc SQL queries and write data using Cypher queries.
Note that another strategy would be importing data from a CSV file, with the LOAD CSV FROM statement, which is available from Cypher 2.1 at http://docs.neo4j.org/chunked/milestone/import-importing-data-from-a-single-csv-file.html.
Entities
Because we have to create a node with its attributes, we have to read data using a SQL statement that returns all the data we need to create a node. Of course, you can migrate an entity in more steps, but we would usually prefer to perform only one CREATE query for performance reasons because otherwise we would have to migrate a huge database.
1. For example, let's start by migrating the Authors entity. This entity is easy to deal with; in fact, all attributes are only in one table:
2. select ID, NAME, SURNAME
from AUTHORS
This SQL query returns all the Authors entities in the database. Now, we have to iterate on each returned row to create a new node per row:
CREATE (:Author { id: {id},
name: {name},
surname: {surname} })
Clearly, this is the perfect situation to use parameters. In fact, we will run a lot of similar queries and take advantage of the cached execution plans as this will give a boost to the migration, as we learned in the previous chapter.
3. We can deal with the Publisher entity in the same way. Let's start reading from the table:
4. select NAME
from Publishers
Then, we can create a node for each returned row using the same parameters:
CREATE (:Publisher { name: {name} })
5. Assuming that we have chosen to store tags in an array property, the first problem is when we have to create the Reference entities. In the SQL database, in fact, the entity is split into two tables, so the migration must be done in two steps: creating the Reference nodes and then setting the tag property on the node.
For the first step, we need to load the references from the database:
select ID, TITLE, ABSTRACTTEXT
from REFERENCEENTRIES
Then we need to create the nodes:
CREATE (:Reference { id: {id},
title: {title},
abstractText: {abstractText} })
For the second step, we need to query the SQL database again. For each reference found in the first step, we must query the database to get the tags of that reference:
select TAG
from EntryTags
where ReferenceId = ?
The ID of the reference is passed as the SQL parameter. Once we have got the tags of a reference, we have to update the node, setting the tags property, which is shown in the following code:
MATCH (r:Reference{id: {id}})
SET r.tags = {tags}
Of course, you could also build a single command to create the node and set its tags at one time instead of performing two Cypher queries:
CREATE (:Reference{ id: {id},
title: {title},
abstractText: {abstractText},
tags: {tags} })
Relationships
Well, now we have migrated all the entities, it's time to migrate relationships. The following are the steps:
1. The easiest relation to migrate is the one between cited references. We must look into the ReferenceCitations table:
2. select CitationId
3. from ReferenceCitations
where ReferenceId = ?
By iterating the result set, we have to create a relationship for every row:
MATCH (r:Reference{id: {idRef}}),
(c:Reference{id: {idCit}})
CREATE (r)-[:Cites]->(c)
This query will find the involved nodes and will create the relationship between them.
4. Migrating the relation between the Reference entity and the Publisher entity is easy as well. We can read for each reference the publisher information as follows:
5. select ID, PublishedYear, PublishedBy
from ReferenceEntries
Then, we can store this information as a relationship in the right node:
MATCH (r:Reference{id: {id}})
MERGE (p:Publisher{name: {pubId}})
CREATE (r)-[:PublishedBy {year: {publishedYear}}]->(p)
The preceding query only works if a Reference node is found with the given ID. If so, it finds the publisher with the given name or creates a name, if the Reference node is not found. Finally, it creates a relationship between them. An important thing you can note is that unlike SQL databases, Neo4j cannot do anything to guarantee that you will have only one publisher per reference. This is a responsibility that now rests at the application level. What you can do is delete all publishers related to a reference before creating any relationship with the following code:
MATCH (:Reference{id: {id}}) -[r:PublishedBy]->()
DELETE r
You can put this query and the previous one in a transaction to ensure that you do not leave the database in a strange state (a reference without any publisher). This can also be achieved in a single query:
MATCH (a:Reference { id: {id} })
OPTIONAL MATCH (a)-[r:PublishedBy]->()
WITH a, r
MERGE (p:Publisher { name: {pubId} })
CREATE (a)-[:PublishedBy { year: {publishedYear} }]->(p)
DELETE r
The preceding query will find the reference with the given ID and, optionally, the existing PublishedBy relation. Then, it will create the new relation and finally it will delete the old relation, if it exists.
