Elasticsearch: The Definitive Guide (2015)
Part I. Getting Started
Chapter 2. Life Inside a Cluster
SUPPLEMENTAL CHAPTER
As mentioned earlier, this is the first of several supplemental chapters about how Elasticsearch operates in a distributed environment. In this chapter, we explain commonly used terminology like cluster, node, and shard, the mechanics of how Elasticsearch scales out, and how it deals with hardware failure.
Although this chapter is not required reading—you can use Elasticsearch for a long time without worrying about shards, replication, and failover—it will help you to understand the processes at work inside Elasticsearch. Feel free to skim through the chapter and to refer to it again later.
Elasticsearch is built to be always available, and to scale with your needs. Scale can come from buying bigger servers (vertical scale, or scaling up) or from buying more servers (horizontal scale, or scaling out).
While Elasticsearch can benefit from more-powerful hardware, vertical scale has its limits. Real scalability comes from horizontal scale—the ability to add more nodes to the cluster and to spread load and reliability between them.
With most databases, scaling horizontally usually requires a major overhaul of your application to take advantage of these extra boxes. In contrast, Elasticsearch is distributed by nature: it knows how to manage multiple nodes to provide scale and high availability. This also means that your application doesn’t need to care about it.
In this chapter, we show how you can set up your cluster, nodes, and shards to scale with your needs and to ensure that your data is safe from hardware failure.
An Empty Cluster
If we start a single node, with no data and no indices, our cluster looks like Figure 2-1.

Figure 2-1. A cluster with one empty node
A node is a running instance of Elasticsearch, while a cluster consists of one or more nodes with the same cluster.name that are working together to share their data and workload. As nodes are added to or removed from the cluster, the cluster reorganizes itself to spread the data evenly.
One node in the cluster is elected to be the master node, which is in charge of managing cluster-wide changes like creating or deleting an index, or adding or removing a node from the cluster. The master node does not need to be involved in document-level changes or searches, which means that having just one master node will not become a bottleneck as traffic grows. Any node can become the master. Our example cluster has only one node, so it performs the master role.
As users, we can talk to any node in the cluster, including the master node. Every node knows where each document lives and can forward our request directly to the nodes that hold the data we are interested in. Whichever node we talk to manages the process of gathering the response from the node or nodes holding the data and returning the final response to the client. It is all managed transparently by Elasticsearch.
Cluster Health
Many statistics can be monitored in an Elasticsearch cluster, but the single most important one is cluster health, which reports a status of either green, yellow, or red:
GET /_cluster/health
On an empty cluster with no indices, this will return something like the following:
{
"cluster_name": "elasticsearch",
"status": "green", ![]()
"timed_out": false,
"number_of_nodes": 1,
"number_of_data_nodes": 1,
"active_primary_shards": 0,
"active_shards": 0,
"relocating_shards": 0,
"initializing_shards": 0,
"unassigned_shards": 0
}
![]()
The status field is the one we’re most interested in.
The status field provides an overall indication of how the cluster is functioning. The meanings of the three colors are provided here for reference:
green
All primary and replica shards are active.
yellow
All primary shards are active, but not all replica shards are active.
red
Not all primary shards are active.
In the rest of this chapter, we explain what primary and replica shards are and explain the practical implications of each of the preceding colors.
Add an Index
To add data to Elasticsearch, we need an index—a place to store related data. In reality, an index is just a logical namespace that points to one or more physical shards.
A shard is a low-level worker unit that holds just a slice of all the data in the index. In Chapter 11, we explain in detail how a shard works, but for now it is enough to know that a shard is a single instance of Lucene, and is a complete search engine in its own right. Our documents are stored and indexed in shards, but our applications don’t talk to them directly. Instead, they talk to an index.
Shards are how Elasticsearch distributes data around your cluster. Think of shards as containers for data. Documents are stored in shards, and shards are allocated to nodes in your cluster. As your cluster grows or shrinks, Elasticsearch will automatically migrate shards between nodes so that the cluster remains balanced.
A shard can be either a primary shard or a replica shard. Each document in your index belongs to a single primary shard, so the number of primary shards that you have determines the maximum amount of data that your index can hold.
NOTE
While there is no theoretical limit to the amount of data that a primary shard can hold, there is a practical limit. What constitutes the maximum shard size depends entirely on your use case: the hardware you have, the size and complexity of your documents, how you index and query your documents, and your expected response times.
A replica shard is just a copy of a primary shard. Replicas are used to provide redundant copies of your data to protect against hardware failure, and to serve read requests like searching or retrieving a document.
The number of primary shards in an index is fixed at the time that an index is created, but the number of replica shards can be changed at any time.
Let’s create an index called blogs in our empty one-node cluster. By default, indices are assigned five primary shards, but for the purpose of this demonstration, we’ll assign just three primary shards and one replica (one replica of every primary shard):
PUT /blogs
{
"settings" : {
"number_of_shards" : 3,
"number_of_replicas" : 1
}
}
Our cluster now looks like Figure 2-2. All three primary shards have been allocated to Node 1.

