Elasticsearch: The Definitive Guide (2015)
Part I. Getting Started
Chapter 4. Distributed Document Store
In the preceding chapter, we looked at all the ways to put data into your index and then retrieve it. But we glossed over many technical details surrounding how the data is distributed and fetched from the cluster. This separation is done on purpose; you don’t really need to know how data is distributed to work with Elasticsearch. It just works.
In this chapter, we dive into those internal, technical details to help you understand how your data is stored in a distributed system.
CONTENT WARNING
The information presented in this chapter is for your interest. You are not required to understand and remember all the detail in order to use Elasticsearch. The options that are discussed are for advanced users only.
Read the section to gain a taste for how things work, and to know where the information is in case you need to refer to it in the future, but don’t be overwhelmed by the detail.
Routing a Document to a Shard
When you index a document, it is stored on a single primary shard. How does Elasticsearch know which shard a document belongs to? When we create a new document, how does it know whether it should store that document on shard 1 or shard 2?
The process can’t be random, since we may need to retrieve the document in the future. In fact, it is determined by a simple formula:
shard = hash(routing) % number_of_primary_shards
The routing value is an arbitrary string, which defaults to the document’s _id but can also be set to a custom value. This routing string is passed through a hashing function to generate a number, which is divided by the number of primary shards in the index to return the remainder. The remainder will always be in the range 0 to number_of_primary_shards - 1, and gives us the number of the shard where a particular document lives.
This explains why the number of primary shards can be set only when an index is created and never changed: if the number of primary shards ever changed in the future, all previous routing values would be invalid and documents would never be found.
NOTE
Users sometimes think that having a fixed number of primary shards makes it difficult to scale out an index later. In reality, there are techniques that make it easy to scale out as and when you need. We talk more about these in Chapter 43.
All document APIs (get, index, delete, bulk, update, and mget) accept a routing parameter that can be used to customize the document-to- shard mapping. A custom routing value could be used to ensure that all related documents—for instance, all the documents belonging to the same user—are stored on the same shard. We discuss in detail why you may want to do this in Chapter 43.
How Primary and Replica Shards Interact
For explanation purposes, let’s imagine that we have a cluster consisting of three nodes. It contains one index called blogs that has two primary shards. Each primary shard has two replicas. Copies of the same shard are never allocated to the same node, so our cluster looks something likeFigure 4-1.
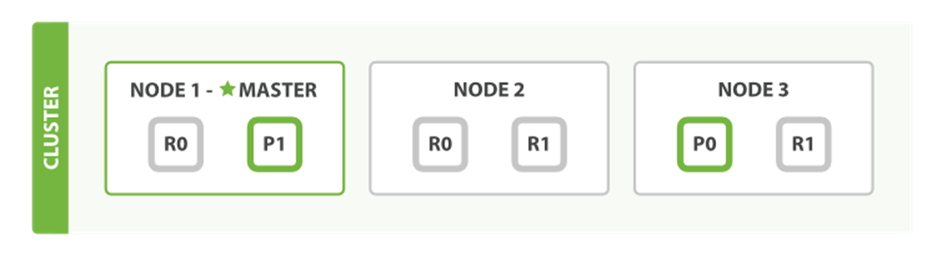
Figure 4-1. A cluster with three nodes and one index
We can send our requests to any node in the cluster. Every node is fully capable of serving any request. Every node knows the location of every document in the cluster and so can forward requests directly to the required node. In the following examples, we will send all of our requests toNode 1, which we will refer to as the requesting node.
TIP
When sending requests, it is good practice to round-robin through all the nodes in the cluster, in order to spread the load.
Creating, Indexing, and Deleting a Document
Create, index, and delete requests are write operations, which must be successfully completed on the primary shard before they can be copied to any associated replica shards, as shown in Figure 4-2.