6. The approach to migrate the relation between the Reference and Authors entity is similar. First of all, we must read Authors for each Reference entity:
7. select ID, NAME, SURNAME
8. from AUTHORS
9. join ReferenceAuthors
10. on ReferenceAuthors.AuthorId = Authors.Id
11. where ReferenceId = ?
order by SortOrder
Now, we can create the relationships:
MATCH (r:Reference{id: {id}})
MERGE (a:Author {id: {authorId},
name: {name},
surname: {surname} })
CREATE (r)-[:AuthoredBy{sortIndex: {sortIndex}}]->(a)
This query is similar to the query used to link a publisher to a reference; it creates the Authors entity if it is not present in the database. Note that the sortIndex value is set in the relationship, and it is deduced since we ordered the SQL query by the SortOrdervalue.
Migrating queries
Since Neo4j supports ACID transactions, you won't need to change the infrastructure of your application to simulate a transaction (this will be required if we are migrating from SQL to a non-transactional database), but you will still need to rewrite your queries.
CRUD
First and foremost, we must migrate the Create, Read, Update, and Delete ( CRUD ) queries. We already did this step in the previous section, but we overlooked a point—how do we migrate auto-incremented IDs (identities) from SQL to Neo4j? You could use the node ID generated and autoincremented by Neo4j. Yet, as we noticed in Chapter 1, Querying Neo4j Effectively with Pattern Matching, Neo4j could recompute the node IDs, and you should not trust them. If you really need an auto-incremented reliable ID, you will have to simulate the creation of an auto-incremented ID. Suppose we want to create an Author entity, and we want the application to set the next available ID. For this, we can write the following code:
CREATE (a:Author { name: {name},
surname: {surname} })
SET a.id = ID(a)
RETURN a.id
The preceding query is formed in two steps: in the first step, it creates the Author entity with the name and surname, then in the second, it sets the id property to the Neo4j internal ID. The internal ID is so fixed once for all in the id property, and you can use it externally from Neo4j in your application code.
Note that the uniqueness of the id property is also guaranteed by the constraint we already created in the previous section.
To summarize from the previous section, you will gather that:
· SQL insert queries become CREATE or MATCH ... SET queries in Cypher while working with multivalue attributes
· SQL update queries become MATCH ... SET queries in Cypher
We miss the delete SQL clause. For example, let's delete one Author entity from the database:
delete from Authors
where ID = ?
Of course, this will generate a constraint violation error if the Author entity is linked to a reference, and the relation is assured by a foreign key constraint, as usually is the case. The effect is the same if we delete the Author entity with Cypher, and the Author entity is related to a Reference node:
MATCH (a:Author { id: {id}})
DELETE a
In fact, in Neo4j, all nodes have an implicit constraint—a node can't be deleted if it is related to any other node.
You have to perform two queries in SQL to delete the Author entity with its relationships, while with Cypher, one query with OPTIONAL MATCH is enough:
MATCH (a:Author { id: {id}})
OPTIONAL MATCH (a)-[r]-()
DELETE a, r
We already saw this type of query in Chapter 3, Manipulating the Database.
Searching queries
To be suitable for a useful application, besides CRUD operations, the database should support the following queries:
· The list of references found by titles
· The list of all reference entries with a given tag
Consider the first item, that is, the query to find a reference entry, when its title is given. In SQL, this will be:
select * from REFERENCEENTRIES
where title like '%Neo4j%'
It looks for references that have a title with the word Neo4j in it.
The LIKE clause of SQL can be easily translated in Cypher using regular expressions:
MATCH (a:Reference)
WHERE a.title =~ '.*Neo4j.*'
RETURN a
If the SQL database is not case sensitive (for example, SQL server), the WHERE clause must be changed to WHERE a.title =~ '(?i).*Neo4j.*'. For more details about regular expressions supported by Cypher, please refer to Chapter 2, Filter, Aggregate, and Combine Results.
Note
A regular expressions search is still not supported by indexes. Although this limitation will be removed in a next release, at the moment, every time you perform a text search based on a regular expression, Cypher will run through the whole dataset to collect items that fulfill the filter even though the property is indexed.
Now, let's take a look at the following example that has the list of references with a certain tag. In SQL, the query would need to make a join and look into the EntryTags tables:
select ReferenceEntries.*
from EntryTags
join ReferenceEntries
on ReferenceEntries.ID = EntryTags.ReferenceId
where Tag = 'Neo4j'
The query is shorter and more readable in Cypher:
MATCH (r:Reference)
WHERE ANY ( tag IN r.tags WHERE tag = 'Neo4j' )
RETURN r
This query will search the tag Neo4j in the array property tags of references. The Cypher query is simpler because in SQL, we had to introduce a table to store a multivalue attribute and this is not needed in Neo4j.