Figure 2-2. A single-node cluster with an index
If we were to check the cluster-health now, we would see this:
{
"cluster_name": "elasticsearch",
"status": "yellow", ![]()
"timed_out": false,
"number_of_nodes": 1,
"number_of_data_nodes": 1,
"active_primary_shards": 3,
"active_shards": 3,
"relocating_shards": 0,
"initializing_shards": 0,
"unassigned_shards": 3 ![]()
}
![]()
Cluster status is yellow.
![]()
Our three replica shards have not been allocated to a node.
A cluster health of yellow means that all primary shards are up and running (the cluster is capable of serving any request successfully) but not all replica shards are active. In fact, all three of our replica shards are currently unassigned—they haven’t been allocated to a node. It doesn’t make sense to store copies of the same data on the same node. If we were to lose that node, we would lose all copies of our data.
Currently, our cluster is fully functional but at risk of data loss in case of hardware failure.
Add Failover
Running a single node means that you have a single point of failure—there is no redundancy. Fortunately, all we need to do to protect ourselves from data loss is to start another node.
STARTING A SECOND NODE
To test what happens when you add a second node, you can start a new node in exactly the same way as you started the first one (see “Running Elasticsearch”), and from the same directory. Multiple nodes can share the same directory.
As long as the second node has the same cluster.name as the first node (see the ./config/elasticsearch.yml file), it should automatically discover and join the cluster run by the first node. If it doesn’t, check the logs to find out what went wrong. It may be that multicast is disabled on your network, or that a firewall is preventing your nodes from communicating.
If we start a second node, our cluster would look like Figure 2-3.
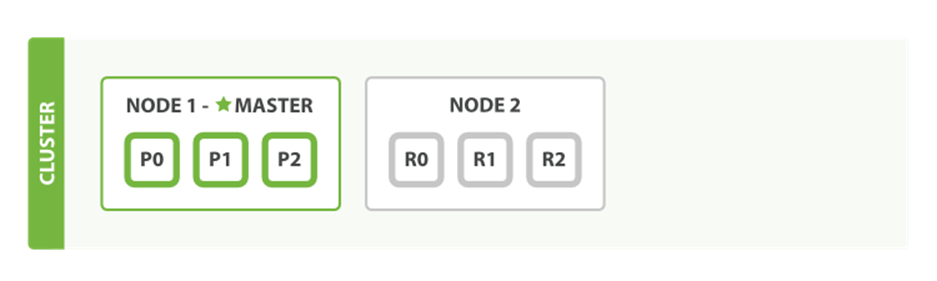
Figure 2-3. A two-node cluster—all primary and replica shards are allocated
The second node has joined the cluster, and three replica shards have been allocated to it—one for each primary shard. That means that we can lose either node, and all of our data will be intact.
Any newly indexed document will first be stored on a primary shard, and then copied in parallel to the associated replica shard(s). This ensures that our document can be retrieved from a primary shard or from any of its replicas.
The cluster-health now shows a status of green, which means that all six shards (all three primary shards and all three replica shards) are active:
{
"cluster_name": "elasticsearch",
"status": "green", ![]()
"timed_out": false,
"number_of_nodes": 2,
"number_of_data_nodes": 2,
"active_primary_shards": 3,
"active_shards": 6,
"relocating_shards": 0,
"initializing_shards": 0,
"unassigned_shards": 0
}
![]()
Cluster status is green.
Our cluster is not only fully functional, but also always available.
Scale Horizontally
What about scaling as the demand for our application grows? If we start a third node, our cluster reorganizes itself to look like Figure 2-4.
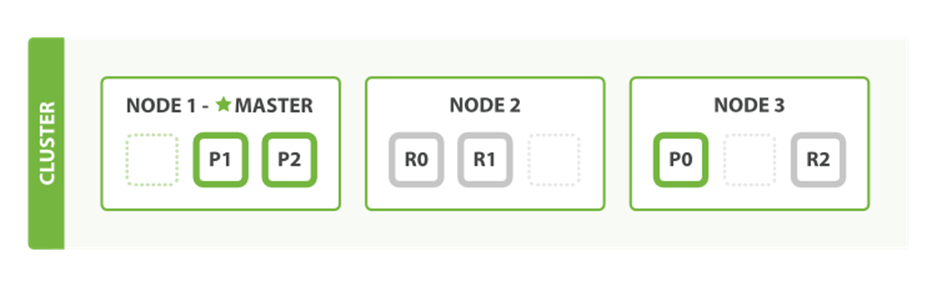
Figure 2-4. A three-node cluster—shards have been reallocated to spread the load
One shard each from Node 1 and Node 2 have moved to the new Node 3, and we have two shards per node, instead of three. This means that the hardware resources (CPU, RAM, I/O) of each node are being shared among fewer shards, allowing each shard to perform better.
A shard is a fully fledged search engine in its own right, and is capable of using all of the resources of a single node. With our total of six shards (three primaries and three replicas), our index is capable of scaling out to a maximum of six nodes, with one shard on each node and each shard having access to 100% of its node’s resources.
