Elasticsearch: The Definitive Guide (2015)
Part I. Getting Started
Chapter 9. Distributed Search Execution
Before moving on, we are going to take a detour and talk about how search is executed in a distributed environment. It is a bit more complicated than the basic create-read-update-delete (CRUD) requests that we discussed in Chapter 4.
CONTENT WARNING
The information presented in this chapter is for your interest. You are not required to understand and remember all the detail in order to use Elasticsearch.
Read this chapter to gain a taste for how things work, and to know where the information is in case you need to refer to it in the future, but don’t be overwhelmed by the detail.
A CRUD operation deals with a single document that has a unique combination of _index, _type, and routing values (which defaults to the document’s _id). This means that we know exactly which shard in the cluster holds that document.
Search requires a more complicated execution model because we don’t know which documents will match the query: they could be on any shard in the cluster. A search request has to consult a copy of every shard in the index or indices we’re interested in to see if they have any matching documents.
But finding all matching documents is only half the story. Results from multiple shards must be combined into a single sorted list before the search API can return a “page” of results. For this reason, search is executed in a two-phase process called query then fetch.
Query Phase
During the initial query phase, the query is broadcast to a shard copy (a primary or replica shard) of every shard in the index. Each shard executes the search locally and builds a priority queue of matching documents.
PRIORITY QUEUE
A priority queue is just a sorted list that holds the top-n matching documents. The size of the priority queue depends on the pagination parameters from and size. For example, the following search request would require a priority queue big enough to hold 100 documents:
GET /_search
{
"from": 90,
"size": 10
}
The query phase process is depicted in Figure 9-1.
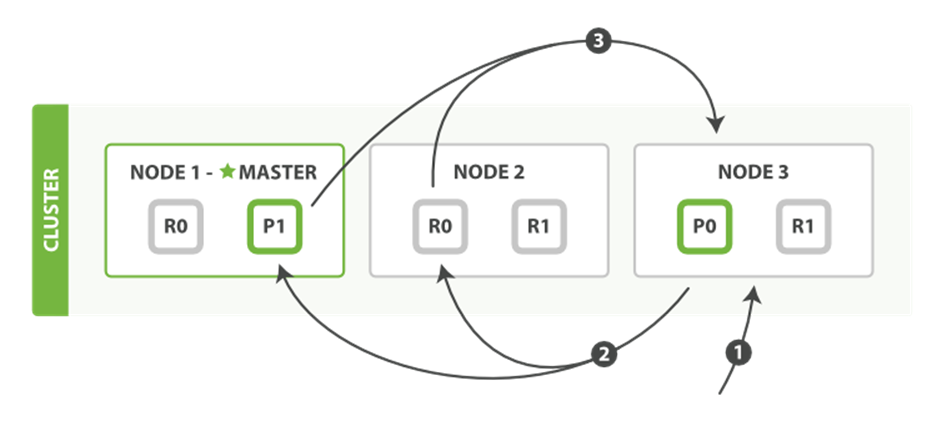
Figure 9-1. Query phase of distributed search
The query phase consists of the following three steps:
1. The client sends a search request to Node 3, which creates an empty priority queue of size from + size.
2. Node 3 forwards the search request to a primary or replica copy of every shard in the index. Each shard executes the query locally and adds the results into a local sorted priority queue of size from + size.
3. Each shard returns the doc IDs and sort values of all the docs in its priority queue to the coordinating node, Node 3, which merges these values into its own priority queue to produce a globally sorted list of results.
When a search request is sent to a node, that node becomes the coordinating node. It is the job of this node to broadcast the search request to all involved shards, and to gather their responses into a globally sorted result set that it can return to the client.
The first step is to broadcast the request to a shard copy of every node in the index. Just like document GET requests, search requests can be handled by a primary shard or by any of its replicas. This is how more replicas (when combined with more hardware) can increase search throughput. A coordinating node will round-robin through all shard copies on subsequent requests in order to spread the load.
Each shard executes the query locally and builds a sorted priority queue of length from + size—in other words, enough results to satisfy the global search request all by itself. It returns a lightweight list of results to the coordinating node, which contains just the doc IDs and any values required for sorting, such as the _score.
The coordinating node merges these shard-level results into its own sorted priority queue, which represents the globally sorted result set. Here the query phase ends.
NOTE
An index can consist of one or more primary shards, so a search request against a single index needs to be able to combine the results from multiple shards. A search against multiple or all indices works in exactly the same way—there are just more shards involved.