Grouping queries
A minimal set of analysis queries needed for our application is as follows:
· The list of most-cited references that have a certain tag
· The list of most-cited authors, each with a number of citations
The first query is complex in SQL. It is given as follows:
select Id, CNT
from (
select ReferenceEntries.Id,
Count(ReferenceCitations.ReferenceId) as CNT
from EntryTags
join ReferenceEntries
on ReferenceEntries.ID = EntryTags.ReferenceId
join ReferenceCitations
on ReferenceCitations.CitationId = ReferenceEntries.Id
where Tag = 'Neo4j'
group by ReferenceEntries.Id
) refQ
order by refQ.CNT desc
The preceding SQL query needs to be split into two parts. It needs an inner part to select the references and count the number of citations it has in other references. Note that this part needs two joins: to tags and to citations. Then, the outer query will sort the references in a descending order to show the most cited at the top of the list. This split is required only because an orderby-clause together with the groupby-clause is not supported by all RDBMS.
The simpler the model, the simpler the queries. In fact, the same query in Cypher is far shorter and easier to read. It is given as follows:
MATCH (r:Reference) <-[cit:Cites]- (:Reference)
WHERE ANY ( tag IN r.tags WHERE tag = 'Neo4j' )
RETURN r, COUNT(cit) as cnt
ORDER BY cnt DESC
This query matches the Reference-Citations relationship, filtering nodes by tag, and returns the starting nodes and the count of their citations in other documents. Finally, the dataset is sorted by this number.
The last query to migrate is the list of the most-cited authors entity, each with its number of cited articles. This is the SQL query, where the differences with the previous one are highlighted:
select AuthorId, CNT
from (
select ReferenceAuthors.AuthorId,
Count(ReferenceCitations.ReferenceId) as CNT
from EntryTags
join ReferenceEntries
on ReferenceEntries.ID = EntryTags.ReferenceId
join ReferenceCitations
on ReferenceCitations.CitationId = ReferenceEntries.Id
join ReferenceAuthors
on ReferenceAuthors.ReferenceId = ReferenceEntries.Id
group by ReferenceAuthors.AuthorId
) refQ
order by refQ.CNT desc
The most-cited authors entity has one more join to the relation table of authors, but the grouping clause is different. The Cypher query is also similar to the previous one, which is as follows:
MATCH (a:Author)<-[aut:AuthoredBy]-(r:Reference)<-[cit:Cites]-(:Reference),
RETURN a, COUNT(cit) as cnt
ORDER BY cnt DESC
The main difference (highlighted in the code) is that we added one more MATCH expression to get the Authors entity of each reference.
From this example, we can generalize that in the SQL query for each JOIN with an entity, the Cypher query will have a MATCH expression.
Summary
In this final chapter, we learned a practical approach to migrate a database from SQL to Neo4j.
We started migrating the database schema. We saw that the migration will be straightforward if we think more in terms of entities and relations (E-R)than in terms of tables and columns. In other words, if we come back to the relational model, the entities will become nodes, while the relations will become graph relationships. The attributes will become properties.
Then, we migrated the data. We started migrating entities with their attributes, and then we migrated the relations. During this task, we learned how to migrate CRUD queries from SQL to Cypher.
Finally, we migrated some complex queries used in a real-world application. We learned how to migrate searching queries (in place of LIKE we have regular expressions in Cypher) and grouping queries.
This was the last chapter. Now, you should be able to use Cypher with any real-world application you want to develop, from design to implementation to tuning performances.
When you need a short and quick reference to all the Cypher clauses and patterns you learned in this book, I suggest you read the Neo4j Cypher refcard at (http://docs.neo4j.org/refcard/2.0/). In additions to this, the Appendix contains a detailed list of all the operators and almost all functions supported by Cypher.
All materials on the site are licensed Creative Commons Attribution-Sharealike 3.0 Unported CC BY-SA 3.0 & GNU Free Documentation License (GFDL)
If you are the copyright holder of any material contained on our site and intend to remove it, please contact our site administrator for approval.
© 2016-2026 All site design rights belong to S.Y.A.