Then Scale Some More
But what if we want to scale our search to more than six nodes?
The number of primary shards is fixed at the moment an index is created. Effectively, that number defines the maximum amount of data that can be stored in the index. (The actual number depends on your data, your hardware and your use case.) However, read requests—searches or document retrieval—can be handled by a primary or a replica shard, so the more copies of data that you have, the more search throughput you can handle.
The number of replica shards can be changed dynamically on a live cluster, allowing us to scale up or down as demand requires. Let’s increase the number of replicas from the default of 1 to 2:
PUT /blogs/_settings
{
"number_of_replicas" : 2
}
As can be seen in Figure 2-5, the blogs index now has nine shards: three primaries and six replicas. This means that we can scale out to a total of nine nodes, again with one shard per node. This would allow us to triple search performance compared to our original three-node cluster.
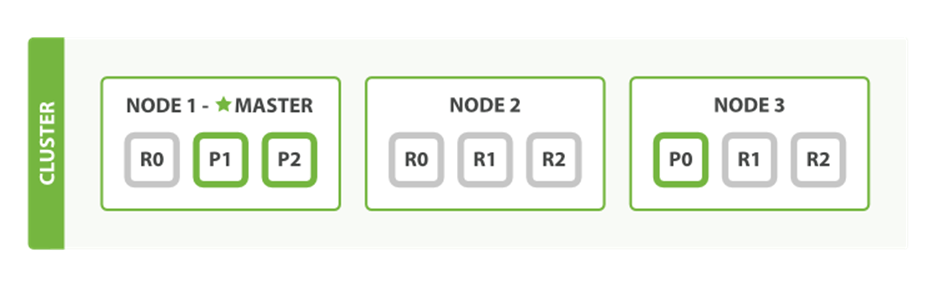
Figure 2-5. Increasing the number_of_replicas to 2
NOTE
Of course, just having more replica shards on the same number of nodes doesn’t increase our performance at all because each shard has access to a smaller fraction of its node’s resources. You need to add hardware to increase throughput.
But these extra replicas do mean that we have more redundancy: with the node configuration above, we can now afford to lose two nodes without losing any data.
Coping with Failure
We’ve said that Elasticsearch can cope when nodes fail, so let’s go ahead and try it out. If we kill the first node, our cluster looks like Figure 2-6.
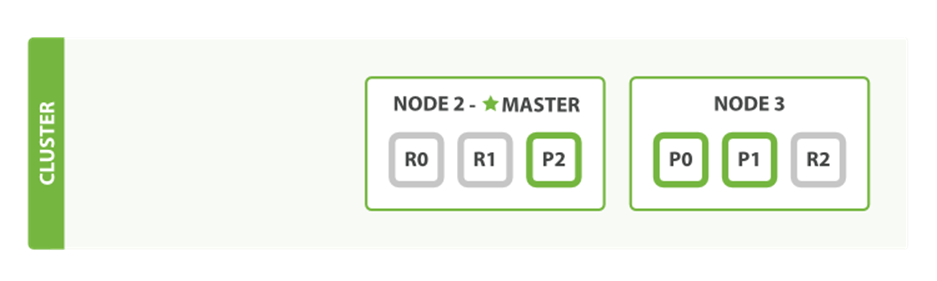
Figure 2-6. Cluster after killing one node
The node we killed was the master node. A cluster must have a master node in order to function correctly, so the first thing that happened was that the nodes elected a new master: Node 2.
Primary shards 1 and 2 were lost when we killed Node 1, and our index cannot function properly if it is missing primary shards. If we had checked the cluster health at this point, we would have seen status red: not all primary shards are active!
Fortunately, a complete copy of the two lost primary shards exists on other nodes, so the first thing that the new master node did was to promote the replicas of these shards on Node 2 and Node 3 to be primaries, putting us back into cluster health yellow. This promotion process was instantaneous, like the flick of a switch.
So why is our cluster health yellow and not green? We have all three primary shards, but we specified that we wanted two replicas of each primary, and currently only one replica is assigned. This prevents us from reaching green, but we’re not too worried here: were we to kill Node 2 as well, our application could still keep running without data loss, because Node 3 contains a copy of every shard.
If we restart Node 1, the cluster would be able to allocate the missing replica shards, resulting in a state similar to the one described in Figure 2-5. If Node 1 still has copies of the old shards, it will try to reuse them, copying over from the primary shard only the files that have changed in the meantime.
By now, you should have a reasonable idea of how shards allow Elasticsearch to scale horizontally and to ensure that your data is safe. Later we will examine the life cycle of a shard in more detail.
All materials on the site are licensed Creative Commons Attribution-Sharealike 3.0 Unported CC BY-SA 3.0 & GNU Free Documentation License (GFDL)
If you are the copyright holder of any material contained on our site and intend to remove it, please contact our site administrator for approval.
© 2016-2025 All site design rights belong to S.Y.A.