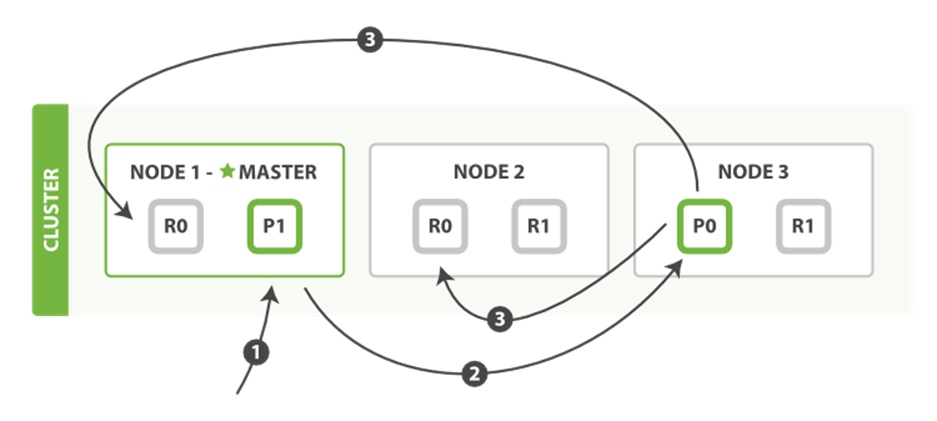
Figure 4-2. Creating, indexing, or deleting a single document
Here is the sequence of steps necessary to successfully create, index, or delete a document on both the primary and any replica shards:
1. The client sends a create, index, or delete request to Node 1.
2. The node uses the document’s _id to determine that the document belongs to shard 0. It forwards the request to Node 3, where the primary copy of shard 0 is currently allocated.
3. Node 3 executes the request on the primary shard. If it is successful, it forwards the request in parallel to the replica shards on Node 1 and Node 2. Once all of the replica shards report success, Node 3 reports success to the requesting node, which reports success to the client.
By the time the client receives a successful response, the document change has been executed on the primary shard and on all replica shards. Your change is safe.
There are a number of optional request parameters that allow you to influence this process, possibly increasing performance at the cost of data security. These options are seldom used because Elasticsearch is already fast, but they are explained here for the sake of completeness:
replication
The default value for replication is sync. This causes the primary shard to wait for successful responses from the replica shards before returning.
If you set replication to async, it will return success to the client as soon as the request has been executed on the primary shard. It will still forward the request to the replicas, but you will not know whether the replicas succeeded.
This option is mentioned specifically to advise against using it. The default sync replication allows Elasticsearch to exert back pressure on whatever system is feeding it with data. With async replication, it is possible to overload Elasticsearch by sending too many requests without waiting for their completion.
consistency
By default, the primary shard requires a quorum, or majority, of shard copies (where a shard copy can be a primary or a replica shard) to be available before even attempting a write operation. This is to prevent writing data to the “wrong side” of a network partition. A quorum is defined as follows:
int( (primary + number_of_replicas) / 2 ) + 1
The allowed values for consistency are one (just the primary shard), all (the primary and all replicas), or the default quorum, or majority, of shard copies.
Note that the number_of_replicas is the number of replicas specified in the index settings, not the number of replicas that are currently active. If you have specified that an index should have three replicas, a quorum would be as follows:
int( (primary + 3 replicas) / 2 ) + 1 = 3
But if you start only two nodes, there will be insufficient active shard copies to satisfy the quorum, and you will be unable to index or delete any documents.
timeout
What happens if insufficient shard copies are available? Elasticsearch waits, in the hope that more shards will appear. By default, it will wait up to 1 minute. If you need to, you can use the timeout parameter to make it abort sooner: 100 is 100 milliseconds, and 30s is 30 seconds.
NOTE
A new index has 1 replica by default, which means that two active shard copies should be required in order to satisfy the need for a quorum. However, these default settings would prevent us from doing anything useful with a single-node cluster. To avoid this problem, the requirement for a quorum is enforced only when number_of_replicas is greater than 1.
Retrieving a Document
A document can be retrieved from a primary shard or from any of its replicas, as shown in Figure 4-3.
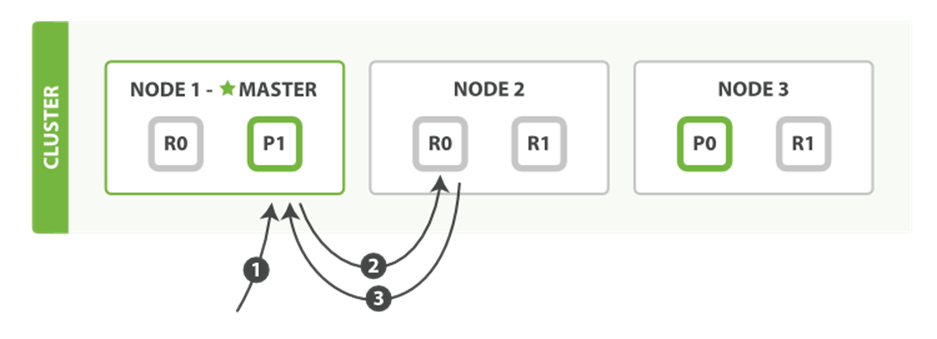
Figure 4-3. Retrieving a single document
Here is the sequence of steps to retrieve a document from either a primary or replica shard:
1. The client sends a get request to Node 1.
2. The node uses the document’s _id to determine that the document belongs to shard 0. Copies of shard 0 exist on all three nodes. On this occasion, it forwards the request to Node 2.