Fetch Phase
The query phase identifies which documents satisfy the search request, but we still need to retrieve the documents themselves. This is the job of the fetch phase, shown in Figure 9-2.
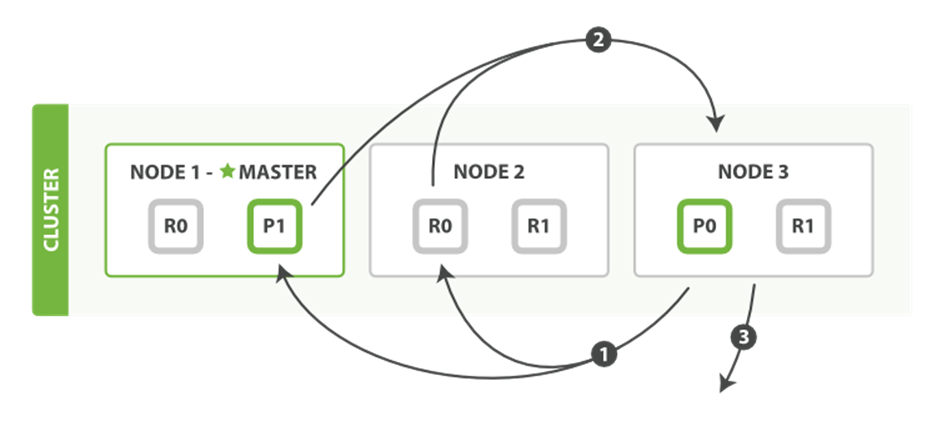
Figure 9-2. Fetch phase of distributed search
The distributed phase consists of the following steps:
1. The coordinating node identifies which documents need to be fetched and issues a multi GET request to the relevant shards.
2. Each shard loads the documents and enriches them, if required, and then returns the documents to the coordinating node.
3. Once all documents have been fetched, the coordinating node returns the results to the client.
The coordinating node first decides which documents actually need to be fetched. For instance, if our query specified { "from": 90, "size": 10 }, the first 90 results would be discarded and only the next 10 results would need to be retrieved. These documents may come from one, some, or all of the shards involved in the original search request.
The coordinating node builds a multi-get request for each shard that holds a pertinent document and sends the request to the same shard copy that handled the query phase.
The shard loads the document bodies—the _source field—and, if requested, enriches the results with metadata and search snippet highlighting. Once the coordinating node receives all results, it assembles them into a single response that it returns to the client.
DEEP PAGINATION
The query-then-fetch process supports pagination with the from and size parameters, but within limits. Remember that each shard must build a priority queue of length from + size, all of which need to be passed back to the coordinating node. And the coordinating node needs to sort through number_of_shards * (from + size) documents in order to find the correct sizedocuments.
Depending on the size of your documents, the number of shards, and the hardware you are using, paging 10,000 to 50,000 results (1,000 to 5,000 pages) deep should be perfectly doable. But with big-enough from values, the sorting process can become very heavy indeed, using vast amounts of CPU, memory, and bandwidth. For this reason, we strongly advise against deep paging.
In practice, “deep pagers” are seldom human anyway. A human will stop paging after two or three pages and will change the search criteria. The culprits are usually bots or web spiders that tirelessly keep fetching page after page until your servers crumble at the knees.
If you do need to fetch large numbers of docs from your cluster, you can do so efficiently by disabling sorting with the scan search type, which we discuss later in this chapter.
Search Options
A few optional query-string parameters can influence the search process.
preference
The preference parameter allows you to control which shards or nodes are used to handle the search request. It accepts values such as _primary, _primary_first, _local, _only_node:xyz, _prefer_node:xyz, and _shards:2,3, which are explained in detail on the searchpreference documentation page.
However, the most generally useful value is some arbitrary string, to avoid the bouncing results problem.
BOUNCING RESULTS
Imagine that you are sorting your results by a timestamp field, and two documents have the same timestamp. Because search requests are round-robined between all available shard copies, these two documents may be returned in one order when the request is served by the primary, and in another order when served by the replica.
This is known as the bouncing results problem: every time the user refreshes the page, the results appear in a different order. The problem can be avoided by always using the same shards for the same user, which can be done by setting the preference parameter to an arbitrary string like the user’s session ID.
timeout
By default, the coordinating node waits to receive a response from all shards. If one node is having trouble, it could slow down the response to all search requests.
The timeout parameter tells the coordinating node how long it should wait before giving up and just returning the results that it already has. It can be better to return some results than none at all.
The response to a search request will indicate whether the search timed out and how many shards responded successfully:
...
"timed_out": true, ![]()
"_shards": {
"total": 5,
"successful": 4,
"failed": 1 ![]()
},
...
![]()
The search request timed out.
![]()
One shard out of five failed to respond in time.
If all copies of a shard fail for other reasons—perhaps because of a hardware failure—this will also be reflected in the _shards section of the response.
routing
In “Routing a Document to a Shard”, we explained how a custom routing parameter could be provided at index time to ensure that all related documents, such as the documents belonging to a single user, are stored on a single shard. At search time, instead of searching on all the shards of an index, you can specify one or more routing values to limit the search to just those shards:
GET /_search?routing=user_1,user2
This technique comes in handy when designing very large search systems, and we discuss it in detail in Chapter 43.
search_type
While query_then_fetch is the default search type, other search types can be specified for particular purposes, for example:
GET /_search?search_type=count
count
The count search type has only a query phase. It can be used when you don’t need search results, just a document count or aggregations on documents matching the query.
query_and_fetch
The query_and_fetch search type combines the query and fetch phases into a single step. This is an internal optimization that is used when a search request targets a single shard only, such as when a routing value has been specified. While you can choose to use this search type manually, it is almost never useful to do so.
dfs_query_then_fetch and dfs_query_and_fetch
The dfs search types have a prequery phase that fetches the term frequencies from all involved shards in order to calculate global term frequencies. We discuss this further in “Relevance Is Broken!”.
scan
The scan search type is used in conjunction with the scroll API to retrieve large numbers of results efficiently. It does this by disabling sorting. We discuss scan-and-scroll in the next section.
scan and scroll
The scan search type and the scroll API are used together to retrieve large numbers of documents from Elasticsearch efficiently, without paying the penalty of deep pagination.
scroll
A scrolled search allows us to do an initial search and to keep pulling batches of results from Elasticsearch until there are no more results left. It’s a bit like a cursor in a traditional database.
A scrolled search takes a snapshot in time. It doesn’t see any changes that are made to the index after the initial search request has been made. It does this by keeping the old data files around, so that it can preserve its “view” on what the index looked like at the time it started.
scan
The costly part of deep pagination is the global sorting of results, but if we disable sorting, then we can return all documents quite cheaply. To do this, we use the scan search type. Scan instructs Elasticsearch to do no sorting, but to just return the next batch of results from every shard that still has results to return.
To use scan-and-scroll, we execute a search request setting search_type to scan, and passing a scroll parameter telling Elasticsearch how long it should keep the scroll open:
GET /old_index/_search?search_type=scan&scroll=1m ![]()
{
"query": { "match_all": {}},
"size": 1000
}
![]()
Keep the scroll open for 1 minute.
The response to this request doesn’t include any hits, but does include a _scroll_id, which is a long Base-64 encoded string. Now we can pass the _scroll_id to the _search/scroll endpoint to retrieve the first batch of results:
GET /_search/scroll?scroll=1m ![]()
c2Nhbjs1OzExODpRNV9aY1VyUVM4U0NMd2pjWlJ3YWlBOzExOTpRNV9aY1VyUVM4U0 ![]()
NMd2pjWlJ3YWlBOzExNjpRNV9aY1VyUVM4U0NMd2pjWlJ3YWlBOzExNzpRNV9aY1Vy
UVM4U0NMd2pjWlJ3YWlBOzEyMDpRNV9aY1VyUVM4U0NMd2pjWlJ3YWlBOzE7dG90YW
xfaGl0czoxOw==
![]()
Keep the scroll open for another minute.
![]()
The _scroll_id can be passed in the body, in the URL, or as a query parameter.
Note that we again specify ?scroll=1m. The scroll expiry time is refreshed every time we run a scroll request, so it needs to give us only enough time to process the current batch of results, not all of the documents that match the query.
The response to this scroll request includes the first batch of results. Although we specified a size of 1,000, we get back many more documents. When scanning, the size is applied to each shard, so you will get back a maximum of size * number_of_primary_shards documents in each batch.
NOTE
The scroll request also returns a new _scroll_id. Every time we make the next scroll request, we must pass the _scroll_id returned by the previous scroll request.
When no more hits are returned, we have processed all matching documents.
TIP
Some of the official Elasticsearch clients provide scan-and-scroll helpers that provide an easy wrapper around this functionality.