3. Node 2 returns the document to Node 1, which returns the document to the client.
For read requests, the requesting node will choose a different shard copy on every request in order to balance the load; it round-robins through all shard copies.
It is possible that, while a document is being indexed, the document will already be present on the primary shard but not yet copied to the replica shards. In this case, a replica might report that the document doesn’t exist, while the primary would have returned the document successfully. Once the indexing request has returned success to the user, the document will be available on the primary and all replica shards.
Partial Updates to a Document
The update API , as shown in Figure 4-4, combines the read and write patterns explained previously.
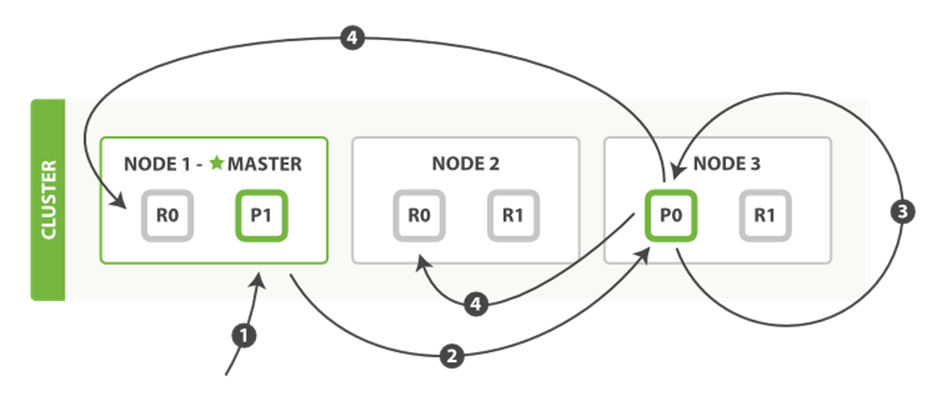
Figure 4-4. Partial updates to a document
Here is the sequence of steps used to perform a partial update on a document:
1. The client sends an update request to Node 1.
2. It forwards the request to Node 3, where the primary shard is allocated.
3. Node 3 retrieves the document from the primary shard, changes the JSON in the _source field, and tries to reindex the document on the primary shard. If the document has already been changed by another process, it retries step 3 up to retry_on_conflict times, before giving up.
4. If Node 3 has managed to update the document successfully, it forwards the new version of the document in parallel to the replica shards on Node 1 and Node 2 to be reindexed. Once all replica shards report success, Node 3 reports success to the requesting node, which reports success to the client.
The update API also accepts the routing, replication, consistency, and timeout parameters that are explained in “Creating, Indexing, and Deleting a Document”.
DOCUMENT-BASED REPLICATION
When a primary shard forwards changes to its replica shards, it doesn’t forward the update request. Instead it forwards the new version of the full document. Remember that these changes are forwarded to the replica shards asynchronously, and there is no guarantee that they will arrive in the same order that they were sent. If Elasticsearch forwarded just the change, it is possible that changes would be applied in the wrong order, resulting in a corrupt document.
Multidocument Patterns
The patterns for the mget and bulk APIs are similar to those for individual documents. The difference is that the requesting node knows in which shard each document lives. It breaks up the multidocument request into a multidocument request per shard, and forwards these in parallel to each participating node.
Once it receives answers from each node, it collates their responses into a single response, which it returns to the client, as shown in Figure 4-5.
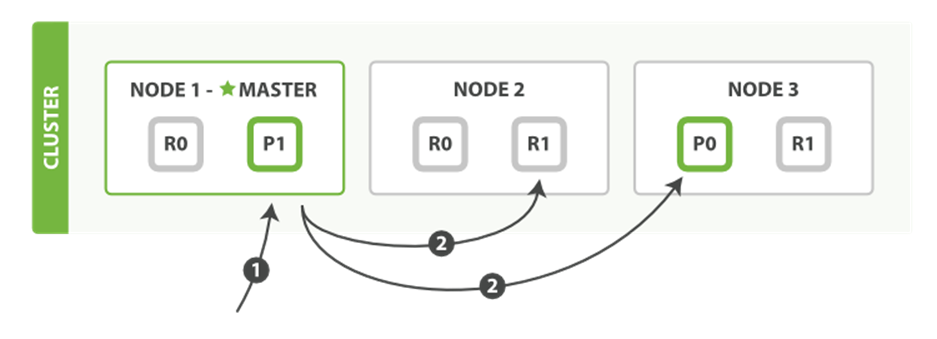
Figure 4-5. Retrieving multiple documents with mget
Here is the sequence of steps necessary to retrieve multiple documents with a single mget request:
1. The client sends an mget request to Node 1.
2. Node 1 builds a multi-get request per shard, and forwards these requests in parallel to the nodes hosting each required primary or replica shard. Once all replies have been received, Node 1 builds the response and returns it to the client.
A routing parameter can be set for each document in the docs array.
The bulk API, as depicted in Figure 4-6, allows the execution of multiple create, index, delete, and update requests within a single bulk request.
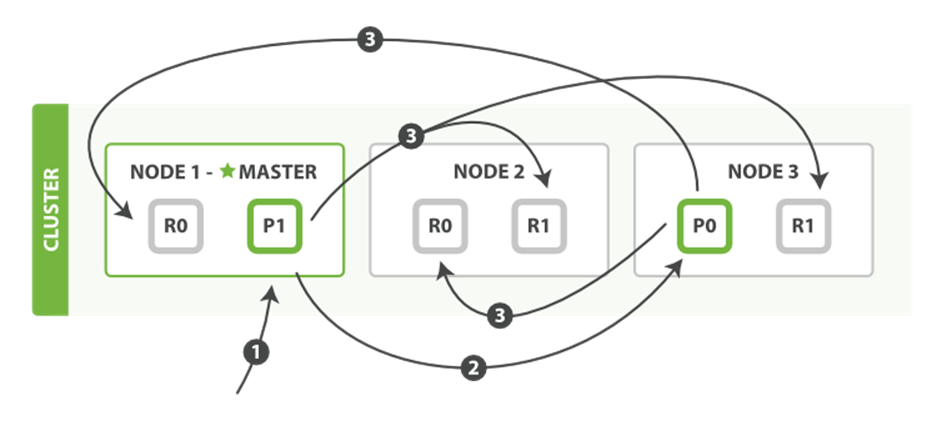
Figure 4-6. Multiple document changes with bulk
The sequence of steps followed by the bulk API are as follows:
1. The client sends a bulk request to Node 1.
2. Node 1 builds a bulk request per shard, and forwards these requests in parallel to the nodes hosting each involved primary shard.
3. The primary shard executes each action serially, one after another. As each action succeeds, the primary forwards the new document (or deletion) to its replica shards in parallel, and then moves on to the next action. Once all replica shards report success for all actions, the node reports success to the requesting node, which collates the responses and returns them to the client.
The bulk API also accepts the replication and consistency parameters at the top level for the whole bulk request, and the routing parameter in the metadata for each request.
Why the Funny Format?
When we learned about bulk requests earlier in “Cheaper in Bulk”, you may have asked yourself, “Why does the bulk API require the funny format with the newline characters, instead of just sending the requests wrapped in a JSON array, like the mget API?”
To answer this, we need to explain a little background: Each document referenced in a bulk request may belong to a different primary shard, each of which may be allocated to any of the nodes in the cluster. This means that every action inside a bulk request needs to be forwarded to the correct shard on the correct node.
If the individual requests were wrapped up in a JSON array, that would mean that we would need to do the following:
§ Parse the JSON into an array (including the document data, which can be very large)
§ Look at each request to determine which shard it should go to
§ Create an array of requests for each shard
§ Serialize these arrays into the internal transport format
§ Send the requests to each shard
It would work, but would need a lot of RAM to hold copies of essentially the same data, and would create many more data structures that the Java Virtual Machine (JVM) would have to spend time garbage collecting.
Instead, Elasticsearch reaches up into the networking buffer, where the raw request has been received, and reads the data directly. It uses the newline characters to identify and parse just the small action/metadata lines in order to decide which shard should handle each request.
These raw requests are forwarded directly to the correct shard. There is no redundant copying of data, no wasted data structures. The entire request process is handled in the smallest amount of memory possible.
All materials on the site are licensed Creative Commons Attribution-Sharealike 3.0 Unported CC BY-SA 3.0 & GNU Free Documentation License (GFDL)
If you are the copyright holder of any material contained on our site and intend to remove it, please contact our site administrator for approval.
© 2016-2026 All site design rights belong to S.Y.A.